Fast State Stabilization using Deep Reinforcement Learning for Measurement-based Quantum Feedback Control
Abstract
The stabilization of quantum states is a fundamental problem for realizing various quantum technologies. Measurement-based-feedback strategies have demonstrated powerful performance, and the construction of quantum control signals using measurement information has attracted great interest. However, the interaction between quantum systems and the environment is inevitable, especially when measurements are introduced, which leads to decoherence. To mitigate decoherence, it is desirable to stabilize quantum systems faster, thereby reducing the time of interaction with the environment. In this paper, we utilize information obtained from measurement and apply deep reinforcement learning (DRL) algorithms, without explicitly constructing specific complex measurement-control mappings, to rapidly drive random initial quantum state to the target state. The proposed DRL algorithm has the ability to speed up the convergence to a target state, which shortens the interaction between quantum systems and their environments to protect coherence. Simulations are performed on two-qubit and three-qubit systems, and the results show that our algorithm can successfully stabilize random initial quantum system to the target entangled state, with a convergence time faster than traditional methods such as Lyapunov feedback control and several DRL algorithms with different reward functions. Moreover, it exhibits robustness against imperfect measurements and delays in system evolution.
Index Terms:
deep reinforcement learning (DRL), feedback control, learning control, quantum state stabilizationI Introduction
Quantum control theory focuses on manipulating quantum systems using external control fields or operations to regulate their behaviors [1]. A significant objective in quantum control is the preparation of target states, particularly quantum entangled states, which serve as vital resources for various quantum applications, including quantum teleportation [2, 3], fast quantum algorithms [3, 4], and quantum computations [5]. Achieving high-fidelity entangled states often involves in using classical control methods, with feedback control technology being particularly noteworthy. Quantum systems can be stabilized at target states or spaces through feedback control methods that continuously monitor the system and design feedback controllers based on real-time feedback information. In quantum measurement-based feedback, quantum measurements, while providing valuable information, introduce stochastic noise, complicating the state preparation process. To address the challenges posed by stochastic nonlinear problems in quantum systems due to measurements, some classical control methods, such as the Lyapunov method [6, 7, 8], have been applied. However, devising feedback strategies remains a formidable task, given the vast space of possibilities where different responses may be required for each measurement outcome. Moreover, opportunities exist for further enhancing stability and convergence speed.
Recently, quantum learning control, first introduced in [9], has proven potential in addressing various quantum control problems. Its popularity has grown with the incorporation of additional machine learning (ML) algorithms that exhibit excellent optimization performance and promising outcomes. Quantum learning control concerns to apply proper ML algorithms as tools for improving quantum system performance [10, 9, 11, 12, 13], and can offer robust solutions for developing effective quantum control and estimation methods [10]. For instance, the utilization of gradient algorithms in quantum learning control has demonstrated its significance in addressing quantum robust control problems [14]. Another example involves a widely used class of algorithms, evolutionary algorithms (EAs), which gains attention in learning control due to their ability to avoid local optima and their independence from gradient information[1]. Nonetheless, the real-time nature and randomness of measurement feedback control pose challenges, expanding the decision space significantly due to randomness [15]. This randomness makes it almost impossible to reproduce the same measurement trajectory, bringing challenges for EAs to apply control policies from certain sample trajectories to entirely different ones.
Our study is motivated by the application of suitable deep reinforcement learning (DRL) algorithms within feedback loops to exploit information obtained from measurements, thereby achieving predefined objectives. This approach holds the potential to enhance feedback control schemes, leading to a reduction in the convergence time to reach target states and exhibiting robustness in the face of uncertainties. RL techniques have been applied for target state preparation in many-body quantum systems of interacting qubits, where a sequence of unitaries was applied and a measurement was implemented at the final time to provide reward information to the agent [16]. The similar idea was then utilized in harmonic oscillator systems, to achieve different target state preparations, through an ancilla qubit in [17], where a final reward measurement (POVM) was carefully designed to provide reward information to the agent for different tasks of state preparation. In recent years, DRL (RL) approaches also started to play an important role in quantum algorithms, such as QAOA, for ground state preparation in different quantum systems [18, 19]. The similar state preparation problem has also been considered in [20], where the system is a double-well system and the reward is a unique function of the measurement results. In [21, 22], DRL-based approaches were employed for the preparation of cavity Fock state superpositions using fidelity-based reward functions, with system states as the training information under continuous weak measurement. In this study, we aim to devise a feedback control scheme based on DRL algorithms to enhance state stabilization, such as Bell states and GHZ states, for multi-qubit systems under continuous weak measurement. The designed algorithm can be applied to multi-qubit systems and provides a high fidelity and faster convergence to a given target state.
To achieve the objectives, we exploit the information derived from quantum measurement as the input signal to train our DRL agent. The agent actively interacts with the quantum system, making control decisions based on the received input. We design a generalized reward function that quantifies the similarity between the current quantum state and the desired target state. This incentivizes the DRL agent to iteratively learn control strategies that maximize rewards, ultimately leading to more effective control strategies for stabilizing entangled quantum states. Our work shows the potential of DRL in solving complex quantum control challenges, contributing to the fields of quantum information processing and quantum computation.
The main contributions of this paper are as follows:
-
1.
A DRL algorithm is proposed to achieve the stabilization of given entangled states in multi-qubit systems under continuous measurement. We design an effective and versatile reward function based on the distance between the system state and the target state, allowing flexible parameter adjustment for different objectives to enhance the performance of the DRL agent.
-
2.
We compare the proposed DRL-based control strategy with the Lyapunov method and other DRL methods, for state preparation through numerical simulations. Our DRL method achieves a faster stabilization for both target states, which effectively reduces the noise generated during system-environment interactions.
-
3.
We analyze the robustness of our DRL scheme under the presence of imperfect measurements and time delays in the feedback loop. The trained DRL agent exhibits remarkable adaptability to uncertainties in the environment, particularly excelling in the pursuit of robust control fields to achieve quantum state stability.
-
4.
We conduct ablation studies to showcase the superiority of the proposed reward function. By comparing several commonly used reward function designs, our reward function shows better performance in stabilizing the target states.
The following is the organization of this paper. Section II briefly introduces the stochastic master equation for quantum systems under continuous weak measurements. Section III explains in detail the logic and implementation behind DRL. Section IV gives some details of the implementation of DRL in the quantum measurement feedback control. Numerical results are given in Section V. In Section VI, the performance of the proposed algorithm is analyzed through ablation studies and comparisons with other related methods. Section VII is the conclusion.
II Quantum System Dynamics
For a quantum system, its state can be represented by a density matrix defined in the Hilbert space . This density matrix exhibits essential properties: Hermitian (), trace unity (), and positive semi-definite (). The dynamics of the quantum system may be observed through continuous weak measurements, enabling us to acquire pertinent measurement information for the design of an appropriate feedback controller. The evolution of the quantum trajectory can be described by the stochastic master equation (SME) [15, 23]:
| (1) | ||||
where , the reduced Planck constant is used throughout this paper; the Hermitian operator and are the free Hamiltonian and control Hamiltonians, respectively; is a real-valued control signal, which can be interpreted as the strength of the corresponding control Hamiltonians ; and are measurement strength and efficiency, respectively; is a standard Wiener process caused by measurement; the Hermitian operator is an observable; the superoperators and are related to the measurement, e.g., they can describe the disturbance to the system state, and the information gain from the measurement process, respectively [24], and have the following forms:
| (2) |
On any given trajectory the corresponding measured current is [25, 23] where
| (3) |
With the measurement result , information on the standard Wiener process can be collected from (3). Utilizing (1), an estimate of the system state can be obtained and utilized to construct a feedback controller.
In this paper, we consider the DRL-based feedback stabilization of the target quantum states. We will show our algorithm in stabilizing a GHZ entangled states of a three-qubit system and an eigenstate of an angular momentum system, while our scheme has the potential to be extended to other quantum systems.
III Deep Reinforcement Learning
Abstracting a real-world problem into a Markov decision process (MDP) serves as the foundational step in applying DRL [26]. MDP provides a formal framework for modeling the interaction between an agent and its environment (quantum systems in this work), offering a structured specification of the agent’s decision-making problem. The environment is abstracted with essential elements such as states, actions, rewards, and more. The agent is a pivotal component of DRL, representing a learning entity or decision-maker that, through interactions with the environment, learns to take actions to achieve objectives and continually refines its decision strategies to enhance the effectiveness of its actions. This process of agent-environment interaction and learning constitutes the core mechanism through which DRL efficiently tackles real-world challenges and achieves desirable outcomes.
An MDP is a structured representation denoted by the tuple , where each element serves as a crucial role in modeling the problem and applying DRL:
-
•
represents the set of states. At each time step , the environment presents a specific quantum state to the agent, who subsequently makes decisions based on this state.
-
•
signifies the set of actions, incorporating the actions that the agent can undertake at each time step. In this context, the actions correspond to the control signals defined in (1), with values ranging from any bounded control strength, for example, in this paper.
-
•
denotes the reward function. This paper considers the task of stabilizing the current state to the target state, thus the immediate reward can be simplified as
(4) In this study, the reward function is defined using the trace-based distance :
(5) which quantifies the difference between the current state and the target state . When , the system state has stabilized at the target state .
-
•
is the state transition function. It indicates how the environment transitions to the next state after taking action in the current state . It is consistent with the stochastic evolution of the quantum system described in (1).
-
•
is the discount factor, which determines the emphasis placed on future rewards, influencing the agent’s decision-making process in a long-term perspective.
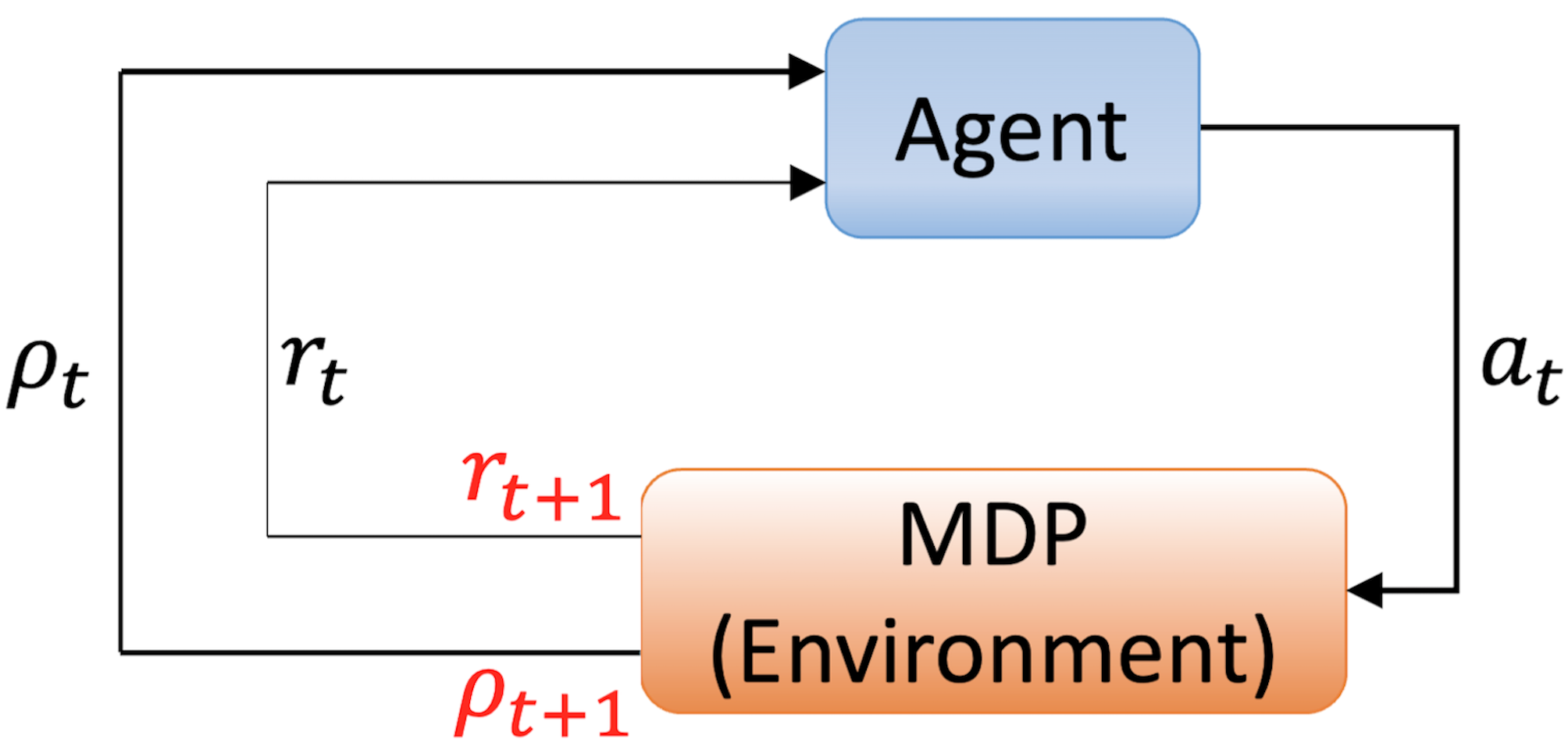
An MDP is a time-dependent and ongoing process, involving continuous interaction between the agent and the environment. The interaction can be illustrated as shown in Fig. 1. For simplicity, we consider the interaction between the agent and the environment as a discrete time series (e.g., ). Starting from with the known initial state , the agent selects an action based on and applies it to the environment. Subsequently, the environment undergoes a state transition according to the state transition function , resulting in the next state , and provides an immediate reward based on the reward function . The environment also utilizes a classical computer to solve the SME (1) to estimate the density matrix of , which is then fed back to the agent. This process is iterated until completion. Therefore, the MDP and the agent jointly generate a sequence or trajectory as follows:
| (6) |
The function that selects an action from the set of actions based on the current state is referred to as a policy . The objective of the MDP is to find the policy that allows the agent to make optimal decisions, effectively maximizing long-term cumulative rewards. Different methods, including value-based, policy-based and actor-critic-based, have been developed to update the policy in the DRL [27, 28, 29]. In this paper, a highly effective actor-critic style proximal policy optimization (PPO) algorithm [30] will be applied.
