FOSTER: Feature Boosting and Compression for Class-Incremental Learning
Abstract
The ability to learn new concepts continually is necessary in this ever-changing world. However, deep neural networks suffer from catastrophic forgetting when learning new categories. Many works have been proposed to alleviate this phenomenon, whereas most of them either fall into the stability-plasticity dilemma or take too much computation or storage overhead. Inspired by the gradient boosting algorithm to gradually fit the residuals between the target model and the previous ensemble model, we propose a novel two-stage learning paradigm FOSTER, empowering the model to learn new categories adaptively. Specifically, we first dynamically expand new modules to fit the residuals between the target and the output of the original model. Next, we remove redundant parameters and feature dimensions through an effective distillation strategy to maintain the single backbone model. We validate our method FOSTER on CIFAR-100 and ImageNet-100/1000 under different settings. Experimental results show that our method achieves state-of-the-art performance. Code is available at https://github.com/G-U-N/ECCV22-FOSTER.
Keywords:
class-incremental learning, gradient boosting1 Introduction
The real world is constantly changing, with new concepts and categories continuously springing up [14, 52, 39, 50]. Retraining a model every time new classes emerge is impractical due to data privacy [5] and expensive training costs. Therefore, it is necessary to enable the model to continuously learn new categories, namely class-incremental learning [48, 53, 38]. However, directly fine-tuning the original neural networks on new data causes a severe problem known as catastrophic forgetting [11] that the model entirely and abruptly forgets previously learned information. Inspired by this, class-incremental learning aims to design a learning paradigm that enables the model to continuously learn novel categories in multiple stages while maintaining the discrimination ability for old classes.
In recent years, many approaches have been proposed from different aspects. So far, the most widely recognized and utilized class-incremental learning strategy is based on knowledge distillation [19]. Methods [28, 34, 1, 42, 47, 51] retain an old model additionally and use knowledge distillation to constrain output for original tasks of the new model to be similar to that of the old one [28]. However, these methods with a single backbone may not have enough plasticity [17] to cope with the coming new categories. Besides, even with restrictions of KD, the model still suffer from feature degradation [44] of old concepts due to limited access [5] to old data. Recently, methods [44, 29, 9] based on dynamic architectures achieve state-of-the-art performance in class-incremental learning. Typically, they preserve some modules with their parameters frozen to maintain important sections for old categories and expand new trainable modules to strengthen plasticity for learning new categories. Nevertheless, they have two inevitable defects: First, constantly expanding new modules for coming tasks will lead to a drastic increase in the number of parameters, resulting in severe storage and computation overhead, which makes these methods not suitable for long-term incremental learning. Second, since old modules have never seen new concepts, directly retaining them may harm performance in new categories. The more old modules kept, the more remarkable the negative impact.
In this paper, we propose a novel perspective from gradient boosting to analyze and achieve the goal of class-incremental learning. Gradient boosting methods use the additive model to gradually converge the ground-truth target model where the subsequent one fits the residuals between the target and the prior one. In class-incremental learning, since distributions of new categories are constantly coming, the distribution drift will also lead to the residuals between the target label and model output. Therefore, we propose a similar boosting framework to solve the problem of class-incremental learning by applying an additive model, gradually fitting residuals, where different models mainly handle their special tasks (with nonoverlapping sets of classes). And as we discuss later, our boosting framework is a more generalized framework for dynamic structure methods (e.g., DER[44]). It has positive significance in two aspects: On the one hand, the new model enhances the plasticity and thus helps the model learn to distinguish between new classes. On the other hand, training the new model to classify all categories might contribute to discovering some critical elements ignored by the original model. As shown in Fig. 1, when the model learns old categories, including tigers, cats, and monkeys, it may think that stripes are essential information but mistakenly regard auricles as meaningless features. When learning new categories, because the fish and birds do not have auricles, the new model will discover this mistake and correct it.
However, as we discussed above, creating new models not only leads to an increase in the number of parameters but also might cause inconsistency between the old and the new model at the feature level. To this end, we compress the boosting model to remove unnecessary parameters and inconsistent features, thus avoiding the above-mentioned drawbacks of dynamic structure-based methods, preserving crucial information, and enhancing the robustness of the model.
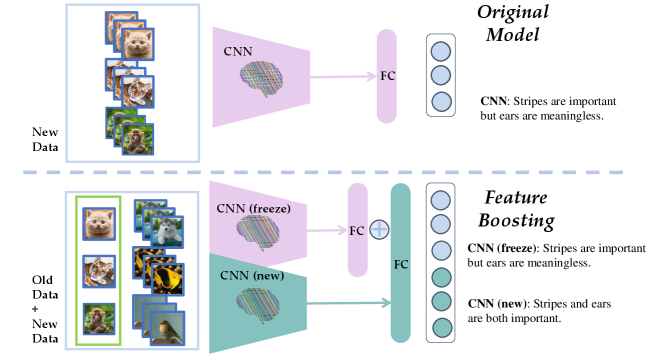
In conclusion, our paradigm can be decoupled into two steps: boosting and compression. The first step can be seen as boosting to alleviate the performance decline due to the arrival of new classes. Specifically, we retain the old model with all its parameters frozen. Then we expand a trainable new feature extractor and concatenate it with the extractor of the old model and initialize a constrained, fully-connected layer to transform the super feature into logits, which we will demonstrate later in detail. In the second step, we aim to eliminate redundant parameters and meaningless dimensions caused by feature boosting. Specifically, we propose an effective distillation strategy that can transfer knowledge from the boosting model to a single model with negligible performance loss, even if the data is limited when learning new tasks. Extensive experiments on three benchmarks, including CIFAR-100, ImageNet-100/1000 show that our method Feature BoOSTing and ComprEssion for class-incRemental learning (FOSTER) obtains the state-of-the-art performance.
2 Related Work
Many works have been done to analyze the reasons for performance degradation in class-incremental learning and alleviate this phenomenon. In this section, we will give a brief discussion of these methods and boosting algorithms.
Knowledge Distillation. Knowledge distillation [19] aims to transfer dark knowledge [25] from the teacher to the student by encouraging the outputs of the student model to approximate the outputs of the teacher model [28]. LwF [28] retains an old model additionally and applies a modified cross-entropy loss to constrain the outputs for old categories of the new model to preserve the capability for the old one. Bic [42], WA [47] propose effective strategies to alleviate the bias of the classifier caused by imbalanced training data after distillation.
Rehearsal. The rehearsal strategy enables the model to have partial access to old data. [34, 42, 47, 40] allocate a memory to store exemplars of previous tasks for replay when learning tasks. [22] preserves low dimensional features instead of raw instances to reduce the storage overhead. In [43], instances are synthesized by a generative model [16] for rehearsal. [32] test various exemplar selection strategies, showing that different ways of exemplar selection have a significant impact on performance and herding surpass other strategies in most settings.
Dynamic Architectures. Many works [10, 15, 21, 36, 41] create new modules to handle the growing training distribution [45, 27] dynamically. However, an accurate task id, which is usually unavailable in real-life, is needed for most of these approaches to help them choose the corresponding id-specific module. Recently, methods [44, 29, 9] successfully apply the dynamic architectures into class incremental learning where the task id is unavailable, showing their advantages over the single backbone methods. However, as we illustrate in Sec. 1, they have two unavoidable shortcomings: Continually adding new modules causes unaffordable overhead. Directly retaining old modules leads to noise in the representations of new categories, harming the performance in new classes.
Boosting. Boosting represents a family of machine learning algorithms that convert weak learners to strong ones [54]. AdaBoost [12] is one of the most famous boosting algorithms, aiming to minimize the exponential loss of the additive model. The crucial idea of AdaBoost is to adjust the weights of training samples to make the new base learner pay more attention to samples that the former ensemble model cannot recognize correctly. In recent years, gradient boosting [13] based algorithms [2, 24, 7] achieve excellent performance on various tasks.
3 Preliminary
In this section, we first briefly discuss the basic process of gradient boosting in Sec. 3.1. Then, we describe the setting of class-incremental learning in Sec. 3.2. In Sec. 4, we will give an explicit demonstration of how we apply the idea of gradient boosting to the scenario of class-incremental learning.
3.1 Gradient Boosting
Given a training set , where is the instance and is the corresponding label, the gradient boosting methods seek a hypothesis to minimize the empirical risk (with loss function )
| (1) |
by iteratively adding a new weighted weak function chosen from a specific function space (e.g., the set of all possible decision trees) to gradually fit residuals. After iterations, the hypothesis can be represented as
| (2) |
where is the coefficient of . Then we are supposed to find for further optimization of the objective
| (3) |
However, directly optimizing the above function to find the best is typically infeasible. Therefore, we use the steepest descent step for iterative optimization:
| (4) |
where is the objective for to approximate. Specifically, if is the mean-squared error (MSE), it transforms into
| (5) |
Ideally, let , if can fit for each , is the optimal function, minimizing the empirical error.
3.2 Class-Incremental Learning Setup
Unlike the traditional case where the model is trained on all classes with all training data available, in class-incremental learning, the model receives a batch of new training data in the stage. Specifically, is the number of training samples, is the input image, and is the corresponding label for . Label space of all seen categories is denoted as , where for . In the stage, rehearsal-based methods also save a part of old data as , a limited subset of . Our model is trained on and is required to perform well on all seen categories.
4 Method
In this section, we give a description of FOSTER and how it works to prompt the model to simultaneously learn all classes well. Below, we first give a full demonstration of how the idea of the gradient boosting algorithm is applied to class-incremental learning in Sec. 4.1. Then we propose novel strategies to further enhance and balance the learning, which greatly improves the performance in Sec. 4.2. Finally, in order to avoid the explosive growth of parameters and remove redundant parameters and feature dimensions, we utilize a straightforward and effective compression method based on knowledge distillation in Sec. 4.3.
4.1 From Gradient Boosting to Class-Incremental Learning
Assuming in the stage, we have saved the model from the last stage. can be further decomposed into feature embedding and linear classifier: , where and . When a new data stream comes, directly fine-tuning on the new data will impair its capacity for old classes, which is inadvisable. On the other hand, simply freezing causes it to lose plasticity for new classes, making the residuals between target and large for . Inspired by gradient boosting, we train a new model to fit the residuals. Specifically, the new model consists of a feature extractor and a linear classifier . can be further decomposed into , where and . Accordingly, the training process can be represented as
| (6) |
Similar to Sec. 3.1, let be the mean-squared error function, considering the strong feature representation learning ability of neural networks, we expect can fit residuals of and for every . Ideally, we have
| (7) |
where is the softmax operation, is set to zero matrix or fine-tuned on with frozen, and is the corresponding one-hot vector of . We set to zero matrix as default in our discussion.
