Flexible risk design using bi-directional dispersion
Abstract
Many novel notions of “risk” (e.g., CVaR, tilted risk, DRO risk) have been proposed and studied, but these risks are all at least as sensitive as the mean to loss tails on the upside, and tend to ignore deviations on the downside. We study a complementary new risk class that penalizes loss deviations in a bi-directional manner, while having more flexibility in terms of tail sensitivity than is offered by mean-variance. This class lets us derive high-probability learning guarantees without explicit gradient clipping, and empirical tests using both simulated and real data illustrate a high degree of control over key properties of the test loss distribution incurred by gradient-based learners.
1 Introduction
What does it mean for a learner to successfully generalize? Broadly speaking, this is an ambiguous property of learning systems that can be defined, measured, and construed in countless ways. In the context of machine learning, however, the notion of “success” in off-sample generalization is almost without exception formalized as minimizing the expected value of a random loss , where is a candidate parameter, model, or decision rule, and is a random variable on a probability space [41, 53]. The idea of quantifying the risk of an unexpected outcome (here, a random loss) using the expected value dates back to the Bernoullis and Gabriel Cramer in the early 18th century [5, 25]. In a more modern context, the emphasis on average performance is the “general setting of the learning problem” of Vapnik, [58], and plays a central role in the decision-theoretic learning model of Haussler, [27]. Use of the expected loss to quantify off-sample generalization has been essential to the development of both the statistical and computational theories of learning [16, 34].
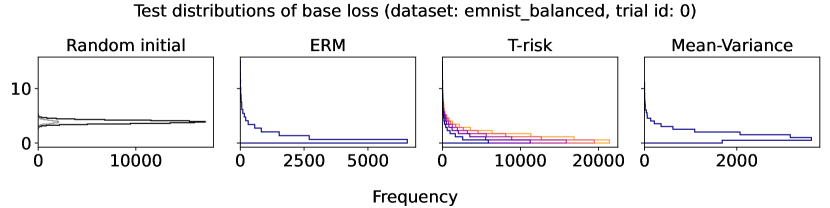
While the expected loss still remains pervasive, important new lines of work on risk-sensitive learning have begun exploring novel feedback mechanisms for learning algorithms, in some cases derived directly from new risk functions that replace the expected loss. Learning algorithms designed using conditional value-at-risk (CVaR) [13, 31] and tilted (or “entropic”) risk [19, 37, 38] are well-known examples of location properties which emphasize loss tails in one direction more than the mean itself does. This is often used to increase sensitivity to “worst-case” events [33, 55], but in special cases where losses are bounded below, sensitivity to tails on the downside can be used to realize an insensitivity to tails on the upside [36]. This strong asymmetry is not specific to the preceding two risk function classes, but rather is inherent in much broader classes such as optimized certainty equivalent (OCE) risk [7, 8, 36] and distributionally robust optimization (DRO) risk [6, 17, 18, 24]. Unsurprisingly, naive empirical estimators of these risks are particularly fragile under outliers coming from the “sensitive direction,” as is evidenced by the plethora of attempts in the literature to design robust modifications [30, 45, 60]. In general, however, loss distributions can display long tails in either direction over the learning process (see Figure 3), particularly when losses are unbounded below (e.g., negative rewards [54], unhinged loss [57]), and loss functions whose empirical mean has no minimum appear frequently (e.g., separable logistic regression [1, 50]). Since the tail behavior of stochastic losses and gradients is well-known to play a critical role in the stability and robustness of learning systems [12, 61], the inability to control tail sensitivity in both directions represents a genuine limitation to machine learning methodology.
A natural alternative class of risk functions that gives us control over tail sensitivity in both directions is that of the “M-location” of the loss distribution, namely any value in
| (1) |
where is assumed to be such that this set of minimizers is non-empty. Here various special choices of let us recover well-known locations, such as the mean (with ), median (), arbitrary quantiles (via “pinball” function [56]), and even further beyond to “expectiles” (using curved variants of the pinball function [21]). The obvious limitation here is that while computing (1) using empirical estimates is easy, minimization as a function of is in general a difficult bi-level programming problem. As an alternative approach, in this paper we study the potential benefits and tradeoffs that arise in using performance criteria of the form
| (2) |
where . By making a sacrifice of fidelity to the M-location (1), we see that the criterion in (2) suggests a congenial objective function (joint in ). Intuitively, one minimizes the sum of generalized “location” and “dispersion” properties, and the nature of this dispersion impacts the fidelity of the location term to the original M-location induced by . These two locations align perfectly in the special case where we set and , since (2) is equivalent to the mean-variance objective , but more generally, it is clear that allowing for more diverse choices of gives us new freedom in terms of tail control with respect to both location and dispersion. We consider a concrete yet flexible class of risk functions that generalizes beyond (2), allows for easy implementation, and is analytically tractable from the standpoint of providing formal learning guarantees. Our main contributions are as follows:
- •
- •
-
•
Strong empirical evidence of the flexibility and utility inherent in T-risk learners. In particular: robustness to unbalanced noisy class labels without regularization (Figure 4), sharp control over sensitivity to outliers in regression with convex base losses (Figure 5), and smooth interpolation between mean and mean-variance minimizers on clean, normalized benchmark classification datasets (Figures 6, 7 and 14–18).
The overall flow of the paper is as follows. Background information on notation and related literature is given in §2, and we introduce the new risk class of interest in §3. Formal aspects of the learning problem using these risks are treated in §4, and empirical findings are explained and discussed in §5. All formal proofs and supplementary results are organized in §A–§D of the appendix, and code for reproducing all the results in this paper is provided in an online repository.111https://github.com/feedbackward/bdd
2 Background
2.1 Notation
Random quantities
To start, let us clarify the nature of the random losses we consider. With the context of the underlying probability space , we write to refer to a random variable (i.e., a -measurable function) on , though we only use the form in the body of this paper. When we talk about “sampling” losses or a “random draw” of the losses, this amounts to computing a realization . We use standard notation for taking expectation, e.g., . These conventions extend to random quantities based on the losses (e.g., the gradient considered in §4.1). Similarly, we will use as a general-purpose probability function, representing both and product measures; when the source of randomness is not immediate from the context, it will be stated explicitly. We will use as a generic symbol for risk functions (often modified with subscripts), with the understanding that maps random losses to real values. We will overload this notation, writing when the role of is unimportant, and writing when we want to emphasize the dependence on . This convention will be applied to other quantities as well, such as writing for the expected dispersion induced by , first defined in (22).
Norms
We will use as a general-purpose notation for all norms that appear in this paper. That is, we do not use different notation to distinguish different norm spaces. The reason for this is that we will never consider two distinct norms on the same set; each norm is associated with a distinct set, and thus as long as it is clear which set a particular element belongs to, there should be no confusion. The only exception to this rule is the special case of , in which we write for the absolute value, as is traditional. For a function in one variable, we use to denote the usual derivative. More general notions (e.g., Gateaux or Fréchet differentials) only make an appearance in §4, and the generality they afford us is not crucial to the main narrative, so the details can be easily skipped over if the reader is unfamiliar with such concepts. All the other undefined notation we use is essentially standard, and can be found in most introductory analysis textbooks.
Miscellaneous
For a function in one variable, we use to denote the usual derivative. More general notions (e.g., Gateaux or Fréchet differentials) only make an appearance in §4, and the generality they afford us is not crucial to the main narrative, so the details can be easily skipped over if the reader is unfamiliar with such concepts. All the other undefined notation we use is essentially standard, and can be found in most introductory analysis textbooks. Particularly in formal proofs, we will frequently make use of the notation , where is a scaling parameter.
2.2 Review of key risk functions
OCE-type risks
As a computationally convenient way to interpolate between the mean and the extreme values of , the tilted risk [37, 38] is a natural choice, defined for as
| (3) |
This is simply a re-scaling of the cumulant distribution function of , viewed as a function of , where taking and lets us approach the supremum and infimum of , respectively. Another important class of risk functions is based upon the conditional value-at-risk (CVaR) [46], defined for as
| (4) |
This is the expected loss at , conditioned on the event that the loss exceeds the -quantile of , denoted here by . Both of these risk functions can be re-written in a form similar to that of (2), namely
| (5) |
where yields (basic calculus), and yields (see Rockafellar and Uryasev, [46, 47]). When is restricted to be a non-decreasing, closed, convex function which satisfies both and , the mapping given in (5) is called an optimized certainty equivalent (OCE) risk [7, 8, 36]. The class of OCE risks strictly generalizes the expected value (noting is valid), and includes when , as well as . The mean-variance is sometimes stated to be an OCE risk [36, Table 1], but this fails to hold when losses are unbounded above and below.
DRO-type risks
Another important class of risk functions is that of robustly regularized risks which are designed to ensure that risk minimizers are robust to a certain degree of divergence in the underlying data model. Making this concrete, it is typical to assume the random losses are the outputs of a loss function depending on the candidate and some random data , i.e., , with as our reference model. To measure divergence from this reference model, it is convenient to use the Cressie-Read family of divergence functions [17, 60], namely for any and assuming (absolutely continuity) holds, functions of the form
| (6) |
and is the Radon-Nikodym density of with respect to .222For background on absolute continuity and density functions, see Ash and Doléans-Dade, [3, §2.2]. The resulting robustly regularized risk, called the DRO risk, is defined as
| (7) |
where the constrained set of random losses , determined by and , is defined as
| (8) |
For this particular family of divergences, the risk can be characterized as the optimal value of a simple optimization problem [17], namely we have that
| (9) |
where . While strictly speaking this is not an OCE risk, note that if we set , then the DRO risk can be written as
| (10) |
giving us an expression of this risk as the sum of a threshold and an asymmetric dispersion. When we set , this yields the well-known special case of -DRO risk [26, 60]. In addition to the one-directional nature of the dispersion term in these risks, all of these risks are at least as sensitive to loss tails (on the upside) as the classical expected loss is; this holds for CVaR (with ), tilted risk (with ), and even robust variants of DRO risk [60].
