FakeTracer: Catching Face-swap DeepFakes via Implanting Traces in Training
Abstract
Face-swap DeepFake is an emerging AI-based face forgery technique that can replace the original face in a video with a generated face of the target identity while retaining consistent facial attributes such as expression and orientation. Due to the high privacy of faces, the misuse of this technique can raise severe social concerns, drawing tremendous attention to defend against DeepFakes recently. In this paper, we describe a new proactive defense method called FakeTracer to expose face-swap DeepFakes via implanting traces in training. Compared to general face-synthesis DeepFake, the face-swap DeepFake is more complex as it involves identity change, is subjected to the encoding-decoding process, and is trained unsupervised, increasing the difficulty of implanting traces into the training phase. To effectively defend against face-swap DeepFake, we design two types of traces, sustainable trace (STrace) and erasable trace (ETrace), to be added to training faces. During the training, these manipulated faces affect the learning of the face-swap DeepFake model, enabling it to generate faces that only contain sustainable traces. In light of these two traces, our method can effectively expose DeepFakes by identifying them. Extensive experiments corroborate the efficacy of our method on defending against face-swap DeepFake.
Index Terms:
DeepFake, Multimedia Forensics, Proactive Defence.I Introduction
The significant advances in Deep Neural Networks (DNNs) have greatly improved the performance of the generative models [1, 2], leading to a surge of AI-based face forgery techniques, known as DeepFake [3]. DeepFake can manipulate the attributes of original faces such as the identity [4], facial expression and lip movements [5] with high realism using less manual effort, causing severe concerns in society, e.g., the dependability of face recognition systems, the integrity of information on the Internet [6], psychological security, and political stability [7] , etc.
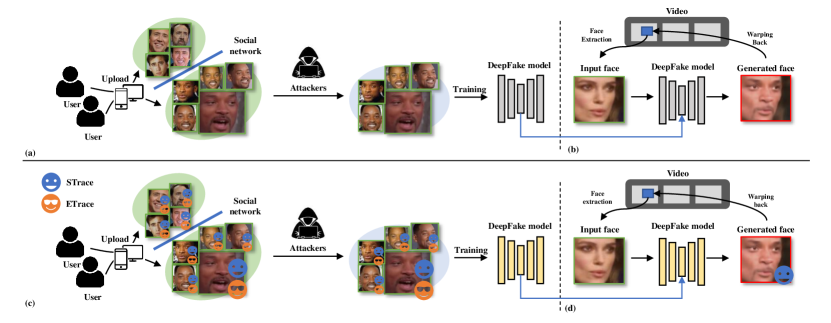
In recent years, lots of countermeasures have emerged to combat DeepFake, e.g., [8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]. In particular, one typical solution for defense is DeepFake detection, which aims to identify forgery faces based on artifacts ranging from spatial to temporal domain [8, 9, 10, 11, 12]. However, even though they can effectively distinguish real and fake faces, they can not intervene in the generation of DeepFake faces, thus failing to prevent the creation and spread of DeepFake videos. As shown in Fig.1(a,b), the adversary could easily access the target identity’s face images from social networks and utilize them to train a DeepFake model.
Proactive defense is a new category of countermeasures that has attracted much attention recently [26, 25, 23, 24, 20, 19, 21, 22]. Compared to DeepFake detection, proactive DeepFake defense goes one step ahead to intentionally manipulate the training or testing process of the DeepFake model, in order to control the generation of DeepFake faces, such as disrupting the visual quality of generated faces using adversarial perturbations [23, 24] or inserting specific watermarks into generated faces [21]. Since we know the detail of the intervention process, the generated faces can be more easily identified.
In this paper, we focus our scope on the face-swap DeepFake, a prevalent forgery technique that can replace the original faces with newly generated faces imperceptibly (See Section II-A) and describe a new proactive method called FakeTracer to defend against face-swap DeepFakes. As shown in Fig. 1(c,d), the goal of our method is to implant specific traces into the face images of users intentionally, and these traces can significantly affect the training of DeepFake model, enabling the model to generate target faces with the desired pattern of traces. We then develop effective interpreters to detect these traces. Note that the existing methods either only disturbs the testing (generation) phase 111The generation phase is equivalent to the testing phase in this paper for better understanding. [22, 23, 24, 25] or focus on defending against the face-synthesis DeepFake, a technique that creates fake faces from random noise by GAN models [21] (See Section II-B). To disturb the testing phase, the input face images must be processed by adding specific perturbations, which limits the practicality of defense methods, and the DeepFake model still has the potential for a generation. In contrast, our method is devoted to implanting traces into the training of face-swap DeepFake models. In this way, the generation ability of the DeepFake model can be affected, and the input face images in the testing phase are not required to be processed. Unlike face-synthesis DeepFake, the face-swap DeepFake models are usually auto-encoder architectures trained in an unsupervised way, involving the identity switch and encoding-decoding process. Despite some methods of defending against face-synthesis DeepFake considers manipulating the training phase, the discrepancy between face-synthesis DeepFake and face-swap DeepFake naturally results in a significant difference in defense workflows (See Section III-C).
To defend against face-swap DeepFake, we design two types of traces: sustainable trace (STrace) and erasable trace (ETrace). The STrace is an imperceptible perturbation that can be retained by the DeepFake model in the training phase, while the ETrace is a fragile perturbation that can be easily wiped off by the DeepFake encoding process. Then we can identify the authenticity of faces by detecting these two traces. The faces are fake if STrace is detected, while the faces are real if no traces are detected, or if both STrace and ETrace are detected (See Section III-B for details). To achieve this goal, we develop an STrace generator to create STrace and create an identifier to recover the binary sequence by giving the STrace and DeepFake face. The successful recovery of the binary sequence represents the DeepFake face containing the STrace. Since the detail of the face-swap DeepFake model may not be accessible in reality, we design an auto-encoder architecture to simulate the encoding-decoding process by performing face reconstruction. Once the users add these two kinds of traces to the face images before uploading them to the social networks, the DeepFake model trained using these traced face images can generate fake faces with sustainable traces but no erasable traces (See Fig. 4). Then the DeepFake faces can be exposed by deciding whether the face contains sustainable and erasable traces: the face is fake if only sustainable traces are detected, and the face is real if no traces are detected, or both sustainable and erasable traces are detected.
Extensive experiments conducted on the Celeb-DF dataset [27] demonstrate our method’s efficacy. We thoroughly study our method under various settings, considering the capacity confronting different DeepFake model architectures, strategies of implanting traces, robustness against many post-processing, etc.
The contributions of this work can be summarized as follows.
-
1.
We describe a new proactive defense method (FakeTracer) to combat the generation of face-swap DeepFake, by only implanting two kinds of traces, sustainable traces and erasable trace, into the training faces for the face-swap DeepFake model, without modifying the model architecture, training and testing process, or other parameters.
-
2.
We comprehensively summarize the difference between face-synthesis DeepFake and face-swap DeepFake, and provide insights for corresponding proactive defense.
-
3.
We thoroughly study the effect of our method on proactively defending against face-swap DeepFake, including the effect of different DeepFake model architectures, contamination fractions, human study on the visual quality of generated faces, strategies of generating sustainable traces, and robustness against post-processing.