IV Applying DRL to Quantum Measurement-based Feedback Control
In this section, we apply the DRL to the quantum systems and aim to design a measurement-based feedback strategy to stabilize a given target state. The application is comprised of training and testing parts. In the training part, the primary objective lies in the agent’s policy function , constructed by a neural network with the adjustable parameter set . This parameter set is updated aiming for a higher reward by using data that is generated through the interaction between the agent and the environment. Once the agent finishes training, it can be applied to the quantum systems to generate real-time feedback control signals in achieving the stabilization of target states.
IV-A Environment: States and Actions
The environment’s state is represented by the quantum system’s density matrix, , which contains all the information about the quantum state. To use in DRL, it needs to be converted into a format suitable for neural networks. We achieve this by flattening the density matrix into a vector that includes both its real and imaginary parts. For example, for a single-qubit system with it is converted to: .This process keeps all the quantum state information and makes it usable for the neural network.
The policy function maps the quantum state’s vectorized form to a set of control actions . These actions correspond to the control signals applied to the control Hamiltonians . For example, if there are two control Hamiltonians, the actions at each time step are given by , where and are the control amplitudes.
The DRL algorithm trains the policy to select actions that stabilize the quantum state. At each time step , the agent uses the policy to choose an action based on the state . The environment then updates the quantum state to according to the system dynamics and provides a reward . This reward encourages the agent to take actions that reduces the difference between and the target state .
It is important to note that the resulting state may not be a valid quantum state due to the inherent randomness in measurements and cumulative errors in solving the SME using classical computers [31]. For example, the state matrix may contain non-physical (negative) eigenvalues. To address this issue, a suitable approach is to check the eigenvalues of the estimated matrix at each step. When negative values are encountered, the state should be projected back onto a valid physical state. This can be achieved by finding the closest density matrix under the 2-norm [32]. This approximation ensures that a non-physical density matrix is transformed into the most probable positive semi-definite quantum state with a trace equal to .
As mentioned in Section III, the interaction between the agent and the environment forms an episode where is the final step of the episode, , with denoting the total number of possible sequences. Without confusion, we use to represent a single episode. The primary goal of the agent is to maximize the expected cumulative reward across all possible episodes. The construction of the reward function will be discussed in detail in the following section.
IV-B Reward
The design of the reward function is critical in DRL. For instance, [16, 17] proposed sparse reward functions, i.e., providing rewards only at the end of each trajectory by evaluating the final state. While this approach is straightforward and easy to implement, it often suffers from slow learning or even training failure in complex systems due to the sparsity of reward signals. To address this, [21] and [22] introduced a scheme that collects fidelity information at each step and applies a higher-weighted reward for high-fidelity states. However, these methods still face challenges in balancing exploration and exploitation, particularly in systems with high-dimensional state spaces.
In this work, we propose a Partitioned Nonlinear Reward (PNR) function based on the distance (5). A lower indicates better alignment with the target state. The reward at each time step is defined as:
| (7) |
where and are the upper and lower bounds of the distance , and are the upper and lower bounds of the reward, and and are parameters that regulate the slope of the reward curve.
In general, this reward function is motivated from the inverse proportional function (the relation between and when other parameters in (7) are fixed), which ensures that the reward value increases when the distance decreases. More specifically, the bounds and are designed to ensure . The distance is mapped to a reward value constrained within the range . The two tunable parameters, and are used to adjust the steepness when is approaching and , respectively.
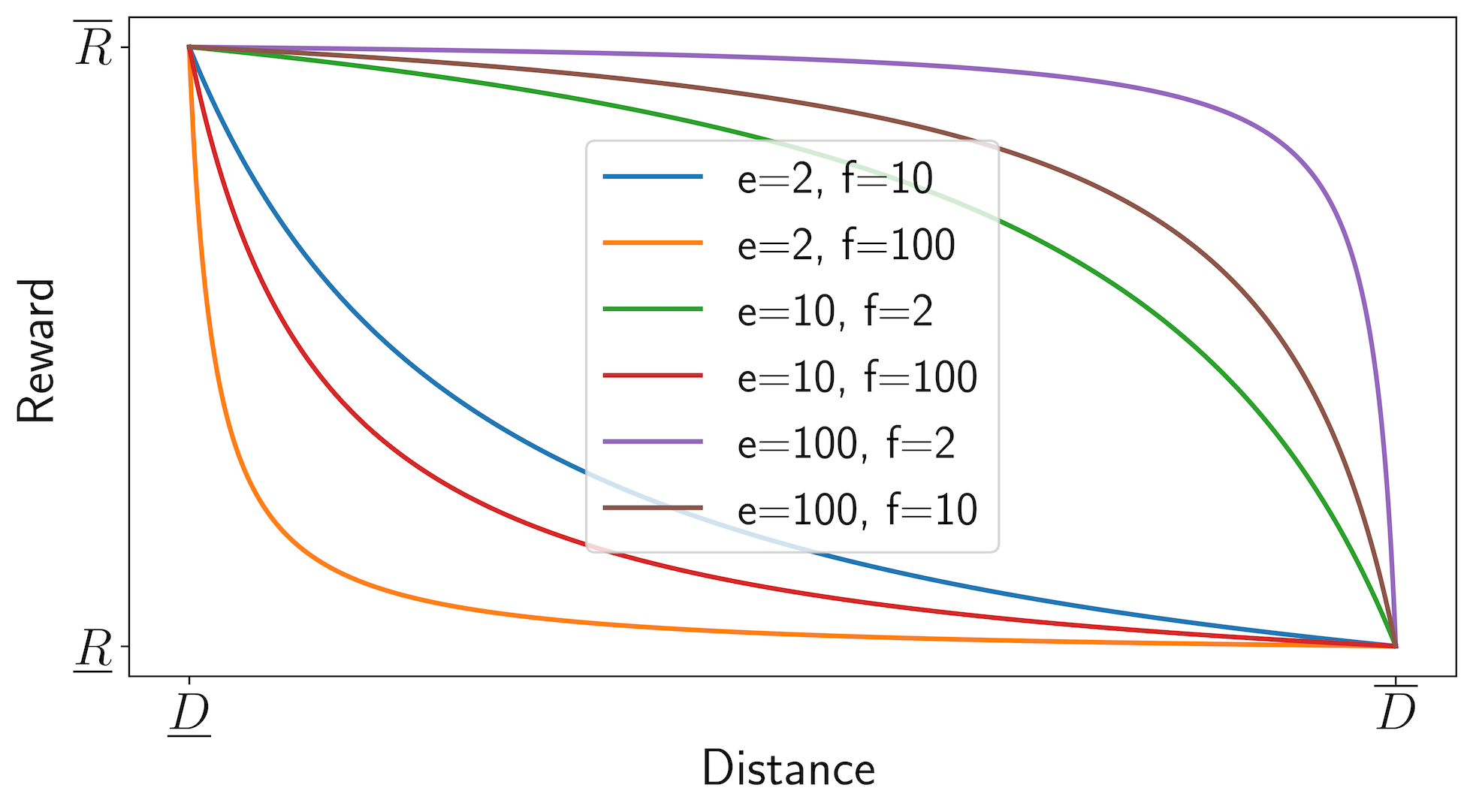
The detailed effects of different and are plotted in Fig. 2. For the given bounds , and , when , the reward curve near is steeper than that near . This indicates that the rate of increase in the reward value is more pronounced as approaches . Conversely, when , the trend is reversed.
In most existing work, the upper and lower bounds of are fixed at and , respectively. The reward function in Eq. (7), however, offers the flexibility to adjust these bounds, as well as the corresponding reward values and . This flexibility enables the division of the state space into multiple regions, which is particularly useful for addressing complex problems. Moreover, by adjusting and , it becomes possible to assign positive reward values in certain regions of the state space and negative reward values (penalties) in others. This feature allows for more efficient and effective optimization, resulting in improved performance.
In this paper, we divide the state space into two regions using a partition parameter . These two regions are denoted as Proximity Zone () and Exploration Zone (). The same reward function in the formula (7) will be used in both of these two zones, and the corresponding bounds, are determined by the partition parameter . This division provides more flexibility to balance the reward and the penalty in the whole state space. One possible curve of the reward function in these two zones are shown in Fig. 3.
