FORWARD: Feasibility Oriented Random-Walk Inspired Algorithm
for Radial Reconfiguration in Distribution Networks
Abstract
We consider an optimal flow distribution problem in which the goal is to find a radial configuration that minimizes resistance-induced quadratic distribution costs while ensuring delivery of inputs from multiple sources to all sinks to meet their demands. This problem has critical applications in various distribution systems, such as electricity, where efficient energy flow is crucial for both economic and environmental reasons. Due to its complexity, finding an optimal solution is computationally challenging and NP-hard. In this paper, we propose a novel algorithm called FORWARD, which leverages graph theory to efficiently identify feasible configurations in polynomial time. By drawing parallels with random walk processes on electricity networks, our method simplifies the search space, significantly reducing computational effort while maintaining performance. The FORWARD algorithm employs a combination of network preprocessing, intelligent partitioning, and strategic sampling to construct radial configurations that meet flow requirements, finding a feasible solution in polynomial time. Numerical experiments demonstrate the effectiveness of our approach, highlighting its potential for real-world applications in optimizing distribution networks.
Keywords: Optimal flow distribution; Graph partitioning; Greedy radial reconfiguration; Minimum spanning forest.
I Introduction
We consider a network-flow distribution problem over a bidirectional distribution network with nodes, edges, a set of source nodes , and sink nodes , each with specified input and output. We let be the output vector and be the input vector, where (resp. ) for (resp. ) and (resp. ) otherwise. The assumption is that inputs match outputs, i.e., . The goal is to find an (oriented) radial configuration that delivers the input flow from the source nodes to the sink nodes with minimal overall cost, see Fig. 1. This cost results from the ‘resistance’ or ‘toll’ along the edges, characterized as a quadratic function of the flow across them.
Definition 1 (Set of radial configurations)
A radial configuration is a polyforest111A polyforest (or directed forest or oriented forest) is a directed acyclic graph whose underlying undirected graph is a forest. A forest is a type of graph that contains no loops. Consequently, forests consist solely of trees that might be disconnected, leading to the term ‘forest’ being used [1]. that includes all the nodes , has roots at and the undirected version of its edges are subset of . We denote the set of these polyforest digraphs by . For brevity, when clear from context, we will use only .
The problem of interest can be formalized as
| (1a) | |||
| (1b) | |||
where is the flow across the link , is the incidence matrix of the radial configuration (a decision variable of the optimization problem), is the coefficient of the cost of edge . The constraints confine the radial configuration to and enforce the flow conservation (Kirchhoff’s law) at the nodes. Throughout this paper, we assume that there are several radial configurations for which the input can meet the specified output. Thus, the feasible solution set of the optimization problem (1) is non-empty.
 |
| (a) Original network. |
 |
| (b) Radial configuration. |
Problem (1) is highly relevant to various potential flow applications, including natural gas, water, and electricity distribution networks. For instance, in power systems, the efficient and reliable distribution of energy has become increasingly critical with the growing integration of renewable energy and distributed generation sources. Modern power distribution networks, comprising multiple distributed generators, must operate in a radial configuration to adhere to engineering and safety standards. Minimizing energy loss within these networks is vital for both economic viability and environmental sustainability. Consequently, radial configurations cannot be chosen arbitrarily; they must be designed to ensure feasibility and to optimize energy loss (cost of operation).
Optimal radial reconfiguration problems are NP-hard problems, primarily due to the exponential growth in possible configurations as the number of distribution links increases. Specific instance (1) is often cast as Mixed-Integer Non-Linear Programming (MINLP) because of problem-specific side constraints, but for the purposes of this paper we focus on this linear abstraction to address the salient complexities associated with modeling (1b). These problems remain computationally intensive, often requiring extensive computational time and lacking guarantees of optimality [3].
