Fast Monocular Hand Pose Estimation on Embedded Systems
Abstract
Hand pose estimation is a fundamental task in many human-robot interaction-related applications. However, previous approaches suffer from unsatisfying hand landmark predictions in real-world scenes and high computation burden. This paper proposes a fast and accurate framework for hand pose estimation, dubbed as “FastHand”. Using a lightweight encoder-decoder network architecture, FastHand fulfills the requirements of practical applications running on embedded devices. The encoder consists of deep layers with a small number of parameters, while the decoder makes use of spatial location information to obtain more accurate results. The evaluation took place on two publicly available datasets demonstrating the improved performance of the proposed pipeline compared to other state-of-the-art approaches. FastHand offers high accuracy scores while reaching a speed of 25 frames per second on an NVIDIA Jetson TX2 graphics processing unit.
keywords:
hand pose estimation , landmark localization , hand detection , encoder-decoder network , heatmap regression1 Introduction
Gesture recognition is an essential component needed for a robust Human-Robot Interaction (HRI) [1, 2, 3, 4, 5, 6]. Since robot malfunctions may occur due to the noisy sensor measurements or operator’s speech disabilities, an alternative technique has to be adopted to allow the agent to understand the human’s intentions and, consequently, react accordingly [7]. However, gesture recognition is a challenging problem in the robotics community as the hand is defined through a small area compared to the human body. Moreover, it exhibits a high degree of freedom and similarity, i.e., among the finger joints’ visual appearance. The timing required for a robot to interact with its operator constitutes another considerable challenge in HRI since real-time responses are necessary for a reliable application. Skeleton-based methods [8, 9, 10, 11], generally follow two processing steps. At first, they detect hand landmarks, a task widely known as hand pose estimation, and subsequently, they recognize gestures according to these points. Some approaches make use of depth cameras to locate the 3D hand landmarks [12, 13, 14, 15, 16]. Nevertheless, these modules are expensive for small and low-cost platforms. Therefore, it is urgent to study hand pose estimation using a monocular camera as the primary sensing modality.
Based on the technique they use to tackle the problem, modern methods can be divided into the top-down and bottom-up ones. The former firstly detect the hand and afterward locate its landmarks. On the contrary, bottom-up frameworks initially detect the landmarks, and next, they cluster them to form a hand. Both strategies present advantages and disadvantages. The top-down methods repeatedly run on each hand bounding box to localize landmarks, resulting in the linearly increased run-time. The bottom-up approaches detect landmarks from the whole image but have a low recall rate because the complex background causes false positives.
Furthermore, hand pose estimation pipelines are divided into two categories according to their output. Methods that utilize coordinate regression are placed in the first [17, 18, 19], whereas algorithms that extract heatmaps belong to the second one [20, 21, 22, 23, 24, 25]. More specifically, approaches that fall into the first category directly predict the landmark coordinates from images. However, this is not accurate and has limitations when encountering occlusions and large poses. Frameworks belonging to the second category infer each hand joint’s likelihood heatmap and then generate their coordinates. These techniques offer high accuracy scores; nevertheless, they present the disadvantage of a slower execution time, making them impracticable for resource-constrained mobile platforms. This is mainly due to their used network structure since they do not follow a lightweight architecture.

Considering the reasons above, we propose a lightweight and top-down pose estimation technique, dubbed “FastHand” in this paper. Our method firstly detects the hand using a monocular camera, afterward crops the Region Of Interest (ROI), and then localizes its 2D landmarks based on a heatmap regression (Fig. 1). An encoder-decoder network design is employed. Regarding the encoder, a low amount of parameters are maintained while learning high-level information by using convolution, skip connection [26], and depthwise separable convolutions [27]. Concerning the decoder, an improvement in feature map resolution is achieved through a deconvolution process, which preserves the high resolution of the hand and avoids the false recognition of the background. Moreover, the heatmap regression accuracy is also improved. Extensive experiments are conducted on two publicly available datasets demonstrating our method’s superior performance compared to other state-of-the-art frameworks. The main contributions can be summarized below:
-
1.
