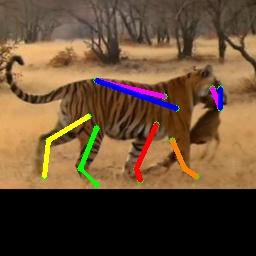
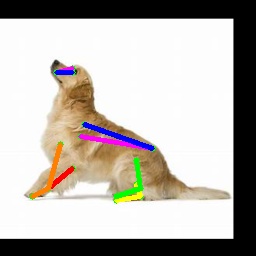
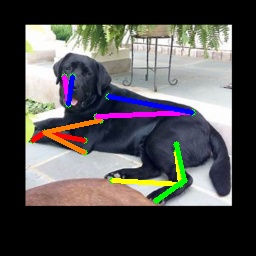
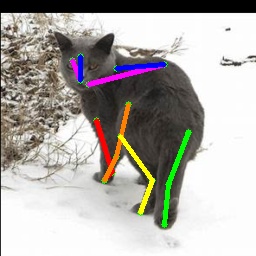
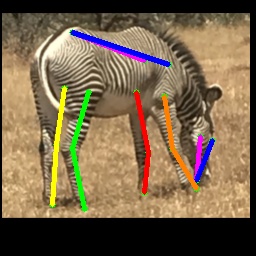
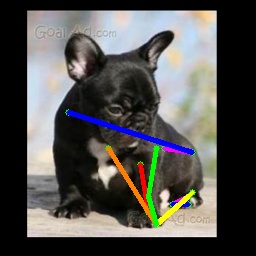
From Synthetic to Real: Unsupervised Domain Adaptation
for Animal Pose Estimation
Abstract
Animal pose estimation is an important field that has received increasing attention in the recent years. The main challenge for this task is the lack of labeled data. Existing works circumvent this problem with pseudo labels generated from data of other easily accessible domains such as synthetic data. However, these pseudo labels are noisy even with consistency check or confidence-based filtering due to the domain shift in the data. To solve this problem, we design a multi-scale domain adaptation module (MDAM) to reduce the domain gap between the synthetic and real data. We further introduce an online coarse-to-fine pseudo label updating strategy. Specifically, we propose a self-distillation module in an inner coarse-update loop and a mean-teacher in an outer fine-update loop to generate new pseudo labels that gradually replace the old ones. Consequently, our model is able to learn from the old pseudo labels at the early stage, and gradually switch to the new pseudo labels to prevent overfitting in the later stage. We evaluate our approach on the TigDog and VisDA 2019 datasets, where we outperform existing approaches by a large margin. We also demonstrate the generalization ability of our model by testing extensively on both unseen domains and unseen animal categories. Our code is available at the project website111https://github.com/chaneyddtt/UDA-Animal-Pose.
1 Introduction
Animal pose estimation has received increasing attention over the last few years because of many potential applications in zoology, biology and aquaculture. Despite the great success of applying deep neural networks to human pose estimation, the lack of well-labeled animal pose data makes it infeasible to directly leverage on the powerful deep learning approaches. Existing works overcome this problem by transferring knowledge from other more accessible domains such as synthetic animal data [26, 5, 49, 50, 51] or human data [6]. The advantage of synthetic data is that it is low cost and convenient to generate a large scale of data with accurate ground truth. Moreover, the domain gap between synthetic and real animals is more manageable than that between other domains such as human and animals. This is evident from the results of [6], where sufficient labeled data in the real animal domain is needed for the network to work despite the use of sophisticated domain adaptation techniques.
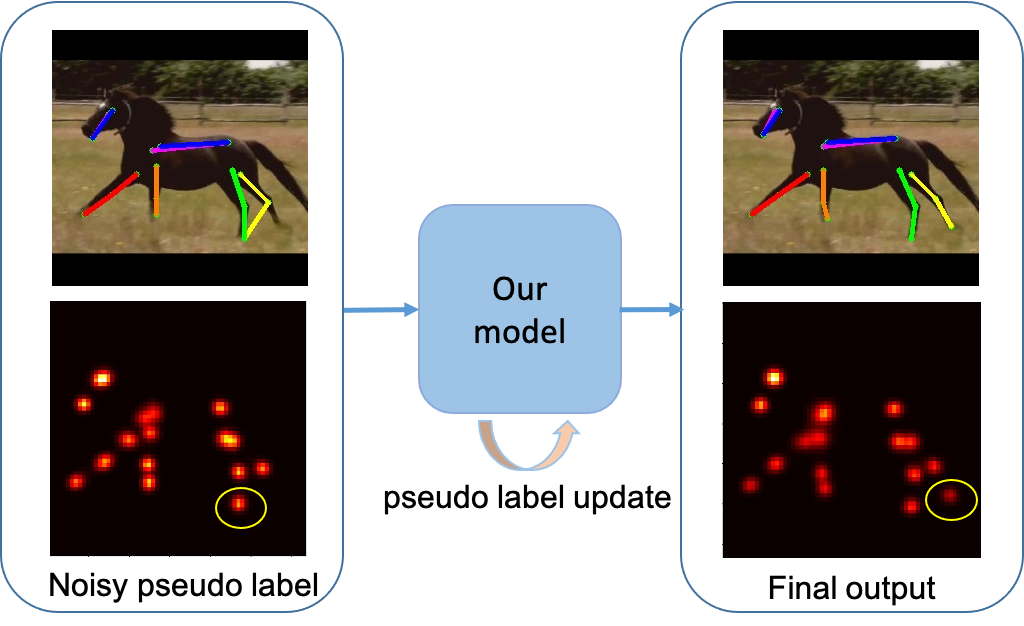
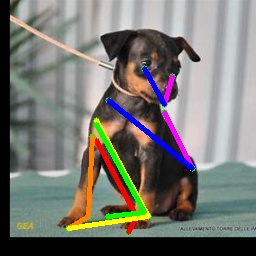
The domain gap between synthetic and real animals mainly comes from the differences in texture and background, and the limited pose variance of synthetic data. To solve the domain shift problem, existing works first generate pseudo labels with a model trained on synthetic data, and then gradually incorporate more pseudo labels into the training according to the confidence score. However, these pseudo labels are inaccurate even with refinement techniques such as confidence-based filtering [6] or geometry-based consistency check [26]. Fig. 1 shows an example where a model trained on synthetic animals gives wrong predictions (\egthe hind hoof) with high confidence (marked in yellow circle in the heatmap). This kind of noisy pseudo labels cannot be filtered out based on the confidence score and will lead to degraded performance when used naively for training.
