Frame Theory for Signal Processing in Psychoacoustics
Abstract.
This review chapter aims to strengthen the link between frame theory and signal processing tasks in psychoacoustics. On the one side, the basic concepts of frame theory are presented and some proofs are provided to explain those concepts in some detail. The goal is to reveal to hearing scientists how this mathematical theory could be relevant for their research. In particular, we focus on frame theory in a filter bank approach, which is probably the most relevant view-point for audio signal processing. On the other side, basic psychoacoustic concepts are presented to stimulate mathematicians to apply their knowledge in this field.
1. Introduction
In the fields of audio signal processing and hearing research, continuous research efforts are dedicated to the development of optimal representations of sound signals, suited for particular applications. However, each application and each of these two disciplines has specific requirements with respect to optimality of the transform.
For researchers in audio signal processing, an optimal signal representation should allow to extract, process, and re-synthesize relevant information, and avoid any useless inflation of the data, while at the same time being easily interpretable. In addition, although not a formal requirement, but being motivated by the fact that most audio signals are targeted at humans, the representation should take human auditory perception into account. Common tools used in signal processing are linear time-frequency analysis methods that are mostly implemented as filter banks.
For hearing scientists, an optimal signal representation should allow to extract the perceptually relevant information in order to better understand sound perception. In other terms, the representation should reflect the peripheral “internal” representation of sounds in the human auditory system. The tools used in hearing research are computational models of the auditory system. Those models come in various flavors but their initial steps in the analysis process usually consist in several parallel bandpass filters followed by one or more nonlinear and signal-dependent processing stages. The first stage, implemented as a (linear) filter bank, aims to account for the spectro-temporal analysis performed in the cochlea. The subsequent nonlinear stages aim to account for the various nonlinearities that occur in the periphery (e.g. cochlear compression) and at more central processing stages of the nervous system (e.g. neural adaptation). A popular auditory model, for instance, is the compressive gammachirp filter bank (see Sec. 2.2). In this model, a linear prototype filter is followed by a nonlinear and level-dependent compensation filter to account for cochlear compression. Because auditory models are mostly intended as perceptual analysis tools, they do not feature a synthesis stage, i.e. they are not necessarily invertible. Note that a few models do allow for an approximate reconstruction, though.
It becomes clear that filter banks play a central role in hearing research and audio signal processing alike, although the requirements of the two disciplines differ. This divergence of the requirements, in particular the need for signal-dependent nonlinear processing in auditory models, may contrast with the needs of signal processing applications. But even within each of those fields, demands for the properties of transforms are diverse, as becoming evident by the many already existing methods. Therefore, it can be expected that the perfect signal representation, i.e. one that would have all desired properties for arbitrary applications in one or even both fields, does not exist.
This manuscript demonstrates how frame theory can be considered a particularly useful conceptual background for scientists in both hearing and audio processing, and presents some first motivating applications. Frames provide the following general properties: perfect reconstruction, stability, redundancy, and a signal-independent, linear inversion procedure. In particular, frame theory can be used to analyze any filter bank, thereby providing useful insight into its structure and properties. In practice, if a filter bank construction (i.e. including both the analysis and synthesis filter banks) satisfies the frame condition (see Sec. 4), it benefits from all the frame properties mentioned above. Why are those properties essential to researchers in audio signal processing and hearing science?
Perfect reconstruction property: With the possible exception of frequencies outside the audible range, a non-adaptive analysis filter bank , i.e. one that is general, not signal-dependent, has no means of determining and extracting exactly the perceptually relevant information. For such an extraction, signal-dependent information would be crucial. Therefore, the only way to ensure that a linear, signal-independent analysis stage111As given by any fixed analysis filter bank., possibly followed by a nonlinear processing stage, captures all perceptually relevant signal components is to ensure that it does not lose any information at all. This, in fact, is equivalent to being perfectly invertible, i.e. having a perfect reconstruction property. Thus, this property benefits the user even when reconstruction is not intended per-se. Note that in general “being perfectly invertible” need not necessarily imply that a concrete inversion procedure is known. In the frame case, a constructive method exists, though.
Stability: For sound processing, stability is essential in the sense that, for the analysis stage, when two signals are similar (i.e., their difference is small), the difference between their corresponding analysis coefficients should also be small. For the synthesis stage, a signal reconstructed from slightly distorted coefficients should be relatively close to the original signal, that is the one reconstructed from undistorted coefficients. From an energy point of view, signals which are similar in energy should provide analysis coefficients whose energy is also similar. So the respective energies remain roughly proportional. In particular, considering a signal mixture, the combination of stability and linearity ensures that every signal component is represented and weighted according to its original energy. In other terms, individual signal components are represented proportional to their energy, which is very important for, e.g., visualization. Even in a perceptual analysis, where inaudible components should not be visualized equally to audible components having the same energy, this stability property is important. To illustrate this, recall that the nonlinear post-processing stages in auditory models are signal dependent. That is, also the inaudible information can be essential to properly characterize the nonlinearity. For instance, consider again the setup of the compressive gammachirp model where an intermediate representation is obtained through the application of a linear analysis filter bank to the input signal. The result of this linear transform determines the shape of the subsequent nonlinear compensation filter. Note that the whole intermediate representation is used. Consequently, the proper estimation of the nonlinearity crucially relies on the signal representation being accurate, i.e. all signal components being represented and appropriately weighted. This accurateness comes for free if the analysis filter bank forms a frame.
Signal-independent, linear inversion: A consistent (i.e. signal-independent) inversion procedure is of great benefit in signal processing applications. It implies that a single algorithm/implementation can perform all the necessary synthesis tasks. For nonlinear representations, finding a signal-independent procedure which provides a stable reconstruction is a highly nontrivial affair, if it is at all possible. With linear representations, such a procedure is easier to determine and this can be seen as an advantage of the linearity. The linearity provided by the reconstruction algorithm also significantly simplifies separation tasks. In a linear representation, a separation in the coefficient (time-frequency) domain, i.e. before synthesis, is equivalent to a separation in the signal domain. Such a property is highly relevant, for instance, to computational auditory scene analysis systems that, to some extent, are sound source separators (see Sec. 2.4).
Redundancy: Representations which are sampled at critical density are often unsuitable for visualization, since they lead to a low resolution, which may lead to many distinct signal components being integrated into a single coefficient of the transform. Thus, the individual coefficients may contain information from a lot of different sources, which makes them hard to interpret. Still, the whole set of coefficients captures all the desired signal information if (and only if) the transform is invertible. Redundancy provides higher resolution and so components that are separated in time or in frequency can be separated in the transform domain. Furthermore, redundant representations are smoother and therefore easier to read than their critically sampled counterparts.
Moreover, redundant representations provide some resistance against noise and errors. This is in contrast to non-redundant systems, where distortions can not be compensated for. This is used for de-noising approaches. In particular, if a signal is synthesized in a straight-forward way from noisy (redundant) coefficients, the synthesis process has the tendency to reduce the energy of the noise, i.e. there is some noise cancellation.
Besides the above properties, which are direct consequences of the frame inequalities, the generality of frame theory enables the consideration of additional important properties. In the setting of perceptually motivated audio signal analysis and processing, these include:
Perceptual relevance: We have stressed that the only way to ensure that all perceptually relevant information is kept is to accurately capture all the information by using a stable and perfectly invertible system for analysis. However, in an auditory model or in perceptually motivated signal processing, perceptually irrelevant components should be discarded at some point. If only a linear signal processing framework is desired, this can be achieved by applying a perceptual weighting222Different frequency ranges are given varying importance in the auditory system and a masking model, see Sec. 2. If a nonlinear auditory model like the compressive gammachirp filter bank is used, recall that the nonlinear stage is mostly determined by the coefficients at the output of the linear stage. Therefore, all information should be kept up to the nonlinear stage. In other words, discarding information already in the analysis stage might falsify the estimation of the nonlinear stage, thereby resulting in an incorrect perceptual analysis. We want to stress here the importance of being able to selectively discard unnecessary information, in contrast to information being involuntarily lost during the analysis and/or synthesis procedures.
A flexible signal processing framework: All stable and invertible filter banks form a frame and therefore benefit from the frame properties discussed above. In addition, using filter banks that are frames allows for flexibility. For instance, one can gradually tune the signal representation such as the time-frequency resolution, analysis filters’ shape and bandwidth, frequency scale, sampling density etc., while at the same time retaining the crucial frame properties. It can be tremendously useful to provide a single and adaptable framework that allows to switch model parameters and/or transition between them. By staying in the common general setting of filter bank frames, the linear filter bank analysis in an auditory model or signal processing scheme can be seen as an exchangeable, practically self-contained block in the scheme. Thus, the filter bank parameters, e.g. those mentioned before, can be tuned by scientists according to their preference, without the need to redesign the remainder of the model/scheme. Such a common background leads to results being more comparable across research projects and thus benefits not only the individual researcher, but the whole field. Two main advantages of a common background are the following: first, the properties and parameters of various models can be easily interpreted and compared across contributions; second, by the adaption of a linear model to obtain a nonlinear model the new model parameters remain interpretable.
Ease of integration: Filter banks are already a common tool in both hearing science and signal processing. Integrating a filter bank frame into an existing analysis/processing framework will often only require minor modifications of existing approaches. Thus, frames provide a theoretically sound foundation without the need to fundamentally re-design the remainder of your analysis (or processing) framework.
In some cases, you might already implicitly use frames without knowing it. In that case, we provide here the conceptual background necessary to unlock the full potential of your method.
The rest of this chapter is organized as follows: In Section 2, we provide basic information about the human auditory system and introduce some psychoacoustic concepts. In Section 3 we present the basics of frame theory providing the main definitions and a few crucial mathematical statements. In Section 4 we provide some details on filter bank frames. The chapter concludes with Section 5 where some examples are given for the application of frame theory to signal processing in psychoacoustics.
2. The auditory analysis of sounds
This section provides a brief introduction to the human auditory system. Important concepts that are relevant to the problems treated in this chapter are then introduced, namely auditory filtering and auditory masking. For a more complete description of the hearing organ, the interested reader is referred to e.g. [32, 73].
2.1. Ear’s anatomy
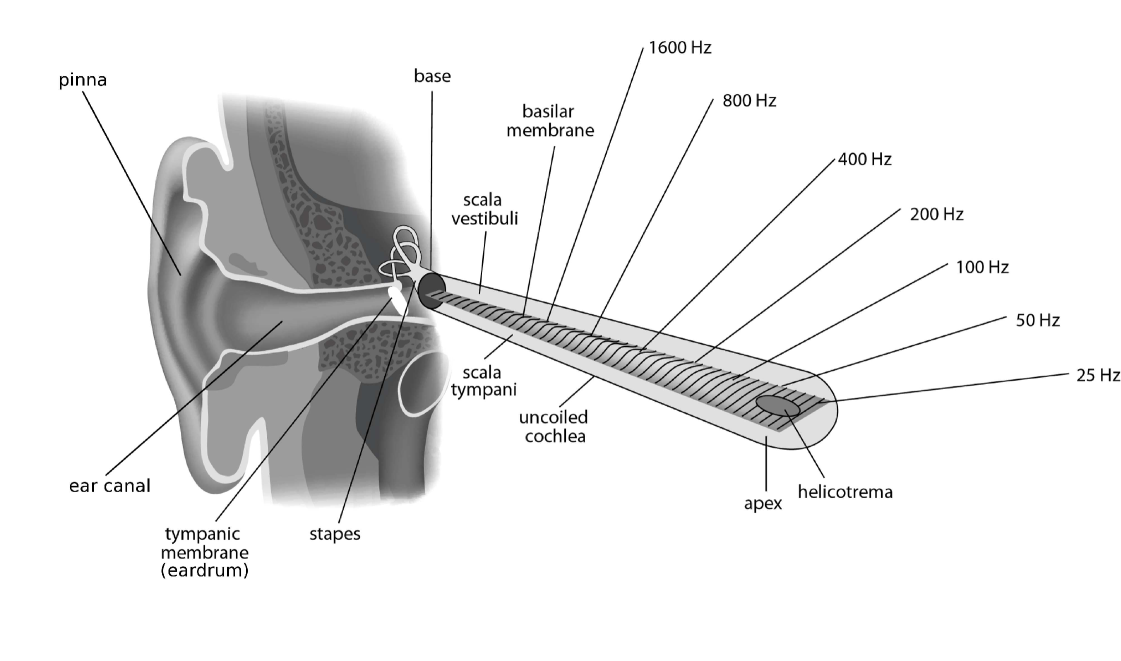
The human ear is a very sensitive and complex organ whose function is to transform pressure variations in the air into the percept of sound. To do so, sound waves must be converted into a form interpretable by the brain, specifically into neural action potentials. Fig. 1 shows a simplified view of the ear’s anatomy. Incoming sound waves are guided by the pinna into the ear canal and cause the eardrum to vibrate. Eardrum vibrations are then transmitted to the cochlea by three tiny bones that constitute the ossicular chain: the malleus, incus, and stapes. The ossicular chain acts as an impedance matcher. Its function is to ensure efficient transmission of pressure variations in the air into pressure variations in the fluids present in the cochlea. The cochlea is the most important part of the auditory system because it is where pressure variations are converted into neural action potentials.
The cochlea is a rolled-up tube filled with fluids and divided along its length by two membranes, the Reissner’s membrane and basilar membrane (BM). A schematic view of the unrolled cochlea is shown in Fig. 1 (the Reissner’s membrane is not represented). It is the response of the BM to pressure variations transmitted through the ossicular chain that is of primary importance. Because the mechanical properties of the BM vary across its lengths (precisely, there is a gradation of stiffness from base to apex), BM stimulation results in a complex movement of the membrane. In case of a sinusoidal stimulation, this movement is described as a traveling wave. The position of the peak in the pattern of vibration depends on the frequency of the stimulation. High-frequency sounds produce maximum displacement of the BM near the base with little movement on the rest of the membrane. Low-frequency sounds rather produce a pattern of vibration which extends all the way along the BM but reaches a maximum before the apex. The frequency that gives the maximum response at a particular point on the BM is called the “characteristic frequency” (CF) of that point. In case of a broadband stimulation (e.g. an impulsive sound like a click), all points on the BM will oscillate. In short, the BM separates out the spectral components of a sound similar to a Fourier analyzer.
