Fast Online and Relational Tracking
Abstract
To overcome challenges in multiple object tracking task, recent algorithms use interaction cues alongside motion and appearance features. These algorithms use graph neural networks or transformers to extract interaction features that lead to high computation costs. In this paper, a novel interaction cue based on geometric features is presented aiming to detect occlusion and re-identify lost targets with low computational cost. Moreover, in most algorithms, camera motion is considered negligible, which is a strong assumption that is not always true and leads to ID Switch or mismatching of targets. In this paper, a method for measuring camera motion and removing its effect is presented that efficiently reduces the camera motion effect on tracking. The proposed algorithm is evaluated on MOT17 and MOT20 datasets and it achieves the state-of-the-art performance of MOT17 and comparable results on MOT20. The code is also publicly available111https://github.com/mhnasseri/for_tracking.
1 Introduction
Multiple Object Tracking (MOT) is a widely researched and challenging task in computer vision and video surveillance. It is a hard problem to solve due to the similarity of targets, existence of occlusion of targets, entering new targets, and exiting targets [25]. The most used paradigm to solve this problem is tracking-by-detection [2]. In this paradigm, first, a detection algorithm localizes targets in a frame and generates a set of bounding boxes. Next, a tracking algorithm assigns an identity to them by associating detections in the current frame with predicted targets in the current frame. The tracking algorithm computes a similarity score between detections and tracklets and a matching algorithm such as Hungarian algorithm [5, 14], network flow [1, 2, 11, 6], and multiple hypothesis tracking [9, 20] use this score for the assignment.
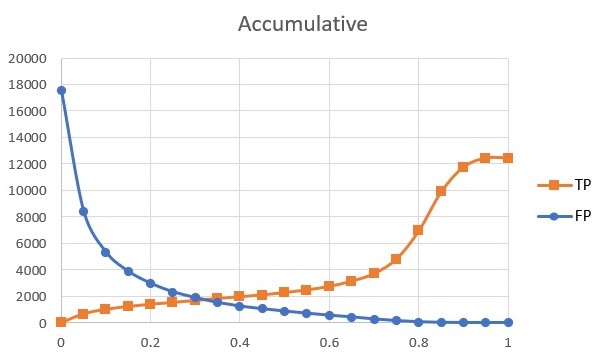
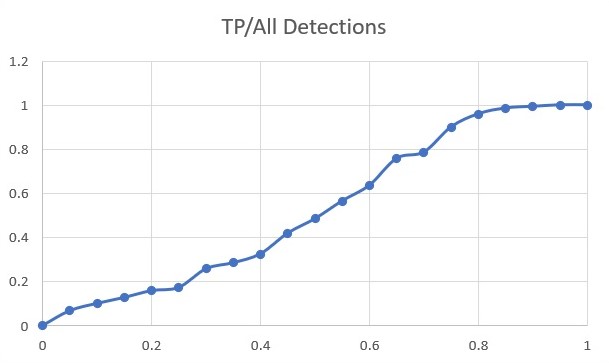
The detection algorithm additionally reports a confidence score for each detection that shows how likely the detection is true. So, it is expected that detections with the highest score correspond to real targets. Evidently, as the score of detection decreases, it is more likely that the detection is a false positive. In Fig. 1(a) the accumulative number of true positives and false positives according to their score for sequence 10 of the MOT17 [25] dataset is presented. In Fig. 1(b) the ratio of true positive to all detections in each score range is plotted. As it can be seen, most high score detections are true positives and the ratio of true positives to all detections is close to one. As the confidence score decreases, the number of true positives and the ratio decreases too. For scores below 0.1, this ratio comes near to zero. This suggests the tracking algorithm faces with high scored detections differently than low scored detections. In this paper, a high score and a low score threshold are defined in the tracking algorithm and matching is performed in a cascade manner. In the first step, the minimum similarity for matching is set near to increase the association between detections and tracks. In the second step, detections with lower confidence , which are more probable to be false positives, are used for association. Thus, the minimum similarity is set to a higher number to only highly similar detections match with the tracks that are not matched in the first step.
 |
 |
| (a) | (b) |
To compute similarity, tracking algorithms usually use one or a combination of motion, appearance, and interaction models. A motion model uses geometric features of bounding boxes such as size, position, and velocity of bounding boxes. An appearance model uses the color values of pixels inside the bounding box. This imposes a higher computational cost for using appearance cues. The appearance model is more effective for detecting occlusion and re-identifying occluded tracklets after reappearance. In the proposed algorithm pay attention to the relation of tracklets to detect occlusion and to help re-identify occluded tracklets effectively with low computational cost.
