Finding Friends and Flipping Frenemies:
Automatic Paraphrase Dataset Augmentation Using Graph Theory
Abstract
Most NLP datasets are manually labeled, so suffer from inconsistent labeling or limited size. We propose methods for automatically improving datasets by viewing them as graphs with expected semantic properties. We construct a paraphrase graph from the provided sentence pair labels, and create an augmented dataset by directly inferring labels from the original sentence pairs using a transitivity property. We use structural balance theory to identify likely mislabelings in the graph, and flip their labels. We evaluate our methods on paraphrase models trained using these datasets starting from a pretrained BERT model, and find that the automatically-enhanced training sets result in more accurate models.
1 Introduction
Having high quality annotated data is crucial for training supervised machine learning models. However, producing large datasets with good labeling quality is expensive and labor intensive. Most NLP datasets rely on labels provided by human annotators with varying skills and limited training and expertise. The label instances are also often based on ambiguous definitions and guidelines.
To address this problem, we study automated techniques to improve datasets for training and testing. In particular, we focus on paraphrase identification task, which aims to determine whether two given sentences are semantically equivalent. The sentences and labels in a dataset can be viewed as nodes and edges of a graph. Moving from single labeled sentence pairs to a graph provides a better understanding of the sentence relations of the dataset, which can be exploited to infer additional edge labels. In particular, since paraphrases are an equality relation, we can perform a transitive closure on the graph to infer additional labels. In addition, we use the notion of balance (Harary, 1953) for signed graphs to identify conflicted relations. In the context of semantic relationships between pairs of sentences, any paraphrases of a given sentence cannot be a non-paraphrase of each other since they should all share an identical meaning.
Contributions. We show the benefits of representing sentence pair relations as a graph. We first construct a paraphrase graph with the original pairs and their relation labels from the Quora Question Pairs (QQP) dataset (Iyer et al., 2017) following the structure of a signed graph. With the graph structure and the transitivity of paraphrases, we can automatically infer new sentence pair relations directly from the original dataset (Section 3.1). In addition, we identify and correct likely mislabeled pairs based on violations of expected structural balance properties we expect a valid paraphrase graph to satisfy (Section 3.2). We found 90 seemingly mislabeled sentence pairs in the QQP dataset. We show that fine-tuning a BERT model on the augmented set improves its performance on both the original and augmented testing sets, decreasing the error rate from 10% to under 6% when testing on the augmented test set. We released the augmented QQP dataset and the implementation code. (https://github.com/hannahxchen/automatic-paraphrase-dataset-augmentation)
2 Representing Datasets as Graphs
A signed graph is a graph where each edge is labeled either positive or negative to indicate a relationship between the two connected nodes. For undirected graphs, this relationship is symmetric. A path is a set of connected edges with no repeated nodes, and a path with the last node connecting back to the first node forms a cycle. Given semantic interpretations of the edge labels, all paths in a signed graph should have certain properties.
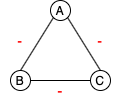
Structural Balance. Balance theory was proposed by Heider (1946) to study interpersonal relationships in social psychology. The idea was generalized to signed graphs by Harary (1953). A graph is said to be balanced if the product of the edge signs in every cycle is positive. There are only two types of conditions exist in a balanced signed graph: (1) all the nodes are connected with only positive edges, or (2) nodes can be divided into subsets such that nodes within each subset are connected with positive edges and nodes from different subsets are connected with negative edges. Figure 1 illustrates four possible sign combinations for a triad.
