cyt1012@jlu.edu.cn (Y. Chen), liyong@jlu.edu.cn (Y. Li)
Finding similarity of orbits between two discrete dynamical systems via optimal principle
Abstract
Whether there is similarity between two physical processes in the movement of objects and the complexity of behavior is an essential problem in science. How to seek similarity through the adoption of quantitative and qualitative research techniques still remains an urgent challenge we face. To this end, the concepts of similarity transformation matrix and similarity degree are innovatively introduced to describe similarity of orbits between two complicated discrete dynamical systems that seem to be irrelevant. Furthermore, we present a general optimal principle, giving a strict characterization from the perspective of dynamical systems combined with optimization theory. For well-known examples of chaotic dynamical systems, such as Lorenz attractor, Chua’s circuit, Rssler attractor, Chen attractor, L attractor and hybrid system, with using of the homotopy idea, some numerical simulation results demonstrate that similarity can be found in rich characteristics and complex behaviors of chaotic dynamics via the optimal principle we presented.
keywords:
similarity, optimal principle, homotopy , discrete dynamical system, chaotic attractor.37N40, 49K15, 65K10
1 Introduction
Discrete dynamical systems described by iteration of mappings appear everywhere, showing directive laws from physical science or result from simulations to better understand differential equations numerically. Generally, it is much more difficult but interesting to investigate how complex behavior happens to discrete dynamical systems than continuous dynamical systems after some iterations, since there are probably greater covered ranges and more ghost phenomena. Along with the development of computer technology, modeling problems by means of discrete dynamical systems mathematically has already been gained in different fields such as biology, economics, demography, engineering, and so on. It is universally acknowledge that no matter how different the various technologies develop as well as the objects appear in the research process, there are certain underlying similarities.
Similarity, in addition to being frequently encountered, is viewed as a fundamental concept in scientific research. The idea of similarity has gained widespread popularity in the era of big data and machine learning by various means. For instance, scale similarity is found in many natural phenomena in the universe [1]. An embedding-based vehicle method with deep representation learning drastically accelerates trajectory similarity computation [2]. A novel brain electroencephalography (EEG) clustering algorithm not only handles the problem of unlabeled EEG, but also avoids the time-consuming task of manually marking the EEG [3]. Based on the cosine similarity, a transductive long short-term memory model is developed for temperature forecasting [4]. Self-similar coordinates are investigated in Lattice Boltzmann equation, showing that the time averaged statistics for velocity and vorticity express self-similarity at low Reynolds [5]. Many other applications include gene expression [6], image registration [7], web pages and scientific literature [8], fuzzy linguistic term sets [9], collaborative filtering [10], pattern analysis [11] and preferential attachment [12]. Indeed, the ubiquitous similarity is attributed to facilitate prediction of indeterminate events by analyzing known data, being an essential task in many natural systems and phenomena of real life.
A core part of similarity search is the so-called similarity measure whose famous characteristic is able to assess how similar two sequences are, in other words, the degree to which a given sequence resembles another. Many researchers have paid great attention to devise a proper similarity measure and have achieved several valuable results, which can be roughly categorized into two sorts. One sort is based on the traditional measures, such as Euclidean distance, dynamic time warping, cosine and cotangent similarity measures and Pearson correlation coefficient [13]. The other sort is some transform-based methods, such as singular value decomposition, principal component analysis, Fourier coefficients, auto-regression and moving average model [14, 15]. The cautious selection of similarity measure scheme has long been a research hotspot, affecting the accuracy of further data mining tasks directly, such as classification, clustering and indexing [16, 17].
Up to now, whether there is similarity between two physical processes and how to seek similarity through a mathematical principle are still remain a significant challenge. Several theoretical approaches are available to deal with this problem by taking into account asymptotic equivalence, synchronization and stability just as some kind of similarity. Furthermore, almost all similarity measure criteria are exploited according to application background and actual data, which can only be regarded as quantitative representations to estimate pairwise similarity of a given series resembles another under certain conditions.
Determining similarity between orbits derived from chaotic systems generally characterized by highly complex behavior is particularly difficult when the general similarity measure is employed. Having in view that, for any two chaotic dynamical systems, what are their similarities and how do we find them are both fundamental but challenging subjects in science and engineering. For this purpose, we will try to touch these problems.
