B \authorlist\breakauthorline4 \authorentry[ktokuda@icn.cce.i.kyoto-u.ac.jp]Kairi TokudanlabelA\MembershipNumber \authorentryRyoichi ShinkumaflabelB\MembershipNumber0001040 \authorentryTakehiro SatomlabelA\MembershipNumber1010972 \authorentryEiji OkiflabelA\MembershipNumber9414827 \affiliate[labelA]The authors are with the \EICdepartmentGraduate School of Informatics \EICorganizationKyoto University \EICaddressYoshida-honmachi, Sakyo-ku, Kyoto, 606-8501 JAPAN \affiliate[labelB]The author is with the \EICdepartmentFaculty of Engineering \EICorganizationShibaura Institute of Technology \EICaddressShibaura, Minato-ku, Tokyo 135-8548 JAPAN
Feature-based model selection for object detection from point cloud data
keywords:
deep learning, machine learning, object detection, point cloud, smart monitoringSmart monitoring using three-dimensional (3D) image sensors has been attracting attention in the context of smart cities. In smart monitoring, object detection from point cloud data acquired by 3D image sensors is implemented for detecting moving objects such as vehicles and pedestrians to ensure safety on the road. However, the features of point cloud data are diversified due to the characteristics of light detection and ranging (LIDAR) units used as 3D image sensors or the install position of the 3D image sensors. Although a variety of deep learning (DL) models for object detection from point cloud data have been studied to date, no research has considered how to use multiple DL models in accordance with the features of the point cloud data. In this work, we propose a feature-based model selection framework that creates various DL models by using multiple DL methods and by utilizing training data with pseudo incompleteness generated by two artificial techniques: sampling and noise adding. It selects the most suitable DL model for the object detection task in accordance with the features of the point cloud data acquired in the real environment. To demonstrate the effectiveness of the proposed framework, we compare the performance of multiple DL models using benchmark datasets created from the KITTI dataset and present example results of object detection obtained through a real outdoor experiment. Depending on the situation, the detection accuracy varies up to 32% between DL models, which confirms the importance of selecting an appropriate DL model according to the situation.
1 Introduction
Smart cities aim to provide services that improve the quality of our lives by combining various types of sensors, networks, and data processing technologies. Du et al. suggested that smart monitoring systems for smart cities will improve our living conditions in terms of comfort and safety [1]. In particular, a smart monitoring system that utilizes information acquired by three-dimensional (3D) image sensors such as a light detection and ranging (LIDAR) unit is expected to be an effective countermeasure against the increasing number of traffic accidents, which have become a problem in recent years [2].
Object detection is a task in computer vision that automatically detects objects as a rectangle or cuboid bounding box by using the data representing real space acquired by the image sensor as input. In recent years, object detection has been attracting attention in various fields, including robotics [3]. Object detection is also required from the perspective of smart monitoring, since it is essential to identify the position of each moving object (e.g., vehicles and pedestrians) in order to ensure safety on the road. The detection accuracy of moving objects impacts the performance of subsequent applications such as multi-object tracking [4].
The features of point cloud data acquired in a real environment are diversified due to different measurement situations. For example, in situations where relatively inexpensive sensors are used, or where sensors are installed at high altitudes, the density of points drops. This leads to a degradation of data quality. While various deep learning (DL) methods111In this paper, we refer to specific DL algorithms as DL methods, and inference models trained by the DL methods based on training data as DL models. for object detection have been developed and have shown competitive performances to date [5] [6] [7] [8] [9], the performances have typically been measured using datasets that consist of good quality data. Although several studies have provided simple comparisons of DL methods for object detection [10] [11], they do not consider data with incompleteness, such as low density of points and noise added to points. In terms of the no free lunch (NFL) theorem [12], it is difficult to imagine a DL model that would work well for all of the diverse data.
There are several works that consider rules for selecting the learning algorithms that handle simple tasks (such as classification) depending on the features of problems [13] [14]. However, no studies have addressed the selection of DL models for object detection. The algorithms of DL methods for object detection have a broad range of features, and each method can be classified according to which features it has. We need to clarify how the detection accuracies of DL models change when data acquired under adverse conditions are used and how to determine a suitable DL model for each situation accordingly in the field of object detection.
This paper proposes a feature-based model selection framework for object detection from point cloud data. The proposed framework creates various DL models using multiple DL methods with different features and then selects a model of the method with the most suitable features in accordance with the features of the point cloud data. In order to improve the detection accuracy for data with specific incompleteness, the proposed framework uses training data with pseudo incompleteness generated by two artificial techniques: sampling and noise adding. We report our comparison of the performance of multiple DL models using various data simulating measurement situations created from the KITTI dataset [15]. In addition, we present example results of object detection obtained through a real outdoor experiment. Our findings show that even simple features describing the algorithm briefly are capable of explaining the strengths and weaknesses of each model for each situation, which indicates that the concept of the feature-based model selection in the proposed framework is effective.
The main contributions of this paper can be summarized as follows.
-
•
We discuss the possible incompleteness of point cloud data and the features of detected objects. Then, we suggest that a DL method that provides high-accuracy object detection differs depending on types of objects and point cloud data, and that we need to use different DL methods according to the situation.
-
•
We propose a feature-based model selection framework for object detection from point cloud data. In the proposed framework, multiple DL models are created to deal with various situations. The proposed framework selects an appropriate DL method based on the size of the target object and the data quality, and then selects a DL model using training data whose degree of incompleteness is the closest to the inference data. In the proposed framework, training data with pseudo incompleteness is used to improve the detection accuracy of DL models for data with incompleteness.
-
•
The performance of the proposed framework is evaluated using the KITTI dataset and point cloud data acquired through outdoor experiments using actual equipment. These results confirm the necessity of using different DL methods according to the situation, the effect of adding pseudo incompleteness to the training data, and the effectiveness of the proposed framework.
The remainder of this paper is as follows. In Section 2, we review various DL methods for object detection from point cloud data, approaches to improve the performance of object detection using multiple DL methods, and data augmentation techniques. Section 3 presents the details of the proposed framework. In Section 4, we report the performance evaluations using the KITTI dataset. In Section 5, we discuss examples from an outdoor experiment. We conclude in Section 6 with a brief summary.
2 Related work
2.1 Object detection from point cloud data
To date, DL methods have been developed extensively to perform object detection. DL methods that use point cloud data acquired by 3D image sensors have been attracting attention recently, since point clouds have rich 3D information. There are also methods that use point clouds and 2D images as input simultaneously[16][17]. This paper assumes the situation where 2D images are not available and focuses on DL methods that use only point cloud data.
A wide variety of DL methods for object detection from point cloud data exists. Some of the algorithms share certain broad features, which can be used to roughly classify the methods into those with common features. In the following, we explain these features, referring to related DL methods. We summarize the DL methods in Table 1.
2.1.1 Number of stages
DL methods can be broadly divided into two-stage and one-stage methods depending on the number of stages in the architecture. In the two-stage methods, possible regions containing objects (generally called proposals) are generated on the basis of encoded features of input point clouds in the first stage. Then, in the second stage, the proposals are refined to generate the final bounding boxes. Shi et al. suggested that refining the 3D proposals in the second stage improves the detection performance [8]. In contrast, the one-stage methods estimate the bounding boxes directly. The one-stage methods are generally faster than the two-stage methods due to its simpler structure [18]. For this reason, the one-stage methods are often used to pursue real-time performance for applications, such as autonomous driving [5] [6].
2.1.2 Processing unit of point clouds
In 2018, Zhou et al. developed VoxelNet [19]. In a voxel-based process such as that used in VoxelNet, irregular point clouds are divided into units of 3D rectangular spaces, which are called voxels, and the features of the points in each voxel are generally aggregated and encoded. Then, a 3D convolutional neural network (CNN) is used to aggregate the voxel-wise features. Part-A2 net simply takes the average of the features of included points as the initial voxel-wise feature in the first stage [8]. The voxel-based process is generally computationally efficient due to the regular arrangement of voxels. Submanifold sparse convolution [20] was adopted to further speed up the process [5] [8] [21].
Lang et al. claimed that 3D convolution creates a bottleneck in the processing speed and developed PointPillars using 2D convolution as an alternative [6]. PointPillars divides point clouds into sets of vertical pillars and then encodes the features of each pillar using the features of the included points. BirdNet also divides the x-y plane into cells and encodes the features of each cell using the features of included points, such as the number of points [22]. The process of handling point clouds for each grid on the x-y plane is called the pillar-based process.
In contrast, the process of directly handling the raw point cloud without quantization is generally called the point-based process. After Qi et al. developed PointNet to directly manipulate raw point cloud data [23], point-based methods that use it and its variant, PointNet++, was developed [24]. In 2019, Shi et al. developed PointRCNN, which performs a point-based process using PointNet++ in all stages to avoid information loss due to quantization [7].
Some of the two-stage methods use different processing units for the first and second stages. PV-RCNN performs a voxel-based process similar to Part-A2 net in the first stage and then a point-based process using PointNet-based networks in the second stage [9]. In contrast, STD performs a point-based process using PointNet++ in the first stage and then a voxel-based process in the second stage [25]. On the other hand, P2V-RCNN adopts a point-to-voxel feature learning approach to improve detection performance, which takes advantage of both structured voxel-based and accurate point-based point cloud representations in the first stage [26].
2.1.3 Box generation strategy
There are two main ways to generate proposals or bounding boxes: an anchor-based strategy and an anchor-free strategy [27].
The anchor-based strategy can be generally divided into one-stage methods and two-stage methods. Both of them first tile a large number of preset anchors on the image, then predict the category and refine the coordinates of these anchors by one or several times, and finally output these refined anchors as detection results. Since two-stage methods refine anchors more times than one-stage methods do, the former ones have more accurate results while the latter ones have higher computational efficiency. In the anchor-based strategy, the region proposal network (RPN) head is adapted to the 2D feature map encoded by the previous convolution layer, and boxes are generated by using anchors for each object class that have been defined in advance [28]. To date, several methods including SECOND have used a single shot multibox detector (SSD)-like [29] architecture to build the RPN [5].