In this paper, we propose a novel approach to learn from synthetic animal data. We design a multi-scale domain adaptation module (MDAM) to reduce the domain gap. Our MDAM consists of a pose estimation module and a domain classifier. We first train the pose estimation module with the synthetic data [26] to generate an initial set of pseudo labels for the real animal images. We then train our MDAM on the synthetic labels and the pseudo labels. However, the accuracy of MDAM is limited by the presence of noise in the pseudo labels. To alleviate this problem, we introduce an online coarse-to-fine pseudo label updating strategy. Specifically, we propose a self-distillation module in the inner coarse-update loop and a mean-teacher [34] in the outer fine-update loop to generate better pseudo labels that gradually replace the old noisy ones.
We design our pseudo label updating strategy according to the memorization effect [3, 45] of deep networks, which states that deep networks learn from clean samples at the early stage before eventually memorizing (\ieoverfits to) the noisy ones. To avoid the memorization effect, we rely more on the initial pseudo labels at the early stage when the self-distillation module and mean-teacher are still at their infancy in training. Our coarse-to-fine pseudo label updating strategy gradually replaces the noisy initial labels when the self-distillation module and mean-teacher gained enough competency to generate more reliable pseudo labels. Consequently, we are able to supervise our network with more accurate pseudo labels and prevent overfitting at the same time. As illustrated in Fig. 1, our model can successfully locate the joint (hind hoof on the right image) although the initial pseudo label is not accurate.
We validate our approach on the TigDog Dataset [10], where we outperform existing unsupervised domain adaptation techniques by a large margin. We also demonstrate the generalization capacity of our approach by directly testing on the Visual Domain Adaptation Challenge dataset (VisDA2019), the Zebra dataset [49] and the Animal-Pose dataset [6]. Experimental results show that our approach can generalize well to both unseen domains and unseen animal categories. Our main contributions are as follows:
-
•
We design an unsupervised domain adaptation pipeline for animal pose estimation, which consists of a multi-scale domain adaptation module, a self-distillation module and a mean-teacher network.
-
•
We propose an online coarse-to-fine pseudo label updating strategy to alleviate the negative effect of unreliable pseudo labels.
-
•
Our approach achieves state-of-the-art results on the TigDog dataset and the VisDA2019 dataset, and can also generalize well to unseen domains and unseen animal categories.
2 Related Work
Human Pose estimation.
Human pose estimation has been an active research field for decades. One of the most popular early approaches is the pictorial structure [9, 2, 32] which uses a tree structure to model the spatial relationships among body parts. These methods do not perform well in complex scenarios because of the limited representation capabilities. Recently, deep learning based approaches [31, 27, 8, 42, 38, 7, 41, 29] have achieved significant progress due to the availability of large scale training data such as the MPII dataset [1] and the COCO keypoint detection dataset [23]. Existing works can be divided into two categories. The first category [7, 41, 29] adopts a single stage backbone network, typically ResNet [15], to generate deep features, after which upsampling or deconvolution is applied to generate heatmaps with higher spatial resolution. The second category [27, 8, 42, 38] is based on a multi-stage architecture where the generated results from the previous stage are refined step by step. In this paper, we adopt the single stage approach as our basic structure so that we can directly apply domain adaptation to the output of the backbone network.
Animal Pose Estimation.
Animal pose estimation is relatively under-explored compared to human pose estimation mainly due to the lack of labeled data. To solve this problem, Mu et al.[26] use synthetic animal data generated from CAD models to train their model, which is then used to generate pseudo labels for the unlabeled real animal images. Subsequently, the generated pseudo labels are gradually incorporated into training based on three consistency check criteria. Cao et al.[6] propose a cross-domain adaptation scheme to learn a shared feature space between human and animal images such that their network can learn from existing human pose datasets. They also select pseudo labels into the training based on the confidence score. In contrast to [26] which does not need any labels for real animal images, [6] needs part of the real animal images to be labeled in their dataset to facilitate a successful transfer. Similar to [26], we focus on unsupervised domain adaptation from synthetic animal data. Instead of gradually incorporating pseudo labels into training, we conduct an online coarse-to-fine pseudo label update to alleviate the negative effect of noisy pseudo labels.
In addition, there are also several works focusing on 3D animal pose and shape estimation [51, 50, 49, 5, 19, 4]. [51] builds a statistical 3D shape model SMAL by learning from scans of toy animals. To recover more detailed 3D shape of animals, [50] regularizes the deformation of the mesh from SMAL to constrain the final shape. [49] trains a neural network on a digitally generated dataset to predict 3D pose, shape and texture for the SMAL model.
Unsupervised Domain Adaptation.
Unsupervised domain adaptation aims to learn a model from a labeled source domain which can perform well on an unlabeled target domain. One mainstream approach is based on adversarial learning [11, 16, 36, 39], where a feature extractor tries to learn domain-invariant features in order to fool a domain discriminator. The alignment with adversarial learning can facilitate the transfer of labels from the source to the target domain. Besides feature level alignment, other works also try to reduce the domain shift in the input [16] or output level [35, 43]. In this paper, we apply a domain classifier to the feature maps of multiple scales such that both global and local features can be aligned.
Learning from Noisy Data
Learning from noisy labels is an important research topic especially for the deep learning community. This is because deep learning algorithms rely heavily on large scale labeled training data that is costly to collect. To reduce the negative effect of noisy labels, some approaches focus on training noise robust models by designing robust losses [12, 37, 47] or by correcting the loss with a transition matrix [30, 13, 40]. Sample selection based approaches [25, 18, 14, 44] attempt to select possibly clean samples in each iteration for training. One of the most representative methods is Co-teaching [14, 44], which trains on all samples at the beginning and gradually drops the samples with large loss values. This small-loss trick , which is based on the memorization effect [3, 45] of deep networks, has also adopted by other works [18, 33] to select more reliable labels. Given the noisy pseudo labels, we also conduct sample selection similar to the Co-teaching. Moreover, We gradually update the pseudo labels with the knowledge from a self-distillation module and a teacher network.
