Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition
Abstract
Micro-Expression Recognition has become challenging, as it is extremely difficult to extract the subtle facial changes of micro-expressions. Recently, several approaches proposed several expression-shared features algorithms for micro-expression recognition. However, they do not reveal the specific discriminative characteristics, which lead to sub-optimal performance. This paper proposes a novel Feature Refinement (FR) with expression-specific feature learning and fusion for micro-expression recognition. It aims to obtain salient and discriminative features for specific expressions and also predict expression by fusing the expression-specific features. FR consists of an expression proposal module with attention mechanism and a classification branch. First, an inception module is designed based on optical flow to obtain expression-shared features. Second, in order to extract salient and discriminative features for specific expression, expression-shared features are fed into an expression proposal module with attention factors and proposal loss. Last, in the classification branch, labels of categories are predicted by a fusion of the expression-specific features. Experiments on three publicly available databases validate the effectiveness of FR under different protocol. Results on public benchmarks demonstrate that our FR provides salient and discriminative information for micro-expression recognition. The results also show our FR achieves better or competitive performance with the existing state-of-the-art methods on micro-expression recognition.
keywords:
Micro-expression recognition , deep learning , attention mechanism , shared feature, feature refinement1 Introduction
Micro-expression, a very brief and involuntary form of facial expressions occurring when people want to conceal one’s true feelings, usually lasts between 0.04s to 0.2s [1]. Automatic micro-expression analysis involves micro-expression spotting and micro-expression recognition (MER) [2]. Micro-expression spotting aims to automatically detect the temporal interval (from onset to offset) of a micro-movement in a sequence of video frames, also including the apex frame spotting, while MER refers to the classification task of identifying the micro-expression involved in the well-segmented video from onset to offset [2, 3]. Our focus in this work is micro-expression recognition.
As an essential way of human emotional behavior understanding, MER has attracted increasing attention in human-centered computing in the past decades. Its potential applications e.g. in police case diagnosis and psychoanalysis [4, 1] make it a core component in the next generation of computer system, in which a natural human machine interface enables the user to account for subtle appearance changes of human faces, to reveal the hidden emotions [5, 6] of humans, and to help understanding people’s deceitful behaviors.
Although advances have been made, due to complex factors, e.g. the subtle changes of micro-expressions, it is extremely difficult for MER to achieve superiority performance. Amongst, one critical research issue is how to extract salient and discriminative features from micro-expression. Currently, amount of feature descriptor methods have been proposed. They are commonly categorized into handcrafted features and deep learning features. However, these existing methods characterize the discrimination of micro-expressions inefficiently. On the other hand, it is time-consuming to design handcrafted feature [7] and manually adjust the optimal parameters [8].
To address these issues, we proposed a simple yet efficient method, termed as Feature Refinement (FR), is proposed to extract the expression-specific feature. The FR consists of three feature refinement stages: expression-shared feature learning, expression-specific feature distilling, and expression-specific feature fusion. In the first stage, a shallow two-stream Inception network with Inception blocks is designed to capture global and local information of optical flows for expression-shared feature learning. In the expression-specific feature distilling stage, based on expression-shared features, the proposal module with attention mechanism and proposal loss is proposed to distill expression-specific features for obtaining salient and discriminative features. The constraint of expression-specific objective function is designed to lead separate and different feature mapping. In the last stage, the element-wise sum function is used to fuse the separate expression-specific features for modeling expression-refined features under the deep network for expression categories prediction. The fusion of expression-specific feature can boost the feature learning. These three stages constitute the whole process of feature refinement. Across these three stages of feature learning, the novel deep network obtains the salient and discriminative representations for MER.
Overall, our contributions can be summarized as follows,
-
1.
We propose a deep learning based three-level feature refinement architecture for MER. This architecture can effectively and automatically learn the salient and discriminative feature for micro-expression recognition by distilling expression-specific features and fusing these features to final expression-refined features for expression classification.
-
2.
We propose a constructive but straightforward attention strategy and a simple proposal loss in expression proposal module for expression-specific feature learning. Specifically, attention factors can capture the characteristics from the subtle changes of micro-expressions. On the other hand, penalization of the proposal loss can optimize the discrimination of features.
-
3.
We extensively validate our FR on three benchmarks of MER. The experiment results sufficiently demonstrate the efficiency of expression-specific feature learning for micro-expression recognition, and provided the latest results for micro-expression recognition across three commonly available experimental protocols.
The rest of the paper is organized as follows. Section II introduces the related works. Section III presents our Inception-based feature learning algorithm in detail. Section IV reports our experimental analysis. Section V discusses conclusions and future research directions.
2 Related Work
2.1 Handcrafted features
The success of existing traditional approaches in MER is attributed in good part to the quality of the handcrafted visual features representation. Normally, handcrafted features are fed into a supervised classifier e.g. Support Vector Machines [9] to train a recognizer for the target expressions. The features are generally categorized into appearance-based and geometric-based features.
2.1.1 Appearance-based features
Local Binary Pattern from Three Orthogonal Planes (LBP-TOP) [10] is the most widely used appearance-based feature for micro-expression recognition. It combines the temporal features along with the spatial features from three orthogonal planes of the image sequence. As one of the earlier works in MER, LBP-TOP has been widely used in micro-expression analysis. Due to its low computational complexity, many LBP-TOP variants has been proposed, e.g. LBP from three Mean Orthogonal Planes (LBP-MOP) [11], Spatiotemporal Completed Local Quantized Patterns (STCLQP) [12], and hierarchical spatiotemporal descriptors [13]. Wang et al. [14] proposed a spatiotemporal descriptor utilizing six intersection points namely LBP with Six Intersection Points (LBP-SIP) to suppress redundant information in LBP-TOP and preserve more efficient computational complexity. Wang et al. [15, 16] explored the influence of the color space for features extraction and extracted Tensor features from Tensor Independent Color Space (TICS), validating that color information can improve the recognition effect of LBP-TOP. Huang et al. [17] proposed Spatiotemporal LBP with integral projection (STLBP-IP), which used facial shape information to improve recognition performance. Huang et al. [18] further proposed discriminative spatiotemporal LBP with revisited integral projection (DiSTLBP-RIP) to reveal the discriminative information. Besides the LBP family, 3D Histograms of Oriented Gradients (3DHOG) [19, 20] was another appearance-based feature counting occurrences of gradient orientation in localized portions of the image sequence.
2.1.2 Geometric-based features
Geometric-based features aim to represent micro-expression samples by the aspect of face geometry, e.g. shapes and location of facial landmarks. They can be categorized into optical flow based and texture variations based features. To estimate the apparent motion of objects, the optical flow method was mostly introduced to extract motion features in MER. To suppress facial identity appearance information on micro-expression, Lu et al. [8] proposed Delaunay-based Temporal Coding Model (DTCM), which encoded the local temporal variation in each sub-region by Delaunay triangulation and standard deviation analysis. Liu et al. [21] proposed the Main Directional Mean Optical Flow (MDMO) to reduce the feature dimension by using optical flow in the main direction. The MDMO was least affected by the varied number of frames in the image sequence. Xu et al. [7] designed Facial Dynamics Map (FDM) to suppress abnormal optical flow vectors which resulted from noise or illumination changes. Liong et al. [22] proposed Bi-Weighted Oriented Optical Flow (Bi-WOOF), which applied two schemes to weight the HOOF [23] descriptor locally and globally. The Bi-WOOF can obtain promising performance using only the onset and apex frame, increasing its effectiveness by a large margin.
Overall, handcrafted feature extraction approach mostly relies on the manually designed extractor, which needs professional knowledge and complex parameter adjustment process. Meanwhile, each method suffers from poor generalization ability and robustness. Furthermore, due to the limited representation ability, engineered features may hardly handle the challenge of nonlinear feature warping caused by complicated situations, e.g. under different environments.
2.2 Deep learning features
Recently, deep learning has been considered as an efficient way to learn feature representations. According to the different evaluation mechanisms, the existing methods were evaluated on the sole database, on Composite Database Evaluation protocol, and on Cross-database Micro-expression Recognition protocol, respectively.
2.2.1 Features evaluated on the single database
Evaluation on the single database means the training and testing samples are from the same micro-expression database. Leave-One-Subject-Out (LOSO), Leave-One-Video-Out (LOVO) or -Fold rule is commonly used to evaluate deep learning model. For example, Kim et al. [24] proposed a feature representation for the spatial information at different temporal states, which was based on the Long Short-Term Memory (LSTM) [25] recurrent neural network and only evaluated on a single dataset of CASME II [26]. Peng et al. [27] proposed Dual Temporal Scale Convolutional Neural Network (DTSCNN), which was evaluated on CASME [28] and CASME II databases. The DTSCNN was the first work in MER that utilized shallow two-stream neural network with inputs of optical-flow sequences. Nag et al. [29] proposed an unified architecture for micro-expression spotting and recognition, in which spatial and temporal network extracts time-contrasted features from the feature maps to contrast out subtle motions of micro-expressions. Wang et al. proposed transferring Long-term Convolutional Neural Network (TLCNN) [30] which utilized transfer learning from macro-expression to micro-expression database for MER. So far, there were many other deep learning features evaluated on the single database, e.g. Spatiotemporal Recurrent Convolutional Networks (STRCN) [31], Three-stream 3D flow convolutional neural network [32], Lateral Accretive Hybrid Network (LEARNet) [33], and 3D-Convolutional Neural Network method [34].
2.2.2 Features evaluated on Composite Database Evaluation protocol
The Composite Database Evaluation (CDE) protocol [35] means all the micro-expression databases are composited into one database and LOSO validation rule is used to evaluate the algorithm. As a deep learning work based on CDE protocol, Optical Flow Feature from Apex frame Network (OFF-ApexNet) [36] extracted optical flow features from the onset and apex frames of each video, then learned features representation by feeding horizontal and vertical components of optical flows into a two-stream CNN network. Since the CNN network was shallow, it reduced the over-fitting caused by the scarcity of data in the micro-expression databases.
