Chiang-Lin Tai1,2, Hung-Shin Lee1, Pin-Yuan Chen1, Yi-Wen Liu2, and Hsin-Min Wang1
\address
1Institute of Information Science, Academia Sinica, Taiwan
2Department of Electrical Engineering, National Tsing Hua University, Taiwan
Filter-based Discriminative Autoencoders for Children Speech Recognition
Abstract
Automatic speech recognition (ASR) for children is indispensable, but it is challenging due to the diversity of children’s speech, such as pitch, and the insufficiency of transcribed data. Many studies have used a large corpus of adult speech to help the development of children ASR systems. Along this direction, we propose filter-based discriminative autoencoders for acoustic modeling. To filter out the influence from various speaker types and pitches, auxiliary information of the speaker and pitch features is input into the encoder together with the acoustic features to generate the phonetic embedding. In the training phase, the decoder uses the auxiliary information and the phonetic embedding extracted by the encoder to reconstruct the acoustic features. The encoder and decoder are trained by simultaneously minimizing the ASR loss (LF-MMI) and the feature reconstruction error. The framework can be applied to any acoustic model of ASR by treating the acoustic model as the encoder and adding an additional decoder. It can make the phonetic embedding purer, thereby producing more accurate phoneme-state scores. Our experiments are conducted on the CMU Kids and WSJ corpora. Evaluated on the test set of the CMU Kids corpus, our system achieves 7.8% and 5.2% relative WER reductions compared to the baseline systems using TDNN and CNN-TDNNF based acoustic models, respectively. For domain adaptation, our systems also outperform the baselines on the American-accent CMU Kids and British-accent PF-STAR tasks.
children speech recognition, pitch filter, speaker filter, discriminative autoencoders
1 Introduction
Today, the technology of automatic speech recognition (ASR) is mature enough to be applied to the daily life of adults. However, children need it but cannot benefit as much as adults. According to the research in [Potamianos2003], the word error rate (WER) of children speech recognition can reach 5 times that of adults. The first reason is the lack of children corpora. The transcribed adult speech is usually much easier to access from news broadcasts and regular recordings. But the above scenarios are rare for children. By 2016, there were only 13 children speech corpora that contained partial or complete word transcriptions [Chen2016]. To address the limitation caused by the lack of children resources, many efforts have been made to jointly use a large adult speech corpus and a relatively small children speech corpus for training acoustic models for children speech recognition [Shahnawazuddin2016, Ahmad2017, Shahnawazuddin2017a, Shahnawazuddin2017b, Serizel2014a, Serizel2014b, Tong2017]. Experiments have shown that the joint training approach (a.k.a. multi-condition training) can reduce WER compared to the training method that uses children speech alone.
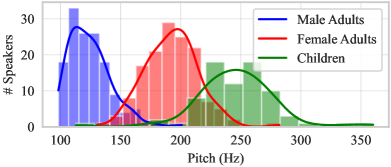
In addition to changes in volume, prosody, and articulation that make adult voices and children voices different, research has shown that children speech has greater changes in pitch, with a fundamental frequency range of approximately 100 Hz to 350 Hz. Therefore, the pronunciation variation of children speech becomes the second difficulty in the development of children ASR. Figure 1 shows the pitch distribution of 283 adult speakers of the WSJ corpus and 76 child speakers of the CMU Kids corpus. The pitch value of a person in Hz is derived by averaging the estimated pitch values of a series of voiced frames in all utterances he/she spoke. Obviously, the distribution of pitch in the group of children is wider, twice that of male or female adults. This phenomenon indicates that the features derived from the high-pitched speech are insufficient for training children ASR, but the features from low-pitched speech can be supplemented by adult speech.
Pitch makes child speech distinct from adult speech. Acoustic features, such as Mel-frequency cepstrum coefficients (MFCCs), are supposed to be independent of pitch. However, the studies in [Ghai2009, Shahnawazuddin2016] show that children MFCCs are barely free from the effect of pitch, especially in the case of higher pitch. To alleviate the negative effect, several techniques have been proposed. In [Shahnawazuddin2016], the algorithm for feature extraction was reformed to filter out the high-pitch components of the acoustic feature according to a speaker pitch level. In [Ahmad2017], pitch scaling was used to adjust the child pitch downwards, so that the pitch variation of the adjusted child speech could correspond to the adult pitch range. In [Shahnawazuddin2017a], not only pitch adaptation was considered, but the children speaking rate was modified. In [Serizel2014b], vocal tract length normalization (VTLN) was performed to compensate the spectral variation caused by the vocal tract length among adults and children. The above methods focus on the feature normalization or feature adaptation, with the purpose of reducing the inter-speaker acoustic variability.