This paper extends our preliminary conference paper [28] in several aspects: (1) We elaborate on the difference between face-synthesis DeepFake and face-swap DeepFake in the aspects of training, testing, and architectures, as well as the challenges of defending against face-swap DeepFake in the training phase; (2) We conduct more comprehensive evaluations on defense concerning various thresholds for bit accuracy, and perform more study on various settings, including the effect of using different DeepFake model architectures, the effect of using different strategies of STrace generator, the robustness performance against many post-processing operations, and the human study on the visual quality of generated faces; (3) More tentative experiments are conducted including the efforts on implanting traces in the local region and the performance on the faces with extreme angles.
The rest of the paper is organized as follows. Section II introduces the backgrounds of face-swap and face-synthesis DeepFake, and reviews the related works on defending against DeepFakes. Section III describes the problem settings, including formulation, defense workflow, and the challenges of our method. Section IV describes a preliminary validation of the feasibility of our method. Section V and VI elaborate on the details of creating STrace and ETrace, and Section VII shows extensive experiments.
II Backgrounds and Related Works
II-A Face-swap DeepFake
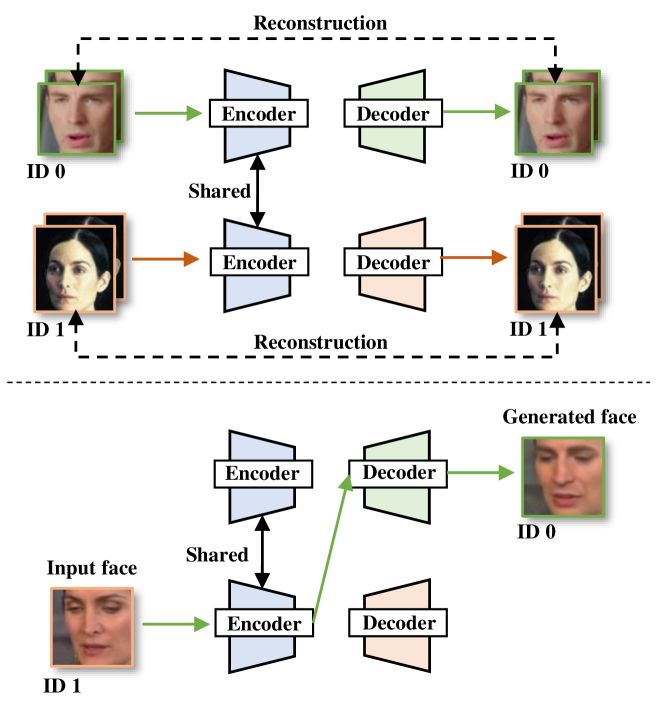
DeepFake stands for Deep Learning and Fake Face, which stems from a Reddit account in 2017 [3]. Originally, DeepFake was a face-swapping technique that could generate a face of the target identity with high realism and replace it with the face of the source identity in a video while retaining consistent facial attributions such as facial expressions and orientations. The basic architecture in DeepFake is an auto-encoder [2]. The encoder can remove the identity-related attributes but retain other attributes, such as facial expressions and orientations. The decoder can recover the appearance of the target identity on the retained facial attributes. The training of the face-swap model is usually in an unsupervised way [29]. Given two independent face sets of source and target identity, one encoder for both identities is utilized, and two encoders corresponding to each identity are created. For one iteration in training, a face of a particular set is forwarded into the encoder to create a latent representation. This representation is sent into the corresponding decoder for face reconstruction. For the next iteration, a face from another set is forwarded into the encoder and another decoder for face reconstruction. These two identities are trained alternately until the generation quality is satisfied. In the testing phase (generation phase), we can select the encoder and a desired decoder as the face-swap DeepFake model. This training pipeline is simple and effective, which is still widely used in current open-source face-swap tools, e.g., FaceSwap222https://faceswap.dev/, DeepFaceLab333https://github.com/iperov/DeepFaceLab. These tools attract tremendous attention due to their low-cost deployment and friendly usage (each has more than stars on GitHub). Note that this technique can impersonate the behavior of the target identity. Thus the abuse of it can cause severe threats, such as making revengeful pornographic videos or forging unreal comments of public figures [3]. Fig. 2 shows the detail of training and testing of the face-swap DeepFake model.
II-B Face-synthesis DeepFake
With the popularization of AI techniques, DeepFake has become a more generalized term for AI-based face forgery techniques. Besides the face-swap technique, another direction is based on GAN models, which can create new faces that do not exist in reality by only giving random noises, e.g., [1, 30, 31, 32, 33]. In general, a GAN model contains a generator and a discriminator. During training, the generator aims to create a new face from random noise, and the discriminator is used to distinguish the authenticity of the generated faces. The generator and discriminator combat each other until a balance is reached. In the testing phase, only the generator is used to map the random noise to a new face with high realism. The architecture, training, and generation process of face-synthesis DeepFake are shown in Fig. 3.

II-C DeepFake Detection
DeepFake detection attempts to determine the authenticity of given faces based on different feature signals, such as physiological signal [34], synthesis artifacts [9], domain transformation [35, 10], and data-driven training with various strategies, such as new designed architectures [36, 11, 8], augmentations [37] and preprocessing [38]. Specifically, the physiological signals used for DeepFake detection include speaking-action pattern [34], heartbeat rhythm [39] and the combinations of multiple physiological signals [40]. For synthesis artifacts, Face X-ray [9] and Self-consistency [41] improve the simulation process, leading to a large performance boost. Gu et al. [16] propose a progressive enhancement learning framework to utilize both the RGB and fine-grained frequency clues for face forgery detection. For data-driven training, Luo et al. [11] utilize high-frequency noise to improve cross-database scenarios. Zhao et al. [8] utilize multiple spatial attention heads and textural feature enhancement blocks to boost performance. RFM [37] proposes an attention-based data augmentation framework to guide the detector to refine and enlarge its attention to boost detection performance. Asnani et al. [15] propose fingerprint estimation and model parsing from generated images to boost detection performance. ITSNet [17] explores the discriminant inconsistency representation by considering both RGB and frequency domain. Guo et al. [18] combine a gradient operator with CNNs to highlight the manipulation traces left by face forgeries and further improve detection performance. Passive DeepFake defense attracts a lot of attention due to its good performance on multiple datasets. However, the passive DeepFake defense can only be used after DeepFake generation, which cannot obstruct the process of DeepFake generation.
II-D Proactive DeepFake Defense
In general, proactive methods tend to add marks in face images in advance, so as to disrupt the generation of DeepFakes. As of today, there are a few proactive DeepFake defense methods, e.g., [25, 23, 24, 20, 19, 21, 22].
