FreeCompose: Generic Zero-Shot
Image Composition with Diffusion Prior
Abstract

We offer a novel approach to image composition, which integrates multiple input images into a single, coherent image. Rather than concentrating on specific use cases such as appearance editing (image harmonization) or semantic editing (semantic image composition), we showcase the potential of utilizing the powerful generative prior inherent in large-scale pre-trained diffusion models to accomplish generic image composition applicable to both scenarios. We observe that the pre-trained diffusion models automatically identify simple copy-paste boundary areas as low-density regions during denoising. Building on this insight, we propose to optimize the composed image towards high-density regions guided by the diffusion prior. In addition, we introduce a novel mask-guided loss to further enable flexible semantic image composition. Extensive experiments validate the superiority of our approach in achieving generic zero-shot image composition. Additionally, our approach shows promising potential in various tasks, such as object removal and multi-concept customization.
Project webpage: https://github.com/aim-uofa/FreeCompose
Keywords:
Image composition Zero-shot Diffusion prior1 Introduction
Image Composition is a fundamental task in computer vision [TJP13, ZKSE15, TSL+17], which aims to fuse the foreground object from one image with the background of another image to generate a smooth natural image. It has a wide range of applications in many fields, such as image restoration, art design, game development, virtual reality, and so on.
For this reason, a large amount of research has been conducted on image composition [TJP13, ZKSE15, TSL+17, CZN+20]. Depending on whether there is a change in the semantic structure of the composite image, image composition can be broadly categorized as image harmonization [ZKSE15, TSL+17] and semantic image composition [YGZ+23, CHL+24]. The former modifies only the statistical information of the local area after pasting the foreground pixels into the background image, to obtain an image with a smooth transition between the front and background. In contrast, the latter fine-tunes the structure of the image according to the global image context and semantically blends the foreground and background.
As deep learning [LBH15] gains its popularity, mainstream solutions for image composition adopt the learning-based pipeline [TSL+17, CZN+20]. They require model training on data triplet of foreground, background, and composite images to achieve image combination. However, due to the difficulty in obtaining the triplets, these models can only be trained on a limited amount of training data with a specific data distribution, making it difficult to generalize to various scenarios in real-world applications.
In contrast, recent text-to-image diffusion models [RBL+22, RDN+22, SCS+22] have achieved large-scale pre-training using simple graphical data pairs, demonstrating strong generalization over open-world data distributions. Inspired by this, we attempt to utilize the image prior of the pre-trained diffusion model to realize generic image composition, in zero shot. Our key assumption is that the pre-trained diffusion model can accurately predict the noise component in natural images, while inaccurately for unnatural image regions that deviate from the pre-training data distribution. Based on this, we can localize the unnatural regions in a composite image after simply copying and pasting.

To validate this hypothesis, we conduct preliminary explorations on composite images, as shown in Figure 2. Based on the above observations, we propose FreeCompose, which optimizes the pixels in the image such that it can be consistent with the image prior of the pre-trained diffusion model.
In our method, we aim to use the prior of the diffusion model to combine the object with the background without having to train the diffusion model itself (referred to as Training-free in this field). We propose a generic pipeline for composition that consists of three phases: object removal, image harmonization, and semantic image composition. Unlike current works [TLNZ23, YGZ+23] that rely on task-specific training for image harmonization or semantic image composition, our FreeCompose can directly utilize a pre-trained diffusion model and achieve composition in zero-shot. During the object removal phase, our pipeline eliminates the foreground in the original image by manipulating the , values of the diffusion UNet’s self-attention layer. In the image harmonization phase, the new object is combined with the background to create a harmonious scene. If additional conditions for semantic image composition are provided, the composition is guided by the difference between the conditions, while preserving the object’s identity through an additional replacement of the , in the self-attention.
Based on these phases and techniques, FreeCompose can be effectively used for various tasks with promising results. These tasks include basic object removal, image harmonization, and semantic image composition. Moreover, FreeCompose demonstrates the ability to stylize objects by utilizing prompts during the image harmonization phase. Additionally, when combined with existing works, it can be applied to a wide range of tasks, such as multi-character customization.
To summarize, our contributions are listed as follows.
-
•
Our findings indicate that the diffusion prior can automatically identify and focus on regions in the composite image that appear unnatural.
-
•
Developing from the vanilla DDS loss, we explore and prove the possibility of additional designs for specific tasks including mask-guided loss and operations on , embeddings. These enhancements expand the range of applications for this loss format.
-
•
FreeCompose achieves competitive results on both image harmonization and semantic image composition. Moreover, it facilitates broad applications including object removal and multi-character customization.
-
•
In contrast to existing methods that train separate models for individual image composition problems, the diffusion prior that we use offers a generalized natural image prior that can effectively perform both image harmonization and semantic image composition in a zero-shot manner.
