Fixed-Parameter Tractability of the (1+1) Evolutionary Algorithm on Random Planted Vertex Covers
Abstract
We present the first parameterized analysis of a standard (1+1) Evolutionary Algorithm on a distribution of vertex cover problems. We show that if the planted cover is at most logarithmic, restarting the (1+1) EA every steps will find a cover at least as small as the planted cover in polynomial time for sufficiently dense random graphs . For superlogarithmic planted covers, we prove that the (1+1) EA finds a solution in fixed-parameter tractable time in expectation.
We complement these theoretical investigations with a number of computational experiments that highlight the interplay between planted cover size, graph density and runtime.
1 Introduction
Combinatorial problems with planted solutions have been an important subject of study on a wide range of settings. In this scenario, a fixed solution is hidden within a large random structure such as a graph. The canonical example of this is the planted clique problem where a fixed complete subgraph of size is placed within a large Erdős-Rényi random graph on vertices. The task is to either recover the hidden solution [AKS98] or one of size at least [Jer92]. These problems have important applications in cryptography [JP00] for example. In the context of randomized search heuristics, Storch [Sto07] investigated the planted clique problem for random local search (RLS) and the (1+1) EA. More recently, Doerr et al. [DNS17] considered randomly generated propositional satisfiability problems with planted assignments and proved that the (1+1) EA requires at most time to solve this problem provided that the constraint density is high enough.
Planted vertex covers have recently been studied in the context of systematically incomplete data [BK18] in networks. In this view, true node interactions can only be observed among some core set , whereas a potentially much larger set of fringe nodes lies outside this sphere of observability. This may occur, for example, in social networks and communication data sets [RUK19] where a company only knows about links within the company and between an employee and the outside world, but not about links between external entities. This translates to a planted vertex cover problem on a graph . An adversary knows of a subset which is a vertex cover, and the task is to identify a set as close to as possible.
In the model, a graph is constructed on a set of vertices by taking a size- subset to be the core. An edge appears in with probability unless it connects two vertices in , in which it occurs with probability zero. Therefore, is guaranteed to have a -vertex cover. Note that a graph can be constructed from this model by drawing a standard Erdős-Rényi graph and subsequently deleting all edges that connect fringe vertices.
This model is a special case of the stochastic block model of random graphs from network theory [HLL83] in which the vertex set is partitioned into disjoint communities and edge probabilities are specified by a symmetric matrix where a vertex in community is connected to a vertex in community with probability . The stochastic block model allows for the generation of graphs from which the community subgraphs might be recovered partially or in full from the graph data [AS15]. This models the detection of community structure in networks, which is a fundamental problem in computer science. The model we study in this work is a stochastic block model with and probability matrix
In this paper, we are interested in the performance of simple randomized search heuristics on planted vertex cover problems in the context of parameterized complexity. We prove that, for sufficiently “dense” graphs (i.e., large enough ), the (1+1) EA is with high probability a fixed-parameter tractable heuristic for the -vertex cover problem where is the size of the planted solution. More precisely, if is at most logarithmic, we prove there is a threshold on such that above this threshold the (1+1) EA is very likely to find a -cover in almost linear time. For larger values of , we show that the (1+1) EA runs in time where is a function of and (but not ).
The first parameterized result on vertex cover is due to Kratsch and Neumann [KN12] who demonstrated that Global SEMO using instance-specific mutation operators has expected optimization time on any graph where is the size of the optimal vertex cover of . This result can be tightened to by incorporating the cost of an optimal fractional vertex cover provided by an LP solver into the fitness function. A recent study by Baguley et al. [BFN+23] extended these multi-objective approaches to the W-separator problem. Using a special focused jump-and-repair mechanism, Branson and Sutton [BS21] showed that evolutionary algorithms can solve the vertex cover problem in expected time by probabilistically simulating an iterative compression routine.
The above results hold for all graphs with vertex cover size . In this paper, we sacrifice the generality of the problem slightly in order to investigate a more general algorithm, i.e., the (1+1) EA. To our knowledge, we present here the first parameterized complexity result on vertex cover problems for a standard evolutionary algorithm that does not rely on any special mutation operators.
Our results. For random planted graph models with vertices, edge density and planted cover size , we show that if , then if for any constant , a restart framework for the (1+1) EA finds a -cover in , where is a constant. If , then we show for any , the expected time of the (1+1) EA is , i.e., the (1+1) EA runs in FPT time parameterized by and .
We also provide the results of computational experiments that investigate regimes that our theorem does not cover, for example when both and are small. These results elucidate the relationship between and and the runtime of the (1+1) EA, and hint at new interesting directions for future theoretical study.
2 Preliminaries
Given a graph on vertices, we encode subsets of as elements of in the usual way. For , denote as as the number of bits set to in (i.e., the cardinality of the set to which it corresponds). The fitness function typically employed by evolutionary algorithms on the minimum vertex cover problem first penalizes infeasible sets (sets that do not cover all edges in ), then penalizes larger feasible covers:
| (1) |
This fitness function is quite natural for searching for a minimal cover, and was originally designed by Khuri and Bäck [KB94]. It has been studied extensively both empirically and theoretically [KB94, OHY09, FHH+10].
We point out that this is a so-called vertex-based representation for which there are currently no bounds on the approximation ratio for the (1+1) EA. It is possible to obtain a guaranteed 2-approximation with the (1+1) EA by using edge-based representations instead [JOZ13]. This is rather notable, as minimum vertex cover is likely hard to approximate below a factor [KR08].
Many of our theoretical results make use of multiplicative drift with tail bounds, which we state in the following theorem for reference.
Theorem 1 (Multiplicative Drift [DG10, KK19]).
Let be a stochastic process over , and let . Suppose that and, for all , it holds that , and there exists some such that, for all , , then,
-
1.
, and
-
2.
The fitness function in Equation (1) ensures that Algorithm 1 quickly finds a feasible cover, which is captured in Theorem 2, which was proved asymptotically in [FHH+10, Theorem 1]. We restate this result here with a simple upper bound with leading constants using drift.
Theorem 2.
The expected time until the (1+1) EA finds a feasible cover for any graph on vertices is at most .
Proof.
Let be the stochastic process that counts the number of edges uncovered by the candidate solution in iteration of the (1+1) EA. For any vertex , denote as the count of uncovered edges incident to in iteration . Since any vertex is flipped with probability , and an increase in uncovered edges is never accepted, we may bound the drift of as
since each of the uncovered edges is counted twice in the sum over . The claim follows by Theorem 1. ∎
Definition 1.
Let and . The model of random planted graphs is a distribution of random graphs on vertices defined by construction as follows.
Let be a set of (labeled) vertices. Choose a -subset uniformly at random, and for each , if , add edge to with probability .
In the resulting graph , we refer to as the core, and each as a core vertex. We refer to vertices in as fringe vertices.
3 Small
In this section we consider where . Our results rely heavily on the following property of planted vertex cover graphs, which we call -heaviness.
Definition 2.
Let be a graph drawn from the model. For a constant , we say is -heavy if for every subset where , every core vertex in is adjacent to at least vertices in .
Lemma 1.
Let be a graph drawn from the model. Let be constants. If , then is -heavy with probability .
Proof.
Fix an arbitrary and an arbitrary -sized subset . We first bound the probability that is adjacent to no more than vertices in . Let be the random variable that counts the edges between and vertices in . Each edge from to a vertex in appears independently with probability , so is the sum of independent Bernoulli random variables, each with success probability so . By Hoeffding’s inequality [Hoe63], for any , , thus the probability that is adjacent to at most vertices in can be estimated by
We have assumed , so this probability is at most
Note that we have used here the fact that and . Taking a union bound over all vertices , the probability that any core vertex is adjacent to fewer than vertices in is at most
A final union bound over all subsets of size shows the probability that is not -heavy is at most
Since , and and are taken to be positive constants, we have , and the probability that is not -heavy is , which completes the proof. ∎
Theorem 3.
Consider the model with and for some constant . Then for all but an exponentially-fast vanishing fraction of all graphs sampled from , if is the runtime for the (1+1) EA to find a -cover on , we have
Proof.
Since is sufficiently large, by Lemma 1, all but an -fraction of graphs drawn from are -heavy. Thus, we assume for the remainder of the proof that is -heavy.
Let be the event that after exactly iterations of the (1+1) EA, the following conditions hold:
-
1.
The core vertices belong to the current solution of the (1+1) EA,
-
2.
There are at least fringe vertices that are not part of the current solution of the (1+1) EA.