To address these challenges, this paper constructs a polynomial-time solution for (1) by leveraging the graph-like characteristics of distribution systems and how potential flows naturally navigate through a network. Our algorithm uses a greedy radial construction process starting from source nodes, incrementally adding edges while considering the flow across constructed components and the demanded output of the remaining nodes to reach. We draw inspiration from the similarities between electric flow in power networks and random walks [4], developing a novel ‘sampling’ method222Although our radial configuration construction is deterministic, we use ‘sampling’ as a conceptual analogy. for constructing radial configurations. In the random walk approach to describing electricity distribution in a given network, a weight proportional to the inverse of the resistance along the corresponding link in the power network is assigned to each link. This creates a notion of the edge weights being the conductance of the edge. Just as electricity flows through paths of least resistance, a random walk probabilistically selects paths based on transition probabilities influenced by edge weights.
Our method assigns weights to edges based on cost and downstream output, ensuring flow distribution aligns with network requirements and effectively delivers a radial configuration that meets demand. This methodology ensures the process aligns with both the physical properties of flow and the optimization constraints of the problem, enabling the efficient identification of feasible and near-optimal radial configurations in polynomial time. Our particular innovation is incorporating a mechanism (Net-Concad function explained in Section II-C) in our incremental ‘sampling’ process that addresses the shortsightedness of greedy selections by informing the process of the comprehensive demand of the remaining nodes. Numerical examples demonstrate the effectiveness of our proposed algorithm.
 |
 |
 |
| (a) | (b) MST | (c) |
 |
 |
 |
| (a) | (b) MST | (c) MSF |
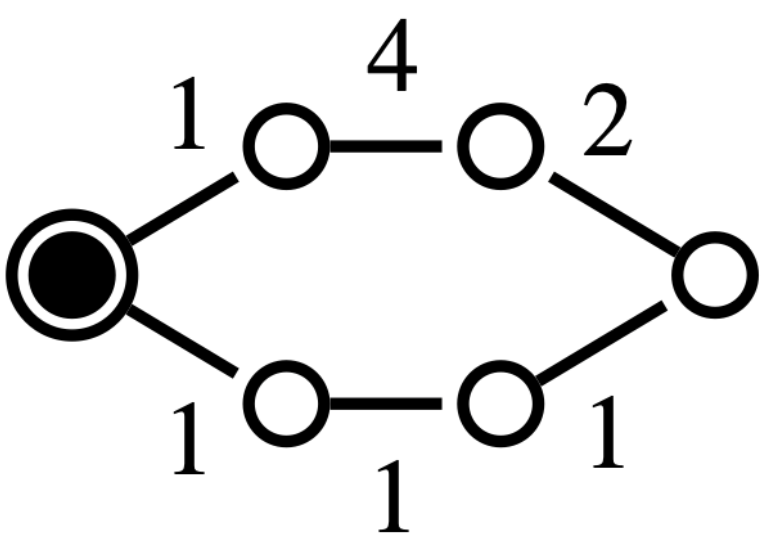
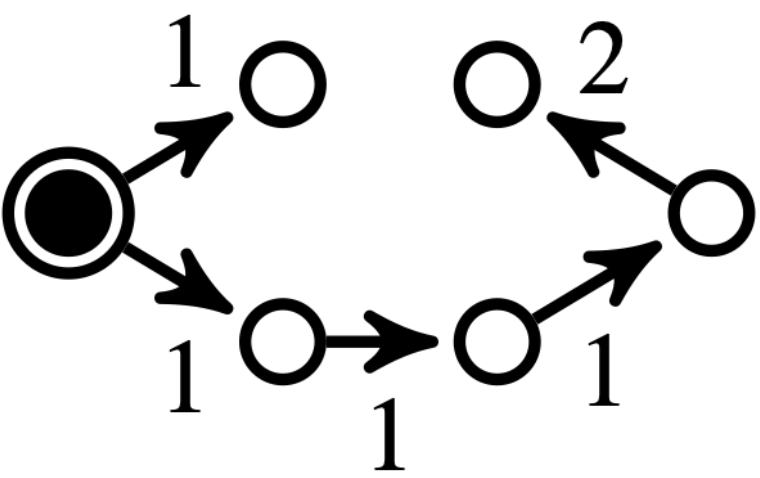
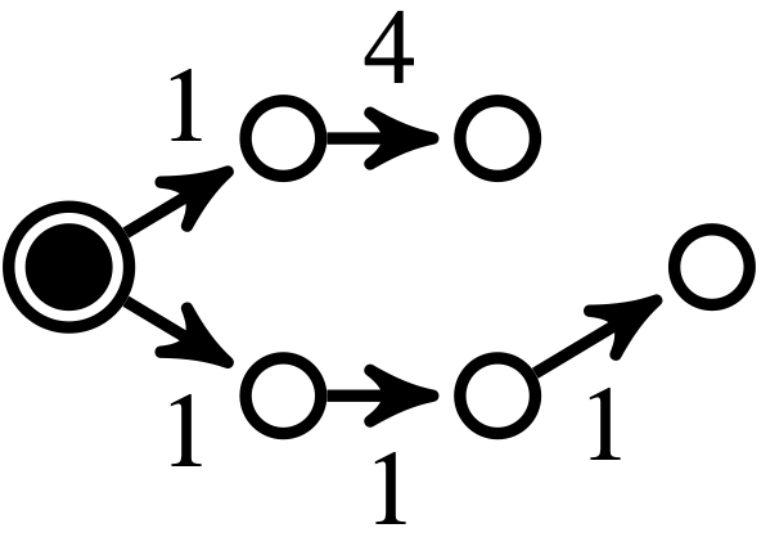
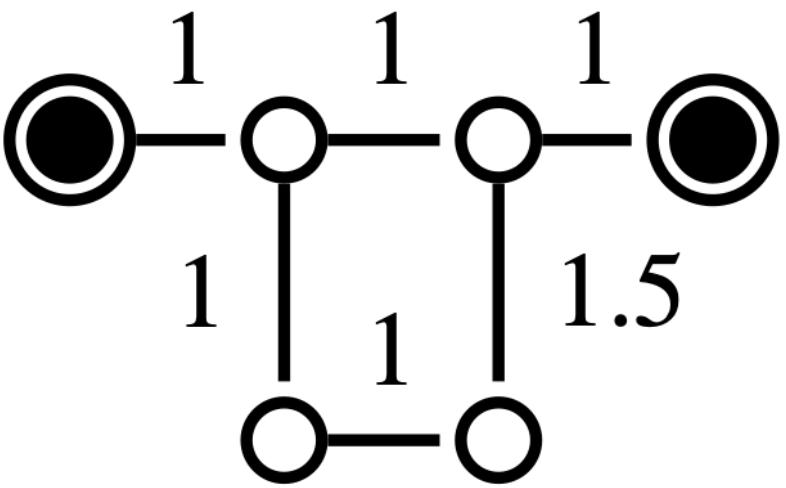
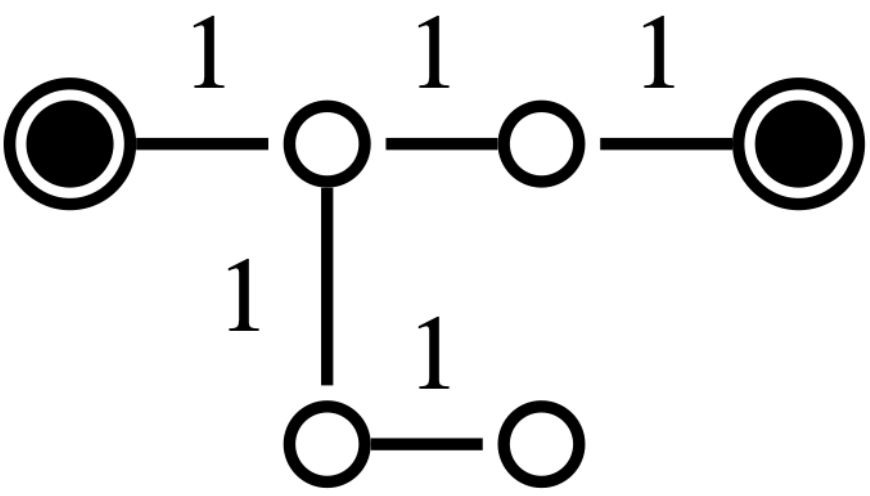
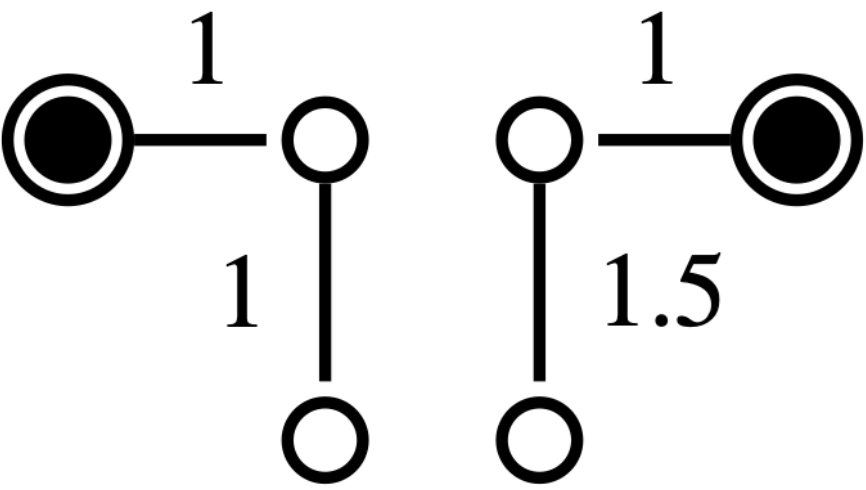
Related work: Several methods in the literature, especially in power networks applications, leverage topological properties to address the reconfiguration problem [5]. For example, [6] [7] use spectral clustering followed by local greedy search to identify radial configurations. In [8], the reconfiguration problem is linked to the maximum flow problem, based on Ford-Fulkerson’s work [9], which has been extensively studied in both single- and multi-source contexts [10], [11], [12]. These approaches often include a repair procedure for unfeasible solutions, which can be inefficient. While some methods address minimum-cost distribution, radiality remains a critical constraint [13], and cycle-breaking methods used to tackle it offer limited guarantees for large graphs [14]. Other approaches, such as those based on the minimum spanning tree (MST) problem, face challenges due to the constraints of the reconfiguration problem, making the MST approach NP-hard in this context (see Fig. 2). Moreover, although algorithms like Kruskal’s or Prim’s [15] can find MSTs in polynomial time, they lose their optimality when multiple sources are involved, note that the minimum spanning forest (MSF) is not necessarily a subset of the MST (see Fig. 3).
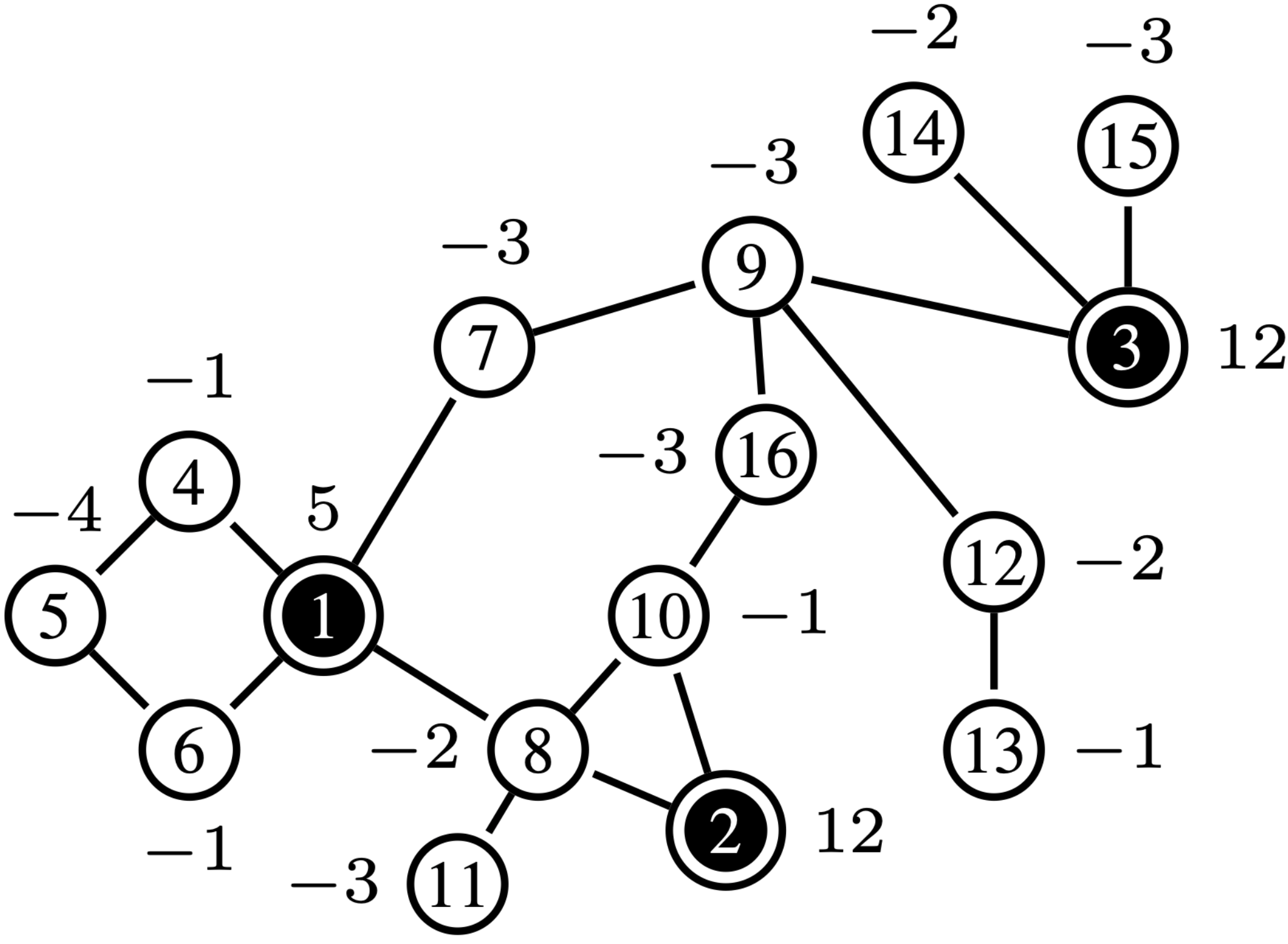
|
|
|
| (a) Original graph . | (b) Pre-processor output . | (c) Islander splits , creating and . |
|
|
|
| (d) Net-Concad creates for the sub-graphs given in plot (b). | (e) after multiple sampling. | (f) Net-Concad output when its input graph in plot (e). |
II Algorithm design
Our proposed algorithm follows a greedy structure, typical of MST algorithms. Starting from an empty edge set , we iteratively add edges connecting the nodes, guided by a heuristic to ensure feasibility. Inspired by the similarity between flow in distribution networks and random walks [4], we use a dual graph where edge weights represent the inverse of distribution costs. Our random walk starts at source nodes, assigning weights (intuitively interpreted as probabilities) to edges and adding the one with the highest probability of traversal to the growing forest.
