Fast and Locally Adaptive Bayesian Quantile Smoothing using Calibrated Variational Approximations
Takahiro Onizuka1, Shintaro Hashimoto1 and Shonosuke Sugasawa2
1Department of Mathematics, Hiroshima University
2Faculty of Economics, Keio University
Abstract
Quantiles are useful characteristics of random variables that can provide substantial information on distributions compared with commonly used summary statistics such as means. In this study, we propose a Bayesian quantile trend filtering method to estimate the non-stationary trend of quantiles. We introduce general shrinkage priors to induce locally adaptive Bayesian inference on trends and mixture representation of the asymmetric Laplace likelihood. To quickly compute the posterior distribution, we develop calibrated mean-field variational approximations to guarantee that the frequentist coverage of credible intervals obtained from the approximated posterior is a specified nominal level. Simulation and empirical studies show that the proposed algorithm is computationally much more efficient than the Gibbs sampler and tends to provide stable inference results, especially for high/low quantiles.
Key words: calibration; shrinkage prior; trend filtering; variational Bayes; nonparametric quantile regression; model misspecification
Introduction
Smoothing or trend estimation is an important statistical method to investigate characteristics of data, and such methods have been applied in various scientific fields such as astronomical spectroscopy (e.g. Politsch et al., 2020), biometrics (e.g. Faulkner et al., 2020), bioinformatics (e.g. Eilers and De Menezes, 2005), economics (e.g. Yamada, 2022) and environmetrics (e.g. Brantley et al., 2020) among others. For estimating underlying trends, the trend filtering (Kim et al., 2009; Tibshirani, 2014) is known to be a powerful tool that can flexibly capture local abrupt changes in trends, compared with spline methods. The trend filtering is known to be a special case of the generalized lasso proposed by Tibshirani and Taylor (2011). Furthermore, fast and efficient optimization algorithms for trend filtering have also been proposed (e.g. Ramdas and Tibshirani, 2016). Due to such advantages in terms of flexibility and computation, extensions of the original trend filtering to spatial data (Wang et al., 2015) and functional data (Wakayama and Sugasawa, 2023, 2024) have been considered. However, the majority of existing studies focus on estimating mean trends with a homogeneous variance structure, and these methods may not work well in the presence of outliers or data with heterogeneous variance. Additionally, we are often interested in estimating quantiles rather than means. Recently, Brantley et al. (2020) proposed a quantile version of trend filtering (QTF) by adding a penalization to the well-known check loss function, but the literature on quantile trend filtering remains scarce.
The main difficulty in applying the optimization-based trend filtering as considered in Brantley et al. (2020) is that uncertainty quantification for trend estimation is not straightforward. Moreover, the frequentist formulation includes tuning parameters in the regularization, but the data-dependent selection of the tuning parameter is not obvious, especially with quantile smoothing. A reasonable alternative is to employ a Bayesian formulation for trend filtering by introducing priors. In particular, Roualdes (2015) and Faulkner and Minin (2018) proposed the use of shrinkage priors for differences between parameters and Kowal et al. (2019) also considered a Bayesian formulation based on a dynamic shrinkage process under Gaussian likelihood to estimate the mean trend. However, the existing approach suffers mainly from three problems; 1) The current methods cannot be applied to quantile smoothing, 2) The posterior computation could be computationally intensive for a large sample size, and 3) The current methods cannot avoid the bias induced by model misspecification, therefore the resulting credible interval may not be valid.
In this study, we first proposed a Bayesian quantile trend filtering method. To this end, we employed the asymmetric Laplace distribution as a working likelihood (Yu and Moyeed, 2001; Sriram et al., 2013). Combining the data augmentation strategy by Kozumi and Kobayashi (2011), we then constructed an efficient Gibbs sampling algorithm and a mean-field variational Bayes (MFVB) algorithm under two types of shrinkage priors; Laplace (Park and Casella, 2008) and horseshoe (Carvalho et al., 2010) priors. It is well-known that the variational Bayes method enables the quick calculation of point estimates, while the MFVB algorithm tends to provide narrower credible intervals than that of Gibbs sampling (e.g. Blei et al., 2017). Additionally, the (possibly) misspecified asymmetric Laplace likelihood may produce invalid credible intervals. To overcome such problems, we proposed a new simulation-based calibration algorithm for variational posterior distribution which is expected to provide fast and valid credible intervals. We demonstrated the usefulness of the proposed methods through extensive simulation studies and real data examples.
The remainder of the paper is structured as follows: In Section 2, we formulate a Bayesian quantile trend filtering method and provide Gibbs sampling and variational Bayes algorithms. In Section 3, we describe the main proposal of this paper, a new calibration algorithm for approximating posterior distribution with variational Bayes approximation. In Section 4, we illustrate simulation studies to compare the performance of the proposed methods. In Section 5, we apply the proposed methods to real data examples. Concluding remarks are presented in Section 7. Additional information on the proposed algorithms and numerical experiments are provided in the Supplementary Material. R code implementing the proposed methods is available at GitHub repository (https://github.com/Takahiro-Onizuka/BQTF-VB).
Bayesian quantile trend filtering
Trend filtering via optimization
Let be a sequence model, where is an observation, is a true location and is a noise. The estimate of trend filtering (Kim et al., 2009) is given by solving the optimization problem
| (1) |
where , , is a difference operator matrix of order , and is a tuning constant. Depending on the different order , we can express various smoothing such as piecewise constant, linear, quadratic, and so forth (see e.g. Tibshirani, 2014). A fast and efficient optimization algorithm for the problem (1) was proposed by Ramdas and Tibshirani (2016).
Recently, Brantley et al. (2020) proposed quantile trend filtering, defined as the optimization problem
| (2) |
where is a tuning constant and is a check loss function given by
| (3) |
To solve the problem (2), Brantley et al. (2020) proposed a parallelizable alternating direction method of multipliers (ADMM) algorithm, and also proposed the selection of smoothing parameters using a modified criterion based on the extended Bayesian information criterion.
Bayesian formulation and shrinkage priors for differences
To conduct Bayesian inference of the quantile trend, we often use the following model:
| (4) |
where and are unknown parameters, is a fixed quantile level, and denotes the asymmetric Laplace distribution with the density function
where is a fixed constant which characterizes the quantile level, (not ) is a scale parameter, and is a check loss function defined by (3). However, we often handle multiple observations per grid point in practice. Hereafter, we considered the following model which accounts for multiple observations per grid point:
| (5) |
where is a -th quantile in the location , is the number of locations data are observed, and is the amount of data for each location . It is a natural generalization of the sequence model (4) (see also Heng et al., 2022). Note that the model (5) is a nonparametric quantile regression with a single covariate, and the proposed approach can easily be generalized for additive regression with multiple covariates. For simplicity in notation, we dropped the subscript from for the remainder of the paper.
We then introduce shrinkage priors on differences. We define the th order difference operator as
where is identity matrix, is zero matrix and is standard difference matrix that is defined by
We consider flexible shrinkage priors on , and the priors are represented by
where represents local shrinkage parameters for each element in and is a global shrinkage parameter. Since the is non-singular matrix, the prior of can be rewritten as
| (6) |
Note that since for , () is not related to shrinkage of difference. For this reason, we assumed the conjugate inverse gamma distribution for . For , we considered two types of distribution; and . These priors were motivated from Laplace or Bayesian lasso prior (Park and Casella, 2008) and horseshoe prior (Carvalho et al., 2010), respectively. Regarding the other parameters, we assigned and . The default choice of hyperparameters is and .
Remark 1.
We follow Tibshirani (2014) for discussion about an extension to the proposed method for the situation where data is observed at an irregular grid. It is equal so that the locations of data have the ordering and is not constant. This issue is related to nonparametric quantile regression. When the locations are irregular and strictly increasing, Tibshirani (2014) proposed an adjusted difference operator for
where and when , is equal to (see also Heng et al., 2022). The matrix is given by
where is a zero matrix.
Gibbs sampler
We first derived a Gibbs sampler by using the stochastic representation of the asymmetric Laplace distribution (Kozumi and Kobayashi, 2011). For , we have the following stochastic expression:
where and for and . From the above expression, the conditional likelihood function of is given by
| (7) |
Under the prior (6), the full conditional distributions of and are given by
respectively, where
and denotes the generalized inverse Gaussian distribution. The full conditional distribution of the scale parameter is given by
where is the number of observed values and
By using the augmentation of the half-Cauchy distribution (Makalic and Schmidt, 2015), the full conditional distribution of the global shrinkage parameter is given by
where is an augmented parameter for . For , we assumed the prior for , and then the full conditional distribution of is given by
The full conditional distribution of local shrinkage parameter () depends on the choice of the prior, either Laplace or horseshoe prior.
-
-
(Laplace-type prior) The full conditional distributions of , , and were already derived. For Laplace-type prior, we set and assume for . Then we have . Noting that , sampling from the standard half-Cauchy prior is equivalent to and using the augmentation technique (Makalic and Schmidt, 2015). Hence, the full conditional distributions of , and are, respectively, given by
-
-
(Horseshoe-type prior) The full conditional distributions of , , and were already derived. For Horseshoe-type prior, we assume for . By using the representation and , the full conditional distributions of and are, respectively, given by
Variational Bayes approximation
The MCMC algorithm presented in Section 2.3 can be computationally intensive when the sample size is large. For the quick computation of the posterior distribution, we derived the variational Bayes approximation (e.g. Blei et al., 2017; Tran et al., 2021) of the joint posterior. The idea of the variational Bayes method is to approximate an intractable posterior distribution by using a simpler probability distribution. Note that the variational Bayes method does not require sampling from the posterior distribution like MCMC, and it searches for an optimal variational posterior by using the optimization method. In particular, we employed the mean-field variational Bayes (MFVB) approximation algorithms that require the forms of full conditional distributions as given in Section 2.3.
The variational distribution is defined by the minimizer of the Kullback-Leibler divergence from to the true posterior distribution
| (8) |
If is decomposed as and parameters are mutually independent, each variational posterior can be updated as
where denotes the parameters other than and denotes the expectation under the probability density given parameters except for . Such a form of approximation is known as the MFVB approximation. If the full conditional distribution of has a familiar form, the above formula is easy to compute. According to the Gibbs sampling algorithm in Section 2.3, we used the following form of variational posteriors:
where
| (9) | ||||
For , we assume the prior for , and then the variational distribution of is given by
The variational distributions of the other parameters depended on the specific choice of the distributional form of , which are provided as follows:
-
-
(Laplace-type prior) The variational distributions for (), and are given by
-
-
(Horseshoe-type prior) The variational distributions for and () are given by
To obtain the variational parameters in each distribution, we update the parameters by using the coordinate ascent algorithm (e.g. Blei et al., 2017). The two proposed variational algorithms based on the above variational distributions are given in Algorithm 1 and 2. Note that we set as the convergence criterion in the simulation study, is a unit vector that the th component is 1, is the th row of difference matrix , and is the modified Bessel function of the second kind with order in Algorithms 1 and 2.
Initialize: . Set under Laplace prior.
-
1.
Cycle the following:
-
2.
For iteration in step 1 and convergence criterion , if , stop the algorithm.
Initialize: .
-
1.
Cycle the following:
-
2.
For some iteration in step 1 and convergence criterion , if , stop the algorithm.
Calibrated variational Bayes approximation
The main proposal of this study is described below. When we use the mean field variational Bayes method, the posterior credible intervals are calculated based on the quantile of the variational posterior. In the proposed model, the variational distribution of the parameter of interest is represented by the normal distribution , where the mean and variance are defined in Section 2.4. Although the variational approximation provides the point estimate quickly, the corresponding credible interval tends to be narrow in general (e.g. Wand et al., 2011; Blei et al., 2017). Additionally, it is well-known that the credible interval can be affected by model misspecification, as addressed by Sriram et al. (2013) and Sriram (2015) in the Bayesian linear quantile regression. Hence, if the asymmetric Laplace working likelihood in the proposed model is mis-specified, the proposed model would not have been able to provide valid credible intervals even if we use the MCMC algorithm.
