Full Shape Cosmology Analysis from BOSS in configuration space using Neural Network Acceleration
Abstract
Recently, a new wave of full modeling analyses have emerged within the Large-Scale Structure community, leading mostly to tighter constraints on the estimation of cosmological parameters, when compared with standard approaches used over the last decade by collaboration analyses of stage III experiments. However, the majority of these full-shape analyses have primarily been conducted in Fourier space, with limited emphasis on exploring the configuration space. Investigating n-point correlations in configuration space demands a higher computational cost compared to Fourier space because it typically requires an additional integration step. This can pose a limitation when using these approaches, especially when considering higher-order statistics. One avenue to mitigate the high computation time is to take advantage of neural network acceleration techniques. In this work, we present a full shape analysis of Sloan Digital Sky Survey III/BOSS in configuration space using a neural network accelerator. We show that the efficacy of the pipeline is enhanced by a time factor without sacrificing precision, making it possible to reduce the error associated with the surrogate modeling to below percent which is compatible with the precision required for current stage IV experiments such as DESI. We find , and . Our results on public BOSS data are in good agreement with BOSS official results and compatible with other independent full modeling analyses. We explore relaxing the prior on and varying , without significant changes in the mean values of the cosmological parameters posterior distributions, but enlarging their widths. Finally, we explore the information content of the multipoles when constraining cosmological parameters.
1 Introduction
Over the last decade, the study of the clustering of galaxies through Large Scale Structure (LSS) surveys has emerged as a crucial probe within precision Cosmology. Spectroscopic surveys, such as the Sloan Digital Sky Survey222www.sdss.org (SDSS) and the Dark Energy Spectroscopic Instrument333www.desi.lbl.gov (DESI) provide three-dimensional maps of the Universe, where angular positions and redshifts of millions of galaxies are measured with high accuracy. These maps constitute appropriate data sets for quantifying the clustering characteristics of galaxies, including correlation functions and other summary statistics, which then can be compared to models’ theoretical predictions.
The study of clustering statistics has primarily relied on two significant sources of cosmological information. First, Baryon Acoustic Oscillations (BAO) in the early Universe freeze up at the drag epoch, whose signature can be observed at later times in the correlation function as a well-distinguished peak around a scale of 150 Mpc. Second, peculiar velocities of galaxies contributes to the redshift that we measure adding to the Hubble flow component. Since this contribution occurs only along the line-of-sight direction, we observe an apparent anisotropic distortion in the matter distribution, and hence, galaxy statistics which otherwise would be isotropic become dependent on the angle of observation. This effect is known as Redshift Space Distortions (RSD).
RSD and BAO effects most of the relevant information about the correlation function of galaxies. Consequently, the SDSS-III BOSS [1, 2, 3] and SDSS-IV eBOSS [4, 5, 6] collaborations have chosen compressed methodologies for their standard analysis. In such approaches, the cosmological parameters of the matter power spectrum are fixed to fiducial values, and a set of parameters characterizing the BAO and RSD effects are explored. Given that RSD depends on the average velocity of galaxies, it is sensitive to the growth rate of structure, so one of the chosen parameters is . Two additional degrees of freedom should be included to account for the distortions in the position of the BAO along and across the line-of-sight, which arise from potential mismatches between the fiducial and true cosmologies, that is, the Alcock-Paczyński effect [7].
On the other hand, the Effective Field Theory of LSS (hereafter simply EFT) [8, 9, 10, 11, 12, 13] built on top of Perturbation Theory [14] has been developed during the past years, and by now is currently used in analyses that confront theoretical models of the galaxy distribution directly to the data gathered by our telescopes. These methods are commonly known as full-modeling or full-shape analyses, and operate in a similar fashion that it has been done for the CMB over the years. Nowadays, these full-shape templates are used routinely to constrain cosmological parameters [15, 16, 17, 18, 19, 20], including higher-order statistics [21, 22] and even beyond CDM models [23, 24, 25, 26, 27].
One of the primary advantages of the compressed methodology is its agnostic nature: the parameters it explores are relatively model-independent when compared with those obtained from a direct, full-shape analysis. However, generating full-shape theoretical templates of the power spectrum comes with significant computational costs, which, until recently, hindered our ability to perform cosmological parameter estimation. This is one of the reasons why the compressed methodology has been favored by some part of the community. But even if the full-shape analysis is expensive and model-dependent, it is capable of extracting more cosmological information from the power spectrum. Therefore, both the compressed and full-shape methodologies have their own merits, and there should be an incentive to pursue both approaches in parallel.
As we transition into a new era of cosmological surveys, the costs of full-shape models are set to increase even further. This is due to the unprecedented precision achieved in measurements on small scales of the correlation function (smaller than 50 ), where the nonlinearities of perturbations exert a none negligible influence on halo distributions. Furthermore, at these small scales, the relationship between the clustering of observable astrophysical tracers and the underlying dark matter halos becomes complex. As a consequence, building accurate templates at these small scales might require the evaluation of even more complicated models, thereby introducing more intricate calculations and increasing the computational cost of an individual template. Finally, the analytical modeling of higher order statistics will pose new computational time challenges.
In recent years, a number of avenues have been developed to tackle these difficulties and going beyond the standard three parameters compress methodology and into more intricate models at this smaller scales. One possible road is to expand the compress approach by introducing a small subset of new free parameters that encompass most of the remaining relevant information in the power spectrum [28]. Another possibility is to perform full shape analyses encompassing various cosmological parameters. To achieve this, several optimizations in the computational methods used to construct theoretical templates have been developed, significantly reducing the computational cost of full shape analyses.
As a result, many groups have reanalyzed the BOSS and eBOSS data using full-shape modeling. The optimized methodologies employed for these analyses can be categorized into two groups: efficient theoretical templates of the power spectrum [e.g. 15, 16, 17, 29, 30, 31] or emulator techniques that learn how to reproduce expensive models [e.g. 32]. The consensus from all of these reanalysis methods is that the constraints on cosmological parameters like the Hubble constant are significantly tighter when using these improved approaches [33].
In configuration space, the number of analyses in the literature is reduced, mainly because the consensus is that direct-fits are more constrictive in Fourier space. Nevertheless, working directly in configuration space has its benefits, particularly when dealing with the well localized BAO peak, which in Fourier space becomes distributed across a wide range wave numbers. Adding to that, some of the observational systematic have different effects in Fourier and configuration space. Consequently there is an incentive to study both spaces simultaneously. In ref.[30] the main analysis is performed in Fourier space but the authors have also worked out the correlation function as a consistency check. On the other hand, the work of [19] is devoted to perform fitting only to the correlation function using the PyBird code. The main difference with our approach is that we work from the beginning in a Lagrangian framework, and get directly the correlation function without the necessity of obtain first the power spectrum (plus adding infrared resummations) as an intermediate steps, to at the end Fourier Transform the results to the obtain the correlation function.
The number of free parameters to explore in full shape analysis is generally large when compared to the standard approach. With this in mind, considerable efforts have been made in building efficient sampling methods [34, 35, 36] which reduce the number of model evaluations required to run Markov Chain Monte Carlo (MCMC) explorations. However, the models will most likely continue to increase in complexity in the next years, since higher loop contribution or higher order statistics can be considered in the analyses. Therefore, there is an incentive to reduce the computational cost of generating these theoretical templates.
Machine Learning algorithms like Neural Network have been successfully used to drastically reduce the evaluation times of complex models [e.g. 37]. These techniques use datasets of pre-computed templates at different points within the parameter space and learn how to reproduce them. When trained correctly, neural networks can reproduce fairly complex models with an error smaller than the precision needed by LSS surveys. Also, given that neural networks are not local interpolators, in principle the errors in their predictions are not as strongly dependent on the distance of the nearest point within the training set, as methodologies like Gaussian processes emulators would be.
In this work, we model the redshift space correlation function up to one-loop perturbation theory using a Gaussian Streaming model [38, 39, 40, 41, 12] in combination with Effective Field theory (EFT). Throughout this work, we refer to our modeling as EFT-GSM. To implement our model, we release a code444https://github.com/alejandroaviles/gsm that uses a brute force approach, but still can compute the correlation function in time, as described in section 3.1. However, the number of evaluations required to build a convergent MCMC chain for our baseline analysis is large, and this process can take a considerably amount of time. Therefore, we also built a neural network emulator to accelerate the computation of individual templates, reducing the running time of an MCMC chain from a few tens of hours to around 60 minutes (using the same computing settings) and below 20 minutes when we run the code in parallel depending on the cluster settings.
We utilize our methodology to reanalyze the BOSS DR12 LRG data obtaining the tightest constraints on the CDM parameters using the 2-point correlation function alone. Throughout this study, we pursue two primary objectives. The first is to bring forward the potential of our full shape modelling approach in configuration space for extracting cosmological information when compared to its counterpart in Fourier space. The second objective is to demonstrate that neural network surrogate models can be used safely to optimize cosmological analysis, leading to significant savings in both time and computational resources without sacrificing accuracy when analyzing real data.
We have also tested extended regions in parameter space compared with the baseline analysis to include scenarios with prior configurations beyond Planck [42] and Big Bang Nucleosynthesis (BBN) [43] on parameters and that will serve us to explore the potential of LSS observables standalone. This serves as a test of the full methodology in highly more degenerated scenarios than the baseline and with aim to prove the viability of the use of neural network in this larger and more complex parameter space.
This paper is organized as follows, we begin in section 2, introducing the data from the BOSS collaboration that we analyze here, as well as introducing a set of different mock simulations that we use for testing our methodology and building the covariance matrices required for our likelihood estimations. Then in section 3 we introduce the EFT-GSM model that we utilize to construct our theoretical templates. Then, in section 4 we introduce our neural network methodology, which is used as a surrogate model instead of the EFT-GSM model, we also quantify how much efficiency is gained with this. In section 5 we describe the fitting methodology, including a brief description of full shape fits. Here we also emphasise our parameter space and the priors that we impose on each parameter. Section 6 presents the validation of the methodology with high precision mocks and section 7 presents the results of our baseline analysis and how it compares with published alternative analysis of BOSS. We also include a subsection with results expanding the priors for cosmological parameters usually constrained independently by other observables and a subsection exploring the information content in the multipoles.
2 Data and Simulations
2.1 Data
We analyse the publicly available data from Sloan Baryon Oscillation Spectroscopic Survey (BOSS) [2], which was a part of the Sloan Digital Sky Survey III [SDSS-III; 1]. Specifically, we utilize the Data Release 12 galaxy catalogues [3], gathered using the 2.5-meter telescope situated at the Apache Point Observatory in New Mexico, USA [44], and all the spectra were measured using a set of multi-object spectrographs [45]. The details about the data reduction methodology can be found at [46].