A novel, lightweight encoder-decoder network, entitled “FastHand”, is proposed for hand pose estimation based on heatmap regression. The proposed framework is able to perform on a mobile robot in real-time.
-
2.
A 2D hand landmark dataset is generated based on the Youtube3D Hands image-sequence [28]. The generation code111https://github.com/AnshanTJU/Youtube3DHands-2D is made available to facilitate future studies.
-
3.
Extensive experiments are performed to demonstrate the effectiveness of the proposed method.
2 RELATED WORK
2.1 Coordinate Regression-Based Approaches
FreiHAND [17] proposed the first large-scale, multi-view, and 3D annotated real dataset, wherein a Convolutional Neural Network (CNN) was trained [17]. Subsequently, this framework could predict hand poses from the incoming RGB images with a certain ability of generalization. NSRM [18] adopted a cascaded multi-task architecture aiming to jointly learn the hand structure and its landmarks’ representation [18]. A novel CNN with a “self-attention” module was proposed in [19]. This network is lightweight and is capable of deployment on embedded systems. A deep regression network, combined with a specific label distribution learning network, is proposed to learn hand landmarks from 3D point cloud [29]. “MediaPipe Hands” [30] first determines the position of hands with a palm detector and then inputs the bounding-box containing hands to the landmark model to regress 21 2.5D hand landmarks directly.
2.2 Heatmap Regression-Based Approaches
Methods based on heatmap regression showed an improved performance regarding the final accuracy than the one achieved via the coordinate regression. In [21], a deep network was proposed to estimate the 3D hand pose originated from RGB images. This framework detected the hand’s location, and then it cropped the selected region. Subsequently, an encoder-decoder network extracted the 2D score maps for landmarks definition. Finally, 3D hand poses were estimated from these points by another network trained a priori on 3D data. A multi-view training method [25] used Convolutional Pose Machines (CPM) [31] as a detector and achieved similar performance to RGB-D systems. In [32], two stages determine the network’s functionality. Firstly, the hand mask prediction took place, while the pose prediction followed. For a given RGB image, the hand bounding box and landmarks were obtained simultaneously through a single forward pass of an encoder-decoder network in [33]. Afterward, the hand region was used as feedback to determine whether a cycle detection was performed. The monocular 3D hand tracking performed well even in challenging occlusion scenarios through the synthetic generation of the training data [22]. Cai et al. [23] adopted a weakly-supervised pipeline trained on RGB-D images and predicted 3D joints from the incoming color frames. Utilizing a CNN for depth and heatmap estimation, 2.5D poses are obtained in [24]. Adaptive Graphical Model Network (AGMN) [34] integrated a CNN with a graphical model for accurate 2D estimation. Similarly, a Rotation-invariant Mixed Graph Model Network (R-MGMN) performed 2D gesture estimation through a monocular RGB camera [35]. The authors in [36] proposed the InterHand2.6M dataset and InterNet for cases where two hands are used. Boukhayma1 et al. introduced the first end-to-end deep learning method, which was formed by an encoder-decoder structure placed in series [37]. 2D landmark information was utilized to facilitate the learning of a 3D hand pose. A graph CNN-based method was proposed to estimate 3D hand joints and reconstructed its 3D mesh of the surface in [20]. Our network is based on heatmap regression because of its high accuracy.
3 PROPOSED METHOD
An overview of the proposed pipeline is outlined in Fig. 2. The input image is fed into the hand detection network to get the corresponding bounding box. We obtain a stabilized box through the information provided by the previous boxes. Afterward, this ROI is placed on the landmark localization network for computing the heatmaps. Finally, D positions of the hand landmarks are extracted.
