From Threat Reports to Continuous Threat Intelligence: A Comparison of Attack Technique Extraction Methods from Textual Artifacts
Abstract
The cyberthreat landscape is continuously evolving. Hence, continuous monitoring and sharing of threat intelligence have become a priority for organizations. Threat reports, published by cybersecurity vendors, contain detailed descriptions of attack Tactics, Techniques, and Procedures (TTP) written in an unstructured text format. Extracting TTP from these reports aids cybersecurity practitioners and researchers learn and adapt to evolving attacks and in planning threat mitigation. Researchers have proposed TTP extraction methods in the literature, however, not all of these proposed methods are compared to one another or to a baseline. The goal of this study is to aid cybersecurity researchers and practitioners choose attack technique extraction methods for monitoring and sharing threat intelligence by comparing the underlying methods from the TTP extraction studies in the literature. In this work, we identify ten existing TTP extraction studies from the literature and implement five methods from the ten studies. We find two methods, based on Term Frequency-Inverse Document Frequency(TFIDF) and Latent Semantic Indexing (LSI), outperform the other three methods with a F1 score of 84% and 83%, respectively. We observe the performance of all methods in F1 score drops in the case of increasing the class labels exponentially. We also implement and evaluate an oversampling strategy to mitigate class imbalance issues. Furthermore, oversampling improves the classification performance of TTP extraction. We provide recommendations from our findings for future cybersecurity researchers, such as the construction of a benchmark dataset from a large corpus; and the selection of textual features of TTP. Our work, along with the dataset and implementation source code, can work as a baseline for cybersecurity researchers to test and compare the performance of future TTP extraction methods.
1 Introduction
Information technology (IT) systems have been gaining continuous attention from threat actors with financial motives [19] and organized backing (i.e., state sponsored [26]). For example, in 2021, Sonatype reported that software supply chain attacks increased by 650% in 2020 from the previous year [40]. Moreover, a cyberattack on the Colonial pipeline [46], JBS [31] and Ireland health services [27] show that threat actors can destabilize millions of people’s lives by fuel price surge, food supply shortage, and disruption in healthcare services. Thwarting cyberattacks has become more complicated as the threat landscape evolves rapidly. Hence, continuous monitoring and sharing of threat intelligence has become a priority, as emphasized in Section 2(iv) of the US Executive Order 14028: Improving the Nation’s cybersecurity: “service providers share cyber threat and incident information with agencies, doing so, where possible, in industry-recognized formats for incident response and remediation.“ [18].
Threat reports, published by cybersecurity vendors and researchers, contain detailed descriptions on how malicious actors utilize specific tactics, relevant techniques, and describe procedures for performing the attack - known as Tactics, Techniques, Procedures (TTP) (see Section 2.2) [44, 42, 24]) - to launch cyberattacks. Consider a threat report from FireEye describing the attack procedures of the Solarwinds supply chain attack [7] in Example 1, where we show the attackers’ actions in bold text. One of the observed (mentioned in the report) TTP is T1518.001: Security Software Discovery which allows an attacker to bypass the security defense by discovering security software running in the system [23]. The rise in cyberattack incidents with evolving attack techniques results in a growing number and volume of threat reports. Extracting the TTP from threat reports can help cybersecurity practitioners and researchers with cyberattack characterization, detection, and mitigation [14] from the past knowledge of cyberattacks. Analyzing TTP also helps cybersecurity practitioners in continuous monitoring and sharing of threat intelligence. For example, organizations can learn how to adapt to the evolution of cyberattacks. Cybersecurity red and blue teams also benefit in threat hunting by threat intelligence sharing [44], attack profiling [29], and forecasting [37].
Threat reports contain a large amount of text and manually extracting TTP is error-prone and inefficient [14]. Cybersecurity researchers have proposed automated extraction of TTP from threat reports (e.g. [34, 14, 15, 28, 5, 29]). Moreover, the MITRE [2] organization uses an open-source tool [3] for finding TTP from threat reports. These TTP extraction work use natural language processing (NLP) along with supervised and unsupervised machine learning (ML) techniques to classify texts to the corresponding TTPs. However, no comparison among this existing work has been conducted, and the research has not involved an established ground truth dataset [34], highlighting the need for a comparison of underlying methods of existing TTP extraction work. A comparative study among these methods would provide cybersecurity researchers and practitioners a baseline for choosing the best method for TTP extraction, finding room for improvement.
Rahman et al. systematically surveyed the literature and obtained ten TTP extraction studies [34]. None of these studies compared their work with a common baseline and only two of these studies [5, 15] compared their results with one other. In our work, we first select five studies [29, 28, 14, 5, 21] from the ten based on inclusion criteria (Section 3.2) and implement the underlying methods of the five selected studies. We then compare the performance of classifying text (i.e., attack procedure description) to the corresponding attack techniques. Moreover, as the number of attack techniques are growing due to the evolution of attack techniques, we also investigate (i) how the methods perform given that the dataset has class imbalance problems (existence of majority and minority classes); and (ii) how the methods perform when we increase the classification labels (labels are the name of techniques that would be classified from attack procedure descriptions).
The goal of this study is to aid cybersecurity researchers and practitioners choose attack technique extraction methods for monitoring and sharing of threat intelligence by comparing underlying method from the TTP extraction studies in the literature. We investigate these following research questions (RQs):
- RQ1: Classification performance
-
How do the TTP extraction methods perform in classifying textual descriptions of attack procedures to attack techniques across different classifiers?
- RQ2: Effect of class imbalance mitigation
-
What is the effect on the performance of the compared TTP extraction methods when oversampling is applied to mitigate class imbalance?
- RQ3: Effect of increase in class labels
-
How do the TTP extraction methods perform when the number of class labels is increased exponentially?
We implement the underlying methods of these five studies: [29, 28, 14, 5, 21]. We construct a pipeline for comparing the methods on the same machine learning workflow. We run the comparison utilizing a dataset constructed from the MITRE ATT&CK framework [24]. We also run the methods on oversampled data to investigate how the effect of class imbalance can be mitigated. Finally, we use six different multiclass classification settings ( where denotes the number of class labels) to investigate how the methods perform in classifying a large number of available TTP. We list our contributions below.
-
•
A comparative study of the five TTP extraction methods from the literature. This article, to the best of our knowledge, is the first study to conduct direct comparisons of the TTP extraction methods.
-
•
A sensitivity analysis on the effect of using oversampling and multiclass classification on the compared method. Our work investigates these two important aspects of classification as the number of techniques is more than hundred and the technique enumeration is being updated gradually resulting in majority and minority classes.
-
•
A pipeline for conducting the comparison settings which ensure the methods are executed in the same machine learning workflow. We also make our dataset and implementation source code available at [4] for future researchers. The pipeline along with the dataset and implementation sources serve as a baseline for cybersecurity researchers to test and compare the performance of the future TTP extraction method.
-
•
We provide recommendations on how the methods can be improved for better extraction performance.
The rest of the article is organized as follows. In Section 2, we discuss a few key concepts relevant to this study. In Section 3 and 4, we discuss our process to identify the selected studies for comparison. In Section 5, we discuss our methodology for designing and running the experiment. In Section 6 and 7, we report and discuss our observations from the experiment. In Section 9 and 8, we identify several limitations to our work followed by highlighting potential future research paths. In Section 10, we discuss related work in the literature followed by concluding the article in Section 11. We report a few supplementary information in the Appendix.
2 Key Concepts
In this section, we discuss several key concepts relevant in the context of our study.
2.1 Threat Intelligence:
Threat intelligence - also known as Cyberthreat intelligence (CTI) - is defined as ‘evidence-based knowledge, including context, mechanisms, indicators, implications, and actionable advice about an existing or emerging menace or hazard to assets that can be used to inform decisions regarding the subject’s response to that menace or hazard‘ [22]. Threat intelligence can be used to forecast, prevent and defend attacks.
2.2 Tactics, techniques and procedures (TTP):
Tactics are high level goals of an attacker, whereas techniques are lower level descriptions of the execution of the attack in the context of a given tactic [24, 44]. Procedures are the lowest level step by step execution of an attack being performed. TTP can be used to profile or analyze the lifecycle of an attack on a targeted system. For example, privilege escalation is a tactic for gaining elevated permission on a system. One technique for privilege escalation can be access token manipulation [24]. An attacker can gain elevated privilege in a system by tampering the access token to bypass the access control mechanism. An example procedure is an attacker manipulating an access token by using Metasploit’s named-pipe impersonation [24].
2.3 ATT&CK:
The MITRE [2] organization developed ATT&CK [24], a framework derived from real world observations of adversarial TTPs deployed by attack groups. ATT&CK contains an enumeration of high level attack stages known as tactics. Each tactic has an enumeration of corresponding techniques, and each technique has associated procedure description(s). Procedures are written in unstructured text and describe how a particular technique has been used by the attacker to gain an objective of the corresponding tactic to launch a cyberattack. ATT&CK was first introduced in 2013 to model the lifecycle and common TTP utilized by threat actors in launching APT (advanced persistent threat) attacks. In our research, we utilized Version 9 of the ATT&CK framework which consists of 14 Tactics, 170 Techniques, and 8,104 procedures.
3 Selection of TTP extraction methods
In this section, we discuss the methodology for selecting and comparing the TTP extraction methods in five studies [29, 28, 14, 5, 21] found in literature.
3.1 Finding TTP extraction work from the literature:
Rahman et al. [34] systematically collected automated threat intelligence extraction-related studies from scholarly databases and found 64 relevant studies. From these, the first author of this paper identified ten studies that extracted TTP from the text automatically using NLP and ML techniques. We select these ten work as potential candidates for our comparison study. We refer to these ten works as the candidate set. In the Appendix, Table 7, we list the bibliographic information of the candidate set.
| Id | Dataset type | Dataset source | # threat reports | NLP/ML techniques and features |
| * | Data breach incident reports | Github APTnotes [6] and custom search engine [1] | 327 | Latent Semantic Indexing(LSI) |
| * | APT attack reports | Github APTnotes | 445 | Dependency parsing, TFIDF of independent noun phrases |
| APT attack reports | Github APTnotes | 50 | Named entity recognition(NER) | |
| * | APT attack reports | Github APTnotes | 18,257 | TFIDF |
| Malware report | Github APTnotes, MicrosoftS/Adobe Security Bulletins, National Vulnerability Database description | 474 | NER, Cybersecurity ontology | |
| * | APT attack reports | Attack technique dataset (Source not reported) | 200 | LSI |
| Computer security literature and Android developer documentation | IEEE S&P, CCS, USENIX articles, Android API [12] | 1,068 | Dependency parsing | |
| - | - | 18 | NER, Dependency parsing, Basilisk | |
| * | Malware report | Symantec threat reports | 17,000 | Dependency parsing, BM25 |
| Malware report | Symantec threat reports | 2,200 | Dependency parsing, BM25 | |
| Id with (*) symbol denotes that the study is selected for comparison | ||||
3.2 Inclusion criteria for TTP extraction work:
A comprehensive comparison of TTP extraction methods is not a straightforward task. One difficulty in setting up the study is to find a labelled and universally agreed upon dataset. Moreover, constructing such a dataset is inherently challenging as the set of TTP is subject to change with evolution of the manner of attack. Another challenge is to determine whether the extraction should be performed on the sentence level or paragraph level. Finally, in the candidate set, TTP extraction methods were designed targeting different use cases, such as transforming the extracted TTP to structured threat intelligence formats [14] or building a knowledge graph [32]. Hence, not every study in the candidate set is able to extract all known TTPs. Hence, we define the following inclusion criteria:
-
1.
All methods selected for the comparison can work on the same textual artifacts
-
2.
Besides labelling the text to corresponding technique, no other manual labelling is required for comparison
-
3.
All methods can be compared using the same set of technique names which will be used as labels for classification tasks.
3.3 Filtering the TTP extraction work for comparison:
In Table 1, we report the dataset type, dataset source, and relevant NLP/ML techniques used for our candidate set. Next, we report how we filter the candidate set.
-
•
We drop , , and because Named Entity Recognition (NER) labelling of words from the text is required (violates filtering criteria [2]).
-
•
We drop because this work (a) uses Android development documentation (violates filtering criteria [1]), and (b) extracts the features for Android-specific malware only (violates filtering criteria [3]).
-
•
We drop because the work requires additional manual work on identifying relevant verbs and objects from Wikipedia articles on computing and cybersecurity related concepts (violates filtering criteria [2]).
Finally, we keep the remaining work for our comparison study: , , , , and . and utilized Latent Semantic Indexing (LSI) [20]; and utilized Term frequency - inverse document frequency (TFIDF); and utilized dependency parsing and BM25.