We introduce some preliminary steps to sampling to compensate shortsightedness in greedy decision making algorithms by reducing the set of possible edges to select at each iteration. The first step is implementing the Pre-processor function which is followed by the Islander function to simplify the search space. Then, we apply sequentially Net-Concad and Sampler functions for finite number of times to construct the radial configuration. These four functions constitute the elements of our proposed algorithm, which we call FORWARD as defined in the title of the paper. These functions are explained one by one below. Before that we introduce some notations. We define the input vector , associated with the nodes . This vector will be updated at each iteration of the algorithm, thus we denote it by at each iteration . We initialize at for and if . In what follows, we define the operator as the nodes of the sampled edge set , as the set of edges in interconnecting nodes in and as the set of nodes connected to nodes in . Also, denotes a directed edge indicating flow from node to . Given a directed edge set , returns the undirected edge version of .
II-A Pre-processor
Distribution networks often exhibit a small-world graph structure [16], which implies the presence of numerous nodes with low degree of connectivity. Consequently, this structure suggests that some radial sub-graphs are likely part of the original network . It is important to note that the edges of any radial sub-graph within conforms a unique solution, see Section III, so it is more efficient to aggregate them together. To address this, we introduce the Pre-processor function, which removes these trivially must-sampled components from the distribution network and adds them to the growing .
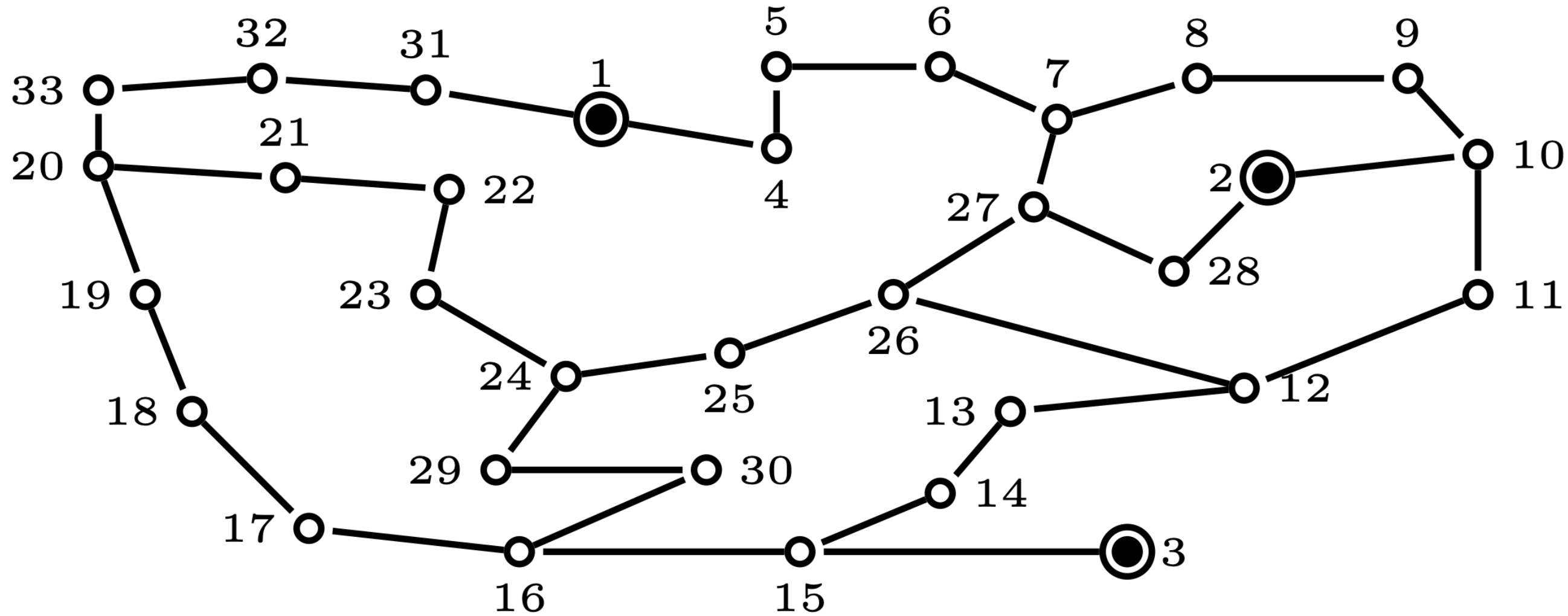
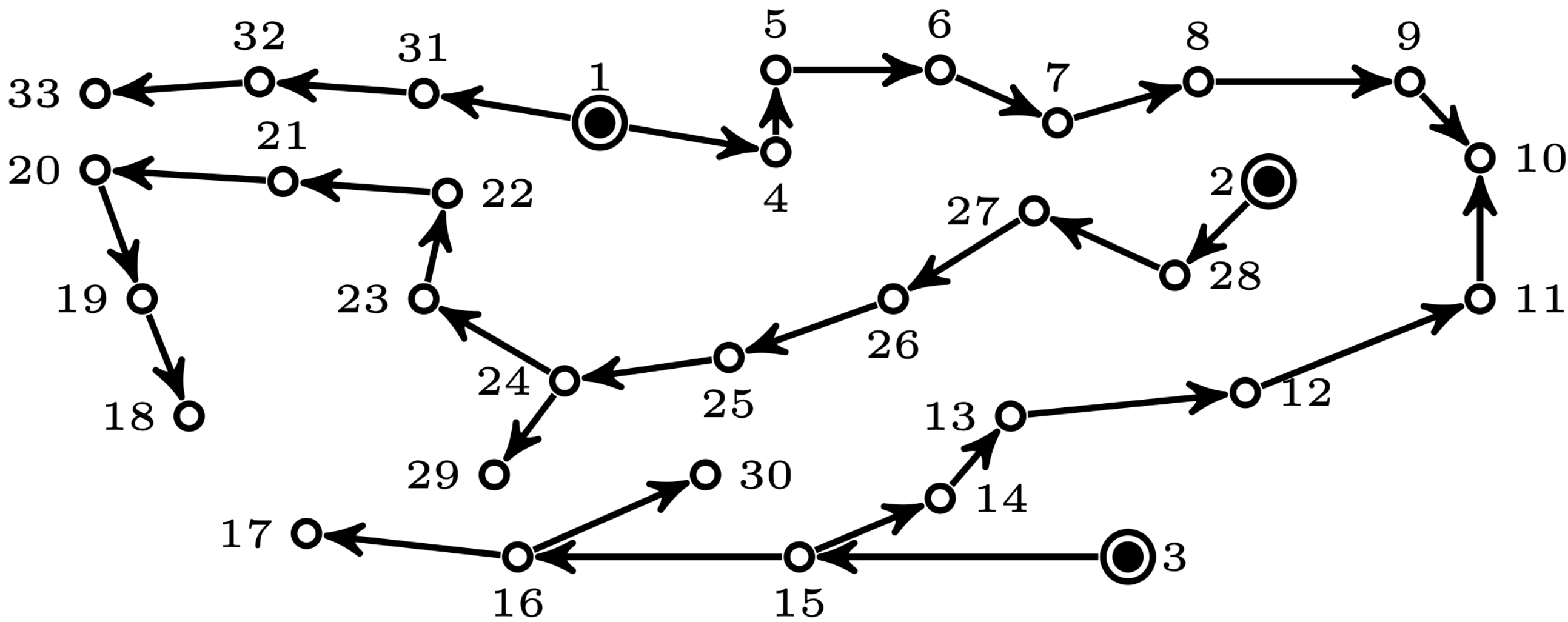
The Pre-processor function, described in Algorithm 1, takes as input a graph and the associated input vector of the nodes, . Then, it samples every edge connecting single degree nodes, so-called pendant nodes (e.g., edges , , , , and in Fig. 4), and adds these edges to . Once these edges and nodes are added to the solution set , Pre-processor removes the pendant nodes and their connecting edges, redistributes their input/output back to the parent nodes, and repeats the process until no pendant nodes remain in the updated graph. The result of implementing the Pre-processor function on the network in Fig. 4 is shown in Fig. 4. After the network is simplified by Pre-processor, all nodes in the resulting graph are at least 2-connected.
