Feeling of Presence Maximization: mmWave-Enabled Virtual Reality Meets Deep Reinforcement Learning
Abstract
This paper investigates the problem of providing ultra-reliable and energy-efficient virtual reality (VR) experiences for wireless mobile users. To ensure reliable ultra-high-definition (UHD) video frame delivery to mobile users and enhance their immersive visual experiences, a coordinated multipoint (CoMP) transmission technique and millimeter wave (mmWave) communications are exploited. Owing to user movement and time-varying wireless channels, the wireless VR experience enhancement problem is formulated as a sequence-dependent and mixed-integer problem with a goal of maximizing users’ feeling of presence (FoP) in the virtual world, subject to power consumption constraints on access points (APs) and users’ head-mounted displays (HMDs). The problem, however, is hard to be directly solved due to the lack of users’ accurate tracking information and the sequence-dependent and mixed-integer characteristics. To overcome this challenge, we develop a parallel echo state network (ESN) learning method to predict users’ tracking information by training fresh and historical tracking samples separately collected by APs. With the learnt results, we propose a deep reinforcement learning (DRL) based optimization algorithm to solve the formulated problem. In this algorithm, we implement deep neural networks (DNNs) as a scalable solution to produce integer decision variables and solve a continuous power control problem to criticize the integer decision variables. Finally, the performance of the proposed algorithm is compared with various benchmark algorithms, and the impact of different design parameters is also discussed. Simulation results demonstrate that the proposed algorithm is more energy-efficient than the benchmark algorithms.
Index Terms:
Virtual reality, coordinated multipoint transmission, feeling of presence, parallel echo state network, deep reinforcement learningI Introduction
Virtual reality (VR) applications have attracted tremendous interest in various fields, including entertainment, education, manufacturing, transportation, healthcare, and many other consumer-oriented services [1]. These applications exhibit enormous potential in the next generation of multimedia content envisioned by enterprises and consumers through providing richer and more engaging, and immersive experiences. According to market research [2], the VR ecosystem is predicted to be an billion market by 2025, roughly the size of the desktop PC market today.
However, several major challenges need to be overcome such that businesses and consumers can get fully on board with VR technology [3], one of which is to provide compelling content. To this aim, the resolution of provided content must be guaranteed. In VR applications, VR wearers can either view objects up close or across a wide field of view (FoV) via head-mounted or goggle-type displays (HMDs). As a result, very subtle defects such as poorly rendering pixels at any point on an HMD may be observed by a user up close, which may degrade users’ truly visual experiences. To create visually realistic images across the HMD, it must have more display pixels per eye, which indicates that ultra-high-definition (UHD) video frame transmission must be enabled for VR applications. However, the transmission of UHD video frames typically requires times the system bandwidth occupied for delivering a regular high-definition (HD) video [4, 5]. Further, to achieve good user visual experiences, the motion-to-photon latency should be ultra-low (e.g., ms) [6, 7, 8]. High motion-to-photon values will send conflicting signals to the Vestibulo-ocular reflex (VOR) and then might cause dizziness or motion sickness.
Hence, today’s high-end VR systems such as Oculus Rift [9] and HTC Vive [10] that offer high quality and accurate positional tracking remain tethered to deliver UHD VR video frames while satisfying the stringent low-latency requirement. Nevertheless, wired VR display may degrade users’ seamless visual experiences due to the constraint on the movement of users. Besides, a tethered VR headset presents a potential tripping hazard for users. Therefore, to provide ultimate VR experiences, VR systems or at least the headset component should be untethered [6].
Recently, the investigation on wireless VR has attracted numerous attention from both industry and academe; of particular interest is how to a) develop mobile (wireless and lightweight) HMDs, b) how to enable seamless and immersive VR experiences on mobile HMDs in a bandwidth-efficiency manner, while satisfying ultra-low-latency requirements.
I-A Related work
On the aspect of designing lightweight VR HMDs, considering heavy image processing tasks, which are usually insufficient in the graphics processing unit (GPU) of a local HMD, one might be persuaded to transfer the image processing from the local HMD to a cloud or network edge units (e.g., edge servers, base stations, and access points (APs)). For example, the work in [1] proposed to enable mobile VR with lightweight VR glasses by completing computation-intensive tasks (such as encoding and rendering) on a cloud/edge server and then delivering video streams to users. The framework of fog radio access networks, which could significantly relieve the computation burden by taking full advantages of the edge fog computing, was explored in [11] to facilitate the lightweight HMD design.
In terms of proposing VR solutions with improved bandwidth utilization, current studies can be classified into two groups: tiling and video coding [12] As for tiling, some VR solutions propose to spatially divide VR video frames into small parts called tiles, and only tiles within users’ FoV are delivered to users [13, 14, 15]. The FoV of a user is defined as the extent of the observable environment at any given time. By sending HD tiles in users’ FoV, the bandwidth utilization is improved. On the aspect of video coding, the VR video is encoded into multiple versions of different quality levels. Viewers receive appropriate versions based on their viewing directions [16].
Summarily, to improve bandwidth utilization, the aforementioned works [13, 14, 15, 16] either transmit relatively narrow user FoV or deliver HD video frames. Nevertheless, wider FoV is significantly important for a user to have immersive and presence experiences. Meanwhile, transmitting UHD video frames can enhance users’ visual experiences. To this aim, advanced wireless communication techniques (particularly, millimeter wave (mmWave)), which can significantly improve data rates and reduce propagation latency via providing wide bandwidth transmission, are explored in VR video transmission [4, 17, 18]. For example, the work in [4] utilized a mmWave-enabled communication architecture to support the panoramic and UHD VR video transmission. Aiming to improve users’ immersive VR experiences in a wireless multi-user VR network, a mmWave multicast transmission framework was developed in [17]. Besides, the mmWave communication for ultra-reliable and low latency wireless VR was investigated in [18].