The last step of peripheral processing is the conversion of BM vibrations into neural action potentials. This is achieved by the inner hair cells that sit on top of the BM. There are about 3500 inner hair cells along the length of the cochlea (35 mm in humans). The tip of each cell is covered with sensor hairs called stereocilia. The base of each cell directly connects to auditory nerve fibers. When the BM vibrates, the stereocilia are set in motion, which results in a bio-electrical process in the inner hair cells and, finally, in the initiation of action potentials in auditory nerve fibers. Those action potentials are then coded in the auditory nerve and conveyed to the central system where they are further processed to end up in a sound percept. Because the response of auditory nerve fibers is also frequency specific and the action potentials vary over time, the “internal representation” of a sound signal in the auditory nerve can be likened to a time-frequency representation.
2.2. The auditory filters concept
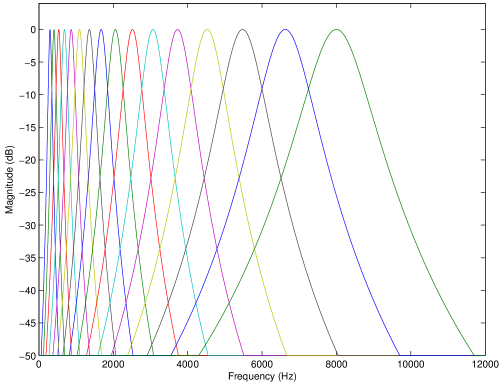
Because of the frequency-to-place transformation (also called tonotopic organization) in the cochlea, and the transmission of time-dependent neural signals, the BM can be modeled in a first linear approximation as a bank of overlapping bandpass filters, named “critical bands” or “auditory filters”. The center frequencies and bandwidth of the auditory filters, respectively, approximate the CF and width of excitation on the BM. Noteworthy, the width of excitation depends on level as well: patterns become wider and asymmetric as sound level increases (e.g. [37]). Several auditory filter models have been proposed based on the results from psychoacoustics experiments on masking (see e.g. [59] and Sec. 2.3). A popular auditory filter model is the gammatone filter [71] (see Fig 2). Although gammatone filters do not capture the level dependency of the actual auditory filters, their ease of implementation made them popular in audio signal processing (e.g. [90, 96]). More realistic auditory filter models are, for instance, the roex and gammachirp filters [37, 88]. Other level-dependent and more complex auditory filter banks include for example the dual resonance non-linear filter bank [58] or the dynamic compressive gammachirp filter bank [49]. The two approaches in [58, 49] feature a linear filter bank followed by a signal-dependent nonlinear stage. As mentioned in the introduction, this is a particular way of describing a nonlinear system by modifying a linear system. Finally, it is worth noting that besides psychoacoustic-driven auditory models, mathematically founded models of the auditory periphery have been proposed. Those include, for instance, the wavelet auditory model [12] or the “EarWig” time-frequency distribution [67].
The bandwidth of the auditory filters has been determined based on psychoacoustic experiments. The estimation of bandwidth based on loudness perception experiments gave rise to the concept of Bark bandwidth defined by [98]
| (1) |
where denotes the frequency and denotes the bandwidth, both in Hz. Another popular concept is the equivalent rectangular bandwidth (ERB), that is the bandwidth of a rectangular filter having the same peak output and energy as the auditory filter. The estimations of ERBs are based on masking experiments. The ERB is given by [37]
| (2) |
and are commonly used in psychoacoustics and signal processing to approximate the auditory spectral resolution at low to moderate sound pressure levels (i.e. 30–70 dB) where the auditory filters’ shape remains symmetric and constant. See for example [37, 88] for the variation of with level.
Based on the concepts of Bark and ERB bandwidths, corresponding frequency scales have been proposed to represent and analyze data on a scale related to perception. To describe the different mappings between the linear frequency domain and the nonlinear perceptual domain we introduce the function where is an auditory unit that depends on the scale. The Bark scale is [98]
| (3) |
and the ERB scale is [37]
| (4) |
Both auditory scales are connected to the ear’s anatomy. One AUD unit indeed corresponds to a constant distance along the BM. 1 corresponds to 1.3 mm [32] while 1 corresponds to 0.9 mm [37, 38].
2.3. Auditory masking
The phenomenon of masking is highly related to the spectro-temporal resolution of the ear and has been the focus of many psychoacoustics studies over the last 70 years. Auditory masking refers to the increase in the detection threshold of a sound signal (referred to as the “target”) due to the presence of another sound (the “masker”). Masking is quantified by measuring the detection thresholds of the target in presence and absence of the masker; the difference in thresholds (in dB) thus corresponds to the amount of masking. In the literature, masking has been extensively investigated in the spectral or temporal domain. The results were used to develop models of spectral or temporal masking that are currently implemented in audio applications like perceptual coding (e.g. [70, 76]) or sound processing (e.g. [9, 41]. Only a few studies investigated masking in the joint time-frequency domain. We present below some typical psychoacoustic results on spectral, temporal, and spectro-temporal masking. For more results and discussion on the origins of masking the interested reader is referred to e.g. [32, 64, 62].
In the following, we denote by , , and the frequency, duration, and level, respectively, of masker or target. Those signal parameters are fixed by the experimenter, i.e. they are known. The frequency shift between masker and target is and the time shift is defined as the onset delay between masker and target. Finally, denotes the amount of masking in dB.
2.3.1. Spectral masking
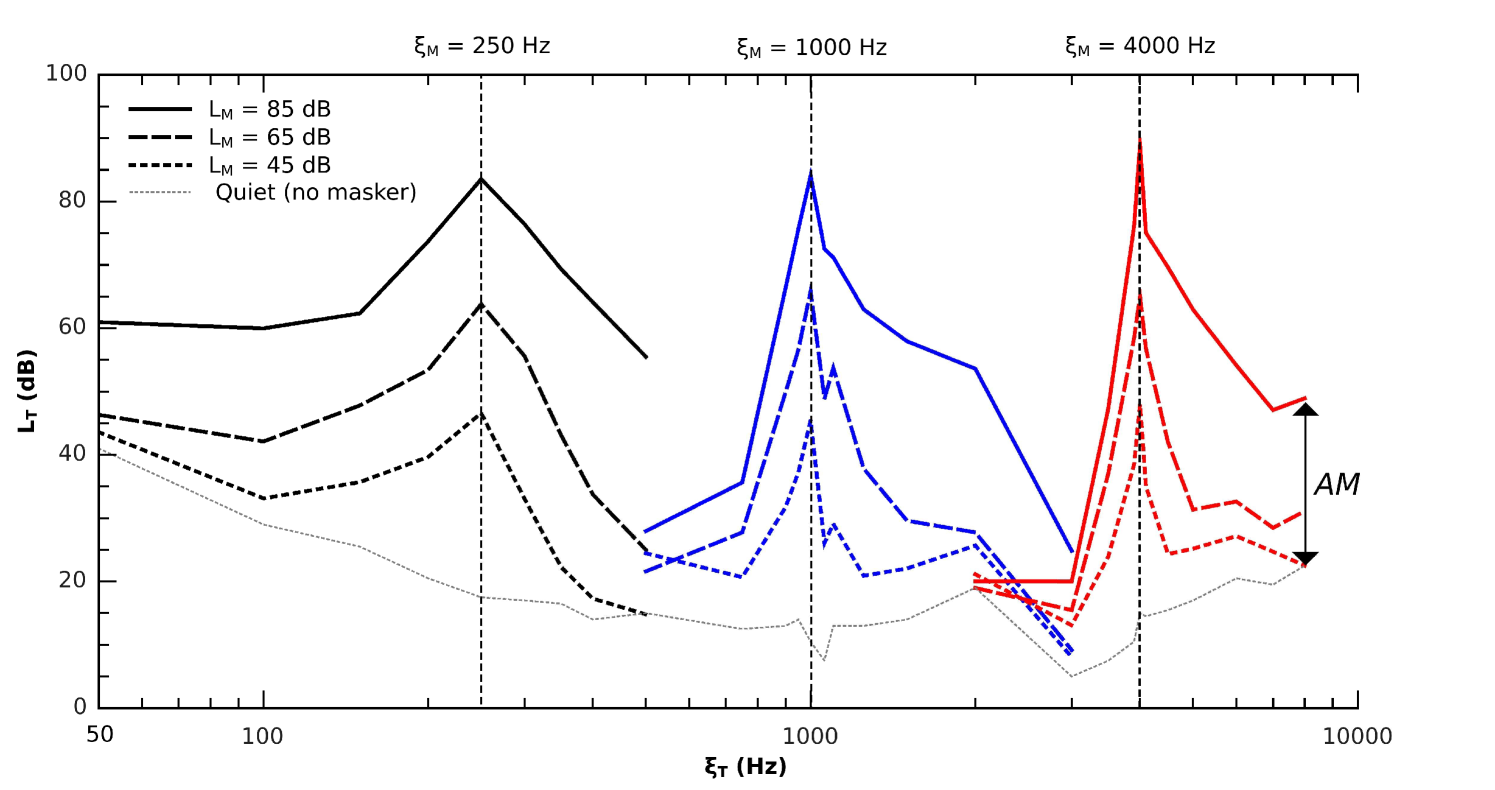
To study spectral masking, masker and target are presented simultaneously (since usually , this is equivalent to saying that 0 ) and is varied. There are two ways to vary , either fix and vary or vice versa. Similarly, one can fix and vary or vice versa. In short, various types of masking curves can be obtained depending on the signal parameters. A common spectral masking curve is a masking pattern that represents or as a function of or (see Fig. 3). To measure masking patterns, and are fixed and is measured for various . Under the assumption that corresponds to a certain ratio of masker-to-target energy at the output of the auditory filter centered at , masking patterns measure the responses of the auditory filters centered at the individual s. Thus, masking patterns can be used as indicator of the spectral spread of masking of the masker or, in other terms, the spread of excitation of the masker on the BM. This spectral spread can in turn be used to derive a masking threshold, as used for example in audio codecs [70]. See also Sec. 5.2.
Fig. 3 shows typical masking patterns measured for narrow-band noise maskers of different levels ( = 45, 65, and 85 dB SPL, as indicated by the different lines) and frequencies ( = 0.25, 1, and 4 kHz, as indicated by the different vertical dashed lines). In this study, = 200 ms. The masker was a 80-Hz-wide band of Gaussian noise centered at . The target was also a 80-Hz band of noise centered at . The main properties to be observed here are:
-
(i)
For a given masker (i.e. a pair of and ), is maximum for = 0 and decreases as increases. This reflects the decay of masker excitation on the BM.
-
(ii)
Masking patterns broaden with increasing level. This reflects the broadening of auditory filters with increasing level [37].
- (iii)
2.3.2. Temporal masking
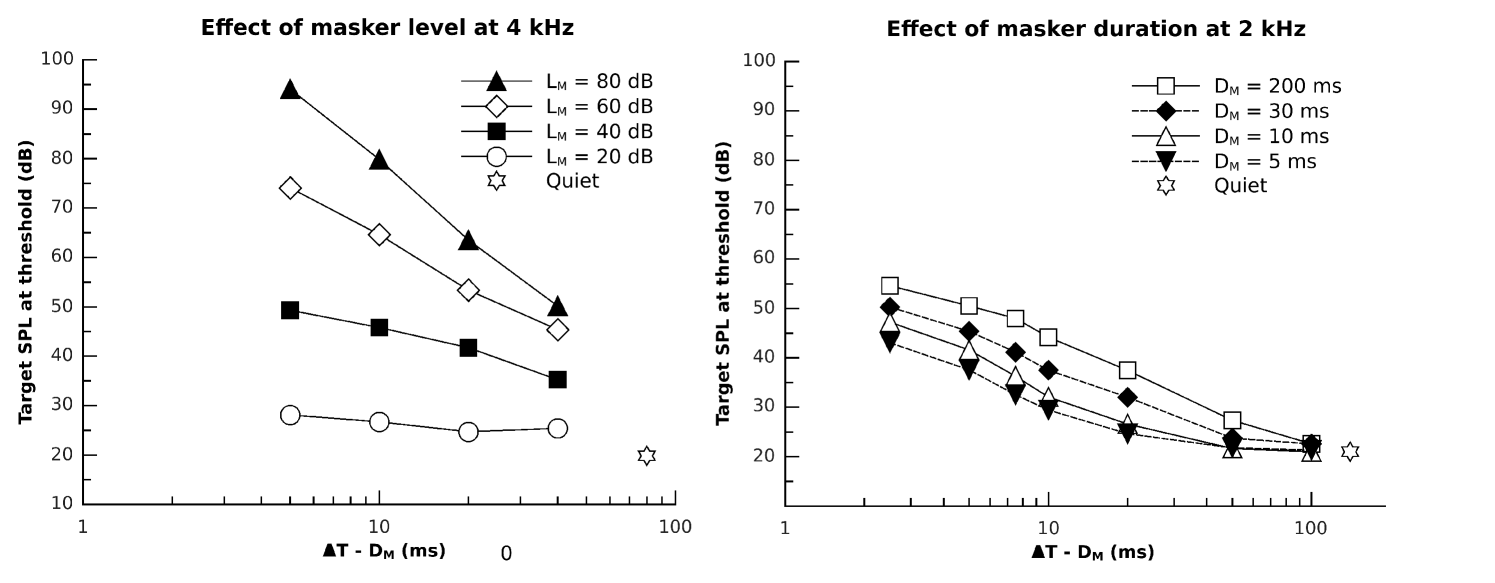
By analogy with spectral masking, temporal masking is measured by setting = 0 and varying . Backward masking is observed for 0, that is when the target precedes the masker in time. Forward masking is observed for , that is when the target follows the masker. Backward masking is hardly observed for -20 ms and is mainly thought to result from attentional effects [79, 32]. In contrast, forward masking can be observed for + 200 ms. Therefore, in the following we focus on forward masking.
