Fast Deep Predictive Coding Networks for Videos Feature Extraction without Labels
Abstract
Brain-inspired deep predictive coding networks (DPCNs) effectively model and capture video features through a bi-directional information flow, even without labels. They are based on an overcomplete description of video scenes, and one of the bottlenecks has been the lack of effective sparsification techniques to find discriminative and robust dictionaries. FISTA has been the best alternative. This paper proposes a DPCN with a fast inference of internal model variables (states and causes) that achieves high sparsity and accuracy of feature clustering. The proposed unsupervised learning procedure, inspired by adaptive dynamic programming with a majorization-minimization framework, and its convergence are rigorously analyzed. Experiments in the data sets CIFAR-10, Super Mario Bros video game, and Coil-100 validate the approach, which outperforms previous versions of DPCNs on learning rate, sparsity ratio, and feature clustering accuracy. Because of DCPN’s solid foundation and explainability, this advance opens the door for general applications in object recognition in video without labels.
1 Introduction
Sparse model is significant for the systems with a plethora of parameters and variables, as it selectively activates only a small subset of the variables or coefficients while maintaining representation accuracy and computational efficiency. This not only efficiently reduces the demand and storage for data to represent a dynamic system but also leads to more concise and easier access to the contained information in the areas including control, signal processing, sensory compression, etc.
In the control theory sense, a model for a dynamic process is often described by the equations
where is a set of measurements associated with a changing state through a mapping function , the states , also known as the signal of interest, is produced from a past one and an input through an evolution function , is the measurement noise and is the modeling error. Given measurements and input , the Kalman filter [1, 2] has emerged as a widely-employed technique for estimating states [3, 4] and mapping functions using neural networks [5] in a sparse way [6, 7, 8]. Therein, it is typically constrained to estimate one variable, namely the state. Can both state and input variables be estimated? For many dynamic plants characterized by natural and complex signals, latent variables often exhibit residual dependencies as well as non-stationary statistical properties. Can data with non-stationary statistics be well represented? Additionally, (deep) neural networks (NNs) [9, 10, 11, 5] with multi-layered structures are extensively used for sparse modeling of dynamic systems [12, 13, 14]. Similarly structured, convolutional NNs have demonstrated significant success in tasks such as target detection and feature classification in computer vision and control applications [15, 16, 17, 18, 19]. As we all know, these methods are mathematically uninterpretable, and the NN architecture is a feedforward pass through stacks of convolutional layers. As studied in [20], a bi-directional information pathway, including not only a feedforward but also a feedforward and recurrent passing, is used by brain for effective visual perception. Can dynamics be represented in an interpretable way with bi-directional connections and interactions?
These goals can be achieved by the hierarchical predictive coding networks [21, 22, 23, 24], also known as deep-predictive-coding networks (DPCNs) [25, 26, 27, 28, 29, 30, 31], where, inspired by [20], a hierarchical generative model is formulated as
where denotes layers. Measurements for layer are the causes of the lower layer, i.e., for . The causes link the layers, and the states link the dynamics over time . The model admits a bi-directional information flow [32, 30], including feedforward, feedback, and recurrent connections. That is, measurements travel through a bottom-up pathway from lower to higher visual areas (for rapid object recognition) and simultaneously a top-down pathway running in the opposite direction (to enhance the recognition) [33]. The previous DPCNs either use linear filters for sound [25, 26] or convolutions to better preserve neighborhoods in images [27, 28]. With fovea vision, non-convolutional DPCNs may offer a more automated and straightforward implementation [31, 30]. In both types of DPCNs, the proximal gradient descent methods, such as fast iterative shrinkage-thresholding algorithm (FISTA) [34], are frequently used for variable and model inferences in [27, 31, 30] for accelerated inference. Can the DPCNs inference be faster while maintaining high sparsity?
This paper answers these questions by studying vector DPCN with an improved inference procedure for both variable and models (dictionary) that is applicable to the two types, and that will be tested for proof of concept to model and capture objects in videos. Given measurements from the real world, the DPCNs infer model parameters and variables through feedforward, feedback, and recurrent connections represented by optimization problems with sparsity penalties. Inspired by the maximization minimization (MM) [35] and the value iteration of reinforcement learning (RL) [36], this paper proposes a MM-based unsupervised learning procedure to enhance the inference of DPCNs by introducing a majorizer of the sparsity penalty. This is called MM-DPCNs and offers the following advantages:
-
•
The learning procedure does not need labels and offers accelerated inference.
-
•
The inference results guarantee sparsity of variables and representation accuracy of features.
-
•
Rigorous proofs show convergence and interpretability.
-
•
Experiments validate the higher performance of MM-DPCNs versus previous DPCNs on learning rate, sparsity ratio, and feature clustering accuracy.
2 Dynamic Networks for DPCNs
| -th patch of video frame at time | |
|---|---|
| , | the causes from layer |
| state at layer for | |
| cause at layer for a group of | |
| model parameters at layer |
Based on the hierarchical generative model [20, 31] briefly reviewed in the Introduction, we now review the dynamic networks for DPCNs [31, 30] in terms of sparse optimization problems for sparse model and feature extraction of videos.
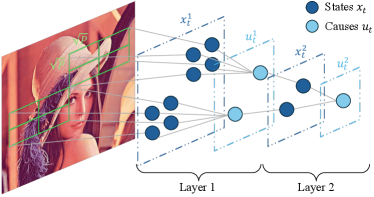
The structure of DPCN is shown in Fig. 1, and the involved denotations are show in Table 1. Given a video input, the measurements of each video frame are decomposed into multiple contiguous patches in terms of position, which is denoted by , a vectorized form of square patch. These measurements are injected to the DPCNs with a hierarchical multiple-layered structure. From the second layer, the causes from a lower layer serve as the input of the next layer, i.e., . At every layer, the network consists of two distinctive parts: feature extraction (inferring states) and pooling (inferring causes). The parameters to connect states and causes are called model (dictionary), going along states and causes (inferring model). The networks and connections at each layer are given in terms of objective functions for the inferences. In the following, we would omit the layer superscript for simplicity.
For inferring states given a patch measurement , a linear state space model using an over-complete dictionary of -filters, i.e., with , to get sparse states . Also, a state-transition matrix is applied to keep track of historical sparse states dynamics. To this end, the objective function for states is given by
| (1) |
where and are weighting parameters, is the -norm denoting energy, and is the -norm serving as the penalty term to make solution sparse [37].
For inferring causes given states, multiplicatively interacts with the accumulated states through in the way that whenever a component in is active, the corresponding set of components in are also likely to be active. This is for significant clustering of features even with non-stationary distribution of states [38]. To this end, the objective function for causes is given by
| (2) |
where and are weighting parameters.