As presented in the previous subsection, the conditional prior and likelihood of were given by (6) and (7), respectively. Here we add a common (non-random) scale parameter , and then replace (6) and (7) with
respectively. Based on these representations, the variational posterior of is given by
The constant in the likelihood and conditional prior controls the scale of the variational posterior. Indeed, it is natural that the scale of the posteriors was determined by the scale of the likelihood and prior. If the scale parameter is given locally for each (i.e. ), then the variational posterior of is also given by for each . We used the formulation to calibrate credible intervals after the point estimation. The proposed calibration algorithm is given in Algorithm 3.
For calibration of variational posterior at the quantile level , we set the monotonically increasing sequence and run the following four steps:
-
1.
Estimate the variational posterior for -th quantile trend filtering using the observed data .
-
2.
Run the variational algorithm and estimate the variational posterior for -th quantile using the observed data .
-
3.
Generate bootstrap samples based on the residuals , and calculate the variational posteriors as using bootstrap samples .
-
4.
Regarding as posterior samples, for , evaluate the empirical coverage probability
where is % credible intervals under . Then, selecte the optimal value so that
and is the calibrated variational posterior distribution.
Algorithm 3 is similar to the calibration method for general Bayes credible regions proposed by Syring and Martin (2019), but the proposed algorithm drastically differs from the existing calibration method in that it computes variational Bayes posteriors for times while the calibration method by Syring and Martin (2019) runs MCMC algorithms for times. Thus, the proposed algorithm is computationally much faster than the existing calibration algorithm. Further, compared with the Gibbs sampler presented in Section 2.3, steps 3 and 4 in Algorithm 3 can be parallelized so that a significant reduction of computational costs can be attained with the proposed method.
After we obtain the optimal value of using Algorithm 3, we use as the calibrated variational posterior distribution. We then construct the calibrated credible interval of () by calculating the quantile of the marginal distribution of . Here we used the residual bootstrap method (e.g. Efron, 1982) to obtain bootstrap samples in Algorithm 3. Since this algorithm is based on such semiparametric bootstrap sampling, robust uncertainty quantification can be expected even if the asymmetric Laplace assumption is violated.
Remark 2.
In Algorithm 3, we employed the residual bootstrap using 50% quantile trend estimate as a fitted value when we estimated any quantile level. At first glance, it might seem like it is better to use bootstrap sampling based on residue , where is -th quantile trend estimate. However, since our aim is to re-sample from the empirical distribution of the original dataset , the use of a 50% quantile trend estimated as a fitted value in residual bootstrap is reasonable in practice. This is the critical point of Algorithm 1.
To show the theoretical results of Algorithm 3 is not easy as well as the algorithm by Syring and Martin (2019) because it needs to evaluate the approximation errors of both bootstrap and variational approximations. We confirm the proposed algorithm through numerical experiments in the next section.
Simulation studies
We illustrate the performance of the proposed method through simulation studies.
Simulation setting
To compare the performance of the proposed methods, we considered the following data generating processes (see also Faulkner and Minin, 2018; Brantley et al., 2020): We assumed that the data generating process was
where is a true function and is a noise function. First, we considered the following two true functions:
-
-
Piecewise constant (PC)
-
-
Varying smoothness (VS)
Since the scenario (PC) has three change points at , , and , we aim to assess the ability to catch a constant trend and jumping structure. The second scenario (VS) is smooth and has a rapid change near . Hence, the scenario is reasonable to confirm the shrinkage effect of the proposed methods and the adaptation of localized change. As noise functions, we considered the following three scenarios that represented the heterogeneous variance and various types of model misspecification.
-
(I)
Gaussian noise: .
-
(II)
Beta noise: .
-
(III)
Mixed normal noise: .
For each scenario, simulated true quantile trends are summarized in Figure S1 of the Supplementary Materials. True quantile trends were computed from the quantiles of point-wise noise distributions. We next introduce the details of simulations. We used the two MCMC methods (denoted by MCMC-HS and MCMC-Lap), two non-calibrated variational Bayes methods (denoted by VB-HS and VB-Lap), and two calibrated variational Bayes methods (denoted by CVB-HS and CVB-Lap), where HS and Lap are the horseshoe and Laplace priors, respectively. Note that we implemented CVB without parallelization although the bootstrap calibration steps in CVB can be parallelized. To compare with the frequentist method, we used the quantile trend filtering based on the ADMM algorithm proposed by Brantley et al. (2020), where the penalty parameter of Brantley’s method was determined by the extended Bayesian information criteria. The method can be implemented using their R package in https://github.com/halleybrantley/detrendr. For the order of trend filtering, we considered for (PC) and for (VS). Note that express the piecewise constant and the piecewise linear, respectively. We generated 7,500 posterior samples by using the Gibbs sampler presented in Section 2.3, and then only every 10th scan was saved (thinning). As criteria to measure the performance, we adopted the mean squared error (MSE), mean absolute deviation (MAD), mean credible interval width (MCIW), and coverage probability (CP) which are defined by
respectively, where represent the % posterior quantiles of and are true quantiles of at location . Additional simulation results under a different true function are provided in the Supplementary Materials.
Simulation results
We show the simulation results for each scenario. Note that the point estimates of the variational Bayes method were the same as those of the calibrated variational method because the difference between them was only the variance of the variational posterior distribution. Hence, we omitted the results of the CVB-HS and CVB-Lap in Tables 1 and 3. The frequentist quantile trend filtering by Brantley et al. (2020) is denoted by “ADMM”.
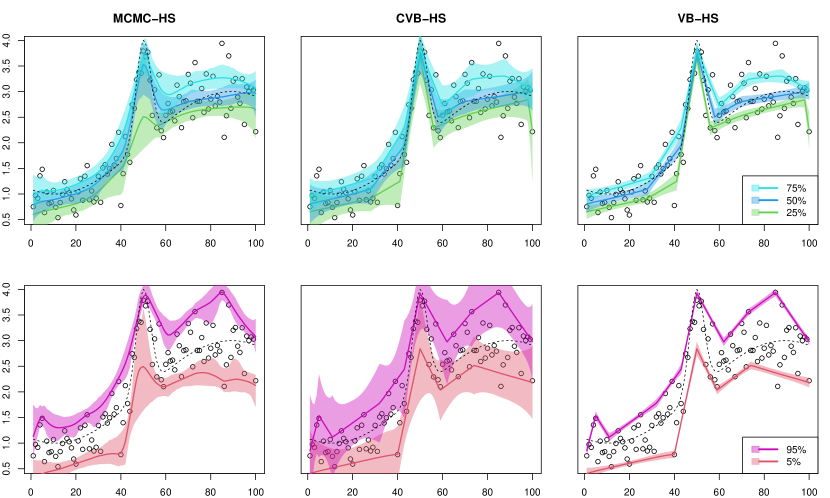
Piecewise constant. We summarized the numerical results of the point estimate and uncertainty quantification in Tables 1 and 2, respectively. From Table 1, we observed that the point estimates of the MCMC-HS method performed the best in all cases, and the frequentist ADMM method performed the worst in terms of MSE and MAD. For uncertainty quantification, it was shown that the MCMC methods have reasonable coverage probabilities for center quantiles such as , , and except for the case of beta distributed noise, while the MCMC methods for extremal quantiles such as and appear to be far away from the nominal coverage rate . The MCIW of the VB-HS and VB-Lap methods tended to be shorter than that of the MCMC therefore, the corresponding coverage probabilities were extremely underestimated. However, the CVB-HS and CVB-Lap methods could quantify the uncertainty in almost all cases including extremal quantiles. We also show one-shot simulation results under the Gaussian noise in Figure 1. As shown in the figure, the credible intervals of CVB-HS are similar to those of MCMC-HS for , , and quantiles. Furthermore, the calibrated credible intervals by CVB-HS are wider than those of the MCMC for extremal quantiles.
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.046 | 0.013 | 0.009 | 0.013 | 0.046 | 0.168 | 0.083 | 0.069 | 0.083 | 0.168 |
| VB-HS | 0.094 | 0.033 | 0.026 | 0.034 | 0.053 | 0.198 | 0.133 | 0.112 | 0.132 | 0.182 |
| MCMC-Lap | 0.105 | 0.050 | 0.040 | 0.050 | 0.106 | 0.263 | 0.173 | 0.154 | 0.172 | 0.266 |
| VB-Lap | 0.091 | 0.042 | 0.033 | 0.038 | 0.059 | 0.213 | 0.155 | 0.139 | 0.149 | 0.191 |
| ADMM | 0.384 | 0.040 | 0.045 | 0.102 | 0.304 | 0.357 | 0.147 | 0.168 | 0.190 | 0.343 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.004 | 0.003 | 0.004 | 0.007 | 0.020 | 0.026 | 0.027 | 0.040 | 0.056 | 0.109 |
| VB-HS | 0.001 | 0.006 | 0.009 | 0.014 | 0.020 | 0.014 | 0.039 | 0.058 | 0.082 | 0.112 |
| MCMC-Lap | 0.013 | 0.015 | 0.015 | 0.019 | 0.038 | 0.078 | 0.081 | 0.086 | 0.102 | 0.156 |
| VB-Lap | 0.059 | 0.009 | 0.011 | 0.014 | 0.019 | 0.083 | 0.060 | 0.072 | 0.086 | 0.106 |
