Fully Context-Aware Image Inpainting with a Learned Semantic Pyramid
Abstract
Restoring reasonable and realistic content for arbitrary missing regions in images is an important yet challenging task. Although recent image inpainting models have made significant progress in generating vivid visual details, they can still lead to texture blurring or structural distortions due to contextual ambiguity when dealing with more complex scenes. To address this issue, we propose the Semantic Pyramid Network (SPN) motivated by the idea that learning multi-scale semantic priors from specific pretext tasks can greatly benefit the recovery of locally missing content in images. SPN consists of two components. First, it distills semantic priors from a pretext model into a multi-scale feature pyramid, achieving a consistent understanding of the global context and local structures. Within the prior learner, we present an optional module for variational inference to realize probabilistic image inpainting driven by various learned priors. The second component of SPN is a fully context-aware image generator, which adaptively and progressively refines low-level visual representations at multiple scales with the (stochastic) prior pyramid. We train the prior learner and the image generator as a unified model without any post-processing. Our approach achieves the state of the art on multiple datasets, including Places2, Paris StreetView, CelebA, and CelebA-HQ, under both deterministic and probabilistic inpainting setups.
keywords:
Image Inpainting , Multi-Scale Semantic Priors , Learned Semantic Pyramid , Stochastic Semantic Inference1 Introduction
Inpainting is an important image processing method, which is widely used in many applications including image restoration [1], object removal [2], and photo editing [3]. Specifically, given the damaged image and the corresponding mask, image inpainting aims to synthesize the plausible visual content for the missing area, and make the recovered content consistent with the remaining area. In general, the key challenge in generating meaningful and clear visual details lies in how to properly harness the context ambiguity between low-level structures and high-level semantics.
Existing approaches focus more on the consistency of local textures. Earlier work [3] usually exploit low-level similarity to perform texture transformations from valid image regions to missing regions. These methods work well in stationary backgrounds but usually fail to handle complex structures due to a lack of global semantic understanding. In recent years, the development of deep learning has stimulated the emergence of many image inpainting methods in forms of neural networks [4, 5, 6, 7]. These methods try to solve the image inpainting problem by using the image-to-image translation framework. In particular, some literature [7, 6] have introduced different structural guidance to specifically supervise the completion of missing areas. Although the learning-based methods remarkably improve the quality of the generated images, as shown in Fig. 1, they still show distorted objects and blur textures, especially for complex scenes. An important reason is that these methods focus more on pixel-level image representations, but do not explicitly consider semantic consistency of context representations across multiple visual levels, and thus fail to establish a global understanding of the corrupted images.
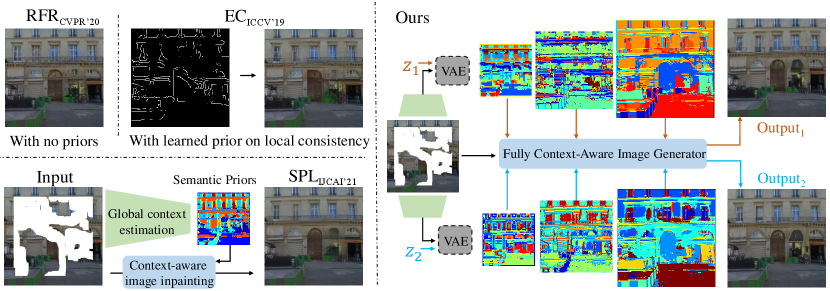
In contrast to the above literature, we propose to acquire multi-scale semantic priors from specific pretext tasks and leverage them in image inpainting. Motivated by this idea, we present a fully context-aware image inpainting model named Semantic Pyramid Network (SPN), which contains two main components. The first one is the semantic prior learner, which distills a pyramid of visual representations from different levels of a pre-trained multi-label classification model111Various pretext tasks can be used to provide semantic supervisions, whose effect is compared in the experiments. In the rest of the paper, we adopt multi-label classification as a typical pretext task without loss of generality.. By optimizing the semantic learner in the entire image reconstruction pipeline, we enable the model to adaptively transfer the common knowledge from the pretext task. In this process, the high-level visual priors contain more discriminative representations and thus can effectively reduce the ambiguity of global semantics (see Fig. 1), while the low-level visual priors provide further guidance for restoring the local textures. Based on the learned semantic prior pyramid, we present the second component of SPN, that is, the fully context-aware image generator. Instead of directly concatenating the prior information with image features extracted from pixels, we use the spatially-adaptive normalization [9] to gradually integrate them into different levels of the generator for global context reasoning and local image completion. In this way, SPN allows for more flexible interactions between the learned priors and image features, avoiding potential domain conflicts caused by the use of pretext models from another domain.
This paper presents two new technical contributions that effectively complement our previous work at IJCAI’21 [8]: First, as mentioned above, we extend the prior learner to distill semantic presentations at different scales from the pretext model. Accordingly, we further enable the image generator to incorporate the prior pyramid. By this means, we improve the consistency of global context reasoning and local image completion. Second, we extend our model to probabilistic image inpainting by integrating a plug-and-play variational inference module in the prior learner. In addition to knowledge distillation loss, the prior learner is also optimized to fit the distribution of missing content in a probabilistic way. The main idea is that according to the context of the remaining part of the image, we should consider various semantic possibilities of the missing part. Notably, the multi-label classification may convey diversified semantic relations among multiple objects, which motivates us to use a probabilistic prior learner to extract different relational priors according to certain conditional information. As a result, the stochastic prior pyramid allows the image generator to fill in the missing content in diverse and reasonable ways.
In summary, the key insight of this paper is to show that learning semantic priors from specific pretext tasks can greatly benefit image inpainting. We further strengthen the modeling ability of the learned priors in SPN from the following aspects: 1) Multi-scale semantic priors are learned and organized in a feature pyramid to achieve consistent understanding of the global context and local structures. 2) The prior learner is allowed to be trained in a probabilistic manner. It is inspired by the idea that in stochastic image inpainting, the potential missing content should be driven by the diversity of semantic priors.