For inferring model given states and causes, the overall objective function is given by
| (3) |
Notably, optimization of the functions and are strong convex problems, and we will design learning method to find the unique optimal sparse solution.
3 Learning For Model Inference and Variable Inference
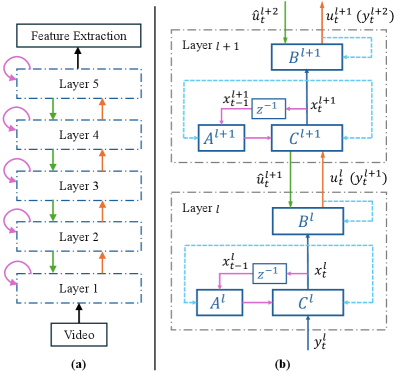
In this section, we propose an unsupervised learning method for self-organizing models and variables with accelerated learning while maintaining high sparsity and accuracy of feature extraction. The flow and connections for the inference are shown in Fig. 2. The inference process includes Model Inference and Variable Inference. The model inference needs repeated interleaved updates on states and causes and updates on model. Then, given a model, the variable inference needs an interleaved updates on states and causes using an extra top-down preference from the upper layer. These form a bi-directional inference process on a bottom-up feedforward path, a top-down feedback path, and a recurrent path.
For the updates of states and causes involved in the Model Inference and Variable Inference, we propose a new learning procedure using the majorization minimization (MM) framework [39, 35] for optimization with sparsity constraint. Different from the frequently used proximal gradient descent methods iterative shrinkage-thresholding algorithm (ISTA) and fast ISTA (FISTA) [34, 40, 41] that use a majorizer for the differentiable non-sparsity-penalty terms [31], this paper uses a majorizer for sparsity penalty. As such the convex non-differentiable optimization problem with sparsity constraint is transformed into a convex and differentiable problem. Moreover, taking advantage of over-complete dictionary and the iteration form inspired by the value iteration of RL [36], the iterations for inference are derived from the condition for the optimal sparse solution to MM-based optimization problems. This also differs from the traditional gradient descent method and adaptive moment estimation (ADAM) [42] method for solving optimization problems.
3.1 MM-Based Model Inference
Model inference seeks by minimizing in (3) with an interleaved procedure to infer states and causes by minimizing (1) and (2).
State Inference
To infer sparse by minimizing (1), first, we let and use the Nesterov’s smooth approximator [43, 44] taking the form
| (4) |
where is a constant and is some vector reaching the best approximation. Then, we find a majorizer for the penalty term [39] in the form
| (5) |
with equality at , where is a vector, with a component-wise division product, and is a constant independent of (see details in Appendix A).
Applying the approximator (4), majorizer (5) and MM principles, the minimization problem of (1) can be transformed to the minimization of
| (6) |
Minimizing with respect to yields the Karush–Kuhn–Tucker (KKT) condition for the optimal sparse state
| (7) |
To find such an optimal state, we propose Algorithm 1 that is applicable for every layer, applying an iterative form of (7). The update of states at each iteration is one-step optimal. We set a positive initial value for state. Note that it cannot be zero because the iteration will never update with . Also, the optimal state in (7) is expected to be sparse, namely some components of go to zero. This makes entries of go to infinity, leading to numerically inaccurate results. We avoid this by using and the matrix inverse lemma [45]
| (8) |
Note that the matrix is invertible due to positive semi-definite and positive definite diagonal . To further accelerate the computation, we can avoid directly computing the inverse term by using the conjugate gradient method to compute .
Cause Inference
To infer sparse causes by minimizing (2), we find a majorizer of as
| (9) |
with equality at , where . Therefore, based on MM principles, we transform the minimization of in (2) to the minimization of
| (10) |
where . Minimizing with respect to yields the KKT condition
| (11) |
To find such an optimal cause, we propose Algorithm 2 that is applicable for every layer, applying the iterative form of (11) for causes inference. Since and the iteration never update with , we set an initial value .
With fixed model parameter , states and causes can be updated interleavely until they converge. Since sparsity penalty terms are replaced by a majorizer in the learning, small values of the variables are clamped via thresholds, for states and for causes, to be zero. As such, the states and causes become sparse at finite iterations.
1. Initialization: initial values of states , initial iteration step .
2. Update State at patch and time
| (12) | |||
| (13) |
3. Set and repeat 2 until it converges.
1. Initialization: initial values of causes , initial iteration step .
2. Update Causes at time :
| (14) | |||
| (15) |
3. Set and repeat 2 until it converges.
Model Parameters Inference
By fixing the converged states and causes, the model parameters are updated based on the overall objective function (3). For time-varying input, to keep track of parameter temporal relationships, we put an additional constraint on the parameters [30, 31], i.e., , where is Gaussian transition noise as an additional temporal smoothness prior. Along with this constraint, each matrix can be updated independently using gradient descent. It is encouraged to normalize columns of matrices and after the update to avoid any trivial solution.
3.2 MM-Based Variable Inference with Top-Down Preference
Given the learned model, the updates of states and causes in variable inference process are the same as Section IV-A except for adding (2) with a top-down preference for causes inference. Since the causes at a lower layer serves as the input of an upper layer, therefore, a predicted top-down reference using the states from the layer above is injected into causes inference of the lower layer. That is,
| (16) |
where is the top-down prediction [46]. Determination of its value can be found in Appendix A and [31]. Similar to Section 3.1, using the majorizer (9) to replace the -norm penalty in , minimizing (16) becomes minimizing
| (17) |
with respect to , which yields the KKT condition
| (18) |
for every layer, where denotes identity matrix. Since the diagonal matrix is non-singular, we develop the iterative form in Algorithm 3.
Since inferences at each layer are independent, the complete learning procedure for each layer is summarized in Algorithm 4. For better convergence of state inference and cause inference that are interleaved in an alternating minimization manner, we encourage to run Algorithm 1 for several iterations and then Algorithm 2 for several iterations .
1. Initialization: initial values of causes , initial iteration step .
2. Update Causes at time :
| (19) | |||
| (20) |
3. Set and repeat 2 until it converges.
4 Convergence Analysis of MM-Based Variable Inference
In this section, we analyze the convergence of the proposed Algorithm 1 for state inference and Algorithm 2 for cause inference, respectively.
Convergence of State Inference
States inference is independent at each patch and each layer , hence we analyze the convergence of the objective function of (1) using Algorithm 1 by removing the subscript and for simplicity. To do this, we introduce an auxiliary objective function
| (21) |
where and . Rewrite in (6) for each patch as
| (22) |
where with equality at as shown in (5). This admits the unique minimizer
| (23) |
Theorem 1
Consider the sequence for a patch generated by Algorithm 1. Then, converges, and for any we have
| (24) |
where , , with if , if , if , and otherwise. Notably, denotes the -th elements of a vector.