3 Our Method
We propose an unsupervised domain adaptation approach for animal pose estimation. The labeled source domain consists of synthetic animal images and the corresponding pose labels generated from CAD models, and the unlabeled target domain consists of in-the-wild animal images without pose labels. The goal is to learn a pose estimation model that can adapt well to the unlabeled target domain. To this end, we design a student-teacher network as shown in Fig. 2. The student and teacher networks share the same architecture: a basic pose estimation module (PEM), a self-distillation module (SDM) and a domain classifier (DC). We first pretrain the PEM on and use it to generate pseudo labels for . However, those pseudo labels are noisy due to the domain gap between the synthetic and real images, and can hurt the performance when used naively in training. To alleviate this negative effect, we propose an online coarse-to-fine pseudo label updating strategy with the self-distillation module and teacher network.
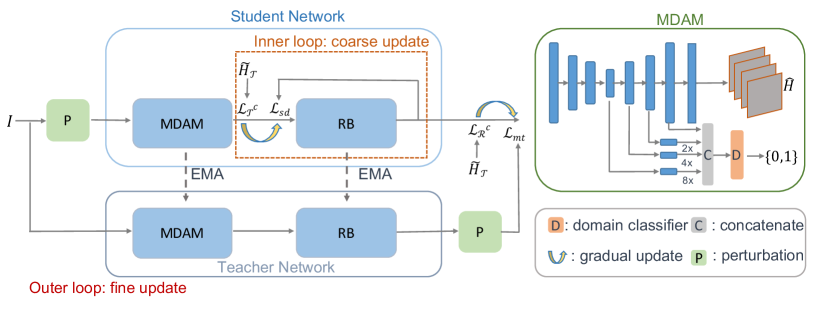
3.1 Multi-scale Domain Adaptation Module
Our MDAM consists of a pose estimation module and a domain classifier . The pose estimation module follows an encoder-decoder architecture, where the encoder is the feature extractor and the decoder is the pose estimator . Given a pair of images from the source and target domains, we feed them into the pose estimation module to get the corresponding feature maps and heatmaps :
| (1) |
Similar to human pose estimation [27], we define the animal pose estimation loss in the source domain as the mean-square error (MSE) between the estimated and ground truth heatmaps:
| (2) |
where , represents the ground truth heatmaps with resolution and represents the total number of joints.
We use the pseudo labels for the target domain since the ground truth for the target domain is not available:
| (3) |
Note that these pseudo labels and their corresponding confidence scores are generated from our pose estimation module pretrained on the source domain data following the training procedure from [26].
To bridge the domain gap between the source and target domains, we apply a domain classifer [11, 16, 36] to the output of the feature extractor . The domain classifier attempts to classify the real target data from the synthetic source data using a cross-entropy loss :
| (4) |
while the feature extractor tries to fool the domain classifier by maximize :
| (5) |
We use a gradient reversal layer [11] for optimization.
We apply the domain classifier to the feature maps at multiple scales given that both local (\ega small batch around a joint) and global information (\egthe relationship between different joints) are important for joint detection. More specifically, we concatenate the intermediate outputs of the pose estimator and feed them into the domain classifier, as shown in the right part of Fig. 2.
3.2 Coarse-to-Fine Pseudo Label Update
The pseudo labels we use in Eq. (3) are noisy although we filter the samples based on the consistency-check criteria described in [26]. To circumvent this problem, we propose the coarse-to-fine pseudo label updating strategy to gradually replace the noisy pseudo labels with more accurate ones. As shown Fig. 2, our coarse-to-fine pseudo label updating strategy consists of two nested loops.
Inner coarse-update loop:
As shown in Fig. 2, the inner loop consists of the self-distillation module: a refinement block(RB) and a self-feedback loop. The input to the refinement block is the output of MDAM , and we denote its output as . The output of MDAM is supervised by the output of the refinement block via the self-feedback loop with a self-distillation loss:
| (6) |
We also supervise the output of MDAM concurrently with the noisy pseudo labels , \ie
| (7) |
, and in contrast to Eq. 3, do not sum over , \ie is the loss term per joint. is the set of joint indices with a loss value smaller than the threshold , which dynamically decreases as the training proceeds. This means that we start the training with all the pseudo labels and gradually drop those with large loss values. The intuition is that the clean samples tend to exhibit smaller losses than noisy ones before the network eventually overfit to the noisy ones [3, 45]. On the other hand, we assign a gradually increasing weight to in the total loss. This results in a net effect of gradually replacing the initial noisy pseudo labels with better pseudo labels produced by the refinement block at the later stage of training.
Outer fine-update loop:
As shown in Fig. 2, the outer loop is a student-teacher architecture. The student network consists of the multi-scale domain adaptation module and the self-distillation module. The teacher network has an identical architecture with the student network with the exception of the self-feedback loop in the self-distillation module. Furthermore, we follow the mean-teacher [34] paradigm to update the teacher model with the exponential moving average (EMA) of the student model :
| (8) |
where denotes the training step and denotes a smoothing coefficient. The output of the teacher network is used to supervise the student network, \iethe output of the refinement block . We apply a random perturbation to the input of the student network, and we denote the output of the teacher network as . The random perturbation is concurrently applied to the output of the teacher network, \ie. We then enforce the self-consistency loss on the student-teacher network:
| (9) |
is generated from random image rotation, flipping, occlusion, and Gaussion noise. Note that we only apply perturbations that will affect the final output to the teacher network, \ierandom rotation and flipping. Similar to the self-distillation module, we also concurrently supervise the output of the refinement block with the noisy pseudo labels via the following loss function:
| (10) |
We use the dynamic threshold to gradually drop the large loss terms. Similar to the noisy pseudo label on MDAM loss in Eq. 7, does not sum over .
It is shown in [28] that the teacher network is able to provide more stable learning signal than the pseudo labels since it is a temporal ensemble of networks. Therefore, we also add a gradually increasing weight term to in the total loss. This means that the outputs of the teacher network are taken to be better pseudo labels to replace the old noisy ones at the later stage of training, and thus preventing overfitting to the noisy pseudo labels.