In the rest of this paper, we first review the related work on image inpainting and knowledge distillation in Section 2, and introduce the details of our model SPN as well as its deterministic and probabilistic learning schemes in Section 3. In Section 4, we perform in-depth empirical analyses of the proposed SPN and compare it with the state of the art on four datasets. More importantly, we extend the experiments in our preliminary work by qualitatively and quantitatively evaluating the model under stochastic image inpainting setups. Further, we compare the effectiveness of learning the semantic prior pyramid using different types of pretext models. In Section 5, we present the conclusions and the prospect of future research.
2 Related Work
2.1 Rule-Based Image Inpainting
Early work for image inpainting mainly focuses on capturing pixel relationships using various low-level image features and designing specific rules to perform texture reasoning. These methods can be roughly divided into two groups. The first one includes the patch-based methods, which assume that missing image regions can be filled with similar patches searched from valid image regions or external database [2, 3, 10]. However, these algorithms are often computationally expensive, and similar image patches are difficult to access for complex scenes. The second group includes diffusion-based methods that progressively propagate visual content from boundary regions into missing regions [11]. These methods are usually based on specific boundary conditions and use partial differential equations to guide the pixel propagation. Although these methods can produce vivid visual details for the plain background and repeated textures, they often fail to generate realistic image content for complex scenes because only low-level visual structures are modeled without any semantic understanding.
2.2 Learning-Based Image Inpainting
2.2.1 Deep networks for deterministic image inpainting
In recent years, many deep learning models based on the architectures of conditional GAN have been proposed for deterministic image inpainting [12, 13, 1, 14, 15]. These models also greatly benefit from the adversarial training scheme as well as further designs. Pathak et al. [16] first exploited the auto-encoder framework to perform global context encoding and image decoding. Iizuka et al. [17] proposed to use multiple discriminators based on stacked dilated convolutional layers to enhance the consistency of global and local visual context. Other architectures are also explored in recent work such as the multi-scale learning modules [5, 18]. Unlike the existing work, our model specifically leverages the multi-scale information as the semantic prior pyramid, which is learned in a multi-level knowledge distillation module.
More recent studies take advantage of the attention module in capturing long-range contextual relations [13, 19, 20]. For instance, Deepfill [13] follows a coarse-to-fine generation framework with patch-wise aggregation to enhance the restoration of high-frequency information. Besides, some methods propose various network architectures to eliminate the undesired influence from invalid pixels in context feature extraction [21, 4]. Although these approaches perform generally better than rule-based approaches at generating realistic images, they still struggle with structural distortion in complex scenes. This is because they cannot deal well with the ambiguous context of the missing area due to the limitation of the deterministic training paradigm.
2.2.2 Probabilistic image inpainting models
To cope with the multi-modal data distribution between the corrupted input images and the expected output images, different probabilistic models have been proposed, which can model the probability of the potential content in the missing area and produce diverse results. PICNet [22] exploits the framework of VAE in two different network branches to learn the conditional distribution within the missing areas. UCTGAN [23] also uses a similar architecture with the manifold projection module. Also, there are GAN-based methods [24, 25] and auto-regressive methods [26] that explicitly consider the diversity of generated images. Unlike all of the above methods, our model is particularly designed to harness the multi-modal distribution by leveraging a plug-and-play variational inference module in the learning process of semantic priors, instead of directly using it in the image generator.
2.2.3 Visual priors in image inpainting
Some state-of-the-art approaches also use explicit visual priors as the learning supervision to improve the quality of image inpainting. Nazeri et al. [6] and Xiong et al. [12] presented two-stage frameworks that first learn to generate the images of object edges under external supervisions, and then use them to guide texture restoration. Some methods also use color-smooth images [27, 7, 28] or semantic maps [29] to provide more dense, structural, and meaningful supervisions. However, these methods either suffer from the accumulated errors through the two processing stages, or require heavy human annotations, which is difficult to scale to real-world applications. In contrast, first, the semantic priors in our model are jointly learned with the image generator, which greatly reduce error accumulation; Second, the priors are learned from the pyramid of feature maps of a pretext model, which are more accessible. The concept of knowledge distillation was first proposed in the work from Hinton et al. [30] to transfer pre-learned knowledge from a large teacher network to a smaller student network. Although Suin et al. [31] also used a joint-training autoencoder as distillation target, it lacks pre-learned semantic knowledge which are important for structural guidance. Here, we adapt the knowledge distillation framework to high-level semantic priors and low-level texture priors simultaneously from the pretext model, both of which are important for context-aware image inpainting.
3 Approach
In this section, we introduce the details of the Semantic Pyramid Network (SPN) which aims to learn and transfer semantic priors from a particular pretext model to improve image inpainting. We emphasize that, in SPN, the semantic priors have the following properties: First, they should be learned and presented in a multi-scale feature pyramid to improve conditional image generation by reducing inconsistency between the global context and local textures. Second, they should be endowed with a probabilistic training procedure, which enables SPN to generate diverse inpainting results by extracting various semantic priors from an individual damaged image. The overall architecture of SPN is shown in Fig. 2. It mainly consists of two network components: 1) (Stochastic) semantic prior learner: It extracts multi-scale visual priors into a feature pyramid from a pretext model. It also exploits an optional, variational inference module to handle the stochasticity of image inpainting. 2) Fully context-aware image generator: It performs the affine transformation mechanism based on SPADE [9] to progressively and adaptively integrate the learned semantic priors in the process of image restoration.