Typical forward masking curves are represented in Fig. 4. The left panel shows the effect of for = 4 kHz (mean data from [51]). In this study, masker and target were sinusoids ( = 300 ms, = 20 ms). The main features to be observed here are (i) the temporal decay of forward masking is a linear function of and (ii) the rate of this decay strongly depends on . The right panel shows the effect of for = 2 kHz and = 60 dB SPL (mean data from [97]). In this study, the masker was a pulse of uniformly masking noise (i.e. a broad-band noise producing the same at all frequencies in the range 0–20 kHz, see [32]). The target was a sinusoid with = 5 ms. It can be seen that the (i.e. the difference between the connected symbols and the star) at a given increases with increasing , at least for 100 ms. Finally, a comparison of the two panels in Fig. 4 for = 60 dB indicates that, for 50 ms, the 300-ms sinusoidal masker (empty diamonds left) produces more masking than the 200-ms broad-band noise masker (empty squares right). Despite the difference in , increasing the duration of the noise masker to 300 ms is not expected to account for the difference in of up to 20 dB observed here [32, 97].
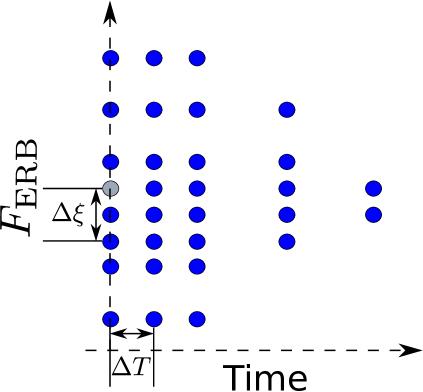
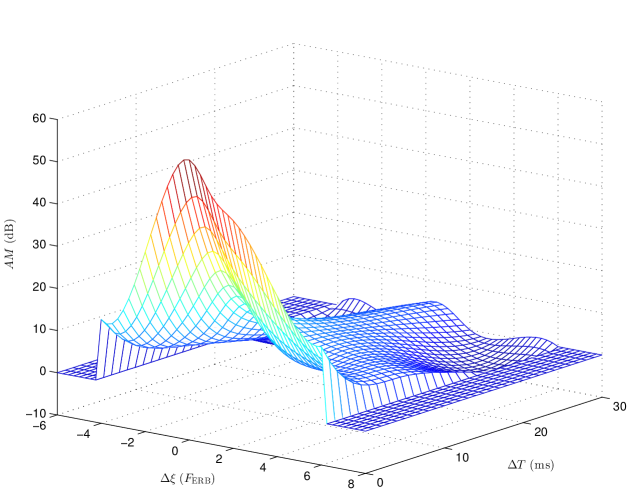
2.3.3. Time-frequency masking
Only a few studies measured spectro-temporal masking patterns, that is and both systematically varied (e.g. [53, 79]). Those studies mostly involved long ( 100 ms) sinusoidal maskers. In other words, those studies provide data on the time-frequency spread of masking for long and narrow-band maskers. In the context of time-frequency decompositions, a set of elementary functions, or “atoms”, with good localization in the time-frequency domain (i.e. short and narrow-band) is usually chosen, see Sec. 3. To best predict masking in the time-frequency decompositions of sounds, it seems intuitive to have data on the time-frequency spread of masking for such elementary atoms, as this will provide a good match between the masking model and the sound decomposition. This has been investigated in [64]. Precisely, spectral, forward, and time-frequency masking have been measured using Gabor atoms of the form with as masker and target. According to the definition of Gabor atoms in (7), the masker was defined by , where denotes the imaginary part, with a Gaussian window and = 4 kHz. The masker level was fixed at = 80 dB. The target was defined by with . The set of time-frequency conditions measured in [64] is illustrated in Fig. 5a. Because in this particular case we have , the target term reduces to . The mean masking data are summarized in Fig. 5b. These data, together with those collected by Laback et al on the additivity of spectral [56] and temporal masking [55] for the same Gabor atoms, constitute a crucial basis for the development of an accurate time-frequency masking model to be used in audio applications like audio coding or audio processing (see Sec. 5).
2.4. Computational auditory scene analysis
The term auditory scene analysis (ASA), introduced by Bregman [16], refers to the perceptual organization of auditory events into auditory streams. It is assumed that this perceptual organization constitutes the basis for the remarkable ability of the auditory system to separate sound sources, especially in noisy environments. A demonstration of this ability is the so-called “cocktail party effect”, i.e. when one is able to concentrate on and follow a single speaker in a highly competing background (e.g. many concurring speakers combined with cutlery and glass sounds). The term computational auditory scene analysis (CASA) thus refers to the study of ASA by computational means [92]. The CASA problem is closely related to the problem of source separation. Generally speaking, CASA systems can be considered as perceptually motivated sound source separators. The basic work flow of a CASA system is to first compute an auditory-based time-frequency transform (most systems use a gammatone filter bank, but any auditory representation that allows reconstruction can be used, see Sec. 5.1). Second, some acoustic features like periodicity, pitch, amplitude and frequency modulations are extracted so as to build the perceptive organization (i.e. constitute the streams). Then, stream separation is achieved using so-called “time-frequency masks”. These masks are directly applied to the perceptual representation; they retain the “target” regions (mask = 1) and suppress the background (mask = 0). Those masks can be binary or real, see e.g. [92, 96]. The target regions are then re-synthesized by applying the inverse transform to obtain the signal of interest. Noteworthy, a perfect reconstruction transform is of importance here. Furthermore, the linearity and stability of the transform allow a separation of the audio streams directly in the transform domain. Most gammatone filter banks implemented in CASA systems are only approximately invertible, though. This is due to the fact that such systems implement gammatone filters in the analysis stage and their time-reversed impulse responses in the synthesis stage. This setting implies that the frequency response of the gammatone filter bank has an all-pass characteristic and features no ripple (equivalently in the frame context, that the system is tight, see 4.3). In practice, however, gammatone filter banks usually consider only a limited range of frequencies (typically in the interval 0.1–4 kHz for speech processing) and the frequency response features ripples if the filters’ density is not high enough. If a high density of filters is used, the audio quality of the reconstruction is rather good [85, 96]. Still, the quality could be perfect by using frame theory [66]. For instance, one could render the gammatone system tight (see Proposition 2) or use its dual frame (see Sec. 3.1.2).
The use of binary masks in CASA is directly motivated by the phenomenon of auditory masking explained above. However, time-frequency masking is hardly considered in CASA systems. As a final remark, an analogy can be established between the (binary) masks used in CASA and the concept of frame multipliers defined in Sec. 3.2. Specifically, the masks used in CASA systems correspond to the symbol in (15). This analogy is not considered in most CASA studies, though, and offers the possibility for some future research connecting acoustics and frame multipliers.
3. Frame theory
What is an appropriate setting for the mathematical background of audio signal processing? Since real-world signals are usually considered to have finite energy and technically are represented as functions of some variable (e.g. time), it is natural to think about them as elements of the space . Roughly speaking, contains all functions with finite energy, i.e. with . For working with sampled signals, the analogue appropriate space is ( denoting a countable index set) which consists of the sequences with finite energy, i.e. .
Both spaces and are Hilbert spaces and one may use the rich theory ensured by the availability of an inner product, that serves as a measure of correlation, and is used to define orthogonality, of elements in the Hilbert space. In particular, the inner product enables the representation of all functions in in terms of their inner products with a set of reference functions: A standard approach for such representations uses orthonormal bases (ONBs), see e.g. [42]. Every separable Hilbert space has an ONB and every element can be written as
| (5) |
with uniqueness of the coefficients , . The convenience of this approach is that there is a clear (and efficient) way for calculating the coefficients in the representations using the same orthonormal sequence. Even more, the energy in the coefficient domain (i.e., the square of the -norm) is exactly the energy of the element :
| (Parseval equality) |
Furthermore, the representation (5) is stable - if the coefficients are slightly changed to , one obtains an element close to the original one .
However, the use of ONBs has several disadvantages. Often the construction of orthonormal bases with some given side constraints is difficult or even impossible (see below).
“Small perturbation”of the orthonormal basis’ elements may destroy the orthonormal structure [95].
Finally, the uniqueness of the coefficients in (5) leads to a lack of exact
reconstruction when some of these coefficients are lost or disturbed during transmission.
This naturally leads to the question how the concept of ONBs could be generalized to overcome those disadvantages. As an extension of the above-mentioned Parseval equality for ONBs, one could consider inequalities instead of an equality, i.e. boundedness from above and below (see Def. 1). This leads to the concept of frames, which was introduced by Duffin and Schaeffer [29] in 1952. It took several decades for scientists to realize the importance and applicability of frames. Popularized around the 90s in the wake of wavelet theory [27, 43, 26], frames have seen increasing interest and extensive investigation by many researchers ever since. Frame theory is both a beautiful abstract mathematical theory and a concept applicable in many other disciplines like e.g. engineering, medicine, and psychoacoustics, see Sec. 5.
Via frames, one can avoid the restrictions of ONBs while keeping their important properties. Frames still allow perfect and stable reconstruction of all the elements of the space, though the representation-formulas in general are not as simple as the ones via an ONB (see Sec. 3.1.2). Compared to orthonormal bases, the frame property itself is much more stable under perturbations (see, e.g., [22, Sec. 15]). Also, in contrast to orthonormal bases, frames allow redundancy which is desirable e.g. in signal transmission, for reconstructing signals when some coefficients are lost, and for noise reduction. Via redundant frames one has multiple representations and this allows to choose appropriate coefficients fulfilling particular constraints, e.g. when aiming at sparse representations. Furthermore, frames can be easier and faster to construct than ONBs. Some advantageous side constraints can only be fulfilled for frames. For example, Gabor frames provide convenient and efficient signal processing tools, but good localization in both time and frequency can never be achieved if the Gabor frame is an ONB or even a Riesz basis (cf. Balian-Low Theorem, see e.g. [22, Theor. 4.1.1]), while redundant Gabor frames for this purpose are easily constructed (for example using the Gaussian function). See Sec. 2.3.3 on how good localization in time and frequency is important in masking experiments.
Some of the main properties of frames were already obtained in the first paper [29]. For extensive presentation on frame theory, we refer to [18, 40, 22, 42].
In this section we collect the basics of frame theory relevant to the topic of the current paper. All the statements presented here are well known. Proofs are given just to make the paper self-contained, for convenience of the readers, and to facilitate a better understanding of the mathematical concepts. They are mostly based on [22, 29, 40]. Throughout the rest of the section, denotes a separable Hilbert space with inner product , - the identity operator on , - a countable index set, and (resp. ) - a sequence (resp. ) with elements from . The term operator is used for a linear mapping. Readers not familiar with Hilbert space theory can simply assume for the remainder of this section.
3.1. Frames: A Mathematical viewpoint
The frame concept extends naturally the Parseval equality permitting inequalities, i.e., the ratio of the energy in the coefficient domain to the energy of the signal may be bounded from above and below instead of being necessarily one:
Definition 1.
A countable sequence is called a frame for the Hilbert space if there exist positive constants and such that
| (6) |
The constant (resp. ) is called a lower (resp. upper) frame bound of . A frame is called tight with frame bound if is both a lower and an upper frame bound. A tight frame with bound is called a Parseval frame.
Clearly, every ONB is a frame, but not vice-versa. Frames can naturally be split into two classes - the frames which still fulfill a basis-property, and the ones that do not:
Definition 2.
A frame for which is a Schauder basis333A sequence is called a Schauder basis for if every element can be written as with unique coefficients . for is called a Riesz basis for . A frame for which is not a Schauder basis for is called redundant (also called overcomplete).
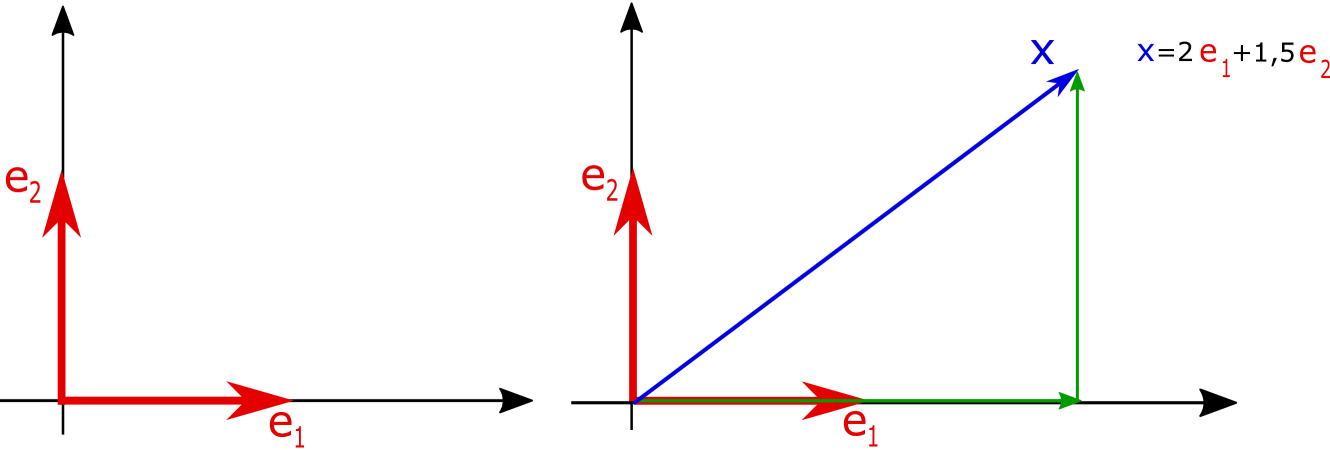
Note that Riesz bases were introduced by Bari [11] in different but equivalent ways. Riesz bases also extend ONBs, but contrary to frames, Riesz bases still have the disadvantages resulting from the basis-property, as they do not allow redundancy. For more on Riesz bases, see e.g. [95]. As an illustration of the concepts of ONBs, Riesz bases, and redundant frames in a simple setting, consider examples in the Euclidean plane, see Fig. 6.