Key differences
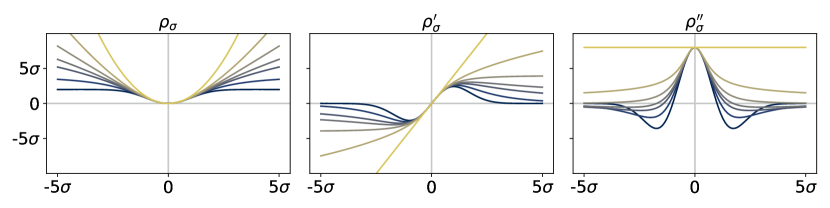
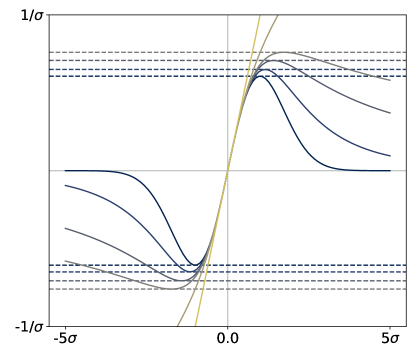
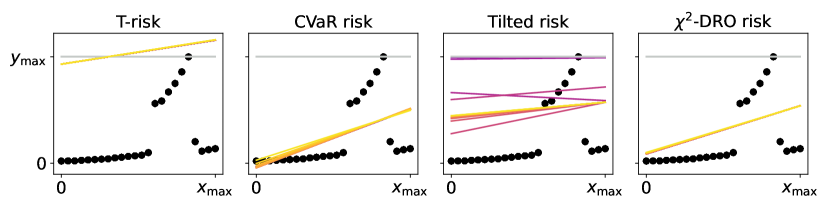
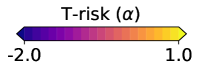
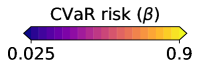
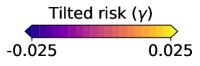
While it is clear that the form of the preceding risk classes given in (5) and (10) based on various choices of is the same as our -based risk of interest in (2), they are fundamentally different in that none of the choices of induce a meaningful M-location; since all these are monotonic on , both minimization and maximization of is trivially accomplished by taking . In stark contrast, is assumed to be such that the solution set in (1) is a subset of the real line. We will introduce a concrete and flexible class from which will be taken in §3, and in Figure 1 give a side-by-side comparison with the functions discussed in the preceding paragraphs.
2.3 Closely related work
This work falls into the broad context of machine learning driven by novel risk functions [28]. Of all the papers cited above, the works of Lee et al., [36] on OCE risks, and Li et al., 2021b [38], Li et al., 2021a [37] on tilted risks are of a similar nature to our paper, with the obvious difference being that the class of risks is fundamentally different, as described in the preceding paragraphs. Indeed, many of our empirical tests involve direct comparison with the risk classes studied in these works (e.g., Figures 2, 4, and 12), and so they provide critical context for our work. Previous work by Holland, [30] studies a rudimentary special case of what we call “minimal T-risk” here; the focus in that work was on obtaining learning guarantees (in expectation) when the risk is potentially non-convex and non-smooth in , but with convex , and no comparison was made with OCE/DRO risk classes. We build upon these results here, considering a broad class of dispersions which are differentiable but need not be convex (see (15)); we how such risk classes can readily admit high-probability learning guarantees for stochastic gradient-based algorithms (Theorem 3), provide bounds on the average loss incurred by empirical risk minimizers using our risk (Proposition 7), and make detailed empirical comparisons with each of the key existing risk classes.
3 Threshold risk
To ground ourselves conceptually, let us refer to as the base loss incurred by . The exact nature of is left completely abstract for the moment, as all that matters is the probability distribution of this base loss. By selecting an arbitrary threshold , we define a broad class of properties as
| (11) |
Here is a weighting parameter allowed to be negative, and as a bare minimum, is assumed to be such that the resulting M-location(s) are well-defined in the sense that the inclusion in (1) holds. We call the (random) dispersion of the base loss, taken with respect to threshold , and we refer to in (11) as the threshold risk (or simply T-risk) under .
3.1 Minimal T-risk and M-location
Arguably the most intuitive special case of T-risk is the minimal T-risk, where minimization is with respect to the threshold . Let us denote this risk and the optimal threshold set as
| (12) |
Clearly, if is bounded above or grows too slowly, we will have and no real-valued minimizers, i.e., . Letting denote the M-locations in (1), for we have
| (13) |
although the converse does not hold in general.333For example, consider choices of that are “re-descending” [32]. When , these two solution sets align, i.e., we have . More generally, depending on the sign of , the optimal thresholds can be either larger or smaller than the corresponding M-locations. More precisely, for any , as long as is non-empty, there exists such that .
Special case minimized by quantiles
The form given in (11) is very general, but it can be understood as a straightforward generalization of the convex objective used to characterize quantiles. More precisely, taking and denoting the -quantile of the base loss using , it is well-known that in the special case of , we have
| (14) |
for any choice of , as long as is finite [35]. The T-risk in (11) simply allows for a more flexible choice of , and thus generalizes the dispersion term in this objective function.
3.2 T-risk with scaled Barron dispersion
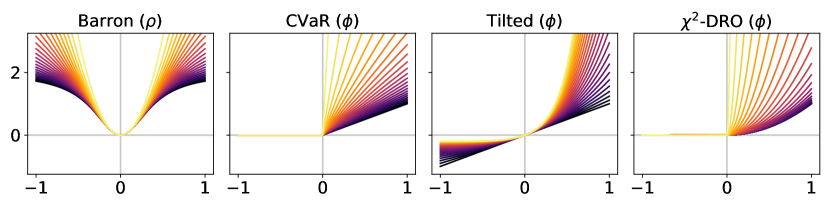
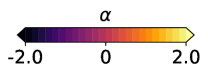
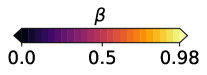
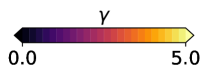
In order to capture a range of sensitivities to loss tails in both directions, we would like to select from a class of functions that gives us sufficient control over scale, boundedness, and growth rates. As a concrete choice, we propose to set in (11) as , where is a scaling parameter, and with shape is a family of functions that ranges from bounded and logarithmic growth on the lower end to quadratic growth on the upper end, defined as:
| (15) |
At a high level, is approximately quadratic near zero for any choice of shape , but its growth as one deviates far from zero depends greatly on . We refer to (15) as the Barron class of functions for computing dispersion.444The reason for this naming is that Barron, [4] recently studied this class in the context of designing loss functions for computer vision applications. We remark that this differs considerably from our usage in computing the dispersion of random losses, where the loss function underlying the base loss is left completely arbitrary. Recalling the risks reviewed in §2.2, since is flat at zero and symmetric about zero, the Barron class clearly takes us beyond the functions allowed by OCE risks (5) and used in typical DRO risk definitions (10); see Figure 1 for a visual comparison.
As mentioned in §2.1, we will often use the generic shorthand notation , and drop the dependence on when clear from context. The shape parameter gives us direct control over the conditions needed for a finite T-risk , as the following lemma shows.
Lemma 1 (Finiteness and shape).
Let be from the Barron class (15). Then in order to ensure holds for all , each of the following conditions (depending on the value of ) is sufficient. For , let . For , let for some . For , let be -measurable. Furthermore, for the cases where , the above conditions are also necessary.
Assuming -integrability as in Lemma 1, the Barron class furnishes a non-empty set of M-locations for any choice of , and when restricted to with appropriate settings of and , the optimal threshold set contains a single unique solution (see Lemma 10). For any valid choice of , the function is twice continuously differentiable on (see §D.3 for exact expressions). All the limits in behave as we would expect: as for (see §B.2 for details). For , the dispersion function is unbounded, with growth ranging from logarithmic to quadratic depending on the choice of . For , the dispersion function is bounded. The mapping is convex on for , and for it is only convex between , and concave elsewhere (see Lemma 8). The class of T-risks (11) under the scaled Barron dispersion is the central focus of this paper.
3.3 Sensitivity to outliers and tail direction
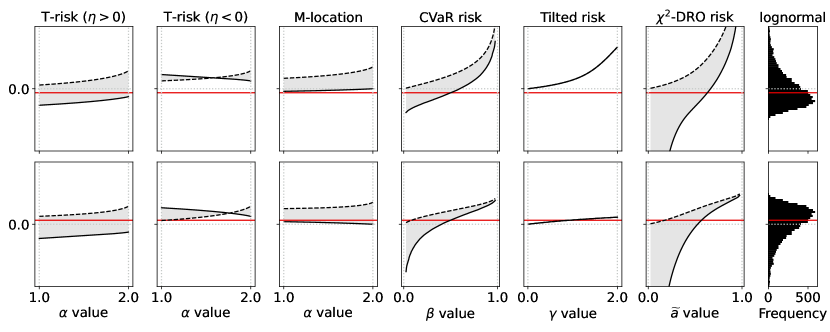
Before we consider the learning problem, which typically involves the evaluation of many different loss distributions over the course of training, here we consider a fixed distribution, and numerically compare the T-risk (11) and M-location (1) induced by from the Barron class in §3.2, along with the key OCE and DRO risks discussed in §2.2.
Experiment setup
We generate random values to simulate loss distributions, and evaluate how the values returned by each risk function change as we modify their respective parameters. Letting denote the random base loss we are simulating, we specify a parametric distribution for , from which we take an independent sample . In all cases, we center the true distribution such that . We use this common sample to compare the values returned by each of the aforementioned risks, as well as the optimal choice of threshold parameter . To ensure that key trends are consistent across samples, we take a large sample size of . For T-risk, we adjust and , and for M-location, just . In both cases, we leave fixed. For CVaR, we modify the quantile level . For tilted risk, we modify the parameter . For -DRO risk, we modify , having re-parameterized in (8) by , as is common practice [60].
Representative results
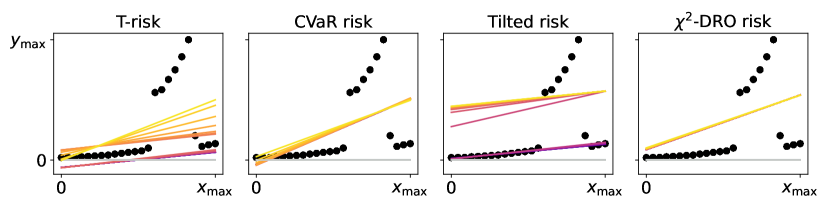
An illustrative example is given in Figure 2, where we look at how each risk class behaves under a centered asymmetric distribution, before and after flipping it (i.e., under and −). Starting from the two left-most plots, we show (dashed curves) and (solid curves) from (12) as a function of , coloring the area between these graphs in gray. The first plot corresponds to , the second to . Similarly for the M-location we plot (solid) and (dashed). Analogous values are plotted for each of the other classes; note that for the tilted risk (3) with , the optimal threshold and the risk value are in fact the same value (see §B.1). The right-most plot is a histogram of the random sample , here from a centered log-Normal distribution. All plots share a common vertical axis, and horizontal rules are drawn at the median (red, solid) and at the mean (gray, dotted; always zero due to centering). The critical point to emphasize here is how all the OCE and DRO risks here are highly asymmetric in terms of their tail sensitivity, in stark contrast with both the M-location and the T-risk. Turning tail sensitivity high enough in each of these classes (e.g., , , , ), note how flipping the distribution tails from the upside (top row) to the downside (bottom row) leads to a dramatic decrease in all risks but the T-risk and M-location. Finally, note how the T-risk thresholds close in on the M-location from above/below depending on whether is negative/positive. Results for numerous distributions are available in our online repository (cf. §1).