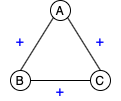
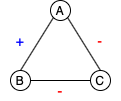
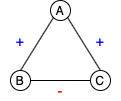
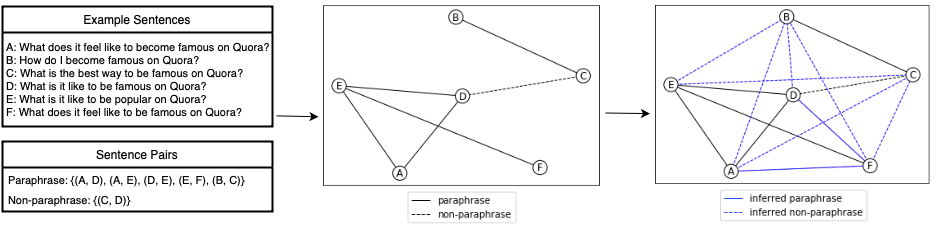
Paraphrase Graph. The definition of a paraphrase remains ambiguous and varies by task, but the most common definitions are similar to the one from Bhagat and Hovy (2013), which define paraphrases as sentences that convey the same meaning but are expressed in different forms. Since this notion is a symmetric relation, we can form an undirected signed graph by linking the sentence pairs from the paraphrase dataset with their annotated relations. Sentence pairs labeled as paraphrases are connected with positive edges; sentences labeled as non-paraphrases are connected with negative edges. A paraphrase cluster contains sentences connected with positive edges, and all sentences in the cluster should share the same meaning. Figure 2 shows how a paraphrase graph is constructed from selected labeled pairs in the QQP dataset.
3 Improving Datasets using Graphs
Typically, training sets for paraphrase identification are constructed by using annotations for sentence pairs provided by human annotators. Based on the semantics implied by the paraphrase and non-paraphrase labels, we can augment and correct the sentence-level paraphrase graph. Our method infers labels based on transitivity (Section 3.1), and identifies likely mislabelings based on expected graph consistency properties (Section 3.2).
3.1 Inferring New Labels (Finding Friends)
Since paraphrase is a reflexive, symmetric, and transitive relation, we can identify a set of semantically equivalent sentences if they are reachable by one another along the paraphrase links. We use Dijkstra’s shortest path algorithm (Dijkstra, 1959) implemented by Networkx (Hagberg et al., 2008) to find paraphrase paths between nodes. Furthermore, we can infer additional non-paraphrase edges between nodes from two different paraphrase clusters if they are connected with one or more non-paraphrase links. Figure 2 illustrates how a paraphrase graph with inferred edge labels is constructed. For example, we can infer a positive link from node A to F, and a negative link from node A to C since A and D are paraphrases and C and D are non-paraphrases. By applying this method to the entire dataset, we expand the training set size for QQP by 60.7% (Section 4.1).
3.2 Fixing Mislabelings (Flipping Frenemies)
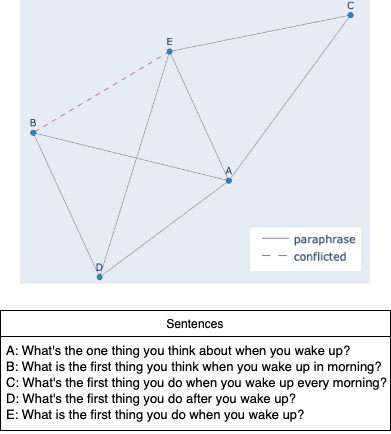
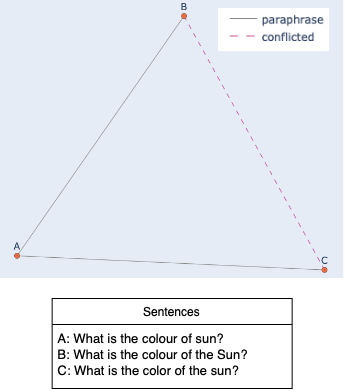
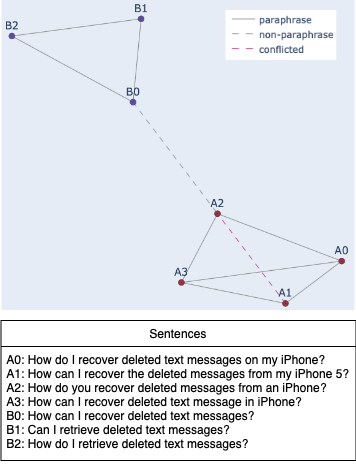
Based on the concept of structural balance for signed graphs, a balanced paraphrase graph can either have the entire sets of sentences being paraphrases of each other, or multiple subset groups of paraphrases with several sentences from different groups being connected with negative links. Our algorithm finds inconsistencies by identifying negative edges within a paraphrase cluster. Given the transitive relation of paraphrases, we correct the false negative links into positive. We found 88 mislabeled pairs in the QQP training set, and 2 pairs in the testing set. See Appendix A.1 for some examples, and A.3 for entire list of identified pairs.
