Fragmentation properties of two-dimensional Proximity Graphs considering random failures and targeted attacks
Abstract
The pivotal quality of proximity graphs is connectivity, i.e. all nodes in the graph are connected to one another either directly or via intermediate nodes. These types of graphs are robust, i.e., they are able to function well even if they are subject to limited removal of elementary building blocks, as it may occur for random failures or targeted attacks. Here, we study how the structure of these graphs is affected when nodes get removed successively until an extensive fraction is removed such that the graphs fragment. We study different types of proximity graphs for various node removal strategies. We use different types of observables to monitor the fragmentation process, simple ones like number and sizes of connected components, and more complex ones like the hop diameter and the backup capacity, which is needed to make a network resilient. The actual fragmentation turns out to be described by a second order phase transition. Using finite-size scaling analyses we numerically assess the threshold fraction of removed nodes, which is characteristic for the particular graph type and node deletion scheme, that suffices to decompose the underlying graphs.
pacs:
07.05.Tp, 64.60.an, 64.60.F-I Introduction
The pivotal issue of standard percolation Stauffer (1979); Stauffer and Aharony (1992) is connectivity. A basic example is random site percolation, where one studies a lattice in which a random fraction of the sites is “occupied”. Clusters composed of adjacent occupied sites are then analyzed regarding their geometric properties. Depending on the fraction of occupied sites, the geometric properties of the clusters change, leading from a “fragmented” phase with rather small and disconnected clusters to a phase, where there is basically one large connected cluster covering the lattice. Therein, the appearance of an infinite, i.e. percolating, cluster is described by a second-order phase transition.
Similar to the issue of connectivity is the robustness, i.e. the ability of networks to function well even if they are subject to random failures or targeted attacks of their elementary building blocks, e.g., node removal. This is of particular importance for more applied real-world networks, which may fail even if they are still connected, e.g., when the dynamics of nodes is not synchronous due to an failure. Also, many real-world networks are not embedded in two-dimensions, they may even exhibit an infinite-dimensional, i.e., mean-field structure. E.g., electrical power grids must ensure power supply for entire resident population Albert et al. (2004), urban road networks Jiang and Claramunt (2004) and airline networks Choi et al. (2006) facilitate social and economical interaction, and the internet Barabási et al. (2000), which has become essential in almost all aspects of life. In general, networks are represented by a set of nodes, i.e. the elementary building blocks of a network, and pairs of nodes might be joined by edges. One possibility to characterize a network (or graph for that matter) is by means of its degree distribution, where the degree of a node refers to the number of its adjacent neighbors. Several real-world networks, such as the hyperlink-network of the internet, exhibit a scale-free degree distribution Barabási et al. (2000). During the last decade, various studies have been published that focus on this prototypical type of degree distribution. In particular, the fragmentation properties of scale-free Barabási-Albert (BA) networks Albert et al. (2000); Callaway et al. (2000); Crucitti et al. (2004a); Gallos et al. (2005); Holme et al. (2002); Cohen et al. (2001) (and also of several other ones Huang et al. (2011); Kurant et al. (2007); Paul et al. (2004); Shargel et al. (2003); Tanizawa et al. (2012)) have been put under scrutiny. In the aforementioned articles, different node-removal strategies have been considered to investigate the fragmentation properties of the considered networks. It turns out that scale-free networks are robust against random node removals, but very vulnerable to intentional attacks targeting particular “important” nodes. Note that there are many different local and global measures to quantify whether a node is important. Popular choices are, e.g., the degree of a node, its betweenness-centrality Brandes (2008) (subject to a particular metric used to measure the length of shortest paths between pairs of nodes), or, somewhat more specific to the hyperlink structure of the internet, the “PageRank” Page et al. (1999) relevance measure for web pages.
In the presented work we focus on types of networks, which are completely different from scale free graphs. The networks considered here are constructed from sets of points distributed in the two-dimensional Euclidean plane. More precisely, we consider three types of proximity graphs, namely relative neighborhood graphs (RNGs) Toussaint (1980), Gabriel graphs (GGs) Gabriel and Sokal (1969), and Delaunay triangulations (DTs) Sibson (1978). These are planar graphs Essam and Fisher (1970) where pairs of nodes are connected by undirected edges if they are considered to be close in some sense (see definitions in Sec. II). In addition, we consider also a certain type of (non planar) geometric random network, termed minimum-radius graph (MR), where pairs of nodes are connected if their distance does not exceed a particular threshold value. The above proximity graphs where already studied in different scientific fields such as the simulation of epidemics Toroczkai and Guclu (2007), percolation Bertin et al. (2002); Becker and Ziff (2009); Billiot et al. (2010); Melchert (2013), and message routing and information dissemination in ad-hoc networking Jennings and Okino (2002); Santi (2005); Li et al. (2005); Rajaraman (2002). To elaborate on the latter point, proximity graphs find application in the construction of planar “virtual backbones” for ad-hoc networks, i.e. collections of radio devices without fixed underlying infrastructure, along which information can be efficiently transmitted Karp and Kung (2000); Bose et al. (2001); Jennings and Okino (2002); Yi et al. (2010); Kuhn et al. (2003). Routing with guaranteed node-to-node connectivity (at least in a multi-hop manner) is especially important to ensure a complete broadcast of information in ad-hoc networks Jennings and Okino (2002). Here, we consider three types of node removal strategies with different levels of severity, see Sec. III, and we numerically assess the threshold fraction of removed nodes (characteristic for the particular graph type and node deletion scheme) that suffices to decompose the underlying graphs into “small” clusters.
The remaining article is organized as follows. In Sec. II we introduce the four different graph types that were considered in the presented study. In Sec. III we describe the three node-removal strategies that were used in order to characterize the fragmentation process for each of these graph types. In Sec. IV we introduce the observables that were recorded during the fragmentation procedure and we list the results of our numerical simulations. Finally, Sec. V concludes with a summary.
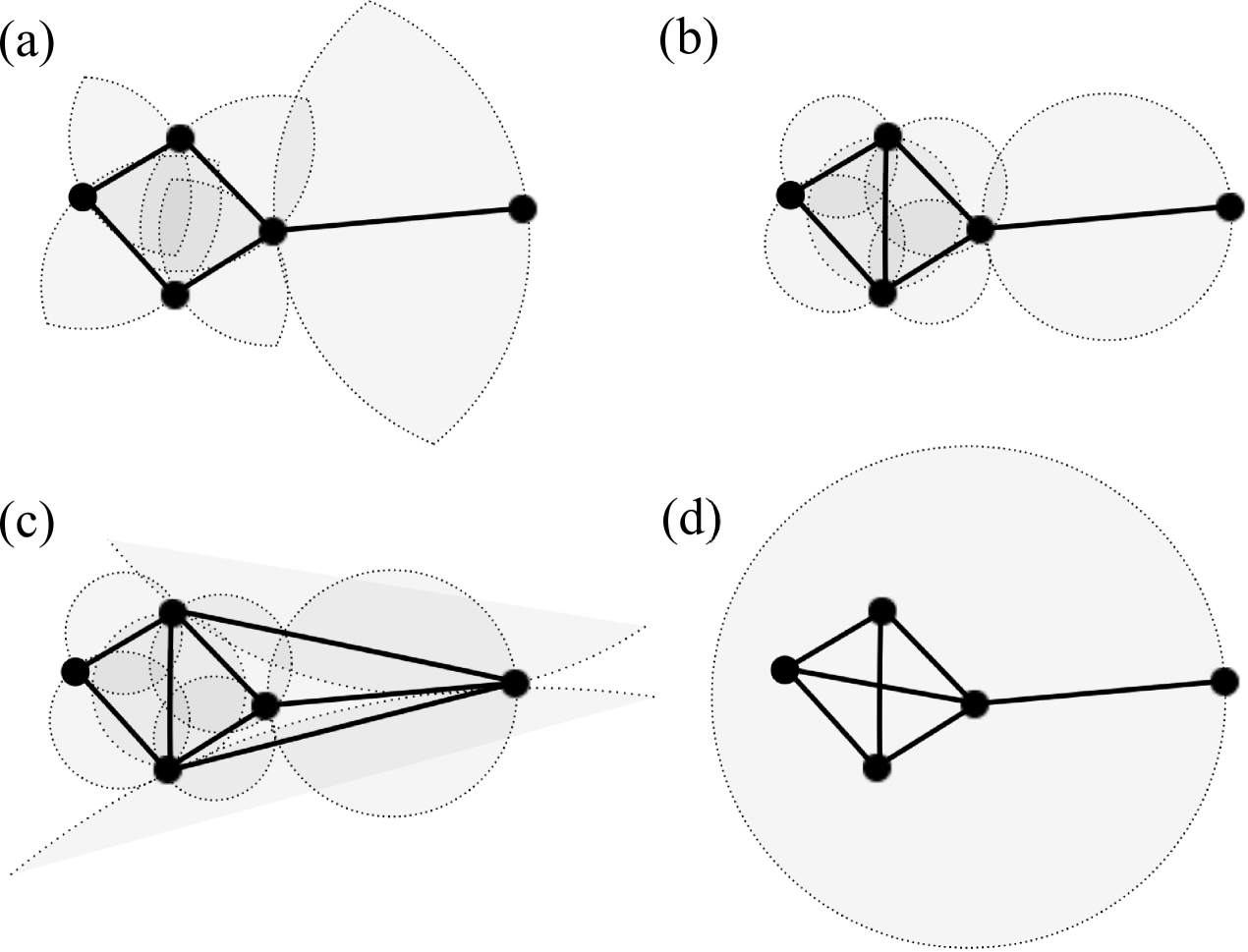
II Graph Types
Subsequently we introduce four different types of graphs for a planar set of, say, points and we characterize the fragmentation process on each of these graph types following three different node-removal strategies, detailed in Sec. III. Three of these graph types, introduced in Subsects. II.1 through II.3 belong to the class of proximity graphs Jaromczyk and Toussaint (1992). The fourth graph type, detailed in Subsect. II.4, is a particular type of a random geometric graph. Below, a graph is referred to as , where comprises its node-set (; where is also referred to as “system size”), and where () signifies the respective edge-set Essam and Fisher (1970). Each of the nodes represents a point in the two-dimensional unit square for which the coordinates and are drawn uniformly and independently at random. So as to compute the distance between two nodes we consider the Euclidean metric under which . We further consider open boundary conditions. Thus an increase of the system size corresponds to increasing the density of nodes on the unit square. On the other hand, so as to maintain the density of nodes while increasing , the networks can be pictured as having an effective side-length . A common feature of these four types of graphs is that their edge-set encodes proximity information regarding the close neighbors of the terminal nodes of a given edge. The different graph types can be distinguished by the precise linking-rule that is used to construct the edge-set for a given set of nodes. In this section the linking-rules that define the four types of proximity graphs will be detailed.
II.1 Relative Neighborhood Graphs (RNGs)
One particular proximity graph type that will be considered subsequently is the relative neighborhood graph (RNG) Toussaint (1980). In order to determine whether in the construction procedure for an instance of a RNG two nodes need to be connected to each other, it is necessary to check if there is a third node with and . If such a node does not exist, and will get linked. In geometrical terms, for each pair and of points, the respective distance can be used to construct the lune . The lune is given by the intersection of two circles with equal radius , centered at and , respectively. If no other point lies within , i.e. if the lune is empty, both nodes are connected by means of an edge. To facilitate intuition, an example of a RNG for a small set of nodes is sketched in Fig. 1(a). A larger example that illustrates the principal structure of a RNG is shown in Fig. 2(a).
