Fair Adaptive Experiments111This manuscript is accepted for publication at NeurIPS 2023.
Abstract
Randomized experiments have been the gold standard for assessing the effectiveness of a treatment, policy, or intervention, spanning various fields, including social sciences, biomedical studies, and e-commerce. The classical complete randomization approach assigns treatments based on a pre-specified probability and may lead to inefficient use of data. Adaptive experiments improve upon complete randomization by sequentially learning and updating treatment assignment probabilities using accrued evidence during the experiment. Hence, they can help achieve efficient data use and higher estimation efficiency. However, their application can also raise fairness and equity concerns, as assignment probabilities may vary drastically across groups of participants. Furthermore, when treatment is expected to be extremely beneficial to certain groups of participants, it is more appropriate to expose many of these participants to favorable treatment. In response to these challenges, we propose a fair adaptive experiment strategy that simultaneously enhances data use efficiency, achieves an “envy-free” treatment assignment guarantee, and improves the overall welfare of participants. An important feature of our proposed strategy is that we do not impose parametric modeling assumptions on the outcome variables, making it more versatile and applicable to a wider array of applications. Through our theoretical investigation, we characterize the convergence rate of the estimated treatment effects and the associated standard deviations at the group level and further prove that our adaptive treatment assignment algorithm, despite not having a closed-form expression, approaches the optimal allocation rule asymptotically. Our proof strategy takes into account the fact that the allocation decisions in our design depend on sequentially accumulated data, which poses a significant challenge in characterizing the properties and conducting statistical inference of our method. We further provide simulation evidence and two synthetic data studies (in the Supplementary Materials) to showcase the performance of our fair adaptive experiment strategy.
1 Introduction
1.1 Motivation and contribution
Randomized experiments are considered gold standards for evaluating the effectiveness of public policies, medical treatments, or advertising strategies [33, 35, 36]. They involve randomly assigning participants to different treatment groups, allowing for rigorous causal conclusions and robust evidence for decision-making and policy implementation. However, classical randomized experiments, which maintain fixed treatment assignment probabilities, often do not optimize data utilization. This limitation is problematic due to the high costs associated with conducting such experiments. Consequently, maximizing information gain is crucial, but classical randomized experiments do not prioritize this objective [26, 47].
Compared to classical randomized experiments, adaptive experiments provide enhanced information gain, leading to improved statistical efficiency. As a result, adaptive experiments have gained popularity in diverse domains such as field experiments, online A/B testing, and clinical trials [27, 57, 64, 65]. The information gain of adaptive experiments stems from their ability to iteratively adjust treatment allocations based on refined knowledge obtained from accumulated data during the experiment. This iterative process often favors the treatment arm that offers more informative or beneficial outcomes, maximizing the information gained from each participant and optimizing the overall statistical efficiency of the experiment [46]. Moreover, adaptive experiments, thanks to their adept utilization of data resources, often exhibit greater statistical testing power when practitioners employ the collected data to assess the null hypothesis of zero treatment effect upon experiment completion [15].
Despite their appealing benefits in improving data use efficiency and boosting statistical power, adaptive experiments potentially bring fairness concerns in applications. This issue is neither sufficiently explored nor fully addressed in the existing literature. Below, we shall concretely discuss the fairness concerns under a scenario where the study population can be divided into distinct groups based on demographic information or biomarkers — a scenario frequently encountered in field experiments or clinical trials. The first fairness concern in adaptive experiments arises when there are significant disparities in treatment allocations among different participant groups [15]. This is because when the treatment is potentially beneficial, it is crucial to ensure a fair chance for each group to receive beneficial treatment. Similarly, it is important to avoid disproportionately burdening any specific group with unfavorable treatment. However, conventional adaptive experiments prioritizing efficiency gains may inadvertently result in unfair treatment allocations. For example, if the outcome of a particular group of participants exhibits a higher variance in response to the treatment, more participants in the group will be allocated to the treatment arm. Consequently, this group would have a significantly higher treatment assignment probability than the others, regardless of the sign and magnitude of the treatment effect. This may lead to an unfair allocation of treatments among participants. Completely randomized experiments with fixed one-half treatment assignments would avoid this challenge, but they suffer from information loss. The second fairness concern arises when the adaptive treatment allocation does not adequately account for the overall welfare of experimental participants. This is crucial as a fair experiment is expected to not only assign a large proportion of participants to a beneficial treatment arm but also assign a small proportion of participants to a harmful treatment to avoid adverse effects.