4 Learning algorithm analysis
We now proceed to consider the learning problem, in which the goal is ultimately to select a candidate such that the distribution of is “optimal” in the sense of achieving the smallest possible value of T-risk in (11), with taken from the Barron class (15), and taken from some set . An obvious take-away of the integrability conditions (Lemma 1) is that even when the base loss is heavy-tailed in the sense of having infinite higher-order moments, we can always adjust the dispersion function in such a way that transforming the base loss to obtain new feedback
| (16) |
gives us an unbiased estimator of the finite T-risk, i.e., . Intuitively, one expects that a similar property can be leveraged to control heavy-tailed stochastic gradients used in an iterative learning algorithm. We explore this point in detail in §4.1. We will then complement this analysis by considering in §4.2 the basic properties of T-risk at the minimal threshold given in (12), viewed from the perspectives of axiomatic risk design and empirical risk minimization.
4.1 T-risk and stochastic gradients
For the time being let us fix an arbitrary threshold , and assuming the gradient is -almost surely finite, denote the partial derivative of the transformed losses (16) with respect to by
| (17) |
Writing for the gradient of , an analogue of Lemma 1 for gradients holds.
Lemma 2 (Unbiased gradients).
Let be an open subset of any metric space such that . Let the base loss map be Fréchet differentiable on (-almost surely), with gradient denoted by for each . Fixing any choice of , we have that
| (18) |
with the implied equality valid on all of .
Consider a setting in which the gradients are heavy-tailed, i.e., where for . If the ultimate goal of learning is minimization of , then in order to obtain high-probability guarantees of finding a nearly-stationary point with rates matching the in-expectation case, one cannot naively use the raw gradients , but must rather carry out a delicate truncation which accounts for the bias incurred [14, 22, 23, 42]. On the other hand, if the ultimate objective is , then using (17) there is zero bias by design (Lemma 2), and when we take the shape parameter of our dispersion function such that , we have
| (19) |
for an appropriate choice of under standard loss functions such as quadratic and logistic losses, even when the random losses and gradients are heavy-tailed (see Corollary 4).
To see how this plays out for the analysis of learning algorithms, let us consider plugging the raw stochastic gradients into a simple update procedure. Given an independent sequence of random losses , let us denote by the transformed losses computed via (16), and for a sequence let denote the resulting stochastic gradients for any integer . Fixing and letting denote an arbitrary initial value, we consider a particular sequence generated using the following update rule:
| (20) |
where is a non-negative step-size we control, and the update direction satisfies
| (21) |
with also being a controllable parameter. This is an unconstrained, normalized stochastic gradient descent routine using momentum; it modifies the procedure of Cutkosky and Mehta, [14] in that we do not truncate . Note that if is a Banach space and its dual, in general we have that and are elements of . When is reflexive (e.g., any Hilbert space), it is always possible to construct from .555Given any , we can always find such that [39, §5.6]. The following theorem shows how the gradient norms incurred by this algorithm can be bounded with high probability.
Theorem 3 (Stationary points with high probability).
Let be a reflexive Banach space, with a Fréchet differentiable norm satisfying for any . In addition, assume the losses are such that (19) holds on , for any , and , where . Run the learning algorithm in (20)–(21) for iterations, with and for all steps , assuming each . Taking any , it then follows that
with probability no less than , using coefficients defined as
for any choice of .
These high-probability rates match standard guarantees in the stochastic optimization literature under non-convex objectives in expectation [15, 20]. The main take-away of Theorem 3 is that even if the random losses and gradients are unbounded and heavy-tailed, as long as the dispersion function is chosen to modulate extreme values (such that (19) holds), we can obtain confidence intervals for the T-risk gradient norms incurred by stochastic gradient updates. Distribution control is implied by the risk design, and thus there is no additional need for truncation or bias control. The following corollary illustrates how the bounded gradient condition in Theorem 3 is satisfied under very weak assumptions on the data.
Corollary 4.
Assume the random losses are driven by random data , where takes values in a Banach space , and has finite diameter. Consider the following losses:
-
E1.
Quadratic loss: , with and , where is zero-mean, has finite variance, and is independent of .
-
E2.
Logistic loss: , where we have classes, with each , and is a one-hot representation of the class label assigned to .
If we set with , then under the examples E1.–E2., as long as , we have that the bounds assumed by Theorem 3, including (19), are satisfied on .
In practice, the threshold will not typically be fixed arbitrarily, but rather selected in a data-dependent fashion, potentially optimized alongside ; the impact of such algorithmic choices will be evaluated in our empirical tests in §5. In the following sub-section, we consider some key properties of the special case in which threshold is always taken to yield the smallest overall T-risk value.
Limitations
An obvious limitation of our analysis is that we have assumed that each ; this matches the setup of [14], but the condition that will sometimes require to have a finite diameter. Modifying the procedure to allow for projection of the iterates to is a point of technical interest, but is out of this paper’s scope. Another limitation is that our current approach using smoothness properties (Lemma 12) necessitates an assumption of gradients with finite second-order moments. In the special case where , arguments based on smoothness can be replaced with arguments based on weak convexity [15, 30]; but this fails for more general since is not convex for , and not Lipschitz for . Another potential option is to split the sample, leverage stronger guarantees available in expectation for gradient descent run on the subsets, and robustly choose the best candidate based on a validation set of data [29].
4.2 T-risk with minimizing thresholds
Recall the minimal T-risk and optimal thresholds defined earlier in (12), here restricted to scaled from the Barron class (15). This is arguably the most natural subset of T-risks, with a functional form aligned with OCE/DRO risks discussed in §2.2. For readability, we denote the dispersion of measured about using as
| (22) |
Here we will overload our notation, writing , , and when we want to leave abstract and focus on random losses in a set . For this risk to be finite, we require , and in addition need for the special case of ; otherwise, the dispersion term grows too slowly and we have (Lemma 10). When finite, the optimal threshold is unique, and overloading our notation once more we use to denote it. The following lemma summarizes some basic properties of the minimal T-risk.
Lemma 5.
Let be such that for each we have , and let , , and be such that . Under these assumptions, the dispersion part of the minimal T-risk is translation invariant, i.e., for any , we have . This dispersion term is always non-negative, and if , then we have for any , even if is constant. If is convex, then so is the map . The optimal threshold is translation equivariant in that we have for any choice of , and it is monotonic in that whenever and almost surely, we have .
Let us briefly discuss the properties described in Lemma 5 with a bit more context. One of the best-known classes of risk functions is that of coherent risks [2], typically characterized by properties of convexity, monotonicity, translation equivariance, and positive homogeneity [52]. Our general notion of “dispersion” is often referred to as “deviation” in the risk literature, and the properties of translation invariance, sub-linearity (implying convexity), non-negativity, and definiteness (i.e., zero only for constants) allow one to establish links between deviations and coherent risks [49]. In general, the risk takes us outside of this traditional class, while still maintaining lucid connections as summarized in the preceding lemma.
Remark 6 (Risk quadrangle).
It should also be noted that our T-risks are not what would typically be called “risks” in the context of the “expectation quadrangle” in the framework developed by Rockafellar and Uryasev, [48]. With their Example 7 as a clear reference for comparison, our function corresponds to their “error integrand” , and the risk derived from their quadrangle would be
where and denotes the M-location (1) under . Under appropriate choice of , this is an OCE-type risk, and evidently our optimal thresholds with do not make an appearance in risks of this form, highlighting the distinct nature of .
Next, we briefly consider the question of how algorithms designed to minimize perform in terms of the classical risk, namely the expected loss . This is a big topic, but as an initial look, we consider how the expected loss incurred by minimizers of the empirical T-risk can be controlled given sufficiently good concentration of the M-estimators induced by , and the empirical mean. Let us denote any empirical T-risk minimizer by
| (23) |
where for simplicity is an iid sample of random losses.
Proposition 7.
We have left the upper bound in Proposition 7 rather abstract to emphasize the key factors that can be used to control expected loss bounds for empirical T-risk minimizers and keep the overall narrative clear. Note that in the special case of one has , and more generally taking sends this difference to zero. There exists tension due to the coefficient on the dispersion term. All other terms, including the dispersion itself, are free of . Note also that the remaining term is the (uniform) difference between the M-estimator induced by and the classical risk; this can be modulated directly using the scale parameter , and sharp bounds for a broad classes of M-estimators have been established recently [40]. Our Proposition 7 is analogous to Theorem 7 of Lee et al., [36], with the key difference being that we study (minimal) T-risks instead of OCE risks, without assuming that losses are bounded (below or above).
5 Learning applications
To complement the “static” empirical analysis in §3.3 and the formal insights for learning algorithms in §4, here we empirically investigate how risk function design and data properties impact the behaviour of stochastic gradient-based learners.
5.1 Classification with noisy and unbalanced labels
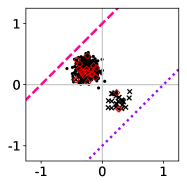
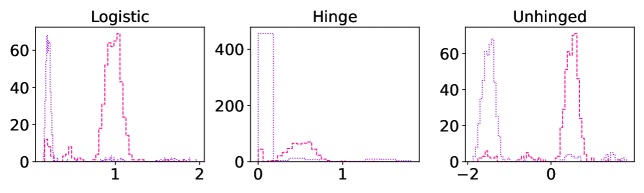
Experiment setup
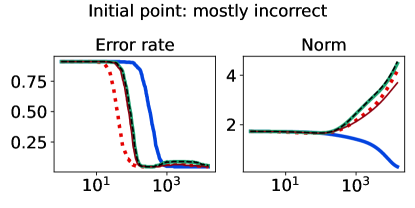
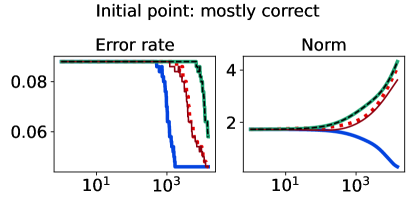
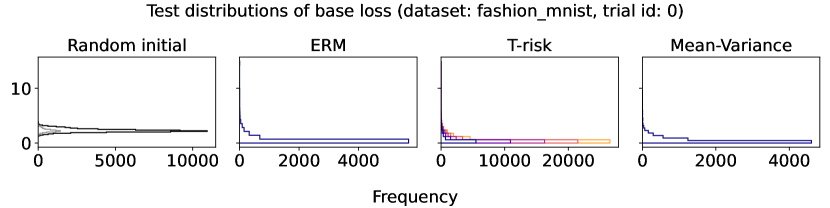
As an initial example using simulated data, we design a binary classification problem by generating 500 labeled data points as shown in Figure 3 (left-most plot). The majority class comprises 95% of the sample, and we flip 5% of the labels uniformly at random. Aside from the flipped labels, the data is linearly separable. We consider two candidate classifiers to initialize an iterative learning algorithm: one candidate that does well on the majority class (dotted purple), and one candidate that does well on the minority class (dashed pink). Due to class imbalance, the loss distributions incurred by these two candidates are highly asymmetric and differ in their long tail direction (Figure 3, remaining plots). We run empirical risk minimization for each risk class described in §2.2 (joint in ), implemented by 15,000 iterations of full-batch gradient descent, using a step size of , and three different choices of base loss function (logistic, hinge, unhinged). We run this procedure on the same data for a wide range of risk parameters (T-risk), (CVaR), (tilted), and (-DRO), and choose a representative setting for each risk class as the one achieving the best final training classification error.