I-B Motivation and contributions
Although mmWave techniques can alleviate the current bottleneck for UHD video delivery, mmWave links are prone to outage as they require line-of-sight (LoS) propagation. Various physical obstacles in the environment (including users’ bodies) may completely break mmWave links [19]. As a result, VR requirements for a perceptible image-quality degradation-free uniform experience cannot be accommodated. However, the mmWave VR-related works in [4, 17, 18] did not effectively investigate the crucial issue of guaranteeing the transmission reliability of VR video frames. To significantly improve the transmission reliability of VR video frames under low-latency constraints, the coordinated multipoint (CoMP) transmission technique, which can improve the reliability via spatial diversity, can be explored [20]. Besides, it is extensively considered that proactive computing (e.g., image processing or frame rendering) enabled by adopting machine learning methods is a crucial ability for a wireless VR network to mandate the stringent low-latency requirement of UHD VR video transmission [1, 21, 19, 22]. Therefore, this paper investigates the issue of maximizing users’ feeling of presence (FoP) in their virtual world in a mmWave-enabled VR network incorporating CoMP transmission and machine learning. The main contributions of this paper are summarized as follows:
-
•
Owing to the user movement and the time-varying wireless channel conditions, we formulate the issue of maximizing users’ FoP in virtual environments as a mixed-integer and sequential decision problem, subject to power consumption constraints on APs and users’ HMDs. This problem is difficult to be directly solved by exploring conventional numerical optimization methods due to the lack of accurate users’ tracking information (including users’ locations and orientation angles) and mixed-integer and sequence-dependent characteristics.
-
•
As users’ historical tracking information is separately collected by diverse APs, a parallel echo state network (ESN) learning method is designed to predict users’ tracking information while accelerating the learning process.
-
•
With the predicted results, we develop a deep reinforcement learning (DRL) based optimization algorithm to tackle the mixed-integer and sequential decision problem. Particularly, to avoid generating infeasible solutions by simultaneously optimizing all variables while alleviating the curse of dimensionality issue, the DRL-based optimization algorithm decomposes the formulated mixed-integer optimization problem into an integer association optimization problem and a continuous power control problem. Next, deep neural networks (DNNs) with continuous action output spaces followed by an action quantization scheme are implemented to solve the integer association problem. Given the association results, the power control problem is solved to criticize them and optimize the transmit power.
-
•
Finally, the performance of the proposed DRL-based optimization algorithm is compared with various benchmark algorithms, and the impact of different design parameters is also discussed. Simulation results demonstrate the effectiveness of the proposed algorithm.
II System Model and problem formulation
As shown in Fig. 2, we consider a mmWave-enabled VR network incorporating a CoMP transmission technique. This network includes a centralized unit (CU) connecting to distributed units (DUs) via optical fiber links, a set of access points (APs) connected with the DUs, and a set of of ground mobile users wearing HMDs. To acquire immersive and interactive experiences, users will report their tracking information to their connected APs via reliable uplink communication links. Further, with collected users’ tracking information, the CU will centrally simulate and construct virtual environments and coordinately transmit UHD VR videos to users via all APs in real time. To accomplish the task of enhancing users’ immersive and interactive experiences in virtual environments, joint uplink and downlink communications should be considered. We assume that APs and users can work at both mmWave (exactly, 28 GHz) and sub-6 GHz frequency bands, where the mmWave frequency band is reserved for downlink UHD VR video delivery, and the sub-6 GHz frequency band is allocated for uplink users’ tracking information transmission. This is because an ultra-high data rate can be achieved on the mmWave frequency band, and sub-6 GHz can support reliable communications. Besides, to theoretically model the joint uplink and downlink communications, we suppose that the time domain is discretized into a sequence of time slots in the mmWave-enabled VR network and conduct the system modelling including uplink and downlink transmission models, FoP model, and power consumption model.
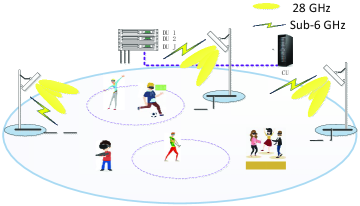
II-A Uplink and downlink transmission models
II-A1 Uplink transmission model
Denote as the three dimensional (3D) Cartesian coordinate of the HMD worn by user for all at time slot and is the user height. is the two dimensional (2D) location of user at time slot . Denote as the 3D coordinate of the antenna of AP and is the antenna height. Owing to the reliability requirement, users’ data information (e.g., users’ tracking information and profiles) is required to be successfully decoded by corresponding APs. We express the condition that an AP can successfully decode the received user data packets as follows
| (1) |
where is an association variable indicating whether user ’s uplink data packets can be successfully decoded by AP at time slot . The data packets can be decoded if ; otherwise, . is the uplink transmit power of user ’s HMD, is the Rayleigh channel gain, is the uplink path-loss from user to AP with being the fading exponent, denotes the Euclidean distance between user and AP , denotes the single-side noise spectral density, represents the uplink bandwidth. is the target signal-to-noise ratio (SNR) experienced at AP for successfully decoding data packets from user . Besides, considering the reliability requirement of uplink transmission and the stringent power constraint on HMDs, frequency division multiplexing (FDM) technique is adopted in this paper. The adoption of FDM technique can avoid the decoding failure resulting from uplink signal interferences and significantly reduce power consumption without compensating the signal-to-interference-plus-noise ratio (SINR) loss caused by uplink interferences.
Additionally, we assume that each user can connect to at most one AP via the uplink channel at each time slot , i.e., , . This is reasonable because it is unnecessary for each AP to decode all users’ data successfully at each time slot . A user merely connects to an AP (e.g., the nearest AP if possible) will greatly reduce power consumption. Meanwhile, considering the stringent low-latency requirements of VR applications and the time consumption of processing (e.g., decoding and checking) received user data packets, we assume that an AP can serve up to users during a time slot, i.e., , .
II-A2 Downlink transmission model
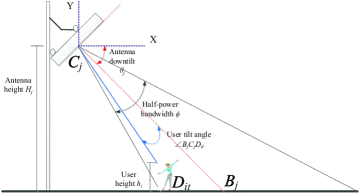
In the downlink transmission configuration, antenna arrays are deployed to perform directional beamforming. For analysis facilitation, a sectored antenna model [23], which consists of four components, i.e., the half-power beamwidth , the antenna downtilt angle , the antenna gain of the mainlobe , and the antenna gain of the sidelobe , shown in Fig. 2, is exploited to approximate actual array beam patterns. The antenna gain of the transmission link from AP to user is
| (2) |
where represents user ’s tilt angle towards AP , the location of the point ‘’ can be determined by AP ’s 2D coordinate and , the point ‘’ represent user ’s position, the point ‘’ denotes the position of AP ’s antenna.
For any AP , the 2D coordinate of point ‘’ can be given by
| (3) |
| (4) |
where , , and is 2D coordinate of the center point of the considered communication area.