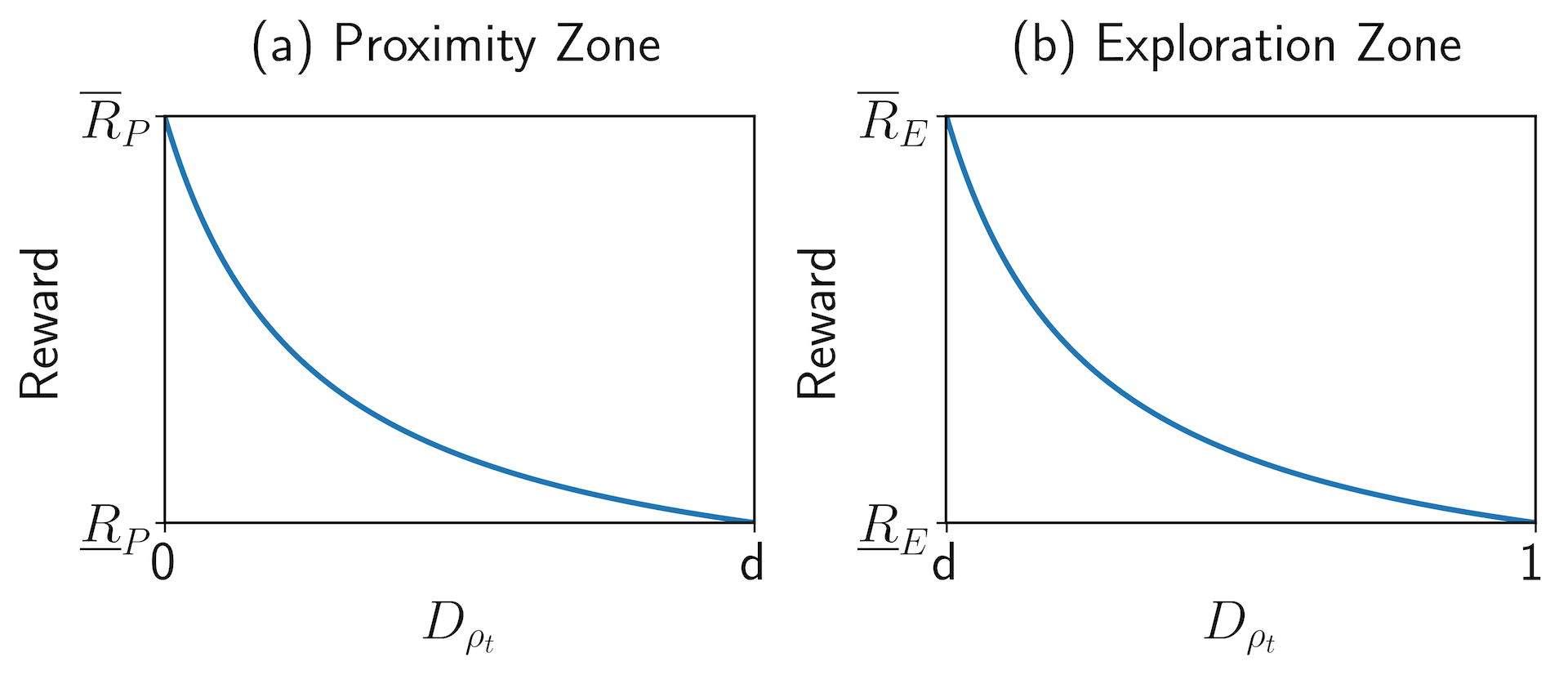
In the Proximity Zone (), the state is considered close to success. Positive rewards encourage the agent to converge rapidly to the target state. The distance bounds in this region are and , while the reward bounds are . As shown in Fig. 3(a), the reward function ensures that the slope of the curve increases as approaches zero, emphasizing rapid stabilization near the target state.
In the Exploration Zone (), the system is considered far from the target state, and penalties are applied to guide exploration. The boundaries of this zone are and , with the reward range satisfying . As illustrated in Fig. 3(b), the penalty decreases as approaches , with the slope of the curve ensuring a progressively faster reduction. This mechanism encourages the state to transition into the Proximity Zone.
Remark 1: In the Exploration Zone, when the distance approaches , we reduce penalties rather than introduce large positive rewards. This approach avoids potential reward hacking [33], where the agent might exploit increasing rewards by staying near without fully reaching the target. By applying small penalties at each step, the agent is encouraged to explore more broadly while progressively improving its policy.
Additionally, a small penalty proportional to the number of steps taken before stabilization is introduced to encourage efficiency. For example, the first step incurs a penalty of , the second step , and so forth. This step-based penalty discourages unnecessary delays and motivates the agent to achieve stabilization promptly.
The proposed reward function adjusts based on the distance , with steeper slopes in both regions as the system approaches the target state. This design encourages exploration in the Exploration Zone while driving efficient convergence in the Proximity Zone. We show the superiority of our design by simulating different reward functions in Section VI.
With this reward function, we are now in the position to maximize the cumulative expected reward of the sequence, so for a complete sequences , its cumulative reward can be expressed as
| (8) |
is known as the advantage function in the field of RL, which is utilized to assess the desirability of taking a specific action at state . represents the action-value function, indicating the expected discounted reward for choosing action in state , i.e., the cumulative sum of rewards until the end of the episode after executing this action. is the reward function in (7). The value of lies between and , determining the emphasis on long-term rewards (close to ) or short-term rewards (close to ). It effectively introduces a discounting mechanism for future rewards, thereby shaping the agent’s preference for future reward consideration when making decisions. is referred to as the state-value function (or baseline) and is modeled by a neural network with the same structure as the policy network but with different parameters . It is primarily employed to approximate the discounted rewards from state to the end of an episode. Specifically, if the current state is , and for all possible actions , they correspond to discounted rewards . As represents the expected value of the discounted rewards at , we can use as features to approximate the value of , representing the expected value of rewards in state . When , action is considered better than average and is worth increasing the probability of being chosen in subsequent iterations while decreasing the probability otherwise.
IV-C Training
The essence of employing DRL to address MDPs is centered on the training regimen of the agent, which is governed by the policy . This study implements the PPO algorithm, a model-free policy gradient method within the domain of DRL. PPO incorporates a “clip ratio” mechanism that limits the extent of policy updates, thereby enhancing the stability and reliability of the learning process. This approach mitigates the requirement for extensive environmental sampling, which is a common feature of traditional policy gradient techniques, and consequently, it improves the efficiency of the training phase. The PPO algorithm operates with three sets of network parameters: the primary policy parameters, policy parameter duplicates, and value network parameters. These parameters are instrumental in the iterative policy refinement and state value estimation processes. The comprehensive algorithmic details and the underlying mathematical formalism are presented in the Appendix.
Our DRL algorithm is implemented using the open-source Python library Stable-Baselines3 [34], while the quantum dynamic environment is constructed within the Gymnasium framework [35]. All simulations in this study are conducted on a computer equipped with an Apple M1 Pro chip and GB of memory, utilizing Python , stable-baselines3 , and Gymnasium . We design a reasonable reward function to guide the DRL agent through iterative learning, aiming to train an excellent DRL agent capable of generating control signals to achieve the stability of the target entangled state.
Reward Function Parameters: We set , which is the partition parameter of the reward function mentioned in Section IV-B. This means that when the distance is less than , the system is considered to be close to the target and receives a positive reward. In this case, the fidelity of the system state can easily exceed . Ideally, the smaller the value of , the higher the control fidelity of the trained agent. However, as decreases, the training process becomes increasingly challenging and time consuming. Therefore, the choice of should strike a balance between achieving high fidelity and managing training complexity.
The upper and lower bounds of the reward in the Proximity Zone, and , are set to and , respectively, encouraging the system to get as close as possible to the target. In the Exploration Zone, the upper and lower bounds of and are set to and , respectively, maintaining a penalty without overly punishing the agent.
We set and , emphasizing a steeper reward escalation as approaches .
Initial State: During training, the state is randomly reset to a quantum state after the completion of each episode, which means that at each episode in the training iteration, the agent starts from a new state and explores the environment from that point.
Early Termination: Regarding early termination, continuous quantum measurement feedback control can be modeled as an infinite-horizon MDP, but during training, each episode is simulated on a finite time horizon. Additionally, practical applications require a finite system evolution time. Therefore, we set fixed duration or termination conditions to end an episode. The termination conditions include the following:
-
•
If the system is measured continuously for iterations, and the distance remains within the interval for all measurements, the system is considered to have reached the target state with high fidelity. At this point, the task is concluded.
-
•
In a specific system, the maximum training time for a trajectory is set to a fixed value. For example, for the two-qubit state stabilization problem in Section V-A, we set the maximum training time arbitrary units (a.u.). When the evolution time reaches a.u., regardless of whether it has converged to the goal or not, the training trajectory is halted. This approach not only greatly saves training time but also significantly reduces the issue of overfitting.
These early termination conditions bias the data distribution towards samples that are more relevant to the task, thereby saving training time and preventing undesirable behaviors. During agent testing, the time is typically not limited to evaluate the agent’s performance in a real environment and assess its ability to complete tasks within a reasonable time frame.
The pseudo-code for the PPO in quantum state stabilization is shown in Algorithm 1.
V Numerical Simulation
V-A Two-Qubit System
We consider a two-qubit system in a symmetric dispersive interaction with an optical probe, as described in [36]. The system’s dynamics are governed by the SME in (1), where we utilize a DRL control scheme to stabilize the system to a target entangled state from arbitrary initial states. Denote the Pauli matrices
Control Hamiltonians in (1) are chosen as
| (9) |
which implies that two control channels are applied to this quantum system. And the forms of and represent rotations on the first and second qubits, respectively, enabling independent control over each qubit.
The observable operator is chosen as:
| (10) |
which corresponds to the measurement of -like observable for the two qubits.
Specify the target state as
| (11) |
which is a symmetric two-qubit Bell state.
We utilize the previously summarized PPO algorithm to train the DRL agent. For the training trajectories, we set a time interval of a.u. for each measurement step, with a maximum evolution time of a.u., corresponding to a maximum of steps. At each step, the DRL agent interacts with the environment, obtaining system information to generate control signals, which are then stored for iterative updates of the policy. The total number of training steps is set to . On the computer with configuration in Section IV-C, the training process requires approximately minutes. However, the primary focus of this study is the performance of the trained agent rather than the optimization of training time. In practical implementations, employing a pre-trained agent is feasible. Once the target state is specified, the agent does not require repeated updates and can be directly utilized after training is completed.