Very recently, more deep learning features were proposed [37, 38, 39, 40] in MEGC 2019 [35]. More specifically, Expression Magnification and Reduction (EMR) with adversarial training [39] was a part-based deep neural network approach with adversarial training and expression magnification. With the special data augmentation strategy of expression magnification and reduction, EMR won the first place in MEGC 2019. Shallow Triple Stream Three-dimensional CNN (STSTNet) [37] is an extended version of OFF-ApexNet. Besides the horizontal and vertical components of optical flows, STSTNet extracted the handcrafted feature named optical strain to learn more efficient features. By concentrating the three optical features to a single 3D image and then feeding the concentrated images to a shallow three-dimensional CNN, STSTNet achieved state-of-the-art performance on CDE protocol among the methods without data augmentation. Dual-Inception [38] was achieved by feeding the optical flow features extracted from the onset and mid-position frames into a designed two-stream Inception network. With data augmentation methods, Quang et al. [40] applied Capsule Networks (CapsuleNet) based on the apex frames to MER .
2.2.3 Features evaluated on Cross-database Micro-expression Recognition protocol
Cross-database Micro-expression Recognition (CDMER) protocol means the samples of training and testing are selected from two different micro-expression databases [41, 42, 43]. Based on the emotion classification, Zong et al. proposed domain generators approach for cross-database micro-expression recognition [44]. Holdout-database Evaluation (HDE) protocol [42], which is considered as a specific type of CDMER, was advocated in MEGC 2018 [42]. This protocol aims to tackle the recognition of micro-expressions based on AU-centric objective classes rather than emotion classes. The two earliest works that introduced Deep Neural Network (DNN) on the HDE protocol were proposed by Peng et al. [45] and Khor et al. [46]. Specifically, Peng et al. used Resnet10 as a backbone and introduced transfer learning from macro-expression databases to learn micro-expression features [45]. Khor et al. adopted Enriched Long-term Recurrent Convolutional Network (ELRCN) to improve the recognition performance [46], which contained the channel-wise for spatial enrichment and the feature-wise for temporal enrichment predicted the micro-expression by passing the feature vector through LSTM.
Although the aforementioned works have studied the problem of feature learning for MER, they primarily focused on learning expression-shared features from the input, ignoring resolving how to obtain salient and discriminative features. Due to the low intensity of micro-expression, generic feature learning lacks of revealing the intrinsic different characteristic of different micro-expressions. Expression-shared feature learning aims to learn identical feature space in the process of classification [47]. However, in [47], the identical features for all categories may hardly lead to optimized performance. To solve these issues of expression-shared feature learning, this paper leverages expression-specific discriminant mapping features for MER. Specifically, a straightforward feature refinement framework is proposed to learn salient and discriminative features for micro-expression recognition, which combines expression-specific features from expression-shared features by an expression proposal module with the attention mechanism.
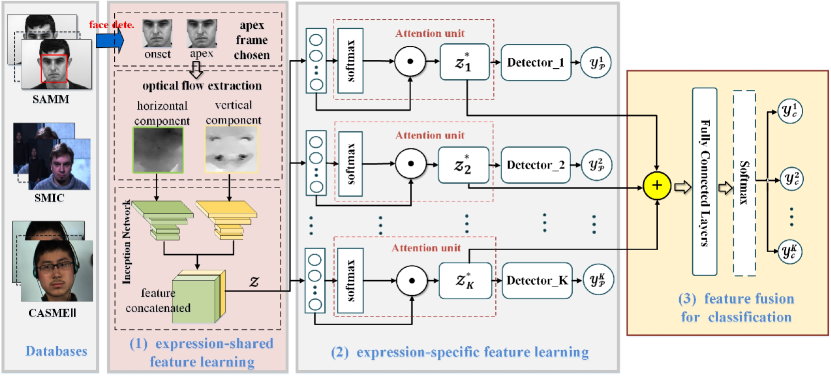
3 Proposed Method
Fig. 1 describes our proposed FR architecture. It leverages two-stream Inception network as a backbone for expression-shared feature learning, an expression proposal module with attention mechanism for expression-specific feature learning, and a classification module for label prediction by fused expression-refined features.
3.1 Expression-shared feature learning
As shown in Fig. 1, the expression-shared feature learning module consists of three critical components: apex frame chosen, optical flow extraction and two-stream Inception network.
Note that, as SMIC database [48] doesn’t supply the human-annotated apex frame, the apex frame spotting becomes very necessary. Several apex frame spotting algorithms have been proposed in recent years [49, 3, 50, 51, 52, 38]. For example, the mid-position frame is straightforwardly chosen as the apex frame [52, 38]. Moreover, Liu et al. [39] used motion difference to locate the apex frame. Quang et al. [40] divided the face image into ten regions, and then computed the absolute pixel differences to find the apex frame. Considering a trade-off between efficiency and effectiveness, the inter-frame difference method (interframe-Diff) is presented to locate apex frame on SMIC database. The interframe-Diff defines the index of apex frames as follows:
| (1) |
where denotes the -th frame of each sample, computes the mean absolute value of the pixel value difference between the onset and the -th frames at .
As a motion information feature, the optical flow is extensively used by [37, 36, 53] for micro-expression recognition. More specifically, the optical flow of each sample is extracted from the onset and apex frames, where onset and apex frames mean the frames with neutral-expression and the highest expression intensity, respectively. For FR, TV-L1 optical flow method [54] is utilized to obtain motion feature from the onset and apex frames of each micro-expression video. As shown in Fig. 1, for preserving more motion information, two optical flow components are extracted to represent the facial change along horizontal and vertical directions.
Furthermore, Considering horizontal and vertical components of optical flow, FR designs two-stream Inception network based on the Inception V1 block [55], which complements with two-layer depths. Specifically, inception block is designed to capture both the global and local information of the optical component for feature learning. Distinguishing from traditional convolution with a fixed size of filters, Inception blocks parallelize filters of multiple sizes at the same level. Additionally, motivated by LeNet [56], the number of filters in the first and second layers is set at 6 and 16, respectively. Finally, the flattened two sets of feature maps are concentrated into an expression-shared feature.
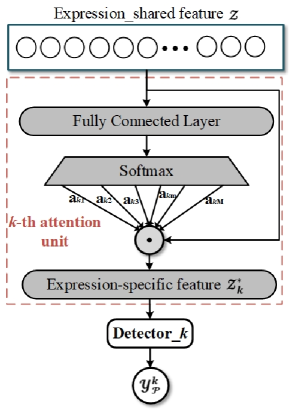
3.2 Expression-specific feature learning
As illustrated in Fig. 1, based on the expression-shared feature, expression proposal module with the attention mechanism and proposal loss is introduced to learn the expression-specific features. Given a micro-expression sample and an expression-shared feature , a proposal module with sub-branches is designed, where each of sub-branch learns a set of specific-feature for each micro-expression category (total categories). The proposal module becomes the core component of FR to obtain salient and discriminative features. The attention and proposal loss are described as follows.
Softmax attention: Attention mechanism provides the flexibility to our model to learn expression-specific features from the same set of expression-shared feature. attention units are shown in the part (2) of Fig. 1, and the detail of each attention unit is depicted in Fig. 2. Specifically, the expression-shared feature is connected with fully connected layers separately. After activated by , we gain the attention weight of for each specific expression,
| (2) |
where is a vector that has the same dimension as , and . Then, the representation for each specific expression is given by:
| (3) |
Proposal loss: Besides the inducing of attention strategy, expression-specific feature learning is also constrained with a prososal loss which is averaged from expression-specific detection losses in the proposal module. Each expression-specific detector (‘Detector’ in Fig. 1) is aligned with a feature vector , which contains two fully connected layers with a layer as the output. Thus, each sub-proposal branch is trained by optimizing the following detection loss,
| (4) |
where and denote the ground truth (either 1 or 0) and the probability of the -th sample as the -th category expression, respectively. is the total number of training samples. allows the network to generate expression-specific features for every expression. Based on the loss occurring in each sub-proposals, the loss of the proposal module consisted of sub-branches is defined as the average of detection losses:
| (5) |
By the restraint of the proposal loss of and the attention mechanism, the proposal module obtains salient and discriminative expression-specific feature for micro-expression recognition.
3.3 Fused expression-refined features for classification
Generally, a simple way is to concatenate the expression-specific features into one feature vector, which is directly fed into Fully Connected Layers. However, this method will cause the high dimension and contain more trainable parameters. Motivated by the feature fusion method in [57], this work utilizes a simple but efficient method, namely, the element-wise sum as a fusion function. The efficiency evaluation about element-wise sum for fusion can be referred to Section 4.3. Consequently, the aggregated feature representation is defined as follows:
| (6) |
Then, the expression-refined feature is fed into the final classification module which consists of two fully connected layers. To avoid over-fitting, the first fully connected layer was followed by a Dropout layer (with dropout probability being 0.5). Lastly, the output of the last fully connected layer is activated by a unit. Hence, the classification loss is expressed as:
| (7) |
where is the class label for the -th training instance.
4 Experiments
4.1 Datasets
Experiments are conducted on three commonly used spontaneous micro-expression databases: SMIC [48], CASME II [26], and SAMM [58].
SMIC [48]: The SMIC database contains SMIC-HS (recorded by a high-speed camera of 100 fps), SMIC-VIS (by a normal visual camera of 25 fps), and SMIC-NIR (by a near-infrared camera). SMIC-HS has 164 micro-expression clips from 16 subjects, while SMIC-VIS/SMIC-NIR consists of 71 samples from 8 participants. Additionally, these samples in three sub-databases are annotated as Negative, Positive, and Surprise. The sample resolution is pixels and the facial area is around pixels.
CASME II [26] : The CASME II contains two versions: the first one includes 247 samples of 5 micro-expression classes (Happiness, Surprise, Disgust, Repression, and Others), and the second has 256 samples of 7 classes (Happiness, Surprise, Disgust, Sadness, Fear, Repression, and Others). All the samples are gathered from 26 subjects. It was recorded by a camera with 200 fps. The resolution of the samples are pixels and the resolution of facial area is around pixels.
SAMM [58]: The SAMM database contains 159 micro-expression instances from 32 participants at 200 fps. The resolution of the samples are pixels and the resolution of facial area is around pixels. Samples in SAMM are categorized into Happiness, Surprise, Disgust, Repression, Angry, Fear, Contempt, and Others.
4.2 Experiment settings
Since the apex frame annotation in SMIC database is not available, interframe-Diff method as described in Section III is applied to spot the apex frame. For the CASME II and SAMM databases, the ground truth of the apex frames is directly used. The Libfacedetection [59] is utilized to crop the facial area out of onset and apex frames. TV-L1 optical flow is extracted from the onset and apex frames. Two components of optical flow images are resized to pixels before feeding to the Inception network. All the experiments are conducted with Ubuntu 16.04, Python 3.6.2 with Keras 2.2.4 and Tensorflow 1.11.0 on 1 NVIDIA GTX Titan X GPU (12 GB).