Then, user ’s tilt angle towards AP can be written as
| (5) |
where direction vectors and .
A mmWave link may be blocked if a user turns around; this is because the user wears an HMD in front of his/her forehead. Denote as the maximum angle within which an AP can experience LoS transmission towards its downlink associated users. For user at time slot , an indicator variable introduced to indicate the blockage effect of user ’s body is given by
| (6) |
where represents the orientation angle of user at time slot , which can be determined by locations of both user and AP ,111In this paper, we consider the case of determining users’ orientation angles via the locations of both APs and users. Certainly, our proposed learning method is also applicable to scenarios where users’ orientation angles need to be predicted. is a direction vector. When , the direction vector . is a direction vector between the AP and user .
Given and , we can calculate the orientation angle of user that is also the angle between and by
| (7) |
The channel gain coefficient of an LoS link and a non line-of-sight (NLoS) link between the -th antenna element of AP and user at time slot can take the form [23]
| (8) |
where (in Hz) is the carrier frequency, (in m/s) the light speed, (in dB) and (in dB) the path-loss exponents of LoS and NLoS links, respectively, (in dB) and (in dB).
For any user , to satisfy its immersive experience requirement, its downlink achievable data rate (denoted by ) from cooperative APs should be no less than a data rate threshold , i.e.,
| (9) |
Define as an association variable indicating whether the user ’s data rate requirement can be satisfied at time slot . indicates that its data rate requirement can be satisfied; otherwise, . Then, for any user at time slot , according to Shannon capacity formula and the principle of CoMP transmission, we can calculate by
| (10) |
where is a channel gain coefficient vector with denoting the number of antenna elements, is the transmit beamformer pointed at user from AP , represents the downlink system bandwidth. Owing to the directional propagation, for user , not all users will be its interfering users. It is regarded that users whose distances from user are small than will be user ’s interfering users, where is determined by antenna configuration of APs (e.g., antenna height and downtilt angle). Denote the set of interfering users of user at time slot by , then, we have .
II-B Feeling of presence model
In VR applications, FoP represents an event that does not drag users back from engaging and immersive fictitious environments [24]. For wireless VR, the degrading FoP can be caused by the collection of inaccurate users’ tracking information via APs and the reception of low-quality VR video frames. Therefore, we consider the uplink user tracking information transmission and downlink VR video delivery when modelling the FoP experienced by users. Mathematically, over a period of time slots, we model the FoP experienced by users as the following
| (11) |
where with , with .
II-C Power consumption model
HMDs are generally battery-driven and constrained by the maximum instantaneous power. For any user ’s HMD, define as its instantaneous power consumption including the transmit power and circuit power consumption (e.g., power consumption of mixers, frequency synthesizers, and digital-to-analog converters) at time slot , we then have
| (12) |
where , denotes the HMD’s circuit power consumption during a time slot, and is a constant. Without loss of generality, we assume that all users’ HMDs are homogenous.
The instantaneous power consumption of each AP is also constrained. As CoMP transmission technique is explored, for any AP , we can model its instantaneous power consumption at time slot as the following
| (13) |
where is a constant representing the circuit power consumption, is the maximum instantaneous power of AP .
II-D Objective function and problem formulation
To guarantee immersive and interactive VR experiences of users over a period of time slots, uplink user data packets should be successfully decoded, and downlink data rate requirements of users should be satisfied at each time slot; that is, users’ FoP should be maximized. According to (1) and (11), one might believe that increasing the transmit power of users’ HMDs would be an appropriate way of enhancing users’ FoP. However, as users’ HMDs are usually powered by batteries, they are encouraged to work in an energy-efficient mode to prolong their working duration. Further, reducing HMDs’ power consumption indicates less heat generation, which can enhance users’ VR experiences. Therefore, our goal is to maximize users’ FoP while minimizing the power consumption of HMDs over a period of time slots. Combining with the above analysis, we can formulate the problem of enhancing users’ immersive experiences as below
| (14a) | |||
| (14b) | |||
| (14c) | |||
| (14d) | |||
| (14e) | |||
| (14f) | |||
| (14g) | |||
where .
However, the solution to (14) is highly challenging due to the unknown users’ tracking information at each time slot. Given users’ tracking information, the solution to (14) is still NP-hard or even non-detectable. It can be confirmed that (14) is a mixed-integer non-linear programming (MINLP) problem as it simultaneously contains zero-one variables, continuous variables, and non-linear constraints. Further, we can know that (9) and (13) are non-convex with respect to (w.r.t) and , , , by evaluating the Hessian matrix. To tackle the tricky problem, we develop a novel solution framework as depicted in Fig. 4. In this framework, we first propose to predict users’ tracking information using a machine learning method. With the predicted results, we then develop a DRL-based optimization algorithm to solve the MINLP problem. The procedure of solving (14) is elaborated in the following sections.
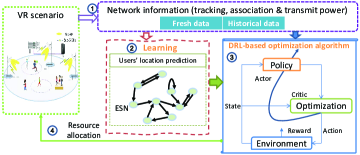
III Users’ Location Prediction
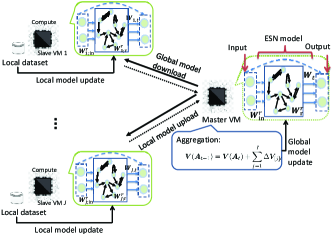
As analyzed above, the efficient user-AP association and transmit power of both HMDs and APs are configured on the basis of the accurate perception of users’ tracking information. If the association and transmit power are identified without knowledge of users’ tracking information, users may have degrading VR experiences, and the working duration of users’ HMDs may be dramatically shortened. Meanwhile, owing to the stringent low latency requirement, the user-AP association and transmit power should be proactively determined to enhance users’ immersive and interactive VR experiences. Hence, APs must collect fresh and historical tracking information for users’ tracking information prediction in future time slots. With predicted tracking information, the user-AP association and transmit power can be configured in advance. Certainly, from (7), we observe that users’ orientation angles can be obtained by their and APs’ locations; thus, we only predict users’ locations in this section. Machine learning is convinced as a promising proposal to predict users’ locations. In machine learning methods, the accuracy and completeness of sample collection are crucial for accurate model training. However, the user-AP association may vary with user movement, which indicates that location information of each user may scatter in multiple APs, and each AP may only collect partial location information of its associated users after a period of time. To tackle this issue, we develop a parallel machine learning method, which exploits slave virtual machines (VMs) created in the CU to train learning models for each user, as shown in Fig. 4. Besides, for each AP, it will feed its locally collected location information to a slave VM for training. In this way, the prediction process can also be accelerated. With the predicted results, the CU can then proactively allocate system resources by solving (14).