FaceGuard[19] designs a pattern of traces that are added to face images uploaded on social networks, and the traces can be eliminated in the DeepFake generation process. Then they detect whether the face images contain these traces. The face is regarded as real if it contains traces. Despite this method provides a concept for proactive DeepFake defense, it is not applicable, because real clean444Clean means real face images not being processed by any method. faces and DeepFake faces can not be distinguished since both can contain no traces. In contrast, FakeTagger[20] encodes traces into face images and retains the traces after the DeepFake generation process. In other words, the generated faces would contain the traces. Note that the defined traces has a specific meaning. Then the DeepFake face can be detected if the traces can be correctly interpreted. Proactive-IMD[22] focuses on detecting images manipulated by GAN models. They do not interfere with the training of generative models. They propose to learn a set of templates adding onto real images. Their detection module could better discriminate the real images with templates and their manipulated counterparts. Disrupting-DeepFakes[24] disrupt DeepFakes by adapting adversarial attack methods to image translation networks. They do not interfere with the training process of generative models. By adding perturbations on input images, the image translation networks could only generate images with bad visual quality. Similarly, the work of [23] also applies an adversarial attack on images to cause the image translation model to fail in converting an image to the model’s designed outcome. They design two strategies to make the generative model either output a similar or unmodified version of the input image or output a broken and disfigured image. OGAN[25] improves [23] by proposing the Oscillating GAN(OGAN) attack method. These aforementioned works are commonly designed for the testing (generation) phase of the DeepFake model. They all regard the DeepFake model as one type of data perturbation process, which thereby does not affect the DeepFake model. Moreover, these methods cannot simply use clean images as input for a generation. Instead, they require all input faces for testing to be processed. Fingerprint [21] considers manipulating the training process of models. They train the model with images all being added on specific traces. In this way, the generated images would also be with traces. However, this method mainly focuses on GAN models, i.e., face-synthesis DeepFake. Since there is a large gap between face-swap DeepFake and face-synthesis DeepFake, it does not apply well on face-swap DeepFakes. Moreover, Fingerprint is designed for model inventors instead of protecting users, as it can not distinguish real faces from traces and fake faces.
These above works either focus on the testing phase, or the training stage of the face-synthesis DeepFake model. Still, they lack exploration on manipulating the training of face-swap DeepFake models. Fig. 2 and Fig. 3 exhibit the difference between face-synthesis and faces-swap DeepFakes tasks. There are significant differences in their application scenarios, as well as in their input forms during the training and testing phases. In this paper, we focus on defending against the face-swap DeepFake by only implanting specific traces into training images.
III Problem Settings
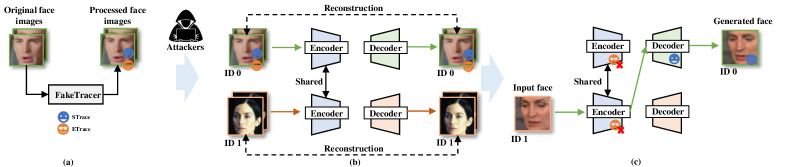
The attackers can collect target face images from the Internet and use these images to train a face-swap DeepFake model. Then they can input the faces of the source identity to generate the faces of the target identity. To obstruct the generation of DeepFake, this paper proposes a new method to disrupt the DeepFake model by only manipulating the faces used for training. The overview of our method is shown in Fig. 4.
III-A Problem Formulations
Denote as the mapping function of DeepFake model with parameters , where is the image space. Given an input face image , the generated face can be denoted as 555We omit the notation of parameters for simplicity hereafter.. Let and denote Sustainable Trace (STrace) and Erasable Trace (ETrace), and corresponding trace generators respectively. Our goal is to manipulate the training of the DeepFake model by adding these two traces on the training faces without any other intervention to the training process. Note that should be embedded into the generation process while should be eliminated by the generation process. By adding these two traces, the DeepFake model is learned only to insert STrace on generated faces. Denote and as the trace interpreter of traces and respectively. Exposing DeepFakes can be formulated as and .
III-B Defense Workflow
To expose DeepFakes, the trace generators and trace interpreters are provided to users as priors. Then the users can create STraces and ETraces, and implant them to the face images uploaded to the Internet (See Fig. 4(a)). Once the attackers train the DeepFake model using these face images, the DeepFake model will be manipulated to generate faces containing STrace but no ETrace. Note that before training, only the face images of the target identity (i.e., the user is willing to be protected) are added these traces, and the training faces of source identity remain untouched. This setting is consistent with reality, as the users are expected to protect themselves by only modifying their face images (See Fig. 4(b,c)). Then we can identify the authenticity of faces using the following criterion: we regard the faces as fake if STrace is detected, and the face as real if no traces are detected, or both STrace and ETrace are detected(Table I).
| STrace | ETrace | Generated? | Remark |
|---|---|---|---|
| ✗ | ✗ | No | Clean images |
| ✓ | ✓ | No | FakeTracer processed images |
| ✓ | ✗ | Yes | FakeTracer identified images |
III-C Challenges
The scenario in our method is more challenging compared to previous methods [19, 20, 22, 23, 24, 25], as we manipulate the training process instead of the testing process, in order to affect the generation of DeepFake model from the root, and the manipulation in this phase is restricted to the training face images. Some other methods focus on defending against face-synthesis DeepFake by manipulating the training process [21]. However, these methods can hardly be employed to defend against face-swap DeepFake, as face-synthesis DeepFake focuses on face generation, which can create new faces based on random noises without considering the encoding process in identity switching. Thus their generator can be easily affected by the manipulated training face images. We take Fingerprint [21] as an example for illustration. By inserting a specific pattern of traces into training faces, the generator can be guided to learn the mapping function from the random noises to the faces with traces added on. However, the case is different in defending against face-swap DeepFake, as it takes face images as input instead of random noises and has an encoding process in training, which likely disrupts the traces implanted on training faces. Moreover, the training process of face-swap DeepFake is more complicated, as it utilizes an unsupervised training scheme involving two identities switching. Therefore, defending against face-swap DeepFake is more challenging.