This is a rather fortunate event for the (1+1) EA, because such a candidate solution is already a feasible vertex cover (as all vertices in are present), so after this point no infeasible covers would be accepted. Moreover, since is -heavy, every core vertex is adjacent to at least uncovered edges (by condition (2) above). Thus in order to remove a core vertex from the cover, a single mutation operation would need to change at least neighbors of to remain feasible. In contrast, it is always possible to remove any fringe vertex from the current cover. Thus if there are fringe vertices in the current solution, the probability to improve the fitness is at least . Furthermore, the probability of flipping at least vertices in a single mutation is .
Let denote the stochastic process that tracks the number of fringe vertices in the cover at time . The drift of conditioned on and starting at iteration is at least . By Theorem 1,
It remains to bound the probability of . Let be the event that the initial solution to the (1+1) EA contains every vertex in and let be the event that the core vertices in are not mutated during the first iterations of the (1+1) EA. Conditioning on , the (1+1) EA already starts with a feasible solution and does not remove any core vertices during the first steps.
Let be the random variable that measures the number of iterations until the first time the number of fringe vertices in the cover drops below a -fraction. Again applying tail bounds on multiplicative drift, and noting that for constant , under the condition , the (1+1) EA has reduced the number of fringe vertices in the cover from at most to at most with probability at least . Applying the law of total probability we have
where we have used in the final inequality. ∎
Theorem 3 provides a lower bound on the probability that a run of length at least finds a -cover of a random graph with sufficient density. This bound vanishes with , but slowly enough that a simple cold-restart strategy (periodically starting over from a randomly generated cover) is guaranteed to be efficient. This is captured by the following corollary.
Corollary 1 (to Theorem 3).
Consider the model with and . Running the (1+1) EA with cold restarts (Algorithm 2) with finds a -cover on all but an exponentially-fast vanishing fraction of graphs in fitness evaluations where is a constant depending on .
Proof.
Let . Since , we have . Thus the conditions for Theorem 3 are satisfied, and the success probability for an independent run of length of the (1+1) EA is . Under this condition, the number of independent runs until a success is geometrically distributed with expectation , and can be chosen appropriately. ∎
4 Large
We now consider in which . We will make use of the following probabilistic bound on the size of independent sets in the core.
Lemma 2.
Suppose is drawn from the model with . Then with probability , the largest independent set in has size at most .
Proof.
Set . There are size- vertex sets in . We label these sets from to and consider a sequence of indicator random variables over where
Consider the sum and note that if and only if there are no independent sets of size or larger in . By Markov’s inequality,
since . ∎
Theorem 4.
Consider a graph drawn from the model with . Then with probability (taken over the model), the expected runtime of the (1+1) EA to find a cover of size at most on is .
Proof.
By Theorem 2, the (1+1) EA takes at most steps in expectation to find a feasible solution, after which the (1+1) EA never accepts an infeasible solution.
Consider the potential function and note that when , is a feasible cover of size at most . Moreover, cannot increase during the run of the (1+1) EA.
By Lemma 2, the largest independent set in the core of contains at most vertices with probability , and we condition on this event for the remainder of the proof. Consider the stochastic process , which corresponds to the potential in the -th iteration.
We seek to bound the drift of after finding a feasible solution. Assume that the (1+1) EA has already found a feasible solution, and let be the core vertices of . Let be the current solution. We make the following case distinction on .