The BOSS target selection was designed to collect data for two different samples: the low-redshift sample (LOWZ), which targeted luminous red galaxies at redshifts , and the Constant Stellar Mass sample, (CMASS), which targeted massive galaxies in the redshift range. As explained in [47, 48], LOWZ and CMASS samples were later combined into three partially overlapping bins, this was done to optimise obtaining the strongest constraints on the dark energy parameters. Throughout this work we will refer to these bins as , and respectively. The catalogue construction is described in [49, 50, 48] where the masks, completeness, and weights of the sample are also discussed. The main properties of these samples are summarized in Table 1.
Our final analysis is performed using the low and high redshift bins ( and , respectiveely) which do not overlap in redshift and have a similar effective volume, .555The effective volume is defined by where is the volume of the shell at with . The value of is chosen for being the amplitude of the power spectrum where the BAO signal is larger [49, 51].
| Name | -range | ||||
|---|---|---|---|---|---|
| LOWZ | 0.32 | 361,762 | 2.87 | 3.7 | |
| CMASS | 0.57 | 777,202 | 7.14 | 10.8 | |
| BOSS | 0.38 | 604,001 | 3.7 | 6.4 | |
| BOSS | 0.51 | 686,370 | 4.2 | 7.3 | |
| BOSS | 0.61 | 594,003 | 4.1 | 12.3 |
2.2 Simulations
In this work, we employ two distinct sets of simulations that we require for constructing the necessary covariance matrices for our likelihood estimations (see section 5), and for validating our methodology using high-precision mocks. We now present a brief overview of these simulations.
-
•
The NSERIES [48] mocks are a suit of high-resolution N-body simulations that were used in both BOSS DR12 and eBOSS DR16 analysis. Their main purpose was to test the various fitting methodologies used for theoretical systematics. NSERIES consists of 84 mock catalogues.
These mocks are generated from seven independent simulations conducted in a volume of and created using the -body code GADGET2 [52]. Furthermore, each simulation is projected into seven different orientations and cuts, resulting in a total of 84 distinct mock datasets. These mocks are populated with galaxies using an HOD scheme designed so that the galaxy catalogue matches the CMASS sample. The cosmological parameters adopted for N-Series are: , , , , and . Here, we use the cutsky NSERIES mocks, whose footprint and number density correspond to that of CMASS north galactic cap at a redshift of z=0.55.
-
•
The MultiDark Patchy BOSS DR12 mocks (hereafter MD-Patchy mocks) [53, 54] are a suit of 1000 simulations used to estimate the covariance matrix required for analyzing BOSS data. MD-Patchy mocks are based on second-order Lagrange perturbation theory and use a stochastic halo biasing scheme calibrated on high-resolution N-body simulations. Each mock is built from a box of and is populated with halos following an HOD scheme calibrated to match the BOSS samples. The MD-Patchy cosmology is: , , , and . MD-Patchy mocks were designed to match the number density and footprint of both the CMASS and LOWZ samples from Data Release 12 and were also split into the 3 redshift bins defined above.
3 Modelling the redshift space correlation function
In this work we adopt a Lagrangian approach, on which we follow the trajectories of cold dark matter particles with initial position through the map
| (3.1) |
where is the Lagrangian displacement field. The observed positions of objects are distorted by the Doppler effect induced by their peculiar velocities relative to the Hubble flow, . That is, for a tracer located at a comoving real space position , its apparent redshift-space position becomes , with along the line-of-sight “velocity”
| (3.2) |
where we are using the distant observer approximation on which the angular observed direction of individual galaxies are replaced by a single line-of-sight direction , which is representative to the sample of observed objects. The map between Lagrangian coordinates and redshift-space Eulerian positions becomes
| (3.3) |
The correlation function of tracer counts in redshift space is given by the standard definition
| (3.4) |
where the tracer fluctuation in redshift space is . Now, the conservation of number of tracers , that reads , yields the redshift-space correlation function [39]
| (3.5) |
where and . The density weighted pairwise velocity generating function is
| (3.6) |
where .
The generating function is now expanded in cumulants . That is,
| (3.7) |
where in the second equality we use the Taylor series of about . The cumulants are then obtained by
| (3.8) |
Then,
| (3.9) |
On the other hand, the generating function can be alternatively expanded in moments as follows
| (3.10) |
which lead us to relations between cumulants and moments
| (3.11) | ||||
| (3.12) | ||||
| (3.13) |
where we introduced the pairwise velocity along the line of sight and the pairwise velocity dispersion along the line of sight moment and cumulant, and , respectively. These relations will serve us below, since moments are more directly computed from the theory than cumulants.
Using eq. (3.9), the correlation function in redshift space is
| (3.14) |
If we stop at the second order cumulant , the -integral can be formally performed analytically, giving
| (3.15) |
which is the Gaussian Streaming Model correlation function.
Now, depending on how one computes the ingredients , and , different methods can be adopted from here. For example: 1) Reference [40] computed within the Zeldovich approximation, but the pairwise velocity () and pairwise velocity dispersion () using Eulerian linear theory. 2) In [41] Convolution Lagrangian Perturbation Theory (CLPT) is used for the three ingredients, but instead of computing , the authors computed . This latter reference also released a widely used code by the community.666Available at github.com/wll745881210/CLPT_GSRSD.
Here, we will use the method of [55, 56, 57], where all moments are computed using CLPT. Further, in our modeling we consider a Lagrangian biasing function that relates the galaxies and matter fluctuations through [58, 59]
| (3.16) |
In the second equality is the Fourier transform of , with arguments and spectral parameters , dual to . A key assumption that we follow here, is the number conservation of tracers,777Notice the number conservation assumption of tracers is not even true for halos. However, the biasing expansion obtained in this way is automatically renormalized and coincides with other more popular methods that introduce the biasing through the symmetries of the theory; see [60] for a review. from which one obtains
| (3.17) |
and evolves initially biased tracer densities using the map between Lagrangian and Eulerian coordinates given by eq. (3.1). Renormalized bias parameters are obtained as [58, 59]
| (3.18) |
with covariance matrix components , and . We notice are local Lagrangian bias parameters, and is the curvature bias. In this work we consider only and . However, tidal Lagrangian bias, , can be easily introduced following [56].888Indeed, our code gsm-eft consider tidal bias, but we use the formulae presented in [61], which differ slightly from that in [56].
To obtain the cumulants we need to compute the moments. The procedure is exactly the same as with the correlation function (the zero order moment), but now we have to keep track of the velocity fields. That is, using
we obtain
where we defined and used .
The real space correlation function , which corresponds to the zeroth-order moment for tracer , is obtained within CLPT, [62, 63, 12, 55, 64, 59],
| (3.19) |
where the matrix , with , is the correlation of the difference of linear displacement fields for initial positions separated by a distance , which is further split in linear and loop pieces:
| (3.20) |
where is the linear matter power spectrum. We further use the linear (standard perturbation theory) correlation function
| (3.21) |
and the functions
| (3.22) |
The involved and dependent tensors are , , and .
The first and second moments of the generating function yield the pairwise velocity
| (3.23) |
and the pairwise velocity dispersion
| (3.24) |
with -coordinate dependent correlators
| (3.25) |
As in the case of the undotted function, we have omitted to write the superscripts when these are zero; e.g, .
Now, consider the terms inside the curly brackets in eq. (3). Taking its large scales limit (), we obtain
| (3.26) |
which is a non-zero zero-lag correlator. However, since perturbation theory cannot model accurately null separations, one needs to add an EFT counterterm that has the same structure. This new contribution shifts the pairwise velocity dispersion as [56]
| (3.27) |
As the separation distance increases, the ratio approaches unity, then the EFT counterterm adds as a constant shift to the pairwise velocity dispersion at large scales. That is, we can identify it with the phenomenological parameter widely used in early literature to model Fingers of God (FoG). Comparisons for the modeling of the second moment when using the EFT parameter and the constant shift can be found in [61] (see for example Fig. 2 of that reference where a particular example exhibits a clear improvement of the EFT over the phenomenological constant shift). Finally, we notice our counterterm is related to that in [56] by .
There are others EFT counterterms entering the CLPT correlation function and the pairwise velocity and velocity dispersion, but they are either degenerated with curvature bias (as is the case of ) or subdominant with respect to the contribution of eq. (3.27) (see the discussion in [56]). So, in this work we keep only .
Since this EFT parameter modifies the second cumulant of the pairwise velocity generation function, its effect on the redshift space monopole correlation function is small, while the quadrupole is quite sensitive to it, particularly at intermediate scales .
Now, let us comeback to eq. (3.14), that we formally integrated to obtain eq. (3.15). However, notice the matrix is not invertible since and hence . Hence in the following we will approach this integration differently that will also serves us to rewrite the resulting equation in a more common form and also more directly related with the computational algorithms in a code.
We decompose the vectors , and in components parallel and perpendicular to the line of sight :
| (3.28) |
with , and so on. We will use the following definitions
| (3.29) | ||||
| (3.30) | ||||
| (3.31) |
with and , and
| (3.32) |
Then, we can split the integral eq. (3.14) in parallel and perpendicular to the line-of-sight integrations,
obtaining a Dirac delta function from the integral of the perpendicular component and a Gaussian kernel from the parallel one.
Hence, the correlation function within the GSM becomes
| (3.33) |
with . This is a wide popular expression, but remind that here is the second cumulant of the density weighted velocity generating function, instead of its second moment. Also, it suffers correction from EFT counterterms.
The streaming models [65, 38, 39] describe how the fractional excess of pairs in redshift space is modified with respect to their real-space counterpart :
| (3.34) |
Here and . The above expression is exact; see eqs.(1)-(12) of [39]. This means that a knowledge of the form of the pairwise velocity distribution function at any separation , yields a full mapping of real- to redshift-space correlations. In the GSM approximation, the distribution function becomes Gaussian centered at and with width equal to .
The main drawback of this approach is that the is, of course, not a Gaussian [39, 40, 66]. In [66], the authors extract the ingredients of the pairwise velocity disribution moments directly from simulations and use them to obtain the correlation function multipoles using the GSM and the Edgeworth streaming model of [55], finding good agreement with the redshift space correlation function extracted from the same simulations, but only above scales of around . Our findings also indicate that our modeling and pipeline fits well the simulations above this same scale.