Proof: Please see Appendix B.
Theorem 2
Let be the optimal solution to minimizing (1) for a single patch at a layer. The upper bound of its convergence satisfies
| (25) |
where .
Proof: Please see Appendix B.
Convergence of Causes Inference
The convergence of cause inference can be analyzed similarly. We rewrite the function (2) at a single layer as
| (26) |
where . We also rewrite (10) with (9) as
| (27) |
Theorem 3
Consider the sequence generated by Algorithm 2. Then, converges, and for any we have
| (28) |
where , , with if , if , if , and otherwise.
Proof: Please see Appendix B.
We have a similar conclusion for Algorithm 3. In Algorithm 3, we set initial . With a diagonal positive-definite matrix , i.e., , given , (19) with a normalized matrix yields . Using similar proof of Algorithm 2, we can induce that Algorithm 3 will make sparse and minimizes in (17). Based on the MM principles, it also minimizes the function in (16).
5 Experiments
We report the performance of MM-DPCNs on image sparse coding and video feature clustering. We compare MM-based algorithm used for MM-DPCNs with the methods FISTA [34], ISTA [40], ADAM [42] to test optimization quality of sparse coding on the CIFAR-10 data set. For video feature clustering, we compare our MM-DPCNs to previous DPCNs version FISTA-DPCN [31] and methods auto-encoder (AE) [47], WTA-RNN-AE [48] (architecture details are provided in Appendix C) on video data sets OpenAI Gym Super Mario Bros environment [49] and Coil-100 [50]. Note that these are the standard data sets used for sparse coding and feature extraction [51, 52]. We use indices including clustering accuracy (ACC) as the completeness score, adjusted rand index (ARI) and the sparsity level (SPA) to evaluate the clustering quality, learning convergence time (LCT) for sparse coding optimization on each frame. More results on a geometric moving shape data set can be found in Appendix C. The implementations are written in PyTorch-Python, and all the experiments were run on a Linux server with a 32G NVIDIA V100 Tensor Core GPU.
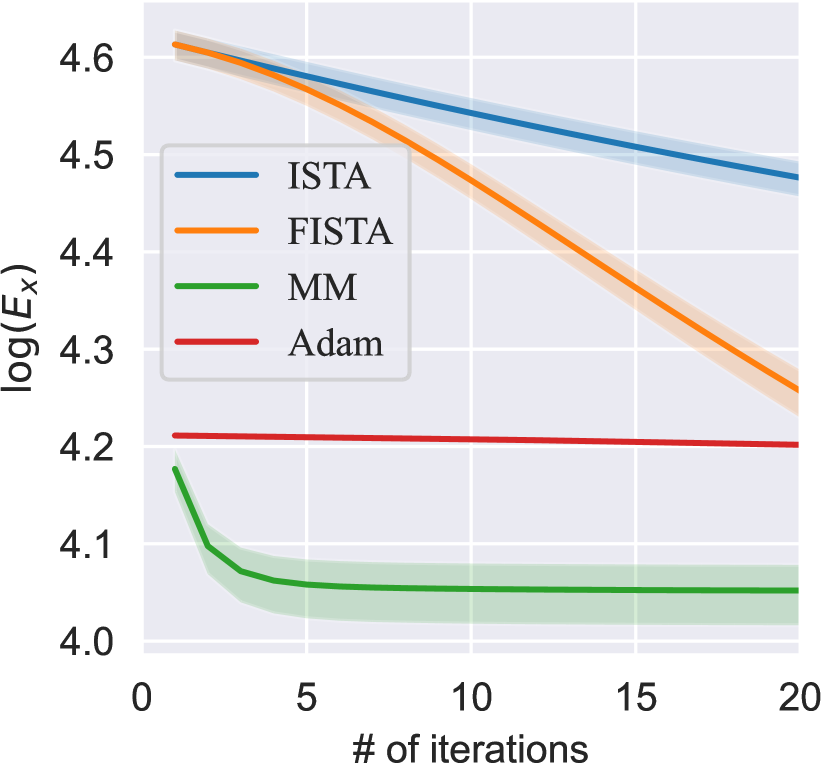
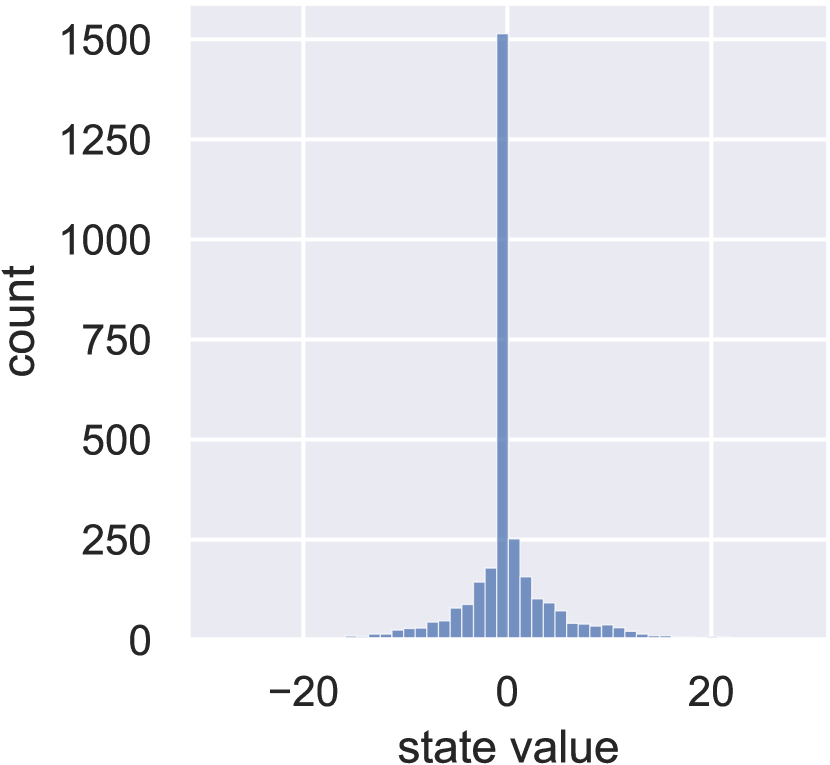
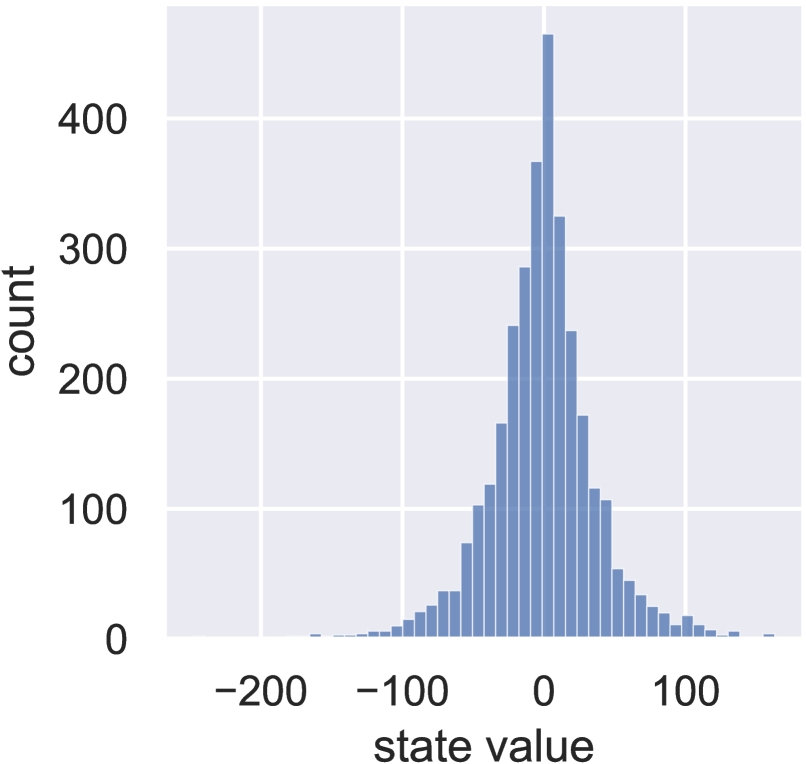
5.1 Comparison on Image Sparse Coding
| Methods | SPA | |
|---|---|---|
| ISTA | ||
| FISTA | ||
| Adam | ||
| MM |