III-A Echo state network
In this section, the principle of echo state network (ESN) is exploited to train users’ location prediction model as the ESN method can efficiently analyze the correlation of users’ location information and quickly converge to obtain users’ predicted locations [25]. It is noteworthy that there are some differences between the traditional ESN method and the developed parallel ESN learning method. The traditional ESN method is a centralized learning method with the requirement of the aggregation of all users’ locations scattered in all APs, which is not required for the parallel ESN learning method. What’s more, the traditional ESN method can only be used to conduct data prediction in a time slot while the parallel ESN learning method can predict users’ locations in time slots. An ESN is a recurrent neural network that can be partitioned into three components: input, ESN model, and output, as shown in Fig. 4. For any user , the -dimensional input vector is fed to an -dimensional reservoir whose internal state is updated according to the state equation
| (15) |
where and are randomly generated matrices with each matrix element locating in the interval .
The evaluated output of the ESN at time slot is given by
| (16) |
where , are trained based on collected training data samples.
To train the ESN model, suppose we are provided with a sequence of desired input-outputs pairs of user , where is the target location of user at time slot . Define the hidden matrix as
| (17) |
The optimal output weight matrix is then achieved by solving the following regularized least-square problem
| (18) |
where , is a positive scalar known as regularization factor, the loss function , the regulator , and the target location matrix .
III-B Parallel ESN learning method for users’ location prediction
Based on the principle of the ESN method, we next elaborate on the procedure of the parallel ESN learning method for users’ location prediction. To facilitate the analysis, we make the following assumptions on the regulator and the loss function.
Assumption 1.
Assumption 2.
The function are -smooth, i.e., , , and , we have
| (20) |
where represents the gradient of .
According to Fenchel-Rockafeller duality, we can formulate the local dual optimization problem of (18) in the following way.
Lemma 1.
For a set of slave VMs and a typical user , the dual problem of (18) can be written as follows
| (21) |
where
| (22) |
| (23) |
is a Lagrangian multiplier matrix, is a column vector with the -th element being one and all other elements being zero, is a lightened notation of , and is an element of matrix at the location of the -th row and the -th column.
Proof.
Please refer to Appendix A. ∎
Denote the objective function of (21) as , and define , we can then rewrite as
| (24) |
where , , and is a square matrix with blocks. In , the block in the -th row and -th column is a identity matrix with being the cardinality of a set and all other blocks are zero matrices, is an index set including the indices of data samples fed to slave VM .
Note that the second term of the right-hand side (RHS) of (25) includes the local changes of each VM , while the first term involves the global variations.
As is -strongly convex, is then -smooth [26]. Thus, we can calculate the upper bound of as follows
| (26) |
where , is a data dependent constant measuring the difficulty of the partition to the whole samples.
From (27), we observe that the problem of maximizing can be decomposed into subproblems, and slave VMs can then be exploited to optimize these subproblems separately. If slave VM can optimize using its collected data samples by maximizing the RHS of (27), the resultant improvements can be aggregated to drive toward the optimum. The detailed procedure is described below.
As shown in Fig. 4, during any communication round , a master VM produces using updates received at the last round and shares it with all slave VMs. The task at any slave VM is to obtain by maximizing the following problem
| (28) |
Calculate the derivative of over , and force the derivative result to be zero, we have
| (29) |
where .
Next, slave VM , , sends to the master VM. The master VM updates the global model as . Finally, alteratively update and on the global and local sides, respectively. It is expected that the solution to the dual problem can be enhanced at every step and will converge after several iterations.
At time slot , based on the above derivation, the parallel ESN learning method for predicting locations of user , , in time slots can be summarized in Algorithm 1.
| (31) |
| (32) |
IV DRL-based Optimization Algorithm
Given the predicted locations of all users, it is still challenging to solve the original problem owing to its non-linear and mixed-integer characteristics. Alternative optimization is extensively considered as an effective scheme of solving MINLP problems. Unfortunately, the popular alternative optimization scheme cannot be adopted in this paper. This is because the alternative optimization scheme is of often high computational complexity, and the original problem is also a sequential decision problem requiring an MINLP problem to be solved at each time slot. Remarkably, calling an optimization scheme with a high computational complexity at each time slot is unacceptable for latency-sensitive VR applications.
Reinforcement learning methods can be explored to solve sequential decision problems. For example, the works in [27, 28] proposed reinforcement learning methods to solve sequential decision problems with a discrete decision space and a continuous decision space, respectively. However, how to solve sequential decision problems simultaneously involving discrete and continuous decision variables (e.g., the problem (14)) is a significant and understudied problem.
In this paper, we propose a deep reinforcement learning (DRL)-based optimization algorithm to solve (14). Specifically, we design a DNN joint with an action quantization scheme to produce a set of association actions of high diversity. Given the association actions, a continuous optimization problem is solved to criticize them and optimize the continuous variables. The detailed procedure is presented in the following subsections.
IV-A Vertical decomposition
Define a vector and a vector , , . Let matrix and matrix . As for matrices and of compatible dimensions, the signal power received by user can be expressed as . Likewise, by introducing a square matrix with blocks, the transmit power for serving users can be written as . Besides, each block in is a matrix. In , the block in the -th row and -th column is a identity matrix, and all other blocks are zero matrices. Then, by applying and , we can convert (14) to the following problem
| (33a) | |||
| (33b) | |||
| (33c) | |||
| (33d) | |||
| (33e) | |||
| (33f) | |||
Like (14), (33) is difficult to be directly solved; thus, we first vertically decompose it into the following two subproblems.
-
•
Uplink optimization subproblem: The uplink optimization subproblem is formulated as
(34a) (34b) -
•
Downlink optimization subproblem: The downlink optimization subproblem can be formulated as follows
(35a) (35b)
Next, we propose to solve the two subproblems separately by exploring DRL approaches.
IV-B Solution to the uplink optimization subproblem
(34) is confirmed to be a mixed-integer and sequence-dependent optimization subproblem. Fig. 5 shows a DRL approach of solving (34).