For clusters with only negative edges like the triad in Figure 1(c), even though the relation is imbalanced according to the definition, we are unable to determine whether there should be a pair of paraphrases in the graph without knowing the actual semantic meaning of the sentences. Therefore, we use the weaker form of structural balance to represent graphs with all negative edges. We only consider the negative links within a paraphrase cluster as potentially mislabeled relations.
4 Experiments
To understand the effectiveness and impact of our augmentation and correction methods, we compare the preforms of BERT models fine-tuned to the paraphrase identification task on the original QQP dataset and three datasets derived using the graph-based methods from the previous section.
4.1 Datasets
The Quora Question Pairs (QQP) dataset (Iyer et al., 2017) is based on questions extracted from Quora, where they aim to reduce the frequency of duplicated questions. Each pair is labeled as duplicate or non-duplicate. Duplicated questions are identified as having the same intent, meaning that they can be answered by the same answer. We consider the duplicate and non-duplicate labels comparable to paraphrase and non-paraphrase, and use the more familiar paraphrase terminology hereafter. This dataset is well suited to our approach since there are many sentences that appear in different pairs.
In addition to the original QQP dataset, we derived three additional datasets using the data augmentation and label correcting methods introduced in Section 3. Table 1 summarizes the four datasets.
Our inference method (Section 3.1) finds over 114,000 new paraphrase pairs and 137,000 non-paraphrase pairs across the dataset, expanding the training set by over 60%, and the testing set around 75%. The paraphrase ratio of the augmented training set remains similar as the original set. However, the ratio increases in the augmented testing set indicating the paraphrase clusters are sparser in the testing set. Our inconsistent label detection method (Section 3.2) detects 88 problematic labels in the training set and 2 problematic labels in the testing set. We flip the values of these labels in the Original-Flipped and Augmented-Flipped.111Other approaches would be worth exploring in future work such as removing the problematic pairs, manually inspecting them, and considering other labels involving sentences in problematic pairs as also likely to be problematic.
| Training Set Size | Testing Set Size | Paraphrase Ratio (%) | ||||
|---|---|---|---|---|---|---|
| Dataset | Paraphrase | Non-paraphrase | Paraphrase | Non-paraphrase | Training | Testing |
| Original | 134,378 | 229,468 | 14,885 | 25,545 | 36.93 | 36.82 |
| Original-Flipped | 134,446 | 229,380 | 14,886 | 25,544 | 36.96 | 36.82 |
| Augmented | 220,890 | 363,986 | 42,570 | 28,164 | 37.77 | 60.18 |
| Augmented-Flipped | 220,978 | 363,898 | 42,572 | 28,162 | 37.78 | 60.19 |
4.2 Model Training
We fine-tune the pretrained BERTBASE model on the four datasets with the default configuration (Devlin et al., 2019), and implement early stopping during training. We train the model on each dataset five times independently, and report the average accuracies and F1 scores in Table 2 and the detailed results with standard deviation in Appendix A.2.