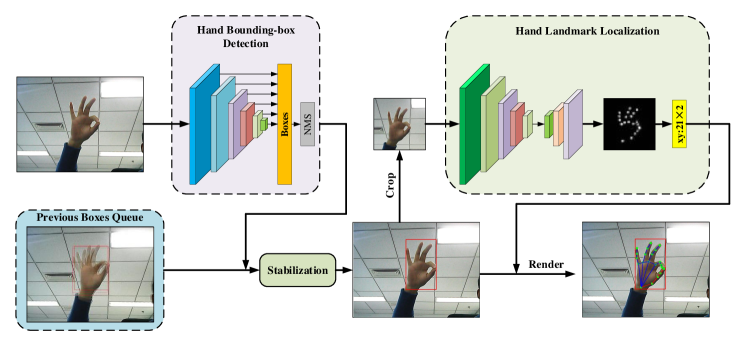
3.1 Hand Detection and Stablization
3.1.1 Hand Detection
Top-down approaches firstly detect the ROI, i.e., the hand, in the visual sensory information, and then localize its landmarks on the chosen area. In this way, a computational complexity reduction is achieved, which is our main focus. We select to utilize the MobileNet-SSD framework to detect human hands, which is based on MobileNetV2 [38] as the network’s backbone and Single Shot multi-box Detector (SSD) [39] for the detection.
3.1.2 Stabilization of the Bounding-Box
As we adopt the top-down approach, the detection box’s inevitable jitters occur, affecting the landmarks’ localization. Aiming for more accurate prediction scores, we added a fast and straightforward method to stabilize the hand bounding box. Since early perceived frames present a higher correlation with the current box, we perform a weighted average according to the exponentially decreasing weight. This way, we exploit the correlation between the current box and the previous ones as the weight’s value is higher for neighboring images. The current bounding-box coordinates are calculated as:
| (1) |
where represents the previous frame’s index (e.g. denotes the current frame, while is the previous one) and corresponds to the multitude of the examined frames. This value was set heuristic to 6 ( = 6). are the coordinates of the bounding-box. Finally, the last term of Eqn. 1, i.e., , is the exponentially decreasing weight.
3.2 Landmark Localization
For the landmarks’ detection, we design a heatmap regression method following the encoder-decoder architecture outlined in Fig. 3. At first, resize the image obtained from the previous steps to , and then feed it to the proposed network to extract high-level information. The feature map resolution is restored to through the decoder to generate the heatmaps, which are processed to extract the 2D coordinates of the landmarks.
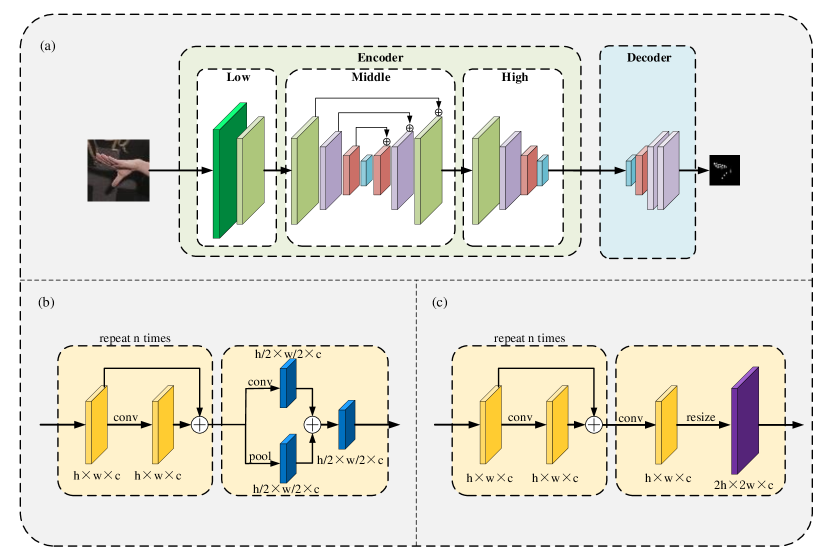
3.2.1 The Encoder Network
The encoder network utilizes convolution, skip connection [26], and depthwise separable convolutions [27], since we aim to a lightweight solution. The network structure follows the design of “MediaPipe Hands” [30]. The network preserves a small number of parameters while learning more high-level information. Three parts define its structure, namely the Low, the Middle, and the High (Fig. 3 (a)). More specifically, low-level features are extracted via the first part, composed of repeated residual blocks () and downsampling operation. In the Middle part, the utilization of parameters is improved through an encoder-decoder network and skip connection. In the encoder, a downsampling operation is utilized to reduce the resolution with residual blocks repeated four times, as illustrated in Fig. 3 (b). Then in the decoder part, the resolution can be improved through the upsampling module, which consists of residual blocks, a convolution, and a resize operation, as shown in Fig. 3 (c). At last, in the High part, more high-level information is extracted while the downsampling module reduces the resolution, as shown in Fig. 3 (b).