| ADMM | 0.793 | 0.003 | 0.011 | 0.101 | 0.442 | 0.437 | 0.041 | 0.085 | 0.164 | 0.411 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.089 | 0.036 | 0.029 | 0.039 | 0.102 | 0.235 | 0.136 | 0.123 | 0.141 | 0.250 |
| VB-HS | 0.247 | 0.080 | 0.067 | 0.085 | 0.125 | 0.316 | 0.209 | 0.190 | 0.216 | 0.275 |
| MCMC-Lap | 0.191 | 0.094 | 0.078 | 0.095 | 0.204 | 0.365 | 0.240 | 0.217 | 0.242 | 0.379 |
| VB-Lap | 0.137 | 0.079 | 0.069 | 0.079 | 0.126 | 0.282 | 0.213 | 0.201 | 0.215 | 0.273 |
| ADMM | 0.315 | 0.183 | 0.123 | 0.170 | 0.236 | 0.386 | 0.271 | 0.266 | 0.284 | 0.351 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.549 | 0.447 | 0.412 | 0.437 | 0.543 | 0.757 | 0.950 | 0.970 | 0.943 | 0.761 |
| CVB-HS | 1.034 | 0.620 | 0.471 | 0.596 | 1.015 | 0.929 | 0.924 | 0.904 | 0.920 | 0.922 |
| VB-HS | 0.117 | 0.205 | 0.221 | 0.205 | 0.117 | 0.189 | 0.477 | 0.611 | 0.462 | 0.187 |
| MCMC-Lap | 0.775 | 0.764 | 0.785 | 0.759 | 0.762 | 0.806 | 0.923 | 0.960 | 0.926 | 0.800 |
| CVB-Lap | 1.039 | 0.822 | 0.606 | 0.792 | 0.990 | 0.926 | 0.952 | 0.910 | 0.953 | 0.941 |
| VB-Lap | 0.404 | 0.562 | 0.596 | 0.556 | 0.408 | 0.568 | 0.852 | 0.907 | 0.871 | 0.607 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.113 | 0.137 | 0.186 | 0.245 | 0.295 | 0.975 | 0.959 | 0.940 | 0.916 | 0.676 |
| CVB-HS | 0.282 | 0.202 | 0.207 | 0.360 | 0.640 | 0.992 | 0.938 | 0.864 | 0.894 | 0.926 |
| VB-HS | 0.034 | 0.069 | 0.094 | 0.099 | 0.063 | 0.805 | 0.682 | 0.573 | 0.405 | 0.167 |
| MCMC-Lap | 0.377 | 0.326 | 0.326 | 0.309 | 0.390 | 0.952 | 0.927 | 0.902 | 0.807 | 0.756 |
| CVB-Lap | 0.281 | 0.305 | 0.307 | 0.385 | 0.407 | 0.908 | 0.929 | 0.899 | 0.889 | 0.835 |
| VB-Lap | 0.214 | 0.274 | 0.307 | 0.296 | 0.264 | 0.855 | 0.916 | 0.899 | 0.827 | 0.676 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.871 | 0.730 | 0.696 | 0.730 | 0.863 | 0.797 | 0.943 | 0.972 | 0.947 | 0.784 |
| CVB-HS | 1.536 | 0.926 | 0.780 | 0.942 | 1.577 | 0.929 | 0.931 | 0.919 | 0.928 | 0.955 |
| VB-HS | 0.177 | 0.318 | 0.342 | 0.316 | 0.177 | 0.212 | 0.453 | 0.518 | 0.434 | 0.206 |
| MCMC-Lap | 1.129 | 1.135 | 1.135 | 1.125 | 1.097 | 0.830 | 0.940 | 0.963 | 0.942 | 0.795 |
| CVB-Lap | 1.573 | 1.155 | 0.891 | 1.159 | 1.572 | 0.947 | 0.960 | 0.920 | 0.962 | 0.954 |
| VB-Lap | 0.548 | 0.778 | 0.818 | 0.770 | 0.556 | 0.575 | 0.852 | 0.897 | 0.851 | 0.595 |
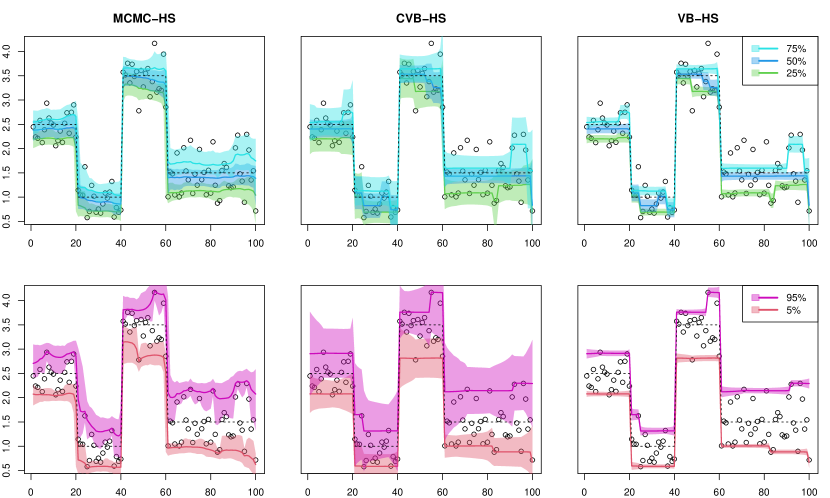
Varying smoothness. The results for the (VS) scenario are reported in Tables 3 and 4. From Table 3, the MCMC-HS method also performed well relative to the other methods in terms of point estimation, while the variational Bayes methods under horseshoe prior also provided comparable point estimates. Different from the (PC) scenario, the MCMC methods had slightly worse coverage probabilities. In particular, the MCMC-HS and MCMC-Lap under the mixed normal noise, which is a relatively high degree of misspecification, appeard to be far from the nominal coverage rate of . Although the MCIW of the variational Bayes methods without calibration also tended to be shorter than that of MCMC, the calibrated variational Bayes dramatically improved the coverage even under the mixed normal case. We also show one-shot simulation results under the Gaussian noise in Figure 2.
Finally, we assessed the efficiency of posterior computation. To this end, we calculated the raw computing time and effective sample size per unit time. The latter is defined as the effective sample size divided by the computation time in seconds. Note that the effective sample size for the variational Bayes methods (VB and CVB) was 7,500 since i.i.d. samples could be drawn from variational posterior distributions. The values averaged over 100 replications of simulating datasets are presented in Table 5. The results show that the proposed algorithm provides posterior samples much more efficiently than the MCMC algorithm. Such computationally efficient property of the proposed method is a benefit of a novel combination of variational approximation and posterior calibration.
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.068 | 0.034 | 0.017 | 0.019 | 0.041 | 0.179 | 0.119 | 0.097 | 0.104 | 0.156 |
| VB-HS | 0.133 | 0.026 | 0.020 | 0.025 | 0.056 | 0.229 | 0.119 | 0.105 | 0.117 | 0.180 |
| MCMC-Lap | 0.064 | 0.039 | 0.026 | 0.028 | 0.057 | 0.194 | 0.138 | 0.122 | 0.128 | 0.188 |
| VB-Lap | 0.097 | 0.052 | 0.027 | 0.028 | 0.058 | 0.209 | 0.143 | 0.121 | 0.128 | 0.190 |
| ADMM | 0.177 | 0.075 | 0.031 | 0.035 | 0.097 | 0.237 | 0.163 | 0.123 | 0.137 | 0.230 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.004 | 0.004 | 0.004 | 0.007 | 0.014 | 0.042 | 0.037 | 0.046 | 0.058 | 0.092 |
| VB-HS | 0.101 | 0.005 | 0.006 | 0.009 | 0.020 | 0.107 | 0.044 | 0.053 | 0.069 | 0.106 |
| MCMC-Lap | 0.006 | 0.005 | 0.006 | 0.009 | 0.022 | 0.054 | 0.046 | 0.057 | 0.072 | 0.115 |
| VB-Lap | 0.022 | 0.005 | 0.006 | 0.010 | 0.021 | 0.067 | 0.043 | 0.056 | 0.072 | 0.113 |
| ADMM | 0.204 | 0.057 | 0.011 | 0.018 | 0.094 | 0.171 | 0.100 | 0.068 | 0.088 | 0.199 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.147 | 0.130 | 0.077 | 0.055 | 0.090 | 0.253 | 0.214 | 0.181 | 0.172 | 0.230 |
| VB-HS | 0.167 | 0.062 | 0.047 | 0.056 | 0.114 | 0.279 | 0.181 | 0.162 | 0.178 | 0.258 |
| MCMC-Lap | 0.108 | 0.085 | 0.061 | 0.060 | 0.112 | 0.255 | 0.198 | 0.180 | 0.188 | 0.265 |
| VB-Lap | 0.147 | 0.106 | 0.072 | 0.066 | 0.114 | 0.274 | 0.206 | 0.186 | 0.194 | 0.263 |
| ADMM | 0.195 | 0.088 | 0.057 | 0.066 | 0.138 | 0.284 | 0.202 | 0.174 | 0.192 | 0.287 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.498 | 0.476 | 0.447 | 0.444 | 0.446 | 0.730 | 0.890 | 0.930 | 0.903 | 0.728 |
| CVB-HS | 1.010 | 0.592 | 0.496 | 0.572 | 1.097 | 0.911 | 0.935 | 0.936 | 0.937 | 0.956 |
| VB-HS | 0.124 | 0.196 | 0.209 | 0.195 | 0.118 | 0.206 | 0.505 | 0.584 | 0.518 | 0.215 |
| MCMC-Lap | 0.545 | 0.571 | 0.562 | 0.553 | 0.524 | 0.760 | 0.897 | 0.929 | 0.914 | 0.756 |
| CVB-Lap | 1.335 | 0.890 | 0.602 | 0.821 | 1.240 | 0.961 | 0.960 | 0.937 | 0.977 | 0.968 |
| VB-Lap | 0.207 | 0.326 | 0.369 | 0.348 | 0.227 | 0.346 | 0.705 | 0.788 | 0.726 | 0.364 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.162 | 0.178 | 0.213 | 0.241 | 0.260 | 0.931 | 0.941 | 0.925 | 0.898 | 0.713 |
| CVB-HS | 0.445 | 0.259 | 0.209 | 0.347 | 0.724 | 0.927 | 0.950 | 0.884 | 0.935 | 0.969 |
| VB-HS | 0.051 | 0.085 | 0.103 | 0.104 | 0.065 | 0.502 | 0.656 | 0.606 | 0.487 | 0.219 |
| MCMC-Lap | 0.251 | 0.248 | 0.282 | 0.306 | 0.304 | 0.953 | 0.952 | 0.942 | 0.903 | 0.736 |
| CVB-Lap | 0.522 | 0.362 | 0.268 | 0.458 | 0.673 | 0.968 | 0.976 | 0.923 | 0.969 | 0.954 |
| VB-Lap | 0.108 | 0.164 | 0.199 | 0.201 | 0.136 | 0.723 | 0.874 | 0.854 | 0.756 | 0.368 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.600 | 0.636 | 0.654 | 0.655 | 0.666 | 0.692 | 0.838 | 0.874 | 0.876 | 0.743 |
| CVB-HS | 1.271 | 0.854 | 0.747 | 0.850 | 1.540 | 0.909 | 0.926 | 0.927 | 0.934 | 0.961 |
| VB-HS | 0.172 | 0.286 | 0.303 | 0.284 | 0.178 | 0.211 | 0.490 | 0.558 | 0.496 | 0.226 |
| MCMC-Lap | 0.727 | 0.755 | 0.765 | 0.768 | 0.755 | 0.753 | 0.885 | 0.907 | 0.891 | 0.749 |
| CVB-Lap | 1.780 | 1.214 | 0.891 | 1.249 | 1.972 | 0.963 | 0.942 | 0.924 | 0.969 | 0.979 |
| VB-Lap | 0.279 | 0.400 | 0.458 | 0.455 | 0.324 | 0.330 | 0.647 | 0.711 | 0.677 | 0.394 |
| (PC) Piecewise constant | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Computation time (second) | ESS (per second) | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 33 | 32 | 32 | 32 | 33 | 13 | 39 | 45 | 40 | 13 |
| CVB-HS | 13 | 9 | 11 | 9 | 12 | 603 | 869 | 699 | 867 | 613 |
| MCMC-Lap | 37 | 36 | 36 | 36 | 37 | 12 | 81 | 109 | 82 | 13 |
| CVB-Lap | 12 | 9 | 9 | 7 | 11 | 662 | 848 | 862 | 1120 | 687 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 32 | 32 | 32 | 32 | 33 | 13 | 61 | 59 | 41 | 13 |
| CVB-HS | 8 | 7 | 9 | 8 | 10 | 1006 | 1089 | 874 | 991 | 792 |
| MCMC-Lap | 37 | 37 | 37 | 37 | 37 | 11 | 79 | 126 | 74 | 12 |
| CVB-Lap | 6 | 5 | 8 | 4 | 6 | 1306 | 1654 | 894 | 1791 | 1287 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 32 | 31 | 31 | 32 | 32 | 13 | 35 | 40 | 35 | 13 |
| CVB-HS | 16 | 11 | 12 | 10 | 15 | 493 | 724 | 606 | 731 | 497 |
| MCMC-Lap | 36 | 36 | 36 | 36 | 36 | 13 | 78 | 98 | 79 | 14 |
| CVB-Lap | 15 | 12 | 9 | 9 | 13 | 513 | 634 | 807 | 883 | 586 |
| (VS) Varying smoothness | ||||||||||
| Computation time (second) | ESS (per second) | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 32 | 32 | 32 | 32 | 32 | 13 | 31 | 37 | 35 | 14 |
| CVB-HS | 12 | 8 | 11 | 8 | 13 | 620 | 897 | 679 | 923 | 575 |
| MCMC-Lap | 36 | 35 | 35 | 35 | 36 | 13 | 53 | 72 | 65 | 13 |
| CVB-Lap | 16 | 13 | 11 | 11 | 15 | 471 | 588 | 684 | 713 | 519 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 33 | 33 | 33 | 33 | 33 | 12 | 48 | 45 | 38 | 14 |