II.2 Gabriel Graphs (GGs)
Another proximity graph that will be considered in this article is the Gabriel graph (GG) Gabriel and Sokal (1969); Bertin et al. (2002). To determine whether in the construction procedure for an instance of a GG two nodes need to be connected, , i.e. the smallest of all possible circles which embeds both nodes is considered, which has a diameter . These two nodes will be connected unless there is another node which is located within the area enclosed by . To facilitate intuition, the linking rule for the GG is illustrated in Fig. 1(b). A larger example that illustrates the principal structure of a GG is shown in Fig. 2(b). Further, note that the GG is a super-graph of the RNG. This is due to the circumstance that , which is relevant in the construction procedure of a GG instance for a given set of nodes encloses a subarea of , being relevant in the construction procedure of the corresponding RNG instance (compare the grey shaded surfaces in Figs. 1(a,b)). Therefore, all edges contained in the RNG are also included in the GG. Note that this can also be seen in Figs. 2(a,b).
II.3 Delaunay Triangulations (DTs)
The construction of the Delaunay triangulation (DT; also a type of proximity graph) Sibson (1978) is quite similar. Two nodes will be connected if any circle exists which embeds as well as but no further nodes. To facilitate intuition, the result of this linking-rule is shown in Fig. 1(c). A larger example that illustrates the principal structure of a DT is shown in Fig. 2(c). From the definition of these linking-rules, since the GG graph also involves the construction of a circle, it is evident that an instance of a DT for a given set of nodes must be a super-graph of the corresponding GG instance. As a consequence, being a sub-graph of the GG, the RNG is also a sub-graph of the DT. This can be observed in Figs. 1(a-c) (Figs. 2(a-c)), where the RNG, GG and DT are illustrated for the same set of () nodes.
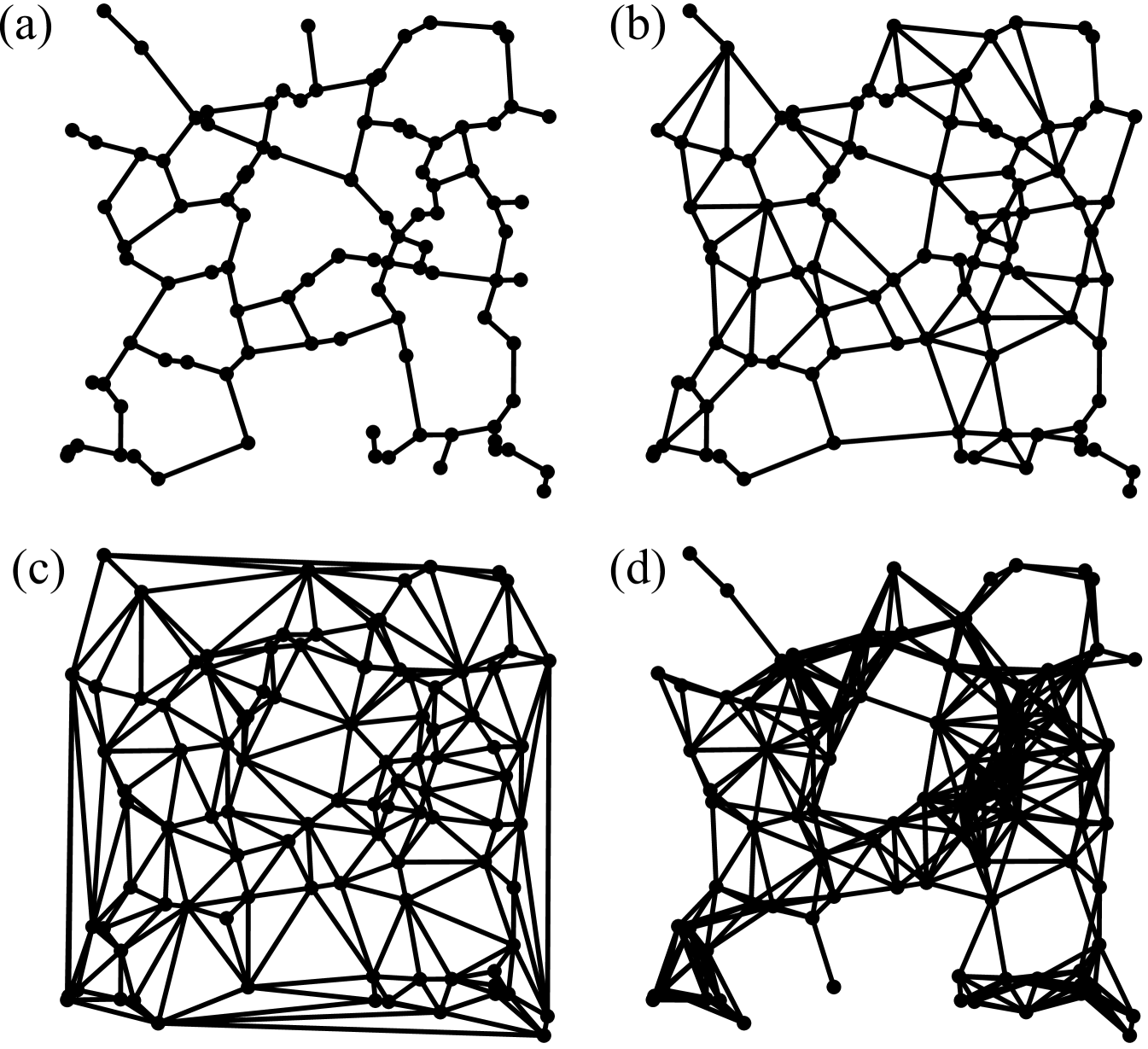
II.4 Minimum Radius Graphs (MRs)
The fourth network topology that will be considered is the minimum radius graph (MR). In the construction procedure of an instance of a MR, two nodes will be joined by an edge, if . Therein, the “connectivity radius” specifies the smallest possible value which ensures that all nodes are connected to one another, possibly in a multi-hop manner. It becomes evident from Figs. 1(d) and 2(d) that, in contrast to the previous graphs, the MR might feature crossing edges.
II.5 Graph construction
In order to construct the RNG and GG, we made use of the sub-graph hierarchy . I.e., for a given set of nodes we first obtained the DT by means of the Qhull computational geometry library Barber (1995) (the DT for a set of points can be computed in time Preparata and Shamos (1985); Barber (1995)) and then pruned the resulting edge-set until the linking requirements of GG or RNG are met. Here, we amend the naive implementation of this two-step procedure Toussaint (1980), yielding an algorithm with running time , by means of the “cell-list” method Melchert (2013), resulting in a sub-quadratic running time. In this regard, note that Ref. Jaromczyk and Toussaint (1992) provides an overview of several algorithmic approaches for the construction of RNGs and GGs. Finally, note that RNGs and GGs can be found as the limiting cases of a parameters family of proximity graphs, termed -skeletons Kirkpatrick and Radke (1985).
At this point, note that due to a yet unmentioned property of minimum weight spanning trees (MST; i.e. a spanning tree in which the sum of Euclidean edge lengths is minimal, see Ref. Cormen et al. (2001)) we can set the “connectivity radius” of MRs, i.e. a geometric random graph, in context to proximity graphs. Bear in mind that the longest edge present in any instance of a MR specifies the smallest possible edge length which ensures that all nodes are connected to one another. Exactly this edge length characterizes the longest edge in the MST of the corresponding node-set. For a given set of nodes, a MST is a spanning sub-graph of the RNG Toussaint (1980); Melchert (2013). Thus, considering MSTs, the previously mentioned sub-graph hierarchy can be extended to . This allows for a fast construction of a MR instance for a given set of points via a convenient three-step procedure: (i) compute the DT for the given set of points, (ii) filter the edge-set of the DT to determine the corresponding MST, and, (iii) use the length of the longest MST edge as “connectivity radius” to construct the respective MR. Therein, the overall running time is dominated by step (iii), which, in its most naive implementation has computational cost . Note that during the latter step, the previously mentioned “cell-list” method can be used to achieve an improved running time.
Subsequently we will introduce the node-removal strategies that will be considered in the numerical simulations carried out to characterize the fragmentation process for the above graph types.
III Node-removal strategies
As pointed out above, in the presented article we aim at characterizing the fragmentation processes for the graph types introduced in Sec. II. Therefore we consider three different types of node-removal strategies that are used throughout the literature Albert et al. (2000); Callaway et al. (2000); Crucitti et al. (2004a); Gallos et al. (2005); Holme et al. (2002). For convenience these will be detailed subsequently. Therefore, note that the basic procedure to study the fragmentation process for a single network instance consists in successively removing nodes until the network is decomposed into many small clusters of nodes, thereby recording observables that provide information about the current characteristics of the network (see Sec. IV).
The most simplistic node-removal strategy followed here is termed random failure. According to this strategy, a node is picked uniformly at random and deleted from the network (along with all its incident edges).
Depending on the context into which the networks are set, it might be useful to associate a measure of relevance to each node. Then it is also intuitive to ask for node-removal strategies that preferentially target the most relevant nodes. Removal strategies that capitalize on the relevance of a node are termed targeted attacks. Here, we consider two different targeted attack strategies
(i) degree-based attack (conveniently abbreviated as “attack 1”), where the relevance of a node is simply measured by its degree (i.e. the number of its incident edges). The higher the degree of a node, the more relevant it is assumed to be. Accordingly, at each elementary node removal step during the fragmentation process, the node with the currently highest degree is selected for deletion. If, at a given step, there are many nodes exhibiting the currently highest degree, one of these nodes is chosen uniformly at random. Note that the degree of a node is a local property only, i.e. for a given node one only has to determine the number of its nearest neighbors. Thus, from a computational point of view the node degree is a very inexpensive relevance measure.
(ii) betweenness-based attack (conveniently abbreviated as “attack 2”), where the relevance of a node is measured by its betweenness centrality Brandes (2008). The betweenness centrality of node is the number of shortest paths between all node pairs that pass through . The larger the value of the betweenness centrality, the more relevant a node is assumed to be. In some applications, the Euclidean distance along the edges is relevant for determining shortest paths Cormen et al. (2001). However, here we instead considered the hop-metric, where distances are simply measured in terms of node-to-node hops. Consequently, the shortest path problem can be solved by means of a breadth-first search Cormen et al. (2001). During each elementary node-removal step, the node exhibiting the currently highest value of betweenness centrality gets removed. As before, if several nodes have the same value, one of them is chosen uniformly at random. Note that the betweenness centrality is a global property deduced from the underlying network, i.e. for the betweenness centrality of a particular node, the configuration of shortest paths between all pairs of nodes is of relevance. From a computational point of view this is, of course, considerably more expensive than the computation of the local node degree.
Subsequently, we will use the above node-removal strategies in order to characterize the fragmentation process for the graph types described in Sec. II by means of numerical simulations.
IV Results
In the current section we will report on numerical simulations for the different graph types for planar sets of up to points, where results are averaged over 2000 independent graph instances. In Sec. IV.1 we first report on some topological properties of the graphs, in Sec. IV.2 the analysis of the fragmentation procedure is summarized. In Sec. IV.3 further issues concerning the resilience of the networks seen as transport networks (“ stability”) are discussed. Finally, in Sec. IV.3, the networks will be compared under the assumption that they all exhibit the same summed-up edge length.
Subsequently, albeit we will present results for all relevant combinations of the four graph types and three node-removal strategies, we will not show figures with results for all these combinations. Instead, so as to illustrate the analyses performed in the following section, we mainly present figures for the RNG proximity graphs subject to a degree-based node removal strategy.