As for the methods applied to the model itself, researchers have focused on adaptive [Shivakumar2020, Tong2017, Shivakumar2014, Serizel2014a] or multi-task learning [Tong2017] of acoustic models. In [Shivakumar2020], the transfer learning strategies for adapting the acoustic and pronunciation variability were discussed separately. In [Tong2017], two different softmax layers were optimized with adult speech and children speech respectively to differentiate the phonemes of children speech from those of adult speech. Nonetheless, any additional adjustments to the model cannot avoid the risk of catastrophic forgetting or over-fitting due to the scarcity of the children corpus. To reduce the inter-speaker distinction, another potential approach is to provide auxiliary information, such as speaker embeddings (e.g., i-vectors and x-vectors) [Saon2013, Peddinti2015a, Kanagasundaram2011, Snyder2017, Snyder2018] and prosodic features (e.g., pitch and loudness) [Serizel2014b, Kathania2018], to the model.
In [Yang2017, Huang2019], discriminative autoencoder-based (DcAE) acoustic modeling was proposed to separate the acoustic feature into the components of phoneme, speaker and environmental noise. Such model-space innovation takes a great advantage of unsupervised learning to extract pure phonetic components from the acoustic feature to better recognize speech. Inspired by this creativity, we combine the strength of the auxiliary information, i.e., i-vector and pitch-related vector (called p-vector in this paper) into autoencoder-based acoustic modeling to deal with very high-pitched speech (mainly children’s speech). Because the use of i-vector and/or p-vector in DcAE-based acoustic modeling can be regarded as a filtering mechanism with inducers to purify the phonetic information in the acoustic feature, our model is called filter-based DcAE (f-DcAE for short).
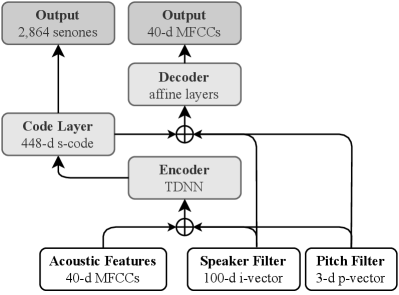
2 Proposed Model
2.1 Filtering Mechanism for Acoustic Modeling
Our ASR model belongs to the GMM/DNN/HMM topology and is developed based on the chain setting of the Kaldi toolkit [Povey2011]. The DNN training process takes the MFCCs and i-vectors as input with two loss functions: cross-entropy for frame-level training and lattice free MMI (LF-MMI) [Povey2016] for sentence-level training. The main function of using i-vectors for acoustic modeling is to eliminate factors such as speaker variation and channel mismatch in the acoustic features, thereby purifying the phonetic embedding. In this study, considering the extremely high-pitched characteristics of children, in addition to the i-vector, the p-vector is also used to reduce the impact of pitch on model adaptation.
To import the advantage of unsupervised learning in [Yang2017, Huang2019] into our acoustic modeling, the DNN model for generating the emission probabilities of the output labels can be regarded as the encoder, and the decoder is used to reconstruct the acoustic features, as shown in Figure 2. The output of the penultimate layer of the encoder is supposed to be a pure phoneme-related vector without any information irrelevant to the phonetic content. Therefore, it can be regarded as a latent embedding vector representing the phonetic information (called p-code below). The p-code is concatenated with the i-vector, the p-vector, or the fusion of the two as the input of the decoder to reconstruct the original MFCCs.