3.2.2 The Decoder Network
The decoder network aims to restore the resolution of the feature map. Since the human hand presents a different structure from the face or other human parts, presenting higher degrees of freedom, we improve the feature map resolution through a deconvolution () performed to preserve spatial position information. This technique offers a better modeling capability than a direct, coordinate regression and can provide improved accuracy. When heatmaps are used as ground truth to predict the landmarks, they must have high resolution. In our method, the encoder’s output is . As a result, we use the decoder to increase the resolution to . This way, we manage to retain more position-related information. Three layers of deconvolutions are used to restore the feature map size. The proposed pipeline outputs heatmaps. Finally, the 2D coordinates of the 21 hand landmarks are derived by extracting the peak points at each channel.
4 EXPERIMENTS
In this section, extensive experiments are conducted to demonstrate the effectiveness of FastHand. Due to the lack of the 2D hand pose dataset, we generate a large-scale dataset using image-sequences from YouTube3D Hands [28]. Two widely-used datasets, STB [40] and RHD [21], are selected for the method’s evaluation. Subsequently, we introduce the experimental settings, which include the training parameters and evaluation metrics. Finally, we provide quantitative and qualitative results to fully demonstrate the overall performance of our method.
4.1 2D Hand Pose Dataset Generation
There are several limitations of the existed 2D hand pose dataset. The datasets, such as STB [40], MHP [41], HO3D [42], only have limited scenes and hand movements. On the other hand, synthetic datasets are always unreal. It is difficult to collect and annotate a 2D hand pose because it has high degrees of freedom, self-occlusion, and mutual occlusion.
We generate a 2D hand pose dataset based on the YouTube3D Hands [28] dataset, which is a large-scale image-sequence including hand actions. It provides 109 videos in total. 102 of them are the training sets, while the rest are the test ones. As this dataset offers the 3D vertex coordinates of hands, we need to extract the 2D information of the hand landmarks. Through the average of 10 vertices around each hand skeleton, we get the 3D coordinates of the 21 hand landmarks. Subsequently, we project them onto the 2D plane to obtain the 2D points. The generated 2D hand pose dataset is referred to as YouTube2D Hands. As a final note, the images are resized to and augmented by 10 times using random scaling and cropping. Besides, we use the GANeratedHands dataset [22] for the network’s training since, through the utilization of real-world images, we cannot cover all gestures, and the annotation in real data is always inaccurate. A brief description of each dataset is shown in Table 1.
4.2 Experimental Settings
4.2.1 Training Process
The training are conducted on four NVIDIA Tesla P40 GPU. The entire network was trained for a total of 50 epochs, while we decreased the learning rate exponentially after the first three ones. The initial learning rate was set to and the batch size was set to 64. The Adam optimizer [43] was utilized as well. Finally, the network’s implementation was based on TensorFlow [44].
4.2.2 Evaluation Metrics
Sum of Squares Error (SSE), end-point error (EPE), and Probability of Correct Keypoint (PCK) within a normalized distance threshold, are used as evaluation metrics:
| (2) |
| (3) |
| (4) |
| (5) |
where the term is the ground truth of landmark , and is the system’s predicted coordinate. represents the landmark indexes and represents the index of hand sample. and are the ground truth root joint and the predicted root joint. denotes the number of samples in the dataset, while and are the original images’ width and height, respectively. In Eq. 4, is the indicator function and is the threshold. If distance between the predicted landmark and the ground truth is less than , the indicator function is set to 1, otherwise to 0. represents the metric of landmark at the ratio of , which is an empirical value of .