| CVB-HS | 9 | 7 | 10 | 7 | 11 | 861 | 1118 | 780 | 1075 | 699 |
| MCMC-Lap | 36 | 36 | 36 | 36 | 36 | 11 | 78 | 105 | 69 | 12 |
| CVB-Lap | 11 | 6 | 9 | 6 | 9 | 740 | 1202 | 813 | 1181 | 879 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 32 | 32 | 32 | 32 | 32 | 14 | 25 | 30 | 30 | 15 |
| CVB-HS | 14 | 10 | 13 | 10 | 16 | 555 | 756 | 593 | 779 | 481 |
| MCMC-Lap | 36 | 36 | 36 | 36 | 36 | 14 | 36 | 49 | 51 | 14 |
| CVB-Lap | 22 | 20 | 17 | 19 | 23 | 359 | 392 | 463 | 412 | 335 |
Real data analysis
Nile data
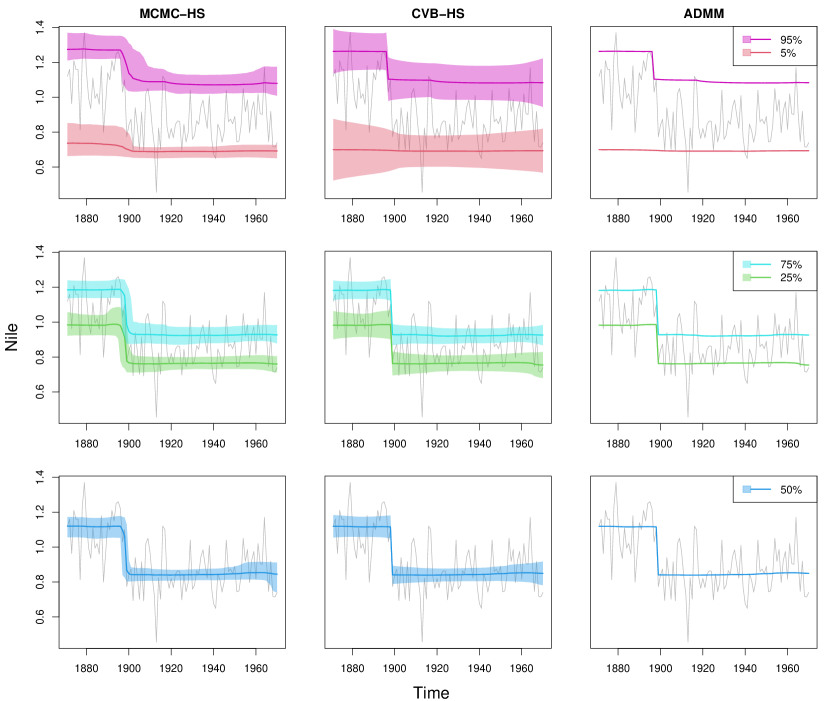
We first applied the proposed methods to the famous Nile river data (Cobb, 1978; Balke, 1993). The data contains measurements of the annual flow of the river Nile from 1871 to 1970, and we found an apparent change-point near 1898. We considered and compared the three methods, that is MCMC-HS, CVB-HS, and ADMM. We generated 60,000 posterior samples after discarding the first 10,000 posterior samples as burn-in, and then only every 10th scan was saved. For the Bayesian methods, we adopted as hyperparameters in the inverse gamma prior to . The resulting estimates of quantiles and the corresponding 95% credible intervals are shown in Figure 3. In terms of point estimation, the horseshoe prior appears to capture the piecewise constant structures well, and the point estimates of CVB-HS and ADMM are comparable for all quantiles. For uncertainty quantification, the lengths of credible intervals of the MCMC-HS and CVB-HS are comparable for 25%, 50%, and 75% quantiles, while the CVB-HS method has wider credible intervals than those of the MCMC method especially for extremal quantiles such as 5% and 95% (see also Table 6). This is consistent with the simulation results in Section 4.2. In Table 7, we provided the effective sample size per unit time of the proposed algorithm and MCMC, which showed significant improvement of computational efficiency by the proposed method. Hence, we could conclude that the proposed algorithm performs better than the MCMC for this application, in terms of both qualities of inference and computational efficiency.
Munich rent data
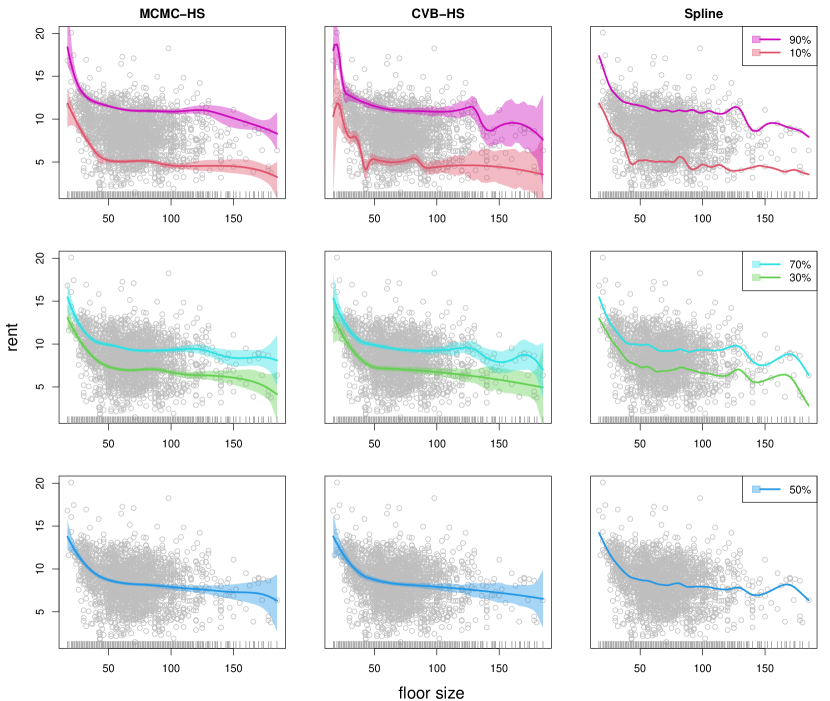
The proposed methods can also be applied to multiple observations with an irregular grid. We used Munich rent data (https://github.com/jrfaulkner/spmrf) which includes the value of rent per square meter and floor space in Munich, Germany (see also Rue and Held, 2005; Faulkner and Minin, 2018; Heng et al., 2022). The data has multiple observations per location and an irregular grid. Let the response be the rent and the location be the floor size. At the location , the response has multiple observations per location, that is, . Furthermore, the difference is not always constant, therefore the floor spaces are unequally spaced. This is a different situation from the example in Section 5.1. The data contains observations and the floor space (or location) has 134 distinct values. We applied the third-order adjusted difference operator defined in Remark 1 to the proposed Bayesian quantile trend filtering methods (i.e. MCMC-HS and CVB-HS with ). Since Brantley’s quantile trend filtering method (Brantley et al., 2020) cannot be applied to the data with multiple observations per location, we applied the quantile smoothing spline method by Nychka et al. (2017) as a frequentist competitor. The method could be implemented by using qsreg function in R package fields. The details of the method are provided in Nychka et al. (1995) and Oh et al. (2004), and the smoothing parameter was chosen by using cross-validation. For these methods, we analyzed the five quantile levels such as , , , and . For the Bayesian methods, we generated 60,000 posterior samples after discarding the first 10,000 posterior samples as burn-in, and then only every 10th scan was saved.
The results of the point estimate and credible interval are shown in Figure 4. The frequentist smoothing spline method is denoted by “Spline” in Figure 4. The CVB-HS and Spline methods gave comparable baseline estimates, while the MCMC-HS method provided slightly smoother point estimates than the other two methods, especially for the large floor size. These decreasing trends mean that the houses with small floor sizes have a greater effect on their rent. Such a trend was also observed in the Bayesian mean trend filtering by Faulkner and Minin (2018). Compared with the MCMC-HS, the CVB-HS method has a wider length of 95% credible intervals for large values of floor size. The phenomenon appears to be reasonable because the data are less in such regions. Additionally, two Bayesian methods provided almost the same results for the center quantile levels such as 30%, 50%, and 70%, while the credible intervals of CVB-HS were wider than those of the MCMC-HS especially for extremal quantile levels such as 90% and 10% (see also Table 6). This indicates that the MCMC-HS method possibly underestimated extremal quantile regions. We again computed the effective sample size per unit time of the proposed algorithm and the MCMC, and the results are given in Table 7. From the results, we concluded that the proposed algorithm performs better than the MCMC for this application, in terms, not only of the quality of inference, but also of computational efficiency.
Discussion
Concluding remarks
This study proposed a quick and accurate calibration algorithm for credible intervals using a mean-field variational Bayes method. The proposed CVB method can reasonably calibrate credible intervals with possible model misspecifications. In numerical experiments, it was shown that the proposed method worked especially well in the inference for high/low quantile levels. We also showed that the computational efficiency of the proposed CVB methods is higher than the MCMC versions in terms of the efficient sample size and computation time. If computation time is not a concern, then MCMC-based methods may be capable of providing accurate point and interval estimates. However, the estimation of low/high quantile tends to be unstable, and if the model is misspecified, estimation of other quantile points will also be unstable. The method of Syring and Martin (2019) could also be used in such cases, but the proposed CVB method is capable of parallel computation and is thus much more computationally efficient. Finally, as drawbacks of the variational posterior approximations, the proposed CVB method may not accurately reflect prior beliefs about parameters. It was observed that the CVB-HS and Spline had remarkably similar results in terms of the trajectories of the trends in the Munich rent example. We believe this is due to the variational approximation of the posterior distribution. However, the proposed method still has the advantage of providing point estimation results comparable to those of the optimization method and of allowing the quick and accurate evaluation of uncertainty under finite samples.
In our study, we focused on the use of asymmetric Laplace likelihood, but it would be possible to extend the framework to extended asymmetric Laplace (e.g. Yan and Kottas, 2017). In the setting, it is possible to develop a similar computation algorithm to obtain posterior distribution and a valid credible interval, which will be left to future research. Furthermore, it may be more suitable to use a skewed distribution as a variational distribution of the quantile trends which can provide asymmetric credible intervals. However, when a different variational distribution was adopted, the mean-filed approximation algorithm used in this paper was no longer applicable, therefore a detailed investigation extends the scope of this study.
Acknowledgement
The authors would like to thank the Associate Editor and a reviewer for their valuable comments and suggestions to improve the quality of this article. This work was supported by JST, the establishment of university fellowships towards the creation of science technology innovation, Grant Number JPMJFS2129. This work is partially supported by Japan Society for Promotion of Science (KAKENHI) grant numbers 21K13835 and 21H00699.
References
- Balke (1993) Balke, N. S. (1993). Detecting level shifts in time series. Journal of Business & Economic Statistics 11(1), 81–92.
- Blei et al. (2017) Blei, D. M., A. Kucukelbir, and J. D. McAuliffe (2017). Variational inference: A review for statisticians. Journal of the American statistical Association 112(518), 859–877.
- Brantley et al. (2020) Brantley, H. L., J. Guinness, and E. C. Chi (2020). Baseline drift estimation for air quality data using quantile trend filtering. The Annals of Applied Statistics 14(2), 585–604.
- Carvalho et al. (2010) Carvalho, C. M., N. G. Polson, and J. G. Scott (2010). The horseshoe estimator for sparse signals. Biometrika 97(2), 465–480.