There are evident challenges in addressing fairness concerns while optimizing information gain in adaptive experiments due to the potential trade off among fairness concerns, welfare improvement, and information gain. For example, if most of the participants are assigned to the beneficial treatment to maximize welfare, then there would be insufficient sample size in the control arm, resulting in imprecisely estimated treatment effect and hence reduced statistical efficiency for conducting inference. To overcome these challenges, we propose a fair adaptive experimental design strategy that balances competing objectives: improving fairness, enhancing overall welfare, and gaining efficiency. By rigorously demonstrating the effectiveness of our approach and providing statistical guarantees, we offer a practical solution that is both grounded in theory and reconciles fairness concerns with the requirement for robust information gain in adaptive experiments. Our contributions can be summarized as follows:
First, in comparison to existing adaptive experiments, our proposed strategy integrates fairness and welfare considerations while optimizing information gain. As a result, the treatment allocation probability generated by our method avoids extreme values and exhibits minimal necessary variations across different groups. These desirable characteristics are supported by our simulation studies and empirical illustration using synthetic data. It is important to note that due to the additional constraints of welfare and fairness, the optimal treatment allocation probability does not have a closed-form expression, which brings additional technical challenges to studying the theoretical properties of our design. Despite this challenge, we demonstrate that the constructed treatment allocation rule for each group of our design converges to its oracle counterpart (Theorem 2). This implies that our proposed designs in Section 2.3, despite not relying on prior knowledge about the underlying data distribution before the start of the experiment, can allocate treatments in a similar manner to a scenario where perfect knowledge of the data distribution is available.
Second, we do not impose any specific parametric modeling assumptions on the outcomes beyond mild moment conditions. We instead estimate the mean and variance of potential outcomes at the group level, which are further incorporated into our algorithm. The nonparametric nature of our procedure delivers an efficient and accurate estimation of the average treatment effect. As an important theoretical contribution, we prove that those group-level estimates are asymptotically consistent (Theorem 1).
Third, our theoretical framework addresses the challenges and complexities associated with adaptive experiment design, where data are sequentially accumulated, and treatment allocation decisions are adaptively revised, resulting in non-independently and non-identically distributed data. By leveraging the martingale methods, we demonstrate that the estimate of the average treatment effect is consistent and asymptotically normally distributed (Theorems 1 and 3). An important methodological and practical innovation of our framework is that it does not require the number of participants enrolled in the first stage to be proportional to the overall sample size. This flexibility allows researchers to allocate more participants in later stages of the experiment, enabling a truly adaptive approach to experiment design and implementation. This innovation has significant implications for the methodology and practical application of adaptive experiments.
1.2 Related literature
Our proposed fair adaptive experiment strategy has a natural connection with the response adaptive randomization (RAR) design literature. The early work develops the randomized play-the-winner rule in clinical trial settings based on urn models [47, 49, 61]. Theoretical properties of urn models are investigated in [7] and [30]. Another conventional response adaptive design is the doubly adaptive biased coin (DBCD) design [16, 27, 28, 54]. However, to our best knowledge, many existing works on response adaptive designs do not take fair treatment allocations into account [25, 48]. An insightful work in [34] proposes an efficient RAR design to minimize the variance of the average treatment effects and discusses some directions for fair experimental design. Compared with [34], our method does not require estimating outcome models, which can be challenging in the presence of correlated data in RAR designs. In addition, our design centers around “group” fairness, aiming to enhance participants’ well-being while avoiding extra fairness complications among distinct individuals. Furthermore, RAR designs that further incorporate covariate information are known as covariate-adjusted response adaptive (CARA) designs [8, 10, 38, 50, 58, 72, 73]. Some early work proposes to balance covariates based on the biased coin design [45, 70]. Later work considers CARA designs that account for both efficiency and ethics [29] and extends the CARA design framework to incorporate nonparametric estimates of the conditional response function [2]. It is worth mentioning that another strand of literature focuses on ethical designs using Bayesian frameworks. Some recent work proposes to use the Gittins index to improve participants’ welfare [56, 59]. A later work develops a Bayesian ethical design to further improve statistical power [63]. Some other ethical designs are discussed in [19, 53, 69].
Our manuscript also relates to the literature on semiparametric efficiency and treatment effect estimation [21, 43, 55]. Our algorithm adaptively allocates participants to treatment and control arms, with the aim of not only minimizing the variance of the estimated average treatment effect but also incorporating constraints on fairness and welfare. There is also a large literature on efficient estimation of treatment effects and, more broadly, on estimation and statistical inference in semiparametric models. See, for example, [9, 11, 12, 13, 17, 23, 39, 40, 60, 62] and references therein. Our algorithm takes the group structure as given. Another strand of literature studies stratified randomization. Some recent contributions in this area include [6, 52].
Lastly, our proposed design is connected to the multi-armed bandit (MAB) literature. [51] studies the trade-off between regret and statistical estimation efficiency by formulating a minimax multi-objective optimization problem and proposing an effective Pareto optimal MAB experiment. They provide insightful theoretical results on the sufficient and necessary conditions for the Pareto optimal solutions. Our procedure attains the minimax lower bound for fair experiment design problems. Our work has a different focus on uncovering the underlying causal effect by providing an adaptive procedure for efficient treatment effect estimation while incorporating fairness and welfare considerations. Furthermore, in the theoretical investigations, we focus on the asymptotic normality of the proposed estimator and its variance estimator, which enables valid statistical inference. Our work broadly connects with fair contextual bandit literature [14, 18, 20, 32, 41, 44]. [66] and [67] propose algorithms under subpopulation fairness and equity requirements for the tasks of best arm identification and ranking and selection. The work in [31] characterizes fairness under the contextual bandit setting by bridging the fair contextual bandit problems with “Knows What It Knowns” learning. While [31] defines fairness metric on the individual level, we focus on group-level fairness and further incorporate a welfare constraint.