Remarks:
Note that we place the self-distillation module in the inner loop for coarse update since self-distillation is based on the self-feedback loop with a softer regulatory strength compared to the mean-teacher based on self-consistency. It is beneficial to do the softer self-distillation before the stronger outer loop fine updates by the mean-teacher in the nested loops. The softer regulations from self-distillation prevents the mean-teacher from making drastic replacement of the initial noisy pseudo labels too quickly in the training. Consequently, this allows the network to avoid the memorization effect [3, 45], and therefore benefit from the noisy pseudo labels at the early stage and then the better pseudo labels at the later stage of training.
3.3 MixUp Regularizer
We further adopt the recently proposed MixUp [46] to further enhance the robustness of our network to the noisy pseudo labels. Specifically, MixUp reduces the negative effect of noisy pseudo labels by combining pseudo labels with the ground truth labels. Given a pair of images from the source and target domains, and the corresponding ground truth and pseudo label heatmaps , we perform MixUp to construct virtual training examples by :
| (11) |
is the Beta distribution, where we set both hyperparameters to be . is the parameter to determine the weight of the MixUp from the source and target domains. and are the input image and label heatmap in the source domain after MixUp. We take the maximum value of such that is closer to than to . This is to ensure that the domain label for is unchanged after applying MixUp. We also generate virtual example for by simply changing the max(.,.) to the min(.,.) operator.
3.4 Optimization
The overall objective function to train our network can be expressed as:
| (12) |
where
is the fully supervised loss in the source domain (cf. Eq. 2) and represents the adversarial loss (cf. Eq. 5). consists of the two loss terms in the inner loop: 1) the self-distillation loss (cf. Eq. 6) and 2) noisy pseudo labels on MDAM loss (cf. Eq. 7). is the two loss terms in the outer loop: 1) mean-teacher loss (cf. Eq. 9) and 2) noisy pseudo labels on the refinement block loss (cf. Eq. 10). Furthermore, the domain classifier concurrently minimizes (cf. Eq. 4), and the adversarial training is implemented with the gradient reversal layer.
, , , , are the weights to balance all losses. As mentioned in the previous section, we gradually increase and from 0 to their maximum value at the first 10 epochs of training by using a sigmoid-shape function [34], where . At the same time, we also decrease the and at each epoch until to the minimum value. Note that and are responsible for balancing the losses, and play no role in removing the noisy pseudo labels in the training. The dynamic threshold in and is responsible for removing noisy pseudo labels. We determine using Algorithm 1, where it is dynamically set to the value of the smallest value of or . is the cut-off index, which we initialize to and gradually decrease it during training.
4 Experiments
We use Resnet [15] as our feature extractor , followed by several deconvolutional layers as the pose estimator . As in [7], the intermediate feature maps of the pose estimation module are upsampled and then concatenated. The output is fed into both the domain classifier and the refinement block. The domain classifier has a fully-convolutional architecture, which consists of six convolutional layers with leaky Relu as the activation function. The refinement block has one bottleneck block followed by one convolutional layer. We first pretrain the pose estimation module on the synthetic dataset for 100 epochs, and then use it to generate pseudo labels for real images. Both synthetic and real data are used to train the whole network for 80 epochs. The learning rate starts at 0.00025 and is decreased using the polynomial decay with power of 0.9 [35]. Our model is optimized with Adam [20] with default parameters in Pytorch. More training details are included in the supplementary materials.
4.1 Datasets
We train our network with images and pose annotations for horse and tiger from the Synthetic Animal dataset [26] and real images from the TigDog dataset[10], and test our model on the test split of the TigDog dataset. We test the generalization capacity of our model on the VisDA2019 dataset, which contains the same animal categories as the TigDog dataset. Moreover, we also test our model on unseen animal categories in the Zebra dataset [49] and the Animal-Pose dataset [6].
Synthetic Animal Dataset:
The dataset contains images for five animal categories, including horse, tiger, sheep hound and elephant, with 10000 images for each animal category. The texture of animals are randomly genrated from the COCO dataset or from the original CAD models.
TigDog Dataset:
The dataset provides keypoint annotations for horse and tiger, where the images are taken from YouTube (for horse) and National Geographic documentaries (for tiger). There are 19 keypoints in the dataset, including eyes, chin, shoulders, legs, hip and neck. We only use the images from this dataset for training and evaluate on 18 keypoints which does not include neck following [26].
VisDA2019 Dataset:
The dataset is designed for multi-source domain adaptation and semi-supervised domain adaptation on image classification task. There are in total six domains, including real, sketch, clipart, painting, infograph and quickdraw. [26] manually annotates the keypoints for horse and tiger from the sketch, painting and clipart domains. We use this dataset to test the generalization capacity of our approach to unseen domains.
Zebra and Animal-Pose Datasets:
The Zebra dataset contains images of Gravy’s zebra, which are collected in Kenya with pre-computed bounding boxes. The Animal-Pose dataset contains annotations for five animal categories: dog, cat, horse, sheep and cow. We use these two datasets to test the generalization capacity of our model on unseen animals from unseen domains.
