Forward and Inverse Uncertainty Quantification using Multilevel Monte Carlo Algorithms for an Elliptic Nonlocal Equation
Abstract
This paper considers uncertainty quantification for an elliptic nonlocal equation. In particular, it is assumed that the parameters which define the kernel in the nonlocal operator are uncertain and a priori distributed according to a probability measure. It is shown that the induced probability measure on some quantities of interest arising from functionals of the solution to the equation with random inputs is well-defined; as is the posterior distribution on parameters given observations.
As the elliptic nonlocal equation cannot be solved approximate posteriors are constructed.
The multilevel Monte Carlo (MLMC) and
multilevel sequential Monte Carlo (MLSMC) sampling algorithms are used for a priori and a posteriori
estimation, respectively, of quantities of interest. These algorithms
reduce the amount of work to estimate posterior expectations, for a given level
of error, relative to Monte Carlo and i.i.d. sampling from the posterior
at a given level of approximation of the solution of the elliptic nonlocal equation.
Key words: Uncertainty quantification, multilevel Monte Carlo, sequential Monte Carlo,
nonlocal equations, Bayesian inverse problem
AMS subject classification: 82C80, 60K35.
1 Introduction
Anomalous diffusion, where the associated underlying stochastic process is not Brownian motion, has recently attracted considerable attention [2]. This case is interesting because there may be long-range correlations, among other reasons. Anomalous superdiffusion can be be related to fractional Laplacian operators and/or so-called nonlocal operators [10], defined point-wise by their operation on a function as
| (1.1) |
The fractional Laplacian is actually a special case of this equation. The present work will focus on these operators and in particular the associated stationary equation, analogous to the local elliptic equation. It should be noted that these nonlocal operators and the associated equations can be applied not only to problems of anomalous diffusion, but to a wide range of phenomena, including peridynamic models of continuum mechanics which allow crack nucleation and propagation [17, 10].
In this work it will be assumed that the kernel appearing above is parametrized by a (possibly infinite-dimensional) parameter ; is assumed random. Furthermore, some partial noisy observations of the solution will be available. In a probabilistic framework, a prior distribution is placed on and the posterior distribution results from conditioning on the observations. The joint distribution can often trivially be derived and evaluated in closed form for a given pair , as . Hence, the posterior for a given observed value of can be evaluated, up to a normalizing constant. One aims to approximate quantities of interest for some , where for the forward problem and for the inverse problem. The likelihood is often concentrated in a small, possibly nonlinear, subspace of . This posterior concentration generically precludes the naive application of standard forward approximation algorithms independently to the numerator, , and denominator, . It is noted that, typically, (1.1) will have to be approximated numerically, and this will lead to an approximate posterior density.
Monte Carlo (MC) and Sequential Monte Carlo (SMC) methods are amongst the most widely used computational techniques in statistics, engineering, physics, finance and many other disciplines. In particular, if i.i.d. samples may be obtained, the MC sampler simply iterates this times and approximates . SMC samplers [8] are designed to approximate a sequence of probability distributions on a common space, whose densities are only known up-to a normalising constant. The method uses samples (or particles) that are generated in parallel, and are propagated with importance sampling (often) via Markov chain Monte Carlo (MCMC) and resampling methods. Several convergence results, as grows, have been proved (see e.g. [7]).
For problems which must first be approximated at finite resolution, as is the case in this article, and must subsequently be sampled from using MC-based methods, a multilevel (ML) framework may be used. This can potentially reduce the cost to obtain a given level of mean square error (MSE) [14, 11, 12], relative to performing i.i.d. sampling from the approximate posterior at a given (high) resolution. A telescopic sum of successively refined approximation increments are estimated instead of a single highly resolved approximation. The convergence of the refined approximation increments allows one to balance the cost between levels, and optimally obtain a cost for MSE . This is shown in the context of the models in this article. Specifically, it is shown that the cost of MLMC, to provide a MSE of , is less than i.i.d. sampling from the most accurate prior approximation.