2 Fair adaptive experiment
2.1 Problem formulation and notation
In this section, we formalize our adaptive experiment framework and introduce necessary notations. In adaptive experiments, participants are sequentially enrolled across stages. We denote the total number of enrolled participants as , where is the number of participants in Stage , . In line with the existing literature [25, 26, 29], we assume , and is small relative to the overall sample size , meaning that we have many opportunities to revise the treatment allocation rule during the experiment (see Assumption 3 below). At Stage , we denote participant ’s treatment assignment status as , , with being the treatment arm and being the control arm. Denote participant ’s covariate information as and the observed outcome as .
Next, we quantify causal effects under the Neyman-Rubin potential outcomes framework. Define as the potential outcome we would have observed if participant receives treatment at Stage , . The observed outcome can be written as
| (1) |
In accordance with classical adaptive experiments literature, we assume that the outcomes are observed without delay, and their underlying distributions do not shift over time [26]. The average treatment effect (ATE) is the mean difference between the two potential outcomes:
| (2) |
In our proposed fair adaptive experiment strategy, to protect the participant’s welfare (more discussions in Section 2.2), we also consider the group-level treatment effects. We assume the study population can be partitioned based on demographics or biomarkers, which is frequently seen in clinical settings or social science studies [4, 37, 68]. More concretely, by dividing the sample space of the covariate into non-overlapping regions, denoted as , we define the treatment effect in each group as
| (3) |
We further denote the total number of participants enrolled in the group as .
In adaptive experiments, as we aim to adaptively revise the treatment assignment probabilities based on the evidence accrued during the experiment to meet our fairness and efficiency goals, we define treatment assignment probability (or propensity scores) for participants in groups at stage as
| (4) |
The goal of our experiment is to dynamically revise for efficiency improvement, fairness guarantee, and welfare enhancement.
2.2 Design objective in an oracle setting
Classical adaptive experiments, aimed at reducing variance (or, equivalently, efficiency improvement), often assign treatment using Neyman allocation for participants in each group, that is,
| (5) |
where , denotes the variance of the potential outcome under treatment arm in group . Although Neyman allocation improves the estimation efficiency of the ATE, it brings two critical fairness concerns. First, different groups of participants may have substantially different probabilities of receiving treatments. The form of Eq (5) implies that the treatment assignment probabilities solely rely on group-level variances under different arms. More specifically, the group of participants with a larger variance under the treatment arm will have a higher probability of being treated, which may lead to disproportionate treatment allocations across different groups. Second, some participants’ welfare could be harmed under the adaptive experiment strategy in Eq (5). To see this, assume a group of participants exhibits a large variance yet rather negative responses under the treatment arm. However, more participants in this group will be assigned to the treatment arm to improve the estimation efficiency of ATE despite the impairment of those participants’ welfare.
To address fairness concerns and facilitate the introduction of our experimental goals, we begin with an infeasible “oracle” setting, where we possess knowledge of the true underlying data distribution before the experiment begins. Since adaptive experiments naturally allow for sequential learning of unknown parameters and adjustment of treatment allocations during the experiment, we will present our adaptive experimental design strategy in the following section (Section 2.3), which attains the same theoretical guarantee for estimating the ATE as in the oracle setting (see Theorems 2 and 3 for justification).
In the oracle setting, given we have perfect knowledge of the underlying data distribution (thus and are known to us), our goal is to find optimal treatment allocations that solve the following optimization problem:
| Problem | |||||
| s.t. | |||||
where and . Here, the objective function captures the goal of improving information gain from study participants, which is formalized as minimizing the asymptotic variance of the inverse probability weighting estimator of the ATE (c.f. Theorem 3). The “feasibility” constraint restricts that the treatment assignment probability in each group is bounded away from and by a positive constant .
To ensure fair treatment assignment and mitigate significant disparities in treatment allocations among participant groups, we introduce the “envy-freeness” constraint. This constraint limits the disparity in treatment assignment probabilities across different groups in an acceptable pre-specified range. The concept of “envy-freeness” originates from game theory literature and ensures that agents are content with their allocated resources without envying their peers [3, 5, 24, 42]. By incorporating this envy-freeness constraint, we address the first fairness concern and promote equitable treatment allocation.
To enhance the overall welfare of experiment participants, we introduce the “welfare” constraint. This constraint ensures that a group of participants is more likely to receive the treatment if their treatment effects are positive and less likely to receive the treatment otherwise. Specifically, when the group-level treatment effect , indicating that group benefits from the treatment, we want the treatment assignment probability to be larger than . The welfare constraint achieves this by ensuring that the sign of aligns with the sign of . When incorporating the welfare constraint, we effectively address the second fairness concern by providing more treatment to beneficial groups.
2.3 Learning oracle strategy in adaptive experiments
In this section, we present our fair adaptive experimental design strategy for realistic scenarios where we lack prior knowledge about the underlying data distribution, and our approach achieves the same desirable properties as in the oracle setting (refer to Section 3 for justification).
We present our proposed fair adaptive experiment strategy in Algorithm 1.