- Case 1:
-
. In this case, all of the vertices in are in the cover described by . Thus, any fringe vertex can be removed from the current cover and the resulting set is still a cover. A particular vertex is removed from the cover with probability and there are fringe vertices, so the drift in this case is
- Case 2:
-
. In this case, some of the core vertices are not in the cover described by . Let be the set of core vertices that are not in the current cover. Note that since is feasible must be an independent set in (otherwise there would be an uncovered edge in ).
Let be an arbitrary set of exactly fringe vertices that belong to the current solution , i.e., with . Such a must exist, otherwise we would have . Let denote the event that mutation changes all of the zero-bits corresponding to into one-bits, and all of the of one-bits corresponding to to zero. Since each bit is mutated independently, we may invoke the principle of deferred decisions [MU05] and assume that the choices are first made for the bits in and to produce a partially mutated offspring. Hence, we assume that has occurred, and consider the random choices on the remaining bits corresponding to . There are fringe vertices in , and after removing fringe vertices, there are still fringe vertices that have not yet been considered for mutation, so we may assume that we are in Case 1, now with exactly fringe vertices remaining in the cover. Since , by the law of total expectation, we can bound the drift from below as follows.
since .
In either case, the drift is at least , but we have assumed via Lemma 2 that for sufficiently large (and hence , as ). Therefore, by the multiplicative drift theorem, the expected time until a -cover is found is at most
since . ∎
5 Computational Experiments
To fill in the gaps left open by the previous sections, we report here on a number of experiments that investigate the relationship between the parameters of the planted vertex cover problem. For each experiment, we sample from the model by constructing a random graph on vertices choosing each edge with probability as long as at least one incident vertex is in the set . After this, we run the standard (1+1) EA (Algorithm 1) until . For each setting of , , , we run the algorithm for 100 trials (but sample a new graph from each time.
To better understand how the runtime depends on on dense graphs in which is a small function of , we plot the average runtime, varying and fixing . This is plotted in Figure 1(a), where we observe a stable runtime varying almost linearly with . In Figure 1(b), we show the same data for runs where is also varied with , i.e., . This corresponds to much sparser graphs, and we see that the runtime has much higher variability, especially for slower growing .
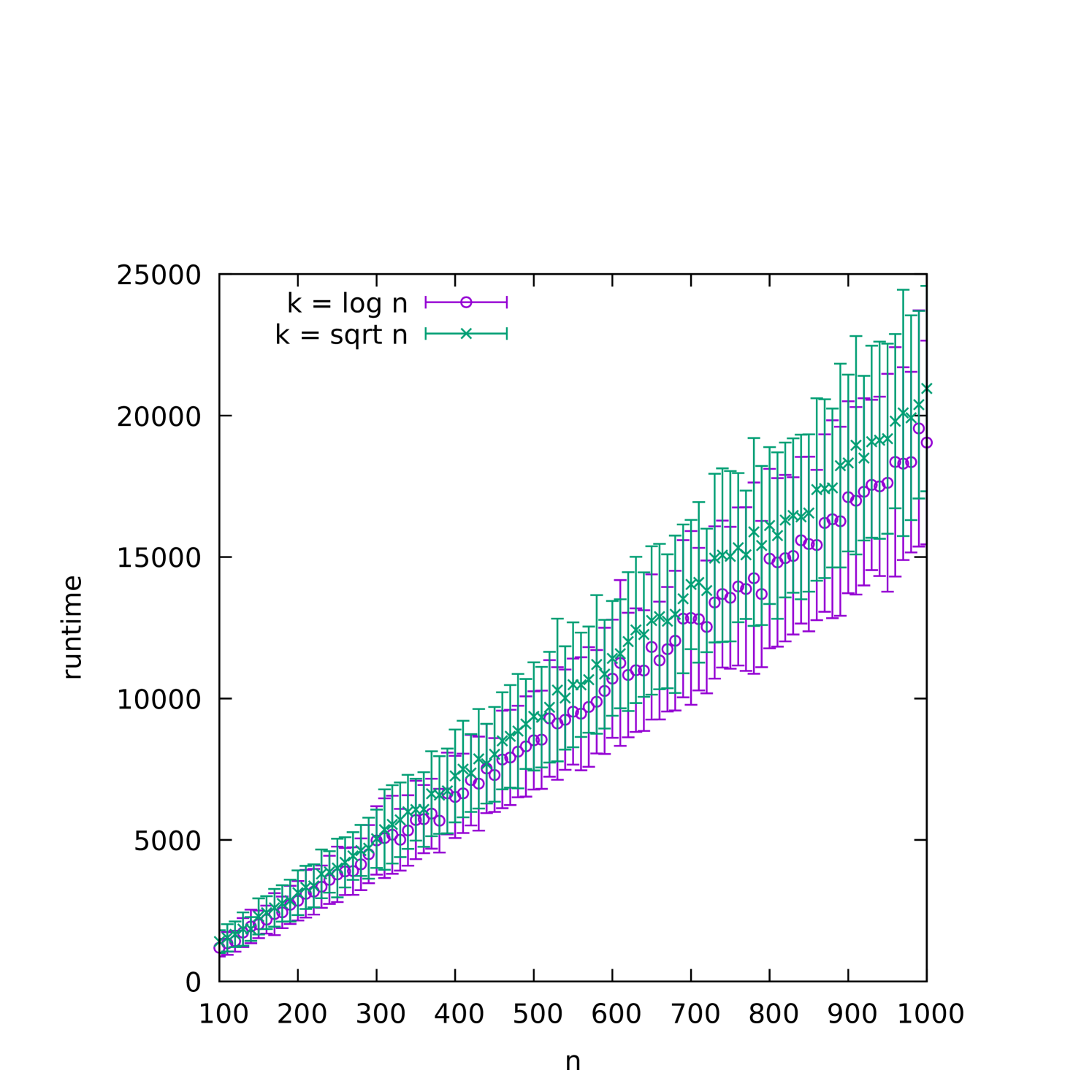
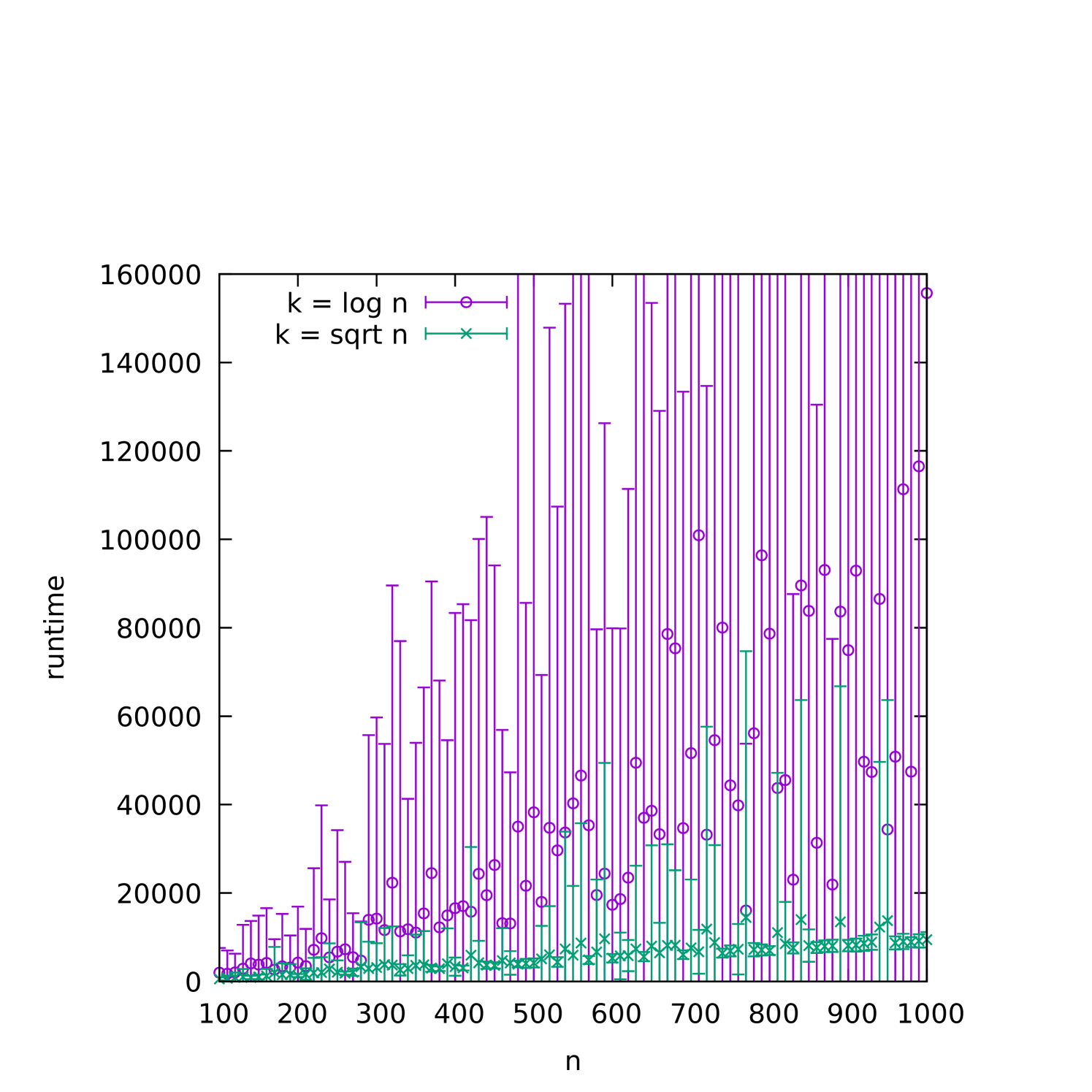
This scaling behavior is not so surprising, as we expect that random planted graphs are particularly easy for the (1+1) EA. Similar to the case of random planted satisfiability [DNS17], the relatively uniform structure of the problem is likely to provide a good fitness signal for hill-climbing type algorithms.
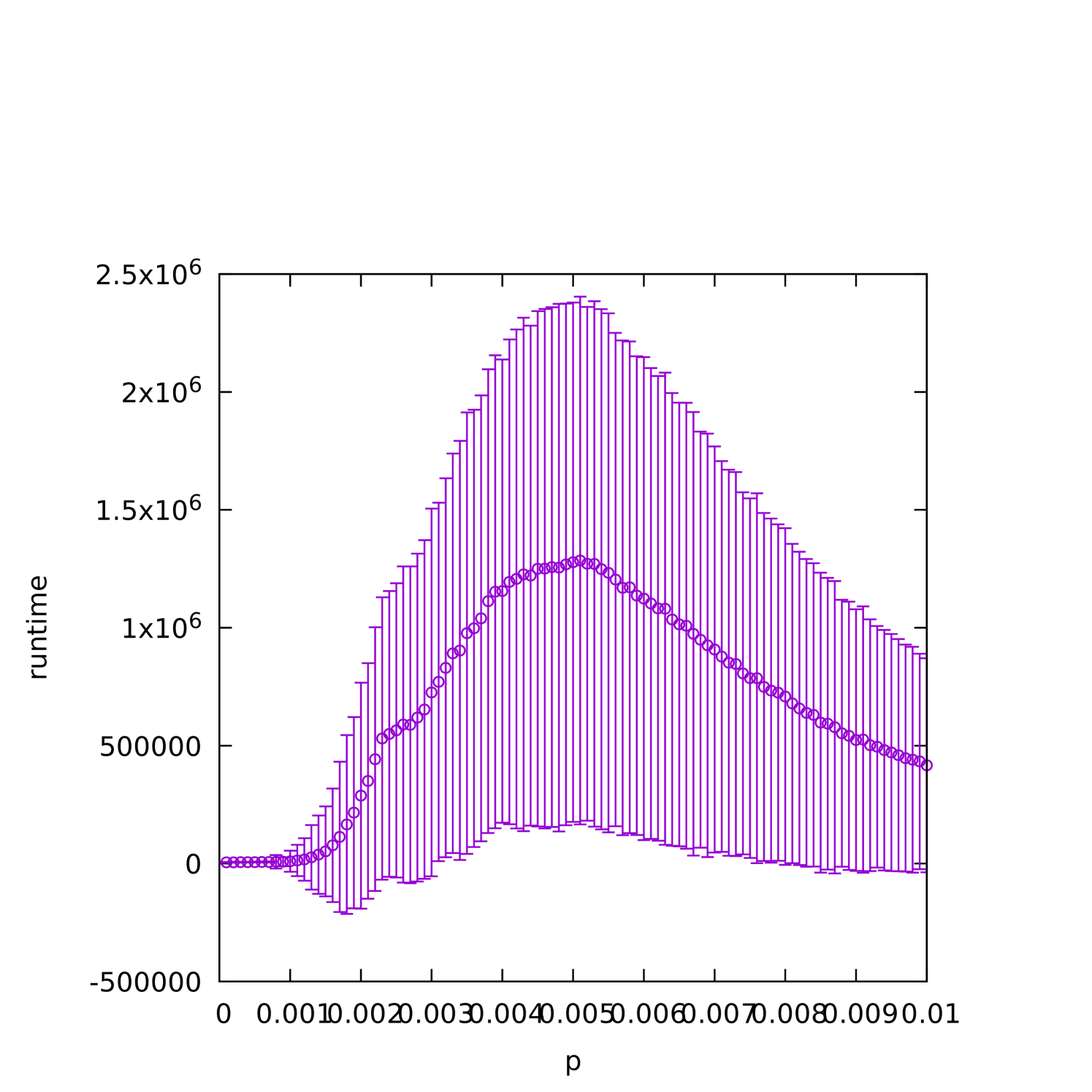
Random distributions of problems often undergo a so-called phase transition as various system parameters are varied. Very often, problems sampled near a critical density tend to be (empirically) harder to solve by different algorithms. For example, empirical evidence suggests critically-constrained planted propositional satisfiability formulas are difficult for the (1+1) EA when they are sampled near a critical density [DNS17]. To study the performance of the (1+1) EA on as a function of graph density, we plot the dependence of the average runtime on in Figures 2(a) and 2(b), holding fixed and averaging over all values of . We also see in this case a dependence on graph density in which the (1+1) EA performs worse in a band of not-too-sparse but not-too-dense graphs.