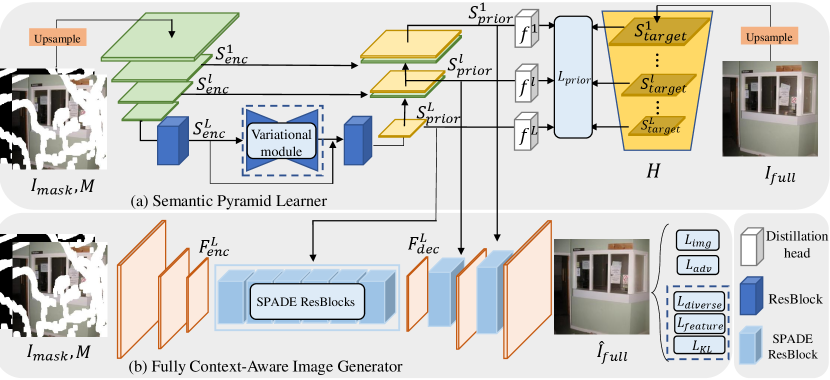
3.1 Semantic Prior Learner
3.1.1 Learning deterministic prior pyramid
As shown in Fig. 2(a), the semantic prior learner follows the U-Net architecture. It distills multi-scale visual priors from a particular pretext model given a full image , a damaged image , and a corresponding binary mask where represents the locations for invalid pixels and represents those for valid pixels. Considering that the global scene understanding usually involves multiple objects, in this work, we borrow a pretext multi-label classification model, denoted by , to provide feature maps as the supervisions of learning the semantic priors. Unless otherwise specified, the pretext model is trained on the OpenImage dataset [33] with the asymmetric loss (ASL) [32]. Note that we do not fine-tune the model on any inpainting datasets used in this paper. We hope the pretext model can provide more discriminative representations on specific objects, allowing the common knowledge to be transferred to the unsupervised image inpainting task. To generate the supervisions of knowledge distillation, specifically, we up-sample the full image to obtain , and then feed to to obtain feature maps in total at multiple scales:
| (1) |
where has a spatial size of . denotes the number of scales of the used semantic priors. In all experiments, we set and the spatial size in each scale is , , and , respectively.
At the beginning of the semantic prior learner, down-sampling layers are used, and a residual blockis applied after the last down-sampling layer to extract features from the masked image at different scales. To align with the spatial resolution of , we also up-sample into . The corresponding mask is also up-sampled to in the same manner, and concatenated with to form the input of the semantic prior learner:
| (2) |
where is the image representation learned from visible image contents that has the same spatial size as the semantic supervision . We here adopt the common practice about in previous literature, keeping the region of known during training and testing and focusing more on the recovery of missing content. Next, we exploit multiple residual blocks and up-sampling layers to generate a pyramid of semantic priors with multi-scale skip connections:
| (3) |
where indicates the pixel-shuffle layer for up-sampling and indicates the prior pyramid. For each , it has the spatial sizes of , and is followed by a distillation head of a convolutional layer. Finally, we apply a set of distillation losses to the deterministic semantic prior learner:
| (4) |
where denotes the Hadamard product, is the resized mask with spatial size equal to , and is for the additional constraints on masked areas. The above objective functions are jointly used with final image reconstruction loss. In this way, the knowledge at different levels of the pretexts model can flow into the prior pyramid to best facilitate image inpainting. Notably, the distillation heads and the pretext model are only used in the training phase and are all removed from SPN during testing.
3.1.2 Learning stochastic prior pyramid
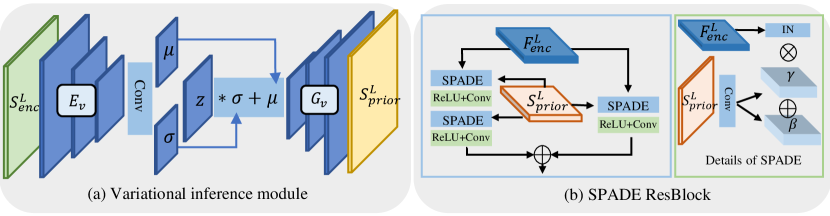
To resolve the contextual ambiguity, it is natural to consider various possibilities of the missing content in image inpainting. Therefore, in addition to learning a prior pyramid, we further improve our previous work at IJCAI’21 [8] by introducing a variational inference module in the semantic learner. This module is optional and handles the multi-modal distribution of possible missing content in the high-level feature space conditioned on the remaining part of the image. By injecting this module in the semantic learner, we can easily extend SPN to probabilistic image inpainting, that is, generating diverse restoration results given an individual damaged image. More specifically, we reformulate the semantic prior learner based on a Gaussian stochastic neural network. In practice, as shown in Fig. 2(a), we simply embed a variational inference module between the high-level image representation and the corresponding learned priors . The details of this module are shown in Fig. 3(a). It consists of an encoder that estimates the parameters of the posterior distribution of high-level semantics and a generator that produces diverse prior pyramids with the re-parameterization trick:
| (5) |
The multiple-level distillation losses are then used in the same way as the learning deterministic prior pyramid, which is shown in Eq. (4). We also optimize the KL divergence to constrain the distance between the learned posterior distribution and a prior distribution :
| (6) |
where represents the learned posterior distribution.
By optimizing the KL divergence within the semantic prior learner, our model is very different from existing approaches for stochastic image inpainting in the following perspective: It incorporates the distribution of potential semantics as a part of the learned priors, in the sense that different knowledge is distilled from the pretext model in a probabilistic way.
3.2 Fully Context-Aware Image Generator
As shown in Fig. 2(b), we first exploit three convolutional layers to extract low-level visual representation from the masked image and mask :
| (7) |
where has the same spatial size of as that of the learned semantic prior .
In the subsequent part of the image generator, we use the learned prior pyramid as semantic guidance to gradually refine the image encoding features . However, we find it challenging to effectively combine these two branch of features into unified representations. First, since the prior pyramid is distilled from a pretext model that is learned in another domain, there may be significant domain conflicts between them. Second, the image encoding branch directly extracts low-level image features and focuses more on textures and local structure, while the prior pyramid branch focuses more on global scene understanding due to the effect of knowledge distillation from the multi-label classification model. As a result, we observe that fusing these two representation branch through concatenations will make them conflict, not only affecting local texture restoration but also increasing the difficulty of global context reasoning.
To adaptively incorporate the semantic priors into image encoding features and reduce the conflicts between these two branches, we exploit the spatially-adaptive normalization module (SPADE) [9] (see Fig. 3(b)) as the key component of the image generator. The SPADE module is originally proposed for image synthesis to maintain the spatial information of the semantic layout. Instead of using semantic maps or semantic layouts, in SPN, we take the learned prior pyramid along with the image encoding features as the inputs of SPADE, and perform non-parametric instance normalization on the image encoding features. Next, two sets of parameters and are generated from the learned semantic priors to perform pixel-wise affine transformations on the image features. We here take the image feature as an example and have:
| (8) |
where and is the number of channels. indicates non-parametric instance normalization. In this way, the SPADE module provides adaptive refinements on the image encoding features guided by the prior pyramid, greatly facilitating context-aware image restoration.