IV Preliminary Validation
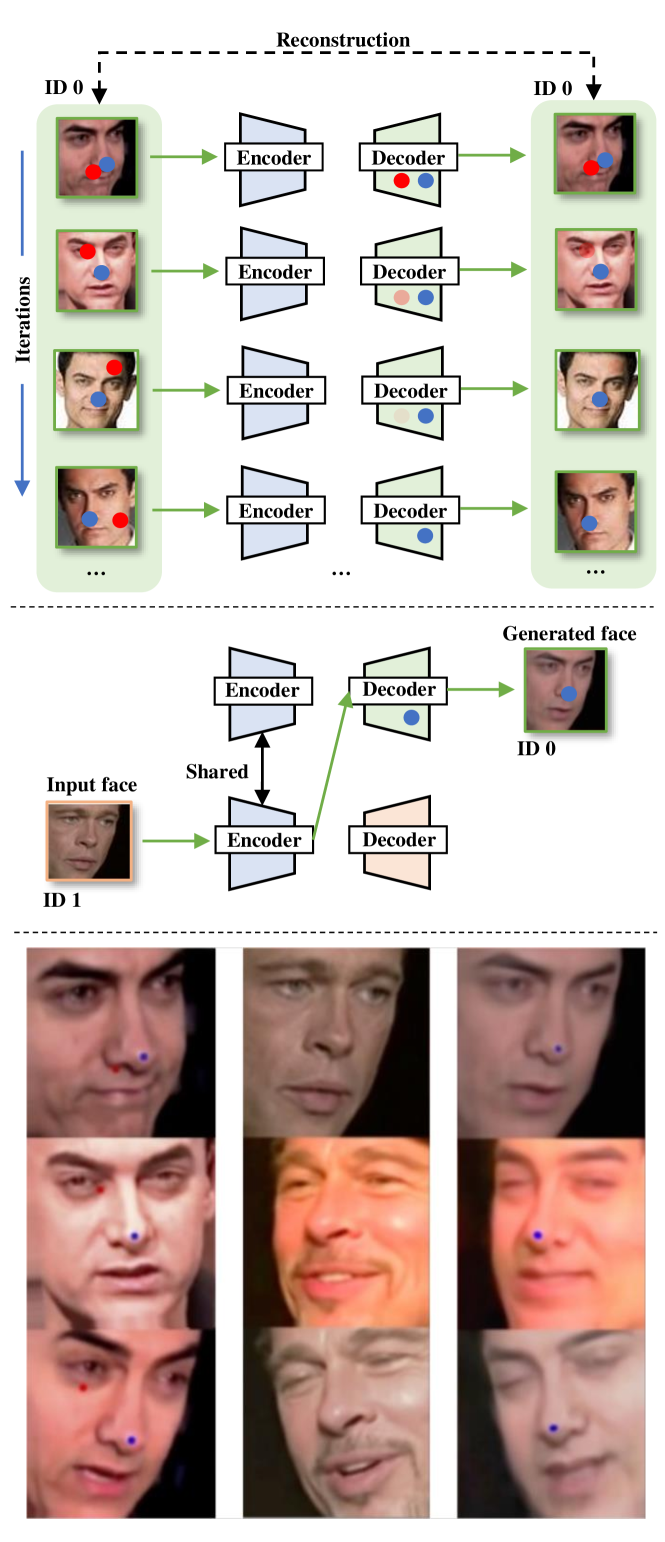
To demonstrate the feasibility of our idea, we conduct a preliminary validation on DeepFake model using two identities of faces for training. Concretely, we design a blue circle, which is on the tip of nose on faces, determined by the facial landmarks. The blue circle is stable in the same relative position of all faces. Thus it is likely regarded as a part of face attributes that are expected to be retained by the encoder and learned by the decoder. The blue circle is analog to the STraces that can be retained in DeepFake generation. Analog to the ETrace, we design a red circle, which is added on a random face position. Due to the randomness, the red circle is irrelevant to the face content, thereby likely viewed as a part of the background that the encoder will ignore. Denote the source faces as ID 0, and the target faces as ID 1. We only manipulate the faces of ID 0 but keep the faces of ID 1 unchanged. As shown in Fig. 5(top), we add these two circles on the training face images of ID 0. During the training, the blue circle is captured by the decoder and can generate faces with this mark. In contrast, the red circle is gradually viewed as background and wiped off by the encoder. After training, a clean face of ID 1 is selected as the ingredient fed into the encoder and corresponding decoder to generate a face of ID 0. Since the decoder learns the pattern of the blue circle, it can generate faces with this mark, see Fig. 5(middle). Several visual examples are shown in Fig. 5(bottom). The left column is the training face images of ID 0 with blue circles on the tip of noises and red circles on random face positions. The middle column shows the input faces of ID 1 for face swapping. The right column corresponds to the generated faces of ID 0. We can observe that the DeepFake model can learn to perfectly retain the blue circle on the tip of the nose while removing the red circle on the faces, which can preliminarily prove that the DeepFake model can be affected by only adding these two marks on training faces. However, the blue and red circles are visible, hindering the practical use of defense. Thus in this paper, we intend to design less noticeable traces to substitute the blue and red circles.
V Sustainable Traces
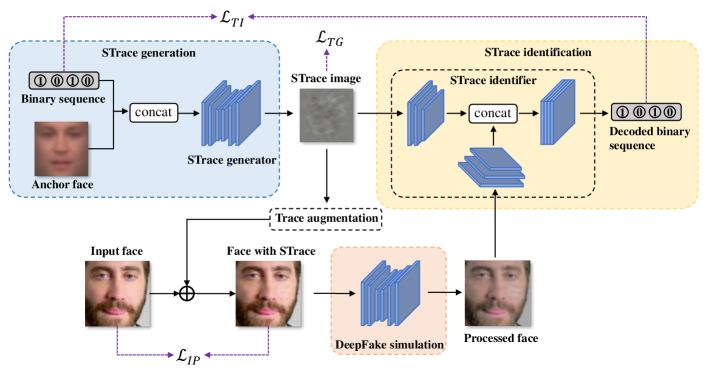
The Sustainable Traces (STrace) implanted on training faces should meet the following three criteria: 1) have minimal effect on the visual quality of face images, 2) can be identifiable, and 3) can be embedded into DeepFake model. To achieve this goal, we develop a STrace generator to create traces, a STrace identifier to decode the traces, and a DeepFake simulator to imitate the process of face swapping, and design objectives to train these architectures jointly. The overview of creating STrace is shown in Fig. 6.
V-A STrace Generation
The STrace generator is an encoder-decoder network where the input is an anchor face image and a binary input sequence, and the output is the image of STrace. The anchor face image is created by averaging all the faces in the training set, which is used to reduce the variance of generated traces. The binary sequence corresponds to the generated traces, which is arbitrarily predefined by users. This network consists of convolutional layers and upsampling layers. A ReLU function except the last one follows each convolutional layer. Let the STrace generator as , the anchor face image as , and the input sequence as . The generated STrace can be defined as .
V-B STrace Identification
Given a face, we should identify the STrace to determine its authenticity. The STrace is successfully identified if the predefined binary sequence is recovered from the given face image. By doing so, we develop a STrace identifier to interpret the STrace from faces. Specifically, the STrace identifier is a two-branch network. One branch is the prior encoder, which corresponds to the input of generated STrace, and the other is the image encoder, which corresponds to the input of a given face. As shown in Fig. 6, one branch encodes the STrace into a vector, and the other encodes the given face into another vector. These two vectors are concatenated and forwarded to a sub-network to recover the binary sequence. Concretely, the STrace identifier contains convolutional layers and fully-connected layer in the prior encoder, convolutional layers and fully-connected layer in image encoder, and fully-connected layers in sub-network. A ReLU function follows each convolutional layer. It is noteworthy that the STrace generator is given to users in advance. Thus the users can know the pattern of STrace before identification, which is thereby used as an auxiliary to improve identification accuracy. Denote the STrace identifier as . Given a generated face , the recovered binary sequence can be defined as .