2 Related Work
Image Harmonization Image harmonization aims to generate a realistic combination of foreground and background contents from different images. It focuses on adjusting low-level appearances, like the global and local color distribution change caused by light and shadows, while maintaining the content structure unchanged. Early works on image harmonization[PKD05, COSG+06, RAGS01, TJP13, SJMP10] rely on hand-crafted priors on color [PKD05], gradient [TJP13], or both [SJMP10]. With the advance of deep learning [LBH15], recent methods [ZKSE15, TSL+17, CZN+20, JZZ+21, LXS+21, HIF20, CNZ+20, SPK21, CFYZ24] explore learning-based methods for image harmonization. For example, Zhu et al. [ZKSE15] train a discriminative model to judge the realism of a composited image, and leverage the model to guide the appearance adjustment of a composed image. Tsai et al. [TSL+17] propose the first end-to-end network for image composition. Subsequently, DoveNet [CZN+20] leverages a domain verification discriminator to migrate the domain gap between the foreground and background images. Recently, Tan et al. [TLNZ23] proposed a new end-to-end net named DocuNet by leveraging the channels of images and achieved excellent success. While effective, these image harmonization models are trained on domain-specific datasets, and struggle to generalize to open-world images. By contrast, we leverage the natural image prior preserved in large-scale pre-trained diffusion models for zero-shot image harmonization in the wild. Chen et al. [HHL+24] also attempted to use diffusion model as a base model for harmonization by a method called Diff-harmonization composed of inversion and re-denoising, but limited to harmonization.
Image Editing Text editing is a broad area that encompasses many research topics, including image-to-image translation [IZZE17, ZPIE17, KCK+17, MM20, ZCG+18], inpainting [LDR+22, KZZ+23, ISSI17, PKD+16, YLL+16, GG17, LRS+18], text-driven editing [HMT+22, XYXW20, ALF22a, PWS+21, TBT+22], etc. We refer readers to [HHL+24, ZYW+23] for more comprehensive review. Here we focus on the image inpainting task. Traditional image inpainting takes the masked image as input, and predicts the masked pixels from the image context. For example, LaMa [SLM+22] enlarges the receptive fields from the perspective of both modeling and losses, thus achieving inpainting in large masks and complex scenarios. Recently, benefiting from large-scale pre-trained text-to-image generative models [RDN+22, RBL+22], researchers explore additional text input to guide the inpainting process [ALF22b, AFL23]. For example, Blended Latent Diffusion [AFL23] proposes to smoothly blend the latent of the foreground region and the background areas to achieve text-guided inpainting. Another line of work [YGZ+23, CHL+24] inpaints the masked image with an example image, which is also known as semantic image composition [YGZ+23]. Different from image harmonization which only alters low-level statistics, semantic image composition semantically transfers the foreground object (often with structural changes) during composition. A representative work Paint-by-Example [YGZ+23] fine-tunes the pre-trained Stable Diffusion model to take additional exemplar images as input for inpainting. AnyDoor [CHL+24] improves the semantic image composition pipeline to preserve the texture details in exemplar images and leverage the multi-view information in video datasets for effective training.
Diffusion Models Diffusion models [HJA20, SDWMG15] have emerged as powerful generative models for images. Large-scale pre-trained diffusion models, like DALLE-2 [RDN+22], Imagen [SCS+22], Stable Diffusion [RBL+22], and SDXL [PEL+23], demonstrate unprecedented text-to-image generation capacities in terms of both realism and diversity. Motivated by the success of diffusion models, attempts have been made to leverage pre-trained image diffusion models as the prior for other generative tasks [PJBM22, WLW+24, KPCOL23]. Considering the data scarcity of 3D assets, DreamFusion [PJBM22] uses Imagen [SCS+22] as a generative prior, and proposes a novel Score Distillation Sampling (SDS) loss for optimizing the implicit representation of a 3D object. Subsequently, ProlificDreamer [WLW+24] models the parameters of 3D assets as a random variable and proposes the variational score distillation to alleviate the over-saturation and over-smoothness in DreamFusion. Different from these works that focus on text-to-3D generation, DDS [HACO23] tackles the task of text-guided image editing, and identifies the editing region by referencing the original image and its corresponding prompt. In this work, we also leverage diffusion models as the generative prior (diffusion prior). Our key observation is that diffusion prior helps locate unnatural areas in simple copy-paste image composition. Based on this, a masked guided loss is proposed to enable generic smooth image composition.