Setup: To evaluate the effect of each module of FR, an ablation study is first designed to investigate the backbone selection, strategy selection, and fusion module selection. Second, three groups of experiments, namely, CDE experiment, CDMER experiment, and the single database experiment, are designed to validate the effectiveness of the proposed method. For fair comparison, all the experiments on CDE and the single database evaluation are conducted with Leave-One-Subject-Out (LOSO) cross-validation, where samples from one subject are held out as the testing set while all remaining samples for training. For CDMER, the model is trained on the source dataset and tested on the target dataset.
The detail settings for model ablation experiment, CDE experiment, CDMER experiment, and the single database experiment can be referred to Section 6.
Performance metric: Here, this work applies different performance metric for the three groups.
-
1.
For CDE protocol, according to the MEGC 2019, Unweighted F1-score (UF1) and Unweighted Average Recall (UAR) are used to measure the performance of various methods on composite and individual databases.
-
2.
For CDMER protocol, according to [41], Accuracy (Acc) and UF1 are reported for evaluating the performance.
-
3.
For the evaluation on the single database, Acc is used.
All results of each type of experiments are the average of at least ten rounds. The evaluation metrics can be also referred to Section 6.
| Model | UF1 | UAR |
|---|---|---|
| Dual-Inception [38] | 0.7322 | 0.7278 |
| Basic Inception | 0.7360 | 0.7391 |
| Model | UF1 | UAR |
|---|---|---|
| FR-fc | 0.7377 | 0.7443 |
| FR | 0.7838 | 0.7832 |
| Model | UF1 | UAR |
|---|---|---|
| FR-concatenated | 0.7632 | 0.7727 |
| FR | 0.7838 | 0.7832 |
4.3 Model ablation
The ablation study is performed on the composite database of CDE protocol. Table 1 reports the results in terms of UAR and UF1 on different models.
| Groups | Approaches | Composite | SMIC-HS | CASME II | SAMM | ||||
|---|---|---|---|---|---|---|---|---|---|
| UF1 | UAR | UF1 | UAR | UF1 | UAR | UF1 | UAR | ||
| Handcrafted features | LBP-TOP [10] | 0.5882 | 0.5785 | 0.2000 | 0.5280 | 0.7026 | 0.7429 | 0.3954 | 0.4102 |
| Bi-WOOF [22] | 0.6296 | 0.6227 | 0.5727 | 0.5829 | 0.7805 | 0.8026 | 0.5211 | 0.5139 | |
| Deep learning features | AlexNet [60] | 0.6933 | 0.7154 | 0.6201 | 0.6373 | 0.7994 | 0.8312 | 0.6104 | 0.6642 |
| GoogLeNet [55] | 0.5573 | 0.6049 | 0.5123 | 0.5511 | 0.5989 | 0.6414 | 0.5124 | 0.5992 | |
| VGG16 [61] | 0.6425 | 0.6516 | 0.5800 | 0.5964 | 0.8166 | 0.8202 | 0.4870 | 0.4793 | |
| CapsuleNet [40] | 0.6520 | 0.6506 | 0.5820 | 0.5877 | 0.7068 | 0.7018 | 0.6209 | 0.5989 | |
| OFF-ApexNet [36] | 0.7196 | 0.7096 | 0.6817 | 0.6695 | 0.8764 | 0.8681 | 0.5409 | 0.5392 | |
| Dual-Inception [38] | 0.7322 | 0.7278 | 0.6645 | 0.6726 | 0.8621 | 0.8560 | 0.5868 | 0.5663 | |
| STSTNet [37] | 0.7353 | 0.7605 | 0.6801 | 0.7013 | 0.8382 | 0.8686 | 0.6588 | 0.6810 | |
| EMR [39] | 0.7885 | 0.7824 | 0.7461 | 0.7530 | 0.8293 | 0.8209 | 0.7754 | 0.7152 | |
| FR (Ours) | 0.7838 | 0.7832 | 0.7011 | 0.7083 | 0.8915 | 0.8873 | 0.7372 | 0.7155 | |
(1) Backbone selection for the expression-shared feature learning
To better capture the subtle motion of micro-expression for our proposed model, we make a backbone selection for the expression-shared feature learning.
a. Dual-Inception [38]: The model straightforwardly uses the mid-position frame of each sample as the apex frame for MER.
b. Basic Inception: Different from [38], Basic Inception uses interframe difference algorithm described in Section III to approximately locate the apex frames for SMIC-HS database, and uses ground truth of apex frames in CASME II and SAMM.
Table 2(a) compares basic Inception to Dual-Inception on the composite database. Basic Inception outperforms Dual-Inception in terms of UAR and UF1. Thus, the Basic Inception is chosen as the backbone of our framework to learn the expression-shared feature.
(2) Strategy selection for the expression-specific feature learning
In the proposal module, two followed strategies are presented to learn expression-specific features:
a. FR-fc: FR-fc only uses fully-connected layers in the proposal module for the expression-specific feature learning, and then uses the element-wise sum mode to aggregate expression-specific features of each expression category for classification.
b. FR: FR differs from FR-fc using attention strategy to learn expression-specific features.
From Table 2(b), FR with attention mechanism boosts the performance from 0.7377 to 0.7838 in terms of UF1, from 0.7443 to 0.7832 in terms of UAR. This suggests that attention factors in the proposal module have the capability to highlight specific characteristics and generate salient features.
(3) Fusion mode selection to obtain the expression-refined feature
To validate the fusion mode for fusing the expression-specific features, this part compares element-wise sum mode used in this paper to concatenated mode.
a. FR-concatenated: FR-concatenated model directly concatenates the expression-specific features.
b. FR: FR model uses element-wise sum mode to obtain expression-refined features.
According to Table 2(c), FR outperforms the FR-concatenated. It may attribute to that element-wise sum mode alleviates the over-fitting problem as element-wise sum model more suppress the dimension of expression-refined feature than concatenated method. Consequently, the element-wise sum mode is chosen for expression-specific features fusion to obtain expression-refined features.
4.4 Performance evaluation on CDE protocol
Table 2 compares our method to several state-of-the-art methods on CDE protocol. These methods contain two handcrafted features (LBP-TOP [10] and Bi-WOOF [22]), six deep learning features without data augmentation technology (AlexNet [60], GoogLeNet [55], VGG16 [61], OFF-ApexNet [36], Dual-Inception [38], and STSTNet [37]), and two deep learning features with data augmentation (CapsuleNet [40] and EMR [39]). Specifically, AlexNet, GoogLeNet, and VGG16 were reproduced by Liong et al. [37] instead by the inputs of optical flow features.
4.4.1 Comparison with handcrafted features
When comparing to LBP-TOP, our proposed FR improves the baseline consistently with gains of 19.56%, 50.11%, 18.89%, and 34.18% in terms of UF1 for composite, SMIC-HS, CASME II, and SAMM databases, respectively. It increases the performance of the baseline by 20.47%, 18.03%, 14.44%, and 30.53% in terms of UAR for composite, SMIC-HS, CASME II, and SAMM databases, respectively. FR consistently improves the Bi-WOOF by a large margin. It indirectly suggests that FR learns discriminative and meaningful features on micro-expression database, which is better than the traditional handcrafed features.
4.4.2 Comparison with deep learning features
Table 2 indicates that our proposed FR outperforms most state-of-the-art algorithms on all the databases. It is explained by that the scarcity of data causes the existing deep-depth networks the over-fitting. The promising results further suggest that the shallow neural networks with fewer parameters alleviate the over-fitting problem in MER.
-
1.
FR achieves better performance than OFF-ApexNet, CapsuleNet, Dual-Inception, and STSTNet. The similarity between FR and these three models is that they all learn features by feeding the extracted optical flows into designed shallow networks. But the major difference is that our proposed FR distills more meaningful characteristic from the expression-shared features for MER by expression-specific feature learning and fusion, while they focus on the expression-shared feature learning.
-
2.
As we know, STSTNet is an extension of OFF-ApexNet, which learns deep learning features for MER with three pre-extracted optical flows. The considerable result of STSTNet indirectly suggests that the more pre-processing features input, the better performance the method obtains. Although our proposed FR and STSTNet belongs to multi-stream feature learning approach, with expression-specific feature learning and fusion, FR gains improvements of 5.03% and 2.07% in terms of average UF1 and UAR across four databases, respectively, though the performance of STSTNet are relatively high. The improvement indicates that exploring features with more salient and discriminative characteristic based on fewer pre-processing is a more promising approach.
-
3.
EMR used Eulerian Video Magnification (EVM) for magnifying micro-expression, in which EVM has been shown its effectiveness to micro-expression recognition [62]. Comparing with EMR, FR slightly degrades the performance by 0.64% in terms of average UF1 across four databases, while increases the performance by 0.58% in terms of average UAR across four databases. Thus, FR still obtains a competitive performance to EMR. On the other hand, FR is built on more simple pre-process e.g. facial cropped and apex frame chosen than EMR e.g. macro-expression samples relabeling to three categories and micro-expressions magnification.