V-C DeepFake Simulation
We aim to manipulate the DeepFake model to generate faces with predefined binary sequences. The optimal solution for this goal is to train the STrace generator and identifier with the help of the face-swap DeepFake models. However, it is usually impractical to access the details of the DeepFake model in the wild. Therefore, we develop a substitute model to imitate the generation process of face-swap DeepFake. Considering the generation of face-swap DeepFake involves two key aspects, the encoding-decoding process and the identity switch. Compared to the identity switch, the encoding-decoding process has a significant impact on the STrace, as the STrace should survive the encoding process and be learned by the decoding process. To simulate this process, we develop a DeepFake simulator, which is an auto-encoder network similar to the face-swap DeepFake model, but is used only for face reconstruction. Despite not involving face swapping, it can well simulate the encoding-decoding process in the face-swap DeepFake model. The simulator is trained using self-collected faces in advance and then is deployed to reconstruct the faces added on STrace. With the help of this simulator, the STrace identifier can be promoted to learn the informative clues in STrace. DeepFake Simulator’s encoder consists of convolutional layers, each followed by a LeakyReLU function; Its decoder consists of upsampling layers, convolutional layer and Sigmoid layer. There are linear layers and upsampling layer between the DeepFake Simulator’s encoder and decoder.
V-D Objectives and Training
We jointly train the STrace generator and STrace identifier to achieve corresponding functions. Specifically, we develop three loss terms, which are trace generation loss , image perceptual loss , and trace identification loss , respectively. The overall objective function can be written as
| (1) |
The trace generation loss aims to minimize the magnitude of generated noise map as . The image perceptual loss is to maintain the quality of face images after adding traces. We use LPIPS metric [42] in the experiment. The trace interpretation loss is used to recover the input sequence back from the generated faces, which is defined as cross-entropy loss , where denotes the position of the sequence. are weight factors to balance each loss term.
V-E STrace Augmentation
Note that our method is applied in the setting where only the training data can be manipulated in the training process of the DeepFake model. Since the encoding process can naturally disrupt the implanted traces on training faces, we propose augmentation strategies to improve the resistance of STrace against the encoding process. Specifically, we randomly set pixels of trace map as zero and multiply a scaling factor ranging from to . After the trace is added to the input face, we apply other augmentations such as warping, blurring, noise adding, and JPEG compression to increase the diversity further.
VI Erasable Traces
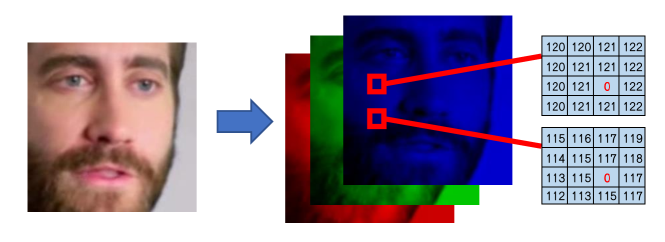
Erasable Trace (ETrace) is proposed to help determine the authenticity of real faces not processed by our method. Specifically, the design of ETraces should also meet three criteria: 1) have minimal effect on the visual quality of face images, 2) can be identifiable, and 3) can be discarded in the DeepFake generation process. To achieve this goal, we create traces independent of the face content, based on the validation in Section IV that the DeepFake decoder can not learn a pattern irrelevant to the face attributes. As shown in Fig. 7, we select a set of positions on the image and set a predefined value to the blue channel of these positions. These positions and predefined values are prior information known to users. Thus the trace can be inserted into any position with any value. This process is imperceptible to human observers, but it can be easily identified if this prior information is provided.
VII Experiment
VII-A Experimental Settings
Dataset. We use DeepFake dataset Celeb-DF [27] for experiments. For embedding sustainable traces, we randomly select 5000 real faces covering all the identities for training and another 5000 real faces for testing. All the faces have the size of .
DeepFake Model. We employ the DeepFake model proposed in Celeb-DF [27] as a demonstration. Specifically, we follow the same training protocol that one encoder and decoders for different identities are trained alternatively. For simplicity, we use identities. Note that in each training pair, only the target identity’s faces are added sustainable and erasable traces, while the faces of the source identity are clean.
Metrics. We use five metrics for evaluation: B-Acc, SSIM, PSNR, FID, and D-Acc. (1) B-Acc is the bit accuracy between the decoded binary sequence and the original input sequence, which indicates how well STrace is retained after DeepFake generation. (2) SSIM, PSNR, and FID are calculated between clean images and images processed with our method. They are used to evaluate the quality of faces with traces on them. (3) D-Acc stands for detection accuracy, which indicates whether a face is correctly classified as real or generated. The face is considered fake if STrace is detected and no ETrace is detected (As shown in Table I). The face contains STrace if B-Acc is larger than a threshold. 666We refer to B-Acc on generated images, D-Acc on generated images, and D-Acc on real images as B-G, D-G, and D-R, respectively.
Compared Methods. To demonstrate the efficacy of our method, we employ two passive detection methods, CNND [43] and RFM[37], and proactive method Fingerprint [21] for comparison. We use the default settings provided by the authors.
Implementation Details. Our method is implemented using PyTorch 1.7.1 on Ubuntu 18.04 with an Nvidia 3090 GPU. In the experiments, we set the length of the binary sequence as bits. The batch size is set as , initial learning rate, are set as . For optimizer we utilize Adam optimizer. We test the decoded message accuracy every 5000 iterations. If the accuracy is higher than a threshold(set as ), we multiply by ; If the accuracy is lower than the threshold, we multiply by . The B-Acc threshold for deciding whether the face is with STrace in D-Acc is .
VII-B Results
B-Acc on generated Faces. We train the DeepFake model for different pairs of identities and each identity uses around 4000 faces for training. Bit Accuracy for the generated images (B-Acc on G) of different pairs of identities is shown in Table II. The indicates the source identity to the target identity. We can observe that our method can interpret the binary sequence from the generated faces precisely (over ), which indicates that the sustainable traces can resist the generation process in the DeepFake model.
| ID pairs | 59 | 57 | 56 | 54 | 45 | 42 |
|---|---|---|---|---|---|---|
| 2 | 4 | 5 | 7 | 16 | 19 | |
| B-Acc on G | 0.93 | 0.93 | 0.92 | 0.97 | 0.94 | 0.92 |
D-Acc and SSIM. To obtain D-Acc, we need to tell whether the face contains STrace and ETrace. The detection of ETrace is accurate, which can achieve accuracy on both real and generated images. Thus we only need to decide whether the face contains STrace. Table III shows the performance of our method on averaging six identities with comparison to the state-of-the-art passive detection methods CNND [43], RFM[37], and proactive method Fingerprint [21] and Proactive-IMD[22]. From results, we can observe that Fingerprint and Proactive-IMD are not effective to defend against face-swap DeepFake compared to us. Moreover, our method can achieve competitive performance with RFM and outperforms CNND by a large margin. Additionally, the SSIM score indicates the traces have a small visible effect on the image quality.
| Methods | D-G | D-R | SSIM | PSNR | FID |
| CNND[43] | 0.03 | 0.99 | / | / | / |
| RFM[37] | 0.99 | 0.82 | / | / | / |
| Fingerprint [21] | 0.0 | 1.0 | 0.99 | 47.54 | 3.36 |
| Proactive-IMD [22] | 0.0 | 1.0 | 0.98 | 42.95 | 38.97 |
| FakeTracer | 0.95 | 0.84 | 0.89 | 36.22 | 21.91 |
Visual Examples. Fig.8 illustrates several visual examples created by our method. We could observe that traces added by our method have less effect on image quality (Fig.8(a, b)), and generated faces with the traces have a similar quality to the ones generated by DeepFake in regular training (Fig.8(e, d)).