In the motion model, it is assumed that camera motion is negligible. But in practice, there is significant camera motion in some frames that mislead the tracking algorithm and causes some tracklets do not match or some of them match with the wrong detection. In our algorithm, we introduce a method for measuring the camera motion and removing its effect in data association that significantly improves the tracking performance in the presence of camera motion.
In summary, our contributions are:
-
•
a novel and fast online relational multiple object tracking algorithm
-
•
a cascade association based on the detection score
-
•
a novel interaction model based on geometric features for occlusion detection and target re-identification
-
•
an algorithm to estimate camera motion to decrease the non-linearity motion of targets
-
•
a new similarity metric which considers detection’s size
2 Related Work
In tracking-by-detection [5, 39, 43, 28] paradigm, first a deep learning-based detection algorithm [16, 30, 42, 18, 7, 34, 29] generates detections which are input of the tracking algorithm. In the joint detection and tracking paradigm [22, 32, 3, 15], the detections are extracted as the first step in the tracking algorithm and the features computed in this step can be used in tracking. With having detections, the next step is to compute the similarity between tracks and detections. For computing similarity, geometric features, appearance features, and interaction and relational features can be used. Some simple methods such as SORT [5] only use position and motion features. Some other methods such as DeepSort [39] use appearance alongside geometric features and use deep neural networks for extracting appearance features. Although the results of the DeepSort algorithm become less attractive after a few years, recently in [13] a new deep neural network is used for extracting appearance features and could achieve near the state of the art results. The most drawback of using appearance features is the high computational cost that decreases the speed of the algorithm and makes it hard to use the algorithm for online applications.
In recent years, more attention is paid to the interaction features alongside other features. The graph convolutional neural network is used by a category of algorithms to model the interaction of tracks in spatial-temporal domains. In [28] tracklets and detections are considered as nodes of a graph and if the similarity between a tracklet and a detection is higher than a threshold, an edge is created to connect the detection and tracklet. These graphs which are generated for each frame are the input of GCNN. The geometry and appearance features of nodes interact to generate more discriminative features. In [36] the GNN is used in a joint paradigm to detect objects and associate them simultaneously. Also in [38] a GNN is used for feature extraction to fuse the 2D and 3D features of objects.
The transformers were first used in [35] for natural language processing. But after that, some researchers used the transformer to model the interaction of objects and used in the tracking by attention paradigm. In [24] an end-to-end algorithm is presented which detects objects and associates them to tracklets by formulating MOT as a set prediction problem and association is performed through the concept of track queries. In [44] another end-to-end algorithm using transformers is presented. The [40] uses the concept of tracking the center of objects which was introduced in [47] and a transformer-based architecture is used for tracking the center of targets. In [33] a joint method for detection and association is presented using the transformer to share the knowledge of detection in re-identification. Also, in [10] the graph used in the transformer to model the interaction of objects. In this algorithm, a cascade association framework is used that first associate easy cases with only using Intersection over Union (IoU) and then use the transformer to associate hard cases. The cascade association in this algorithm decreases the computation cost.
recently, an algorithm is presented in [45] which only uses geometric features. In this work, low confidence detections are used to improve the results. In this paper, the detections of many recent papers [47, 33, 37, 21, 27] are used as input to the presented tracking algorithm and show that their algorithm produces state-of-the-art results.
In this paper, a novel method for modeling the interaction of tracklets is presented by improving the basic concept of the covered percent which is introduced in [26]. This parameter is used for occlusion detection and it helps to keep the lost tracklets more efficiently for re-identification.
