Free Lunch in Pathology Foundation Model: Task-specific Model Adaptation with Concept-Guided Feature Enhancement
Abstract
Whole slide image (WSI) analysis is gaining prominence within the medical imaging field. Recent advances in pathology foundation models have shown the potential to extract powerful feature representations from WSIs for downstream tasks. However, these foundation models are usually designed for general-purpose pathology image analysis and may not be optimal for specific downstream tasks or cancer types. In this work, we present Concept Anchor-guided Task-specific Feature Enhancement (CATE), an adaptable paradigm that can boost the expressivity and discriminativeness of pathology foundation models for specific downstream tasks. Based on a set of task-specific concepts derived from the pathology vision-language model with expert-designed prompts, we introduce two interconnected modules to dynamically calibrate the generic image features extracted by foundation models for certain tasks or cancer types. Specifically, we design a Concept-guided Information Bottleneck module to enhance task-relevant characteristics by maximizing the mutual information between image features and concept anchors while suppressing superfluous information. Moreover, a Concept-Feature Interference module is proposed to utilize the similarity between calibrated features and concept anchors to further generate discriminative task-specific features. The extensive experiments on public WSI datasets demonstrate that CATE significantly enhances the performance and generalizability of MIL models. Additionally, heatmap and umap visualization results also reveal the effectiveness and interpretability of CATE. The source code is available at https://github.com/HKU-MedAI/CATE.
1 Introduction
Multiple Instance Learning (MIL) lu2021data ; shmatko2022artificial ; lipkova2022artificial ; chen2022scaling is widely adopted for weakly supervised analysis in computational pathology, where the input of MIL is typically a set of patch features generated by a pre-trained feature extractor (i.e., image encoder). Although promising progress has been achieved, the effectiveness of MIL models heavily relies on the quality of the extracted features. A robust feature extractor can discern more distinctive pathological features, thereby improving the predictive capabilities of MIL models. Recently, several studies have explored using pretrained foundation models on large-scale pathology datasets with self-supervised learning as the feature extractors for WSI analysis wang2022transformer ; filiot2023scaling ; chen2024towards ; vorontsov2023virchow . Additionally, drawing inspiration from the success of Contrastive Language-Image Pretraining (CLIP) radford2021learning ; lai2023clipath in bridging visual and linguistic modalities, some works have aimed to develop a pathology vision-language foundation model (VLM) to simultaneously learn representations of pathology images and their corresponding captions ikezogwo2024quilt ; lu2024visual . The intrinsic consistency between the image feature space and caption embedding space in the pathology VLM enables the image encoder to extract more meaningful and discriminative features for downstream WSI analysis applications lu2024visual .
Although the development of these pathology foundation models has significantly advanced computational pathology, these models are designed for general-purpose pathology image analysis and may not be optimal for specific downstream tasks or cancer types, as the features extracted by the image encoder may contain generic yet task-irrelevant information that will harm the performance of specific downstream tasks. For example, as illustrated in Figure 1(a), the features extracted by the image encoder of a pathology VLM can include both task-relevant information (e.g., arrangement or morphology of tumor cells) and task-irrelevant elements(such as background information, stain styles, etc.). The latter information may act as "noise", distracting the learning process of MIL models tailored to specific tasks, and potentially impairing the generalization performance of these models across different data sources. Consequently, it is crucial to undertake task-specific adaptation to enhance feature extraction of generic foundation models and enable MIL models to concentrate on task-relevant information and thus improve analysis performance and generalization robey2021model ; wu2021collaborative .
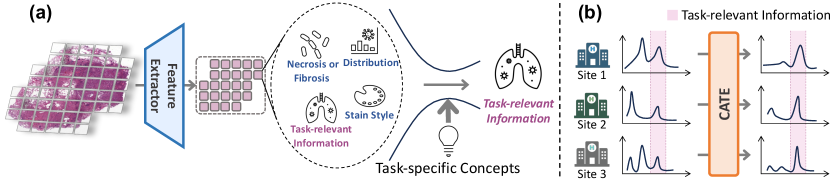
In this paper, we propose a novel paradigm, named Concept Anchor-guided Task-specific Feature Enhancement (CATE), to enhance the generic features extracted by the pathology VLM for specific downstream tasks (e.g., cancer subtyping). Without requiring additional supervision or significant computational resources, CATE offers an approximately "free lunch" in the context of pathology VLM. Specifically, we first derive a set of task-specific concept anchors from the pathology VLM with task-specific prompts, and these prompts rely on human expert design or are generated through querying large language models (LLMs), necessitating a certain level of pathological background knowledge. Based on these concept anchors, we design two concept-driven modules, i.e., the Concept-guided Information Bottleneck (CIB) module and the Concept-Feature Interference (CFI) module, to calibrate and generate task-specific features for downstream analysis. Particularly, with the task-specific concepts as the guidance, the CIB module enhances task-relevant features by maximizing the mutual information between the image features and the concept anchors and also eliminates task-irrelevant information by minimizing the superfluous information, as shown in Figure 1(a). Moreover, the CFI module further generates discriminative task-specific features by utilizing the similarities between the calibrated image features and concept anchors (i.e., concept scores). By incorporating the CATE into existing MIL frameworks, we not only obtain more discriminative features but also improve generalization regarding domain shift by eliminating task-irrelevant features and concentrating on pertinent information, as shown in Figure 1(b).
In summary, the main contributions of this work are threefold:
-
•
We introduce a novel method, named CATE, for model adaptation in computational pathology. To the best of our knowledge, this is the first initiative to conduct task-specific feature enhancement based on the pathology foundation model for MIL tasks.
-
•
We design a new CIB module to enhance the task-relevant information and discard irrelevant information with the guidance of task-specific concepts, and a new CFI module to generate task-specific features by exploiting the similarities between image features and concept anchors.
-
•
Extensive experiments on Whole Slide Image (WSI) analysis tasks demonstrate that CATE significantly enhances the performance and generalization capabilities of MIL models.
2 Related Work
Multiple Instance Learning (MIL) for WSI Analysis. MIL is the predominant paradigm for WSI analysis, treating each WSI as a bag of patch instances and classifying the entire WSI based on aggregated patch-level features. Attention-based methods ilse2018attention ; lu2021data ; javed2022additive ; yufei2022bayes are highly regarded for their ability to determine the significance of each instance within the bag. For instance, Ilse et al. ilse2018attention introduced an attention-based MIL model, while Lu et al. lu2021data proposed clustering-constrained-attention to refine this mechanism further. To model the relationships among instances, graph-based and Transformer-based methods have been developed hou2022h2 ; chen2022scaling ; huang2023conslide . For example, Chen et al. chen2022scaling introduced a Transformer-based hierarchical network to capitalize on the inherent hierarchical structure of WSIs.
Pathology Foundation Model. With the advancement of foundation models in computer vision, several pathology foundation models have been developed to serve as robust image encoders for WSI analysis. Riasatian et al. riasatian2021fine proposed fine-tuning the DenseNet huang2017densely on the TCGA dataset, while Filiot et al. filiot2023scaling utilized iBOT zhou2021ibot to pretrain a vision Transformer using the Masked Image Modeling framework. Recently, Chen et al. chen2024towards pre-trained a general-purpose foundation model on large-scale pathology datasets using DINOv2 oquab2023dinov2 , which has demonstrated strong and readily usable representations for WSI analysis. Inspired by CLIP radford2021learning , Ikezogwo et al. ikezogwo2024quilt , Huang et al. huang2023visual , and Lu et al. lu2024visual developed vision-language foundation models by training on large-scale pathology datasets with image-caption pairs. These foundation models have demonstrated superior performance in downstream tasks due to their ability to extract more discriminative features for WSI analysis.
Feature Enhancement in Computational Pathology. Several methods have been developed to obtain more discriminative features for WSI analysis by adapting pathology foundation models zhang2023text ; lu2024pathotune or designing new plug-and-play modules tang2024feature . For instance, Zhang et al. zhang2023text suggested aligning the image features with text features extracted from a pre-trained natural language model to enhance the feature representation of WSI patch images, while it operates solely at the patch level, without considering the informational relationship between image and text features. Recently, Tang et al. tang2024feature introduced Re-embedded Regional Transformer for feature re-embedding, aimed at enhancing WSI analysis when integrated with existing MIL methods. However, while this method considers the spatial information of WSIs and adds flexibility to MIL models, it falls short in extracting task-specific discriminative information for WSI analysis.