User Study for Visual Perceptibility. This part describes a user study for the visual perceptibility of faces processed by our method. Specifically, we design an online questionnaire to study whether the traces can influence identity recognition by human observers. For each question, we first demonstrate clean face images from the same identity and ask the volunteers to score how much they feel like these images belong to the same identity. The scores are ranging from to . We then represent these face images with traces added on and ask the volunteers to repeat the assessment process. The smaller difference between these two scores represents a smaller influence caused by our method on human eyes. Concretely, we choose identities in each questionnaire and ask volunteers to score. The final score of the mean absolute value difference is , which is quite small compared to the score ranging . This user study demonstrates that our method has little influence on visual perceptibility.
VII-C Ablation Study
Effect of Different Components and Strategies. We explore the effects of different components or strategies for embedding STrace in Table IV. Specifically, we study two strategies that are used for trace enhancement, which are random zero setting (RZS) and random scaling (RS). We could observe that the B-Acc notably drops while the SSIM score is improved, which is because the STrace generator learns to generate less intensive sustainable trace and those traces are missing on the generated faces. Moreover, we study the effect of the prior encoder and DeepFake Simulator (DFS) respectively. From Table IV we could observe that removing the prior encoder reduces B-Acc on generated images significantly, which demonstrates that the prior encoder is an effective component for decoding sequence. We can also observe that DeepFake Simulator is critical to the performance compared to using random zero setting and random scaling, which largely drops the B-Acc once it is removed.
| Methods | B-Acc on G | SSIM | PSNR | FID |
|---|---|---|---|---|
| All | 0.94 | 0.89 | 36.22 | 21.91 |
| w/o RZS | 0.82 | 0.98 | 40.14 | 8.51 |
| w/o RS | 0.69 | 0.94 | 39.07 | 10.23 |
| w/o RZS + RS | 0.76 | 0.98 | 42.16 | 7.03 |
| w/o prior encoder | 0.75 | 0.98 | 38.92 | 7.68 |
| w/o DFS | 0.58 | 0.98 | 44.12 | 24.67 |
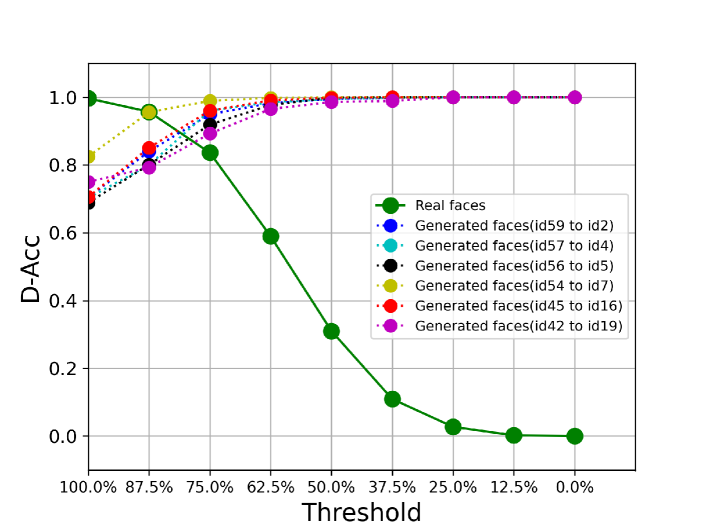
The Effect of Different B-Acc threshold on D-Acc. Fig.9 illustrates D-Acc along with different values of B-Acc thresholds. Note that the threshold denotes the decoded binary sequence completely matching the input binary sequence. We can observe that the D-Acc on real images drops with threshold reducing, as the sequence with less bit matched can be treated as generated faces. On the contrary, D-Acc on generated faces increases with threshold reducing. Thus we select as the threshold for a better balance.
The Effect of Different Fraction of Faces with Traces in Training. We are motivated to investigate the effect of using different fractions of faces with traces in training, as it is unlikely to implant traces on all training faces collected by attackers in real-world scenarios. Thus it is important to study whether the proactive defense can succeed when a small part of training images are processed. To this end, we conduct experiments using different fractions of faces with traces implanted. The results are shown in Table V, where represents that all the training faces are processed by our method and the same to the fraction of and . From Table V, we can observe that our method remains effective even if a portion of training images are processed. Specifically, our method can still perform well at a fraction of . Despite the performance of using training faces with traces being degraded, STrace can still be detected in over half () generated faces.
| Fraction | B-Acc on G | D-Acc on G | D-Acc on R |
|---|---|---|---|
| 0.94 | 0.95 | 0.84 | |
| 0.85 | 0.80 | 0.84 | |
| 0.73 | 0.58 | 0.84 |
The Effect of Different DeepFake Model Architectures. This part investigates the generalization of our method toward different DeepFake models. Note the default DeepFake model used in our experiments has an input size of and an output size of . To increase the diversity of the DeepFake model, we create new architectures using the following rules. For DeepFake encoders, we create two more variants that have input sizes of . Specifically, we add corresponding downsampling convolutional layers, which have kernel size of and stride of . Similarly, we create two more variants for DeepFake decoders which have input sizes of as well. Then we create a new DeepFake model by randomly combining one DeepFake encoder and a DeepFake decoder. To fit in the newly created DeepFake model, our method downsamples the face image resolution without changing the architecture and training details. The performance of our method on different DeepFake models is shown in Table VI. Note that denotes that the DeepFake model consists of a DeepFake encoder that has an input size of and a DeepFake decoder that has an output size of . On the one hand, the results illustrate that the detection performance is highly relevant to the DeepFake decoder architecture. The larger the output size of the DeepFake decoder is, the better the performance our method can achieve. On the other hand, the variance in the input size of DeepFake encoder has little influence on the performance. This is mainly due to that a high capacity of the decoder can learn more clues of implanted traces, which thereby can generate faces with STrace even though the DeepFake encoder is small. We also evaluate our method on DeepFaceLab[4]. Table VI shows that our method also performs favorably on this architecture, showing well generalization ability.
| Architecture | B-G | D-G | D-R |
|---|---|---|---|
| 0.94 | 0.95 | 0.84 | |
| 0.94 | 0.94 | 0.84 | |
| 0.91 | 0.92 | 0.84 | |
| 0.81 | 0.70 | 0.83 | |
| 0.83 | 0.74 | 0.83 | |
| 0.73 | 0.55 | 0.86 | |
| 0.73 | 0.55 | 0.86 | |
| DeepFaceLab[4] | 0.89 | 0.87 | 0.84 |
Evaluation on other datasets. We evaluate our method on another two DeepFake datasets, DFDC and FaceForensics++. We select 6 pairs of identities from each dataset and repeat the same evaluation method. The results are shown in Table VII. It can be observed that the performance of our method is stable across different datasets.
| Datasets | B-G | D-G | D-R | SSIM | PSNR | FID |
| Celeb-DF | 0.94 | 0.95 | 0.84 | 0.89 | 36.22 | 21.91 |
| DFDC | 0.92 | 0.90 | 0.81 | 0.90 | 36.23 | 24.25 |
| FF++ | 0.92 | 0.92 | 0.82 | 0.88 | 36.23 | 31.43 |
VII-D Robustness
The robustness of our method is essential for real-world applications, as the generated faces possibly go through a variety of post-processing operations when uploading them to the Internet. To demonstrate the robustness of our method, we apply different types of post-processing operations to the generated faces and the faces processed by our method for training DeepFake and then evaluate the defense performance. This setting is practical as both the generated faces and the faces processed by our method for training DeepFake can be subject to these post-processing operations on the Internet. Specifically, we use three kinds of post-processing operations, which are JPEG compression (quality factor as ), Gaussian blurring (sigma , kernel size ), and Gaussian noise (sigma , mean value ) respectively.