- Cobb (1978) Cobb, G. W. (1978). The problem of the nile: Conditional solution to a changepoint problem. Biometrika 65(2), 243–251.
- Efron (1982) Efron, B. (1982). The jackknife, the bootstrap and other resampling plans. SIAM.
- Eilers and De Menezes (2005) Eilers, P. H. and R. X. De Menezes (2005). Quantile smoothing of array cgh data. Bioinformatics 21(7), 1146–1153.
- Faulkner et al. (2020) Faulkner, J. R., A. F. Magee, B. Shapiro, and V. N. Minin (2020). Horseshoe-based bayesian nonparametric estimation of effective population size trajectories. Biometrics 76(3), 677–690.
- Faulkner and Minin (2018) Faulkner, J. R. and V. N. Minin (2018). Locally adaptive smoothing with markov random fields and shrinkage priors. Bayesian analysis 13(1), 225.
- Heng et al. (2022) Heng, Q., H. Zhou, and E. C. Chi (2022). Bayesian trend filtering via proximal markov chain monte carlo. arXiv preprint arXiv:2201.00092.
- Kim et al. (2009) Kim, S.-J., K. Koh, S. Boyd, and D. Gorinevsky (2009). trend filtering. SIAM review 51(2), 339–360.
- Kowal et al. (2019) Kowal, D. R., D. S. Matteson, and D. Ruppert (2019). Dynamic shrinkage processes. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 81(4), 781–804.
- Kozumi and Kobayashi (2011) Kozumi, H. and G. Kobayashi (2011). Gibbs sampling methods for bayesian quantile regression. Journal of Statistical Computation and Simulation 81(11), 1565–1578.
- Makalic and Schmidt (2015) Makalic, E. and D. F. Schmidt (2015). A simple sampler for the horseshoe estimator. IEEE Signal Processing Letters 23(1), 179–182.
- Nychka et al. (2017) Nychka, D., R. Furrer, J. Paige, and S. Sain (2017). fields: Tools for spatial data. R package version 9.6.
- Nychka et al. (1995) Nychka, D., G. Gray, P. Haaland, D. Martin, and M. O’connell (1995). A nonparametric regression approach to syringe grading for quality improvement. Journal of the American Statistical Association 90(432), 1171–1178.
- Oh et al. (2004) Oh, H.-S., D. Nychka, T. Brown, and P. Charbonneau (2004). Period analysis of variable stars by robust smoothing. Journal of the Royal Statistical Society: Series C (Applied Statistics) 53(1), 15–30.
- Park and Casella (2008) Park, T. and G. Casella (2008). The bayesian lasso. Journal of the American Statistical Association 103(482), 681–686.
- Politsch et al. (2020) Politsch, C. A., J. Cisewski-Kehe, R. A. Croft, and L. Wasserman (2020). Trend filtering–i. a modern statistical tool for time-domain astronomy and astronomical spectroscopy. Monthly Notices of the Royal Astronomical Society 492(3), 4005–4018.
- Ramdas and Tibshirani (2016) Ramdas, A. and R. J. Tibshirani (2016). Fast and flexible admm algorithms for trend filtering. Journal of Computational and Graphical Statistics 25(3), 839–858.
- Roualdes (2015) Roualdes, E. A. (2015). Bayesian trend filtering. arXiv preprint arXiv:1505.07710.
- Rue and Held (2005) Rue, H. and L. Held (2005). Gaussian Markov Random Fields: Theory and Applications. CRC Press.
- Sriram (2015) Sriram, K. (2015). A sandwich likelihood correction for bayesian quantile regression based on the misspecified asymmetric laplace density. Statistics & Probability Letters 107, 18–26.
- Sriram et al. (2013) Sriram, K., R. Ramamoorthi, and P. Ghosh (2013). Posterior consistency of bayesian quantile regression based on the misspecified asymmetric laplace density. Bayesian Analysis 8(2), 479–504.
- Syring and Martin (2019) Syring, N. and R. Martin (2019). Calibrating general posterior credible regions. Biometrika 106(2), 479–486.
- Tibshirani (2014) Tibshirani, R. J. (2014). Adaptive piecewise polynomial estimation via trend filtering. The Annals of statistics 42(1), 285–323.
- Tibshirani and Taylor (2011) Tibshirani, R. J. and J. Taylor (2011). The solution path of the generalized lasso. The Annals of Statistics 39(3), 1335–1371.
- Tran et al. (2021) Tran, M.-N., T.-N. Nguyen, and V.-H. Dao (2021). A practical tutorial on variational bayes. arXiv preprint arXiv:2103.01327.
- Wakayama and Sugasawa (2023) Wakayama, T. and S. Sugasawa (2023). Trend filtering for functional data. Stat 12(1), e590.
- Wakayama and Sugasawa (2024) Wakayama, T. and S. Sugasawa (2024). Functional horseshoe smoothing for functional trend estimation. Statistica Sinica 34(3).
- Wand et al. (2011) Wand, M. P., J. T. Ormerod, S. A. Padoan, and R. Frühwirth (2011). Mean field variational bayes for elaborate distributions. Bayesian Analysis 6(4), 847–900.
- Wang et al. (2015) Wang, Y.-X., J. Sharpnack, A. Smola, and R. Tibshirani (2015). Trend filtering on graphs. In Artificial Intelligence and Statistics, pp. 1042–1050. PMLR.
- Yamada (2022) Yamada, H. (2022). Trend extraction from economic time series with missing observations by generalized hodrick–prescott filters. Econometric Theory 38(3), 419–453.
- Yan and Kottas (2017) Yan, Y. and A. Kottas (2017). A new family of error distributions for bayesian quantile regression. arXiv preprint arXiv:1701.05666.
- Yu and Moyeed (2001) Yu, K. and R. A. Moyeed (2001). Bayesian quantile regression. Statistics & Probability Letters 54(4), 437–447.
Supplementary Materials for “Fast and Locally Adaptive Bayesian Quantile Smoothing using Calibrated Variational Approximations”
This Supplementary Material provides algorithm details and additional information on simulation study and real data examples.
Full conditional distributions in Gibbs sampler
We provide the details of the full conditional distributions.
-
•
The full conditional distribution of .
which is , where
-
•
The full conditional distributions of for and .
which is .
-
•
The full conditional distribution of .
which is , where
-
•
The full conditional distribution of .
which is .
-
•
The full conditional distribution of .
which is .
-
•
The full conditional distributions of for .
which is .
The full conditional distributions of for and their argumentation parameters are derived separately for Laplace-type and horseshoe-type priors.
Laplace-type
For , we assume .
-
•
The full conditional distributions of for .
which is .
-
•
The full conditional distribution of
which is .
-
•
The full conditional distribution of .
which is .
Horseshoe-type
For , we assume .
-
•
The full conditional distributions of for .
which is .
-
•
The full conditional distributions of for .
which is .
Variational distributions
We summarize the derivations of variational distributions.
-
•
The variational distribution of .
which is , where
-
•
The variational distributions of for and .
which is , where
where is a unit vector that the th component is 1.
-
•
The variational distribution of .
which is , where
-
•
The variational distribution of .
which is , where
-
•
The variational distribution of .
which is .
-
•
The variational distributions of for .
which is .
The variational distributions of for and their argumentation parameters are derived separately for Laplace-type and horseshoe-type priors.
Laplace-type
In Laplace-type prior, we set . For , we assume .
-
•
The variational distributions of for .
which is .
-
•
The variational distributions of .
which is , where .
-
•
The variational distributions of .
which is , where .
Horseshoe-type
For , we assume .
-
•
The variational distributions of ().
which is , where .
-
•
The variational distributions of ().
which is .
Additional information on simulation studies
Smooth Gaussian process
In Section 4 of the main manuscript, we provided simulation results under (PC) piecewise constant and (VS) varying smoothness. In this subsection, we provide simulation results under the smooth Gaussian process (denoted by (GP)) as a true data-generating scenario. The plots of simulated true quantiles are shown in Figure S1. The additional description and results under (GP) are as follows.
-
(GP)
Smooth Gaussian process
The scenario (GP) generates observations from the Gaussian process with squared exponential covariance function (see also Faulkner and Minin, 2018). We set , and . The function was generated with the same random number seed for all scenarios (Gaussian, Beta, and Mixed normal noise functions). The aim of the scenario (GP) is to test the ability of the proposed methods to handle a smoothly varying function with no local change. To this end, we consider in this scenario.
The results are represented in Table S1. The raw computing time and effective sample size per unit time are also reported in Table S2. Note that the simulation is conducted without parallel computation as well as those of Section 4 in the main text.