| Testing Set: | Original | Original-Flipped | Augmented | Augmented-Flipped | |||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | |
| Training Set | Original | 90.35 | 87.05 | 90.09 | 86.72 | 89.72 | 91.50 | 89.72 | 91.50 |
| Original-Flipped | 90.15 | 86.78 | 90.16 | 86.80 | 93.47 | 94.59 | 93.46 | 94.58 | |
| Augmented | 90.61 | 87.48 | 90.61 | 87.48 | 93.89 | 94.95 | 93.87 | 94.94 | |
| Augmented-Flipped | 90.96 | 88.01 | 90.95 | 88.00 | 94.21 | 95.23 | 94.19 | 95.22 | |
4.3 Result Analysis
As shown in Table 2, the model trained on the Augmented-Flipped dataset has the best performance (both Accuracy and F1) on all testing datasets. The improvement in model accuracy on the Original dataset due to augmenting the training set is modest, but significant. The improvement increases when the flipped training sets are used, and is most substantial (reaching an error rate below 6%, compared to the original 10% error rate) when the testing is done using the Augmented testing set. According to the leaderboard of GLUE benchmark (Wang et al., 2018), an ALBERT based model (Lan et al., 2019) and ERNIE (Sun et al., 2019) are currently the top two models on QQP task with an accuracy of 91.0% and 90.9% on the original testing setComparing to these state-of-the-art models, we can reach a competitive performance with the simple data augmentation proposed in this work.
The models that trained on the Original set has a small performance drop when tested on the Augmented testing set. Since this testing set has a much higher paraphrase ratio, it means that the original model is better at predicting non-paraphrases than paraphrases. It fails to give correct predictions on the augmented paraphrase pairs. This also shows the benefit of augmenting the sentence pairs by representing sentence pair relations as a graph, which helps us generate more paraphrase pairs for training and improve model accuracy on paraphrases.
Since there are only two mislabeled sentence pairs in the testing set (and 88 in the training set), it is unsurprising that the impact of flipping the inconsistent labels is small. Still, in all cases we observe the models trained with the flipped training sets have higher accuracy than those trained on the corresponding dataset with the problematic labels. Interestingly, we find that the model trained on Original-Flipped reaches a similar performance as the model trained on Augmented, when tested on the Augmented and Augmented-Flipped testing sets. This shows the benefits of correcting the labels identified as problematic.
5 Related Work
The most closely related work from Shakeel et al. (2020) also applies paraphrase graphs to generate additional paraphrase and non-paraphrase pairs. Similar to our method, they infer non-paraphrase pairs from sentences within different paraphrase groups, and use transitivity to find new paraphrase pairs. Different from our work, they generate additional paraphrase pairs by pairing sentences to themselves, and reversing the order of each sentence pair. Other than using structural balance, their method can only identify conflicted labels between pairs of sentences. In addition, they only apply data augmentation on the training sets and evaluate their models directly on the original testing sets. We infer additional data and identify conflicts for both training and testing, which illustrates the full potential of our data augmentation method.
Besides, Chen et al. (2012) propose a graph-based method to improve the quality of paraphrase generation. They represent phrases as nodes and translation similarities as edges from a bilingual parallel corpus, and infer paraphrases with the pivot based method, which finds phrases with the same translation. However, this method can only infer new paraphrases within a path length of two. Homma et al. (2017) use a simpler approach by generating new paraphrase pairs with the reflexive and symmetric property of paraphrases with no graph involved. The non-paraphrase pairs are sentences randomly selected from two different pairs, which can not be guaranteed to have a correct relation.
6 Conclusion
In this paper, we show the benefit of representing datasets as graphs. We develop methods based on graph theory to automatically expand a paraphrase dataset and improve labeling consistency. Our experiments show an improvement on the Augmented-Flipped testing set after correcting the conflicted labels in the Original training set, and the combination of the two methods produce a model that gives the best performance across all testing sets.
References
- Bhagat and Hovy (2013) Rahul Bhagat and Eduard Hovy. 2013. Squibs: What is a paraphrase? Computational Linguistics, 39(3):463–472.
- Chen et al. (2012) Mei-Hua Chen, Shi-Ting Huang, Chung-Chi Huang, Hsien-Chin Liou, and Jason S. Chang. 2012. PREFER: Using a graph-based approach to generate paraphrases for language learning. In Proceedings of the Seventh Workshop on Building Educational Applications Using NLP.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers).