4 Overview of the selected studies for comparison
We report a brief overview of the studies selected for comparison followed by observed similarities and dissimilarities.
-
The authors used the data breach incident reports produced by cybersecurity vendors and then searched high level attack patterns from those reports. The authors used the ATT&CK framework for the common vocabulary of attack pattern names. They used LSI for searching the attack pattern names from the texts. Finally, they correlated these searched attack patterns with responsible APT actor groups.
-
The authors used APT attack related articles as dataset and MITRE ATT&CK framework for the common vocabulary of TTP. Then they extracted independent noun phrases from the corpus that appear in the corpus at least once without being part of a larger noun phrase. Then they computed TFIDF vectors of these noun phrases. Finally, using these vectors, they retrieved the most relevant set of articles associated with specific TTP keywords such as data breach, privilege escalation.
-
The authors used APT attack-related articles and Symantec threat reports as dataset and MITRE ATT&CK framework for the common vocabulary of TTP. They computed TFIDF vectors of the articles and then applied three bias correction techniques named kernel mean matching [13], Kullback-Liebler importance estimation procedure [43], and relative density ratio estimation. Finally, they used SVM classifier on bias corrected data.
-
The authors used advanced persistent threat (APT) attack related online articles as dataset and MITRE ATT&CK framework for the common vocabulary of TTP. They first computed the TFIDF vectors of the description of TTP. Then they applied LSI on articles for retrieving a set of topics. After that, for each article, the authors computed the cosine similarity score between TFIDF vectors of each TTP and the retrieved topics. Then they used these computed similarity scores as features. Finally, the authors used two multi-label classification techniques named Binary Relevance and Label Powerset [36, 41].
-
The authors used Symantec threat reports as dataset and MITRE ATT&CK framework for the common vocabulary of TTP. First, they created an ontology of threat actions from the description of ATT&CK. Then they extracted threat actions as (subject, verb, object) tuples from each sentence in the corpus. Finally, they computed BM25 score for threat actions against their created ontology and mapped the extracted threat actions to the corresponding entities in their ontology and converted the reports to the Structured Threat Intelligence Exchange (STIX [30]) format.
From the above description, we see the following similarities among the articles:
-
•
Threat reports are used as dataset,
-
•
The MITRE ATT&CK framework is used as the common vocabulary of TTP
-
•
NLP techniques (such as TFIDF, LSI, BM25) are used for feature extraction or computation from text.
-
•
The extracted or computed textual features are fed to machine learners.
However, we also observed the following dissimilarities among the studies as well:
-
•
The purpose of the TTP extraction is different. For example, correlated extracted TTP with APT actor groups while constructed STIX threat intelligence format from unstructured threat reports
-
•
Not all studies used classification techniques, such as ,
-
•
Bias correction on dataset is only applied in
-
•
Only one study () modelled their approach as multi label classification problem
5 Comparison Study
In this section, we provide our research steps for the comparison study. We report how we design and utilize a five-step TTP extraction pipeline (see Section 5.3) for running the comparison study. We construct our dataset from MITRE ATT&CK framework. Next, we apply pre-processing to the corpus. After that, we implement the underlying method of the five selected studies. Finally, we feed the extracted/computed features to classifiers with oversampling (see Section 5.7) and multiclass classification (see Section 5.9) settings.
5.1 Comparison scope
In Section 4, we report similarities and dissimilarities among the articles we choose for comparison and as a result, we define the following scope of the comparison.
-
•
We mention in Section 2 that ATT&CK contains the mapping between (a) tactics and techniques, and (b) techniques and textual descriptions of procedures. Classifying the procedure description to the corresponding technique would find the corresponding tactics as well as ATT&CK provides the tactics-technique mapping as part of the framework. Hence, for TTP extraction, we choose to classify techniques from a given text (which are procedure descriptions), which will also give us the associated tactics from the tactic-technique mapping.
-
•
We assume that a piece of text (i.e., sentence(s)) is related to one technique. Hence, we will use classifiers to classify a piece of text to its corresponding technique.
-
•
All methods will be compared using the same dataset, class labelling, same set of classifiers
-
•
All the methods will be compared in the same machine learning pipeline (See Section 5.3)
As we will use the same dataset, labels, and classifiers, hence, we will only compare the NLP methods for extracting textual features that we will feed towards classifiers.
-
1.
For , we will use LSI vectors as features. We will refer this method as M:LSI.
-
2.
For , we will use TFIDF of unique noun phrases (See Section 4) as features. We will refer this method as M:TFIDF-NP.
-
3.
For , we will use TFIDF vectors of the corpus as features. We will refer this method as M:TFIDF.
-
4.
For , we will use the cosine similarity score as features. The score is computed from TFIDF vector of each technique description and vectors of topics generated by LSI. We will refer this method as M:LSI-Co.
-
5.
For , we will use BM25 score of (subject, verb, object) tuples of TTP description and corpus texts as features. We will refer this method as M:BM25.
5.2 Metrics for performance measurement
We use the following metrics for measuring the performance of TTP extraction methods we are comparing.
- Precision
-
the ratio of true positives and the sum of true positives and false positives indicating the relevance of the performed classification. The higher the precision score is, the better the classifier is in finding relevant examples from a given class.
- Recall
-
the ratio of true positives and the sum of true positives and false negatives indicating the completeness of the performed classification. The higher the recall score is, the better the classifier is in finding all examples from a given class.
- F1 score
-
The harmonic mean of precision and recall indicating how good the classification task in terms of both precision and recall. The higher the F1 score is, the better the classifier is in both classifying relevant examples to correct classes and classifying all examples correctly belonging to the same class.
- AUC score
-
the area under the curve of Receiver Operating Characteristics indicating the ability of a classifier to separate the true positive and true negative examples. Higher AUC score indicates better performance in classification. AUC score equalling denotes that the classifier is as good as a random guess only, less than means worse than a random guess. AUC closer to is desirable and a higher AUC score indicates the classifier is able to choose a randomly selected true positive example with higher confidence than choosing a true negative example.
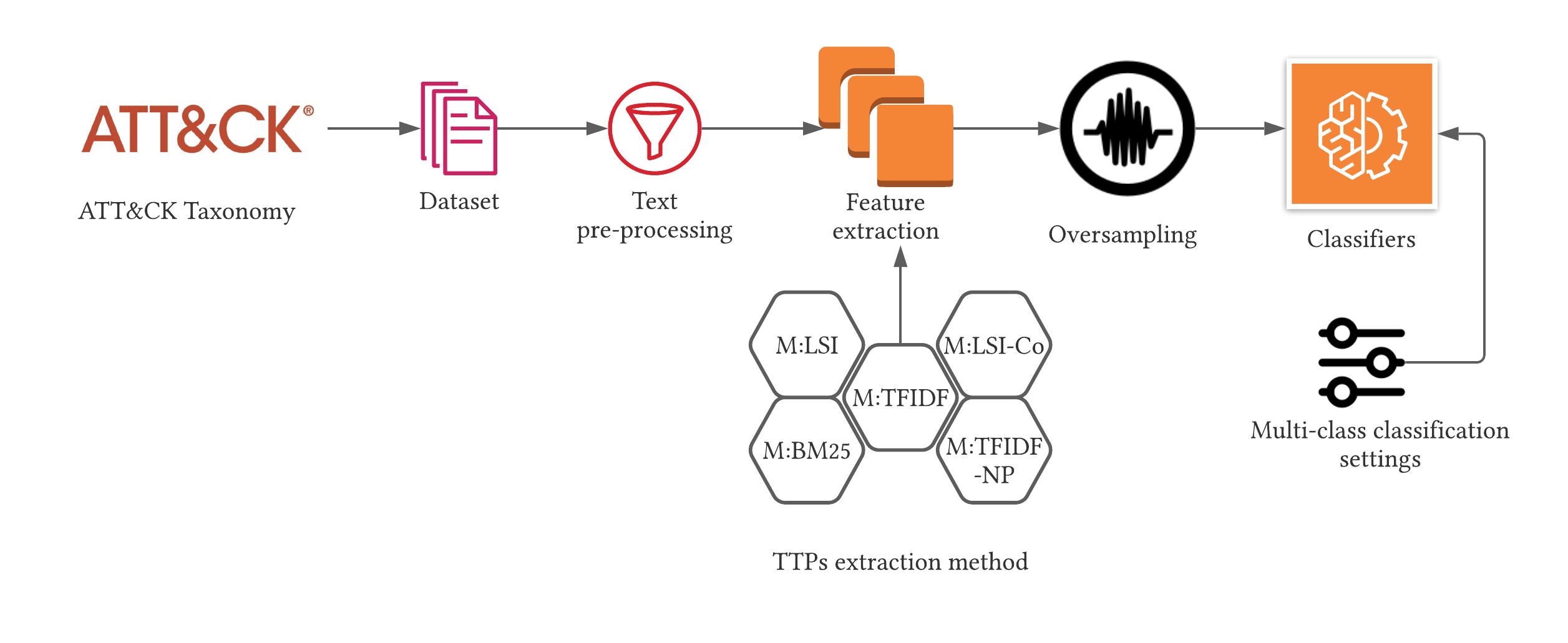
5.3 TTP extraction pipeline for comparison
We construct a TTP extraction pipeline for comparing the methods through five steps, as defined below.
Step 1: dataset collection In this step, we collect the dataset (Section 5.4) for the comparison experiment. The dataset contains (a) the textual description of attack procedures; and (b) ground truth for the classification task which are the corresponding attack techniques used in the description.
Step 2: text pre-processing In this step, we apply the following on the corpus: (a) pre-processed for filtering the punctuation marks and whitespaces; (b) tokenization; (c) stop word removal; (d) stemming; and (e) lemmatization.
Step 3: feature extraction The underlying methods of the selected TTP extraction work (see Section 4) varies from one another in the context of NLP techniques used and the choice of the classifiers. Hence, in this step, we implement the methods we discuss in Section 4 to extract the textual features that we would provide to classifiers.
Step 4: oversampling (optional) In this step, we apply oversampling to our dataset to mitigate the introduced bias by class imbalance in the dataset. This step is optional and the methods would be compared both with this step and without this step.
Step 5: classification In this step, we train the classifiers with a portion from our dataset and then test the classification performance with the rest of the dataset that we do not use for training purposes.
We instantiate these five steps in the following five subsections. Figure 1 shows the instantiated pipeline.
| Procedure Id | Procedure description | Technique Id | Technique name |
|---|---|---|---|
| G0016 | APT29 has used encoded PowerShell scripts uploaded to CozyCar installations to download and install SeaDuke. APT29 also used PowerShell to create new tasks on remote machines, identify configuration settings, evade defenses, exfiltrate data, and to execute other commands. | T1059 | Command and Scripting Interpreter |
| S0045 | Most of the strings in ADVSTORESHELL are encrypted with an XOR-based algorithm; some strings are also encrypted with 3DES and reversed. API function names are also reversed, presumably to avoid detection in memory | T1027 | Obfuscated Files or Information |
| S0154 | Cobalt Strike can conduct peer-to-peer communication over Windows named pipes encapsulated in the SMB protocol. All protocols use their standard assigned ports. | T1071 | Application Layer Protocol |
| G007 | APT28 has downloaded additional files, including by using a first-stage downloader to contact the C2 server to obtain the second-stage implant | T1105 | Ingress Tool Transfer |
| S0449 | Maze has used the "Wow64RevertWow64FsRedirection" function following attempts to delete the shadow volumes, in order to leave the system in the same state as it was prior to redirection | T1070 | Indicator Removal On Host |
5.4 Step 1: dataset collection
We construct the dataset from the textual description of attacks procedures mentioned in the MITRE ATT&CK framework. In the MITRE ATT&CK framework, each of the tactics has a one-to-many mapping with techniques and each of these techniques has a one-to-many mapping with textual descriptions of procedures taken from real-world cybersecurity incidents described in threat reports. We choose MITRE ATT&CK framework for constructing the dataset for the following reasons:
-
•
Although there is an abundance of threat reports in the internet, threat reports have to be manually filtered for relevance and manual labelled to TTP for each sentence of those threat reports. On the other hand, in the ATT&CK framework, the mapping between techniques and descriptions of procedures are already present and these mappings have been performed by cybersecurity professionals and researchers. The procedure-technique mapping done by these professionals are our ground truth.
-
•
All studies we selected for comparison use the ATT&CK framework for the common vocabulary of attack technique names.
-
•
The dataset contains textual descriptions of the attack procedures listed in the ATT&CK framework. The textual description of attack procedures consists of a few sentences and has the mapping to the associated technique name.