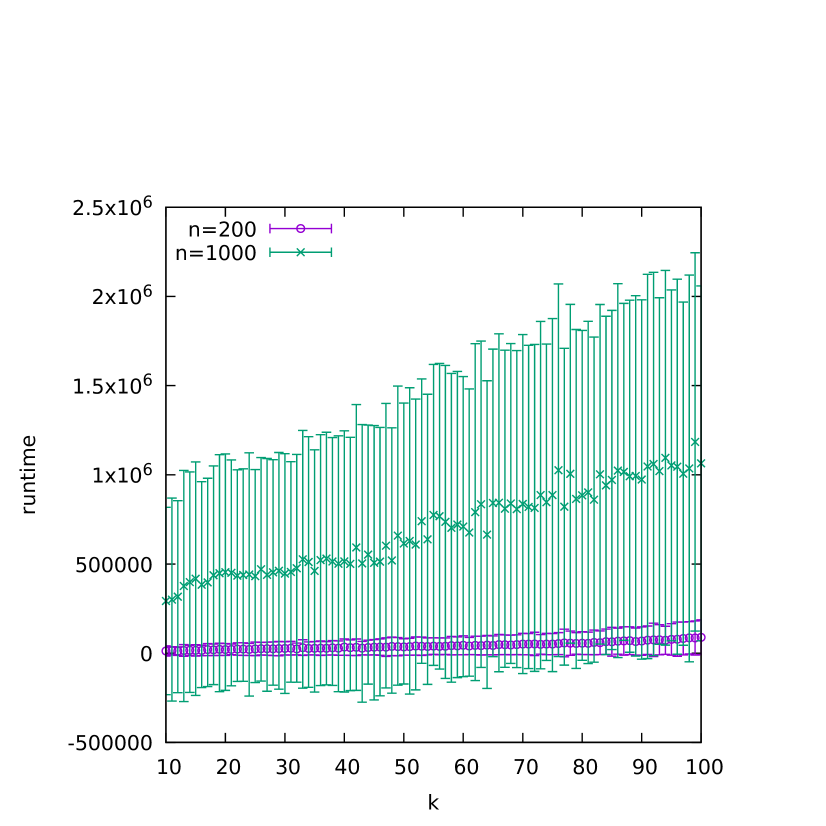
The dependence of runtime on , however, is more uniform as we can see in Figure 3. Here we have aggregated over all values, which likely explains the large variance, especially in the larger problems.
A more detailed picture is provided by Figures 4(a) and 4(b), where we display two-dimensional color plots showing the runtime dependence on both and simultaneously. On these plots one can see how the density and the cover size influences the efficiency of the (1+1) EA. We conjecture that there is a critical value (or range) of at which the (1+1) EA struggles to find a -cover.
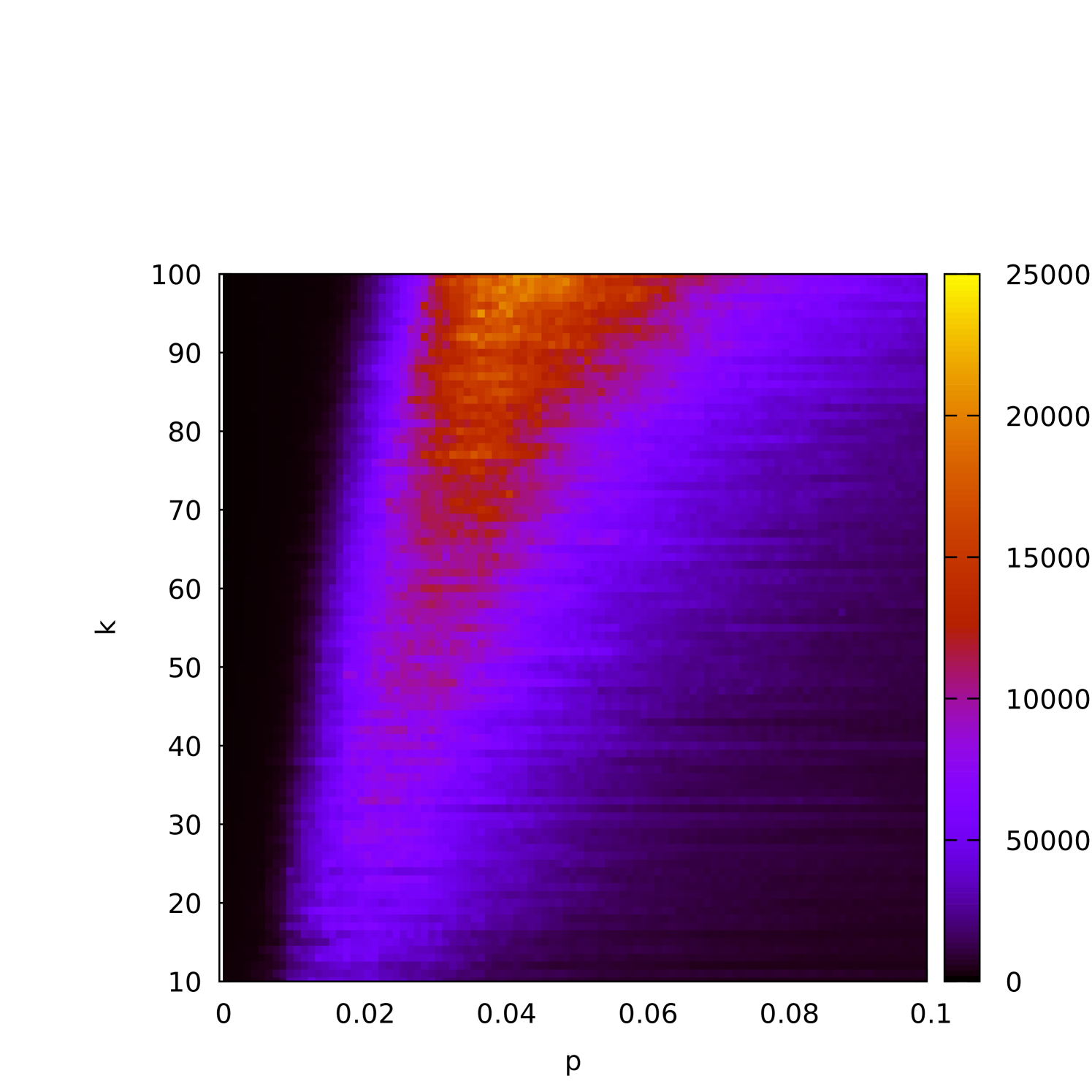