Representative results
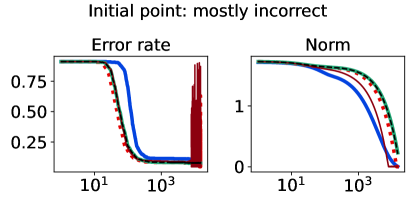
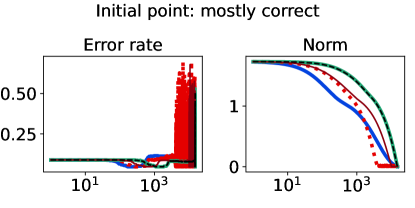
The full-batch (training) classification error and norm trajectories for these representatives initialized at each of the two candidates just mentioned (“mostly correct” and “mostly incorrect”) and trained using the unhinged loss as a base loss are shown in Figure 4. Regardless of the direction of the initial loss distribution tails, we see that using the Barron-type T-risk has the flexibility to achieve both a stable and superior long-term error rate, while at the same time penalizing exceedingly overconfident correct examples (via bi-directionality), and thereby keeping the norm of the linear classifier small. An almost identical trend is also observed under the (binary) logistic loss, whereas classification error rates under the hinge loss tend to be less stable (see Figures 10–11 in §B.6).
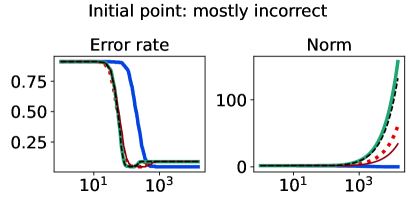
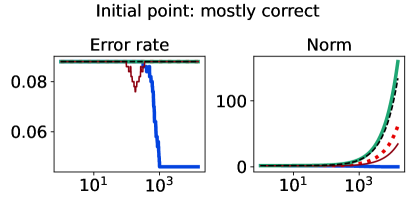

5.2 Control of outlier sensitivity
Experiment setup
For a crystal-clear example of real data that induces losses with heavy tails, we consider the famous Belgian phone call dataset [51, 59] with input features normalized to the unit interval, and raw outputs used as-is. We conduct two regression tasks: the first uses the original data just stated, and the second has us modify such that it is an outlier on both the horizontal and vertical axes (we just multiply the original data point by 5); such points are said to have “high leverage” [32, Ch. 7]. For these two tasks, once again we run empirical risk minimization under each of the risk classes of interest, implemented using 15,000 iterations of full-batch gradient descent, with fixed step size 0.005. To illustrate the flexibility of the T-risk, here instead of minimizing (11) jointly in , we fix at the start of the learning process along with and , iteratively optimizing only (i.e., is not updated at any point). For simplicity, we set and both to be the median of the losses incurred at initialization. All other risk classes are precisely as in the previous experiment.
Representative results
The final regression lines obtained under each risk setting by running the learning procedure just described are plotted along with the data in Figure 5. Colors correspond to the individual risk function choices within each risk family, as denoted by color bars under each plot. The gray regression line denotes the common initial value used by all methods. Algorithm outputs using CVaR and -DRO are always at least as sensitive to outliers as the ordinary least-squares (OLS) solution. While the tilted risk does let us interpolate between lower and upper quantiles, this transition is not smooth; even trying 20 values within the small window of , the algorithm outputs essentially jump between two extremes. This difference is particularly lucid in the bottom plots of Figure 5, where we have a high-leverage point. In contrast, with all other parameters of T-risk fixed, note that just tweaking gives us a remarkable degree of flexibility to control the final output; while the base loss is fixed to the squared error, the regression lines range from those that ignore outliers to those that are very sensitive to outliers. In the high-leverage case, it is well-known that this cannot be achieved by simply changing to a different convex base loss (e.g., MAE instead of OLS), giving a concise illustration of the flexibility inherent in the T-risk class. Algorithm behavior can be sensitive to initial value; see §B.5 and Figure 13 in the appendix for an example where the naive median-based procedure described here causes gradient-based algorithms to stall out.
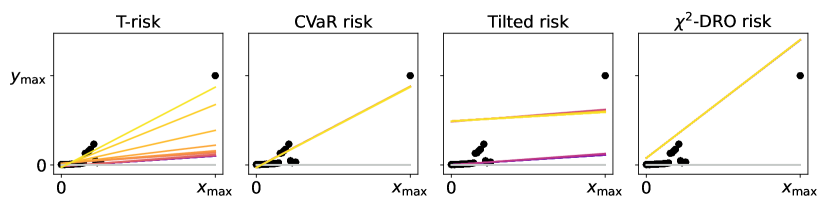
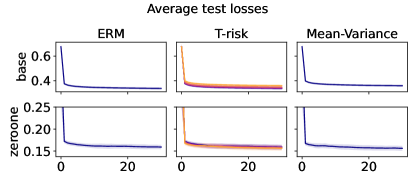
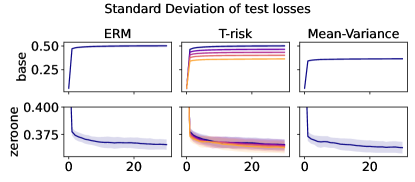
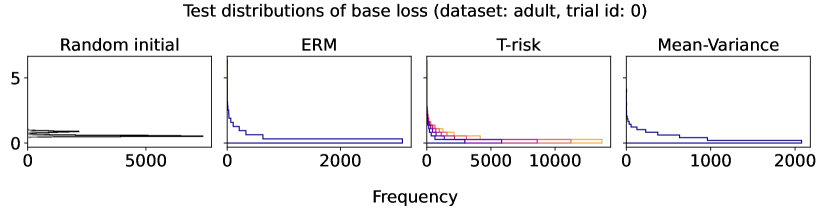
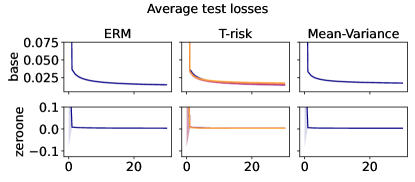
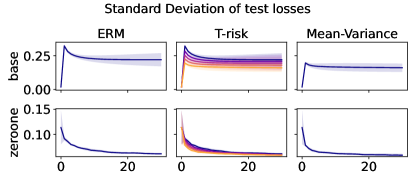
5.3 Distribution control under SGD on benchmark datasets
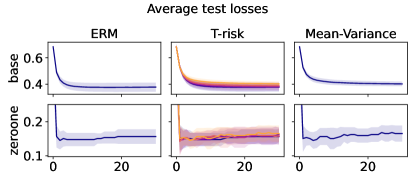
Experiment setup
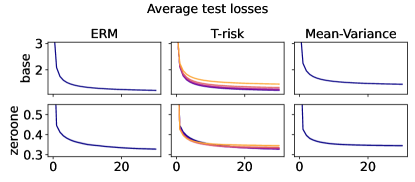
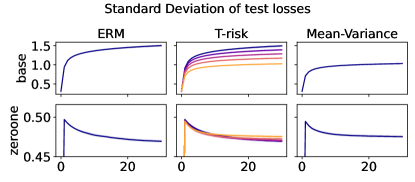
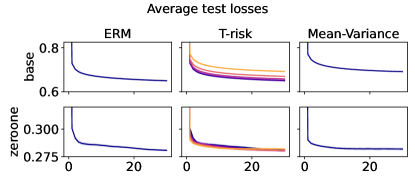
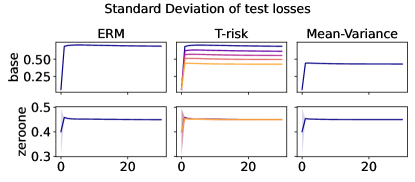
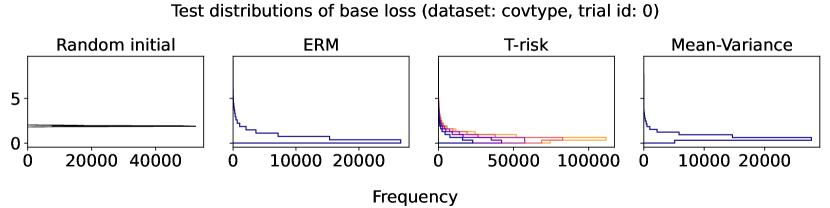
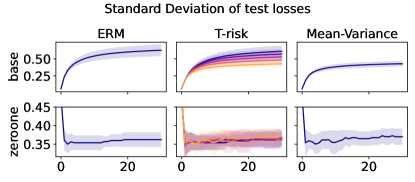
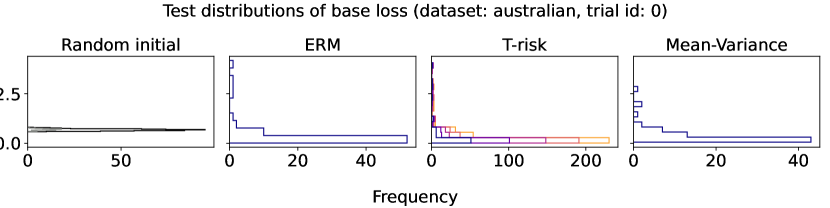
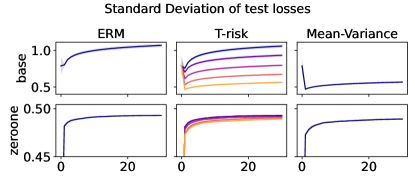
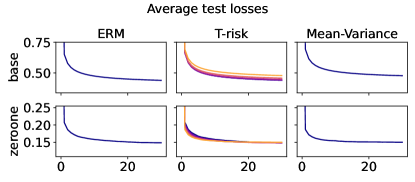
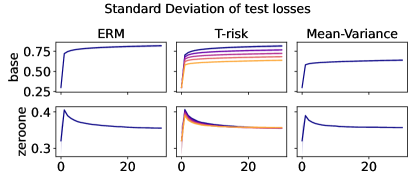
Finally we consider tests using datasets and models which are orders of magnitude larger than the previous two experimental setups. We use several well-known benchmark datasets for multi-class classification; details are given in §B.5. All features are normalized to the unit interval (categorical variables are one-hot), and scores for each class are computed by a linear combination of features. As a base loss, we use the multi-class logistic regression loss. Here we investigate how a stochastic gradient descent implementation (with averaging) of the empirical T-risk minimization (joint in ) behaves as we control the shape parameter of the Barron class, with and fixed throughout. We record the base loss (logistic loss) and zero-one loss (misclassification error) at the start and end of each epoch. We also record the full base loss distribution after the last epoch concludes. We run 5 independent trials, in which the data is shuffled and initial parameters are determined randomly. In each trial, for all datasets and methods, we use a mini-batch size of 32, and we run 30 epochs. As reference algorithms, we consider “vanilla” ERM, using the traditional risk , and mean-variance implemented as a special case of T-risk (with and ). 80% of the data is used for training, 10% for validation, and 10% for testing. For each risk class, we try five different step sizes. Validation data is used to evaluate different step sizes and choose the best one for each risk setting. All the results we present here are based on loss values computed on the test set: solid lines represent averages taken over trials, and shaded areas denote standard deviation over trials.