-
•
The ATT&CK framework is regularly updated and maintained with the evolution of attacks, hence, we get the latest set of TTP with the latest version of the ATT&CK framework.
We use Version 9 of the ATT&CK framework [25]. The dataset contains 8,104 attack procedure descriptions and corresponding techniques used in a real world cyber attack. The dataset contains 170 techniques. However, some techniques have more than hundreds of procedure descriptions while other techniques have only one. In our study, we use techniques that have at least 30 procedure descriptions, resulting in 7,061 procedure descriptions and 64 techniques. In Table 2, we show a few examples of techniques and textual description of procedures. For each of the textual descriptions, the mapped technique name will be used as the label for the classification task.
5.5 Step 2: text pre-processing
We first remove the urls and citations. Then, we use the gensim.parsing.preprocessing from gensim Python library for removing punctuation, whitespaces, stop-words and performing tokenization, stemming and lemmatization.
5.6 Step 3: feature extraction
- M:TFIDF
-
We compute the TFIDF vectors of the corpus. Then, we normalize the TFIDF vectors to unit length. Finally, we feed these normalized TFIDF vectors to classifiers. We use
TfidfVectorizerfrom thescikit-learnPython package. - M:LSI
-
We first compute the TFIDF vectors of the corpus. Then we normalize the TFIDF vectors to unit length. Then, we apply LSI to apply dimensionality reduction of the computed vectors. Finally we feed these normalized TFIDF vectors to classifiers. We use
tfidfmodelandlsimodelfromgensimPython packages. - M:LSI-Co
-
We apply pre-processing on the corpus as well as textual description of the techniques mentioned in the ATT&CK framework. Then, we compute the TFIDF vector for each of the technique description in the ATT&CK framework followed by normalization. After that, we apply LSI to each textual description in the corpus. We then compute the cosine similarity between TFIDF vectors (of each of the techniques) and topic vectors (of each of the textual descriptions from the corpus). Finally, we use these cosine similarities as features that we will feed towards classifiers. We use
tfidfmodel,lsimodelfromgensim, andscipyPython packages. - M:TFIDF-NP
-
We use parts of speech tagging to determine the noun phrases in the corpus. Then we construct a list of all noun phrases identified in the corpus. After that, we identify the noun phrases from the list which have been found in the corpus at least once without being part of a larger noun phrase. Then we compute the TFIDF vectors of these independent noun phrases for each procedure description. Then we normalize the TFIDF vectors to unit length. Finally, we feed these normalized TFIDF vectors to classifiers. We use
TfidfVectorizerfromscikit-learnandspacyPython package. - M:BM25
-
We first apply pre-processing to the corpus and textual description of the techniques from the ATT&CK framework. We then apply dependency parsing to both the corpus and textual description of the techniques from the ATT&CK framework. After that, we then extract the
(subject, verb, object)(SVO) tuples from both the corpus and textual description of techniques from the ATT&CK framework. We randomly select 100 procedure descriptions and the first two authors manually verified the tuple extraction performance. The first author finds 74% of the tuples extracted and the second author finds 88% of the tuples extracted by our implementation. Next, we construct Bag-of-words representation of the extracted(subject, verb, object)tuples from both the corpus and textual description of techniques from the ATT&CK framework. After that, we compute the similarity score using BM25 ranking method for the extracted(subject, verb, object)tuples for each corpus and(subject, verb, object)tuples for each technique from ATT&CK framework. Finally, we use these similarity scores as features that we would feed to the classifiers. We usespacy,BM25Okapi.
5.7 Step 4: oversampling (optional)
As we mention in Section 5.4, in our dataset, the techniques do not have the same amount of procedure descriptions. Some techniques have more than hundreds and some of the techniques have only 30. As a result, there are majority and minority classes in the dataset leading to class imbalance in the dataset. We use oversampling to mitigate the class imbalance problem in our dataset, and we apply a technique called SMOTE which stands for Synthetic Minority Oversampling Technique [10]. SMOTE works by choosing a random example from a minority class and then selecting the nearest neighbors of that minority class to generate more synthetic examples of that minority class. We ran all methods with and without oversampling technique to observe their performance with and without handling the class imbalance issue. As SMOTE can only apply oversampling to numeric features, we applied SMOTE on the computed features in each method, such as TFIDF vectors, similarity score. We use SMOTE Python package to implement the oversampling.
| # Classes | # Descriptions | |
|---|---|---|
| Before oversampling | After oversampling | |
| 890 | 1,064 | |
| 1,492 | 2,128 | |
| 2,448 | 4,256 | |
| 3,688 | 8,512 | |
| 5,390 | 17,024 | |
| 7,061 | 34,048 | |
5.8 Step 5: classification
We use six classifiers named Naive Bayes(NB), Support Vector Machine(SVM), Neural Network(NN), K-nearest Neighbor(KNN), Decision Tree(DT) and Random Forest(RF) classifiers. Collectively, these six classifiers are used by the authors of the study selected for the comparison. We use scikit-learn Python package for these classifiers and we use GaussianNB, SVC, KNeighborsClassifier, MLPClassifier, DecisionTreeClassifier, and RandomForestClassifier for NB, SVM, KNN, NN, DT, and RF classifiers respectively.
5.9 Multi-class classification settings
We mention in Section 5.4 that our dataset contains 64 technique names. Hence, in a corpus, a piece of text can be classified to one of the maximum 64 possible technique names. Thus, in this experiment, the TTP extraction can be considered a multi-class classification problem. We run each of the methods with the classifiers in these two following cases: (a) where a piece of text can be classified to one from two possible technique names, and (b) where a piece of text can be classified to one from more than two possible technique names to observe how the method performs in both cases. For case (a), we sort the technique names by the count of the corresponding procedure descriptions in the dataset, and then we select the top two techniques and their corresponding descriptions. For case (b), we we sort the technique names by the count of the corresponding procedure descriptions in the dataset, and then we select the top (here, is the number of possible classification labels) techniques and their corresponding descriptions. We run all methods in the following six different cases ( where denotes the number of class labels) which we will refer as multiclass classification settings settings. We report the procedure description count for each of the multiclass classification settings before and after oversampling in Table 3.
5.10 Cross-validation
We apply K-fold cross-validation technique to split our dataset into different sets of training and testing set. We choose K=5 and for each fold, we use of the dataset as training set and rest of the dataset () as testing set.
5.11 Hyperparameters
We use the default hyperparameter settings reported in the scikit-learn package for the classifiers. For SMOTE, we choose for generating synthetic examples from the nearest neighbors. Finally, before executing any method, we set the np.random.RandomState property of the Python environment to to ensure the replicability of our results from execution. For determining the number of topics for LSI model, we use the coherencemodel.get_coherence() method from lsimodel to get the coherence value for num_topic from 1 to 500. We observe that the coherence value increases monotonically. Hence, for LSI models, we use the num_topic = 500.
6 Results
In this section, we report the findings for each of the RQs.
6.1 RQ1: Classification performance
We report the precision, recall, F1 score, and AUC scores for all implemented methods paired with each of the six classifiers in Table 4. Each corresponding cell in the table reports the score in format where is the minimum observed score, is the maximum observed score, and is the arithmetic average of a method run with a classifier in all multiclass classification settings (see Section 5.9): where denotes the number of class labels in the dataset. For example, the top left cell containing denotes the precision score of M:TFIDF method paired with KNN classifier. The minimum and maximum precision scores observed are and , respectively, from all of six possible multi-class classification settings (), and the average precision score observed is . We bold the cell which shows the maximum average score for each method paired with six classifiers. We report the performance score of all methods across six classifiers, all oversampling settings, and all multiclass classification settings at Table 8 in Appendix.
| M | C | P | R | F | A |
|---|---|---|---|---|---|
| M:TFIDF | KNN | 63-88(76) | 55-84(71) | 56-85(71) | 88-93(91) |
| NB | 28-71(41) | 25-71(40) | 25-71(40) | 62-71(64) | |
| SVM | 77-92(87) | 65-90(81) | 68-90(83) | 98-99(99) | |
| DT | 58-89(77) | 56-84(74) | 56-84(74) | 80-88(85) | |
| RF | 72-92(85) | 66-89(82) | 67-89(82) | 98-99(98) | |
| NN | 74-91(86) | 71-90(84) | 71-90(84) | 97-99(98) | |
| M:TFIDF-NP | KNN | 39-77(59) | 33-74(55) | 33-73(55) | 79-86(84) |
| NB | 31-83(54) | 35-76(53) | 30-77(51) | 76-88(82) | |
| SVM | 42-80(63) | 28-78(55) | 30-77(56) | 88-89(89) | |
| DT | 48-81(68) | 46-78(66) | 45-77(66) | 77-86(83) | |
| RF | 58-84(75) | 53-82(73) | 53-81(72) | 93-96(95) | |
| NN | 57-84(73) | 52-82(71) | 53-81(71) | 92-94(93) | |
| M:LSI | KNN | 61-84(71) | 51-81(64) | 53-81(65) | 86-89(87) |
| NB | 62-72(67) | 55-69(61) | 40-69(59) | 62-94(86) | |
| SVM | 75-92(87) | 67-90(83) | 69-90(83) | 98-98(99) | |
| DT | 35-87(66) | 35-86(66) | 35-86(66) | 71-86(81) | |
| RF | 67-90(83) | 55-86(77) | 57-86(78) | 95-98(97) | |
| NN | 72-86(80) | 70-85(78) | 70-84(77) | 82-98(94) | |
| M:LSI-Co | KNN | 32-70(49) | 25-69(47) | 25-69(47) | 75-81(79) |
| NB | 28-71(44) | 23-67(40) | 18-68(38) | 74-82(79) | |
| SVM | 37-71(51) | 21-67(41) | 22-67(41) | 74-87(81) | |
| DT | 22-75(46) | 22-75(46) | 21-75(46) | 63-75(70) | |
| RF | 39-77(59) | 31-77(56) | 32-77(56) | 85-90(88) | |
| NN | 33-71(49) | 29-66(45) | 29-66(45) | 77-88(83) | |
| M:BM25 | KNN | 35-80(59) | 26-78(55) | 27-78(56) | 77-90(84) |
| NB | 31-82(56) | 23-82(52) | 22-82(51) | 79-90(85) | |
| SVM | 55-86(74) | 36-85(65) | 39-85(66) | 93-96(95) | |
| DT | 28-77(55) | 28-76(55) | 27-76(54) | 68-81(75) | |
| RF | 42-85(67) | 36-84(64) | 36-84(64) | 90-95(93) | |
| NN | 47-87(72) | 45-87(70) | 45-87(71) | 93-96(95) |
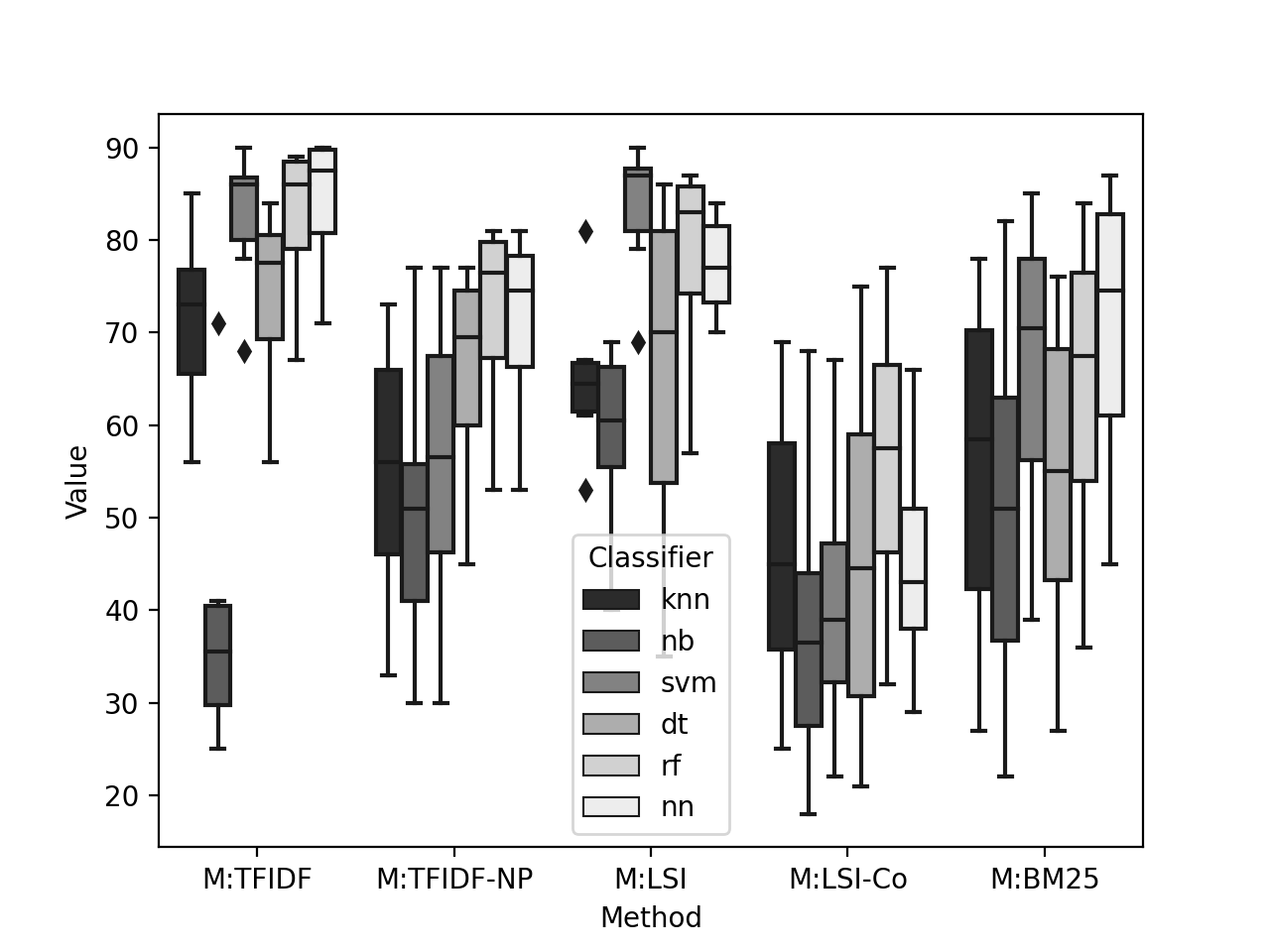
We also report the boxplot of F1 score of for all implemented methods paired with each of the six classifiers in Figure 2. Each of the classifiers were run using all values of . We discuss our observations from Table 4 and Figure 2.