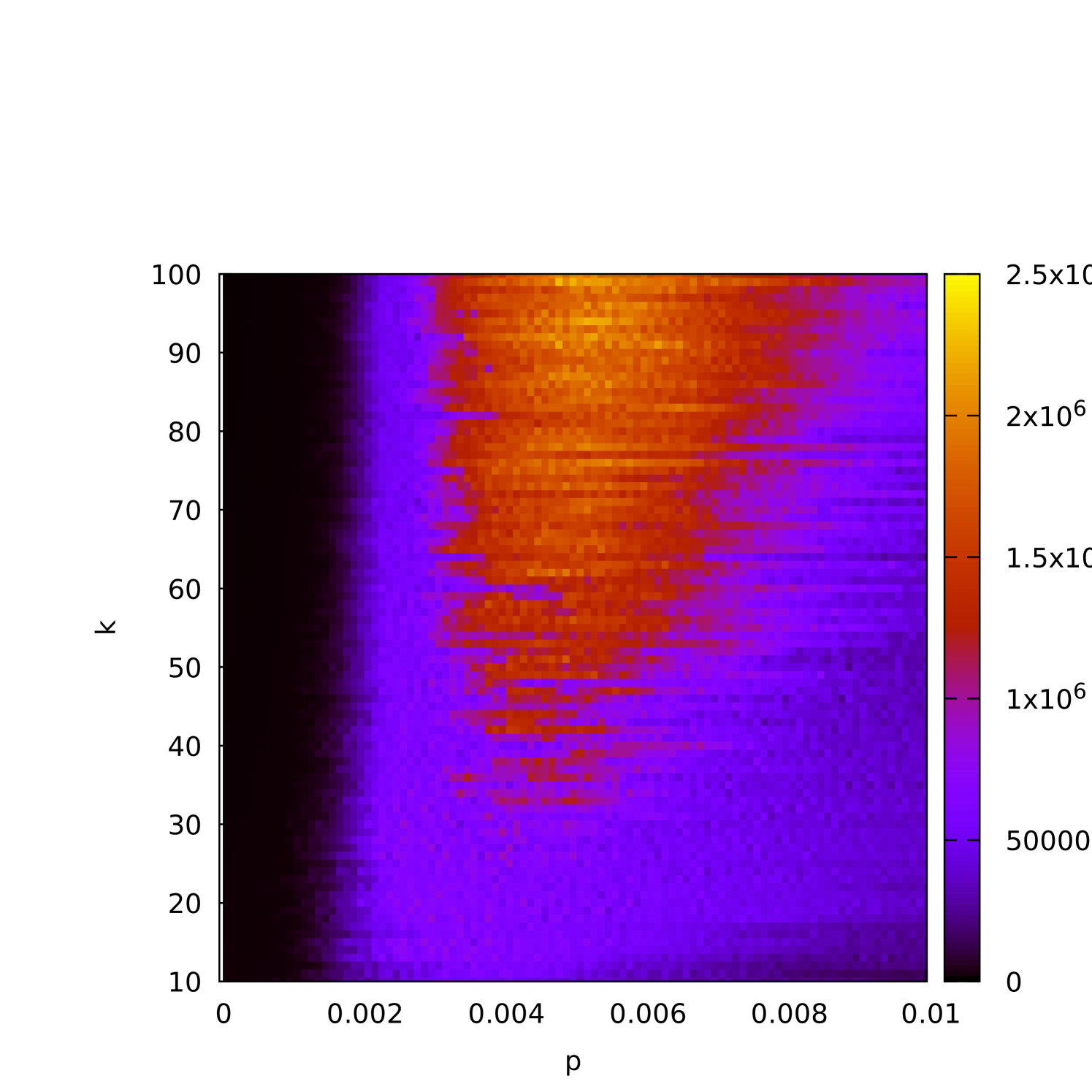
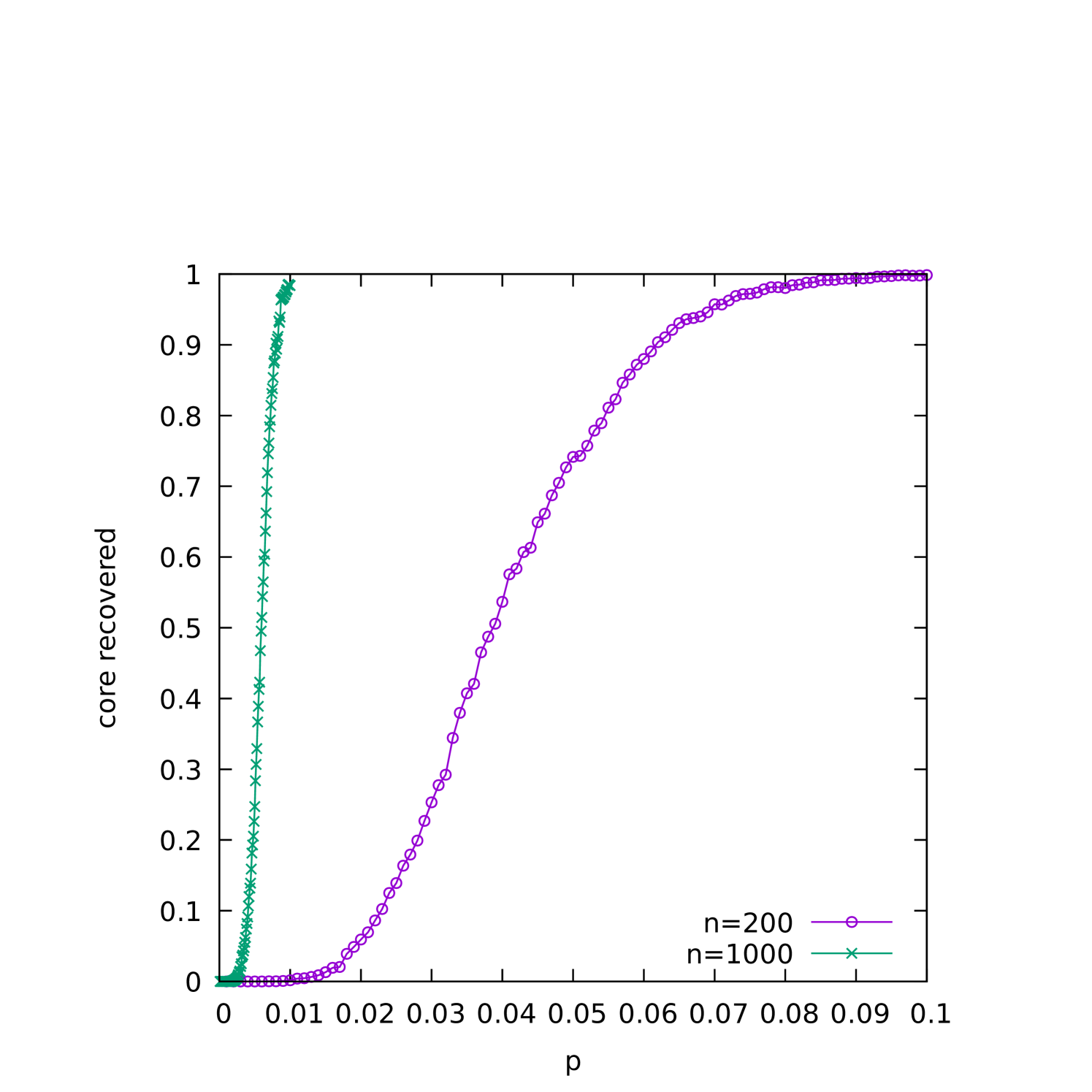
The (1+1) EA completes execution as soon as it finds a -cover. However, this is not necessarily guaranteed to be the -cover that was planted in the graph. Indeed, for smaller densities, we would expect many other -covers in the graph. To investigate this, in Figure 5(a) we plot the proportion of runs in which the planted -core was recovered (as opposed to some different -cover) as a function of . The dependence of this characteristic as a function of is plotted in Figure 5(b), and Figures 5(c) and 5(d) display this in a color plot for both and simultaneously.