3 Preliminaries
3.1 DDS Loss
The Delta Denoising Score (DDS) [HACO23] is developed froma modification of the diffusion loss and Score Distillation Sampling [RLJ+23] for image editing. Given an input image , the diffusion model encodes it into a latent variable . Using a prompt for theto generation ofe a text embedding , a timestep is randomly chosen from a uniform distribution , and noise is sampled from a normal distribution . A noised latent variable can then be represented as , where is determined by a noise scheduler based on .
Given a pre-trained diffusion model with parameter set , a modified predicted noise according to classifier-free guidance [HS22] can be expressed as
where is the raw noise predicted by the diffusion model conditioned on , is unconditioned noise, and is a weight for balance.
Using two image-text pairs and , the DDS loss with respect to parameter can be expressed in gradient form as:
| (1) |
where is predicted from and is predicted from with the same and . For simplicity, this loss is denoted as .
3.2 Perceptual Loss
The perceptual loss [JAFF16] is proposed to measure the perceptual similarity of images based on the features of VGG-16 [SZ14]. Although originally designed for the super-resolution task by maintaining the features of the original image, it also allows for the preservation of selected regions. We denote the perceptual loss between and as .
4 Method
Given a target image with the object’s mask and a background image with a designated region for placing the object, our goal is to compose a new coherent image that retains the background from while incorporating the target image’s object as the foreground.
To achieve generic image composition, our method comprises three phases: object removal, image harmonization, and semantic image composition. This design allows for the composition of various foreground object and background images. In Figure 3, we illustrate the pipeline with special segments of different phases. The overview of the pipeline is presented in § 4.1, followed by details of object removal in § 4.2, image harmonization in § 4.3, and semantic image composition in § 4.4.
4.1 Overall pipeline
The removal stage takes and as inputs to generate a background image with the object in removed. Subsequently, the composition stage produces a coherent image given . Furthermore, if conditions are provided to transfer the object from the original condition to the target condition , the editing stage can integrate these conditions onto to synthesize image . The conditions can take the form of text or other formats accepted by T2I-Adapter[MWX+23]. Each stage is optimized with different loss functions: , and .
The method follows a general pipeline across all three phases, as depicted in Figure 3. With inputs including an image , an original prompt , and a target prompt , the pipeline initializes with an optimized image and guides its progression to the output image using a phase-specific loss function.
and are set as general prompts for object removal and image harmonization as elaborated in § 4.2 and § 4.3, whereas for semantic image composition, they are taken as input conditions.
In general, the DDS loss can modify images but may also distort them during optimization. Meanwhile, the perceptual loss helps maintain object identity. When used together, these losses can create a balanced loss function that forms the backbone of the pipeline. At the same time, minimum adjustment to the loss function enables other specific tasks, as detailed in the following sections.
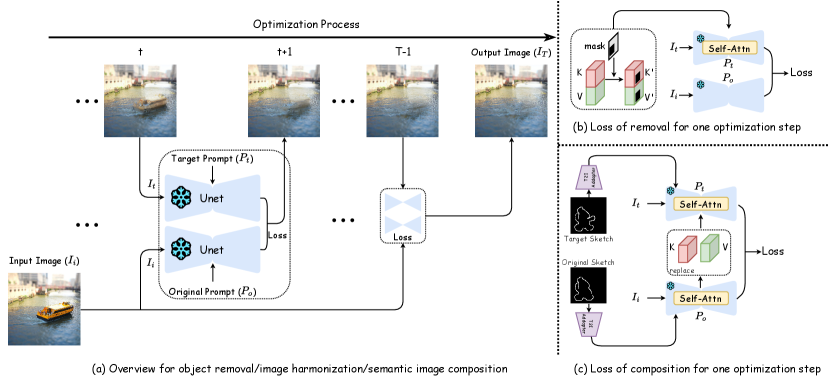
4.2 Object Removal
In this phase, we take as the input image , and the object region mask is required. and are set as placeholder prompts, such as “Something in some place” and “Some place,” when no prompt is provided. These prompts are partially effective, but they do not have the capability to directly eliminate the object, as shown in the ablation study (see Figure 7).
We add an extra segment during the calculation of the DDS loss to enhance the ability of removal, as shown in Figure 3(b). The diffusion model is based on a UNet architecture, composed of residual, self-attention and cross-attention blocks. In the self-attention blocks, features are projected into quires , keys and values , and the output can be represented as:
| (2) |
where is the dimension of the hidden states.
Based on previous work such as [HLQC23], the , values of the self-attention layer during the denoising step are observed to have an effect on the semantic result. Guided by this discovery, we use to discard some , values partially. Specifically, for a or value of shape , where represent the batch size, sequence length, and input dimension, respectively, we resize the mask to shape and flatten it to a sequence with length . By selecting indices from , where represents the value of index in the sequence, the semantic information of the masked region is replaced by its surroundings, thereby achieving the objective of removal. This mask guided loss can be represented as with the gradient form:
The only difference with Eq. 1 is the , which means that the , values of the self-attention layers masked by are excluded during noise prediction.