Concretely, in Stage (line 2–3), because we have no prior knowledge about the unknown parameters, we obtain initial estimates of the group-level treatment effect and the associated variances . Then, in Stage (line 6–8), our design solves the following sample analog of Problem at each experimental stage:
| Problem | |||||
| s.t. | |||||
Here, we define
| (6) | ||||
One important feature of Problem B is that we introduce a relaxation of the welfare constraint through . From a theoretical perspective, the function should be strictly positive, and satisfies and . For implementation, we recommend using . It is also possible to incorporate the standard error of the estimated subgroup treatment effects into the welfare constraint, which motives the more sophisticated version:
where is the adaptively estimated standard deviation defined in the Supplementary Materials. Scaling the welfare constraint by , a measure of randomness in , delivers a more clear interpretation: the above now corresponds to a t-test for the subgroup treatment effect with a diverging threshold, and the specific choice stems from Schwarz’s minimum BIC rule.
After the final Stage , we have the group-level treatment effect estimates , the variance estimates , and the group proportions (that is, we omit the time index for estimates obtained after the completion of the experiment). Together with valid standard errors, one can conduct statistical inference at a some pre-specified level . To be precise, the estimated ATE is , and we define the following
| (7) | ||||
Lastly, we can construct the two-sided confidence intervals for and as
| (8) |
3 Theoretical investigations
In this section, we investigate the theoretical properties of our proposed fair adaptive experiment strategy, and we demonstrate that our approach achieves the same desirable properties as in the oracle setting. We work under the following assumptions:
Assumption 1.
For and , the covariates and the potential outcomes, , are independently and identically distributed; the potential outcomes have bounded fourth moments: for .
Assumption 2.
The group proportions are bounded away from 0: there exists such that for all .
Assumption 3.
The sample size for each stage, , are of the same order: there exists such that .
Assumption 1 imposes a mild moment condition on the potential outcomes over different stages. Assumption 2 assumes that the proportion of each group is nonzero. Assumption 3 requires that the sample size in each stage are of the same order. We remark that this assumption can be easily relaxed.
Theorem 1 (Consistent treatment effect and variance estimation).
Theorem 1 shows consistency of the group-level treatment effects and the associated variance estimators. This further implies the consistency of the average treatment effect estimator. The proof of Theorem 1 leverages the martingale methods [22].
Building on Theorem 1, we can establish the theoretical properties of the actual treatment allocation under our design strategy.
Theorem 2 (Convergence of actual treatment allocation).
Theorem 2 is a key result. It suggests that despite having minimum knowledge regarding the distribution of the potential outcomes at the experiment’s outset, we are able to adaptively revise the treatment allocation probability using the accrued information, and the actual treatment probabilities under our proposed fair adaptive experiment strategy converges to their oracle counterparts. Building on Theorem 1 and Theorem 2, we are able to establish the asymptotic normality results of our proposed estimators, and show that the standard errors are valid.
Theorem 3 (Asymptotic normality and valid standard errors).
Theorem 3 shows the asymptotic normality results of the estimated treatment effects under our proposed adaptive experiment strategy. In addition, Theorem 3 verifies that the constructed confidence intervals in Eq (8) attain the nominal coverage thanks to the consistency of standard errors. The proof of Theorem 3 relies on the convergence of the actual treatment allocation in Theorem 2 and and the martingale central limit theorem [22].
4 Simulation evidence
In this section, we evaluate the performance of our proposed fair adaptive experiment strategy through simulation studies. We summarize the takeaways from the simulation studies as follows. First, our proposed fair adaptive experiment strategy achieves higher estimation efficiency than the complete randomization design. Second, compared to a classical adaptive experiment strategy, our method avoids disproportionate treatment assignment probabilities across different groups of participants and accounts for participants’ welfare.
Our simulation design generates the potential outcomes under two data-generating processes. DGP 1: Continuous potential outcomes where , , and . The group proportions are . The group-level treatment effects are . DGP 2: Binary potential outcome: , where , . The group proportions are . To mimic our case study, consider the log relative risk as the parameter of interest: . The group-level treatment effects are .
We compare three experiment strategies for treatment assignment: (1) our proposed fair adaptive experiment strategy, (2) the doubly adaptive biased coin design (DBCD) [71], and (3) the complete randomization design, which fixes the treatment allocation probability to be throughout the experiments. To mimic the fully adaptive experiments, we fix stage sample size at and for , where the total number of stages ranges from . We evaluate the performance of each strategy from two angles. First, we compare the standard deviation of the ATE estimates to evaluate the estimation efficiency. Second, we compare the fraction of participants assigned to the treatment arm in each group to evaluate the fairness in treatment allocation. The simulation results are summarized in Figure 1.