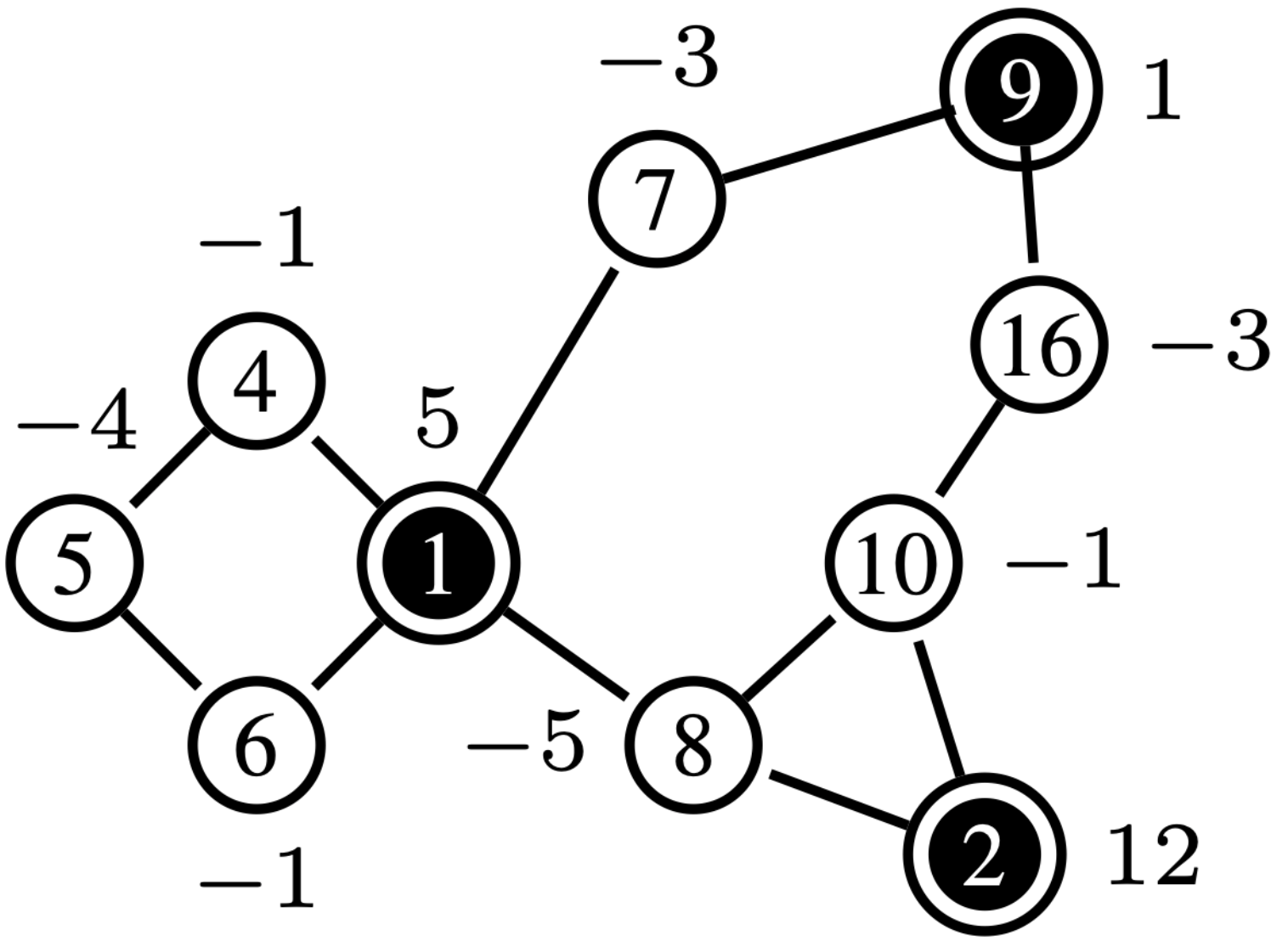
II-B Islander
Islander, described in Algorithm 2, takes as input graph generated by Pre-processor, the source nodes in and its input vector , and proceeds to partition the graph into disjoint sub-graphs induced by removing the articulation source nodes 333An articulation node in a graph is a node which, if removed, graph is disconnected. A bi-connected graph is a graph with no articulation nodes.. The results are , , where is the number of sub-graphs obtained in the process. The input vector of each articulation super node will then be adjusted to balance the overall input-output in each sub-graph; the result of this process can change the role of the super nodes from a source to sink or vice versa. For example, after feeding the input graph in Fig. 4 whose source nodes are , and , to Islander, the function partitions the graph into two sub-graphs as shown Fig. 4, in which the role of node in each graph is different.
Islander enables us to search for radial configuration in each sub-graph in parallel, speeding up the process. Note that if two sub-graphs are only connected through an articulation node, and if both sub-graphs present a radial configuration, the overall graph remains radial.
II-C Net-Concad
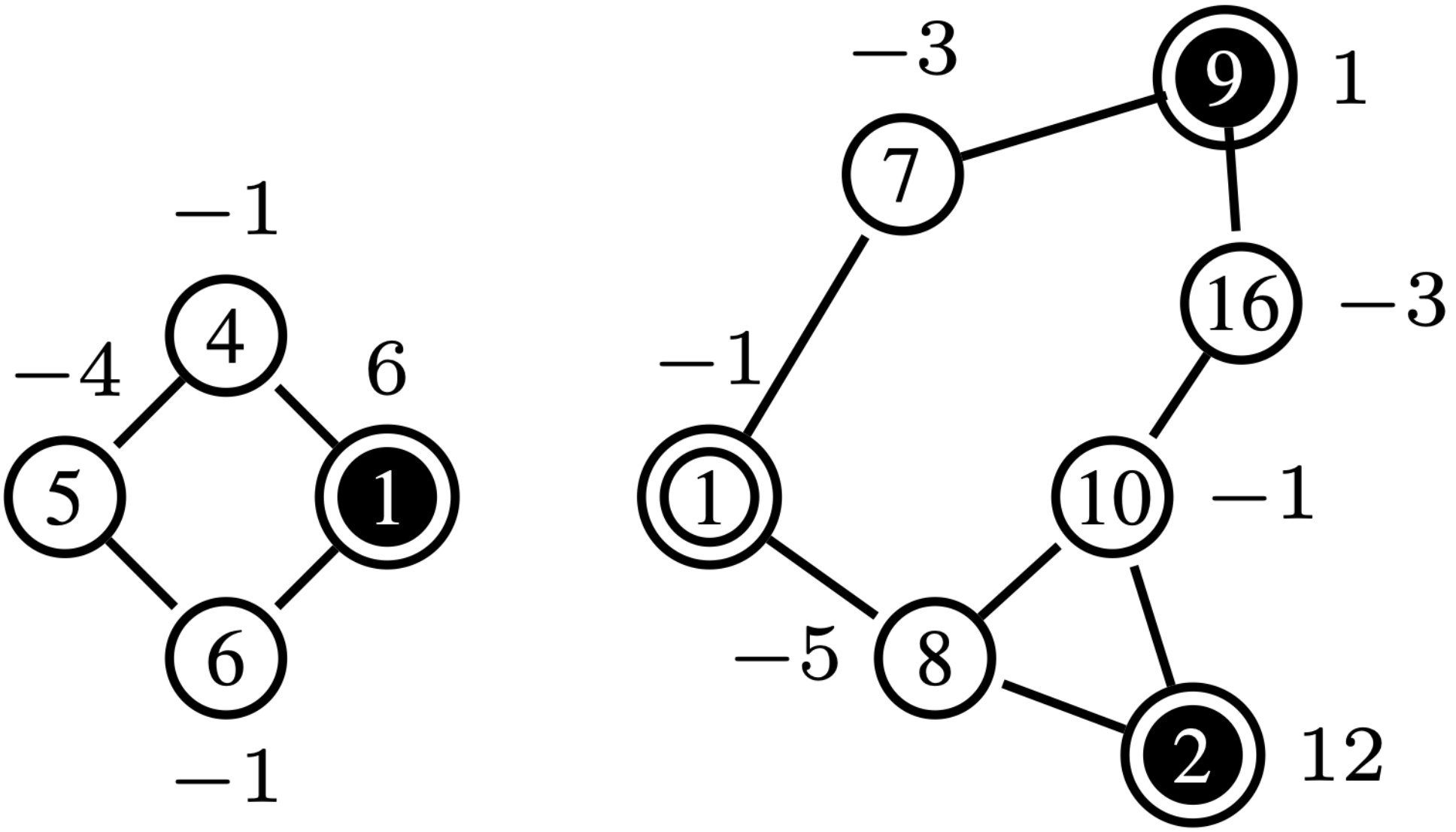
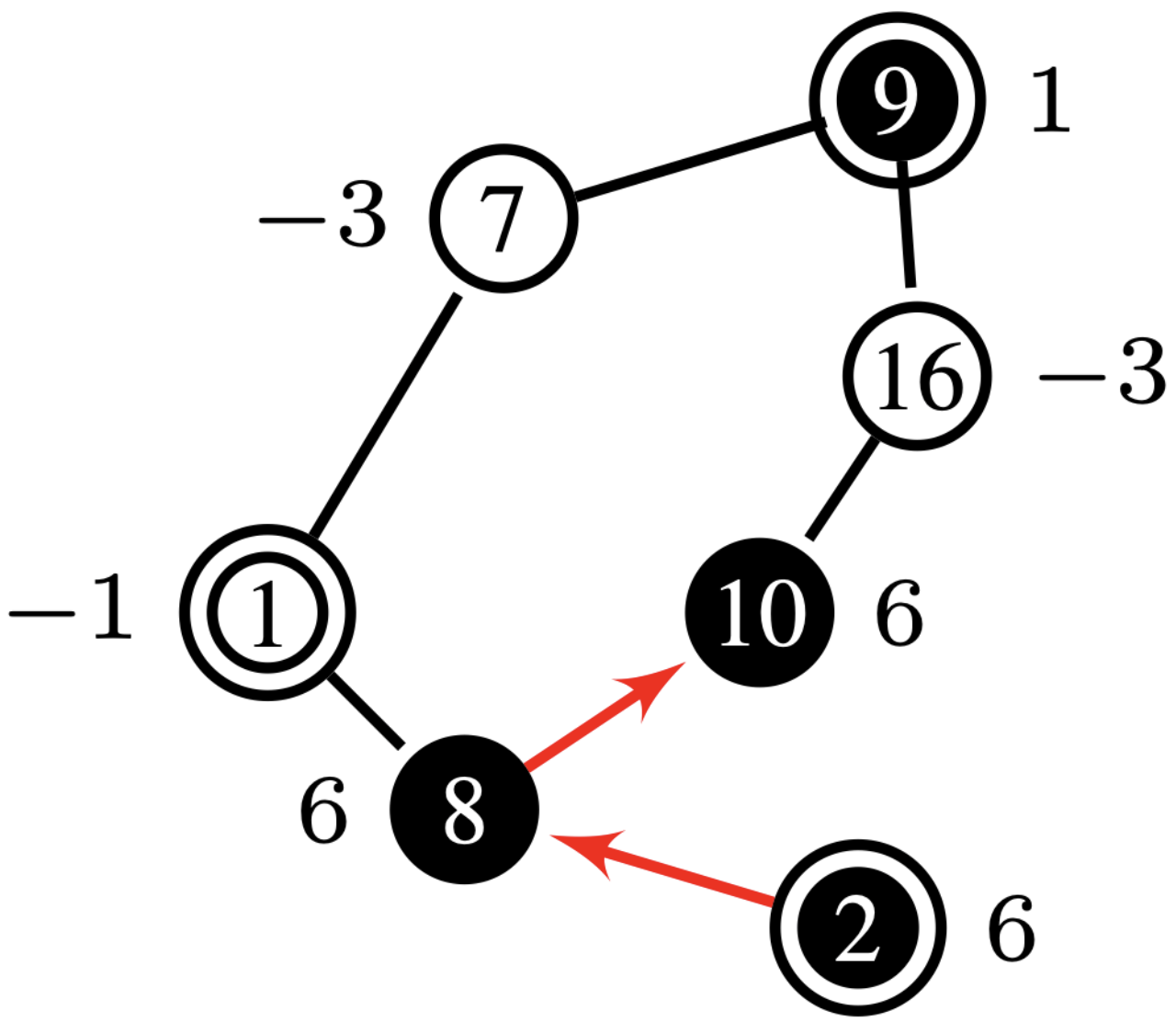
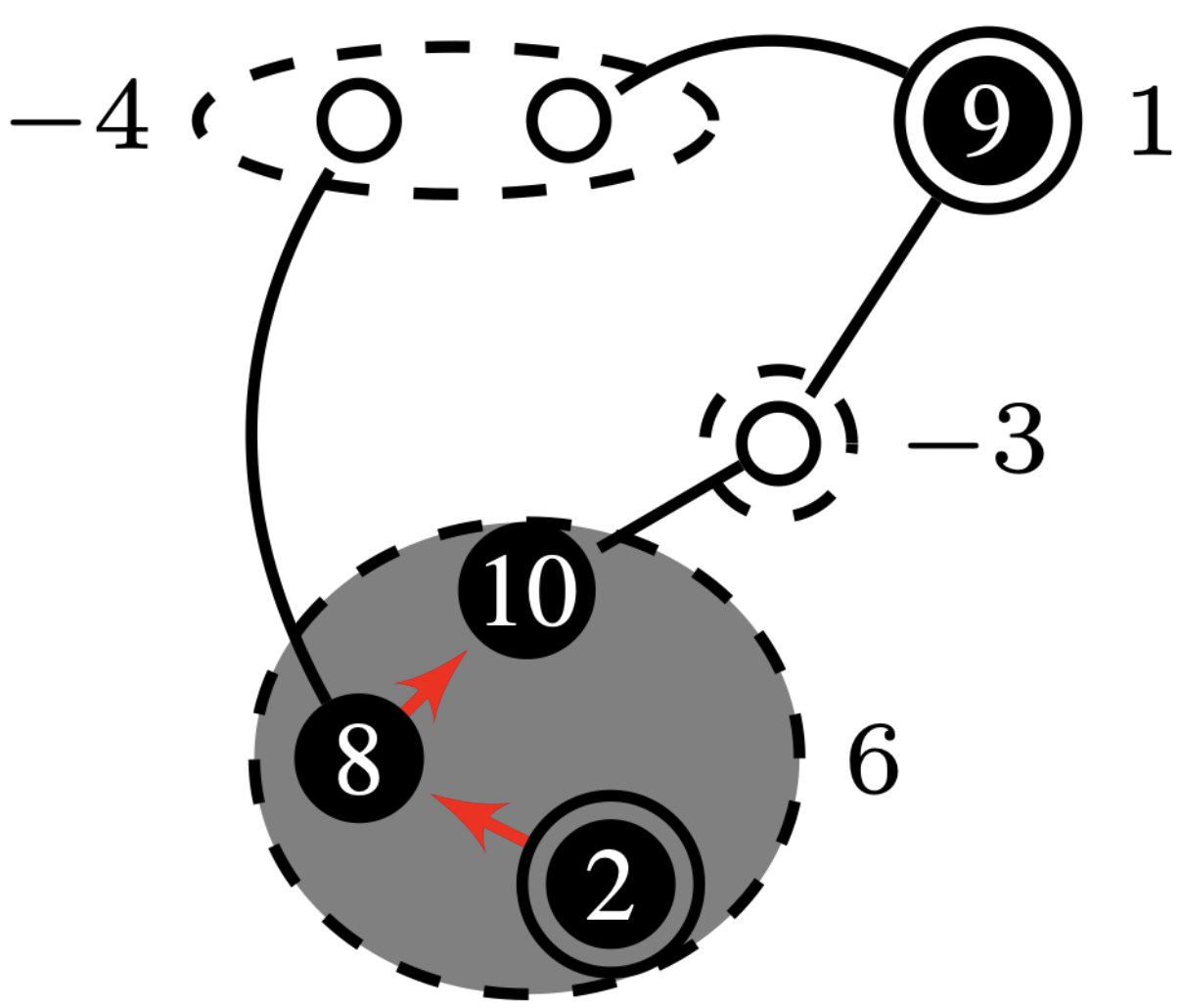
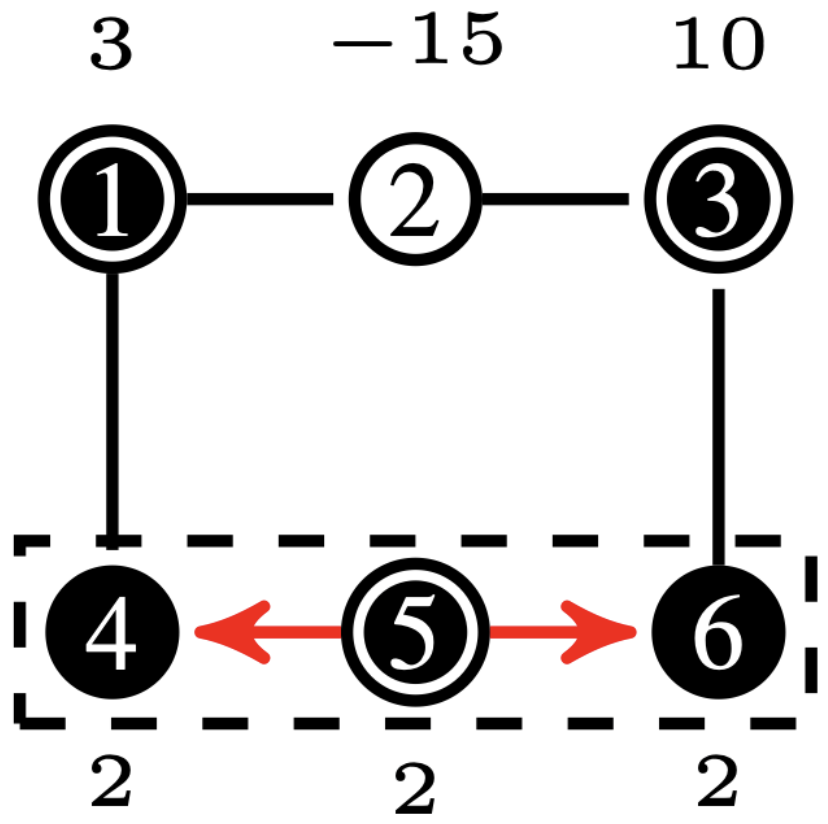
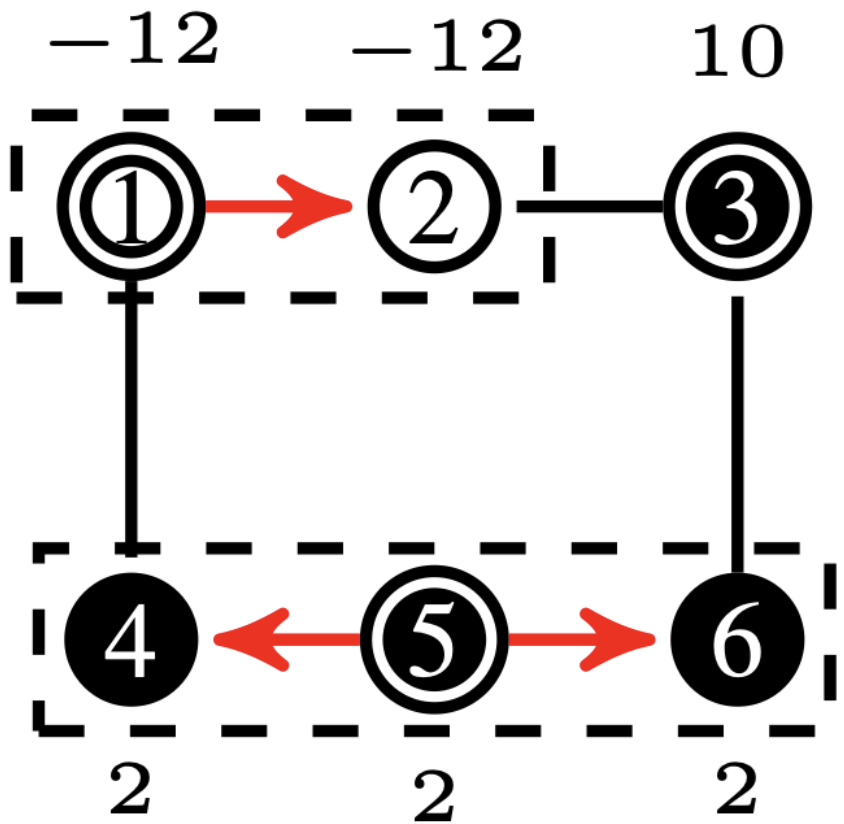
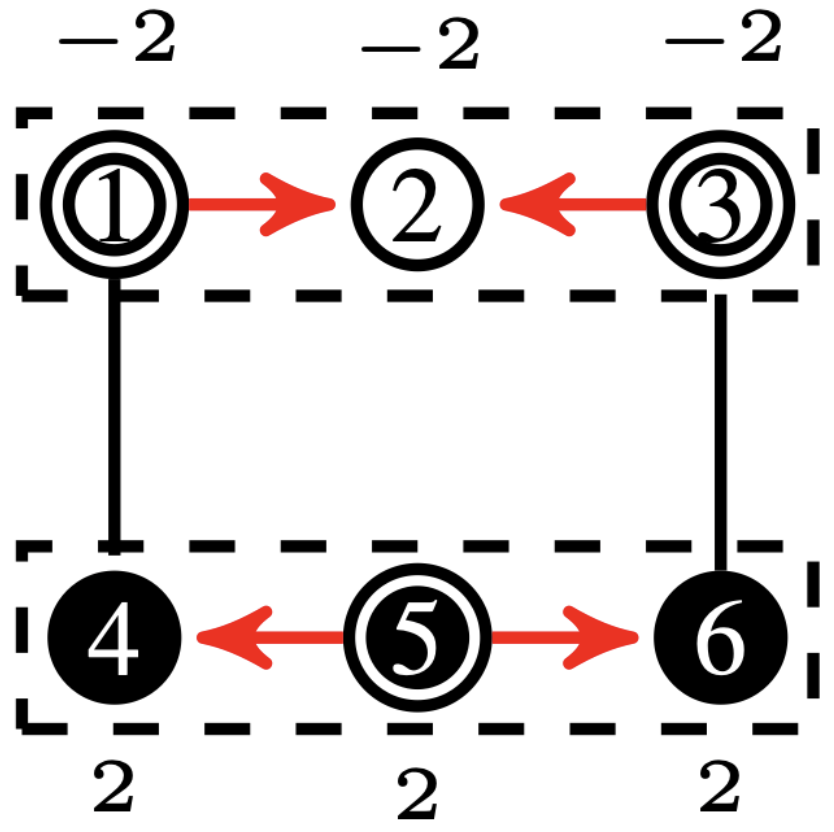
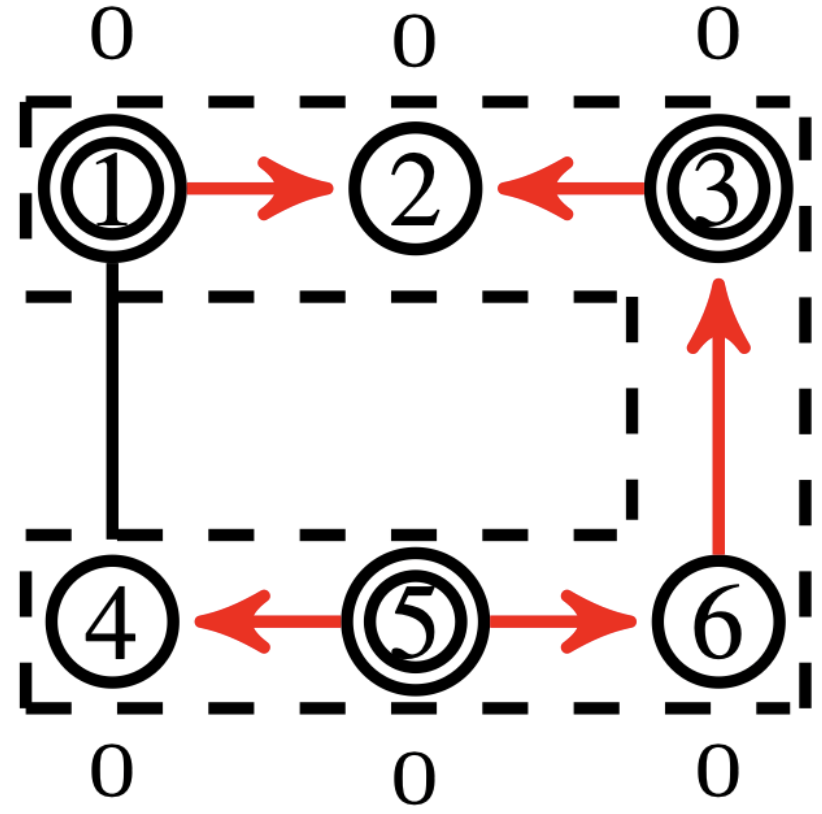
Net-Concad, described in Algorithm 3, takes as input a graph , the existing sampled radial polytrees in and its input vector . The existing radial polytrees, starting from the source nodes, are incrementally built by the Sampler to channel the input flow from the sources to the sinks. Here, represents the number of polytrees already formed in the graph, which will be, at most, equal to the number of sources in the graph. An important notion we employ is that all nodes within a polytree have positive input to supply. Therefore, based on the flow vector , at iteration some nodes can assume “pseudo” roles. See Fig. 4 for an example of input graph and existing polytrees in it.