The overall loss function, thus, comprises two terms:
| (3) |
Here, is the reversed mask of , denotes the Hadamard production of two images, and is a hyperparameter used to balance the two losses.
4.3 Image Harmonization
Applying the bounding box of , a copy-paste image and its corresponding object mask can be obtained from . This image is used as input image () in this phase. Without designated prompts, an empty prompt and “A harmonious scene” are initialized as for the DDS loss. The perceptual loss is used separately for the background and the foreground to preserve background appearance and object identity. The overall loss consists of three terms:
| (4) |
where is the revered mask of , is a hyperparameter used to balance the perceptual loss related to the background and is a hyperparameter used to balance the perceptual loss related to the target object.
4.4 Semantic Image Composition
This phase accepts either the copy-paste image or the composition result and requires two additional conditions: and . If the conditions are in text form, they will be directly used as and for the DDS loss. Conditions in other forms will be translated by T2I-Adapter[MWX+23] and added to the diffusion UNet as shown in Figure 3(c).
An additional design is employed to maintain the identity of the object during the editing procedure. As displayed in Figure 3(c), FreeCompose replaces the optimized image ’s , values with ’s , values during the calculation of DDS loss. Specifically, for a DDS loss with , where represent the , values of , and represent the , values of , we modify the calculation of self-attention in the diffusion UNet concerning as follows:
where is the count of optimization, is the layer index of the self-attention layer, and are hyperparameters indicating the count number and layer index of self-attention to start such replacement. Because the background is also preserved along with the replacement, no perceptual loss is required. Therefore, the complete loss has the same format as the DDS loss:
where represents the DDS loss using as substitutes for conditions in forms besides text, with an additional design of , replacement during calculation.
5 Experiments
| Image Harmony | Object Removal | |
|---|---|---|
| Repaint[LDR+22] | ||
| SD Inpainting[KZZ+23] | ||
| Lama[SLM+22] | ||
| FreeCompose (ours) |
| Image Harmony | Object Identity Preserving | |
|---|---|---|
| Diff Harmonization[HHL+24] | ||
| DucoNet[TLNZ23] | ||
| FreeCompose (ours) |
5.1 Implementation Details
5.1.1 Global Hyperparameters.
We use Stable Diffusion V2.1111https://huggingface.co/stabilityai/stable-diffusion-2-1 as the pre-trained model for real images, and AnyLoRA222https://huggingface.co/Lykon/AnyLoRA as the pre-trained model for anime and cartoon images. We align the resolution of input images with the diffusion model to . The Adam optimizer is adopted with a fixed learning rate of .
5.1.2 Hyperparameters.
In the object removal phase, the DDS loss outside the mask resized from to the latent size is multiplied by 0.2 to limit the transformation of the background. Additionally, . In the image harmonization phase, and . The semantic image composition only uses the DDS loss with and for the replacement design.
5.1.3 Prompt Usage.
Two prompts, and , are required for every calculation of the DDS loss. Providing specific prompts will improve the optimization procedure. Our FreeCompose does not rely on user-provided text prompts for image composition. Instead, we predefined the prompts for different phases. Specifically, in the object removal phase, we set as “Something in some place.” and as “Some place.”, respectively. Similarly, we adopt empty prompts for and “A harmonious scene.” for in the image harmonization phase. These prompts have proven to be effective.
5.2 Main Results
5.2.1 Object removal

In Figure 4, we present the results of object removal, comparing them with previous work on removal and inpainting. When using the default prompts in § 5.1.3, Lama [SLM+22], Stable Diffusion Inpainting [KZZ+23], and Repaint [LDR+22] require the same input as our method. This includes one original image along with a corresponding mask for the region that needs to be removed. As shown, SD Inpainting and Repaint struggle to completely remove the object, leaving some parts unchanged or replaced by something that doesn’t fit well, like the outline of the dog in the second case and the unknowns in the fourth case. Although Lama performs better in removing the object and reconstructing the background, it fails to remove certain attachments of the object, such as the shadow in the third case. In general, our method demonstrates a stronger capability in removing the object and seamlessly filling the resulting areas, as can be observed in the third case where other methods perform poorly.
5.2.2 Image harmonization

As shown in Figure 5, Diff Harmonization successfully generates primary shadow as surface variation in the first candle case. However, it struggles to retain identity features such as the color of the second emoji case and the shape of the third dog case’s eye. On the other hand, DucoNet preserves these features well but lacks realistic shadow and light effect under certain environments. For instance, in the first case, DucoNet simply illuminates the entire object, without accurately transforming the dark and bright sections according to the original image. In contrast, our method is capable of both preserving the object’s identity and generating realistic lighting effects. For example, in the first case, FreeCompose enables the object to be covered by the shadow of the surroundings, resulting in the corresponding dark section while maintaining the object’s identity.