To the authors best knowledge, this is the first work to develop a mathematical framework, studying the connection of orbits between two discrete dynamical systems from the perspective of dynamical systems combined with optimization theory. Novel contributions and results of this paper include 1) proposing the concepts of similarity transformation matrix and similarity degree to describe what extent the orbits derived from two discrete dynamical systems are similar; 2) presenting a general optimality principle by employing variational method when orbits of two discrete dynamical systems are similar at some step; 3) constructing hybrid dynamical system with richer and more complex dynamical behavior via the idea of homotopy, applying to numerical simulation.
The remainder of this paper begins with review of several typical chaotic attractors related to this study. We formalize the similarity via optimization techniques and give the definitions of similarity transformation matrix and similarity degree mathematically to assess what extent the orbits of two dynamical systems are similar, followed by establishing the main results of this paper in Section 3. Section 4 reports numerical simulation results of chaotic systems to support the theoretical findings. Conclusions are drawn in Section 5.
2 Chaotic systems
Among a broad variety of dynamical systems in the universe, we consider some typical chaotic systems such as Lorenz attractor, Chua’ circuit, Rssler attractor, Chen attractor, L attractor and their hybrid systems.
Lorenz attractor, the first chaotic dynamical system, was obtained by Lorenz in 1963 from simplified mathematical model developed for atmospheric convection while modelling meteorological phenomena [18]. The chaotic system is a typical nonlinear system with three differential equations known as the Lorenz equations
| (1) |
where , , represent the system states and the system parameters are selected as , , . The initial conditions are , , , then the behavior of Lorenz attractor resembling a butterfly or figure eight is illustrated in Fig. 2.
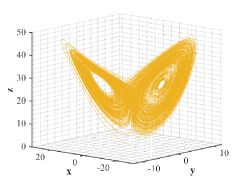
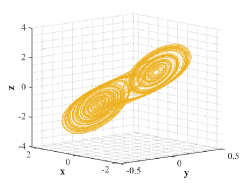
Chua’s circuit is the simplest electronic circuit known as nonperiodic oscillator [19]. It has been confirmed by numerous experimental simulations and rigorous mathematical analysis that this circuit is able to produce an oscillating waveform exhibiting classic chaos behavior and many well-known bifurcation phenomena. Three ordinary differential equations are found as below in the analysis of Chua’s circuit
| (2) |
where , denote the voltage of capacities, represents inductance current and the parameters , are determined by the particular values of the circuit components. The function is defined as a piece-linear function, describing the electrical response of nonlinear resistor
| (3) |
Fig. 2 shows the double scroll attractor from Chua’s circuit, in which the initial states are , , , and the parameters are determined as , , , .
Rssler attractor behaves similar to Lorenz attractor, and it is the most simple chaotic attractor from the topological point of view. This attractor is applied to modelling equilibrium in chemical reactions which is a chaotic solution to the system of three differential equations
| (4) |
where , , denote the system states and three parameters , and are assumed to be positive [20]. We select numerical values of parameters as , , and give a typical orbit of Rssler attractor, which admits chaotic behavior, as shown in Fig. 4.
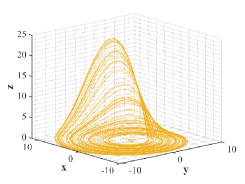
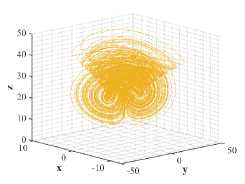
Chen attractor is found in the pursuit of chaotification, being similar but topologically not equivalent to Lorenz attractor [21]. Despite Chen attractor with simple structure is the dual to Lorenz system, it is considered displaying even more sophisticated dynamical behaviors [22]. The three-dimensional autonomous system of ordinary differential equations with quadratic nonlinearities that describe Chen system are
| (5) |
where , , are the system states and , , are real parameters. For parameters values , , , we obtain a Lorenz-based wing attractor as shown in Fig. 4.
L attractor is another example that captures the paradigms of chaotic system, which connects Lorenz attractor and Chen attractor and represents the transition from one to the other [23, 24]. In order to reveal the topological structure of this chaotic attractor, consider its controlled system which is obtained by adding a constant to the second equation of L system
| (6) |
where , , denote the system states, , , are the system parameters. By varying the parameter considered as “controller” of the controlled system, one can observe different dynamical behaviors, contributing to a better understanding of all similar and closely related chaotic system [25]. When , , , all the simulation figures are summarized in Fig. 5.