Representative results
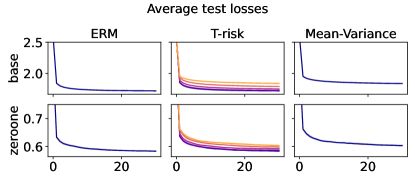
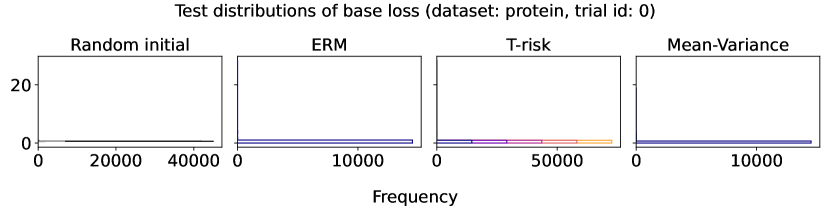
In Figures 6–7, we give results based on the following two datasets: “extended MNIST” (47 classes, balanced) [11], and “cover type” (7 classes, imbalanced) [9]. We plot the average and standard deviation of the base and zero-one losses as a function of epoch number, plus give a histogram of test (base) losses for a single trial, compared with the loss distribution incurred by a random initialization of the same model (left-most plot; gray is test, black is training). Colors are analogous to previous experiments, here evenly spaced over the allowable range (). It is clear how modifying the Barron dispersion function shape across this range lets us flexibly interpolate between the test (base) loss distribution achieved by a traditional ERM solution and a mean-variance solution, in terms of both the mean and standard deviation. This monotonicity (as a function of ) is salient in the base loss, but this does not always appear for the zero-one loss. Since these datasets have normalized features with negligible label noise, egregious outliers are rare, and thus the trends observed for the mean and standard deviation here also hold for outlier-resistant location-dispersion pairs such as the median and the median-absolute-deviations about the median. Similar results for several other datasets are provided in §B.6, and we remark that the key trends hold across all datasets tested. We have seen in our previous experiments how under heavy-tailed losses/gradients the T-risk solution can differ greatly from that of the vanilla ERM solution, so it is interesting to observe how under large, normalized, clean classification datasets, the T-risk allows us to very smoothly control a tradeoff between average test loss and variance on the test set.
Acknowledgments
This work was supported by JST ACT-X Grant Number JPMJAX200O and JST PRESTO Grant Number JPMJPR21C6.
References
- Albert and Anderson, [1984] Albert, A. and Anderson, J. A. (1984). On the existence of maximum likelihood estimates in logistic regression models. Biometrika, 71(1):1–10.
- Artzner et al., [1999] Artzner, P., Delbaen, F., Eber, J.-M., and Heath, D. (1999). Coherent measures of risk. Mathematical Finance, 9(3):203–228.
- Ash and Doléans-Dade, [2000] Ash, R. B. and Doléans-Dade, C. A. (2000). Probability and Measure Theory. Academic Press, 2nd edition.
- Barron, [2019] Barron, J. T. (2019). A general and adaptive robust loss function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4331–4339.
- Bassett, [1987] Bassett, Jr, G. W. (1987). The St. Petersburg paradox and bounded utility. History of Political Economy, 19(4):517–523.
- Ben-Tal et al., [2013] Ben-Tal, A., Den Hertog, D., De Waegenaere, A., Melenberg, B., and Rennen, G. (2013). Robust solutions of optimization problems affected by uncertain probabilities. Management Science, 59(2):341–357.
- Ben-Tal and Teboulle, [1986] Ben-Tal, A. and Teboulle, M. (1986). Expected utility, penalty functions, and duality in stochastic nonlinear programming. Management Science, 32(11):1445–1466.
- Ben-Tal and Teboulle, [2007] Ben-Tal, A. and Teboulle, M. (2007). An old-new concept of convex risk measures: The optimized certainty equivalent. Mathematical Finance, 17(3):449–476.
- Blackard and Dean, [1999] Blackard, J. A. and Dean, D. J. (1999). Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables. Computers and Electronics in Agriculture, 24(3):131–151.
- Boyd and Vandenberghe, [2004] Boyd, S. and Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press.
- Cohen et al., [2017] Cohen, G., Afshar, S., Tapson, J., and Van Schaik, A. (2017). EMNIST: an extension of MNIST to handwritten letters. arXiv preprint arXiv:1702.05373v2.
- Şimşekli et al., [2019] Şimşekli, U., Sagun, L., and Gürbüzbalaban, M. (2019). A tail-index analysis of stochastic gradient noise in deep neural networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), volume 97 of Proceedings of Machine Learning Research, pages 5827–5837.
- Curi et al., [2020] Curi, S., Levy, K. Y., Jegelka, S., and Krause, A. (2020). Adaptive sampling for stochastic risk-averse learning. In Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pages 1036–1047.
- Cutkosky and Mehta, [2021] Cutkosky, A. and Mehta, H. (2021). High-probability bounds for non-convex stochastic optimization with heavy tails. arXiv preprint arXiv:2106.14343v2.
- Davis and Drusvyatskiy, [2019] Davis, D. and Drusvyatskiy, D. (2019). Stochastic model-based minimization of weakly convex functions. SIAM Journal on Optimization, 29(1):207–239.
- Devroye et al., [1996] Devroye, L., Györfi, L., and Lugosi, G. (1996). A Probabilistic Theory of Pattern Recognition. Springer.
- Duchi and Namkoong, [2018] Duchi, J. and Namkoong, H. (2018). Learning models with uniform performance via distributionally robust optimization. arXiv preprint arXiv:1810.08750v6.
- Duchi and Namkoong, [2019] Duchi, J. and Namkoong, H. (2019). Variance-based regularization with convex objectives. Journal of Machine Learning Research, 20(68):1–55.
- Föllmer and Knispel, [2011] Föllmer, H. and Knispel, T. (2011). Entropic risk measures: Coherence vs. convexity, model ambiguity and robust large deviations. Stochastics and Dynamics, 11(02n03):333–351.
- Ghadimi et al., [2016] Ghadimi, S., Lan, G., and Zhang, H. (2016). Mini-batch stochastic approximation methods for nonconvex stochastic composite optimization. Mathematical Programming, 155(1-2):267–305.
- Gneiting, [2011] Gneiting, T. (2011). Making and evaluating point forecasts. Journal of the American Statistical Association, 106(494):746–762.
- Gorbunov et al., [2020] Gorbunov, E., Danilova, M., and Gasnikov, A. (2020). Stochastic optimization with heavy-tailed noise via accelerated gradient clipping. In Advances in Neural Information Processing Systems 33 (NeurIPS 2020).
- Gorbunov et al., [2021] Gorbunov, E., Danilova, M., Shibaev, I., Dvurechensky, P., and Gasnikov, A. (2021). Near-optimal high probability complexity bounds for non-smooth stochastic optimization with heavy-tailed noise. arXiv preprint arXiv:2106.05958.
- Gotoh et al., [2018] Gotoh, J.-y., Kim, M. J., and Lim, A. E. (2018). Robust empirical optimization is almost the same as mean–variance optimization. Operations Research Letters, 46(4):448–452.
- Hacking, [2006] Hacking, I. (2006). The emergence of probability: a philosophical study of early ideas about probability, induction and statistical inference. Cambridge University Press, 2nd edition.
- Hashimoto et al., [2018] Hashimoto, T. B., Srivastava, M., Namkoong, H., and Liang, P. (2018). Fairness without demographics in repeated loss minimization. In Proceedings of the 35th International Conference on Machine Learning (ICML), volume 80 of Proceedings of Machine Learning Research, pages 1929–1938.
- Haussler, [1992] Haussler, D. (1992). Decision theoretic generalizations of the PAC model for neural net and other learning applications. Information and Computation, 100(1):78–150.
- [28] Holland, M. J. (2021a). Designing off-sample performance metrics. arXiv preprint arXiv:2110.04996v1.
- [29] Holland, M. J. (2021b). Robustness and scalability under heavy tails, without strong convexity. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 130 of Proceedings of Machine Learning Research.
- Holland, [2022] Holland, M. J. (2022). Learning with risks based on M-location. Machine Learning.
- Holland and Haress, [2021] Holland, M. J. and Haress, E. M. (2021). Learning with risk-averse feedback under potentially heavy tails. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 130 of Proceedings of Machine Learning Research.
- Huber and Ronchetti, [2009] Huber, P. J. and Ronchetti, E. M. (2009). Robust Statistics. John Wiley & Sons, 2nd edition.
- Kashima, [2007] Kashima, H. (2007). Risk-sensitive learning via minimization of empirical conditional value-at-risk. IEICE Transactions on Information and Systems, 90(12):2043–2052.
- Kearns and Vazirani, [1994] Kearns, M. J. and Vazirani, U. V. (1994). An Introduction to Computational Learning Theory. MIT Press.
- Koltchinskii, [1997] Koltchinskii, V. I. (1997). -estimation, convexity and quantiles. The Annals of Statistics, pages 435–477.
- Lee et al., [2020] Lee, J., Park, S., and Shin, J. (2020). Learning bounds for risk-sensitive learning. In Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pages 13867–13879.
- [37] Li, T., Beirami, A., Sanjabi, M., and Smith, V. (2021a). On tilted losses in machine learning: Theory and applications. arXiv preprint arXiv:2109.06141v1.
- [38] Li, T., Beirami, A., Sanjabi, M., and Smith, V. (2021b). Tilted empirical risk minimization. In The 9th International Conference on Learning Representations (ICLR).
