Format Preserving Encryption in the Bounded Retrieval Model
Abstract
In the bounded retrieval model, the adversary can leak a certain amount of information from the message sender’s computer (e.g., percent of the hard drive). Bellare, Kane and Rogaway give an efficient symmetric encryption scheme in the bounded retrieval model. Their scheme uses a giant key (a key so large only a fraction of it can be leaked.) One property of their scheme is that the encrypted message is larger than the original message. Rogaway asked if an efficient scheme exists that does not increase the size of the message. In this paper we present such a scheme.
1 Introduction
The present paper attempts to solve the problem of format preserving encryption in the bounded retrieval model, by constructing a pseudorandom permutation and providing concrete security bounds in the random oracle model. The bounded retrieval model was introduced to study cryptographic protocols that remain secure in the presence of an adversary that can transmit or leak private information from the host’s computer to a remote home base. One example of such an adversary is an APT (Advanced Persistent Threat), which is a malware that stays undetected in the host’s network and tries to ex-filtrate the secret keys used by the host. The premise of the bounded retrieval model is that such an adversary cannot move a large amount of data to a remote base without being detected or that it can only communicate with the remote base through a very narrow channel. That is, the model assumes an upper bound on the amount of data that an adversary can leak. In [1] Bellare, Kane and Rogaway introduce an efficient symmetric encryption scheme in this model and give concrete security bounds for it. They assume that the secret key is very large and model the leaked data as a function that takes the secret key as the input and outputs a smaller string. The length of this string is a parameter on which the security bounds depend. Their algorithm uses a random seed along with the big key to generate a key of conventional length that is indistinguishable from a random string of the same length even when the function used to model the leaked data depends on calls to the random oracle that the algorithm uses. It then uses this newly generated key and any of the conventionally available symmetric encryption schemes, say an AES mode of operation, to create a ciphertext . Finally it outputs .
The above scheme is not format preserving since the final ciphertext is longer than the original message . A question posed by Phillip Rogaway (personal communication) is whether a secure format preserving encryption scheme exists in the bounded retrieval model. Another way to pose this question is as follows : If the adversary is allowed to leak data, is it possible to construct a pseudorandom permutation that is secure under some notion of security, say the CCA notion of security? The aim of this paper is to answer this question. Unfortunately it is not possible to come up with a pseudorandom permutation that is secure under the strong notion of CCA security. This is because in the CCA model, before trying to distinguish between a random permutation and the pseudorandom permutation, the adversary can choose to look at a sequence of plaintext-ciphertext pairs that he chooses. If a leakage of data is allowed, the adversary can simply leak a single plaintext-ciphertext pair and use it to gain a very high CCA advantage. Hence we weaken the notion of security by requiring that the adversary can only look at a sequence of plaintext-ciphertext pairs where the plaintexts are uniformly random and distinct. We then ask her to distinguish between a truly random permutation and the pseudorandom permutation.
(See Section 3 for a precise definition of the security in our setup.)
In the present paper, we operate in the setting of the random oracle model (see [2]). Our contribution is to give a pseudorandom permutation in the bounded retrieval model and prove that it is secure in the weak sense that is discussed above.
Just as in [1] we use a big key. We now give a brief sketch of our approach. Note that if one fixes the string of leaked bits, the key is a uniform sample from the preimage of the leaked string. If the length of the leaked string is small, then on average the preimage is very large. What this means is that even when the leakage is known, with a high probability the total entropy of the key is high. This implies that the sum of entropies of each bit in our key is large. This means that many of the bits in the key are “unpredictable” in the sense that the probabilty of is not close to or . So, if one uses a random oracle to look at various positions of the key and take an XOR, it is likely that the resulting bit is close to an unbiased random bit. This idea of probing the key is similar to the one used in [1]. The content of Sections 6 and 7, which form the heart of this paper, is to show that bits generated by probing the key are close to i.i.d. unbiased random bits. To construct a pseudorandom permutation using these bits, we use a particular card shuffling scheme called the Thorp shuffle, just as in [9]. This construction is given in the next section.
2 Thorp shuffle/maximally unbalanced Feistel network
One method of turning a pseudorandom function into a pseudorandom permutation is to use a Feistel network (see [5]). The maximally unbalanced Feistel network is also known as the Thorp shuffle. Round of this shuffle can be described as follows. Suppose that the current binary string (i.e., the value of the message after the first rounds of encryption) is , where and . Then round transforms the string to , where
and is a pseudorandom function. Let denote the result of Thorp shuffles on message . The novel idea in the present paper is to use a pseudorandom function based on a big key .