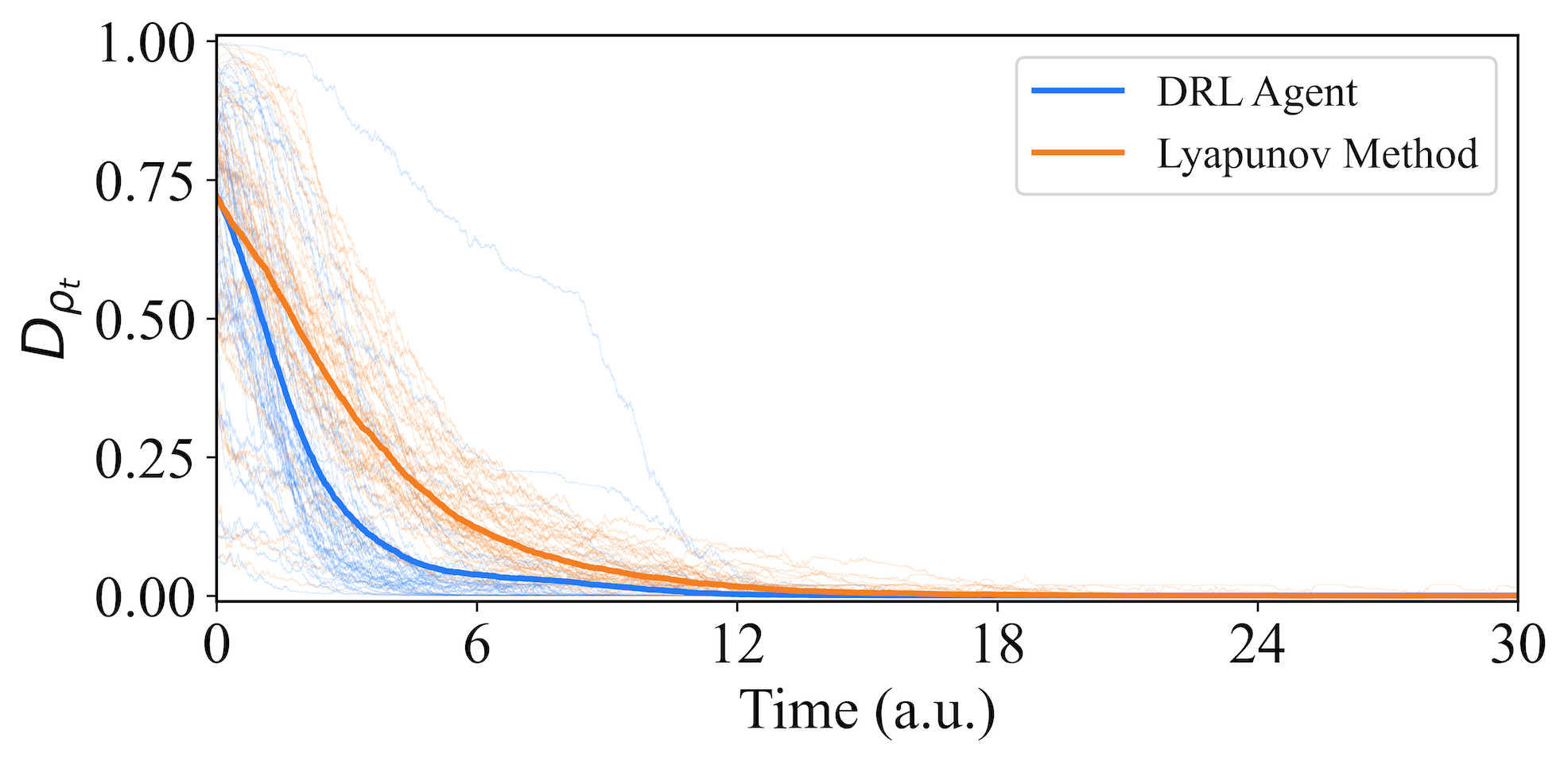
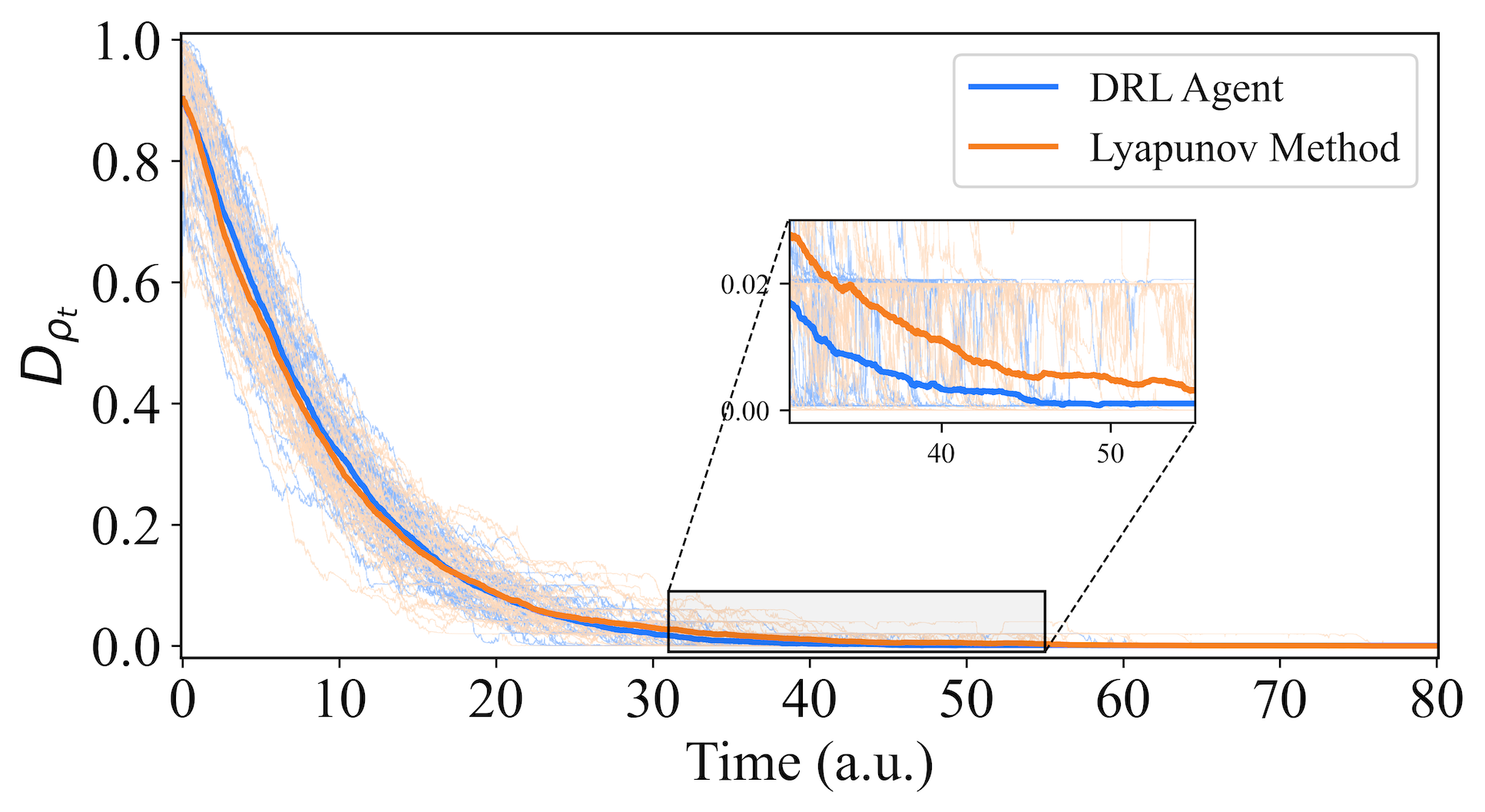
In order to evaluate its performance, we test the proposed strategy on randomly selected distinct initial quantum states (corresponding to different initial distances , as indicated by the blue line in Fig. 4). The light blue lines represent the evolution trajectory of a specific initial state with respect to the target state, averaged over different trajectories under varying environmental noise, while the dark blue line depicts the average evolutionary trajectory of all the different initial states, i.e., the average trajectory of different evolutionary trajectories. Smaller values of the distance indicate that the system is closer to the target state. It is worth noting that a trained agent can successfully stabilize any initial state to the target state with high fidelity. Furthermore, for comparison with the Lyapunov method mentioned in [36], we retain the same sets of randomly selected initial states and obtain the orange trajectories in Fig. 4 using the Lyapunov method. It can be observed that the control signals generated by the DRL agent outperform the Lyapunov method. Assuming that the time when the distance is less than is the evolution time of the system, the average evolution time of the trajectories under the guidance of the DRL agent is a.u., while the average time using the Lyapunov method is a.u.. The DRL’s average stabilization time is improved by over the Lyapunov method. This indicates that our DRL approach successfully stabilizes these quantum states to the target state faster than the Lyapunov method.
V-B GHZ State
We then consider a more complex problem of preparing three-qubit entangled GHZ states, which are special entangled states and have been regarded as maximally entangled states in many measures [37], [38]. A GHZ entangled state is defined in the following form [37, 39]:
| (12) |
where is the number of qubits. Its density matrix can be expressed as . For the three-qubit GHZ state, we choose , which gives the following density matrix:
| (13) |
A degenerate observable is required according to the quantum state collapse after measurement [36, 8, 40]. The quantum state collapse states that the system in (1) will randomly converge to an eigenstate or eigenspace of without any control. Hence, we choose an observable in the following diagonal form:
| (14) |
where , and is the eigenvalue corresponding to the target state , i.e., .
Due to the degenerate form of the observable in (14), the system may converge to other state in the corresponding eigenspace related to , two control channels and based on Lyapunov method have been applied in [36, 8, 40] to solve this problem. For subsequent performance comparisons, two control channels are also used in this paper.
For any training trajectory, we take a time interval a.u. for each measurement step. Given that we have set the maximum evolution time as a.u., it means the maximum number of evolution steps for any trajectory during training is . The total number of training steps is .
For all instances, in order to compare with the Lyapunov methods presented in [8], we choose the same system Hamiltonian as . The diagonal form of which indicates that the eigenvalues correspond to the energy levels of the system in the computational basis (where for three qubits). The target state is (13), and the observable is chosen to be:
| (15) |
to measure correlations between the z-components of different pairs of qubits in a three-qubit system and also ensure that the target state is an eigenstate. The control Hamiltonians and are chosen as
| (16) |
and
| (17) |
Similar to the two-qubit systems, two control channels represented by and together with their strengths and provide control over the system’s dynamics. The forms of control Hamiltonian represent how the control action is applied to the three-qubit system. For example, the form of generally represents an independent -axis control to the third qubit and a correlated -axis interaction between the first and the second qubits.
We test the trained DRL agent in various environments to evaluate its performance and robustness. The goal is to assess how well the agent generalizes its learned policies to different scenarios and how it copes with perturbations and variations in the environment. To achieve this, we expose the trained DRL agent to a set of diverse environments, each with unique characteristics and challenges. These environments are carefully designed to represent a wide range of scenarios and potential disturbances that the agent might encounter in real-world applications. During the testing phase, we measure the agent’s performance in terms of its ability to achieve the desired objectives and maintain stability in each environment. In particular, we examine its response to changes in the measurement efficiency and time delay disturbances to assess its robustness and adaptability.
We first investigate the “perfect case”. In this paper, the “perfect case” entails assuming that negligible delay in solving the SME (1) by classical computers, and perfect detection, that is, measurement efficiency . In contrast, situations where there is delay or imperfect detection within the system are collectively referred to as “imperfect cases”. We then show some performance indications for “imperfect cases”.
V-B1 Stabilization of the GHZ state under perfect case
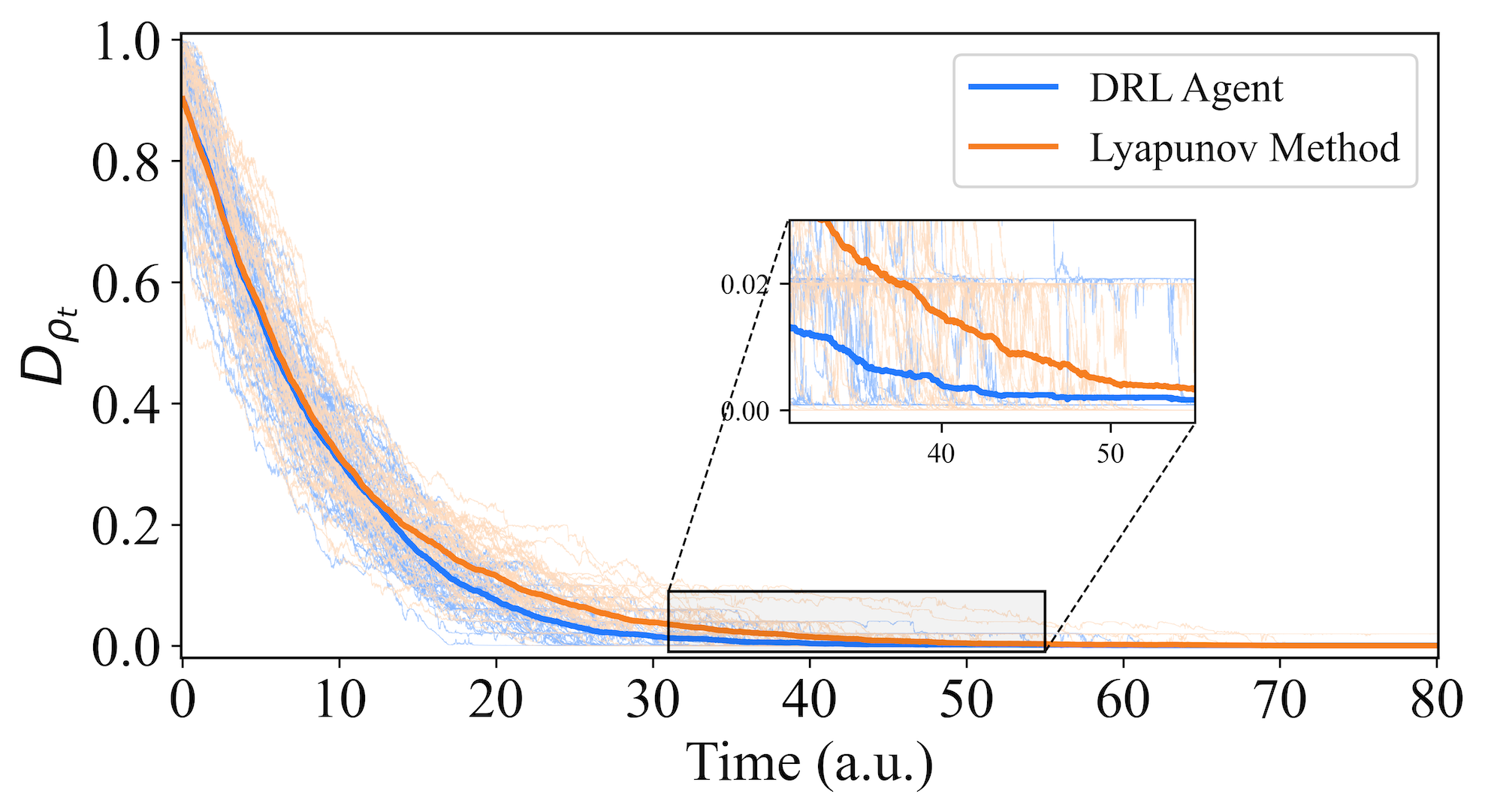
We initiate the testing phase to evaluate the ability of arbitrary initial states to stabilize to the target GHZ state within a specified time frame. As shown in Fig. 5, we employ the comparative approach mentioned in Section V-A, randomly selecting distinct initial states for control using the DRL agent and the Lyapunov method. The blue and orange lines correspond to the DRL method and the Lyapunov method, respectively. The average evolution time of 2500 trajectories guided by the DRL agent is shorter than that of the Lyapunov method (DRL: 10.41 a.u. vs. Lyapunov: 12.33 a.u.). This indicates that our DRL approach successfully stabilizes quantum states to the target GHZ state more rapidly.