In contrast, the anchor-free strategy does not use an anchor box but rather generates boxes directly from foreground points in a bottom-up manner. Shi et al. suggested that this strategy is generally lightweight and memory efficient [8]. The anchor-free strategy directly finds objects without preset anchors in two different ways [27]. One way is to first locate several pre-defined or self-learned keypoints and then bound the spatial extent of objects. This type of anchor-free strategies is called keypoint-based methods. Another way is to use the center point or region of objects to define positives and then predict the four distances from positives to the object boundary. This kind of anchor-free strategies is called center-based methods. CenterNet3D achieves accurate bounding box regression using the corner attention module, which forces the CNN backbone to pay attention to the object boundaries for effective corner heatmap learning [21]. The anchor-free strategy is able to eliminate its hyper-parameters related to anchors and has achieved similar performance with the anchor-based strategy, making anchors more potential in terms of generalization ability.
| References | DL method | Number of stages | Point-based | Voxel-based | Pillar-based | Anchor-free | Anchor-based |
| Yan et al. [5] | SECOND | 1 | ✓ | ✓ | |||
| Lang et al. [6] | PointPillars | 1 | ✓ | ✓ | |||
| Shi et al. [7] | PointRCNN | 2 | ✓ | ✓ | |||
| Shi et al. [8] | Part-A2 | 2 | ✓ | ✓ | ✓ | ||
| Shi et al. [9] | PV-RCNN | 2 | ✓ | ✓ | ✓ | ||
| Zhou et al. [19] | VoxelNet | 1 | ✓ | ✓ | |||
| Wang et al. [21] | CenterNet3D | 1 | ✓ | ✓ | |||
| Beltrán et al. [22] | BirdNet | 2 | ✓ | ✓ | |||
| Yang et al. [25] | STD | 2 | ✓ | ✓ | ✓ | ||
| Li et al. [26] | P2V-RCNN | 2 | ✓ | ✓ | ✓ |
2.2 Ensemble learning
Ensemble learning is an approach that aims to improve performance by using multiple machine learning methods, which is said to enhance the generalizability [30]. In the field of object detection, box ensemble techniques simply mix the output boxes of each model so that there is only one box per object. Non-maximum suppression (NMS) and soft-NMS are already well used as a way to keep only the most likely correct box from among multiple boxes representing the same object [31]. Solovyev et al. developed Weighted Boxes Fusion, in which the output boxes of each model are weighted and fused in accordance with their scores [32]. Casado et al. claimed that box mixing blindly risks many false positives, and devised the box ensemble method which uses different voting strategies and is independent of the detector’s algorithm [33]. Since these ensemble methods need to obtain results from multiple models, the computation cost increases with the number of models used. However, due to the limited computational resources of most edge devices, there is a limit to the number of models that can be handled at the same time, which makes it difficult to take full advantage of the ensemble learning. In our framework, the edge device only uses one model, so only the minimum number of resources is required.
2.3 Data augmentation
The technique of adding modified data to the training data is called data augmentation. Shorten et al. summarized the data augmentation for DL as a way to avoid overfitting and to train models with high generalizability [34]. However, the more training data are added, the more training time and additional memory are required. There are several data augmentation techniques that add some degraded data to the training data for solving the bias of training data [35] [36] [37]. Ma et al. developed an adversarial data augmentation method, PointDrop, which jointly optimizes the data augmenter and detector to improve robustness for point cloud data with a small number of points [37]. Thus, the use of degraded data as training data is common in the context of data augmentation. Differently from such data augmentation, our framework uses only data with pseudo incompleteness in order to deal with the situation where the inference data consists only of data with incompleteness, such as low density of points and noise added to points.
3 Proposed framework
3.1 System model
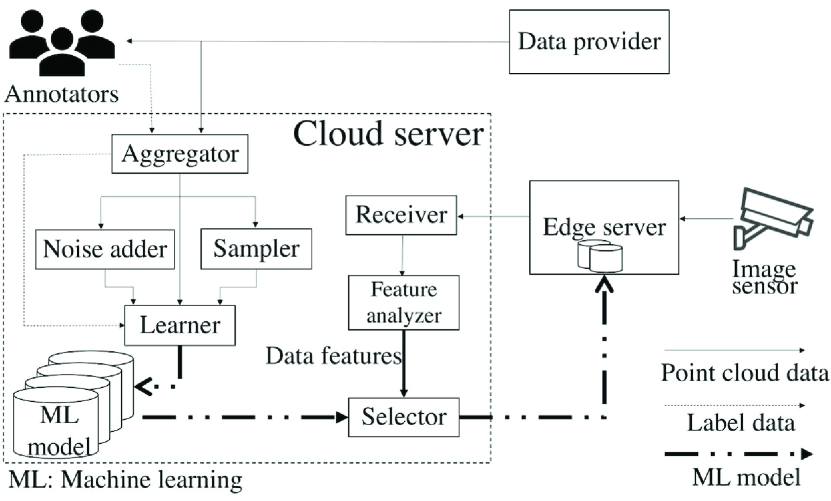
Fig. 1 shows the block diagram of the system model assumed in the proposed framework. The main components of this system are a cloud server, a 3D image sensor, and an edge server. The cloud server consists of an aggregator to collect training data, a sampler to thin out point clouds, a noise adder to add artificial noise to point clouds, a learner to train DL models, a receiver to receive point cloud data from the edge server, a feature analyzer to analyze the features of the point cloud, and a selector to choose a suitable DL model.
This system assumes that the 3D image sensor is installed at a fixed position near specific intersections or roads to acquire point cloud data. The 3D image sensor sends the acquired point cloud data to the edge server in the form of streaming data. In the inference stage, the point cloud data are input to a DL model placed on the edge server for object detection.
On the cloud server, multiple DL models are trained and the proposed framework selects a suitable DL model to be placed on the edge server. The point cloud data used for training the DL models are not the data acquired by the 3D image sensor in this system but rather high-quality data acquired from anywhere in the world. The data provider represents the source of such training data, and the aggregator of the cloud server receives the point cloud data from the data provider in the training stage. At the same time, the aggregator receives the label data necessary for training the DL models from the annotators, who manually create accurate 3D label data using any data useful for labeling, such as 2D image data with color in addition to point cloud data. Then, the aggregator links the point cloud data and label data to each other and stores them. Next, the aggregator replicates the training data and sends them to the sampler and the noise adder, in order to artificially produce data with low density of points and with noise, respectively. Then, the learner receives multiple sets of training data and combines them with multiple DL methods to train multiple DL models.
In the beginning or middle of the inference stage, the edge server sends the point cloud data acquired by the 3D image sensor and target data that indicate which class of objects is to be detected to the cloud server first. On the cloud server, the receiver receives the point cloud data and passes them to the feature analyzer. The feature analyzer analyzes the features of the point clouds of the received data (inference data), such as the spatial distribution of points, compares them with those of the original training data, and sends the comparison result (data features) to the selector. Then, the selector picks a suitable DL model based on the target data and the data features according to the predetermined procedure and sends it back to the edge server.
We summarize the operations of the training and inference stages in Algorithms 1 and 2, respectively.
3.2 Factors for multi-model selection
This section explains the details of the feature-based DL model selection, which is the key component of the proposed framework. The features of the point cloud data acquired in the real world are diversified due to various factors. We focus here on three factors: object class, density of points, and noise. In order to deal with these factors, the proposed framework uses multiple models of methods with different features and selects them appropriately, rather than using only a single model. In the following part, for each factor, we discuss which model should be selected in accordance with the features.
3.2.1 Object class
In an actual intersection of roads, various types of moving objects can be expected to appear; the targets of smart monitoring systems include not only cars on the road but also pedestrians and cyclists. The biggest difference between these objects is their size. The size of pedestrians and cyclists is naturally smaller than that of cars, and even within the category of cars, the size of large vehicles such as buses and trucks is quite different from that of private cars. The smaller the object size is, the physically smaller the number of points belonging to the same object is, and the fewer features there are to represent each object. Therefore, small-size objects are generally more difficult to detect. We assume that each object has a different algorithm that would be most effective for detection. The proposed framework is designed to select the most suitable model for each object.
The difference described above stems from the difference in the distance between the object center and the point clouds on the object surface. Due to the nature of point clouds acquired by 3D image sensors, they are always distributed on the surface of each object. In the anchor-free strategy, which generates the boxes (i.e., proposals) directly from the foreground points, the farther the distance between each foreground point on the object surface and the center of the ground-truth box is, the larger the center regression error is. Shi et al. [8] presented a regression method to reduce this effect, but it is still not suitable for detecting large-size objects. For small-size objects, the center regression error is small and the anchor-free strategy works fine. On the other hand, the anchor-based strategy typically has a high detection accuracy and a small distance between the center of the anchor and the ground-truth box, since the boxes are generated by fitting the anchor all over the entire space. Therefore, the anchor-based strategy is suitable for detecting large-size objects. However, for small-size objects, there is a possibility that the objects may be overlooked, since the box is not generated directly from the foreground point in the anchor-based strategy. Thus, it is reasonable to select the anchor-based strategy when targeting large-size objects and the anchor-free strategy when targeting small-size objects. On the basis of the above, the proposed framework first selects the box generation strategy in accordance with the size of the object to be detected.
3.2.2 Density of points
We next focus on the density of points as a spatial distribution, which is one of the features of the point cloud data. The density of points depends largely on the performance and set position of the 3D image sensor used for measurement. For example, according to the product guide, the Velodyne HDL-64E LIDAR has 64 vertical channels and a horizontal resolution of 0.08, and can acquire up to 1,300,000 points per second [38]. However, a 3D image sensor with a performance this good is still expensive to install and cannot be used easily. In contrast, according to the product guide, the relatively inexpensive Velodyne VLP-16 LIDAR has 16 vertical channels, a horizontal resolution of 0.1, and can acquire up to 300,000 points per second [38]. In this case, the difference in the number of vertical channels is particularly big, and the density of points is proportionally dropped to a quarter. In addition, even when the same 3D image sensor is used, the density of points physically drops when the set position is at a high altitude. Thus, such low density of points is a factor of the incompleteness of data addressed in this paper.
Drop in density of points decreases the detection accuracy. A possible specific cause of this is the poorness of spatial features. Since spatial features are determined by the features of points in the vicinity, the fewer points there are, the poorer the spatial features needed to determine the class and location of objects are. This leads to difficulty with object detection, the extent of which depends on the processing unit of the point clouds adopted by each method. The voxel-based process is generally considered effective and efficient for feature learning and box generation [8]. However, the voxel-based (and pillar-based) process might not work in a situation where there are few points and each point is highly important. This is because the quantization of points may result in the loss of valuable features. In contrast, the point-based process to handle each point directly can use all the valuable points as they are, and thus makes good use of these features. Therefore, we assume that models created by the method that adopts the point-based process are robust against the drop in density of points. On the basis of the above, the proposed framework selects the processing unit of point clouds in accordance with the spatial distribution of the inference data.
3.2.3 Noise
The point clouds acquired by a 3D image sensor can often contain noise. The point clouds generated by sensors using image-based 3D reconstruction techniques, which are often used in indoor measurements, have a lot of noise and outliers mainly due to matching ambiguities or image imperfections[39]. On the other hand, the time-of-flight (TOF) sensor, which can be used outdoors, generates point clouds by directly measuring the distance of objects, and thus does not generate noise due to the former factor. However, even with this type of sensor, which is assumed to be used in this system, noise may occur due to environmental issues such as illumination, material reflectance, and so on [40]. TOF sensors can basically be divided into two types: indirect TOF (ITOF) sensors and direct TOF (DTOF) sensors. LIDARs are categorized into the DTOF sensors that can measure long distances. In addition, there are different types of LIDAR, such as a scanning LIDAR and a flash LIDAR, with different measurement methods and different tolerance to noise caused by environmental issues[41]. As described above, the severity of the noise varies depending on the mechanism of the sensor and environmental issues. When the noise is severe, the accuracy of object detection also generally decreases. Thus, such noise added to points is the other factor of the incompleteness of data addressed in this paper.
A possible specific cause of noise is the change in the relationship between each point. Noise shifts the coordinates of each point from original places, which changes the distribution of point clouds. This leads to inaccuracy of spatial features and difficulty of object detection, while the effect of this also depends on the processing unit of point clouds adopted by each method. The point-based process, which processes each point one by one, picks up all the changes in the relationship between points, so the effect of inaccuracies in spatial features is accentuated. On the other hand, voxel-based and pillar-based processes with quantization can mitigate these effects, since they interrupt the process of taking the average or maximum value of the features of included points during feature aggregation. Therefore, in contrast to the case of the low density of points, the models that adopt the voxel-based or pillar-based process are more robust against the noise than those that adopt the point-based process, which is taken into account in the proposed framework.