The proposed MM Algorithms 1 is applicable for general sparse optimization problems such as Lasso problems [53]. We apply the MM Algorithm 1, as well as the well-known ISTA [40], FISTA [34] for comparison, on the CIFAR-10 data set with the reconstruction and sparsity loss (1) (, , and randomized ). We also compare the performance with the Adam algorithm [42] to optimize the smooth majorizer, which is of particular interest to the Deep Learning optimization community. The images are preprocessed by splitting into four equally-sized patches. FISTA and ISTA have learning rates, set as , while MM is learning-rate-free.
Fig. 3(a) shows that the MM Algorithm 1 converges in less than 10 steps, much faster than the others. Also, it enjoys a higher sparsity level of the learned state, to be a direct benefit of fast convergence rate, as shown in Fig. 3(b) and Fig. 3(c). The statistics of the optimization results are summarized in Table 2, where MM Algorithm 1 produces the least loss value while maintaining the highest sparsity level. The results reveal three potential advantages for MM-DPCN: 1. Faster computation. 2. Higher level sparsity for the latent space embeddings. 3. More faithful reconstructions. The last two advantages enable the algorithm to produce highly condensed and faithful information embedded into the latent space, which also benefits feature clustering.
5.2 Comparison on Video Clustering
Super Mario Bors data set
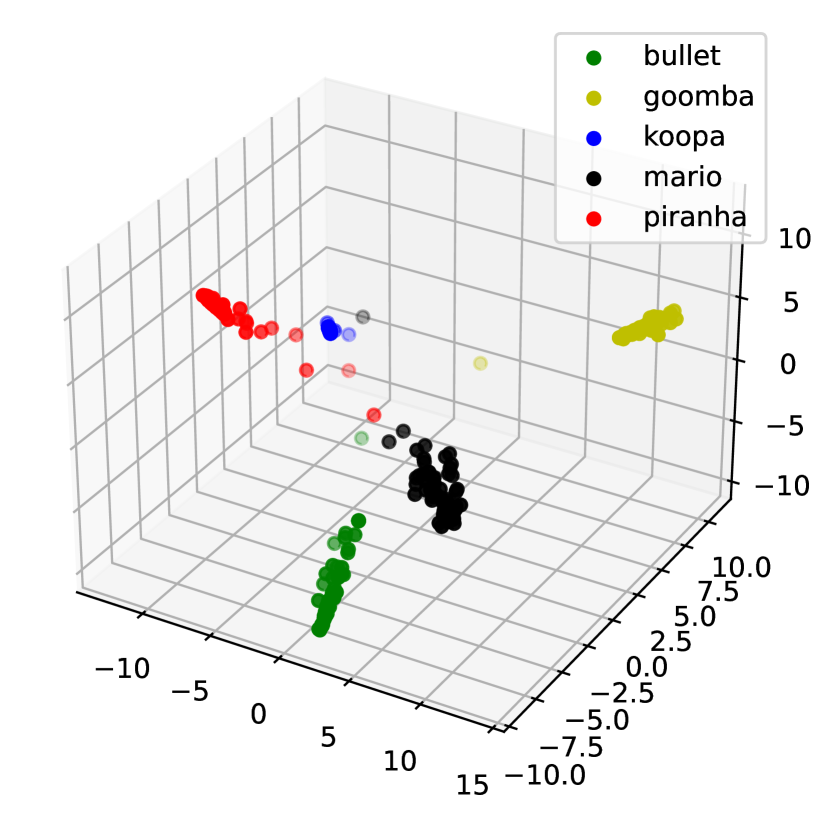
We picked five main objects of the Mario [49] data set from the video sequence played by humans: Bullet Bill, Goomba, Koopa, Mario, and Piranha Plant. They exhibit various movements, such as jumping, running, and opening or closing, against diverse backgrounds. Both training and testing videos contain 500 frames ( pixels), with 100 consecutive frames per object. For DPCNs, each frame is divided into four vectorized patches normalized between 0 and 1. It is initialized with , , , , and model matrices , . We set and for MM-DPCN and and for FISTA-DPCN. Figure 4 shows that MM-DPCN produces a clean separation while keeping each cluster compact. Figure 5(a) demonstrates the optimal reconstruction quality produced by MM-DPCN in comparison to alternative methods. We obseve from Table 3 that MM-DPCN achieves the best ACC, ARI, SPA, and is much faster than previous version FISTA-DPCN.