5.2.3 Semantic image composition

Figure 6 illustrates the results of our semantic image composition. By using an input image (either a copy-paste image or an image after harmonization), FreeCompose is able to generate a composed image that maintains semantic consistency, guided by the disparity between two input conditions. As shown, the top-left case makes use of the difference between two prompts to transfer the dog from a lying posture to a running posture. In other cases, with the same prompt during calculation, the features extracted by T2i-Adapter [MWX+23] from different sketch images serve as guidance for semantic composition, proving the feasibility of wider usage.
5.2.4 Quantitative comparison.
Since our primary focus is on open domain questions, we believe that evaluating performance through user studies is more appropriate. We have planned a user study to assess the results of object removal and image harmonization, comparing them with previous works with five cases respectively. The study involves more than twenty volunteers. To evaluate the effectiveness of object removal, participants are asked to assess the outcomes based on two criteria: (1) the level of image harmony achieved after the object is removed, and (2) the extent to which the object removal is executed. In terms of image harmonization, participants are instructed to assess the results based on two aspects: (1) the level of visual coherence achieved after integrating the object into the composition, and (2) the degree to which the object’s identity is preserved. Each metric is rated on a scale ranging from 1 to 5.
The results are shown in Table 1 and Table 2. As demonstrated, our method excels in both aspects for object removal. Our method in image harmonization received the highest rating for “Image Harmony”, but it lagged behind DucoNet in terms of “Object Identity Preservation.” One possible reason is that our method employs a stronger composition strategy by restricting the weight of the foreground loss, resulting in partial degradation of the object’s identity.
5.3 Ablation Study
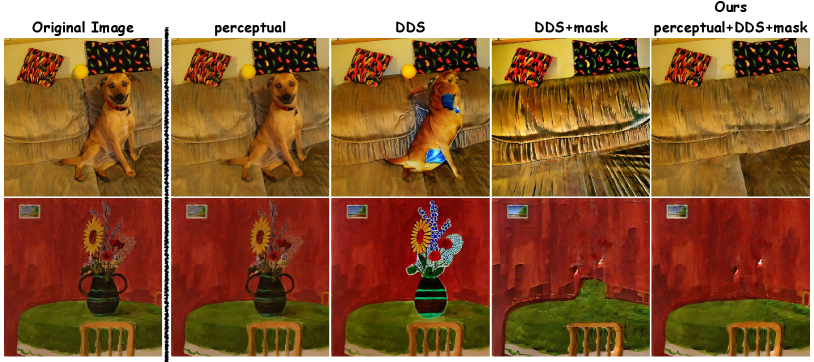
We conducted an ablation study to validate our designs and analyze their functions. by disassembling and visualizing each design to clearly demonstrate their effects.
5.3.1 Object Removal Phase.
In Figure 7, designs of the object removal phase are disassembled for analysis. The perceptual loss alone maintains the original image without any changes as the the “perceptual” column displayed. When using a raw DDS loss with default prompts, the object cannot be completely eliminated, resulting in some variations in the object in line with the “DDS” column. The introduced mask design in §4.2, which selectively discards specific KV values based on the mask of the object, overcomes this limitation and enables the loss to successfully remove the object. However, such mask guided loss affects the background which should be preserved, as presented in the “DDS+mask” column. The last addition of perceptual loss section helps preserve the background while calculating the mask guided loss and generates the background image independently from the original foreground as demonstrated in the “Ours” column.
5.3.2 Image Harmonization Phase.

In Figure 8, different sections of the loss are ablated for observation of their respective functions. The perceptual loss, comprising the background perceptual loss and the foreground perceptual loss, ensures the consistency with the original copy-paste image, as seen in the “perceptual” column. When using the raw DDS loss, it allows for seamless blending of the object with the background, but may unintentionally remove certain features from both the foreground and the background, compatible with the “DDS” column. By employing distinct perceptual loss functions for the foreground and the background, the trade-off among the degree of integration, the identity of the object and the features of the background is achieved, enabling the generation of a harmonious image as shown in the “Ours” column.
6 Conclusion
We present FreeCompose, a generic zero-shot image composition method that utilizes diffusion prior. In this work, we noticed that pre-trained diffusion models are capable of detecting inharmonious portions in copy-paste images. Building on this observation, we successfully apply this prior to both image harmonization and semantic image composition. FreeCompose is a zero-shot method, allowing easy usage without additional training. Moreover, it’s suitable for various applications, showcasing the potential of the diffusion model prior.
We believe that the prospect of diffusion prior extends beyond what we have achieved thus far. In the future, we plan to explore additional uses for other composition tasks and to apply our method to video, capitalizing on its full capabilities.