| Horse Accuracy | Tiger Accuracy | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Eye | Chin | Shoulder | Hip | Elbow | Knee | Hooves | Mean | Eye | Chin | Shoulder | Hip | Elbow | Knee | Hooves | Mean | |
| Real | 79.04 | 89.71 | 71.38 | 91.78 | 82.85 | 80.80 | 72.76 | 78.98 | 96.77 | 93.68 | 65.90 | 94.99 | 67.64 | 80.25 | 81.72 | 81.99 |
| \hdashlineSyn | 46.08 | 53.86 | 20.46 | 32.53 | 20.20 | 24.20 | 17.45 | 25.33 | 23.45 | 27.88 | 14.26 | 52.99 | 17.32 | 16.27 | 19.29 | 21.17 |
| Cycgan [48] | 70.73 | 84.46 | 56.97 | 69.30 | 52.94 | 49.91 | 35.95 | 51.86 | 71.80 | 62.49 | 29.77 | 61.22 | 36.16 | 37.48 | 40.59 | 46.47 |
| BDL [22] | 74.37 | 86.53 | 64.43 | 75.65 | 63.04 | 60.18 | 51.96 | 62.33 | 77.46 | 65.28 | 36.23 | 62.33 | 35.81 | 45.95 | 54.39 | 52.26 |
| Cycada [16] | 67.57 | 84.77 | 56.92 | 76.75 | 55.47 | 48.72 | 43.08 | 55.57 | 75.17 | 69.64 | 35.04 | 65.41 | 38.40 | 42.89 | 48.90 | 51.48 |
| CC-SSL [26] | 84.60 | 90.26 | 69.69 | 85.89 | 68.58 | 68.73 | 61.33 | 70.77 | 96.75 | 90.46 | 44.84 | 77.61 | 55.82 | 42.85 | 64.55 | 64.14 |
| Ours | 91.05 | 93.37 | 77.35 | 80.67 | 73.63 | 81.83 | 73.67 | 79.50 | 97.01 | 91.18 | 46.63 | 78.08 | 50.86 | 61.54 | 70.84 | 67.76 |
4.2 Results on the TigDog Dataset
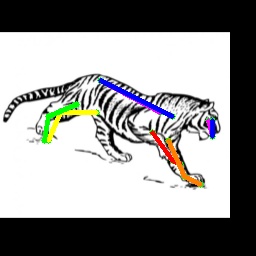
The Percentage of Correct Keypoints (PCK), which reports the percentage of detections that fall within a normalized distance, is used as the evaluation metric following [26]. We train a unified model on all animal categories instead of training one model for each animal category as in [26]. We believe that this is more practical in real setting. The PCK@0.05 accuracy of our approach and existing unsupervised domain adaptation approaches, which are taken from [26], are shown in Tab. 1. The ‘Real’ represents model trained with the real animal pose data and ‘Syn’ represents model trained only with synthetic data. As can be seen from Tab. 1, our model outperforms existing unsupervised domain techniques by a large margin. For horse category, our approach improves the state-of-the-art CC-SSL by 12.34% , and even outperform the model trained with real data. For tiger category, we also achieve the best performance among other UDA techniques with an improvement of 5.64% comparing to CC-SSL. We did not outperform the supervised model for tiger. The reason is that tigers generally live in forests, where occlusion by surrounding floras happens frequently. However, this kind of occlusion do not occur in the synthetic data, and thus making it very challenging for our model to adapt to the severe occlusion scenario. This also explains why all UDA methods in Tab. 1 show better performance for horse, which lives in the grasslands with lesser occlusions.
4.3 Generalization to Unseen Domains
We test the generalization capacity of our model by directly applying it to the unseen domains in the VisDA2019 dataset. The PCK@0.05 accuracy of our approach for horse and tiger under sketch, painting and clipart domains are shown in Tab. 2. Following [26], we evaluate our model under two settings: 1) The Visible Kpts Accuracy represents accuracy for only visible joints, and 2) the Full Keypoints Accuracy represents accuracy for all joints including self-occluded joints. Both CC-SSL and our approach outperform the model trained on real images, which demonstrates the importance of learning from other domains. Furthermore, our approach also outperforms CC-SSL by a large margin, especially for horse under the painting domain (80.05 \vs73.71, 78.42 \vs71.56) and for tiger under all domains. We also show some qualitative results for horse and tiger in each domain in the first row of Fig. 3.
| Horse | Tiger | |||||||||||
| Visible Kpts Accuracy | Full Kpts Accuracy | Visible Kpts Accuracy | Full Kpts Accuracy | |||||||||
| Sketch | Painting | Clipart | Sketch | Painting | Clipart | Sketch | Painting | Clipart | Sketch | Painting | Clipart | |
| Real | 65.37 | 64.45 | 64.43 | 61.28 | 58.19 | 60.49 | 48.10 | 61.48 | 53.36 | 46.23 | 53.14 | 50.92 |
| CC-SSL [26] | 72.29 | 73.71 | 73.47 | 70.31 | 71.56 | 72.24 | 53.34 | 55.78 | 59.34 | 52.64 | 48.42 | 54.66 |
| Ours | 76.65 | 80.05 | 75.45 | 73.74 | 78.42 | 73.61 | 60.85 | 61.54 | 65.12 | 59.58 | 56.09 | 60.66 |
4.4 Generalization to Unseen Animals from Unseen Domains
We further test the generalization capacity of our model in a more challenging scenario, where our model is directly applied to unseen animal categories from unseen domains. Note that our model is trained only with horse and tiger categories, and we test on both the Zebra dataset and the Animal-Pose dataset.
| Eye | Chin | Shoulder | Hip | Elbow | Knee | Hooves | Mean | |
|---|---|---|---|---|---|---|---|---|
| Zebra3D*[49] | - | - | - | - | - | - | - | 59.5 |
| \hdashlineCC-SSL [26] | 60.06 | 82.29 | 30.30 | 0 | 32.45 | 65.13 | 61.97 | 50.07 |
| Ours | 65.33 | 87.50 | 23.74 | 0 | 45.32 | 76.02 | 69.77 | 57.23 |
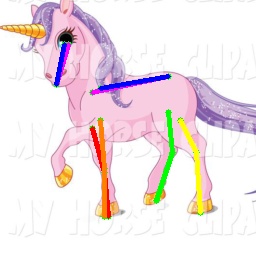
The Zebra dataset contains images of Gravy’s zebra collected in Kenya, and 28 keypoints are provided with each image . We only test on the 18 keypoints that are described in the TigDog dataset. The PCK@0.05 accuracy of our proposed approach is shown in Tab. 3. Zebra3D represents the approach used in [49] for 3D zebra pose estimation. This model is trained on a synthetic zebra dataset, which is generated from zebra models with appearance taking from real zebra images. We compare with their results without the post optimization process. The results of CC-SSL are obtained by running their public available checkpoint. As they train one model for each animal category, we use the one that gives better accuracy on this dataset. We can see that our approach outperforms CC-SSL with an improvement of 14.3%. Our approach also achieves comparable results to Zebra3D although our model has not been trained on the zebra category. Note that the accuracy of our approach and CC-SSL for joint hip is zero because the joint locations for hip are defined differently for the Synthetic Animal dataset (which is used to train our model) and the Zebra dataset. This is another reason why our approach and CC-SSL are not as good as Zebra3D.