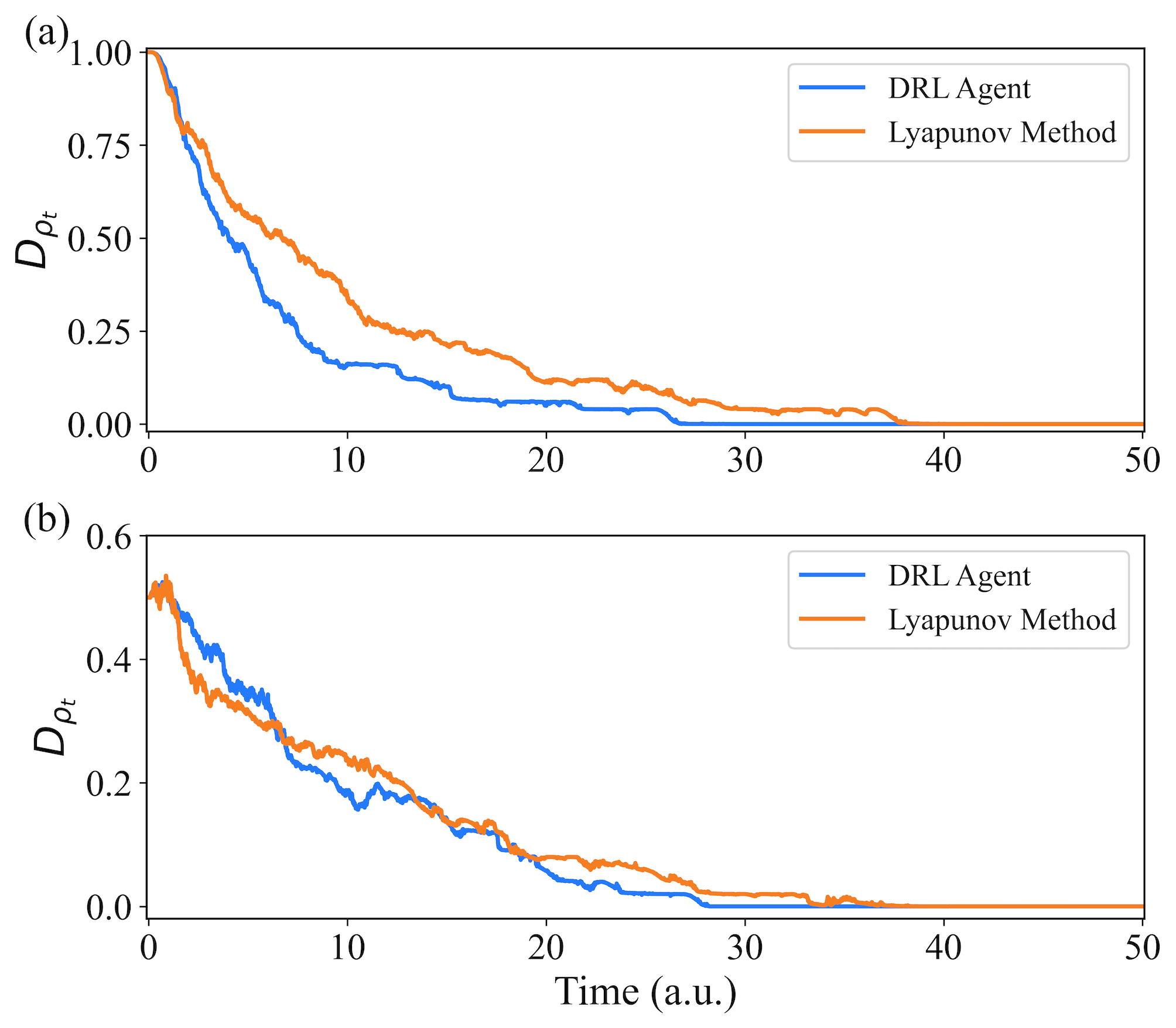
In addition, we also explore the evolution of two specific initial states, denoted as and , mentioned in [8] as examples. We repeat their stabilization times each to obtain averaged convergence curves that approximate the system’s evolution. Fig. 6(a) and Fig. 6(b) depict the evolution of these two distinct initial states. The blue curve represents the evolution controlled by the DRL agent, while the orange curve represents the evolution controlled by the Lyapunov method from [8]. It can be observed that the well-trained DRL agent not only achieves stable convergence to the target state but also showcases faster convergence compared to the Lyapunov method.
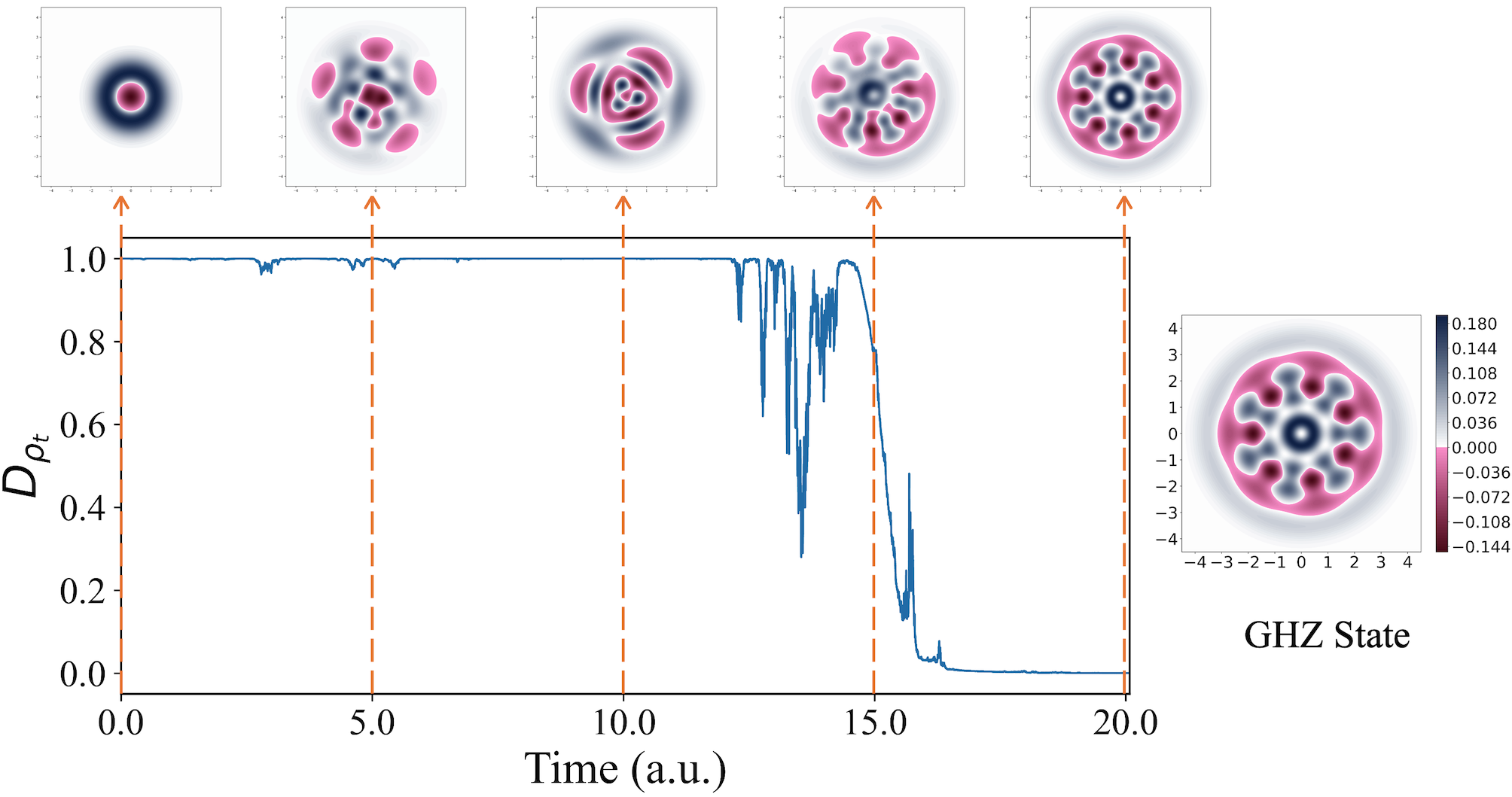
We randomly select a single trajectory under the control of a DRL agent with initial state . The left subplot of Fig. 7 illustrates the evolutionary trajectory with , and the top images display the Wigner function of the system state at five different evolution times. In contrast, the subplot on the right serves as a reference plot for the target three-qubit GHZ state. A comparison reveals that the phase-space distribution of the system state gradually approaches the target state over time, and at a.u., the system state is identical to the target state.
In practical agent training and application, uncertainties often exist. For example, the efficiency of measurements is typically not perfect, and there are frequently issues related to time delays in the feedback process. In the following two subsections we explore the robustness of our DRL agent to these two imperfections.
V-B2 Stabilization of the GHZ state with imperfect measurement
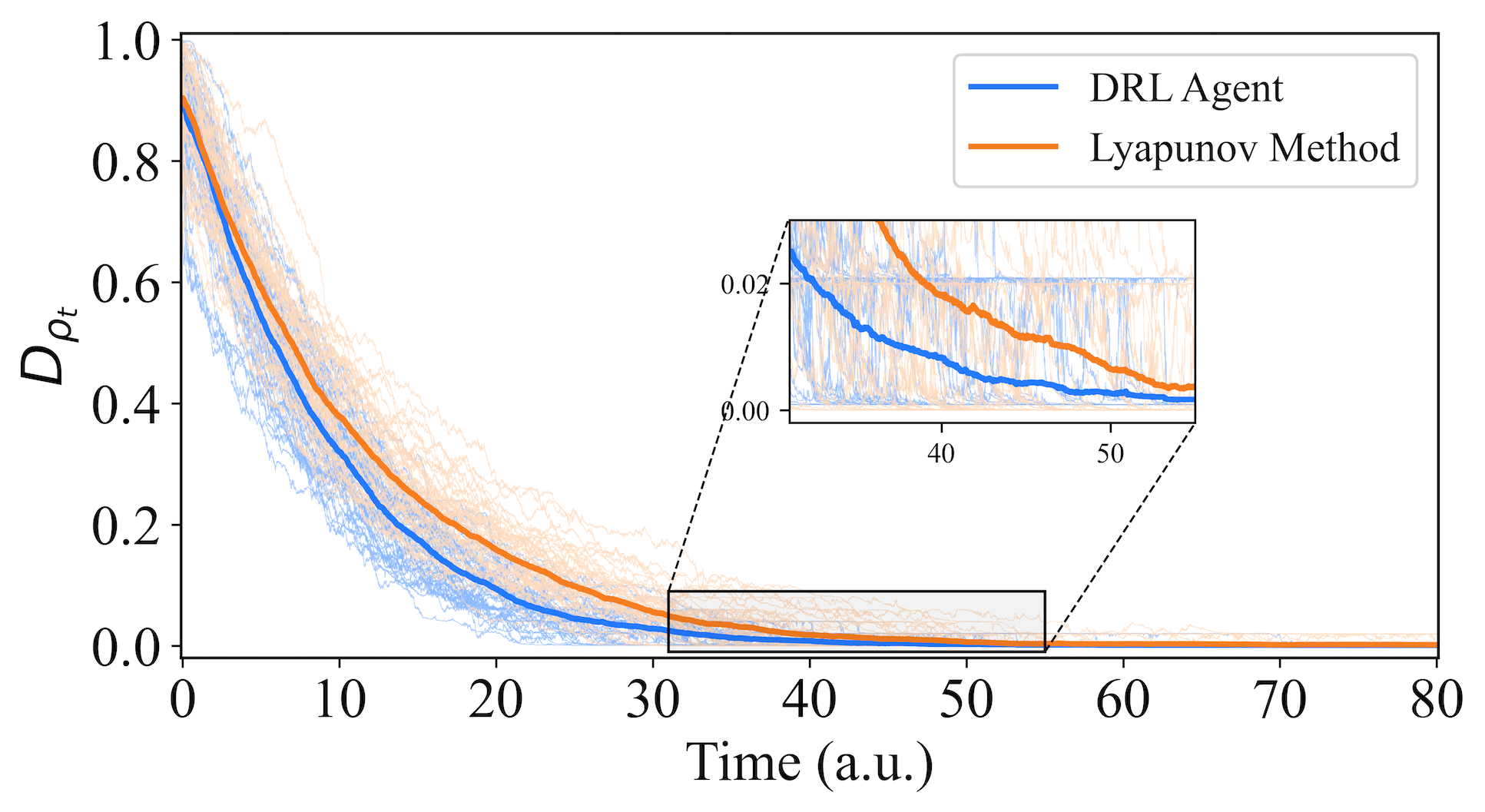
We first investigate the impact of reduced measurement efficiency, focusing on the robustness of an agent trained under the assumption of “perfect case”. In this test, we consider a measurement efficiency of , which represents a relatively high level achievable in current laboratory environments [41]. As shown in Fig. 8, both the DRL-based agent and the Lyapunov-based method successfully stabilize randomly selected initial states to the target GHZ state. Moreover, the DRL agent demonstrates slightly superior performance. These results highlight that the DRL agent, trained under ideal conditions, retains significant robustness even in the presence of reduced measurement efficiency.