Acknowledgement
This work was supported by National Key R&D Program of China (No. 2022ZD0118700). The authors would like to thanks Hangzhou City University for accessing its GPU cluster.
Appendix
Appendix 0.A More Applications

0.A.0.1 Object stylization.
During the image harmonization phase, the default prompts do not favor any particular style. However, if an object is composed onto a background that differs in style (for example, from a real plane to an oil-painting background as shown in Figure 9), these prompts can be used to transfer the object to match the style of the background.
0.A.0.2 Zero-shot multi-character customization.
Animate Anyone[HGZ+23] is a method that customizes images into videos by allowing zero-shot customization of a single character with a similar background. With the implementation of this method, it becomes possible to compose multiple customized characters together, thus enabling zero-shot multi-character customization.
Appendix 0.B More Implementation Details
0.B.0.1 Optimization Steps.
The best results in different cases are achieved through various optimization steps. Generally, we use 150 steps for object removal and 200 steps for image harmonization. However, for semantic image composition, the specific format of the conditions requires different numbers of steps. For instance, text requires 500 steps, while sketch and canny require 200 steps.
0.B.0.2 Timestep Choice.
According to our observations, different timesteps have varying levels of influence on the optimization results. During the object removal phase, we use timesteps ranging from 50 to 400 to enhance efficiency. For the image harmonization phase, timesteps between 50 and 950 are employed to achieve a more balanced outcome. In the semantic image composition phase, timesteps between 50 and 100 are used specifically for the final fifty optimization steps to ensure smoothness in the resulting image..
0.B.0.3 T2I-Adapter Model.
We utilize the T2I-Adapter, which was released by TencentARC333https://huggingface.co/TencentARC, to apply the diffusion model to conditions in formats other than text. When it comes to image composition, sketch and canny are conditions more suitable than other formats, used for cases in our results.
0.B.0.4 Running Times.
The running times depend on the optimization steps chosen for a specific task. In general, when using an RTX 3090 with a float 16 precision, the first 50 steps take approximately 30 seconds, including preparation time for each phase. Subsequent sets of 50 steps take around 25 seconds.
Appendix 0.C More Results
0.C.1 Object Removal

We show some more object removal results in Figure 10. Our method can be widely applied to different types of objects and scenes, and can achieve good results in most cases.
0.C.2 Image Harmonization

We show some more image harmonization results in Figure 11. Our method automatically analyze the light and shadow of the environments and harmonize the object accordingly.
0.C.3 Semantic Image Composition

We show some more semantic image composition results in Figure 12. Our method enables the use of various conditions as guidance to guide the composition process. In cases where more intricate texture or structure is desired, canny edges can be employed as conditions to achieve superior outcomes, as demonstrated in the right column.
Appendix 0.D Plug-and-Play On other Diffusion Models

0.D.0.1 Plug-and-Play on SDXL Model.
We apply FreeCompose to a pre-trained SDXL model444https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0., and the results are displayed in Figure 13. Thanks to the exceptional prior of the SDXL model, the results are particularly impressive, especially in terms of image harmonization. As shown in the right column, it can be observed that the bottle’s reflection on the table in the first case and the object’s shadow in the second case are well integrated with the background through our method.
Appendix 0.E Algorithm
0.E.1 Object Removal
The pseudocode for our method in object removal phase is shown in Algorithm 1. The critical part is the calculation of the mask guided loss, which uses the mask for discarding semantic message during denoising of the target image.
0.E.2 Image Harmonization
The pseudocode for our method in image harmonization is presented in Algorithm 2. This section balances various losses to find a tradeoff between object identity, background features, and overall harmony.
0.E.3 Semantic Image Composition
The pseudocode for our method in semantic image composition is demonstrated in Algorithm 3. The key aspect is the utilization of condition features to guide the transformation and the replacement of the self-attention features of the target image, which forms the core of the semantic image composition phase.
Appendix 0.F Discussion
0.F.1 Limitations
The first limitation concerns the object removal phase. Through the use of mask guided loss, the pipeline replaces the semantic information of the object with that of the background. However, if the mask is too large, the remaining background information may not be enough to accurately reconstruct the entire background, leading to the creation of artifacts. Additionally, it is important that the mask fully covers the object to be removed; otherwise, certain portions of the object may still be visible in the final result. In situations where there are similar objects present in the background, the pipeline may mistakenly replace the removed object with these similar objects, as they share a similar semantic message.
The second limitation pertains to the image harmonization phase. Although the pipeline achieves excellent results in terms of light and shadow, it struggles to strike a balance between the object’s features and the overall naturalness when there is a significant contrast between the object and the background. For instance, when dealing with an object that has dark shadows against a bright background.