SMC within the ML framework has been primarily developed in [3, 9, 16]. These methodologies, some of which consider a similar context to this article, have been introduced where the ML approach is thought to be beneficial, but i.i.d. sampling is not possible. Indeed, one often has to resort to advanced MCMC or SMC methods to implement the ML identity; see for instance [15] for MCMC. SMC for nonlocal problems however, is a very sensible framework to implement the ML identity, as it will approximate a sequence of related probabilities of increasing complexity; in some cases, exact simulation from couples of the probabilities is not possible. As a result, SMC is the computational framework which we will primarily pursue in this article. It is shown that the cost of MLSMC, to provide a MSE of , is less than i.i.d. sampling from the most accurate posterior approximation. It is noted, however, that some developments both with regards to theoretical analysis and implentation of the algorithm, must be carefully considered in order to successfully use MLSMC for nonlocal models.
This article is structured as follows. In section 2 the nonlocal elliptic equations are given, along with the Bayesian inverse problem, and well-posedness of both are established. In particular, it is shown that the posterior has a well-defined Radon-Nikodym derivative w.r.t. prior measure. In section 3 we consider how one can approximate expectations w.r.t. the prior and the posterior, specifically using MLMC and MLSMC methods. Our complexity results are given also. Section 4 provides some numerical implementations of MLMC and MLSMC for the prior, and posterior, respectively.
2 Nonlocal elliptic equations
2.1 Setup
Consider the following equation
| (2.1) | |||||
| (2.2) |
where is given by (1.1), the domain is simply connected, and its “boundary” is sufficiently regular and nonlocal, in the sense that it has non-zero volume in ,
Under appropriate conditions on , , for , with only for the limiting local version in which (or a similar uniformly elliptic form) [10]. Following [10] denotes the volume constrained space of functions, and the fractional Sobolev space is defined as follows, for ,
| (2.3) |
where
We define for ease of notation.
For , the dual with respect to of some space , the weak formulation of (2.2) can be defined as follows. Integrate the equation against an arbitrary test function . Now, find (satisfying the boundary conditions) such that
| (2.4) |
where
2.2 Numerical methods for forward solution
Let denote the maximum diameter of an element of . The finite approximation of (2.4) is stated as follows. Identify some such that
| (2.5) |
Assuming the spaces are spanned by elements , then one can substitute the ansatz into the above equation, resulting in the finite linear system
| (2.6) |
In particular, the spaces will be comprised of discontinuous elements, so that the method described is a discontinuous Galerkin finite element method (FEM) [4]. Piecewise polynomial discontinuous element spaces are dense in for , and are therefore conforming when for , so there is no need to impose penalty terms at the boundaries as one must do for smoother problems in which the discontinuous elements are non-conforming.
2.3 Forward UQ
The following assumption will be made for simplicity
Assumption 2.1.
, with norm and inner product . is continuous with , and there exist such that for all
| (2.7) |
As shown in Section 6 of [13], this implies that for all
-
•
is continuous: ;
-
•
is continuous: ;
-
•
is coercive: for some . This actually follows from the Poincaré-type inequality derived in Proposition 2.5 of [1].
Hence, Lax-Milgram lemma ([5], Thm. 1.1.3) can be invoked, guaranteeing existence of a unique solution such that
In other words, the map is continuous. The system (2.6) inherits solvability since the bilinear is a fortiori coercive on , so that
Let be a parametrization of , where and , and either or compact. Then the following theorem holds.
Theorem 2.2 (Well-posedness of forward UQ).
If Assumption 2.1 holds almost surely for and the map is continuous from to , then the map is almost surely continuous. Hence for all , i.e. all moments exist. here denotes the space of random variables such that .
Proof.
Since Assumption 2.1 holds almost surely for , then uniformly. So, the quantity of interest for all . Therefore, for any such that , the result follows, since then for all . ∎
Corollary 2.3 (Well-posedness of finite approximation).
If Assumption 2.1 holds almost surely for and the map is continuous from to , then the map through the discrete system is almost surely continuous and .
2.4 Inverse UQ
For the inverse problem, let us assume that some data is given in the form
| (2.8) |
where
| (2.9) |
Then the following theorem holds.
Theorem 2.4 (Well-posedness of inverse UQ).
The posterior distribution of is well-defined and takes the form
| (2.10) |
with .
Proof.