Table VIII shows the D-Acc of our method against these post-processing operations on generated faces. The training protocol is the same as Table II. Table IX shows the D-Acc of our method with these post-processing operations on the face images processed by our method for training the DeepFake model. The results in these tables reveal that the performance of our method only slightly drops with these post-processing operations, which is mainly because the strategies we develop for trace enhancement in training improve the ability of trace interpreters, and the proposed DeepFake Simulator improves the generalization of learning.
| Perturbations | D-Acc on G | D-Acc on R |
|---|---|---|
| None | 0.95 | 0.84 |
| JPEG | 0.93 | 0.84 |
| GB | 0.92 | 0.84 |
| GN | 0.95 | 0.84 |
| Perturbations | D-Acc on G | D-Acc on R |
|---|---|---|
| None | 0.95 | 0.84 |
| JPEG | 0.93 | 0.84 |
| GB | 0.94 | 0.84 |
| GN | 0.92 | 0.84 |
VIII Discussion
The Role of Anchor Face in STrace Generation. The anchor face in STrace generation aims to provide extra guidance to the encoding process from binary sequence to the trace map. Since the anchor face is obtained on average of many faces, it likely inserts face-relevant information into the generation, leading to a stable training of STrace.
The Connection between Generation Ability and Defense Performance. Our method highly associates with the generation quality of the DeepFake model, i.e., the generation ability of the DeepFake model. Our method can perform well on powerful DeepFake models, as they are competent in learning the pattern of STrace. The case differs from compromised models as they can not generate faces well, much less the STrace. Nevertheless, low-quality generated faces always have apparent artifacts which humans can easily distinguish. Thus it is not necessary to defend against these compromised models. Fig. 10 shows examples of faces generated by a DeepFake model trained with frontal faces. When given an input face with an extreme angle, the DeepFake model cannot generate a high-quality face, subsequently affecting the detection of STrace.

The Feasibility of Implanting Traces Locally. It remains an open question of what kind of STrace can affect the DeepFake model best. In this part, we investigate the feasibility of implanting the traces into the local region. As shown in Fig. 11, we add traces only on the region around the nose, as this region is usually complex that can better hide traces. However, the trace becomes very intensive, largely downgrading the visual quality.

IX Conclusion
This paper describes a new method named FakeTracer to proactively defend against face-swap DeepFake faces. Specifically, we design two types of traces, sustainable trace and erasable trace, that can be added to the training faces to affect the training of DeepFake models. By training on these traced face images, the DeepFake model can learn to insert sustainable traces on generated faces while wiping off the erasable trace. Then we develop different interpreters to decode these traces from face images. Extensive experiments on the Celeb-DF dataset demonstrate the efficacy of our method.
Future Work. We would like to reduce the distortion of STrace further while increasing its load of information. Specifically, we aim to improve the architecture of the STrace generator and identifier with the newly proposed ViTs as the backbone network. Moreover, we intend to further improve the robustness of STrace by incorporating more effective enhancement strategies.
Acknowledgments. This material is based upon work supported by the China Postdoctoral Science Foundation under Grant No. 2021TQ0314 and 2021M703036, and the Fundamental Research Funds for the Central Universities.
References
- [1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Advances in Neural Information Processing Systems (NeurIPS), vol. 27, 2014.
- [2] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” stat, vol. 1050, p. 1, 2014.
- [3] T. T. Nguyen, Q. V. H. Nguyen, C. M. Nguyen, D. Nguyen, D. T. Nguyen, and S. Nahavandi, “Deep learning for deepfakes creation and detection: A survey,” arXiv preprint arXiv:1909.11573, 2019.
- [4] K. Liu, I. Perov, D. Gao, N. Chervoniy, W. Zhou, and W. Zhang, “Deepfacelab: integrated, flexible and extensible face-swapping framework,” Pattern Recognition, p. 109628, 2023.
- [5] A. Gupta, R. Mukhopadhyay, S. Balachandra, F. F. Khan, V. P. Namboodiri, and C. Jawahar, “Towards generating ultra-high resolution talking-face videos with lip synchronization,” in IEEE Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 5209–5218.
- [6] Z. Akhtar, “Deepfakes generation and detection: A short survey,” Journal of Imaging, vol. 9, no. 1, p. 18, 2023.
- [7] K. A. Pantserev, “The malicious use of ai-based deepfake technology as the new threat to psychological security and political stability,” Cyber defence in the age of AI, smart societies and augmented humanity, pp. 37–55, 2020.
- [8] H. Zhao, W. Zhou, D. Chen, T. Wei, W. Zhang, and N. Yu, “Multi-attentional deepfake detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 2185–2194.
- [9] L. Li, J. Bao, T. Zhang, H. Yang, D. Chen, F. Wen, and B. Guo, “Face x-ray for more general face forgery detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5001–5010.
- [10] Y. Qian, G. Yin, L. Sheng, Z. Chen, and J. Shao, “Thinking in frequency: Face forgery detection by mining frequency-aware clues,” in European Conference on Computer Vision (ECCV). Springer, 2020, pp. 86–103.
- [11] Y. Luo, Y. Zhang, J. Yan, and W. Liu, “Generalizing face forgery detection with high-frequency features,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 16 317–16 326.
- [12] J. Li, H. Xie, J. Li, Z. Wang, and Y. Zhang, “Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 6458–6467.
- [13] T. Qiao, R. Shi, X. Luo, M. Xu, N. Zheng, and Y. Wu, “Statistical model-based detector via texture weight map: Application in re-sampling authentication,” IEEE Transactions on Multimedia (TMM), vol. 21, no. 5, pp. 1077–1092, 2018.
- [14] B. Chen, W. Tan, G. Coatrieux, Y. Zheng, and Y.-Q. Shi, “A serial image copy-move forgery localization scheme with source/target distinguishment,” IEEE Transactions on Multimedia (TMM), vol. 23, pp. 3506–3517, 2020.
- [15] V. Asnani, X. Yin, T. Hassner, and X. Liu, “Reverse engineering of generative models: Inferring model hyperparameters from generated images,” arXiv preprint arXiv:2106.07873, 2021.
- [16] Q. Gu, S. Chen, T. Yao, Y. Chen, S. Ding, and R. Yi, “Exploiting fine-grained face forgery clues via progressive enhancement learning,” in AAAI Conference on Artificial Intelligence (AAAI), vol. 36, no. 1, 2022, pp. 735–743.
- [17] J. Wu, B. Zhang, Z. Li, G. Pang, Z. Teng, and J. Fan, “Interactive two-stream network across modalities for deepfake detection,” IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2023.