Furthermore, we adopt the SPADE ResBlock from the work of Park et al. [9] to organize multiple SPADE modules in an imbalanced two-branch architecture, which uses different numbers of SPADE modules in different branches. The basic idea is to make the model adaptively respond to the different importance of integrating semantic priors in the process of image generation. More specifically, we apply eight consecutive SPADE ResBlocks to the image features with the smallest spatial resolution to derive , and one SPADE ResBlock to each level of image decoding features followed by an up-sampling layer (). We obtain the final results by
| (9) |
Different from our previous work [8], we make the image generator fully context-aware by leveraging the SPADE ResBlocks to adaptively and progressively incorporate the learned feature pyramid of multi-scale priors. The new architecture of the image generator eases the joint training of global contextual reasoning and local texture completion.
3.3 Final Objective Functions
We exploit multi-scale semantic supervisions from the pretext model and jointly optimize the prior learner and the fully context-aware image generator. SPN can alternatively handle deterministic or probabilistic image inpainting by using or not using the variational inference module in the prior learner. In this part, we introduce the overall loss functions under each setup separately.
3.3.1 Losses for deterministic inpainting
We use the reconstruction and adversarial losses to train SPN for deterministic inpainting. The reconstruction loss is in an form and constrains the pixel-level distance between the ground truth images and the inpainting results, with more attention on the missing content:
| (10) |
The adversarial loss, as adopted in existing approaches [4, 6], is used to encourage realistic inpainting results:
| (11) |
where represents the discriminator and encourages the discriminator to distinguish real and generated images. By combining with the aforementioned loss terms, the full objective function can be written as
| (12) |
where the form of is shown in Eq. (4). The grid search range for is and the range for is same as . We finally set , , and . Similarly, we set in Eq. (4).
3.3.2 Losses for probabilistic inpainting
Except for the loss funtions in Eq. (12), we further use the feature matching loss, the perceptual loss and the perceptual diversity loss [24] to train the entire model for probabilistic inpainting.
The feature matching loss measures the distance between feature maps extracted from layers of the discriminator given real and generated images. We use to denote the mapping function from the input image to the feature map at the -th layer in the discriminator. For the perceptual loss, we use a fixed VGG19 model pre-trained on ImageNet to extract multi-scale visual representations and reduce their distance in the semantic space. We use to denote the feature map from the -th layer in the VGG19 model and is the total number of layers we use. Combined with the feature matching loss that has similar forms, the two loss terms can be summarized as
| (13) |
As for the perceptual diversity loss, it encourages SPN to produce semantically diverse results in the missing areas. It is also conducted on the feature maps from the pre-trained VGG19 model:
| (14) |
where and denote restored images generated from the same damaged image but with different noises, is the resized mask which has the same spatial size as , and is the perturbation term to avoid the outlier. The full objective function for probabilistic image inpainting can be written as
| (15) |
The grid search range for both and is and the range for is . Finally, we have , , and . We refer to SPADE [9] to set other parameters including , , and .
4 Experiments
4.1 Experimental Setups
4.1.1 Datasets
We validate the effectiveness of SPN on four datasets in total. Under the deterministic image inpainting setup, we evaluate SPN on three datasets. For the probabilistic inpainting setup, we use the CelebA-HQ [34] and Paris StreetView dataset [35].Furthermore, we use an external dataset to provide irregular masks. In both training and testing phases, for CelebA, we follow the common practice [4, 5] to perform center crop on images and then resize them to . For other datasets, raw images are resized to directly.
-
1.
Places2 [36]. It is one of the most challenging datasets containing over million images from different scenes. We use the standard training set with million images for training and perform evaluations on the first images in the validation set.
-
2.
CelebA [37]. It contains about diverse celebrity facial images. we use the original training set that includes over images for training and use the first images in the test set for testing.
-
3.
Paris StreetView [35]. It collects images from street views of Paris and mainly contains different highly structured facades. We use images for training and images for testing. We use this dataset under both deterministic and probabilistic setups.
- 4.
- 5.
4.1.2 Compared methods
We extend our previous work by providing stronger baseline models. For the deterministic setup, we compare SPN with RFR [5], RN [4], MFE [7], EC [6], WF [39], and CTSDG [28]. Particularly, we denote our previous work as SPL [8], short for the Semantic Prior Learner. Among these methods, RN, RFR, and WF introduce different network architectures to improve both encoding and decoding stages. On the other hand, EC, CTSDG, and MFE try to use edge maps or smooth images as additional structural supervisions to help image completion. However, they still suffer from distorted structures due to the lack of global semantic understanding. For probabilistic inpainting, we compare SPN with PIC [22] and DSI [26].
4.1.3 Implementation details
In our experiments, we extract feature maps at three scales from the multi-label classification model to form the distillation targets. The classification model was pre-trained on the OpenImage dataset [33] with the asymmetric loss (ASL) [32], and is not fine-tuned on any datasets used in this work. Besides, we also use the patch-based discriminator for adversarial training as in the previous work [4, 7]. Our model is trained by Adam solver with and . The initial learning rate is set to for all experiments, and we decay the learning rate to in the last quarter of the training process. SPN is trained on two V100 GPUs, and it takes about one day to train our model on Paris StreetView dataset. For more details, please refer to our code and pre-trained models at https://github.com/WendongZh/SPN.