3 Approach
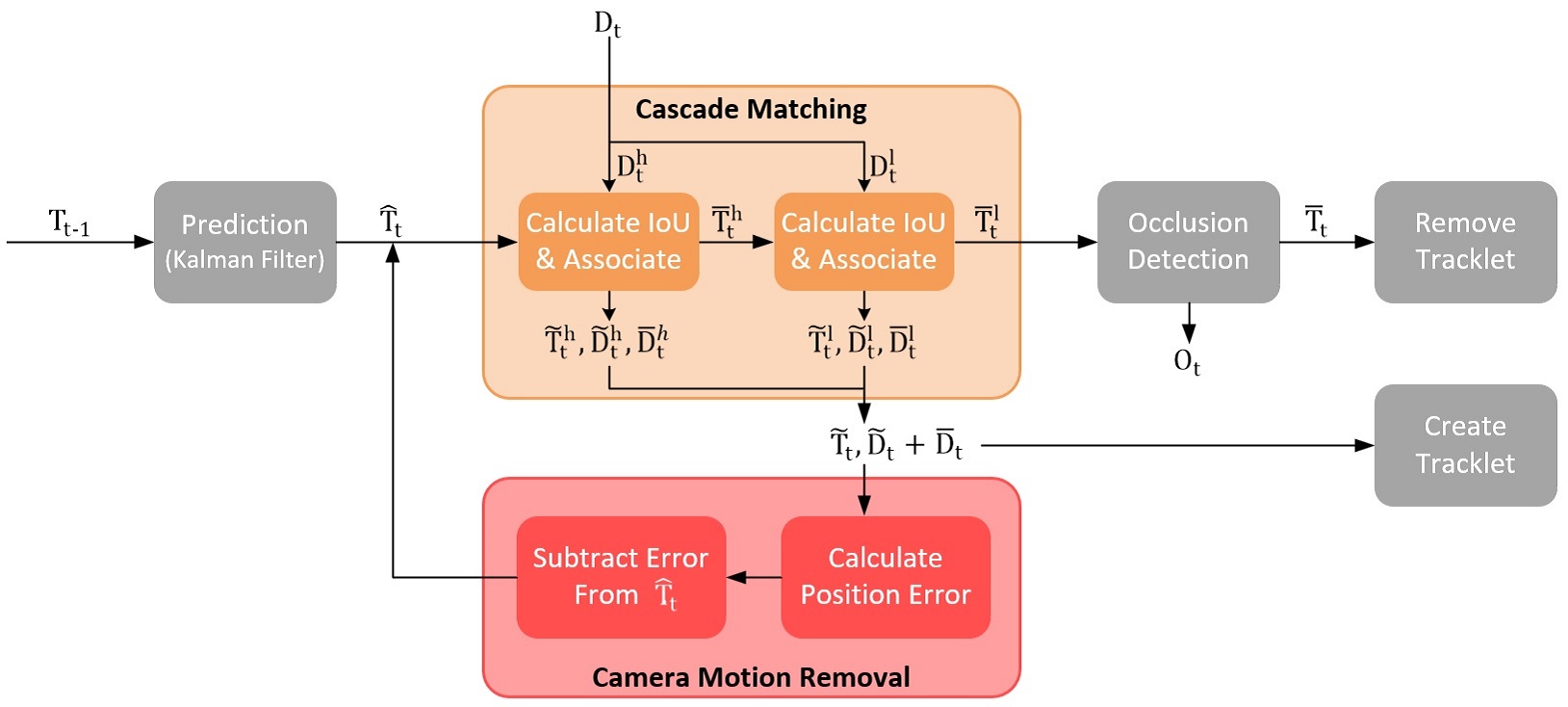
In the proposed algorithm, we assume that two inputs are available at each frame. The first is a set of detections extracted by a detection algorithm at frame which are shown as . The second input is a set of tracklets created till frame , where each tracklet is itself a set of detections assigned with an ID (i.e, target). The set of tracklets is represented by . The diagram of the proposed algorithm is depicted in Fig. 2 and the pseudo-code of it is written in Algorithm 1. In the following the details of each component is explained.
3.1 Prediction
As a first step, the position of tracklets is predicted at the current frame using a motion model. Here, the kalman filter [19] with a constant velocity motion model is used for prediction. The states of this model are:
| (1) |
in which and are the center, is the aspect ratio and is the height of a tracklet box and the next four parameters are their corresponding changing rate. The predicted location of tracklets in the current frame is shown as .
The detections and the prediction of tracklets in the current frame are the inputs of the association part of the proposed algorithm. after association, most of detections are assigned to their corresponding tracklets. These detections are now represented by and the modified tracklets are represented by . Consequently, there are a few unmatched detections and tracklets which are represented by and .
 |
 |
| (a) | (b) |
 |
 |
| (c) | (d) |
3.2 Cascade Matching
For assigning detections to tracklets, an association metric based on the geometric features of bounding boxes are used to reduce the calculation cost. The proposed metric is the so-called normalized Intersection over Union(nIoU). To compute the , we first need to compute the normalized difference between position and size of boxes:
| (2) | |||
Now, the average of these four terms is subtracted from IoU to get normalized IoU:
| (3) |
in which and are the area of detection box and predicted detection box of tracklet in current frame. Also, the function calculates the intersection of these two bounding boxes. From detection algorithm, a confidence score for each detection is also reported that shows the probability of existence of a track. In Fig. 1 detections along with their corresponding score is visualized. Evidently, as the detection score decreases, the chance of track’s existence decreases. Therefore, our tracking algorithm considers this cue in matching detections with tracklets in two steps. Here, the tracking algorithm tries to match most high score detections and match low score detections with more caution. To this end, two thresholds on detection score are defined as and . First, detections with a score higher than are matched with tracklets. In this step, the minimum accepted nIoU is set at a low value to match high score detections whether there is a minimum similarity. The detections with a score between these two thresholds enter the second matching step and are matched with the tracklets which are not matched in the first step. Because the chance of existence of false-positive detections is higher in this step, matching is done with more caution by increasing the minimum accepted similarity. At the end, detections whose score is below than are discarded as with high probability they are false positives. The tracklets which are not matched in the second step are reported as unmatched tracklets. The other variables of the two steps are aggregated and reported as the corresponding variable. The pseudo-code of this block is shown in Algorithm 2.