Denote the parameters of as and as a distance metric (e.g., euclidean metric), this process can be represented as the following optimization problem:
| (8) |
We replace the with and substitute the for the Kullback-Leibler divergence (KLD), then the objective function changes into:
| (9) |
We provide an illustration about the reasons for this substitution in the supplementary material. Therefore, can be further decomposed as an expanded linear classifier and a concatenated super feature extractor , where
| (14) |
Note that , , and are all frozen, the trainable modules are the . Here we explain their roles. Eventually, logits of is
| (17) |
The lower part is the logits of new classes, and the upper part is that of old ones. As we claimed in Sec. 1, the lower part requires the new module to learn how to correctly classify new classes, thus enhancing the model’s plasticity to redeem the performance on new classes. The upper part encourages the new module to fit the residuals between and , thus encouraging to exploit more pivotal patterns for classification.
4.2 Calibration for Old and New
When training on new tasks, we only have an imbalanced training set . The imbalance on categories of will result in a strong classification bias in the model [23, 47, 42, 1]. Besides, the boosting model tends to ignore the residuals of minor classes due to insufficient supervision. To alleviate the classification bias and encourage the model to equally learn old and new classes, we propose Logits Alignment and Feature Enhancement strategies in the following sections.
Logits Alignment. To strengthen the learning of old instances and mitigate the classification bias, we add a scale factor to the logits of the old and new classes in Eq. 17 respectively during training. Thus, the logits during training are:
| (18) |
where , , and is a diagonal matrix composed of and . Through this scaling strategy, the absolute value of logits for old categories is reduced, and the absolute value of logits for new ones is enlarged, thus forcing the model to produce larger logits for old categories and smaller logits for new categories.
We get the scale factors trough the normalized effective number [4] of each class, which can be seen as the summation of proportional series, where equal to the number of instances and is an adjustable hyperparameter
| (19) |
concretely, . Hence the objective is formulated as:
| (20) |
Feature Enhancement. We argue that simply letting a new module fit the residuals of and label is sometimes insufficient. At the extreme,, for instance, the residuals of and is zero. In that case, the new module can not learn anything about old categories, and thus it will damage the performance of our model for old classes. Hence, we should prompt the new module to learn old categories further.
Our Feature Enhancement consists of two parts. First, we initialize a new linear classifier to transform the new feature into logits of all seen categories and require the new feature itself to correctly classify all of them:
| (21) |
Hence, even if the residuals of and is zero, the new feature extractor can still learn how to classify the old categories. Besides, it should be noted that simply using one-hot targets to train the new feature extractor in an imbalanced dataset might lead to overfitting to small classes, failing to learn a feature representation with good generalization ability for old categories. To alleviate this phenomenon and provide more supervision for old classes, we utilize knowledge distillation to encourage to have similar output distribution as on old categories,
| (22) |
Note that this process requires only one more time matrix multiplication computation because the forward process of the original model and the expanded model are shared, except for the final linear classifier.
Summary of Feature Boosting. To conclude, feature-boosting consists of three components. First, we create a new module to fit the residuals between targets and the output of the original model, following the principle of gradient boosting. With reasonable simplification and deduction, the optimization objective is transformed into the minimization of KL divergence of the target and the output of the concatenated model. To alleviate the classification bias caused by imbalanced training, we proposed logits alignment (LA) to balance the training of old and new classes. Moreover, we argued that simply letting the new module fit the residuals is sometimes insufficient. To further encourage the new module to learn old instances, we proposed feature enhancement, where aims to make the new module learn the difference among all categories by optimizing the cross-entropy loss of target and the output of the new module, and utilize the original output to instruct the expanded model through knowledge distillation. The final FOSTER loss for boosting combines the above three components:
| (23) |
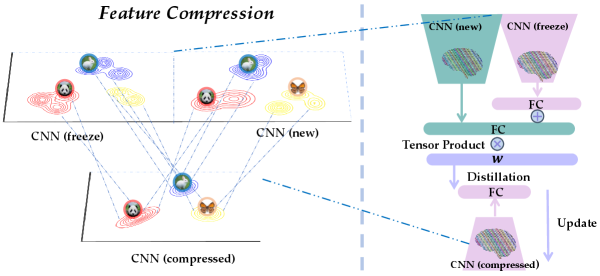
4.3 Feature Compression
Our method FOSTER achieves excellent performance through gradient boosting. However, gradually adding a new module to our model will lead to the growing number of parameters and feature dimensions of our model , making it unable to be applied in long-term incremental learning tasks. Do we really require so many parameters and feature dimensions? For example, we create the same module to learn tasks with 2 classes and 50 classes and achieve similar effects. Thus, there must be redundant parameters and meaningless feature dimensions in the task with 2 classes. Are we able to compress the expanded feature space of to a smaller one with almost no performance degradation?
Knowledge distillation [19] is a simple yet effective way to achieve this goal. Since our model can handle all seen categories with excellent performance, it can give any input a soft target, namely the output distribution on all known categories. Therefore, except for the current training set , we can sample other unlabeled data from a similar domain for further distillation. Note that these unlabeled data can be obtained from the Internet during distillation and discarded after that, so it does not occupy additional memory.
Here, we do not expect any additional auxiliary data to be available and achieve remarkable performance with only the imbalanced dataset .
Balanced Distillation. Suppose there is a single backbone student model to be distilled. To mitigate the classification bias caused by imbalanced training datasets , we should consider the class priors and adjust the weights of distilled information for different classes [46]. Therefore, the Balanced Distillation loss is formulated as:
| (24) |
where means the tensor product (i.e., automatically broadcasting to different batchsizes.) and is the weighted vector obtained from Eq. 19 to make classes with fewer instances have larger weights.
5 Experiments
In this section, we compare our FOSTER with other SOTA methods on benchmark incremental learning datasets. We also perform ablations to validate the effectiveness of FOSTER components and their robustness to hyperparameters.
5.1 Experimental Settings
Datasets. We validate our methods on widely used benchmark of class-incremental learning CIFAR-100 [26] and ImageNet100/1000 [6]. CIFAR-100: CIFAR-100 consists of 50,000 training images with 500 images per class, and 10,000 testing images with 100 images per class. ImageNet-1000: ImageNet-1000 is a large scale dataset composed of about 1.28 million images for training and 50,000 for validation with 500 images per class. ImageNet-100: ImageNet-100 is composed of 100 classes randomly chosen from the original ImageNet-1000.
Protocol. For both the CIFAR-100 and ImageNet-100, we validate our method on two widely used protocols: (i) CIFAR-100/ImageNet-100 B0 (base 0): In the first protocols, we train all 100 classes gradually with 5, 10, 20 classes per step with the fixed memory size of 2,000 exemplars. (ii) CIFAR-100/ImageNet-100 B50 (base 50): We also start by training the models on half the classes. Then we train the rest 50 classes with 2, 5, 10 classes per step with 20 exemplars per class. For ImageNet-1000, we train all 1000 classes with 100 classes per step (10 steps in total) with a fixed memory size of 20,000 exemplars.
| Methods | Average accuracy of all sessions (%) | |||
| B steps | B steps | B steps | B steps | |
| Bound | ||||
| iCaRL [34] | ||||
| BiC [42] | ||||
| WA [47] | ||||
| COIL[51] | - | |||
| PODNet [8] | ||||
| DER [44] | - | |||
| Ours | 72.90 | 70.65 | 67.95 | 63.83 |
| Improvement | (+3.06) | (+2.67) | (+1.59) | (+3.11) |
Implementation Details. Our method and all compared methods are implemented with Pytorch [33] and PyCIL [49]. For ImageNet, we adopt the standard ResNet-18 [18] as our feature extractor and set the batch size to 256. The learning rate starts from 0.1 and gradually decays to zero with a cosine annealing scheduler [30] (170 epochs in total). For CIFAR-100, we use a modified ResNet-32 [34] as the most previous works as our feature extractor and set the batch size to 128. The learning rate also starts from 0.1 and gradually decays to zero with a cosine annealing scheduler (170 epochs in total). For both ImageNet and CIFAR-100, we use SGD with the momentum of 0.9 and the weight decay of 5e-4 in the boosting stage. In the compression stage, we use SGD with the momentum of 0.9 and set the weight decay to 0. We set the temperature scalar to 2. For data augmentation, AutoAugment [3], random cropping, horizontal flip, and normalization are employed to augment training images. The hyperparameter in Eq. 24 is set to 0.97 in most settings, while the in Eq. 20 on CIFAR-100 and ImageNet-100/1000 is set to 0.95 and 0.97, respectively.