SVM and NN classifiers work best for the M:TFIDF method. We find SVM classifier shows the best performance in precision (87) and AUC score (99). The NN classifier shows the best performance in recall (84) and F1 score (84). SVM classifier differs by 3% and 1% in recall and F1 performance respectively compared with the NN classifier. The NN classifier differs by 1% in both precision and AUC performance compared with the SVM classifier. The NB classifier performs the worst among the six classifiers. The F1 performance difference is around 40% compared to NN and SVM classifiers. From Figure 2, we observe that SVM, RF, NN classifier shows close Q1 (25th percentile) and Q3 (75th percentile) in F1 score. KNN and DT classifiers also shows close Q1 and Q3 in F1 score, however, lagging behind the SVM, RF, and NN. NB has no overlap in Q1-Q3 range with rest of the five classifiers and performs the worst than rest of the classifiers.
RF classifiers work best for M:TFIDF-NP method. We find RF classifier shows the best performance in all four metrics. NN classifier performs similar to RF classifier, however, differs by in four metrics compared to RF classifier. Moreover, NB classifier performs the worst among the six classifiers and the performance difference is around 20% in F1 score compared to RF and NN classifiers. From Figure 2, we observe that all six classifiers have mutual overlap in Q1-Q3 range and the interquartile range is bigger than that of M:TFIDF.
SVM classifiers work best for M:LSI method. We find SVM classifier shows the best performance in all four metrics. RF and NN classifier performs similar to one another, however, differs by in f1 score compared to SVM classifier. Moreover, NB classifier performs the worst among the six classifiers in F1 score differing by 24%. From Figure 2, we observe that RF and NN also follow SVM closely. Interquartile range varies among the six classifiers (i.e., DT and rest of the classifiers).
RF classifiers work best for M:LSI-Co method. We find RF classifier shows the best performance in all four metrics. KNN and DT classifier performs similar to one another, however, differs by in f1 score compared to RF classifier. Moreover, NB classifier performs the worst among the six classifiers and the performance difference is around 18% in F1 score compared to RF classifier. From Figure 2, we observe that RF is closely followed by KNN and DT. All six classifiers have mutual overlap with one another in Q1-Q3.
NN classifiers work best for M:BM25 method. We find NN classifier shows the best performance in recall, F1 and AUC metrics. However, SVM classifier performs best in precision and equal to NN in AUC score. Moreover, NB classifier performs the worst among the six classifiers in F1 score differing by 20%. From Figure 2, we observe that there are mutual overlaps among all six classifiers and the interquartile range is bigger than that of M:TFIDF and M:LSI.
| Method | Metric | Oversampling | Gain(%) | |
|---|---|---|---|---|
| No | Yes | |||
| M:TFIDF | F1 | 72 | 92 | 28 |
| AUC | 89 | 97 | 9 | |
| M:TFIDF-NP | F1 | 62 | 82 | 32 |
| AUC | 87 | 95 | 9 | |
| M:LSI | F1 | 71 | 89 | 20 |
| AUC | 91 | 96 | 5 | |
| M:LSI-Co | F1 | 46 | 68 | 48 |
| AUC | 89 | 97 | 9 | |
| M:BM25 | F1 | 60 | 82 | 36 |
| AUC | 88 | 95 | 8 | |
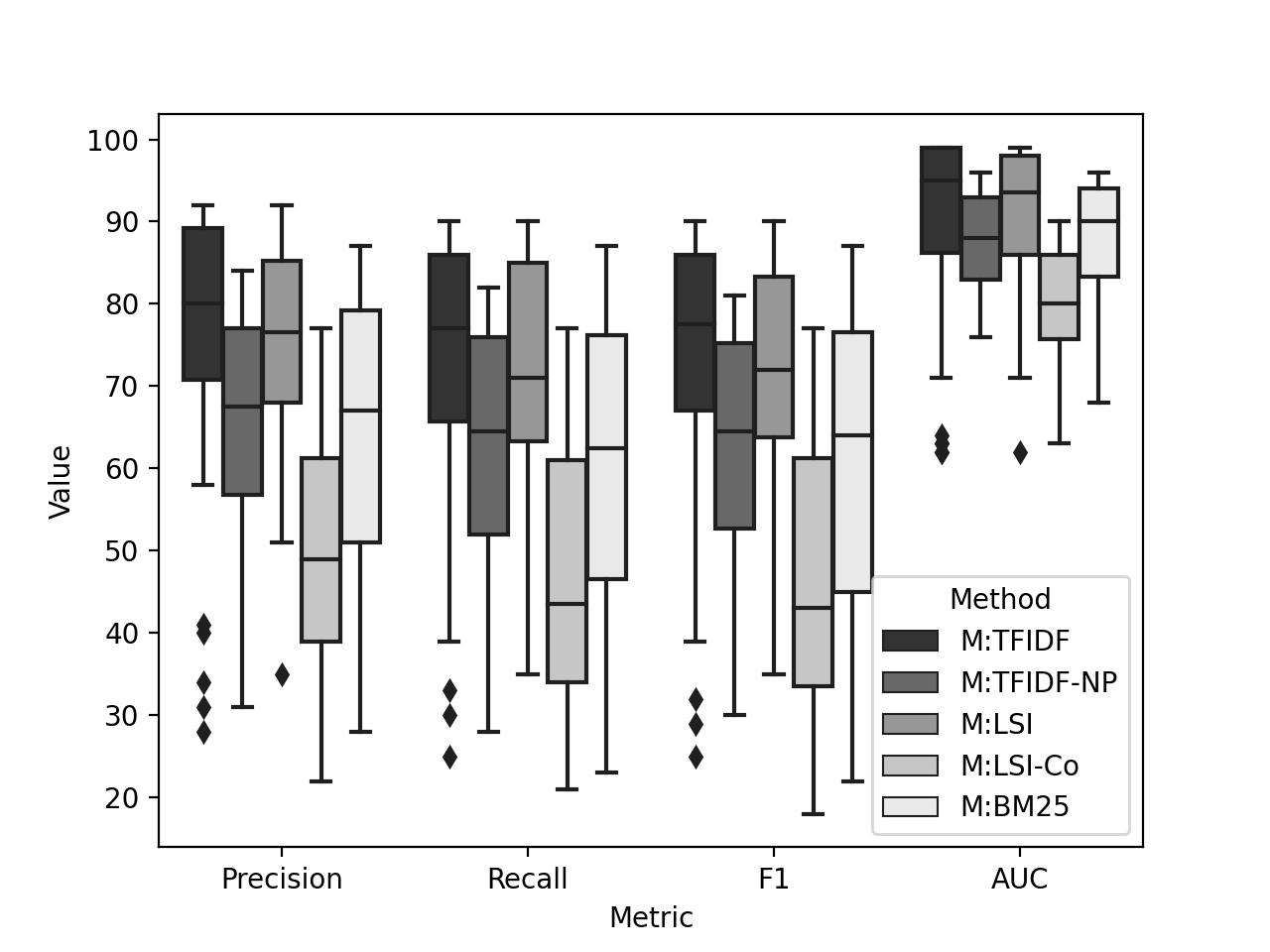
In Figure 3, we report the boxplot of precision, recall, F1 and AUC score of the five methods run with all classifiers and classification settings. We list our observation below.
M:TFIDF and M:LSI performs best on TTP classification. We observe that in all four metrics, M:TFIDF and M:LSI are ahead of the rest three methods. However, M:TFIDF shows slightly better performance than M:LSI. M:TFIDF-NP and M:BM25 show similar median score, however, M:BM25 shows a higher interquartile range than that of M:TFIDF-NP. M:LSI-Co lags behind the rest four methods. We also observe that the interquartile ranges of M:TFIDF and M:LSI are lower than the rest three methods. Finally, in AUC score, all methods are closer than the rest three metrics.
6.2 RQ2: Effect of class imbalance mitigation
We report the average F1 and AUC scores of each method with and without oversampling run with six classifiers and six classification settings in Table 5. We list observations below.
Oversampling helps gaining more performance. We observe that in the case of both F1 and AUC scores, all methods show better performance when oversampling is applied. In case of F1 score, the oversampling improved the score by 20 to 48%. M:LSI-Co gained the most performance (48%) and M:LSI gained the least (20%). In case of AUC score, the oversampling improved the score by 5 to 9%. M:LSI gained the least (5%), and rest of the method gained 8-9%. We also observe that the gain in F1 score is much higher than that of AUC score.
After applying oversampling, order of the methods in terms of performance remains similar. Before applying oversampling, we see M:TFIDF shows the best F1 score, followed by M:LSI, M:TFIDF-NP, M:BM25, and M:LSI-CO. After applying oversampling, we observe the same order except M:TFIDF-NP and M:BM25 having a tie. Although M:BM25, M:LSI-Co, M:TFIDF-NP made the most gain in performance, these three methods still perform worse than M:TFIDF and M:LSI even after applying oversampling.