3.1 gsm-eft code
Together with this work, we release the C-language code gsm-eft999Available at github.com/alejandroaviles/gsm, which computes the multipoles of the one-loop GSM two-point correlation function in about half a second. The code receives as input, the linear power spectrum, as obtained from CAMB, as well as the set of nuisance parameters: These includes the biases , , and , the EFT parameters (a.k.a. ), and , and the cosmological parameter , which is necessary to calculate the growth rate at the output redshift.
Notice that the CLPT integrals involve the -integration with a Gaussian kernel centered at . This can be challenging for large because a naive calculation with the origin centered at will require a very fine grid for the angular integration, which should get finer as gets larger. Hence we adapt the integrals to be always be centered at . This change of variable allows us to perform the angular integration with high accuracy using a Gauss-Legendre method with only gsm_NGL=16 weights.
Finally, when exploring the parameter space in an MCMC algorithm, the cumulant can become negative. To avoid this unphysical behavior we do the following.101010In [56] it is warned that this can happen, and advise to keep only the linear part of in the exponential and expand the rest. This approach is well physically motivated since only the loop terms are expanded, which is also in the spirit of CLPT. However, we indeed tried this method, and find no very satisfactory results. A second approach we followed, yielding even worst results, is to simply impose a sharp minimum cut to to a very small, but still positive number. We split the cumulant of eq. (3.31) as , that is, in linear and loop pieces, the latter containing the EFT counterterm and velocity moments. When , with close but below unity, we transform the variable
| (3.35) |
with
| (3.36) |
where the constants and are given by
| (3.37) | ||||
| (3.38) |
with this transformation the range is shortened to , while the one-loop cumulant stays smooth and is strictly positive. After preliminar tests, we chose the value .
4 Accelerating Modeling with Neural Networks
Our full shape analysis requires an exploration of a relatively large parameter space. Each model requires approximately 1.5 seconds in our computer to run. Given the large number of evaluations required to explore the parameter space (of the order of ), and the large amount of MCMC chains we are interested in running, there is an incentive to optimize the evaluation process of our model.
There are various methodologies available for accelerating the estimation of these statistics. The choice between using one or another depends on several factors, one of them being the number of models that can be constructed to use as a training set. In our case, the Gaussian streaming model presented in Section 3 is relatively cost-efficient. To run our model, we first construct a template of the power spectrum using the publicly available Code for Anisotropies in the Microwave Background (CAMB) [67, 68], which completes in approximately one second. We then utilize this template as input for our gsm-eft code, which requires an additional half-second to compute the correlation function multipoles. Considering this, we can efficiently generate training data sets of several tens of thousands of points within a reasonable computational time. Recently, neural networks, have proved to be a suitable framework to accelerate the estimation of clustering statistics for training sets of this size [e.g. 69, 37]. Moreover, neural networks are particularly efficient in data generalization, affording an almost constant reliability over the full parameter space (i.e. the model error does not strongly depends on the distance with the nearest point used on the training set).
In what follows, we present our emulating methodology. Our approach is derived from the methodology proposed in [37], but we have made modifications to adapt it for configuration space. The following subsection provides a detailed explanation of our methodology and highlights the specific changes we have implemented to transition into configuration space. Once our neural networks are trained, we reduce the evaluation time needed for a single point in parameter space to around 0.015 seconds, which improves in two orders of magnitude the Likelihood evaluation time.
We note that a distinct neural network emulator is necessary for each multipole of the correlation function at a specific redshift.111111One can decide to train a global neural network including the two multipoles. However, it corresponds to expanding the exit layer by a factor of three without a win of information between them. Throughout this study, we utilize the first two non-zero multipoles of the correlation function. Consequently, each analysis presented in this work entails constructing two neural network emulators. The construction process for each emulator takes approximately 30 minutes when performed on our personal laptops. It is worth mentioning that it might be feasible to reduce the building time of a single neural network by adjusting certain parameters, as discussed below. Nevertheless, since the number of neural networks we use is small, we find the current building time to be manageable.
Other methodologies that operate in Fourier space [e.g. 70, 37], aim to predict values for all wave numbers of interest, which typically comprise hundreds of points. If a brute force approach were employed, where one asks the neural network to directly predict the power spectrum, it would need to make hundreds of predictions, which would increase the time required to build the network. Therefore, methodologies utilizing Fourier space often employ techniques such as principal component analysis to address this issue.121212In principal component analysis, the input power spectra matrix is divided into eigenvectors, which are dependent on the wave number, and their corresponding eigenvalues, which only rely on the cosmology. This enables an approximation of the power spectra by considering a linear combination of the most significant eigenvalues and discarding the rest, reducing the number of predictions necessary.
Here, we model the correlation function from 20 to 130 in 22 bins with a 5 width between each bin in redshift space distance , therefore, each emulator needs to predict only 22 numbers.
We have found no necessity to incorporate principal component analysis as part of our methodology as Fourier space works utilize a number of principal components similar to the number of bins we employ.
To train each neural network, we generate 60,000 models distributed across the parameter space. Out of these, 50,000 models are utilized for training, while 5,000 models constitute the validation set. The validation set is employed during the training process to test the data and determine when to decrease the learning rate of the network, as explained below. The remaining 5,000 models form our test set and are reserved for evaluating the accuracy of the methodology on unseen data so that we perform a fair assessment of the trained models.
We use Korobov sequences [71] to select the points in the parameter space used for building and testing our neural networks. Korobov sequences are a robust approach for generating extensive and uniform samples in large dimensional spaces. We run three distinct sequences to create the training, test, and validation sets at each distinct redshift that we model. We also make sure that the three sequences are independent and that there are no overlapping points between them. Finally, we employ our EFT-GSM model pressented in section 3 to calculate the multipoles of the power spectra for all 60,000 data points. These EFT-GSM multipoles are used to train our neural networks, that aim to accurately replicate the GSM predictions for a new point in parameter space.
In order to make the training of the neural network more efficient, it is convenient to keep the values of the output layer neurons in a similar range of values. Here, we use a hyperbolic sinus transformation on each of the training set multipoles for this purpose.
We run our neural networks by adapting the public code from [37],131313Which is available at https://github.com/sfschen/EmulateLSS/tree/main to reflect the changes expressed above. We use the Multi-Layer Perceptron architecture suggested by them, with four hidden layers of 128 neurons each. As we discuss below, the accuracy that we obtain in our predictions is well within the precision we need and this is achieved in a manageable time. Therefore, we decided that no further optimization of the architecture to fit our particular data was necessary. When training our networks, we reduce the learning rate of the algorithm from to in steps of one order of magnitude and double the training batch size at every step. As suggested by several works [e.g. 72, 37], we use the following activation function,
| (4.1) |
which we found outperforms other more common activation functions like Rectified linear units. Here, and are new free parameters of a given hidden layer within the neural network that are fitted during the training process of the network.
The algorithm decreases the learning rate when a predetermined number of training epochs have passed without any significant improvement on the accuracy of the model, this number is commonly referred to as the patience of the algorithm.141414We track the mean square error (MSE) of the validation set, the algorithm records the best value found so far. When a number of epochs equal to our patience value have elapsed whiteout a better MSE being found, the algorithm switches the learning rate. Note that a larger patience allows the model more time to exit local minima, and address slow convergence issues. The patience we use determines the time required to train our neural networks, longer patience usually leads to more accurate models (provided the model is not overfitted). The results presented in this work correspond to waiting 1000 epochs before reducing the learning rate, which, as stated above corresponds to approximately 30 minutes of training time, also, we have monitored our validation set to ensure that there are no signs of overfitting at this point.151515 An overfitted model would start to worsen the MSE of the validation set after a given training epoch. If our goal were to reduce the training time of the algorithm, we could decrease the patience value. However, this would reduce the accuracy of our models, we note that a patience of around 100 epochs reduces the training time to around 5 minutes on our personal laptops while still maintaining sub-percent accuracy in most multipole models.
5 Methodology
In this section, we define the methodology employed to extract cosmological information from galaxy clustering. First, we describe the clustering measurements we utilize. Next, we provide an overview of our full shape methodology. We also discuss the likelihood, priors, covariance, and MCMC samplers used throughout our analysis.
5.1 Clustering measurements and fiducial cosmology
Throughout this work, we focus on the anisotropic 2-point correlation function , which we project under the Legendre polynomial basis following equation 5.1:
| (5.1) |
Here, is the order of the polynomial and is the cosine of the angle between the separation vectors and the line-of-sight direction.
We use the legacy multipoles from BOSS [48] computed with the fiducial cosmology , , , , , , , , , and .
In this work, we utilize the first two non-zero multipoles of the correlation function that correspond to .
5.2 Full Shape Methodology
The full-shape methodology followed to constrain cosmological parameters consists of varying a theoretical model (or the equivalent statistics in Fourier space) at different points in parameter space and comparing the resulting models directly with the measured clustering without any compression of the information. The way in which we select the points to be explored in parameter space is described in section 5.3 below. Throughout this work, we use the GSM-EFT model to build templates of the multipoles of the galaxy correlation function in redshift space, using eq. (3.33). The methodology implemented here can be used with any other perturbation theory correlation function code; e.g. Velocileptors161616https://github.com/sfschen/velocileptors [73, 13]. In order to compute a given correlation function template with GSM-EFT, it is necessary to provide a fixed value of the free parameters of the model. These free parameters can be divided into three distinct subsets. The first subset corresponds to the cosmological cosmological parameters required to construct the linear power spectrum from CAMB, these parameters are , , , , , , . Our second set of parameters are the three nuisance parameters used to model the relationship between galaxies and matter and the EFT counterterms. These parameters are , , and , and and .
As explained in section 4, we use surrogate models built with neural networks to optimize the speed at which we can generate theoretical templates. Clustering measurements employ a reference cosmology for transforming redshift to distance measurements. This reference cosmology introduces Alcock-Paczyński distortions that must be considered when comparing our data and model multipoles. To address this issue, we employ a pair of late-time re-scaling parameters, denoted as and , which introduce the necessary corrections to the galaxy clustering in two directions: along and perpendicular to the line of sight. This approach enables us to account for the impact of an inaccurate fiducial cosmology when calculating the clustering. The components of the separation in the true cosmology (,) are expressed in terms of the components of separation in the fiducial cosmology (,) as follow:
| (5.2) |
The geometric distortion parameters, perpendicular and parallel to the line of sight, are defined as
| (5.3) |
here is the angular diameter distance, is the Hubble parameter, and the superscript indicates that the estimate is done in the reference or fiducial cosmology of the data multipoles. We use an alternative parametrization of the distortion parameters defined as:
| (5.4) |
We implement the distortions directly in the clustering by replacing and , this can be computed using the re-scaling parameters as follows:
| (5.5) | |||
| (5.6) |
The multipoles are estimated in the reference cosmology with and . In order to apply the dilation parameters into our implementation, we interpolate each multipole using , we also compute the observed Legendre polynomials using .