5.2 Quantitative results
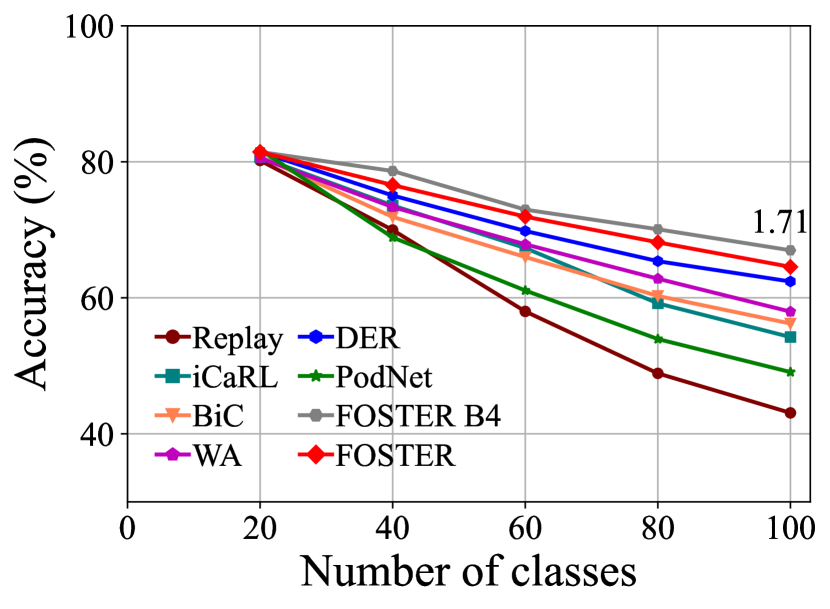
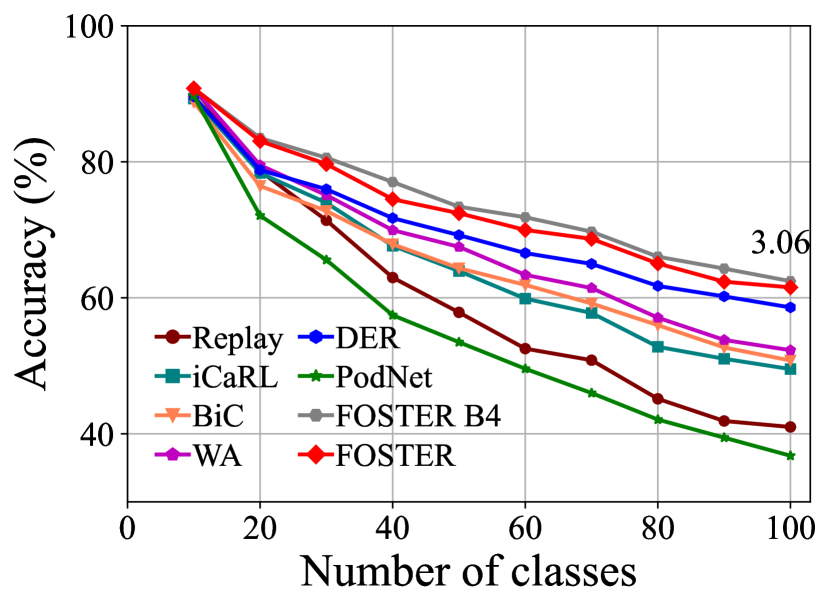
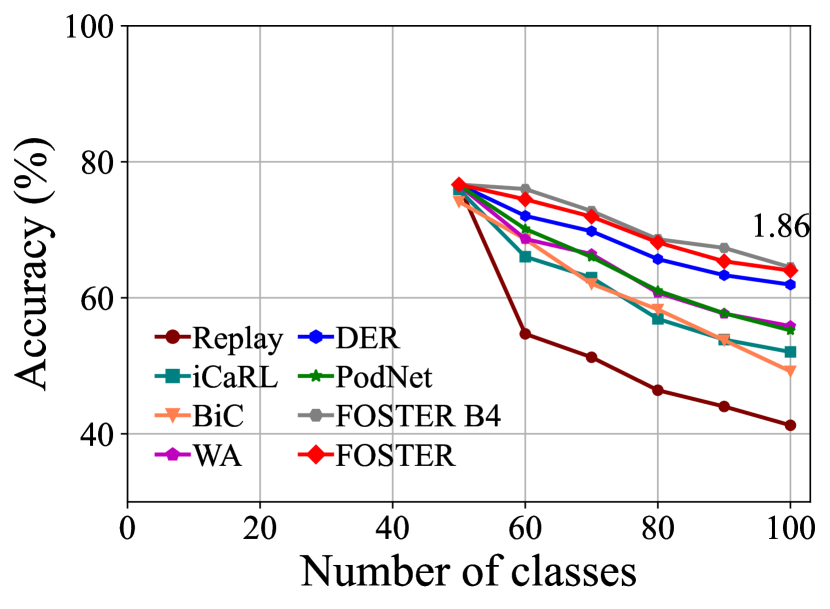
CIFAR-100. Table 1 and Fig. 3 summarize the results of CIFAR-100 benchmark. We use replay as the baseline method, which only uses rehearsal strategy to alleviate forgetting. Experimental results show that our method outperforms the other state-of-the-art strategies in all six settings on CIFAR-100. Our method achieves excellent performance on both long-term incremental learning tasks and large-step incremental learning tasks. Particularly, we achieve 3.11% and 2.67% improvement under the long-term incremental setting of base 50 with 25 steps and base 0 with 20 steps, respectively. We also surpass the state-of-the-art method by 1.71% and 3.06% under the large step incremental learning setting of 20 classes per step and 10 classes per step. It should also be noted that although our method FOSTER expands a new module every time, we compress it to a single backbone every time. Therefore, the parameters and feature dimensions of our model do not increase with the number of tasks, which is our advantage over methods [44, 29, 9] based on dynamic architecture. From Fig. 3, we can see that the compressed single backbone model FOSTER has a tiny gap with FOSTER B4 in each step, which verifies the effectiveness of our distillation method.
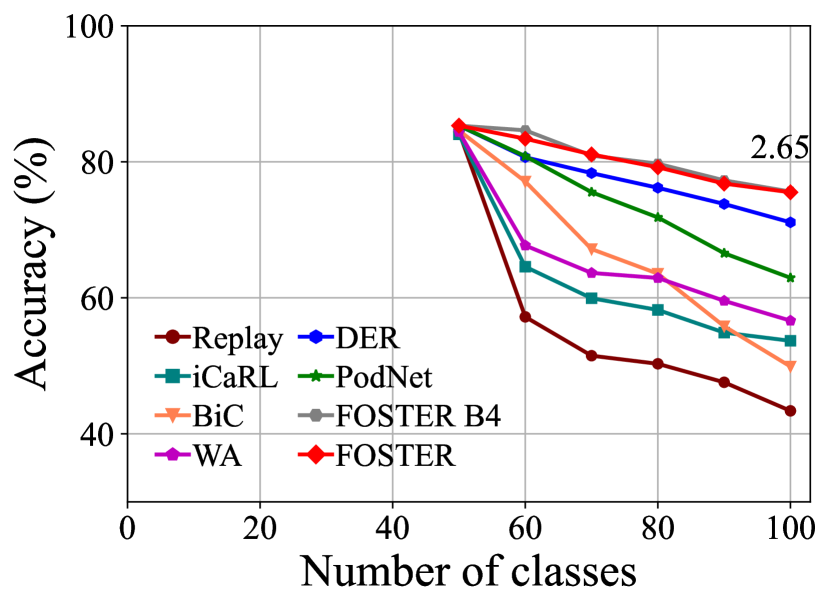
| Methods | Average accuracy of all sessions (%) | |||
| B steps | B steps | B steps | ImageNet-1000 | |
| Bound | ||||
| iCaRL [34] | ||||
| BiC [42] | - | |||
| WA [47] | ||||
| PODNet [8] | - | |||
| DER [44] | - | |||
| Ours | 74.49 | 77.54 | 69.34 | 68.34 |
| Improvement | (+0.7) | (+2.06) | (+1.61) | |
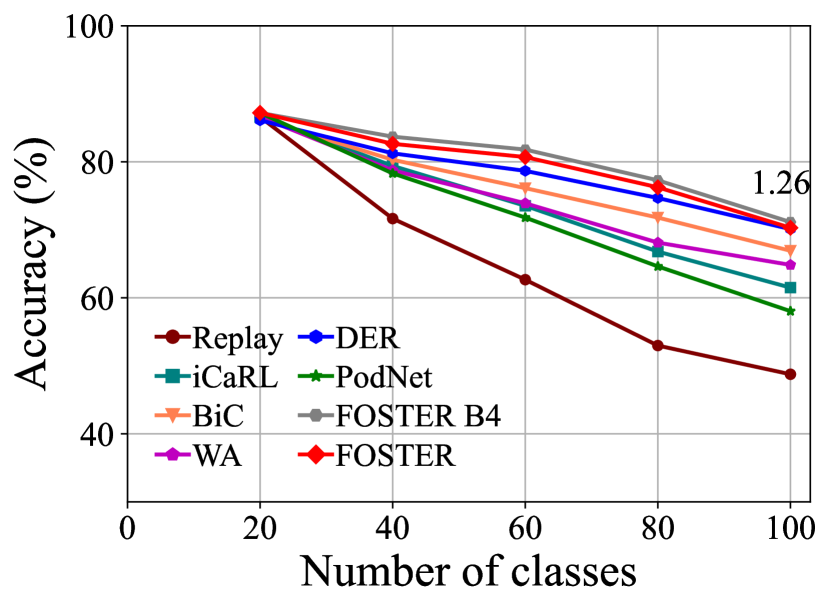
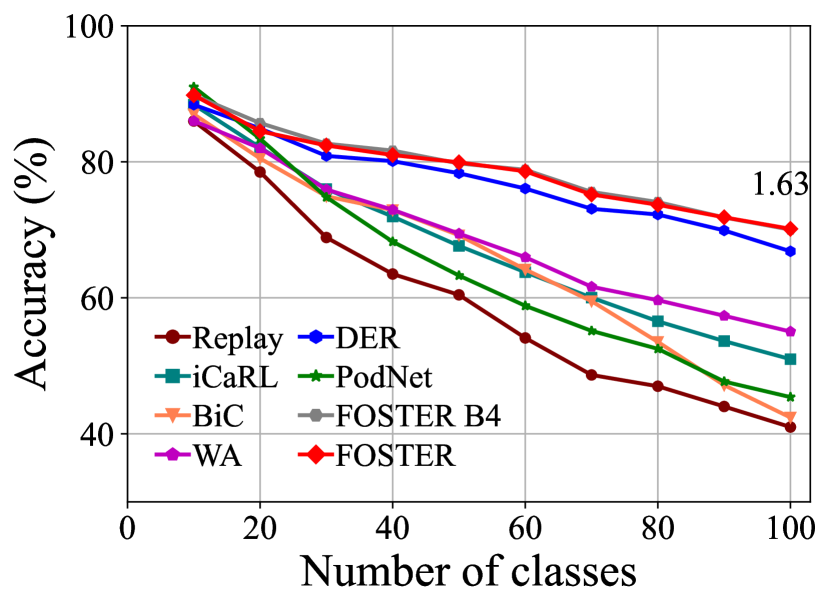
ImageNet. Table 2 and Fig. 4 summarize the experimental results for ImageNet-100 and ImageNet-1000 benchmarks. Our method, FOSTER, still outperforms the other method in most settings. In the setting of ImageNet-100 B0, we surpass the state-of-the-art method by 1.26, 1.63, and 0.7 percent points for, respectively, 5, 10, and 20 steps. The results shown in Fig. 4 again verify the effectiveness of our distillation strategy, where the performance degradation after compression is negligible. The results on ImageNet-1000 benchmark is shown in the rightmost column in Tabel 2. Our method improves the average top-1 accuracy on ImageNet-1000 with 10 steps from 66.73% to 68.34% (+1.61%), showing that our method is also efficacious in large-scale incremental learning.