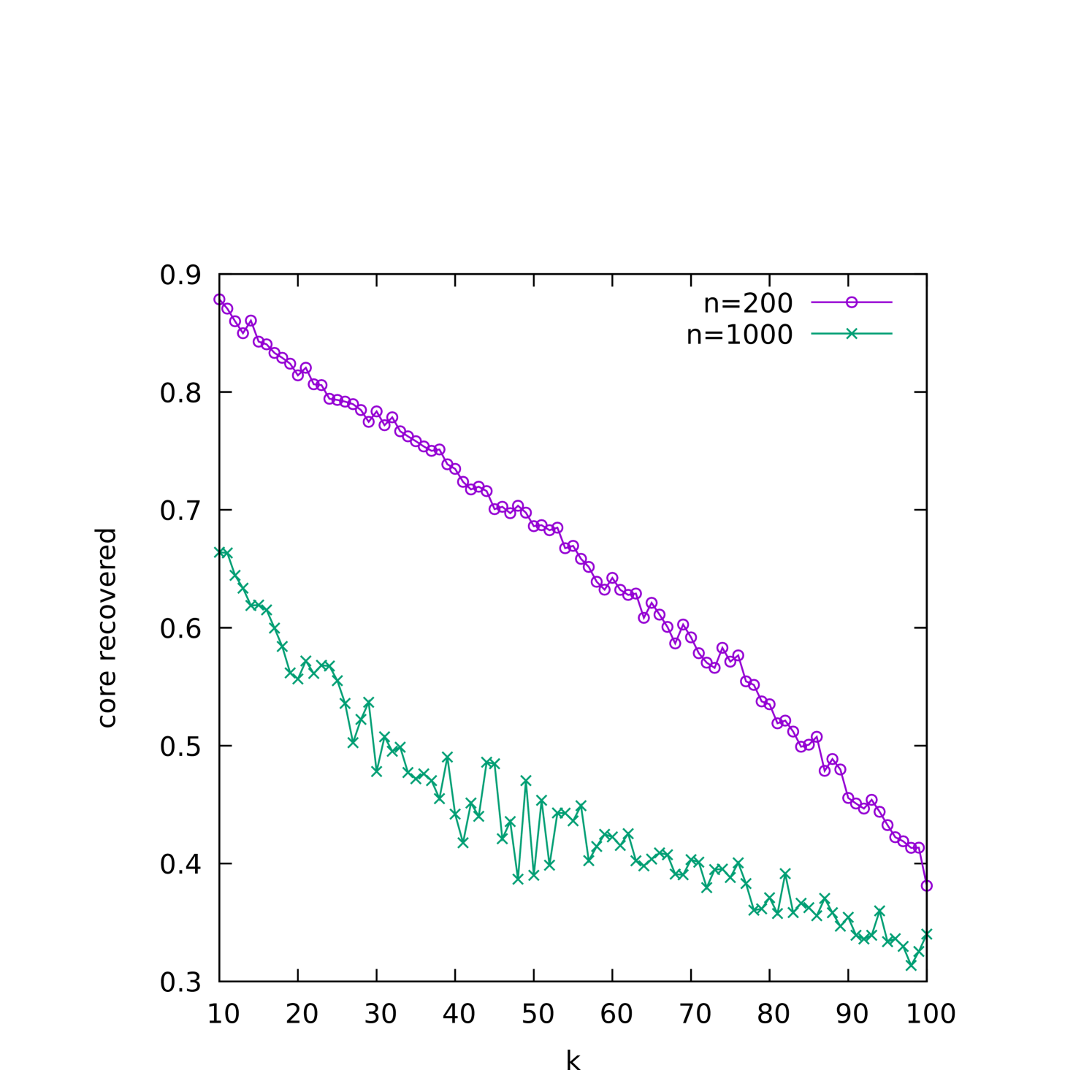
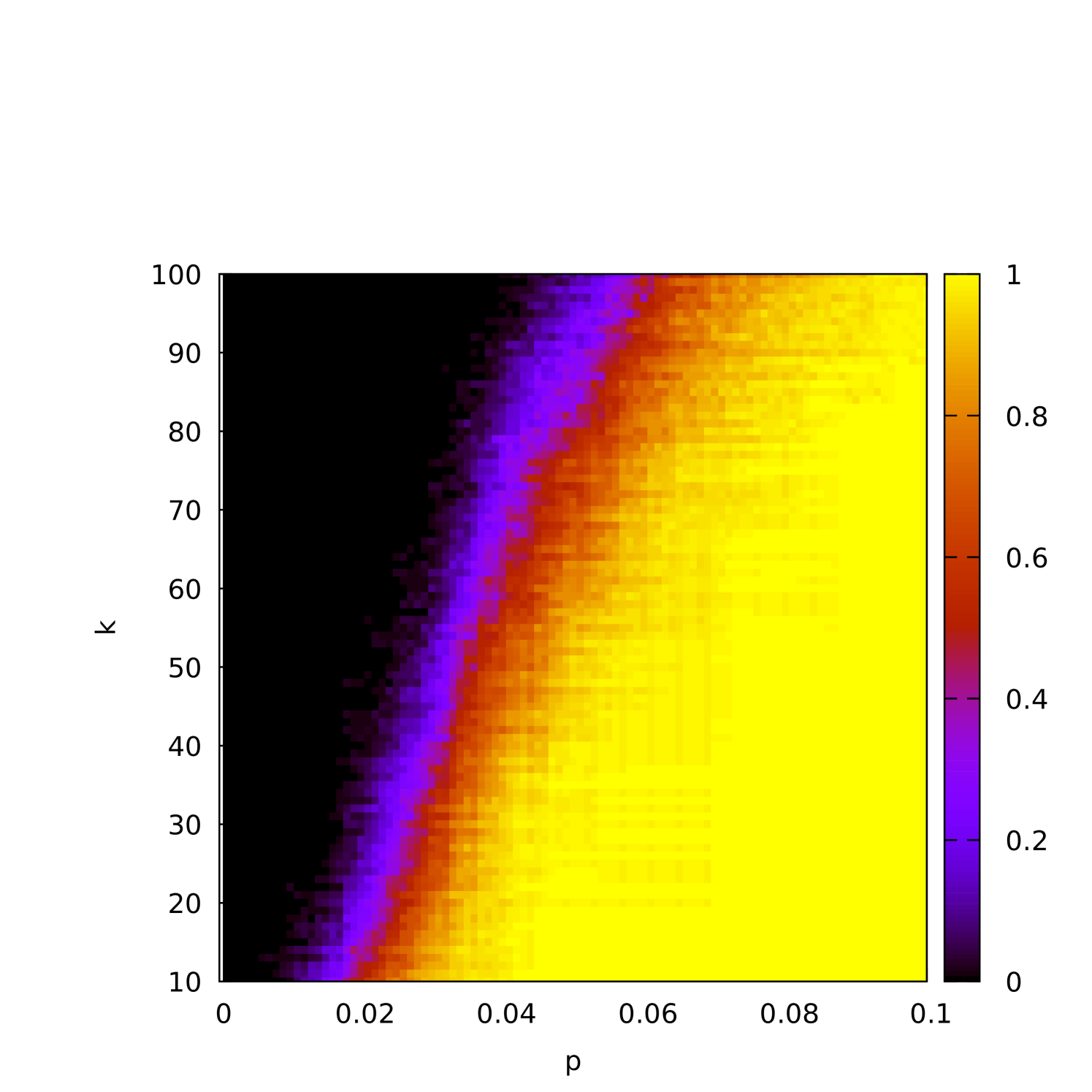
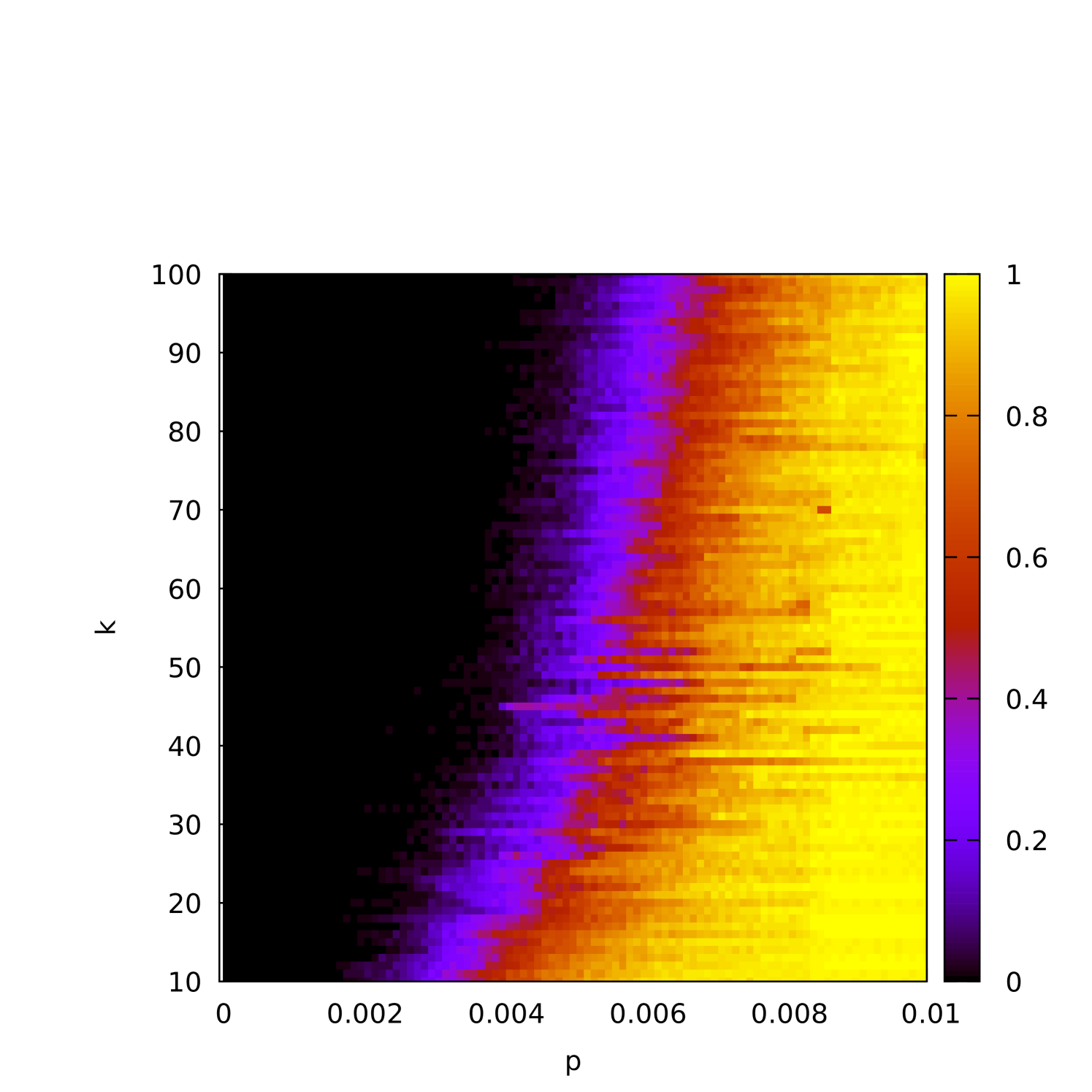
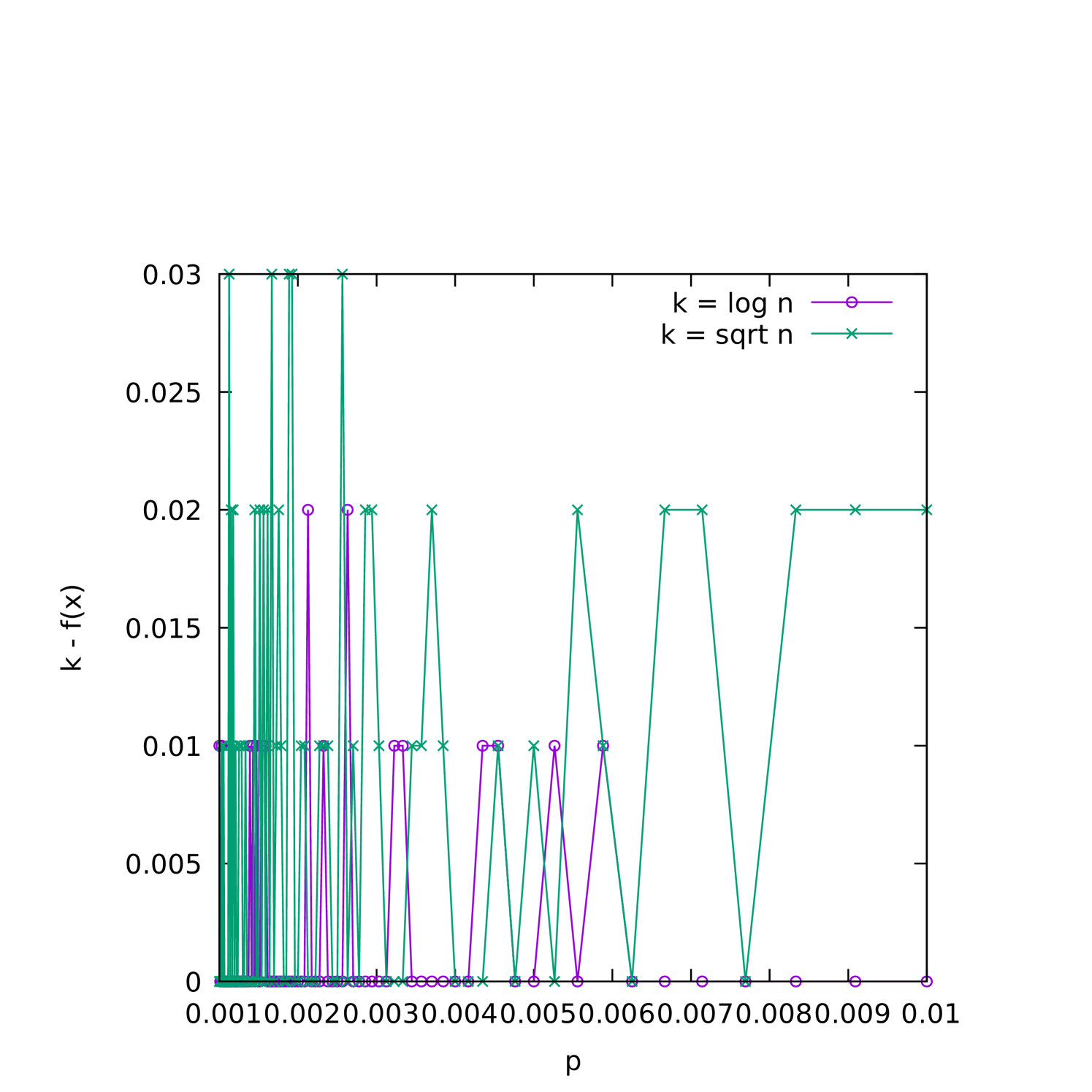
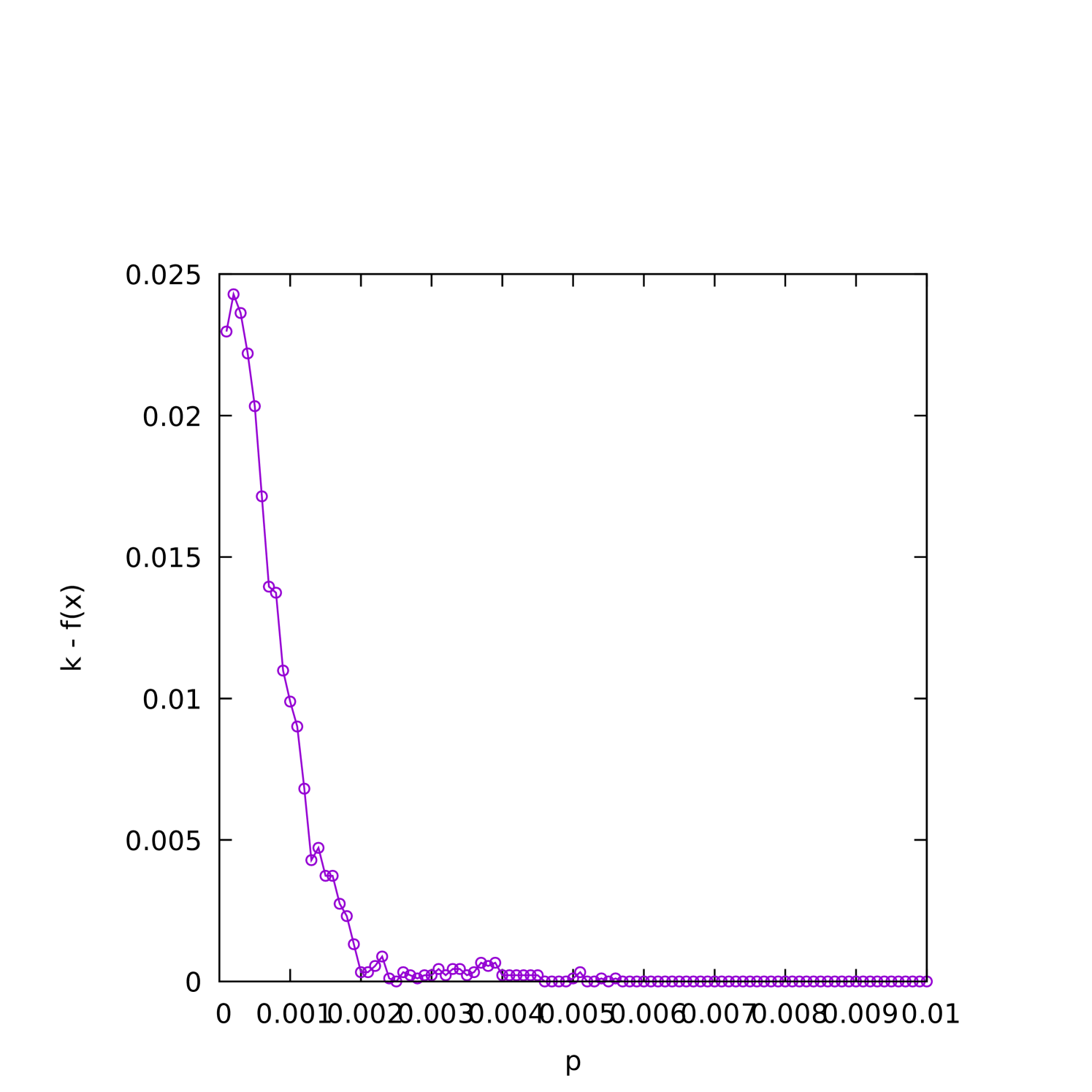
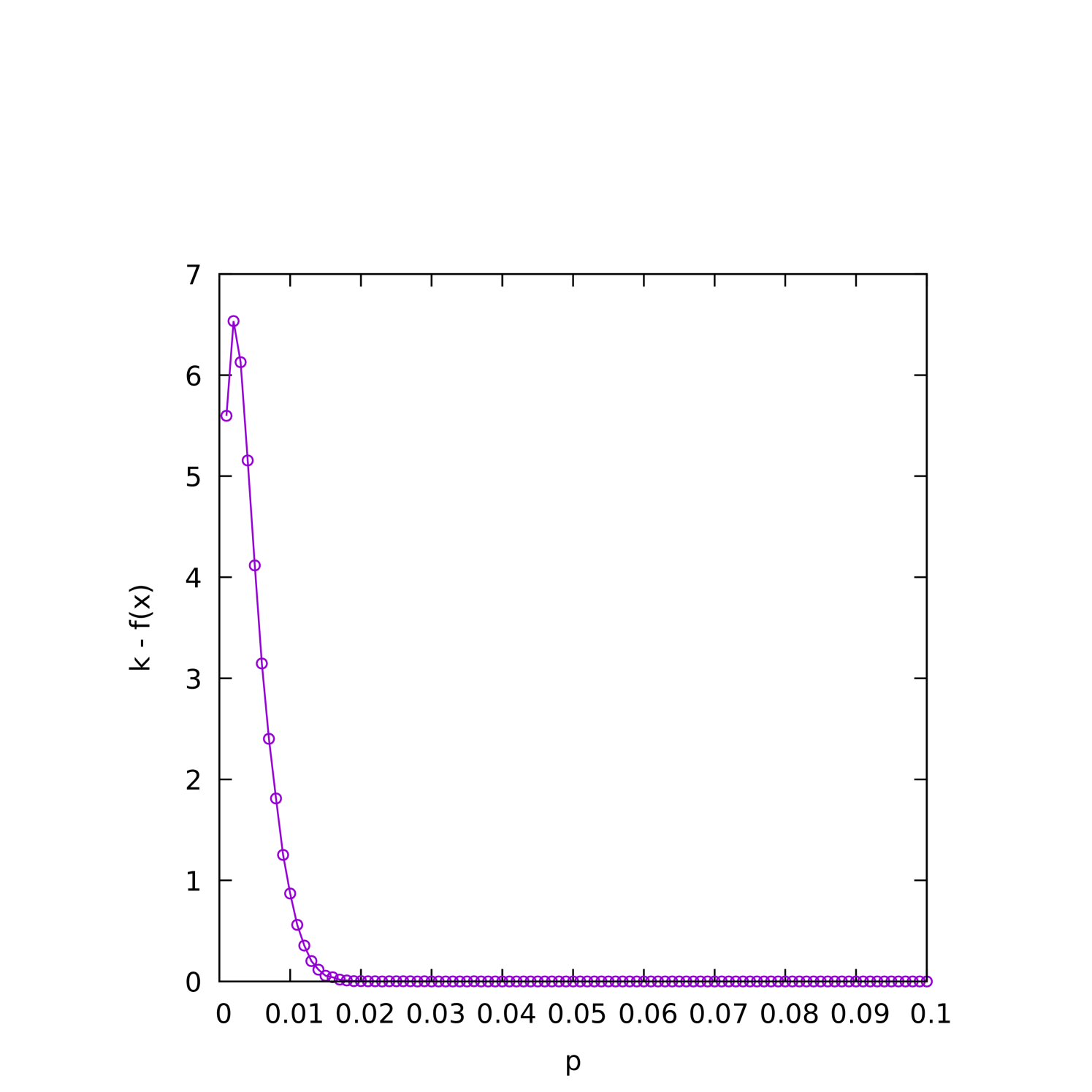
When the graph is relatively sparse, we would also expect the (1+1) EA to “overshoot” by finding an even smaller cover before finding a -cover. To understand better how this depends on and , we plot the average difference between and the best fitness found as a function of on sparse () instances where is varied in Figure 6(a), and on fixed- instances in Figures 6(b) and 6(c).
6 Conclusion
In this paper we have presented a parameterized analysis the (1+1) EA on problems drawn from the random planted vertex cover model. We showed that for dense graphs and small , there is sufficient signal in enough of the space so that the (1+1) EA has a relatively good chance of finding a -cover in a polynomial-length run. When is large, we showed that a feasible cover cannot leave too much of the planted core uncovered, and therefore the (1+1) EA does not require a large effort to make progress. In the end, this translates to a fixed-parameter tractable runtime for the (1+1) EA with high probability over .
To fill in the picture, we also reported a number of computational experiments that measure the runtime on graphs drawn from . These experiments point to a critical value for at which the (1+1) EA requires more time to find any -cover, which suggest an interesting direction for future theoretical work to understand this phenomenon better.
Acknowledgements
This work was supported by the National Science Foundation under grant 2144080 and by the Australian Research Council under grant FT200100536.
References
- [AKS98] Noga Alon, Michael Krivelevich, and Benny Sudakov. Finding a large hidden clique in a random graph. Random Structures & Algorithms, 13(3–4):457–466, 1998.