| Dataset | Places2 | CelebA | Paris StreetView | |||||||
| Mask Ratio | 0.2-0.4 | 0.4-0.6 | All | 0.2-0.4 | 0.4-0.6 | All | 0.2-0.4 | 0.4-0.6 | All | |
| SSIM↑ | EC [6] | 0.847 | 0.695 | 0.832 | 0.922 | 0.815 | 0.905 | 0.880 | 0.740 | 0.849 |
| MFE [7] | 0.816 | 0.652 | 0.804 | 0.916 | 0.807 | 0.900 | 0.872 | 0.707 | 0.834 | |
| RFR [5] | 0.856 | 0.704 | 0.839 | 0.931 | 0.838 | 0.917 | 0.893 | 0.763 | 0.863 | |
| RN [4] | 0.875 | 0.726 | 0.855 | 0.941 | 0.852 | 0.925 | 0.891 | 0.756 | 0.861 | |
| WF [39] | 0.855 | 0.647 | 0.820 | - | - | - | 0.895 | 0.765 | 0.864 | |
| CTSDG [28] | 0.848 | 0.696 | 0.837 | 0.923 | 0.819 | 0.907 | 0.888 | 0.746 | 0.855 | |
| SPL [8] | 0.894 | 0.759 | 0.875 | 0.950 | 0.869 | 0.935 | 0.911 | 0.790 | 0.882 | |
| Ours | 0.897 | 0.763 | 0.877 | 0.952 | 0.871 | 0.937 | 0.916 | 0.795 | 0.886 | |
| PSNR↑ | EC [6] | 24.17 | 20.32 | 25.07 | 29.47 | 24.08 | 30.34 | 27.65 | 22.81 | 27.50 |
| MFE [7] | 22.89 | 19.13 | 23.94 | 29.03 | 23.85 | 30.13 | 27.22 | 22.07 | 27.07 | |
| RFR [5] | 24.38 | 20.42 | 25.48 | 30.33 | 25.09 | 31.38 | 28.32 | 23.71 | 28.36 | |
| RN [4] | 25.44 | 21.08 | 26.37 | 31.17 | 25.51 | 32.17 | 28.44 | 23.53 | 28.37 | |
| WF [39] | 24.57 | 19.31 | 24.77 | - | - | - | 28.66 | 23.88 | 28.21 | |
| CTSDG [28] | 24.16 | 20.36 | 25.54 | 29.48 | 24.21 | 30.62 | 28.08 | 23.39 | 28.11 | |
| SPL [8] | 26.47 | 22.05 | 27.55 | 32.17 | 26.43 | 33.23 | 29.34 | 24.47 | 29.38 | |
| Ours | 26.65 | 22.18 | 27.72 | 32.39 | 26.54 | 33.52 | 29.76 | 24.67 | 29.69 | |
| MAE↓ () | EC [6] | 0.221 | 0.456 | 0.248 | 0.111 | 0.274 | 0.140 | 0.148 | 0.364 | 0.204 |
| MFE [7] | 0.266 | 0.542 | 0.296 | 0.119 | 0.284 | 0.145 | 0.159 | 0.412 | 0.226 | |
| RFR [5] | 0.212 | 0.445 | 0.240 | 0.099 | 0.237 | 0.121 | 0.134 | 0.324 | 0.182 | |
| RN [4] | 0.187 | 0.412 | 0.218 | 0.091 | 0.229 | 0.115 | 0.136 | 0.337 | 0.187 | |
| WF [39] | 0.216 | 0.583 | 0.285 | - | - | - | 0.132 | 0.330 | 0.185 | |
| CTSDG [28] | 0.220 | 0.452 | 0.237 | 0.109 | 0.267 | 0.135 | 0.138 | 0.338 | 0.189 | |
| SPL [8] | 0.164 | 0.363 | 0.191 | 0.080 | 0.203 | 0.102 | 0.115 | 0.292 | 0.161 | |
| Ours | 0.158 | 0.351 | 0.185 | 0.077 | 0.200 | 0.099 | 0.109 | 0.282 | 0.154 | |
| FID↓ | EC [6] | 9.63 | 23.04 | 6.08 | 10.41 | 14.40 | 7.24 | 43.45 | 87.70 | 44.95 |
| MFE [7] | 21.07 | 48.74 | 15.38 | 11.12 | 15.42 | 7.95 | 47.22 | 100.85 | 50.33 | |
| RFR [5] | 8.43 | 21.82 | 5.27 | 10.22 | 14.57 | 7.15 | 37.51 | 77.15 | 39.44 | |
| RN [4] | 9.27 | 25.00 | 6.10 | 11.39 | 18.00 | 8.16 | 64.78 | 134.00 | 66.54 | |
| WF [39] | 7.75 | 42.46 | 9.37 | - | - | - | 33.20 | 73.31 | 38.36 | |
| CTSDG [28] | 15.88 | 42.19 | 12.36 | 11.32 | 17.57 | 8.14 | 46.52 | 98.76 | 49.19 | |
| SPL [8] | 8.30 | 23.98 | 5.56 | 10.27 | 12.94 | 6.88 | 41.41 | 93.41 | 46.13 | |
| Ours | 7.68 | 20.73 | 4.73 | 10.16 | 12.38 | 6.77 | 34.00 | 70.76 | 36.82 | |
4.2 Deterministic Image Inpainting
We first provide both quantitative and qualitative comparison results under the deterministic inpainting setup in Table 1 and Figure 4, respectively. For quantitative comparisons, we use the structural similarity (SSIM), peak signal-to-noise ratio (PSNR), and mean error (MAE) as evaluation metrics, which are commonly used in previous works [4, 5]. Besides, we also use Fréchet inception distance (FID) [40] as the human perception-level metric. For each dataset, we first randomly select mask images from the entire irregular mask dataset to obtain the mask set for evaluation. The mask selections are performed independently between different image datasets, and the selected masks are randomly assigned to test set images to form the mask-image pairs. For the same image dataset, the mask-image pairs are held for different methods to obtain fair comparison results. Since the mask dataset contains mask images with different mask ratios, we also show detailed quantitative results within different mask intervals. Specifically, as shown in Table 1, the results in columns denoted by “ALL” are obtained on the entire testing set; In other columns, the results are obtained throughout mask-images pairs within corresponding mask intervals.
4.2.1 Quantitative comparisons
We have the following observations from Table 1. First, the proposed SPN achieves the best results in most evaluation metrics on all three datasets. It not only outperforms its previous version SPL, but also obtains significant improvements (up to dB for PSNR) compared with other methods. Second, the improvements from our model are consistent across the three datasets. Particularly, SPN obtains the most significant improvements over other competitors such as EC and MFE on the Place2 dataset, which demonstrates that SPN can handle more difficult image scenarios. Third, for FID, our model greatly improves the results of its previous work SPL, achieving the best performance among all compared models. This improvement indicates the effectiveness of the newly proposed multi-scale prior learner and fully context-aware image generator in better capturing global context semantics.