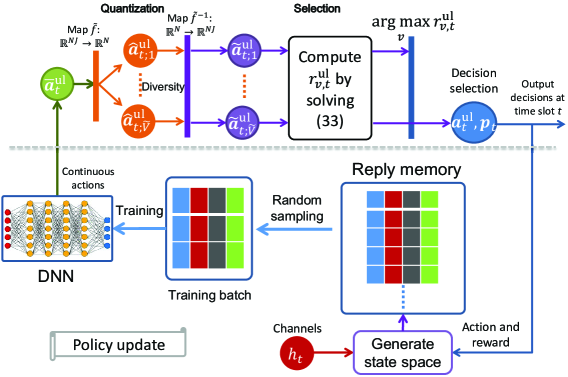
In this figure, a DNN is trained to produce continuous actions. The continuous actions are then quantized into a group of association (or discrete) actions. Given the association actions, we solve an optimization problem to select an association action maximizing the reward. Next, we describe the designing process of solving (34) using a DRL-based uplink optimization method in detail.
IV-B1 Action, state, and reward design
First, we elaborate on the design of the state space, action space, and reward function of the DRL-based method. The HMDs’ transmit power and the varying channel gains caused by users’ movement and/or time-varying wireless channel environments have a significant impact on whether uplink transmission signals can be successfully decoded by APs. In addition, each AP has a limited ability to decode uplink transmission signals simultaneously. Therefore, we design the state space, action space, and reward function of the DRL-based method as the following.
-
•
state space : is a column vector, where , , denotes the number of users successfully access to AP at time slot . Besides, the state space involves the path-loss from user to AP , , , , , and the transmit power of user ’s HMD at time slot , , , .
-
•
action space : with . The action of the DRL-based method is to deliver users’ data information to associated APs.
-
•
reward : given , the reward is the objective function value of the following power control subproblem.
(36a) (36b)
IV-B2 Training process of the DNN
For the DNN module shown in Fig. 5, where and represents network parameters, we explore a two-layer fully-connected feedforward neural network with network parameters being initialized by a Xavier initialization scheme. There are and neurons in the and hidden layers of the constructed DNN, respectively. Here, we adopt the ReLU function as the activation function in these hidden layers. For the output layer, a sigmoid activation function is leveraged such that relaxed association variables satisfy . In the action-exploration phase, the exploration noise is added to the output layer of the DNN, where decays over time and .
To train the DNN effectively, the experience replay technique is exploited. This is because there are two special characteristics in the process of enhancing users’ fictitious experiences: 1) the collected input state values incrementally arrive as users move to new positions, instead of all made available at the beginning of the training; 2) APs consecutively collect state values indicating that the collected state values may be closely correlated. The DNN may oscillate or diverge without breaking the correlation among the input state values. Specifically, at each training epoch , a new training sample is added to the replay memory. When the memory is filled, the newly generated sample replaces the oldest one. We randomly choose a minibatch of training samples from the replay memory, where is a set of training epoch indices. The network parameters are trained using the ADAM method [29] to reduce the averaged cross-entropy loss
| (37) |
As evaluated in the simulation, we can train the DNN every epochs after collecting a sufficient number of new data samples.
IV-B3 Action quantization and selection method
In the previous subsection, we design a continuous policy function and generate a continuous action space. However, a discrete action space is required in this paper. To this aim, the generated continuous action should be quantized, as shown in Fig. 5. A quantized action will directly determine the feasibility of the optimization subproblem and then the convergence performance of the DRL-based optimization method. To improve the convergence performance, we should increase the diversity of the quantized action set, which including all quantized actions. Specifically, we quantize the continuous action to obtain groups of association actions and denote by the -th group of actions. Given , (36) is reduced to a linear programming problem, and we can derive its closed-form solution as below
| (38) |
Besides, a great will result in higher diversity in the quantized action set but a higher computational complexity, and vice versa. To balance the performance and complexity, we set and propose a lightweight action quantization and selection method. The detailed steps of quantizing and selecting association actions are given in Algorithm 2.
| (39) |
| (40) |
| (41) |
Summarily, the proposed DRL-based uplink optimization method can be presented in Algorithm 3.
IV-C Solution to the downlink optimization subproblem
Like (34), (35) is also a mixed-integer and sequence-dependent optimization problem. Therefore, the procedure of solving (35) is similar to that of solving (34), and we do not present the detailed steps of the DRL-based downlink optimization method in this subsection for brevity. However, there are differences in some aspects, for example, the design of action and state space and the reward function. For the DRL-based downlink optimization method, we design its action space, state space, and the reward function as the following.
-
•
state space : is a column vector, where indicates the number of users to which AP transmits VR video frames, , denotes whether user is the interfering user of user , and .
-
•
action space : with . The action of the DRL-based method at time slot is to transmit VR video frames to corresponding users.
-
•
reward : given , the reward is the objective function value of the following power control subproblem.
(42a) (42b)
To solve (42), Algorithm 2 can be adopted to obtain the downlink association action . However, given , it is still hard to solve (42) as (42) is a non-convex programming problem with the existence of the non-convex low-rank constraint (33e). To handle the non-convexity, a semidefinite relaxation (SDR) scheme is exploited. The idea of the SDR scheme is to directly drop out the non-convex low-rank constraint. After dropping the constraint (33e), it can confirm that (42) becomes a standard convex semidefinite programming (SDP) problem. This is because (33b) are (33c) are linear constraints w.r.t and (42a) is a constant objective function. We can then explore some optimization tools such as MOSEK to solve the standard convex SDP problem effectively. However, owing to the relaxation, power matrices obtained by mitigating (42) without low-rank constraints will not satisfy the low-rank constraint in general. This is due to the fact that the (convex) feasible set of the relaxed (42) is a superset of the (non-convex) feasible set of (42). The following lemma reveals the tightness of exploring the SDR scheme.
Lemma 2.
Proof.
The Karush-Kuhn-Tucker (KKT) conditions can be explored to prove the tightness of resorting to the SDR scheme. Nevertheless, we omit the detailed proof for brevity as a similar proof can be found in Appendix of the work [30]. ∎
With the conclusion in Lemma 2, we can recover beamformers from the obtained power matrices. If , , then execute eigenvalue decomposition on , and the principal component is the optimal beamformer ; otherwise, some manipulations such as a randomization/scale scheme [31] should be performed on to impose the low-rank constraint.
Note that (42) should be solved for times at each time slot. To speed up the computation, they can be optimized in parallel. Moreover, it is tolerable to complete the computation within the interval as users’ locations in time slots are obtained.