The form of the posterior is obtained by a change of variables to }, which are independent by assumption. Note the change of variables has Jacobian 1. So, changing variables back, this also gives the joint density. The posterior is obtained by normalizing for the observed value of . The form of the observation operator guarantees , where and is defined as in the proof of Theorem 2.2, and is the matrix norm. ∎
Now define
Corollary 2.5 (Well-posedness of inverse UQ for finite problem).
The finite approximation of the posterior distribution of is well-defined and takes the form
| (2.11) |
with .
Remark 2.6.
The forcing may also be taken as uncertain, although the uniformity will require it to be defined on a compact space. The probability space will be taken as compact for simplicity, as it is then easy to verify Assumption 2.1.
3 Approximation of expectations
The objective here is to approximate expectations of some functional with respect to a probability measure ( or ), denoted The solution of (2.2) above must be approximated by some , with a degree of accuracy which depends on . Indeed there exists a hierarchy of levels (where may be arbitrarily large) of increasing accuracy and increasing cost. For the inverse problem this manifests in a hierarchy of target probability measures via the approximation of (2.10). For the forward problem for all , but it will be assumed that the function requires evaluation of the solution of (2.2), as in Theorem 2.2, and the corresponding approximations will be denoted by . One may then compute the estimator , where for the forward problem it may be that for all . The mean square error (MSE) is given by
| (3.1) |
Now assume there is some discretization level, say of diameter , which gives rise to an error estimate on the output of size , for example arising from the deterministic numerical approximation of a spatio-temporal problem. This also translates to a number of degrees of freedom proportional to , where is the spatio-temporal dimension. Now the complexity of typical forward solves will range from a dot product (linear) to a full Gaussian elimination (cubic). In this problem one aims to find , so one would find the cost controlled by , for . If one can obtain independent, identically distributed samples , then the necessary number of samples to obtain a variance of size is given by . The total cost to obtain a mean-square error tolerance of is therefore .
3.1 Multilevel Monte Carlo
For the forward UQ problem, in which one can sample directly from , one very popular methodology for improving the efficiency of solution to such problems is the multilevel Monte Carlo (MLMC) method [14, 11]. Indeed there has been an explosion of recent activity [12] since its introduction in [11]. In this methodology the simple estimator above for a given desired is replaced by a telescopic sum of unbiased increment estimators where are i.i.d. samples, with marginal laws , , respectively, carefully constructed on a joint probability space. This is repeated independently for . The overall multilevel estimator will be
| (3.2) |
under the convention that . A simple error analysis shows that the mean squared error (MSE) in this case is given by
| (3.3) | |||||
Notice that the bias is given by the finest level, whilst the variance is decomposed into a sum of variances of the increments. The variance of the increment estimator has the form , where the terms decay, following from refinement of the approximation of and/or . One can therefore balance the variance at a given level with the number of samples . As the level increases, the corresponding cost increases, but the variance decreases, allowing fewer samples to achieve a given variance. This can be optimized, and results in a total cost of , in the optimal case.
To be explicit, denote by the level approximation of the quantity of interest . Introduce the following assumptions
-
(A1)
There exist , and a such that
(3.4) where denotes the cost to evaluate .
We have the following classical MLMC Theorem [12]
Theorem 3.1.
3.2 Multilevel sequential Monte Carlo sampler
Now the inverse problem will be considered. There is a sequence of probability measures on a common measurable space , and for each there is a measure , such that
| (3.7) |
where the normalizing constant is unknown. The objective is to compute:
for potentially many measurable integrable functions .
3.2.1 Notations
Let be a measurable space. The notation denotes the class of bounded and measurable real-valued functions, and the supremum norm is written as . Consider non-negative operators such that for each the mapping is a finite non-negative measure on and for each the function is measurable; the kernel is Markovian if is a probability measure for every . For a finite measure on , and a real-valued, measurable , we define the operations:
We also write . In addition , , denotes the norm, where the expectation is w.r.t. the law of the appropriate simulated algorithm.