V-B3 Stabilization of the GHZ state with time delay
We evaluate the performance of the trained agent under the presence of time delays in the feedback process. In rapidly evolving quantum systems, the time required for traditional computers to solve the SME (1) is often non-negligible. To account for this, we incorporate fixed time compensation during agent testing. For example, assuming a time delay of a.u., the agent only receives the initial state as input from a.u. to a.u., and generates control signals based on this state to guide the system’s evolution. At a.u., the agent receives the state , and subsequently at each step, it processes the state , which corresponds to the state from a.u. earlier. As illustrated in Figure 9, using randomly selected initial states, we observe that both the trained DRL agent and the Lyapunov-based method handle time delays effectively. Moreover, the DRL agent demonstrates superior performance compared to the Lyapunov-based approach.
VI Analyzing the Advantages of PNR Reward Function
In this section, the 3-qubit example will be used to analyze the advantages of the PNR reward function. As described in Section IV-B, the PNR employs a partition parameter to divide the state space into two regions: the Proximity Zone () and the Exploration Zone (). The reward function in each region follows the nonlinear form specified in (7).
The parameters for the PNR are set as follows:
-
•
, , ;
-
•
, , , .
To evaluate the effectiveness of the proposed approach, we consider several alternative reward functions for training DRL agent. For fair comparisons, all agents are trained with the same parameters for a given target state, with the only difference being the reward functions used during training. The purpose of the analysis is to give us a clear and comprehensive understanding to the impact of the various modules of the designed reward function on the control performance, as well as to compare its performance with existing reward function designs.
The following assumptions are made:
-
•
The maximum evolution time of the system, denoted as , is set to a.u.. For any trajectory where the system does not converge to the target state within (i.e., ), it is considered a non-convergent trajectory. For the purpose of the follow-up calculation of the average time to convergence, the “convergence time” for these non-converging trajectories up to a.u. is set to a.u..
-
•
A metric termed the Stabilization Success Rate is defined. During testing, distinct initial states are considered for stabilization to the target, with each initial state being stabilized under different environmental noise conditions. This results in a total of individual trajectories. The Stabilization Success Rate is calculated as the ratio of the number of convergent trajectories within to the total number of trajectories ().
VI-A Reward Function Designs
The reward functions tested are categorized as follows:
-
•
Partitioned Nonlinear Reward 1 (PNR1): This follows the structure of PNR, with the only difference being the parameters and , such that the slope decreases as the distance diminishes.
-
•
Partitioned Linear Reward (PLR): This design mirrors the partitioned structure of PNR but employs a linear reward function in each region instead of a nonlinear one. The bounds remain consistent with PNR.
-
•
Partitioned Sparse Reward (PSR): [16, 17] use a sparse reward structure that provides rewards only at the last time step. We consider similar design ideas, retaining the partition structure for consistency:
-
–
In the Proximity Zone, the reward is a fixed positive constant.
-
–
In the Exploration Zone, no reward is assigned.
-
–
-
•
Non-Partitioned Nonlinear Reward (NPNR): This reward design does not use partitioning of the state space. Common reward function designs, such as those in [21, 22], apply a uniform reward structure across all states, treating the entire state space equally without distinguishing between different regions. The NPNR reward function adopts the nonlinear form described in (7), defined over the entire state space . The rewards are non-positive, ranging from , where the penalty magnitude decreases as gets closer to .
-
•
Non-Partitioned Linear Negative Reward (NPLNR): Similar to NPNR, this design does not partition the state space. The reward function is linearly defined over and is always non-positive . The penalty decreases linearly as approaches .
-
•
Non-Partitioned Linear Positive Reward (NPLPR): The only distinction between this design and NPLNR is that the non-partitioned reward values are strictly positive, ranging from . The reward increases linearly as approaches .
-
•
Fidelity-Based Positive Reward (FPR): This non-partitioned reward is based on fidelity, a common approach in machine learning for quantum measurement feedback problems[21, 22]. Specifically, we adopt the reward function proposed in [22]:
(18) where is the fidelity at time . The reward is positive and increases as approaches .
VI-B Performance Comparison
To facilitate comparison, the reward functions are categorized into three types. Our PNR serves as the baseline for evaluating and comparing these categories.
VI-B1 Category 1: Partitioned Nonlinear Rewards
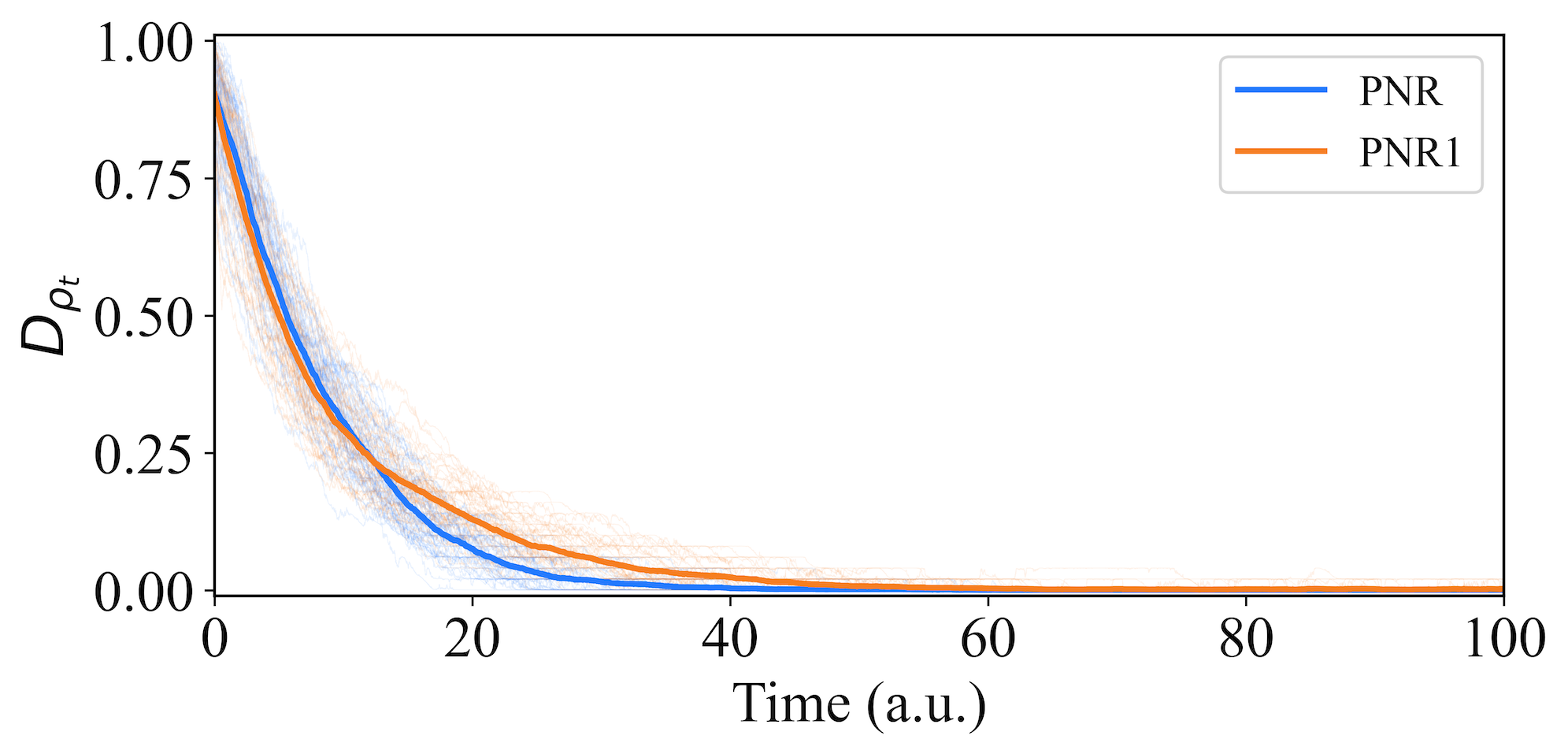
This category contains PNR1. The effect of the parameters and on the performance of the agent is evaluated. Using random initial states, each averaged over trajectories, the results in Fig. 10 show that PNR1 performs worse than PNR. The average convergence time for PNR1 is a.u., compared to a.u. for PNR. Additionally, the convergence success rate for PNR1 is , lower than the success rate of PNR. These results suggest that setting smaller than is more effective, meaning the reward function’s steepness increases as the target is approached.