| Groups | Feature Descriptors | Exp.1: HV | Exp.2: VH | Exp.3: HN | Exp.4: NH | Exp.5: VN | Exp.6: NV | Average |
|---|---|---|---|---|---|---|---|---|
| Handcrafted features | LBP-TOP(R3P8) [10] | 0.8002/0.8028 | 0.5421/0.5427 | 0.5455/0.5352 | 0.4878/0.5488 | 0.6186/ 0.6338 | 0.6078/0.6338 | 0.6003/0.6162 |
| LBP-TOP(R1P4) [10] | 0.7185/0.7183 | 0.3366/0.4024 | 0.4969/0.4930 | 0.3457/0.4024 | 0.5480/0.5775 | 0.5085/0.5915 | 0.4924/0.5332 | |
| LBP-TOP(R1P8) [10] | 0.8561/0.8592 | 0.5329/0.5366 | 0.5164/0.5775 | 0.3246/0.3537 | 0.5124/0.5775 | 0.4481/0.5070 | 0.5318/0.5686 | |
| LBP-TOP(R3P4) [10] | 0.4656/0.4930 | 0.4122/0.4512 | 0.3682/0.4085 | 0.3396/0.4085 | 0.5069/0.5915 | 0.5144/0.6056 | 0.4345/0.4931 | |
| LBP-SIP(R1) [14] | 0.6290/0.6338 | 0.3447/0.4085 | 0.3249/0.3380 | 0.3490/0.4207 | 0.5477/0.6056 | 0.5509/0.6056 | 0.4577/0.5020 | |
| LBP-SIP(R3) [14] | 0.8574/0.8592 | 0.4886/0.5000 | 0.4977/0.5493 | 0.4038/0.4268 | 0.5444/0.5915 | 0.3994/0.4648 | 0.5319/0.5653 | |
| LPQ-TOP(decorr=0.1) [63] | 0.9455/0.9437 | 0.5523/0.5488 | 0.5456/0.6197 | 0.4729/0.4756 | 0.5416/0.5775 | 0.6365/0.6620 | 0.6157/0.6379 | |
| LPQ-TOP(decorr=0) [63] | 0.7711/0.7746 | 0.4726/0.4878 | 0.6771/0.6761 | 0.4701/0.4817 | 0.7076/0.7183 | 0.6963/0.7042 | 0.6325/0.6405 | |
| HOG-TOP(p=4) [62] | 0.7068/0.7183 | 0.5649/0.5732 | 0.6977/0.7042 | 0.2830/0.2927 | 0.4569/0.4930 | 0.3218/0.3662 | 0.4554/0.4847 | |
| HOG-TOP(p=8) [62] | 0.7364/0.7465 | 0.5526/0.5610 | 0.3990/0.4648 | 0.2941/0.3232 | 0.4137/0.4648 | 0.3245/0.3803 | 0.4453/0.4901 | |
| HIGO-TOP(p=4) [62] | 0.7933/0.8028 | 0.4775/0.5061 | 0.4023/0.4789 | 0.3445/0.3598 | 0.5000/0.5352 | 0.3747/0.4085 | 0.4821/0.5152 | |
| HIGO-TOP(p=8) [62] | 0.8445/0.8451 | 0.5186/0.5366 | 0.4793/0.5493 | 0.4322/0.4390 | 0.5054/0.5493 | 0.4056/0.4648 | 0.5309/0.5640 | |
| Deep learning features | C3D-FC1 (Sports1M) [64] | 0.1577/0.3099 | 0.2188/0.2378 | 0.1667/0.3099 | 0.3119/ 0.3415 | 0.3802/0.4930 | 0.3032/0.3662 | 0.2564/0.3431 |
| C3D-FC2 (Sports1M) [64] | 0.2555/0.3662 | 0.2974/0.2927 | 0.2804/0.3380 | 0.3239/0.3659 | 0.4518/0.4789 | 0.3620/0.3803 | 0.3285/0.3703 | |
| C3D-FC1 (UCF101) [64] | 0.3803/0.4648 | 0.3134/0.3476 | 0.3697/0.4789 | 0.3440/0.3476 | 0.3916/0.4789 | 0.2433/0.2958 | 0.3404/0.4023 | |
| C3D-FC2 (UCF101) [64] | 0.4162/0.4648 | 0.2842/0.3232 | 0.3053/0.4225 | 0.2531/0.2805 | 0.3937/0.4789 | 0.2489/0.3239 | 0.3169/0.3823 | |
| FR (Ours) | 0.7065/0.7149 | 0.5971/0.5968 | 0.5335/0.5673 | 0.5137/0.5200 | 0.7934/0.7910 | 0.7921/0.7921 | 0.6561/0.6636 |
| Groups | Feature Descriptors | Exp.7: C H | Exp.8: HC | Exp.9: CV | Exp.10: VC | Exp.11: CN | Exp.12: NC | Average |
|---|---|---|---|---|---|---|---|---|
| Handcrafted features | LBP-TOP(R3P8) [10] | 0.3697/0.4512 | 0.3245/0.4846 | 0.4701/0.5070 | 0.5367/0.5308 | 0.5295/0.5211 | 0.2368/0.2385 | 0.4112/0.4555 |
| LBP-TOP(R1P4) [10] | 0.3358/0.4451 | 0.3260/0.4769 | 0.2111/0.3521 | 0.1902/0.2692 | 0.3810/0.4366 | 0.2492/0.2692 | 0.2823/0.3749 | |
| LBP-TOP(R1P8) [10] | 0.3680/0.4390 | 0.3339/0.5462 | 0.4624/0.4930 | 0.5880/0.5769 | 0.3000/0.3380 | 0.1927/0.2308 | 0.3742/0.4373 | |
| LBP-TOP(R3P4) [10] | 0.3117/0.4390 | 0.3436/0.4462 | 0.2723/0.3944 | 0.2356/0.2846 | 0.3818/0.4.30 | 0.2332/0.2538 | 0.2964/0.3852 | |
| LBP-SIP(R1) [14] | 0.3580/0.4512 | 0.3039/0.4462 | 0.2537/0.3803 | 0.1991/0.2692 | 0.3610/0.4648 | 0.2194/0.2692 | 0.2825/0.3802 | |
| LBP-SIP(R3) [14] | 0.3772/0.4268 | 0.3742/0.5615 | 0.5846/0.5915 | 0.6065/0.6000 | 0.3469/0.3521 | 0.2790/0.2769 | 0.4279/0.4681 | |
| LPQ-TOP(decorr=0.1) [63] | 0.3060/0.4207 | 0.3852/0.4846 | 0.2525/0.3380 | 0.4866/0.4769 | 0.3020/0.3521 | 0.2094/0.2385 | 0.3236/0.3851 | |
| LPQ-TOP(decorr=0) [63] | 0.2368/0.4390 | 0.2890/0.5154 | 0.2531/0.3803 | 0.3947/0.4077 | 0.2369/0.3521 | 0.4008/0.4154 | 0.3019/0.4183 | |
| HOG-TOP(p=4) [62] | 0.3156/0.3476 | 0.3502/0.4769 | 0.3266/0.3521 | 0.4658/0.4692 | 0.3219/0.3521 | 0.2163/0.2746 | 0.3327/0.3791 | |
| HOG-TOP(p=8) [62] | 0.3992/0.4390 | 0.4154/0.5231 | 0.4403/0.4507 | 0.4678/0.4769 | 0.4107/0.4085 | 0.1390/0.2077 | 0.3787/0.4177 | |
| HIGO-TOP(p=4) [62] | 0.2945/0.3963 | 0.3420/0.5385 | 0.3236/0.4085 | 0.5590/0.5538 | 0.2887/0.2958 | 0.2668/0.3154 | 0.3458/0.4181 | |
| HIGO-TOP(p=8) [62] | 0.2978/0.4146 | 0.3609/0.5000 | 0.3679/0.4366 | 0.5699/0.5462 | 0.3395/0.3380 | 0.1743/0.2231 | 0.3517/0.4098 | |
| Deep learning features | C3D-FC1 (Sports1M) [64] | 0.1994/0.4268 | 0.2394/0.5615 | 0.1631/0.3239 | 0.1075/0.1923 | 0.1631/0.3239 | 0.2397/0.5615 | 0.1854/0.3983 |
| C3D-FC2 (Sports1M) [64] | 0.1994/0.4268 | 0.1317/0.2462 | 0.1631/0.3239 | 0.1075/0.1923 | 0.1631/0.3239 | 0.2397/0.5615 | 0.1674/0.3458 | |
| C3D-FC1 (UCF101) [64] | 0.1581/0.3110 | 0.1075/0.1923 | 0.1886/0.3944 | 0.1075/0.1923 | 0.1886/0.3944 | 0.2397/0.5615 | 0.1650/0.3410 | |
| C3D-FC2 (UCF101) [64] | 0.1994/0.4268 | 0.1705/0.1923 | 0.1631/0.3239 | 0.1075/0.1923 | 0.1631/0.3239 | 0.1075/0.1923 | 0.1414/0.2753 | |
| FR (Ours) | 0.4670/0.4905 | 0.4883/0.5380 | 0.5678/0.6101 | 0.5929/0.6019 | 0.4399/0.4823 | 0.5963/0.6081 | 0.5254/0.5552 |
4.5 Performance evaluation on CDMER benchmark
In this experiment, the proposed FR is further evaluated by using CDMER protocol [41]. CDMER protocol contains 12 sub-experiments from the TYPE-I and TYPE-II tasks. The detail setting of CDMER is referred to Section 6 and Table 10. Table 3 and Table 4 compare FR to the state-of-the-art algorithms referred by [43]. Their parameter settings are described as follows:
-
1.
For LBP-TOP [10], the uniform pattern is used. For the neighboring radius and the number of the neighboring points , experiments consider three cases: (R1P4), (R1P8), (R3P4), and (R3P8).
-
2.
For LBP-SIP [14], the neighboring radius is set at 1 and 3, respectively.
-
3.
For LPQ-TOP [63], the size of the local window in each dimension is set as , and the factor for correlation model is set as [0.1, 0.1] and [0, 0], respectively.
-
4.
The number of bins is set as 4 and 8 for HOG-TOP and HIGH-TOP [62], respectively.