3.2.4 Producing data with incompleteness for DL model creation
Machine learning, especially supervised learning, is built on the premise that the training data are sufficient representations of the inference data [42]. Therefore, the quickest way to improve the performance of a DL model is to prepare training data according to the spatial distribution of the inference data. The best way is of course to use the point cloud data acquired by the 3D image sensor in Fig. 1 as the training data. However, the labeling process, which is essential for training, is costly and time-consuming; generally, manual labeling has become a serious bottleneck as collecting and storing data have become easier and large amounts of training data are required [43]. In comparison, it is much easier to label only one good quality dataset and then directly manipulate the dataset to reproduce the incompleteness. Therefore, the proposed framework uses the training data for reproducing the incompleteness, such as low density of points and noise. In this way, the proposed framework can avoid collecting and labeling the training data on its own before installing the system, which significantly reduces the time spent on preparing the training data. The training time itself depends on the training time of the DL method selected by the proposed framework.
Mukhaimar et al. suggested that training on data with certain inaccuracies can produce models that are resistant to those inaccuracies [44]. On the other hand, they also noted that data inaccuracy is generally unpredictable and it is not advisable to use models that focus on specific inaccuracy. However, it is not a problem to prepare a model specialized for each incompleteness in the proposed framework, for two reasons: 1) as mentioned in Section 3.2.2, the density of points is easy to predict since it is caused by the performance of the 3D image sensor and the installation position, and 2) in this system, the model placed in the edge server is not fixed, but is selected based on the analysis of which factor of incompleteness exists.
3.3 DL model selection procedure
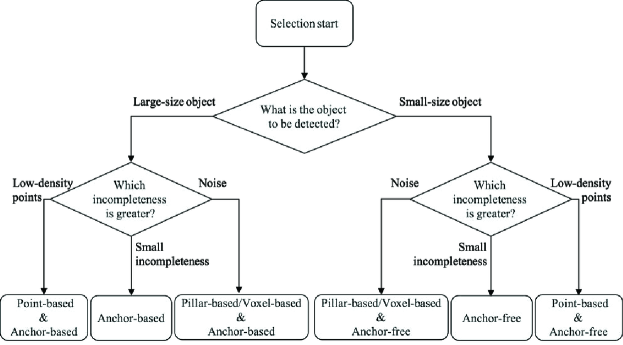
This section explains the procedure for selecting the model of a suitable DL method to be sent to the edge server in the proposed framework, using the flowchart in Fig. 2. As described in Section 3.1, the selector selects a suitable DL method based on the features of the inference data analyzed by the feature analyzer. In general, DL models perform object detection in the following steps: extracting areas where objects may exist, classifying object categories according to predefined confidence thresholds, and refining their locations. As a result, information about the category and location of each object is output. With this, before selecting a DL model, it is necessary to decide the target object manually, i.e., which object is to be detected, though it is possible to change it during system operation. Then, the proposed framework uses a selected DL model to identify the location of the determined target object.
In Fig. 2, for DL-method selection, the first branch regarding the box generation strategy occurs depending on the size of the target object. Specifically, it is narrowed down to DL methods that adopt the anchor-based strategy for large-size objects and the anchor-free strategy for small-size objects. Once that is done, the next branch regarding the processing unit of point clouds occurs depending on the type and degree of incompleteness of the inference data. Specifically, it is narrowed down to DL methods that adopt the point-based process when the density of points is low, and the pillar-based or the voxel-based process when noise is severe. However, it should be noted that, if the degree of incompleteness is small or there is a trained model using data with incompleteness close to the inference data, first, a DL method is selected only in accordance with the size of the target object. Then, at the next branch, the option after the arrow of ‘small incompleteness’ is selected. After selecting the DL method, DL model selection is performed among the DL models trained by the selected DL method. At this time, the DL model using the training data which has the closest degree of incompleteness to the inference data is selected.
The detection time of the DL model depends on the DL method used for training. Therefore, the maximum detection time of the proposed framework is the slowest detection time among the candidate DL methods. If there is a requirement for the detection speed, the user needs to prepare multiple DL methods whose detection speed satisfies the requirement, and select one of them using a modified flowchart, which has an additional branch by detection speed in the first stage of Fig. 2.
The flowchart in Fig. 2 helps us to determine which DL method should be used in accordance with the target object and the inference data. In reality, to implement DL-method selection based on this flowchart, we need to design quantitative selection criterion, i.e., which type of objects is categorized into large- or small-size object, what density of points is high or low, what level of noise is severe or not, and so on. The performance evaluation presented in Section 4 suggests how to design such selection criterion. In addition, these evaluation results reveal the difference in detection accuracy for each feature and ensure the validity of the flowchart in Fig. 2.
3.4 Discussion about feature combination
As the proposed framework tries to do, it is common in the field of object detection to use an appropriate DL method for a specific purpose of application, e.g., car detection. To this end, so far we discussed the appropriate feature of DL method for each feature of the point cloud data. On the other hand, it may be possible to take an approach that combines these features to build one DL method with multiple purposes of application. In this regard, however, it should be noted that some features are difficult to combine in one method at the same time. For example, in terms of processing units of point clouds, point-based and pillar-based processes have opposite features in terms of quantization granularity. Future research is awaited to examine whether their strengths will be compatible or cancel each other out when they are combined to expand the range of applicable point cloud data. We believe that it is worthwhile to combine the features of DL methods based on the above discussion in order to build one appropriate DL method for a specific purpose of application (e.g., car detection in noisy point cloud data).
4 Evaluations
This section presents our evaluations that show a suitable model varies depending on the measurement situation, in order to demonstrate the effectiveness of the proposed framework.
4.1 DL methods
In this evaluation, we compared the detection performance of PointRCNN [7], Part-A2 net [8], PV-RCNN [9], SECOND [5], and PointPillars [6]. For Part-A2 net, two frameworks are provided that adopt anchor-based and anchor-free box generation strategies, respectively; we treat them as two distinct methods denoted as Part-A2-anchor and Part-A2-free, respectively, following Shi et al.’s work [8]. The features of the above six methods are summarized in Table 2. We adopt the six methods to exhaustively cover the features of DL methods to demonstrate the effectiveness of the proposed feature-based model selection framework. We consider that the evaluation using these six methods can capture the impact of DL method features on detection accuracy since the architectures adopted in these six methods are also representative ones commonly adopted in many of the later DL methods (e.g., voxel-based Region Proposal Network in SECOND [5]). Note that these features are broad categories; having the same features does not necessarily mean that the algorithm is exactly the same. For example, although PointRCNN and PV-RCNN both perform a point-based process in the second stage, PointRCNN applies PointNet++ to raw point clouds in the same proposal simply to aggregate point-wise features, while PV-RCNN uses PointNet to aggregate the features of surroundings key points into grid points in each proposal. Among these six methods, Part-A2-free has the longest detection time, which is average 0.35 seconds per frame, as shown in [45]; the maximum detection time of the proposed framework is about 0.35 seconds per frame in this case.
| DL method | Features | ||
|---|---|---|---|
| First stage | Second stage | Box generation strategy | |
| PointRCNN | Point-based | Point-based | Anchor-free |
| Part-A2-free | Voxel-based | Voxel-based | Anchor-free |
| Part-A2-anchor | Voxel-based | Voxel-based | Anchor-based |
| PV-RCNN | Voxel-based | Point-based | Anchor-based |
| SECOND | Voxel-based | – | Anchor-based |
| PointPillars | Pillar-based | – | Anchor-based |
4.2 Dataset
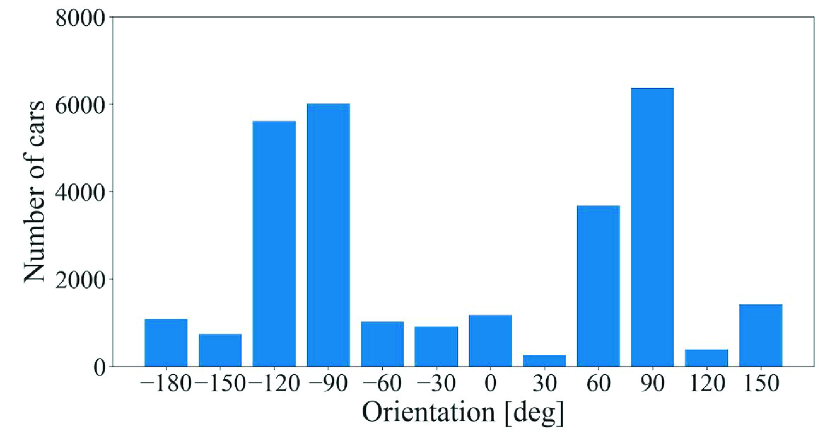
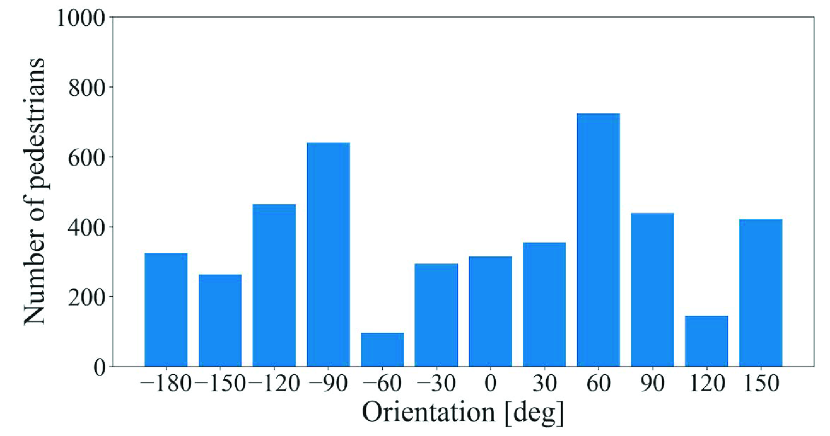
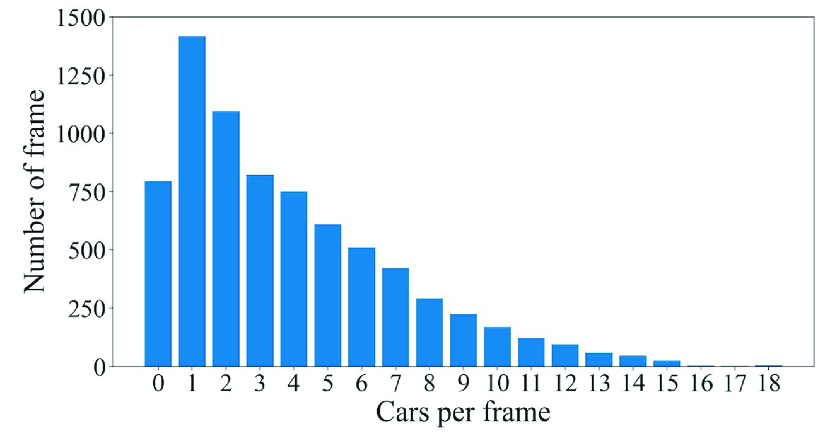
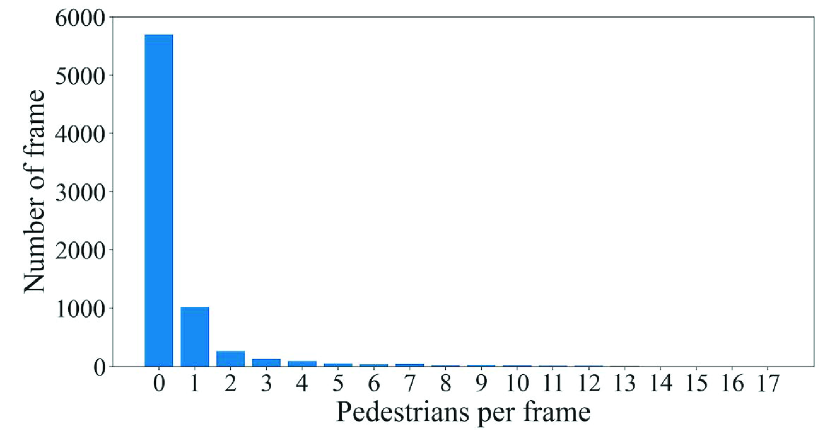
We utilized the KITTI dataset [15] in this evaluation, which is often used to evaluate 3D object detection for autonomous driving. This dataset contains a training sample of 7481 frames and a test sample of 7518 frames. We used the training sample in this evaluation, as only the training sample provides the label data. The training sample is further divided into a training split of 3712 frames and a validation split of 3769 frames. We use the training split to train DL models and the validation split to evaluate the detection accuracy.