4.3 Comparison with the State-of-the-art Techniques
We compare the proposed pipeline against four state-of-the-art methods, namely SRHandNet [33], NSRM Hand [18], MediaPipe Hands [30], and InterHand [36]. As shown in Table 2, our FastHand ranks first in most metrics on the STB and RHD datasets. The proposed approach achieves a score of 0.3490 on the STB dataset, surpassing the second-best (0.4853). For the metric on the STB dataset, our method is slightly higher than InterHand [36]. One can conclude that our method is competitive against state-of-the-art, yielding accurate locating performance of the hand landmarks.
In Tables 3 and 4, we compare the execution times and the networks’ size, respectively. The execution time reported here is only the time of landmark localization, that is, the model forward time. As one can observe, our model has a size of 13.0 MB, which is less than 1/3 of SRHandNet. MediaPipe Hands is the smallest model because the official implementation has many optimizations, such as quantization. Furthermore, we list the inference runtime for different methods showing that FastHand can execute at 25FPS on an NVIDIA Jetson TX2 GPU and 31FPS on an NVIDIA GeForce 940 MX GPU of a laptop outperforming each other method, without adopting any acceleration. Note that since the official implementation of MediaPipe Hands is based on TFlite222https://www.tensorflow.org/lite/guide with considerable acceleration operations, for a fair evaluation, it is not involved in the inference runtime comparison.
4.4 Qualitative Evaluation
We show the visualization results of the proposed pipeline in Fig. 4. Different perspectives of the hand pose are shown in each column. Our framework can accurately detect the landmarks of open hands, such as “Num 5”, while performs favorably in cases where occlusions occur, such as the fingertips for the pose of “thumbs-up” and “claw”. The high-accuracy hand landmark localization is due to our decoder design, which extracts high-resolution feature maps. In our experiments, we found that our method can recognize the hand gestures of numbers to and other basic ones, including the self-occluding poses. In Fig. 5 and Fig. 6, we show the results obtained by FastHand and the other methods on the STB and RHD datasets. As can be seen, our network predicts accurate coordinates outperforming the rest of the approaches. The hand pose estimation videos can be found here: https://youtu.be/r9CKDhXXs3Y.



5 CONCLUSIONS
This paper proposes a fast 2D hand pose estimation pipeline, referred to as “FastHand”. The core of our framework is based on a lightweight encoder-decoder network. Through hand detection and stabilization, the ROI is cropped and fed into our network for landmark localization. The proposed network is trained over our large-scale 2D hand pose dataset and a synthetic one while evaluated on two publicly available datasets. Compared to several state-of-the-art techniques, the proposed approach shows a favorable performance while maintaining a real-time speed (over 25 frames per second) on a low-cost GeForce 940MX GPU and an NVIDIA Jetson TX2 GPU. Future works can explore the utility of our method in complex robot applications and utilize Part Affinity Fields [45] to differentiate between left hand and right hand.
6 ACKNOWLEDGEMENT
This work was supported by grants from the National Key Research and Development Program of China (Grant No. 2020YFC2006200).
References
- [1] L. Brethes, P. Menezes, F. Lerasle, J. Hayet, Face tracking and hand gesture recognition for human-robot interaction, in: Proc. IEEE Int. Conf. Robotics and Automation (ICRA), Vol. 2, 2004, pp. 1901–1906.
- [2] G. Cicirelli, C. Attolico, C. Guaragnella, T. D’Orazio, A kinect-based gesture recognition approach for a natural human robot interface, Int. J. Advanced Robotic Systems 12 (3) (2015) 22.
- [3] K. Ehlers, K. Brama, A human-robot interaction interface for mobile and stationary robots based on real-time 3d human body and hand-finger pose estimation, in: IEEE 21st Int. Conf. Emerging Technologies and Factory Automation (ETFA), 2016, pp. 1–6.
- [4] O. Mazhar, S. Ramdani, B. Navarro, R. Passama, A. Cherubini, Towards real-time physical human-robot interaction using skeleton information and hand gestures, in: Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2018, pp. 1–6.