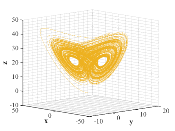
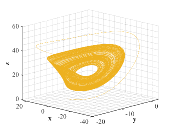
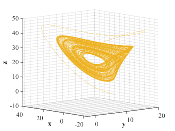
The high sensitivity of chaotic systems to small perturbations of the initial states, together with the complex dynamical behavior characterized by rapidly changing solutions, make the research on chaotic dynamical systems challenging. The purpose of this paper focuses on finding similarity between the orbits of chaotic attractors via the general optimality principle, which will be discussed in next section.
3 Main results
We are now in the position to demonstrate that similarity of orbits derived by discrete dynamical systems can be found through a strict mathematical principle. This allows us to better understanding the motion trajectory and predicting process trend when looking at the rich behavior of complex physical processes.
3.1 Simple Dynamical Systems
Consider the following two discrete dynamical system
| (7) |
| (8) |
where the mappings are of . Starting from initial states and , the solutions of (7) and (8) are denoted as
| (9) |
| (10) |
respectively. We introduce a new concept of similarity transformation matrix to deal with the problem of drawing a relation of similarity between (7) and (8).
Definition 3.1.
Let denote the set . There exists an order matrix satisfies:
denotes some matrix element, where and are the th row and th column of , respectively;
is a bounded closed convex set of whose interior ;
.
From the definition given above, it follows that the way to estimate similarity transformation matrix is to minimize the cost functional
| (11) |
Motivated by first-order optimality condition which is the foundation for many of optimization algorithms, we know that the optimal solution of (11) is equivalent to
| (12) |
In the following, we give the estimate of variational equation (10), which plays an important role in analysis of the optimal principle. The result can be shown by induction. For the case , from the fact that , we have
| (45) |
When , it follows from the iterative formula and (3.1) that
Let us make the induction hypothesis, assuming that the following expression is true for , that is
| (49) |
We now show that it continues to hold for . By combining (10) with (49), we obtain
Then, if is generated by (10), we deduce that
| (50) |
For the second term of the right-hand side in (12), we obtain the following equation by means of derivative rule of compound function,
| (51) |
It is obvious that
| (52) |
Together with (50), it yields that
| (56) | ||||
| (60) | ||||
| (61) |
In this way, one of the main results in this paper is built up by substituting (3.1), (62) and (3.1) into (12).
Proposition 3.2.
3.2 Homotopy Dynamical Systems
In light of above analysis, a natural extension of that is a more complex similarity study for general dynamical systems.
Consider hybrid systems formed by two chaotic attractors via homotopy method, which will show richer and more interesting dynamical behavior. Two simple systems as shown in (7) and (8) can be connected by constructing such a homotopy
| (69) |
where is an embedding parameter. Note that the homotopy is exactly a path connecting and such that and . As the parameter increases from 0 to 1, the homotopy varies continuously from one system to another.
Take into account two dynamical systems with the following forms
| (70) |
| (71) |
where homotopies (70) and (71) stand for general hybrid dynamical systems with the embedding parameters changing per iteration. The solutions of (70) and (71) are denoted as
| (72) |
| (73) |
respectively. At this point, the similarity transformation matrix, becoming related to the parameter , is re-expressed as . Let the cost functional be written in the form
| (74) |
According to Karush-Kuhn-Tucker (KKT for short) optimality conditions that are often checked for investigating whether a solution of nonlinear programming problem is optimal, is a stationary point of (74) if and only if
| (75) |
and
| (76) |
simultaneously. The derivation of (75) is the same as (12), and hence the details are omitted here.
For the first term of the right-hand side in (76), by direct calculation, we get
| (80) | ||||
| (84) | ||||
| (88) | ||||
| (89) |
For the second term of the right-hand side in (76), it follows from derivative rule of compound function that
| (90) |
On the one hand,
| (94) | ||||
| (95) |
On the other hand,
| (99) | ||||
| (103) | ||||
| (104) |
Combining (3.2) and (99) with (90), we obtain
| (105) |
For the last term of the right-hand side in (76), it is obvious that
| (112) | ||||
| (113) |
According to all derivations above, we deduce the other main result of this paper, which deals with how similar between orbits of general dynamical systems. By substituting (3.2), (105) and (3.2) into (76), we give the existence of the solution of (74).
Proposition 3.3.
Let and be generated by (70) and (71), respectively. If matrix and parameter are the optimal solutions of (74), then there exist the following general optimal principle:
| (114) |
and
| (115) |
where the similarity transformation matrix becomes related to the parameter , and stands for some matrix element of , other representations of components have the same meanings as before.