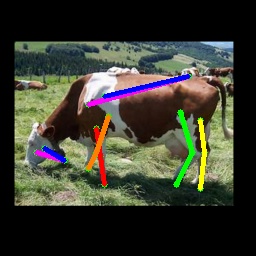
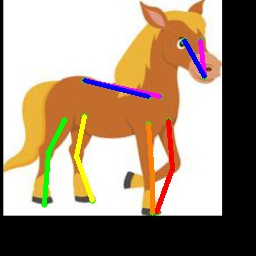
We also test on the 1000 images from the Animal-Pose dataset, with 200 images for each animal category. All animal categories in this dataset are unseen except for horse. We show our results in Tab. 4, where the results for CC-SSL are from the checkpoint that gives better average accuracy. We can see that our approach can generalize well to unseen animal categories such as sheep and cow, with an accuracy close to horse. The performance of our model for dog and cat is not as good as that for sheep and cow. We attribute this to two reasons: 1) The shape and size of dogs and cats are very differ from horses (or tigers), especially for cats with much smaller size. 2) Dog and cat are always in a sit or prone pose, which is not the case for horse or tiger living in the wild environment. We show some failed examples in Fig. 3 for illustration (the last three examples in the last row). We also show qualitative results for each animal category in Fig. 3. We can see that our model successfully estimates some challenging poses, such as the jumping horse, the lying down cat and the running dog.
| Horse | Dog | Cat | Sheep | Cow | Mean | |
|---|---|---|---|---|---|---|
| CC-SSL [26] | 65.35 | 30.27 | 15.05 | 52.39 | 63.71 | 47.60 |
| Ours | 72.84 | 42.48 | 27.65 | 59.51 | 71.31 | 56.77 |



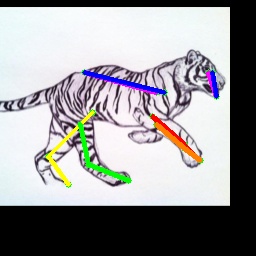

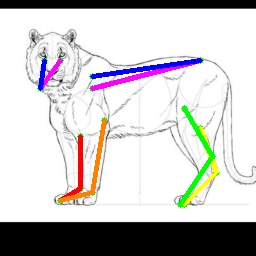

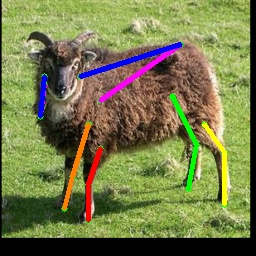

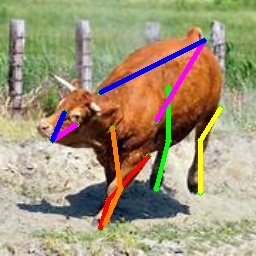







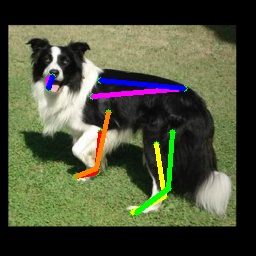
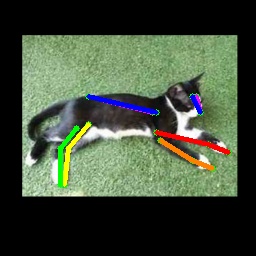
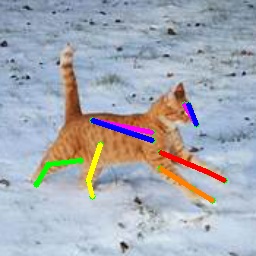

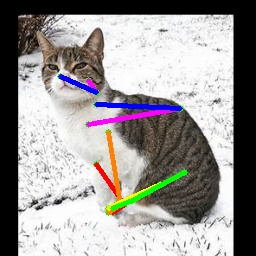

4.5 Ablation Study
We conduct ablation study on the TigDog dataset and the results are shown in Tab. 5. We use the multi-scale domain adaptation module as our backbone architecture and train it with only the pseudo labels (mdam+pl) or the supervision from the teacher network (mdam+mt). We also compare with CC-SSL[26] where the authors train the model and update the pseudo label in an iterative way. We can see that our backbone MDAM outperforms CC-SSL because we explicitly enforce the network to learn domain invariant features by applying a domain classifier. The MDAM trained with the teacher network is not as good as the one trained with pseudo labels, suggesting that the teacher network alone can not provide enough supervision. The performance is improved by adding the outer fine-update loop (mdam+mt+outlp), where we gradually update the pseudo labels with the teacher network. This demonstrates the importance of our progressive updating strategy, which helps the network learn from pseudo labels at the early stage and then from the more accurate teacher network. Moreover, the performance is further improved by adding the inner coarse-update loop (mdam+mt+outerlp+inlp). This shows the efficiency of updating the pseudo labels in a coarse-to-fine manner. Finally, our model is further enhanced with the MixUp regularizer (full model).
| Horse | Tiger | Mean | |
|---|---|---|---|
| CC-SSL [26] | 70.77 | 64.14 | 67.52 |
| mdam + pl | 74.42 | 64.90 | 69.69 |
| mdam + mt | 74.74 | 62.62 | 68.70 |
| mdam + mt + outlp | 78.38 | 67.15 | 72.70 |
| mdam + mt + outlp + inlp | 78.53 | 68.01 | 73.25 |
| full model | 79.50 | 67.76 | 73.66 |
5 Conclusion
We propose an approach for unsupervised domain adaptation on animal pose estimation. A multi-scale domain adaptation module is designed to transfer knowledge from the synthetic source domain to the real target domain. In addition, a coarse-to-fine pseudo label updating strategy is further introduced to gradually replace noisy pseudo labels with more accurate ones during training. As a result, we enable our network to benefit from the noisy pseudo labels at the early stage, and the updated labels at the later stage without suffering from the “memorization effect". Extensive experiments on several benchmark datasets show the effectiveness of our approach.
Acknowledgement
This work is supported by the Tier 2 grant MOE-T2EP20120-0011 from the Singapore Ministry of Education.
References
- [1] Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, and Bernt Schiele. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, pages 3686–3693, 2014.
- [2] Mykhaylo Andriluka, Stefan Roth, and Bernt Schiele. Pictorial structures revisited: People detection and articulated pose estimation. In 2009 IEEE conference on computer vision and pattern recognition, pages 1014–1021, 2009.