5.3 Ablation Study
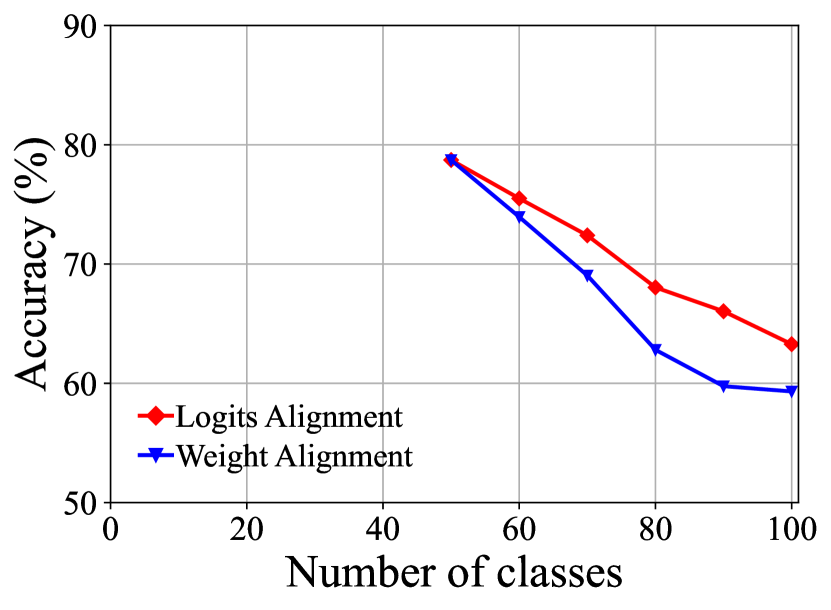
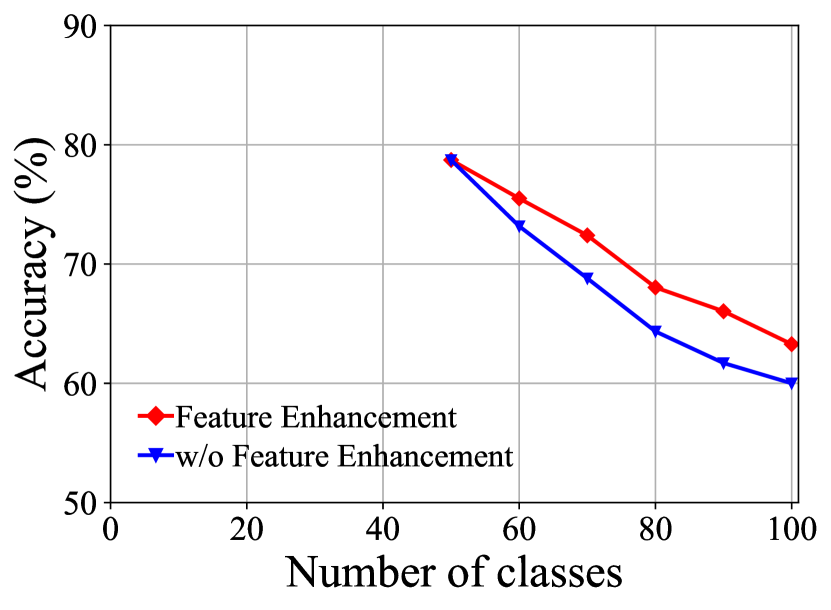
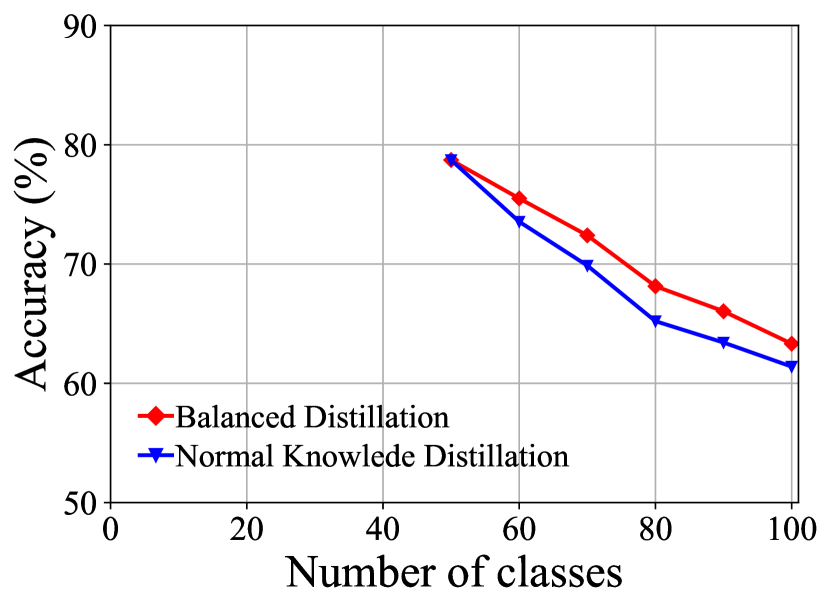
Different Components of FOSTER. Table 5 demonstrates the results of our ablative experiments on CIFAR-100 B50 with 5 steps. Specifically, we replace logits alignments (LA) with the post-processing method weight alignment (WA) [47]. The performance comparison is shown in Fig. 5(a), where LA surpasses WA by about 4% in the final accuracy. This shows that our LA is a more efficacious strategy than WA in calibration for old and new classes. We remove feature enhancement and compare its performance with the original result in Fig. 5(b), the model suffers from more than 3% performance decline in the last stage. We find that, in the last step, there is almost no difference in the accuracy of new classes between the model with feature enhancement and the model without that. Nevertheless, the model with feature enhancement outperforms the model without that by more than 4 % on old categories, showing that feature enhancement encourages the model to learn more about old categories. We compare the performance of balanced knowledge distillation (BKD) with that of normal knowledge distillation (KD) in Fig. 5(c). BKD surpasses KD in all stages, showing that BKD is more effective when training on imbalanced datasets.
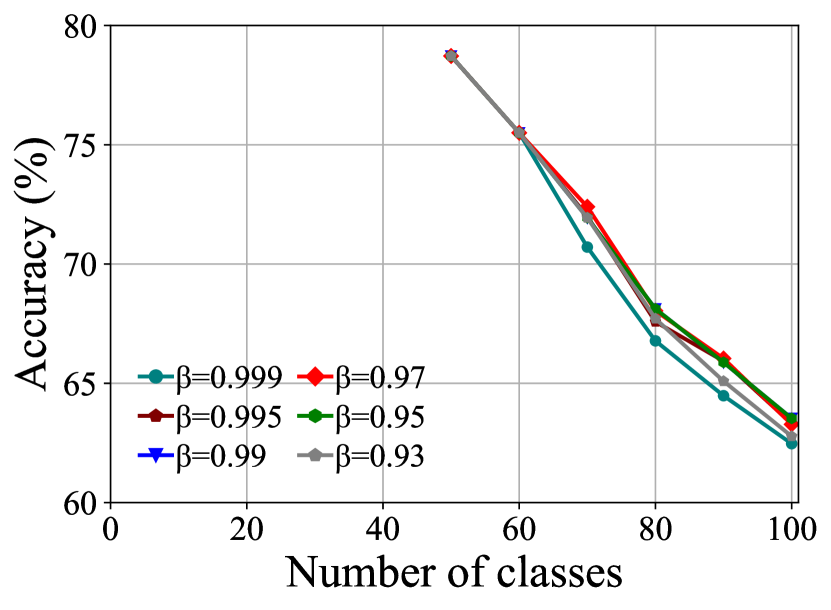
Sensitive Study of Hyper-parameters. To verify the robustness of FOSTER, we conduct experiments on CIFAR-100 B50 5 steps with different hyperparameters . Typically, is set to more than . We test , , , , , respectively. The experimental results are shown in Fig. 6(a). We can see that the performance changes are minimal under different s.
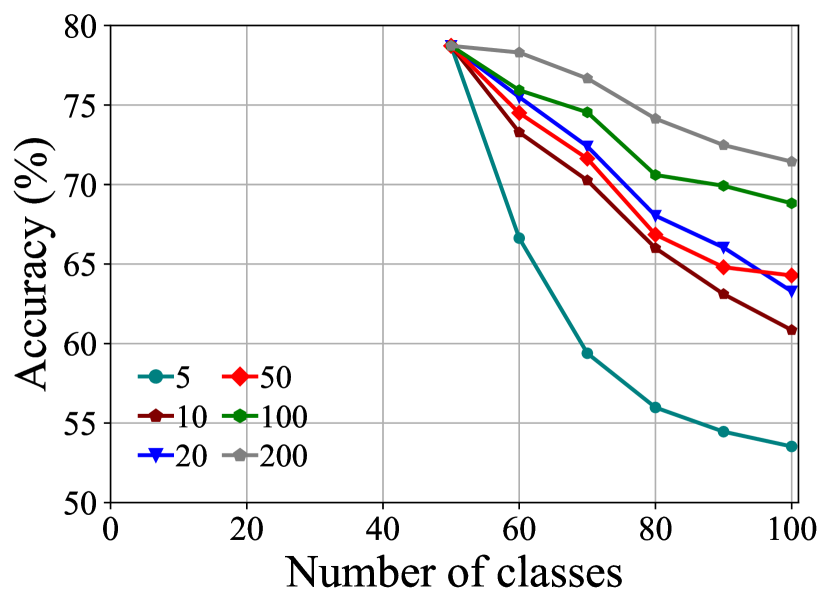
Effect of Number of Exemplars. In Fig. 6(b), We gradually increase the number of exemplars from 5 to 200 and record the performance of the model on CIFAR-100 B50 with 5 steps. The accuracy in the last step increases from 53.53% to 71.4% as the number of exemplars for every class changes from 5 to 200. From the results, we can see that with the increase in the number of exemplars, the accuracy of the last stage of the model gradually improves, indicating that our model can make full use of more exemplars to improve performance. In addition, notice that our model achieves more than 60% accuracy in the last round, even when there are only 10 exemplars for each class, surpassing most state-of-the-art methods using 20 exemplars shown in Fig. 3(c). This indicates that FOSTER is more effective and robust; it can overcome forgetting even with fewer exemplars.
Visualization of Grad-CAM. We visualize the grad-CAM before and after feature boosting. As shown in Fig. 7 (left), the freeze CNN only focuses on the head of the birds, ignoring the rest of their bodies, while the new CNN learns that the whole body is important for classification, which is consistent with our claim in Sec. 1. Similarly, the middle and right figures show that the new CNN also discovers some essential but ignored patterns of the mailbox and the dog.

6 Conclusions
In this work, we apply the concept of gradient boosting to the scenario of class-incremental learning and propose a novel learning paradigm FOSTER based on that, empowering the model to learn new categories adaptively. At each step, we create a new module to learn residuals between the target and the original model. We also introduce logits alignment to alleviate classification bias and feature enhancement to balance the representation learning of the old and new classes. Furthermore, we propose a simple yet effective distillation strategy to remove redundant parameters and dimensions, compressing the expanded model into a single backbone model. Extensive experiments on three widely used incremental learning benchmarks show that our method obtains state-of-the-art performance.
Acknowledgments.
This research was supported by National Key R&D Program of China (2020AAA0109401), NSFC (61773198, 61921006,62006112), NSFC-NRF Joint Research Project under Grant 61861146001, Collaborative Innovation Center of Novel Software Technology and Industrialization, NSF of Jiangsu Province (BK20200313), CCF-Hikvision Open Fund (20210005). Han-Jia Ye is the corresponding author.