- 5.
| Groups | Approaches | SMIC-HS | CASME II | CASME II | SAMM | Average |
| (5 classes) | (4 classes) | |||||
| Handcrafted features | LBP-TOP [10] | 0.4878 | - | 0.4090∗ | 0.4150∗ | 0.4357 |
| OSF + OS weighted LBP-TOP [67] | 0.5244 | - | - | - | 0.5244 | |
| OS [68] | 0.5356 | - | - | - | 0.5356 | |
| OS weighted LBP-TOP [69] | 0.5366 | 0.4200 | - | - | 0.4783 | |
| STM [70] | 0.4434 | 0.4378 | - | - | 0.4406 | |
| LBP-MOP [11] | 0.5061 | 0.4413 | - | - | 0.4737 | |
| LBP-TOP + ROIs [71] | 0.5400 | 0.4600 | - | - | 0.5000 | |
| LBP-SIP [14] | 0.4451 | 0.4656 | 0.4570∗ | 0.4170∗ | 0.4462 | |
| LBP-TOP + DMDSP [72] | 0.5800 | 0.4900 | - | - | 0.5350 | |
| LBP-TOP + Adaptive MM [73] | 0.5191 | - | - | - | 0.5191 | |
| HFOFO [74] | 0.5183 | 0.5664 | - | - | 0.5424 | |
| STCLQP [12] | 0.6402 | 0.5839 | - | - | 0.6121 | |
| STLBP-IP [17] | 0.5793 | 0.5951 | 0.5510∗ | 0.5680∗ | 0.5734 | |
| MMFL [75] | 0.6315 | 0.5981 | - | - | 0.6148 | |
| Hierarchical STLBP-IP [13] | 0.6078 | 0.6383 | - | - | 0.6231 | |
| STRBP [76] | 0.6098 | 0.6437 | - | - | 0.6268 | |
| DiSTLBP-RIP [18] | 0.6341 | 0.6478 | - | - | 0.6410 | |
| MDMO [21] | 0.6150∗ | - | 0.5100∗ | - | 0.5630 | |
| FDM [7] | 0.5488 | 0.4593 | 0.4170∗ | - | 0.4750 | |
| Bi-WOOF [22] | 0.5930∗ | - | 0.5890∗ | 0.5980∗ | 0.5930 | |
| OF Maps [77] | - | 0.6535 | - | - | 0.6535 | |
| Bi-WOOF + Phase [78] | 0.6829 | 0.6255 | - | - | 0.6542 | |
| HIGO [62] | 0.6524 | 0.5709 | - | - | 0.6117 | |
| Deep learning features | Image-based CNN [79] | 0.3120∗ | - | 0.4440∗ | 0.4360∗ | 0.3973 |
| 3D-FCNN [32] | 0.5549 | 0.5911 | - | - | 0.5730 | |
| CNN + LSTM [24] | - | 0.6098 | - | - | 0.6098 | |
| STRCN-A [31] | 0.4810 | - | 0.4710 | 0.4880 | 0.4800 | |
| STRCN-G [31] | 0.5760 | - | 0.6210 | 0.6420 | 0.6130 | |
| FR (Ours) | 0.5790 | 0.6285 | 0.6838 | 0.6013 | 0.6232 | |
| means that we directly extracted the result from [31] as the original papers did not report these relevant results. | ||||||
4.5.1 Comparison with handcrafted features
As seen from Table 3 and Table 4, our proposed FR outperforms all handcrafted features in terms of both unweighted F1-score and accuracy. Additionally, two important observations are concluded as follows:
-
1.
The performance of handcrafted features fluctuates greatly with the adjustment of parameters. For example, in Table 3, as the results of LBP-TOP in Exp.1 of Type-I task showed, it gains considerable performance (0.8561 / 0.8592) under R1P8, but worse result (0.4656 / 0.4930) under R3P4. The same to LBP-SIP in Exp.9 of Table 4.
-
2.
Varied parameters lead to perform unsteadily for Engineered features on all tasks. Instead, our proposed FR achieves the stable performance. For example, although LPQ-TOP(decorr=0.1) obtains better results (with UF1 being 0.9455, with Acc being 0.9437) than our proposed FR (with UF1 being 0.7065, with Acc being 0.7149) in Exp.1 of TYPE-I task, but dramatically degrades performance in Exp.3 of TYPE-II task. Therefore, the both two observations indicate that our proposed method performs more stable and robust (database-invariant) to different situations than engineered features.
4.5.2 Comparison with deep learning features
FR outperforms image-based C3D, which used the small scale of micro-expression data and low intensity of micro-expressions. It suggests that exploiting available information e.g. optical flow and shallow network will benefit to MER.
Finally, the results of experiments on CDE and CDMER protocols demonstrate that FR performs robust recognition in complex situations, e.g. cross-database MER.
4.6 Performance evaluation on the single database
Table 5 compares our proposed FR to the state-of-the-art algorithms on four single micro-expression database.
4.6.1 Comparison with handcrafted features
FR outperforms most of the handcrafted features listed in Table 5 in terms of average recognition accuracy, except STRBP [76], DiSTLBP-RIP [18], OF Maps [77], and Bi-WOOF with Phase [78]. It suggests that although almost many of the research fields in computer vision are focusing on the deep learning century, traditional machine learning features play an importance role in MER. It is explained by the scale of data.
As we know, OF Maps and Bi-WOOF with Phase need more process to extract better features and are based on professional knowledge. Specifically, they all need to compute direction and magnitude statistical profiles of optical flow, and Bi-WOOF with Phase also needs using Riesz transform to extract phase information. On the other hand, LBP-based features of STRBP and DiSTLBP-RIP are based on the entire sequence of samples, which also need to use temporal interpolation method (TIM) [80] to normalize each video for performance improvement. In contrast, our proposed FR only needs simple pre-processing, e.g. face detection, apex frame chosen, and optical flow extraction.
4.6.2 Comparison with deep learning features
Furthermore, Table 5 compares our proposed FR to Image-based CNN [79], 3D-FCNN [32], CNN with LSTM [24], and Spatiotemporal Recurrent Convolutional Networks (STRCN) [31], of which experiments were conducted on the same database and micro-expression categories to ours. Specifically, STRCN contains STRCN-A and STRCN-G. The first one vertorizes one channel of a frame into a column of the matrix for the appearance features, while the latter one uses optical flow images as the input to train the model. First, Table 5 shows all the handcrafted features outperform the Image-based CNN feature [79], because Image-based CNN feature ignored the temporal information. On the other hand, other works on CNN [32, 24] demonstrate temporal information significantly boosts the performance of CNN. Thus, these results suggest that when designing CNN for MER, temporal information should be considered. Furthermore, FR gains a considerable improvement of 14.32% by comparing with STRCN-A. FR obtains competitive performance to STRCN-G. The comparison suggests that geometric-based features may become a complementary information to deep learning model. Additionally, the comparison motivates us to consider how the geometric-based features are embedded in our FR model in future. Finally, our FR suppresses all the deep learning features. The comparison results demonstrate that both expression-specific feature and feature fusion contribute the discriminative information to MER in deep learning methods.
| Model | UF1 | UAR |
|---|---|---|
| Basic Inception | 0.7360 | 0.7391 |
| FR | 0.7838 | 0.7832 |
4.7 Analysis on feature’s salience and discrimination
As previously described in Section 3, expression-specific feature learning and fusion aim to learn the salient and discriminative feature. Here, to better reveal the effect of expression-specific feature learning and fusion module to FR, the comparison is conducted to compare the expression-refined features to the expression-shared features obtained by the Basic Inception on the composite database. The CDE protocol is used.
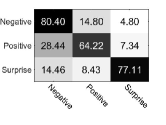
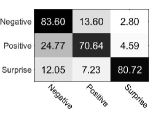
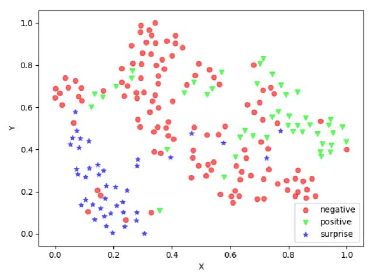
Table 6 reports comparison results in terms of UF1 and UAR. It is seen that with expression-specific feature learning and fusion module FR obtains the significant improvement which improves the Basic Inception from 73.60% to 78.38% in terms of UF1, from 73.91% to 78.32% in terms of UAR. This suggests that expression-specific feature learning and fusion module is the most contributed module for our FR. Furthermore, Fig. 3 shows the confusion matrices of Basic Inception and FR on each micro-expression category. As seen from Fig. 3, FR obtains the accuracy of 83.60%, 70.64%, and 80.72% for negative, positive, and surprise, respectively. When adding expression-specific feature learning and fusion module to FR, FR improves Basic Inception consistently with gains of 3.2%, 6.42%, and 3.61% for negative, positive, and surprise, respectively. This indicates that the expression-refined features can improve the salience in each class and highlight the specific characteristics of each type of expression, and thus perform better than the expression-shared features in individual categories.
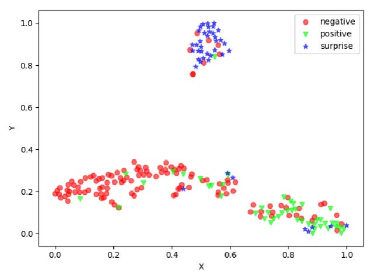
In order to get more reasonable and stable feature distribution visualization, 34 subjects are randomly chosen, where 282 samples are used for training and the rest for testing. Fig. 4 shows the feature distribution of Basic Inception and FR from the testing samples, where all features are mapped to 2D using t-SNE [81]. For the Basic Inception model, the features are from the concentrated layer before the classifier, while for FR, the expression-refined features are obtained before the finally classification module. It is observed that the feature representations learned by FR are better separated, making the intra-class distribution more compact and the inter-class distribution more dispersed. These visualization results indicate that expression-refined features learned by FR are more discriminative than the expression-shared features learned by Basic Inception.
| Methods | SMIC-HS | CASME II (4 classes) | SAMM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | Parameter | ET | Acc | Parameter | ET | Acc | Parameter | ET | |
| () | () | () | () | () | () | ||||
| Basic Inception | 0.5612 | 6.4803 | 15.0610 | 0.6601 | 6.4813 | 32.9442 | 0.5783 | 6.4813 | 18.5792 |
| FR | 0.5790 | 10.2418 | 15.5559 | 0.6838 | 11.4231 | 36.7728 | 0.6013 | 11.4231 | 20.6564 |
4.8 Analysis on the complexity of the expression-specific feature learning and fusion
As previously described in Section 3, FR with the backbone of Basic Inception learns expression-shared feature, while FR with the expression-specific feature learning and fusion module learns and aggregates expression-specific feature. To analyze the complexity of the expression-specific feature learning and fusion of FR, Table 7 compares FR to Basic Inception in terms of accuracy (Acc), learnable parameters (Parameters), and execution time (ET) on three micro-expression databases.
According to Table 7, compared with the number of parameters in Basic Inception, the learnable parameters size indeed increases significantly in FR which is caused by the expression-specific feature learning and fusion. In other words, as SMIC-HS contains three categories, FR includes three expression-specific feature learning sub-branches. It leads to more 3.7615 parameters to learn, but only more 0.4949 to execute for FR when compared with Basic Inception. It reveals that although the number of parameters increases by adding expression-specific feature learning and fusion module, the additional execution time is still acceptable. The comparison results and analysis validate expression-specific feature learning and fusion is still efficient and effective for MER.
| Protocols | Experiments | Acc | Validation rule |
|---|---|---|---|
| CDE | - | 0.6951 | LOSO |
| CDMER | Exp.2: VH | 0.5968 | 5-fold |
| Exp.4: NH | 0.5200 | 5-fold | |
| Exp.7: CH | 0.4905 | 5-fold | |
| Single database | - | 0.5790 | LOSO |
4.9 Discussion on three protocols
This previous parts extensively discuss on results under CDE, CDMER, and the single database evaluation protocols. According to the previously discussed results, several observations can be concluded in the following. First, algorithm in the single database of SMIC-HS obtained worse results than by using CDMER protocol. Second, algorithm failed to achieve same or similar performance under CDE protocol and in the single database experiment. The following will discuss these two observations.