After partitioning the graph by Islander, Net-Concad proceeds to condensing each sub-graph by removing the formed polytrees (grouped in super source nodes) and turning the resulted connected components [17] into super sink nodes as shown in Fig. 4 and Fig. 4. In this new configuration we can assume, without loss of generality, that each sub-graph is a bi-connected and quasi-bipartite graph in terms of super source nodes as one group and super sink nodes as the other.
Definition 2
A quasi-bipartite graph is a graph where all its vertex can be divided into two disjoints subsets such as most of the edges exists between these subsets. However, conversely to bipartite graphs, few edges may occur within one of the subsets.
It is important to note that each sub-graph for generated by Islander is irreducible; specifically, the super source nodes introduced at each iteration of Net-Concad do not become articulation points.
Lemma II.1
Each partitioned sub-graph is an irreducible graph.
Proof:
Since each is a 2-connected graph and growing the super source nodes does not affect this property, the graph does not include an articulation super source and thus it is irreducible. ∎
II-D Sampler
In order to choose which is the “most probable” edge to sample from a set of candidates we proceed with calling Sampler function. The Sampler assumes that some weight is assigned to each candidate edge, which gets updated after sampling. These weights are defined by the problem context and the physical specificity of the flow. We give an example case in Section IV, where the underlying problem is an electric power distribution.
In order to keep the growing polyforest in the feasible domain, Sampler needs to guarantee the available flow in the network does not get stuck in it. Therefore it operates by a priority queue which first samples edges connecting pendant sources in each partition. Then, it also prioritizes edges which connect nodes which can provide the output demand of its children, so that the balance . Finally, to prevent the creation of cycles, taking inspiration from Loop-erase Random-Walk algorithm [18], we implement an edge-delete procedure (line 4 in Algorithm 4) where, prior to sample any edge, the Sampler looks for edges in , whose nodes are already included in one of the existing .