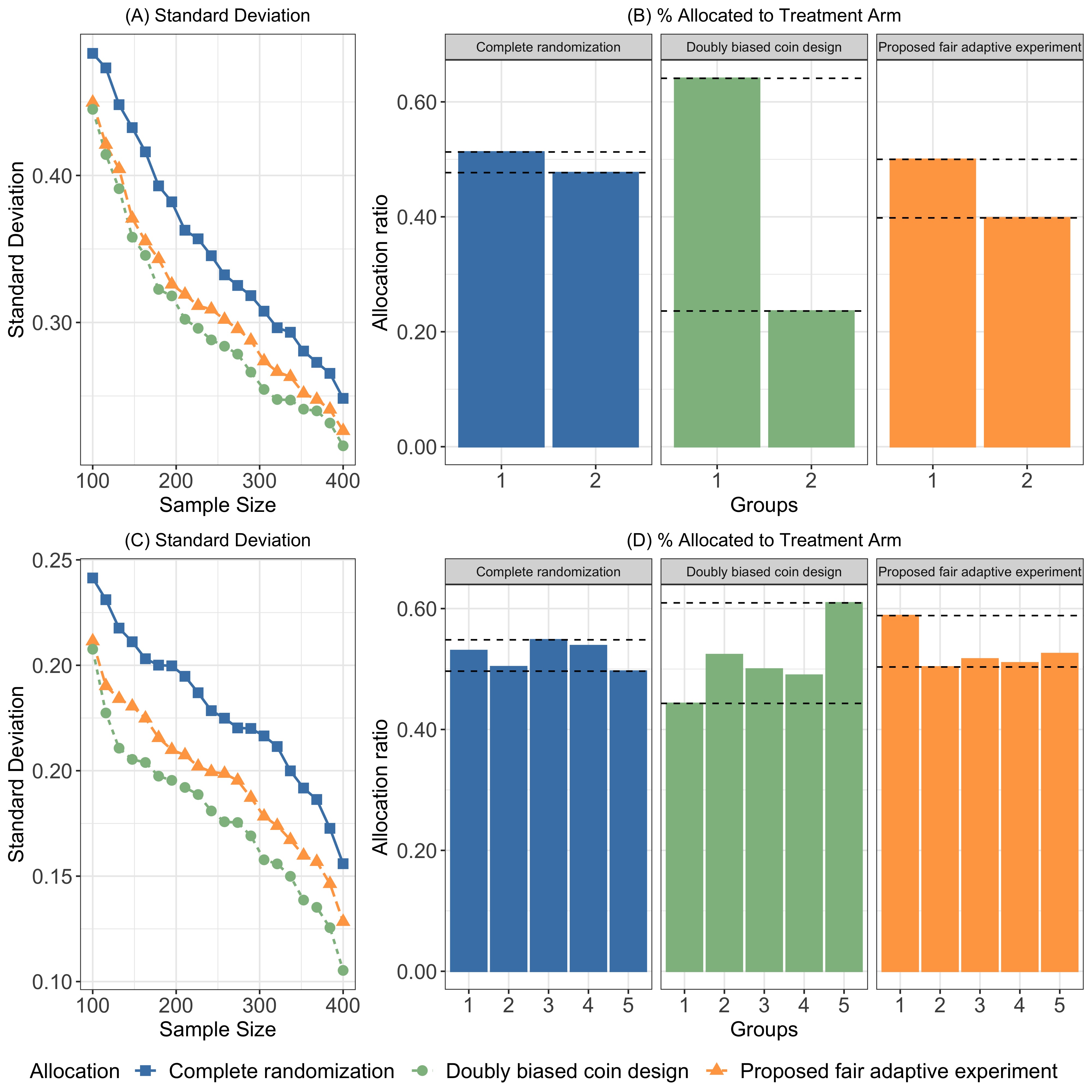
We first focus on panels (A) and (B), which correspond to DGP 1. Panel (A) depicts standard deviations of the treatment effect estimates under the three experiment designs. It clearly demonstrates that our proposed method achieves higher estimation efficiency compared to complete randomization. Figure (B) shows the treatment assignment probabilities produced by the three experiment design strategies. Not surprisingly, complete randomization allocates 50% participants to the treatment arm regardless of their group status. On the other hand, the DBCD design may produce extreme treatment allocations. In addition, participants in different groups may receive drastically different treatment allocations, which can raise fairness concerns. Encouragingly, our approach generates treatment assignment probabilities that not only are closer to 50% (i.e., less extreme) but also exhibit less variation across groups. Panel (C) and (D) summarize the simulation evidence for DGP 2 in which the outcome variable is binary. A similar pattern emerges: our fair adaptive experiment design approach improves upon complete randomization, as it delivers more precise treatment effect estimates. It also accounts for fairness and participants’ welfare in assigning treatments.
The simulation results demonstrate the clear trade-off between fairness/welfare and statistical efficiency by adopting our proposed fair adaptive experiment strategy. Although it involves a minor sacrifice in estimation efficiency when contrasted with the DBCD design, our approach delivers more fair treatment allocations and safeguards participant well-being. As our proposed method does not restrict each group to have exactly the same treatment assignment probabilities as in the complete randomization design, it improves the estimation efficiency of ATE. We provide additional simulation results and synthetic data analyses in the Supplementary Materials.
5 Discussion
In this work, we propose an adaptive experimental design framework to simultaneously improve statistical estimation efficiency and fairness in treatment allocation, while also safeguarding participants’ welfare. One practical limitation of the proposed design is that its objective mainly aligns with the experimenter’s interests in estimating the effect of a treatment, as opposed to the interests of the enrolled participants. This aspect offers opportunities for future research exploration.
References
- [1]
- Aletti et al. [2018] Aletti, G., Ghiglietti, A., and Rosenberger, W. F. (2018). “Nonparametric covariate-adjusted response-adaptive design based on a functional urn model,” The Annals of Statistics, 46(6B), 3838–3866.