- [AS15] Emmanuel Abbe and Colin Sandon. Community detection in general stochastic block models: Fundamental limits and efficient algorithms for recovery. In 2015 IEEE 56th Annual Symposium on Foundations of Computer Science (FOCS), pages 670–688, 2015.
- [BFN+23] Samuel Baguley, Tobias Friedrich, Aneta Neumann, Frank Neumann, Marcus Pappik, and Ziena Zeif. Fixed parameter multi-objective evolutionary algorithms for the w-separator problem. In Genetic and Evolutionary Computation Conference (GECCO ’23), 2023.
- [BK18] Austin R. Benson and Jon M. Kleinberg. Found graph data and planted vertex covers. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett, editors, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pages 1363–1374, 2018.
- [BS21] Luke Branson and Andrew M. Sutton. Focused jump-and-repair constraint handling for fixed-parameter tractable graph problems. In Proceedings of the 16th ACM/SIGEVO Conference on Foundations of Genetic Algorithms. Association for Computing Machinery, New York, NY, USA, 2021.
- [DG10] Benjamin Doerr and Leslie Ann Goldberg. Drift analysis with tail bounds. In Proceedings of the Eleventh International Conference on Parallel Problem Solving from Nature (PPSN XI), volume 6238 of Lecture Notes in Computer Science, pages 174–183. Springer, 2010.
- [DNS17] Benjamin Doerr, Frank Neumann, and Andrew M. Sutton. Time complexity analysis of evolutionary algorithms on random satisfiable k-CNF formulas. Algorithmica, 78(2):561–586, June 2017.
- [FHH+10] Tobias Friedrich, Jun He, Nils Hebbinghaus, Frank Neumann, and Carsten Witt. Approximating covering problems by randomized search heuristics using multi-objective models. Evolutionary Computation, 18(4):617–633, June 2010.
- [HLL83] Paul W. Holland, Kathryn Blackmond Laskey, and Samuel Leinhardt. Stochastic blockmodels: First steps. Social Networks, 5(2):109–137, 1983.
- [Hoe63] Wassily Hoeffding. Probability inequalities for sums of bounded random variables. Journal of the American Statistical Association, 58(301):13–30, 1963.