(a) ONB for
(b) unique representation of via
(c) Riesz basis for (d) unique representation of via
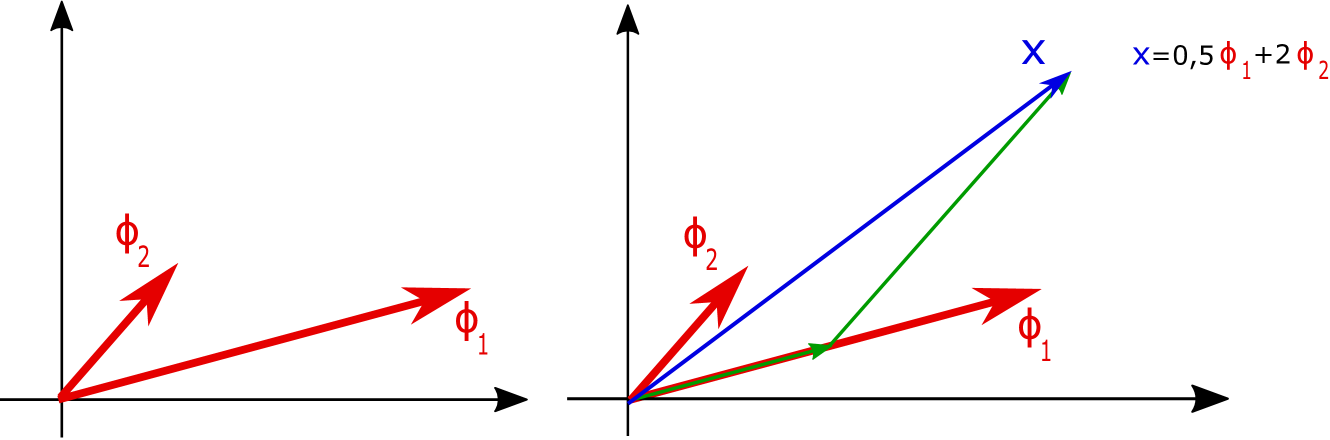
(e) frame for (f) non-unique representation of via
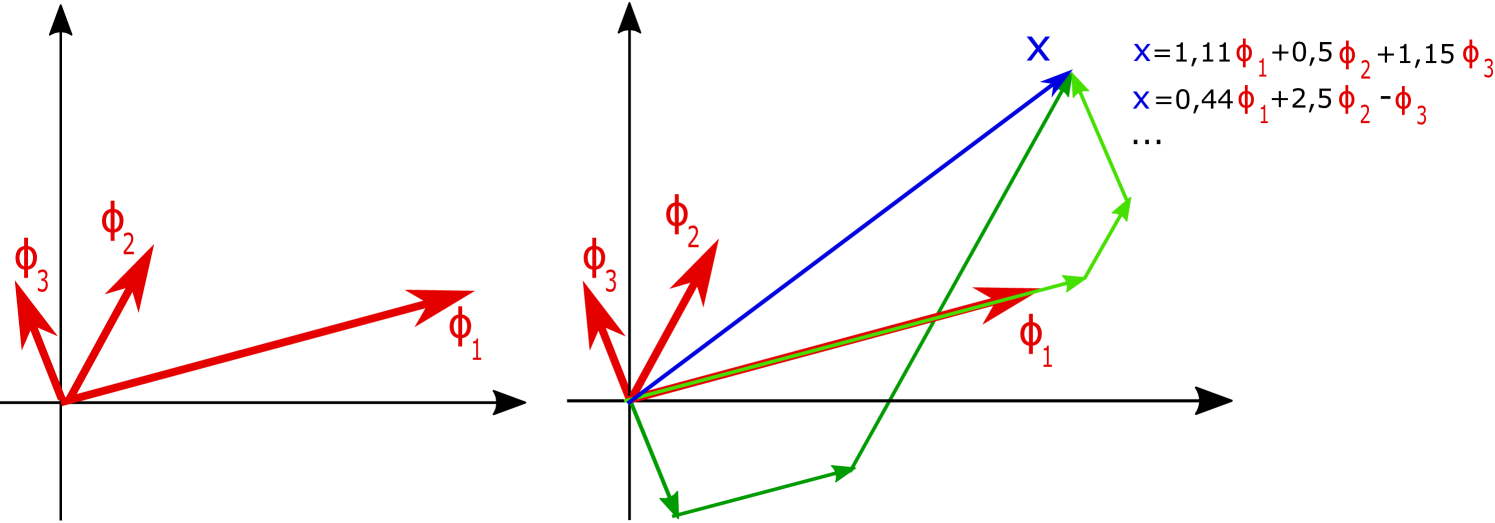
Note that in a finite dimensional Hilbert space, considering only finite sequences, frames are precisely the complete sequences (see, e.g., [22, Sec. 1.1]), i.e., the sequences which span the whole space. However, this is not the case in infinite-dimensional Hilbert spaces - every frame is complete, but completeness is not sufficient to establish the frame property [29]. For results focused on frames in finite dimensional spaces, refer to [4, 17].
As non-trivial examples, let us mention a specific type of frames used often in signal processing applications, namely Gabor frames. A Gabor system is comprised of atoms of the form
| (7) |
with function called the (generating) window and with time- and frequency-shift , respectively. To allow perfect and stable reconstruction, the Gabor system is assumed to have the frame-property and in this case is called a Gabor frame. Note that the analysis operator of a Gabor frame corresponds to a sampled Short-Time-Fourier transform (see, e.g., [40]) also referred to as Gabor transform.
Most commonly, regular Gabor frames are used; these are frames of the form for some positive and satisfying necessarily (but in general not sufficiently ) . To mention a concrete example - for the Gaussian , the respective regular Gabor system is a frame for if and only if (see, e.g., [40, Sec. 7.5] and references therein).
Other possibilities include using alternative sampling structures, on subgroups [94] or irregular sets [19]. If the window is allowed to change with time (or frequency) one obtains the non-stationary Gabor transform [6]. There it becomes apparent that frames allow to create adaptive and adapted transforms [7], while still guaranteeing perfect reconstruction.
If not continuous but sampled signals are considered, Gabor theory works similarly. Discrete Gabor frames can be defined in an analogue way, namely, frames of the form for with , where is necessary for the frame property. For readers interested in the theory of Gabor frames on , see, e.g., [91]. For constructions of discrete Gabor frames from Gabor frames for through sampling, refer to [50, 81].
3.1.1. Frame-related operators
Given a frame for , consider the following linear mappings:
| Analysis operator: | |||||
| Synthesis operator: | |||||
| (8) | Frame operator: |
These operators are tremendously important for the theoretical investigation of frames as well as for signal processing. As one can observe, the analysis (resp. synthesis, frame) operator corresponds to analyzing (resp. synthesizing, analyzing and re-synthesizing) a signal. In the following statement the main properties of the frame-related operators are listed.
Theorem 1.
(e.g. [22, Sec. 5]) Let be a frame for with frame bounds and (). Then the following holds.
-
(a)
is a bounded injective operator with bound .
-
(b)
is a bounded surjective operator with bound and .
-
(c)
is a bounded bijective positive self-adjoint operator with .
-
(d)
is a frame for with frame bounds .
Proof.
(a) By the frame inequalities (6) we have for every ; the upper inequality implies the boundedness and the lower one - the injectivity, i.e. the operator is one-to-one.
(b) First show that is well defined, i.e., that converges for every . Without loss of generality, for simplicity of the writing, we may denote as . Fix arbitrary . For every , ,
which implies that converges in as . Using the adjoint of , for every and every , one has that
Therefore , implying also the boundedness of .
For every , we have , which implies (see, e.g., [78, Theorem 4.15]) that is surjective, i.e. it maps onto the whole space .
(c) The boundedness and self-adjointness of follow from (a) and (b). Since, , is positive and the frame inequalities (6) mean that
| (9) |
implying that for all . Then the norm of the bounded self-adjoint operator satisfies
which by the Neumann theorem (see, e.g., [45, Theor. 8.1]) implies that is bijective.
(d) As a consequence of (c), is bounded, self-adjoint, and positive. In the language of partial ordering of self-adjoint operators (see, e.g., [45, Sec. 68]), (9) can be written as
| (10) |
Since is positive and commutes with and , one can multiply the inequalities in (10) with (see, e.g., [45, Prop. 68.9]) and obtain
which means that
| (11) |
For every , denote and use the fact that is self-adjoint to obtain
Now (11) completes the conclusion that is a frame for with frame bounds , . ∎
3.1.2. Perfect reconstruction via frames
Here we consider one of the most important properties of frames, namely, the possibility to have perfect reconstruction of all the elements in the space.
Theorem 2.
(e.g. [40, Corol. 5.1.3]) Let be a frame for . Then there exists a frame for such that
| (12) |
Proof.
By Theorem 1(d), the sequence is a frame for . Take . Using the boundedness and the self-adjointness of , for every ,
∎
Let be a frame for . Any frame for , which satisfies (12), is called a dual frame of . By the above theorem, every frame has at least one dual frame, namely, the sequence
| (13) |
called the canonical dual of . When the frame is a Riesz basis, then the coefficient representation is unique and thus there is only one dual frame, the canonical dual. When the frame is redundant, then there are other dual frames different from the canonical dual (see, e.g., [22, Lemma 5.6.1]), even infinitely many. This provides multiple choices for the coefficients in the frame representations, which is desirable in some applications (see, e.g., [7]). The canonical dual has a minimizing property in the sense that the coefficients in the representation have the minimal -norm compared to the coefficients in all other possible representations . However, for certain applications other constraints are of interest - e.g. sparsity, efficient algorithms for representations or particular shape restrictions on the dual window [93, 72]. The canonical dual is not always efficient to calculate nor does it always have the desired structure; in such cases other dual frames are of interest [23, 57, 15]. The particular case of tight frames is very convenient for efficient reconstructions, because the canonical dual is simple and does not require operator-inversion:
Corollary 1.
(e.g. [22, Sec. 5.7]) The canonical dual of a tight frame with frame bound is the sequence .
Proof.
Let be a tight frame for with frame bound . It follows from (10) that and thus the canonical dual of is . ∎
In acoustic applications, it can be of big advantage to not be forced to distinguish between analysis and synthesis atoms. So, one may aim to do analysis and synthesis with the same sequence as an analogue to the case with ONBs. However, such an analysis-synthesis strategy would perfectly reconstruct all the elements of the space if and only if this sequence is a Parseval frame:
Proposition 1.
Proof.
The above statement characterizes the sequences which provide reconstructions exactly like ONBs - these are precisely the Parseval frames. A trivial example of such a frame which is not an ONB is the sequence , where denotes an ONB for . Clearly, any tight frame with frame bound is easily converted into a Parseval frame by dividing the frame elements by the square root of . Given any frame, one can always construct a Parseval frame as follows:
Proposition 2.
(e.g. [22, Theor. 5.3.4]) Let be a frame for . Then has a positive square root and forms a Parseval frame for .
Proof.
Since is a bounded positive self-adjoint operator, there is a unique bounded positive self-adjoint operator, which is denoted by , with . Furthermore, commutes with . For every ,
By Proposition 1 this means that is a Parseval frame for . ∎
Finally, note that frames guarantee stability. Let be a frame for with frame bounds . Then for , which implies that close signals lead to close analysis coefficients and vice versa. Furthermore, the representations via and a dual frame is stable. If a signal is transmitted via the coefficients but, during transmission, the coefficients are slightly disturbed (i.e. modified to a sequence with small -difference), then by Theorem 1(b) the “reconstructed” signal will be close to : .
3.2. Frame multipliers
Multipliers have been used implicitly for quite some time in applications, as time-variant filters, see e.g. [60]. The first systematic theoretical development of Gabor multipliers appeared in [33]. An extension of the multiplier concept to general frames in Hilbert spaces was done in [3] and it can be derived as an easy consequence of Theorem 1:
Proposition 3.
[3] Let and be frames for and let be a complex scalar sequence in . Then the series converges for every and determines a bounded operator on .
Proof.
Due to above proposition, frame multipliers can be defined as follows:
Definition 3.
Given frames and for and given complex scalar sequence , the operator determined by
| (15) |
is called a frame multiplier with a symbol .
Thus, frame multipliers extend the frame operator, allowing different frames for the analysis and synthesis step, and modification in between (for an illustration, see Figure 7). However, in contrast to frame operators, multipliers in general loose the bijectivity (as well as self-adjointness and positivity). For some applications it might be necessary to invert multipliers, which brings the interest to bijective multipliers and formulas for their inverses - for interested readers, we refer to [10, 82, 83, 84] for some investigation in this direction.