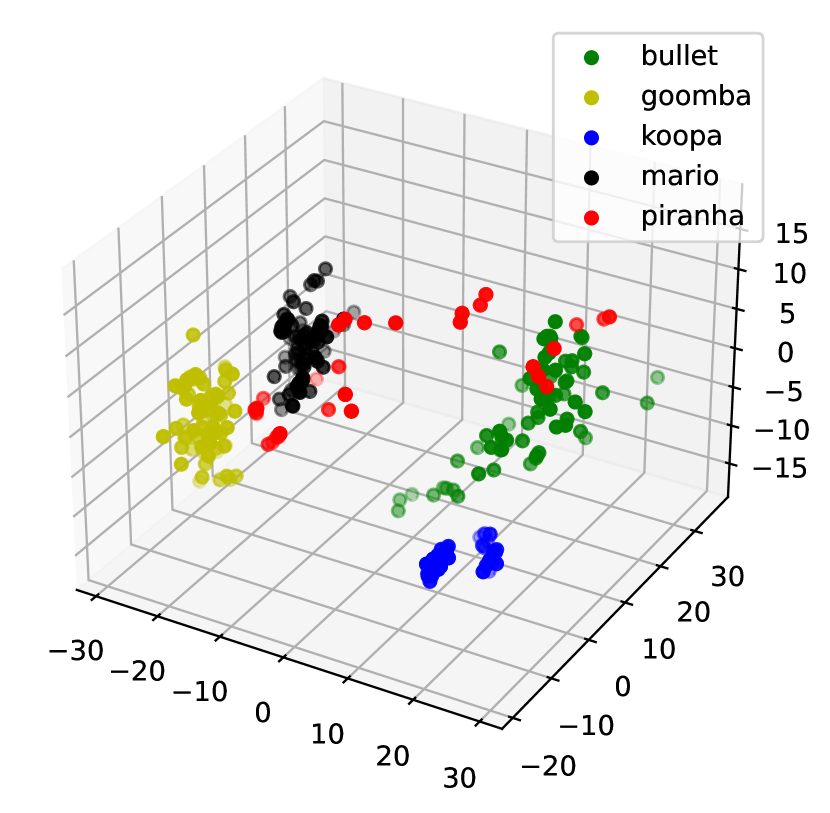
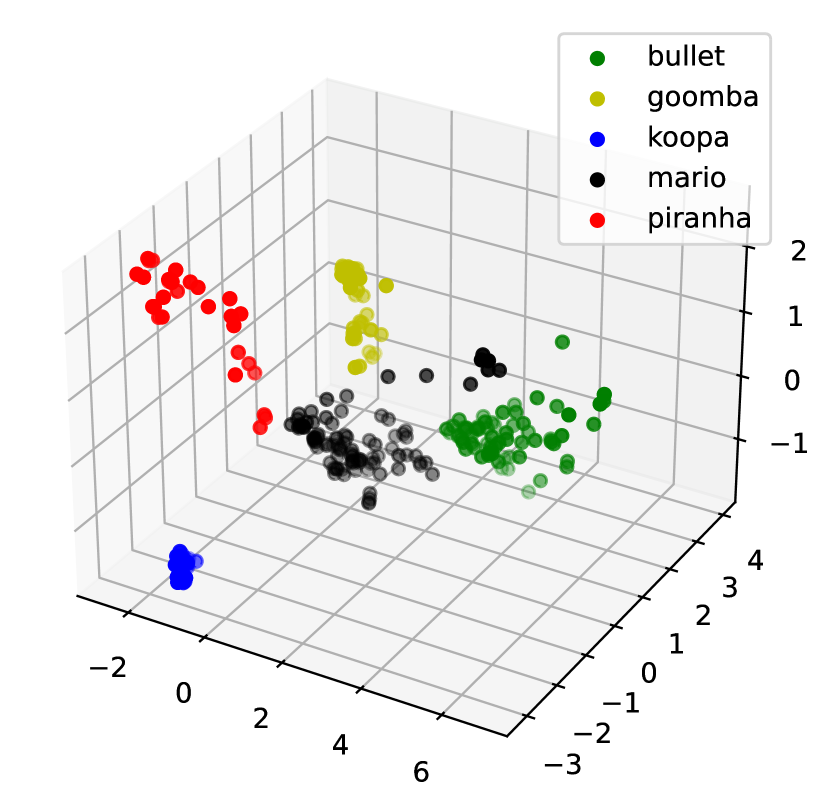
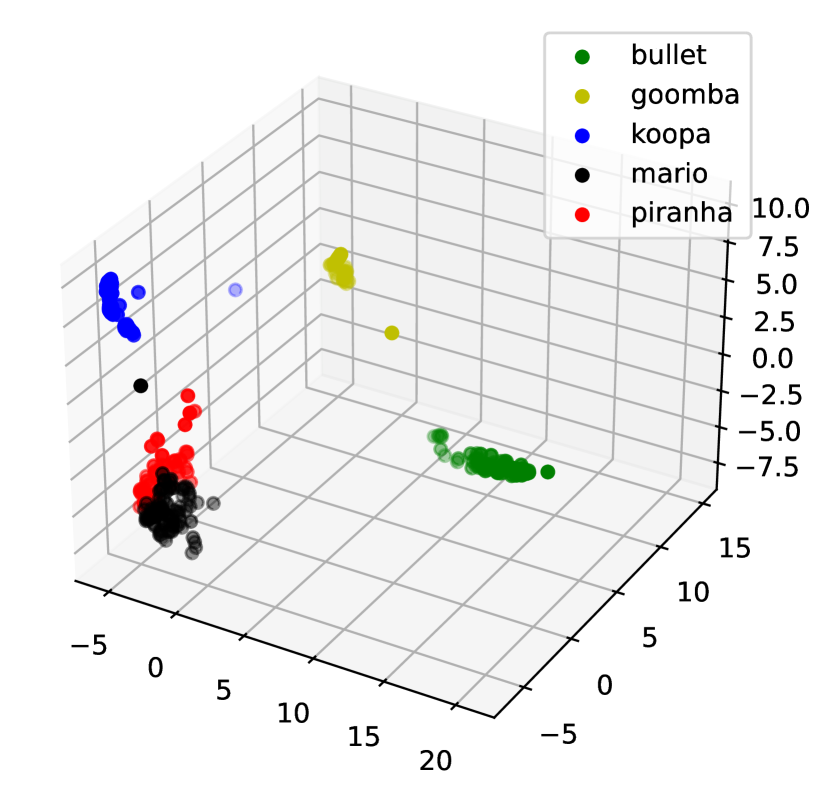
Coil-100 data set
The Coil-100 data set [50] consists of 100 videos of different objects, with each 72 frames long. The frames are resized into 32×32 pixels and normalized between 0 and 1. We used the first 50 frames of all the objects for training, while the rest 22 frames for testing. We initialize our MM-DPCNs with randomized model , , and , , and . We set , for MM-DPCN and , for FISTA-DPCN. We extract the causes from the last layer of MM- and FISTA-DPCNs and use PCA to project them into three-dimensional vectors, then apply K-Means for clustering. This same process is applied to the learned latent space encodings for both AE and WTA-RNN-AE, constructed using MLPs and ReLU.