3 Method
3.1 Overview
The proposed CATE can be seamlessly integrated with any MIL framework to adapt the existing pathology foundation model (Pathology VLM) for performance-improved WSI analysis via task-specific enhancement. Specifically, consider a training set of WSI-label pairs, where is a set of patch features with dimension of (i.e., ) extracted by the image encoder of pathology VLM, denotes the number of patches, and is the corresponding label. The objective of CATE is to obtain the corresponding enhanced task-specific feature set from the original feature with the guidance of pre-extracted concepts anchors (see description below) for downstream usage:
| (1) |
As illustrated in Figure 2, we design two different modules to enhance the extracted features from foundation models: (1) Concept-guided Information Bottleneck (CIB) module calibrates original image features with the guidance of concept anchors with information bottleneck principle; and (2) Concept-Feature Interference (CFI) module generates discriminative task-specific features by leveraging the similarities between the calibrated image features and concept anchors. Specifically, the enhanced patch features can be represented as , where is the concatenation of the calibrated feature and the interference feature generated by CIB and CFI module:
| (2) |
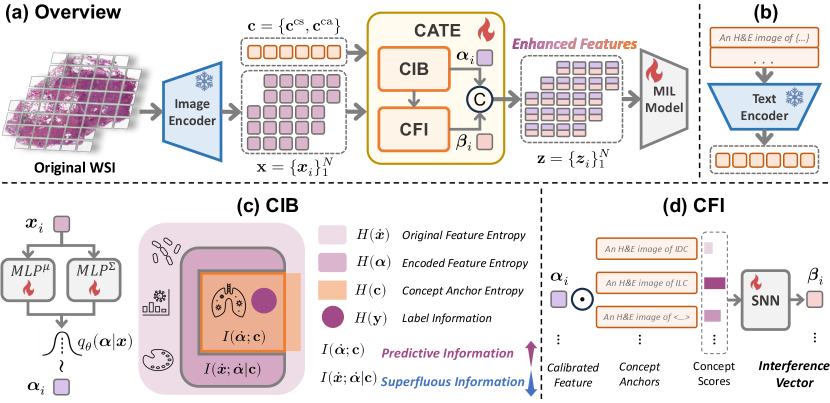
Concept Extraction. We extract two kinds of task-specific concept anchors, , comprising class-specific concepts (e.g., subtyping classes) and class-agnostic concepts (e.g., adipose, connective, and normal tissues), with and representing the numbers of class-specific and class-agnostic concepts, respectively. These concepts are generated by the text encoder of pathology VLM with prompt . Each prompt consists of a class name (e.g., "invasive ductal carcinoma") and a template (e.g., "An image of <CLASSNAME>"). To obtain more robust concepts, we use multiple prompts for each class and the final concept anchor is the average of the embeddings generated by different prompts. Details of class names and templates for various tasks are provided in Appendix G. Note that due to the inherent consistency between the image and text embedding space in VLM, these extracted concepts can also be regarded as image concept vectors.
3.2 Concept-guided Information Bottleneck
The objective of this module is to find a distribution that maps the original image feature into a representation , which contains enhanced task-discriminative characteristics and suppressed task-irrelevant information. WSIs typically contain various cell types or tissues (e.g., tumor cells, normal cells, adipose tissue, connective tissue), while only a subset of patches (e.g., with tumor cells) is crucial for certain tasks such as tumor subtyping. We thus define as the representative subset of the original feature set (e.g., tumor tissue patches), where denotes the number of representative patches. Note that this selection can be conducted with a simple comparison of image features with class-specific concepts (see discussion below). To this end, the corresponding enhanced feature set is and we want to find the conditional distribution to map the selected patch feature into a more discriminative enhanced feature , which is discriminative enough to identify the label .
Sufficiency and Consistency Requirements. To quantify the informativeness requirement of the calibrated feature , we consider the sufficiency of for . As defined in Appendix E.1, the encoded feature derived from the original feature is sufficient for determining the label if and only if the amount of task-specific information remains unchanged after calibration, i.e., . However, the label pertains to the slide level and specific labels cannot be assigned to each instance due to the absence of patch-level annotations.
To address this challenge, we propose using the task-specific concept anchor as the guidance for each single . Specifically, we posit that the concept anchor is distinguishable for the task and contains task-relevant information for label . Given the consistency between image and text features in pathology VLM, any representation containing all information accessible from both image feature and concept will also encapsulate the discriminative information required for the label. This consistency requirement is detailed in Appendix E.1. Thus, if is sufficient for (i.e., ), then is as predictive for label as the joint of original feature and concept anchor . Applying the chain rule of mutual information, we derive:
| (3) |
According to the consistency between the concept anchor and original feature, the mutual information term represents the predictive information for the task, while the conditional information term denotes task-irrelevant information (i.e., superfluous information) in original patch feature , which can be minimized to enhance the robustness and generalization ability of downstream MIL models. As a result, the main objective of the feature calibration in this module can be formalized as maximize predictive information while minimize the superfluous information .
Predictive Information Maximization (PIM). The predictive information in Equ (3) equals to the mutual information between the calibrated feature and concept anchors. To maximize this, we choose the InfoNCE oord2018representation to estimate the lower bound of the mutual information, which can be obtained by comparing positive pairs sampled from the joint distribution to pairs and built using a set of negative class concepts and class-agnostic concepts :
| (4) |
We set with in practice following oord2018representation . By maximizing this mutual information lower bound, will be proportional to the density ratio as proved in oord2018representation . Hence, preserves the mutual information between the calibrated feature and concept anchor. The detailed derivation can be found in Appendix E.2. The loss function for PIM can be denoted as:
| (5) |
Superfluous Information Minimization (SIM). To compress task-irrelevant information, we aim to minimize the superfluous information term as defined in Equ (3). This objective can be achieved by minimizing the mutual information . In practice, we conduct SIM for all patches in the subset , as each patch may contain task-irrelevant information. Following alemi2016deep , it can be represented as:
| (6) |
After that, we let the distribution of : (e.g., Gaussian distribution in this work), be a variational approximation to the marginal distribution , and we can obtain the upper bound for :
| (7) |
Furthermore, we use a variational distribution with parameter to approximate and we implement the parameterization of the variational distribution with MLP by predicting the mean and variance of the Gaussian distribution and sample the calibrated feature from this distribution:
| (8) |
In practice, we implement this by utilizing the reparameterization trick kingma2013auto to obtain an unbiased estimate of the gradient and further optimize the variational distribution. The detailed derivation can be found in Appendix E.3. The minimization of the upper bound of equals to the minimization of the Kullback-Leibler divergence between and . Therefore, the loss function can be represented as:
| (9) |
Discussion. We further provide explanation of CIB module with the information plane geiger2021information ; federici2020learning in Appendix F. It should be noted that the PIM supervises only the representative subset containing task-relevant information (selected by the similarity between image features and corresponding class-specific concepts). Meanwhile, the SIM is applied to all patches in , as any patch may carry information irrelevant to the task (e.g., background information and stain styles). Besides, SIM cannot be directly optimized without the guidance of concept anchors (i.e., PIM) due to the absence of patch-level labels. As demonstrated in the ablation study in Section 4.4, the absence of concept anchor guidance leads to the collapse of discriminative information in the calibrated feature, adversely affecting downstream task performance. By maximizing predictive information and minimizing superfluous details, the CIB module effectively enhances the discriminative capacity of the original features and aligns them with the task-specific concept anchors for improved prediction.
3.3 Concept-Feature Interference
We also propose the Concept-Feature Interference (CFI) module to utilize the similarity characteristic between calibrated features and concept anchors to further obtain robust and discriminative information for the downstream tasks. Our primary focus is on the class-specific concept anchors . Specifically, for each CIB encoded feature , we calculate the cosine similarity between and each class-specific concept . It is important to note that the number of class-specific concepts is larger than the number of classes, as we use multiple <CLASSNAME> and templates to generate the concept anchor for each class, as shown in the Appendix G. Thus, we can obtain the similarity vector by concatenating the similarity scores between and each class-specific concept . To integrate the interference information (similarity relationship) into the enhanced feature, we align the similarity vector with the calibrated feature using a Self-Normalizing Network (SNN) layer klambauer2017self . This allows us to obtain the final interference vector of CFI:
| (10) |
The interference vector contains superficial information that indicates the similarity between the calibrated feature and concept anchor directly. This is completely different from the calibrated feature of the CIB module, which contains discriminative latent information for the downstream tasks. Therefore, integrating the interference feature can further provide robust and discriminative information for the downstream tasks.
Discussion. The CFI module is designed to utilize the similarity characteristic between calibrated feature and concept anchor as a discriminative feature, which can be further integrated into the calibrated feature for downstream tasks. This is different from other studies that directly compare the similarity between visual features and textual concept features of different classes to perform zero-shot classification lu2024visual .
3.4 Training Objective
The overall training objective of the CATE framework can be represented as the combination of the cross entropy loss for the downstream tasks, the predictive information maximization loss , and the superfluous information minimization loss :
| (11) |
where and are hyperparameters and influence of them is discussed in Appendix C.