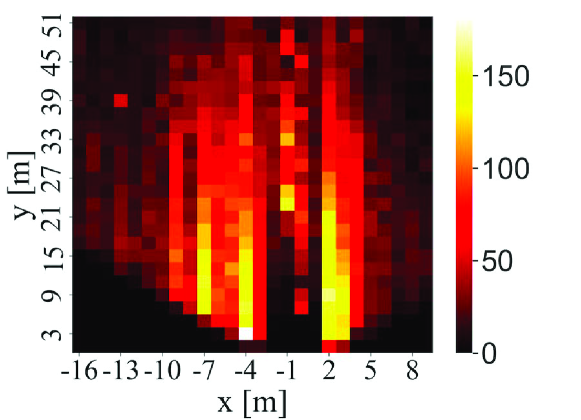
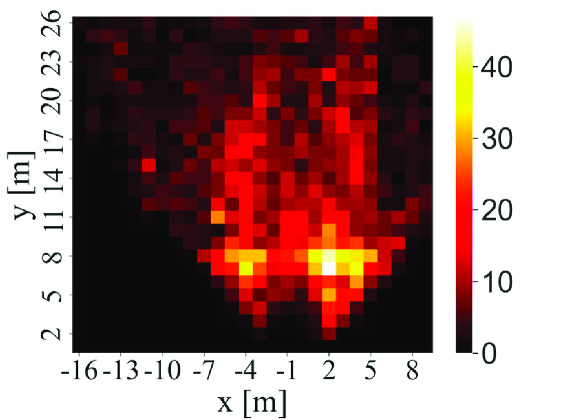
The point cloud data included in this dataset were acquired by a Velodyne HDL-64E LIDAR on the roof of a car while driving around a city in Germany. Therefore, this dataset is not time-series data that have been continuously acquired at a particular location. In addition, this dataset has a variety of occurrence patterns of objects. According to [15], the frames in this dataset are selected so that it can be a diverse dataset with high entropy in the distribution of object orientation and number of non-occluded objects. Figs. 3, 4, and 5 show the distributions of objects in terms of positions, orientations, and the numbers of objects, respectively, appearing in the training sample of 7481 frames. In Fig. 3, we can see that objects are not only gathered on the lane or sidewalk, but also spread out to the front left and right. In Fig. 4, we can also see that this dataset contains objects of various orientations, not limited to the orientation along the lane and sidewalk (i.e., and ). Fig. 5 shows that the distribution of the number of objects per frame has a wide tail. By using such a dataset to train the DL models, it is possible to generate a general model that can be applied to any road or intersection as it is, rather than a model specific to a certain location.
4.3 Model implementation
This section gives specific explanations about training the DL models. We prepared training data with pseudo incompleteness, as discussed in Section 3.2.4. Here, we explain the sampling schemes to drop the density of points in Section 4.3.1, the way of adding noise to points in Section 4.3.2, and the details of the training, including the various parameters we used, in Section 4.3.3.
4.3.1 Sampling of training data
In this evaluation, two sampling schemes were used to reproduce the drop in density of points. First, a brief explanation of each scheme is given, followed by a discussion of the differences between the two and the reasons for their adoption.
Voxel Grid Filter: A commonly used scheme for sampling is the Voxel Grid Filter included in the point cloud library (PCL) [46]. This scheme first creates a 3D voxel grid by dividing the entire space into voxels of the specified size. After that, the average of each feature (x-y-z coordinates and intensity) of the points in the same voxel is calculated. Finally, all points in the voxel are deleted and a point with the previously calculated features is added in their place. As a result, there is one point at the centroid of each voxel.
Uniform Sampling: Another sampling scheme is Uniform Sampling, which is also included in the PCL library. This scheme is the same as the Voxel Grid Filter up to the stage of creating the 3D voxel grid. The difference is that, among the points included in the same voxel, only a point with the shortest distance to the center coordinate of the voxel is kept.
Discussion about sampling: Both Voxel Grid Filter and Uniform Sampling are capable of uniformly downsampling the entire point cloud. In general, Voxel Grid Filter is used for point cloud downsampling to lighten the processing. The advantage of this filter is that it does not affect the overall spatial distribution much, though it has the disadvantage of causing points to appear in locations where they should not. This is similar to the effect of noise, which means that a factor other than density of points may be involved. For this reason, our evaluation also uses Uniform Sampling, which leaves the originally existing point cloud for one point per voxel.
For simplicity, we used the number of points contained in each frame as the density of points of that frame. By setting the same voxel size for the two sampling schemes, the ratio of the number of points before sampling to after sampling (hereafter “normalized number of points”) can be made equal in each frame. In this evaluation, three patterns with different lengths of one side of the voxel were prepared: 10 cm, 20 cm, and 40 cm. Due to the nature of the sampling schemes, while the normalized number of points per frame varied widely, the average values for all frames were about 0.478, 0.263, and 0.123, respectively. Hereafter, the models trained on the sampled data are called “Voxel Grid 1/2 model,” “Voxel Grid 1/4 model,” “Uniform 1/8 model,” etc. by approximating the normalized number of points as described above. We did not prepare a Voxel Grid 1/8 model for PV-RCNN or Part-A2-anchor, since they could not be trained due to program settings.
4.3.2 Adding noise to training data
Noise in point clouds generated by 3D image sensors is typically modeled as additive white Gaussian noise with mean 0 [40][47]. Therefore, the noise added to the training data is also Gaussian noise. In this evaluation, data with two patterns of Gaussian noise were prepared, where the mean is 0 and the standard deviation is 0.04 and 0.08. The models trained with each pattern are called “Noise 0.04 model” and “Noise 0.08 model,” respectively.
4.3.3 Training details
A selection of the training parameters addressed here is shown in Table 3. Basically, these parameters and all other parameters were determined according to the settings of OpenPCDet [48]. Some slight changes to batch size were made to match the performance of the graphics processing unit (GPU) used (single NVIDIA GeForce RTX 2070 GPU with 8G memory). While seven models with different ways of sampling were prepared (refer to Section 4.3.1) for each method, the same values are set to all the parameters for each model.
| DL method | Training parameters | ||
|---|---|---|---|
| Batch size | Leaning rate | Epochs | |
| PointRCNN | 2 | 0.01 | 80 |
| Part-A2-free | 4 | 0.003 | 80 |
| Part-A2-anchor | 2 | 0.01 | 80 |
| PV-RCNN | 1 | 0.01 | 80 |
| SECOND | 4 | 0.003 | 80 |
| PointPillars | 4 | 0.003 | 80 |
4.4 Evaluation method
The KITTI dataset contains multiple moving objects, including cars, vans, trucks, trams, pedestrians, and cyclists. Among them, we focus on detecting cars, pedestrians, and cyclists in this evaluation. This is because these objects are commonly used as targets for performance evaluations using this dataset, as used in [6] [7]. Note that the proposed framework can be applied for other objects since it makes decisions based on the size of the object.
We use Average Precision (AP) with a rotated 3D Intersection over Union (IoU) threshold of 0.7 for cars and 0.5 for pedestrians and cyclists as the evaluation metric, which is also used in the KITTI benchmark [49]. Note that KITTI has several evaluation benchmarks, such as 3D, BEV, and AOS, among which this evaluation uses the 3D. While there are several ways to calculate AP [50], we chose the type that calculates it based on 40-point recall positions, as in [51].
Sampling and adding noise to the validation data are also performed to simulate various measurement situations. Mukhaimar et al. [44] used Random Sampling to reduce the number of points to evaluate the robustness of DL methods for 3D shape recognition for low density of points. Similarly, this evaluation used Random Sampling to reproduce the data with low density of points with a normalized number of points of 0.5, 0.25, and 0.125. For noise, Gaussian noise with mean 0 was used as in Section 4.3.2. This evaluation reproduced the data with Gaussian noise with standard deviations of 0.02, 0.04, 0.06, 0.08, and 0.1.
4.5 Results
This section reports the evaluation results of each model for data simulating various measurement situations. In the following, the models trained on the original training data without sampling are called the “Original model,” and the original validation data are called the “original data.” Note that all accuracies in Figs. 6 to 8 are results of the moderate class, which is the class of detection difficulty defined by the KITTI benchmark.
4.5.1 Comparison of models created by different DL methods for each object class
| Car | Pedestrian | Cyclist | |||||||
| DL method | Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard |
| PointRCNN | 89.3 | 80.1 | 78.0 | 61.8 | 54.6 | 47.9 | 92.4 | 72.8 | 68.9 |
| Part-A2-free | 91.6 | 80.0 | 77.8 | 68.2 | 62.1 | 55.9 | 88.7 | 72.9 | 68.9 |
| Part-A2-anchor | 92.3 | 82.2 | 79.8 | 61.6 | 53.0 | 47.2 | 90.2 | 72.7 | 68.7 |
| PV-RCNN | 92.2 | 82.8 | 80.5 | 55.7 | 48.1 | 44.1 | 88.4 | 72.3 | 67.8 |
| SECOND | 88.4 | 78.8 | 75.8 | 52.4 | 47.0 | 42.6 | 81.9 | 66.8 | 62.1 |
| PointPillars | 86.7 | 75.7 | 72.6 | 50.4 | 43.7 | 39.0 | 82.1 | 62.9 | 59.0 |
Table 4 summarizes the detection accuracy of the Original model of each method using the original data. The methods in the third and fourth rows are the ones that adopt the anchor-free strategy, and the others are the ones that adopt the anchor-based strategy. When we look at the bold numbers representing the maximum value in each column, it is clear that the anchor-based strategy was superior for detecting cars, which are large-size objects, and the anchor-free strategy was superior for detecting pedestrians and cyclists, which are small-size objects. This result confirms that the DL method that achieves the highest detection accuracy changes depending on the target object size, and that the proposed framework, which selects the box generation strategy in accordance with the size of the object to be detected, works effectively.