6.3 RQ3: Effect of increase in class labels
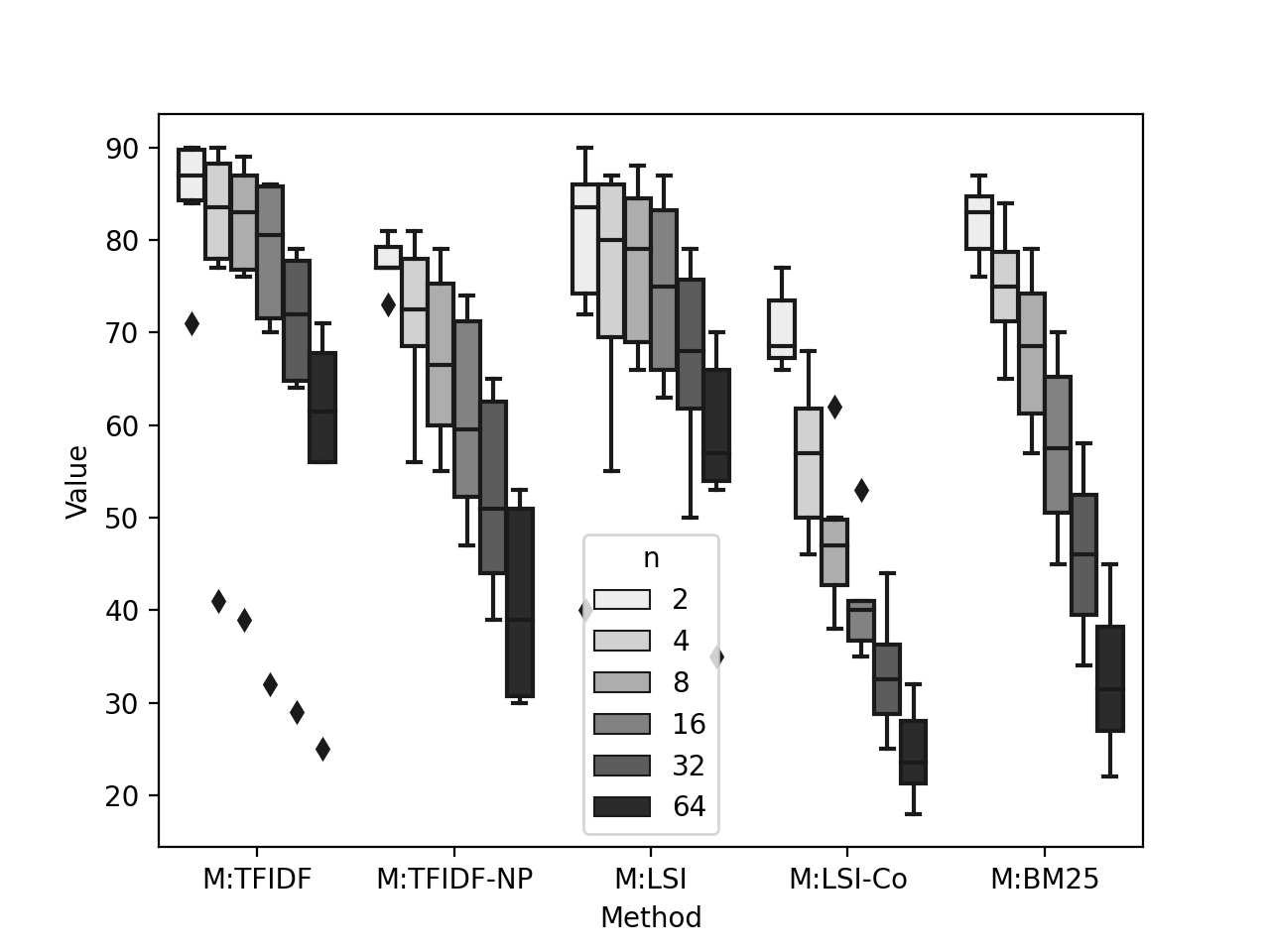
We report the boxplot of F1 and AUC scores using six classification settings () of all methods run with and without applying oversampling in Figure 4, 5, 6, and 7. We list our observations from the figure below.
The F1 score monotonically decrease when oversampling was not applied. We observe from Figure 4 that all the methods’ F1 score drops strictly when increases, indicating that (i) methods perform better if the classifiers need to classify on two labels, (ii) methods show strictly decreasing order of performance when classifiers need to classify in multiclass classification, the more is the number of class labels, the less the performance is. We also observe that M:TFIDF and M:LSI show more robustness than the rest three methods when we increase the value of .
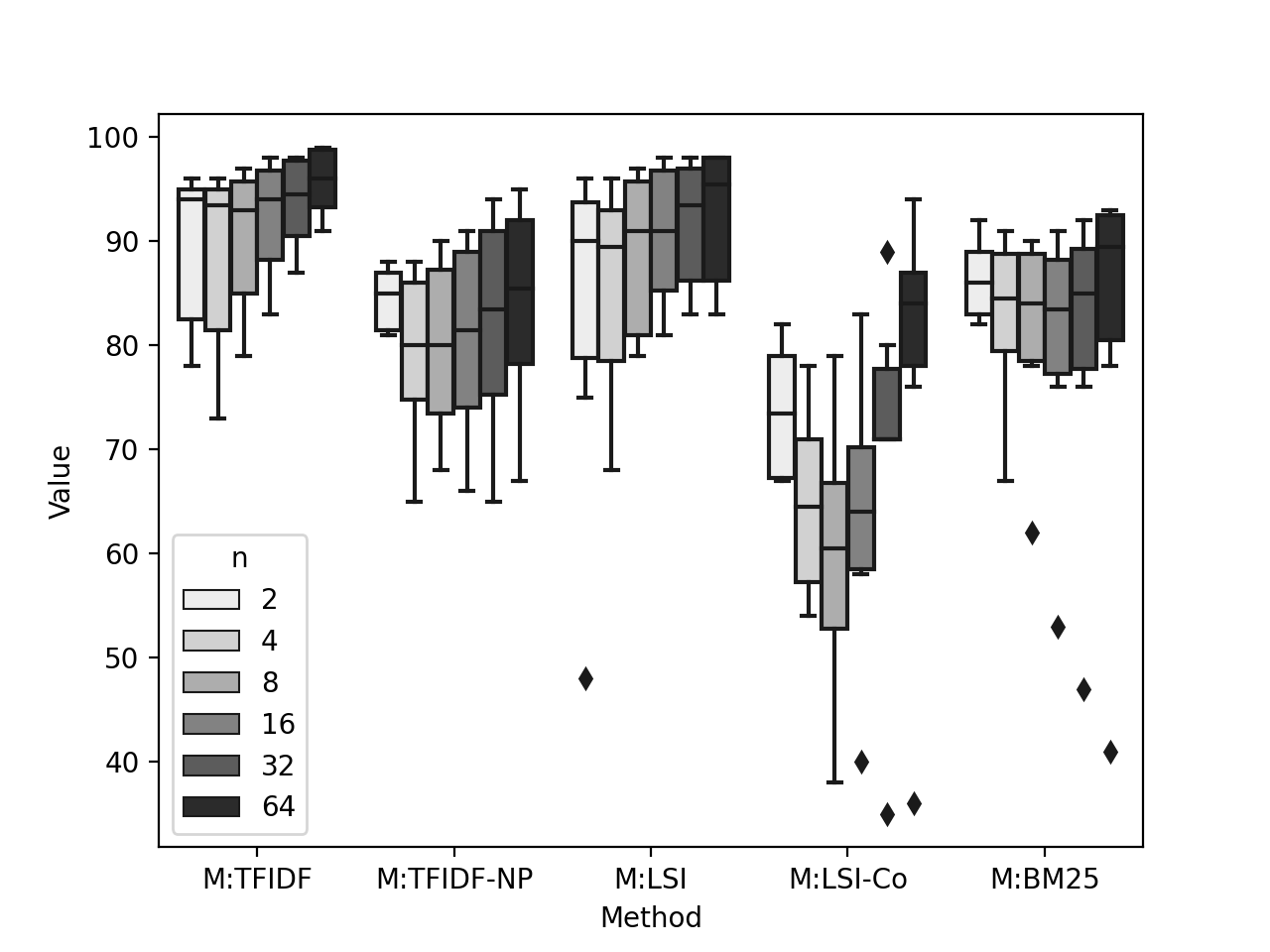
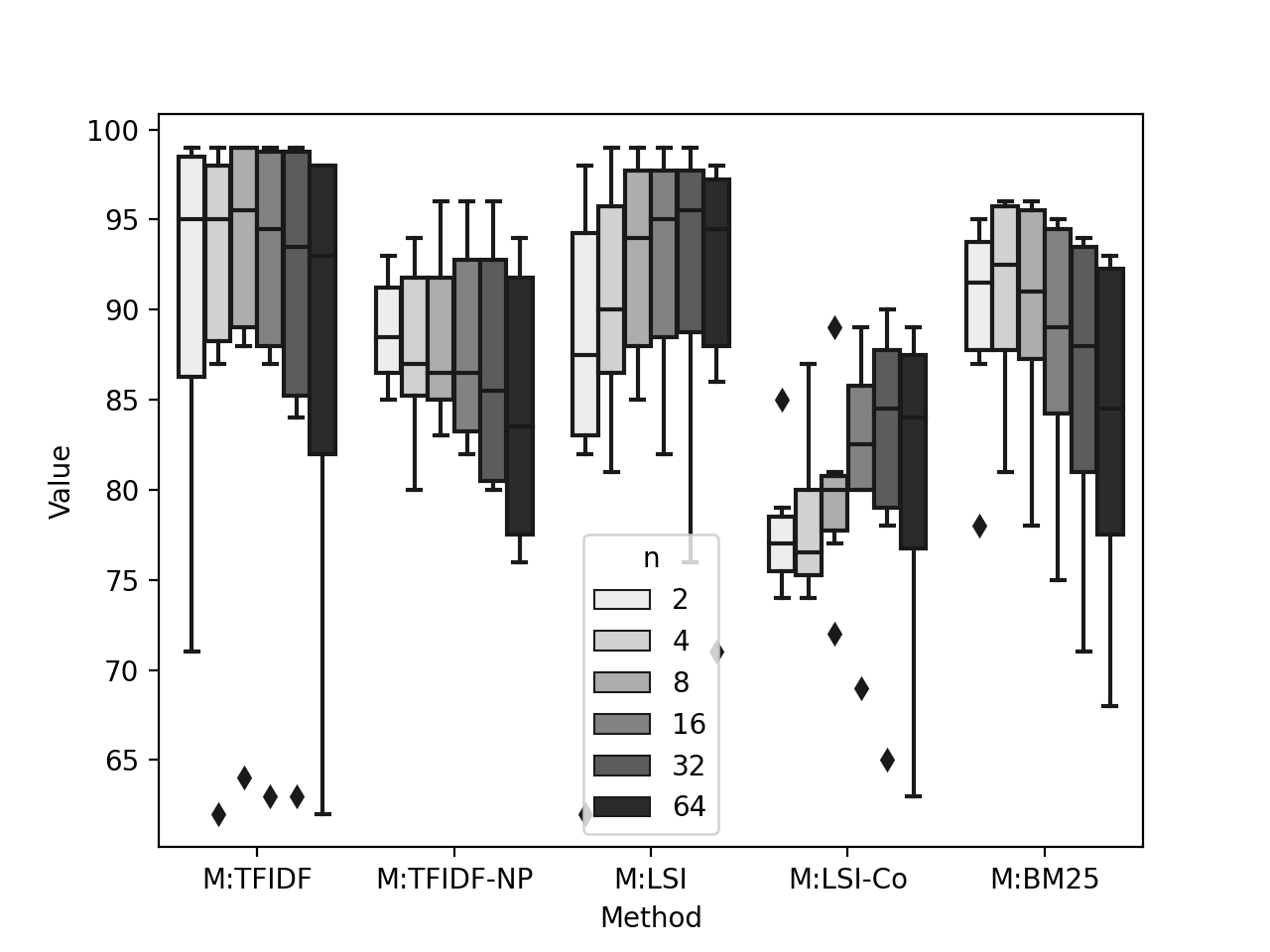
The F1 score does not monotonically increase or decrease when oversampling was applied. We observe Figure 5 that, on oversmapled data, the methods behave differently to one another when we increase the value of . M:TFIDF, M:TFIDF-NP, M:LSI, and M:BM25 show increase in performance, however, not in strict order. We also observe M:LSI-Co drops the performance from to , however, then the performance increases bettering the case: .