3.2.2 Algorithm
As described in Section 1, the context of interest is when a sequence of densities , as in (3.7), are associated to an ‘accuracy’ parameter , with as , such that . In practice one cannot treat and so must consider these distributions with . The laws with large are easy to sample from with low computational cost, but are very different from , whereas, those distributions with small are hard to sample with relatively high computational cost, but are closer to . Thus, we choose a maximum level and we will estimate
By the standard telescoping identity used in MLMC, one has
| (3.8) |
Suppose now that one applies an SMC sampler [8] to obtain a collection of samples (particles) that sequentially approximate . We consider the case when one initializes the population of particles by sampling i.i.d. from , then at every step resamples and applies a MCMC kernel to mutate the particles. We denote by , with , the samples after mutation; one resamples according to the weights , for indices . We will denote by the sequence of MCMC kernels used at stages , such that . For , , we have the following estimator of :
We define
The joint probability distribution for the SMC algorithm is
If one considers one more step in the above procedure, that would deliver samples , a standard SMC sampler estimate of the quantity of interest in (3.8) is ; the earlier samples are discarded. Within a multilevel context, a consistent SMC estimate of (3.8) is
| (3.9) |
and this will be proven to be superior than the standard one, under assumptions.
The relevant MSE error decomposition here is:
| (3.10) |
3.2.3 Multilevel SMC
We will now restate an analytical result from [3] that controls the error term in expression (3.10). For any and we write: The following standard assumptions will be made ; see [3, 7].
-
(A2)
There exist such that
-
(A3)
There exists a such that for any , , :
Under these assumptions the following Theorem is proven in [3]
The following additional assumption will now be made
-
(A4)
There exist , and a such that
(3.11) where denotes the cost to evaluate .
The following Theorem may now be proven
Theorem 3.3.
Proof.
The MSE can be bounded using (3.10). Following from (A(A4))(ii), the second term requires that , and assuming for some , this translates to . As in [3], the additional error term is dealt with by first ignoring it and optimizing , for a given , where . This requires that . The constraint then requires that , where , so one has
It was shown in [3] that the result follows, provided . In fact, re-examining the additional term as in Section 3.3 of [3], one has
where the second line follows from the inequality and the definition of . Now substituting for the 3 cases and recalling the assumption gives for the costs in (3.13).
∎
3.2.4 Verification of assumptions
Assume a uniform prior . Following from (2.8), the unnormalized measures will be given by
| (3.14) |
where , and
and is the solution of the numerical approximation of (2.2). Notice that these are uniformly bounded, over both and over , following from Corollary 2.5 for finite , and Theorem 2.4 in the limit.
It is shown in [3] Section 4 that
| (3.15) |
One proceeds similarly to that paper, and finds that
| (3.16) |
Note that , so inserting the bound (3.15) into (3.14), and observing the boundedness of the noted above, one can see that Assumption (A(A2)) holds. Now inserting (3.15) and (3.16) into (3.14), one can see that in order to establish Assumption (A(A4)), it suffices to establish rates of convergence for . In particular, Assumption (A(A2)) and the C2 inequality (Minkowski plus Young’s) provide that
Therefore, the rate of convergence of is the required quantity for both the forward (for Lipschitz ) and the inverse multilevel estimation problems. By the triangle inequality it suffices to consider the approximation of the truth , and by Céa’s lemma ([5], Thm. 2.4.1), Assumption 2.1 guarantees the existence of a such that
| (3.17) |
Theorem 6.2 of [10] provides rates of convergence of the best approximation above, in the case that and the FEM triangulation is shape regular and quasi-uniform. In particular, their Case 1 corresponds to the case of a singular kernel, i.e. not even integrable, and , for , so the solution operator is smoothing. Their Case 2 corresponds to a slightly more regular kernel than ours, where in fact , rather than as given by Assumption 2.1 and consequently . It is shown that in Case 2, if the solution , for polynomial elements of order and some , then convergence with respect to the norm is in fact . So, for linear elements, second order convergence can be obtained, leading to in (3.11).
Recall that 2.1 ensures well-posedness of the solution from , and so discontinuities are allowed. This is actually a strength of nonlocal models and one impetus for their use. It is reasonable to expect that if the the nodes of the discontinuous elements match up with the discontinuities, i.e. there is a node at each point of discontinuity for or there are nodes all along a curve/surface of discontinuity for , and if the solution is sufficiently smooth in the subdomains, then the rates of convergence should match those of the smooth subproblems. For example, if there is a point discontinuity such that the domain can be separated at that point into and one has and , where is the restriction of to the set , then one expects the convergence rate of to be preserved. This is postulated and verified numerically in [4]. It is also illustrated numerically in that work that even with discontinuous elements, if there is no node at the discontinuity then the convergence rate reverts to , so in (3.11).