The Big Key Pseudorandom Function:
Let be the length of the big key . To compute , apply the random oracle to to obtain , where is samples with replacement from and is a uniform random subset of that is independent of . By analogy with [1], we define the random subkey by . Finally, define
That is, is the XOR of a randomly chosen subsequence of the subkey. For a given key we define our cipher to be for some fixed positive integer .
Remark: We conjecture that it would also work (i.e., we would get a suitable pseudorandom function)
if we took the XOR of the entire subkey;
the current definition is used because it makes the proof simpler.
3 Security of the Cipher
In this section we introduce a notion of security for pseudorandom permutations under the assumption that there is a leakage of data.
Let denote the set of keys and let denote the set of messages. We assume that the adversary can leak bits of data and just as in [1], use a function to model this. Henceforth we will refer to this function as the leakage function. The adversary has the power to choose this function and this function can depend on calls to the random oracle. For a key , we will use to denote the output one gets by applying the leakage function to it. We will call this the leakage. We allow the adversary to make random oracle calls and decide on a leakage function . After the adversary has chosen a leakage function, consider the following two worlds.
World 1: In this world, we first choose distinct uniformly random messages . Then, for a uniformly random key , we set where is the Thorp shuffle based cipher we defined in Section 2 and is some fixed positive integer. We give the adversary access to the leakage , the input-output pairs and the random oracle calls that were used by the algorithm
to compute the .
World 0: In this world, again we choose distinct uniformly random messages . We once again choose a random key and compute and all the random oracle calls necessary to evaluate the , just like world 1. However, instead of setting to be the outputs of the cipher, we choose a uniformly random
permutation and set . Just as in world 1, the adversary is provided access to the input-output pairs for the messages, the leakage and the random oracle calls.
We now place him in these two worlds one at a time without telling him which world he is in. In each of these cases we ask the adversary to guess which world he is in. Let and denote the answers he gives in world 0 and world 1 respectively. Then, we define the advantage of an adversary as
| (1) |
where is the probability measure in world . Define the maximum advantage
| (2) |
where the maximum is taken over all adversaries satisfying the above mentioned conditions. Note that in the above setup if we allow the messages to be chosen by the adversary instead of being random, we get the notion of security of a block cipher against chosen plain text attack (CPA) under leakage. Security against CPA is weaker than security against CCA (chosen ciphertext attack). Unfortunately, if a leakage is allowed, it is not possible to design a cipher that is secure in the CPA framework. This is because of the adversary who does the following: Let . Assume that the message length is less than . For each key , the adversary includes the ciphertext into the leakage, for a fixed message . Then, the adversary answers as follows. If then the adversary guesses that he is in world 1. Else, the guess is world 0. In this case, and . Hence this adversary has a very high advantage. By instead providing the adversary with uniform random plaintext-ciphertext pairs, we get the notion of secuirty against a known plain text attack (KPA) under leakage. The main result of this paper is the following bound on the maximum advantage of such an adversary.
Theorem 1
The adversary’s advantage satisfies
where is the number of random oracle calls, , is an integer satisfying the equation and is the inverse of the function restricted to , where is defined by .
Lets try to make sense of this bound. The first two terms have exponents that we can control by choosing the parameters of the cipher. Specifically, we can, with modest assumptions on the number of queries and amount of leakage, make the first term as small as desired by running the cipher for rounds and make the second term equally small by sampling probes in each round.
To make sense of the last two terms, lets consider an adversary which we will call the naive adversary. The naive adversary chooses a set of messages and uses their bits of leakage to leak the ciphertext of each message in . Next, when placed in either world 0 or world 1, the naive adversary checks if any of the q random messages provided is from the collection . The naive adversary answers "world 1" if the corresponding ciphertext matches the laked ciphertext. Otherwise, they answer "world 0". If none of the provided messages are from , then the naive adversary answers based on the flip of an independent fair coin. Let denote the advantage of the naive adversary. Then,
Recall that the distinct messages are sampled uniformly, and that . Let . Then is a hypergeometric random variable and
Using the bound
for hypergeometric random variables, we get
With the modest assumption that , and the fact that , we can simplify this bound to
Returning to the bound of the advantage of the optimal adversary, if we assume that and , then
Thus, with realistic assumptions, no adversary can do much better than the naive adversary. To make this precise consider the following example. Let bits and bits, i.e. the key has a size of 1 terabyte out of which, or about 125 gigabytes can be leaked. Assume that the message length is bits. Fix , and . Let denote the two leading terms on the RHS of the above inequality, i.e.