Finally we construct , as the sum of the multipoles times their respective Legendre polynomial, and the observed multipoles in the reference cosmology become
| (5.7) |
As expected, when using the distortion parameters the different multipoles get mixed, and so the matrix is not diagonal. In principle, since we are working up to one-loop the sum is truncated at . However, notice first that the for a fixed , the dominant coefficient is . Secondly, the loop contributions of multipoles and 8 are highly suppressed, in comparison to the one-loop contribution of ultipoles and 4, because the correlation function is a very smooth function on at large scales. Because of this, it is an excellent approximation to truncate the sum at .
That is, to simplify our data analysis, we have chosen not to incorporate the dilation parameters nor their effects into our neural network training.
This choice has two advantages: first, the neural network is trained without specifying a reference cosmology, leaving the possibility of changing it in order to compare different reference cosmologies; second, training the network to reproduce the multipole vectors is more convenient than training it to reproduce the 2D correlation function.
As we have stated, our primary objective is to determine the posterior distributions of the cosmological parameters given our data multipoles.
These posterior distributions are found by doing a thorough exploration of the parameter space using MCMC chains. In the following section, we present the methodology we employ for this exploration.
5.3 Likelihood and Priors
Since we are not interested in model comparison, we can express the posterior distribution of a point in parameter space as:
| (5.8) |
Here, and are the likelihood and the prior distributions, respectively. We assume Gaussian errors on the 2-point correlation function data, and therefore, the likelihood can be written as
| (5.9) |
where is the number of degrees of freedom, and is defined as:
| (5.10) |
where and are the model and data vectors, respectively, and is the covariance matrix of the data.
Our sample covariance matrix, between bins and , is computed from the 1000 MD-Patchy mock realizations, as presented in section 2.2, using the following expression:
| (5.11) |
where represents the number of mock samples, and denotes the average of the bin in the analysis. We also include the Hartlap corrections [74], which involve rescaling the inverse sample covariance matrix as
| (5.12) |
Our parameter space exploration is done using emcee [34], an open MCMC code that implements the affine invariant ensemble sample proposed in [75]. The boundaries of the regions explored are delineated by a set of predefined priors, which are presented in Table 2. As shown in the table, we explore seven parameters and held the remaining parameters constant. Almost all of our parameters are assigned flat priors that correspond to the boundaries of the hyperspace within which our neural network is trained. We have checked that these boundaries are sufficiently large so the priors can be considered uniform. The only exception is , for which we have employed a Gaussian prior.
For this work we decided to use a local Lagrangian bias prescription, which means to fix and to zero. Further, since is highly degenerate with higher-derivative bias, we also keep it fixed to zero. Hence, the only nuisance parameters considered in this work, are , and . Further, as we show in the upcoming sections, using this simplification we can recover the cosmological parameters of simulated data with high accuracy, and our posteriors when fitting the BOSS DR12 correlation function are competitive with other analyses of the full-shape power spectrum in the literature.171717In a work currently in preparation (Sadi Ramirez et al, In prepararion), which compares compressed and full-shape methodologies, we will relax these assumptions We observe that our approach is not a complete one-loop theory because of the constraints on the free parameters. Consequently, we expect that the posterior distributions we have obtained would be more extensive if all parameters were unrestricted. However, it is worth noting that the existing full-shape studies in the literature rely on Gaussian priors for certain biasing, EFT, or shot noise parameters. Therefore, they also do not constitute full one-loop analyses.
In table 2 we show the varied parameters and their priors for our baseline full-shape analyses. We keep fixed the slope , the effective number of relativistic degrees of freedom , and the massive neutrino abundance .
| Free parameters and priors | |
|---|---|
| Cosmological | |
| Nuisances | |
Finally, to ensure convergence, we utilized the integrated autocorrelation time, checking it at intervals of 100 steps. Convergence criteria were considered reached if two conditions were met simultaneously: the chain’s length exceeded 100 times the estimated autocorrelation time, and the change in this estimation remained below the 1 per cent.
6 Validating our Methodology with High Precision Mocks
We have introduced our methodology for generating full-shape EFT-GSM models of the correlation function multipoles. Our ultimate objective is to re-analyze the BOSS data sets presented in section 2.1. We will present all the results on real data in section 7 below. In this section, we establish a series of tests to evaluate the performance of our methodology. These tests involve applying our methodology to the NSERIES simulations presented in section 2.2.
We begin in section 6.1 by assessing the accuracy and precision with which our methodology can recover the parameters of the simulations. The results presented in this section are built utilising the surrogate models built with the neural network presented in section 4, here we assume that these surrogates are a fair representation of the EFT-GSM models. Then, in section 6.2, we test this assumption by comparing the results of our neural network surrogate models with those from the EFT-GSM model.
6.1 Testing EFT-GSM Model
As stated above, we assess the effectiveness of our methodology by recovering the known free parameters of the N-series simulations. In this section, we show the accuracy and precision of these results. We fit the mean multipole of the 84 mocks instead of fitting one individual mock. This approach effectively mitigates shot noise errors in the multipole models caused by inaccuracies in the shape of a single multipole.
Our error estimates are computed using one thousand MD-Patchy simulations, which are introduced in section 2.2. For estimating the sample covariance we used the multipoles from the combined sample that includes NGC and SGC which corresponds to a . We rescale the covariance matrix by a factor of (), this is done to test the methodology in a volume of the order of DESI volume, so that we can assess whether our methodology accuracy will suffice for the upcoming next-generation surveys.
Given the complexity of modelling clustering statistics at weakly non-linear scales, we should assess the scales in redshift space distance at which our model still generates accurate fits. With this in mind, we simultaneously fit both the monopole and quadrupole of the correlation function using three different ranges with varying lower limits: and . We use these fits to determine the range at which our model estimate of the parameters gets closer to the true values. Throughout this work, we maintain a fixed upper limit for our fits at , and we fix the width of our distance bins to 5 .
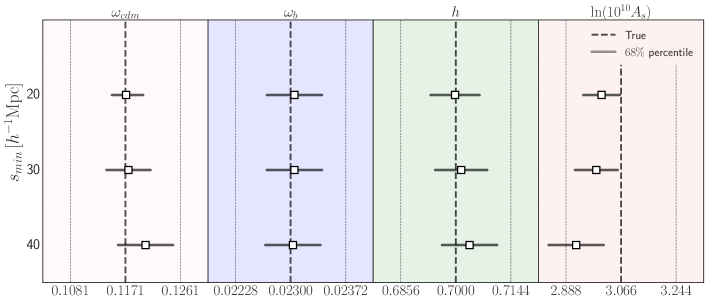
The resulting parameter estimations, along with the error estimates obtained through Markov Chain Monte Carlo (MCMC), are presented in Table 3. The table illustrates that, in general, the errors become narrower as the minimum scale decreases. Specifically, when employing a minimum scale of , we recover the most stringent constraints on all parameters and still consistent with the simulation Cosmology.
| Parameter | |||
|---|---|---|---|
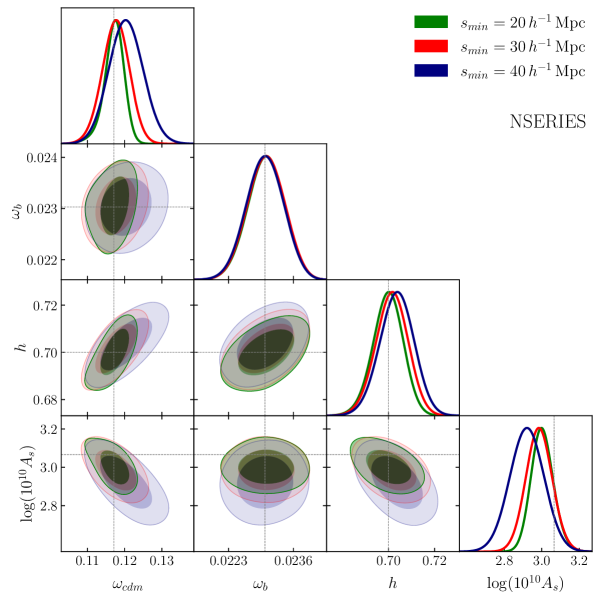
We are also interested in assessing the accuracy of our models, which involves comparing the mean values obtained from our MCMC chains with the actual cosmological values from the NSERIES simulations for our four non-fixed cosmological parameters. Figure 1 illustrates a triangular plot of our MCMC results. In this plot, the gray lines represent the NSERIES cosmological values, while the colored histograms depict the 1D distribution of each parameter.
We observe that for all four parameters, the predictions with a minimum range of perform worse than in the other two cases. This discrepancy is particularly noticeable when comparing the histograms, which appear more centered around the gray lines in the other two scenarios. This trend can be attributed to the smaller scale bins having smaller error bars, and therefore when we exclude them the overall constraining power of the model decreases.
The colored contours in the figure represent the and confidence surfaces. It is worth noting that the actual NSERIES cosmology falls within of the mean value for the case, as indicated by the intersection of all gray lines within the solid green contours. Figure 2 summarizes this information in a more easily interpretable format. The plot demonstrates that, in general, all three models can reproduce , , and within . However, the model with a minimum scale of deviates further from the true values for both and . Additionally, only the the model agrees with the true value of within . It is also worth noting that the constraints on both and are tighter in the model with a minimum scale of compared to the one with a minimum scale of .
Given that the constraints show to be more accurate and precise than the other two cases, in the following we fix to this value.