3.3 Camera Motion Removal
In constant velocity motion model, the assumption is that targets moves with the constant velocity and the camera motion is negligible. But this is a strong assumption which is not always valid. Sometimes the camera motion is so significant that causes challenges in matching. When the camera moves, detections move in the opposite direction and the amount of their movement is proportional to the camera movement. In such cases, the camera motion influences the matching of detections with tracklets and increases the risk of ID switch or mismatching. This effect is even sever for the tracks who are far from the camera and their bounding boxes are small.
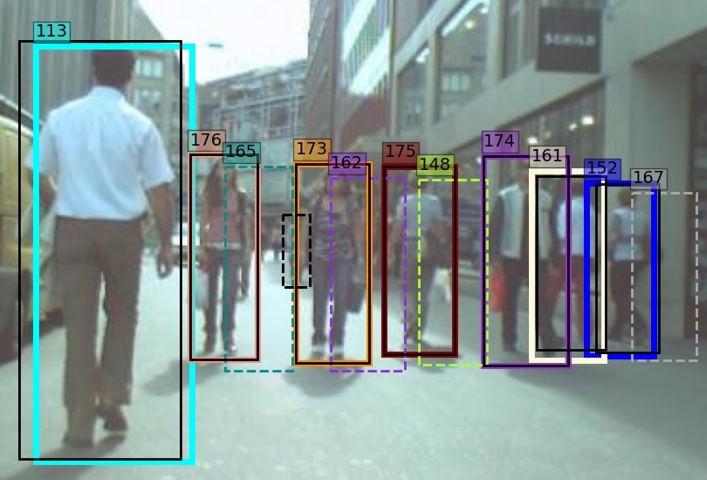
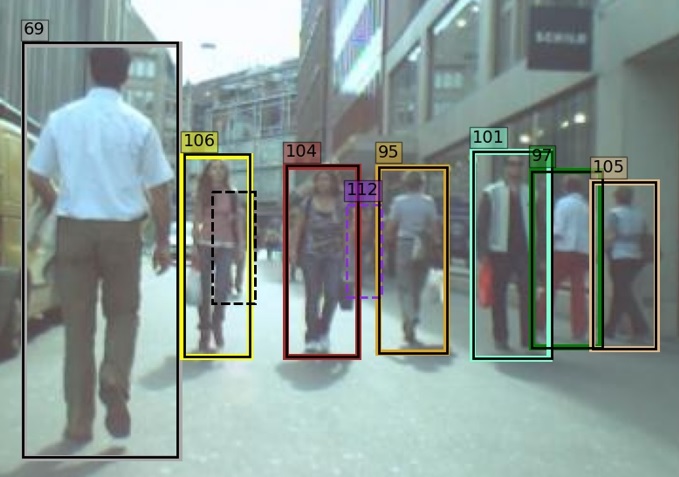
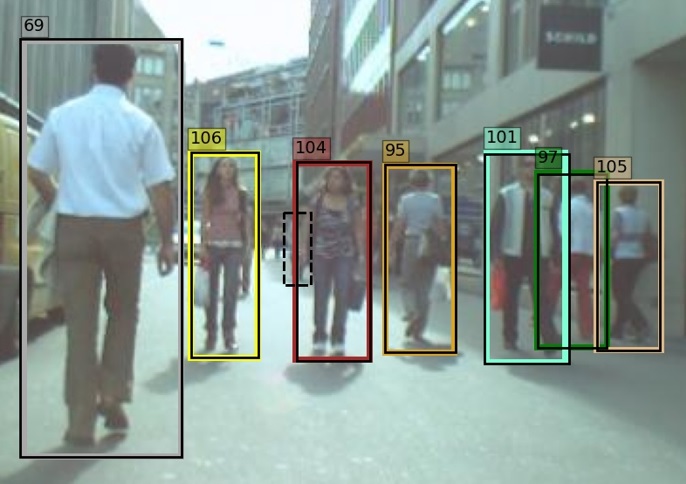
In the proposed algorithm, we introduce a novel method for measuring camera motion and removing it’s effect on association. When the camera motion is high, all tracks have displacement relative to their predicted position. So, after matching, the difference between the position of matched pair of detection-tracklet is calculated in each direction. These differences are averaged and reported as the amount of camera motion. This value is subtracted from the position of all tracklet boxes and the matching step is repeated with the modified predicted position of tracklets. In Fig. 3 the effect of the proposed method for two consecutive frames with significant camera motion is shown. In the top figures, the camera motion removal is not applied. As can be seen, some tracklets are not matched or matched incorrectly. At the bottom, the camera motion removal is applied. As it can be seen, the identity of tracklets is preserved correctly.