II-E FORWARD
After Sampler is done, FORWARD, presented in Algorithm 5, proceed to update the information of the network. Note that the process is an adaptive procedure where the flow remaining in the system must decrease as sampling. Indeed, flow decreases proportionally to the output of the new node added to a polytree. Then Net-Concad and Sampler are applied again till convergence when all nodes are connected to a polytree, which will happen after iterations at most.
Remark II.1 (Complexity of FOWARD)
Notice that Pre-processor has a complexity of , Net-Concad runs in which obeys the complexity of the contraction algorithm, which the same complexity as Islander, and, finally, Sampler runs over the edges that belong to the neighbourhood of the growing forest which is, in the worst-case scenario, all the edges of , so that . Therefore, proposed procedure has a complexity of . As distribution networks is a small-world graph, the number of edges is close to the number of nodes , therefore, complexity can be reduced to in the worst case scenario, which is polynomial time. However, it must be noticed that after Pre-Processor the remaining graph will have less than nodes and that Islander will partition the graph to even smaller sub-graphs which can be solved in parallel. Therefore, real implementation complexity can be significantly reduced.
III Feasibility analysis
To find a feasible radial distribution configuration from that can channel the inputs from the sources to the sinks and meet their demanded output is a non-trivial task. In what follows, we show that the FORWARD algorithm is guaranteed to generate such a feasible radial distribution configuration because of the inherent structure of the condensed dual graph. We start our demonstration with some auxiliary lemmas and remarks.
Lemma III.1
Any tree graph (undirected) admits a unique flow distribution from its sources to its sinks nodes as long as the total input meets the total demand, i.e., the (directed) polytree generated to deliver the input from the sources to the sinks is unique.