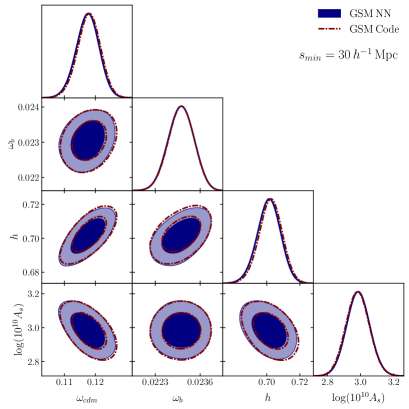
6.2 Testing Neural Networks
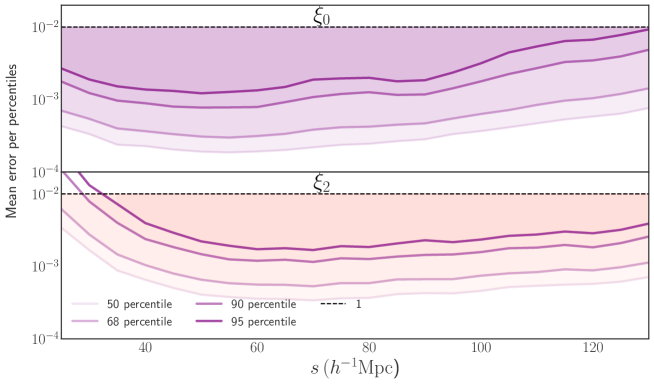
In what follows we present a set of tests of the accuracy of the neural network methodology presented in section 4. We begin by testing the ability of our models to predict the multipoles of the GSM templates of section 3. This is done by asking our trained networks to predict the multipoles of our 5000 test set points at redshift of . For the test point, we define the percent error of the network prediction as . Where is the value of the multipole predicted by the GSM and is the value predicted by the neural network. This error quantifies the size of the emulator errors when compared with the size of our original statistics.
Figure 3 illustrates the percentile plots for the , , , and percentiles of the errors. These plots show the threshold below which the specified percentage of our 5000 errors lie for a given . We note that all lines are situated below the percentile accuracy line (black line), except for the percentile of the quadrupole at small scales, which is only slightly above. This indicates that our neural network models are capable of reproducing the multipoles of the GSM model with an accuracy below . Additionally, it is worth noting that the percentile line is positioned around the error threshold, implying that the majority of our multipoles are predicted with a precision of one-tenth of a percent, while models with an accuracy around one percent are rare.
As a second test of our methodology, we conducted two sets of different MCMC fits to the mean mock of the NSERIES from section 2.2. The first set utilizes the GSM model outlined in section 3, while the second set employed a neural network surrogate model trained to replicate the behavior of the GSM model at the redshift of the NSERIES mock. We run both sets utilising two different configurations, the first is our standard range configuration of 20 to 130 , and the second changes the minimum range to 30 .
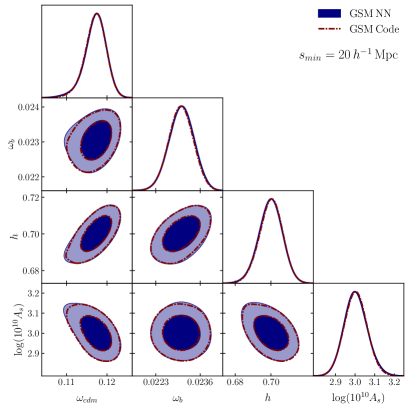
Figure 4 shows the triangular plots comparing the likelihood contours of both models. The 1-D histograms exhibit remarkable similarity in both plots. This results in parameter predictions that are virtually indistinguishable from each other when using the EFT-GSM model or the surrogate model. It’s worth mentioning that when ussing our standard 20 configuration there are negligible differences in the 2D contours that do not affect the best fits values and errors.
Given that our neural network surrogate models can accurately reproduce the data with a significantly lower convergence time for MCMC chains, all fits presented throughout the rest of this work are built using surrogate models.
7 Results with SDSS-III BOSS Catalogues
In the previous section we have shown the capability of the EFT-GSM model for recovering the cosmological parameters of the NSERIES simulations, we also tested that our surrogate models accurately reproduce the results of our EFT-GSM code. In what follows, we apply our methodology to our real galaxy data and compute our constraints on the cosmological parameters from the BOSS DR12 LRG correlation function.
7.1 Baseline Analysis
We begin this section by introducing our constraints on the cosmological parameters obtained by applying our baseline methodology. We computed three distinct fits, each using a different combination of the BOSS samples introduced in Section 2.1. The first two fits utilize the monopole and quadrupole moments of the datasets and respectively. The third fit is a combined analysis where both the and multipoles were fitted simultaneously. We labeled the resulting model as . As mentioned in section 6.1, we select a scale range from to as our standard configuration. As with our NSERIES tests, our covariance matrix is computed using the MD-Patchy mocks introduced in section 2.2.
| Parameter | |||
|---|---|---|---|
Table 4 shows the constraints on our four varied cosmological parameters. We note that the error bars for and are similar, whereas the constraints for are slightly tighter, with and having error estimates that are smaller then the and predictions. And the errors on being around smaller than the one from .
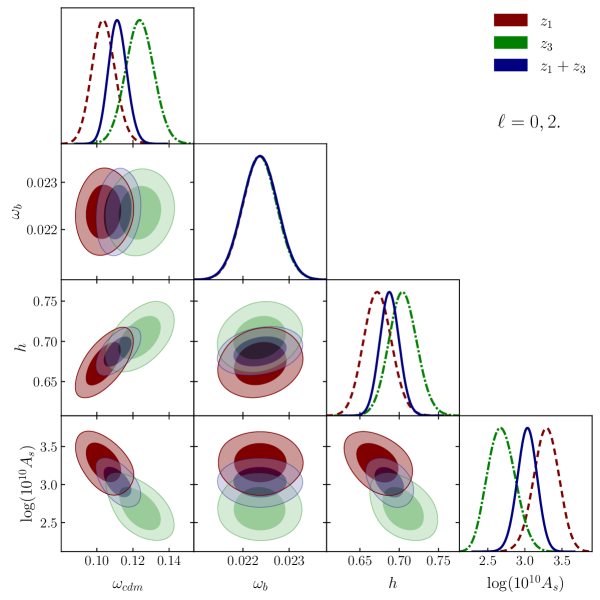
Figure 5 shows the triangular plot of the MCMC fits to our three BOSS datasets. We observe that all parameters agree with each other within , except for , which only agrees at the level for and . Mismatches between the estimated parameters for the redshift bins and are well-known, and has been reported in other works [15, 30], particularly in the full-shape correlation function analysis of [30]. We notice that predicts lower values for and , while predicts a lower value for . As expected, the predictions for each parameter in fall between the predictions from the individual samples. Notably, the predictions for are indistinguishable across all three samples as the constraints on are dominated by the prior. This is explored further in section 7.3 where we widen the prior to explore the capability of LSS alone to constraint cosmological parameters and to test the methodology in a more extended parameter space.
7.2 Comparison to other Full Shape Analysis
As stated at the beginning of this work, several groups have reanalyzed BOSS data using a full-shape methodology. We also mentioned that most of these analyses have been conducted in Fourier space. In contrast, our work is carried out in configuration space, therefore we are interested in assessing the agreement between these two different methodologies. In this section, we compare the parameter estimations obtained from our configuration space model with a set of Fourier space results (D’Amico [16], Ivanov [15], Philcox [17], Troster [29], and Chen [30]), we also compare with the configuration space results from Zhang [19]. To ensure a fair comparison we exclusively consider Zhang constraints derived using BOSS data, without incorporating information from other observations. As stated above an alternative to full-shape analysis is to expand the parameter space of the compression methodology by introducing a small subset of new free parameters that account for the slope of the power spectrum. The Shapefit methodology, as presented in Brieden [76], employs this approach to reanalyze the BOSS data, their methodology is also developed in Fourier space. In this section, we also compare the parameter estimations obtained using our model to those obtained using the Shapefit method.
All of the analyses mentioned so far were carried out on the BOSS DR12 data, with most of them analyzing the data by dividing it into the and samples we have utilized. The only exception is D’Amico [16], who employ the LOWZ and CMASS samples instead. Since all these studies investigate the same dataset, and the majority of them use the same samples from this dataset, we expect the parameter estimations to be consistent with each other within the uncertainty inherent to each methodology.
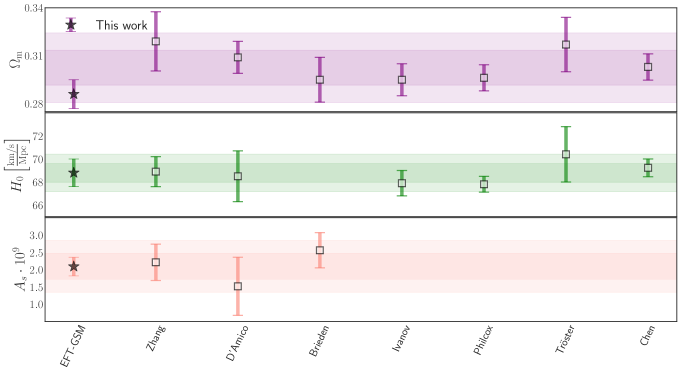
The parameter estimations from these methodologies are depicted as square markers in Figure 6, the first column of the figure presents our parameter estimations for comparison, indicated by starred markers. We present results for three key parameters: , and the total mass density , which includes mass energy density from all matter sources, including dark matter and baryons. These specific parameters were selected to facilitate the comparison with the other works. We highlight that only two works we are comparing with include in their reports. Our results using these derived parameters are displayed in Table 4.
Figure 6 shows that our predictions for both and are consistent within with the results of other studies. We also note that our predictions of agree within with all results, except for three: D’Amico [16], Zhang [19] and Tröster [29], with whom we agree within . We point out that D’Amico utilises the LOWZ and CMASS samples, instead of the and samples that we use, these samples are at slightly different redshifts and use different subsets of the BOSS galaxy sample. Which should contribute to the disagreement between our measurements. Tröster employs a wide prior on the parameter , which remains constant throughout our standard methodology. Varying this parameter has an impact on the fitting results for and , which should contribute to our slight disagreement. For Zhang, the difference observed could be explained by the two extra parameters they varied, and , which can explain the difference in error bars and the position of the mean. In Section 7.3 below, we explore the effects of varying on our methodology. We show that when this parameter is left unfixed, it influences the position of the mean fit value of and , consequently leading to a deviation on .
Our model exhibit a level of precision similar to most works, with the exception of Philcox [17] and Chen [30], who report narrower constraints than ours. This is attributed to that both studies incorporate geometrical information from the post-reconstruction of BAO in Fourier and Configuration space, which helps tighten their constraints. Additionally, Tröster [29] present slightly broader constraints compared to our results, which we attribute to their use of broader priors.
We conclude that our results with EFT-GSM are in agreement with other full-shape analyses, we found differences within 1-2 ( D’Amico, Troster and Zhang), this level of agreement can be attributed to the differences in the samples, number of free cosmological parameters, and priors. Therefore, we consider that our EFT-GSM model is a competitive and robust configuration space analysis, that can serve as a complement to other Fourier space methodologies.