IV.1 Topological properties
To emphasize structural differences between the graph types of the sub-graph hierarchy we first consider the respective average node degree. Therefore, the scaling behavior of the effective, i.e. system-size dependent, average degree is considered and analyzed using a fit to the function . For the three graph types , and the fits yield asymptotic degrees and scaling exponents , where and (with a reduced chi-square ; note that both, the asymptotic average degree and the scaling exponent compare well to the estimates reported in Ref. Melchert (2013)), and (reduced chi-square ), and (for a reduced chi-square ; note that the average degree of the is known to be ). In Fig. 3 the correction to scaling, i.e. , is shown for the three types of proximity graphs. It is interesting to note that RNG and GG exhibit a similar scaling, involving a correction of the form , whereas the scaling behavior for the average degree for the DT graphs is governed by a significantly larger exponent. Also, note that instances of the three types of proximity graphs are planar, i.e. there are no crossing edges. While the bounding cycles of the finite faces for the instances of RNGs and GGs might consist of an even or odd number of edges, all inner faces for instances of DTs are bounded by three edges.
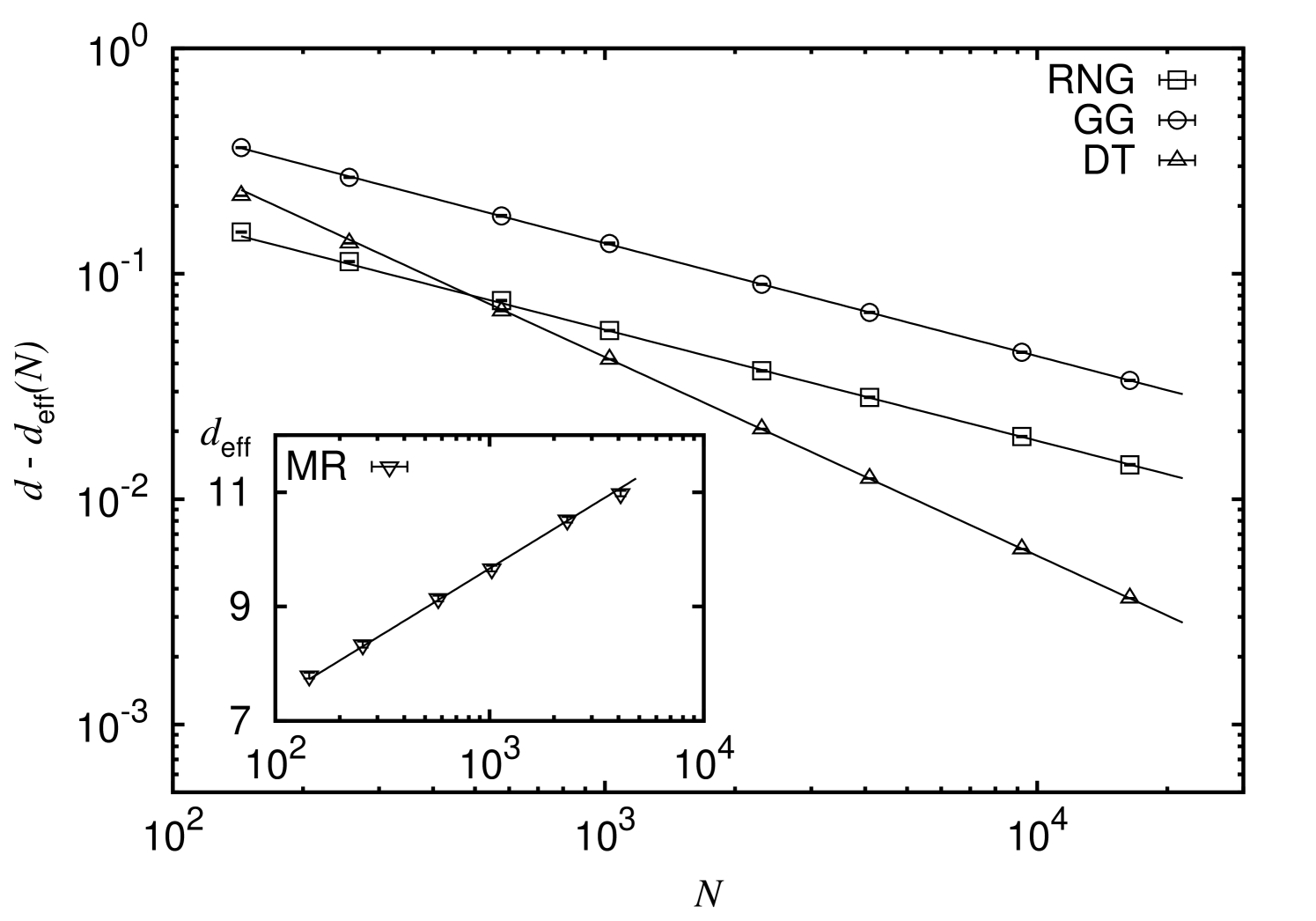
Further, for the minimum radius graph we found that the effective, average degree fits best to a logarithmic scaling function of the form , see inset of Fig. 3 where (reduced chi-square ; however, note that the data can also be fit by a scaling function with a small power-law correction as above, where and ).
Regarding MRs, consider that the longest edge present in any instance of a MST (which specifies the length of the longest edge in the respective MR instance; see discussion above) can by no means exceed the length of the longest edge of any of its super-graphs. Due to the geometric restrictions imposed by going from an instance of a DT to a RNG, it is thus plausible that the maximal edge length found for any MR instance is much shorter than, say, for the corresponding DT instance. This holds in particular for the case of open boundary conditions, where the outer faces of the DT instances feature rather long edges, see Fig. 2(c). For a set of 500 instances of point sets consisting of nodes (i.e. for systems of effective side length ) we found that the longest edge length ratio for the four graph types read , , , and, . For the first three graph types, these values should be more or less independent of the system size. On the other hand, for the minimum radius graphs we found that the finite-size scaling behavior of the connectivity radius as function of the effective system length exhibits a logarithmic scaling of the form , where and (reduced chi-square ), supporting the logarithmic scaling of the average degree. I.e., the respective “connectivity area” , which, if centered at the position of a given node, specifies the area in which all its nearest neighbors can be found, should be almost equal to the previously discussed average degree , because the density of nodes is unity. E.g., at (i.e. ) we find and .
| strategy | RNG | GG | DT | MR |
|---|---|---|---|---|
| random failure | 0.205(1) | 0.365(1) | 0.500(2) | 0.71(1) |
| attack 1 | 0.120(1) | 0.263(1) | 0.377(1) | 0.68(2) |
| attack 2 | 0 | 0 | 0 | 0 |
IV.2 Fragmentation analysis
For the fragmentation analysis we consider instances of the four different graph types, introduced in Sec. II, and successively remove nodes according to one of the node removal strategies, presented in Sec. III, until the initially connected graph decomposes into small clusters. So as to determine the critical fraction of nodes that need to be removed until the graph decomposes we perform a finite-size scaling (FSS) analysis for different observables that are commonly used in studies of percolation Stauffer and Aharony (1992) in Sec. IV.2.1. In addition, in Sec. IV.2.2 we consider the scaling behavior of the hop-diameter, i.e. the longest among all shortest paths measured in terms of node-to-node hops, which, e.g., is relevant in the context of broadcasting problems on networks Jennings and Okino (2002).
IV.2.1 Analysis of typical percolation observables
The observables we consider below can be rescaled following a common scaling assumption. Below, this is formulated for a general observable . This scaling assumption states that if the observable obeys scaling, it might be written as
| (1) |
wherein and represent dimensionless critical exponents (or ratios thereof, see below), signifies the critical point, and denotes an unknown scaling function Stauffer and Aharony (1992); Binder and Heermann (2010). Following Eq. 1, data curves of the observable recorded at different values of and collapse, i.e. fall on top of each other, if is plotted against and if further the scaling parameters , and that enter Eq. 1 are chosen properly. The values of the scaling parameters that yield the best data collapse determine the numerical values of the critical exponents that govern the scaling behavior of the underlying observable . In order to obtain a data collapse for a given set of data curves we here perform a computer assisted scaling analysis, see Refs. Houdayer and Hartmann (2004); Melchert (2009).