In our proposed model, in addition to identifying phonemes, the encoder functions like a phoneme filter that uses speaker and pitch information as guidance to remove impurities that are not related to phonemes from the input acoustic features. The participation of the decoder is to enhance the training of the phoneme filter. The significance of feature reconstruction in the decoder lies in the amplification on purifying the phonetic components in the p-code. The similarity between the input acoustic features and the reconstructed features relies on the high-quality p-code and the strong representations of speaker and pitch characteristics, which can be treated as three orthogonal factors of a speech utterance. By introducing a decoder in the training phase, the encoder is further indirectly guided to yield the p-code that better interprets the phoneme information, while the decoder attempts to reconstruct the original feature from the p-code together with the i-vector and/or the p-vector. The proposed model is called filter-based discriminative autoencoder (f-DcAE). Note that the encoder of f-DcAE can be implemented in any forms, such as the long short-term memory (LSTM) [Lee2017], multi-head attention-based networks [Qin2019a], transformers [Wang2020], and time-delay neural network (TDNN) [Peddinti2015b]. The decoder of f-DcAE in this study is composed of several affine layers or TDNN layers. Moreover, although the decoder nearly doubles the capacity of the entire model, only the encoder is used in the recognition phase. Therefore, the time complexity of f-DcAE in the recognition process is roughly the same as that of the encoder-only counterpart.
2.2 Objective Functions
Given training utterances, we first extract acoustic frames of MFCCs from each utterance , and then use GMM-based forced alignment to obtain the corresponding phoneme-state sequence . The proposed f-DcAE model in Figure 2 is trained with three objective functions.
2.2.1 Phoneme-aware cross-entropy
Unlike most classification tasks that use cross-entropy (CE) as the primary objective function, we take CE as a regularizer. It not only helps prevent over-fitting, but also guides the update direction of the main phoneme-aware objective function, LF-MMI. The CE loss is defined by
| (1) |
where is directly obtained from “Output (phoneme-states)” in Figure 2.
2.2.2 LF-MMI
Maximum mutual information (MMI) is a discriminative objective function designed to maximize the probability of the reference transcription while minimizing the probability of all other transcriptions [Vesely2013]. As in [Hadian2018], the lattice-free MMI is defined by,
| (2) |
where is the reference word sequence of , and the composite HMM graph represents all the possible state sequences pertaining to , and is called the numerator graph. The denominator in Eq. (2) can be further expressed as
| (3) |
where is an HMM graph that includes all possible sequences of words, and is called the denominator graph. The denominator graph has traditionally been estimated using lattices. This is because that the full denominator graph can become large and make the computation significantly slow. More recently, Povey et al. derived MMI training of HMM-DNN models using a full denominator graph (hence the name lattice-free) [Povey2016].
2.2.3 Reconstruction errors
The most straightforward strategy for evaluating the similarity of reconstructed features to input features is through the mean squared error (MSE). The MSE loss is defined by
| (4) |
where is the reconstructed feature vector of the input feature vector , and is the 2-norm operator. Using additional input vectors, the model is forced to determine which aspects of the input feature should be copied for speech recognition, which can often learn useful attributes of the data.
2.2.4 The final objective function
The final loss function to be minimized is the combination of the phoneme-aware cross-entropy, LF-MMI, and reconstruction error and expressed by
| (5) |
where and are the regularization penalty and weighting factor for and , respectively. To the best of our knowledge, there is no existing method that can simultaneously optimize the CE, LF-MMI, and MSE in acoustic model training. We set to and to in our experiments.
3 Experiment Setup
3.1 Datasets
Children speech in our experiments came from the CMU Kids corpus. It contains 9.1 hours of speech from 151 children. It was divided into the training set (6.34 hours of speech from 76 kids, called tr_cmu below) and the test set (2.75 hours of speech from other 75 kids, called cmu below). The WSJ corpus was used as the adult speech corpus. It contains one training set (81.48 hours of speech from 283 adults, called tr_wsj below) and two test sets: eval92 (0.7 hour of speech) and dev93 (1.08 hours of speech). We combined tr_cmu and tr_wsj as a joint training set for multi-condition training in the experiments. Besides the American-accent CMU Kids corpus, the PF-STAR British English children speech corpus [Batliner2005] was also used in the experiments. It contains 14.2 hours of speech from 152 children. It was divided into the training set (8.4 hours of speech from 92 kids, called tr_pfstar below) and the test set (5.82 hours of speech from other 60 kids, called pfstar below).
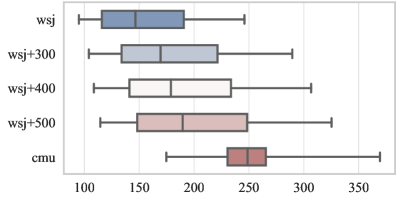
To evaluate the ability of the acoustic models to filter out the effects of pitch, we intentionally used the Sound eXchange toolkit (SoX) to create the high-pitched versions of eval92 and dev93 to simulate the children speech. We raised the pitch of adult speech by setting the parameter pitch to +300, +400, and +500, where the unit of these values are cents, not hertz. Figure 3 shows the pitch distribution of the original test sets and simulated versions of eval92 and dev93. We found that once the pitch was set to +600 or beyond, the adjusted speech sounded considerably unnatural, not similar to the speech of ordinary children and adults. In addition, the simulated speech was occasionally mixed with sharp mechanical noises, which could hardly represented children speech. Therefore, we used +300, +400, and +500 to generate the simulated children test sets.