7.3 Extensions to Baseline analysis
We have introduced our EFT-GSM methodology and demonstrated its capability to accurately recover the cosmology of the NSERIES simulations when assuming an error magnitude similar to that expected from future surveys like DESI. Additionally, we applied our methodology to the BOSS data and found that the results we obtained were consistent with those reported by others groups doing full shape analyses with BOSS data. We are now interested in running our methodology using different configurations of our model. This can teach us how various aspects of our methodology impact our final constraints on the parameters. Our first test involves exploring the capability of our model to constrain cosmological parameters when we modify the priors of two key cosmological parameters , and .
It is common practice, when conducting clustering analysis of large-scale structure (LSS), to constrain the values of certain cosmological parameters that are poorly constrained using LSS with external observables. With this in mind, in our baseline analysis, we held constant with a value specified in Table 2, derived from CMB experiments. We also imposed restrictive priors on . These priors were estimated by measuring the deuterium to hydrogen abundance ratio in a near-pristine absorption system toward a quasar. By assuming a reaction cross-section between deuterium and Helium-3, one can determine strong constraints on values. We refer to these priors as Big Bang Nucleosynthesis (BBN) priors throughout this work.
Here, we explore the constrains we obtain on the cosmological parameters when extending the analysis in these two cosmological parameters, by relaxing the priors on and letting free:
| (7.1) | ||||
| (7.2) |
The results of these analysis are shown in Table 5 and Figure 8. We note that, when comparing yellow (BBN prior) posteriors/contours with green ( BBN priors), that in general widening the priors on reduces the precision of all other cosmological parameters in particular in and , the error is 2 and 1.6 times larger, although there are no significant shifts of the central values of the posteriors.
This is consistent with the results reported in Tröster [29], they use priors of around 10 times the BBN results and find wider posteriors than other reanalysis of the BOSS DR12 data. This is shown in figure 6.
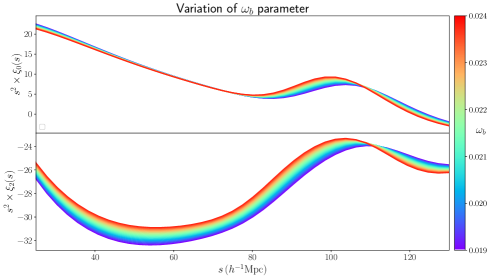
Ivanov [15] also investigated the effect of varying the priors on , finding significantly weaker constraints on and milder effects on , this is consistent with our results as less constraining power in translates to . Brieden [77] also explored extending the priors in Full Shape (and ShapeFit) analysis. They find that in their Full Shape fits the constraints on derived from the amplitude of the BAO depends on the ratio . Therefore, in the prior-dominated regime the tight constraints on helps to fix the shape and narrows the posterior of . When using wider priors the ability of the model to fit the amplitude of the BAO drives the accuracy of the fitting results.
We would like to highligth that in the case of the configuration space multipoles the effect of varying is not isolated in the shape or position of the BAO peak as shown in Figure 7.
We also analyze the effect of varying the parameter , which as stated above is originally fixed to the Planck value in our baseline analysis. By comparing the yellow ( fixed) and magenta ( with a flat prior) contours in Figure 8 we note that fixing has a strong effect on the precision of but a smaller effect on (as been observed in previous analysis in the Fourier space [15]), the rational is that and information is coming from the slope, thus again fixing the shape contributes to find tighter constraints on . The results are shown in Table 5, the case with varying and keeping the BBN prior on shows 2 times larger errors in and times in also affecting the constraints in by 1.4 factor in the errors. We observe as well that with free , the posteriors of and are shifted towards higher values but still consistent between them within , this behavior is also consistent with previous analysis in Fourier space where shifts of and 0.5 in and respectively [15].
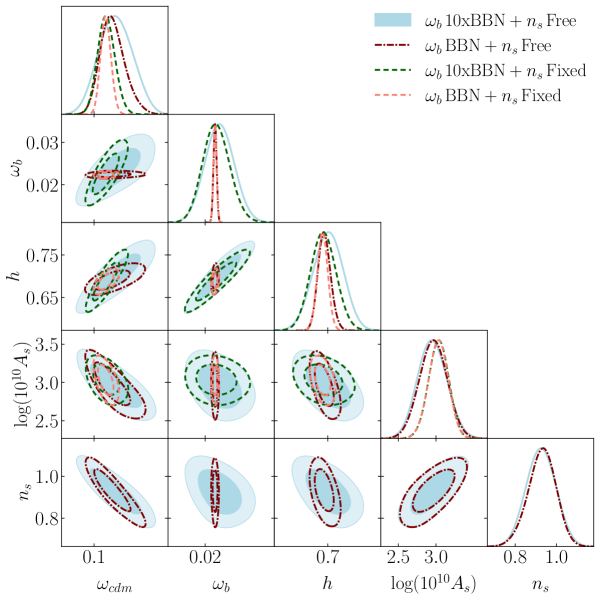
| Parameter | –, Free | –BBN, Free | –10, Fixed | –BBN, Fixed |
|---|---|---|---|---|
7.4 Exploring the Information Content of Multipoles
This last section we explore the information content and constraining power of the multipoles. Our last test consists of running a new MCMC fit on the dataset using our standard configuration. However, this time, we only fit the monopole of the correlation function. Figure 9 displays the results of this monopole-only fit (red dashed lines) and compare to our baseline analysis, which utilizes both the monopole and quadrupole (blue lines and filled contours).
The results for both cases are summarized in Table 6. Interestingly, we observe that the monopole-only approach is capable of recovering our core cosmological parameters, namely and , with nearly the same level of accuracy (, and ) and precision (, and ) as when including the quadrupole. As expected, most of the valuable cosmological information resides within the monopole of the correlation function. However, becomes poorly constrained.
This is also expected, because RSD, mainly affects the amplitude of the quadrupole to monopole ratio at large scales, which breaks the degeneracy in the parameter . Since is highly degenerate with the large-scale bias, the inclusion of the quadrupole induces tighter estimations on . The results obtained in this section are expected on theoretical grounds. However, the quadrupole also contains information on the BAO scales, and one would expect that this will translate on better estimation of and , perhaps only a small improvement. Nevertheless, according to our results, the latter is not happening at all, which we find sligthly surprising.
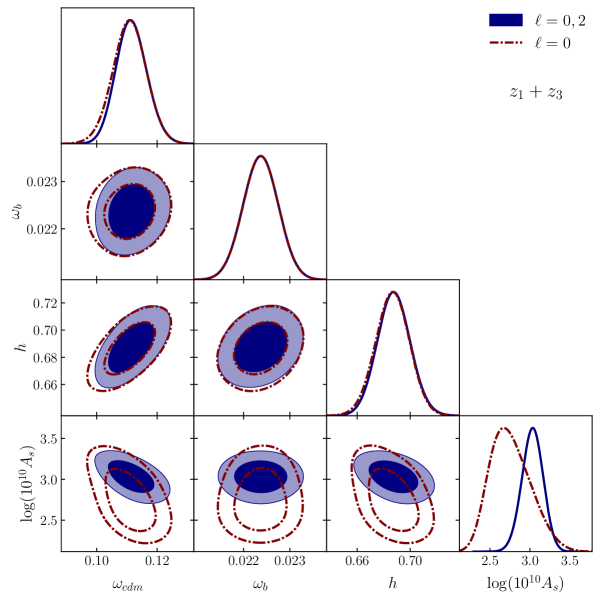
| BOSS Combined z1+z3 | ||||
|---|---|---|---|---|
.
8 Conclusions
There are two distinct philosophies for extracting cosmological information from the shape of the 2PS of LSS. In the first approach, denoted as the compressed methodology, the cosmological template is fixed and fits are done over a small set of compressed variables related to the BAO and RSD observables. By construction, the compressed methodology is designed to be more agnostic about the model but offers less modeling freedom.
In the second approach, denoted as full modeling or full shape modeling, the fits are done with a varying template where all the parameters of an a priori chosen model are simultaneously fitted, including the cosmological parameters. Full Modelling has shown more constraining power compared with the classical compressed approaches. However, it is naturally more costly in computational time, even if in recent years, several methods that make full shape analysis efficient have been developed. Extensions of the compressed methodology have been proposed as well, achieving similar levels of accuracy than full shape methodology. Since these methodologies complement each other and have different strengths and weaknesses, stage IV experiments are currently working to determine the optimal methodology for extracting cosmological information.
In this work we focused on investigating the full shape methodology in configuration space. Until now, most of the analyzes of last-generation surveys with a full-shape methodology has been developed in Fourier space. Therefore, there is an incentive to explore full-shape analysis in configuration space. We present a full-shape analysis of the BOSS DR12 galaxy sample two-point correlation function. Our goal was two-folded: 1) to explore the potential of configuration space analysis and contrast it with its fourier space counterpart, and 2) to show the efficiency and robustness of using neural network acceleration for analysing real data.
In order to analyze the anisotropic clustering signal in configuration space we use an EFT-GSM model, to build second-order perturbation theory templates of the correlation function. While the running time of our model implementation is relatively short (on the order of two seconds), executing a complete MCMC chain using our current EFT-GSM model implementation would require approximately 48 hours with 128 CPUs, due to the substantial number of evaluations required. This represents a significant computational expense. To alleviate the computational cost of our methodology, we employ neural network emulators to construct surrogate models of our EFT-GSM templates. These neural networks are significantly faster to execute and can converge in as little as 15 minutes when using the same 128 CPUs.
We performed a systematic validation of our methodology in two categories:
-
1.
Model Accuracy. We tested the ability of our methodology to reproduce the cosmological values of the high-resolution NSERIES simulation correspondant to an . We tested three minimum scales: , , . Our conclusion is that by utilizing a minimum scale of , we maximize the accuracy and precision of our methodology. Additionally, the predicted value of only agrees with the true value to within at this scale. The cosmological parameter estimation is the least accurate when , which can be attributed to missing the data bins with the smaller error bars.
-
2.
Emulator Accuracy. The models presented in this work do not directly use the EFT-GSM model. Instead, we employ neural networks to construct surrogate models of the multipoles. We assessed the ability of these surrogate models to reproduce the true predictions made by the full EFT-GSM model. We tested this by constructing a test set of points in parameter space. We calculated the multipoles using both the EFT-GSM code and the surrogate model independently. We observed that the percentage difference between these models is usually less than , and for most models, it’s closer to . Furthermore, we noticed that the MCMC fits generated using our surrogate models provide parameter estimations that are virtually indistinguishable from those produced by the full model.