- Arnsperger [1994] Arnsperger, C. (1994). “Envy-freeness and distributive justice,” Journal of Economic Surveys, 8(2), 155–186.
- Assmann et al. [2000] Assmann, S. F., Pocock, S. J., Enos, L. E., and Kasten, L. E. (2000). “Subgroup analysis and other (mis) uses of baseline data in clinical trials,” The Lancet, 355(9209), 1064–1069.
- Aziz et al. [2022] Aziz, H., Li, B., Moulin, H., and Wu, X. (2022). “Algorithmic fair allocation of indivisible items: A survey and new questions,” ACM SIGecom Exchanges, 20(1), 24–40.
- Bai [2022] Bai, Y. (2022). “Optimality of matched-pair designs in randomized controlled trials,” American Economic Review, 112(12), 3911–40.
- Bai and Hu [2005] Bai, Z.-D. and Hu, F. (2005). “Asymptotics in randomized urn models,” The Annals of Applied Probability, 15(1B), 914–940.
- Bandyopadhyay and Biswas [1999] Bandyopadhyay, U. and Biswas, A. (1999). “Allocation by randomized play-the-winner rule in the presence of prognostic factors,” Sankhyā B, 397–412.
- Belloni et al. [2017] Belloni, A., Chernozhukov, V., Fernández-Val, I., and Hansen, C. (2017). “Program evaluation and causal inference with high-dimensional data,” Econometrica, 85(1), 233–298.
- Bugni et al. [2019] Bugni, F. A., Canay, I. A., and Shaikh, A. M. (2019). “Inference under covariate-adaptive randomization with multiple treatments,” Quantitative Economics, 10(4), 1747–1785.
- Cattaneo [2010] Cattaneo, M. D. (2010). “Efficient semiparametric estimation of multi-valued treatment effects under ignorability,” Journal of Econometrics, 155(2), 138–154.
- Cattaneo et al. [2019] Cattaneo, M. D., Jansson, M., and Ma, X. (2019). “Two-step estimation and inference with possibly many included covariates,” The Review of Economic Studies, 86(3), 1095–1122.
- Chen et al. [2003] Chen, X., Linton, O., and Van Keilegom, I. (2003). “Estimation of semiparametric models when the criterion function is not smooth,” Econometrica, 71(5), 1591–1608.
- Chen et al. [2020] Chen, Y., Cuellar, A., Luo, H., Modi, J., Nemlekar, H., and Nikolaidis, S. (2020). “Fair contextual multi-armed bandits: Theory and experiments,” In Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI), 124, 181–190, PMLR.
- Chien et al. [2022] Chien, I., Deliu, N., Turner, R., Weller, A., Villar, S., and Kilbertus, N. (2022). “Multi-disciplinary fairness considerations in machine learning for clinical trials,” In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 906–924.
- Eisele [1994] Eisele, J. R. (1994). “The doubly adaptive biased coin design for sequential clinical trials,” Journal of Statistical Planning and Inference, 38(2), 249–261.
- Farrell [2015] Farrell, M. H. (2015). “Robust inference on average treatment effects with possibly more covariates than observations,” Journal of Econometrics, 189(1), 1–23.
- Gillen et al. [2018] Gillen, S., Jung, C., Kearns, M., and Roth, A. (2018). “Online learning with an unknown fairness metric,” In Proceedings of the 32nd International Conference on Neural Information Processing Systems, 31, 2605–2614.
- Giovagnoli [2021] Giovagnoli, A. (2021). “The Bayesian design of adaptive clinical trials,” International Journal of Environmental Research and Public Health, 18(2), 530.
- Grazzi et al. [2022] Grazzi, R., Akhavan, A., Falk, J. I., Cella, L., and Pontil, M. (2022). “Gairness in learning: Classic,” In Proceedings of the 36th Conference on Neural Information Processing Systems, 35, 24392–24404.
- Hahn [1998] Hahn, J. (1998). “On the role of the propensity score in efficient semiparametric estimation of average treatment effects,” Econometrica, 66(2), 315–331.
- Hall and Heyde [2014] Hall, P. and Heyde, C. C. (2014). Martingale Limit Theory and Its Application: Academic Press.
- Hirano et al. [2003] Hirano, K., Imbens, G. W., and Ridder, G. (2003). “Efficient estimation of average treatment effects using the estimated propensity score,” Econometrica, 71(4), 1161–1189.
- Hossain et al. [2020] Hossain, S., Mladenovic, A., and Shah, N. (2020). “Designing fairly fair classifiers via economic fairness notions,” In Proceedings of The Web Conference 2020, 1559–1569.
- Hu and Rosenberger [2003] Hu, F. and Rosenberger, W. F. (2003). “Optimality, variability, power: Evaluating response-adaptive randomization procedures for treatment comparisons,” Journal of the American Statistical Association, 98(463), 671–678.
- Hu and Rosenberger [2006] Hu, F. and Rosenberger, W. F. (2006). The Theory of Response-adaptive Randomization in Clinical Trials: John Wiley & Sons.