Remark 3.4.
Remark 3.5.
The existing literature on the variation of functional with respect to matrix rather than just vector or even scalar is rare, as considered in (11) and (74). Taking variation of a matrix can be converted to the partial derivative of each matrix elements, which is exactly the tedious calculations of derivation, especially when the number of iterations is large.
For most cases, it is almost impossible to find similarity transformation matrix that makes solutions between two discrete dynamical systems exactly similar. By virtue of the characterizations of function
we define a similarity function by setting . When no similarity transformation matrix can be found to make two orbits completely similar, we also ask to what extent they are similar.
Definition 3.6.
The similarity degree of solutions between two discrete dynamical systems is defined as
| (116) |
It is easy to see that , according to the above definition.
We close this section by summing up that the solutions of two systems are said to be completely similar if , otherwise, some are similar.
4 Experimental results
In this section, some examples are given to show the utility of general optimal principle proposed in this paper. All codes are written in MATLAB R2021a and run on PC with 1.80 GHz CPU processor and 8.00 GB RAM memory. Unless otherwise specified, the numerical results are accurate to four decimal places throughout this paper.
To cope with over-fitting, L2-norm regularization is introduced naturally. In reinforcement learning and neural networks, this happens frequently when samples are limited and computation is expensive. The cost functional in (11) or (74) is augmented to include a L2-norm penalty of matrix with the following form
| (117) |
where is a positive constant called regularization parameter that balances the two objective terms.
In the optimal control theory, the most fundamental but crucial two optimization methods are Pontryagin’s maximum principle and Bellman’s dynamic programming. Taking into account the proposed optimal principles, we conduct the numerical simulations by following Pontryagin’s maximum principle and Bellman’s dynamic programming respectively for similarity of orbits between various chaotic systems.
The chaotic systems chosen in this section are all solved numerically by means of the widely used fourth-order Runge-Kutta method with time step size equal 0.01. The following numerical experiments mainly include two parts.
4.1 Pontryagin’s maximum principle
As a necessary condition to solve optimal control problems, Pontryagin’s maximum principle was proposed by Pontryagin and his group in the 1960s [26]. Outstanding feature of Pontryagin’s maximum principle lies in that the optimal control signal transfering dynamical system from one state to another can be found under the condition that the state or input is fixed. The following examples concern to verify Pontryagin’s maximum principle formulated in terms of the proposed optimal principle (3.2) when studying the similarity of orbits between two chaotic attractors.
Example 4.1. Similarity of orbits between Lorenz attractor and Chua’s circuit.
Let and be the numerical solutions derived from Lorenz and Chua systems for 2000 time steps (namely, ) from the same initial states
We divide the sequences into multi-stage decisions consisting of 10 steps for each (denoted by ), with the final state of previous stage as the initial condition of current stage. The optimal similarity transformation matrix of each stage is found by optimal principle (3.2) whose accuracy performance is assessed by similarity degree (116).
Figs. 6-7 describe three dimensional stereograms and two dimensional plans of Lorenz attractor, Chua’s circuit and the trajectory acted by the optimal similarity transformation matrix for each stage. Enlarge the trajectories marked by dotted box so as to find similarity of orbits between and more clearly. We can observe that Lorenz attractor and Chua’s circuit with different orbits become mainly similar after the optimal similarity transformation matrix is employed according to Figs. 6a and 7a. As can be seen in Figs. 6b and 7b, if the regularization parameter is selected as , the orbit under action of optimal similarity transformation matrix is surprisingly close to the orbit , supporting the availability of tuning parameter and the stability of L2-norm regularization.
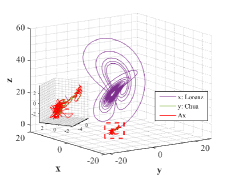
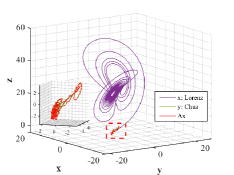
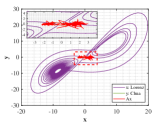
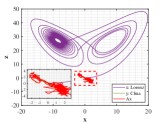
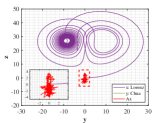
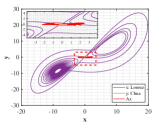
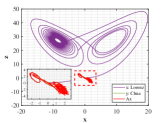

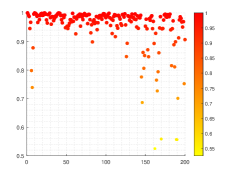
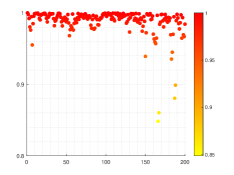
Results of similarity degree are shown in Fig. 8. From Fig. 8a, we can see that the values of similarity degree can achieve over 0.9 in the majority of results. When L2-norm penalty is introduced, only 4 results are less than 0.9. This exactly implies that the stability of solution is improved by introducing L2-norm regularization with suitable regularization parameter.