After validating the methodology, we conducted fits to the BOSS data using our baseline analysis. We used the combined sample used in BOSS DR12 final analysis, and we fitted separately the redshift bins and respectively, while the final fit was built on both bins fitted simultaneously. The fit including both bins resulted in slightly tighter constraints on the cosmological parameters. The measured values of the cosmological parameters are in agreement with each other across all three samples, within 1, with the only exception being the predicted value of between and , which agrees at the 2 level. with the combined sample having constrains on and that are smaller than on the individual samples, and smaller that the constrain of the bin constrain.
We compared our results with previous full-shape analysis performed on BOSS data. We include in the comparison six full-shape methodologies: five of them in Fourier space [16],[15], [17],[29],[30] and one in configuration space [19]. We also compare our results with those obtained using the Shape Fit methodology [76]. We find that our predictions for both and agree within with the results from all seven works we compare with. Our predictions for agree within with four out of the seven works, but we only agree within with the remaining three. We propose that these tensions can be explained by two of these three works using broader priors in , and by the other work using a slightly different dataset. We also notice that our constraints have a level of precision comparable to that of five out of the seven works. The remaining two works included post-reconstruction information of the power spectrum and are therefore able to achieve better precision than us.
We performed complementary tests to gain a better understanding of the impact of priors on our constraints. We have explored extending the baseline analysis by relaxing the priors on by 10 times the current range and by letting be a free parameter with a flat prior of [0.5, 1.5]. When we relax the priors on , we find significantly weaker constraints on and, a milder effect on . When we vary we note a strong effect on the precision of but a smaller effect on , this is due to and having a strong effect on the slope of the multipoles. All of these observations are consistent with what other works have found.
Finally, we explored the information content of the multipoles. We conducted our standard fit using only the monopole of the correlation function and compared it with our baseline analysis that includes both the monopole and quadrupole. We discovered that the monopole-only fit already provides constraints on and with similar accuracy and precision as when using both multipoles. This suggests that the majority of relevant cosmological information is contained in the monopole of the correlation function, which we find slightly surprising, given that the quadrupole also contains some BAO information. We also noted that the constraints on do worsen significantly, as expected.
Acknowledgments
This work was supported by the high-performance computing clusters Seondeok at the Korea Astronomy and Space Science Institute. MV, SR and SF acknowledges PAPIIT IN108321, PAPIITA103421, PAPIIT116024 and PAPIIT-IN115424. MV acknowledges CONACyT grant A1-S-1351. This research was partially sup- ported through computational and human resources provided by the LAMOD UNAM project through the clusters Atocatl and Tochtli. LAMOD is a collaborative effort between the IA, ICN and IQ institutes at UNAM. AA is supported by Ciencia de Frontera grant No. 319359, and also acknowledges partial support to grants Ciencia de Frontera 102958 and CONACyT 283151.
References
- [1] D. J. Eisenstein, D. H. Weinberg, E. Agol, H. Aihara, C. Allende Prieto, S. F. Anderson et al., SDSS-III: Massive Spectroscopic Surveys of the Distant Universe, the Milky Way, and Extra-Solar Planetary Systems, AJ 142 (Sept., 2011) 72, [1101.1529].
- [2] K. S. Dawson, D. J. Schlegel, C. P. Ahn, S. F. Anderson, É. Aubourg, S. Bailey et al., The Baryon Oscillation Spectroscopic Survey of SDSS-III, AJ 145 (Jan., 2013) 10, [1208.0022].
- [3] S. Alam, F. D. Albareti, C. Allende Prieto, F. Anders, S. F. Anderson, T. Anderton et al., The Eleventh and Twelfth Data Releases of the Sloan Digital Sky Survey: Final Data from SDSS-III, ApJS 219 (July, 2015) 12, [1501.00963].
- [4] A. Raichoor, A. de Mattia, A. J. Ross, C. Zhao, S. Alam, S. Avila et al., The completed SDSS-IV extended Baryon Oscillation Spectroscopic Survey: large-scale structure catalogues and measurement of the isotropic BAO between redshift 0.6 and 1.1 for the Emission Line Galaxy Sample, MNRAS 500 (Jan., 2021) 3254–3274, [2007.09007].
- [5] A. J. Ross, J. Bautista, R. Tojeiro, S. Alam, S. Bailey, E. Burtin et al., The Completed SDSS-IV extended Baryon Oscillation Spectroscopic Survey: Large-scale structure catalogues for cosmological analysis, MNRAS 498 (Oct., 2020) 2354–2371, [2007.09000].
- [6] B. W. Lyke, A. N. Higley, J. N. McLane, D. P. Schurhammer, A. D. Myers, A. J. Ross et al., The Sloan Digital Sky Survey Quasar Catalog: Sixteenth Data Release, ApJS 250 (Sept., 2020) 8, [2007.09001].
- [7] C. Alcock and B. Paczynski, An evolution free test for non-zero cosmological constant, Nature 281 (Oct., 1979) 358.
- [8] P. McDonald, Clustering of dark matter tracers: Renormalizing the bias parameters, Phys. Rev. D 74 (2006) 103512, [astro-ph/0609413].
- [9] P. McDonald and A. Roy, Clustering of dark matter tracers: generalizing bias for the coming era of precision LSS, JCAP 08 (2009) 020, [0902.0991].
- [10] D. Baumann, A. Nicolis, L. Senatore and M. Zaldarriaga, Cosmological Non-Linearities as an Effective Fluid, JCAP 07 (2012) 051, [1004.2488].
- [11] J. J. M. Carrasco, M. P. Hertzberg and L. Senatore, The Effective Field Theory of Cosmological Large Scale Structures, JHEP 09 (2012) 082, [1206.2926].
- [12] Z. Vlah, M. White and A. Aviles, A Lagrangian effective field theory, JCAP 09 (2015) 014, [1506.05264].
- [13] S.-F. Chen, Z. Vlah, E. Castorina and M. White, Redshift-Space Distortions in Lagrangian Perturbation Theory, JCAP 03 (2021) 100, [2012.04636].
- [14] F. Bernardeau, S. Colombi, E. Gaztanaga and R. Scoccimarro, Large scale structure of the universe and cosmological perturbation theory, Phys. Rept. 367 (2002) 1–248, [astro-ph/0112551].
- [15] M. M. Ivanov, M. Simonović and M. Zaldarriaga, Cosmological Parameters from the BOSS Galaxy Power Spectrum, JCAP 05 (2020) 042, [1909.05277].
- [16] G. D’Amico, J. Gleyzes, N. Kokron, K. Markovic, L. Senatore, P. Zhang et al., The Cosmological Analysis of the SDSS/BOSS data from the Effective Field Theory of Large-Scale Structure, JCAP 05 (2020) 005, [1909.05271].
- [17] O. H. E. Philcox, M. M. Ivanov, M. Simonović and M. Zaldarriaga, Combining full-shape and BAO analyses of galaxy power spectra: a 1.6% CMB-independent constraint on H0, JCAP 2020 (May, 2020) 032, [2002.04035].
- [18] S.-F. Chen, Z. Vlah and M. White, A new analysis of galaxy 2-point functions in the BOSS survey, including full-shape information and post-reconstruction BAO, JCAP 02 (2022) 008, [2110.05530].
- [19] P. Zhang, G. D’Amico, L. Senatore, C. Zhao and Y. Cai, BOSS Correlation Function analysis from the Effective Field Theory of Large-Scale Structure, JCAP 2022 (Feb., 2022) 036, [2110.07539].
- [20] J. Donald-McCann, R. Gsponer, R. Zhao, K. Koyama and F. Beutler, Analysis of Unified Galaxy Power Spectrum Multipole Measurements, 2307.07475.
- [21] O. H. E. Philcox and M. M. Ivanov, BOSS DR12 full-shape cosmology: CDM constraints from the large-scale galaxy power spectrum and bispectrum monopole, Phys. Rev. D 105 (2022) 043517, [2112.04515].
- [22] O. H. E. Philcox, M. M. Ivanov, G. Cabass, M. Simonović, M. Zaldarriaga and T. Nishimichi, Cosmology with the redshift-space galaxy bispectrum monopole at one-loop order, Phys. Rev. D 106 (2022) 043530, [2206.02800].
- [23] A. Chudaykin, K. Dolgikh and M. M. Ivanov, Constraints on the curvature of the Universe and dynamical dark energy from the Full-shape and BAO data, Phys. Rev. D 103 (2021) 023507, [2009.10106].
- [24] G. D’Amico, Y. Donath, L. Senatore and P. Zhang, Limits on Clustering and Smooth Quintessence from the EFTofLSS, 2012.07554.
- [25] P. Carrilho, C. Moretti and A. Pourtsidou, Cosmology with the EFTofLSS and BOSS: dark energy constraints and a note on priors, JCAP 01 (2023) 028, [2207.14784].
- [26] L. Piga, M. Marinucci, G. D’Amico, M. Pietroni, F. Vernizzi and B. S. Wright, Constraints on modified gravity from the BOSS galaxy survey, JCAP 04 (2023) 038, [2211.12523].
- [27] A. He, R. An, M. M. Ivanov and V. Gluscevic, Self-Interacting Neutrinos in Light of Large-Scale Structure Data, 2309.03956.
- [28] S. Brieden, H. Gil-Marín and L. Verde, ShapeFit: extracting the power spectrum shape information in galaxy surveys beyond BAO and RSD, JCAP 2021 (Dec., 2021) 054, [2106.07641].
- [29] T. Tröster, A. G. Sánchez, M. Asgari, C. Blake, M. Crocce, C. Heymans et al., Cosmology from large-scale structure. Constraining CDM with BOSS, A&A 633 (Jan., 2020) L10, [1909.11006].
- [30] S.-F. Chen, Z. Vlah and M. White, A new analysis of galaxy 2-point functions in the BOSS survey, including full-shape information and post-reconstruction BAO, JCAP 2022 (Feb., 2022) 008, [2110.05530].
- [31] A. Semenaite, A. G. Sánchez, A. Pezzotta, J. Hou, A. Eggemeier, M. Crocce et al., Beyond - CDM constraints from the full shape clustering measurements from BOSS and eBOSS, MNRAS 521 (June, 2023) 5013–5025, [2210.07304].
- [32] R. Neveux, E. Burtin, V. Ruhlmann-Kleider, A. de Mattia, A. Semenaite, K. S. Dawson et al., Combined full shape analysis of BOSS galaxies and eBOSS quasars using an iterative emulator, MNRAS 516 (Oct., 2022) 1910–1922, [2201.04679].