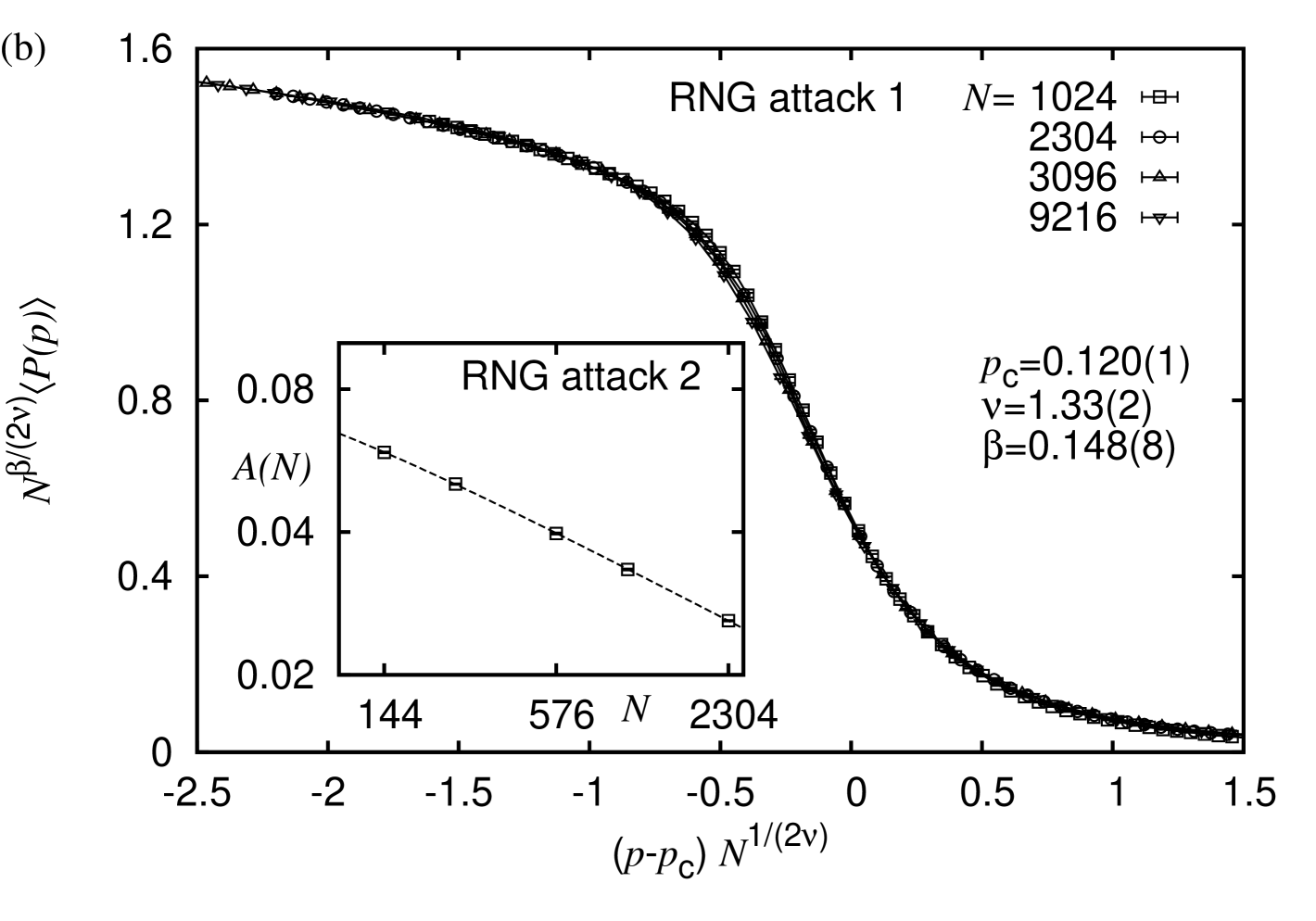
Order parameter:
As first observable we consider , i.e. the relative size of the largest cluster of connected nodes. Averaged over different instances of, say, size , at a given value of this yields the order parameter
| (2) |
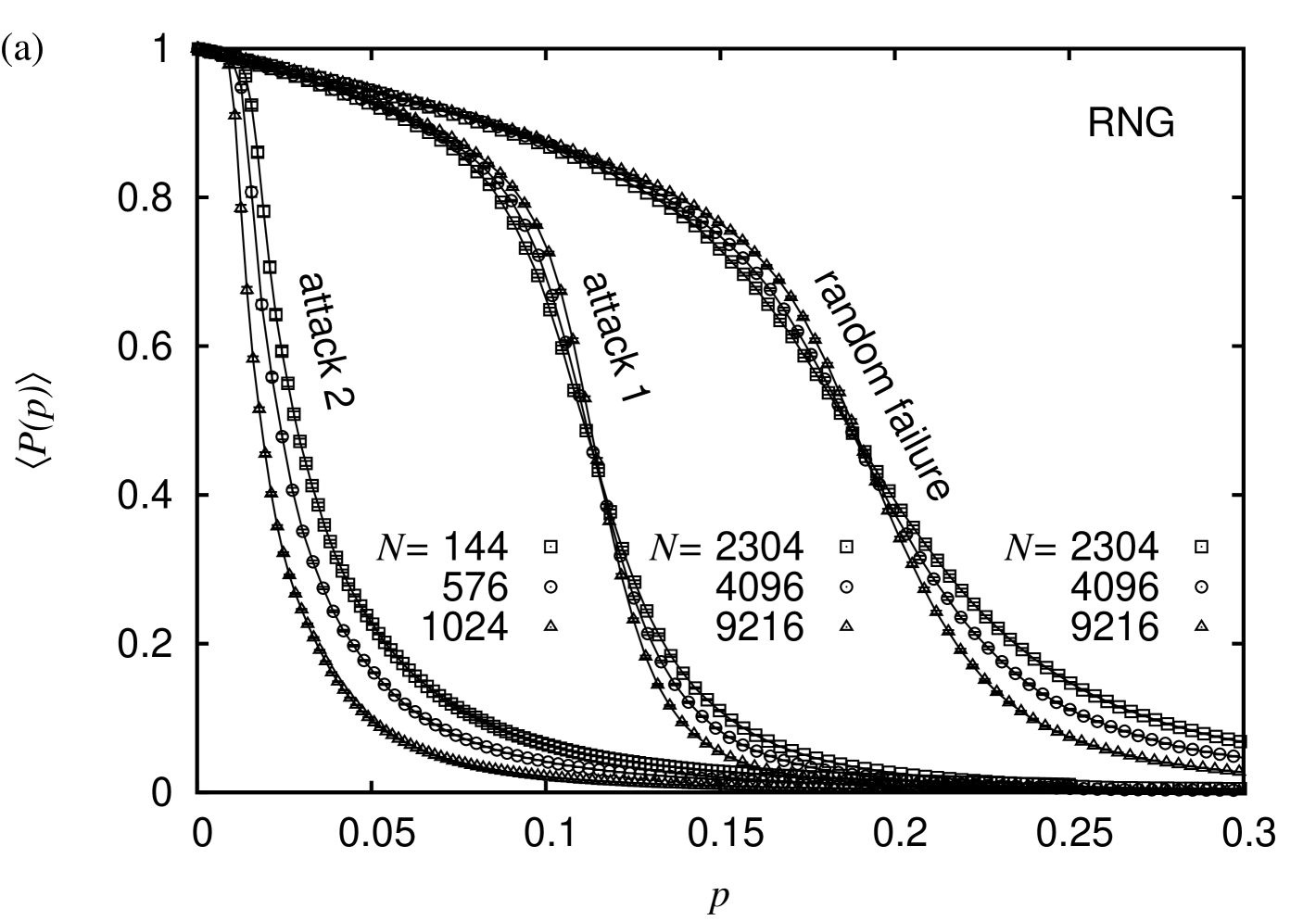
This observable scales according to Eq. (1), where and is the order-parameter exponent. The data curves for the RNG proximity graphs for all three types of node removal strategies are shown in Fig. 4(a).
For the RNG and GG, the random failure node removal strategy simply corresponds to ordinary random percolation. An extended study of site and bond percolation for the RNG type proximity graphs can be found in Ref. Melchert (2013) and in Ref. Norrenbrock (2014) for the GG type proximity graphs, respectively. However, note that in these articles signifies the fraction of occupied bonds/nodes as opposed to the fraction of deleted nodes. The respective values of are listed in Tab. 1. It is apparent, that in the order RNG, GG, DT and MR, the graphs become less and less susceptible to fragment under random node removal. This correlates well to the average degree .
Regarding the degree-based attack strategy for the RNGs we found that the best data collapse (obtained for the three system sizes in the range ) yields , , and with a quality (see Refs. Houdayer and Hartmann (2004); Melchert (2009)), see Fig. 4(b). Note that the numerical values of the critical exponents match the expected values for 2D percolation, i.e. and , quite well. Restricting the data analysis to the slightly smaller interval , enclosing the critical point on the rescaled -axis, the optimal scaling parameters are found to be , , and with a quality . Further, fixing and to their exact values, thus leaving only one parameter to adjust, yields with a data-collapse quality . Hence, for RNGs subject to a degree-based attack strategy, a fraction of seems to suffice in order to decompose the graph instance into small clusters. Note that this is already significantly smaller than the above value found for the case of random node failures.
The analysis for the proximity graph types GG and DT for the above two node-removal strategies (i.e. random failure and degree-based attack) were carried out in similar fashion. For the DT ensemble, considering the degree-based node-removal strategy, the scaling parameters obtained by the FSS analysis read , , and with a data-collapse quality (obtained for the three system sizes in the range ). For comparison: the critical point for the random node removal strategy is known to be ; from our simulated data we find , , and with a quality (similar system sizes as above, only in the range ).
For the case of the GG graphs, we found , and in respect to the degree-based node-removal strategy (obtained for the system sizes in the range with quality ).
However, note that for the geometric MR graphs, an analysis of the order parameter following a scaling assumption of the form of Eq. 1 did not lead to any conclusive results. I.e. the data curves did not give a satisfactory data collapse. Nevertheless, based on the analysis of the fluctuations of the order parameter, we were able to obtain estimates for the critical point, see below. In summary, as obvious from Tab. 1, degree-based attacks are more severe than random removals. Again, the resilience against attacks correlates well with the average degree.
Considering the centrality-based attack strategy for the RNGs, we start out with a more simplified initial analysis. As evident from Fig. 4(a), the data curves that describe the scaling of the order parameter for this setup drop to zero at rather small values of . Thus, a FSS analysis (as carried out above) comes along with several difficulties (related to the accessibility of data points in the critical scaling window). Hence, we first determine the area under the order-parameter curves and assess its scaling behavior with increasing system size to see whether it converges to a finite value at all. From a fit to the function we find , , and (reduced chi square ; see inset of Fig. 4(b)), indicating that indeed . If we neglect the smallest system, we find that a pure power law fits the data well (reduced chi-square ). From this we conclude that for RNGs, subject to a centrality-based attack strategy one has . Following this procedure, we also found that under this attack strategy holds true for GGs, DTs, and MRs. Thus, due to its propensity to fragment graphs at negligible values of , this strategy is much more efficient than the degree-based strategy, independent of the type of graph.
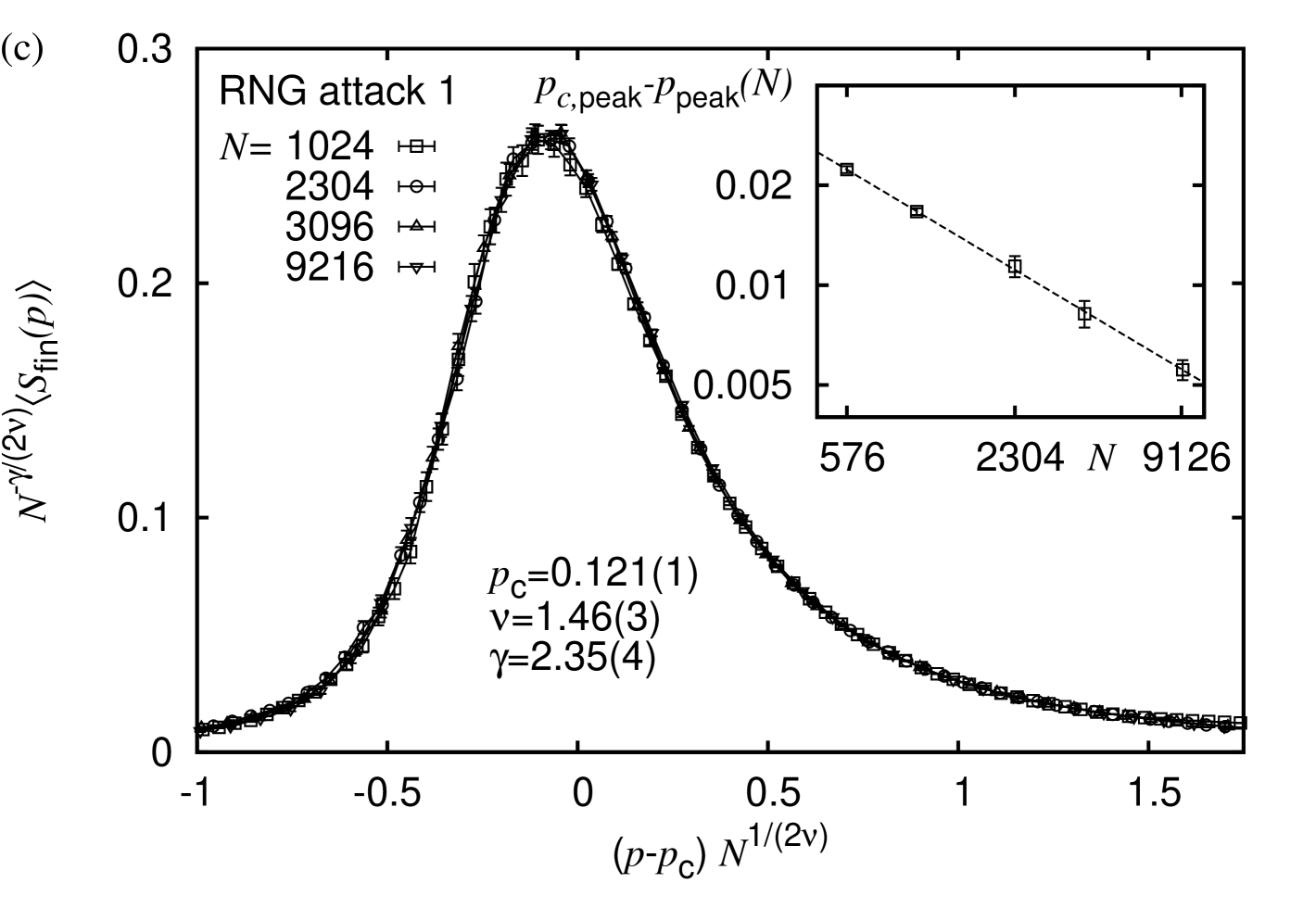
Average size of the finite clusters
As second observable we consider the average size of all finite clusters for a particular graph instance, averaged over different graph instances. The definition of this observable reads Stauffer and Aharony (1992)
| (3) |
where signifies the probability mass function of cluster sizes for a single graph instance at a given value of . The prime indicates that the sums run over all clusters excluding the largest cluster for each graph instance. The average size of all finite clusters is expected to scale according to Eq. 1, where . Therein, for 2D percolation, the critical exponent assumes a value of .