The third limitation relates to the semantic image composition phase. The quality of the output is partially influenced by the format and quality of the input conditions. When it comes to text prompts, the pipeline can only generate subtle variations. As for sketches, certain details are challenging to render realistically. Canny edges appear to be the most suitable format for conditions, but they are less accessible and more intricate.
0.F.2 Future Work
FreeCompose enables flexible composition among different objects and backgrounds by utilizing pre-trained diffusion models, without the need for additional training. In the future, we plan to expand our method to cover more composition tasks and further explore the potential of the pipeline. We also intend to investigate the feasibility of applying our method to video models and other generative models. Additionally, we will improve the user-friendliness and efficiency of the pipeline in future updates.
0.F.3 Negative Impact
Our FreeCompose aims to utilize the prior knowledge of pre-trained diffusion models and extend their use to tasks beyond their original purpose. However, it is important to acknowledge the potential for malicious applications of our method, such as generating deceptive images that composing real individuals with fabricated surroundings for the purpose of misinformation and disinformation. This is a common issue with generative models.
One possible way to address the negative impact is to adopt methods similar to that proposed by Pham et al. [PMC+24]. These methods leverage the capability of diffusion models to identify fake images and help prevent the abuse of our method. Furthermore, it is crucial to be mindful of employing unseen watermarks and other techniques to authenticate images in order to prevent the misuse of our method.
References
- [AFL23] Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion. ACM Trans. Graphics, 2023.
- [ALF22a] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2022.
- [ALF22b] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2022.
- [CFYZ24] Xiuwen Chen, Li Fang, Long Ye, and Qin Zhang. Deep video harmonization by improving spatial-temporal consistency. J. Mach. Learn. Res., 2024.
- [CHL+24] Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level image customization. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2024.
- [CNZ+20] Wenyan Cong, Li Niu, Jianfu Zhang, Jing Liang, and Liqing Zhang. Bargainnet: Background-guided domain translation for image harmonization. arXiv: Comp. Res. Repository, 2020.
- [COSG+06] Daniel Cohen-Or, Olga Sorkine, Ran Gal, Tommer Leyvand, and Ying-Qing Xu. Color harmonization. ACM Trans. Graphics, 2006.
- [CZN+20] Wenyan Cong, Jianfu Zhang, Li Niu, Liu Liu, Zhixin Ling, Weiyuan Li, and Liqing Zhang. Dovenet: Deep image harmonization via domain verification. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2020.
- [GG17] Ruohan Gao and Kristen Grauman. On-demand learning for deep image restoration. In Proc. IEEE Int. Conf. Comp. Vis., 2017.
- [HACO23] Amir Hertz, Kfir Aberman, and Daniel Cohen-Or. Delta denoising score. In Proc. IEEE Int. Conf. Comp. Vis., 2023.
- [HGZ+23] Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, and Liefeng Bo. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. arXiv: Comp. Res. Repository, 2023.
- [HHL+24] Yi Huang, Jiancheng Huang, Yifan Liu, Mingfu Yan, Jiaxi Lv, Jianzhuang Liu, Wei Xiong, He Zhang, Shifeng Chen, and Liangliang Cao. Diffusion model-based image editing: A survey. arXiv: Comp. Res. Repository, 2024.
- [HIF20] Guoqing Hao, Satoshi Iizuka, and Kazuhiro Fukui. Image harmonization with attention-based deep feature modulation. In Trans. Mach. Learn. Res., 2020.
- [HJA20] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Proc. Advances in Neural Inf. Process. Syst., 2020.
- [HLQC23] Jiancheng Huang, Yifan Liu, Jin Qin, and Shifeng Chen. Kv inversion: Kv embeddings learning for text-conditioned real image action editing. arXiv: Comp. Res. Repository, 2023.
- [HMT+22] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv: Comp. Res. Repository, 2022.
- [HS22] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv: Comp. Res. Repository, 2022.
- [ISSI17] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Globally and locally consistent image completion. ACM Trans. Graphics, 2017.
- [IZZE17] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
- [JAFF16] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. arXiv: Comp. Res. Repository, 2016.
- [JZZ+21] Yifan Jiang, He Zhang, Jianming Zhang, Yilin Wang, Zhe Lin, Kalyan Sunkavalli, Simon Chen, Sohrab Amirghodsi, Sarah Kong, and Zhangyang Wang. Ssh: A self-supervised framework for image harmonization. arXiv: Comp. Res. Repository, 2021.
- [KCK+17] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee, and Jiwon Kim. Learning to discover cross-domain relations with generative adversarial networks. arXiv: Comp. Res. Repository, 2017.
- [KPCOL23] Oren Katzir, Or Patashnik, Daniel Cohen-Or, and Dani Lischinski. Noise-free score distillation. arXiv: Comp. Res. Repository, 2023.