4.5.2 Comparison of models created by different DL methods for density of points
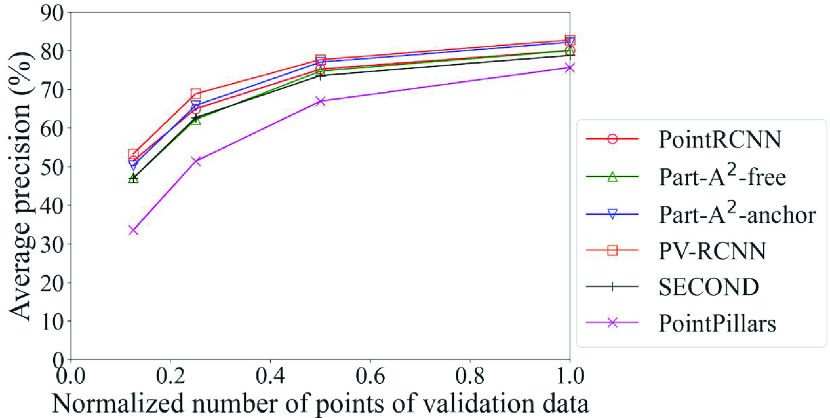
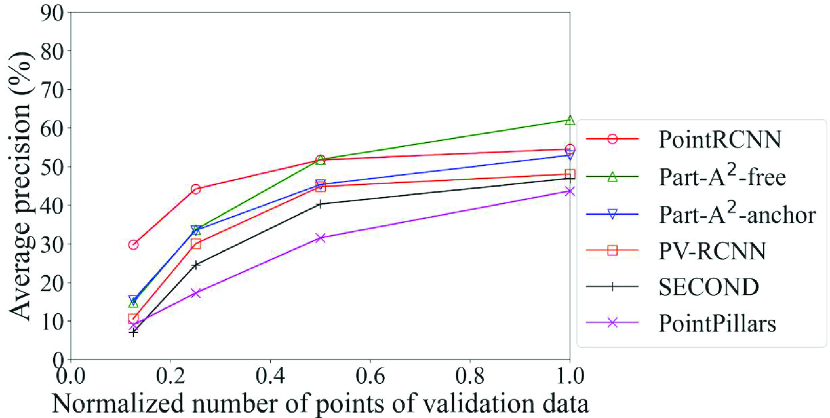
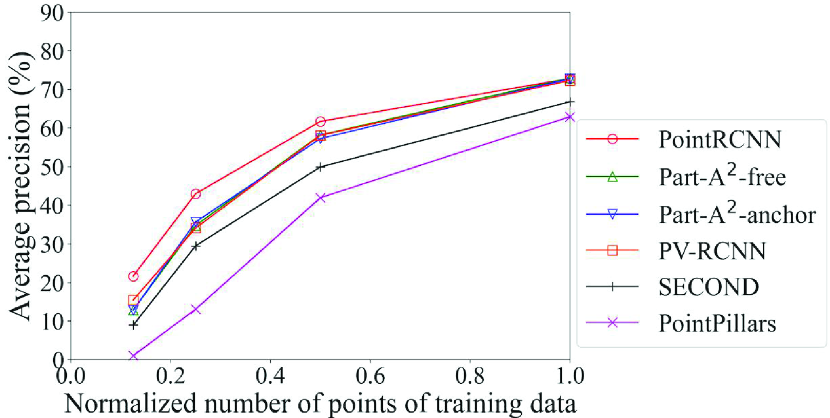
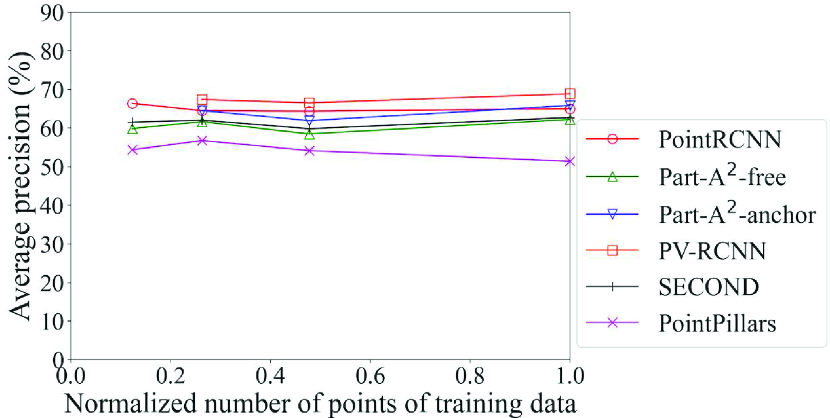
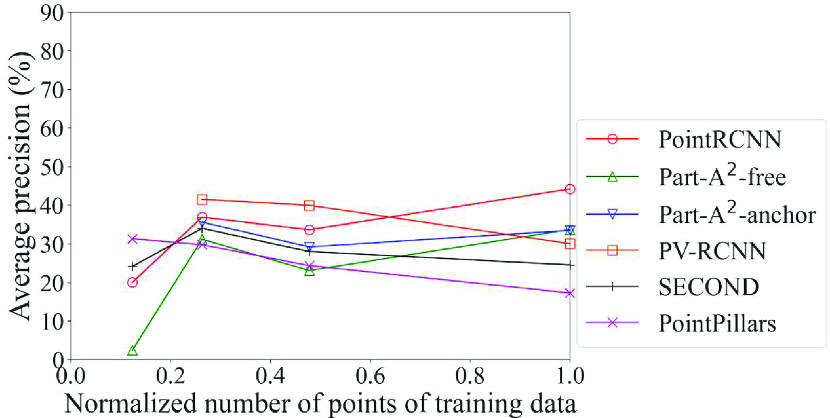
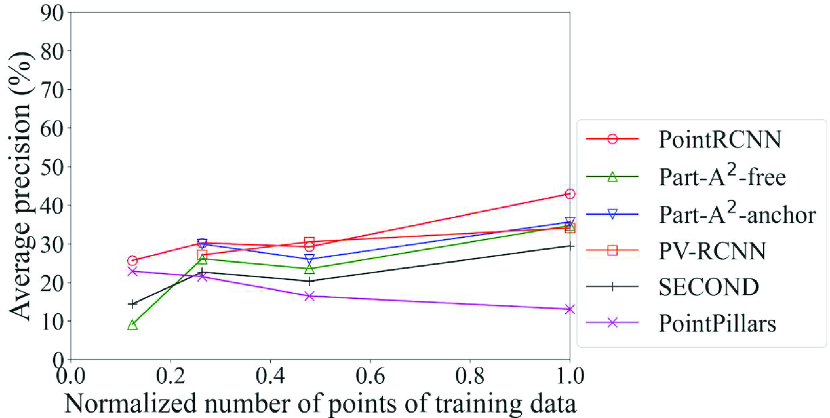
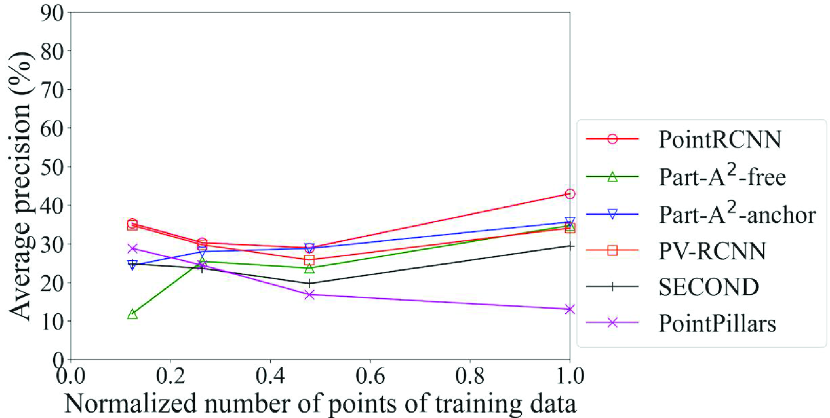
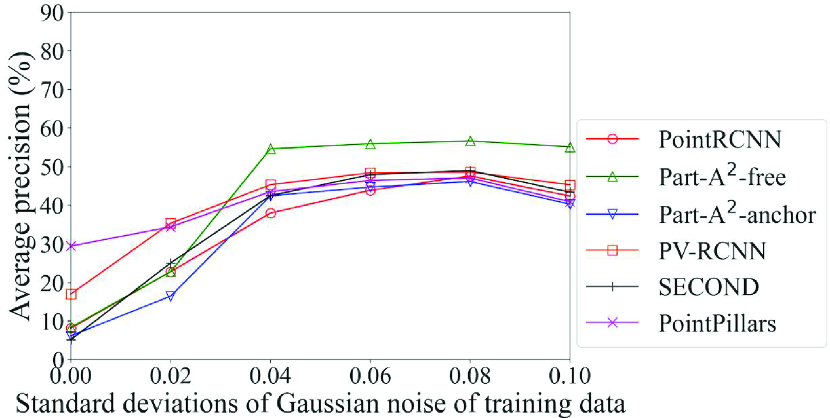
Fig. 6 shows the detection accuracy of the Original models of each method for density of points. Two of the six methods, PointRCNN and PV-RCNN, adopt the point-based process. We can see here that the accuracy of the methods that adopt the point-based process was higher than the others in all classes for data with fewer points, especially for data with the normalized number of points of 0.25 and 0.125. For example, the accuracy of car detection for data with the normalized number of points of 0.125 can differ by up to 20% (PointRCNN with point-based process vs. PointPillars with pillar-based process). In contrast, the accuracy of the methods that adopt the voxel-based or pillar-based process decreased sharply. Especially for pedestrians and cyclists, we can see that Part-A2-free, which had the maximum accuracy for the original data, was overtaken by the methods that adopt the point-based process as the drop in density of points became more severe. This result confirms that the DL method that achieves the highest detection accuracy changes depending on the density of points, and that the proposed framework, which selects the processing unit of point clouds in accordance with the spatial distribution of the inference data, works effectively. In addition, since PointRCNN adopts the anchor-free strategy and PV-RCNN adopts the anchor-based strategy, it is confirmed that the selection of box generation strategy by object size (described in Section 4.5.1) is compatible even for data with low density of points.
4.5.3 Comparison of models created with different sampling rates
| DL method | Car | Pedestrian | Cyclist |
|---|---|---|---|
| PointRCNN | Voxel Grid 1/8 | Original | Original |
| Part-A2-free | Original | Original | Original |
| Part-A2-anchor | Uniform 1/4 | Voxel Grid 1/4 | Original |
| PV-RCNN | Uniform 1/4 | Voxel Grid 1/4 | Uniform 1/8 |
| SECOND | Original | Voxel Grid 1/4 | Original |
| PointPillars | Uniform 1/4 | Uniform 1/4 | Uniform 1/8 |
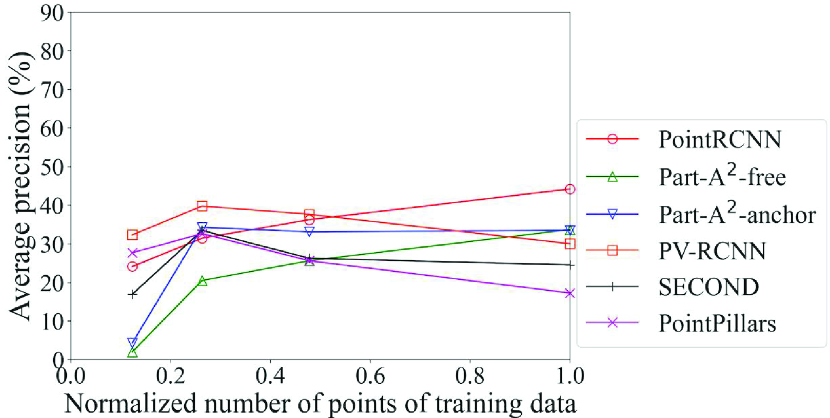
Figs. 7 and 8 show the detection accuracy of models created with sampling data (sampling models) for data with low density of points. Fig. 7 is related to the Voxel Grid models and Fig. 8 is related to the Uniform models, both using the validation data with the normalized number of points of 0.25. Table 5 summarizes the models with the maximum accuracy for each method and each class. As we expected, basically, the accuracy is improved by bringing the normalized number of points in the training data closer to that of the inference data (0.25 in this case). It is an exception that, for the methods in the second and third rows that adopt the anchor-free strategy, the Original model achieved the maximum accuracy in most cases. This is because this strategy generates the boxes directly from the foreground points; the benefit of making the spatial distribution of the training data similar to the inference data was small. When we look at the detection accuracy of cars of the models created by methods using the anchor-based strategy in Figs. 7a and 8a, i.e., Part-A2 net, PV-RCNN, SECOND, and PointPillars, we see that the Uniform model achieved the maximum accuracy in three out of four methods, while the Voxel Grid model had lower accuracy than the Original model in three out of four methods. These results confirm that, basically, the selection procedure in the proposed framework can work effectively. They also suggest that the Uniform model is used for the large-size objects for which the anchor-based strategy is effective, while the Original model is used for the small-size objects for which the anchor-free strategy is effective.