- [33] M. Maus, S.-F. Chen and M. White, A comparison of template vs. direct model fitting for redshift-space distortions in BOSS, JCAP 2023 (June, 2023) 005, [2302.07430].
- [34] D. Foreman-Mackey, D. W. Hogg, D. Lang and J. Goodman, emcee: The MCMC Hammer, Publ. Astron. Soc. Pac. 125 (2013) 306–312, [1202.3665].
- [35] M. Karamanis and F. Beutler, Ensemble slice sampling: Parallel, black-box and gradient-free inference for correlated & multimodal distributions, arXiv preprint arXiv: 2002.06212 (2020) .
- [36] M. Karamanis, F. Beutler and J. A. Peacock, zeus: A python implementation of ensemble slice sampling for efficient bayesian parameter inference, arXiv preprint arXiv:2105.03468 (2021) .
- [37] J. DeRose, S.-F. Chen, M. White and N. Kokron, Neural network acceleration of large-scale structure theory calculations, JCAP 2022 (Apr., 2022) 056, [2112.05889].
- [38] K. B. Fisher, On the validity of the streaming model for the redshift space correlation function in the linear regime, Astrophys. J. 448 (1995) 494–499, [astro-ph/9412081].
- [39] R. Scoccimarro, Redshift-space distortions, pairwise velocities and nonlinearities, Phys. Rev. D70 (2004) 083007, [astro-ph/0407214].
- [40] B. A. Reid and M. White, Towards an accurate model of the redshift space clustering of halos in the quasilinear regime, Mon. Not. Roy. Astron. Soc. 417 (2011) 1913–1927, [1105.4165].
- [41] L. Wang, B. Reid and M. White, An analytic model for redshift-space distortions, Mon. Not. Roy. Astron. Soc. 437 (2014) 588–599, [1306.1804].
- [42] Planck collaboration, N. Aghanim et al., Planck 2018 results. VI. Cosmological parameters, Astron. Astrophys. 641 (2020) A6, [1807.06209].
- [43] R. J. Cooke, M. Pettini and C. C. Steidel, One Percent Determination of the Primordial Deuterium Abundance, ApJ 855 (Mar., 2018) 102, [1710.11129].
- [44] J. E. Gunn, W. A. Siegmund, E. J. Mannery, R. E. Owen, C. L. Hull, R. F. Leger et al., The 2.5 m Telescope of the Sloan Digital Sky Survey, AJ 131 (Apr., 2006) 2332–2359, [astro-ph/0602326].
- [45] S. A. Smee, J. E. Gunn, A. Uomoto, N. Roe, D. Schlegel, C. M. Rockosi et al., The Multi-object, Fiber-fed Spectrographs for the Sloan Digital Sky Survey and the Baryon Oscillation Spectroscopic Survey, AJ 146 (Aug., 2013) 32, [1208.2233].
- [46] A. S. Bolton, D. J. Schlegel, É. Aubourg, S. Bailey, V. Bhardwaj, J. R. Brownstein et al., Spectral Classification and Redshift Measurement for the SDSS-III Baryon Oscillation Spectroscopic Survey, AJ 144 (Nov., 2012) 144, [1207.7326].
- [47] L. Anderson, É. Aubourg, S. Bailey, F. Beutler, V. Bhardwaj, M. Blanton et al., The clustering of galaxies in the SDSS-III Baryon Oscillation Spectroscopic Survey: baryon acoustic oscillations in the Data Releases 10 and 11 Galaxy samples, MNRAS 441 (June, 2014) 24–62, [1312.4877].
- [48] S. Alam, M. Ata, S. Bailey, F. Beutler, D. Bizyaev, J. A. Blazek et al., The clustering of galaxies in the completed SDSS-III Baryon Oscillation Spectroscopic Survey: cosmological analysis of the DR12 galaxy sample, MNRAS 470 (Sept., 2017) 2617–2652, [1607.03155].
- [49] B. Reid, S. Ho, N. Padmanabhan, W. J. Percival, J. Tinker, R. Tojeiro et al., SDSS-III Baryon Oscillation Spectroscopic Survey Data Release 12: galaxy target selection and large-scale structure catalogues, MNRAS 455 (Jan., 2016) 1553–1573, [1509.06529].
- [50] A. J. Ross, F. Beutler, C.-H. Chuang, M. Pellejero-Ibanez, H.-J. Seo, M. Vargas-Magaña et al., The clustering of galaxies in the completed SDSS-III Baryon Oscillation Spectroscopic Survey: observational systematics and baryon acoustic oscillations in the correlation function, MNRAS 464 (Jan., 2017) 1168–1191, [1607.03145].
- [51] L. Anderson, É. Aubourg, S. Bailey, F. Beutler, V. Bhardwaj, M. Blanton et al., The clustering of galaxies in the SDSS-III Baryon Oscillation Spectroscopic Survey: baryon acoustic oscillations in the Data Releases 10 and 11 Galaxy samples, MNRAS 441 (June, 2014) 24–62, [1312.4877].
- [52] V. Springel, The Cosmological simulation code GADGET-2, Mon. Not. Roy. Astron. Soc. 364 (2005) 1105–1134, [astro-ph/0505010].
- [53] F. S. Kitaura, G. Yepes and F. Prada, Modelling baryon acoustic oscillations with perturbation theory and stochastic halo biasing., MNRAS 439 (Mar., 2014) L21–L25, [1307.3285].
- [54] F.-S. Kitaura, S. Rodríguez-Torres, C.-H. Chuang, C. Zhao, F. Prada, H. Gil-Marín et al., The clustering of galaxies in the SDSS-III Baryon Oscillation Spectroscopic Survey: mock galaxy catalogues for the BOSS Final Data Release, MNRAS 456 (Mar., 2016) 4156–4173, [1509.06400].
- [55] C. Uhlemann, M. Kopp and T. Haugg, Edgeworth streaming model for redshift space distortions, Phys. Rev. D 92 (2015) 063004, [1503.08837].
- [56] Z. Vlah, E. Castorina and M. White, The Gaussian streaming model and convolution Lagrangian effective field theory, JCAP 12 (2016) 007, [1609.02908].
- [57] G. Valogiannis, R. Bean and A. Aviles, An accurate perturbative approach to redshift space clustering of biased tracers in modified gravity, JCAP 2020 (Jan., 2020) 055, [1909.05261].
- [58] T. Matsubara, Nonlinear perturbation theory with halo bias and redshift-space distortions via the Lagrangian picture, Phys. Rev. D 78 (2008) 083519, [0807.1733].
- [59] A. Aviles, Renormalization of Lagrangian bias via spectral parameters, Phys. Rev. D 98 (2018) 083541, [1805.05304].
- [60] V. Desjacques, D. Jeong and F. Schmidt, Large-Scale Galaxy Bias, Phys. Rept. 733 (2018) 1–193, [1611.09787].
- [61] G. Valogiannis, R. Bean and A. Aviles, An accurate perturbative approach to redshift space clustering of biased tracers in modified gravity, JCAP 2001 (2020) 055, [1909.05261].
- [62] T. Matsubara, Resumming Cosmological Perturbations via the Lagrangian Picture: One-loop Results in Real Space and in Redshift Space, Phys. Rev. D 77 (2008) 063530, [0711.2521].
- [63] J. Carlson, B. Reid and M. White, Convolution Lagrangian perturbation theory for biased tracers, Mon. Not. Roy. Astron. Soc. 429 (2013) 1674, [1209.0780].
- [64] Z. Vlah and M. White, Exploring redshift-space distortions in large-scale structure, JCAP 1903 (2019) 007, [1812.02775].
- [65] M. Davis and P. J. E. Peebles, A survey of galaxy redshifts. V. The two-point position and velocity correlations., ApJ 267 (Apr., 1983) 465–482.
- [66] D. Bianchi, W. Percival and J. Bel, Improving the modelling of redshift-space distortions II. A pairwise velocity model covering large and small scales, Mon. Not. Roy. Astron. Soc. 463 (2016) 3783–3798, [1602.02780].
- [67] A. Lewis, A. Challinor and A. Lasenby, Efficient computation of CMB anisotropies in closed FRW models, ApJ 538 (2000) 473–476, [astro-ph/9911177].
- [68] A. Lewis and S. Bridle, Cosmological parameters from CMB and other data: A Monte Carlo approach, PRD 66 (2002) 103511, [astro-ph/0205436].
- [69] A. Spurio Mancini, D. Piras, J. Alsing, B. Joachimi and M. P. Hobson, COSMOPOWER: emulating cosmological power spectra for accelerated Bayesian inference from next-generation surveys, MNRAS 511 (Apr., 2022) 1771–1788, [2106.03846].
- [70] K. Heitmann, D. Higdon, M. White, S. Habib, B. J. Williams, E. Lawrence et al., The Coyote Universe. II. Cosmological Models and Precision Emulation of the Nonlinear Matter Power Spectrum, ApJ 705 (Nov., 2009) 156–174, [0902.0429].
- [71] A. Korobov, The approximate computation of multiple integrals, in Dokl. Akad. Nauk SSSR, vol. 124, pp. 1207–1210, 1959.
- [72] J. Alsing, H. Peiris, J. Leja, C. Hahn, R. Tojeiro, D. Mortlock et al., SPECULATOR: Emulating Stellar Population Synthesis for Fast and Accurate Galaxy Spectra and Photometry, ApJS 249 (July, 2020) 5, [1911.11778].
- [73] S.-F. Chen, Z. Vlah and M. White, Consistent Modeling of Velocity Statistics and Redshift-Space Distortions in One-Loop Perturbation Theory, JCAP 07 (2020) 062, [2005.00523].
- [74] J. Hartlap, P. Simon and P. Schneider, Why your model parameter confidences might be too optimistic. unbiased estimation of the inverse covariance matrix, Astronomy and Astrophysics 464 (08, 2006) .
- [75] J. Goodman and J. Weare, Ensemble samplers with affine invariance, Communications in Applied Mathematics and Computational Science 5 (Jan., 2010) 65–80.
- [76] S. Brieden, H. Gil-Marín and L. Verde, Model-independent versus model-dependent interpretation of the SDSS-III BOSS power spectrum: Bridging the divide, PRD 104 (Dec., 2021) L121301, [2106.11931].
- [77] S. Brieden, H. Gil-Marín and L. Verde, Model-agnostic interpretation of 10 billion years of cosmic evolution traced by BOSS and eBOSS data, JCAP 2022 (Aug., 2022) 024, [2204.11868].