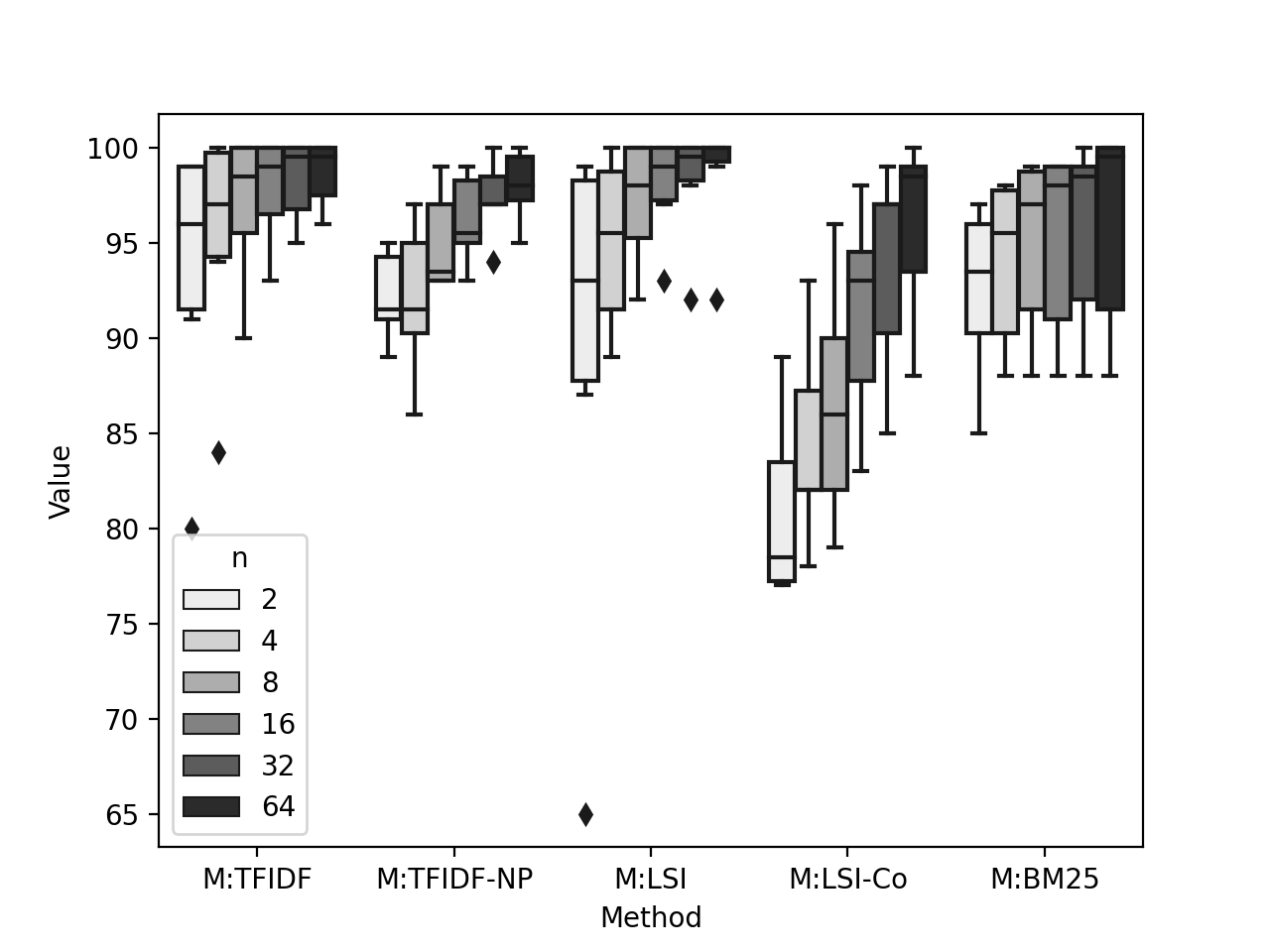
The AUC score first starts to increase and then decrease when oversampling was not applied. We observe Figure 6 that, for all methods, with the increase of , the scores first increase, reach a plateau, and then decrease. We observe that M:TFIDF shows the least variation of performance change, while M:LSI-Co shows the most variance.
The AUC score monotonically increase when oversampling was applied. We observe Figure 7 that for all methods, AUC scores strictly increase with the increase of . M:TFIDF-NP and M:LSI-Co made the most gain in AUC score. M:TFIDF demonstrates the least variance of AUC score with the increase of .
7 Discussion
We observe the following order of performance for the compared methods: M:TFIDF, M:LSI, M:TFIDF-NP, M:BM25, M:LSI-Co. The performance rank of the methods does not change over different settings. We observe, with or without applying oversampling and across all multi-class classification settings, the M:TFIDF and M:LSI methods perform better than the other three methods. These two methods use the TFIDF vector from the whole corpus as features, while the other three methods use vectors of certain parts of speeches or similarity score. These results suggest that the specific existence of noun or verbs related to TTP is likely to be the most dominant feature for extracting TTP.
Table 6 shows the maximum observed score from our implemented methods and the reported maximum performance score of the corresponding publications [29, 28, 5, 21, 14]. We observe similarity in the performance score of methods and corresponding studies. M:LSI and M:TFIDF shows 90% F1 score while their corresponding work , and shows F1 score of 96% and accuracy score of 86% respectively. M:LSI-Co is the least performing method from our observation and the reported score of the corresponding work is also associated with the least F1 score. In the case of M:BM25, we observe 87% F1 score and the reported F1 score in the corresponding work is 86%.
Precision and recall performance do not vary by a large margin. We observe that precision and recall performance of each row in Table 4 do not have more than 9% difference, which is observed in the case of M:BM25 paired with SVM classifier. Our observations suggest that the methods offer a similar proportion of relevance and completeness while classifying TTP from a given text.
We observe that AUC scores of all methods are higher than F1 score of each method, indicating that (a) there could be a certain set of classification hyperparameters that would make the classification performance better; and (b) there could be bias in the dataset which impacts the precision and recall score.
We implement SVO tuples for comparing M:BM25 method, where we observe that our implementation for extracting SVO tuples is not perfect as the implementation cannot completely extract all words of objects in the case of: (i) when the object consists of multiple nouns; and (b) when the sentence is complex or written in passive voice. Improving the SVO tuple extraction, converting the passive voice to active voice, and breaking down a complex sentence to multiple simple sentences could make the performance better.
| Study | Reported Score(F1) | Implementation | Observed Score(F1) |
| 96 | M:LSI | 90 | |
| - | M:TFIDF-NP | 81 | |
| 86* | M:TFIDF | 90 | |
| 57 | M:LSI-Co | 77 | |
| 86 | M:BM25 | 87 | |
| *: the reported score in is accuracy | |||
| -: no performance score is reported in | |||
8 Future research direction
We advocate cybersecurity researchers and practitioners to investigate the performance of the discussed methods on applying a large corpus of threat reports. Moreover, we recommend establishing a benchmark dataset of large threat report corpus for conducting such experiments. Moreover, using NER, patterns of verb and noun co-occurrence, and regular expression of specific IoCs as features could have made the classification performance better. We recommend cybersecurity researchers investigate the performance benefits of incorporating these features while extracting TTP. As we discussed in Section 7, existence of specific TTP related nouns and verbs could be the most dominant feature for TTP classification, and hence, we recommend researchers investigate the best performing textual features for the classification task through feature selection and ranking techniques. We run six classifiers with their default parameters, researchers can investigate the optimal set of hyperparameter [39] for each classifier for the best classification performance. Finally, classifying texts to corresponding tactics, procedures and applying multi-label classification (a sentence can be related to more than one TTP) could also be investigated.
9 Threats to validity
We report the limitations we identify in this study. We did not compare the methods on corpus constructed from large threat reports. We also assume that one sentence is associated with only one corresponding attack technique. However, in threat reports, there could be sentences that might have more than one corresponding technique which can be classified with multi-label classifiers. For classification tasks, the dataset contains 64 technique names and hence, the classification performance for rest of the TTP is not evaluated. We also do not perform hyperparameter tuning for individual classifiers, which would have led to better performance. We also applied SMOTE technique to generate synthetic samples from numeric textual features, which might have introduced bias in the dataset. We did not perform a comparison study of all ten identified work and we also did not compare the five methods with tools from the industry such as [3]. Finally, we implement the underlying methods from the study with our best effort, however there could be additional bias introduced along with our implementation.
10 Related work
Rahman et al. [33] performed a systematic literature review on threat intelligence extraction from unstructured texts where they found 34 relevant studies and 8 data sources. The authors later surveyed 64 related studies in the extraction of threat intelligence from unstructured text where they identified ten CTI extraction goals [34]. The authors proposed a generic pipeline for CTI extraction and surveyed the NLP and ML techniques utilized for extraction. Bridges et al. [8] performed a comparison study of prior work [9, 17, 16] on cybersecurity entity extraction techniques. The authors used online blog articles on cybersecurity, National Vulnerability Database, and Common Vulnerabilities and Exposure (CVE) databases as corpus. The authors reported low recall of the compared methods and lack of published dataset. Our work differs from this work from Bridges et al. as our work compares the studies on TTP extraction while Bridges et al. compared the cybersecurity entity extraction from text. Tounsi et al. [44] defined the four categories of CTI and discussed technical CTI, existing issues, emerging research, and trends in CTI domain. They also compared the features of existing CTI gathering and sharing tools. Wagner et al. [47] evaluated the technical and nontechnical challenges in state-of-the-art CTI sharing systems. Sauerwein et al. [38] studied 22 CTI-sharing platforms enabling automation of the generation, refinement, and examination of security data. Tuma et al. [45] conducted a systematic literature review on 26 methodologies on applicability, outcome, and ease of access of cyberthreat analysis. While these work focuses on CTI extraction and technical aspects of CTI tools, in our work, we focus on comparing TTP extraction methods to determine what method performs best and what are the areas for further enhancement.
11 Conclusion
In this work, we compare the underlying methods of five existing TTP extraction work [29, 28, 5, 21, 14] and the corresponding implementations are M:LSI, M:TFIDF-NP, M:TFIDF, M:LIS-Co, and M:BM25, respectively. We compared these methods on the performance of classifying textual descriptions of procedures to the corresponding technique names given in the ATT&CK framework. From our experiment, we observe that: (a) M:TFIDF and M:LSI perform best in TTP classification from text; (b) performance of the methods drops when we increase the class labels in the classification task; and (c) oversampling improves the performance by mitigating the bias introduced by majority and minority classes in the dataset. We recommend (i) constructing an agreed-upon benchmark dataset; (ii) investigating all TTP extraction work from the literature and industry on large corpus dataset, and (iii) selecting optimal features for extracting TTPs from text. Cybersecurity researchers can use our work as a baseline for comparing and testing future TTP extraction methods.
Availability
The dataset and source code of the implemented methods are available to download at this Github repository: [4].
References
- [1] Programmable search engine. https://cse.google.com/cse?cx=003248445720253387346:turlh5vi4xc, 2016. [Online; accessed 1-December-2020].
- [2] The MITRE Corporation. https://www.mitre.org/, 2021. [Online; accessed 14-May-2021].
- [3] Threat report - ATT&CK mapping. https://github.com/center-for-threat-informed-defense/tram, 2021. [Online; accessed 14-May-2021].
- [4] usenix-22-ttps-extraction-comparison. https://github.com/brokenquark/usenix-22-ttps-extraction-comparison/tree/main Accessed 4 Oct 2021, 2021.
- [5] Gbadebo Ayoade, Swarup Chandra, Latifur Khan, Kevin Hamlen, and Bhavani Thuraisingham. Automated threat report classification over multi-source data. In 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), pages 236–245. IEEE, 2018.
- [6] Kiran Bandla. APTnotes. https://github.com/aptnotes/data, 2016. [Online; accessed 1-December-2020].
- [7] FireEye Threat Research Blog. Highly Evasive Attacker Leverages SolarWinds Supply Chain to Compromise Multiple Global Victims With SUNBURST Backdoors. https://www.fireeye.com/blog/threat-research/2020/12/evasive-attacker-leverages-solarwinds-supply-chain-compromises-with-sunburst-backdoor.html, 2020. [Online; accessed 22-August-2020].
- [8] Robert A Bridges, Kelly MT Huffer, Corinne L Jones, Michael D Iannacone, and John R Goodall. Cybersecurity automated information extraction techniques: Drawbacks of current methods, and enhanced extractors. In 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 437–442. IEEE, 2017.
- [9] Robert A Bridges, Corinne L Jones, Michael D Iannacone, Kelly M Testa, and John R Goodall. Automatic labeling for entity extraction in cyber security. arXiv preprint arXiv:1308.4941, 2013.
- [10] Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002.
- [11] Yumna Ghazi, Zahid Anwar, Rafia Mumtaz, Shahzad Saleem, and Ali Tahir. A supervised machine learning based approach for automatically extracting high-level threat intelligence from unstructured sources. In 2018 International Conference on Frontiers of Information Technology (FIT), pages 129–134. IEEE, 2018.
- [12] Google. Android api reference. https://developer.android.com/reference Accessed 4 Oct 2021, 2021.
- [13] Arthur Gretton, Alex Smola, Jiayuan Huang, Marcel Schmittfull, Karsten Borgwardt, and Bernhard Sch0lkopf. Covariate shift by kernel mean matching. Dataset shift in machine learning, 3(4):5, 2009.
- [14] Ghaith Husari, Ehab Al-Shaer, Mohiuddin Ahmed, Bill Chu, and Xi Niu. Ttpdrill: Automatic and accurate extraction of threat actions from unstructured text of cti sources. In Proceedings of the 33rd Annual Computer Security Applications Conference, pages 103–115, 2017.
- [15] Ghaith Husari, Xi Niu, Bill Chu, and Ehab Al-Shaer. Using entropy and mutual information to extract threat actions from cyber threat intelligence. In 2018 IEEE International Conference on Intelligence and Security Informatics (ISI), pages 1–6. IEEE, 2018.
- [16] Corinne L Jones, Robert A Bridges, Kelly MT Huffer, and John R Goodall. Towards a relation extraction framework for cyber-security concepts. In Proceedings of the 10th Annual Cyber and Information Security Research Conference, pages 1–4, 2015.
- [17] Arnav Joshi, Ravendar Lal, Tim Finin, and Anupam Joshi. Extracting cybersecurity related linked data from text. In 2013 IEEE Seventh International Conference on Semantic Computing, pages 252–259. IEEE, 2013.