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.084 | 0.020 | 0.016 | 0.019 | 0.040 | 0.187 | 0.109 | 0.099 | 0.107 | 0.153 |
| VB-HS | 0.174 | 0.024 | 0.019 | 0.023 | 0.048 | 0.243 | 0.118 | 0.107 | 0.117 | 0.168 |
| MCMC-Lap | 0.093 | 0.021 | 0.017 | 0.020 | 0.043 | 0.195 | 0.110 | 0.100 | 0.108 | 0.159 |
| VB-Lap | 0.048 | 0.019 | 0.017 | 0.020 | 0.048 | 0.170 | 0.107 | 0.100 | 0.110 | 0.171 |
| ADMM | 0.050 | 0.024 | 0.023 | 0.026 | 0.049 | 0.174 | 0.120 | 0.115 | 0.123 | 0.172 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.004 | 0.003 | 0.005 | 0.007 | 0.014 | 0.041 | 0.037 | 0.048 | 0.062 | 0.092 |
| VB-HS | 0.009 | 0.004 | 0.006 | 0.008 | 0.017 | 0.037 | 0.041 | 0.054 | 0.067 | 0.101 |
| MCMC-Lap | 0.003 | 0.003 | 0.005 | 0.007 | 0.015 | 0.039 | 0.036 | 0.048 | 0.061 | 0.096 |
| VB-Lap | 0.003 | 0.003 | 0.005 | 0.007 | 0.018 | 0.030 | 0.036 | 0.049 | 0.063 | 0.104 |
| ADMM | 0.004 | 0.004 | 0.006 | 0.009 | 0.017 | 0.040 | 0.039 | 0.055 | 0.069 | 0.103 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.169 | 0.064 | 0.037 | 0.041 | 0.089 | 0.278 | 0.177 | 0.150 | 0.158 | 0.234 |
| VB-HS | 0.205 | 0.087 | 0.043 | 0.047 | 0.106 | 0.309 | 0.196 | 0.159 | 0.169 | 0.254 |
| MCMC-Lap | 0.171 | 0.067 | 0.037 | 0.040 | 0.094 | 0.282 | 0.178 | 0.149 | 0.158 | 0.242 |
| VB-Lap | 0.100 | 0.043 | 0.035 | 0.041 | 0.103 | 0.250 | 0.164 | 0.149 | 0.160 | 0.252 |
| ADMM | 0.106 | 0.056 | 0.046 | 0.053 | 0.111 | 0.259 | 0.187 | 0.170 | 0.183 | 0.261 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.510 | 0.478 | 0.462 | 0.458 | 0.414 | 0.738 | 0.906 | 0.935 | 0.908 | 0.723 |
| CVB-HS | 1.267 | 0.616 | 0.486 | 0.599 | 1.161 | 0.950 | 0.943 | 0.921 | 0.941 | 0.980 |
| VB-HS | 0.145 | 0.217 | 0.232 | 0.216 | 0.124 | 0.221 | 0.546 | 0.610 | 0.538 | 0.235 |
| MCMC-Lap | 0.520 | 0.494 | 0.478 | 0.470 | 0.422 | 0.748 | 0.913 | 0.944 | 0.916 | 0.720 |
| CVB-Lap | 1.534 | 0.864 | 0.589 | 0.792 | 1.226 | 0.994 | 0.996 | 0.972 | 0.991 | 0.982 |
| VB-Lap | 0.185 | 0.291 | 0.309 | 0.289 | 0.182 | 0.333 | 0.721 | 0.777 | 0.713 | 0.330 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.161 | 0.179 | 0.214 | 0.244 | 0.233 | 0.948 | 0.946 | 0.923 | 0.891 | 0.693 |
| CVB-HS | 0.490 | 0.272 | 0.214 | 0.350 | 0.725 | 0.991 | 0.962 | 0.885 | 0.933 | 0.972 |
| VB-HS | 0.045 | 0.087 | 0.109 | 0.111 | 0.066 | 0.474 | 0.674 | 0.621 | 0.507 | 0.215 |
| MCMC-Lap | 0.161 | 0.182 | 0.221 | 0.252 | 0.239 | 0.956 | 0.950 | 0.936 | 0.902 | 0.692 |
| CVB-Lap | 0.608 | 0.377 | 0.271 | 0.459 | 0.737 | 0.993 | 0.990 | 0.951 | 0.981 | 0.977 |
| VB-Lap | 0.069 | 0.119 | 0.149 | 0.154 | 0.102 | 0.770 | 0.855 | 0.808 | 0.697 | 0.307 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.674 | 0.740 | 0.706 | 0.680 | 0.628 | 0.693 | 0.905 | 0.937 | 0.901 | 0.728 |
| CVB-HS | 1.652 | 0.921 | 0.746 | 0.847 | 1.650 | 0.966 | 0.939 | 0.929 | 0.934 | 0.976 |
| VB-HS | 0.203 | 0.329 | 0.348 | 0.317 | 0.193 | 0.218 | 0.515 | 0.609 | 0.559 | 0.236 |
| MCMC-Lap | 0.693 | 0.758 | 0.725 | 0.702 | 0.646 | 0.710 | 0.913 | 0.946 | 0.916 | 0.724 |
| CVB-Lap | 1.909 | 1.145 | 0.878 | 1.134 | 1.783 | 0.993 | 0.995 | 0.981 | 0.993 | 0.985 |
| VB-Lap | 0.274 | 0.425 | 0.452 | 0.421 | 0.275 | 0.324 | 0.693 | 0.769 | 0.697 | 0.333 |
| Computation time (second) | ESS (per second) | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 32 | 32 | 32 | 32 | 32 | 14 | 38 | 44 | 41 | 15 |
| CVB-HS | 13 | 8 | 11 | 8 | 13 | 575 | 943 | 692 | 980 | 576 |
| MCMC-Lap | 35 | 35 | 35 | 35 | 35 | 13 | 56 | 69 | 59 | 14 |
| CVB-Lap | 20 | 17 | 17 | 12 | 16 | 378 | 442 | 431 | 627 | 475 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 32 | 32 | 32 | 32 | 32 | 13 | 48 | 45 | 42 | 14 |
| CVB-HS | 9 | 7 | 8 | 7 | 11 | 859 | 1144 | 907 | 1113 | 714 |
| MCMC-Lap | 35 | 35 | 35 | 35 | 35 | 11 | 73 | 88 | 59 | 13 |
| CVB-Lap | 30 | 8 | 12 | 8 | 10 | 257 | 915 | 639 | 997 | 728 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 32 | 32 | 32 | 32 | 32 | 15 | 36 | 42 | 39 | 15 |
| CVB-HS | 15 | 10 | 14 | 9 | 16 | 503 | 732 | 526 | 849 | 487 |
| MCMC-Lap | 35 | 35 | 35 | 35 | 35 | 14 | 51 | 59 | 53 | 14 |
| CVB-Lap | 29 | 32 | 25 | 20 | 24 | 259 | 241 | 304 | 375 | 320 |
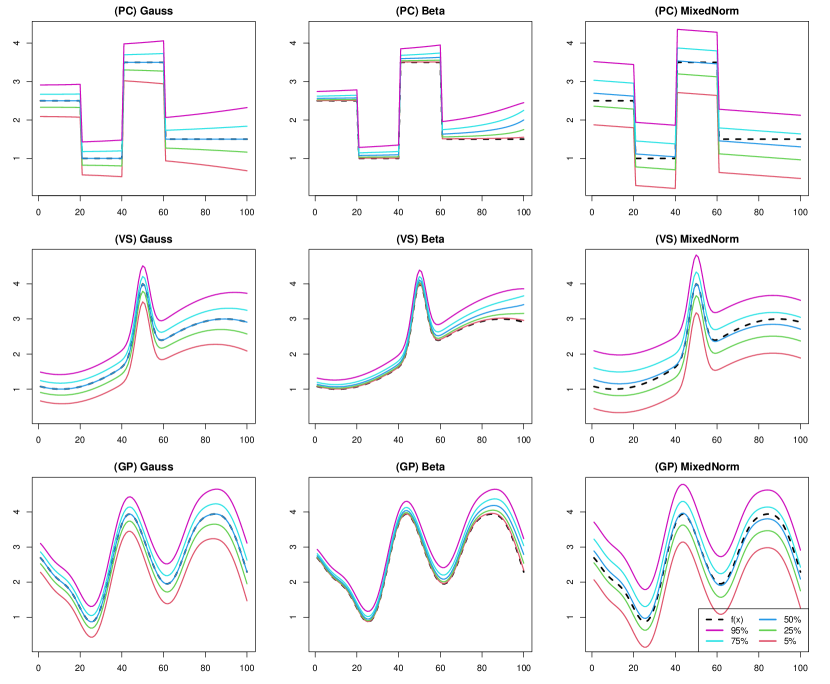
Multiple observations
We provide simulation results under multiple observations per location. The setting of simulation is as follows. Data was simulated by the equation (5) in the main manuscript, where the number of data at each location () was simulated from a multinomial distribution with outcomes 2, 3, and 4 with probabilities . We used the same noise distributions as those of Section 4 in the main manuscript (Gauss, Beta, and Mixed normal). The number of locations was set as , while the total sample size was 200 to 400 because of the randomness of . As true data-generating functions, (PC), (VS) and (GP) were adopted. The convergence criterion of variational Bayes methods was set as , which is slightly different from that of the main simulation. We compared the proposed methods with the quantile smoothing spline method (denoted by Spline for short) by Nychka et al. (2017) as a frequentist method, which was also applied to Munich rent data in Section 5.2 of the main manuscript. The reason is that Brantley’s quantile trend filtering cannnot apply to multiple observations per location.
The results of the simulations are summarized in Tables S3, S4 and S5. From these results, the MCMC-HS method was the best and the VB-HS method was at least better than the Spline method for almost all scenarios in terms of point estimation. Compared with the results of a single observation in the main manuscript, the MSE and MAD were smaller for each method, and it seems that a larger sample size induces more accurate point estimation. Although the CVB method tended to be over-coverage, it gave wider credible intervals than those of the MCMC method as seen in the MCIW, and conservatively improved coverage probability as well as single observation.
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0322 | 0.0052 | 0.0033 | 0.0049 | 0.0332 | 0.1350 | 0.0535 | 0.0436 | 0.0518 | 0.1387 |
| VB-HS | 0.0387 | 0.0182 | 0.0132 | 0.0180 | 0.0400 | 0.1516 | 0.0971 | 0.0812 | 0.0946 | 0.1564 |
| MCMC-Lap | 0.0582 | 0.0205 | 0.0167 | 0.0208 | 0.0576 | 0.1917 | 0.1110 | 0.0996 | 0.1111 | 0.1921 |
| VB-Lap | 0.0589 | 0.0190 | 0.0154 | 0.0190 | 0.0587 | 0.1950 | 0.1060 | 0.0950 | 0.1053 | 0.1974 |
| Spline | 0.1154 | 0.0671 | 0.0548 | 0.0672 | 0.1141 | 0.2214 | 0.1586 | 0.1473 | 0.1582 | 0.2247 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0011 | 0.0013 | 0.0022 | 0.0037 | 0.0155 | 0.0180 | 0.0177 | 0.0276 | 0.0412 | 0.0948 |
| VB-HS | 0.0008 | 0.0029 | 0.0048 | 0.0079 | 0.0162 | 0.0109 | 0.0270 | 0.0416 | 0.0606 | 0.0991 |
| MCMC-Lap | 0.0046 | 0.0040 | 0.0056 | 0.0092 | 0.0247 | 0.0433 | 0.0398 | 0.0514 | 0.0702 | 0.1236 |
| VB-Lap | 0.0042 | 0.0040 | 0.0056 | 0.0093 | 0.0308 | 0.0351 | 0.0386 | 0.0511 | 0.0709 | 0.1420 |
| Spline | 0.1120 | 0.0580 | 0.0424 | 0.0659 | 0.1042 | 0.1240 | 0.0992 | 0.1021 | 0.1257 | 0.1736 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0656 | 0.0136 | 0.0094 | 0.0143 | 0.0669 | 0.2004 | 0.0889 | 0.0728 | 0.0885 | 0.2016 |
| VB-HS | 0.0822 | 0.0397 | 0.0281 | 0.0406 | 0.0827 | 0.2277 | 0.1507 | 0.1239 | 0.1519 | 0.2286 |
| MCMC-Lap | 0.1124 | 0.0433 | 0.0355 | 0.0443 | 0.1129 | 0.2754 | 0.1642 | 0.1473 | 0.1650 | 0.2745 |
| VB-Lap | 0.1043 | 0.0381 | 0.0313 | 0.0397 | 0.1061 | 0.2649 | 0.1526 | 0.1372 | 0.1545 | 0.2658 |
| Spline | 0.1559 | 0.0866 | 0.0763 | 0.0871 | 0.1595 | 0.2915 | 0.2053 | 0.1919 | 0.2067 | 0.2958 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.391 | 0.271 | 0.246 | 0.272 | 0.394 | 0.723 | 0.938 | 0.960 | 0.947 | 0.720 |
| CVB-HS | 1.097 | 0.664 | 0.429 | 0.675 | 1.125 | 0.983 | 0.991 | 0.967 | 0.994 | 0.985 |
| VB-HS | 0.108 | 0.181 | 0.187 | 0.184 | 0.110 | 0.228 | 0.568 | 0.675 | 0.602 | 0.219 |
| MCMC-Lap | 0.476 | 0.533 | 0.532 | 0.537 | 0.476 | 0.734 | 0.941 | 0.964 | 0.943 | 0.732 |
| CVB-Lap | 1.296 | 0.678 | 0.497 | 0.690 | 1.323 | 0.981 | 0.979 | 0.953 | 0.982 | 0.985 |
| VB-Lap | 0.203 | 0.342 | 0.362 | 0.344 | 0.204 | 0.288 | 0.804 | 0.871 | 0.809 | 0.275 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.054 | 0.084 | 0.124 | 0.171 | 0.216 | 0.972 | 0.951 | 0.932 | 0.902 | 0.606 |