- [Jer92] Mark Jerrum. Large cliques elude the metropolis process. Random Structures & Algorithms, 3(4):347–359, 1992.
- [JOZ13] Thomas Jansen, Pietro S. Oliveto, and Christine Zarges. Approximating vertex cover using edge-based representations. In Frank Neumann and Kenneth A. De Jong, editors, Proceedings of the Twelfth Workshop on Foundations of Genetic Algorithms (FOGA XII), Adelaide, SA, Australia, January 16-20, 2013, pages 87–96. ACM, 2013.
- [JP00] Ari Juels and Marcus Peinado. Hiding cliques for cryptographic security. Designs, Codes and Cryptograrphy, 20(3):269–280, 2000.
- [KB94] Sami Khuri and Thomas Bäck. An evolutionary heuristic for the minimum vertex cover problem. In J. Kunze and H. Stoyan, editors, Workshops of the Eighteenth Annual German Conference on Artificial Intelligence (KI-94), Saarbrücken, Germany, pages 86–90, 1994.
- [KK19] Timo Kötzing and Martin S. Krejca. First-hitting times under drift. Theoretical Computer Science, 796:51–69, 2019.
- [KN12] Stefan Kratsch and Frank Neumann. Fixed-Parameter Evolutionary Algorithms and the Vertex Cover Problem. Algorithmica, 65(4):754–771, May 2012.
- [KR08] Subhash Khot and Oded Regev. Vertex cover might be hard to approximate to within . Journal of Computer and System Sciences, 74(3):335–349, 2008. Computational Complexity 2003.
- [MU05] Michael Mitzenmacher and Eli Upfal. Probability and Computing : Randomized Algorithms and Probabilistic Analysis. Cambridge University Press, 2005.
- [OHY09] Pietro S. Oliveto, Jun He, and Xin Yao. Analysis of the (1+1) EA for finding approximate solutions to vertex cover problems. IEEE Transactions on Evolutionary Computation, 13(5):1006–1029, 2009.
- [RUK19] Daniel M. Romero, Brian Uzzi, and Jon M. Kleinberg. Social networks under stress: Specialized team roles and their communication structure. ACM Trans. Web, 13(1):6:1–6:24, 2019.
- [Sto07] Tobias Storch. Finding large cliques in sparse semi-random graphs by simple randomized search heuristics. Theoretical Computer Science, 386:114–131, 2007.