- Luenberger, [1969] Luenberger, D. G. (1969). Optimization by Vector Space Methods. John Wiley & Sons.
- Minsker, [2019] Minsker, S. (2019). Uniform bounds for robust mean estimators. arXiv preprint arXiv:1812.03523v4.
- Mohri et al., [2012] Mohri, M., Rostamizadeh, A., and Talwalkar, A. (2012). Foundations of Machine Learning. MIT Press.
- Nazin et al., [2019] Nazin, A. V., Nemirovsky, A. S., Tsybakov, A. B., and Juditsky, A. B. (2019). Algorithms of robust stochastic optimization based on mirror descent method. Automation and Remote Control, 80(9):1607–1627.
- Nesterov, [2004] Nesterov, Y. (2004). Introductory Lectures on Convex Optimization: A Basic Course. Springer.
- Penot, [2012] Penot, J.-P. (2012). Calculus Without Derivatives, volume 266 of Graduate Texts in Mathematics. Springer.
- Prashanth et al., [2020] Prashanth, L. A., Jagannathan, K., and Kolla, R. K. (2020). Concentration bounds for CVaR estimation: The cases of light-tailed and heavy-tailed distributions. In 37th International Conference on Machine Learning (ICML), volume 119 of Proceedings of Machine Learning Research, pages 5577–5586.
- Rockafellar and Uryasev, [2000] Rockafellar, R. T. and Uryasev, S. (2000). Optimization of conditional value-at-risk. Journal of Risk, 2:21–42.
- Rockafellar and Uryasev, [2002] Rockafellar, R. T. and Uryasev, S. (2002). Conditional value-at-risk for general loss distributions. Journal of Banking & Finance, 26(7):1443–1471.
- Rockafellar and Uryasev, [2013] Rockafellar, R. T. and Uryasev, S. (2013). The fundamental risk quadrangle in risk management, optimization and statistical estimation. Surveys in Operations Research and Management Science, 18(1-2):33–53.
- Rockafellar et al., [2006] Rockafellar, R. T., Uryasev, S., and Zabarankin, M. (2006). Generalized deviations in risk analysis. Finance and Stochastics, 10(1):51–74.
- Rousseeuw and Christmann, [2003] Rousseeuw, P. J. and Christmann, A. (2003). Robustness against separation and outliers in logistic regression. Computational Statistics & Data Analysis, 43(3):315–332.
- Rousseeuw and Leroy, [1987] Rousseeuw, P. J. and Leroy, A. M. (1987). Robust Regression and Outlier Detection. John Wiley & Sons.
- Ruszczyński and Shapiro, [2006] Ruszczyński, A. and Shapiro, A. (2006). Optimization of convex risk functions. Mathematics of Operations Research, 31(3):433–452.
- Shalev-Shwartz and Ben-David, [2014] Shalev-Shwartz, S. and Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press.
- Sutton and Barto, [2018] Sutton, R. S. and Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press, 2nd edition.
- Takeda and Sugiyama, [2008] Takeda, A. and Sugiyama, M. (2008). -support vector machine as conditional value-at-risk minimization. In Proceedings of the 25th International Conference on Machine Learning (ICML), pages 1056–1063.
- Takeuchi et al., [2006] Takeuchi, I., Le, Q. V., Sears, T. D., and Smola, A. J. (2006). Nonparametric quantile estimation. Journal of Machine Learning Research, 7:1231–1264.
- Van Rooyen et al., [2016] Van Rooyen, B., Menon, A., and Williamson, R. C. (2016). Learning with symmetric label noise: The importance of being unhinged. In Advances in Neural Information Processing Systems 28 (NIPS 2015), pages 10–18.
- Vapnik, [1999] Vapnik, V. N. (1999). The Nature of Statistical Learning Theory. Statistics for Engineering and Information Science. Springer, 2nd edition.
- Venables and Ripley, [2002] Venables, W. N. and Ripley, B. D. (2002). Modern Applied Statistics with S. Springer, 4th edition.
- Zhai et al., [2021] Zhai, R., Dan, C., Kolter, J. Z., and Ravikumar, P. (2021). DORO: Distributional and outlier robust optimization. In 38th International Conference on Machine Learning (ICML), volume 139 of Proceedings of Machine Learning Research, pages 12345–12355.
- Zhang et al., [2020] Zhang, J., Karimireddy, S. P., Veit, A., Kim, S., Reddi, S., Kumar, S., and Sra, S. (2020). Why are adaptive methods good for attention models? In Advances in Neural Information Processing Systems, volume 33, pages 15383–15393.
Appendix A Appendix summary
For ease of reference, we start the appendix with a concise tables of contents.
- •
- •
- •
Appendix B Supplementary information
Here we provide additional details that did not fit into the main body of the paper.
B.1 Details for tilted risk
Let be an arbitrary random variable. Assuming the distribution is such that we can differentiate through the integral, we have
| (24) |
Let be any value that satisfies the first-order optimality condition in (24). It follows that
It is easy to confirm that setting gives us a valid solution. For more background, see the recent works of Li et al., 2021b [38], Li et al., 2021a [37] and the references therein. Note also that this log-exponential criterion appears (with ) in Rockafellar and Uryasev, [48, Ex. 8].
B.2 Details for Barron class limits
For the limit as , use the fact that for any , we have
| (25) |
This equality is sometimes known as Halley’s formula. For the limit as , first note that for any we can write , and thus . With this in mind, for any we can observe
where the limit is taken as , and follows from the classical limit characterization of the exponential function. For the limit as , first note that
and that as long as , we can write
where we have introduced . Taking amounts to , and thus using the fact that as , the desired result follows from straightforward analysis.
B.3 Additional lemmas for Barron class and T-risk
Lemma 8 (Dispersion function convexity and smoothness).
Consider with from the Barron class (15), with parameter . The following properties hold for any choice of .
-
•
Case of :
is convex and -smooth on . -
•
Case of :
is convex on , and is -Lipschitz and -smooth on . -
•
Case of :
is convex on , and is -Lipschitz and -smooth on . -
•
Otherwise:
is -smooth on . When , is convex on . When , is also -Lipschitz on . Else, when , we have that is convex between , and is -Lipschitz on .
Furthermore, all these coefficients are tight (see also Figure 9).
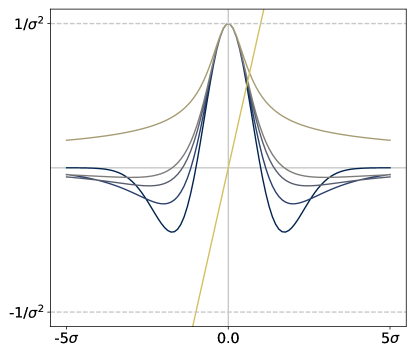
The dispersion plays a prominent role in the risk definitions considered in this paper, and one is naturally interested in the properties of the map . The following lemma shows that using from the Barron class, we can differentiate under the integral without needing any additional conditions beyond those required for finiteness.
Lemma 9.
Let be as in Lemma 8. Assume that the random loss is -measurable in general, and that holds whenever . It follows that the first two derivatives are -integrable, namely that
| (26) |
for any . Furthermore, the function is twice-differentiable on , and satisfies the Leibniz integration property for both derivatives, that is
| (27) |
for any .666Let us emphasize that and denote the first and second derivatives of , which differ from and by a -dependent factor; see §D.3 for details.
With first-order information about the expected dispersion in hand, one can readily obtain conditions under which the special case of T-risk is finite and determined by a meaningful “optimal threshold.”
Lemma 10.
Remark 11.
We have overloaded our notation in Lemma 10, recalling that we have used the same notation to denote the set of optimal thresholds for the T-risk in (11). This saves us from having to introduce additional symbols, and should not lead to any confusion since we only do this overloading when the solution set contains a single unique solution.
B.4 Smoothness of the T-risk
When the objective in (11) is sufficiently smooth, we can apply well-established analytical techniques to control the gradient norms of stochastic gradient-based learning algorithms. Assuming we have unbiased first-order stochastic feedback as in (17)–(18), we will always have to deal with terms of the form . Defining for readability, and considering the function difference at two arbitrary points and , first note that
| (29) |
In the case of from the Barron class (15), when , we have that is both bounded () and Lipschitz continuous on (see Lemma 8). This means that all we need in order to control is for to be smooth (for control of ) and for to have a norm bounded over (for control of ); see §C.2 for more details. Things are more difficult in the case of , since the dispersion function is not (globally) Lipschitz, meaning that . Even if is smooth, when the threshold parameter is left unconstrained, it will always be possible for as , impeding smoothness guarantees for in this setting.
Let us proceed by distilling the preceding discussion into a set of concrete conditions that are sufficient to make amenable to standard analysis techniques for stochastic gradient-based algorithms. For readability, we write .
-
A1.
Moment bound for loss gradient. For any choice of , , and , the loss is differentiable at , and satisfies
(30) -
A2.
Loss is smooth in expectation. There exists such that for any choice of , we have .
-
A3.
Dispersion is Lipschitz and smooth. The function is such that , and there exists such that for all .
If is a convex set, then the first inequality in A1. holds trivially. Note that under A2., the right-hand side of (30) will be finite for whenever has bounded diameter and for some . As for A3., all the requirements are clearly met by the Barron class with . These conditions imply a Lipschitz property for the gradients, as summarized in the following lemma.
Lemma 12.
Remark 13 (Norm on product spaces).
In Lemma 12 we have to deal with norms on product spaces, and in all cases we just use the traditional choice of summing the norms of the constituent elements, i.e., on , we have . Similarly, we have that the gradient , a pair of linear functionals. As such, the norm of defined as the sum of the norms of these two constituent functionals.
B.5 Experimental details
Here we provide some additional details for the empirical analysis carried out in §3.3 and §5. Detailed hyperparameter settings and seeds for exact re-creation of all the results in this paper are available at the GitHub repository cited in §1, and thus here we will not explicitly write all the step sizes, shape settings, etc., but rather focus on concise exposition of points on which we expect readers to desire clarification.
Static risk analysis
For our experiments in §3.3, we gave just one plot using a log-Normal distribution, but analogous tests were run for a wide variety of parametric distributions. In total, we have run tests for Bernoulli, Beta, , Exponential, Gamma, log-Normal, Normal, Pareto, Uniform, Wald, and Weibull distributions. The settings of each distribution to be sampled from has not been tweaked at all; we set the parameters rather arbitrarily before running any tests. As for the fixed value of in the T-risk across all tests, we tested several values of ranging from to , and based on the rough position of in the Normal case, we determined as a reasonable representative value; indeed, this settings performs quite well across a very wide range of distributions. Regarding the optimization involved in solving for the optimal threshold (for T-risk, OCE risks, and DRO risk), we use minimize_scalar from SciPy, with bounded solver type, and valid brackets set manually.