Example 4.2. Similarity of orbits between Lorenz attractor and R attractor.
Let and be the numerical solutions of Lorenz and R systems, sharing the same initial states . We perform the same experimental procedure as in Example 4.1.
Figs. 9 and 10 shown the stereograms and plans of Lorenz attractor, Rssler attractor and the trajectory acted by optimal similarity transformation matrix for each stage when . Even if overlapped trajectories marked by dotted box are enlarged, we could still observe that the orbits of Rssler system almost coincides with that of Lorenz system acted by optimal similarity transformation matrix.
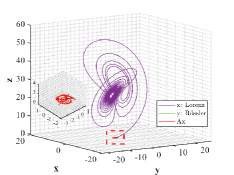
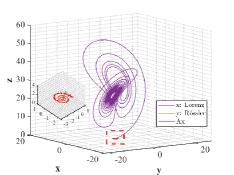
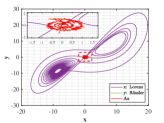
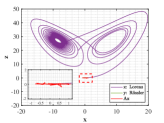
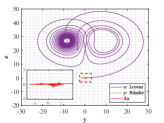
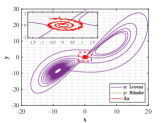
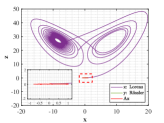
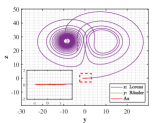
Lorenz attractor with butterfly shape and R attractor with spiral shape that appear to be different geometrically, become remarkably similar within the proper precision under the action of Pontryagin’s maximum principle using optimal principle (3.2), which is greatly an amazing finding.
Surprisingly, the numerical results indicated in Fig. 11 show that only six results are less than 0.95 without regularization term. It should be point out that when we carry out tests to find optimal similarity transformation matrix based on L2-norm penalty (117), all values of similarity degree are greater than 0.98.
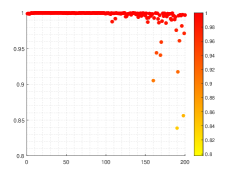
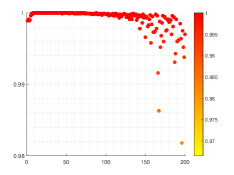
To summarize, even without the use of L2-norm regularization, we can still get very satisfactory results to some extent.
4.2 Bellman’s dynamic programming
Dynamic programming was studied by Bellman to deal with situations where the best decisions are made in stages [27]. Whatever the initial state and initial decision are, the decisions that will follow must also constitute an optimal policy for the remaining problems, when the stage and state formed by the first step decision are considered as initial conditions. Applying Bellman’s dynamic programming in terms of the proposed optimal principle, we analyze the similarity of orbits between two chaotic attractors, see the following three examples.
Example 4.3. Similarity of orbits between Lorenz attractor and Chen attractor.
Let and be the numerical solutions obtained from Lorenz and Chen systems for 2000 time steps. Instead of solving 2000 steps one at a time, we consider multi-stage decision making process by breaking the complex problems into ten simple subproblems denote as with 10 steps for each.
More precisely, for stage , the initial conditions of two systems are determined as
with unknown. Make use of Runge-Kutta method, we calculate the states of this stage including the values of and whose components are represented by expressions containing elements of . By solving a nonlinear equations formulated by (3.2), we obtain an approximate solution with a high precision.
For the following stages, we do the same actions and compare the current similarity transformation matrix with the one obtained by previous stage denoted as subject to similarity degree defined in (116), then let
be the optimal similarity transformation matrix of this stage. We obtain the approximate solution which makes similarity degree reach 1.0000 for each stage.
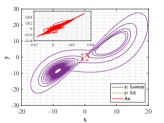
As shown in Figs. 12-14, Lorenz and Chen systems with different orbits can become distinct similar through the adjustment of similarity transformation matrix derived by the proposed optimal principle.