- [18] Joseph R. Biden Jr. Executive order on improving the nations cybersecurity. https://www.whitehouse.gov/briefing-room/presidential-actions/2021/05/12/executive-order-on-improving-the-nations-cybersecurity/ Accessed 4 Oct 2021, 2021.
- [19] Swati Khandelwal. New Group of Hackers Targeting Businesses with Financially Motivated Cyber Attacks. https://thehackernews.com/2019/11/financial-cyberattacks.html, 2019. [Online; accessed 22-August-2020].
- [20] Thomas K Landauer, Peter W Foltz, and Darrell Laham. An introduction to latent semantic analysis. Discourse processes, 25(2-3):259–284, 1998.
- [21] Mengming Li, Rongfeng Zheng, Liang Liu, and Pin Yang. Extraction of threat actions from threat-related articles using multi-label machine learning classification method. In 2019 2nd International Conference on Safety Produce Informatization (IICSPI), pages 428–431. IEEE, 2019.
- [22] Rob McMillan. Definition: threat intelligence. Gartner. com, 2013.
- [23] MITRE. Software Discovery: Security Software Discovery. https://attack.mitre.org/techniques/T1518/001/, 2020. [Online; accessed 22-August-2020].
- [24] MITRE. MITRE ATT&CK. https://attack.mitre.org/, 2021. [Online; accessed 14-May-2021].
- [25] MITRE. MITRE ATT&CK. https://attack.mitre.org/versions/v9/resources/working-with-attack/, 2021. [Online; accessed 14-May-2021].
- [26] Angela Moon. State-sponsored cyberattacks on banks on the rise: report. https://www.reuters.com/article/us-cyber-banks/state-sponsored-cyberattacks-on-banks-on-the-rise-report-idUSKCN1R32NJl, 2019. [Online; accessed 22-August-2020].
- [27] BBC News. Cyber-crime: Irish health system targeted twice by hackers. https://www.bbc.com/news/world-europe-57134916 Accessed 4 Oct 2021, 2021.
- [28] Amirreza Niakanlahiji, Jinpeng Wei, and Bei-Tseng Chu. A natural language processing based trend analysis of advanced persistent threat techniques. In 2018 IEEE International Conference on Big Data (Big Data), pages 2995–3000. IEEE, 2018.
- [29] Umara Noor, Zahid Anwar, Tehmina Amjad, and Kim-Kwang Raymond Choo. A machine learning-based fintech cyber threat attribution framework using high-level indicators of compromise. Future Generation Computer Systems, 96:227–242, 2019.
- [30] OASIS. Introduction to stix. https://oasis-open.github.io/cti-documentation/stix/intro.html Accessed 4 Oct 2021, 2021.
- [31] Ericka Pingol. Meat supply giant jbs suffers cyberattack. https://www.trendmicro.com/en_us/research/21/f/meat-supply-giant-jbs-suffers-cyberattack.html Accessed 4 Oct 2021, 2021.
- [32] Aritran Piplai, Sudip Mittal, Anupam Joshi, Tim Finin, James Holt, and Richard Zak. Creating cybersecurity knowledge graphs from malware after action reports. IEEE Access, 8:211691–211703, 2020.
- [33] Md Rayhanur Rahman, Rezvan Mahdavi-Hezaveh, and Laurie Williams. A literature review on mining cyberthreat intelligence from unstructured texts. In 2020 International Conference on Data Mining Workshops (ICDMW), pages 516–525. IEEE, 2020.
- [34] Md Rayhanur Rahman, Rezvan Mahdavi-Hezaveh, and Laurie Williams. What are the attackers doing now? automating cyber threat intelligence extraction from text on pace with the changing threat landscape: A survey. arXiv preprint arXiv:2109.06808, 2021.
- [35] Roshni R Ramnani, Karthik Shivaram, and Shubhashis Sengupta. Semi-automated information extraction from unstructured threat advisories. In Proceedings of the 10th Innovations in Software Engineering Conference, pages 181–187, 2017.
- [36] Jesse Read, Bernhard Pfahringer, Geoff Holmes, and Eibe Frank. Classifier chains for multi-label classification. Machine learning, 85(3):333–359, 2011.
- [37] Carl Sabottke, Octavian Suciu, and Tudor Dumitra\textcommabelows. Vulnerability disclosure in the age of social media: Exploiting twitter for predicting real-world exploits. In 24th USENIX Security Symposium (USENIX Security 15), pages 1041–1056, 2015.
- [38] Clemens Sauerwein, Christian Sillaber, Andrea Mussmann, and Ruth Breu. Threat Intelligence Sharing Platforms: An Exploratory Study of Software Vendors and Research Perspectives. In Jan Marco Leimeister and Walter Brenner, editors, Proceedings of the 13th International Conference on Wirtschaftsinformatik (WI 2017), pages 837–851, 2017.
- [39] Rui Shu, Tianpei Xia, Jianfeng Chen, Laurie Williams, and Tim Menzies. How to better distinguish security bug reports (using dual hyperparameter optimization). Empirical Software Engineering, 26(3):1–37, 2021.
- [40] Sonatype. 2021 state of the software supply chain. https://www.sonatype.com/resources/state-of-the-software-supply-chain-2021 Accessed 4 Oct 2021, 2021.
- [41] Newton Spolaor, Everton Alvares Cherman, Maria Carolina Monard, and Huei Diana Lee. A comparison of multi-label feature selection methods using the problem transformation approach. Electronic Notes in Theoretical Computer Science, 292:135–151, 2013.
- [42] DNS Stuff. What is Threat Intelligence. https://www.dnsstuff.com/what-is-threat-intelligence, 2020. [Online; accessed 22-August-2020].
- [43] Masashi Sugiyama, Taiji Suzuki, Shinichi Nakajima, Hisashi Kashima, Paul von Bunau, and Motoaki Kawanabe. Direct importance estimation for covariate shift adaptation. Annals of the Institute of Statistical Mathematics, 60(4):699–746, 2008.
- [44] Wiem Tounsi and Helmi Rais. A survey on technical threat intelligence in the age of sophisticated cyber attacks. Computers & security, 72:212–233, 2018.
- [45] Katja Tuma, Gul Çalikli, and Riccardo Scandariato. Threat analysis of software systems: A systematic literature review. Journal of Systems and Software, 144:275–294, 2018.
- [46] William Turton and Kartikay Mehrotra. Hackers breached colonial pipeline using compromised password. https://www.bloomberg.com/news/articles/2021-06-04/hackers-breached-colonial-pipeline-using-compromised-password Accessed 4 Oct 2021, 2021.
- [47] Thomas D Wagner, Khaled Mahbub, Esther Palomar, and Ali E Abdallah. Cyber threat intelligence sharing: Survey and research directions. Computers & Security, 87:101589, 2019.
- [48] Ziyun Zhu and Tudor Dumitraş. Featuresmith: Automatically engineering features for malware detection by mining the security literature. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pages 767–778, 2016.
Appendix
| Id | Publication |
|---|---|
| [29] | Noor, Umara, Zahid Anwar, Tehmina Amjad, and Kim-Kwang Raymond Choo. "A machine learning-based FinTech cyberthreat attribution framework using high-level indicators of compromise." Future Generation Computer Systems 96 (2019): 227-242. |
| [28] | Niakanlahiji, Amirreza, Jinpeng Wei, and Bei-Tseng Chu. "A natural language processing based trend analysis of advanced persistent threat techniques." In 2018 IEEE International Conference on Big Data (Big Data), pp. 2995-3000. IEEE, 2018. |
| [11] | Ghazi, Yumna, Zahid Anwar, Rafia Mumtaz, Shahzad Saleem, and Ali Tahir. "A supervised machine learning based approach for automatically extracting high-level threat intelligence from unstructured sources." In 2018 International Conference on Frontiers of Information Technology (FIT), pp. 129-134. IEEE, 2018. |
| [5] | Ayoade, Gbadebo, Swarup Chandra, Latifur Khan, Kevin Hamlen, and Bhavani Thuraisingham. "Automated threat report classification over multi-source data." In 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), pp. 236-245. IEEE, 2018. |
| [32] | Piplai, Aritran, Sudip Mittal, Anupam Joshi, Tim Finin, James Holt, and Richard Zak. "Creating cybersecurity knowledge graphs from malware after action reports." IEEE Access 8 (2020): 211691-211703. |
| [21] | Li, Mengming, Rongfeng Zheng, Liang Liu, and Pin Yang. "Extraction of Threat Actions from Threat-related Articles using Multi-Label Machine Learning Classification Method." In 2019 2nd International Conference on Safety Produce Informatization (IICSPI), pp. 428-431. IEEE, 2019. |
| [48] | Zhu, Ziyun, and Tudor Dumitraş. "Featuresmith: Automatically engineering features for malware detection by mining the security literature." In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 767-778. 2016. |
| [35] | Ramnani, Roshni R., Karthik Shivaram, and Shubhashis Sengupta. "Semi-automated information extraction from unstructured threat advisories." In Proceedings of the 10th Innovations in Software Engineering Conference, pp. 181-187. 2017. |
| [14] | Husari, Ghaith, Ehab Al-Shaer, Mohiuddin Ahmed, Bill Chu, and Xi Niu. "Ttpdrill: Automatic and accurate extraction of threat actions from unstructured text of cti sources." In Proceedings of the 33rd Annual Computer Security Applications Conference, pp. 103-115. 2017. |