| Tracker | MOTA | IDF1 | HOTA | MT | ML | FP | FN | IDS | FM |
| FairMOT [46] | 73.7 | 72.3 | 59.3 | 1017 | 408 | 27507 | 117477 | 3303 | 8073 |
| GCNNMatch [28] | 57.3 | 56.3 | 45.4 | 575 | 787 | 14100 | 225042 | 1911 | 2837 |
| GSDT [36] | 73.2 | 66.5 | 55.2 | 981 | 411 | 26397 | 120666 | 3891 | 8604 |
| Trackformer [24] | 74.1 | 68.0 | 57.3 | 1113 | 246 | 34602 | 108777 | 2829 | 4221 |
| TransTrack [33] | 75.2 | 63.5 | 54.1 | 1302 | 240 | 50157 | 86442 | 3603 | 4872 |
| TransCenter [40] | 73.2 | 62.2 | 54.5 | 960 | 435 | 23112 | 123738 | 4614 | 9519 |
| TransMOT [10] | 76.7 | 75.1 | 61.7 | 1200 | 387 | 36231 | 93150 | 2346 | 7719 |
| ReMOT [41] | 77.0 | 72.0 | 59.7 | 1218 | 324 | 33204 | 93612 | 2853 | 5304 |
| ByteTrack [45] | 80.3 | 77.3 | 63.1 | 1254 | 342 | 25491 | 83721 | 2196 | 2277 |
| OCSORT [8] | 78.0 | 77.5 | 63.2 | 966 | 492 | 15129 | 107055 | 1950 | 2040 |
| Ours | 80.4 | 77.7 | 63.3 | 1311 | 255 | 28887 | 79329 | 2325 | 4689 |
| Tracker | MOTA | IDF1 | HOTA | MT | ML | FP | FN | IDS | FM |
| FairMOT [46] | 61.8 | 67.3 | 54.6 | 855 | 94 | 103440 | 88901 | 5243 | 7874 |
| GCNNMatch [28] | 54.5 | 49.0 | 40.2 | 407 | 317 | 9522 | 223611 | 2038 | 2456 |
| GSDT [36] | 67.1 | 67.5 | 53.6 | 660 | 164 | 31507 | 135395 | 3230 | 9878 |
| Trackformer [24] | 68.6 | 54.7 | 65.7 | 666 | 181 | 20348 | 140373 | 1532 | 2474 |
| TransTrack [33] | 65.0 | 59.5 | 48.9 | 622 | 167 | 27191 | 150197 | 3608 | 11352 |
| TransCenter [40] | 61.0 | 49.8 | 43.5 | 601 | 192 | 49189 | 147890 | 4493 | 8950 |
| TransMOT [10] | 77.5 | 75.2 | 61.9 | 878 | 113 | 34201 | 80788 | 1615 | 2421 |
| ReMOT [41] | 77.4 | 73.1 | 61.2 | 846 | 123 | 28351 | 86659 | 1789 | 2121 |
| ByteTrack [45] | 77.8 | 75.2 | 61.3 | 859 | 118 | 26249 | 87594 | 1223 | 1460 |
| OCSORT [8] | 75.7 | 76.3 | 62.4 | 813 | 160 | 19067 | 105894 | 942 | 1086 |
| Ours | 76.8 | 76.4 | 61.4 | 856 | 133 | 27106 | 91740 | 1446 | 3053 |
3.4 Occlusion Handling
One of the challenges in multiple object tracking algorithms is where a tracklet is covered partially or completely by other objects or tracklets and is not observed by the camera. In [45] the low score detections are used to find partially seen tracklets between them. As explained in the previous sections, the probability of false positives between these detections is high. So, in our approach for detecting occlusion, a method based on the relation of tracklets is developed. As the tracklet boxes are known, occlusion can be detected by considering their position relative to each other. To quantify the relation of them, the tracklet covered ratio is defined based on the similar concept in [26] as:
| (4) |
This parameter shows the maximum ratio of a tracklet box that is covered by any of the other tracklets. The difference between this parameter and IoU is that the intersection of two bounding boxes is divided into the area of one bounding box, instead of the union of two bounding boxes. The high amount of this parameter can point to the occurrence of occlusion. To improve the precision of occlusion detection, another parameter is used alongside this as the tracklet’s confidence:
| (5) |
in which is the total number of frames that tracklet is existed, or time since observed is the number of successive frames the tracklet is not matched with any detection and is the normalized area of tracklet box which is calculated by division of area of tracklet box to the average area of all tracklet boxes. This parameter measures the confidence of a reported tracklet by tracking algorithm. When a tracklet is tracked for more frames and is nearer to the camera and seen bigger, the probability of its existence is higher. On the other hand, when a tracklet is not visible for more frames, this confidence is decreased.