(1) Why does algorithm under single database evaluation not always outperform under CDMER protocol?
According to Table 8, the performance of SMIC-HS database under the single database protocol is only better than that of CDMER protocol in the and . In contrast, it works worse than CDMER in the . In and , the data between SMIC-NIR/CASME II and SMIC-HS is heterogeneous. In other words, the data were collected under different conditions. In contrast, in , samples in SMIC-VIS recorded by a normal visual camera are more similarly to the sample in SMIC-HS database. As well, both databases contains the same participants.
The recent works [39, 45, 30] have indicated that the model leveraging on macro-expression can boost the deep neural network. The way may benefit to micro-expression recognition: Compared with collecting more micro-expressions of a person to reveal one’s true feeling, it is much easier to collect the person’s macro-expressions. It motivates us to leverage macro-expressions transferring learning method to boost our proposed FR in future. Additionally, leveraging the subject information and transfer learning strategy allows us to obtain better recognition performance.
(2) Why does algorithm under CDE protocol outperform that under the single database evaluation?
This is explained by that increasing number of samples from other micro-expression databases and the optical flow feature contribute to FR. As we know, more samples can partly avoid from the overfitting problem. On the other hand, in our framework, optical flow is fed into FR. Optical flow mainly focuses on extracting motion feature of samples, which mostly suppresses the facial identity. Consequently, besides transfer learning and other domain adaption mechanisms, adding samples from different micro-expression databases and also utilizing proper motion feature to train the model is a considerable approach to obtain better performance of MER.
5 Conclusion
In this paper, we propose a novel approach for micro-expression recognition, which involves three feature refinement stages: expression-shared feature learning, expression-specific feature distilling, and expression-specific feature fusion. Different from the existing deep learning methods in MER which focus on learning expression-shared features, our approach aims to learn a set of expression-refined features by expression-specific feature learning and fusion. To make the learned feature more salient and discriminative, we propose a constructive but straightforward attention strategy and a simple proposal loss in expression proposal module for expression-specific feature learning. Experiments on three publicly available micro-expression databases and three different evaluation scenarios testify the efficacy of our proposed approach. In the future, we will consider an end-to-end approach for MER, find more effective ways to enrich the micro-expression samples, and use transfer learning from the large-scale databases to make benefit for MER.
6 Appendix: experiment settings and evaluation metrics for experiments
6.1 Detail experiment settings for four types of experiments
Firstly, to easily understand the settings of the four types of experiments, we give the detailed description of the experiment settings as follows.
6.1.1 Settings of model ablation
Ablation study is conducted on the CDE protocol in MEGC 2019 [35], where this study focuses on choosing the backbone for expression-shared feature learning, the strategy for expression-specific feature learning, and the fusion mode for expression-specific features aggregating.
According to the CDE protocol, LOSO validation is used to evaluate the model performance. SMIC-HS, CASME II, and SAMM are merged into one dataset. To make these databases share the common types of expression, original emotion classes are re-grouped into three main categories, i.e. Positive, Surprise, and Negative. Specifically, samples of Happiness are given Positive labels while the labels of Surprise samples are unchanged. Samples of Disgust, Repression, Anger, Contempt, Fear, and Sadness are grouped into Negative. Table 9 presents the detail information about three databases used for CDE protocol.
In the ablation experiment, without momentum, the batch size, learning rate, and loss function weight factor are set as 32, 0.001, and 0.85, respectively.
| Database | Micro-Expression Category | Subjects | |||
| Negative | Positive | Surprise | Total | ||
| SMIC-HS [48] | 70 | 51 | 43 | 164 | 16 |
| CASME II [26] | 88† | 32 | 25 | 145 | 24 |
| SAMM [58] | 92§ | 26 | 15 | 133 | 28 |
| Composite | 250 | 109 | 83 | 442 | 68 |
| Negative class of CASME II: Disgust and Repression. | |||||
| Negative class of SAMM: Anger, Contempt, Disgust, Fear and Sadness. | |||||
| Type | CDMER Task | Source Database | Target Database |
|---|---|---|---|
| Type-I | Exp.1: HV | SMIC-HS | SMIC-VIS |
| Exp.2: VH | SMIC-VIS | SMIC-HS | |
| Exp.3: HN | SMIC-HS | SMIC-NIR | |
| Exp.4: NH | SMIC-NIR | SMIC-HS | |
| Exp.5: VN | SMIC-VIS | SMIC-NIR | |
| Exp.6: NV | SMIC-NIR | SMIC-VIS | |
| Type-II | Exp.7: CH | CASME II | SMIC-HS |
| Exp.8: HC | SMIC-HS | CASME II | |
| Exp.9: CV | CASME II | SMIC-VIS | |
| Exp.10: VC | SMIC-VIS | CASME II | |
| Exp.11: CN | CASME II | SMIC-NIR | |
| Exp.12: NC | SMIC-NIR | CASME II |
| Database | Micro-Expression Category | |||
|---|---|---|---|---|
| Negative | Positive | Surprise | Total | |
| SMIC-HS [48] | 70 | 51 | 43 | 164 |
| SMIC-NIR [48] | 23 | 28 | 20 | 71 |
| SMIC-VIS [48] | 23 | 28 | 20 | 71 |
| CASME II [26] | 73† | 32 | 25 | 130 |
| Negative class of CASME II: Disgust, Sadness and Fear. | ||||
6.1.2 Settings of CDE experiment
Our proposed FR compares with the baseline of MEGC 2019 [82, 10], three popular deep learning networks [60, 55, 61], and several state-of-the-art methods [22, 36, 38, 37, 39, 40]. In the experiments, we use the same expression grouped rules and parameters setting for CDE evaluation to the experiment of model ablation.
6.1.3 Settings of CDMER experiment
This paper evaluates the proposed FR with [10, 14, 63, 62, 64] under CDMER protocol 111http://aip.seu.edu.cn/cdmer/ [41]. Five-fold cross validation.
CDMER protocol: Four publicly available micro-expression databases are used in the CDMER benchmark: SMIC-HS, SMIC-VIS, SMIC-NIR, and CASME II. Different from CDE protocol, in each experiment of CDMER, two of four databases are chosen, where one is used as source database and another as target database. Thus, there are 12 sub-experiments in CDMER. The detail setup is depicted in Table 10. Each source to target sub-experiment of CDMER is denoted by , where is the number of this sub-experiment, and are the source and target databases, respectively.
Table 11 describes the sample distribution for CDMER experiments. The re-group rule for Positive and Surprise classes is the same to the CDE protocol, while the samples with Disgust, Sadness, and Fear classes belong to Negative class. In the CDMER experiment, the learning rate is set as 0.0005, with the momentum rate of 0.8. Batch size and are set as 32 and 0.85, respectively.
| Database | Micro-Expression Category | Subjects | ||||
|---|---|---|---|---|---|---|
| Negative | Positive | Surprise | Others | Total | ||
| SMIC-HS [48] | 70 | 51 | 43 | - | 164 | 16 |
| CASME II [26] | 73† | 32 | 25 | 126§ | 256 | 26 |
| (4 classes) | ||||||
| SAMM [58] | 92♯ | 26 | 15 | 26 | 159 | 32 |
| Negative class of CASME II: Disgust, Sadness and Fear. | ||||||
| Others class of CASME II: Repression and Others. | ||||||
| Negative class of SAMM: Disgust, Anger, Contempt, Fear and Sadness. | ||||||
| Database | Micro-Expression Category | Subjects | |||||
|---|---|---|---|---|---|---|---|
| Repression | Happiness | Surprise | Disgust | Others | Total | ||
| CASME II [26] | 27 | 32 | 25 | 64 | 99 | 247 | 26 |
| (5 classes) | |||||||
6.1.4 Settings of the single database experiment
Leave-one-subject-out (LOSO) protocol is used. The parameters settings of the single database experiment are the same to CDMER evaluation. Table 12 lists the detailed information about “CASME II (4 classes)”, SAMM and SMIC-HS databases.
For CASME II, there are two versions of the database. The first version contains 247 samples of 5 classes, while the second version involves 256 samples labeled as 7 classes. To make fair comparison, we use these two versions of CASME II for the single database experiment. For the first version, we directly use 5 micro-expression categories. For convenience, we abbreviate the first version of CASME II with 5 classes as “CASME II (5 classes)” in our experiment. Table 13 describes the detail information of “CASME II (5 classes)”. Following [21, 15, 13, 31], for the second version, the samples with Happiness class belong to Positive class, while the samples with Surprise class remain the original label. The samples with Disgust, Anger, Contempt, Fear, and Sadness classes are assigned to Negative label. Samples of Repression are labeled to Others class. Lastly, the samples in the second version of CASME II are categorized into four classes. Here, we denote it as “CASME II (4 classes)” in the experiment. The same category protocol is used for SAMM database.
6.2 Detail description for performance metrics
The Acc, UAR, and UF1 metrics are defined as follows:
| (9) |
| (10) |
and
| (11) |
where,
| (12) |
and
| (13) |
where is the number of classes, is the number of folds of LOSO, is the total number of samples in the ground truth of the -th class, and is the per-class accuracy scores. For the -th fold of LOSO by the -th class, , , and are true positives, false positives, and false negatives, respectively.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant 61672267, and Grant U1836220, the Postgraduate Research & Practice Innovation Program of Jiangsu Province under Grant KYCX19_1616, Jiangsu Specially-Appointed Professor Program (No. 3051107219003), Jiangsu joint research project of Sino-foreign cooperative education platform, the Talent Startup project of NJIT (No. YKJ201982), and Central Fund of Finnish Cultural Foundation.
References
- [1] P. Ekman, Telling Lies: Clues to Deceit in the Marketplace, Politics,and Marriage (Revised Edition), WW Norton & Company, 2009.