4.2.2 Qualitative comparisons
Fig. 4 gives the showcases of the restored images on three datasets. For the Places2 dataset which contains complex scenes and various objects, our model successfully generates more complete global and local structures for missing regions. In other columns, we can see that the results of RFR still suffer from distorted structures, while SPN can produce more complete structures as well as clearer details. Particularly, for the last column, we perform object detection on the restored images to show whether the compared models generate images by effectively understanding the semantics of the scene. We can see that, compared with other methods, the generated images from SPN lead to correct object detection results with higher confidence scores.
We also provide more samples with highlighted details in Fig 5. We can observe that results from SPN contain more clear and sharp local details, which further demonstrate the effectiveness of the proposed semantic pyramid.
4.3 Probabilistic Image Inpainting
In this part, we train SPN for probabilistic image inpainting and compare with existing probabilistic approaches on CelebA-HQ and Paris StreetView.
4.3.1 Quantitative comparisons
The evaluation process in probabilistic inpainting is similar to that in deterministic inpainting. Since probabilistic models can generate diverse plausible results given a single input image, we select images with the best PSNR performance from different samples to calculate the quantitative results. From Table 2, we can observe that SPN significantly outperforms other probabilistic inpainting approaches in all evaluation metrics on different datasets. Although SPN underperforms our previous deterministic approach SPL [8] on most metrics, it still achieves better results on FID with mask ratio . This result can be explained from two aspects. First, SPN pays extra capacities to learn the multi-model distribution of the generated image, which results in the performance degeneration especially in pixel-level metrics. Second, the learned prior pyramid provides consistent multi-scale semantic guidance, which contributes to the restoration of large missing areas.
4.3.2 Qualitative comparisons
| Dataset | CelebA-HQ | Paris StreetView | |||||||
| Mask Ratio | 0.0-0.2 | 0.2-0.4 | 0.4-0.6 | All | 0.0-0.2 | 0.2-0.4 | 0.4-0.6 | All | |
| SSIM↑ | PIC [22] | 0.962 | 0.875 | 0.742 | 0.860 | 0.944 | 0.844 | 0.660 | 0.802 |
| DSI [26] | 0.964 | 0.880 | 0.758 | 0.868 | - | - | - | - | |
| Ours | 0.971 | 0.894 | 0.777 | 0.881 | 0.966 | 0.896 | 0.763 | 0.865 | |
| PSNR↑ | PIC [22] | 33.80 | 26.56 | 22.13 | 27.49 | 31.96 | 26.16 | 21.28 | 25.93 |
| DSI [26] | 34.42 | 26.92 | 22.75 | 28.03 | - | - | - | - | |
| Ours | 35.72 | 27.68 | 23.32 | 28.90 | 35.03 | 28.71 | 23.66 | 28.56 | |
| MAE↓ () | PIC [22] | 0.046 | 0.161 | 0.359 | 0.187 | 0.067 | 0.185 | 0.473 | 0.261 |
| DSI [26] | 0.044 | 0.155 | 0.329 | 0.175 | - | - | - | - | |
| Ours | 0.038 | 0.140 | 0.305 | 0.160 | 0.045 | 0.127 | 0.323 | 0.179 | |
| FID ↓ | PIC [22] | 8.82 | 16.44 | 27.82 | 8.71 | 40.42 | 72.43 | 120.10 | 68.00 |
| DSI [26] | 7.15 | 12.98 | 21.34 | 6.30 | - | - | - | - | |
| Ours | 3.22 | 8.99 | 16.54 | 4.08 | 34.07 | 45.66 | 78.86 | 46.97 | |
Fig. 6 shows four restored images by each compared model given the same input images on the CelebA-HQ dataset. We can observe that SPN generates more reasonable content than previous approaches. Specifically, images generated by PIC lack diversity among different samples, and results from DSI suffer from distorted structures such as the ears in the upper two rows and the eyes in the bottom two rows. Instead, human faces restored by SPN not only contain plausible details but also has diverse and reasonable local structures. These results show that the stochastic prior pyramid in our model can successfully model the multi-modal distribution of the potential content in the missing area and provide explicit guidance for both global and local restoration.

4.4 Ablation Studies
In this section, we conduct extensive ablation studies to evaluate the contributions proposed in this work. All experiments are conducted on the Paris StreetView dataset under the deterministic setup.
| 6464 | 128128 | 256256 | SSIM↑ | PSNR↑ | MAE↓() | FID↓ |
| ✓ | ✗ | ✗ | 0.882 | 29.38 | 0.161 | 46.13 |
| ✓ | ✓ | ✗ | 0.884 | 29.45 | 0.158 | 41.04 |
| ✓ | ✓ | ✓ | 0.886 | 29.69 | 0.154 | 36.82 |
4.4.1 On each network component
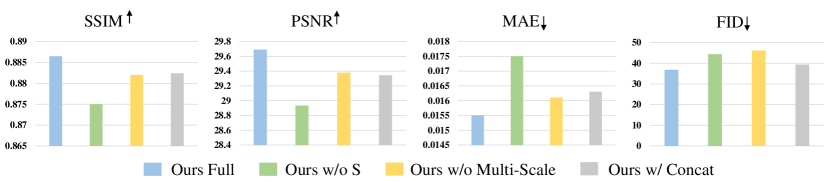
We independently remove different modules of SPN and provide results in Fig. 7. First, we remove all semantic supervisions of knowledge distillation from the prior learner, termed as “w/o ASL” (the green bars). By comparing with the blue bars, we observe a significant decline in the performance of SPN. It demonstrates that the pretext knowledge plays an important role in the context-aware image inpainting, and has been effectively transferred to inpainting task.