- Hu and Zhang [2004] Hu, F. and Zhang, L.-X. (2004). “Asymptotic properties of doubly adaptive biased coin designs for multitreatment clinical trials,” The Annals of Statistics, 32(1), 268–301.
- Hu et al. [2009] Hu, F., Zhang, L.-X., and He, X. (2009). “Efficient randomized-adaptive designs,” The Annals of Statistics, 37(5A), 2543–2560.
- Hu et al. [2015] Hu, J., Zhu, H., and Hu, F. (2015). “A unified family of covariate-adjusted response-adaptive designs based on efficiency and ethics,” Journal of the American Statistical Association, 110(509), 357–367.
- Janson [2004] Janson, S. (2004). “Functional limit theorems for multitype branching processes and generalized Pólya urns,” Stochastic Processes and their Applications, 110(2), 177–245.
- Joseph et al. [2016] Joseph, M., Kearns, M., Morgenstern, J. H., and Roth, A. (2016). “Fairness in learning: Classic and contextual bandits,” In Advances in Neural Information Processing Systems, 29, 325–333.
- Joseph et al. [2018] Joseph, M., Kearns, M., Morgenstern, J., Neel, S., and Roth, A. (2018). “Meritocratic fairness for infinite and contextual bandits,” In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 158–163.
- Karlan and Zinman [2008] Karlan, D. S. and Zinman, J. (2008). “Credit elasticities in less-developed economies: Implications for microfinance,” American Economic Review, 98(3), 1040–68.
- Kato et al. [2020] Kato, M., Ishihara, T., Honda, J., and Narita, Y. (2020). “Efficient adaptive experimental design for average treatment effect estimation,” arXiv preprint arXiv:2002.05308.
- Kharitonov et al. [2015] Kharitonov, E., Vorobev, A., Macdonald, C., Serdyukov, P., and Ounis, I. (2015). “Sequential testing for early stopping of online experiments,” In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, 473–482.
- Kohavi and Longbotham [2017] Kohavi, R. and Longbotham, R. (2017). “Online controlled experiments and A/B testing,” Encyclopedia of Machine Learning and Data Mining, 7(8), 922–929.
- Kubota et al. [2014] Kubota, K., Ichinose, Y., Scagliotti, G., Spigel, D., Kim, J., Shinkai, T., Takeda, K., Kim, S.-W., Hsia, T.-C., Li, R. et al. (2014). “Phase III study (MONET1) of motesanib plus carboplatin/paclitaxel in patients with advanced nonsquamous nonsmall-cell lung cancer (NSCLC): Asian subgroup analysis,” Annals of Oncology, 25(2), 529–536.
- Lin et al. [2015] Lin, Y., Zhu, M., and Su, Z. (2015). “The pursuit of balance: An overview of covariate-adaptive randomization techniques in clinical trials,” Contemporary Clinical Trials, 45(Pt A), 21–25.
- Ma et al. [2023] Ma, X., Sasaki, Y., and Wang, Y. (2023). “Testing limited overlap,” working paper.
- Ma and Wang [2020] Ma, X. and Wang, J. (2020). “Robust inference using inverse probability weighting,” Journal of the American Statistical Association, 115(532), 1851–1860.
- Metevier et al. [2019] Metevier, B., Giguere, S., Brockman, S., Kobren, A., Brun, Y., Brunskill, E., and Thomas, P. S. (2019). “Offline contextual bandits with high probability fairness guarantees,” In Advances in Neural Information Processing Systems, 32, 14922–14933.
- Moulin [2019] Moulin, H. (2019). “Fair division in the internet age,” Annual Review of Economics, 11, 407–441.
- Newey [1990] Newey, W. K. (1990). “Semiparametric efficiency bounds,” Journal of Applied Econometrics, 5(2), 99–135.
- Patil et al. [2021] Patil, V., Ghalme, G., Nair, V., and Narahari, Y. (2021). “Achieving fairness in the stochastic multi-armed bandit problem,” Journal of Machine Learning Research, 22(1), 7885–7915.
- Pocock and Simon [1975] Pocock, S. J. and Simon, R. (1975). “Sequential treatment assignment with balancing for prognostic factors in the controlled clinical trial,” Biometrics, 31(1), 103–115.
- Robertson et al. [2023] Robertson, D. S., Lee, K. M., López-Kolkovska, B. C., and Villar, S. S. (2023). “Response-adaptive randomization in clinical trials: From myths to practical considerations,” Statistical Science, 38(2), 185–208.
- Rosenberger [2002] Rosenberger, W. F. (2002). Randomized Urn Models and Sequential Design: Taylor & Francis.
- Rosenberger and Hu [2004] Rosenberger, W. F. and Hu, F. (2004). “Maximizing power and minimizing treatment failures in clinical trials,” Clinical Trials, 1(2), 141–147.
- Rosenberger and Lachin [1993] Rosenberger, W. F. and Lachin, J. M. (1993). “The use of response-adaptive designs in clinical trials,” Controlled Clinical Trials, 14(6), 471–484.
- Rosenberger et al. [2001] Rosenberger, W. F., Vidyashankar, A., and Agarwal, D. K. (2001). “Covariate-adjusted response-adaptive designs for binary response,” Journal of Biopharmaceutical Statistics, 11(4), 227–236.