4 Experiments
| Method | CATE | BRCA (=1) | |||||||
| OOD-AUC | Gain | OOD-ACC | Gain | IND-AUC | Gain | IND-ACC | Gain | ||
| ABMIL | ✗ | 0.9140.015 | N/A | 0.8520.014 | N/A | 0.9630.044 | N/A | 0.8880.053 | N/A |
| CLAM | ✗ | 0.9070.017 | N/A | 0.8020.053 | N/A | 0.9650.049 | N/A | 0.8880.068 | N/A |
| DSMIL | ✗ | 0.9250.020 | N/A | 0.8360.048 | N/A | 0.9690.040 | N/A | 0.9000.080 | N/A |
| DTFD-MIL | ✗ | 0.9120.012 | N/A | 0.8580.020 | N/A | 0.9440.058 | N/A | 0.8940.070 | N/A |
| TransMIL | ✗ | 0.9180.015 | N/A | 0.8320.046 | N/A | 0.9690.036 | N/A | 0.9180.067 | N/A |
| R2T-MIL† | ✗ | 0.9010.027 | N/A | 0.8160.051 | N/A | 0.9650.033 | N/A | 0.8940.022 | N/A |
| ABMIL | ✓ | 0.9510.003 | 4.05% | 0.8970.026 | 5.28% | 0.9980.006 | 3.63% | 0.9650.045 | 8.67% |
| CLAM | ✓ | 0.9510.005 | 4.85% | 0.9060.020 | 12.97% | 0.9980.006 | 3.42% | 0.9650.037 | 8.67% |
| DSMIL | ✓ | 0.9360.007 | 1.19% | 0.8660.036 | 3.59% | 0.9900.022 | 2.17% | 0.9590.044 | 6.56% |
| DTFD-MIL | ✓ | 0.9470.004 | 3.84% | 0.9060.009 | 5.59% | 0.9850.028 | 4.34% | 0.9530.042 | 6.60% |
| TransMIL | ✓ | 0.9380.005 | 2.18% | 0.8800.023 | 5.77% | 0.9980.006 | 2.99% | 0.9650.027 | 5.12% |
| Method | CATE | BRCA (=2) | |||||||
| OOD-AUC | Gain | OOD-ACC | Gain | IND-AUC | Gain | IND-ACC | Gain | ||
| ABMIL | ✗ | 0.8990.035 | N/A | 0.8920.019 | N/A | 0.9670.019 | N/A | 0.9410.024 | N/A |
| CLAM | ✗ | 0.8930.030 | N/A | 0.8620.019 | N/A | 0.9600.042 | N/A | 0.9350.027 | N/A |
| DSMIL | ✗ | 0.8810.032 | N/A | 0.8520.028 | N/A | 0.9460.057 | N/A | 0.9400.020 | N/A |
| DTFD-MIL | ✗ | 0.9090.019 | N/A | 0.8780.014 | N/A | 0.9730.023 | N/A | 0.9450.041 | N/A |
| TransMIL | ✗ | 0.9040.023 | N/A | 0.8520.090 | N/A | 0.9660.031 | N/A | 0.9360.052 | N/A |
| R2T-MIL† | ✗ | 0.9020.028 | N/A | 0.8730.027 | N/A | 0.9460.060 | N/A | 0.9290.048 | N/A |
| ABMIL | ✓ | 0.9430.006 | 4.89% | 0.9070.018 | 1.68% | 0.9810.018 | 1.45% | 0.9480.030 | 0.74% |
| CLAM | ✓ | 0.9450.008 | 5.82% | 0.8960.030 | 3.94% | 0.9760.023 | 1.67% | 0.9380.043 | 0.32% |
| DSMIL | ✓ | 0.9190.015 | 4.31% | 0.8690.036 | 2.00% | 0.9580.051 | 1.27% | 0.9490.024 | 0.96% |
| DTFD-MIL | ✓ | 0.9460.005 | 4.07% | 0.8870.027 | 1.03% | 0.9770.023 | 0.41% | 0.9460.036 | 0.11% |
| TransMIL | ✓ | 0.9200.011 | 1.77% | 0.8670.046 | 1.76% | 0.9680.045 | 0.21% | 0.9400.026 | 0.43% |
-
*
The best results are highlighted in bold, and the second-best results are underlined.
-
†
R2T-MIL is designed for feature re-embedding that utilize ABMIL as base MIL model.
4.1 Experimental Settings
Tasks and Datasets. We conducted cancer subtyping tasks on three public WSI datasets from The Cancer Genome Atlas (TCGA) project: Invasive Breast Carcinoma (BRCA), Non-Small Cell Lung Cancer (NSCLC), and Renal Cell Carcinoma (RCC). Detailed dataset information is available in Appendix D.
IND and OOD Settings. The datasets in the TCGA contains samples from different source sites (i.e., different hospitals or laboratories), which are indicated in the sample barcodes111https://docs.gdc.cancer.gov/Encyclopedia/pages/TCGA_Barcode/. And different source sites have different staining protocols and imaging characteristics, causing feature domain shifts between different sites cheng2021robust ; de2021deep . Therefore, MIL models trained on several sites may not generalize well to others. To better evaluate the true performance of the models, we selected several sites as IND data (in-domain, the testing and training data are from the same sites), and used data from other sites as OOD data (out-of-domain, the testing and training data are from different sites), and reported the testing performance on both IND and OOD data. Specifically, we designated sites as IND and the remaining as OOD. Each experiment involved splitting the IND data into training, validation, and testing sets, training the models on IND data, and evaluating them on both IND and OOD testing data. For the BRCA dataset, we randomly selected one or two sites as IND data and used the remaining sites as OOD data. However, for NSCLC (2 categories) and RCC (3 categories) datasets, each site contains samples from only one subtype. Therefore, we cannot select only one site as IND data, as it will include one category/subtype in the training data. Instead, we randomly selected one or two corresponding sites for each category as IND data for NSCLC and RCC, and used the other sites as OOD data. Finally, we obtained 1 or 2 IND sites for BRCA, 2 or 4 for NSCLC, and 3 or 6 for RCC.
Evaluation. We report the area under the receiver operating characteristic curve (AUC) and accuracy for the OOD and IND test sets, respectively, with means and standard deviations over 10 runs of Monte-Carlo Cross Validation. Notably, the OOD performance is emphasized for NSCLC and RCC, where each site contains samples from only one cancer subtype. Traditional MIL models tend to recognize site-specific patterns (e.g., staining) as shortcuts and excel in in-domain evaluations, rather than identifying useful class-specific features, making performance less reflective of the models’ actual capability. Therefore, OOD performance more accurately reflects the models’ discriminative and generalization capabilities.
Comparisons. Given that CATE is an adaptable method, we evaluated the performance variations across various MIL models both with and without the integration of CATE. We specifically focused on the following state-of-the-art MIL models: the original ABMIL ilse2018attention , CLAM lu2021data , DSMIL li2021dual , TransMIL shao2021transmil , DTFD-MIL zhang2022dtfd , and R2T-MIL tang2024feature . The R2T-MIL tang2024feature is a feature re-embedding method that utilizes ABMIL as the base MIL model.
Implementation Details. This study begins the image feature extraction process by segmenting the foreground tissue and then splitting the WSI into 512512 pixels patches at 20 magnification. Subsequently, these patches are processed through a pre-trained image encoder from CONCH lu2024visual to extract image features. For concept anchors, we utilize CONCH’s text encoder to derive task-relevant concepts from predefined text prompts, with detailed prompt information available in Appendix G. Model parameters are optimized using the Adam optimizer with a learning rate of . The batch size is set to 1, and all the experiments are conducted on a single NVIDIA RTX 3090 GPU.