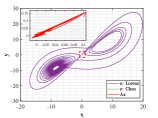
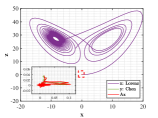
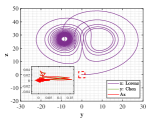
Now we elaborate the advantage of multi-stage dynamic programming with the help of numerical results. For , the optimal similarity transformation matrix can be found according to optimal principle (3.2), which makes similarity degree reach 0.988837. When only the optimal similarity transformation matrix at stage is taken and is still employed in other stages, similarity degree increases to 0.988839. If we adopt the corresponding optimal similarity transformation matrix in both and , the similarity degree rises to 0.9888435, and so on. The final similarity degree of solutions between Lorenz attractor and Chen attractor in this example can reach 0.999995 and each stage is optimal at this point, which meets Bellman’s principle of optimality. To get a better view of the change in similarity degree, the numerical results of each stage are depicted in Fig. 14. We observe that as the number of the optimal similarity transformation matrix in corresponding stage increases, similarity degree is increase progressively.
Example 4.4. Similarity of orbits between Lorenz attractor and L attractor.
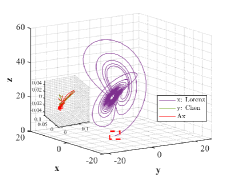
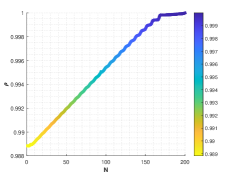
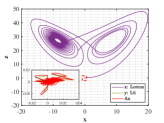
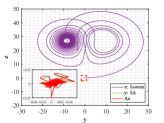
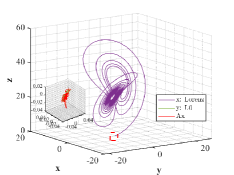
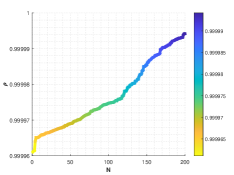
Let and be the numerical solutions got from Lorenz system and L system with for 2000 time steps. Similar to the multi-stage decision in Example 4.3, we also divide the steps into 200 stage. For each stage, only the initial state of sequence is known. The values of similarity degree can reach 1.0000 for all stages, implying the effectiveness of the optimal similarity transformation matrix.
We are surprised by the effectiveness of similarity transformation matrix formulated by the proposed optimal principle, as shown in Figs. 15-17. Even if we enlarge the trajectories represented in dotted box to the coordinate diagram with small horizontal and vertical coordinates, the orbits of L attractor and Lorenz attractor acted by optimal similarity transformation matrix can still coincide almost exactly. The change of similarity degree gradually increase from to with the increase of the number of optimal similarity transformation matrix, satisfying Bellman’s principle of optimality, see Fig. 17.
Example 4.5. Similarity of orbits between Hybrid attractor and L attractor.
The last example concerns hybrid Lorenz-Chua chaotic system formed by Lorenz attractor and Chua’s circuit using the homotopy approach (69), modelling below
| (118) |
where the piece-linear function is defined in (3), and all the same parameters as in (1)-(3). The study on hybrid attractor is more challenging due to its more complex topologies and dynamics.
Different dynamical behaviors in L attractor’s controlled system (6) can be generated by varying the parameter . For the parameters , , and that produce complete attractor, partial attractor, left-attractor and right-attractor, we simulate the similarity between orbits of hybrid Lorenz-Chua system and L attractor respectively.
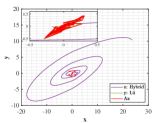
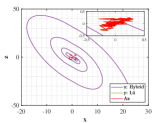
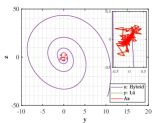
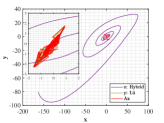
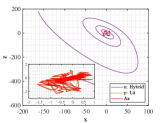
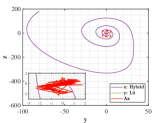

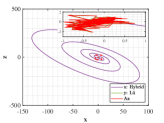
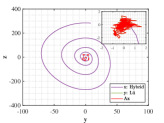
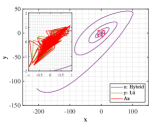
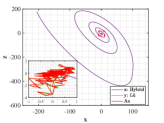
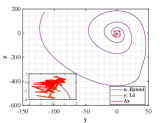
Let and be the numerical solutions obtained from hybrid system (118) and L attractor for 1000 time steps. Breaking the problems into 200 simple subproblems with 5 steps for each, the approximate solutions of parameter and optimal similarity transformation matrix are found by (3.3) and (3.3).