- [3] Devansh Arpit, Stanisław Jastrzębski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S. Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, and Simon Lacoste-Julien. A closer look at memorization in deep networks. In Proceedings of Machine Learning Research, pages 233–242, 2017.
- [4] Benjamin Biggs, Oliver Boyne, James Charles, Andrew Fitzgibbon, and Roberto Cipolla. Who left the dogs out?: 3D animal reconstruction with expectation maximization in the loop. In ECCV, 2020.
- [5] Benjamin Biggs, Thomas Roddick, Andrew Fitzgibbon, and Roberto Cipolla. Creatures great and smal: Recovering the shape and motion of animals from video. In Asian Conference on Computer Vision, pages 3–19, 2018.
- [6] Jinkun Cao, Hongyang Tang, Hao-Shu Fang, Xiaoyong Shen, Cewu Lu, and Yu-Wing Tai. Cross-domain adaptation for animal pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, pages 9498–9507, 2019.
- [7] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7103–7112, 2018.
- [8] Xiao Chu, Wei Yang, Wanli Ouyang, Cheng Ma, Alan L Yuille, and Xiaogang Wang. Multi-context attention for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1831–1840, 2017.
- [9] Matthias Dantone, Juergen Gall, Christian Leistner, and Luc Van Gool. Human pose estimation using body parts dependent joint regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3041–3048, 2013.
- [10] Luca Del Pero, Susanna Ricco, Rahul Sukthankar, and Vittorio Ferrari. Articulated motion discovery using pairs of trajectories. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2151–2160, 2015.
- [11] Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. In International conference on machine learning, pages 1180–1189, 2015.
- [12] Aritra Ghosh, Himanshu Kumar, and PS Sastry. Robust loss functions under label noise for deep neural networks. arXiv preprint arXiv:1712.09482, 2017.
- [13] Jacob Goldberger and Ehud Ben-Reuven. Training deep neural-networks using a noise adaptation layer. In International Conference on Learning Representations, 2017.
- [14] Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Advances in neural information processing systems, pages 8527–8537, 2018.
- [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [16] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In International conference on machine learning, pages 1989–1998, 2018.
- [17] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Proceedings of Machine Learning Research, pages 448–456, 2015.
- [18] Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In International Conference on Machine Learning, pages 2304–2313, 2018.
- [19] Angjoo Kanazawa, Shahar Kovalsky, Ronen Basri, and David Jacobs. Learning 3d deformation of animals from 2d images. In Computer Graphics Forum, pages 365–374, 2016.
- [20] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [21] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, pages 1097–1105, 2012.
- [22] Yunsheng Li, Lu Yuan, and Nuno Vasconcelos. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6936–6945, 2019.
- [23] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755, 2014.
- [24] Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. Rectifier nonlinearities improve neural network acoustic models. In Proc. icml, volume 30, page 3, 2013.
- [25] Eran Malach and Shai Shalev-Shwartz. Decoupling" when to update" from" how to update". In Advances in Neural Information Processing Systems, pages 960–970, 2017.
- [26] Jiteng Mu, Weichao Qiu, Gregory D Hager, and Alan L Yuille. Learning from synthetic animals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12386–12395, 2020.
- [27] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European conference on computer vision, pages 483–499, 2016.
- [28] Duc Tam Nguyen, Chaithanya Kumar Mummadi, Thi Phuong Nhung Ngo, Thi Hoai Phuong Nguyen, Laura Beggel, and Thomas Brox. Self: Learning to filter noisy labels with self-ensembling. 2020.
- [29] George Papandreou, Tyler Zhu, Nori Kanazawa, Alexander Toshev, Jonathan Tompson, Chris Bregler, and Kevin Murphy. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4903–4911, 2017.
- [30] Giorgio Patrini, Alessandro Rozza, Aditya Krishna Menon, Richard Nock, and Lizhen Qu. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1944–1952, 2017.
- [31] Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, Peter V Gehler, and Bernt Schiele. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4929–4937, 2016.
- [32] Benjamin Sapp, Chris Jordan, and Ben Taskar. Adaptive pose priors for pictorial structures. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 422–429, 2010.
- [33] Hwanjun Song, Minseok Kim, and Jae-Gil Lee. Selfie: Refurbishing unclean samples for robust deep learning. In International Conference on Machine Learning, pages 5907–5915, 2019.
- [34] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems, pages 1195–1204, 2017.
- [35] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7472–7481, 2018.
- [36] Riccardo Volpi, Pietro Morerio, Silvio Savarese, and Vittorio Murino. Adversarial feature augmentation for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5495–5504, 2018.
- [37] Yisen Wang, Xingjun Ma, Zaiyi Chen, Yuan Luo, Jinfeng Yi, and James Bailey. Symmetric cross entropy for robust learning with noisy labels. In Proceedings of the IEEE International Conference on Computer Vision, pages 322–330, 2019.
- [38] Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 4724–4732, 2016.
- [39] Yuan Wu, Diana Inkpen, and Ahmed El-Roby. Dual mixup regularized learning for adversarial domain adaptation. In European Conference on Computer Vision, pages 540–555, 2020.
- [40] Xiaobo Xia, Tongliang Liu, Nannan Wang, Bo Han, Chen Gong, Gang Niu, and Masashi Sugiyama. Are anchor points really indispensable in label-noise learning? In Advances in Neural Information Processing Systems, pages 6838–6849, 2019.
- [41] Bin Xiao, Haiping Wu, and Yichen Wei. Simple baselines for human pose estimation and tracking. In Proceedings of the European conference on computer vision (ECCV), pages 466–481, 2018.
- [42] Wei Yang, Shuang Li, Wanli Ouyang, Hongsheng Li, and Xiaogang Wang. Learning feature pyramids for human pose estimation. In proceedings of the IEEE international conference on computer vision, pages 1281–1290, 2017.
- [43] Wei Yang, Wanli Ouyang, Xiaolong Wang, Jimmy Ren, Hongsheng Li, and Xiaogang Wang. 3d human pose estimation in the wild by adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5255–5264, 2018.
- [44] Xingrui Yu, Bo Han, Jiangchao Yao, Gang Niu, Ivor Tsang, and Masashi Sugiyama. How does disagreement help generalization against label corruption? In International Conference on Machine Learning, pages 7164–7173, 2019.