Finally, we can summarize the DRL-based optimization algorithm of mitigating the problem of enhancing users’ VR experiences in Algorithm 4.
V Simulation and Performance Evaluation
V-A Comparison algorithms and parameter setting
To verify the effectiveness of the proposed algorithm, we compare it with three benchmark algorithms: 1) -nearest neighbors (KNN) based action quantization algorithm: The unique difference between the KNN-based algorithm and the proposed algorithm lies in the scheme of quantizing uplink and downlink action spaces. For the KNN-based algorithm, it adopts the KNN method [32] to quantize both uplink and downlink action spaces; 2) DROO algorithm: Different from the proposed algorithm, DROO leverages the order-preserving quantization method [32] to quantize both uplink and downlink action spaces; 3) Heuristic algorithm: The heuristic algorithm leverages the greedy admission algorithm in [33] to determine and at each time slot . Besides, the user consuming less power in this algorithm will establish the connection with an AP(s) on priority.
To test the practicality of the developed parallel ESN learning method, realistic user movement datasets are generated via Google Map. Particularly, for a user, we randomly select its starting position and ending position on the campus of Singapore University of Technology and Design (SUTD). Given two endpoints, we use Google Map to generate the user’s 2D trajectory. Next, we linearly zoom all users’ trajectories into the communication area of size km2.
Additionally, the parameters related to APs and downlink transmission channels are listed as follows: the number of APs , the number of antenna elements , the antenna gain dB, dB, , , MHz, Gb/s, , , , , m, m, , dBm, dBm, m, [19]. User and uplink transmission channel-related parameters are shown as below: uplink system bandwidth MHz, , m, m, , , dBm, dBm, , .
Set other learning-correlated parameters as below: , , , the sample number , the number of future time slots , , , , , and . For both uplink DNN and downlink DNN, the first hidden layer has neurons, and the second hidden layer has neurons. The replay memory capacity +6, , , , , . More system parameters are listed as follows: carrier frequency GHz, light of speed +8 m/s, noise power spectral density dBm/Hz, and time slots.
V-B Performance evaluation
To comprehensively understand the accuracy and the availability of the developed learning and optimization methods, we illustrate their performance results. In this simulation, we first let the AP number and the mobile user number .
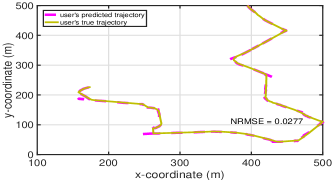
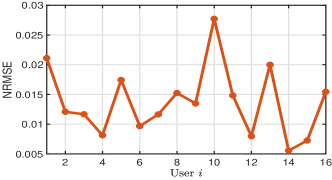
To validate the accuracy of the parallel ESN learning method on predicting mobile users’ locations, we plot the actual trajectory of a randomly selected mobile user and its correspondingly predicted trajectory in Fig. 6(a). In Fig. 6(b), the accuracy, which is measured by the normalized root mean-squared error (NRMSE) [25], of predicted trajectories of mobile users is plotted. From Fig. 6, we can observe that: i) when the orientation angles of users will not change fast, the learning method can exactly predict users’ locations. When users change their moving directions quickly, the method loses their true trajectories. However, the method will re-capture users’ tracks after training ESN models based on newly collected users’ location samples; ii) the obtained NRMSE of the predicted trajectories of all mobile users will not be greater than . Therefore, we may conclude that the developed parallel ESN learning method can be utilized to predict mobile users’ locations.
Next, to evaluate the performance of the proposed DRL-based optimization algorithm comprehensively, we illustrate the impact of some DRL-related crucial parameters such as minibatch size, training interval, and learning rate on the convergence performance of the proposed algorithm. DNN training loss and moving average reward, which is the average of the achieved rewards over the last epochs, are leveraged as the evaluation indicators.
Fig. 7 plots the tendency of the DNN training loss and the achieved moving average reward of the proposed algorithm under diverse minibatch sizes. This figure illustrates that: i) a great minibatch size value will cause the DNN to converge slowly or even not. As shown in Fig. 7(a), when we set . Yet, when we let . The result in Fig. 7(b) shows that DNN does not converge after 10000 epochs when . This is because a great indicates overtraining, resulting in the local minima and degraded convergence performance. Further, a large minibatch size value consumes more training time at each training epoch. Therefore, we set the training minibatch size in the simulation; ii) when , and gradually increase and stabilize at around and , respectively. The fluctuation is mainly caused by the random sampling of training data and user movement.
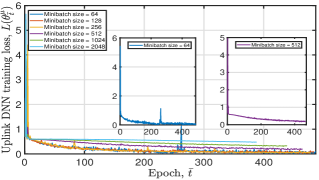
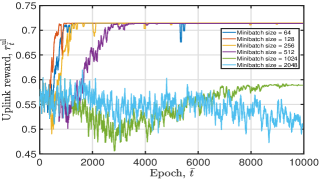
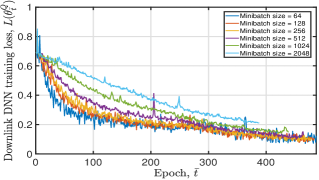
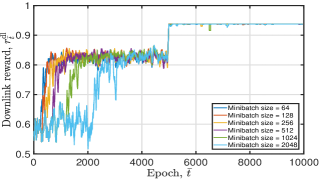
Fig. 8 illustrates the tendency of obtained uplink and downlink DNN training losses and moving average rewards under diverse training interval values. From this figure, we can observe that a small training interval value indicates faster convergence speed. For example, if we set the training interval , the obtained converges to when epoch . If we let the training interval , converges to when epoch , as shown in Fig. 8(b). However, it is unnecessary to train and update the DNN frequently, which will bring more frequent policy updates, if the DNN can converge. Thus, to achieve the trade-off between the convergence speed and the policy update speed, we set in the simulation.