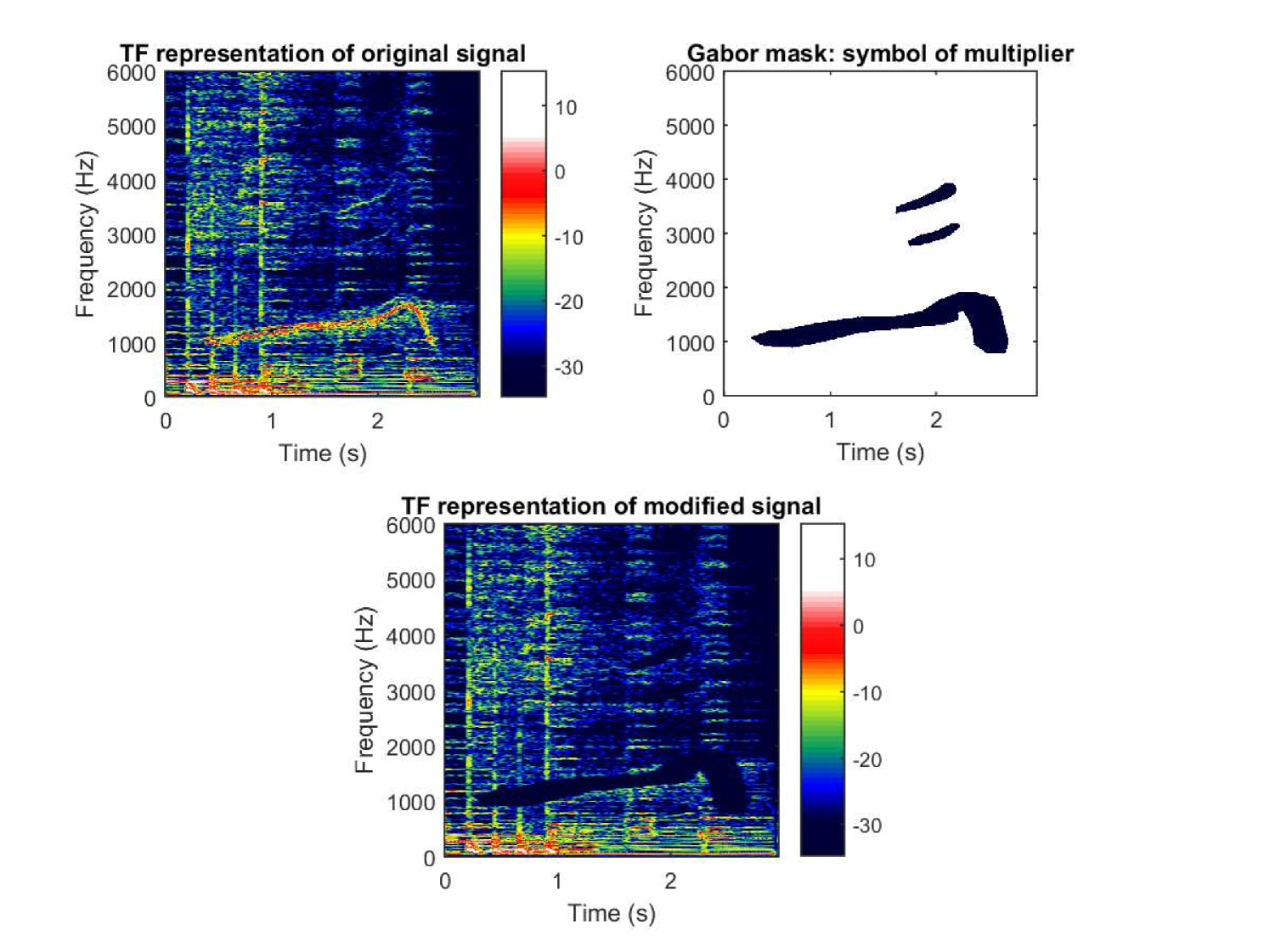
In the language of signal processing, Gabor filters [61] are a particular way to do time-variant filtering. In fact, Gabor filters are nothing but frame multipliers associated to a Gabor frame. A signal is transformed to the time-frequency domain (with a Gabor frame ), then modified there by point-wise multiplication with the symbol , followed by re-synthesis via some Gabor frame providing a modified signal. If some elements of the symbol are zero, the corresponding coefficients are removed, as sometimes used in applications like CASA or percerptual sparsity, see Secs. 2.4 and 5.2.
3.2.1. Implementation
In the finite-dimensional case, frames lend themselves easily to implementation in computer codes [4]. The Large Time-Frequency Analysis Toolbox (LTFAT) [80], see http://ltfat.github.io/, is an open-source Matlab/Octave toolbox intended for time-frequency analysis, synthesis and processing, including multipliers. It provides robust and efficient implementations for a variety of frame-related operators for generic frames and several special types, e.g. Gabor and filter bank frames.
In a recent release, reported in [74], a ’frames framework’ was implemented, which models the abstract frame concept in an object-oriented approach. In this setting any algorithm can be designed to use a general frame. If a structured frame, e.g. of Gabor or wavelet type, is used, more efficient algorithms are automatically selected.
4. Filter bank frames: a signal processing viewpoint
Linear time-invariant filter banks (FB) are a classical signal analysis and processing tool. Their general, potentially non-uniform structure provides the natural setting for the design of flexible, frequency-adaptive time-frequency signal representations [7]. In this section, we recall some basics of FB theory and consider the relation of perfect reconstruction FBs to certain frame systems.
4.1. Basics of filter banks
In the following, we consider discrete signals with finite energy (), interpreted as samples of a continuous signal, sampled at sampling frequency , i.e. the signal was sampled every seconds. Bold italic letters indicate matrices (upper case), e.g. , and vectors (lower case), e.g. . We denote by the th root of unity and by the (discrete) Dirac symbol, with for and otherwise. Observe that for we have
| (16) |
The -transform maps a (discrete-)time domain signal to its frequency domain representation by
By setting for , the -transform equals the discrete-time Fourier transform (). Note that the -transform is uniquely determined by its values on the complex unit circle [68]. It is easy to see that, , a property that we will use later on.
The application of a filter to a signal is given by the convolution of with the time domain representation, or impulse response of the filter
| (17) |
or equivalently by multiplication in the frequency domain , where is the transfer function, or frequency domain representation, of the filter.
Furthermore define the downsampling and upsampling operators by
| (18) |
Here, is called the downsampling or upsampling factor, respectively. In the frequency domain, the effect of down- and upsampling is the following [69]:
| (19) |
In words, downsampling a signal by results in the dilation of its spectrum by and the addition of copies of the dilated spectrum. These copies of the spectrum (the terms for in the sum above) are called aliasing terms. Conversely, upsampling a signal by results in the contraction of its spectrum by .
An FB is a collection of analysis filters , synthesis filters , and downsampling and upsampling factors , , see Fig. 8. An FB is called uniform, if all filters have the same downsampling factor, i.e. for all .
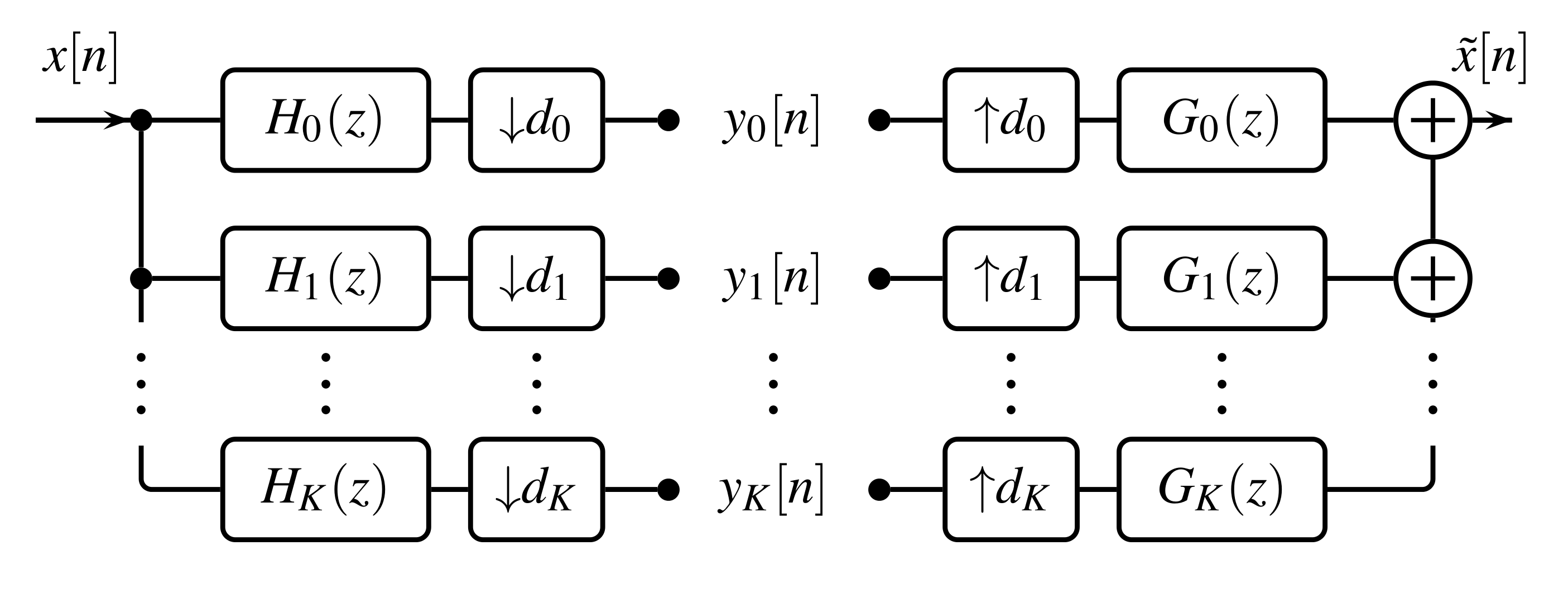
The sub-band components of the system represented in Fig. 8 are given in the time domain by
| (20) |
The output signal is . When analyzing the properties of a filter (bank), it is often useful to transform the expression for to the frequency domain. First, apply the z-transform to the output of a single analysis/synthesis branch, obtaining
| (21) |
where the down- and upsampling properties of the z-transform were applied, see Eq. (19). Now let , i.e. the least common multiple of the downsampling factors, and . Then (21) gives
| (22) |
where ,
The relevance of this equality becomes clear if we use linearity of the z-transform to obtain a frequency domain representation of the full FB output, also called the alias domain representation [89]
| (23) | |||||
where is the alias component matrix [89] and .
An FB system is undersampled, critically sampled or oversampled, if is smaller than, equal to or larger than , respectively. Consequently, a uniform FB is critically sampled if it has exactly subbands. For a deeper treatment of FBs, see e.g. [54, 89].
Perfect reconstruction FBs: An FB is said to provide perfect reconstruction if for all and some fixed . In the case when , the FB output is delayed by . Using the alias domain representation of the FB, the perfect reconstruction condition can be expressed as
| (24) |
for some , as this condition is equivalent to . From this vantage point the perfect reconstruction condition can be interpreted as all the alias components (i.e. from the nd to -th) in being uniformly canceled over all by the synthesis filters , while the first component of remains constant over all (up to a fixed power of ). The perfect reconstruction condition is of tremendous importance for determining whether an FB, including both analysis and synthesis steps, provides perfect reconstruction. However, given a fixed analysis FB, the alias domain representation may fail to provide straightforward or efficient ways to find suitable synthesis filters that provide perfect reconstruction. It can sometimes be used to determine whether such a system can exist, although the process is far from intuitive [46]. Consequently, non-uniform perfect reconstruction FBs are still not completely investigated, and thus frame theory may provide valuable new insights. However, for uniform FBs the perfect reconstruction conditions have been largely treated in the literature [54, 89]. Therefore, before we indulge in the frame theory of FBs, we also show how a non-uniform FB can be decomposed into its equivalent uniform FB. Such a uniform equivalent of the FB always exists [54, 1] and can be obtained as shown in Fig. 9 and described below.
4.2. The equivalent uniform filter bank
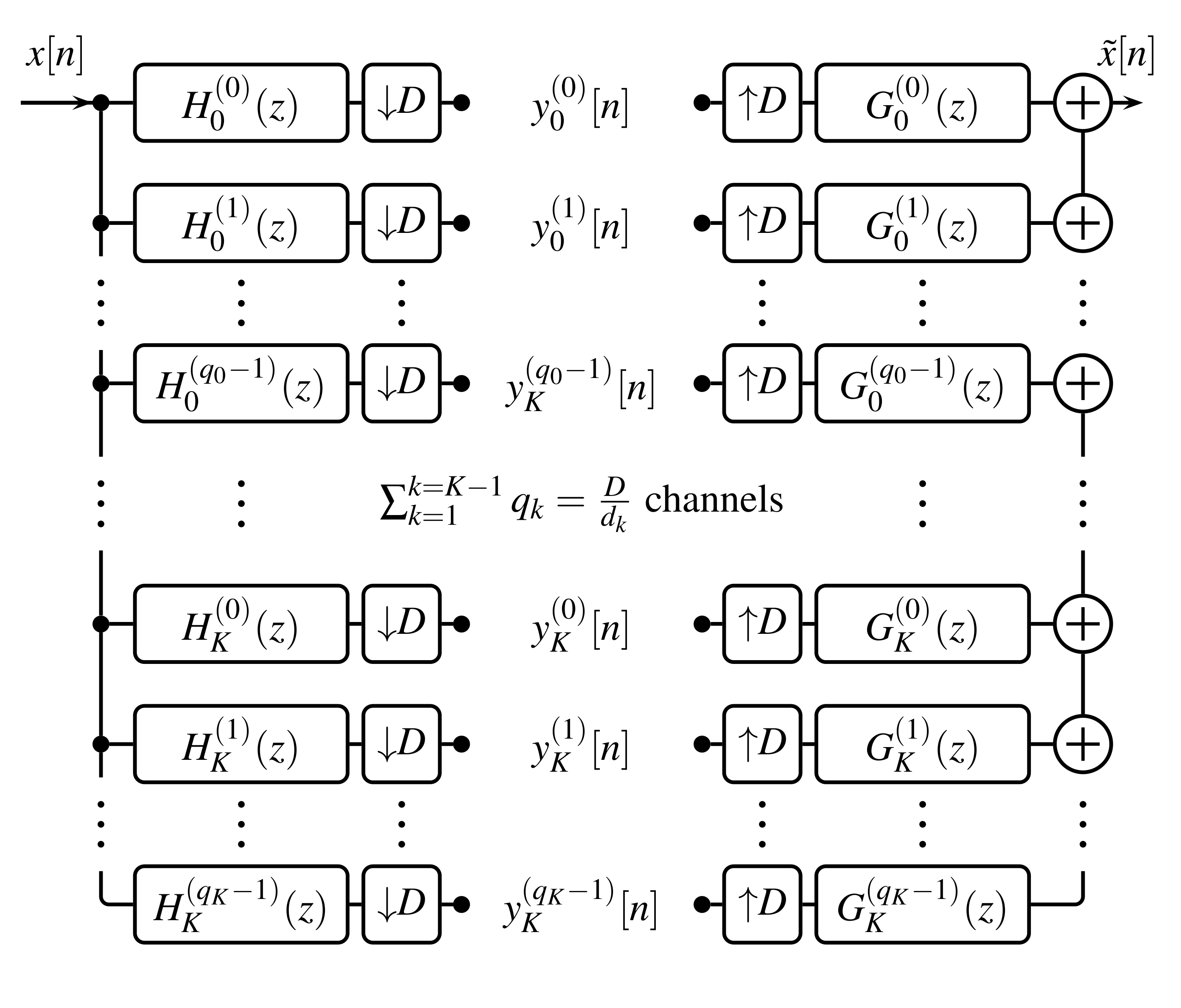
To construct the equivalent uniform FB to a general FB specified by analysis filters , synthesis filters , and downsampling and upsampling factors , , start by denoting again . We first construct the desired uniform FB, before showing that it is in fact equivalent to the given non-uniform FB. For every filter in the non-uniform FB, introduce filters, given by specific delayed versions of :
| (25) |
for . It is easily seen that convolution with equals translation by samples by just checking the definition of the convolution operation (17). Consequently, the sub-band components are
| (26) |
where is the -th sub-band component with respect to the non-uniform FB. Thus, by grouping the corresponding sub-bands, we obtain
In the frequency domain, the filters are given by
Similar to before, the output of the FB can be written as
| (27) | |||||
To obtain the second equality, we have used that . Insert Eq. (16) into (27) to obtain
| (28) | |||||
which is exactly the output of the non-uniform FB specified by the ’s, ’s and ’s, see (23). Therefore, we see that an equivalent uniform FB for every non-uniform FB is obtained by decomposing each -th channel of the non-uniform system into channels. The uniform system then features channels in total with the downsampling factor in all channels.