- [5] J.-Y. Chang, A. Tejero-de Pablos, T. Harada, Improved optical flow for gesture-based human-robot interaction, in: Proc. IEEE Int. Conf. Robotics and Automation (ICRA), 2019, pp. 7983–7989.
- [6] I. Kansizoglou, L. Bampis, A. Gasteratos, An active learning paradigm for online audio-visual emotion recognition, IEEE Trans. Affective Computing (2019).
- [7] S. Goldin-Meadow, The role of gesture in communication and thinking, Trends in cognitive sciences 3 (11) (1999) 419–429.
- [8] J. C. Nunez, R. Cabido, J. J. Pantrigo, A. S. Montemayor, J. F. Velez, Convolutional neural networks and long short-term memory for skeleton-based human activity and hand gesture recognition, Pattern Recognition 76 (2018) 80–94.
- [9] G. Devineau, F. Moutarde, W. Xi, J. Yang, Deep learning for hand gesture recognition on skeletal data, in: 13th IEEE Int. Conf. on Automatic Face & Gesture Recognition (FG), 2018, pp. 106–113.
- [10] X. S. Nguyen, L. Brun, O. Lézoray, S. Bougleux, A neural network based on spd manifold learning for skeleton-based hand gesture recognition, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2019, pp. 12036–12045.
- [11] J. Liu, Y. Liu, Y. Wang, V. Prinet, S. Xiang, C. Pan, Decoupled representation learning for skeleton-based gesture recognition, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5751–5760.
- [12] I. Oikonomidis, N. Kyriazis, A. A. Argyros, Efficient model-based 3d tracking of hand articulations using kinect., in: The British Machine Vision Conference (BMVC), Vol. 1, 2011, p. 3.
- [13] Z. Ren, J. Yuan, J. Meng, Z. Zhang, Robust part-based hand gesture recognition using kinect sensor, IEEE Trans. Multimedia 15 (5) (2013) 1110–1120.
- [14] A. Tagliasacchi, M. Schröder, A. Tkach, S. Bouaziz, M. Botsch, M. Pauly, Robust articulated-icp for real-time hand tracking, in: Computer Graphics Forum, Vol. 34, 2015, pp. 101–114.
- [15] L. Ge, H. Liang, J. Yuan, D. Thalmann, Robust 3d hand pose estimation from single depth images using multi-view cnns, IEEE Trans. Image Processing 27 (9) (2018) 4422–4436.
- [16] C. Wan, T. Probst, L. V. Gool, A. Yao, Self-supervised 3d hand pose estimation through training by fitting, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10853–10862.
- [17] C. Zimmermann, D. Ceylan, J. Yang, B. Russell, M. Argus, T. Brox, FreiHAND: A dataset for markerless capture of hand pose and shape from single rgb images, in: Proc. IEEE Int. Conf. Computer Vision (ICCV), 2019, pp. 813–822.
- [18] Y. Chen, H. Ma, D. Kong, X. Yan, J. Wu, W. Fan, X. Xie, Nonparametric structure regularization machine for 2d hand pose estimation, in: IEEE Winter Conf. Applications of Computer Vision (WACV), 2020, pp. 381–390.
- [19] N. Santavas, I. Kansizoglou, L. Bampis, E. Karakasis, A. Gasteratos, Attention! A Lightweight 2D Hand Pose Estimation Approach, IEEE Sensors Journal (2020).
- [20] L. Ge, Z. Ren, Y. Li, Z. Xue, Y. Wang, J. Cai, J. Yuan, 3d hand shape and pose estimation from a single rgb image, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10833–10842.
- [21] C. Zimmermann, T. Brox, Learning to estimate 3d hand pose from single rgb images, in: Proc. IEEE Int. Conf. Computer Vision (ICCV), pp. 4903–4911.
- [22] F. Mueller, F. Bernard, O. Sotnychenko, D. Mehta, S. Sridhar, D. Casas, C. Theobalt, Ganerated hands for real-time 3d hand tracking from monocular rgb, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2018, pp. 49–59.
- [23] Y. Cai, L. Ge, J. Cai, J. Yuan, Weakly-supervised 3d hand pose estimation from monocular rgb images, in: Proc. Eur. Conf. Computer Vision (ECCV), 2018, pp. 666–682.