| Method | NSCLC (=2) | NSCLC (=4) | ||||||
| OOD-AUC | OOD-ACC | IND-AUC# | IND-ACC# | OOD-AUC | OOD-ACC | IND-AUC# | IND-ACC# | |
| ABMIL | 0.8740.021 | 0.8030.021 | 0.9970.004 | 0.9540.028 | 0.9510.023 | 0.8830.029 | 0.9740.018 | 0.9100.036 |
| CLAM | 0.8750.020 | 0.8010.021 | 0.9970.007 | 0.9630.042 | 0.9310.037 | 0.8700.036 | 0.9770.023 | 0.9260.048 |
| DSMIL | 0.8390.046 | 0.7640.043 | 0.9930.004 | 0.9630.028 | 0.9340.019 | 0.8640.026 | 0.9740.013 | 0.9130.042 |
| DTFD-MIL | 0.9030.023 | 0.8360.026 | 0.9900.009 | 0.9580.049 | 0.9490.010 | 0.8930.012 | 0.9810.012 | 0.9180.040 |
| TransMIL | 0.7900.028 | 0.7120.024 | 0.9970.004 | 0.9540.033 | 0.9170.022 | 0.8320.031 | 0.9770.014 | 0.9230.029 |
| R2T-MIL † | 0.7390.088 | 0.6900.075 | 0.9990.002 | 0.9710.036 | 0.8920.041 | 0.8000.059 | 0.9770.018 | 0.9160.045 |
| CATE-MIL | 0.9450.016 | 0.8400.043 | 0.9850.011 | 0.9380.037 | 0.9690.003 | 0.9060.011 | 0.9670.019 | 0.9050.054 |
| Method | RCC (=3) | RCC (=6) | ||||||
| OOD-AUC | OOD-ACC | IND-AUC# | IND-ACC# | OOD-AUC | OOD-ACC | IND-AUC# | IND-ACC# | |
| ABMIL | 0.9730.005 | 0.8910.017 | 0.9970.004 | 0.9610.032 | 0.9710.007 | 0.8850.010 | 0.9730.010 | 0.8970.023 |
| CLAM | 0.9720.004 | 0.8930.012 | 0.9910.005 | 0.9610.032 | 0.9690.009 | 0.8880.015 | 0.9750.011 | 0.8960.031 |
| DSMIL | 0.9770.002 | 0.8930.010 | 0.9960.006 | 0.9650.026 | 0.9690.008 | 0.8830.016 | 0.9800.012 | 0.9010.022 |
| DTFD-MIL | 0.9750.003 | 0.8970.012 | 0.9960.004 | 0.9430.046 | 0.9710.007 | 0.8930.017 | 0.9740.012 | 0.8780.022 |
| TransMIL | 0.9610.010 | 0.8640.022 | 0.9940.004 | 0.9300.030 | 0.9470.017 | 0.8280.037 | 0.9750.013 | 0.8940.027 |
| R2T-MIL † | 0.9560.018 | 0.8470.022 | 0.9910.008 | 0.9360.030 | 0.9320.020 | 0.8030.048 | 0.9740.012 | 0.8970.029 |
| CATE-MIL | 0.9830.002 | 0.9110.018 | 0.9890.009 | 0.9440.031 | 0.9790.007 | 0.9050.017 | 0.9630.011 | 0.8820.032 |
-
*
The best results are highlighted in bold, and the second-best results are underlined.
-
†
R2T-MIL is designed for feature re-embedding that utilize ABMIL as base MIL model.
-
#
The in-domain performance of NSCLC and RCC does not represent the true ability of the models, as each site contains only samples from one cancer subtype. We primarily focus on the OOD performance for these two datasets.
4.2 Experimental Results
Quantitative Results on BRCA Dataset. To fully evaluate the effectiveness of CATE, we assessed its impact on several state-of-the-art MIL models using the BRCA dataset. The results are shown in Table 1, where the MIL models integrated with CATE outperform their original counterparts in both in-domain (IND) and out-of-domain (OOD) testing, which demonstrates the effectiveness and generalization capabilities of CATE. Comparing with R2T-MIL, which is a feature re-embedding method that utilizes ABMIL as the base MIL model, CATE incorporated with ABMIL consistently achieves better performance in terms of both OOD and IND testing. To further investigate the effectiveness of CATE, we conducted experiments by altering the in-domain sites and applying traditional settings. Detailed results are available in Appendix B.
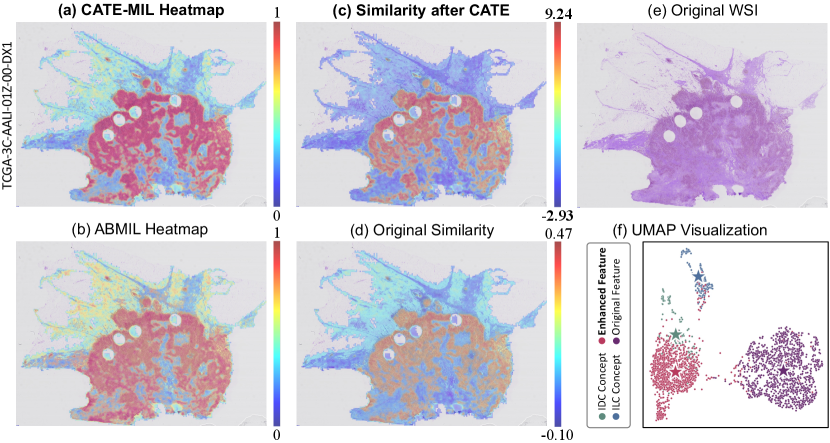
Qualitative Analysis. To qualitatively investigate the effectiveness of CATE, we visualized attention heatmaps, UMAP, and the similarities between original features and corresponding class concept features, as well as calibrated features and class concept features, as shown in Figure 3. Additional visualization results are provided in Appendix H. As shown in Figure 3 (a&b), attention heatmap comparisons reveal that CATE-MIL focuses more intensely on cancerous regions, with a clearer delineation between high and low attention areas. By comparing the similarities of original and calibrated features to class concept features in Figure 3 (c&d), it is evident that the enhanced similarity in cancerous regions is significantly higher than in original features. Moreover, the disparity between cancerous and non-cancerous regions’ similarities is also expanded, which further verifies the ability of CATE to enhance task-relevant information and suppress irrelevant information. We further performed a UMAP visualization of class concept features, original features, and calibrated features. As depicted in Figure 3 (f), calibrated features are notably closer to the corresponding class (IDC) concept features compared to the original features, which demonstrates CATE’s ability to effectively align features with task-relevant concepts and enhance task-relevant information.
4.3 Results on Additional Datasets
For clarity and to highlight the superiority of ABMIL when enhanced with CATE, we developed CATE-MIL by incorporating CATE into ABMIL and compared it against other leading MIL models on NSCLC and RCC datasets. The comparative results in Table 2 confirm that CATE-MIL consistently outperforms other models in both OOD and IND performance. However, it is noted that CATE-MIL performs poorly on the in-domain testing data for NSCLC and RCC. This underperformance may be attributed to the elimination of task-irrelevant information, including site-specific patterns, by CATE, potentially degrading performance on in-domain data for these datasets. Consequently, OOD performance more accurately reflects the discriminative and generalization capabilities of the models.
4.4 Ablation Analysis
We conduct ablation studies to assess the effectiveness of each component within CATE, and the results are shown in Table 3. Initially, incorporating Predictive Information Maximization (PIM) enables ABMIL to achieve improved performance in most experiments, which demonstrates PIM’s efficacy in extracting task-relevant information. However, using Superfluous Information Minimization (SIM) alone results in performance degradation across most experiments, which suggests that SIM may discard some task-relevant information without guidance from a task-relevant concept anchor. Incorporating both PIM and SIM consistently enhances ABMIL’s performance in all experiments, which further verifies that their combination effectively boosts the generalization capabilities of MIL models. We also conduct experiments by only using the interference features in CFI as the input of ABMIL, and the results show that the interference features are also informative for WSI classification tasks. More ablation analysis about the weights of PIM and SIM in CIB module the number of representative patches are in Appendix C.
| Method | PIM | SIM | CFI | BRCA (=1) | BRCA (=2) | NSCLC (=2) | NSCLC (=4) | RCC (=3) | RCC (=6) |
| ABMIL | 0.9140.015 | 0.8990.035 | 0.8740.021 | 0.9510.023 | 0.9730.005 | 0.9710.007 | |||
| ✓ | 0.9320.011 | 0.9390.012 | 0.9060.026 | 0.9010.047 | 0.9760.005 | 0.9730.005 | |||
| ✓ | 0.8950.022 | 0.8850.140 | 0.6560.041 | 0.8980.028 | 0.9520.014 | 0.9540.015 | |||
| ✓ | ✓ | 0.9360.010 | 0.9420.010 | 0.9100.030 | 0.9600.011 | 0.9790.004 | 0.9770.005 | ||
| ✓ | 0.9130.024 | 0.8840.032 | 0.8500.036 | 0.9180.029 | 0.9750.008 | 0.9410.022 | |||
| CATE-MIL | ✓ | ✓ | ✓ | 0.9510.003 | 0.9430.006 | 0.9450.016 | 0.9700.003 | 0.9830.002 | 0.9790.007 |
5 Conclusion and Discussion
In this paper, we introduce CATE, a new approach that offers a "free lunch" for task-specific adaptation of pathology VLM by leveraging the inherent consistency between image and text modalities. CATE shows the potential to enhance the generic features extracted by pathology VLM for specific downstream tasks, using task-specific concept anchors as guidance. The proposed CIB module calibrates the image features by enhancing task-relevant information while suppressing task-irrelevant information, while the CFI module obtains the interference vector for each patch to generate discriminative task-specific features. Extensive experiments on WSI datasets demonstrate the effectiveness of CATE in improving the performance and generalizability of state-of-the-art MIL methods.
Limitations and Social Impact. The proposed CATE offers a promising solution to customize the pathology VLM for specific tasks, significantly improving the performance and applicability of MIL methods in WSI analysis. However, the performance of CATE heavily depends on the quality of the concept anchors, which, in turn, relies on domain knowledge and the quality of the pre-trained pathology VLM. Additionally, while CATE is optimized for classification tasks such as cancer subtyping, it may not be readily applicable to other analytical tasks, such as survival prediction. However, there might be a potential solution to address this challenge. For instance, we could leverage LLMs or retrieval-based LLMs to generate descriptive prompts about the general morphological appearance of WSIs for specific cancer types. By asking targeted questions, we can summarize reliable and general morphological descriptions associated with different survival outcomes or biomarker expressions and further verify these prompts with pathologists. Moreover, since medical data may contain sensitive information, ensuring the privacy and security of such data is crucial.