- [KZZ+23] Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2023.
- [LBH15] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Pattern Recogn., 2015.
- [LDR+22] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2022.
- [LRS+18] Guilin Liu, F. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. Proc. Eur. Conf. Comp. Vis., 2018.
- [LXS+21] Jun Ling, Han Xue, Li Song, Rong Xie, and Xiao Gu. Region-aware adaptive instance normalization for image harmonization. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2021.
- [MM20] Aamir Mustafa and Rafal K. Mantiuk. Transformation consistency regularization- a semi-supervised paradigm for image-to-image translation. arXiv: Comp. Res. Repository, 2020.
- [MWX+23] Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv: Comp. Res. Repository, 2023.
- [PEL+23] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv: Comp. Res. Repository, 2023.
- [PJBM22] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv: Comp. Res. Repository, 2022.
- [PKD05] Francois Pitie, Anil C Kokaram, and Rozenn Dahyot. N-dimensional probability density function transfer and its application to color transfer. In Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, 2005.
- [PKD+16] Deepak Pathak, Philipp Krähenbühl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros. Context encoders: Feature learning by inpainting. Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
- [PMC+24] Minh Pham, Kelly O. Marshall, Niv Cohen, Govind Mittal, and Chinmay Hegde. Circumventing concept erasure methods for text-to-image generative models. In Proc. Int. Conf. Learn. Representations, 2024.
- [PWS+21] Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. arXiv: Comp. Res. Repository, 2021.
- [RAGS01] E. Reinhard, M. Adhikhmin, B. Gooch, and P. Shirley. Color transfer between images. IEEE Computer Graphics and Applications, 2001.
- [RBL+22] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2022.
- [RDN+22] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv: Comp. Res. Repository, 2022.
- [RLJ+23] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2023.
- [SCS+22] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Proc. Advances in Neural Inf. Process. Syst., 2022.
- [SDWMG15] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Proc. Int. Conf. Mach. Learn., 2015.
- [SJMP10] Kalyan Sunkavalli, Micah K Johnson, Wojciech Matusik, and Hanspeter Pfister. Multi-scale image harmonization. ACM Trans. Graphics, 2010.
- [SLM+22] Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2022.
- [SPK21] Konstantin Sofiiuk, Polina Popenova, and Anton Konushin. Foreground-aware semantic representations for image harmonization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021.
- [SZ14] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv: Comp. Res. Repository, 2014.
- [TBT+22] Ming Tao, Bingkun Bao, Hao Tang, Fei Wu, Longhui Wei, and Qi Tian. De-net: Dynamic text-guided image editing adversarial networks. Proc. AAAI Conf. Artificial Intell., 2022.
- [TJP13] Michael W Tao, Micah K Johnson, and Sylvain Paris. Error-tolerant image compositing. Int. J. Comput. Vision, 2013.
- [TLNZ23] Linfeng Tan, Jiangtong Li, Li Niu, and Liqing Zhang. Deep image harmonization in dual color spaces. arXiv: Comp. Res. Repository, 2023.
- [TSL+17] Yi-Hsuan Tsai, Xiaohui Shen, Zhe Lin, Kalyan Sunkavalli, Xin Lu, and Ming-Hsuan Yang. Deep image harmonization. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
- [WLW+24] Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Proc. Advances in Neural Inf. Process. Syst., 2024.
- [XYXW20] Weihao Xia, Yujiu Yang, Jing-Hao Xue, and Baoyuan Wu. Tedigan: Text-guided diverse face image generation and manipulation. arXiv: Comp. Res. Repository, 2020.
- [YGZ+23] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2023.
- [YLL+16] Chao Yang, Xin Lu, Zhe L. Lin, Eli Shechtman, Oliver Wang, and Hao Li. High-resolution image inpainting using multi-scale neural patch synthesis. Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
- [ZCG+18] Ruixiang Zhang, Tong Che, Zoubin Ghahramani, Yoshua Bengio, and Yangqiu Song. Metagan: an adversarial approach to few-shot learning. In Proc. Advances in Neural Inf. Process. Syst., 2018.
- [ZKSE15] Jun-Yan Zhu, Philipp Krahenbuhl, Eli Shechtman, and Alexei A Efros. Learning a discriminative model for the perception of realism in composite images. In Proc. IEEE Int. Conf. Comp. Vis., 2015.
- [ZPIE17] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proc. IEEE Int. Conf. Comp. Vis., 2017.
- [ZYW+23] Fangneng Zhan, Yingchen Yu, Rongliang Wu, Jiahui Zhang, Shijian Lu, Lingjie Liu, Adam Kortylewski, Christian Theobalt, and Eric Xing. Multimodal image synthesis and editing: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell., 2023.