4.3. Connection to Frame Theory
We will now describe in detail the connection between non-uniform FBs and frame theory. The main difference to previous work in this direction, cf. [14, 25, 20, 34], is that we do not restrict to the case of uniform FBs. The results in this section are not new, but this presentation is their first appearance in the context of non-uniform FBs. Besides using the equivalent uniform FB representation, see Fig. 9, we transfer results previously obtained for generalized shift-invariant systems [77, 44] and nonstationary Gabor systems [6, 48, 47] to the non-uniform FB setting. For that purpose, we consider frames over the Hilbert space of finite energy sequences. Moreover, we consider only FBs with a finite number of channels, a setup naturally satisfied in every real- world application. The central observation linking FBs to frames is that the convolution can be expressed as an inner product:
where the bar denotes the complex conjugate. Hence, the sub-band components with respect to the filters and downsampling factors equal the frame coefficients of the system . Note that the upper frame inequality, see Eq. (6), is equivalent to the ’s and ’s defining a system where bounded energy of the input implies bounded energy of the output. We will investigate the frame properties of this system by transference to the Fourier domain [5]; we consider , where denotes the Fourier transform of and the operator denotes modulation, i.e. .
If satisfies at least the upper frame inequality in Eq. (6), then the frame operators and are related by the matrix Fourier transform [2]:
where denotes the discrete-time Fourier transform. Since the matrix Fourier transform is a unitary operation, the study of the frame properties of reduces to the study of the operator . In the context of FBs, the frame operator can be expressed as the action of an FB with analysis filters ’s, downsampling and upsampling factors ’s, and synthesis filters . That is, the synthesis filters are given by the time-reversed, conjugate impulse responses of the analysis filters. This is a very common approach to FB synthesis. But note that it only gives perfect reconstruction if the system constitutes a Parseval frame, see Prop. 1. The z-transform of a time-reversed, conjugated signal is given by . Inserting this into the alias domain representation of the FB (23) yields
| (32) |
or, restricted to the Fourier domain
| (33) |
with
| (34) |
for . Here, we used for all . We call the frequency response and , the alias components of the FB.
Another way to derive Eq. (33) is by using the the Walnut representation of the frame operator for the nonstationary Gabor frame , first introduced in [28] for the continuous case setting.
Proposition 4.
Let , with being (essentially) bounded and . Then the frame operator admits the Walnut representation
| (35) |
for almost every and all .
Proof.
The sums in (35) can be reordered to obtain
where . Inserting and comparing the definition of in (34), we can see that
for almost every and all . Hence, we recover the representation of the frame operator as per (33), as expected. What makes Proposition 4 so interesting, is that it facilitates the derivation of some important sufficient frame conditions. The first is a generalization of the theory of painless non-orthogonal expansions by Daubechies et al. [27], see also [6] for a direct proof.
Corollary 2.
Let , with and . Assume for all , there is with and for almost every . Then is a frame if and only if there are such that
| (36) |
Moreover, a dual frame for is given by , where
| (37) |
Proof.
First, note that the existence of the upper bound is equivalent to , for all . It is easy to see that under the assumptions given, Eq. (35) equals
Hence, is invertible if and only if is bounded above and below, proving the first part. Moreover, is given by pointwise multiplication with and therefore, the elements of the canonical dual frame for , defined in Eq. (13), are given by
∎
In other words, recalling , if the filters are strictly band-limited, the downsampling factors are small and almost everywhere, then we obtain a perfect reconstruction system with synthesis filters defined by
The second, more general and more interesting condition can be likened to a diagonal dominance result, i.e. if the main term is stronger than the sum of the magnitude of alias components , , then the FB analysis provided by the filters and downsampling factors is invertible.
Proposition 5.
Let , with and . If there are with
| (38) |
for almost every , then forms a frame with frame bounds .
Note that (38) impliest for all . Therefore, Proposition 4 applies for any FB that satisfies (38). The proof of Proposition 5 is somewhat lengthy and we omit it here. It is very similar to the proof of the analogous conditions for Gabor and wavelet frames that can be found in [26] for the continuous case. It can also be seen as a corollary of [24, Theorem 3.4], covering a more general setting. A few things should be noted regarding Proposition 5.
(a) As mentioned before, this is a sort of diagonal dominance result. While the sum corresponds to , we have
Since, in fact, the finite number of channels guarantees the existence of if and only if , for all , the result implies that the FB analysis provided by ’s and ’s is invertible, whenever
(b) No explicit dual frame is provided by Proposition 5. So, while we can determine invertibility quite easily, provided the Fourier transforms of the filters can be computed, the actual inversion process is still up in the air. In fact, it is unclear whether there are synthesis filters such that the ’s and ’s form a perfect reconstruction system with down-/upsampling factors . We consider here two possible means of recovering the original signal from the sub-band components .
First, the equivalent unform FB, comprised of the filters , for and all , with downsampling factor can be constructed. Since the non-uniform FB forms a frame, so does its uniform equivalent and hence the existence of a dual FB , for and all , is guaranteed. Note that the are not necessarily delayed versions of , as it is the case for . Then, the structure of the alias domain representation in (23) with can be exploited [14] to obtain perfect reconstruction synthesis. In the finite, discrete setting, i.e. when considering signals in (), a dual FB can be computed explicitly and efficiently by a generalization of the methods presented by Strohmer [86], see also [75]. In practice, both the storage and time efficiency of computing the dual uniform FB rely crucially on being small, i.e. not being much larger than .
If that is not the case, the frame property of guarantees the convergence of the Neumann series
| (39) |
where are the optimal frame bounds of . Instead of computing the elements of any dual frame explicitly, we can apply the inverse frame operator to the FB output
| (40) |
obtaining . This can be implemented with the frame algorithm [29, 39]. However, any frame operator is positive definite and self-adjoint, allowing for extremely efficient implementation via the conjugate gradients (CG) [39, 87] algorithm. In addition to a significant boost in efficiency compared to the frame algorithm, the conjugate gradients algorithm does not require an estimate of the optimal frame bounds and convergence speed depends solely on the condition number of . It provides guaranteed, exact convergence in steps for signals in , where every step essentially comprises one analysis and one synthesis step with the filters and , respectively. If furthermore, , then convergence speed can be further increased by preconditioning [8], considering instead the operator defined by
More specifically, the CG algorithm is employed to solve the system for , given the coefficients . Recall the analysis/synthesis operators (see Sec. 3.1.1), associated to a frame , which are equivalent to the analysis/synthesis stages of the FB. The preconditioned case can be implemented most efficiently, by precomputing an approximate dual FB, defined by and solving instead
for , given the coefficients . Algorithm 1 shows a pseudo-code implementation of such a preconditioned CG scheme, available in the LTFAT Toolbox as the routine ifilterbankiter.
5. Frame Theory: Psychoacoustics-motivated Applications
5.1. A perfectly invertible, perceptually-motivated filter bank
The concept of auditory filters lends itself nicely to the implementation as a FB. As motivated in Sec. 1, it can be expected that many audio signal processing applications greatly benefit from an invertible FB representation adapted to the auditory time-frequency resolution. Despite the auditory system showing significant nonlinear behavior, the results obtained through a linear representation are desirable for being much more predictable than when accounting for nonlinear effects. We call such a system perceptually-motivated FB, to distinguish from auditory FBs that attempt to mimic the nonlinearities in the auditory system. Note that, as mentioned in Section 2.2, the first step in many auditory FBs is the computation of a perceptually-motivated FB, see e.g. [49]. The AUDlet FBs we present here are a family of perceptually-motivated FBs that satisfy a perfect reconstruction property, offer flexible redundancy and enable efficient implementation. They were introduced in [65, 66] and an implementation is available in the LTFAT Toolbox [80].
The AUDlet FB has a general non-uniform structure as presented in Fig. 8 with analysis filters , synthesis filters , and downsampling and upsampling factors . Considering only real-valued signals allows us to deal with symmetric s and process only the positive-frequency range. Therefore let denote the number of filters in the frequency range , where to and is the Nyquist frequency, i.e. half the sampling frequency. If , this range includes an additional filter at the zero frequency. Furthermore, another filter is always positioned at the Nyquist frequency to ensure that the full frequency range is covered. Thus, all FBs below feature filters in total and their redundancy is given by , since coefficients in the st to -th subbands are complex-valued.
| Parameter | Role | Information |
|---|---|---|
| minimum frequency in Hz | ||
| maximum frequency in Hz | ||
| center frequencies in Hz | ||
| (essential) number of channels | ||
| channels per scale unit | , | |
| frequency domain filter prototype | ||
| dilation factors | , (default ) | |
| filter transfer functions | ||
| downsampling factors | , (default non-uniform = 1) | |
| redundancy |
The AUDlet filters ’s, are constructed in the frequency domain by
| (41) |
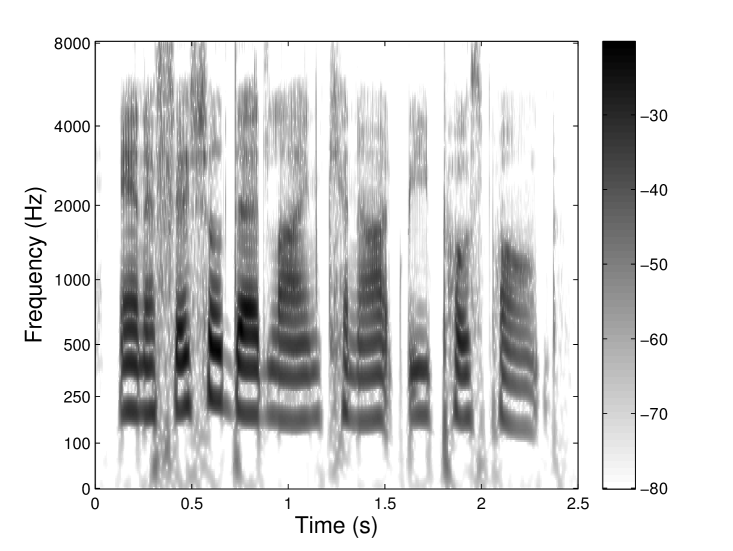
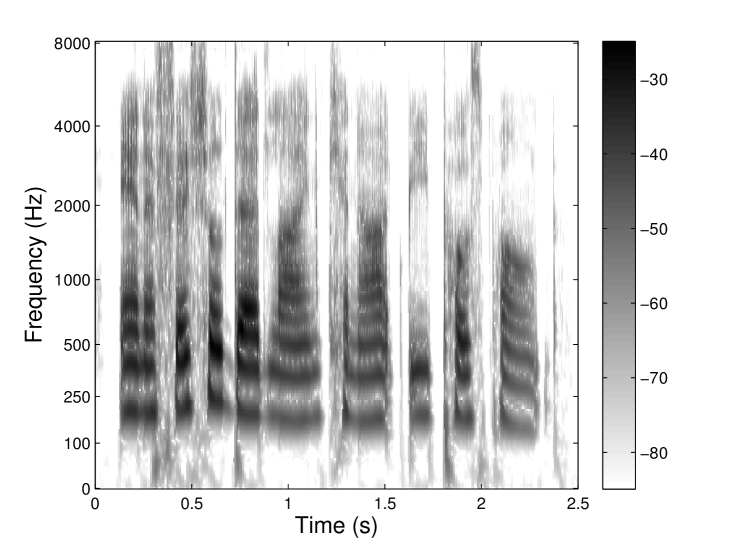
where is a prototype filter shape with bandwidth and center frequency . Here, the shape factor controls the effective bandwidth of and determines its center frequency. The factor ensures that all filters (i.e. for all ) have the same energy. To obtain filters equidistantly spaced on a perceptual frequency scale, the sets and are calculated using the corresponding and formulas, see Tab. 1 for more information on the AUDlet parameters and their relations. Since we emphasize inversion, the default analysis parameters are chosen such that the filters and downsampling factors form a frame. As an example, the AUDlet (a) and gammatone (b) analyses of a speech signal are represented in Fig. 10 using AUD = ERB and = 6 filters per ERB. The filter prototype for the AUDlet was a Hann window. It can be seen that the two signal representations are very similar over the whole time-frequency plane. Since the gammatone filter is an acknowledged auditory filter model, this indicates that the time-frequency resolution of the AUDlet approximates well the auditory resolution.
5.2. Perceptual Sparsity
As discussed in Sec. 2.3 not all components of a sound perceived. This effect can be described by masking models and naturally leads to the following question: Given a time-frequency representation or any representation linked to audio, how can we apply that knowledge to only include audible coefficients in the synthesis? In an attempt to answer this question, efforts were made to combine frame theory and masking models into a concept called the Irrelevance Filter. This concept is somehow linked to the currently very prominent sparsity and compressed sensing approach, see e.g. [35, 31] for an overview. To reduce the amount of non-zero coefficients, the irrelevance filter uses a perceptual measure of sparsity, hence perceptual sparsity. Perceptual and compressed sparsity can certainly be combined, see e.g. [21]. Similar to the methods used in compressed sensing, a redundant representation offers an advantage for perceptual sparsity, as well, as the same signal can be reconstructed from several sets of coefficients.