6 Acknowledgements
This work was supported in part by the Research Grants Council of Hong Kong (27206123 and T45-401/22-N), in part by the Hong Kong Innovation and Technology Fund (ITS/274/22), in part by the National Natural Science Foundation of China (No. 62201483), and in part by Guangdong Natural Science Fund (No. 2024A1515011875).
References
- [1] Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck. arXiv preprint arXiv:1612.00410, 2016.
- [2] Richard J Chen, Chengkuan Chen, Yicong Li, Tiffany Y Chen, Andrew D Trister, Rahul G Krishnan, and Faisal Mahmood. Scaling vision transformers to gigapixel images via hierarchical self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16144–16155, 2022.
- [3] Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Andrew H Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, et al. Towards a general-purpose foundation model for computational pathology. Nature Medicine, 30(3):850–862, 2024.
- [4] Shenghua Cheng, Sibo Liu, Jingya Yu, Gong Rao, Yuwei Xiao, Wei Han, Wenjie Zhu, Xiaohua Lv, Ning Li, Jing Cai, et al. Robust whole slide image analysis for cervical cancer screening using deep learning. Nature communications, 12(1):5639, 2021.
- [5] Kevin de Haan, Yijie Zhang, Jonathan E Zuckerman, Tairan Liu, Anthony E Sisk, Miguel FP Diaz, Kuang-Yu Jen, Alexander Nobori, Sofia Liou, Sarah Zhang, et al. Deep learning-based transformation of h&e stained tissues into special stains. Nature communications, 12(1):1–13, 2021.
- [6] Marco Federici, Anjan Dutta, Patrick Forré, Nate Kushman, and Zeynep Akata. Learning robust representations via multi-view information bottleneck. arXiv preprint arXiv:2002.07017, 2020.
- [7] Alexandre Filiot, Ridouane Ghermi, Antoine Olivier, Paul Jacob, Lucas Fidon, Alice Mac Kain, Charlie Saillard, and Jean-Baptiste Schiratti. Scaling self-supervised learning for histopathology with masked image modeling. medRxiv, pages 2023–07, 2023.
- [8] Bernhard C Geiger. On information plane analyses of neural network classifiers—a review. IEEE Transactions on Neural Networks and Learning Systems, 33(12):7039–7051, 2021.
- [9] R. Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Philip Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.
- [10] Wentai Hou, Lequan Yu, Chengxuan Lin, Helong Huang, Rongshan Yu, Jing Qin, and Liansheng Wang. H^ 2-mil: exploring hierarchical representation with heterogeneous multiple instance learning for whole slide image analysis. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 933–941, 2022.
- [11] Frederick M Howard, James Dolezal, Sara Kochanny, Jefree Schulte, Heather Chen, Lara Heij, Dezheng Huo, Rita Nanda, Olufunmilayo I Olopade, Jakob N Kather, et al. The impact of site-specific digital histology signatures on deep learning model accuracy and bias. Nature communications, 12(1):4423, 2021.
- [12] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- [13] Yanyan Huang, Weiqin Zhao, Shujun Wang, Yu Fu, Yuming Jiang, and Lequan Yu. Conslide: Asynchronous hierarchical interaction transformer with breakup-reorganize rehearsal for continual whole slide image analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 21349–21360, 2023.
- [14] Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. A visual–language foundation model for pathology image analysis using medical twitter. Nature medicine, 29(9):2307–2316, 2023.
- [15] Wisdom Ikezogwo, Saygin Seyfioglu, Fatemeh Ghezloo, Dylan Geva, Fatwir Sheikh Mohammed, Pavan Kumar Anand, Ranjay Krishna, and Linda Shapiro. Quilt-1m: One million image-text pairs for histopathology. Advances in Neural Information Processing Systems, 36, 2024.
- [16] Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. In International conference on machine learning, pages 2127–2136. PMLR, 2018.
- [17] Syed Ashar Javed, Dinkar Juyal, Harshith Padigela, Amaro Taylor-Weiner, Limin Yu, and Aaditya Prakash. Additive mil: Intrinsically interpretable multiple instance learning for pathology. Advances in Neural Information Processing Systems, 35:20689–20702, 2022.
- [18] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [19] Günter Klambauer, Thomas Unterthiner, Andreas Mayr, and Sepp Hochreiter. Self-normalizing neural networks. Advances in neural information processing systems, 30, 2017.
- [20] Zhengfeng Lai, Zhuoheng Li, Luca Cerny Oliveira, Joohi Chauhan, Brittany N Dugger, and Chen-Nee Chuah. Clipath: Fine-tune clip with visual feature fusion for pathology image analysis towards minimizing data collection efforts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2374–2380, 2023.
- [21] Bin Li, Yin Li, and Kevin W Eliceiri. Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2021.
- [22] Hao Li, Ying Chen, Yifei Chen, Rongshan Yu, Wenxian Yang, Liansheng Wang, Bowen Ding, and Yuchen Han. Generalizable whole slide image classification with fine-grained visual-semantic interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11398–11407, 2024.
- [23] Jana Lipkova, Richard J Chen, Bowen Chen, Ming Y Lu, Matteo Barbieri, Daniel Shao, Anurag J Vaidya, Chengkuan Chen, Luoting Zhuang, Drew FK Williamson, et al. Artificial intelligence for multimodal data integration in oncology. Cancer cell, 40(10):1095–1110, 2022.
- [24] Jiaxuan Lu, Fang Yan, Xiaofan Zhang, Yue Gao, and Shaoting Zhang. Pathotune: Adapting visual foundation model to pathological specialists. arXiv preprint arXiv:2403.16497, 2024.
- [25] Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. A visual-language foundation model for computational pathology. Nature Medicine, pages 1–12, 2024.
- [26] Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, Richard J Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathology on whole-slide images. Nature biomedical engineering, 5(6):555–570, 2021.
- [27] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- [28] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- [29] Linhao Qu, Kexue Fu, Manning Wang, Zhijian Song, et al. The rise of ai language pathologists: Exploring two-level prompt learning for few-shot weakly-supervised whole slide image classification. Advances in Neural Information Processing Systems, 36, 2024.
- [30] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [31] Abtin Riasatian, Morteza Babaie, Danial Maleki, Shivam Kalra, Mojtaba Valipour, Sobhan Hemati, Manit Zaveri, Amir Safarpoor, Sobhan Shafiei, Mehdi Afshari, et al. Fine-tuning and training of densenet for histopathology image representation using tcga diagnostic slides. Medical image analysis, 70:102032, 2021.
- [32] Alexander Robey, George J Pappas, and Hamed Hassani. Model-based domain generalization. Advances in Neural Information Processing Systems, 34:20210–20229, 2021.
- [33] Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, et al. Transmil: Transformer based correlated multiple instance learning for whole slide image classification. Advances in Neural Information Processing Systems, 34:2136–2147, 2021.
- [34] Artem Shmatko, Narmin Ghaffari Laleh, Moritz Gerstung, and Jakob Nikolas Kather. Artificial intelligence in histopathology: enhancing cancer research and clinical oncology. Nature Cancer, 3(9):1026–1038, 2022.
- [35] Wenhao Tang, Fengtao Zhou, Sheng Huang, Xiang Zhu, Yi Zhang, and Bo Liu. Feature re-embedding: Towards foundation model-level performance in computational pathology. arXiv preprint arXiv:2402.17228, 2024.
- [36] Eugene Vorontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Siqi Liu, Philippe Mathieu, Alexander van Eck, Donghun Lee, Julian Viret, et al. Virchow: A million-slide digital pathology foundation model. arXiv preprint arXiv:2309.07778, 2023.
- [37] Xiyue Wang, Sen Yang, Jun Zhang, Minghui Wang, Jing Zhang, Wei Yang, Junzhou Huang, and Xiao Han. Transformer-based unsupervised contrastive learning for histopathological image classification. Medical image analysis, 81:102559, 2022.
- [38] Guile Wu and Shaogang Gong. Collaborative optimization and aggregation for decentralized domain generalization and adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6484–6493, 2021.
- [39] Cui Yufei, Ziquan Liu, Xiangyu Liu, Xue Liu, Cong Wang, Tei-Wei Kuo, Chun Jason Xue, and Antoni B Chan. Bayes-mil: A new probabilistic perspective on attention-based multiple instance learning for whole slide images. In The Eleventh International Conference on Learning Representations, 2022.
- [40] Hongrun Zhang, Yanda Meng, Yitian Zhao, Yihong Qiao, Xiaoyun Yang, Sarah E Coupland, and Yalin Zheng. Dtfd-mil: Double-tier feature distillation multiple instance learning for histopathology whole slide image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18802–18812, 2022.