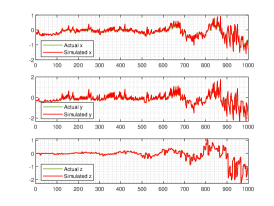
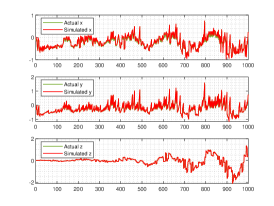
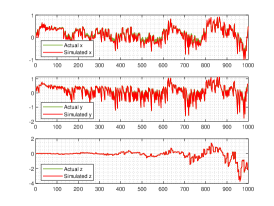
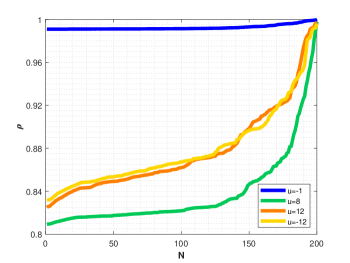
We show the numerical performance in Fig.18 for the four different values of , respectively. For the purpose of demonstrating the optimal principle simulated effect more intuitively, Fig. 19 illustrates the orbit of L system (actual) and that of hybrid Lorenz-Chua attractor acted by the optimal similarity transformation matrix (simulated). In spite of L system exhibits various dynamical behaviors due to varying parameter , the two sequences almost completely coincide, showing the availability and universality of the proposed optimal principle.
For the sake of completeness, the change in similarity degree of four cases of Example 4.5 are shown in Fig. 20, which also fulfill Bellman’s principle of optimality.
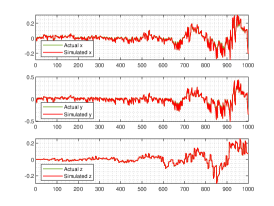
Chaotic systems, are generally characterized by complex behavior and rapidly changing solutions, whose orbits become quite similar taking advantage of the general optimal principle presented in this paper.
5 Conclusions
In scientific research, capturing certain underlying similarity between two complex physical processes is one of the most intensively essential problems. The critical challenge for finding similarity of orbits between dynamical systems arises when facing the high sensitivity to small perturbations with respect to initial states of chaotic systems. Main contribution, in addition to proposing some concepts described what extent the orbits between two markedly different systems are similar, is the general optimal principle built up from the viewpoint of dynamical systems together with optimization theory. This optimal principle is applied to various well-known chaotic attractors and some kind of hybrid chaotic system that is constructed on the basis of homotopy idea, yielding encouraging numerical simulation results surprisingly.
Specifically, attention is paid to find similarity of orbits between dynamical systems with complex behavior, mathematically. As necessary foundations for this paper, the definitions of similarity transformation matrix and similarity degree are introduced. We present a general optimal principle based on optimality condition and variational method, finding some underlying similarity between orbits of two dynamical systems. The numerical simulations concern with both Pontryagin’s maximum principle and Bellman’s dynamic programming formulated in terms of the optimal principle for similarity of orbits between various chaotic systems. The orbits differed markedly become remarkably similar under action of the optimal similarity transformation matrix, and the value of similarity degree also supports this, implying significance of the optimal principle we proposed in this paper.
Acknowledgments
This work was supported by National Basic Research Program of China (2013CB834100), National Natural Science Foundation of China (11571065, 11171132, 12071175), Project of Science and Technology Development of Jilin Province (2017C028-1, 20190201302JC), and Natural Science Foundation of Jilin Province (20200201253JC).
References
- [1] Z. J. Wang and Y. Li, A mathematical analysis of scale similarity, Commun. Comput. Phys., 21 (2017), 149-161.
- [2] Y. Y. Chen, P. Yu, W. W. Chen, Z. W. Zheng and M. Y. Guo, Embedding-based similarity computation for massive vehicle trajectory data, IEEE Internet Things, 9 (2022), 4650-4660.
- [3] C. L. Dai, J. Wu, D. C. Pi, S. I. Becker, L. Cui, Q. Zhang and B. Johnson, Brain EEG time-series clustering using maximum-weight clique, IEEE Trans. Cybern., 52 (2022), 357-371.