Besides, we evaluate the effect of multi-scale features in the prior pyramid by only integrating with the smallest spatial size () into the image generator, termed as “w/o Prior Pyramid” (the yellow bars). In Fig. 7, we can observe that replacing the multi-scale priors with single-scale priors leads to a large performance decline. In Table 3, we further provide a detailed ablation on the usage of semantic priors at different scales. We can observe that as we learn the model with more semantic priors, the FID score is significantly improved. These results show that using multi-scale semantic pyramid indeed help inpainting model generate more perceptually realistic results.
Finally, we show the effectiveness of the SPADE ResBlocks by simply concatenating image features and the corresponding prior features in the image generator. For example, we have in Eq. (9). The results are shown by the grey bars and marked as “w/o SPADE”. We may conclude that the use of SPADE ResBlocks effectively facilitates the joint modeling of both vision features and semantic representations. We also conduct ablations on using different numbers of SPADE ResBlocks in Table 4. We can observe that using too less blocks or too many blocks all degenerate the model performance.
| Block number | Params. | SSIM↑ | PSNR↑ | MAE↓() | FID↓ |
| 4 | 38M | 0.881 | 29.40 | 0.162 | 41.00 |
| 8 | 50M | 0.886 | 29.69 | 0.154 | 36.82 |
| 12 | 62M | 0.886 | 29.61 | 0.155 | 42.50 |
4.4.2 On the choices of semantic supervisions.
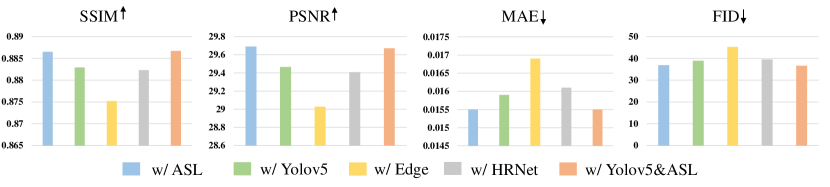
Since other types of structural priors have also been used by existing inpainting methods, we here explore the alternatives of the semantic supervisions , and see whether they can also facilitate context understanding. Specifically, as shown in Fig. 8, we first replace the multi-scale features from the ASL model, whose results are represented by the blue bars, with those from a detection network YoloV5 [41] pre-trained on the MS COCO dataset [42] (the green bars). Similarly, we also take supervisions from a semantic segmentation model HRNet [43] pre-trained on the ADE20K dataset [44] (the grey bars), as well as the edge maps used in the EC method (the yellow bars). Notably, these results cannot be strictly compared with each other due to different pre-training datasets and model architectures. However, we can still obtain some interesting observations. First, the model that uses edge maps as supervisions achieves the worst performance compared with other models using different pre-trained feature maps. Since the edge maps only contain low-level sparse structures instead of high-level semantic information, this result demonstrates that the semantic modeling process can provide more effective guidance for context understanding. Second, object-level tasks such as detection and multi-label classification may result in more discriminative representations for scene understanding.
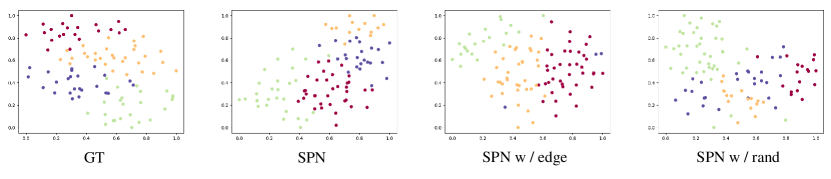
To further evaluate the effectiveness of learning semantic priors from pre-learned networks, we use t-SNE algorithm to visualize the semantic concepts of the generated results. We replace the originally used supervisions with two different features: edge maps and feature maps extracted by a randomly initialized classification model, named “SPN w / edge” and “SPN w / rand” In Fig 9, we can observe that results from SPN have similar cluster patterns with the real data. On the contrary, results from other ablations may suffer from semantic ambiguities. These results show that with the help of semantic modeling, our approach can generate images with more clear semantic concepts.
| Metric | SSIM↑ | PSNR↑ | MAE↓() | FID↓ |
| SPL [8] w/ ASL | 0.886 | 29.38 | 0.154 | 46.13 |
| SPL [8] w/ | 0.881 | 29.21 | 0.163 | 42.30 |
4.5 Analyses of the Learned Prior Pyramid
4.5.1 Semantic knowledge transfer across datasets via the learned prior pyramid
Since image inpainting can also be utilized as a self-supervised representation learning method [16], we thus conduct an extra experiment to answer whether the pre-trained SPN model can also provide meaningful semantic representations for image inpainting. Specifically, we use SPL [8], the preliminary approach of SPN, as the baseline model, and replace the original distillation target with from the pre-trained SPN model on the Places2 dataset. The experiment is conducted on the Paris StreetView dataset. From Table 5, we can see that using pre-trained as the prior distillation target achieves comparable results with using ASL [32]. It even performs better in the FID score. Besides, as is only pre-trained on the Places2 dataset, it also shows that the learned representation have potential generalization abilities.
4.5.2 Visualizations of the learned prior pyramid

Fig. 10 compares the structural information generated by the proposed semantic prior learner and the edge maps from the EC model. Specifically, we directly perform the K-Means clustering algorithm on the output feature maps and use different colors to represent different clusters. We set for all visualization results and release the clustering function at our Github page. From this figure, we observe that the edge maps from the EC model cannot effectively restore reasonable structures for complex scenes, resulting in distorted structures in the final results. Instead, the prior learner can capture more complete context understanding and provide consistent structural information at different spatial scales. We notice that higher-level semantic priors are more discriminative and are helpful for contextual reasoning, while lower-level priors enhance the understanding of local structure and texture details.

Besides, in Fig. 11, we visualize randomly sampled priors in our variational inference module. Given the same input image, we visualize two priors sampled from different latent variables with the largest spatial size (). We can observe that the sampled priors contain different structural layout, resulting in diverse details in final output images. These results demonstrate the effectiveness of our variational inference module in handling probabilistic inpainting.