| CVB-HS | 0.454 | 0.266 | 0.194 | 0.425 | 0.748 | 1.000 | 0.987 | 0.934 | 0.985 | 0.983 |
| VB-HS | 0.026 | 0.065 | 0.086 | 0.097 | 0.056 | 0.845 | 0.795 | 0.702 | 0.543 | 0.184 |
| MCMC-Lap | 0.171 | 0.205 | 0.247 | 0.276 | 0.238 | 0.942 | 0.950 | 0.939 | 0.889 | 0.619 |
| CVB-Lap | 0.496 | 0.311 | 0.231 | 0.451 | 0.797 | 0.992 | 0.976 | 0.912 | 0.970 | 0.964 |
| VB-Lap | 0.070 | 0.136 | 0.172 | 0.177 | 0.090 | 0.737 | 0.863 | 0.836 | 0.710 | 0.161 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.628 | 0.439 | 0.404 | 0.439 | 0.615 | 0.750 | 0.935 | 0.957 | 0.927 | 0.742 |
| CVB-HS | 1.520 | 1.007 | 0.677 | 1.009 | 1.551 | 0.985 | 0.996 | 0.978 | 0.993 | 0.985 |
| VB-HS | 0.169 | 0.272 | 0.276 | 0.273 | 0.169 | 0.229 | 0.524 | 0.632 | 0.527 | 0.217 |
| MCMC-Lap | 0.734 | 0.792 | 0.778 | 0.790 | 0.727 | 0.746 | 0.944 | 0.962 | 0.941 | 0.741 |
| CVB-Lap | 1.789 | 0.950 | 0.702 | 0.958 | 1.809 | 0.987 | 0.982 | 0.953 | 0.979 | 0.987 |
| VB-Lap | 0.319 | 0.497 | 0.517 | 0.496 | 0.318 | 0.336 | 0.806 | 0.867 | 0.805 | 0.339 |
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0246 | 0.0079 | 0.0063 | 0.0073 | 0.0255 | 0.1168 | 0.0667 | 0.0597 | 0.0638 | 0.1192 |
| VB-HS | 0.0313 | 0.0135 | 0.0104 | 0.0138 | 0.0331 | 0.1325 | 0.0846 | 0.0749 | 0.0846 | 0.1370 |
| MCMC-Lap | 0.0346 | 0.0117 | 0.0099 | 0.0113 | 0.0351 | 0.1438 | 0.0838 | 0.0777 | 0.0828 | 0.1458 |
| VB-Lap | 0.0320 | 0.0115 | 0.0098 | 0.0112 | 0.0334 | 0.1373 | 0.0831 | 0.0773 | 0.0821 | 0.1415 |
| Spline | 0.0400 | 0.0151 | 0.0126 | 0.0149 | 0.0423 | 0.1558 | 0.0955 | 0.0878 | 0.0949 | 0.1615 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0016 | 0.0017 | 0.0024 | 0.0036 | 0.0118 | 0.0254 | 0.0249 | 0.0329 | 0.0426 | 0.0817 |
| VB-HS | 0.0017 | 0.0026 | 0.0042 | 0.0065 | 0.0122 | 0.0209 | 0.0289 | 0.0414 | 0.0561 | 0.0842 |
| MCMC-Lap | 0.0015 | 0.0020 | 0.0032 | 0.0051 | 0.0159 | 0.0269 | 0.0284 | 0.0389 | 0.0526 | 0.0977 |
| VB-Lap | 0.0013 | 0.0020 | 0.0032 | 0.0051 | 0.0142 | 0.0199 | 0.0282 | 0.0392 | 0.0527 | 0.0930 |
| Spline | 0.0016 | 0.0022 | 0.0036 | 0.0057 | 0.0144 | 0.0239 | 0.0310 | 0.0430 | 0.0567 | 0.0949 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0494 | 0.0191 | 0.0152 | 0.0178 | 0.0514 | 0.1702 | 0.1048 | 0.0914 | 0.1007 | 0.1758 |
| VB-HS | 0.0649 | 0.0282 | 0.0226 | 0.0275 | 0.0677 | 0.1979 | 0.1274 | 0.1119 | 0.1253 | 0.2030 |
| MCMC-Lap | 0.0695 | 0.0280 | 0.0229 | 0.0255 | 0.0732 | 0.2092 | 0.1298 | 0.1174 | 0.1265 | 0.2153 |
| VB-Lap | 0.0651 | 0.0287 | 0.0228 | 0.0257 | 0.0664 | 0.2003 | 0.1304 | 0.1164 | 0.1259 | 0.2034 |
| Spline | 0.0925 | 0.0354 | 0.0291 | 0.0351 | 0.0917 | 0.2422 | 0.1501 | 0.1352 | 0.1493 | 0.2422 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.337 | 0.277 | 0.275 | 0.278 | 0.341 | 0.731 | 0.897 | 0.921 | 0.913 | 0.734 |
| CVB-HS | 1.134 | 0.592 | 0.403 | 0.617 | 1.172 | 0.994 | 0.989 | 0.965 | 0.994 | 0.994 |
| VB-HS | 0.104 | 0.154 | 0.163 | 0.159 | 0.105 | 0.260 | 0.556 | 0.645 | 0.584 | 0.254 |
| MCMC-Lap | 0.403 | 0.373 | 0.370 | 0.374 | 0.400 | 0.740 | 0.918 | 0.944 | 0.925 | 0.734 |
| CVB-Lap | 1.150 | 0.580 | 0.425 | 0.599 | 1.184 | 0.993 | 0.989 | 0.967 | 0.993 | 0.993 |
| VB-Lap | 0.170 | 0.228 | 0.240 | 0.230 | 0.172 | 0.387 | 0.735 | 0.787 | 0.743 | 0.378 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.084 | 0.110 | 0.136 | 0.162 | 0.200 | 0.940 | 0.931 | 0.904 | 0.864 | 0.648 |
| CVB-HS | 0.082 | 0.131 | 0.191 | 0.233 | 0.237 | 0.887 | 0.927 | 0.931 | 0.900 | 0.738 |
| VB-HS | 0.030 | 0.067 | 0.085 | 0.090 | 0.057 | 0.655 | 0.747 | 0.670 | 0.538 | 0.226 |
| MCMC-Lap | 0.117 | 0.146 | 0.182 | 0.213 | 0.225 | 0.950 | 0.951 | 0.934 | 0.891 | 0.648 |
| CVB-Lap | 0.514 | 0.280 | 0.213 | 0.394 | 0.781 | 0.999 | 0.990 | 0.951 | 0.989 | 0.993 |
| VB-Lap | 0.052 | 0.097 | 0.121 | 0.130 | 0.093 | 0.790 | 0.857 | 0.808 | 0.707 | 0.312 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.486 | 0.418 | 0.406 | 0.415 | 0.491 | 0.720 | 0.882 | 0.911 | 0.893 | 0.717 |
| CVB-HS | 0.719 | 0.647 | 0.592 | 0.646 | 0.733 | 0.844 | 0.957 | 0.962 | 0.956 | 0.852 |
| VB-HS | 0.159 | 0.226 | 0.232 | 0.223 | 0.158 | 0.247 | 0.527 | 0.613 | 0.536 | 0.230 |
| MCMC-Lap | 0.604 | 0.528 | 0.521 | 0.529 | 0.606 | 0.742 | 0.890 | 0.919 | 0.906 | 0.737 |
| CVB-Lap | 1.390 | 0.792 | 0.598 | 0.797 | 1.448 | 0.990 | 0.976 | 0.952 | 0.984 | 0.991 |
| VB-Lap | 0.252 | 0.312 | 0.327 | 0.317 | 0.256 | 0.383 | 0.671 | 0.741 | 0.687 | 0.380 |
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0188 | 0.0079 | 0.0065 | 0.0076 | 0.0204 | 0.1035 | 0.0693 | 0.0635 | 0.0676 | 0.1080 |
| VB-HS | 0.0267 | 0.0109 | 0.0085 | 0.0102 | 0.0264 | 0.1189 | 0.0791 | 0.0718 | 0.0765 | 0.1231 |
| MCMC-Lap | 0.0206 | 0.0083 | 0.0069 | 0.0080 | 0.0224 | 0.1094 | 0.0703 | 0.0646 | 0.0688 | 0.1136 |
| VB-Lap | 0.0222 | 0.0089 | 0.0074 | 0.0086 | 0.0234 | 0.1122 | 0.0729 | 0.0669 | 0.0713 | 0.1168 |
| Spline | 0.0394 | 0.0140 | 0.0110 | 0.0135 | 0.0419 | 0.1547 | 0.0915 | 0.0817 | 0.0900 | 0.1605 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0011 | 0.0014 | 0.0023 | 0.0035 | 0.0084 | 0.0219 | 0.0234 | 0.0329 | 0.0434 | 0.0702 |
| VB-HS | 0.0010 | 0.0021 | 0.0032 | 0.0050 | 0.0095 | 0.0161 | 0.0262 | 0.0375 | 0.0510 | 0.0755 |
| MCMC-Lap | 0.0008 | 0.0014 | 0.0023 | 0.0035 | 0.0094 | 0.0201 | 0.0225 | 0.0321 | 0.0433 | 0.0751 |
| VB-Lap | 0.0008 | 0.0016 | 0.0025 | 0.0039 | 0.0093 | 0.0139 | 0.0241 | 0.0339 | 0.0457 | 0.0752 |
| Spline | 0.0010 | 0.0018 | 0.0028 | 0.0048 | 0.0139 | 0.0171 | 0.0267 | 0.0370 | 0.0515 | 0.0933 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0476 | 0.0192 | 0.0155 | 0.0180 | 0.0427 | 0.1656 | 0.1084 | 0.0975 | 0.1064 | 0.1630 |
| VB-HS | 0.0900 | 0.0228 | 0.0181 | 0.0223 | 0.0538 | 0.2018 | 0.1181 | 0.1060 | 0.1175 | 0.1810 |
| MCMC-Lap | 0.0524 | 0.0197 | 0.0158 | 0.0187 | 0.0480 | 0.1747 | 0.1102 | 0.0989 | 0.1086 | 0.1731 |
| VB-Lap | 0.0672 | 0.0206 | 0.0165 | 0.0199 | 0.0478 | 0.1838 | 0.1130 | 0.1013 | 0.1120 | 0.1723 |
| Spline | 0.0925 | 0.0332 | 0.0265 | 0.0331 | 0.0917 | 0.2421 | 0.1453 | 0.1287 | 0.1446 | 0.2422 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.291 | 0.281 | 0.279 | 0.281 | 0.295 | 0.727 | 0.895 | 0.914 | 0.899 | 0.715 |
| CVB-HS | 1.077 | 0.551 | 0.374 | 0.566 | 1.086 | 0.995 | 0.989 | 0.961 | 0.995 | 0.996 |
| VB-HS | 0.103 | 0.153 | 0.160 | 0.153 | 0.106 | 0.280 | 0.569 | 0.629 | 0.590 | 0.286 |
| MCMC-Lap | 0.305 | 0.294 | 0.294 | 0.294 | 0.308 | 0.732 | 0.907 | 0.930 | 0.911 | 0.723 |
| CVB-Lap | 1.065 | 0.562 | 0.430 | 0.585 | 1.102 | 0.995 | 0.994 | 0.987 | 0.996 | 0.996 |
| VB-Lap | 0.131 | 0.181 | 0.192 | 0.181 | 0.133 | 0.364 | 0.687 | 0.752 | 0.707 | 0.369 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.074 | 0.103 | 0.133 | 0.157 | 0.170 | 0.944 | 0.926 | 0.907 | 0.852 | 0.665 |
| CVB-HS | 0.524 | 0.252 | 0.185 | 0.375 | 0.743 | 1.000 | 0.990 | 0.943 | 0.990 | 0.997 |
| VB-HS | 0.029 | 0.063 | 0.079 | 0.085 | 0.058 | 0.664 | 0.745 | 0.652 | 0.527 | 0.249 |
| MCMC-Lap | 0.072 | 0.104 | 0.137 | 0.162 | 0.179 | 0.950 | 0.940 | 0.921 | 0.871 | 0.661 |
| CVB-Lap | 0.529 | 0.258 | 0.192 | 0.379 | 0.760 | 1.000 | 0.992 | 0.959 | 0.994 | 0.997 |
| VB-Lap | 0.036 | 0.072 | 0.092 | 0.099 | 0.075 | 0.806 | 0.824 | 0.762 | 0.638 | 0.311 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.449 | 0.422 | 0.416 | 0.420 | 0.428 | 0.707 | 0.867 | 0.907 | 0.883 | 0.696 |
| CVB-HS | 1.327 | 0.771 | 0.547 | 0.769 | 1.290 | 0.989 | 0.988 | 0.958 | 0.987 | 0.995 |
| VB-HS | 0.161 | 0.220 | 0.233 | 0.221 | 0.158 | 0.275 | 0.541 | 0.614 | 0.540 | 0.266 |
| MCMC-Lap | 0.478 | 0.441 | 0.436 | 0.439 | 0.461 | 0.712 | 0.881 | 0.921 | 0.896 | 0.703 |
| CVB-Lap | 1.346 | 0.810 | 0.656 | 0.818 | 1.308 | 0.991 | 0.995 | 0.988 | 0.995 | 0.996 |
| VB-Lap | 0.198 | 0.264 | 0.278 | 0.264 | 0.198 | 0.348 | 0.643 | 0.721 | 0.644 | 0.349 |
More locations
In Section 4 of the main manuscript, we set the number of locations to . We considered the same simulation scenarios as those of Section 4, but we set instead of . We note that if we change the number of locations, the (GP) function presented in Subsection S3.1 changes due to the random sampling. To avoid the problem, we considered a linear completion between the original data points. Furthermore, we only compared the following four methods: MCMC-HS, CVB-HS, VB-HS, and ADMM.