| Methods | Mario | Coil-100 | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC | ARI | SPA | LCT () | ACC | ARI | SPA | LCT () | |
| AE | 84.81 | 76.74 | 0.00 | * | 77.74 | 44.04 | 0.00 | * |
| WTA-RNN-AE | 92.76 | 88.22 | 90.00 | * | 79.28 | 44.45 | 90.00 | * |
| FISTA-DPCN | 87.74 | 72.01 | 87.22 | 0.084 | 80.48 | 47.00 | 81.02 | 0.102 |
| MM-DPCN | 94.87 | 91.98 | 95.17 | 0.015 | 82.98 | 48.93 | 57.86 | 0.016 |










Table 3 presents the quantitative clustering and learning results, and Figure 5(b) showcases the qualitative video sequence reconstruction results. WTA-RNN-AE includes an additional RNN to learn video dynamics, which, however, is a trade-off with reconstruction. On the other hand, the FISTA- and MM-DPCNs provide much better reconstruction as the recurrent models are linear and less susceptible to overfitting than RNN, while WTA-RNN-AE tends to blend and blur different objects. Therefore, the efficiency of the iterative process enables MM to provide the best reconstruction quality. As shown in Table 3, WTA-RNN-AE has best SPA since it allows selected sparse level as for encodings, which, however, results in worse ACC and ARI due to over-loss of information. In contrast, MM and FISTA, by selecting sparsity coefficients or how much information can be compressed without resorting to nonlinear DL models, have much better ACC and ARI, where our MM-DPCN has the best ACC and ARI and MSE.
In the learning, the matrix inversion operation involves a conjugate gradient computation with complexity approximately , where is the matrix condition number and is the state size. The memory complexity for storing matrices is , and this requirement arises as state size increases, potentially leading to memory overhead when vector size is too large. This can be mitigated to moderately increasing patches or enlarging hardware memory.
6 Conclusion
We proposed a MM-based DPCNs that circumvents the non-smooth optimization problem with sparsity penalty for sparse coding by turning it into a smooth minimization problem using majorizer for sparsity penalty. The method searches for the optimal solution directly by the direction of the stationary point of the smoothed objective function. The experiments on image and video data sets demonstrated that this tremendously speeds up the rate of convergence, computation time, and feature clustering performance.
Acknowledgments and Disclosure of Funding
This work is partially supported by the Office of the Under Secretary of Defense for Research and Engineering under awards N00014-21-1-2295 and N00014-21-1-2345
References
- [1] Rudolf E Kalman. On the general theory of control systems. In the 1st International Conference on Automatic Control, pages 481–492, 1960.
- [2] R. E. Kalman. A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 82(1):35–45, 1960.
- [3] Bosen Lian, Frank L Lewis, Gary A Hewer, Katia Estabridis, and Tianyou Chai. Robustness analysis of distributed kalman filter for estimation in sensor networks. IEEE Transactions on Cybernetics, 52(11):12479–12490, 2021.
- [4] Bosen Lian, Yan Wan, Ya Zhang, Mushuang Liu, Frank L Lewis, Alexandra Abad, Tina Setter, Dunham Short, and Tianyou Chai. Distributed consensus-based kalman filtering for estimation with multiple moving targets. In IEEE 58th Conference on Decision and Control, pages 3910–3915, 2019.
- [5] Amir Parviz Valadbeigi, Ali Khaki Sedigh, and Frank L Lewis. static output-feedback control design for discrete-time systems using reinforcement learning. IEEE transactions on neural networks and learning systems, 31(2):396–406, 2020.
- [6] Adam Charles, M Salman Asif, Justin Romberg, and Christopher Rozell. Sparsity penalties in dynamical system estimation. In the 45th IEEE conference on information sciences and systems, pages 1–6, 2011.
- [7] Ashish Pal and Satish Nagarajaiah. Sparsity promoting algorithm for identification of nonlinear dynamic system based on unscented kalman filter using novel selective thresholding and penalty-based model selection. Mechanical Systems and Signal Processing, 212(111301):1–22, 2024.
- [8] Tapio Schneider, Andrew M Stuart, and Jinlong Wu. Ensemble kalman inversion for sparse learning of dynamical systems from time-averaged data. Journal of Computational Physics, 470(111559):1–31, 2022.
- [9] Fernando Ornelas-Tellez, J Jesus Rico-Melgoza, Angel E Villafuerte, and Febe J Zavala-Mendoza. Neural networks: A methodology for modeling and control design of dynamical systems. In Artificial neural networks for engineering applications, pages 21–38. Elsevier, 2019.
- [10] Christian Legaard, Thomas Schranz, Gerald Schweiger, Ján Drgoňa, Basak Falay, Cláudio Gomes, Alexandros Iosifidis, Mahdi Abkar, and Peter Larsen. Constructing neural network based models for simulating dynamical systems. ACM Computing Surveys, 55(11):1–34, 2023.
- [11] Kyriakos G Vamvoudakis and Frank L Lewis. Online actor–critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica, 46(5):878–888, 2010.
- [12] Shaowu Pan and Karthik Duraisamy. Long-time predictive modeling of nonlinear dynamical systems using neural networks. Complexity, 2018:1–26, 2018.
- [13] Pawan Goyal and Peter Benner. Discovery of nonlinear dynamical systems using a runge–kutta inspired dictionary-based sparse regression approach. Proceedings of the Royal Society A, 478(20210883):1–24, 2022.
- [14] Yingcheng Lai. Finding nonlinear system equations and complex network structures from data: A sparse optimization approach. Chaos: An Interdisciplinary Journal of Nonlinear Science, 31(082101):1–12, 2021.
- [15] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In IEEE conference on computer vision and pattern recognition, pages 1–9, 2015.
- [16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Computer Vision–ECCV 2016: 14th European Conference, pages 630–645, 2016.
- [18] Pu Li and Wangda Zhao. Image fire detection algorithms based on convolutional neural networks. Case Studies in Thermal Engineering, 19:100625, 2020.
- [19] Dolly Das, Saroj Kumar Biswas, and Sivaji Bandyopadhyay. Detection of diabetic retinopathy using convolutional neural networks for feature extraction and classification (drfec). Multimedia Tools and Applications, 82(19):29943–30001, 2023.