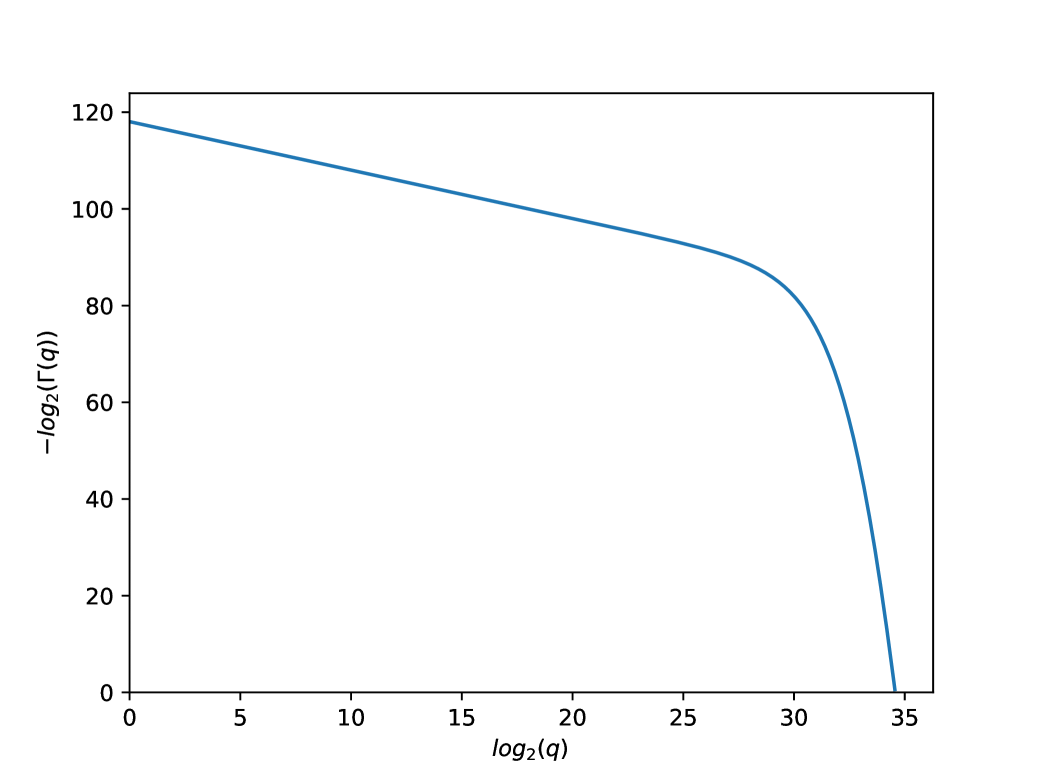
with values of and fixed as discussed above. Figure 1 shows a plot between and , for values of satisfying , , and . From this plot we can see that for the example under consideration, until about , any adversary can only have a slightly higher advantage than 12 times the advantage obtained using the naive strategy.
4 Entropy Background and Notation
Let be two random variables. Then let and denote the law of and the law of given respectively. For example, let be a uniform random variable over and suppose . We write for the random probability measure defined by
That is, if , then is the uniform distribution
over .
Let be the entropy base , that is
For a set , define . That is, is the entropy of the uniform distribution over .
Lemma 2
Let be a uniform random variable over and suppose , where . Define . Then
Furthermore for any ,
Proof: For , let . Note that if then . It follows that
| (3) | |||||
The average (over ) of the quantity is . Therefore, since the function is convex, Jensen’s inequality implies that the quantity (3) is at least
For the second part of the lemma, note that
where the sum is over such that . Since each term in the sum is at most and there are at most terms, the sum is at most .
5 Entropy and Bernoulli Random Variables
Let denote the entropy of a Bernoulli() random variable. That is, define by
The restriction of to is a strictly decreasing and onto function and hence has an inverse . Since is concave and decreasing on , the function is concave. Furthermore, note that for any , we have and hence
| (4) |
Theorem 1.2 of [12] gives the following bound:
| (5) |
where . This implies the following lemma.
Lemma 3
For any , we have
Proof: Let . Then
and hence
| (6) |
Equation (5) implies that
Combining this with (6) gives
and hence
It follows that
Recall that is the entropy of a Bernoulli() random variable and if then . We shall need the following entropy decomposition lemma.
Lemma 4
Suppose that and suppose that is uniformly distributed over . Then
Proof: Note that is the entropy of . Applying the chain rule for entropy on gives
It is well known that for any two discrete random variables on a common probability space, . So the above inequality gives
Finally, note that .