For the tracklets that do not match in the matching step, these two above parameters are calculated. If is higher than and is higher than , that tracklet is reported as occluded in .
| Sequence | Method | MOTA | IDF1 | MT | ML | FP | FN | IDS | FM |
|---|---|---|---|---|---|---|---|---|---|
| Sequence 5 | Without CMR | 81.0% | 75.9% | 95 | 6 | 444 | 691 | 177 | 134 |
| Sequence 5 | With CMR | 82.7% | 78.3% | 98 | 6 | 460 | 666 | 73 | 122 |
| Sequence 10 | Without CMR | 77.5% | 59.5% | 57 | 0 | 673 | 1976 | 237 | 298 |
| Sequence 10 | With CMR | 82.6% | 75.5% | 46 | 0 | 663 | 1486 | 89 | 273 |
| Method | MOTA | IDF1 | MT | ML | FP | FN | IDS | FM |
|---|---|---|---|---|---|---|---|---|
| Ground truth matching | 90.5% | 95.0% | 391 | 18 | 0 | 10697 | 0 | 1856 |
| Proposed algorithm | 90.7% | 85.0% | 442 | 21 | 2947 | 7031 | 488 | 857 |
3.5 Removing Tracklets
The unmatched tracklets which are not detected as occluded are possible candidates for removal. In some works [5, 39, 13, 45], they are kept for a certain number of frames (L frames). If L is a low number such as 3, the occluded tracks after reappearing will get a new identity giving rise to an ID Switch. If a high number such as 30 is chosen for L, the number of kept tracklets increases that causes a high computation cost. The lost tracklets are kept for occlusion cases to the identity of occluded tracks is preserved after reappearing. The target covered ratio () which is used for occlusion detection in the proposed algorithm, is used for keeping lost tracklets, too. While the covered ratio of a tracklet is higher than it is considered as covered. But when the covered ratio of that tracklet comes below this threshold for a few consecutive frames, i.e. 3, it is removed.
3.6 Creating Tracklets
Detections that are not matched with any tracklets may point to existence of new tracklets. If their score is higher than which is close to 1, the probability that they indicate a real tracks is very high. So, for each detection a tracklet is created initialized with that detection. Other unmatched detections are kept and passed for association in the next frame.
4 Experiments
To evaluate the performance of our proposed algorithm and compare its results with other tracking algorithms, the MOT17 [25] and MOT20 [12] datasets are used with private detections. The detections are same as [45] and extracted using YOLOX [17] algorithm.
4.1 Metrics
For comparison of result, the widely used CLEAR MOT metrics [4] which include Multiple Object Tracking Accuracy (MOTA), Multiple Object Tracking Precision (MOTP) are reported. In addition, the HOTA [23] and IDF1 [31] are reported. The MOTA metric consider FP, FN and IDS effect equally. As the number of FP and FN are much higher than IDS, the focus of this metric is more on detection performance. But in HOTA and IDF1 more attention is paid to association performance by focusing on preservation of track’s identity. Also, other popular metrics are used including Mostly Tracked (MT), Mostly Lost (ML), the number of False Negatives (FN), False Positives (FP), ID-Switches (IDS), and track Fragmentation (FM).
4.2 Results
The results of running the proposed algorithm on MOT17 and MOT20 datasets are presented in 1 and 2 respectively. The result of other state-of-the-art algorithms, especially the ones using interaction models are also available in these tables for comparison. All of these algorithms use private detections. The private detections that we used are the same as two other algorithms [45, 8]. So, the results of our algorithm and these two algorithms are separated by a line at bottom of the tables. In MOT17, our algorithm achieves the best results on MOTA, IDF1, HOTA, and, MT among other algorithms. Also in MOT20, the results of our algorithm are comparable with the state-of-the-art algorithms.
4.3 Camera Motion Removal Effectiveness
In the proposed algorithm, a method for removing camera motion is presented. MOT17 dataset is composed of 7 training and 7 test sequences. In most sequences, the camera motion is negligible. So, the camera motion removal has no significant effect. among MOT17 training sequences, sequences 5 and 9 have significant camera motion in several frames. The results of the proposed algorithm with and without camera motion removal block are presented in the table 3. As it can be seen, the camera motion removal could notably improve MOTA, IDF1, and ID Switch metrics.