- [2] Y. Oh, J. See, A. C. L. Ngo, R. C. Phan, V. M. Baskaran, A survey of automatic facial micro-expression analysis: Databases, methods and challenges, Frontiers in Psychology 9 (2018) 1128–1140.
- [3] D. Patel, G. Zhao, M. Pietikäinen, Spatiotemporal integration of optical flow vectors for micro-expression detection, in: Proceedings of the 2015 International Conference of Advanced Concepts for Intelligent Vision Systems Conference (ACIVS), 2015, pp. 369–380.
- [4] P. Ekman, W. V. Friesen, Nonverbal leakage and clues to deception?, Psychiatry-interpersonal & Biological Processes 32 (1) (1969) 88–106.
- [5] N. Michael, M. Dilsizian, D. N. Metaxas, J. K. Burgoon, Motion profiles for deception detection using visual cues, in: Proceedings of the 2010 European Conference on Computer Vision (ECCV), 2010, pp. 462–475.
- [6] P. Ekman, Lie catching and microexpressions, The Philosophy of Deception (2009) 118–136.
- [7] F. Xu, J. Zhang, J. Z. Wang, Microexpression identification and categorization using a facial dynamics map, IEEE Transactions on Affective Computing 8 (2) (2017) 254–267.
- [8] Z. Lu, Z. Luo, H. Zheng, J. Chen, W. Li, A delaunay-based temporal coding model for micro-expression recognition, in: Proceedings of the 2014 Asian Conference on Computer Vision Workshops (ACCV), 2014, pp. 698–711.
- [9] C. Cortes, V. Vapnik, Support-vector networks, Machine Learning 20 (3) (1995) 273–297.
- [10] G. Zhao, M. Pietikäinen, Dynamic texture recognition using local binary patterns with an application to facial expressions, IEEE Transactions on Pattern Analysis and Machine Intelligence 29 (6) (2007) 915–928.
- [11] Y. Wang, J. See, R. C.-W. Phan, Y.-H. Oh, Efficient spatio-temporal local binary patterns for spontaneous facial micro-expression recognition, PLOS ONE 10 (5) (2015) 1–20.
- [12] X. Huang, G. Zhao, X. Hong, W. Zheng, M. Pietikäinen, Spontaneous facial micro-expression analysis using spatiotemporal completed local quantized patterns, Neurocomputing 175 (2016) 564–578.
- [13] Y. Zong, X. Huang, W. Zheng, Z. Cui, G. Zhao, Learning from hierarchical spatiotemporal descriptors for micro-expression recognition, IEEE Transactions on Multimedia 20 (11) (2018) 3160–3172.
- [14] Y. Wang, J. See, R. C. Phan, Y. Oh, LBP with six intersection points: Reducing redundant information in LBP-TOP for micro-expression recognition, in: Proceedings of the 2014 Asian Conference on Computer Vision (ACCV), 2014, pp. 525–537.
- [15] S. Wang, W. Yan, X. Li, G. Zhao, X. Fu, Micro-expression recognition using dynamic textures on tensor independent color space, in: Proceedings of the 2014 International Conference on Pattern Recognition (ICPR), pp. 4678–4683.
- [16] S. Wang, W. Yan, X. Li, G. Zhao, C. Zhou, X. Fu, M. Yang, J. Tao, Micro-expression recognition using color spaces, IEEE Transactions on Image Processing 24 (12) (2015) 6034–6047.
- [17] X. Huang, S. Wang, G. Zhao, M. Pietikäinen, Facial micro-expression recognition using spatiotemporal local binary pattern with integral projection, in: Proceedings of the 2015 International Conference on Computer Vision Workshop (ICCV), 2015, pp. 1–9.
- [18] X. Huang, S. Wang, X. Liu, G. Zhao, X. Feng, M. Pietikäinen, Discriminative spatiotemporal local binary pattern with revisited integral projection for spontaneous facial micro-expression recognition, IEEE Transactions on Affective Computing 10 (1) (2019) 32–47.
- [19] S. Polikovsky, Y. Kameda, Y. Ohta, Facial micro-expressions recognition using high speed camera and 3d-gradient descriptor, in: Proceedings of the 2009 International Conference on Imaging for Crime Detection and Prevention (ICDP), 2009, pp. 1–6.
- [20] S. Polikovsky, Y. Kameda, Y. Ohta, Facial micro-expression detection in hi-speed video based on facial action coding system (FACS), IEICE Transactions 96-D (1) (2013) 81–92.
- [21] Y. Liu, J. Zhang, W. Yan, S. Wang, G. Zhao, X. Fu, A main directional mean optical flow feature for spontaneous micro-expression recognition, IEEE Transactions on Affective Computing 7 (4) (2016) 299–310.
- [22] S. Liong, J. See, K. Wong, R. C. Phan, Less is more: Micro-expression recognition from video using apex frame, Signal Processing: Image Communication 62 (2018) 82–92.
- [23] R. Chaudhry, A. Ravichandran, G. D. Hager, R. Vidal, Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions, in: Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 1932–1939.
- [24] D. H. Kim, W. J. Baddar, Y. M. Ro, Micro-expression recognition with expression-state constrained spatio-temporal feature representations, in: Proceedings of the 2016 ACM Conference on Multimedia (ACM MM), 2016, pp. 382–386.
- [25] S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Computation 9 (8) (1997) 1735–1780.
- [26] W. Yan, X. Li, S. Wang, G. Zhao, Y. Liu, Y. Chen, X. Fu, Casme ii: An improved spontaneous micro-expression database and the baseline evaluation, PLOS ONE 9 (1) (2014) 1–8.
- [27] M. Peng, C. Wang, T. Chen, G. Liu, X. Fu, Dual temporal scale convolutional neural network for micro-expression recognition, Frontiers in Psychology 8 (2017) 1745.
- [28] W. Yan, Q. Wu, Y. Liu, S. Wang, X. Fu, CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces, in: Proceedings of the 2013 International Conference and Workshops on Automatic Face and Gesture Recognition(FG), 2013, pp. 1–7.
- [29] S. Nag, A. K. Bhunia, A. Konwer, P. P. Roy, Facial micro-expression spotting and recognition using time contrasted feature with visual memory, CoRR abs/1902.03514 (2019).
- [30] S. Wang, B. Li, Y. Liu, W. Yan, X. Ou, X. Huang, F. Xu, X. Fu, Micro-expression recognition with small sample size by transferring long-term convolutional neural network, Neurocomputing 312 (2018) 251–262.
- [31] Z. Xia, X. Hong, X. Gao, X. Feng, G. Zhao, Spatiotemporal recurrent convolutional networks for recognizing spontaneous micro-expressions, IEEE Transactions on Multimedia 22 (3) (2020) 626–640.
- [32] J. Li, Y. Wang, J. See, W. Liu, Micro-expression recognition based on 3d flow convolutional neural network, Pattern Analysis and Applications (2018).
- [33] M. Verma, S. K. Vipparthi, G. Singh, S. Murala, Learnet dynamic imaging network for micro expression recognition, CoRR abs/1904.09410 (2019).
- [34] S. P. T. Reddy, S. T. Karri, S. R. Dubey, S. Mukherjee, Spontaneous facial micro-expression recognition using 3d spatiotemporal convolutional neural networks, CoRR abs/1904.01390 (2019).
- [35] J. See, M. H. Yap, J. Li, X. Hong, S. Wang, MEGC 2019 - the second facial micro-expressions grand challenge, in: Proceedings of the 2019 International Conference on Automatic Face & Gesture Recognition (FG), 2019, pp. 1–5.
- [36] Y. S. Gan, S. Liong, W. Yau, Y. Huang, T. L. Ken, Off-apexnet on micro-expression recognition system, Signal Processing: Image Communication 74 (2019) 129–139.
- [37] S. Liong, Y. S. Gan, J. See, H. Khor, Y. Huang, Shallow triple stream three-dimensional CNN (ststnet) for micro-expression recognition, in: Proceedings of the 2019 International Conference on Automatic Face & Gesture Recognition (FG), 2019, pp. 1–5.
- [38] L. Zhou, Q. Mao, L. Xue, Dual-inception network for cross-database micro-expression recognition, in: Proceedings of the 2019 International Conference on Automatic Face & Gesture Recognition (FG), 2019, pp. 1–5.
- [39] Y. Liu, H. Du, L. Zheng, T. Gedeon, A neural micro-expression recognizer, in: Proceedings of the 2019 International Conference on Automatic Face & Gesture Recognition (FG), 2019, pp. 1–4.
- [40] N. V. Quang, J. Chun, T. Tokuyama, Capsulenet for micro-expression recognition, in: Proceedings of the 2019 International Conference on Automatic Face & Gesture Recognition (FG), 2019, pp. 1–7.
- [41] Y. Zong, X. Huang, W. Zheng, Z. Cui, G. Zhao, Learning a target sample re-generator for cross-database micro-expression recognition, in: Proceedings of the 2017 ACM International Conference on Multimedia (ACM MM), 2017, pp. 872–880.
- [42] M. H. Yap, J. See, X. Hong, S. Wang, Facial micro-expressions grand challenge 2018 summary, in: Proceedings of the 2018 International Conference on Automatic Face & Gesture Recognition (FG), 2018, pp. 675–678.
- [43] Y. Zong, W. Zheng, X. Hong, C. Tang, Z. Cui, G. Zhao, Cross-database micro-expression recognition: A benchmark, in: Proceedings of the 2019 International Conference on Multimedia Retrieval (ICMR), 2019, pp. 354–363.
- [44] Y. Zong, W. Zheng, X. Huang, J. Shi, Z. Cui, G. Zhao, Domain regeneration for cross-database micro-expression recognition, IEEE Transactions on Image Processing 27 (5) (2018) 2484–2498.
- [45] M. Peng, Z. Wu, Z. Zhang, T. Chen, From macro to micro expression recognition: Deep learning on small datasets using transfer learning, in: Proceedings of the 2018 International Conference on Automatic Face & Gesture Recognition (FG), 2018, pp. 657–661.
- [46] H. Khor, J. See, R. C. Phan, W. Lin, Enriched long-term recurrent convolutional network for facial micro-expression recognition, in: Proceedings of the 2018 International Conference on Automatic Face & Gesture Recognition (FG), 2018, pp. 667–674.