- [4] Z. Karevan and J. A. K. Suykens, Transductive LSTM for time-series prediction: An application to weather forecasting, Neural Networks, 125 (2020), 1-9.
- [5] A. Zarghami, M. J. Maghrebi, J. Ghasemi and S. Ubertini, Lattice Boltzmann finite volume formulation with improved stability, Commun. Comput. Phys., 12 (2012), 42-64.
- [6] H. Arbela, S. Basua, W. W. Fisherd, A. S. Hammondsd, K. H. Wand and S. Parkd, Exploiting regulatory heterogeneity to systematically identify enhancers with high accuracy, Proc. Natl. Acad. Sci. USA, 116 (2018), 900-908.
- [7] A. Mang and L. Ruthotto, A Lagrangian Guass-Newton-Krylov solver for mass and intensity preserving diffeomorphic image registration, SIAM J. Sci. Comput., 39 (2017), B860-B885.
- [8] B. Wang, J. J. Zhu, E. Pierson, D. Ramazzotti and S. Batzoglou, Visualization and analysis of single-cell RNA-seq data by kernel-based similarity learning, Nat. Methods, 14 (2017), 414-416.
- [9] H. C. Liao, Z. S. Xu and X. J. Zeng, Distance and similarity measures for hesitant fuzzy linguistic term sets and their application in multi-criteria decision making, Inf. Sci., 271 (2014), 125-142.
- [10] H. F. Liu, Z. Hu, A. Mian, H. Tian and X. Z. Zhu, A new user similarity model to improve the accuracy of collaborative filtering, Knowl. Based Syst., 56 (2014), 156-166.
- [11] Z. Zhao, L. Wang, H. Liu and J. P. Ye, On similarity preserving feature selection, IEEE Trans. Knowl. Data Eng., 25 (2013) 619-632.
- [12] F. Papadopoulos, M. Kitsak, M. A. Serrano, M. Boguna and D. Krioukov, Popularity versus similarity in growing networks, Nature, 489 (2012), 537-540.
- [13] T. W. Liao, Clustering of time series data-a survey, Pattern Recognition, 38 (2005), 1857-1874.
- [14] I. Bartolini, P. Ciaccia and M. Patella, WARP: accurate retrieval of shapes using phase of Fourier descriptors and time warping distance, IEEE Trans. Pattern Anal. Mach. Intell., 27 (2005), 142-147.
- [15] T. C. Fu, A review on time series data mining, Eng. Appl. Artif. Intel., 24 (2011), 164-181.
- [16] F. M. Shen, Y. Xu, L. Liu, Y. Yang, Z. Huang and H. T. Shen, Unsupervised deep hashing with similarity-adaptive and discrete optimization, IEEE Trans. Pattern Anal. Mach. Intell., 40 (2018), 3034-3044.
- [17] A. Torrente, Band-based similarity indices for gene expression classifcation and clustering, Nature, 11 (2021), 21609.
- [18] E. N. Lorenz, Deterministic nonperiodic flow, J. Atmospheric Sci., 20 (1963), 130-141.
- [19] L. O. Chua, The genesis of Chua’s circuit, Archiv f. Elektronik u. bertragungstechnik, 46 (1992), 250-257.
- [20] O. E. Rssler, An equation for continous chaos, Phys. Lett. A., 57 (1976), 397-398.
- [21] G. R. Chen and T. Ueta, Yet another chaotic attractor, Internat. J. Bifur. Chaos Appl. Sci. Engrg., 9 (1999), 1465-1466.
- [22] T. Ueta and G. R. Chen, Bifurcation analysis of Chen’s attractor, Int. J. Bifurcat. Chaos, 10 (2000), 1917-1931.
- [23] J. H. L and G. R. Chen, A new chaotic attractor coined, Int. J. Bifurcat. Chaos, 12 (2002), 659-661.
- [24] J. H. L, G. R. Chen and S. C. Zhang, Dynamical analysis of a new chaotic attractor, Int. J. Bifurcat. Chaos, 12 (2002), 1001-1015.
- [25] J. H. L, G. R. Chen and S. C. Zhang, The compound structure of a new chaotic attractor, Chaos Solitons Fractals, 14 (2002), 669-672.
- [26] L. S. Pontryagin, V. G. Boltayanskii, R. V. Gamkrelidze and E. F. Mishchenko, The mathematical theory of optimal processes, Wiley, NewYork, USA, 1962.
- [27] R. Bellman, Dynamic programming, Princeton, N. J., USA: Princeton University Press, 1957.