- [18] Z. Guo, G. Yang, D. Zhang, and M. Xia, “Rethinking gradient operator for exposing ai-enabled face forgeries,” Expert Systems with Applications, vol. 215, p. 119361, 2023.
- [19] Y. Yang, C. Liang, H. He, X. Cao, and N. Z. Gong, “Faceguard: Proactive deepfake detection,” arXiv preprint arXiv:2109.05673, 2021.
- [20] R. Wang, F. Juefei-Xu, M. Luo, Y. Liu, and L. Wang, “Faketagger: Robust safeguards against deepfake dissemination via provenance tracking,” in ACM International Conference on Multimedia (ACMMM), 2021, pp. 3546–3555.
- [21] N. Yu, V. Skripniuk, S. Abdelnabi, and M. Fritz, “Artificial fingerprinting for generative models: Rooting deepfake attribution in training data,” in IEEE International Conference on Computer Vision (ICCV), 2021, pp. 14 448–14 457.
- [22] V. Asnani, X. Yin, T. Hassner, S. Liu, and X. Liu, “Proactive image manipulation detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 15 386–15 395.
- [23] C.-Y. Yeh, H.-W. Chen, S.-L. Tsai, and S.-D. Wang, “Disrupting image-translation-based deepfake algorithms with adversarial attacks,” in IEEE Winter Conference on Applications of Computer Vision Workshops (WCACV), 2020, pp. 53–62.
- [24] N. Ruiz, S. A. Bargal, and S. Sclaroff, “Disrupting deepfakes: Adversarial attacks against conditional image translation networks and facial manipulation systems,” in ECCV Workshops, 2020, pp. 236–251.
- [25] E. Segalis and E. Galili, “Ogan: Disrupting deepfakes with an adversarial attack that survives training,” arXiv preprint arXiv:2006.12247, 2020.
- [26] M. Xue, C. Yuan, C. He, Y. Wu, Z. Wu, Y. Zhang, Z. Liu, and W. Liu, “Use the spear as a shield: An adversarial example based privacy-preserving technique against membership inference attacks,” IEEE Transactions on Emerging Topics in Computing(TETC), vol. 11, no. 1, pp. 153–169, 2022.
- [27] Y. Li, X. Yang, P. Sun, H. Qi, and S. Lyu, “Celeb-df: A large-scale challenging dataset for deepfake forensics,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3207–3216.
- [28] P. Sun, Y. Li, H. Qi, and S. Lyu, “Faketracer: Exposing deepfakes with training data contamination,” in IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 1161–1165.
- [29] M.-Y. Liu, T. Breuel, and J. Kautz, “Unsupervised image-to-image translation networks,” Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017.
- [30] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” in International Conference on Learning Representations (ICLR), 2018.
- [31] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4401–4410.
- [32] F. Peng, L.-P. Yin, L.-B. Zhang, and M. Long, “Cgr-gan: Cg facial image regeneration for antiforensics based on generative adversarial network,” IEEE Transactions on Multimedia (TMM), vol. 22, no. 10, pp. 2511–2525, 2019.
- [33] T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “Analyzing and improving the image quality of stylegan,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8110–8119.
- [34] S. Agarwal, H. Farid, Y. Gu, M. He, K. Nagano, and H. Li, “Protecting world leaders against deep fakes.” in CVPR workshops, vol. 1, 2019.
- [35] H. Li, B. Li, S. Tan, and J. Huang, “Identification of deep network generated images using disparities in color components,” Signal Processing, vol. 174, p. 107616, 2020.
- [36] D. Afchar, V. Nozick, J. Yamagishi, and I. Echizen, “Mesonet: a compact facial video forgery detection network,” in 2018 IEEE international workshop on information forensics and security (WIFS). IEEE, 2018, pp. 1–7.
- [37] C. Wang and W. Deng, “Representative forgery mining for fake face detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 14 923–14 932.
- [38] L. Nataraj, T. M. Mohammed, B. Manjunath, S. Chandrasekaran, A. Flenner, J. H. Bappy, and A. K. Roy-Chowdhury, “Detecting gan generated fake images using co-occurrence matrices,” Electronic Imaging, vol. 2019, no. 5, pp. 532–1, 2019.
- [39] J. Hernandez-Ortega, R. Tolosana, J. Fierrez, and A. Morales, “Deepfakeson-phys: Deepfakes detection based on heart rate estimation,” arXiv preprint arXiv:2010.00400, 2020.
- [40] U. A. Ciftci, I. Demir, and L. Yin, “Fakecatcher: Detection of synthetic portrait videos using biological signals,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
- [41] T. Zhao, X. Xu, M. Xu, H. Ding, Y. Xiong, and W. Xia, “Learning self-consistency for deepfake detection,” in IEEE International Conference on Computer Vision (ICCV), 2021, pp. 15 023–15 033.
- [42] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 586–595.
- [43] S.-Y. Wang, O. Wang, R. Zhang, A. Owens, and A. A. Efros, “Cnn-generated images are surprisingly easy to spot… for now,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8695–8704.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf83643-0f7c-40a2-90f0-e10571bcb80f/sp.jpg) |
Pu Sun is a Ph.D. candidate in the School of Computer Science and Technology, at University of Chinese Academy of Sciences. He received M.S. degree in computer technology at University of Chinese Academy of Sciences in 2021 and B.S. degree in Information Engineering in 2018 at China University of Mining and Technology. His research interest is mainly focused on artificial intelligence security and multimedia forensics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf83643-0f7c-40a2-90f0-e10571bcb80f/hg.png) |
Honggang Qi (Member, IEEE) received the M.S. degree in computer science from Northeast University, Shenyang, China, in 2002, and the Ph.D. degree in computer science from the Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China, in 2008. He is currently a Professor with the School of Computer Science and Technology, University of Chinese Academy of Sciences. His current research interests include computer vision, video coding, and very large scale integration design. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf83643-0f7c-40a2-90f0-e10571bcb80f/lyz.jpg) |
Yuezun Li is a lecturer in the Center on Artificial Intelligence, at Ocean University of China. He was a Senior Research Scientist at the Department of Computer Science and Engineering of the University at Buffalo, SUNY. He received Ph.D. degree in computer science at University at Albany, SUNY in 2020. He received M.S. degree in Computer Science in 2015 and B.S. degree in Software Engineering in 2012 at Shandong University. Dr. Li’s research interest is mainly focused on artificial intelligence security and multimedia forensics. His work has been published in peer-reviewed conferences and journals, including ICCV, CVPR, TCSVT, TNNL, etc. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/aaf83643-0f7c-40a2-90f0-e10571bcb80f/siwei.png) |
Siwei Lyu (Fellow, IEEE) received the B.S. degree in information science and the M.S. degree in computer science from Peking University, China, in 1997 and 2000, respectively, and the Ph.D. degree in computer science from Dartmouth College in 2005. From 2005 to 2008, he was a Post-Doctoral Research Associate with Howard Hughes Medical Institute and the Center for Neural Science of New York University. He is currently a Full Professor in computer science with the University at Buffalo (State University of New York at Buffalo). His research interests include digital media forensics, computer vision, and machine learning. |