- [47] Y. Guo, F. Chung, G. Li, J. Wang, J. C. Gee, Leveraging label-specific discriminant mapping features for multi-label learning, The ACM Transactions on Knowledge Discovery from Data (TKDD) 13 (2) (2019) 24:1–24:23.
- [48] X. Li, T. Pfister, X. Huang, G. Zhao, M. Pietikäinen, A spontaneous micro-expression database: Inducement, collection and baseline, in: Proceedings of the 2013 International Conference and Workshops on Automatic Face and Gesture Recognition (FG), 2013, pp. 1–6.
- [49] S. Liong, J. See, K. Wong, A. C. L. Ngo, Y. Oh, R. C. Phan, Automatic apex frame spotting in micro-expression database, in: Proceedings of the 2015 Asian Conference on Pattern Recognition (ACPR), 2015, pp. 665–669.
- [50] Y. Li, X. Huang, G. Zhao, Can micro-expression be recognized based on single apex frame?, in: Proceedings of the 2018 International Conference on Image Processing (ICIP), 2018, pp. 3094–3098.
- [51] W. Yan, S. Wang, Y. Chen, G. Zhao, X. Fu, Quantifying micro-expressions with constraint local model and local binary pattern, in: L. Agapito, M. M. Bronstein, C. Rother (Eds.), Proceedings of the 2014 European Conference on Computer Vision Workshops (ECCVW), 2014, pp. 296–305.
- [52] M. Peng, C. Wang, T. Bi, Y. Shi, X. Zhou, T. Chen, A novel apex-time network for cross-dataset micro-expression recognition, in: Proceedings of the 2019 International Conference on Affective Computing and Intelligent Interaction?ACII?, pp. 1–6.
- [53] S. Liong, Y. S. Gan, D. Zheng, S. Lic, H. Xua, H. Zhang, R. Lyu, K. Liu, Evaluation of the spatio-temporal features and GAN for micro-expression recognition system, CoRR.
- [54] C. Zach, T. Pock, H. Bischof, A duality based approach for realtime tv-L optical flow, in: Proceedings of the 2007 Pattern Recognition,DAGM Symposium, 2007, pp. 214–223.
- [55] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. E. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, Going deeper with convolutions, in: Proceedings of the 2015 International Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1–9.
- [56] Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE 86 (1998) 2278–2324.
- [57] J. Wu, L. Wang, L. Wang, J. Guo, G. Wu, Learning actor relation graphs for group activity recognition, in: Proceedings of the 2019 Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 9964–9974.
- [58] A. K. Davison, C. Lansley, N. Costen, K. Tan, M. H. Yap, SAMM: A spontaneous micro-facial movement dataset, IEEE Transactions on Affective Computing 9 (1) (2018) 116–129.
- [59] S. Yu, J. Wu, S. Wu, D. Xu, Lib face detection. https://github.com/shiqiyu/libfacedetection/ (2016).
- [60] A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, in: Proceedings of the 2012 Internationla Conference on Neural Information Processing Systems (NeurIPS), 2012, pp. 1106–1114.
- [61] K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, CoRR abs/1409.1556 (2014).
- [62] X. Li, X. Hong, A. Moilanen, X. Huang, T. Pfister, G. Zhao, M. Pietikäinen, Towards reading hidden emotions: A comparative study of spontaneous micro-expression spotting and recognition methods, IEEE Transactions on Affective Computing 9 (4) (2018) 563–577.
- [63] J. Päivärinta, E. Rahtu, J. Heikkilä, Volume local phase quantization for blur-insensitive dynamic texture classification, in: Proceedings of 2011 Scandinavian Conference on Image Analysis (SCIA), 2011, pp. 360–369.
- [64] D. Tran, L. D. Bourdev, R. Fergus, L. Torresani, M. Paluri, Learning spatiotemporal features with 3d convolutional networks, in: Proceedings of the 2015 International Conference on Computer Vision (ICCV), 2015, pp. 4489–4497.
- [65] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, F. Li, Large-scale video classification with convolutional neural networks, in: Proceedings of the 2014 International Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1725–1732.
- [66] K. Soomro, A. R. Zamir, M. Shah, UCF101: A dataset of 101 human actions classes from videos in the wild, CoRR abs/1212.0402 (2012).
- [67] S. Liong, J. See, R. C. Phan, Y. Oh, A. C. L. Ngo, K. Wong, S. Tan, Spontaneous subtle expression detection and recognition based on facial strain, Signal Processing: Image Communication 47 (2016) 170–182.
- [68] S. Liong, R. C. Phan, J. See, Y. Oh, K. Wong, Optical strain based recognition of subtle emotions, in: Proceedings of the 2014 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), IEEE, 2014, pp. 180–184.
- [69] S. Liong, J. See, R. C. Phan, A. C. L. Ngo, Y. Oh, K. Wong, Subtle expression recognition using optical strain weighted features, in: Proceedings of the 2014 Asian Conference on Computer Vision (ACCV), 2014, pp. 644–657.
- [70] A. C. L. Ngo, R. C. Phan, J. See, Spontaneous subtle expression recognition: Imbalanced databases and solutions, in: Proceedings of the 2014 Asian Conference on Computer Vision (ACCV), 2014, pp. 33–48.
- [71] S. Liong, J. See, R. C. Phan, K. Wong, S. Tan, Hybrid facial regions extraction for micro-expression recognition system, Journal of Signal Processing Systems 90 (4) (2018) 601–617.
- [72] A. C. L. Ngo, J. See, R. C. Phan, Sparsity in dynamics of spontaneous subtle emotions: Analysis and application, IEEE Transactions on Affective Computing 8 (3) (2017) 396–411.
- [73] S. Y. Park, S. Lee, Y. M. Ro, Subtle facial expression recognition using adaptive magnification of discriminative facial motion, in: X. Zhou, A. F. Smeaton, Q. Tian, D. C. A. Bulterman, H. T. Shen, K. Mayer-Patel, S. Yan (Eds.), Proceedings of the 2015 ACM Conference on Multimedia Conference (ACM MM), ACM, 2015, pp. 911–914.
- [74] S. L. Happy, A. Routray, Fuzzy histogram of optical flow orientations for micro-expression recognition, IEEE Transactions on Affective Computing 10 (3) (2019) 394–406.
- [75] J. He, J. Hu, X. Lu, W. Zheng, Multi-task mid-level feature learning for micro-expression recognition, Pattern Recognition 66 (2017) 44–52.
- [76] X. Huang, G. Zhao, Spontaneous facial micro-expression analysis using spatiotemporal local radon-based binary pattern, in: Proceedings of the 2017 International Conference on Frontiers and Advances in Data Science (FADS), 2017, pp. 159–164.
- [77] B. Allaert, I. M. Bilasco, C. Djeraba, Consistent optical flow maps for full and micro facial expression recognition, in: F. H. Imai, A. Trémeau, J. Braz (Eds.), Proceedings of the 2017 International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP), SciTePress, 2017, pp. 235–242.
- [78] S. Liong, K. Wong, Micro-expression recognition using apex frame with phase information, in: Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), IEEE, 2017, pp. 534–537.
- [79] M. A. Takalkar, M. Xu, Image based facial micro-expression recognition using deep learning on small datasets, in: Proceedings of the 2017 International Conference on Digital Image Computing: Techniques and Applications (DICTA), 2017, pp. 1–7.
- [80] Z. Zhou, G. Zhao, Y. Guo, M. Pietikäinen, An image-based visual speech animation system, IEEE Transactions on Circuits and Systems for Video Technology 22 (10) (2012) 1420–1432.
- [81] G. H. Laurens van der Maaten, Visualizing data using t-sne, Journal of Machnine Learning Research 9 (2008) 2579–2605.
- [82] T. Pfister, X. Li, G. Zhao, Recognising spontaneous facial micro-expressions, in: Proceedings of the 2011 International Conference on Computer Vision (ICCV), 2011, pp. 1449–1456.
Ling Zhou received her MS degree in in computer science and technology from the Huazhong University of Science and Technology, Wuhan, China in 2011. She is currently working toward the Ph.D. degree with the School of Computer Science and Communication Engineering, Jiangsu University. Her current research interests include multimedia analysis and micro- expression recognition.
Qirong Mao received her MS and Ph.D. degree from Jiangsu University, Zhenjiang, P. R. China in 2002 and 2009, both in computer application technology. She is currently a professor of the School of Computer Science and Communication Engineering, Jiangsu University. Her research interests include affective computing, pattern recognition, and multimedia analysis. Her research is supported by the key project of National Science Foundation of China (NSFC), Jiangsu province, and the Education Department of Jiangsu province. She has published over 50 technical articles, some of them in premium journals and conferences such as IEEE Trans. on Multimedia, IEEE CVPR, ACM Multimedia. She is a member of the IEEE and ACM.
Xiaohua Huang received the B.S. degree in communication engineering from Huaqiao University, Quanzhou, China in 2006. He received his Ph.D degree in Computer Science and Engineering from University of Oulu, Oulu, Finland in 2014. He was a research assistant in Southeast University since 2006. He had been a senior researcher in the Center for Machine Vision and Signal Analysis at University of Oulu in since 2015. He is currently a professor at Nanjing Institute of Technology, China. He has authored or co-authored more than 40 papers in journals and conferences, and has served as a reviewer for journals and conferences. His current research interests include facial expression recognition, micro-expression analysis, group-level emotion recognition, multi-modal emotion recognition and texture classification. He is a member of the IEEE.
Feifei Zhang received the Ph.D. degree in JiangSu Univerisity, Zhenjiang, Jiangsu, China, in 2019. She is currently an Assistant Professor in Multimedia Computing Group, National Laboratory of Pattern Recognition, Institute of Automation Chinese Academy of Sciences, Beijing, China. Her current research interests include multimedia analysis, computer vision, deep learning, especially multimedia computing, facial expression recognition and cross-modal image retrieval. She has published over 10 technical articles (as the first author), some of them in premium journals and conferences such as IEEE Trans. on Image Processing, IEEE CVPR, and ACM Multimedia.
Zhihong Zhang received his BSc degree (1st class Hons.) in computer science from the University of Ulster, UK, in 2009 and the PhD degree in computer science from the University of York, UK, in 2013. He won the K. M. Stott prize for best thesis from the University of York in 2013. He is now an associate professor at the software school of Xiamen University, China. His research interests are wide-reaching but mainly involve the areas of pattern recognition and machine learning, particularly problems involving graphs and networks.