Again, a detailed analysis of this observable for random percolation, which is equivalent to the random failure node-removal strategy, can be found in Ref. Melchert (2013) regarding RNGs, and in Ref. Norrenbrock (2014) with respect to GGs.
Regarding the degree-based attack strategy for RNGs, considering systems of size and restricting the data analysis to the interval on the rescaled -axis, the optimal scaling parameters are found to be , , and with a collapse quality , see Fig. 4(c). Note that here the estimated value of appears to overestimate the expected value somewhat. Apart from that, the numerical values of the extracted exponents are in reasonable agreement with their expected values and the estimate of the critical threshold is consistent with the numerical value found from an analysis of the order parameter.
In addition to the full FSS analysis, we also performed a scaling analysis for the effective critical points at which the curves of assume their maximum. Therefore, polynomials of th order were fitted to the data curves at different system sizes in order to obtain an estimate of the peak position. Thereby, the index labels independent estimates of the peak position as obtained by bootstrap resampling. For the analysis, we considered bootstrap data sets, e.g. resulting in the estimate for the RNG regarding the degree-based attack strategy. Considering systems of size and assuming the scaling form
| (4) |
we yield the fit parameters , and for a reduced chi-square , see inset of Fig. 4(c). This result indicates that the peak seems to be positioned off criticality at a value slightly below , cf. Fig. 4(c). However, including also very small systems we yield , and for a reduced chi-square , in good agreement with the value of obtained from an analysis of the order parameter. Following this procedure by considering RNGs subject to a random node failure we yield , which compares well to estimate obtained from an analysis of the order parameter (see Tab. 1). An analysis of the peak positions for all other types of proximity graphs led to qualitatively similar results. Hence, we do not elaborate on them here.
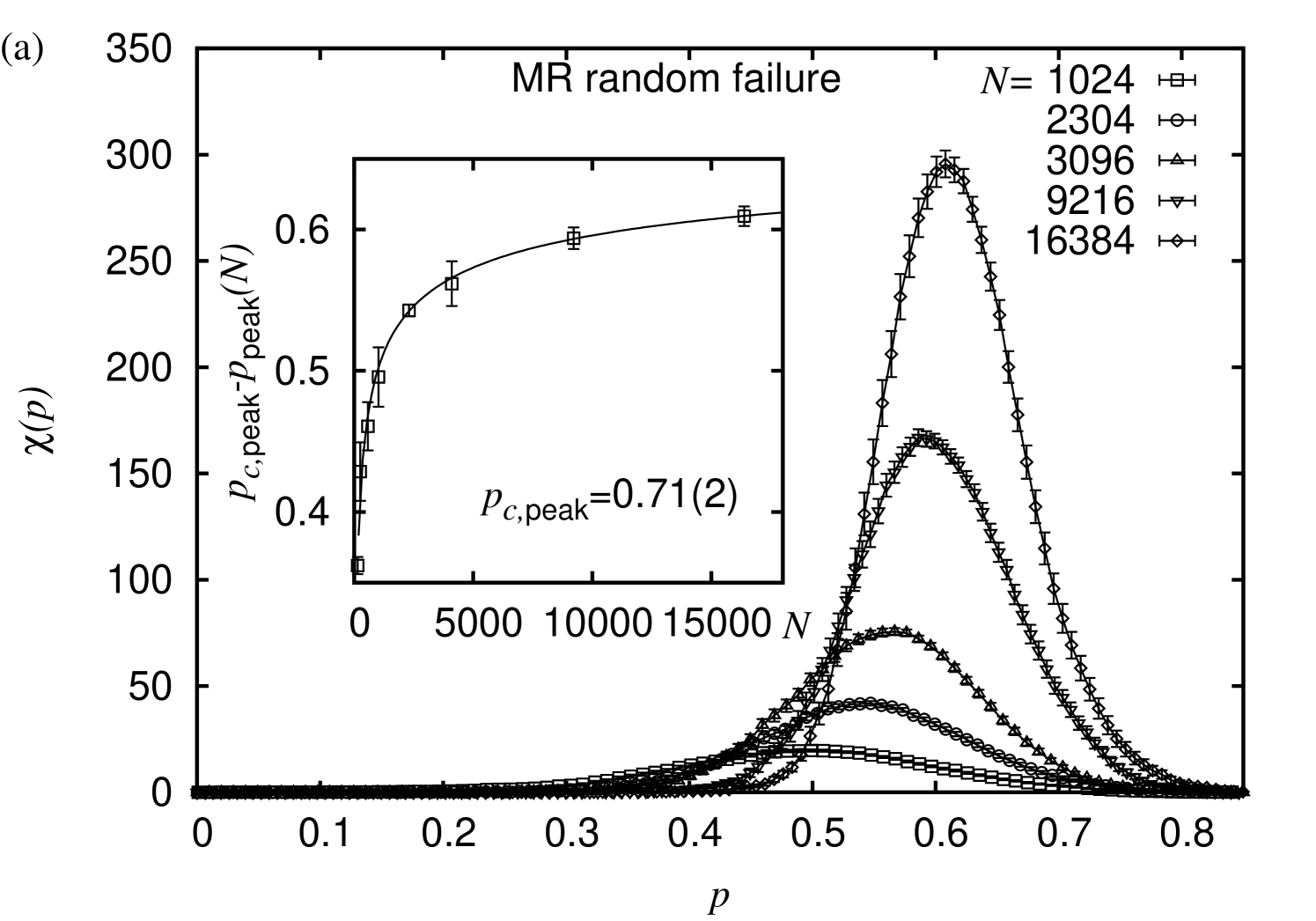
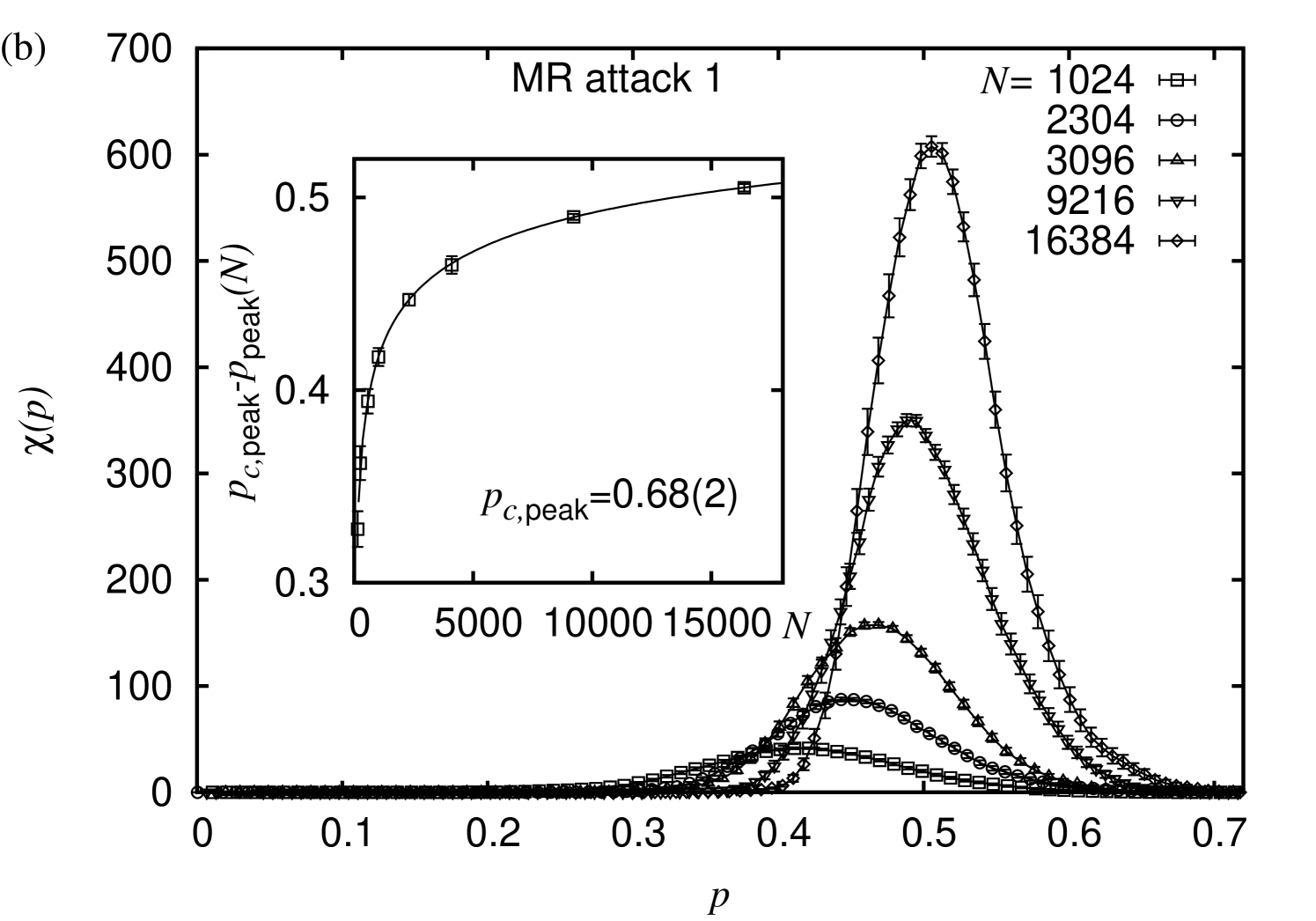
Whenever we analyzed the order parameter, we also analyzed the respective fluctuations, giving rise to the finite-size susceptibility
| (5) |
These curves also feature a pronounced peak and exhibit the same scaling behavior as the average size of the finite clusters discussed above. Here, we also performed a scaling analysis of the peak positions of the curves, similar to that performed for the peaks of the previous observable. Albeit this did not lead to new insight for the various types of proximity graphs, it was a valuable method to estimate critical points for the MR geometric graphs. In this regard, for MRs subject to a random node removal we find , see Fig. 5(a). Further, for MRs subject to the degree-based node removal strategy we obtain , see Fig. 5(b). Hence, for the MRs we cannot rule out that the estimates for both critical points actually agree within error-bars. This might be attributed to the rather high degree of the individual nodes, and, from a statistical point of view, the extensive overlap of the individual node-neighborhoods within the range of the underlying “connectivity radius”. Hence, due to the high number of redundant node-to-node paths which easily allow to compensate for deleted nodes, the effect caused by the removal of a randomly chosen node does not differ much from the effect caused by the removal of a node with a particularly large degree.