VI-B2 Category 2: Partitioned Linear and Sparse Rewards
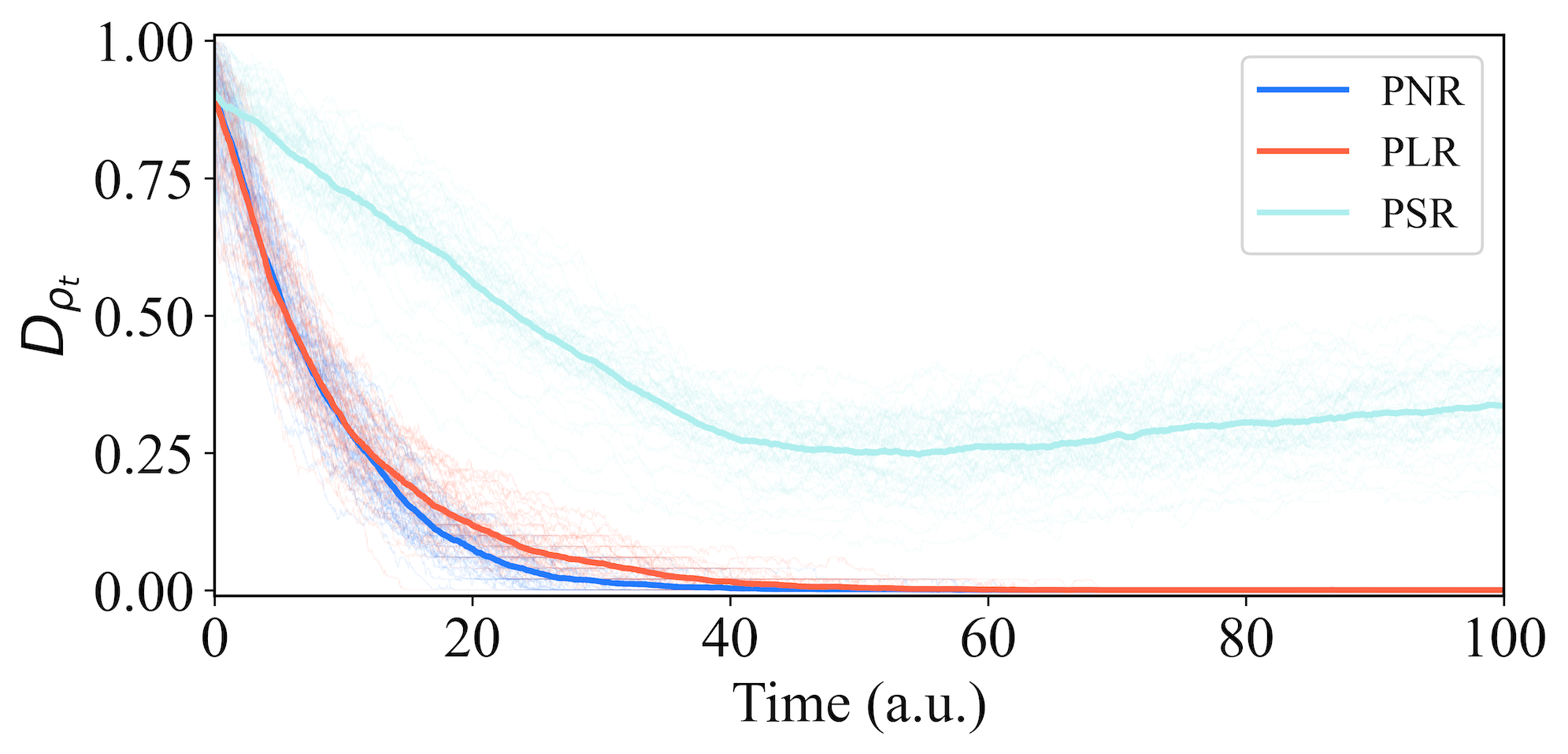
This class includes PLR and PSR, whose only difference from our PNR is that the form of their reward functions are linear and sparse rewards, respectively. As shown in Fig. 11, PLR achieves relatively good performance, with a convergence time of a.u. and a success rate of , although it still underperforms compared to PNR. This highlights the superiority of our designed nonlinear reward function. In contrast, PSR performs poorly, as sparse rewards alone are insufficient for complex systems.
VI-B3 Category 3: Non-Partitioned Rewards
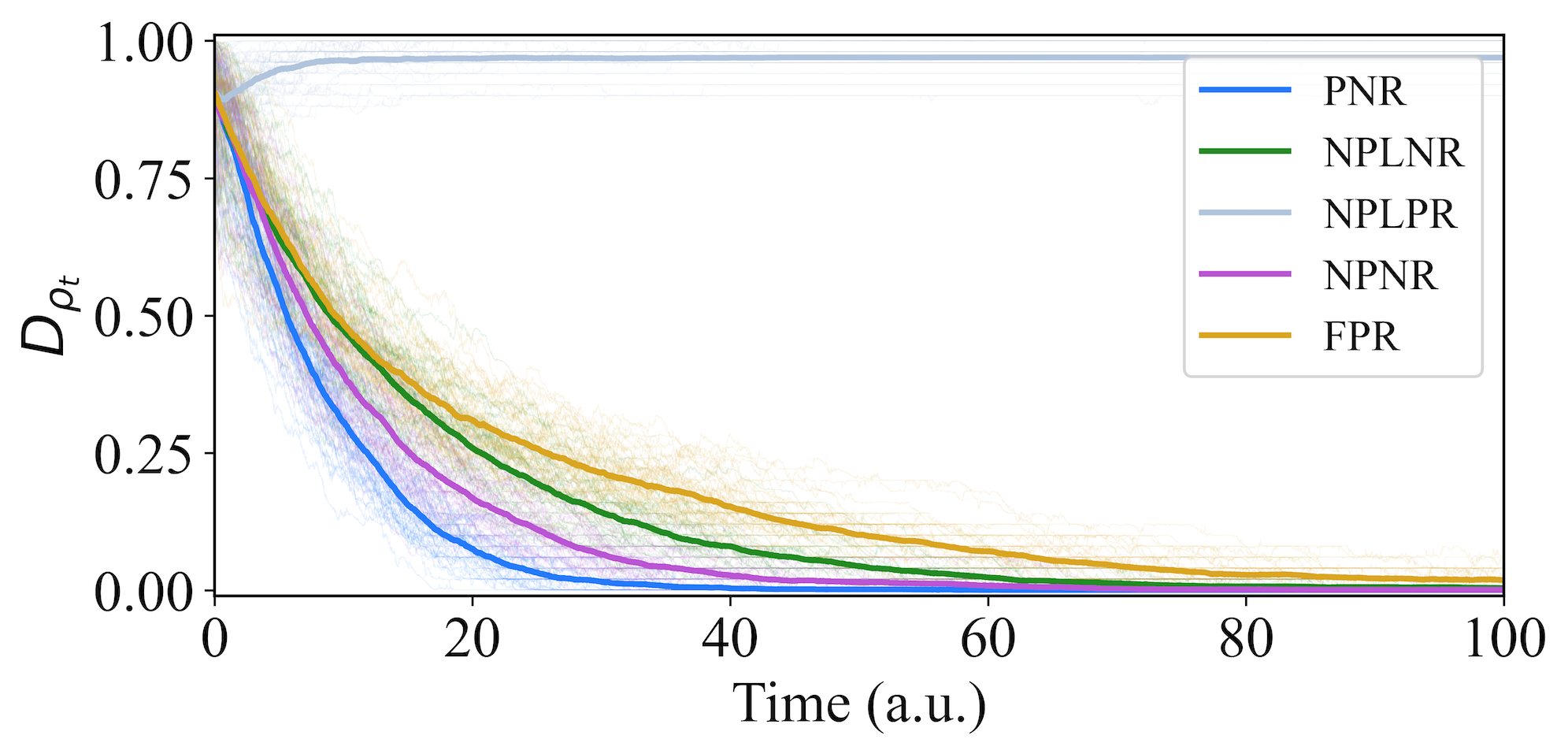
This category evaluates NPNR, NPLNR, NPLPR, and FPR. These non-partitioned reward functions include linear, nonlinear, and fidelity-based, and the reward values are either positively encouraging (gradually increasing the positive reward value) or negatively spurring (gradually decreasing the negative reward value). Fig. 12 shows that among these designs, NPNR and NPLNR perform the best with convergence times of a.u. and a.u. and success rates of and , respectively. These results suggest that decreasing negative penalties near the target is more effective than increasing positive rewards. In addition, the outperformance of NPNR over NPLNR highlights the role of nonlinear reward functions. The commonly used FPR performs poorly, with a convergence time and success rate of a.u. and , respectively, highlighting its limitations in stabilizing complex quantum states. NPLPR’s method of incrementing the positive rewards is nearly ineffective, which coincides with Remark .
Our PNR outperforms other reward designs, demonstrating superior performance in stabilizing complex quantum states like the GHZ state. Nonlinear reward functions, especially when combined with partitioning, are shown to be more effective than linear or sparse reward structures in achieving faster convergence and higher success rates.
Table I summarizes the parameters and characteristics of these reward function designs, as well as their performance.
| Reward Type | Partitioned | Reward Function | PZ Rewards | EZ Rewards | NP Rewards | Time (a.u.) | Success Rate | |
| PNR | Yes | Nonlinear | [1, 100] | [-0.1, 0] | \ | 10.41 | 100% | |
| PNR1 | Yes | Nonlinear | [1, 100] | [-0.1, 0] | \ | 12.19 | 99.2% | |
| PLR | Yes | \ | Linear | [1, 100] | [-0.1, 0] | \ | 11.8 | 99.76% |
| PSR | Yes | \ | Sparse | 1 | 0 | \ | 53.25 | 62.08% |
| NPNR | No | \ | Nonlinear | \ | \ | [-1, 0] | 13.6 | 99.88% |
| NPLNR | No | \ | Linear | \ | \ | [-1, 0] | 18.48 | 99.56% |
| NPLPR | No | \ | Linear | \ | \ | [0, 100] | 97.23 | 3.08% |
| FPR | No | \ | Fidelity-Based | \ | \ | Fidelity | 43.59 | 97.72% |
| PZ (EZ) Rewards: Reward values in Proximity (Exploration) Zone; NP Rewards: Reward values when not partitioned. | ||||||||
VII Conclusions
In this work, we designed a DRL agent and applied it to measurement-based feedback control for stabilizing quantum entangled states. With a designed reward function, the trained agent can quickly stabilize the quantum system to the target state with high fidelity and demonstrates strong robustness.
The DRL agent was tested under a “perfect case” and its performance was mainly compared to a Lyapunov-based switching method, and several other DRL algorithms with different reward functions. The results showed that our approach achieve comparable fidelity in a shorter time, potentially mitigating noise caused by prolonged interactions. The agent was also evaluated under “imperfect cases,” including low measurement efficiency and feedback delay, where it maintained great performance under these challenging conditions.
To analyze our method, we conducted ablation studies on the reward function to identify the role of each component in achieving the final performance. We also compared our reward function with fidelity-based designs from the literature and several variants of our reward function, showing the superior performance of our approach.
The proposed DRL-based framework has the potential to be extended to stabilize any multi-qubit system. Naturally, it is expected that as the system dimension increases, both the training time and the time required for state estimation using the SME will grow. Future research could explore methods to reduce the dimensionality of the state space and enhance the speed of quantum state estimation based on the SME. Furthermore, developing control strategies that rely on less system information, such as using only measurement currents, may allow for efficient stabilization of the target state with sufficient fidelity. These directions aim to further improve the practical applicability of the proposed control framework.
[PPO algorithm] In the field of DRL, PPO algorithm has become a prominent method due to its effectiveness and stability in policy optimization. This appendix is dedicated to elucidating the core algorithmic concepts of PPO and providing a detailed description of its mechanisms. The aim is to provide the reader with a comprehensive understanding of how the algorithm works and facilitate its application in practical scenarios.The core of PPO is to maximize the expected cumulative returns by optimizing the strategy parameters while ensuring that the updates remain stable. The following paragraphs delve into the specifics of these algorithmic ideas.
-A Core Algorithmic Ideas of PPO
The probability of each sequence occurring is multiplied by its corresponding cumulative reward, and the sum of these products yields the expected reward. The probability of a specific sequence occurring given is defined as:
| (19) |
We denote to signify the probability of the occurrence of the EVENT. For example, represents the probability of agent to choose action given while represents the probability of environment transiting at from given the action applied.
When the parameter is given, the expected value of the total reward, denoted as , is evaluated as the weighted sum of each sampled sequence, expressed by
| (20) |
To maximize , which indicates that our chosen policy parameters can lead to higher average rewards, we adopt the well-known gradient descent method. Thus, we take the derivative of the expected reward in (20), resulting in the expression shown in
| (21) | ||||
We use to derive the second row of (21). The last approximate equation is a result of practical gradient computations, where instead of calculating the expected reward for an entire trajectory, rewards contributed by each individual state-action pair () are computed separately. These individual rewards are then summed up to obtain the total cumulative reward for the optimization process. The direction of the policy update is biased towards favoring state-action pairs that contribute to higher cumulative rewards within the sequence. For instance, if an action executed in state leads to a positive cumulative discounted reward, the subsequent update will enhance the probability of choosing action in state , while diminishing the likelihood of selecting other actions. The update equation for the parameters is as follows:
| (22) |
where is the learning rate.