References
- [1] Castro, F.M., Marín-Jiménez, M.J., Guil, N., Schmid, C., Alahari, K.: End-to-end incremental learning. In: ECCV. pp. 233–248 (2018)
- [2] Chen, T., Guestrin, C.: Xgboost: A scalable tree boosting system. In: KDD. pp. 785–794 (2016)
- [3] Cubuk, E.D., Zoph, B., Mane, D., Vasudevan, V., Le, Q.V.: Autoaugment: Learning augmentation strategies from data. In: CVPR. pp. 113–123 (2019)
- [4] Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S.: Class-balanced loss based on effective number of samples. In: CVPR. pp. 9268–9277 (2019)
- [5] Delange, M., Aljundi, R., Masana, M., Parisot, S., Jia, X., Leonardis, A., Slabaugh, G., Tuytelaars, T.: A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
- [6] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: CVPR. pp. 248–255. Ieee (2009)
- [7] Dorogush, A.V., Ershov, V., Gulin, A.: Catboost: gradient boosting with categorical features support. arXiv preprint arXiv:1810.11363 (2018)
- [8] Douillard, A., Cord, M., Ollion, C., Robert, T., Valle, E.: Podnet: Pooled outputs distillation for small-tasks incremental learning. In: ECCV. pp. 86–102. Springer (2020)
- [9] Douillard, A., Ramé, A., Couairon, G., Cord, M.: Dytox: Transformers for continual learning with dynamic token expansion. arXiv preprint arXiv:2111.11326 (2021)
- [10] Fernando, C., Banarse, D., Blundell, C., Zwols, Y., Ha, D., Rusu, A.A., Pritzel, A., Wierstra, D.: Pathnet: Evolution channels gradient descent in super neural networks. arXiv preprint arXiv:1701.08734 (2017)
- [11] French, R.M.: Catastrophic forgetting in connectionist networks. Trends in cognitive sciences 3(4), 128–135 (1999)
- [12] Friedman, J., Hastie, T., Tibshirani, R.: Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). The annals of statistics 28(2), 337–407 (2000)
- [13] Friedman, J.H.: Greedy function approximation: a gradient boosting machine. Annals of statistics pp. 1189–1232 (2001)
- [14] Golab, L., Özsu, M.T.: Issues in data stream management. ACM Sigmod Record 32(2), 5–14 (2003)
- [15] Golkar, S., Kagan, M., Cho, K.: Continual learning via neural pruning. arXiv preprint arXiv:1903.04476 (2019)
- [16] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural information processing systems 27 (2014)
- [17] Grossberg, S.: Adaptive resonance theory: How a brain learns to consciously attend, learn, and recognize a changing world. Neural networks 37, 1–47 (2013)
- [18] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. pp. 770–778 (2016)
- [19] Hinton, G., Vinyals, O., Dean, J., et al.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 2(7) (2015)
- [20] Hu, Z., Hong, L.J.: Kullback-leibler divergence constrained distributionally robust optimization. Available at Optimization Online pp. 1695–1724 (2013)
- [21] Hung, C.Y., Tu, C.H., Wu, C.E., Chen, C.H., Chan, Y.M., Chen, C.S.: Compacting, picking and growing for unforgetting continual learning. Advances in Neural Information Processing Systems 32 (2019)
- [22] Iscen, A., Zhang, J., Lazebnik, S., Schmid, C.: Memory-efficient incremental learning through feature adaptation. In: ECCV. pp. 699–715. Springer (2020)
- [23] Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., Kalantidis, Y.: Decoupling representation and classifier for long-tailed recognition. arXiv preprint arXiv:1910.09217 (2019)
- [24] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., Liu, T.Y.: Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems 30 (2017)
- [25] Korattikara Balan, A., Rathod, V., Murphy, K.P., Welling, M.: Bayesian dark knowledge. Advances in Neural Information Processing Systems 28 (2015)
- [26] Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
- [27] Lesort, T., Caselles-Dupré, H., Garcia-Ortiz, M., Stoian, A., Filliat, D.: Generative models from the perspective of continual learning. In: IJCNN. pp. 1–8. IEEE (2019)
- [28] Li, Z., Hoiem, D.: Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence 40(12), 2935–2947 (2017)
- [29] Li, Z., Zhong, C., Liu, S., Wang, R., Zheng, W.S.: Preserving earlier knowledge in continual learning with the help of all previous feature extractors. arXiv preprint arXiv:2104.13614 (2021)
- [30] Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983 (2016)
- [31] Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research 9(11) (2008)
- [32] Masana, M., Liu, X., Twardowski, B., Menta, M., Bagdanov, A.D., van de Weijer, J.: Class-incremental learning: survey and performance evaluation on image classification. arXiv preprint arXiv:2010.15277 (2020)
- [33] Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., Lerer, A.: Automatic differentiation in pytorch (2017)
- [34] Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: icarl: Incremental classifier and representation learning. In: CVPR. pp. 2001–2010 (2017)
- [35] Rubinstein, R.Y., Kroese, D.P.: The cross-entropy method: a unified approach to combinatorial optimization, Monte-Carlo simulation, and machine learning, vol. 133. Springer (2004)
- [36] Rusu, A.A., Rabinowitz, N.C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., Hadsell, R.: Progressive neural networks. arXiv preprint arXiv:1606.04671 (2016)
- [37] Serra, J., Suris, D., Miron, M., Karatzoglou, A.: Overcoming catastrophic forgetting with hard attention to the task. In: ICML. pp. 4548–4557. PMLR (2018)
- [38] Wang, L., Yang, K., Li, C., Hong, L., Li, Z., Zhu, J.: Ordisco: Effective and efficient usage of incremental unlabeled data for semi-supervised continual learning. In: CVPR. pp. 5383–5392 (2021)
- [39] Wang, L., Zhang, M., Jia, Z., Li, Q., Bao, C., Ma, K., Zhu, J., Zhong, Y.: Afec: Active forgetting of negative transfer in continual learning. NeurIPS 34, 22379–22391 (2021)
- [40] Wang, L., Zhang, X., Yang, K., Yu, L., Li, C., Lanqing, H., Zhang, S., Li, Z., Zhong, Y., Zhu, J.: Memory replay with data compression for continual learning. In: ICLR (2022)
- [41] Wen, Y., Tran, D., Ba, J.: Batchensemble: an alternative approach to efficient ensemble and lifelong learning. arXiv preprint arXiv:2002.06715 (2020)
- [42] Wu, Y., Chen, Y., Wang, L., Ye, Y., Liu, Z., Guo, Y., Fu, Y.: Large scale incremental learning. In: CVPR. pp. 374–382 (2019)
- [43] Wu, Z., Baek, C., You, C., Ma, Y.: Incremental learning via rate reduction. In: CVPR. pp. 1125–1133 (2021)
- [44] Yan, S., Xie, J., He, X.: Der: Dynamically expandable representation for class incremental learning. In: CVPR. pp. 3014–3023 (2021)
- [45] Yoon, J., Yang, E., Lee, J., Hwang, S.J.: Lifelong learning with dynamically expandable networks. arXiv preprint arXiv:1708.01547 (2017)
- [46] Zhang, S., Chen, C., Hu, X., Peng, S.: Balanced knowledge distillation for long-tailed learning. arXiv preprint arXiv:2104.10510 (2021)
- [47] Zhao, B., Xiao, X., Gan, G., Zhang, B., Xia, S.T.: Maintaining discrimination and fairness in class incremental learning. In: CVPR. pp. 13208–13217 (2020)
- [48] Zhou, D.W., Wang, F.Y., Ye, H.J., Ma, L., Pu, S., Zhan, D.C.: Forward compatible few-shot class-incremental learning. In: CVPR. pp. 9046–9056 (2022)
- [49] Zhou, D.W., Wang, F.Y., Ye, H.J., Zhan, D.C.: Pycil: A python toolbox for class-incremental learning. arXiv preprint arXiv:2112.12533 (2021)
- [50] Zhou, D.W., Yang, Y., Zhan, D.C.: Learning to classify with incremental new class. IEEE Transactions on Neural Networks and Learning Systems (2021)
- [51] Zhou, D.W., Ye, H.J., Zhan, D.C.: Co-transport for class-incremental learning. In: ACM MM. pp. 1645–1654 (2021)
- [52] Zhou, D.W., Ye, H.J., Zhan, D.C.: Learning placeholders for open-set recognition. In: CVPR. pp. 4401–4410 (2021)
- [53] Zhou, D.W., Ye, H.J., Zhan, D.C.: Few-shot class-incremental learning by sampling multi-phase tasks. arXiv preprint arXiv:2203.17030 (2022)
- [54] Zhou, Z.H.: Ensemble methods: foundations and algorithms. CRC press (2012)
Supplementary Material
I Rationality Analysis of the Substitution.
We argue that our simplification of replacing the sum of softmax with softmax of logits sum and substituting the distance metric for the Kullback-Leibler divergence (KLD) . KLD can evaluate the residual between the target and the output by calculating the distance between the target label distribution and the output distribution of categories. KLD is more suitable for classification tasks, and there are some works [20, 35] that point out that the KLD has many advantages in many aspects, including faster optimization and better feature representation. Typically, to reflect the relative magnitude of each output, we use non-linear activation softmax to transform the output logits into the output probability. Namely, , where , and is the number of all seen categories. In classification tasks, the target label is usually set to 1, and the non-target label is set to 0. Therefore, we expect the output of the boosting model can be constrained between and . Simply combining the softmax outputs of the original model and can not satisfy the constraints. Suppose that the output of and in class are and , the combination of and is not in line with our expectation since . By replacing the sum of softmax with softmax of logits sum, we can limit the output of the boosting model between 0 and 1, and the judgment of the two models can still be integrated.
II Influence of the Initialization of the Weight
In this section, we discuss the effect of the initialization of the weight in the super linear classifier of our boosting model.
| (3) |
In the main paper, we set to all zero as our default initialization strategy. Therefore, the outputs of the original model for new categories are zero, thus having nothing to do with the classification of new classes.
Here, we introduce three different initialization strategies, including fine-tune (FT), all-zero (AZ), and all-zero with bias (AZB), to further explore the impact of different initialization strategies on performance. Among them, FT is directly training without any restrictions. AZ sets the outputs of the old model on the new class to all zero, and thus the outputs of the model on the new class logits only contain the output of the new model, and the old model does not provide any judgment on the new class. Based on AZ, AZB adds bias learning to balance the logits of the old and new categories.
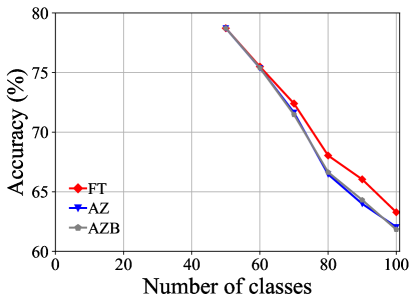
Fig. 1 illustrates the comparison of performance on CIFAR-100 [26] B50 with 5 steps with different initialization strategies. We can see that the performance of using FT initialization strategy is slightly better than that of using AZ and AZB initialization strategies, but the difference is not significant. The performance gap between AZ and AZB is negligible, indicating that the influence of bias is weak.
III Introduction to Compared Methods
In this section, we will describe in detail the methods compared in the main paper.
Fine-tune: Fine-tune is the baseline method that simply updates its parameters when a new task comes, suffering from catastrophic forgetting. By default, weights corresponding to the outputs of previous classes in the final linear classifier are not updated.
Replay: Replay utilizes the rehearsal strategy to alleviate the catastrophic forgetting compared to Fine-tune. We use herding as the default way of choosing exemplars from the old data.
iCaRL [34]: iCaRL combines cross-entropy loss with knowledge distillation loss together. It retains an old model to help the new model maintain the discrimination ability through knowledge distillation on old categories. To mitigate the classification bias caused by the imbalanced dataset when learning new tasks, iCaRL calculates the center of exemplars for each category and uses NME as the classifier for evaluation.