Proof:
For a connected acyclic graph with nodes, such as a tree graph, the incident matrix is full column rank . Therefore, the null space of the incident matrix is trivial and thus there is a unique flow vector that satisfies the flow conservation constraint matrix equation. ∎
Lemma III.1 asserts that in the sub-graphs separated from by the Pre-Processor the (oriented) radial configuration to deliver the inputs to the sinks exists and is unique. Therefore, polytree grown by Pre-Processor belongs to all the configurations that are in the feasible set of optimization problem (1), including the optimal configuration.
Note that the Islander function will not affect the sampling procedure as it re-distributes input vector without disturbing the flow balance. In a similar way, applying Net-Concad to a graph will not modify the sampling space. By construction, edges on the dual condensed graph, created by Net-Concad, are all the existing edges in . Consequently, feasibility is guaranteed if we demonstrate that the FORWARD can always construct a feasible radial configuration in each that delivers inputs in the sub-graph to the sinks (i.e., inputs meet the demands at the sinks).
The first result below shows that any digraph created by Sampler function through iterations is a polyforest (a radial configuration without a cycle).
Lemma III.2
Any , generated by FORWARD is always a radial configuration.
Proof:
The proof hinges on the fact that each edge is sampled at most once by Sampler, and the edge-delete procedure within Sampler prevents the formation of cycles.∎
The following lemma shows that any radial digraph created by FORWARD will visit every node in the graph.
Lemma III.3
FORWARD radial configuration will contain all nodes from a sub-graph , i.e., .
Proof:
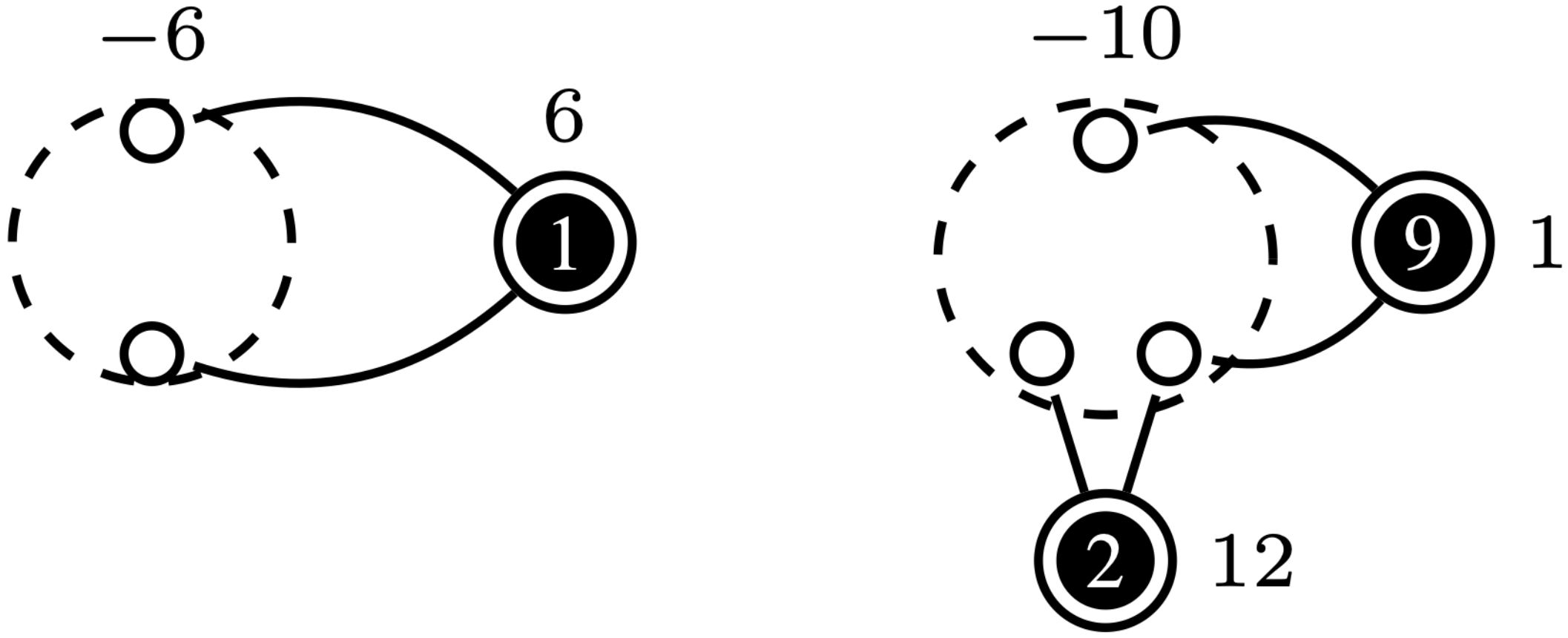
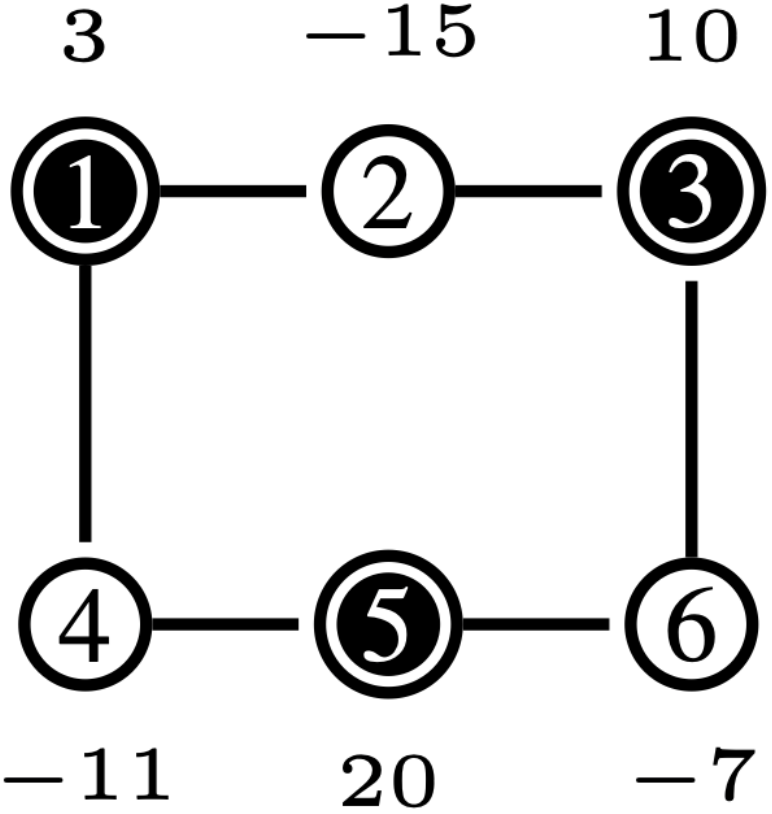
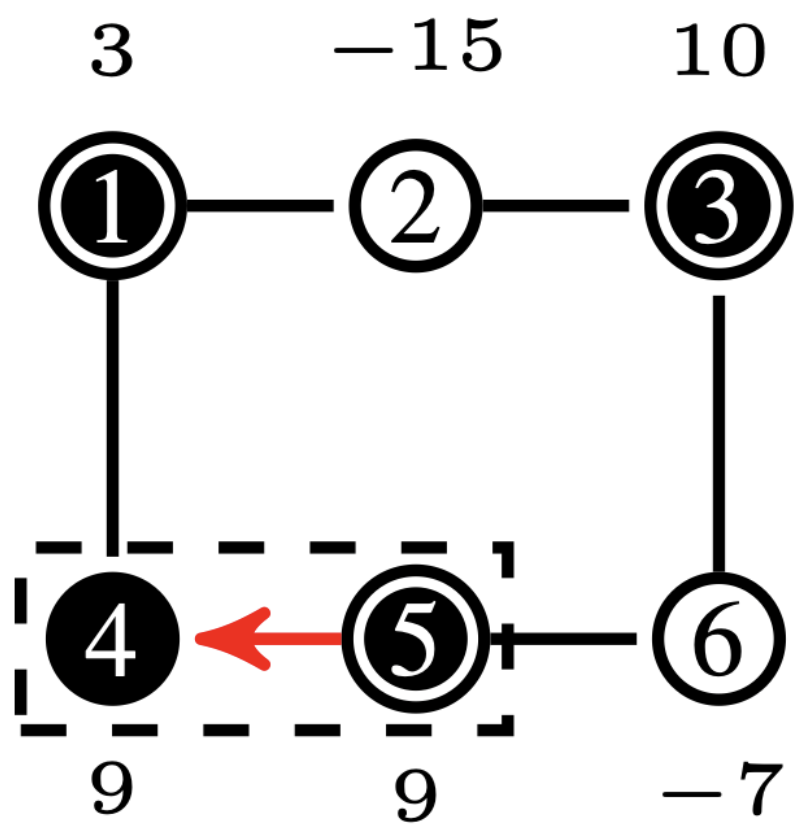
Given that the edge-delete procedure only removes edges between nodes within the sampled polyforest, nodes that have not been connected to any polytree will retain all of their edges in . Consequently, a node can only remain isolated if none of the connected polytrees can provide sufficient input flow to satisfy the output demanded by the node. Assume there exists a node (node 2 in Fig. 5) whose output cannot be supplied by any of its adjacent connected polytrees in (nodes 1, 3 in Fig. 5). Since is bi-connected, each super source node is connected to super sink nodes distinct from (e.g., 1 to 4 and 3 to 6 in Fig. 5). To maintain overall flow balance in , at least one super source node in the partition must have sufficient input flow to meet the output of its neighbors (node 5 in Fig. 5). Moreover, due to the bi-connectedness of , there exists a super sink node such that (nodes 4, 6 in Fig. 5). By definition, .