4.4 Occlusion Detection Effectiveness
The occlusion detection method in the proposed algorithm calculates the covered ratio and confidence of tracklets that are not matched with any detections and report them as tracklet of that frame by checking some conditions on these parameters. So, the tracklets that are marked as occluded, do not have any corresponding detection. To investigate the effectiveness of this block, the detections in training sequences are matched with ground truths. In this way, all the detections match correctly with the corresponding tracks, and the number of false positives and ID switches reaches zero and the best possible result is achieved. In this way no track will be reported when it has no corresponding detection. The results in this situation with the result of the proposed algorithm on the training set are presented in the table 4. As it can be seen, the proposed algorithm could pass the best achievable MOTA by reporting some unmatched tracklets as occluded.
5 Conclusion
In the proposed algorithm a novel interaction model based on geometric features is presented. This model considers the relation of targets to detect occlusion and re-identify lost targets. In comparison to other algorithms with interaction models that are using GCNN or Transformer, the presented algorithm has a lower computational cost. In addition, we introduced a method for measuring camera motion and removing its effect on data association. This method could effectively improve the tracking result in presence of camera motion. Our approach achieves state-of-the-art results on the MOT17 and comparable results on the MOT20 dataset, while it is super fast that makes it ideal for real-time applications.
References
- [1] Mohammadreza Babaee, Yue You, and Gerhard Rigoll. Pixel level tracking of multiple targets in crowded environments. In European Conference on Computer Vision, pages 692–708. Springer, 2016.
- [2] Mohammadreza Babaee, Yue You, and Gerhard Rigoll. Combined segmentation, reconstruction, and tracking of multiple targets in multi-view video sequences. Computer Vision and Image Understanding, 154:166–181, 2017.
- [3] Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. In Proceedings of the IEEE international conference on computer vision, pages 941–951, 2019.
- [4] K. Bernardin and R. Stiefelhagen. Evaluating multiple object tracking performance: the clear mot metrics. EURASIP Journal on Image and Video Processing, 2008(1):246309, 2008.
- [5] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In 2016 IEEE International Conference on Image Processing (ICIP), pages 3464–3468. IEEE, 2016.
- [6] Guillem Brasó and Laura Leal-Taixé. Learning a neural solver for multiple object tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6247–6257, 2020.
- [7] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6154–6162, 2018.
- [8] Jinkun Cao, Xinshuo Weng, Rawal Khirodkar, Jiangmiao Pang, and Kris Kitani. Observation-centric sort: Rethinking sort for robust multi-object tracking. arXiv preprint arXiv:2203.14360, 2022.
- [9] Jiahui Chen, Hao Sheng, Yang Zhang, and Zhang Xiong. Enhancing detection model for multiple hypothesis tracking. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 18–27, 2017.
- [10] Peng Chu, Jiang Wang, Quanzeng You, Haibin Ling, and Zicheng Liu. Transmot: Spatial-temporal graph transformer for multiple object tracking. arXiv preprint arXiv:2104.00194, 2021.
- [11] Afshin Dehghan, Yicong Tian, Philip HS Torr, and Mubarak Shah. Target identity-aware network flow for online multiple target tracking. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1146–1154, 2015.
- [12] Patrick Dendorfer, Hamid Rezatofighi, Anton Milan, Javen Shi, Daniel Cremers, Ian Reid, Stefan Roth, Konrad Schindler, and Laura Leal-Taixé. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv preprint arXiv:2003.09003, 2020.
- [13] Yunhao Du, Yang Song, Bo Yang, and Yanyun Zhao. Strongsort: Make deepsort great again. arXiv preprint arXiv:2202.13514, 2022.
- [14] Kuan Fang, Yu Xiang, Xiaocheng Li, and Silvio Savarese. Recurrent autoregressive networks for online multi-object tracking. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 466–475. IEEE, 2018.
- [15] Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Detect to track and track to detect. In Proceedings of the IEEE international conference on computer vision, pages 3038–3046, 2017.
- [16] Pedro Felzenszwalb, David McAllester, and Deva Ramanan. A discriminatively trained, multiscale, deformable part model. In 2008 IEEE conference on computer vision and pattern recognition, pages 1–8. IEEE, 2008.
- [17] Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021.
- [18] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- [19] Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. 1960.
- [20] Chanho Kim, Fuxin Li, Arridhana Ciptadi, and James M Rehg. Multiple hypothesis tracking revisited. In Proceedings of the IEEE international conference on computer vision, pages 4696–4704, 2015.
- [21] Chao Liang, Zhipeng Zhang, Xue Zhou, Bing Li, Shuyuan Zhu, and Weiming Hu. Rethinking the competition between detection and reid in multiobject tracking. IEEE Transactions on Image Processing, 31:3182–3196, 2022.