| [15] | Husari, Ghaith, Xi Niu, Bill Chu, and Ehab Al-Shaer. "Using entropy and mutual information to extract threat actions from cyber threat intelligence." In 2018 IEEE International Conference on Intelligence and Security Informatics (ISI), pp. 1-6. IEEE, 2018. |
| M | C | OS | n = 2 | n = 4 | n = 8 | n = 16 | n = 32 | n = 64 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F | A | P | R | F | A | P | R | F | A | P | R | F | A | P | R | F | A | P | R | F | A | |||
| M:TFIDF | KNN | No | 88 | 84 | 85 | 93 | 80 | 76 | 77 | 92 | 79 | 76 | 76 | 92 | 76 | 69 | 70 | 91 | 70 | 63 | 64 | 89 | 63 | 55 | 56 | 88 |
| Yes | 85 | 79 | 78 | 91 | 83 | 80 | 78 | 94 | 86 | 85 | 83 | 97 | 88 | 88 | 87 | 98 | 91 | 91 | 90 | 99 | 94 | 94 | 94 | 99 | ||
| NB | No | 71 | 71 | 71 | 71 | 41 | 42 | 41 | 62 | 40 | 39 | 39 | 64 | 34 | 33 | 32 | 63 | 31 | 30 | 29 | 63 | 28 | 25 | 25 | 62 | |
| Yes | 81 | 79 | 79 | 80 | 74 | 74 | 73 | 84 | 80 | 80 | 79 | 90 | 85 | 85 | 83 | 93 | 88 | 88 | 87 | 95 | 92 | 92 | 91 | 97 | ||
| SVM | No | 92 | 90 | 90 | 99 | 90 | 86 | 86 | 99 | 91 | 86 | 87 | 99 | 90 | 84 | 86 | 99 | 84 | 76 | 78 | 99 | 77 | 65 | 68 | 98 | |
| Yes | 96 | 96 | 96 | 99 | 96 | 96 | 96 | 100 | 97 | 97 | 97 | 100 | 98 | 97 | 98 | 100 | 98 | 98 | 98 | 100 | 99 | 99 | 99 | 100 | ||
| DT | No | 89 | 84 | 84 | 84 | 86 | 81 | 81 | 87 | 81 | 80 | 79 | 88 | 78 | 77 | 76 | 87 | 69 | 68 | 67 | 84 | 58 | 56 | 56 | 80 | |
| Yes | 93 | 93 | 93 | 93 | 93 | 92 | 92 | 95 | 91 | 91 | 91 | 95 | 92 | 92 | 92 | 96 | 92 | 92 | 92 | 96 | 93 | 93 | 93 | 96 | ||
| RF | No | 92 | 89 | 89 | 99 | 90 | 89 | 89 | 98 | 88 | 88 | 87 | 99 | 87 | 85 | 85 | 98 | 80 | 77 | 77 | 98 | 72 | 66 | 67 | 98 | |
| Yes | 95 | 95 | 95 | 99 | 95 | 95 | 95 | 99 | 95 | 95 | 95 | 100 | 96 | 96 | 96 | 100 | 97 | 97 | 97 | 100 | 98 | 98 | 98 | 100 | ||
| NN | No | 91 | 90 | 90 | 97 | 91 | 89 | 90 | 98 | 90 | 89 | 89 | 99 | 87 | 87 | 86 | 99 | 80 | 79 | 79 | 99 | 74 | 71 | 71 | 98 | |
| Yes | 95 | 95 | 95 | 99 | 95 | 95 | 95 | 100 | 97 | 96 | 96 | 100 | 98 | 98 | 97 | 100 | 98 | 98 | 98 | 100 | 99 | 99 | 99 | 100 | ||
| M:TFIDF-NP | KNN | No | 77 | 74 | 73 | 85 | 71 | 70 | 68 | 86 | 63 | 60 | 60 | 85 | 56 | 51 | 52 | 84 | 50 | 44 | 44 | 82 | 39 | 33 | 33 | 79 |
| Yes | 82 | 81 | 81 | 89 | 75 | 74 | 74 | 91 | 76 | 75 | 75 | 94 | 77 | 77 | 77 | 95 | 80 | 80 | 79 | 97 | 82 | 82 | 82 | 97 | ||
| NB | No | 83 | 76 | 77 | 88 | 60 | 58 | 56 | 80 | 58 | 57 | 55 | 83 | 49 | 52 | 47 | 82 | 43 | 42 | 39 | 80 | 31 | 35 | 30 | 76 | |
| Yes | 84 | 81 | 81 | 92 | 71 | 66 | 65 | 86 | 77 | 74 | 73 | 93 | 77 | 74 | 73 | 95 | 79 | 74 | 74 | 97 | 81 | 78 | 77 | 98 | ||
| SVM | No | 80 | 78 | 77 | 89 | 71 | 70 | 70 | 88 | 66 | 60 | 60 | 88 | 62 | 52 | 53 | 89 | 55 | 42 | 44 | 89 | 42 | 28 | 30 | 88 | |
| Yes | 84 | 83 | 83 | 91 | 77 | 77 | 77 | 92 | 70 | 68 | 68 | 93 | 69 | 66 | 66 | 96 | 68 | 65 | 65 | 97 | 72 | 67 | 67 | 98 | ||
| DT | No | 81 | 78 | 77 | 86 | 76 | 76 | 75 | 85 | 75 | 74 | 73 | 85 | 68 | 66 | 66 | 83 | 60 | 58 | 58 | 80 | 48 | 46 | 45 | 77 | |
| Yes | 88 | 87 | 87 | 91 | 84 | 84 | 83 | 90 | 86 | 85 | 85 | 93 | 87 | 86 | 86 | 93 | 88 | 88 | 88 | 94 | 89 | 89 | 89 | 95 | ||
| RF | No | 84 | 81 | 80 | 93 | 82 | 82 | 81 | 94 | 81 | 80 | 79 | 96 | 77 | 74 | 74 | 96 | 69 | 65 | 65 | 96 | 58 | 53 | 53 | 94 | |
| Yes | 89 | 88 | 88 | 95 | 88 | 88 | 88 | 97 | 90 | 90 | 90 | 99 | 92 | 91 | 91 | 99 | 94 | 94 | 94 | 100 | 95 | 95 | 95 | 100 | ||
| NN | No | 84 | 82 | 81 | 92 | 80 | 80 | 79 | 93 | 77 | 77 | 76 | 93 | 74 | 72 | 73 | 94 | 67 | 64 | 64 | 94 | 57 | 52 | 53 | 93 | |
| Yes | 88 | 87 | 87 | 95 | 87 | 87 | 87 | 96 | 89 | 88 | 88 | 98 | 90 | 90 | 90 | 99 | 92 | 92 | 92 | 99 | 93 | 93 | 93 | 100 | ||
| M:LSI | KNN | No | 84 | 81 | 81 | 89 | 71 | 67 | 67 | 86 | 70 | 66 | 66 | 87 | 70 | 61 | 63 | 87 | 67 | 59 | 61 | 87 | 61 | 51 | 53 | 86 |
| Yes | 82 | 76 | 75 | 87 | 77 | 75 | 75 | 91 | 81 | 80 | 79 | 95 | 86 | 85 | 85 | 97 | 90 | 90 | 90 | 98 | 94 | 94 | 93 | 100 | ||
| NB | No | 68 | 56 | 40 | 62 | 65 | 55 | 55 | 81 | 69 | 67 | 67 | 91 | 72 | 69 | 69 | 93 | 68 | 64 | 64 | 94 | 62 | 56 | 57 | 94 | |
| Yes | 75 | 58 | 48 | 65 | 74 | 68 | 68 | 89 | 82 | 79 | 79 | 96 | 84 | 80 | 81 | 98 | 86 | 81 | 83 | 99 | 86 | 82 | 83 | 99 | ||
| SVM | No | 92 | 90 | 90 | 98 | 91 | 87 | 87 | 99 | 91 | 87 | 88 | 99 | 90 | 86 | 87 | 99 | 83 | 78 | 79 | 99 | 75 | 67 | 69 | 98 | |
| Yes | 96 | 96 | 96 | 99 | 96 | 96 | 96 | 100 | 97 | 97 | 97 | 100 | 98 | 98 | 98 | 100 | 98 | 98 | 98 | 100 | 98 | 98 | 98 | 100 | ||
| DT | No | 87 | 86 | 86 | 86 | 83 | 83 | 83 | 88 | 76 | 75 | 75 | 85 | 66 | 66 | 65 | 82 | 51 | 51 | 50 | 76 | 35 | 35 | 35 | 71 | |
| Yes | 91 | 90 | 90 | 90 | 89 | 89 | 89 | 93 | 87 | 87 | 87 | 92 | 86 | 86 | 86 | 93 | 85 | 85 | 85 | 92 | 84 | 84 | 84 | 92 | ||
| RF | No | 90 | 86 | 86 | 96 | 90 | 86 | 87 | 97 | 88 | 85 | 85 | 98 | 85 | 80 | 81 | 97 | 78 | 70 | 72 | 97 | 67 | 55 | 57 | 95 | |
| Yes | 95 | 95 | 95 | 99 | 94 | 94 | 94 | 99 | 95 | 95 | 95 | 100 | 96 | 96 | 96 | 100 | 97 | 97 | 97 | 100 | 98 | 98 | 98 | 100 | ||
| NN | No | 77 | 72 | 72 | 82 | 78 | 77 | 77 | 92 | 85 | 85 | 83 | 97 | 86 | 85 | 84 | 98 | 79 | 77 | 77 | 98 | 72 | 70 | 70 | 98 | |
| Yes | 91 | 89 | 90 | 96 | 91 | 91 | 90 | 98 | 96 | 96 | 96 | 100 | 97 | 97 | 97 | 100 | 98 | 98 | 97 | 100 | 98 | 98 | 98 | 100 | ||
| M:LSI-Co | KNN | No | 70 | 69 | 69 | 79 | 61 | 61 | 61 | 81 | 50 | 50 | 49 | 80 | 45 | 41 | 41 | 80 | 38 | 35 | 34 | 78 | 32 | 25 | 25 | 75 |
| Yes | 79 | 79 | 79 | 85 | 72 | 72 | 71 | 89 | 67 | 67 | 67 | 91 | 72 | 72 | 71 | 95 | 81 | 81 | 80 | 97 | 88 | 88 | 88 | 98 | ||
| NB | No | 71 | 67 | 68 | 77 | 52 | 46 | 46 | 74 | 41 | 40 | 38 | 77 | 39 | 37 | 35 | 80 | 33 | 26 | 25 | 82 | 28 | 23 | 18 | 82 | |
| Yes | 71 | 68 | 67 | 77 | 56 | 54 | 54 | 78 | 41 | 41 | 38 | 79 | 44 | 40 | 40 | 86 | 45 | 34 | 35 | 88 | 47 | 37 | 36 | 92 | ||
| SVM | No | 71 | 67 | 67 | 74 | 54 | 51 | 49 | 76 | 47 | 43 | 42 | 80 | 51 | 36 | 36 | 85 | 44 | 30 | 31 | 87 | 37 | 21 | 22 | 86 | |
| Yes | 71 | 69 | 68 | 77 | 61 | 59 | 58 | 82 | 57 | 55 | 55 | 87 | 62 | 57 | 58 | 93 | 74 | 71 | 71 | 97 | 85 | 83 | 84 | 99 | ||
| DT | No | 75 | 75 | 75 | 75 | 62 | 63 | 62 | 75 | 50 | 50 | 50 | 72 | 40 | 39 | 39 | 69 | 28 | 28 | 28 | 65 | 22 | 22 | 21 | 63 | |
| Yes | 79 | 79 | 79 | 79 | 72 | 72 | 71 | 82 | 66 | 66 | 66 | 81 | 68 | 68 | 68 | 83 | 71 | 71 | 71 | 85 | 76 | 76 | 76 | 88 | ||
| RF | No | 77 | 77 | 77 | 85 | 69 | 68 | 68 | 87 | 64 | 61 | 62 | 89 | 57 | 53 | 53 | 89 | 50 | 44 | 44 | 90 | 39 | 31 | 32 | 89 | |
| Yes | 82 | 82 | 82 | 89 | 78 | 78 | 78 | 93 | 80 | 80 | 79 | 96 | 83 | 83 | 83 | 98 | 89 | 89 | 89 | 99 | 94 | 94 | 94 | 100 | ||
| NN | No | 71 | 66 | 66 | 77 | 56 | 54 | 53 | 77 | 48 | 45 | 45 | 81 | 48 | 41 | 41 | 86 | 40 | 37 | 37 | 88 | 33 | 29 | 29 | 88 | |
| Yes | 68 | 67 | 67 | 78 | 58 | 58 | 57 | 82 | 53 | 53 | 52 | 85 | 61 | 60 | 60 | 93 | 72 | 72 | 71 | 97 | 85 | 85 | 84 | 99 | ||
| M:BM25 | KNN | No | 80 | 78 | 78 | 87 | 74 | 72 | 72 | 90 | 68 | 64 | 65 | 88 | 54 | 51 | 52 | 84 | 44 | 38 | 39 | 80 | 35 | 26 | 27 | 77 |
| Yes | 83 | 82 | 82 | 91 | 80 | 79 | 79 | 94 | 80 | 80 | 80 | 96 | 82 | 82 | 81 | 97 | 84 | 84 | 83 | 98 | 89 | 89 | 88 | 99 | ||
| NB | No | 82 | 82 | 82 | 90 | 67 | 68 | 65 | 87 | 62 | 58 | 57 | 87 | 51 | 47 | 45 | 85 | 41 | 35 | 34 | 84 | 31 | 23 | 22 | 79 | |
| Yes | 83 | 83 | 83 | 90 | 71 | 69 | 67 | 89 | 68 | 62 | 62 | 90 | 60 | 53 | 53 | 89 | 55 | 45 | 47 | 90 | 52 | 40 | 41 | 88 | ||
| SVM | No | 86 | 85 | 85 | 94 | 84 | 79 | 79 | 96 | 79 | 74 | 75 | 96 | 74 | 63 | 66 | 95 | 67 | 51 | 53 | 94 | 55 | 36 | 39 | 93 | |
| Yes | 89 | 89 | 89 | 96 | 89 | 88 | 89 | 98 | 89 | 89 | 89 | 99 | 87 | 86 | 86 | 99 | 88 | 87 | 87 | 100 | 91 | 91 | 91 | 100 | ||
| DT | No | 77 | 76 | 76 | 78 | 73 | 72 | 71 | 81 | 61 | 61 | 60 | 78 | 51 | 51 | 50 | 75 | 41 | 41 | 41 | 71 | 28 | 28 | 27 | 68 | |
| Yes | 84 | 83 | 83 | 85 | 81 | 80 | 81 | 88 | 78 | 78 | 78 | 88 | 76 | 76 | 76 | 88 | 76 | 76 | 76 | 88 | 78 | 78 | 78 | 89 | ||
| RF | No | 85 | 84 | 84 | 93 | 81 | 77 | 78 | 95 | 74 | 72 | 72 | 94 | 65 | 62 | 63 | 93 | 55 | 50 | 51 | 92 | 42 | 36 | 36 | 90 | |
| Yes | 89 | 89 | 89 | 96 | 88 | 88 | 88 | 97 | 88 | 88 | 88 | 98 | 89 | 89 | 89 | 99 | 90 | 90 | 90 | 99 | 93 | 93 | 93 | 100 | ||
| NN | No | 87 | 87 | 87 | 95 | 86 | 83 | 84 | 96 | 80 | 79 | 79 | 96 | 71 | 70 | 70 | 95 | 60 | 58 | 58 | 94 | 47 | 45 | 45 | 93 | |
| Yes | 92 | 92 | 92 | 97 | 92 | 91 | 91 | 98 | 91 | 90 | 90 | 99 | 92 | 91 | 91 | 99 | 92 | 92 | 92 | 99 | 93 | 93 | 93 | 100 | ||