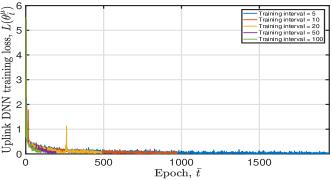
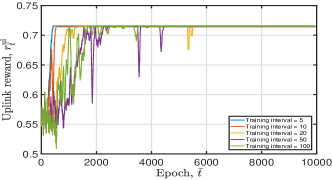
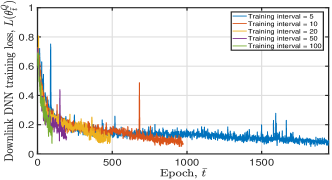
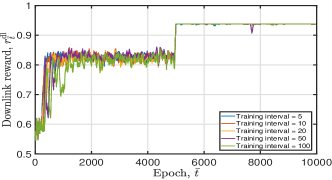
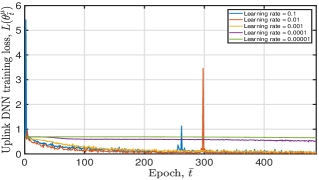
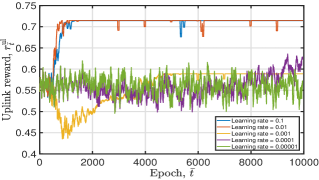
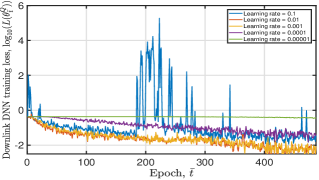
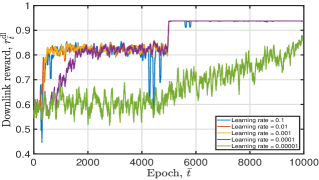
Fig. 9 depicts the tendency of achieved DNN training loss and moving average reward of the proposed algorithm under different learning rate configurations. From this figure, we have the following observations: i) for the uplink DNN, when given a small learning rate value, it may converge to the local optimum or even not; ii) for the downlink DNN, both a small and a great learning rate value will degrade convergence performance. Therefore, when training the uplink DNN, we set the learning rate , which can lead to good convergence performance. For instance, converges to when epoch and the variance of gradually decreases to zero with an increasing epoch . We set the learning rate when training the downlink DNN. Given this parameter setting, the obtained is smaller than after training for epochs.
At last, we verify the superiority of the proposed algorithm by comparing it with other comparison algorithms. Particularly, we plot the achieved objective function values of all comparison algorithms under varying number of mobile users in Fig. 10. Before the evaluation, the proposed algorithm and the other two action quantization algorithms have been trained with independent wireless channel realizations, and their downlink and uplink action quantization policies have converged. This is reasonable because we are more interested in the long-term operation performance for field deployment. Besides, we let the service ability of an AP vary with with the pair being , , , and .
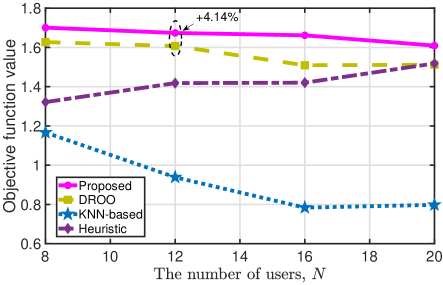
We have the following observations from this figure: i) the proposed algorithm achieves the greatest objective function value. For the DROO algorithm, it gains a smaller objective function value than the proposed algorithm; for example, the achieved objective function value of DROO is less than that of the proposed algorithm. For the KNN-based algorithm, it obtains the smallest objective function value because it offers the smallest diversity in the produced uplink and downlink association action set; ii) except for heuristic algorithm, the achieved objective function values of the other comparison algorithms decrease with the number of users owing to the increasing total power consumption. For the heuristic algorithm, its obtained objective function value increases with mainly because more users can successfully access to APs.
VI Conclusion
This paper investigated the problem of enhancing VR visual experiences for mobile users and formulated the problem as a sequence-dependent problem aiming at maximizing users’ feeling of presence in VR environments while minimizing the total power consumption of users’ HMDs. This problem was confirmed to be a mixed-integer and non-convex optimization problem, the solution of which also needed accurate users’ tracking information. To solve this problem effectively, we developed a parallel ESN learning method to predict users’ tracking information, with which a DRL-based optimization algorithm was proposed. Specifically, this algorithm first decomposed the formulated problem into an association subproblem and a power control subproblem. Then, a DNN joint with an action quantization scheme was implemented as a scalable solution that learnt association variables from experience. Next, the power control subproblem with an SDR scheme being explored to tackle its non-convexity was leveraged to criticize the association variables. Finally, simulation results were provided to verify the accuracy of the learning method and showed that the proposed algorithm could improve the energy efficiency by at least compared with various benchmark algorithms.
-A Proof of Lemma 1
For any user , suppose we are provided with a sequence of desired input-output pairs . With the input-output pairs, generate the hidden matrix and the corresponding target location matrix at time slot . We next introduce an auxiliary matrix , wherein we lighten the notation for . According to the Lagrange dual decomposition method, we can rewrite (18) as follows
| (43) |
where is a column vector with the -th element being one and all other elements being zero, is an index set including the indices of data samples fed to slave VM .
Let , where , and denote as the optimal solution to . Then, calculate the derivative of w.r.t ,
| (44) |
where .
As , the necessary and sufficient condition for obtaining is to enforce . Then, we have
| (45) |
Similarly, denote for any and as the optimal solution to . As , the necessary and sufficient condition for is to execute . By substituting into , we can obtain (23). This completes the proof.
References
- [1] X. Hou, S. Dey, J. Zhang, and M. Budagavi, “Predictive adaptive streaming to enable mobile 360-degree and VR experiences,” IEEE Trans. Multimedia, vol. 23, pp. 716–731, 2021.
- [2] H. Bellini, “The real deal with virtual and augmented reality,” https://www.goldmansachs.com/insights/pages/virtual-and-augmented-reality.html, Feb. 2016.
- [3] C. Wiltz, “5 major challenges for VR to overcome,” https://www.designnews.com/electronics-test/5-major-challenges-vr-overcome, Apr, 2017.
- [4] Y. Liu, J. Liu, A. Argyriou, and S. Ci, “MEC-assisted panoramic VR video streaming over millimeter wave mobile networks,” IEEE Trans. Multimedia, vol. 21, no. 5, pp. 1302–1316, 2019.
- [5] J. Dai, Z. Zhang, S. Mao, and D. Liu, “A view synthesis-based VR caching system over MEC-enabled C-RAN,” IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 10, pp. 3843–3855, 2020.
- [6] Z. Lai, Y. C. Hu, Y. Cui, L. Sun, N. Dai, and H. Lee, “Furion: Engineering high-quality immersive virtual reality on today’s mobile devices,” IEEE Trans. Mob. Comput., vol. 19, no. 7, pp. 1586–1602, 2020.