Here, the effect of the proposed framework is reviewed in detail. Our proposed framework is intended to use the appropriate DL model depending on the situation. Therefore, we refer to the use of a single DL model for all situations as the benchmark for comparison. As an example, let the PointRCNN Original model, which has the highest average precision for pedestrians and cyclists in the original data in Table 4, be the DL model used in the benchmark. For example, in the detection of cars for data with low density of points shown in Fig. 8a, the proposed framework selects PV-RCNN according to the flowchart in Fig. 2. In this case, the proposed framework improves the average precision by 4.5% compared to the benchmark.
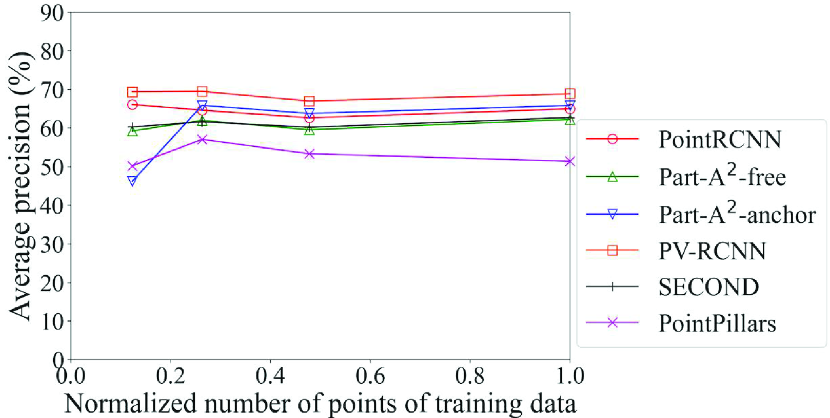
4.6 Model comparison for data with noise
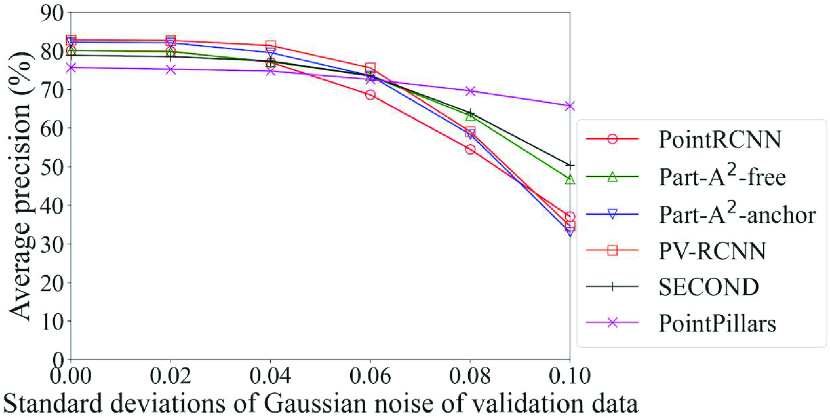
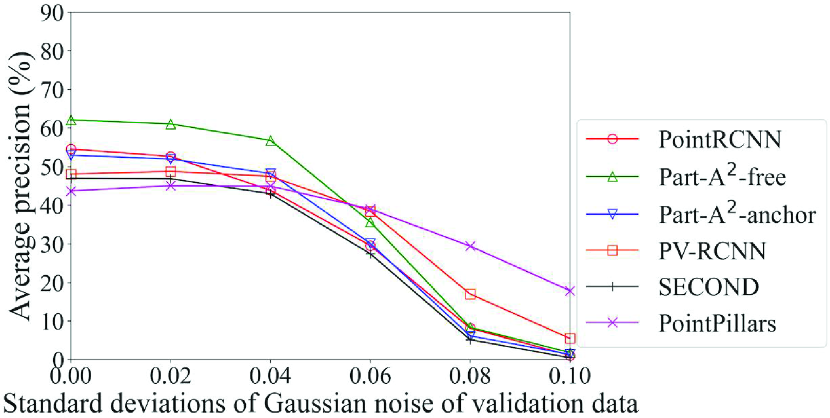
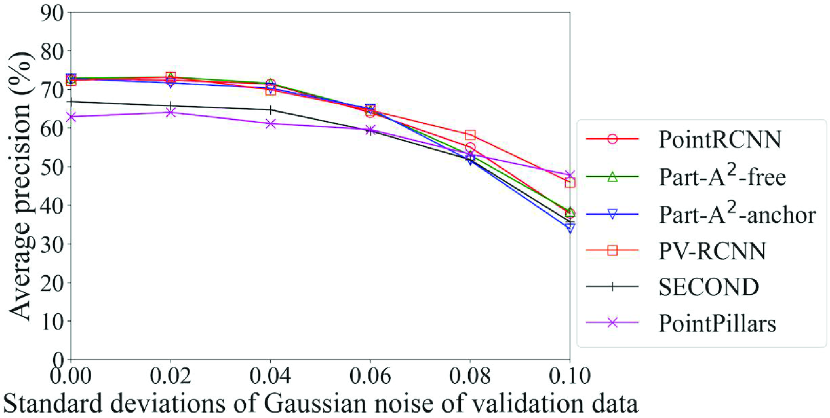
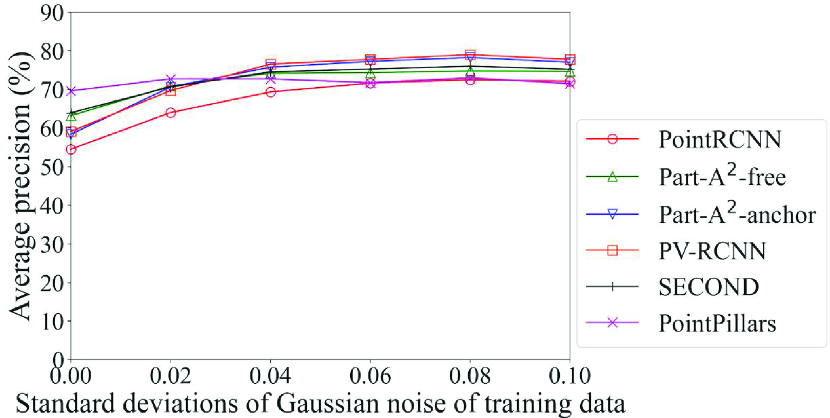
Fig. 9 shows the detection accuracy of the Original models of each method for data with noise. Among the six methods, only PointPillars adopts the pillar-based process. In light of this, it can be seen that the accuracy of the method that adopts the pillar-based process was higher than others in most cases for data with severe noise, especially for data with noise with standard deviations of 0.08 or higher. For example, the accuracy of car detection for data with noise of standard deviation of 0.10 can differ by up to 32% (PointPillars with pillar-based process vs. Part-A2-anchor with voxel-based process). However, in addition to the point-based process, the voxel-based process also showed a sharp drop in accuracy due to noise. This is probably because the quantization granularity of the voxel is finer than that of the pillar; the effect of noise was not fully mitigated. This result confirms that the DL method that achieves the highest detection accuracy changes depending on the noise level, and that the selection procedure in the proposed framework can work effectively. It also suggests that a model of the DL methods that adopt the pillar-based process should be selected for data with severe noise.
4.7 Effect of adding noise to training data
| DL method | Car | Pedestrian | Cyclist |
|---|---|---|---|
| PointRCNN | 0.08 | 0.08 | 0.08 |
| Part-A2-free | 0.08 | 0.08 | 0.08 |
| Part-A2-anchor | 0.08 | 0.08 | 0.06 |
| PV-RCNN | 0.08 | 0.08 | 0.08 |
| SECOND | 0.08 | 0.08 | 0.06 |
| PointPillars | 0.08 | 0.08 | 0.04 |
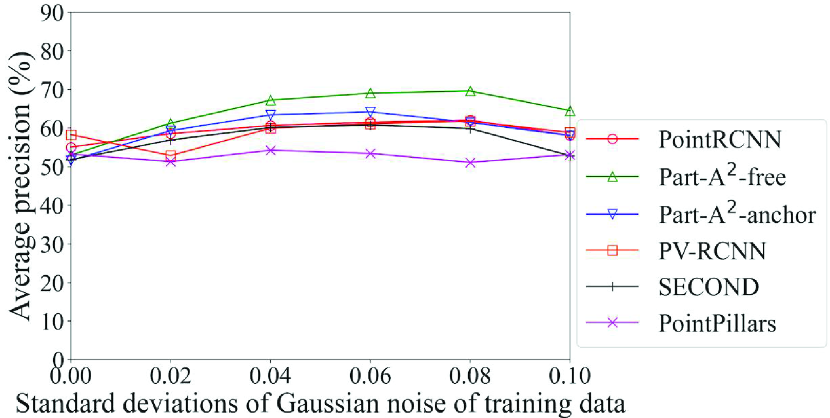
Fig. 10 shows the detection accuracy of the Noise models for data with Gaussian noise with the standard deviation of 0.08. Table 6 also summarizes the models with maximum accuracy for each method and each class. In the case of noise, we can see in Table 6 that for almost all items, the models trained on the data with noise close to that of the inference data (standard deviation of 0.08 in this case) achieved the maximum accuracy. The results in Fig. 10 show that the improvement in the accuracy of methods that adopt the voxel-based process was larger than those of methods that adopt point-based and pillar-based processes. In particular, PointRCNN, which adopts only the point-based process, had high accuracy in detecting pedestrians and cyclists when the incompleteness was small (Fig. 9). These results confirm that the selection procedure in the proposed framework can work effectively. They also suggest that a model of the DL method that adopts the voxel-based process should be selected when using a noise model.
Here, the effect of the proposed framework is reviewed in detail. As in Section 4.5.3, we refer to PointRCNN Original model as the benchmark. For example, in the detection of pedestrians for data with noise shown in Fig. 10b, our proposed framework selects Part-A2-free Noise 0.08 model according to the flowchart in Fig. 2. In this case, the proposed framework improves the average precision by 48% compared to the benchmark.