3.2 Feature and Embedding Extraction
| Inducers | None | i-vector | p-vector | i-vector p-vector | |||
|---|---|---|---|---|---|---|---|
| Test Set\Model | Baseline(o) | Baseline(i) | f-DcAE(i) | Baseline(p) | f-DcAE(p) | Baseline(i+p) | f-DcAE(i+p) |
| cmu | 18.82 | 17.73 | 16.82 | 18.92 | 17.45 | 17.58 | 16.44 |
| eval92+300 | 2.96 | 2.68 | 2.60 | 2.98 | 2.55 | 2.89 | 2.89 |
| eval92+400 | 3.81 | 3.51 | 3.35 | 3.79 | 3.95 | 3.83 | 3.33 |
| eval92+500 | 5.64 | 5.30 | 5.00 | 5.37 | 5.07 | 5.46 | 5.23 |
| dev93+300 | 5.88 | 5.40 | 5.10 | 5.67 | 5.71 | 5.42 | 5.33 |
| dev93+400 | 6.87 | 6.73 | 6.47 | 6.74 | 6.45 | 6.59 | 6.27 |
| dev93+500 | 9.27 | 9.62 | 8.78 | 8.93 | 8.77 | 9.56 | 8.89 |
The size of training data was tripled using speed and volume perturbation [Ko2015]. The 40-dimensional high-resolution raw MFCCs were used as the acoustic features.
The i-vector was 100-dimensional. We trained a diagonal universal background model (UBM) with 512 Gaussian components based on the 40-dimensional MFCCs of a quarter of the training data to get the i-vector. Principal component analysis (PCA) was used for dimension reduction from 280 (a contextual vector consisting of current, left and right consecutive 3 frames) to 40 before UBM training. The i-vector was extracted every 10 frames. The p-vector was 3-dimensional. We computed the average of pitch, delta-pitch and the normalized cross correlation function (NCCF) every 10 frames [Ghahremani2014]. The concatenation of i-vector and p-vector resulted in a 103-dimensional vectorial inducer.
3.3 Model Configuration
We implemented two types of chain-based acoustic models, namely the time-delay neural network (TDNN) [Peddinti2015b] and the convolutional factorized TDNN (CNN-TDNNF) [Povey2018b]. The TDNN model was composed of 1 affine layer, 8 TDNN layers, and 1 dense layer before the softmax function, and the CNN-TDNNF model was composed of 1 IDCT layer, 1 affine layer, 6 CNN layers, 9 TDNNF layers, and 1dense layer. Both models were trained by minimizing the loss function based on cross entropy and LF-MMI with the L2 regularization. We organized our training data (tr_wsj + tr_cmu) to proceed basic recipes, including feature extraction, GMM training/alignment, and DNN training.
To realize our f-DcAE model in Figure 2, on top of the baseline TDNN model, we added a decoder, which consists of 4 affine layers, each with a size of 128. The first affine layer of the decoder was fed with the phonetic embedding (i.e, p-code) extracted by the encoder (i.e., the TDNN of the baseline model) as well as the i-vector and/or the p-vector. On top of the CNN-TDNNF baseline model, we added a decoder, which consists of 10 TDNN layers, each with a size of 448. The first TDNN layer of the decoder was fed with the p-code extracted by the encoder (i.e., the CNN-TDNNF of the baseline model) as well as the i-vector and/or the p-vector.
The 4-gram language model (LM) was used. The perplexities for cmu, pfstar, eval92 and dev93 are 529.7, 693.2, 164.9, and 200.4, respectively. The perplexities of cmu and pfstar stand out dramatically because the LM is trained with news transcripts, and eval92 and dev93 are in the same domain. Hence, there is a domain mismatch between the LM and the two children test sets.