Once the policy is updated, it necessitates the reacquisition of training data prior to the subsequent policy update. This arises due to the alteration in the probability distribution brought about by the modified policy. Following data sampling, the parameter undergoes refinement, leading to the discarding of all prior data. Subsequent parameter updates mandate the collection of fresh data, constituting the fundamental principle underlying the conventional PG algorithm. However, in the context of quantum systems, the process of sampling system information is often characterized by time-intensive and computationally demanding operations. For instance, after each measurement, a classical computer is requisitioned to solve the SME (1) to ascertain the system’s state in the subsequent moment. This inability to reutilize previously acquired data contributes to a protracted training process. To address this challenge, an additional strategy is introduced, mirroring the architecture of . Instead of directly engaging with the environment for data gathering, the primary agent employs the auxiliary agent to interact with the environment and accumulate data. The objective is to subsequently utilize this data to train multiple times, effectively reducing the computational and resource demands for data collection. Ensuring the consistency of data sampled by with that of , importance sampling [42] is introduced to facilitate this synchronization process. This approach contributes to enhancing data reuse and the overall efficiency of the training procedure. (21) is updated as:
| (23) |
Here, all the state-action pairs (or alternatively, all trajectories ) are sampled from . The term represents the importance weight, which dynamically adjusts the weighting of data sampled by in real time to more accurately estimate the expected value under the target policy .
The corresponding objective function from (23) can be calculated as:
| (24) |
Nonetheless, in the absence of constraint, such as when , indicating the desirability of specific action-state combinations, the agent’s inclination would be to elevate their likelihood, effectively amplifying the value. This scenario can lead to policy learning inaccuracies and an erratic learning process, impeding convergence. To counteract this, the PPO introduces a pivotal mechanism, termed the “clip ratio”. This clip ratio imposition serves to confine the proportions between the new and preceding policies, thereby ensuring congruence and augmenting the algorithm’s dependability. The following equation demonstrates the PPO Clipping algorithm, incorporating the clipping term to bound the difference between and during the policy update.
| (25) | |||
where . The last two terms , and in the clip function limit the boundaries of the first term. is a hyperparameter, typically set to or . Exhaustively considering all possible sequences is typically infeasible, and thus in practical training, the objective function (25) is often formulated in the following manner:
| (26) | |||
where and represent finite real numbers that respectively signify the count of collected sequences and the maximum number of steps within each sequence.
Based on the above, we can see that PPO has three sets of network parameters for its update strategy:
-
•
One set of main policy parameters , which is updated every time.
-
•
One set of policy parameter copies , which interact with the environment and collect data. They utilize importance sampling to assist in updating the main policy parameters . Typically, is updated only after several updates of has been performed.
-
•
One set of value network parameters , which are updated based on the collected data using supervised learning to update the evaluation of states. They are also updated every time.
-B Generalized parameter selection for training agents
Neural Network Architecture: Each policy is represented by a neural network that maps a given state to a probability distribution over actions . The action distribution is modeled as a gaussian distribution. The input layer is processed by two fully connected hidden layers, each with neurons, accompanied by a linear output layer with the same dimension as the action space ( in this paper). All hidden layers use the Tanh activation function. The value function is composed of a similar neural network architecture, with the only difference being that the output layer is a single linear unit used to estimate the state-value function. The value function is estimated using the temporal difference (TD) method [43]. Then, the generalized advantage estimator (GAE) [44] is employed to compute the advantage function in (8), which is subsequently used in (25) to calculate the gradient for updating the policy .
Learning Rate: The learning rate is a hyperparameter that determines the step size of the algorithm’s updates based on observed rewards and experiences during training. In our training process, the learning rate is not a constant value but follows a linear schedule. Our learning rate starts at and linearly decreases over time during the training process. This allows the algorithm to explore more in the early stages of training when the policy might be far from optimal. As the training progresses, the policy approaches convergence, and the learning rate decreases to promote stability in the learning process and fine-tune the policy around the optimal solution. This helps the DRL agent achieve better performance and stability during the training process. Please refer to [43, 45] for more details.
References
- [1] D. Dong and I. R. Petersen, Learning and Robust Control in Quantum Technology. Springer Nature, 2023.
- [2] A. Karlsson and M. Bourennane, “Quantum teleportation using three-particle entanglement,” Physical Review A, vol. 58, no. 6, p. 4394, 1998.
- [3] A. Ekert and R. Jozsa, “Quantum algorithms: entanglement–enhanced information processing,” Philosophical Transactions of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences, vol. 356, no. 1743, pp. 1769–1782, 1998.
- [4] R. Jozsa and N. Linden, “On the role of entanglement in quantum-computational speed-up,” Proceedings of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences, vol. 459, no. 2036, pp. 2011–2032, 2003.
- [5] X. Gu, L. Chen, A. Zeilinger, and M. Krenn, “Quantum experiments and graphs. III. high-dimensional and multiparticle entanglement,” Physical Review A, vol. 99, no. 3, p. 032338, 2019.
- [6] S. Kuang, D. Dong, and I. R. Petersen, “Rapid Lyapunov control of finite-dimensional quantum systems,” Automatica, vol. 81, pp. 164–175, 2017.
- [7] Y. Liu, D. Dong, S. Kuang, I. R. Petersen, and H. Yonezawa, “Two-step feedback preparation of entanglement for qubit systems with time delay,” Automatica, vol. 125, p. 109174, 2021.
- [8] Y. Liu, S. Kuang, and S. Cong, “Lyapunov-based feedback preparation of GHZ entanglement of -qubit systems,” IEEE Transactions on Cybernetics, vol. 47, no. 11, pp. 3827–3839, 2016.
- [9] R. S. Judson and H. Rabitz, “Teaching lasers to control molecules,” Physical Review Letters, vol. 68, no. 10, p. 1500, 1992.
- [10] D. Dong and I. R. Petersen, “Quantum estimation, control and learning: opportunities and challenges,” Annual Reviews in Control, vol. 54, pp. 243–251, 2022.
- [11] D. Dong, “Learning control of quantum systems,” in Encyclopedia of Systems and Control, J. Baillieul and T. Samad, Eds. Springer London, 2020, https://doi.org/10.1007/978-1-4471-5102-9_100161-1.
- [12] S. Sharma, H. Singh, and G. G. Balint-Kurti, “Genetic algorithm optimization of laser pulses for molecular quantum state excitation,” The Journal of Chemical Physics, vol. 132, no. 6, p. 064108, 2010.
- [13] O. M. Shir, Niching in derandomized evolution strategies and its applications in quantum control. Leiden University, 2008.
- [14] D. Dong, M. A. Mabrok, I. R. Petersen, B. Qi, C. Chen, and H. Rabitz, “Sampling-based learning control for quantum systems with uncertainties,” IEEE Transactions on Control Systems Technology, vol. 23, no. 6, pp. 2155–2166, 2015.
- [15] H. M. Wiseman, “Quantum theory of continuous feedback,” Physical Review A, vol. 49, no. 3, p. 2133, 1994.
- [16] M. Bukov, A. G. Day, D. Sels, P. Weinberg, A. Polkovnikov, and P. Mehta, “Reinforcement learning in different phases of quantum control,” Physical Review X, vol. 8, no. 3, p. 031086, 2018.
- [17] V. Sivak, A. Eickbusch, H. Liu, B. Royer, I. Tsioutsios, and M. Devoret, “Model-free quantum control with reinforcement learning,” Physical Review X, vol. 12, no. 1, p. 011059, 2022.
- [18] M. M. Wauters, E. Panizon, G. B. Mbeng, and G. E. Santoro, “Reinforcement-learning-assisted quantum optimization,” Physical Review Research, vol. 2, no. 3, p. 033446, 2020.
- [19] J. Yao, L. Lin, and M. Bukov, “Reinforcement learning for many-body ground-state preparation inspired by counterdiabatic driving,” Physical Review X, vol. 11, no. 3, p. 031070, 2021.
- [20] S. Borah, B. Sarma, M. Kewming, G. J. Milburn, and J. Twamley, “Measurement-based feedback quantum control with deep reinforcement learning for a double-well nonlinear potential,” Physical Review Letters, vol. 127, no. 19, p. 190403, 2021.
- [21] R. Porotti, A. Essig, B. Huard, and F. Marquardt, “Deep reinforcement learning for quantum state preparation with weak nonlinear measurements,” Quantum, vol. 6, p. 747, 2022.
- [22] A. Perret and Y. Bérubé-Lauzière, “Preparation of cavity-Fock-state superpositions by reinforcement learning exploiting measurement backaction,” Physical Review A, vol. 109, no. 2, p. 022609, 2024.
- [23] A. C. Doherty, S. Habib, K. Jacobs, H. Mabuchi, and S. M. Tan, “Quantum feedback control and classical control theory,” Physical Review A, vol. 62, no. 1, p. 012105, 2000.
- [24] K. Jacobs and D. A. Steck, “A straightforward introduction to continuous quantum measurement,” Contemporary Physics, vol. 47, no. 5, pp. 279–303, 2006.
- [25] H. M. Wiseman and G. J. Milburn, Quantum Measurement and Control. Cambridge University Press, 2009.
- [26] M. Van Otterlo and M. Wiering, “Reinforcement learning and Markov decision processes,” Reinforcement Learning: State-of-the-Art, pp. 3–42, 2012.
- [27] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602, 2013.
- [28] R. S. Sutton, D. McAllester, S. Singh, and Y. Mansour, “Policy gradient methods for reinforcement learning with function approximation,” Advances in Neural Information Processing Systems, vol. 12, 1999.
- [29] V. Konda and J. Tsitsiklis, “Actor-critic algorithms,” Advances in Neural Information Processing Systems, vol. 12, 1999.
- [30] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [31] B. Qi, Z. Hou, L. Li, D. Dong, G. Xiang, and G. Guo, “Quantum state tomography via linear regression estimation,” Scientific Reports, vol. 3, no. 1, p. 3496, 2013.
- [32] J. A. Smolin, J. M. Gambetta, and G. Smith, “Efficient method for computing the maximum-likelihood quantum state from measurements with additive gaussian noise,” Physical Review Letters, vol. 108, no. 7, p. 070502, 2012.
- [33] D. Hadfield-Menell, S. Milli, P. Abbeel, S. J. Russell, and A. Dragan, “Inverse reward design,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [34] A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning implementations,” Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021.
- [35] M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goulão, A. Kallinteris, M. Krimmel, A. KG et al., “Gymnasium: A standard interface for reinforcement learning environments,” arXiv preprint arXiv:2407.17032, 2024.
- [36] M. Mirrahimi and R. van Handel, “Stabilizing feedback controls for quantum systems,” SIAM Journal on Control and Optimization, vol. 46, no. 2, pp. 445–467, 2007.
- [37] D. M. Greenberger, M. A. Horne, and A. Zeilinger, “Going beyond bell’s theorem,” in Bell’s theorem, quantum theory and conceptions of the universe. Springer, 1989, pp. 69–72.
- [38] W. Dür, G. Vidal, and J. I. Cirac, “Three qubits can be entangled in two inequivalent ways,” Physical Review A, vol. 62, no. 6, p. 062314, 2000.
- [39] T. Monz, P. Schindler, J. T. Barreiro, M. Chwalla, D. Nigg, W. A. Coish, M. Harlander, W. Hänsel, M. Hennrich, and R. Blatt, “14-qubit entanglement: Creation and coherence,” Physical Review Letters, vol. 106, no. 13, p. 130506, 2011.
- [40] S. Kuang, G. Li, Y. Liu, X. Sun, and S. Cong, “Rapid feedback stabilization of quantum systems with application to preparation of multiqubit entangled states,” IEEE Transactions on Cybernetics, vol. 52, no. 10, pp. 11 213–11 225, 2021.
- [41] J. Zhang, Y.-x. Liu, R.-B. Wu, K. Jacobs, and F. Nori, “Quantum feedback: theory, experiments, and applications,” Physics Reports, vol. 679, pp. 1–60, 2017.
- [42] T. Xie, Y. Ma, and Y.-X. Wang, “Towards optimal off-policy evaluation for reinforcement learning with marginalized importance sampling,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [43] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [44] J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage estimation,” arXiv preprint arXiv:1506.02438, 2015.
- [45] X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,” ACM Transactions on Graphics (TOG), vol. 37, no. 4, pp. 1–14, 2018.