- [20] Karl Friston. Hierarchical models in the brain. PLoS computational biology, 4(11):e1000211, 2008.
- [21] Karl Friston and Stefan Kiebel. Predictive coding under the free-energy principle. Philosophical transactions of the Royal Society B: Biological sciences, 364(1521):1211–1221, 2009.
- [22] Andre M Bastos, W Martin Usrey, Rick A Adams, George R Mangun, Pascal Fries, and Karl J Friston. Canonical microcircuits for predictive coding. Neuron, 76(4):695–711, 2012.
- [23] Rajesh PN Rao and Dana H Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nature neuroscience, 2(1):79–87, 1999.
- [24] Janneke FM Jehee, Constantin Rothkopf, Jeffrey M Beck, and Dana H Ballard. Learning receptive fields using predictive feedback. Journal of Physiology-Paris, 100(1-3):125–132, 2006.
- [25] Kuan Han, Haiguang Wen, Yizhen Zhang, Di Fu, Eugenio Culurciello, and Zhongming Liu. Deep predictive coding network with local recurrent processing for object recognition. In the 32nd Conference on Neural Information Processing Systems, pages 1–13, 2018.
- [26] Haiguang Wen, Kuan Han, Junxing Shi, Yizhen Zhang, Eugenio Culurciello, and Zhongming Liu. Deep predictive coding network for object recognition. In International conference on machine learning, pages 5266–5275. PMLR, 2018.
- [27] Rakesh Chalasani and Jose C Principe. Context dependent encoding using convolutional dynamic networks. IEEE Transactions on Neural Networks and Learning Systems, 26(9):1992–2004, 2015.
- [28] Isaac J Sledge and José C Príncipe. Faster convergence in deep-predictive-coding networks to learn deeper representations. IEEE Transactions on Neural Networks and Learning Systems, 34(8):5156–5170, 2021.
- [29] Jamal Banzi, Isack Bulugu, and Zhongfu Ye. Learning a deep predictive coding network for a semi-supervised 3d-hand pose estimation. IEEE/CAA Journal of Automatica Sinica, 7(5):1371–1379, 2020.
- [30] Jose C Principe and Rakesh Chalasani. Cognitive architectures for sensory processing. Proceedings of the IEEE, 102(4):514–525, 2014.
- [31] Rakesh Chalasani and Jose C Principe. Deep predictive coding networks. arXiv preprint arXiv:1301.3541, 2013.
- [32] Daniel J Felleman and David C Van Essen. Distributed hierarchical processing in the primate cerebral cortex. Cerebral cortex (New York, NY: 1991), 1(1):1–47, 1991.
- [33] Thomas Serre, Aude Oliva, and Tomaso Poggio. A feedforward architecture accounts for rapid categorization. Proceedings of the national academy of sciences, 104(15):6424–6429, 2007.
- [34] Amir Beck and Marc Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences, 2(1):183–202, 2009.
- [35] Jérôme Bolte and Edouard Pauwels. Majorization-minimization procedures and convergence of sqp methods for semi-algebraic and tame programs. Mathematics of Operations Research, 41(2):442–465, 2016.
- [36] Frank L Lewis and Draguna Vrabie. Reinforcement learning and adaptive dynamic programming for feedback control. IEEE circuits and systems magazine, 9(3):32–50, 2009.
- [37] Ramzi Ben Mhenni, Sébastien Bourguignon, and Jordan Ninin. Global optimization for sparse solution of least squares problems. Optimization Methods and Software, 37(5):1740–1769, 2022.
- [38] Yan Karklin and Michael S Lewicki. A hierarchical bayesian model for learning nonlinear statistical regularities in nonstationary natural signals. Neural computation, 17(2):397–423, 2005.
- [39] Ivan Selesnick. Penalty and shrinkage functions for sparse signal processing. Connexions, 11(22):1–26, 2012.
- [40] Ingrid Daubechies, Michel Defrise, and Christine De Mol. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 57(11):1413–1457, 2004.
- [41] Mário AT Figueiredo and Robert D Nowak. An em algorithm for wavelet-based image restoration. IEEE Transactions on Image Processing, 12(8):906–916, 2003.
- [42] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [43] Xi Chen, Qihang Lin, Seyoung Kim, Jaime G Carbonell, and Eric P Xing. Smoothing proximal gradient method for general structured sparse regression. The ANNALS of Applied Statistics, 6(2):719–752, 2012.
- [44] Yu Nesterov. Smooth minimization of non-smooth functions. Mathematical programming, 103:127–152, 2005.
- [45] Mário AT Figueiredo, José M Bioucas-Dias, and Robert D Nowak. Majorization minimization algorithms for wavelet-based image restoration. IEEE Transactions on Image processing, 16(12):2980–2991, 2007.
- [46] Koray Kavukcuoglu, Marc’Aurelio Ranzato, and Yann LeCun. Fast inference in sparse coding algorithms with applications to object recognition. arXiv preprint arXiv:1010.3467, 2010.
- [47] Geoffrey E Hinton and Ruslan R Salakhutdinov. Reducing the dimensionality of data with neural networks. science, 313(5786):504–507, 2006.
- [48] Eder Santana, Matthew S Emigh, Pablo Zegers, and Jose C Principe. Exploiting spatio-temporal structure with recurrent winner-take-all networks. IEEE Transactions on Neural Networks and Learning Systems, 29(8):3738–3746, 2017.
- [49] OpenAI. Super mario bros environment for openai gym, 2017.
- [50] S. A. Nene, S. K. Nayar, and H. Murase. Columbia object image library (coil-100). Technical Report CUCS-006-96, 1996.
- [51] Hongming Li, Ran Dou, Andreas Keil, and Jose C Principe. A self-learning cognitive architecture exploiting causality from rewards. Neural Networks, 150:274–292, 2022.
- [52] Zhenyu Qian, Yizhang Jiang, Zhou Hong, Lijun Huang, Fengda Li, Khin Wee Lai, and Kaijian Xia. Multiscale and auto-tuned semi-supervised deep subspace clustering and its application in brain tumor clustering. Computers, Materials & Continua, 79(3), 2024.
- [53] Silvia Cascianelli, Gabriele Costante, Francesco Crocetti, Elisa Ricci, Paolo Valigi, and Mario Luca Fravolini. Data-based design of robust fault detection and isolation residuals via lasso optimization and bayesian filtering. Asian Journal of Control, 23(1):57–71, 2021.