IV.2.2 Analysis of the hop diameter:
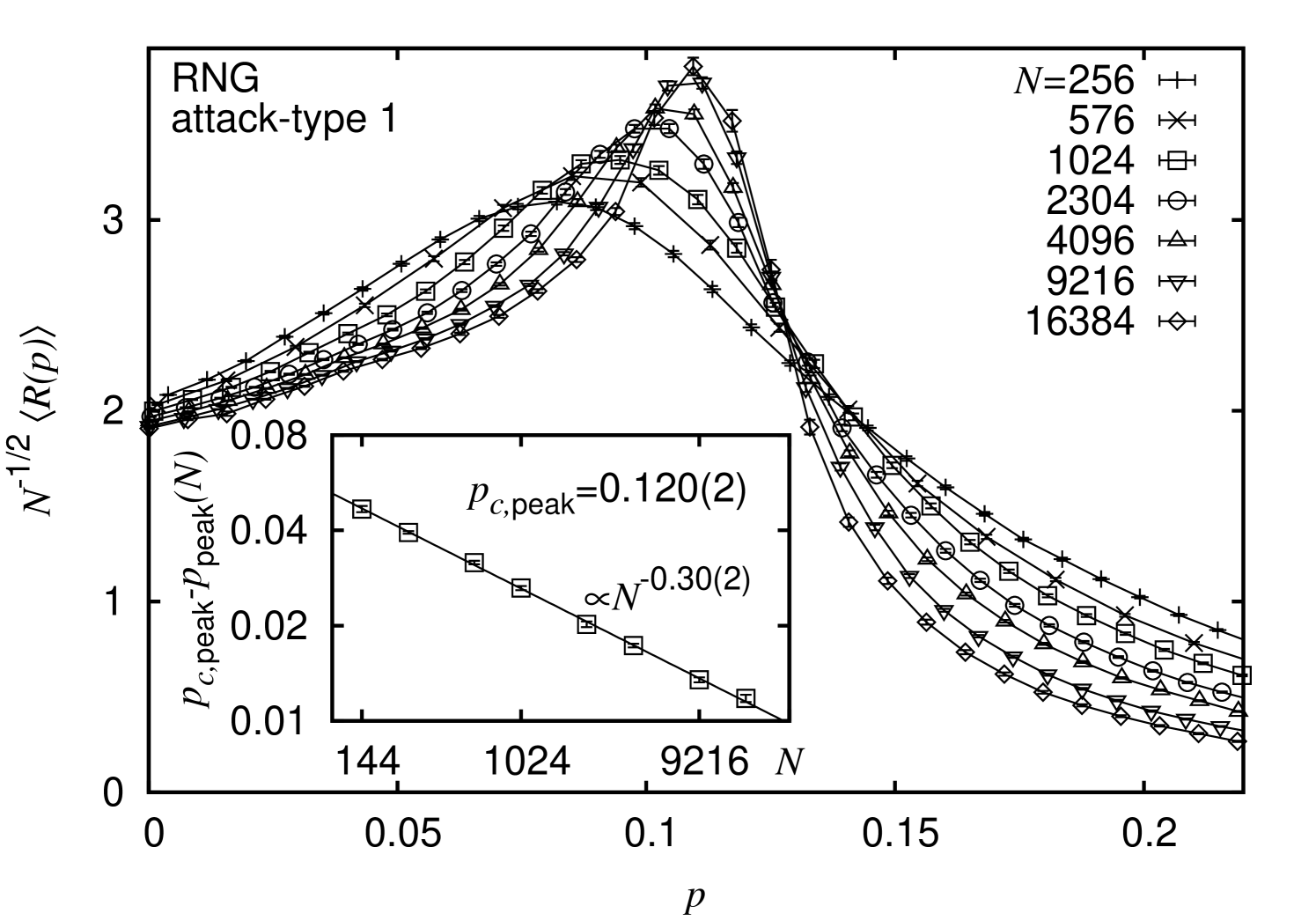
The last observable, studied in the context of the fragmentation analysis is related to the diameter of the graphs as function of the fraction of removed nodes. Here, the diameter of a graph indicates the longest among all finite shortest paths. In Fig. 6, the data curves of the diameter for the particular choice of RNG proximity graphs subject to a degree-based node removal strategy are shown. For the particular case of non-fragmented RNGs, i.e. at , the diameter (averaged over different realizations of point-sets) was previously found to scale as Melchert (2013). In view of these prior results, the data curves in Fig. 6 are scaled so as to assume a fixed value at . As evident from the figure the data curves assume a peak value when a certain fraction of nodes is removed. This appears to be quite intuitive: if nodes are removed from one of the graph instances introduced in Sec. II, redundant edges will disappear (on average) resulting in an increasing node-to-node distance. As soon as the value of exceeds the percolation threshold of the respective setup (i.e. graph type and node removal strategy), the graph instance decomposes into several “small” clusters accompanied by a decreasing node-to-node distance. With increasing system size , the position of the peak shifts towards larger values of . For RNGs subject to a degree-based node removal, a fit-function of the form similar to Eq. 4 yields the fit parameters , and (). Similarly, for DTs we find , and (). The resulting asymptotic peak positions are in good agreement with the value obtained from a FSS analysis of the order parameter, cf. Tab. 1. For the case of a random node failure, the results obtained from the scaling of the peak position fits the results from the order parameter analysis similarly well. E.g., for the case of RNGs we find , cf. Tab. 1. Albeit we performed a similar analyses for GGs and DTs, resulting in qualitatively similar results, we do not elaborate on them here. No analyses were performed for the centrality-based node removal strategy.
IV.3 resilience
The actual most important application example regarding proximity graphs are wireless ad hoc networks. Nevertheless, there might be some other fields of application for them. Proximity graphs ensure connectivity and the total length of all involved edges is small in comparison to many other networks that feature this quality. For applications where edges are expensive and connectivity is crucial, the topology of proximity graphs might be a good candidate to install. Up to here, we have assumed that the capacities of the edges and nodes are infinitely large, so the network components do not overload, regardless how intensive they get strained. In real scenarios, if some nodes or edges malfunction, network components which are hardly used under normal circumstances might become essential at once. In consequence, since the hardly used components are not designed to handle such a burden, this might trigger a cascading breakdown of the whole network Bao et al. (2009); Crucitti et al. (2004b); Motter (2004); Motter and Lai (2002). Therefore, it is reasonable to equip all network components with sufficient capacity.
To ensure that the network operates orderly under all circumstances when one component drops out, referred to as “ resilience” (or stability, or criterion), it is necessary to know the most adverse scenario that can happen. When having a transport model in mind, where some quantities have to be transported between all pairs of nodes, Motter and Lai (2002); Motter (2004); Bao et al. (2009) the betweenness centrality Newman (2001) is a measure of the capacity each node or edge has to provide in a well functioning situation. When one node or edge fails, given that the network is still connected, the loads have to be redistributed, visible from a recalculation of the betweenness centrality. In some nodes or edges the centrality will increase Ouyang et al. (2014); Hartmann (2014), corresponding to a higher capacity these nodes or edges have to provide a priori. The value of the highest increment, which is called backup capacity Hartmann (2014) or , provides an estimate for the additional costs for each node or edge that must be invested to protect the network against cascading failures upon such an incident.
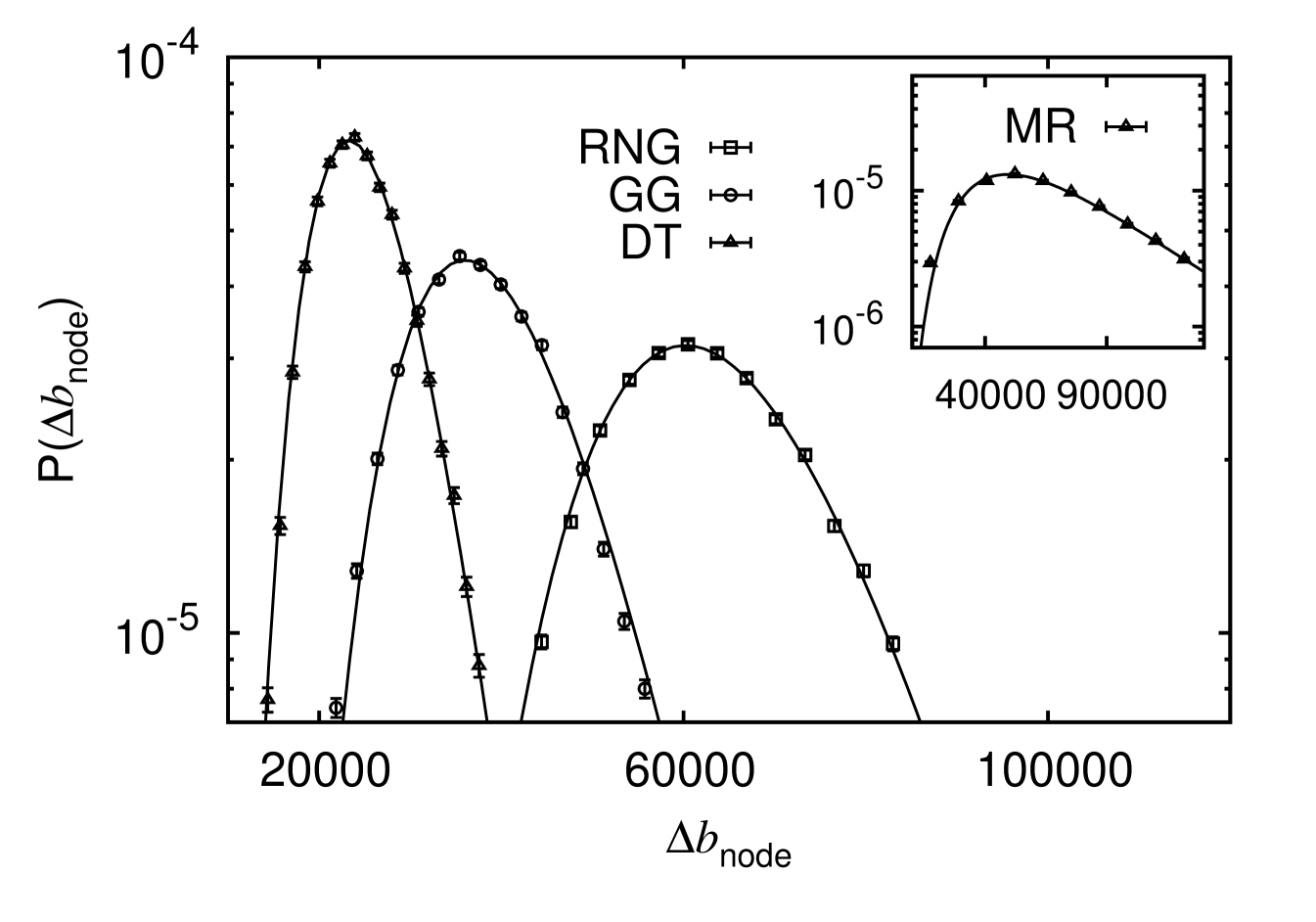
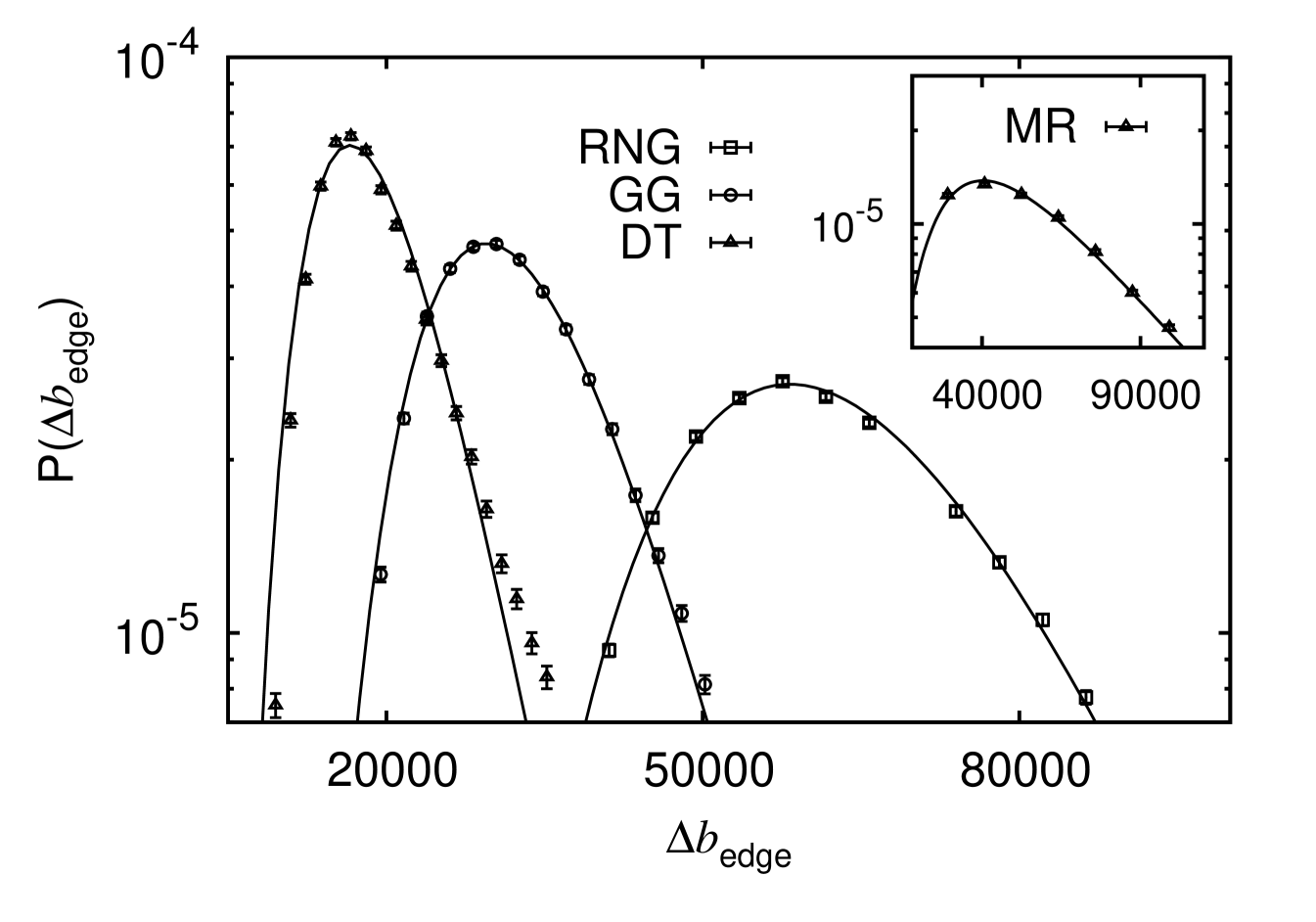
The betweenness centrality has been calculated based on Dijkstra’s algorithm Cormen et al. (2001), i.e. the edge lengths have been taken into account for calculating the shortest path. The resulting probability mass functions of and are illustrated in Fig. 7 and 8, respectively, for different network ensembles.