- [41] Yunkun Zhang, Jin Gao, Mu Zhou, Xiaosong Wang, Yu Qiao, Shaoting Zhang, and Dequan Wang. Text-guided foundation model adaptation for pathological image classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 272–282. Springer, 2023.
- [42] Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832, 2021.
Appendix A Overview
The structure of this supplementary material as shown below,
-
•
Appendix B presents additional experimental results, including changes in in-domain and out-of-domain site splitting, further comparisons on the BRCA dataset under traditional settings, additional results on the PRAD dataset, and results under site-preserved cross-validation.
-
•
Appendix C discusses additional ablation study results concerning hyperparameters, including the impact of loss weights for PIM and SIM, the effect of the number of representative patches , and further ablation studies on the CIB module.
-
•
Appendix D presents detailed descriptions of datasets and experimental settings.
-
•
Appendix E provides the detailed definition and formula derivation.
-
•
Appendix F elaborates on the Concept Information Bottleneck (CIB) module using the information plane.
-
•
Appendix G details the prompts used in our experiments.
-
•
Appendix H presents additional visualization results.
Appendix B Additional Results
B.1 Additional Cancer Subtyping Results with Different IND and OOD Sites
To further evaluate the generalization ability of the proposed CATE method, we conduct additional experiments on TCGA-BRCA dataset with different settings of in-domain (IND) and out-of-domain (OOD) sites. The detailed experimental settings are shown below:
-
•
BRCA (=1): One site as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain site are shown below:
-
–
AR: 44 slides of IDC and 15 slides of ILC.
-
–
-
•
BRCA (=2): Two sites as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain sites are shown below:
-
–
AR: 44 slides of IDC and 15 slides of ILC.
-
–
B6: 39 slides of IDC and 6 slides of ILC.
-
–
The additional results are presented in Table 4. It is evident that the proposed CATE-MIL consistently delivers superior performance in both in-domain and out-of-domain settings, demonstrating its effectiveness in enhancing task-specific information and minimizing the impact of irrelevant data.
B.2 Additional Cancer Subtyping Results with Traditional Experimental Settings
| Method | BRCA (=1) | |||
| OOD-AUC | OOD-ACC | IND-AUC | IND-ACC | |
| ABMIL | 0.916 0.017 | 0.882 0.022 | 0.977 0.029 | 0.953 0.036 |
| CLAM | 0.895 0.031 | 0.842 0.049 | 0.973 0.035 | 0.938 0.043 |
| DSMIL | 0.892 0.017 | 0.863 0.016 | 0.967 0.022 | 0.924 0.048 |
| TransMIL | 0.917 0.008 | 0.878 0.016 | 0.980 0.031 | 0.955 0.038 |
| DTFD-MIL | 0.920 0.023 | 0.881 0.024 | 0.982 0.030 | 0.957 0.038 |
| †R2T-MIL | 0.902 0.022 | 0.835 0.063 | 0.963 0.037 | 0.944 0.039 |
| †CATE-MIL | 0.938 0.014 | 0.895 0.021 | 0.984 0.021 | 0.959 0.038 |
| Method | BRCA (=2) | |||
| OOD-AUC | OOD-ACC | IND-AUC | IND-ACC | |
| ABMIL | 0.914 0.012 | 0.879 0.017 | 0.954 0.035 | 0.910 0.043 |
| CLAM | 0.914 0.021 | 0.890 0.013 | 0.958 0.034 | 0.926 0.050 |
| DSMIL | 0.931 0.007 | 0.900 0.012 | 0.971 0.020 | 0.919 0.034 |
| TransMIL | 0.929 0.009 | 0.897 0.006 | 0.962 0.030 | 0.903 0.039 |
| DTFD-MIL | 0.898 0.009 | 0.868 0.017 | 0.950 0.034 | 0.890 0.037 |
| †R2T-MIL | 0.919 0.017 | 0.893 0.017 | 0.962 0.025 | 0.906 0.026 |
| †CATE-MIL | 0.947 0.005 | 0.920 0.004 | 0.980 0.015 | 0.939 0.022 |
-
•
The best results are highlighted in bold, and the second-best results are underlined.
-
•
† denotes the methods for feature re-embedding that utilize ABMIL as base MIL model.
| Method | AUC | ACC | Training Time | Params Size |
| ABMIL | 0.9220.046 | 0.9020.039 | 67.16 S | 1.26 MB |
| CLAM | 0.9280.030 | 0.9120.034 | 67.99 S | 2.01 MB |
| DSMIL | 0.9340.039 | 0.9100.033 | 72.91 S | 1.26 MB |
| TransMIL | 0.9270.046 | 0.9060.032 | 72.39 S | 5.39 MB |
| DTFD-MIL | 0.9400.030 | 0.9010.041 | 70.99 S | 8.03 MB |
| †R2T-MIL | 0.9360.027 | 0.9030.028 | 68.87 S | 9.28 MB (1.26+8.02) |
| †CATE-MIL | 0.9450.033 | 0.9170.029 | 68.53 S | 4.26 MB (1.26+3.00) |
-
•
The best results are highlighted in bold, and the second-best results are underlined.
-
•
† denotes the methods for feature re-embedding that utilize ABMIL as base MIL model.
| Method | PRAD | |||
| OOD-AUC | OOD-ACC | IND-AUC | IND-ACC | |
| ABMIL | 0.704 0.034 | 0.510 0.075 | 0.742 0.060 | 0.575 0.051 |
| CATE-MIL | 0.755 0.050 | 0.567 0.067 | 0.797 0.044 | 0.643 0.075 |
| Dataset | Method | OOD-AUC | IND-AUC |
| BRCA | ABMIL | 0.912 0.012 | 0.905 0.043 |
| CATE-MIL | 0.935 0.014 | 0.942 0.038 | |
| NSCLC | ABMIL | 0.942 0.016 | 0.941 0.013 |
| CATE-MIL | 0.951 0.015 | 0.943 0.008 | |
| RCC | ABMIL | 0.980 0.001 | 0.986 0.010 |
| CATE-MIL | 0.983 0.001 | 0.989 0.007 |
In the main paper, we divided the dataset into in-domain and out-of-domain sites to evaluate the generalization ability of the proposed CATE method. To further evaluate its effectiveness, we conducted additional experiments under traditional settings, randomly splitting the dataset into training, validation, and testing sets. We report the performance metrics, including means and standard deviations over 10 Monte-Carlo Cross-Validation runs, in Table 5. Additionally, we provide comparisons of training times and parameter sizes for various methods.
It is evident that the proposed CATE-MIL consistently outperforms others in both AUC and ACC metrics, underscoring its superiority. Furthermore, CATE-MIL benefits from shorter training times and smaller parameter sizes compared to the R2T-MIL method.
B.3 Additional Gleason Grading Results on PRAD
CATE is a general framework that can be applied to more complex tasks beyond cancer subtyping, such as Gleason grading in prostate cancer. We have conducted conducted experiments on the TCGA-PRAD dataset to evaluate the performance of CATE-MIL in Gleason grading. Specifically, the samples in PRAD dataset are divided into Gleason pattern 3, 4, and 5, and the task is to classify the samples into these three categories. The results are shown in Table 6. It is evident that CATE-MIL consistently outperforms the base model ABMIL in both in-domain and out-of-domain settings, demonstrating its effectiveness in enhancing task-specific information and minimizing the impact of irrelevant data. In the future, as more studies reveal the connection between morphological features and molecular biomarkers and more powerful pathology VLMs are developed, our framework has the potential to benefit more complex tasks.
B.4 Additional Experiments using Site-Preserved Cross-Validation
To provide a more comprehensive evaluation of the proposed CATE-MIL, we conduct additional experiments using site-preserved cross-validation [11], where the samples from the same site are preserved in the same fold. For each fold, we split the data into training and testing sets, and these testing sets are regarded as in-domain testing data. And the other sites are used as out-of-domain testing data. The results are shown in Table 7. It is evident that CATE-MIL consistently outperforms ABMIL in both in-domain and out-of-domain settings.
Appendix C Additional Ablation Study
C.1 Ablation Study of the Weight of PIM and SIM Losses
The overall objective of the proposed CATE-MIL is a weighted sum of the PIM and SIM losses, along with the classification loss:
| (12) |
We note that the hyperparameters for the weights of the PIM and SIM losses were not specifically tuned in the main paper. To investigate the effect of the weight of PIM and SIM losses on the model performance, we conduct an ablation study on BRCA (=2) with CATE-MIL (ABMIL integrated with CATE), varying the weights of PIM and SIM losses. The results are shown in Figure 4.