Appendix A Appendix for Derivations
For the term where , the smooth approximation on it is given by
| (29) |
The best approximation, as well as the maximum, is reached at such that
| (33) |
The majorizer of the sparsity penalty is given by
| (34) |
where
| (35) |
where and can be any vector. The equality holds only at . By rewriting the left-hand-side majorizer compactly, it becomes (5) where is a constant independent of . Accordingly, the constant in (9) is , , where can be any vector.
The top-down prediction for layer from the upper layer is denoted by which is given by
| (36) | |||
| (39) |
where belongs to layer . At the top layer , we set , which induces some temporal coherence on the final outputs.
Appendix B Appendix for Proofs
We first show a necessary lemma before proving Theorem 1. Since in (5) represents any vector with the same dimension as , for simplification we use as in the following analysis regrading state inference. We also do the same, using as that appears in (9), in the analysis regrading cause inference.
Lemma 1
Let satisfy
| (40) |
For any one has
| (41) |
Proof: Recalling the majorizer for states, i.e., in (5), it can be induced from (22)-(23) that satisfies
| (42) |
Then, we know from (12) that
| (43) |
It follows from (5) that (40) holds. Since and are convex on , we have
| (44) | |||
| (45) |
Hence, with (40), (21) and (22), we have
| (46) |
Note that the fourth line applies (44) and , the seventh line applies (45), and the last line applies (42).
It follows from (5) and Appendix A that
| (47) |
Substituting it into (46) yields (41). This completes the proof.
Proof of Theorem 1
It can be inferred from the derivations that
| (48) |
where the second and third equality hold only at , i.e., satisfies the optimality condition (7). That is, monotonically decreases until satisfies the optimality condition. Moreover, it follows from the approximation shown in (4) that the approximation gap is
| (49) |
where . It indicates that is lower-bounded such that
| (50) |
where . Therefore, is monotonically convergent with boundaries using .
By taking , , and in Lemma 1, we can write
| (51) |
Summing it for iterations yields
| (52) |
Subtracting from the both sides yields
| (53) |
From (48) we infer that . Therefore, (53) becomes
| (54) |
Let be the optimal sparse solution satisfying (7). Since is monotonically decreasing to , as well as the sequence in (13), then is approaching monotonically. Positive or negative initial does not influence result as is used, and the update views as positive and drives it to a non-negative and similarly, views as negative and drives it to a non-positive . Note that we never choose . Therefore, for an optimal value , one has
| (55) |
For an optimal value , one has
| (56) |
For an optimal value , one has
| (57) |
Using (55)-(57) in (54) for , we write
| (58) |
where , , with if , if , if , and otherwise. It can be inferred from uniqueness of and monotonic convergence of that the upper bound at (58) decreases with iterations . This completes the proof.
Proof of Theorem 2
We write in three pairs as
| (59) |
The first and third pairs in (59), i.e., and , are bounded by the gap of approximation shown in (50). That is
| (60) | |||
| (61) |
That is, is upper-bounded by , and is upper-bounded by 0. From Theorem 1, the second pair is bounded by (24). Therefore, we can conclude (25). This completes the proof.
Proof of Theorem 3
It is seen from (14) that given with a normalized matrix . Also, we observe a trade-off between effects on the update from and , either one deviating zero while the other approaching zero. Based on the fact that and where is a constant matrix with non-negative elements, we can infer that the update (14) will not diverge but will have an upper bound for the updated . Recalling Algorithm 2 and the condition (11), we can write (14) as
| (62) |
It follows from (15) that is a diagonal matrix during the learning. Therefore, the update law in Algorithm 2 for causes admits a gradient descent form with a positive-definite diagonal matrix as step size during the learning. The learning will stop when , i.e., , and is minimized. That is, the method will learn until becomes sparse and the optimal condition (11) is met. By taking the first two orders of Taylor expansion of , we have
| (63) |
Combining it with (26)-(27) yields
| (64) |
with equality at . It can be concluded that function decreases using Algorithm 2 for causes inference. This convergence is also verified by the experiments.
Appendix C Appendix for more results and AE architecture details
We used a simple geometric moving shape data set to demonstrate the video clustering mechanism for MM-DPCN further. Each video contains three geometric shapes: diamond, triangle, and square. Each shape appears consistently for 100 frames until another shape shows up. The shape could appear in each patch of the image frame and move within the 100 frames of a single shape.
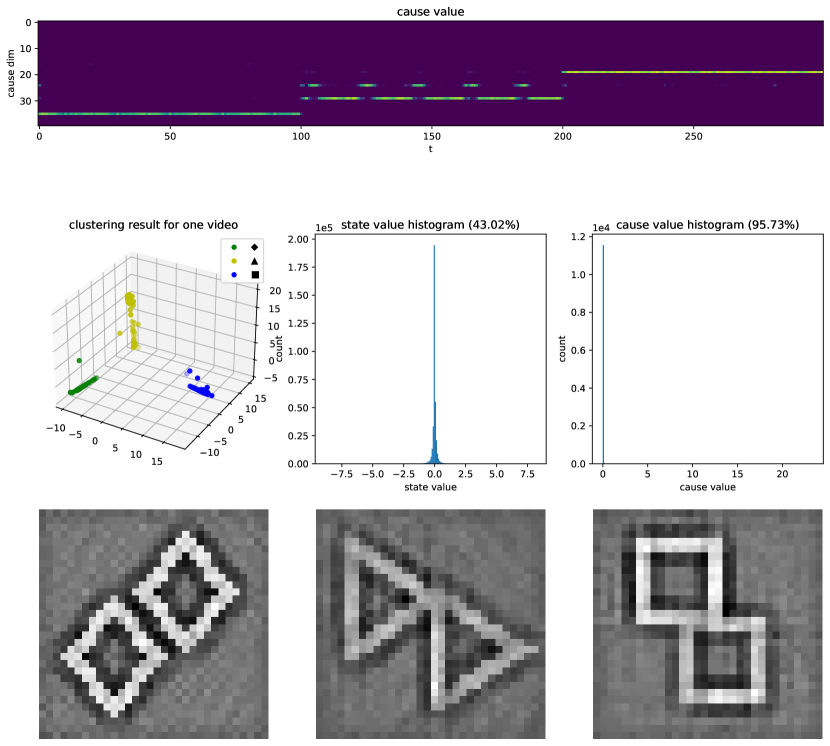
To visualize the learned filters, the plots for matrix are provided in Fig. 7.

The architectures for AE and WTA-RNN-AE used for the comparison results are provided in Table 4. We use the same architectures for both Mario and Coil-100 data sets.
| layer name | AE | WTA-RNN-AE |
| encoder_layer1 | ||
| encoder_layer2 | ||
| encoder_layer3 | ||
| encoder_layer4 | * | |
| encoder_layer5 | * | |
| RNN | * |