6 Main Technical Results
Lemma 5
Let be a random n-bit string. For , set , with the convention that . Also let
| (7) | |||||
Then for a uniformly chosen random subset , we have
| (8) |
Lemma
5 is a well-known consequence of Parseval’s theorem (see page 24 of [11]). For completeness, we give a proof here:
Proof:
Let . Note that , the space of real valued functions on , forms a vector space of dimension over . Define the following inner product on .
where and are i.i.d Bernoulli(1/2) random variables. Observe that when ,
since and is non-empty when . Also observe that
Therefore, forms an orthonormal basis for . Next, let and for . Then, . Now note that
It follows that
Summing the above equation over all subsets and using the fact that form an orthonormal basis, we get
The left hand side of the above equation simplifies to and hence the proof is complete.
Note that is a measure of the bias in the parity of the bits of whose positions are in . More precisely, recall that for probability distributions and on a finite set , the total variation distance
| (9) |
For a -valued random variable , the total variation distance
Equation (7) implies that
and hence
| (10) |
For , define . Then
where the first line follows from equation (10), the second line follows from Jensen’s inequality and the third line follows from Lemma 5. This leads to the following:
Corollary 6
Let be a random string in . Let be a choice of probes. Let be a Bernoulli() random variable, and for , define
If is a uniform random subset of then
This shows that the expectation (taken over the subprobes) of the distance between the random bit and a Bernoulli() random variable can be bounded in terms of the -norm of the distribution of .
7 Main Lemma
Suppose is a uniform random element of and suppose . For , let . Define the probability measure by
and write for the expectation operator with respect to . Note that under , the distribution of is uniform over . For an integer with and probes define
Lemma 7
Suppose that probes are chosen independently and uniformly at random from . If , then
Proof: Fix with . For , and a choice of probes , define
Define . Note that conditional on and , the distribution of is uniform over . Furthermore,
Hence Lemma 4 implies that
| (11) |
For any , we have
| (12) | |||||
| (13) | |||||
| (14) | |||||
| (15) |
Note that for any we have . Hence, the quantity in square brackets in equation (16) is at most
by equation (4). Thus
| (16) |
Recall that the probe is chosen uniformly at random from . It follows that
| (17) | |||||
| (18) |
Recall that in Section 5 we showed that is concave. Thus, Jensen’s inequality implies that the quantity (18) is at most
| (19) | |||||
| (20) |
where the inequality follows from (11) and the fact that is decreasing. Recall that the Harris-FKG inequality (see Section 2.2 of [3]) implies that if is a random variable and (respectively, ) is an increasing (respectively, decreasing) function, then
Now, consider the probability measure that assigns mass to each , and let be the random variable defined by . Let be the identity function on and define by . Then is increasing and since is decreasing, is decreasing. Thus the Harris-FKG inequality implies that the quantity (LABEL:eighteen) is at most
| (22) | |||||
| (23) |
Applying the first part of Lemma 2 with gives
where the second inequality follows from the fact that and . It follows that the quantity (23) is at most
| (24) | |||||
| (25) | |||||
| (26) |
We have shown that for any choice of we have
It follows that
Since this is true for all with , we have
Finally, an argument similar to above (eliminating all sums over and replacing by ) shows that
and the lemma follows.
8 Proof of Main Theorem
In this section we will prove Theorem 1, which bounds the advantage of a KPA adversary with leakage against the cipher described in section 2. Recall that the bound in question is
First, we prove the bound assuming that the adversary makes no random oracle calls.
Let be the uniform random sequence of input/output pairs given to the adversary.
The adversary’s advantage satisfies
where are uniform random queries from a uniform random permuation. Let be uniform random queries from rounds of an idealized Thorp shuffle that uses a uniform random round function instead of a pseudorandom function.
In [9], Morris, Rogaway and Stegers prove the following.
Theorem 8
[9] Let for some whole number , where . Then
Combining this result with a bound on
| (27) |
will give the claimed bound on the adversary’s advantage.
To bound (27) we use a hybrid argument.
For , let be the result of Thorp shuffles starting from , where the round function
used to determine the “random bits” of the shuffle is defined as follows:
-
1.
If then we use the round function .
-
2.
If , then at any step not already determined by the round functions used to evaluate the first queries, we use a uniform random function .