4.7.1 Consideration of model selection by score
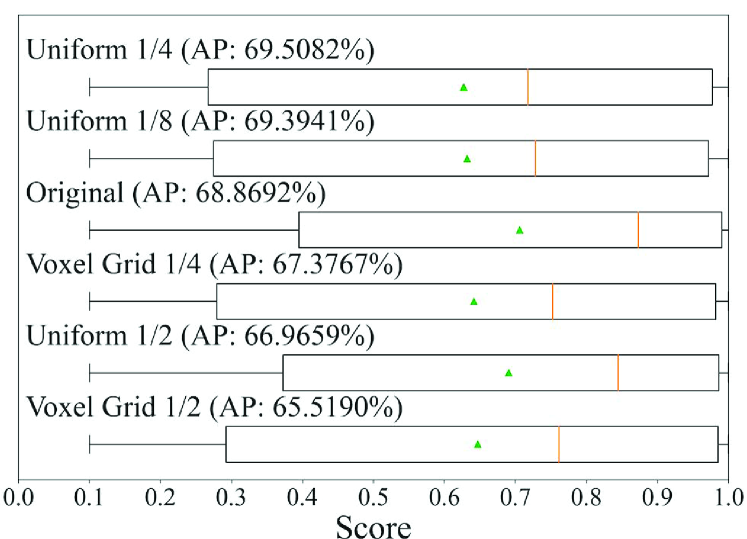
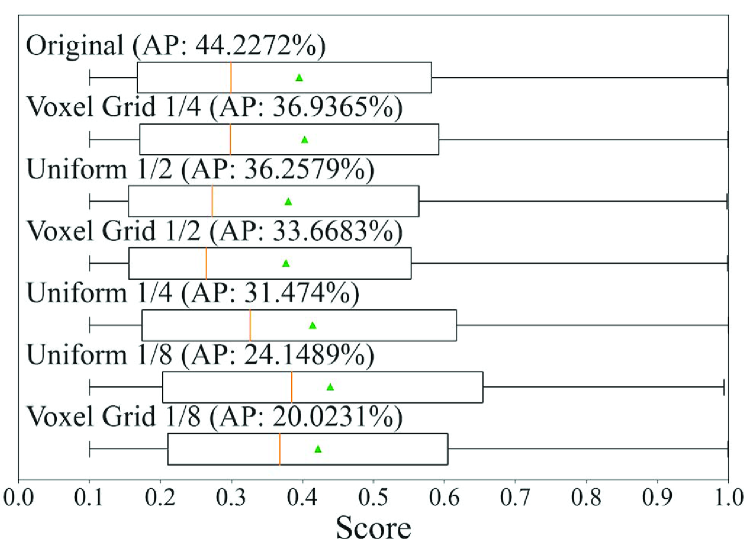
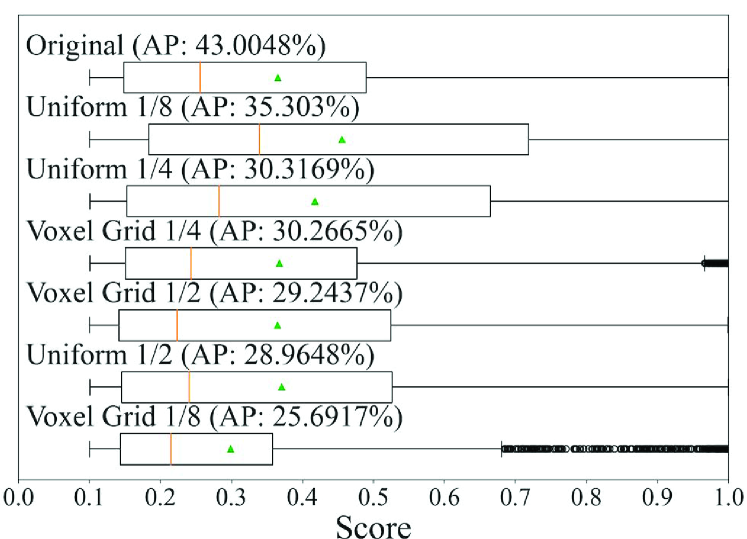
We next consider whether the best model could be preselected in accordance with the scores obtained when training models or not. Fig. 11 shows the relationship between the score distributions of each box detected by each model and the detection accuracies for data with the normalized number of points of 0.25. The score distributions are represented by box plots, and the results of the sampling models of PV-RCNN and PointRCNN, which have the model with the maximum accuracy in each class, are given as examples. Looking at the median (orange line) and mean (green triangle), we can see that the score distribution of the models with high detection accuracy is not necessarily higher than that of the others. This is a mixed situation in which a certain number of objects could be detected without confidence, a certain number of objects could be detected with confidence, and there were a lot of false negatives. This result indicates that the model selection based on the score distribution of the output cannot properly select a model with high accuracy for the data with low density of points. In contrast, the model selection based on the features in our framework can properly select a model with high accuracy, as described in Section 4.5.3.
5 Outdoor experiment examples





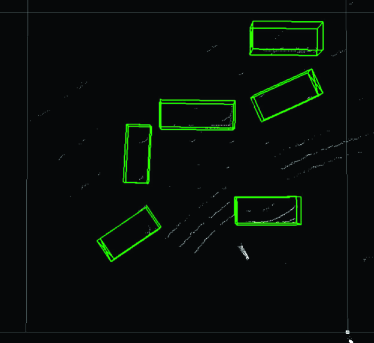


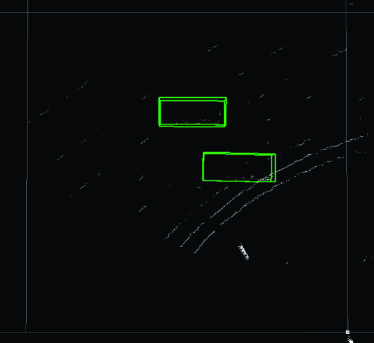
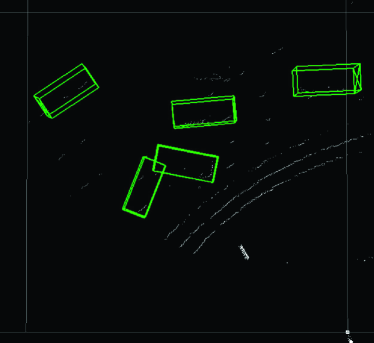
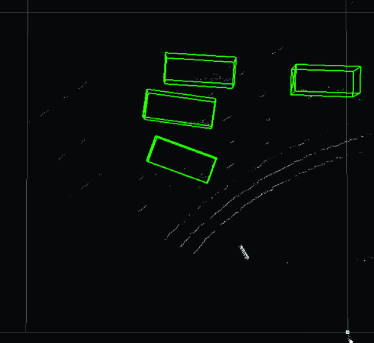
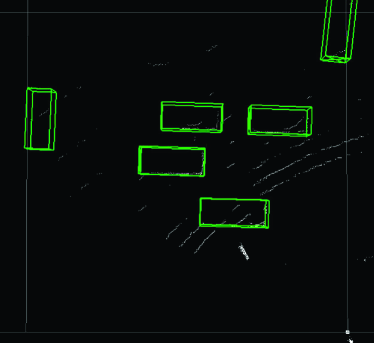
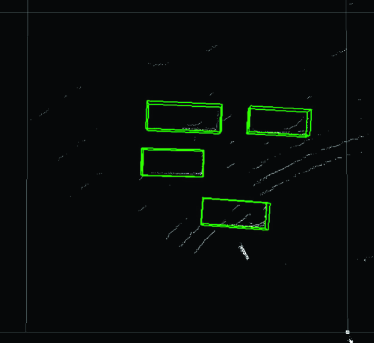
Finally, we present examples from the outdoor experiment using data measured in an actual outdoor environment. Fig. 12 shows the layout of the road near the intersection (Hyakumanben Intersection, Kyoto City, Kyoto Prefecture, Japan) used for this experiment, which includes the setup position of the LIDAR unit we used (Velodyne VLP-16 LIDAR). Fig. 13 shows pictures for checking answers that show the intersection when the point cloud data were actually acquired. This outdoor experiment focused on car detection and evaluated the performance of the Uniform model for data with low density of points. In accordance with the results in Section 4.5.2, the method we used was PV-RCNN, which adopts an anchor-based strategy and point-based process. In addition, since the normalized number of points in the acquired point cloud data was about 0.080, the Uniform 1/8 model trained on the data with the closest normalized number of points was compared to the Original model. Figs. 14–17 show the visualization of the detection results for point cloud data corresponding to each picture in Fig. 13. These figures show the results looking down from above. In Fig. 14, we can see that both models were able to detect all cars in the picture, though the PV-RCNN Original model had three false positives. In Fig. 15, we can see that the PV-RCNN Uniform 1/8 model was able to correctly detect the two cars in the picture, while the PV-RCNN Original model was only able to detect the one in front of it and had three false positives. In Fig. 16, we can also see that the PV-RCNN Uniform 1/8 model was able to detect all cars in the picture, while the PV-RCNN Original model was unable to properly detect the car on the furthest side and had two false positives. In Fig. 17, we can see that both models were able to detect all cars in the picture, though the PV-RCNN Original model had two false positives. These four cases demonstrate that the Uniform model had an advantage in terms of detection accuracy. Therefore, the results of this outdoor experiment are useful for confirming the effectiveness of the Uniform model for data that have dropped in density of points due to differences of performance between 3D image sensors.
6 Conclusion
In this paper, we proposed a feature-based model selection framework to deal with various features of point cloud data acquired by 3D image sensors. The proposed framework uses the broad features of DL methods to select a suitable model in accordance with the features of the point cloud data. The proposed framework uses training data with pseudo incompleteness to reduce the difference between the training and inference data. In the evaluation, we compared multiple models obtained from multiple DL methods with sampling and adding noise to show the effectiveness of the feature-based model selection in the proposed framework. The evaluation results verified that it effectively works to select a suitable DL model in accordance with the features of three factors, i.e., object class, density of points, and noise level. We also demonstrated through an outdoor experiment that the DL model constructed using the training data with a similar feature to the data in the real measurement environment works better than the DL model constructed using the original data.
Acknowledgments
The evaluation results were partly obtained from research commissioned by the National Institute of Information and Communications Technology (NICT), Japan.
References
- [1] R. Du, P. Santi, M. Xiao, A.V. Vasilakos, and C. Fischione, “The sensable city: A survey on the deployment and management for smart city monitoring,” IEEE Communications Surveys & Tutorials, vol.21, no.2, pp.1533–1560, Secondquarter 2019.
- [2] K. Sato, R. Shinkuma, T. Sato, E. Oki, T. Iwai, D. Kanetomo, and K. Satoda, “Prioritized transmission control of point cloud data obtained by lidar devices,” IEEE Access, vol.8, pp.113779–113789, Jun. 2020.
- [3] C. Mertz, L.E. Navarro-Serment, R. MacLachlan, P. Rybski, A. Steinfeld, A. Suppe, C. Urmson, N. Vandapel, M. Hebert, C. Thorpe, D. Duggins, and J. Gowdy, “Moving object detection with laser scanners,” Journal of Field Robotics, vol.30, no.1, pp.17–43, Jan. 2013.
- [4] X. Weng, J. Wang, D. Held, and K. Kitani, “3D multi-object tracking: A baseline and new evaluation metrics,” arXiv preprint arXiv:1907.03961, Jul. 2020.
- [5] Y. Yan, Y. Mao, and B. Li, “SECOND: Sparsely embedded convolutional detection,” Sensors, vol.18, no.10, p.3337, Oct. 2018.
- [6] A.H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “PointPillars: Fast encoders for object detection from point clouds,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.12697–12705, Jun. 2019.