- [24] U. Iqbal, P. Molchanov, T. Breuel Juergen Gall, J. Kautz, Hand pose estimation via latent 2.5 d heatmap regression, in: Proc. Eur. Conf. Computer Vision (ECCV), 2018, pp. 118–134.
- [25] T. Simon, H. Joo, I. Matthews, Y. Sheikh, Hand keypoint detection in single images using multiview bootstrapping, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1145–1153.
- [26] K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [27] F. Chollet, Xception: Deep learning with depthwise separable convolutions, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1251–1258.
- [28] D. Kulon, R. A. Guler, I. Kokkinos, M. M. Bronstein, S. Zafeiriou, Weakly-supervised mesh-convolutional hand reconstruction in the wild, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2020, pp. 4990–5000.
- [29] Y. Xu, X. Wang, 3d hand pose estimation from single depth images with label distribution learning, in: 2020 IEEE International Conference on Embedded Software and Systems (ICESS), IEEE, 2020, pp. 1–5.
- [30] F. Zhang, V. Bazarevsky, A. Vakunov, A. Tkachenka, G. Sung, C.-L. Chang, M. Grundmann, Mediapipe hands: On-device real-time hand tracking, arXiv preprint arXiv:2006.10214 (2020).
- [31] S.-E. Wei, V. Ramakrishna, T. Kanade, Y. Sheikh, Convolutional pose machines, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4724–4732.
- [32] Y. Wang, C. Peng, Y. Liu, Mask-pose cascaded cnn for 2d hand pose estimation from single color image, IEEE Trans. Circuits and Systems for Video Technology 29 (11) (2018) 3258–3268.
- [33] Y. Wang, B. Zhang, C. Peng, SRHandNet: Real-time 2d hand pose estimation with simultaneous region localization, IEEE Trans. Image Processing 29 (2019) 2977–2986.
- [34] D. Kong, Y. Chen, H. Ma, X. Yan, X. Xie, Adaptive graphical model network for 2d handpose estimation, arXiv preprint arXiv:1909.08205 (2019).
- [35] D. Kong, H. Ma, Y. Chen, X. Xie, Rotation-invariant mixed graphical model network for 2d hand pose estimation, in: IEEE Winter Conf. Applications of Computer Vision (WACV), 2020, pp. 1546–1555.
- [36] G. Moon, S.-I. Yu, H. Wen, T. Shiratori, K. M. Lee, InterHand2.6M: A dataset and baseline for 3d interacting hand pose estimation from a single rgb image, arXiv preprint arXiv:2008.09309 (2020).
- [37] A. Boukhayma, R. d. Bem, P. H. Torr, 3d hand shape and pose from images in the wild, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10843–10852.
- [38] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L.-C. Chen, MobileNetV2: Inverted residuals and linear bottlenecks, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2018, pp. 4510–4520.
- [39] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, A. C. Berg, SSD: Single shot multibox detector, in: Proc. Eur. Conf. Computer Vision (ECCV), 2016, pp. 21–37.
- [40] J. Zhang, J. Jiao, M. Chen, L. Qu, X. Xu, Q. Yang, 3d hand pose tracking and estimation using stereo matching, arXiv preprint arXiv:1610.07214 (2016).
- [41] F. Gomez-Donoso, S. Orts-Escolano, M. Cazorla, Large-scale multiview 3d hand pose dataset, Image and Vision Computing 81 (2019) 25–33.
- [42] S. Hampali, M. Oberweger, M. Rad, V. Lepetit, HO-3D: A multi-user, multi-object dataset for joint 3d hand-object pose estimation, arXiv preprint arXiv:1907.01481 (2019).
- [43] D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
- [44] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, et al., Tensorflow: A system for large-scale machine learning, in: 12th USENIX symposium on operating systems design and implementation (OSDI 16), 2016, pp. 265–283.
- [45] Z. Cao, T. Simon, S.-E. Wei, Y. Sheikh, Realtime multi-person 2d pose estimation using part affinity fields, in: Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7291–7299.