The concept of the irrelevance filter was first introduced in [30] and fully developed in [9]. It consists in removing the inaudible atoms in a Gabor transform while causing no audible difference to the original sound after re-synthesis. Precisely, an adaptive threshold function is calculated for each spectrum (i.e. at each time slice) of the Gabor transform using a simple model of spectral masking (see Sec. 2.3.1), resulting in the so-called irrelevance threshold. Then, the amplitudes of all atoms falling below the irrelevance threshold are set to zero and the inverse transform is applied to the set of modified Gabor coefficients. This corresponds to an adaptive Gabor frame multiplier with coefficients in . The application of the irrelevance filter to a musical signal sampled at 16 kHz is shown in Fig. 11. A Matlab implementation of the algorithm proposed in [9] was used. All Gabor transform and filter parameters were identical to those mentioned in [9]. Noteworthy, the offset parameter was set to -2.59 dB. In this particular example, about 48% components were removed without causing any audible difference to the original sound after re-synthesis (as judged by informal listening by the authors). A formal listening test performed in [9] with 36 normal-hearing listeners and various musical and speech signals indicated that, on average, 36% coefficients can be removed without causing any audible artifact in the re-synthesis.
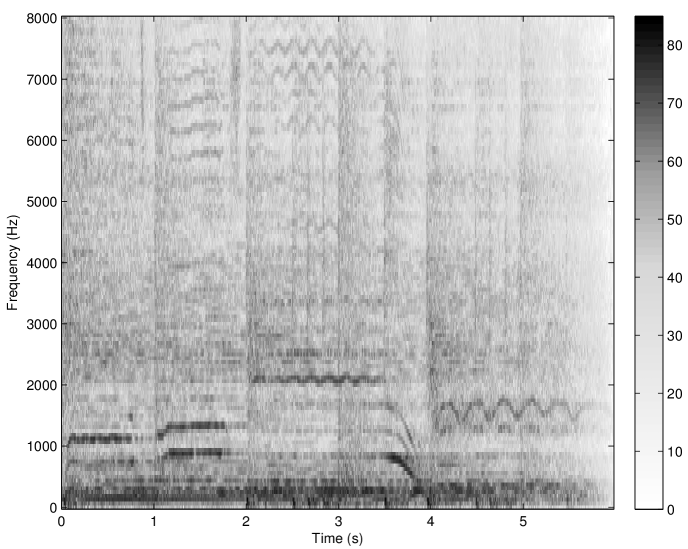
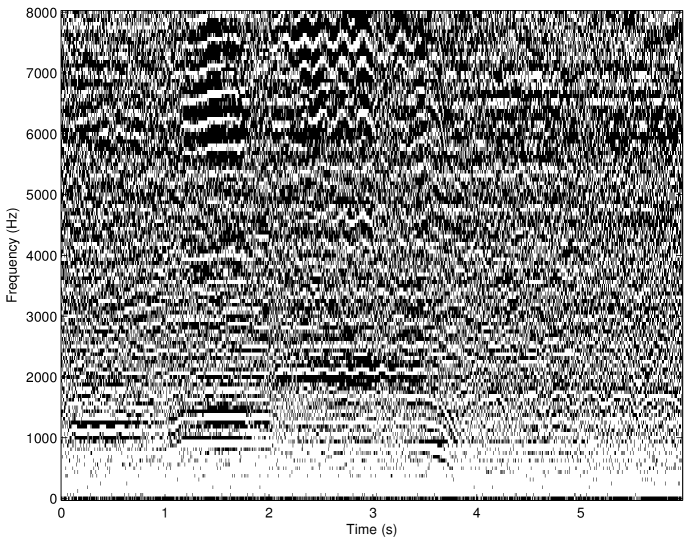
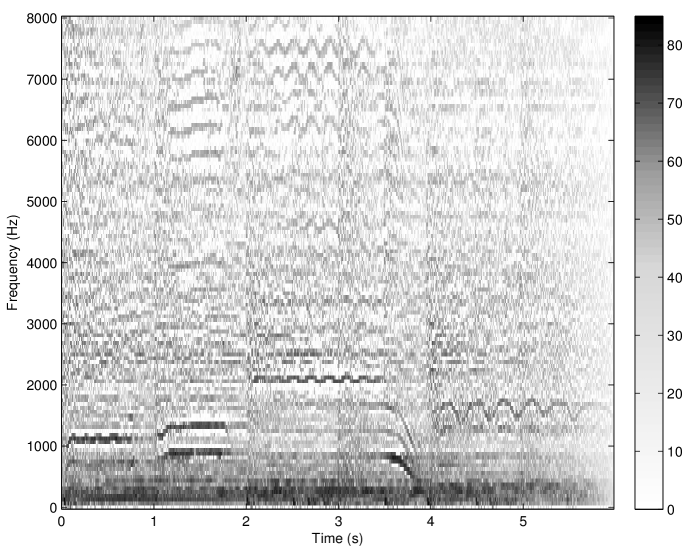
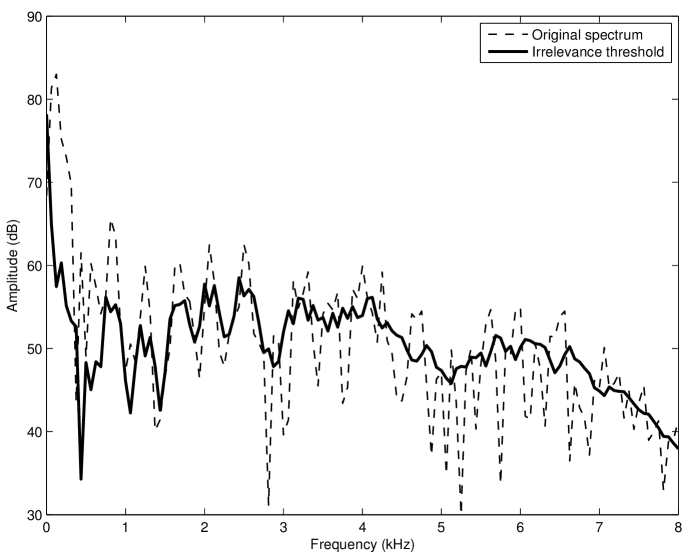
The irrelevance filter as depicted here has shown very promising results but the approach could be improved. Specifically, the main limitations of the algorithm are the fixed resolution in the Gabor transform and the use of a simple spectral masking model to predict masking in the time-frequency domain. Combining an invertible perceptually-motivated transform like the AUDlet FB (Sec. 5.1) with a model of time-frequency masking (Sec. 2.3.3) is expected to improve performance of the filter. This is work in progress. Potential applications of perceptual sparsity include, for instance:
-
(1)
Sound / Data Compression: For applications where perception is relevant, there is no need to encode perceptually irrelevant information. Data that can not be heard should be simply omitted. A similar algorithm is for example used in the MP3 codec. If “over-masking” is used, i.e. the threshold is moved beyond the level of relevance, a higher compression rate can be reached [70].
-
(2)
Sound Design: For the visualization of sounds the perceptually irrelevant part can be disregarded. This is for example used for car sound design [13].
6. Conclusion
In this chapter, we have discussed some important concepts from hearing research and perceptual audio signal processing, such as auditory masking and auditory filter banks. Natural and important considerations served as a strong indicator that frame theory provides a solid foundation for the design of robust representations for perceptual signal analysis and processing. This connection was further reinforced by exposing the similarity between some concepts arising naturally in frame theory and signal processing, e.g. between frame multipliers and time-variant filters. Finally, we have shown how frame theory can be used to analyze and implement invertible filter banks, in a quite general setting where previous synthesis methods might fail or be highly inefficient. The codes for Matlab/Octave to reproduce the results presented in Secs. 3 and 5 in this chapter are available for download on the companion Webpage https://www.kfs.oeaw.ac.at/frames_for_psychoacoustics.
It is likely that readers of this contribution who are researchers in psychoacoustics or audio signal processing have already used frames without being aware of the fact. We hope that such readers will, to some extent, grasp the basic principles of the rich mathematical background provided by frame theory and its importance to fundamental issues of signal analysis and processing. With that knowledge, we believe, they will be able to better understand the signal analysis tools they use and might even be able to design new techniques that further elevate their research.
On the other hand, researchers in applied mathematics or signal processing have been supplied with basic knowledge of some central psychoacoustics concepts. We hope that our short excursion piqued their interest and will serve as a starting point for applying their knowledge in the rich and various fields of psychoacoustics or perceptual signal processing.
Acknowledgments The authors acknowledge support from the Austrian Science Fund (FWF) START-project FLAME (’Frames and Linear Operators for Acoustical Modeling and Parameter Estimation’; Y 551-N13) and the French-Austrian ANR-FWF project POTION (“Perceptual Optimization of Time-Frequency Representations and Audio Coding; I 1362-N30”). They thank B. Laback for discussions and W. Kreuzer for the help with a graphics software.
References
- [1] S. Akkarakaran and P. Vaidyanathan. Nonuniform filter banks: new results and open problems. In Beyond wavelets, volume 10 of Studies in Computational Mathematics, pages 259–301. Elsevier, 2003.
- [2] P. Balazs. Regular and Irregular Gabor Multipliers with Application to Psychoacoustic Masking. PhD thesis, University of Vienna, 2005.
- [3] P. Balazs. Basic definition and properties of Bessel multipliers. J. Math. Anal. Appl., 325(1):571–585, 2007.
- [4] P. Balazs. Frames and finite dimensionality: frame transformation, classification and algorithms. Applied Mathematical Sciences, 2(41–44):2131–2144, 2008.
- [5] P. Balazs, C. Cabrelli, S. B. Heineken, and U. Molter. Frames by multiplication. Current Development in Theory and Applications of Wavelets, 5(2-3):165–186, 2011.
- [6] P. Balazs, M. Dörfler, F. Jaillet, N. Holighaus, and G. A. Velasco. Theory, implementation and applications of nonstationary Gabor frames. J. Comput. Appl. Math., 236(6):1481–1496, 2011.
- [7] P. Balazs, M. Dörfler, M. Kowalski, and B. Torrésani. Adapted and adaptive linear time-frequency representations: a synthesis point of view. IEEE Signal Processing Magazine, 30(6):20–31, 2013.
- [8] P. Balazs, H. G. Feichtinger, M. Hampejs, and G. Kracher. Double preconditioning for Gabor frames. IEEE Trans. Signal Process., 54(12):4597–4610, December 2006.
- [9] P. Balazs, B. Laback, G. Eckel, and W. A. Deutsch. Time-frequency sparsity by removing perceptually irrelevant components using a simple model of simultaneous masking. IEEE Trans. Audio, Speech, Language Process., 18(1):34–49, 2010.
- [10] P. Balazs and D. T. Stoeva. Representation of the inverse of a frame multiplier. J. Math. Anal. Appl., 422(2):981–994, 2015.
- [11] N. K. Bari. Biorthogonal systems and bases in Hilbert space. Uch. Zap. Mosk. Gos. Univ., 148:69–107, 1951.
- [12] J. J. Benedetto and A. Teolis. A wavelet auditory model and data compression. Appl. Comput. Harmon. Anal., 01.Jän:3–28, 1994.
- [13] M. Bézat, V. Roussarie, T. Voinier, R. Kronland-Martinet, and S. Ystad. Car door closure sounds: Characterization of perceptual properties through analysis-synthesis approach. In Proceedings of the 19th International Congress on Acoustics (ICA), Madrid, Spain, September 2007.
- [14] H. Bölcskei, F. Hlawatsch, and H. Feichtinger. Frame-theoretic analysis of oversampled filter banks. IEEE Trans. Signal Process., 46(12):3256–3268, December 1998.
- [15] M. Bownik and J. Lemvig. The canonical and alternate duals of a wavelet frame. Appl. Comput. Harmon. Anal., 23(2):263–272, 2007.
- [16] A. Bregman. Auditory Scene Analysis: The perceptual organization of sound. MIT Press, Cambridge, MA, USA, 1990.
- [17] P. Casazza and G. Kutyniok. Finite Frames: Theory and Applications. Applied and Numerical Harmonic Analysis. Birkhäuser Boston, 2012.
- [18] P. G. Casazza. The art of frame theory. Taiwanese J. Math., 4(2):129–201, 2000.
- [19] P. G. Casazza and O. Christensen. Gabor frames over irregular lattices. Adv. Comput. Math., 18(2-4):329–344, 2003.
- [20] L. Chai, J. Zhang, C. Zhang, and E. Mosca. Bound ratio minimization of filter bank frames. Signal Processing, IEEE Transactions on, 58(1):209 –220, 2010.
- [21] G. Chardon, T. Necciari, and P. Balazs. Perceptual matching pursuit with Gabor dictionaries and time-frequency masking. In Proceedings of the 39th International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2014), 2014.
- [22] O. Christensen. An Introduction to Frames and Riesz Bases. Applied and Numerical Harmonic Analysis. Birkhäuser, Boston, 2003.
- [23] O. Christensen. Pairs of dual Gabor frame generators with compact support and desired frequency localization. Appl. Comput. Harmon. Anal., 20(3):403–410, 2006.
- [24] O. Christensen and S. S. Goh Fourier-like frames on locally compact abelian groups. Journal of Approximation Theory, 192(0):82 – 101, 2015.
- [25] Z. Cvetković and M. Vetterli. Oversampled filter banks. IEEE Trans. Signal Process., 46(5):1245–1255, 1998.
- [26] I. Daubechies. Ten Lectures on Wavelets, volume 61 of CBMS-NSF Regional Conference Series in Applied Mathematics. SIAM, Philadelphia, PA, 1992.