4 Numerical examples
The particular nonlocal model which will be of interest here is that in which the kernel is given by
| (4.1) |
where , and is the characteristic function which takes the value 1 if and zero otherwise, and . Notice that is scalar, but may be defined on either a finite-dimensional subspace of function-space, or in principle in the full infinite dimensional space. This may be of interest to incorporate spatial dependence of material properties.
Following [6] we consider the following model. Let and . For , let . The kernel is defined by,
The following prior is used for the parameters,
This is an extension of an example used in [6], which is identical to this model with and (various values of are used there). To solve the equation with FEM, a uniform partition on is used with , . Thus for each level , . The same discontinuous Galerkin FEM as in [6] is applied to solve the system.
Similar methods to those in [3] are used to estimate the convergence rates for both the forward and inverse problems. The estimated rates are and . The rates and are used for the simulations.
For the inverse problem, data is generated with , and . The observations are , where and . The quantity of interest for both the forward and inverse problem is .
The forward problem is solved in the standard multilevel fashion by generating coupled particles from the prior at each level. The main result, the cost vs. MSE of the estimates is shown in Figure 1. The Bayesian inverse problem is also solved for this model, and the main result is shown in Figure 2.
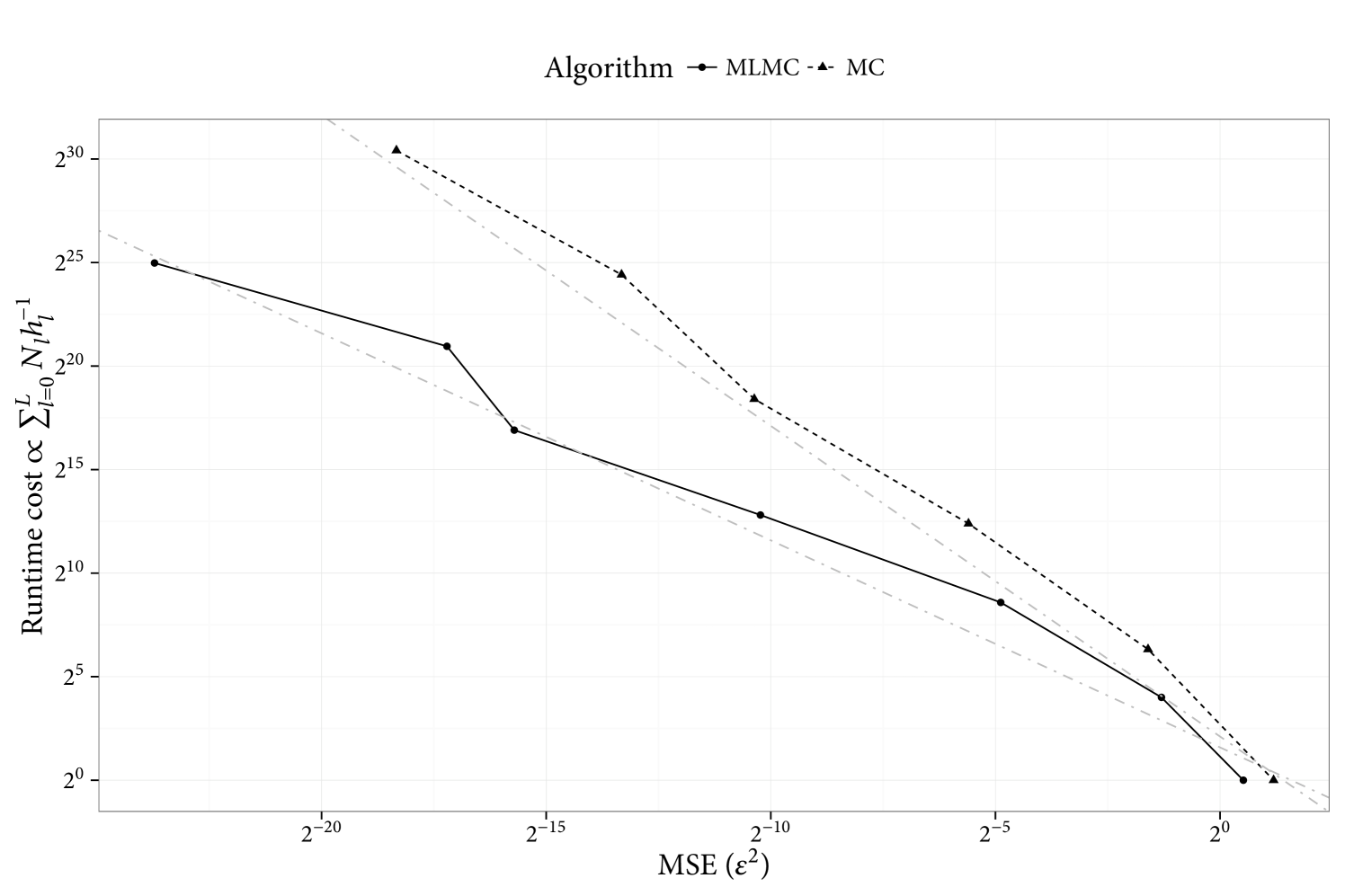
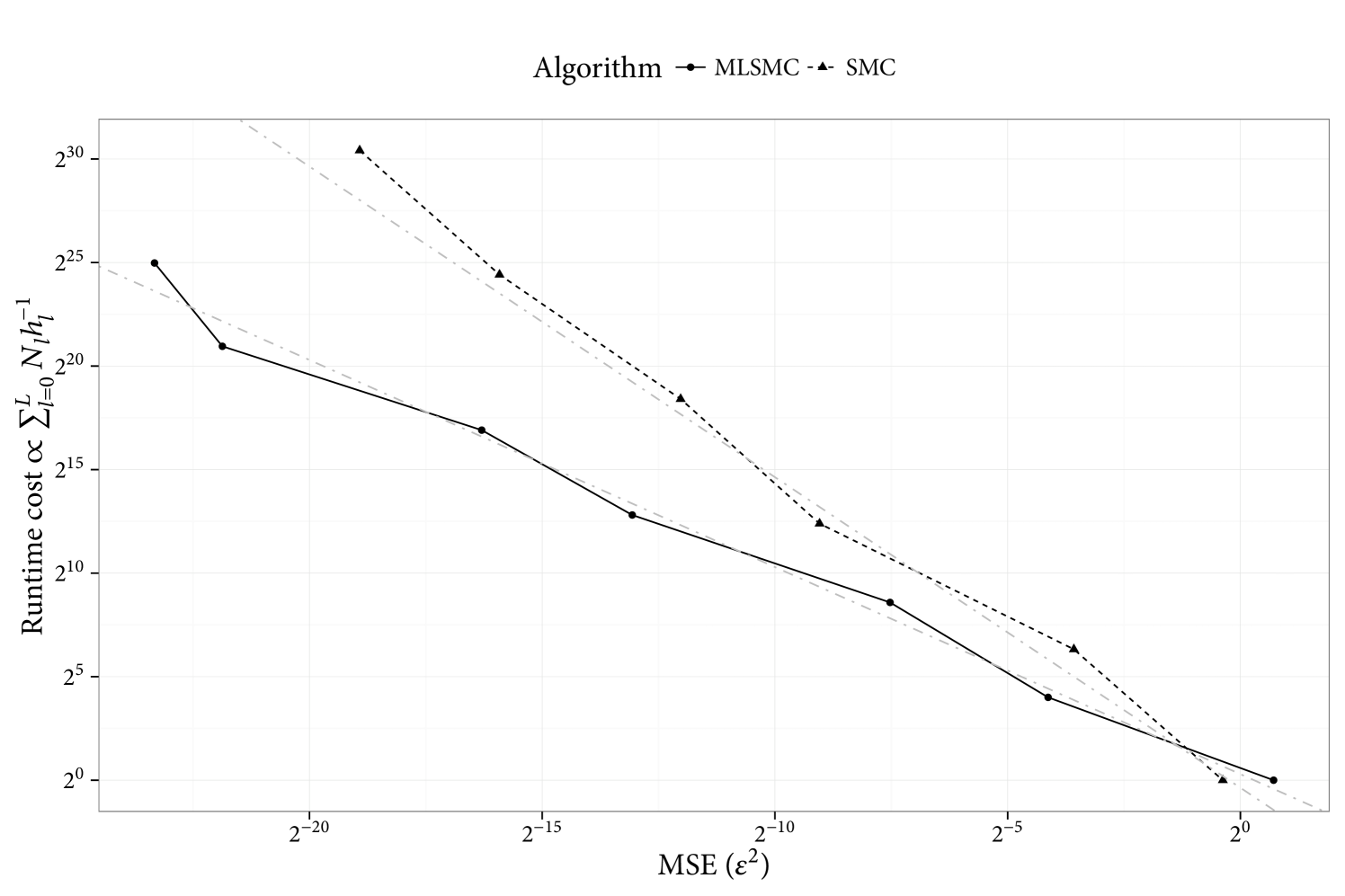
5 Summary
This is the first systematic treatment of UQ for nonlocal models, to the knowledge of the authors. Natural extensions include obtaining rigorous convergence results for piecewise smooth solutions, exploring higher-dimensional examples, spatial parameters, time-dependent models, and parameters defined on non-compact spaces.