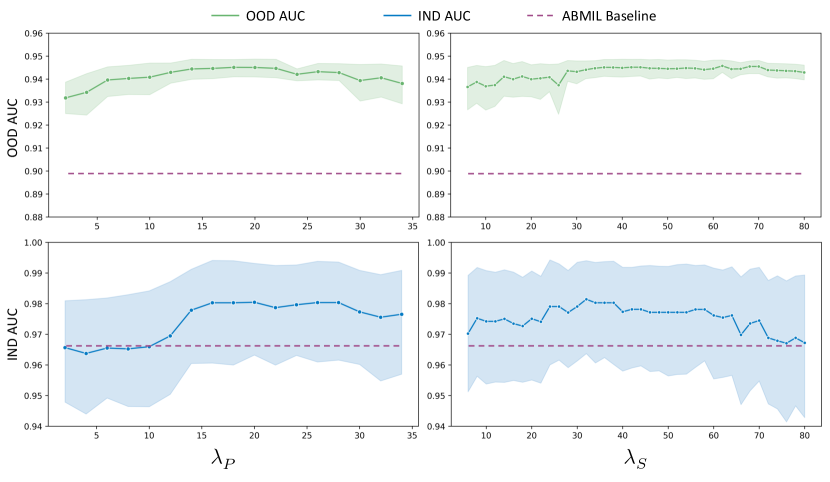
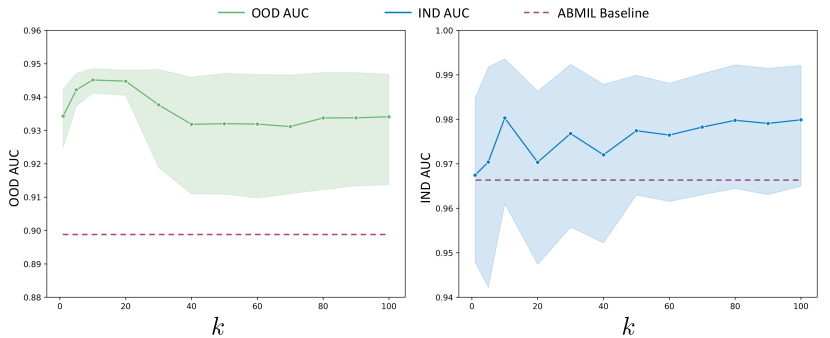
From Figure 4, it is evident that CATE enhances the performance of the base model ABMIL in most scenarios, particularly in out-of-domain settings. When the weight of PIM loss is too low, model performance suffers, underscoring the significant role of PIM loss in enhancing task-specific information. Conversely, an excessively high also diminishes performance, as the model overly prioritizes maximizing mutual information between the original and calibrated features at the expense of optimizing classification loss. Regarding the weight of SIM loss , optimal performance is achieved when is approximately 30. If the is too low, the model fails to effectively eliminate irrelevant information, thereby impairing performance. Conversely, if is too high, the model risks discarding task-relevant information, leading to performance degradation.
C.2 Ablation Study of the Number of Representative Patches
In this section, we conduct an ablation study to investigate the impact of the number of representative patches, , on model performance, as discussed in Section 3.2. In practice, the representative patches are selected based on the similarities between the original image feature and the corresponding class-specific concept anchor.
As shown in Figure 5, it is evident that CATE generally enhances the performance of the base model, ABMIL. When the number of representative patches is too small, model performance degrades due to insufficient capture of task-specific information. Conversely, an excessively large also leads to performance degradation in out-of-domain scenarios, as it introduces noise from irrelevant information. Consequently, we have set the number of representative patches to 10 in the main paper.
C.3 Additional Ablation Study of CIB Module
We further conducted experiments on CATE-MIL without concept alignment (discarding PIM loss and SIM loss of the CIB module) and replaced the CIB module with an MLP to investigate the effect of concept alignment and the increased number of parameters. The results are shown in Table 8. The performance of CATE-MIL significantly decreases in both cases, demonstrating the importance of concept alignment in the CIB module and that the improvements of CATE are not due to the increased number of parameters.
| Method | BRCA (=1) | BRCA (=2) | NSCLC (=2) | NSCLC (=4) | RCC (=3) | RCC (=6) |
| CATE-MIL w/o CFI (Baseline) | 0.9360.010 | 0.9420.010 | 0.9100.030 | 0.9600.011 | 0.9790.004 | 0.9770.005 |
| - w/o concept alignment | 0.9000.017 | 0.8840.033 | 0.7420.059 | 0.8970.022 | 0.9610.011 | 0.9320.016 |
| - Replace CIB with MLP | 0.8880.027 | 0.9020.037 | 0.8160.040 | 0.9310.023 | 0.9660.006 | 0.9510.021 |
Appendix D Datasets Description and Detailed Experimental Settings
In this section, we provide detailed descriptions of the datasets used in the experiments and the detailed experimental settings that we used in the experiments in Section 4.2.
D.1 Datasets Description
-
•
TCGA-BRCA: The dataset contains nine disease subtypes, and this study focuses on the classification of Invasive ductal carcinoma (IDC, 726 slides from 694 cases) and invasive lobular carcinoma (ILC, 149 slides from 143 cases). The dataset is collected from 36 sites with 20 of them having both IDC and ILC slides, and the other 16 sites only have IDC slides or ILC slides.
-
•
TCGA-NSCLC: The dataset contains two disease subtypes, including lung adenocarcinoma (LUAD, 492 slides from 430 cases) and lung squamous cell carcinoma (LUSC, 466 slides from 432 cases). The dataset is collected from 66 sites. Different from TCGA-BRCA, each site only contains one disease subtype.
-
•
TCGA-RCC: The dataset contains three disease subtypes, including clear cell renal cell carcinoma (CCRCC, 498 slides from 492 cases), papillary renal cell carcinoma (PRCC, 289 slides from 267 cases), and chromophobe renal cell carcinoma (CHRCC, 118 slides from 107 cases). The dataset is collected from 55 sites. Similar to TCGA-NSCLC, each site only contains one disease subtype.
D.2 Detailed Experimental Settings
To validate that the proposed CATE effectively improves MIL model performance by enhancing the task-specific information and eliminating the disturbance of task-irrelevant information, we conduct extensive experiments across three datasets under various in-domain and out-of-domain settings.
Specifically, for TCGA-BRCA dataset, we conduct the following experiments:
-
•
BRCA (=1): One site as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain site are shown below:
-
–
D8: 59 slides of IDC and 8 slides of ILC.
-
–
-
•
BRCA (=2): Two sites as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain sites are shown below:
-
–
A8: 48 slides of IDC and 5 slides of ILC.
-
–
D8: 59 slides of IDC and 8 slides of ILC.
-
–
For TCGA-NSCLC dataset, we conduct the following experiments:
-
•
NSCLC (=2): Two sites as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain sites are shown below:
-
–
44: 43 slides of LUAD and 0 slides of LUSC.
-
–
22: 0 slides of LUAD and 36 slides of LUSC.
-
–
-
•
NSCLC (=4): Four sites as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain sites are shown below:
-
–
44: 43 slides of LUAD and 0 slides of LUSC.
-
–
50: 20 slides of LUAD and 0 slides of LUSC.
-
–
22: 0 slides of LUAD and 36 slides of LUSC.
-
–
56: 0 slides of LUAD and 35 slides of LUSC.
-
–
For TCGA-RCC dataset, we conduct the following experiments:
-
•
RCC (=3): Three sites as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain sites are shown below:
-
–
A3: 48 slides of CCRCC, 0 slides of CHRCC, and 0 slides of PRCC.
-
–
KL: 0 slides of CCRCC, 24 slides of CHRCC, and 0 slides of PRCC.
-
–
2Z: 0 slides of CCRCC, 0 slides of CHRCC, and 23 slides of PRCC.
-
–
-
•
RCC (=6): Six sites as the in-domain data, and the other sites as the out-of-domain data. The details of the in-domain sites are shown below:
-
–
A3: 48 slides of CCRCC, 0 slides of CHRCC, and 0 slides of PRCC.
-
–
AK: 15 slides of CCRCC, 0 slides of CHRCC, and 0 slides of PRCC.
-
–
KL: 0 slides of CCRCC, 24 slides of CHRCC, and 0 slides of PRCC.
-
–
KM: 0 slides of CCRCC, 20 slides of CHRCC, and 0 slides of PRCC.
-
–
2Z: 0 slides of CCRCC, 0 slides of CHRCC, and 23 slides of PRCC.
-
–
5P: 0 slides of CCRCC, 0 slides of CHRCC, and 15 slides of PRCC.
-
–
Appendix E Detailed Definition and Formula Derivation
E.1 Definition of Sufficiency and Consistency
In this part, we will define the sufficiency and consistency in the context of the concept information bottleneck (CIB) module.
First, we define the mutual information between two random variables and as:
| (13) |
Sufficiency: To quantify the requirement that the calibrated features should be maximally informative about the label information , we define the sufficiency as the mutual information between the label information and the calibrated features:
Sufficiency. is sufficient for .