Define . Thus, the first queries of correspond to the Thorp shuffle using the pseudorandom round function and the final queries correspond to the Thorp shuffle using a uniform random round function (except at steps that are already “forced” by the trajectories of the first queries.) Note that corresponds to the Thorp shuffle with a uniform random round function and corresponds to the Thorp shuffle with the “big key” pseudorandom round function . Thus, the triangle inequality gives us
To bound the terms of this sum, we prove the following lemma:
Lemma 9
For all we have
Proof: It is sufficient to bound
where
and is the trajectory of message .
Again, we use a hybrid argument. For with , let be the algorithm defined as follows:
Algorithm : For the first queries and for the first rounds of query , we use the pseudorandom function . For rounds of query and for queries , any random bit (that was not already determined by the previous queries) will be defined using a uniform random function .
Let be the value of when algorithm is followed. Note that has the distribution of and has the distribution of . Therefore, by another application of the triangle inequality, we have
The only difference between and is the bit used in round of query . If this bit was determined by the previous queries, then it has the same value in both and . Otherwise, it is a random variable in and it uses the “big key” pseudorandom function in . It is enough to show that the claimed bound on the total variation distance holds even if we condition on the input messages . So let be arbitrary input messages. Let be a function on such that encodes
-
1.
-
2.
the values of and when algorithm is used with key and input messages .
Let . Note that there are at most
possible values of . Define . We can use Lemma 2 to get a bound on the size of that holds with high probability. More precisely, Lemma 2
On the event that , we can use Lemma 7 to bound the total variation distance. Using Lemma 7 with and combining this with Corollary 6 shows that if is the random bit generated by Algorithm then
Since this one random bit is only nondeterministic difference between and , we have
This quantity is independent of , so
Now we use Lemma 9 to bound the sum,
Combining this with Theorem 8 and another application of the triangle inequality gives
| (28) |
Finally, we consider the effect of random oracle calls made by the adversary before calculation of . Let be the set of random oracle calls made by the adversary. Note that
where is the set of random oracle calls where the input is for some . Let be the event that at least one of the random oracle calls used to evaluate the is in . Note that for a uniform random message, the value of (the rightmost bits) after any number of Thorp shuffles is uniform over . Hence, the probability that the random oracle call used in stage of the shuffle is in is . Hence, taking a union bound over queries and time steps gives
On the event , the adversary’s random oracle calls are separate from all the oracle calls used to compute each . Since random oracle calls are independent of all each other, the information from the adversary’s random oracle calls is irrelevant toward determining if they are in world 0 or world 1. Therefore, unless occurs, the adversary is as good as an adversary with no random oracle calls. We complete the theorem by adding to the advantage of an adversary with no random oracle calls.
References
- [1] M. Bellare, D. Kane, and P. Rogaway. Big-Key Symmetric Encryption: Resisting Key Exfiltration. CRYPTO 2016, pp. 373-402, 2016
- [2] M. Bellare, P. Rogaway. Random Oracles are Practical: A Paradigm for Designing Efficient Protocols. ACM Conference on Computer and Communications Security, pp. 62–73.
- [3] G. Grimmett. Percolation. Springer-Verlag, 1999.
- [4] D. Levin, Y. Peres, and E. Wilmer. Markov chains and mixing times. American Mathematical Society, 2008.
- [5] M. Luby and C. Rackoff. How to Construct Pseudorandom Permutations from Pseudorandom Functions. SIAM Journal on Computing, 17 (2), pp. 373–386.
- [6] B. Morris. Improved mixing time bounds for the Thorp shuffle. Combinatorics, Probability and Computing, 22(1), 2013.
- [7] B. Morris. The mixing time of the Thorp shuffle. SIAM J. on Computing, 38(2), pp. 484–504, 2008. Earlier version in STOC 2005.
- [8] B. Morris and P. Rogaway. Sometimes-Recurse shuffle: Almost-random permutations in logarithmic expected time. EUROCRYPT 2014, LNCS vol. 8441, Springer, pp. 311–326, 2014.
- [9] B. Morris, P. Rogaway, and T. Stegers. How to encipher messages on a small domain: deterministic encryption and the Thorp shuffle. CRYPTO 2009, LNCS vol. 2009, Springer, pp. 286–302, 2009.
- [10] B. Morris and Y. Peres. Evolving sets, mixing and heat kernel bounds. Probability Theory and Related Fields, 2005.
- [11] R. O’Donnell. Analysis of Boolean Functions. Cambridge University Press, 2014.
- [12] F. Topsøe. Bounds for entropy and divergence for distributions over a two-element set. Journal of Inequalities in Pure and Applied Mathematics, 2001.