BiC [42]: BiC performs an additional bias correction process compared to iCaRL, retaining a small validation set to estimate the classification bias resulting from imbalanced training. The final logits are computed by
| (6) |
where is the number of old categories and is the number of new ones. the bias correction step is to estimate the appropriate and .
WA [47]: During the process of incremental learning, the norms of the weight vectors of new classes are much larger than those of old classes. Based on that, WA proposes an approach called Weight Alignment to correct the biased weights in the final classifier by aligning the norms of the weight vectors of new classes to those of old classes.
| (7) |
where
PODNet [8]: PODNet proposes a novel spatial-based distillation loss that can be applied throughout the model. PODNet has greater performance on long runs of small incremental tasks.
DER [44]: DER preserves old feature extractors to maintain knowledge for old categories. When new tasks come, DER creates a new feature extractor and concatenates it with old feature extractors to form a higher dimensional feature space. In order to reduce the number of parameters, DER uses the pruning method proposed in HAT [37], but the number of parameters still increases with the number of tasks. DER can be seen as a particular case of our Boosting model. When we set the weight of boosting model can be trainable, and remove feature enhancement and logits alignment proposed in the main paper, boosting model can be reduced to DER.
IV Visualization of Detailed Performance
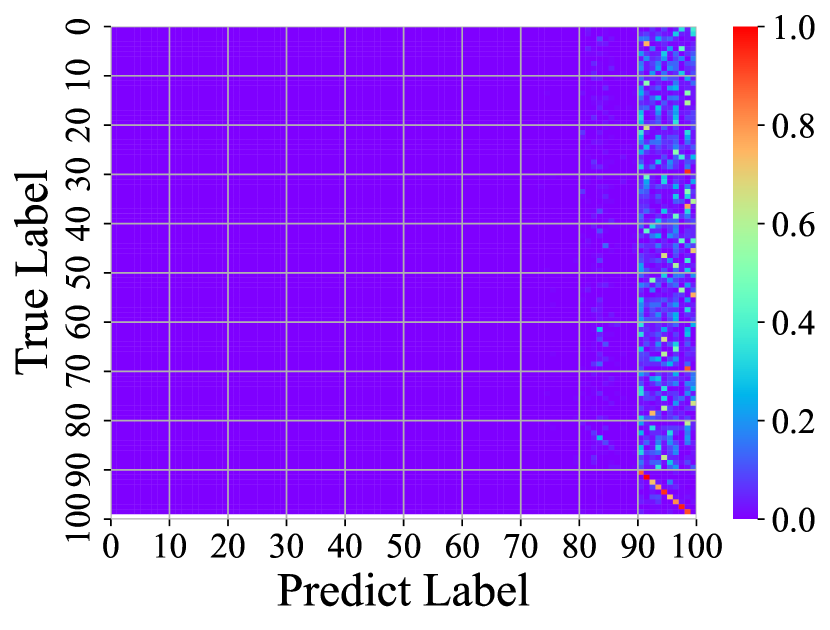
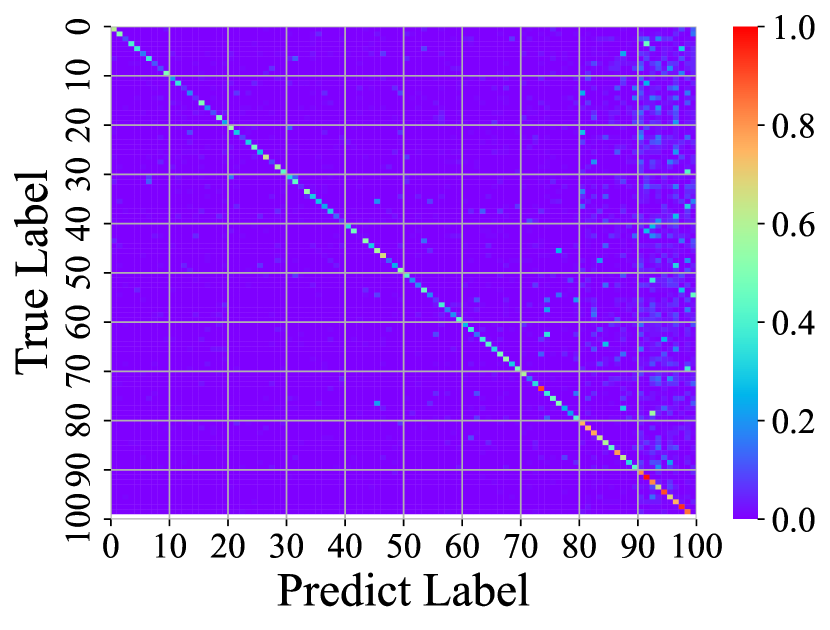
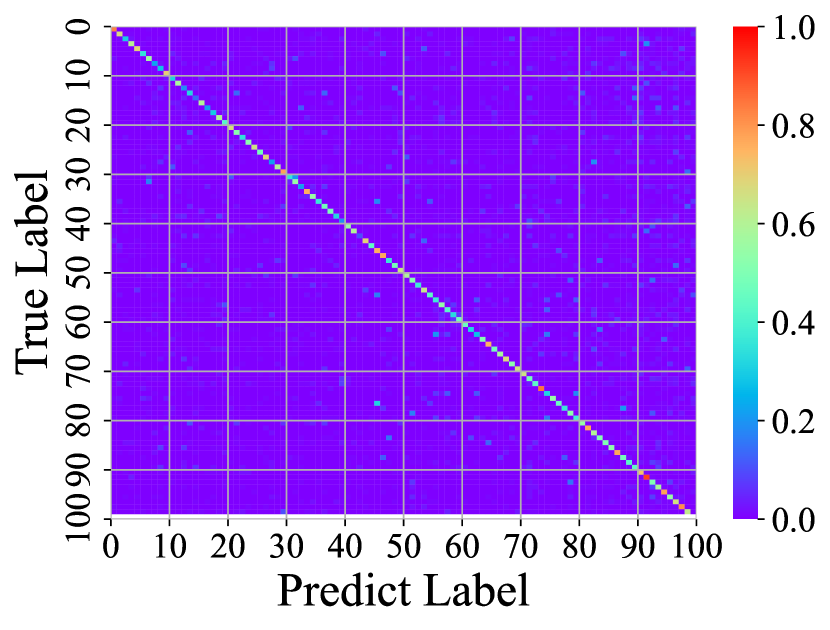
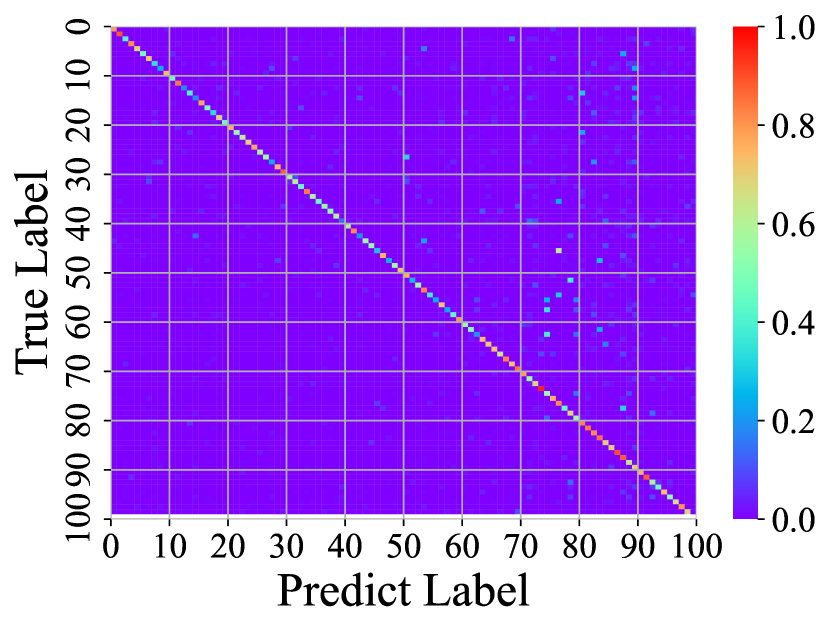