- [7] S. Shi, X. Wang, and H. Li, “PointRCNN: 3D object proposal generation and detection from point cloud,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.770–779, Jun. 2019.
- [8] S. Shi, Z. Wang, J. Shi, X. Wang, and H. Li, “From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.43, no.8, Aug. 2021.
- [9] S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “PV-RCNN: Point-voxel feature set abstraction for 3D object detection,” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.10529–10538, Jun. 2020.
- [10] Y. Guo, H. Wang, Q. Hu, H. Liu, L. Liu, and M. Bennamoun, “Deep learning for 3D point clouds: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.43, no.12, Dec. 2021.
- [11] S. Grigorescu, B. Trasnea, T. Cocias, and G. Macesanu, “A survey of deep learning techniques for autonomous driving,” Journal of Field Robotics, vol.37, no.3, pp.362–386, Apr. 2020.
- [12] D.H. Wolpert and W.G. Macready, “No free lunch theorems for search,” tech. rep., Technical Report SFI-TR-95-02-010, Santa Fe Institute, Feb. 1996.
- [13] S. Ali and K.A. Smith, “On learning algorithm selection for classification,” Applied Soft Computing, vol.6, no.2, pp.119–138, Jan. 2006.
- [14] L. Kotthoff, I.P. Gent, and I. Miguel, “An evaluation of machine learning in algorithm selection for search problems,” AI Communications, vol.25, no.3, pp.257–270, Aug. 2012.
- [15] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the KITTI vision benchmark suite,” 2012 IEEE Conference on Computer Vision and Pattern Recognition, pp.3354–3361, IEEE, Jun. 2012.
- [16] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3D object detection network for autonomous driving,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.6526–6534, Jul. 2017.
- [17] C.R. Qi, W. Liu, C. Wu, H. Su, and L.J. Guibas, “Frustum PointNets for 3D object detection from RGB-D data,” Proceedings of the IEEE conference on computer vision and pattern recognition, pp.918–927, Jun. 2018.
- [18] T.Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.42, no.2, pp.318–327, Feb. 2020.
- [19] Y. Zhou and O. Tuzel, “Voxelnet: End-to-end learning for point cloud based 3D object detection,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.4490–4499, Jun. 2018.
- [20] B. Graham and L. van der Maaten, “Submanifold sparse convolutional networks,” arXiv preprint arXiv:1706.01307, Jun. 2017.
- [21] G. Wang, J. Wu, B. Tian, S. Teng, L. Chen, and D. Cao, “Centernet3D: An anchor free object detector for point cloud,” IEEE Transactions on Intelligent Transportation Systems, early access.
- [22] J. Beltrán, C. Guindel, F.M. Moreno, D. Cruzado, F. Garcia, and A. De La Escalera, “BirdNet: a 3D object detection framework from lidar information,” 2018 21st International Conference on Intelligent Transportation Systems (ITSC), pp.3517–3523, IEEE, Nov. 2018.
- [23] C.R. Qi, H. Su, K. Mo, and L.J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” Proceedings of the IEEE conference on computer vision and pattern recognition, pp.652–660, Jul. 2017.
- [24] C.R. Qi, L. Yi, H. Su, and L.J. Guibas, “PointNet++: Deep hierarchical feature learning on point sets in a metric space,” Proceedings of the 31st International Conference on Neural Information Processing Systems, pp.5105–5114, Dec. 2017.
- [25] Z. Yang, Y. Sun, S. Liu, X. Shen, and J. Jia, “STD: Sparse-to-dense 3D object detector for point cloud,” Proceedings of the IEEE International Conference on Computer Vision, pp.1951–1960, Nov. 2019.
- [26] J. Li, Y. Sun, S. Luo, Z. Zhu, H. Dai, A.S. Krylov, Y. Ding, and L. Shao, “P2V-RCNN: Point to voxel feature learning for 3D object detection from point clouds,” IEEE Access, vol.9, pp.98249–98260, Jul. 2021.
- [27] S. Zhang, C. Chi, Y. Yao, Z. Lei, and S.Z. Li, “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.9756–9765, Jun. 2020.
- [28] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE transactions on pattern analysis and machine intelligence, vol.39, no.6, pp.1137–1149, Jun. 2017.
- [29] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.Y. Fu, and A.C. Berg, “SSD: Single shot multibox detector,” European conference on computer vision, pp.21–37, Springer, Sep. 2016.
- [30] Z.H. Zhou, “Ensemble learning.,” Encyclopedia of biometrics, vol.1, pp.270–273, 2009.
- [31] N. Bodla, B. Singh, R. Chellappa, and L.S. Davis, “Soft-NMS–improving object detection with one line of code,” Proceedings of the IEEE international conference on computer vision, pp.5562–5570, Oct. 2017.
- [32] R. Solovyev, W. Wang, and T. Gabruseva, “Weighted boxes fusion: ensembling boxes from different object detection models,” Image and Vision Computing, vol.107, p.104117, Mar. 2021.
- [33] Á. Casado-García and J. Heras, “Ensemble methods for object detection,” in 24th European Conference on Artificial Intelligence, pp.2688–2695, IOS Press, Aug.–Sep. 2020.
- [34] C. Shorten and T.M. Khoshgoftaar, “A survey on image data augmentation for deep learning,” Journal of Big Data, vol.6, no.60, Jul. 2019.
- [35] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” Proceedings of the AAAI Conference on Artificial Intelligence, pp.13001–13008, Apr. 2020.
- [36] F.J. Moreno-Barea, F. Strazzera, J.M. Jerez, D. Urda, and L. Franco, “Forward noise adjustment scheme for data augmentation,” 2018 IEEE Symposium Series on Computational Intelligence (SSCI), pp.728–734, IEEE, Nov. 2018.
- [37] W. Ma, J. Chen, Q. Du, and W. Jia, “PointDrop: Improving object detection from sparse point clouds via adversarial data augmentation,” 2020 25th International Conference on Pattern Recognition (ICPR), pp.10004–10009, IEEE, Jan. 2021.
- [38] “Velodyne lidar product guide.” https://velodynelidar.com/downloads/#product_guides, (accessed on Aug. 15, 2021).
- [39] K. Wolff, C. Kim, H. Zimmer, C. Schroers, M. Botsch, O. Sorkine-Hornung, and A. Sorkine-Hornung, “Point cloud noise and outlier removal for image-based 3D reconstruction,” 2016 Fourth International Conference on 3D Vision (3DV), pp.118–127, IEEE, Oct. 2016.
- [40] A. Javaheri, C. Brites, F. Pereira, and J. Ascenso, “Subjective and objective quality evaluation of 3D point cloud denoising algorithms,” 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), pp.1–6, IEEE, Jul. 2017.
- [41] P. Padmanabhan, C. Zhang, and E. Charbon, “Modeling and analysis of a direct time-of-flight sensor architecture for LiDAR applications,” Sensors, vol.19, no.24, p.5464, Dec. 2019.
- [42] A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial machine learning at scale,” arXiv preprint arXiv:1611.01236, Feb. 2017.
- [43] T. Nguyen and R. Raich, “Incomplete label multiple instance multiple label learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.44, no.3, pp.1320–1337, Mar. 2022.
- [44] A. Mukhaimar, R. Tennakoon, C.Y. Lai, R. Hoseinnezhad, and A. Bab-Hadiashar, “Comparative analysis of 3D shape recognition in the presence of data inaccuracies,” 2019 IEEE International Conference on Image Processing (ICIP), pp.2471–2475, IEEE, Sep. 2019.
- [45] R. Otsu, R. Shinkuma, T. Sato, E. Oki, D. Hasegawa, and T. Furuya, “Spatial-importance based computation scheme for real-time object detection from 3D sensor data,” IEEE Access, vol.10, pp.5672–5680, Jan. 2022.
- [46] R.B. Rusu and S. Cousins, “3D is here: Point Cloud Library (PCL),” 2011 IEEE International Conference on Robotics and Automation, pp.1–4, IEEE, May 2011.
- [47] M. Gschwandtner, R. Kwitt, A. Uhl, and W. Pree, “BlenSor: Blender sensor simulation toolbox,” International Symposium on Visual Computing, pp.199–208, Springer, Sep. 2011.
- [48] O.D. Team, “OpenPCDet: An open-source toolbox for 3D object detection from point clouds.” https://github.com/open-mmlab/OpenPCDet, 2020 (accessed on Aug. 15, 2021).
- [49] “KITTI 3D object detection benchmark leader board.” http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d, (accessed on Aug. 15, 2021).
- [50] R. Padilla, S.L. Netto, and E.A. da Silva, “A survey on performance metrics for object-detection algorithms,” 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), pp.237–242, IEEE, Jul. 2020.
- [51] A. Simonelli, S.R. Bulo, L. Porzi, M. López-Antequera, and P. Kontschieder, “Disentangling monocular 3D object detection: From single to multi-class recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.44, no.3, pp.1219–1231, Mar. 2022.
Kairi Tokudais currently pursuing his master’s degree at the Graduate School of Informatics, Kyoto University, Kyoto, Japan. He received his B.E. from Kyoto University, Kyoto, Japan, in 2021. His research interests include smart monitoring, machine learning, and virtual networks.
Ryoichi SHINKUMAreceived B.E., M.E., and Ph.D. degrees in communications engineering from Osaka University in 2000, 2001, and 2003, respectively. He joined the Graduate School of Informatics, Kyoto University and worked there as an assistant professor from 2003 to 2011 and as an associate professor from 2011 to 2021. He was a visiting scholar at the Wireless Information Network Laboratory, Rutgers University from 2008 to 2009. In 2021, he joined the Faculty of Engineering, Shibaura Institute of Technology as a professor. His main research interest is cooperation in heterogeneous networks. He received the young researchers’ award, the best tutorial paper award of the Communications Society, the best paper award from the IEICE in 2006, 2019, and 2022, respectively. He also received the Young Scientist Award from Ericsson Japan in 2007 and the TELECOM System Technology Award from the Telecommunications Advancement Foundation in 2016. He is a fellow of the IEICE and a senior member of the IEEE.
Takehiro SATOreceived his B.E., M.E., and Ph.D. degrees in engineering from Keio University in 2010, 2011, and 2016, respectively. He is currently an associate professor at the Graduate School of Informatics at Kyoto University. His research interests include communication protocols and network architecture for next-generation optical networks. From 2011 to 2012, he was a research assistant in the Keio University Global COE Program, “High-level Global Cooperation for Leading-edge Platform on Access Spaces,” established by the Ministry of Education, Culture, Sports, Science and Technology of Japan. From 2012 to 2015, he was a research fellow with the Japan Society for the Promotion of Science. From 2016 to 2017, he was a research associate at the Graduate School of Science and Technology at Keio University. He is a member of the IEEE and IEICE.
Eiji OKIreceived B.E. and M.E. degrees in instrumentation engineering and a Ph.D. in electrical engineering from Keio University, Yokohama, Japan, in 1991, 1993, and 1999. He was with Nippon Telegraph and Telephone Corporation (NTT) Laboratories, Tokyo, from 1993 to 2008, and the University of Electro-Communications, Tokyo, from 2008 to 2017. From 2000 to 2001, he was a Visiting Scholar at Polytechnic University, Brooklyn, New York. In 2017, he joined Kyoto University, Japan, where he is currently a Professor. His research interests include routing, switching, protocols, optimization, and traffic engineering in communication and information networks. He is a Fellow of the IEEE and IEICE.