The sufficiency definition requires that the calibrated features encapsulate all information about the label information that is accessible from the original features . In essence, the calibrated feature of original feature is sufficient for determining label if and only if the amount of information regarding the specific task is unchanged after the transformation.
Consistency: Since the image feature and the concept anchor are consistent in the pathology VLM, we posit that any representation containing all information accessible from both the original feature and the concept anchor also encompasses the necessary discriminative label information. Thus, we define the consistency between the concept anchor and the original feature as:
Consistency. is consistent with for .
The consistency definition requires that the concept anchor and the original feature should be consistent with the label information .
E.2 Maximize Predictive Information with InfoNCE
In this part, we will prove that the predictive information for the concept anchor can be maximized by maximizing the InfoNCE mutual information lower bound, which is defined in Equation 4. As in [27], the optimal value for should be proportional to the density ratio:
| (14) |
And we can get:
| (15) |
where denotes the negative concepts, including both negative class concepts and other type concepts. We can see that the InfoNCE estimation is a lower bound of the mutual information between the concept anchor and the calibrated features:
| (16) |
Thus, the predictive information of calibrated features for the concept anchor can be maximized by maximizing the InfoNCE mutual information lower bound.
E.3 Superfluous Information Minimization
As shown in Equation 3, the mutual information between the original features and the calibrated features can be decomposed into the mutual information between the calibrated features and the concept anchor and the mutual information between the concept anchor and the calibrated features:
| (17) |
As introduced in section 3.2, the first item is the predictive information for the concept anchor, which can be maximized by maximizing the InfoNCE mutual information lower bound. Thus, the second superfluous information item can be minimized by minimizing . In practice, the superfluous information minimization is conducted on all patches in the subset , since the task-irrelevant information is distributed across all patches. Thus, the superfluous information can be minimized by minimizing . As in [1], this mutual information can be represented as:
| (18) |
However, the computing of the marginal distribution is intractable. Thus, we can let the Gaussian distribution approximate the marginal distribution . Since the Kullback-Leibler divergence between two distributions is non-negative, we can get:
| (19) |
Thus, the mutual information have the upper bound:
| (20) |
In practice, to compute this upper bound, we approximate distribution with the empirical distribution:
| (21) |
Thus, the upper bound of the mutual information can be computed as:
| (22) |
where is a variational distribution with parameter to approximate , and we implement this variational distribution with MLP:
| (23) |
where and are implemented with MLPs which output the mean and covariance matrix of the Gaussian distribution. In practice, we utilize the reparameterization trick [18] to sample from the Gaussian distribution to get an unbiased estimate of the gradient to optimize the opjective. Thus, the upper bound can be optimized by minimizing the KL divergence between the variational distribution and the Gaussian distribution :
| (24) |
Appendix F Explanation of CIB with Information Plane
To better understand the concept information bottleneck (CIB) method, we provide an explanation of CIB with the information plane [8, 6].
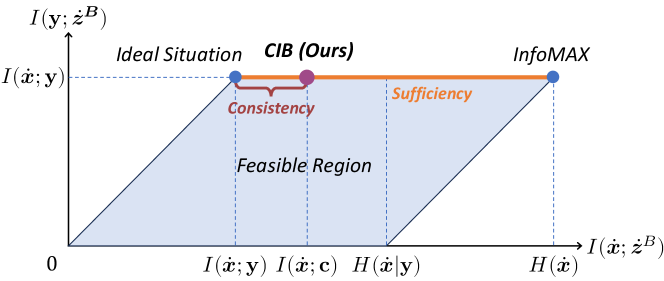
As shown in Figure 6, the information plane is a two-dimensional space where the x-axis represents the mutual information between the original features and the calibrated features of CIB module , and the y-axis represents the mutual information between the label information and the calibrated features . The line colored orange in the information plane defines sufficiency, indicating where the calibrated features are maximally informative about the label information . The consistency definition falls to the left of the sufficiency line, denoting a state where the calibrated features, containing all information from both the original feature and the concept anchor, also include the label information. The InfoMAX principle [9] states that the optimal calibrated feature should be maximally informative about the original feature.
Ideally, a good calibrated feature should be maximally informative about the label information (the sufficiency line in the information plane) while minimally informative about the original features (i.e., the ideal situation in the information plane). This situation can be achieved by directly supervised learning. However, the weakly supervised nature of MIL methods complicates this goal. As demonstrated in the ablation analysis in Section 4.4, if we directly perform superfluous information minimization without the guidance of concept anchor (i.e., predictive information maximization), the calibrated features will be less informative about the label information and the model performance will be degraded significantly. To address this issue, the proposed CIB module introduces the concept anchor to guide the learning process of information bottleneck for each instance. As shown in Figure 6, the CIB module could effectively reduce the mutual information between the original features and the calibrated features while preserving the mutual information between the label information and the calibrated features .
Appendix G Prompts
In this section, we provide the detailed prompt templates and concepts for the datasets, which are used to generate the concept anchor for the CIB module. The prompt templates are shown in Table 9, and the concepts for TCGA-BRCA, TCGA-NSCLC, and TCGA-RCC are shown in Table 10, Table 11, and Table 12, respectively. The templates and the class-agnostic prompts are referred from the original paper of CONCH [25], and the class-specific prompts are generated by querying the LLM with the question such as ‘In addition to tumor tissues, what types of tissue or cells are present in whole slide images of breast cancer?’ The quality of LLM generated prompts has been demonstrated in several recent studies [29, 22]. In principle, we can use LLM (e.g., GPT-4) to generate reliable expert-designed prompts and further verified by pathologists. This strategy can ensure the scalability and reliability of the prompts.
| Templates |
| <CLASSNAME>. |
| a photomicrograph showing <CLASSNAME>. |
| a photomicrograph of <CLASSNAME>. |
| an image of <CLASSNAME>. |
| an image showing <CLASSNAME>. |
| an example of <CLASSNAME>. |
| <CLASSNAME> is shown. |
| this is <CLASSNAME>. |
| there is <CLASSNAME>. |
| a histopathological image showing <CLASSNAME>. |
| a histopathological image of <CLASSNAME>. |
| a histopathological photograph of <CLASSNAME>. |
| a histopathological photograph showing <CLASSNAME>. |
| shows <CLASSNAME>. |
| presence of <CLASSNAME>. |
| <CLASSNAME> is present. |
| an H&E stained image of <CLASSNAME>. |
| an H&E stained image showing <CLASSNAME>. |
| an H&E image showing <CLASSNAME>. |
| an H&E image of <CLASSNAME>. |
| <CLASSNAME>, H&E stain. |
| <CLASSNAME>, H&E |
| Concept Type | Classes | Concept Prompts |
| Class-specific Concept | IDC | invasive ductal carcinoma breast invasive ductal carcinoma invasive ductal carcinoma of the breast invasive carcinoma of the breast, ductal pattern idc |
| ILC | invasive lobular carcinoma breast invasive lobular carcinoma invasive lobular carcinoma of the breast invasive carcinoma of the breast, lobular pattern ilc | |
| Class-agnostic Concept | Adipocytes | adipocytes adipose tissue fat cells fat tissue fat |
| Connective tissue | connective tissue stroma fibrous tissue collagen | |
| Necrotic Tissue | necrotic tissue necrosis | |
| Normal Breast Tissue Cells | normal breast tissue normal breast cells normal breast |
| Concept Type | Classes | Concept Prompts |
| Class-specific Concept | LUAD | adenocarcinoma lung adenocarcinoma adenocarcinoma of the lung luad |
| LUSC | squamous cell carcinoma lung squamous cell carcinoma squamous cell carcinoma of the lung lusc | |
| Class-agnostic Concept | Connective tissue | connective tissue stroma fibrous tissue collagen |
| Necrotic Tissue | necrotic tissue necrosis | |
| Normal Lung Tissue Cells | normal lung tissue normal lung cells normal lung |
| Concept Type | Classes | Concept Prompts |
| Class-specific Concept | CCRCC | clear cell renal cell carcinoma renal cell carcinoma, clear cell type renal cell carcinoma of the clear cell type clear cell rcc |
| PRCC | papillary renal cell carcinoma renal cell carcinoma, papillary type renal cell carcinoma of the papillary type papillary rcc | |
| CHRCC | chromophobe renal cell carcinoma renal cell carcinoma, chromophobe type renal cell carcinoma of the chromophobe type chromophobe rcc | |
| Class-agnostic Concept | Adipocytes | adipocytes adipose tissue fat cells fat tissue fat |
| Connective tissue | connective tissue stroma fibrous tissue collagen | |
| Necrotic Tissue | necrotic tissue necrosis | |
| Normal Kidney Tissue Cells | normal kidney tissue normal kidney cells normal kidney |
Appendix H More Visualization
To further illustrate the effectiveness of the proposed CATE-MIL, we provide more visualization results in this section. The visualization results for IDC and ILC in TCGA-BRCA are shown in Figure 7 and Figure 8, respectively.