Acknowledgements. KJHL was supported by the DARPA FORMULATE project. AJ & YZ were supported by Ministry of Education AcRF tier 2 grant, R-155-000-161-112. We express our gratitude to Marta D’Elia, Pablo Seleson, and Max Gunzburger for useful discussions.
References
- [1] Andreu, F., Mazon, J. M., Jose, M. Rossi, J. & Toledo, J. (2009). A nonlocal p-Laplacian evolution equation with nonhomogeneous Dirichlet boundary conditions. SIAM Journal on Mathematical Analysis, 40, 1815–1851.
- [2] Bakunin, O. G. (2008). Turbulence and diffusion: scaling versus equations. Springer Science & Business Media.
- [3] Beskos, A., Jasra, A., Law, K. J. H, Tempone, R. & Zhou, Y. (2015). Multilevel sequential Monte Carlo samplers. arXiv preprint arXiv:1503.07259.
- [4] Chen, X. & Gunzburger, M. (2011). Continuous and discontinuous finite element methods for a peridynamics model of mechanics. Computer Methods in Applied Mechanics and Engineering, 200, 1237–1250.
- [5] Ciarlet, P. G. (2002). The finite element method for elliptic problems. SIAM.
- [6] D’Elia, M. & Gunzburger, M. (2014). Optimal distributed control of nonlocal steady diffusion problems. SIAM Journal on Control and Optimization. 52, 243–273.
- [7] Del Moral, P. (2004). Feynman-Kac Formulae: Genealogical and Interacting Particle Systems with Applications. Springer: New York.
- [8] Del Moral, P., Doucet, A. & Jasra, A. (2006). Sequential Monte Carlo samplers. J. R. Statist. Soc. B, 68, 411–436.
- [9] Del Moral, P., Jasra, A., Law, K. J. H, & Zhou, Y. (2016). Multilevel sequential Monte Carlo samplers for normalizing constants. arXiv preprint arXiv:1603.01136.
- [10] Du, A., Gunzburger, M., Lehoucq, R. & Zhou, K. (2012). Analysis and approximation of nonlocal diffusion problems with volume constraints. SIAM review, 54, 667–696.
- [11] Giles, M. B. (2008). Multilevel Monte Carlo path simulation. Op. Res. 56, 607-617.
- [12] Giles, M. B (2015). Multilevel Monte Carlo methods. Acta Numerica, 24, 259-328.
- [13] Gunzburger, M. & Lehoucq, R. B. (2010). A nonlocal vector calculus with application to nonlocal boundary value problems. Multiscale Modeling & Simulation, 8, 1581–1598.
- [14] Heinrich, S. (2001). Multilevel Monte Carlo methods. Large-scale scientific computing. Springer Berlin Heidelberg, 2001. 58-67.
- [15] Hoang, V., Schwab, C. & Stuart, A. (2013). Complexity analysis of accelerated MCMC methods for Bayesian inversion. Inverse Prob., 29, 085010.
- [16] Jasra, A., Kamatani, K., Law, K. J., & Zhou, Y. (2015). Multilevel particle filter. arXiv preprint arXiv:1510.04977.
- [17] Silling, S. A., Zimmermann, M & Abeyaratne, R. (2003). Deformation of a peridynamic bar. Journal of Elasticity. 73, 173–190.