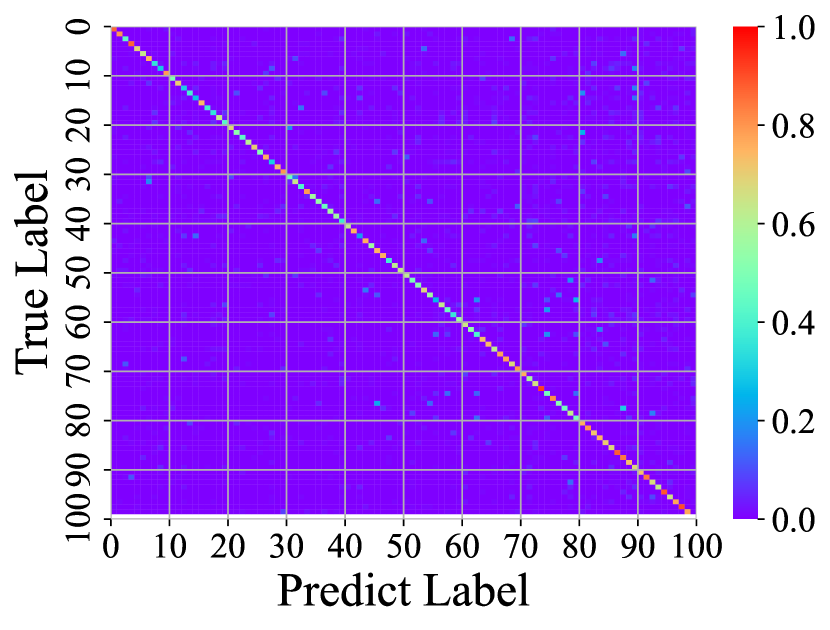
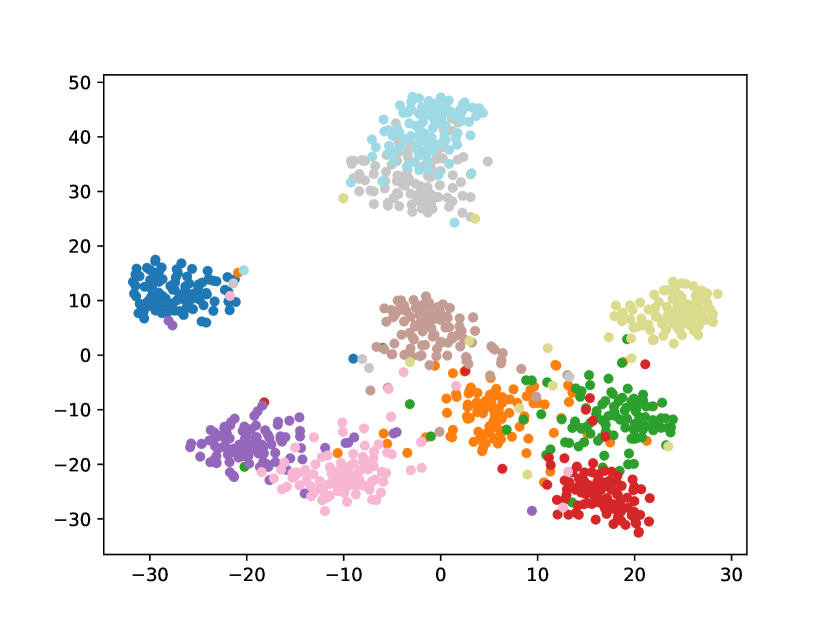
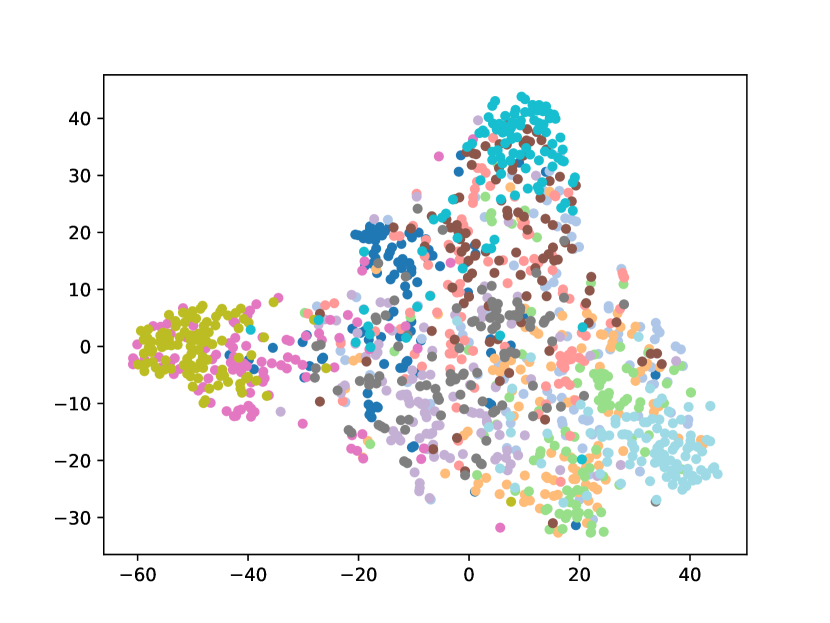
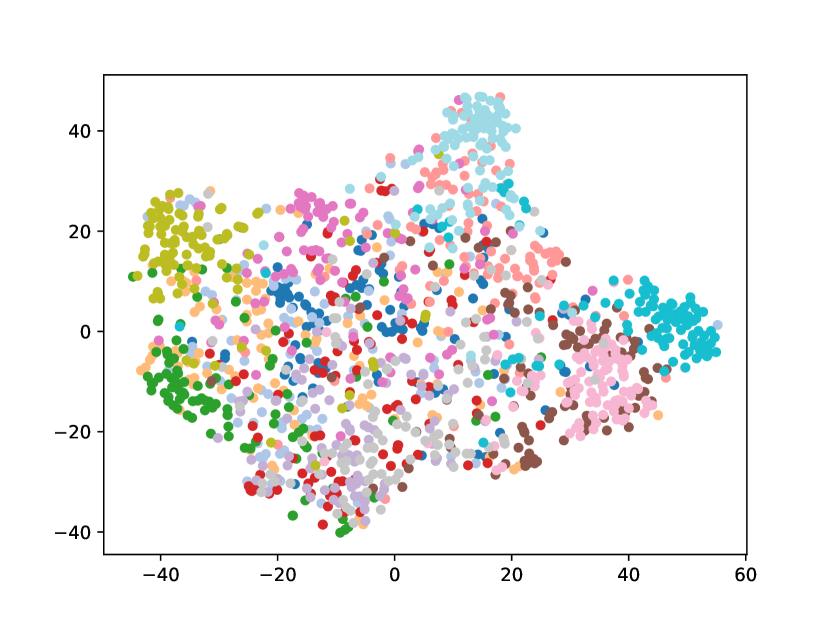
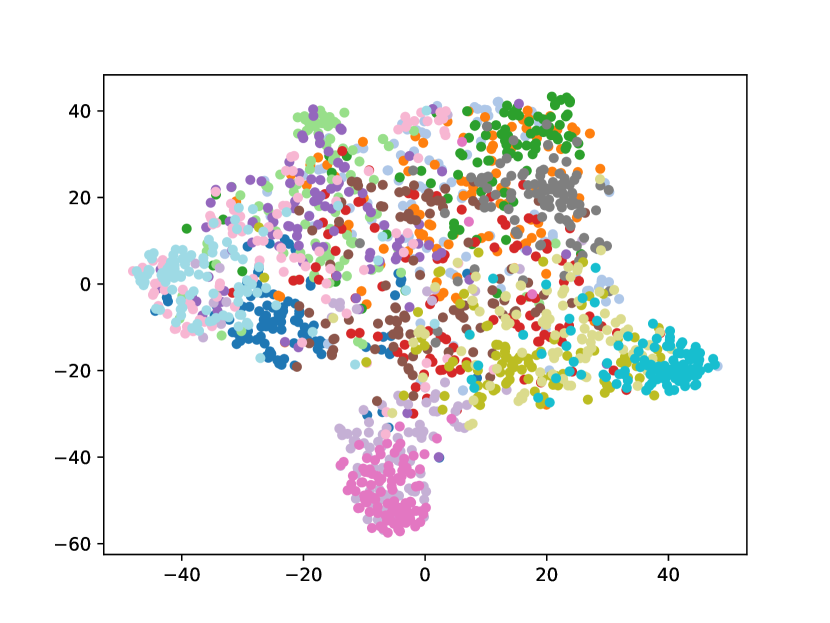
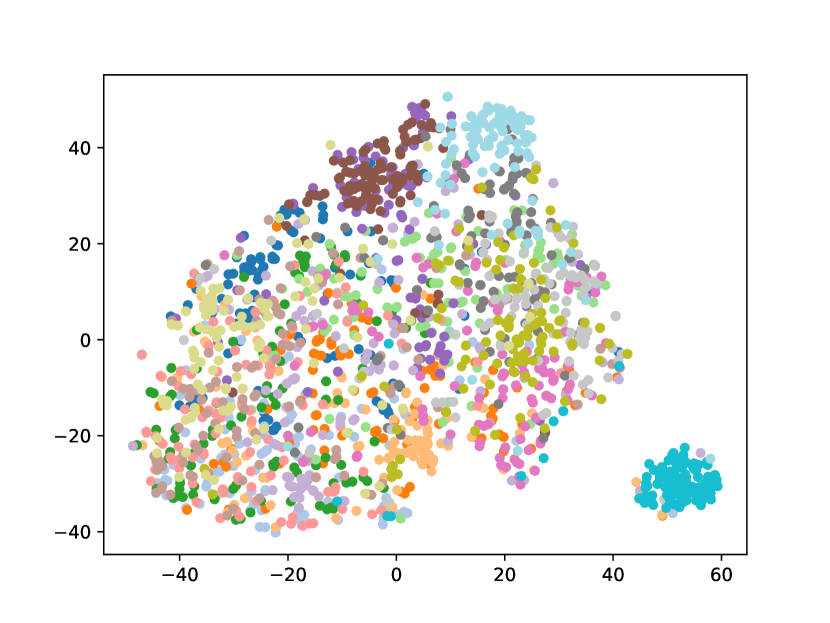
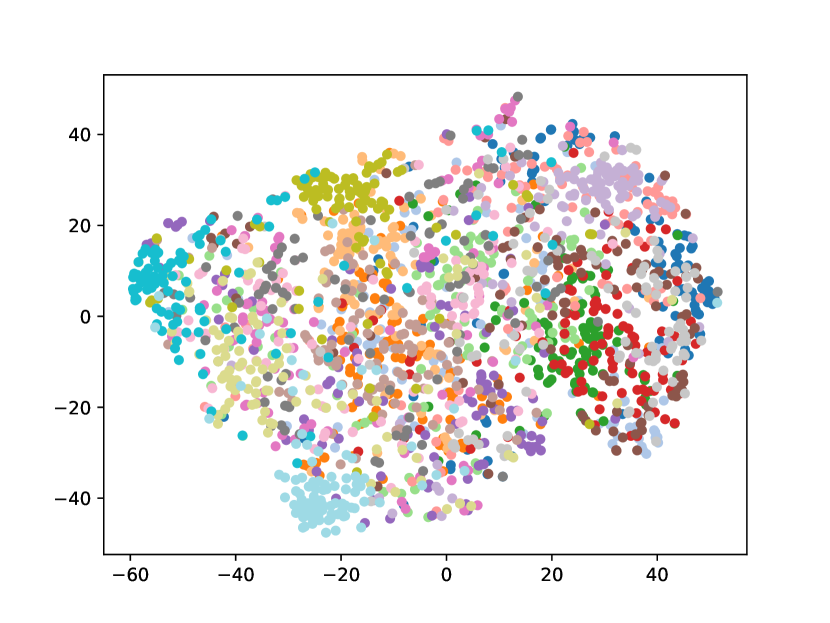
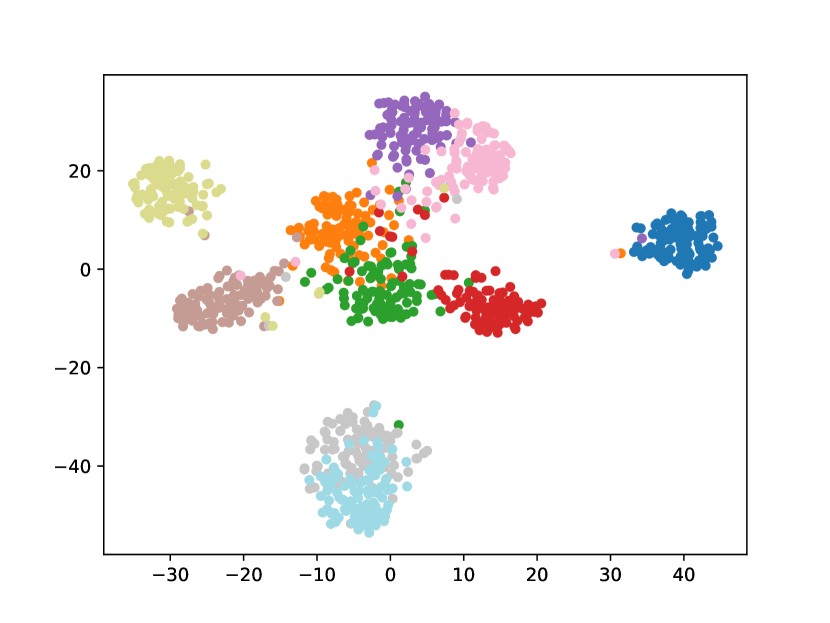
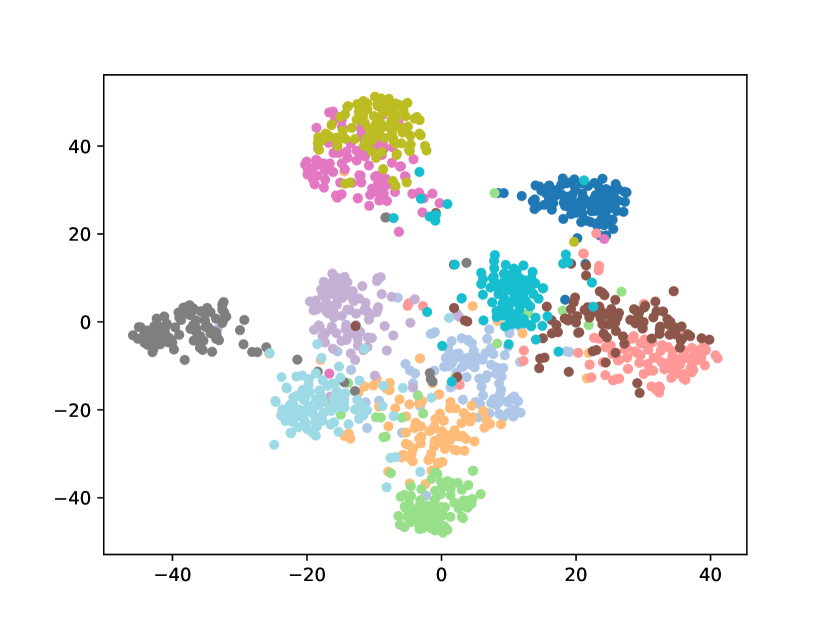
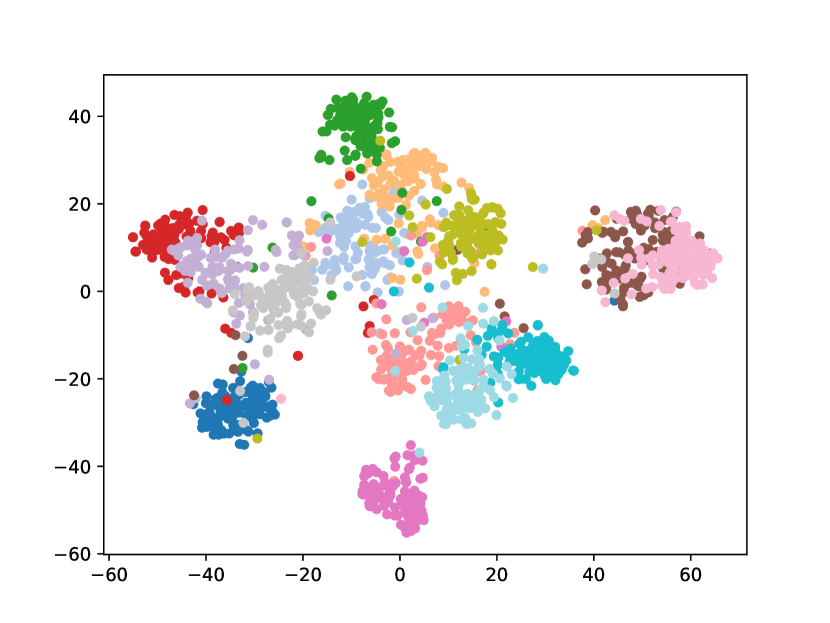
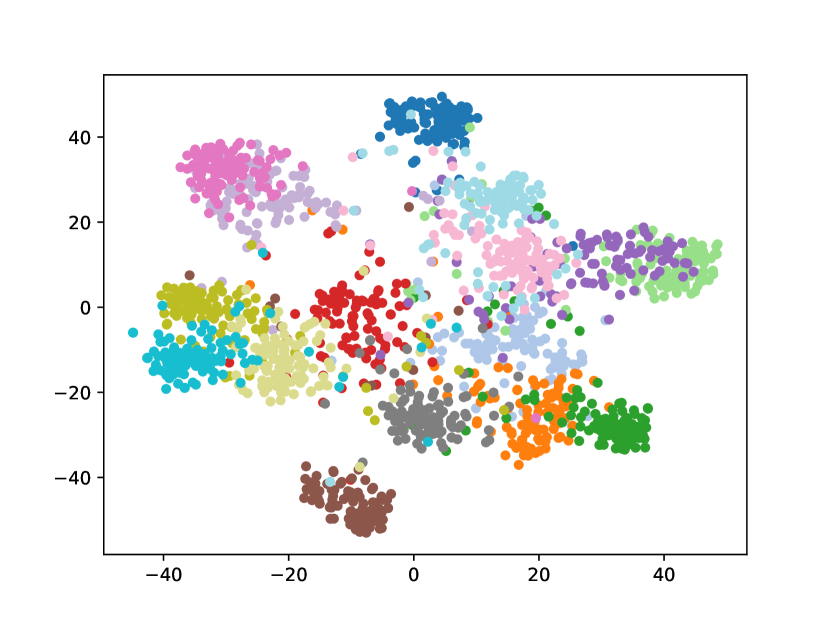
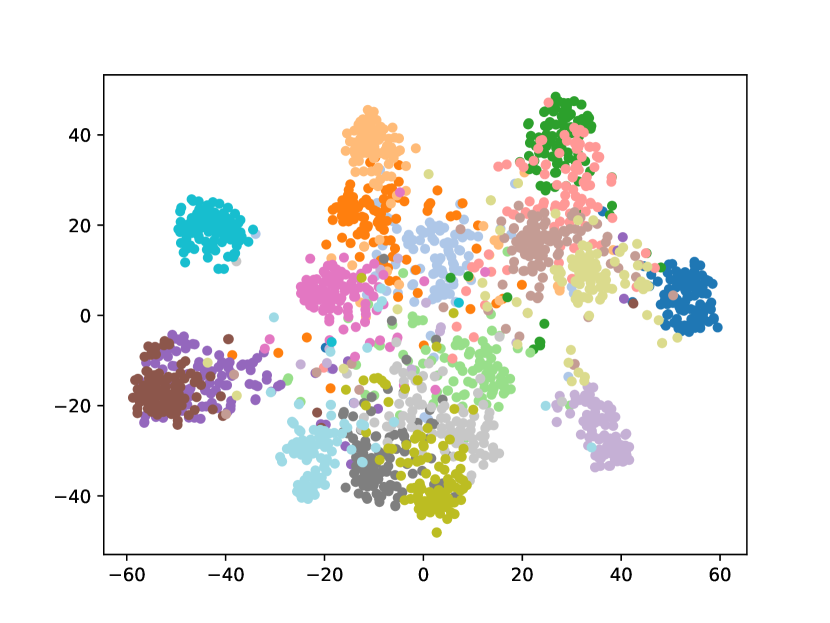
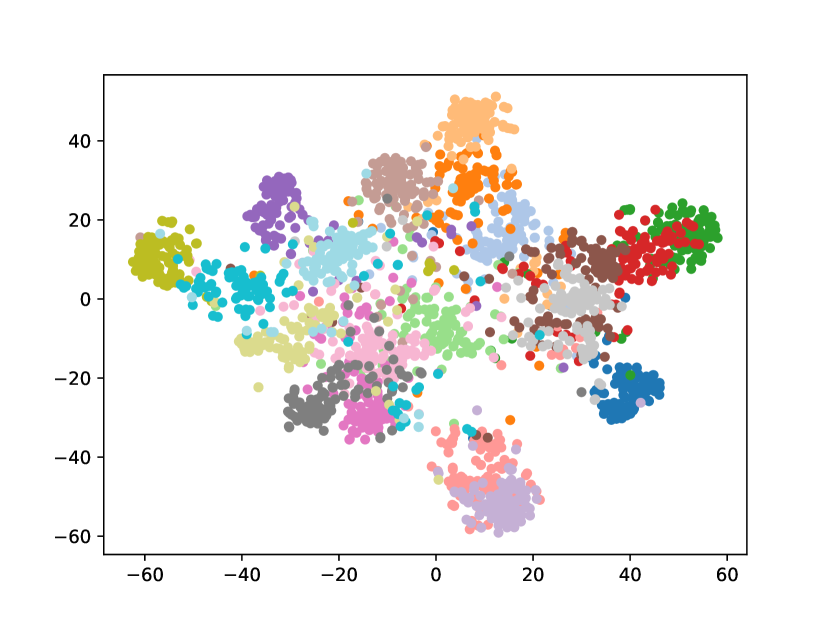
Visualizing Feature Representation. We visualize the feature representations of the test data by t-SNE [31]. Fig. 2 illustrates the comparison of baseline method, fine-tune, with our FOSTER in the setting of CIFAR-100 [26] B50 with 5 steps. As shown in Fig. 2(a) and Fig. 2(g), in the base task, all categories can form good clusters with explicit classification boundaries. However, as shown in Fig. 2(b), Fig. 2(c), Fig. 2(d), Fig. 2(e), and Fig. 2(f), in stages of incremental learning, the result of category clustering becomes very poor without clear classification boundaries. In the last stage which is shown in Fig.2(f), feature points of each category are scattered. On the contrary, as shown in Fig. 2(g), Fig. 2(h), Fig. 2(i), Fig. 2(j), Fig. 2(k), and Fig. 2(l). our FOSTER method can make all categories form good clusters at each incremental learning stage, and has a clear classification boundary, indicating that our FOSTER method is a very effective strategy in feature representation learning and overcoming catastrophic forgetting.