- [27] I. Daubechies, A. Grossmann, and Y. Meyer. Painless nonorthogonal expansions. J. Math. Phys., 27(5):1271–1283, May 1986.
- [28] M. Dörfler and E. Matusiak. Nonstationary Gabor frames - existence and construction. IJWMIP, 12(3), 2014.
- [29] R. J. Duffin and A. C. Schaeffer. A class of nonharmonic Fourier series. Trans. Amer. Math. Soc., 72:341–366, 1952.
- [30] G. Eckel. Ein Modell der Mehrfachverdeckung für die Analyse musikalischerSchallsignale. PhD thesis, University of Vienna, 1989.
- [31] M. Elad. Sparse and Redundant Representations: From Theory to Applications in Signal and Image Processing. Springer, 2010.
- [32] H. Fastl and E. Zwicker. Psychoacoustics — Facts and Models. Springer, third edition, 2006.
- [33] H. G. Feichtinger and K. Nowak. A first survey of Gabor multipliers. In H. G. Feichtinger and T. Strohmer, editors, Advances in Gabor Analysis, Appl. Numer. Harmon. Anal., pages 99–128. Birkhäuser, 2003.
- [34] M. Fickus, M. L. Massar, and D. G. Mixon. Finite frames and filter banks. In Finite Frames, Applied and Numerical Harmonic Analysis, pages 337–379. Birkhäuser Boston, Cambridge, MA, USA, 2013.
- [35] M. Fornasier. Theoretical Foundations and Numerical Methods for Sparse Recovery. Radon Series on Computational and Applied Mathematics 9. Walter de Gruyter, 2010.
- [36] J.S. Garofolo, L.F. Lamel, W.M. Fisher, J.G. Fiscus, D.S. Pallett, and N.L. Dahlgren. TIMIT Acoustic-Phonetic Continuous Speech Corpus LDC93S1 Philadelphia: Linguistic Data Consortium 1993.
- [37] B. R. Glasberg and B. C. J. Moore. Derivation of auditory filter shapes from notched-noise data. Hear. Res., 47:103–138, 1990.
- [38] D. D. Greenwood. A cochlear frequency-position function for several species—29 years later. J. Acoust. Soc. Am., 87(6):2592–2605, June 1990.
- [39] K. Gröchenig. Acceleration of the frame algorithm. IEEE Trans. Signal Process., 41(12):3331–3340, December 1993.
- [40] K. Gröchenig. Foundations of Time-Frequency Analysis. Appl. Numer. Harmon. Anal. Birkhäuser, Boston, MA, 2001.
- [41] T. S. Gunawan, E. Ambikairajah, and J. Epps. Perceptual speech enhancement exploiting temporal masking properties of human auditory system. Speech Commun., 52(5):381 – 393, 2010.
- [42] C. Heil. A Basis Theory Primer. Expanded ed. Applied and Numerical Harmonic Analysis. Birkhäuser, Basel, 2011.
- [43] C. Heil and D. F. Walnut. Continuous and discrete wavelet transforms. SIAM Rev., 31:628–666, 1989.
- [44] E. Hernández, D. Labate, and G. Weiss. A unified characterization of reproducing systems generated by a finite family. II. J. Geom. Anal., 12(4):615–662, 2002.
- [45] H. G. Heuser. Functional analysis. Transl. by John Horvath. A Wiley-Interscience Publication. Chichester etc.: John Wiley & Sons. XV, 408 p., 1982.
- [46] P. Q. Hoang and P. P. Vaidyanathan. Non-uniform multirate filter banks: theory and design. In Circuits and Systems, 1989., IEEE International Symposium on, pages 371–374 vol.1, May 1989.
- [47] N. Holighaus. Structure of nonstationary Gabor frames and their dual systems. Appl. Comput. Harmon. Anal., 37(3):442–463, November 2014.
- [48] N. Holighaus, M. Dörfler, G. Velasco, and T. Grill. A framework for invertible, real-time constant-Q transforms. IEEE Audio, Speech, Language Process., 21(4):775–785, April 2013.
- [49] T. Irino and R. D. Patterson. A dynamic compressive gammachirp auditory filterbank. IEEE Audio, Speech, Language Process., 14(6):2222–2232, November 2006.
- [50] A. Janssen. From continuous to discrete Weyl-Heisenberg frames through sampling. J. Fourier Anal. Appl., 3(5):583–596, 1997.
- [51] W. Jesteadt, S. P. Bacon, and J. R. Lehman. Forward masking as a function of frequency, masker level, and signal delay. J. Acoust. Soc. Am., 71(4):950–962, April 1982.
- [52] A. Kern, C. Heid, W.-H. Steeb, N. Stoop, and R. Stoop. Biophysical parameters modification could overcome essential hearing gaps. PLoS Comput Biol, 4(8):e1000161, 08 2008.
- [53] G. Kidd Jr. and L. L. Feth. Patterns of residual masking. Hear. Res., 5:49–67, 1981.
- [54] J. Kovačević and M. Vetterli. Perfect reconstruction filter banks with rational sampling factors. IEEE Trans. Signal Process., 41(6):2047–2066, 1993.
- [55] B. Laback, P. Balazs, T. Necciari, S. Savel, S. Meunier, S. Ystad, and R. Kronland-Martinet. Additivity of nonsimultaneous masking for short Gaussian-shaped sinusoids. J. Acoust. Soc. Am., 129(2):888–897, February 2011.
- [56] B. Laback, T. Necciari, P. Balazs, S. Savel, and S. Ystad. Simultaneous masking additivity for short Gaussian-shaped tones: Spectral effects. J. Acoust. Soc. Am., 134(2):1160–1171, August 2013.
- [57] J. Leng, D. Han, and T. Huang. Optimal dual frames for communication coding with probabilistic erasures. IEEE Trans. Signal Process., 59(11):5380 –5389, nov. 2011.
- [58] E. A. Lopez-Poveda and R. Meddis. A human nonlinear filterbank. J. Acoust. Soc. Am., 110(6):3107–3118, December 2001.
- [59] R. Lyon, A. Katsiamis, and E. Drakakis. History and future of auditory filter models. In Proc. ISCAS, pages 3809–3812, Paris, France, June 2010. IEEE.
- [60] G. Matz and F. Hlawatsch. Time-frequency transfer function calculus (symbolic calculus) of linear time-varying systems (linear operators) based on a generalized underspread theory. J. Math. Phys., 39(8):4041–4070, 1998.
- [61] G. Matz and F. Hlawatsch. Linear Time-Frequency Filters: On-line Algorithms and Applications, chapter 6 in ’Application in Time-Frequency Signal Processing’, pages 205–271. eds. A. Papandreou-Suppappola, Boca Raton (FL): CRC Press, 2002.
- [62] B. C. J. Moore. An introduction to the psychology of hearing. Emerald Group Publishing, Bingley, UK, sixth edition, 2012.
- [63] B. C. J. Moore, J. I. Alcántara, and T. Dau. Masking patterns for sinusoidal and narrow-band noise maskers. J. Acoust. Soc. Am., 104(2):1023–1038, August 1998.
- [64] T. Necciari. Auditory time-frequency masking: Psychoacoustical measures and application to the analysis-synthesis of sound signals. PhD thesis, Aix-Marseille University, France, 2010.
- [65] T. Necciari, P. Balazs, N. Holighaus, and P. Søndergaard. The ERBlet transform: An auditory-based time-frequency representation with perfect reconstruction. In Proceedings of the 38th International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2013), pages 498–502, 2013.
- [66] T. Necciari, N. Holighaus, P. Balazs, Z. Průša, and P. Majdak. Frame-theoretic recipe for the construction of gammatone and perceptually motivated filter banks with perfect reconstruction. http://arxiv.org/abs/1601.06652.
- [67] J. J. O’Donovan and D. J. Furlong. Perceptually motivated time-frequency analysis. J. Acoust. Soc. Am., 117(1):250–262, January 2005.
- [68] A. V. Oppenheim and R. W. Schafer. Discrete-time Signal Processing. Prentice Hall, Englewood Cliffs, NJ, 1989.
- [69] A. V. Oppenheim, R. W. Schafer, J. R. Buck, et al. Discrete-time signal processing, volume 2. Prentice hall Englewood Cliffs, NJ, 1989.
- [70] T. Painter and A. Spanias. Perceptual coding of digital audio. In Proc. IEEE, volume 88, pages 451–515, April 2000.
- [71] R. D. Patterson, K. Robinson, J. Holdsworth, D. McKeown, C. Zhang, and M. H. Allerhand. Complex sounds and auditory images. In Auditory physiology and perception, Proceedings of the 9th International Symposium on Hearing, pages 429–446, Oxford, UK, 1992. Pergamond.
- [72] N. Perraudin, N. Holighaus, P. Søndergaard, and P. Balazs. Gabor dual windows using convex optimization. In Proceeedings of the 10th International Conference on Sampling theory and Applications (SAMPTA 2013), 2013.
- [73] C. J. Plack. The sense of hearing. Psychology Press, second edition, 2013.
- [74] Z. Průša, P. Søndergaard, N. Holighaus, C. Wiesmeyr, and P. Balazs. The Large Time-Frequency Analysis Toolbox 2.0. In M. Aramaki, O. Derrien, R. Kronland-Martinet, and S. Ystad, editors, Sound, Music, and Motion, Lecture Notes in Computer Science, pages 419–442. Springer International Publishing, 2014.
- [75] Z. Průša, P. Søndergaard, and P. Rajmic. Discrete Wavelet Transforms in the Large Time-Frequency Analysis Toolbox for Matlab/GNU Octave. ACM Trans. Math. Softw. To appear. Preprint available from http://ltfat.github.io/notes/ltfatnote038.pdf.
- [76] E. Ravelli, G. Richard, and L. Daudet. Union of MDCT bases for audio coding. IEEE Trans. Audio, Speech, Language Process., 16(8):1361–1372, 2008.
- [77] A. Ron and Z. Shen. Generalized shift-invariant systems. Constr. Approx., pages OF1–OF45, 2004.
- [78] W. Rudin. Functional Analysis. McGraw-Hill Series in Higher Mathematics. New York etc.: McGraw-Hill Book Comp. XIII, 397 p. , 1973.
- [79] D. Soderquist, A. Carstens, and G. Frank. Backward, simultaneous, and forward masking as a function of signal delay and frequency. The Journal of Auditory Research, 21:227–245, 1981.
- [80] P. Søndergaard, B. Torrésani, and P. Balazs. The Linear Time Frequency Analysis Toolbox. International Journal of Wavelets, Multiresolution and Information Processing, 10(4):1250032, 2012.
- [81] P. Søndergaard. Gabor frames by sampling and periodization. Adv. Comput. Math., 27(4):355–373, 2007.
- [82] D. T. Stoeva and P. Balazs. Invertibility of multipliers. Appl. Comput. Harmon. Anal., 33(2):292–299, 2012.
- [83] D. T. Stoeva and P. Balazs. Canonical forms of unconditionally convergent multipliers. J. Math. Anal. Appl., 399:252–259, 2013.
- [84] D. T. Stoeva and P. Balazs. Riesz bases multipliers. In M. Cepedello Boiso, H. Hedenmalm, M. A. Kaashoek, A. Montes-Rodr�guez, and S. Treil, editors, Concrete Operators, Spectral Theory, Operators in Harmonic Analysis and Approximation, volume 236 of Operator Theory: Advances and Applications, pages 475–482. Birkhäuser, Springer Basel, 2014.
- [85] S. Strahl and A. Mertins. Analysis and design of gammatone signal models. J. Acoust. Soc. Am., 126(5):2379–2389, November 2009.
- [86] T. Strohmer. Numerical algorithms for discrete Gabor expansions. In H. G. Feichtinger and T. Strohmer, editors, Gabor Analysis and Algorithms: Theory and Applications, Appl. Numer. Harmon. Anal., pages 267–294. Birkhäuser Boston, Boston, 1998.
- [87] L. N. Trefethen and D. Bau III. Numerical Linear Algebra. SIAM, Philadelphia, PA, USA, 1997.
- [88] M. Unoki, T. Irino, B. Glasberg, B. C. J. Moore, and R. D. Patterson. Comparison of the roex and gammachirp filters as representations of the auditory filter. J. Acoust. Soc. Am., 120(3):1474–1492, September 2006.
- [89] P. Vaidyanathan. Multirate Systems And Filter Banks. Electrical engineering. Electronic and digital design. Prentice Hall, Englewood Cliffs, NJ, USA, 1993.
- [90] X. Valero and F. Alias. Gammatone cepstral coefficients: Biologically inspired features for non-speech audio classification. IEEE Trans. Multimedia, 14(6):1684–1689, Dec 2012.
- [91] M. Vetterli and J. Kovacević. Wavelets and Subband Coding. Prentice Hall, Englewood Cliffs, NJ, 1995.
- [92] D. Wang and G. J. Brown. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications. Wiley-IEEE Press, 2006.
- [93] T. Werther, Y. C. Eldar, and N. K. Subbana. Dual Gabor frames: theory and computational aspects. IEEE Trans. Signal Process., 53(11):4147– 4158, 2005.
- [94] C. Wiesmeyr, N. Holighaus, and P. Søndergaard. Efficient algorithms for discrete Gabor transforms on a nonseparable lattice. IEEE Trans. Signal Process., 61(20):5131 – 5142, 2013.
- [95] R. M. Young. An introduction to nonharmonic Fourier series. Pure and Applied Mathematics, 93. New York etc.: Academic Press, a Subsidiary of Harcourt Brace Jovanovich, Publishers. X, 246 p. , 1980.
- [96] X. Zhao, Y. Shao, and D. Wang. Casa-based robust speaker identification. IEEE Trans. Audio, Speech, Language Process., 20(5):1608–1616, July 2012.
- [97] E. Zwicker. Dependence of post-masking on masker duration and its relation to temporal effects in loudness. J. Acoust. Soc. Am., 75(1):219–223, January 1984.
- [98] E. Zwicker and E. Terhardt. Analytical expressions for critical-band rate and critical bandwidth as a function of frequency. J. Acoust. Soc. Am., 68(5):1523–1525, November 1980.