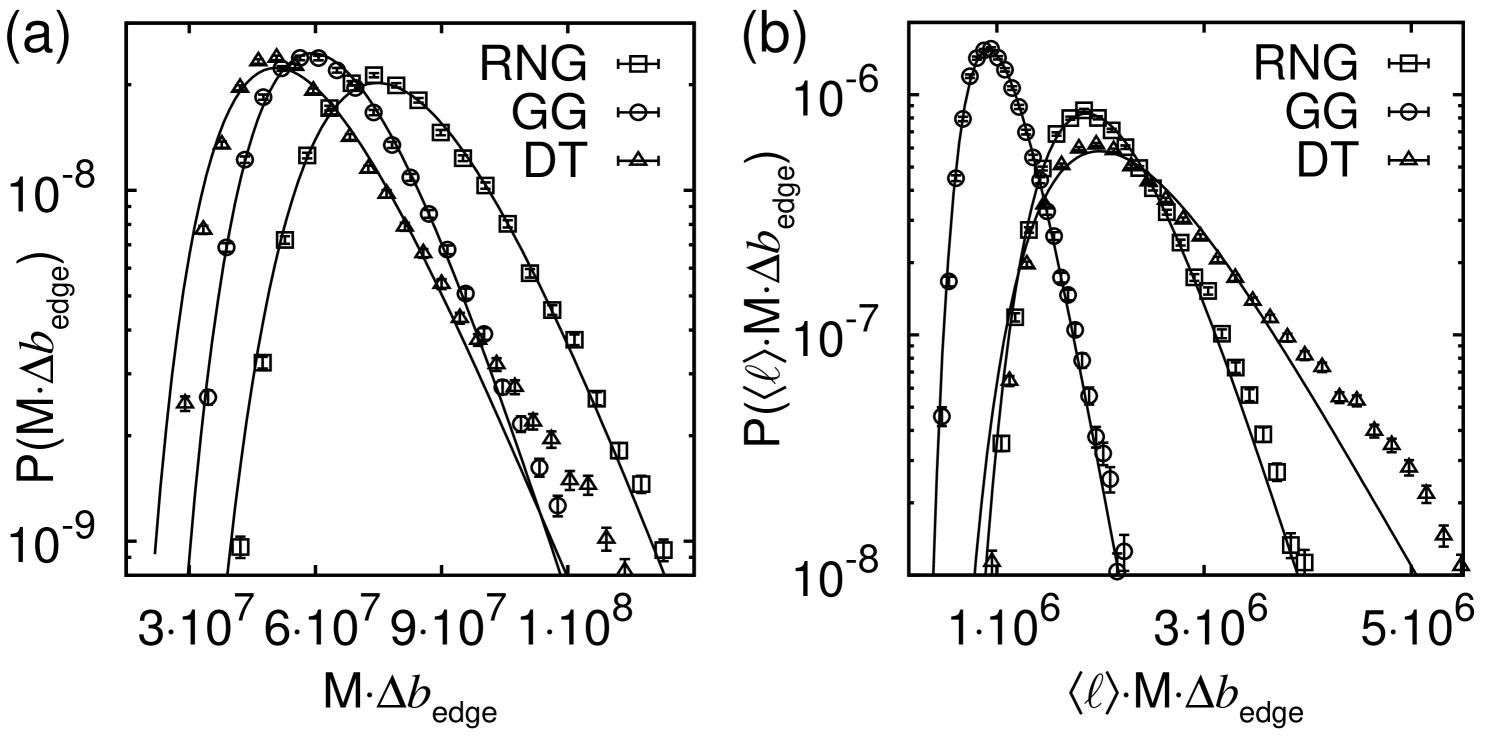
For the case of however, using a breadth-first search, i.e., without taking the actual edge lengths into account, the probability mass functions look qualitatively almost identical to the case of without notable distinctions. From the statistics mediated by the figures it is evident that the typical backup capacity of DT networks is smallest while of RNG networks it is the highest. This means that the structure of the network of RNG networks is more vulnerable such that one has to invest more into the capacity of the edges in order to ensure stability. This is not surprising, since the RNG is a sub-graph of the GG and DT and includes less edges. On the other hand, due to the lack of the additional edges of the RNG in comparison to the others, the investment to provide the backup capacity must be applied for less edges. Thus, it makes sense to ask for the total backup capacity, either per edge, if investments cost are dominated by the number of connections, or per unit length, if investments are dominated by the length of the edges. It becomes evident from Fig. 9(a) that for the former case, the typical total investment () is relatively speaking still the same for all three ensembles. For the second case, i.e., taking also edge lengths into account (Fig. 9(b)), it turns out that the investment of the DT is about the same level as the RNG. The GG appears to be the most cost efficient graph if this scenario is at hand.
IV.4 Networks with same total length
To compensate for the simple resilience effect created by simply exhibiting more edges, we also compared the different topologies of the proximity graphs featuring the same total edge length . Therefore, we measured the scaling behavior of this quantity for the different proximity graph types (see Fig. 10). The figure provides the number of nodes which have to be added to the RNG and GG in order to get same total edge length as the respective DT. E.g., it is evident from the figure that a DT with nodes has the same total edge length on average as a GG with and a RNG with nodes. Since the fragmentation thresholds for the different node-removal strategies are known (Tab. 1), it can be calculated easily () for each topology how many nodes must be removed until the respective network decomposes into small clusters. E.g., if , the RNG will tolerate randomly removed nodes. In contrast, the GG tolerates and the DT tolerates merely nodes that fail randomly.
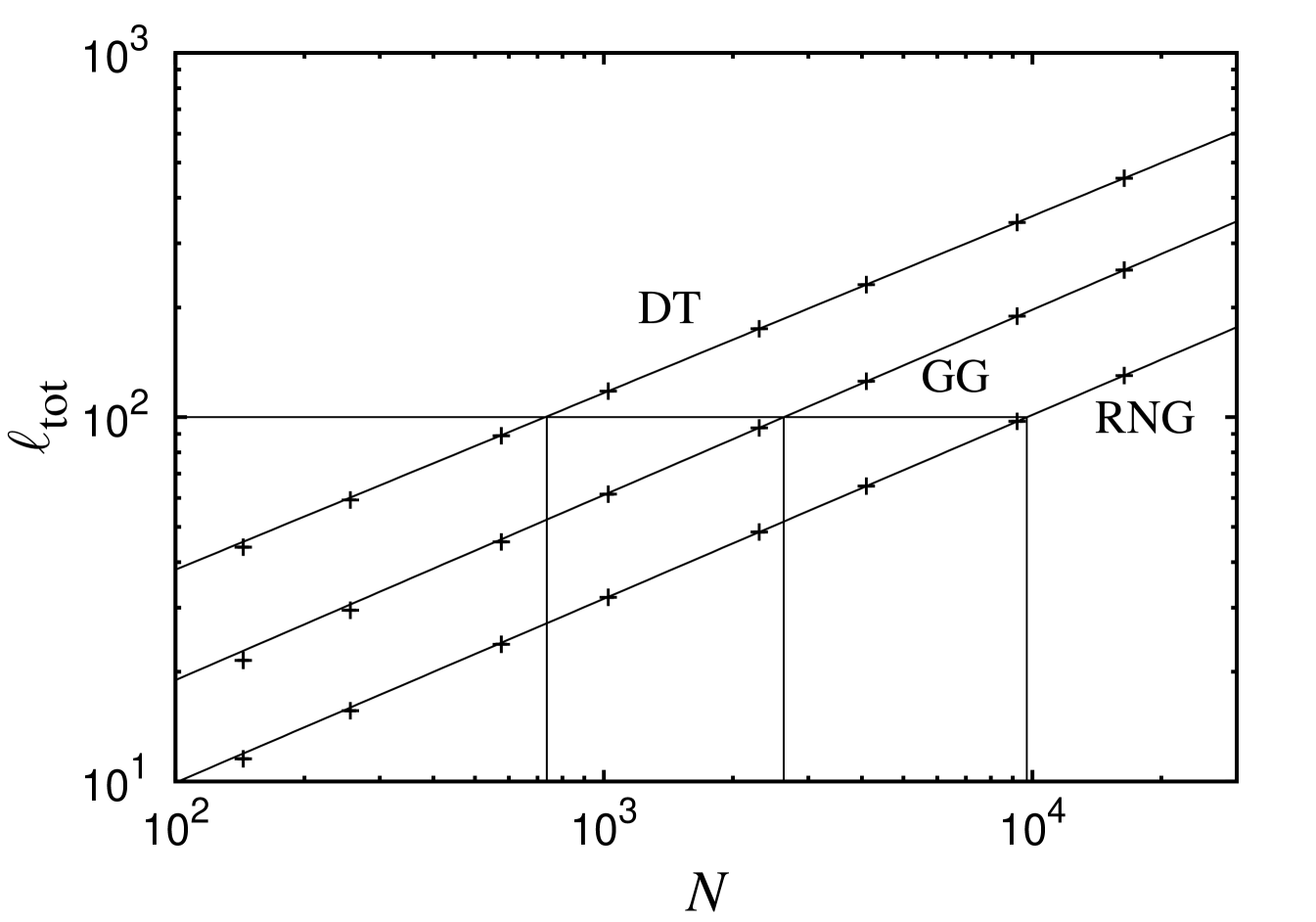
As a consequence, implementing the topology of the RNG will be the most reasonable, if installing edges is much more expensive than adding further nodes. Certainly, the additional edges of the DT and GG increases the stability, but the benefit of those is small in comparison to the edges which are contained in the RNG anyway.