The results are shown in Table S6, S7 and S8. The MSE and MAD for all methods were improved over the results of a smaller sample size in most cases. The point estimation of the MCMC-HS method performed well in many cases as well as the results of observations in terms of point estimation. The coverage probabilities of the MCMC-HS method was also similar to those of observations, which were under 0.90 for extreme quantiles such as 0.05 and 0.95. However, the CVB-HS method provided values over 0.90 except for 0.5 quantile level under (PC) and Beta.
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0397 | 0.0060 | 0.0040 | 0.0062 | 0.0404 | 0.1528 | 0.0547 | 0.0459 | 0.0565 | 0.1542 |
| VB-HS | 0.0358 | 0.0176 | 0.0122 | 0.0172 | 0.0375 | 0.1479 | 0.0934 | 0.0765 | 0.0921 | 0.1511 |
| ADMM | 0.0320 | 0.0238 | 0.0143 | 0.0202 | 0.0366 | 0.1309 | 0.1187 | 0.0912 | 0.1111 | 0.1335 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0052 | 0.0016 | 0.0024 | 0.0042 | 0.0209 | 0.0214 | 0.0200 | 0.0310 | 0.0447 | 0.1112 |
| VB-HS | 0.0005 | 0.0026 | 0.0043 | 0.0077 | 0.0144 | 0.0100 | 0.0265 | 0.0404 | 0.0601 | 0.0944 |
| ADMM | 0.0009 | 0.0021 | 0.0045 | 0.0130 | 0.0185 | 0.0130 | 0.0344 | 0.0514 | 0.0927 | 0.0975 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0777 | 0.0201 | 0.0144 | 0.0181 | 0.0811 | 0.2202 | 0.0958 | 0.0824 | 0.0942 | 0.2234 |
| VB-HS | 0.0866 | 0.0427 | 0.0325 | 0.0440 | 0.0898 | 0.2296 | 0.1510 | 0.1274 | 0.1530 | 0.2309 |
| ADMM | 0.0891 | 0.0638 | 0.0471 | 0.0590 | 0.0940 | 0.2184 | 0.1879 | 0.1596 | 0.1830 | 0.2162 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.474 | 0.286 | 0.251 | 0.280 | 0.477 | 0.746 | 0.942 | 0.957 | 0.927 | 0.746 |
| CVB-HS | 1.003 | 0.507 | 0.374 | 0.497 | 0.991 | 0.973 | 0.967 | 0.943 | 0.962 | 0.968 |
| VB-HS | 0.115 | 0.187 | 0.194 | 0.185 | 0.117 | 0.237 | 0.619 | 0.724 | 0.625 | 0.235 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.066 | 0.094 | 0.136 | 0.185 | 0.270 | 0.976 | 0.948 | 0.920 | 0.895 | 0.625 |
| CVB-HS | 0.359 | 0.229 | 0.161 | 0.327 | 0.662 | 0.997 | 0.975 | 0.892 | 0.947 | 0.977 |
| VB-HS | 0.032 | 0.071 | 0.090 | 0.098 | 0.062 | 0.871 | 0.822 | 0.720 | 0.566 | 0.207 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.758 | 0.463 | 0.425 | 0.455 | 0.758 | 0.778 | 0.924 | 0.949 | 0.927 | 0.778 |
| CVB-HS | 1.435 | 0.766 | 0.629 | 0.756 | 1.449 | 0.979 | 0.968 | 0.949 | 0.962 | 0.975 |
| VB-HS | 0.177 | 0.281 | 0.293 | 0.282 | 0.177 | 0.232 | 0.564 | 0.672 | 0.560 | 0.237 |
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0279 | 0.0101 | 0.0090 | 0.0104 | 0.0279 | 0.1264 | 0.0759 | 0.0701 | 0.0751 | 0.1240 |
| VB-HS | 0.0365 | 0.0147 | 0.0124 | 0.0162 | 0.0362 | 0.1449 | 0.0889 | 0.0810 | 0.0921 | 0.1439 |
| ADMM | 0.0719 | 0.0151 | 0.0138 | 0.0166 | 0.0405 | 0.1659 | 0.0927 | 0.0880 | 0.0968 | 0.1488 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0023 | 0.0019 | 0.0027 | 0.0040 | 0.0115 | 0.0300 | 0.0277 | 0.0365 | 0.0460 | 0.0812 |
| VB-HS | 0.0022 | 0.0025 | 0.0038 | 0.0060 | 0.0134 | 0.0244 | 0.0300 | 0.0419 | 0.0559 | 0.0884 |
| ADMM | 0.0946 | 0.0023 | 0.0037 | 0.0055 | 0.0223 | 0.1058 | 0.0311 | 0.0427 | 0.0552 | 0.1010 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0622 | 0.0269 | 0.0204 | 0.0237 | 0.0576 | 0.1858 | 0.1207 | 0.1080 | 0.1165 | 0.1854 |
| VB-HS | 0.0750 | 0.0310 | 0.0241 | 0.0316 | 0.0795 | 0.2116 | 0.1337 | 0.1175 | 0.1337 | 0.2195 |
| ADMM | 0.0950 | 0.0336 | 0.0289 | 0.0356 | 0.0732 | 0.2168 | 0.1416 | 0.1322 | 0.1456 | 0.2064 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.362 | 0.321 | 0.315 | 0.322 | 0.354 | 0.725 | 0.903 | 0.923 | 0.904 | 0.732 |
| CVB-HS | 1.060 | 0.522 | 0.418 | 0.506 | 1.045 | 0.988 | 0.973 | 0.943 | 0.955 | 0.982 |
| VB-HS | 0.120 | 0.187 | 0.192 | 0.186 | 0.121 | 0.264 | 0.625 | 0.692 | 0.618 | 0.280 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.098 | 0.125 | 0.151 | 0.175 | 0.212 | 0.927 | 0.935 | 0.905 | 0.874 | 0.683 |
| CVB-HS | 0.460 | 0.251 | 0.187 | 0.332 | 0.677 | 0.998 | 0.982 | 0.920 | 0.962 | 0.986 |
| VB-HS | 0.038 | 0.079 | 0.097 | 0.103 | 0.066 | 0.692 | 0.784 | 0.698 | 0.583 | 0.246 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.515 | 0.490 | 0.479 | 0.477 | 0.540 | 0.711 | 0.890 | 0.918 | 0.891 | 0.745 |
| CVB-HS | 1.315 | 0.721 | 0.637 | 0.690 | 1.383 | 0.984 | 0.963 | 0.962 | 0.953 | 0.985 |
| VB-HS | 0.182 | 0.268 | 0.281 | 0.267 | 0.182 | 0.272 | 0.589 | 0.676 | 0.593 | 0.263 |
| MSE | MAD | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0329 | 0.0111 | 0.0094 | 0.0115 | 0.0277 | 0.1309 | 0.0812 | 0.0747 | 0.0815 | 0.1239 |
| VB-HS | 0.1083 | 0.0131 | 0.0107 | 0.0142 | 0.0349 | 0.1854 | 0.0877 | 0.0788 | 0.0885 | 0.1408 |
| ADMM | 0.0409 | 0.0199 | 0.0180 | 0.0218 | 0.0397 | 0.1531 | 0.1077 | 0.1017 | 0.1108 | 0.1516 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.0016 | 0.0017 | 0.0028 | 0.0044 | 0.0100 | 0.0271 | 0.0264 | 0.0373 | 0.0491 | 0.0777 |
| VB-HS | 0.0015 | 0.0023 | 0.0034 | 0.0054 | 0.0120 | 0.0206 | 0.0284 | 0.0406 | 0.0537 | 0.0854 |
| ADMM | 0.0015 | 0.0028 | 0.0047 | 0.0068 | 0.0133 | 0.0209 | 0.0330 | 0.0478 | 0.0613 | 0.0904 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.1091 | 0.0337 | 0.0231 | 0.0265 | 0.0615 | 0.2281 | 0.1367 | 0.1177 | 0.1272 | 0.1936 |
| VB-HS | 0.1447 | 0.0356 | 0.0231 | 0.0276 | 0.0770 | 0.2562 | 0.1375 | 0.1180 | 0.1299 | 0.2163 |
| ADMM | 0.0911 | 0.0471 | 0.0423 | 0.0480 | 0.0939 | 0.2400 | 0.1719 | 0.1618 | 0.1715 | 0.2394 |
| MCIW | CP | |||||||||
| (I) Gauss | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.368 | 0.358 | 0.353 | 0.355 | 0.338 | 0.723 | 0.914 | 0.937 | 0.917 | 0.734 |
| CVB-HS | 1.105 | 0.528 | 0.440 | 0.522 | 1.065 | 0.964 | 0.978 | 0.966 | 0.972 | 0.987 |
| VB-HS | 0.139 | 0.195 | 0.206 | 0.196 | 0.130 | 0.280 | 0.632 | 0.709 | 0.642 | 0.300 |
| (II) Beta | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.096 | 0.126 | 0.160 | 0.188 | 0.190 | 0.947 | 0.948 | 0.913 | 0.875 | 0.670 |
| CVB-HS | 0.462 | 0.252 | 0.204 | 0.333 | 0.693 | 0.999 | 0.986 | 0.945 | 0.968 | 0.990 |
| VB-HS | 0.037 | 0.081 | 0.100 | 0.105 | 0.072 | 0.635 | 0.803 | 0.705 | 0.596 | 0.267 |
| (III) Mixed normal | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| MCMC-HS | 0.5628 | 0.5995 | 0.5890 | 0.5730 | 0.5322 | 0.6995 | 0.9126 | 0.9469 | 0.9162 | 0.7287 |
| CVB-HS | 1.393 | 0.753 | 0.654 | 0.720 | 1.404 | 0.962 | 0.967 | 0.965 | 0.963 | 0.987 |
| VB-HS | 0.198 | 0.283 | 0.300 | 0.281 | 0.194 | 0.260 | 0.595 | 0.690 | 0.615 | 0.278 |
Additional information on real data example
We confirm that the proposed algorithm works well by making a simple diagnosis of sampling efficiency. Here, we especially consider the sampling efficiency in the two real data analyses. We generate 60,000 posterior samples under MCMC in section 2.3 after discarding the first 10,000 posterior samples as burn-in, and then only every 10th scan was saved. For Nile data in Section 5.1 and Munich rent data in Section 5.2, sample paths and autocorrelations of the posterior samples in three selected points are provided in Figures S2 and S3, respectively. The mixing and autocorrelation of the MCMC algorithm seem satisfactory.