4 Results and Discussion
4.1 TDNN-based Baseline versus f-DcAE
Table 1 shows the WERs of the TDNN-based baseline model and f-DcAE model evaluated on various test sets. The model consisting of a TDNN-based encoder with i-vector but no decoder is regarded as a baseline, which is a model widely used in many studies. This baseline is denoted as Baseline(i) in Table 1. Baseline(p) denotes the baseline model using p-vector instead of i-vector. Baseline(i+p) denotes the baseline model that uses both i-vector and p-vector. Baseline(o) denotes the baseline model without using any additional embedding. Corresponding to baseline models Baseline(i), Baseline(p), and Baseline(i+p), the proposed models with a decoder are denoted as f-DcAE(i), f-DcAE(p), and f-DcAE(i+p).
From Table 1, several observations can be drawn. First, Baseline(i) almost always outperforms Baseline(o) on all test sets, except for dev93+500. This result is consistent with past research. Baseline(p) and Baseline(i+p) perform better than Baseline(o) on most test sets. The i-vector with a dimension of 100 mainly contains the speaker characteristics, and the p-vector with a dimension of 3 only focuses on the pitch-related information. This may be the reason why the p-vector is not as useful as the i-vector. But it can provide supplementary information when used together with the i-vector. The results of the baseline models generally indicate that the additional auxiliary embeddings are useful for feature normalization, thereby helping the models distinguish phonemes.
Second, f-DcAE(i), f-DcAE(p), and f-DcAE(i+p) are always better than Baseline(i), Baseline(p), and Baseline(i+p), respectively, on the cmu test set. The WER is relatively reduced by 5.1%, 7.8%, and 6.5%, respectively. This result shows that no matter which type of additional embedding is selected, the proposed DcAE-based filtering mechanism can improve the recognition performance. As for the results of the simulated test sets, we can see that f-DcAE(i), f-Dcae(p), and f-DcAE(i+p) are almost always better than Baseline(i), Baseline(p), and Baseline(i+p), respectively, except for f-DcAE(p) and Baseline(p) evaluated on eval92+400 and dev93+300. In summary, these results generally confirm the effectiveness of the proposed DcAE-based filtering mechanism for acoustic modeling, especially for the challenging children speech recognition task.
Next, we focus on the results of the simulated (pitch-shifted) test sets, namely eval92+xxx and dev93+xxx. From Table 1, we can see that WER has a clear increasing trend with the rise of pitch shift (from +300 to +500). As shown in Figure 3, a higher pitch shift will results in a higher average pitch and a wider pitch range. The proposed models with the filtering mechanism are almost always better than their counterpart baseline models, except for f-DcAE(p) on the eval92+400 and dev93+300 test sets. The proposed models can achieve more WER reduction on the test set with more pitch shifts, e.g., f-DcAE(i) reduces WER by 8.7% (from 9.62% to 8.78%) on the dev93+500 test set compared to Baseline(i).
4.2 Another Type of Encoder: CNN-TDNNF
Table 2 shows the results of the two types of encoders (TDNN and CNN-TDNNF) evaluated on the cmu test set. Two observations can be drawn. First, the CNN-TDNNF-based models always outperform the TDNN-based models (CNN-TDNNF baseline vs TDNN baseline and CNN-TDNNF-based f-DcAE vs TDNN-based f-DcAE) because of the more layers and unique structures in TDNNF (such as bottleneck and skip connection) [Povey2018b]. Second, compared with the TDNN-based baselines, with the help of the decoder, the TDNN-based f-DcAE models can reduce WER by 5.1% (from 17.73% to 16.82%), 7.8% (from 18.92% to 17.45%), and 6.5% (from 17.58% to 16.44%), when the i-vector and/or p-vector are used as the auxiliary input. Compared with the CNN-TDNNF baseline models, the CNN-TDNNF-based f-DcAE models can reduce WER by 4.9% (from 16.56% to 15.75%), 1.0% (from 17.19% to 17.03%), and 5.2% (from 16.69% to 15.83%). The results show that the f-DcAE framework can be applied to the TDNN and CNN-TDNNF acoustic models and further improve their performance.