V Conclusion
In the presented article, the robustness of three types of proximity graphs and a particular geometric random graph (see Sec. II), i.e. their ability to function well even if they are subject to random failures and targeted attacks, was put under scrutiny. For this purpose we generated instances of the considered graph types and successively removed nodes according to three different node removal strategies (see Sec. III). Once the fraction of removed nodes exceeds a certain threshold (characteristic for the particular graph type and node deletion scheme), the underlying graph instance decomposes into many small clusters. Using standard observables from percolation theory (see Sec. IV.2), the critical node removal thresholds were determined for the different graph types and deletion strategies, see Tab. 1. Therein, so as to yield maximally justifiable results through numerical redundancy, we considered various observables to estimate the critical points and exponents. In order of increasing severity, these strategies have an intuitive order: a random node removal mechanism, equivalent to ordinary random percolation, is less severe than a degree-based node removal strategy which takes into account particular node-related local details (i.e. the node-degrees) to optimize the order of node removals during the fragmentation procedure. As evident from Tab. 1, both removal schemes result in finite critical points. The latter strategy is again less severe than the centrality-based node removal mechanism, which takes into account global information (i.e. the set of shortest paths that connect all pairs of nodes) which is used to impose a maximally efficient structural damage by preferentially removing nodes with maximal betweenness centrality (i.e. the most relevant nodes). As evident from Tab. 1 and the discussion in Sec. IV.2, the latter node removal scheme requires to delete only a negligible amount of nodes until the graph decomposes into small clusters. A peculiar result are the fragmentation thresholds related to the random failure and degree-based node removal for the MR geometric graph. As discussed in Sec. IV.2 we cannot rule out that the estimates for both critical points agree within error-bars. This might be attributed to the extensive overlap of the individual node-neighborhoods within the range of the underlying “connectivity radius”. Hence, due to the high number of redundant node-to-node paths which easily allow to compensate for deleted nodes, the effect caused by the removal of a randomly chosen node does not differ much from the effect caused by the removal of a node with a particularly large degree.
For a given node removal strategy, the sequence of critical points for the sub-graph hierarchy follow the commonly accepted belief that the percolation threshold (or here: the fragmentation threshold) is a non decreasing function of the average degree. This is in full accord with the containment principle due to Fisher Fisher (1961), stating that if is a sub-graph of , then it holds that for both, bond and site percolation.
Finally, we considered the backup capacity, which is the largest betweenness-centrality increment of the nodes (or edges) after removing the most important node (or edge) beforehand, for the different graph types. Thus, via sufficient backup a graph is made resilient. Regarding the three studied proximity graph ensembles, it turned out that the DT is the most cost efficient one assuming that the backup investments are dominated by improving the nodes. On the other hand, if one has to backup the edges, the more cost efficient one will be either DT or GG, depending on whether the investment depends mainly on the number or on the length of the edges.
For further studies, it would be very interesting to evaluate these simple spatial planar ensembles in the context of more complex transportation networks, like for steady state power grids in the power-flow approximation, Kundur et al. (1994) or for networks of truly dynamically coupled oscillators as for Kurmatoto-like modelsFilatrella et al. (2008); Rohden et al. (2012); Witthaut and Timme (20).
Acknowledgements.
CN gratefully acknowledges financial support from the Lower Saxony research network “Smart Nord” which acknowledges the support of the Lower Saxony Ministry of Science and Culture through the “Niedersächsisches Vorab” grant program (grant ZN 2764 / ZN 2896). OM gratefully acknowledges financial support from the DFG (Deutsche Forschungsgemeinschaft) under grant HA3169/3-1. The simulations were performed at the HPC Cluster HERO, located at the University of Oldenburg (Germany) and funded by the DFG through its Major Instrumentation Programme (INST 184/108-1 FUGG) and the Ministry of Science and Culture (MWK) of the Lower Saxony State.References
- Stauffer (1979) D. Stauffer, Phys. Rep. 54, 1 (1979).
- Stauffer and Aharony (1992) D. Stauffer and A. Aharony, Introduction to Percolation Theory (Taylor & Francis, 1992).
- Albert et al. (2004) R. Albert, I. Albert, and G. L. Nakarado, Phys. Rev. E 69, 025103 (2004).
- Jiang and Claramunt (2004) B. Jiang and C. Claramunt, GeoInformatica 8, 157 (2004).
- Choi et al. (2006) J. H. Choi, G. A. Barnett, and B.-S. Chon, Global Networks 6, 81 (2006).
- Barabási et al. (2000) A.-L. Barabási, R. Albert, and H. Jeong, Physica A 281, 69 (2000).
- Albert et al. (2000) R. Albert, H. Jeong, and A.-L. Barabasi, Nature 406, 378 (2000).
- Callaway et al. (2000) D. S. Callaway, M. E. J. Newman, S. H. Strogatz, and D. J. Watts, Phys. Rev. Lett. 85, 5468 (2000).
- Crucitti et al. (2004a) P. Crucitti, V. Latora, M. Marchiori, and A. Rapisarda, Physica A 340, 388 (2004a).
- Gallos et al. (2005) L. K. Gallos, R. Cohen, P. Argyrakis, A. Bunde, and S. Havlin, Phys. Rev. Lett. 94, 188701 (2005).
- Holme et al. (2002) P. Holme, B. J. Kim, C. N. Yoon, and S. K. Han, Phys. Rev. E 65, 056109 (2002).
- Cohen et al. (2001) R. Cohen, K. Erez, D. ben Avraham, and S. Havlin, Phys. Rev. Lett. 86, 3682 (2001).
- Huang et al. (2011) X. Huang, J. Gao, S. V. Buldyrev, S. Havlin, and H. E. Stanley, Phys. Rev. E 83, 065101 (2011).
- Kurant et al. (2007) M. Kurant, P. Thiran, and P. Hagmann, Phys. Rev. E 76, 026103 (2007).
- Paul et al. (2004) G. Paul, T. Tanizawa, S. Havlin, and H. E. Stanley, Eur. Phys. J. B 38, 187 (2004).
- Shargel et al. (2003) B. Shargel, H. Sayama, I. R. Epstein, and Y. Bar-Yam, Phys. Rev. Lett. 90, 068701 (2003).
- Tanizawa et al. (2012) T. Tanizawa, S. Havlin, and H. E. Stanley, Phys. Rev. E 85, 046109 (2012).
- Brandes (2008) U. Brandes, Social Networks 30, 136 (2008).
- Page et al. (1999) L. Page, S. Brin, R. Motwani, and T. Winograd, Technical Report, Stanford InfoLab (1999).
- Toussaint (1980) G. T. Toussaint, Pattern Recognition 12, 261 (1980).
- Gabriel and Sokal (1969) R. K. Gabriel and R. R. Sokal, Syst. Biol. 18, 259 (1969).
- Sibson (1978) R. Sibson, Comput. J. 21, 243 (1978).
- Essam and Fisher (1970) J. W. Essam and M. E. Fisher, Rev. Mod. Phys. 42, 272 (1970).
- Toroczkai and Guclu (2007) Z. Toroczkai and H. Guclu, Physica A 378, 68 (2007).
- Bertin et al. (2002) E. Bertin, J.-M. Billiot, and R. Drouilhet, Adv. Appl. Probab. 34, 689 (2002).
- Becker and Ziff (2009) A. M. Becker and R. M. Ziff, Phys. Rev. E 80, 041101 (2009).
- Billiot et al. (2010) J. M. Billiot, F. Corset, and E. Fontenas (2010), preprint: arXiv:1004.5292.
- Melchert (2013) O. Melchert, Phys. Rev. E 87, 042106 (2013).
- Jennings and Okino (2002) E. Jennings and C. M. Okino, in Interntional Symposium on Performance Evaluation of Computer and Telecommunications Systems (2002).
- Santi (2005) P. Santi, ACM Comput. Surv. 37, 164 (2005).
- Li et al. (2005) X.-Y. Li, W.-Z. Song, and Y. Wang, Wirel. Netw. 11, 255 (2005).
- Rajaraman (2002) R. Rajaraman, ACM SIGACT News 33, 60 (2002).
- Karp and Kung (2000) B. Karp and H. T. Kung, in Proceedings of the 6th annual international conference on Mobile computing and networking (ACM, 2000), p. 243.
- Bose et al. (2001) P. Bose, P. Morin, I. Stojmenović, and J. Urrutia, Wirel. Netw. 7, 609 (2001).
- Yi et al. (2010) C.-W. Yi, P.-J. Wan, L. Wang, and C.-M. Su, IEEE Trans. Wirel. Commun. 9, 614 (2010).
- Kuhn et al. (2003) F. Kuhn, R. Wattenhofer, and A. Zollinger, in Proceedings of the 2003 joint workshop on Foundations of mobile computing (ACM, 2003), p. 69.
- Jaromczyk and Toussaint (1992) J. W. Jaromczyk and G. T. Toussaint, Proc. IEEE 80, 1502 (1992).
- Barber (1995) C. B. Barber, Qhull computes the convex hull, Delaunay triangulation, Voronoi diagram, halfspace intersection about a point, furthest-site Delaunay triangulation, and furthest-site Voronoi diagram. (1995), URL www.qhull.org.
- Preparata and Shamos (1985) F. P. Preparata and M. I. Shamos, Computational Geometry: An Introduction (Springer-Verlag, 1985).
- Kirkpatrick and Radke (1985) D. G. Kirkpatrick and J. D. Radke, in Computational Geometry, edited by G. Toussaint (Elsevier North Holland, New York, 1985), p. 217.
- Cormen et al. (2001) T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson, Introduction to Algorithms (MIT Press, 2001).
- Binder and Heermann (2010) K. Binder and D. W. Heermann, Monte Carlo simulation in statistical physics: an introduction (Springer Science & Business Media, 2010).
- Houdayer and Hartmann (2004) J. Houdayer and A. K. Hartmann, Phys. Rev. B 70, 014418 (2004).
- Melchert (2009) O. Melchert (2009), preprint: arXiv:0910.5403v1.
- Norrenbrock (2014) C. Norrenbrock (2014), preprint: arXiv:1406.0663.
- Bao et al. (2009) Z. J. Bao, Y. J. Cao, G. Z. Wang, and L. J. Ding, Phys. Lett. A 373, 3032 (2009).
- Crucitti et al. (2004b) P. Crucitti, V. Latora, and M. Marchiori, Phys. Rev. E 69, 045104 (2004b).
- Motter (2004) A. E. Motter, Phys. Rev. Lett. 93, 098701 (2004).
- Motter and Lai (2002) A. E. Motter and Y.-C. Lai, Phys. Rev. E 66, 065102 (2002).
- Newman (2001) M. E. J. Newman, Phys. Rev. E 64, 016132 (2001).
- Ouyang et al. (2014) B. Ouyang, X. Jin, Y. Xia, and L. Jiang, Eur. Phys. J. B 87, 52 (2014).
- Hartmann (2014) A. K. Hartmann, Eur. Phys. J. B 87, 114 (2014).
- Fisher (1961) M. E. Fisher, J. Math. Phys. 2, 620 (1961).
- Kundur et al. (1994) P. Kundur, N. J. Balu, and M. G. Lauby, Power System Stability and Control (McGraw-Hill Education, 1994).
- Filatrella et al. (2008) G. Filatrella, A. H. Nielsen, and N. F. Pedersen, Eur. Phys. J. B 61, 485 (2008).
- Rohden et al. (2012) M. Rohden, A. Sorge, M. Timme, and D. Witthaut, Phys. Rev. Lett. 109 (2012).
- Witthaut and Timme (20) D. Witthaut and M. Timme, New J. Phys. 14, 083036 (20).