Noisy linear classification
In the tests described in §5.1, we only give error/norm trajectories for “representative” settings of each risk class (Figure 4). For T-risk we consider different choices of , for CVaR we consider , for tilted risk we consider between , and for -DRO we consider . For each of these ranges, we evaluate five evenly-spaced candidates (via np.linspace), and representative settings were selected as those which achieved the best classification error (average zero-one loss) after the final iteration. In the event of ties, the smaller hyperparameter value was always selected (via np.argmin).
Regression under outliers
For the tests introduced in §5.2, we have given results for learning algorithms started at a point which is quite accurate for the majority of the data points, but incurs extremely large errors on the outlying minority. This choice of initial value naturally has a strong impact on the behavior of learning algorithms under each risk. For some perspective, in Figure 13 we provide results using a different initial value (again, in gray), which complement Figure 5. Since the naive strategy fixing at the initial median sets the scale extremely large and close to the loss incurred at most points, even a large number of gradient-based updates result in minimal change. The basic reason for this is quite straightforward. Since the T-risk gradient is modulated by , and all points are such that either (the minority) or (the majority), both cases shrink the norm of the update direction vector . When implementing T-risk in the more traditional way (jointly in ) and choosing , we see results that are very similar to CVaR. Finally, we remark that here we have set the hyperparameter ranges with upper bounds low enough that the learning procedure described here does not run into overflow errors.
Classification under larger benchmark datasets
In §5.3 we make use of several well-known benchmark datasets, and in our figures we identify them respectively by the following keywords: adult,777https://archive.ics.uci.edu/ml/datasets/Adult australian,888https://archive.ics.uci.edu/ml/datasets/statlog+(australian+credit+approval) cifar10,999https://www.cs.toronto.edu/~kriz/cifar.html covtype,101010https://archive.ics.uci.edu/ml/datasets/covertype emnist_balanced,111111https://www.nist.gov/itl/products-and-services/emnist-dataset fashion_mnist,121212https://github.com/zalandoresearch/fashion-mnist and protein.131313https://www.kdd.org/kdd-cup/view/kdd-cup-2004/Data For further background on all of these datasets, please access the URLs provided in the footnotes. As mentioned in the main text, for a -class problem with features, the predictor is characterized by weighting vectors , each of which is and computes scores as for . These weight vectors are penalized using the usual multi-class logistic loss, namely the negative log-likelihood of the -Categorical distribution that arises after passing these scores through the (logistic) softmax function. Regarding step sizes, as mentioned in the main text, we consider choices of factor , and set step size to , where and are as just stated. In Figures 14–18 of §B.6, we provide additional results for the datasets not covered in Figures 6–7 from the main text.
B.6 Additional figures
Here we include a number of figures that complement those provided in the main text. A brief summary is given below.
- •
-
•
Figures 12–13 are related to the regression under outliers task described in §5.2. The first figure shows how different regression lines incur very different loss distributions under different convex base loss functions. The second figure illustrates how a different initial value impacts the learned regression lines under each risk class.
- •


Appendix C Detailed proofs
C.1 Proofs of results in the main text
Proof of Lemma 8.
In this proof, without further mention, we will make regular use of the following two helper results: Lemma 14 (bounded gradient implies Lipschitz continuity) and Lemma 15 (positive definite Hessian implies convexity). For reference, the first and second derivatives of are given in §D.3. We take up each setting one at a time.
First, the case of . For this case, clearly is unbounded, and thus is not (globally) Lipschitz on . On the other hand, since , we have that is -Lipschitz with .
Next, the case of . For any fixed , in both the limits and , we have . Maximum and minimum values are achieved when , and this occurs if and only if . It follows from direct computation that , and thus is -Lipschitz with . Next, recalling that takes the form
we see that this is a product of two factors, one taking values in , and one taking values in . The absolute value of both of these factors is maximized when , and so , meaning that is -Lipschitz with . Finally, regarding convexity, we have that if and only if .
Next, the case of . For any fixed , we have in both the limits and . Furthermore, it is immediate that at the points . Evaluating at these stationary points we have , and thus is -Lipschitz with . Regarding bounds on , first note that as , and . Then to identify stationary points, note that
and thus if and only if , i.e., the stationary points are , both of which yield the same value, namely . Since , we conclude that is -Lipschitz with . Finally, since if and only if , this specifies the region on which is convex.
Finally, all that remains is the general case of where . Note that in order for to hold, we require
which via some basic algebra is equivalent to
Clearly, this is only possible when , so we consider this sub-case first. This implies stationary points , for which we have
Since in both the limits and , we have obtained a maximum value for at , thus implying for the case of that is -Lipschitz, with a coefficient of . For the case of , direct inspection shows
a value which is maximized in the limit . As such, for , we have that is -Lipschitz with . For the case of , is unbounded. To see this, note that for we have
and since , sending clearly implies , and this means that cannot be Lipschitz on when . As for bounds on , recall that
where we have introduced the labels and just as convenient notation. Fixing any , first note that since , we have and thus . Next, direct inspection shows . These two facts immediately imply an upper bound and a lower bound , both of which hold for any . Furthermore, for the case of , we thus have . When however, can be negative. To get matching lower bounds requires , or . To study conditions under which this holds, first note that can be re-written as
and thus we have
| (31) |
To get a more convenient upper bound on this, observe that for any and . It follows immediately that
| (32) |
To get the right-hand side of (32) to be no greater than is equivalent to
| (33) |
For the case of , note that , and using the helper inequality (69), we have
which implies (33) for . All that remains is the case of , which requires a bit more care. Returning to the exact form of given in (31), note that the inequality
| (34) |
is equivalent to the desired property, i.e., . Using Bernoulli’s inequality (71), we can bound the right-hand side of (34) as
Subtracting the left-hand side of (34) from the right-hand side of the preceding inequality, we obtain
| (35) |
where the second step uses the fact that for , we can write and . Note that the right-hand side of (35) is non-negative for all whenever , which via (34) tells us that indeed holds in this case as well. For the case of , note that showing (34) holds is equivalent to showing for all , where for convenience we define the polynomial
The first derivative is
and with this form in hand, solving for , it is straightforward to confirm that given below is a stationary point:
Furthermore, it is clear that , implying that is convex, and that is a minimum. As such, the minimum value taken by on is
We require for all . From the preceding equalities, note that a simple sufficient condition for is
or equivalently
| (36) |
Applying the helper inequality (70) to the left-hand side of (36), we have
This is precisely the desired inequality (36), implying for all , and in fact all real . To summarize, we have for all , and thus the desired -smoothness result follows, concluding the proof. ∎
Proof of Lemma 1.
Let denote any -measurable random variable. The continuity of implies that the integral exists for any ; we just need to prove it is finite.141414This uses the fact that any composition of (Borel) measurable functions is itself measurable [3, Lem. 1.5.7]. Since we are taking from the Barron class (15), we consider each setting separately. Starting with , note that
and thus is sufficient and necessary. For , first note that we have
Let and , where . Note that , and furthermore that for any ,
We may thus conclude that for all , and thus for any we have
It follows that to ensure , it is sufficient if we assume for some . Proceeding to the case of , we have
Any composition of measurable functions is measurable, and since the right-hand side is bounded above by and below by , we have that is -integrable without requiring any extra assumptions on besides measurability. All that remains for the Barron class is the case of non-zero , where we have
Let us break this into two cases: and . Starting with the former case, this is easy since
which is bounded above by and below by for any and , which means the random variable is -integrable without any extra assumptions on . As for the latter case of , first note that the monotonicity of on implies
which means is necessary. That this condition is also sufficient is immediate from the form of just given. This concludes the proof; the desired result stated in the lemma follows from setting and the observation that the choice of in the preceding discussion was arbitrary. ∎
Proof of Lemma 9.
Referring to the derivatives (67)–(68) in §D.3, we know that is measurable, and by the proof of Lemma 8, we know that for all . Thus, as long as is -measurable, we have that is -integrable. For the case of , note that holds, meaning that implies integrability. Similarly for the second derivatives, from the proof of Lemma 8, we see that for all , implying the -integrability of .
The Leibniz integration property follows using a straightforward dominated convergence argument, which we give here for completeness. Letting be any non-zero real sequence such that , we can write
For notational convenience, let us denote the key sequence of functions by
and note that pointwise as . We can then say the following: for all , we have that
for an appropriate choice of . The first inequality follows from the helper Lemma 14. We can always find an appropriate because the sequence is bounded and is eventually monotone, regardless of the choice of . With the fact in hand, recall that we have already proved that under the assumptions we have made, and thus by dominated convergence.151515See for example Ash and Doléans-Dade, [3, Thm. 1.6.9]. As such, we have
which is the desired Leibniz property for the first derivative. A completely analogous argument holds for the second derivative, yielding the desired result. ∎
Proof of Lemma 10.
From Lemma 9, we know that the map is differentiable and thus continuous. Using continuity, taking any and constructing a closed interval , the Weierstrass extreme value theorem tells us that achieves its maximum and minimum on . Furthermore, note that taken from the Barron class (15) satisfies all the requirements of our helper Lemma 16, and thus implies as . We can thus always take the interval wide enough that
This proves the existence of a minimizer of on .
Next, considering the T-risk and minimization with respect to , since we are doing unconstrained optimization, any solution must satisfy , where . Using Lemma 9 again, this can be equivalently re-written as
| (37) |
When , the derivative of the dispersion function has unbounded range, i.e., . As such, an argument identical to that used in the proof of Lemma 16 implies that for any , we can always find a such that (37) holds, recalling that continuity follows via Lemma 9. Combining this with convexity gives us a valid solution. The special case of requires additional conditions, since from Lemma 8, we know that in this case , and thus by an analogous argument, whenever we can find a finite solution.
To prove uniqueness under , direct inspection of the second derivative in (68) shows us that on whenever we have
Re-arranging the above inequality yields an equivalent condition of , a condition which holds on if and only if . Since is positive on , this implies that for all . Using Lemma 9, we have that is equal to the second derivative of with respect to , which implies that and are strictly convex on , and thus their minimum must be unique.161616See for example Boyd and Vandenberghe, [10, Sec. 3.1.4]. ∎
Proof of Lemma 5.
For random loss , using Lemma 9, first-order optimality conditions require
| (38) |
If these conditions hold, then from direct inspection, the same conditions will clearly hold if we replace by , by , and by . This implies both translation-invariance of the dispersions and the translation-equivariance of the optimal thresholds. Non-negativity follows trivially from the fact that . Noting that for all , we have that if and only if almost surely.171717This fact follows from basic Lebesgue integration theory [3, Thm. 1.6.6]. Since by the optimality of , it follows that for any non-constant , we must have . Furthermore, from the optimality condition (38) for , even when is constant, we must have whenever , since if and only if .