- Simchi-Levi and Wang [2023] Simchi-Levi, D. and Wang, C. (2023). “Multi-armed bandit experimental design: Online decision-making and adaptive inference,” In Proceedings of the 26th International Conference on Artificial Intelligence and Statistics, 206, 3086–3097.
- Tabord-Meehan [2023] Tabord-Meehan, M. (2023). “Stratification trees for adaptive randomization in randomized controlled trials,” Review of Economic Studies, 90(5), 2646–2673.
- Thall and Wathen [2007] Thall, P. F. and Wathen, J. K. (2007). “Practical Bayesian adaptive randomisation in clinical trials,” European Journal of Cancer, 43(5), 859–866.
- Tymofyeyev et al. [2007] Tymofyeyev, Y., Rosenberger, W. F., and Hu, F. (2007). “Implementing optimal allocation in sequential binary response experiments,” Journal of the American Statistical Association, 102(477), 224–234.
- van der Vaart [1998] van der Vaart, A. W. (1998). Asymptotic Statistics, New York: Cambridge University Press.
- Villar et al. [2015a] Villar, S. S., Bowden, J., and Wason, J. (2015a). “Multi-armed bandit models for the optimal design of clinical trials: Benefits and challenges,” Statistical Science, 30(2), 199.
- Villar et al. [2018] Villar, S. S., Bowden, J., and Wason, J. (2018). “Response-adaptive designs for binary responses: How to offer patient benefit while being robust to time trends?” Pharmaceutical Statistics, 17(2), 182–197.
- Villar and Rosenberger [2018] Villar, S. S. and Rosenberger, W. F. (2018). “Covariate-adjusted response-adaptive randomization for multi-arm clinical trials using a modified forward looking Gittins index rule,” Biometrics, 74(1), 49–57.
- Villar et al. [2015b] Villar, S. S., Wason, J., and Bowden, J. (2015b). “Response-adaptive randomization for multi-arm clinical trials using the forward looking Gittins index rule,” Biometrics, 71(4), 969–978.
- Wager and Athey [2018] Wager, S. and Athey, S. (2018). “Estimation and inference of heterogeneous treatment effects using random forests,” Journal of the American Statistical Association, 113(523), 1228–1242.
- Wei and Durham [1978] Wei, L. and Durham, S. (1978). “The randomized play-the-winner rule in medical trials,” Journal of the American Statistical Association, 73(364), 840–843.
- Wei et al. [2023] Wei, W., Petersen, M., van der Laan, M. J., Zheng, Z., Wu, C., and Wang, J. (2023). “Efficient targeted learning of heterogeneous treatment effects for multiple subgroups,” Biometrics, 79(3), 1934–1946.
- Williamson et al. [2017] Williamson, S. F., Jacko, P., Villar, S. S., and Jaki, T. (2017). “A Bayesian adaptive design for clinical trials in rare diseases,” Computational Statistics & Data Analysis, 113, 136–153.
- Wu et al. [2022a] Wu, Y., Zheng, Z., Zhang, G., Zhang, Z., and Wang, C. (2022a). “Adaptive A/B Tests and Simultaneous Treatment Parameter Optimization,” arXiv preprint arXiv:2210.06737.
- Wu et al. [2022b] Wu, Y., Zheng, Z., Zhang, G., Zhang, Z., and Wang, C. (2022b). “Non-stationary A/B tests,” In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2079–2089.
- Wu et al. [2023a] Wu, Y., Zheng, Z., and Zhu, T. (2023a). “Best Arm Identification with Fairness Constraints on Subpopulations,” Proceedings of the Winter Simulation Conference.
- Wu et al. [2023b] Wu, Y., Zheng, Z., and Zhu, T. (2023b). “Selection of the Best Policy under Fairness and Equity Constraints,” Working Paper.
- Xu et al. [2016] Xu, Y., Trippa, L., Müller, P., and Ji, Y. (2016). “Subgroup-based adaptive (SUBA) designs for multi-arm biomarker trials,” Statistics in Biosciences, 8(1), 159–180.
- Yin et al. [2012] Yin, G., Chen, N., and Jack Lee, J. (2012). “Phase II trial design with Bayesian adaptive randomization and predictive probability,” Journal of the Royal Statistical Society: Series C (Applied Statistics), 61(2), 219–235.
- Zelen [1994] Zelen, M. (1994). “The randomization and stratification of patients to clinical trials,” Journal of Chronic Diseases, 27(7–8), 365–375.
- Zhang and Rosenberger [2006] Zhang, L. and Rosenberger, W. F. (2006). “Response-adaptive randomization for clinical trials with continuous outcomes,” Biometrics, 62(2), 562–569.
- Zhang et al. [2007] Zhang, L.-X., Hu, F., Cheung, S. H., and Chan, W. S. (2007). “Asymptotic properties of covariate-adjusted response-adaptive designs,” The Annals of Statistics, 35(3), 1166–1182.
- Zhao et al. [2022] Zhao, W., Ma, W., Wang, F., and Hu, F. (2022). “Incorporating covariates information in adaptive clinical trials for precision medicine,” Pharmaceutical Statistics, 21(1), 176–195.