Since is quasi-bipartite, if is not receiving extra input to meet output in , it is because flow from cannot pass through . This scenario arises only if the edge is sampled in before , turning into a “pseudo” source. For instance, in Fig. 5, if or were sampled before or , this contradicts the priority queue in Sampler, which prioritizes polytrees with excess input flow with respect to its neighbours (node 5 in Fig. 5). Thus, by contradiction, this situation cannot occur, ensuring that FORWARD successfully connects all nodes in . ∎
In light of the aforementioned, we can conclude the demonstration by noting that the solution provided by FORWARD will be a feasible radial configuration for flow distribution.
 |
 |
 |
| (a) | (b) step | (c) step |
 |
 |
 |
| (d) step | (e) step | (f) step |
IV Case study
We demonstrated the efficacy of the proposed FORWARD algorithm in solving an optimal power distribution problem and discuss how edge weights (used in line 4 of Sampler, Algorithm 4) can be selected for this problem considering the physical nature of the flow in power networks. It is shown in the literature, single-phase direct current (DC) simplifications can be used to approximate the real three-phase alternating current (AC) flow problem, casting the optimal power flow problem as (1). We refer the readers to [19] for specific details of these simplifications.
In a power network, the demand at the sinks (loads) and the input in the sources (generators) are power. The flow in edges is characterized by the demand of the nodes in each distribution line following Ohm’s law. In power network systems, in the cost function of (1) is the resistance along the edge .
Weight design: Given a radial configuration, the flow at edge is defined as a function of the power demand of all the loads in power line extending from the source and containing edge and the voltage in node . Therefore, the cost due to flow through is
FORWARD constructs the radial configuration by iteratively adding the edges. Therefore, the power line connecting the nodes is not known in advance. Consequently, to have a cost-aware edge choice, the greedy selection process must estimate . For power networks we propose to approximate the energy lost due to flow across an edge , when we want to sample this edge and add it to an existing radial configuration (power line) , to use
| (2) |
where is the power demand at node and is the accumulated cost of power line . Thus, a relevant edge weight (probability) for the random walk could be computed as
| (3) |
where is the input vector characterized as the power remaining in node which decreases in each step by subtracting the power demand on . Therefore, the weights on each edge are dynamically changing in function of the steps taken. We point out here that of use of transition probability for (3) is with a degree of abuse of notation as in function of the parameters can be greater than . Indeed, is normalized at each iteration considering all the edge candidates to be sampled at time .
Numerical demonstration: In order to show computational benefit of using FORWARD in producing a feasible radial configurations for power network problems and the optimality gap of the algorithm, we consider different power distribution networks. Specifically, three IEEE graphs have been used: IEEE with sources, IEEE with sources and IEEE with sources. Note that, as mentioned before, these IEEE graphs have been pre-processed to a single-phase DC network structure. Besides, to test scalability, three random distribution systems have been generated following Watts–Strogatz mechanism [20] in order to create small-world graph structures. These graphs are named: WS , WS and WS , where their number indicates the number of nodes in each network. Networks WS and WS where designed with sources and WS has source nodes. We have modeled our numerical problem in PowerDistributionModel (PMD) framework [21] from Los Alamos National Laboratory, which is coded in Julia. This framework uses Knitro, from Artelys, to solve the MINLP. This numerical study was conducted on a MacBook Air with an M3 chip and GB of RAM. The simulation results are shown in Table I. In this table, power loss is in giga-watts (GW). In time column, stands for processes which has been manually stopped after certain CPU Time, and stands for situations where a solution could not be found after h of computation.
According to Table I, Knitro was only able to return a solution for small-sized networks. For these cases, the CPU time of Knitro is significantly more than the CPU time used to implement FORWARD. Knitro (like other commercial solvers) uses heuristics to warm up the process within the feasible domain. Notably, as the network size increases, these heuristics tend to struggle to find a proper initialization within polynomial time due to the large dimension of the combinatorial space. This often results in prolonged CPU times or even the inability to find an initial point. In contrast, FORWARD was able to construct a feasible radial configuration for all cases in noticeably low time, even for a network of 400 nodes.
The results shown in Table I for the cost indicate that FORWARD attains a promising optimality gap. This could be attributed to the physically flow-aware nature of designing the weights and the sampler mechanism of FORWARD. In our future work, we plan to formally characterize the optimality gap of FORWARD.
| Knitro | FORWARD | |||
|---|---|---|---|---|
| Graph | cost | CPU time | cost | CPU time |
| IEEE 11 | 1.19e-7 | 118.21 | 1.19e-7 | 1.81 |
| IEEE 18 | 1.79e-7 | 141.52 | 1.79e-7 | 1.53 |
| IEEE 33 | 3.18e-09 | 500* | 9.19e-09 | 5.2 |
| WS 120 | - | - | 1.42e-11 | 26.91 |
| WS 240 | - | - | 4.39e-9 | 130.63 |
| WS 400 | - | - | 2.83e-9 | 217.72 |
V Conclusions
We presented an algorithm for finding a feasible radial reconfiguration in distribution networks. Promising results from numerical experimentation allows us to believe the proposed method can serve as an effective warm-up strategy for iterative solvers refining solutions toward optimality. Also, it should be emphasized that despite the algorithm is designed for a simplified transportation problem, it can be seen it handles extended problems with complex physics constraints as they are power systems reconfiguration. For future work, it will be shown how, indeed, proposed problem works as an abstraction over other problems with non-linear constraints.
References
- [1] R. Lyons and Y. Peres, Minimal Spanning Forests, p. 388–409. Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, 2017.
- [2] S. H. Dolatabadi, M. Ghorbanian, P. Siano, and N. D. Hatziargyriou, “An enhanced ieee 33 bus benchmark test system for distribution system studies,” IEEE Transactions on Power Systems, vol. 36, no. 3, pp. 2565–2572, 2021.
- [3] J. Dong, S. Han, X. Shao, L. Tang, R. Chen, L. Wu, C. Zheng, Z. Li, and H. Li, “Day-ahead wind-thermal unit commitment considering historical virtual wind power data,” Energy, vol. 235, p. 121324, Nov. 2021.
- [4] P. G. Doyle and J. L. Snell, “Random walks and electric networks,” 2000.
- [5] A. Clark, “A submodular optimization approach to the metric traveling salesman problem with neighborhoods,” in 2019 IEEE 58th Conference on Decision and Control (CDC), pp. 3383–3390, 2019.
- [6] A. Khodabakhsh, G. Yang, S. Basu, E. Nikolova, M. C. Caramanis, T. Lianeas, and E. Pountourakis, “A submodular approach for electricity distribution network reconfiguration,” EESS, 2017.
- [7] U. von Luxburg, “A tutorial on spectral clustering,” Statistics and Computing, vol. 17, no. 4, pp. 395–416, 2007.
- [8] D. R. Karger, “Minimum cuts in near-linear time,” 1998.
- [9] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein, Introduction to Algorithms. MIT Press and McGraw-Hill, second ed., 2001.
- [10] P. Christiano, J. A. Kelner, A. Madry, D. A. Spielman, and S.-H. Teng, “Electrical flows, laplacian systems, and faster approximation of maximum flow in undirected graphs,” 2010.
- [11] J. A. Kelner, Y. T. Lee, L. Orecchia, and A. Sidford, “An almost-linear-time algorithm for approximate max flow in undirected graphs, and its multicommodity generalizations,” in Proceedings of the Twenty-Fifth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA ’14, (USA), p. 217–226, Society for Industrial and Applied Mathematics, 2014.
- [12] G. Borradaile, P. N. Klein, S. Mozes, Y. Nussbaum, and C. Wulff-Nilsen, “Multiple-source multiple-sink maximum flow in directed planar graphs in near-linear time,” SIAM Journal on Computing, vol. 46, p. 1280–1303, Jan. 2017.
- [13] G. Guex, “Interpolating between random walks and optimal transportation routes: Flow with multiple sources and targets,” Physica A: Statistical Mechanics and its Applications, vol. 450, p. 264–277, May 2016.
- [14] L. Chen, R. Kyng, Y. P. Liu, R. Peng, M. P. Gutenberg, and S. Sachdeva, “Maximum flow and minimum-cost flow in almost-linear time,” 2022.
- [15] S. R. Tate, “Proof of correctness for prim’s algorithm, handout 11,” Nov. 2016. Class Handout, CSC 330: Advanced Data Structures.
- [16] B. Hartmann and V. Sugár, “Searching for small-world and scale-free behaviour in long-term historical data of a real-world power grid,” Scientific Reports, vol. 11, Mar. 2021.
- [17] R. E. Tarjan and U. Zwick, “Finding strong components using depth-first search,” 2022.
- [18] G. F. Lawler, “A self-avoiding random walk,” Duke Mathematical Journal, vol. 47, Sept. 1980.
- [19] D. M. Fobes, H. Nagarajan, and R. Bent, “Optimal microgrid networking for maximal load delivery in phase unbalanced distribution grids: A declarative modeling approach,” IEEE Transactions on Smart Grid, vol. 14, no. 3, pp. 1682–1691, 2023.
- [20] D. J. Watts and S. H. Strogatz, “Collective dynamics of ‘small-world’ networks,” Nature, vol. 393, p. 440–442, June 1998.
- [21] D. M. Fobes, S. Claeys, F. Geth, and C. Coffrin, “Powermodelsdistribution.jl: An open-source framework for exploring distribution power flow formulations,” Electric Power Systems Research, vol. 189, p. 106664, 2020.