In the special case where , we have that is positive on (see §D.3 and Fig. 8). This implies that is strictly convex, and is monotonically increasing. Let almost surely, but say . Using the optimality condition (38), uniqueness of the solution via Lemma 10, and the aforementioned monotonicity of , we have
This is a contradiction, and thus we must have . An identical argument using the exact same properties proves that also holds. Finally, to prove convexity, take any , , and , and note that
The first inequality uses optimality of the threshold in the definition of , whereas the second inequality uses the convexity of . Since the choice of and here were arbitrary, we can set and to obtain the desired inequality
giving us convexity of the threshold risk. As a direct corollary, setting yields the convexity result for . ∎
Proof of Lemma 2.
The crux of this result is an analogue to Lemma 9 regarding the differentials of , this time taken with respect to , rather than . Fixing arbitrary , let us start by considering the following sequence of random variables:
| (39) |
where is any sequence of real values such that as . Before getting into the details, let us unpack the differentiability assumption made on the base loss. Before random sampling, the map is of course a map from to the set of measurable functions , but after sampling, there is no randomness and it is simply a map from to . Having sampled the random loss, the property we desire is that for each , there exists a continuous linear functional such that
| (40) |
The differentiability condition in the lemma statement is simply that
| (41) |
On this “good” event, since the map is differentiable by definition, we have that the composition is also differentiable for any choice of , and a general chain rule can be applied to compute the differentials.181818See Penot, [44, Thm. 2.47] for this key fact, where “” is here, and both “” and “” are here. In particular, we have a pointwise limit of
| (42) |
which also uses the fact that the Fréchet and Gateaux differentials are equal here.191919Luenberger, [39, §7.2, Prop. 2] Technically, it just remains to obtain conditions which imply . In pursuit of a -integrable upper bound on the sequence , note that for large enough , we have
| (43) |
The key to the first of the preceding inequalities is a generalized mean value theorem.202020Considering the proof of Lemma 14 due to Luenberger, [39, §7.3, Prop. 2], just generalize the one-dimensional part of the argument from the original interval to the interval here. Both the first and second inequalities also use the fact that eventually. The final inequality uses the fact that for any choice of . This inequality suggests a natural condition of
| (44) |
under which we can apply a standard dominated convergence argument.212121See for example Ash and Doléans-Dade, [3, Thm. 1.6.9]. If (43) holds for say all , then we can just bound by the greater of (clearly -integrable) and the right-hand side of (43). In particular, the key implication is that
| (45) |
Since we have
where denotes the gradient of , we see that by applying the preceding argument (culminating in (45)) to the modified losses (16), we readily obtain the desired result. ∎
Proof of Theorem 3.
To begin, let us consider the smoothness of the objective under the present assumptions. From Lemma 12 and the basic properties of the Barron class of dispersion functions (Lemma 8), it follows that this function is -smooth with coefficient
| (46) |
where , and
From here, we can leverage the main argument of Cutkosky and Mehta, [14, Thm. 2], utilizing the smoothness property given by (46) above, and the -bound of (19). For completeness and transparency we include the key details here. First, note that if we define , , and , our definitions imply that for each , we have
| (47) |
Using the form (47), it follows immediately that
| (48) |
again for each . By setting and , we trivially have
and one can then easily check that (48) holds for all . Expanding the recursion of (48), we have
| (49) |
We take the summands of (49) one at a time. Since the stochastic gradients are -bounded, we have that for all . Furthermore, we have (Lemma 2) and for each . These bounds can be passed to standard concentration inequalities for martingales on Banach spaces [14, Lem. 14], which using the smoothness property of that we assumed tell us that with probability no less than , we have
| (50) |
Moving on to the second term of (49), note that using -smoothness of the risk function with coefficient given by (46), along with the definition of the update procedure (20)–(21), we have
This implies that using a constant step size , we can control the sum as
| (51) |
Finally, the third term of (49) is easily controlled as . Taking this bound along with (50) and (51), we see that can be bounded above by
| (52) |
on the high-probability event mentioned earlier. To make use of the bound (52), note that using the -smoothness of the losses, the update procedure used here can be shown [14, Lem. 1] to satisfy
| (53) |
Using a union bound, we have that the bound of (52) holds for all with probability no less than . To get some clean bounds out of (52) and (53), first we loosen
and note that and implies . This means that with probability no less than , we have
Dividing both sides by and plugging in the prescribed settings of and , we have
| (54) |
Taking this bound and our setting and applying it to (53), we obtain
| (55) |
To clean this all up, we have
For readability, the proof uses a slightly looser choice of , and instead of iterations, it is stated for iterations. ∎
Proof of Corollary 4.
Let , and note from §D.3 that we have
It thus follows from (17) that
In the case of the quadratic loss with a linear model as assumed here, this becomes
Regarding growth in , note that since , both the numerator and denominator are . As for growth in which accounts for the random noise as well, the numerator is whereas the denominator is , and thus accounting for the randomness of and which can both be potentially unbounded and heavy-tailed, we see that the norm of must be bounded as the norm of the inputs, noise, and/or loss grow large. Trivially, since , the limits where also result in with a norm that is almost surely bounded.
Proceeding to the case of the logistic loss, an analogous argument yields the desired result. First note that under the linear model assumed here, the gradient with respect to any takes the form
where , i.e., the softmax transformation of the score assigned by . By definition, the coefficients are bounded. Furthermore, using our linear model assumption, we have that , and as such the numerator and denominator are both , implying the desired boundedness.
Taking the previous two paragraphs together, we have that the bound (19) is satisfied for a finite under , even when the data is unbounded and potentially heavy-tailed. For , the derivative of shrinks even faster, so the same result follows a fortiori from the case. Finally, the -smoothness assumption in Theorem 3 follows from direct inspection of the forms of given here for each loss, using our assumption of having bounded second moments. ∎
Proof of Proposition 7.
To begin, recall from §3 the notation for the M-locations and for the T-risk optimal thresholds. By Lemma 10, both and have unique solutions, and thus we overload this notation to represent the unique solution. By definition, we have
Similarly, we can obtain a lower bound using the optimality of and as
Taking these two bounds together, we have
| (56) |
for any choice of . The bounds in (56) are stated for ideal risk quantities for the true distribution under , but an identical argument holds if we replace by the empirical measure induced by an iid sample . Writing this out explicitly, let , , and denote the empirical analogues of , , and , and similarly let and be the empirical analogues of and . From the argument leading to (56), it follows that
| (57) |
Next, using the lower bound in (57), for any we have that
| (58) |
Letting be a minimizer of , using the upper bound in (57) and any choice of , we have
| (59) |
Combining (58) and (59), we have that is bounded above by
| (60) |
Some elementary manipulations let us bound the key differences in (60) as
and thus dividing by , we end up with a final bound taking the form
The desired result is just the special case where we set is the expected loss minimizer. ∎
C.2 Smoothness computations (proof of Lemma 12)
Here we provide detailed computations for the smoothness coefficients used in Lemma 12. We assume here that the assumptions A1., A2., and A3. are satisfied. Starting with the difference of expected gradients, using Jensen’s inequality and the smoothness assumption A2., we have
| (61) |
As discussed in §B.4, differences of gradients modulated by are slightly more complicated. In particular, recalling the equality (29), the norm of the difference
| (62) |
can be bounded above by the sum of
| (63) |
and
| (64) |
We take up (63) and (64) one at a time. Starting with (63), from A3. we know that the dispersion derivative is -Lipschitz, and thus we have
| (63) | ||||
| (65) |
Here, the second inequality uses the helper Lemma 14 and our assumption of differentiability, while the third inequality uses our assumption on the expected squared norm of the gradient. We have set the Lipschitz coefficient in (65) to be
This gives us a bound on (63). Moving on to (64), if is bounded on , then we have
| (64) | ||||
| (66) |
with , recalling the bound (61). To summarize, we can use (65) and (66) to control (62) as follows:
where . With these preparatory details organized, it is straightforward to obtain a Lipschitz property on the gradient of , as summarized in Lemma 12, and detailed in the proof below.
Proof of Lemma 12.
Using our upper bounds on (61) and (62), we have
Next, let us look at the partial derivative taken with respect to the threshold parameter . To bound the absolute value of these differences, using the generalized mean value theorem (Lemma 14), we have
Taking the preceding upper bounds together, the gradient difference for can be bounded as
noting that the initial equality follows from the fact that we are using the sum of norms for our product space norm here (see also Remark 13). These bounds on the gradient differences are precisely the desired result. ∎
Appendix D Additional technical facts
D.1 Lipschitz properties
Here we give a fundamental property of differentiable functions that generalizes the mean value theorem.
Lemma 14.
Let and be normed linear spaces, and let be Fréchet differentiable on an open set . Taking any , we have
for any such that for all .
Proof.
See Luenberger, [39, §7.3, Prop. 2]. ∎
Note that Lemma 14 has the following important corollary: bounded gradients imply Lipschitz continuity. In particular, if for all , then it follows immediately that is -Lipschitz on .
A closely related result goes in the other direction. Let be convex and -Lipschitz. If is sub-differentiable at a point , then we have
As such, for convex, sub-differentiable functions, -Lipschitz continuity implies that all sub-gradients are bounded as .
D.2 Convexity
Lemma 15.
Let function be twice continuously differentiable. Then is convex if and only if its Hessian is positive semi-definite, namely when
for all .
Proof.
See Nesterov, [43, Thm. 2.1.4]. ∎
D.3 Derivatives for the Barron class
Let be defined according to (15). Here we compute derivatives of the map , using the shorthand notation . We denote the first derivative of evaluated at by , which is computed as
| (67) |
In the same way, letting denote the second derivative of evaluated at , this is computed as
| (68) |
We emphasize that and are not equal to and , but by a simple application of the chain rule are easily seen to satisfy the relations
for any , , and .
D.4 Elementary inequalities
The following elementary inequalities will be of use.
| (69) |
| (70) |
The inequality below is sometimes referred to as Bernoulli’s inequality.
| (71) |
D.5 Expected dispersion is coercive
Lemma 16 (Expected dispersion is coercive).
Let be any non-negative function which is even (i.e., for all ) and non-decreasing on . Let be any random variable such that for all . Then, we have
and note that this includes the divergent case where as .
Proof of Lemma 16.
By our assumptions, we have and for all , and whenever . With these facts in place, note that for any choice of and such that , we have
| (72) |
For readability, let us write for the limit of as . Trivially, we know that . Using the preceding inequality (72), we have a lower bound of that holds for any . When , the desired result is immediate. When , simply note that as , and thus using the continuity of probability measures, we have as .222222All countably additive set functions on -fields satisfy such continuity properties [3, Thm. 1.2.7]. Thus, the lower bound (72) can be taken arbitrarily close to , implying the desired result. ∎