- [45] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. In International Conference on Learning Representations, 2017.
- [46] Hongyi Zhang, M. Cissé, Yann Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. 2018.
- [47] Zhilu Zhang and Mert Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. In Advances in neural information processing systems, pages 8778–8788, 2018.
- [48] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 2223–2232, 2017.
- [49] Silvia Zuffi, Angjoo Kanazawa, Tanya Berger-Wolf, and Michael Black. Three-d safari: Learning to estimate zebra pose, shape, and texture from images “in the wild”. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 5358–5367, 2019.
- [50] Silvia Zuffi, Angjoo Kanazawa, and Michael J Black. Lions and tigers and bears: Capturing non-rigid, 3d, articulated shape from images. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 3955–3963, 2018.
- [51] Silvia Zuffi, Angjoo Kanazawa, David W. Jacobs, and Michael J. Black. 3d menagerie: Modeling the 3d shape and pose of animals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
From Synthetic to Real: Unsupervised Domain Adaptation
for Animal Pose Estimation
(Supplementary Material)
Chen Li Gim Hee Lee
Department of Computer Science, National University of Singapore
{lic, gimhee.lee}@comp.nus.edu.sg
Implementation details.
We train our network in two stages. We first use the synthetic data to pretrain the pose estimation module, which is used to generate pseudo labels for the second stage. The model is trained for 100 epochs with a learning rate of 0.00025, which decays twice at 60 and 90 epochs respectively. The pseudo labels and the corresponding confidence scores are generated in the same way as in [26]. We then use both the synthetic data and pseudo labels to train our full model. Note that we filter out noisy samples with low confidence instead of using all pseudo labels. and increase gradually from 0 to 90 in the first 10 epochs of training. On the other hand, and decrease gradually from 15 to 8 in the first 15 epochs. We also remove samples with large loss values at the same time. The cut-off index in Algorithm 1 in our main paper is set to 18 (\iethe number of joints) at the beginning, and then decreases by one after each epoch until it reaches the minimum value 9. We apply random flip, rotation (-45∘ - 45∘), scale (0.6 - 1.4), noise (-0.2 - 0.2), and random occlusion to the input image as data augmentation.
Analysis on hyperparameters.
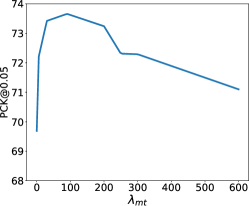
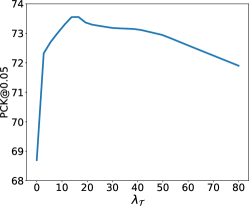
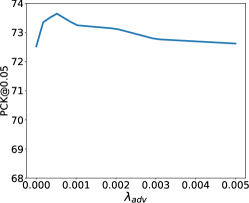
We conduct sensitivity analysis on the hyperparameters we used in the overall objective function (\cfEq. 12). Note that We set and since they are counterparts in the inner and outer loops, respectively. Hence, we only need to tune three weight terms instead of five. We perform analysis over a range of hyperparameters: , and on the TigDog dataset. As shown in Fig. 2, our model shows: 1) performance of initial increase and then flattened at before finally decreasing performance. 2) Initial increase and then flattened at before finally decreasing performance. 3) Initial increase and then flattened at before finally decreasing performance. We select the best performing , and for all our experiments.
The role of the teacher network.
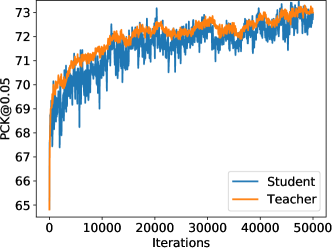
The role of the teacher network is to provide more stable training signal for the student network. To verify this, we show the accuracy of the student and teacher network over 50,000 iterations of training in Fig. 1. We can see that the accuracy of the teacher network improves fast in the first 12,000 iterations and then gradually slows down. This means that the quality of the pseudo labels generated by the teacher network is gradually improved as training proceeds. Moreover, the teacher network is more stable compared to the student network, especially at the beginning of the training. We can also observe from Fig. 1 that the student network gradually becomes stable as the more and more pseudo labels are updated by the teacher network.
Baseline using just synthetic horse or tiger.
We train one model for all animal categories instead of training one model for each animal category as in [26] in our main paper. To verify that our improved results does not come from the combination of data, we also train one model for each animal category and compare with the model trained with all animal categories. The comparative results are 77.06 (trained only on horse) vs 79.50 (trained on both horse & tiger) for horse and 69.05 (trained only on tiger) vs 67.76 (trained on both horse & tiger) for tiger. This ablation study shows that our model gives comparable average accuracy when trained on all categories or a single category.
Architecture for the domain classifier.
The domain classifier has a fully-convolutional architecture. Specifically, there are six convolutional layers, with kernel size of and stride of 2 for the first five layers, and with kernel size of and stride of 1 for the last layer. The number of channels is and each convolutional layer is followed by a leaky Relu [24] except for the last layer.
Architecture for the pose estimator.
We utilize the Resnet50 to extract the feature maps, which are fed into a pose estimator to generate the output heatmaps. The pose estimator consists of one convolutional layer, followed by three deconvolutional layers, and another convolutional layer. The first convolutional layer has channel size of 256. Each deconvolutional layer has filters, with kernel size of and stride of 2. An convolutional layer with channel size of is added at last to generate heatmaps for all joints. Batch normalization [17] and Relu activation [21] are applied after each layer except for the last layer.
Architecture for the refinement block.
The input of the refinement block is the concatenation of intermediate feature maps of the pose estimator. The feature maps are fed into a bottleneck block followed by a convolutional layer to generate the final outputs.
Qualitative results.
We show more qualitative results for the TigDog, Animal-Pose, VisDA2019 and Zebra datasets in Fig. 3. Our model trained on the synthetic dataset is able to generalize well to the in-the-wild images in the TigDog dataset (the first row). Moreover, our model can also generalize well to the unseen domains in the VisDA2019 dataset (the fourth to the fifth row) and the unseen animal categories in the Animal-Pose dataset (the second to the third row) and the Zebra dataset (the first three images in the last row). We also show failure cases in the last three images, where there are severe self-occlusions. More qualitative results for both seen and unseen categories are included in our video.