- [22] Zhichao Lu, Vivek Rathod, Ronny Votel, and Jonathan Huang. Retinatrack: Online single stage joint detection and tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14668–14678, 2020.
- [23] Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taixé, and Bastian Leibe. Hota: A higher order metric for evaluating multi-object tracking. International journal of computer vision, 129(2):548–578, 2021.
- [24] Tim Meinhardt, Alexander Kirillov, Laura Leal-Taixe, and Christoph Feichtenhofer. Trackformer: Multi-object tracking with transformers. arXiv preprint arXiv:2101.02702, 2021.
- [25] Anton Milan, Laura Leal-Taixé, Ian Reid, Stefan Roth, and Konrad Schindler. Mot16: A benchmark for multi-object tracking. arXiv preprint arXiv:1603.00831, 2016.
- [26] Mohammad Hossein Nasseri, Hadi Moradi, Reshad Hosseini, and Mohammadreza Babaee. Simple online and real-time tracking with occlusion handling. arXiv preprint arXiv:2103.04147, 2021.
- [27] Jiangmiao Pang, Linlu Qiu, Xia Li, Haofeng Chen, Qi Li, Trevor Darrell, and Fisher Yu. Quasi-dense similarity learning for multiple object tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 164–173, 2021.
- [28] Ioannis Papakis, Abhijit Sarkar, and Anuj Karpatne. Gcnnmatch: Graph convolutional neural networks for multi-object tracking via sinkhorn normalization. arXiv preprint arXiv:2010.00067, 2020.
- [29] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
- [30] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015.
- [31] Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara, and Carlo Tomasi. Performance measures and a data set for multi-target, multi-camera tracking. In European conference on computer vision, pages 17–35. Springer, 2016.
- [32] Chaobing Shan, Chunbo Wei, Bing Deng, Jianqiang Huang, Xian-Sheng Hua, Xiaoliang Cheng, and Kewei Liang. Tracklets predicting based adaptive graph tracking. arXiv preprint arXiv:2010.09015, 2020.
- [33] Peize Sun, Jinkun Cao, Yi Jiang, Rufeng Zhang, Enze Xie, Zehuan Yuan, Changhu Wang, and Ping Luo. Transtrack: Multiple object tracking with transformer. arXiv preprint arXiv:2012.15460, 2020.
- [34] Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14454–14463, 2021.
- [35] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [36] Yongxin Wang, Kris Kitani, and Xinshuo Weng. Joint object detection and multi-object tracking with graph neural networks.
- [37] Zhongdao Wang, Liang Zheng, Yixuan Liu, Yali Li, and Shengjin Wang. Towards real-time multi-object tracking. In European Conference on Computer Vision, pages 107–122. Springer, 2020.
- [38] Xinshuo Weng, Yongxin Wang, Yunze Man, and Kris Kitani. Gnn3dmot: Graph neural network for 3d multi-object tracking with multi-feature learning. arXiv preprint arXiv:2006.07327, 2020.
- [39] Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. In 2017 IEEE international conference on image processing (ICIP), pages 3645–3649. IEEE, 2017.
- [40] Yihong Xu, Yutong Ban, Guillaume Delorme, Chuang Gan, Daniela Rus, and Xavier Alameda-Pineda. Transcenter: Transformers with dense queries for multiple-object tracking. arXiv preprint arXiv:2103.15145, 2021.
- [41] Fan Yang, Xin Chang, Sakriani Sakti, Yang Wu, and Satoshi Nakamura. Remot: A model-agnostic refinement for multiple object tracking. Image and Vision Computing, 106:104091, 2021.
- [42] Fan Yang, Wongun Choi, and Yuanqing Lin. Exploit all the layers: Fast and accurate cnn object detector with scale dependent pooling and cascaded rejection classifiers. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2129–2137, 2016.
- [43] Fengwei Yu, Wenbo Li, Quanquan Li, Yu Liu, Xiaohua Shi, and Junjie Yan. Poi: Multiple object tracking with high performance detection and appearance feature. In European Conference on Computer Vision, pages 36–42. Springer, 2016.
- [44] Fangao Zeng, Bin Dong, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. Motr: End-to-end multiple-object tracking with transformer. arXiv preprint arXiv:2105.03247, 2021.
- [45] Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. Bytetrack: Multi-object tracking by associating every detection box. arXiv preprint arXiv:2110.06864, 2021.
- [46] Yifu Zhang, Chunyu Wang, Xinggang Wang, Wenjun Zeng, and Wenyu Liu. Fairmot: On the fairness of detection and re-identification in multiple object tracking. International Journal of Computer Vision, 129(11):3069–3087, 2021.
- [47] Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl. Tracking objects as points. arXiv preprint arXiv:2004.01177, 2020.