- [7] X. Hou, Y. Lu, and S. Dey, “Wireless VR/AR with edge/cloud computing,” in ICCCN. IEEE, 2017, pp. 1–8.
- [8] Qualcomm, “Whitepaper: Making immersive virtual reality possible in mobile,” https://www.qualcomm.com/media/documents/files/whitepaper-making-immersive-virtual-reality-possible-in-mobile.pdf, Mar. 2016.
- [9] Oculus, “Mobile VR media overview. Accessed: Sep. 2018,” https://www.oculus.com/, 2018.
- [10] HTC, “HTC Vive. Accessed: Sep. 2018,” https://www.vive.com/us/, 2018.
- [11] T. Dang and M. Peng, “Joint radio communication, caching, and computing design for mobile virtual reality delivery in fog radio access networks,” IEEE J. Sel. Areas Commun., vol. 37, no. 7, pp. 1594–1607, 2019.
- [12] X. Liu, Q. Xiao, V. Gopalakrishnan, B. Han, F. Qian, and M. Varvello, “360∘ innovations for panoramic video streaming,” in HotNets. ACM, 2017, pp. 50–56.
- [13] R. Ju, J. He, F. Sun, J. Li, F. Li, J. Zhu, and L. Han, “Ultra wide view based panoramic VR streaming,” in VR/AR NetworkSIGCOMM. ACM, 2017, pp. 19–23.
- [14] S. Mangiante, G. Klas, A. Navon, G. Zhuang, R. Ju, and M. D. Silva, “VR is on the edge: How to deliver videos in mobile networks,” in VR/AR NetworkSIGCOMM. ACM, 2017, pp. 30–35.
- [15] V. R. Gaddam, M. Riegler, R. Eg, C. Griwodz, and P. Halvorsen, “Tiling in interactive panoramic video: Approaches and evaluation,” IEEE Trans. Multimedia, vol. 18, no. 9, pp. 1819–1831, 2016.
- [16] X. Corbillon, G. Simon, A. Devlic, and J. Chakareski, “Viewport-adaptive navigable 360-degree video delivery,” in ICC. IEEE, 2017, pp. 1–7.
- [17] C. Perfecto, M. S. ElBamby, J. D. Ser, and M. Bennis, “Taming the latency in multi-user VR : A QoE-aware deep learning-aided multicast framework,” IEEE Trans. Commun., vol. 68, no. 4, pp. 2491–2508, 2020.
- [18] M. S. ElBamby, C. Perfecto, M. Bennis, and K. Doppler, “Edge computing meets millimeter-wave enabled VR: paving the way to cutting the cord,” in WCNC. IEEE, 2018, pp. 1–6.
- [19] M. Chen, O. Semiari, W. Saad, X. Liu, and C. Yin, “Federated echo state learning for minimizing breaks in presence in wireless virtual reality networks,” IEEE Trans. Wirel. Commun., vol. 19, no. 1, pp. 177–191, 2020.
- [20] P. Yang, X. Xi, Y. Fu, T. Q. S. Quek, X. Cao, and D. O. Wu, “Multicast eMBB and bursty URLLC service multiplexing in a CoMP-enabled RAN,” IEEE Trans. Wirel. Commun., vol. 20, no. 5, pp. 3061–3077, 2021.
- [21] Q. Cheng, H. Shan, W. Zhuang, L. Yu, Z. Zhang, and T. Q. S. Quek, “Design and analysis of MEC-and proactive caching-based mobile VR video streaming,” IEEE Trans. Multimedia, 2021, in press. DOI: 10.1109/TMM.2021.3067205.
- [22] Y. Sun, Z. Chen, M. Tao, and H. Liu, “Communications, caching, and computing for mobile virtual reality: Modeling and tradeoff,” IEEE Trans. Commun., vol. 67, no. 11, pp. 7573–7586, 2019.
- [23] O. Semiari, W. Saad, M. Bennis, and Z. Dawy, “Inter-operator resource management for millimeter wave multi-hop backhaul networks,” IEEE Trans. Wirel. Commun., vol. 16, no. 8, pp. 5258–5272, 2017.
- [24] S. Bouchard, J. St-Jacques, G. Robillard, and P. Renaud, “Anxiety increases the feeling of presence in virtual reality,” Presence Teleoperators Virtual Environ., vol. 17, no. 4, pp. 376–391, 2008.
- [25] S. Scardapane, D. Wang, and M. Panella, “A decentralized training algorithm for echo state networks in distributed big data applications,” Neural Networks, vol. 78, pp. 65–74, 2016.
- [26] H. H. Yang, Z. Liu, T. Q. S. Quek, and H. V. Poor, “Scheduling policies for federated learning in wireless networks,” IEEE Trans. Commun., vol. 68, no. 1, pp. 317–333, 2020.
- [27] M. Bennis, S. M. Perlaza, P. Blasco, Z. Han, and H. V. Poor, “Self-organization in small cell networks: A reinforcement learning approach,” IEEE Trans. Wirel. Commun., vol. 12, no. 7, pp. 3202–3212, 2013.
- [28] P. Yang, X. Cao, X. Xi, W. Du, Z. Xiao, and D. O. Wu, “Three-dimensional continuous movement control of drone cells for energy-efficient communication coverage,” IEEE Trans. Veh. Technol., vol. 68, no. 7, pp. 6535–6546, 2019.
- [29] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in ICLR (Poster), 2015.
- [30] P. Yang, X. Xi, T. Q. S. Quek, J. Chen, X. Cao, and D. Wu, “How should I orchestrate resources of my slices for bursty URLLC service provision?” IEEE Trans. Commun., vol. 69, no. 2, pp. 1134–1146, 2020.
- [31] Z. Luo, W. Ma, A. M. C. So, Y. Ye, and S. Zhang, “Semidefinite relaxation of quadratic optimization problems,” IEEE Signal Processing Magazine, vol. 27, no. 3, pp. 20–34, 2010.
- [32] L. Huang, S. Bi, and Y. A. Zhang, “Deep reinforcement learning for online computation offloading in wireless powered mobile-edge computing networks,” IEEE Trans. Mob. Comput., vol. 19, no. 11, pp. 2581–2593, 2020.
- [33] J. Tang, B. Shim, and T. Q. S. Quek, “Service multiplexing and revenue maximization in sliced C-RAN incorporated with URLLC and multicast eMBB,” IEEE J. Sel. Areas Commun., vol. 37, no. 4, pp. 881–895, 2019.