- Dijkstra (1959) E. W. Dijkstra. 1959. A note on two problems in connexion with graphs. Numer. Math., 1(1):269–271.
- Hagberg et al. (2008) Aric A. Hagberg, Daniel A. Schult, and Pieter J. Swart. 2008. Exploring network structure, dynamics, and function using NetworkX. In Proceedings of the 7th Python in Science Conference.
- Harary (1953) Frank Harary. 1953. On the notion of balance of a signed graph. Michigan Math. J., 2(2):143–146.
- Heider (1946) Fritz Heider. 1946. Attitudes and cognitive organization. The Journal of Psychology, 21(1):107–112. PMID: 21010780.
- Homma et al. (2017) Yukiko Homma, Stuart Sy, and Christopher Yeh. 2017. Detecting duplicate questions with deep learning.
- Iyer et al. (2017) Shankar Iyer, Nikhil Dandekar, and Kornél Csernai. 2017. First Quora dataset release: Question pairs. https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs.
- Lan et al. (2019) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. ALBERT: A lite BERT for self-supervised learning of language representations.
- Shakeel et al. (2020) Muhammad Shakeel, Asim Karim, and Imdadullah Khan. 2020. A multi-cascaded model with data augmentation for enhanced paraphrase detection in short texts. Information Processing and Management, 57:102204.
- Sun et al. (2019) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, and Haifeng Wang. 2019. ERNIE 2.0: A continual pre-training framework for language understanding.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP.
Appendix A Appendix
A.1 Mislabeling Examples
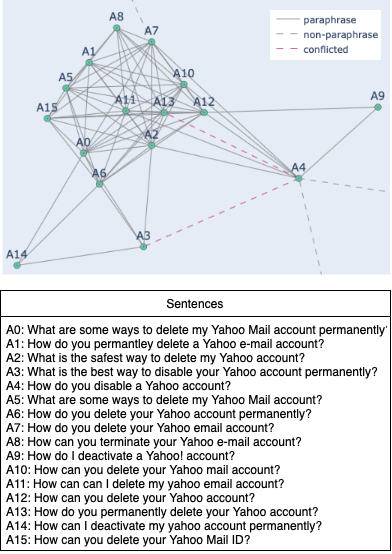
A.2 Evaluation Results
| Testing Set | |||||
|---|---|---|---|---|---|
| Training Set | Original | Original-Flipped | Augmented | Augmented-Flipped | |
| Original | Acc | 90.35 | 90.09 | 89.72 | 89.72 |
| F1 | 87.05 | 86.72 | 91.50 | 91.50 | |
| Recall | 88.13 | 87.92 | 91.99 | 91.99 | |
| Original-Flipped | Acc | 90.15 | 90.16 | 93.47 | 93.46 |
| F1 | 86.78 | 86.80 | 94.59 | 94.58 | |
| Recall | 87.92 | 87.96 | 94.80 | 94.79 | |
| Augmented | Acc | 90.61 | 90.61 | 93.89 | 93.87 |
| F1 | 87.48 | 87.48 | 94.95 | 94.94 | |
| Recall | 89.07 | 89.04 | 95.48 | 95.47 | |
| Augmented-Flipped | Acc | 90.96 | 90.95 | 94.21 | 94.19 |
| F1 | 88.01 | 88.00 | 95.23 | 95.22 | |
| Recall | 90.14 | 90.08 | 96.05 | 96.04 | |
A.3 Sentence Pairs with Conflicted Relation
This section shows all the sentence pairs we identified with conflicted relation in the QQP dataset. All the pairs are originally labeled as non-paraphrase, but are reachable by each other along the paraphrase links in the graph.
| No. | Sentence Pair | |
|---|---|---|
| \csvreader[ separator=semicolon, late after line= | ||
| , late after last line= ]csv_files/mislabeled_train_pairs.csvquestion1=\qone, question2=\qtwo\thecsvrow | \qone | |
| \qtwo | ||