Visualizing Confusion Matrix. To compare with other methods, we visualize the confusion matrices of different methods at the last stage in Fig. 3. In these confusion matrices, the vertical axis represents the real label, and the horizontal axis represents the label predicted by the model. Warmer colors indicate higher prediction rates, and cold colors indicate lower ones. Therefore, the warmer the point color on the diagonal and the colder the color on the other points, the better the performance of the model. Fig. 3(a) shows the confusion matrix of fine-tune. The brightest colors on the right and colder colors elsewhere suggest that the fine-tune method has a strong classification bias, tending to classify inputs into new categories and suffering from severe catastrophic forgetting. Fig. 3(b) shows the confusion matrix of iCaRL [34]. iCaRL has obvious performance improvement compared with fine-tune. However, the columns on the right are still bright, indicating that they also have a strong classification bias. In addition, the points on the diagonal have obvious discontinuities, indicating that they cannot make all categories achieve good accuracy. Fig. 3(c) shows the confusion matrices of WA [47]. Benefiting from Weight Alignment, WA significantly reduces classification bias compared with iCaRL. The rightmost columns have no obvious brightness. Nevertheless, its accuracy in old classes is not high enough. As shown in the figure, most of his color brightness at the diagonal position of the old class is between 0.2 and 0.4. Fig. 3(d) shows the confusion matrices of DER [44]. DER achieves good results in both old and new categories, but the brightness of the upper right corner shows that it still suffers from classification bias and has room for improvement. As shown in Fig. 3(e), our method FOSTER performs well in all categories and well balances the accuracy of the old and new classes.