| Encoder Type | TDNN | CNN-TDNNF | ||
|---|---|---|---|---|
| Inducers\Model | Base. | f-DcAE | Base. | f-DcAE |
| i-vector | 17.73 | 16.82 | 16.56 | 15.75 |
| p-vector | 18.92 | 17.45 | 17.19 | 17.03 |
| i-vector p-vector | 17.58 | 16.44 | 16.69 | 15.83 |
4.3 Adaptation by in-domain and out-of-domain corpora
In this experiment, we studied the effect of model adaptation. We compared the baseline CNN-TDNNF model and the CNN-TDNNF-based f-DcAE model, both of which are with the auxiliary i-vector input. The models in Table 2 were used as the seed models and adapted with one epoch by tr_cmu (in-domain data) and tr_pfstar (out-of-domain data). The results are shown in Table 3. From the table, we can see that adapted with one epoch by tr_cmu, the baseline CNN-TDNNF model can reduce the WER by 9% (from 16.56% to 15.07%), while the CNN-TDNNF-based f-DcAE model can reduce the WER by 5.5% (from 15.75% to 14.89%), when evaluated on cmu. Even though the relative WER reduction of the adapted baseline model is larger than that of the adapted f-DcAE model, the WER of the adapted f-DcAE model is lower than that of the adapted baseline model (14.89% vs 15.07%). When evaluated on pfstar, we can see that before adaptation by tr_pfstar, the baseline and f-DcAE models performed poorly, because pfstar is in British accent while the training data tr_wsj+tr_cmu is in American accent. In this case, model adaptation is more necessary to shift the domain of the model. After adaptation with one epoch by tr_pfstar, the WER of the baseline model was significantly reduced from 58.89% to 17.29%, and the WER of the f-DcAE model was significantly reduced from 59.51% to 16.87%. Again, f-DcAE achieved a lower WER than Baseline (16.87% vs 17.29%).
4.4 Adaptation on the cross-accent acoustic model
In this experiment, for the cmu task, the models were first trained by tr_wsj and tr_cmu, and then adapted by tr_cmu with sufficient training epochs, while for the pfstar task, the models were first trained by tr_wsj and tr_pfstar, and then adapted by tr_pfstar with sufficient training epochs as well. We intended to study whether the tr_wsj adult training set (in American accent) can also help improve the performance of the pfstar task (in British accent). The results are shown in Table 4. We first focus on the performance of the cmu task. Comparing Table 4 and Table 3, we can see that the adapted Baseline and f-DcAE models with more training epochs can achieve better performance than the adapted Baseline and f-DcAE models with one training epoch and the seed Baseline and f-DcAE models (without adaptation). For the pfstar task, comparing Table 4 and Table 3, we first see that the Baseline and f-DcAE models trained by tr_wsj and tr_pfstar perform much better than the Baseline and f-DcAE models trained by tr_wsj and tr_cmu. Obviously, it is because that the former used tr_pfstar in the model training. From Table 4, we also observe that the adapted Baseline and f-DcAE models outperform the seed Baseline and f-DcAE models (without adaptation). The results confirm that an adult training set in another accent helps to improve the performance of a children ASR task. In addition, we observe that the f-DcAE models always outperform the Baseline models in Table 4.
| Adaptation Set | tr_cmu | tr_pfstar | ||
| Test set | cmu | pfstar | ||
| Model\with Adapt. | no | yes | no | yes |
| Baseline | 16.56 | 15.07 | 58.89 | 17.29 |
| f-DcAE | 15.75 | 14.89 | 59.51 | 16.87 |
| Adaptation Set | tr_cmu | tr_pfstar | ||
| Test set | cmu | pfstar | ||
| Model\with Adapt. | no | yes | no | yes |
| Baseline | 16.56 | 14.55 | 17.25 | 15.13 |
| f-DcAE | 15.75 | 13.71 | 16.84 | 14.86 |
5 Conclusions
In this paper, we have proposed a filter-based discriminative autoencoder (f-DcAE) architecture for acoustic modeling. Both the encoder and decoder are fed with the speaker and/or pitch inducers (or called auxiliary embedding inputs). With the help of auxiliary information, the encoder purifies the phonetic information in the input acoustic feature, while the decoder uses the phonetic information extracted by the encoder to reconstruct the input acoustic feature. Our f-DcAE models are implemented with the Kaldi toolkit by treating the TDNN and CNN-TDNNF models as the encoder and adding an additional decoder during model training. Experimental results have shown that our f-DcAE models outperform the counterpart baseline models without using the autoencoder architecture and the filtering mechanism, in particular on the CMU Kids corpus and the simulated high-pitched eval92 and dev93 test sets. After model adaptation by the in-domain and out-of-domain corpora, our f-DcAE models also outperform the counterpart baseline models on the in-domain and out-of-domain test sets.