In Fig. 12, we further visualize the features in the image generator to show how the feature refinement works by integrating the learned semantic priors. We here use and at the smallest spatial scale (), which are extracted before and after using the SPADE ResBlocks. We also visualize for ease of comparison. We can see that is shown to focus more on local texture consistency, while is effectively refined by the learned semantic priors to capture both global context and local texture.
4.6 Analyses of Model Parameters and Inference Time
| Model | EC [6] | MFE [7] | RFR [5] | RN [4] | WF [39] | CTSDG [28] | SPL [8] | Ours |
| Params. | 21M | 130M | 30M | 11M | 49M | 52M | 45M | 50M |
| Time | 0.03s | 0.05s | 0.02s | 0.04s | 0.06s | 0.05s | 0.04s | 0.05s |

The model parameters and single image inference time of different approaches under deterministic setup are shown in Table 6. The inference time is measured on a single GTX3090GPU. On these two metrics, we can observe that our model is comparable with recent approaches such as WF [39] and CTSDG [28], and the additional parameters compared with SPL are limited. For probabilistic models, the parameters of PIC [22], DSI [26], and ours are respectively M, M, and M, and the inference time are respectively s, s, and s. The memory and time consumption of our approach are still at a low level.

4.7 Limitations
Although we have verified the effectiveness of our approach on different datasets, there are still some limitations as shown in Fig. 13. In the first case, we can see that all approaches fail to generate clear window boundaries when large areas of structure information are lost. One possible solution may be using extra user guidance such as sketches to provide explicit constraints. For the second case, all approaches fail to generate the missing leg, even for the Transformer-based approach DSI [26]. We think this case is a typical and also important evidence for the conclusion that existing approaches may not have a complete common sense that dogs usually have four legs, hence these approaches fail to reason the missing leg when it is fully dropped. In addition to introducing extra user guidance, another solution may be using general part-level parser such as Segment Anything [45] to provide explicit guidance to help the model be aware of the common sense of different objects.
5 Conclusion
In this paper, we proposed a novel framework named SPN to learn multi-scale semantic priors to help image restoration. Instead of only considering the local texture consistency, we demonstrated that the feature maps in particular pretext models (e.g., multi-label classification and object detection) contain rich semantic information and can help the global context understanding in image inpainting. To this end, we proposed a differentiable prior learner to adaptively transfer multi-scale semantic priors through knowledge distillation and extended it to model the multi-modal distributions of missing contents in a probabilistic manner. We also presented a fully context-aware image generator that gradually incorporates the multi-scale prior representations to adaptively refine the image encoding features. In the future work, we aim to introduce the explicit part-level segmentation to help inpainting model be aware of more comprehensive common sense for various objects in real word.
Acknowledgments
This work was supported by NSFC (U19B2035, 62106144, U20B2072, 61976137), Shanghai Municipal Science and Technology Major Project (2021SHZDZX0102), and Shanghai Sailing Program (21Z510202133) from the Science and Technology Commission of Shanghai Municipality.
References
- [1] D. Ding, S. Ram, J. J. Rodríguez, Perceptually aware image inpainting, Pattern Recognit. 83 (2018) 174–184.
- [2] A. Criminisi, P. Perez, K. Toyama, Object removal by exemplar-based inpainting, in: CVPR, 2003, pp. II–II.
- [3] C. Barnes, E. Shechtman, A. Finkelstein, D. B. Goldman, Patchmatch: A randomized correspondence algorithm for structural image editing, ACM Transactions on Graphics 28 (3) (2009) 24.
- [4] T. Yu, Z. Guo, X. Jin, S. Wu, Z. Chen, W. Li, Z. Zhang, S. Liu, Region normalization for image inpainting., in: AAAI, 2020, pp. 12733–12740.
- [5] J. Li, N. Wang, L. Zhang, B. Du, D. Tao, Recurrent feature reasoning for image inpainting, in: CVPR, 2020, pp. 7760–7768.
- [6] K. Nazeri, E. Ng, T. Joseph, F. Z. Qureshi, M. Ebrahimi, Edgeconnect: Generative image inpainting with adversarial edge learning, arXiv preprint arXiv:1901.00212 (2019).
- [7] H. Liu, B. Jiang, Y. Song, W. Huang, C. Yang, Rethinking image inpainting via a mutual encoder-decoder with feature equalizations, in: ECCV, 2020, pp. 725–741.
- [8] W. Zhang, J. Zhu, Y. Tai, Y. Wang, W. Chu, B. Ni, C. Wang, X. Yang, Context-aware image inpainting with learned semantic priors, in: IJCAI, 2021, pp. 1323–1329.
- [9] T. Park, M.-Y. Liu, T.-C. Wang, J.-Y. Zhu, Semantic image synthesis with spatially-adaptive normalization, in: CVPR, 2019, pp. 2337–2346.
- [10] J. Sun, L. Yuan, J. Jia, H. Shum, Image completion with structure propagation, ACM Trans. Graph. 24 (3) (2005) 861–868.
- [11] C. Ballester, V. Caselles, J. Verdera, M. Bertalmío, G. Sapiro, A variational model for filling-in gray level and color images, in: ICCV, 2001, pp. 10–16.
- [12] W. Xiong, J. Yu, Z. Lin, J. Yang, X. Lu, C. Barnes, J. Luo, Foreground-aware image inpainting, in: CVPR, 2019, pp. 5840–5848.
- [13] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, T. S. Huang, Generative image inpainting with contextual attention, in: CVPR, 2018, pp. 5505–5514.
- [14] X. Zhang, X. Wang, C. Shi, Z. Yan, X. Li, B. Kong, S. Lyu, B. Zhu, J. Lv, Y. Yin, Q. Song, X. Wu, I. Mumtaz, DE-GAN: domain embedded GAN for high quality face image inpainting, Pattern Recognit. 124 (2022) 108415.
- [15] T. Wang, H. Ouyang, Q. Chen, Image inpainting with external-internal learning and monochromic bottleneck, in: CVPR, 2021, pp. 5120–5129.
- [16] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, A. A. Efros, Context encoders: Feature learning by inpainting, in: CVPR, 2016, pp. 2536–2544.
- [17] S. Iizuka, E. Simo-Serra, H. Ishikawa, Globally and locally consistent image completion, ACM Transactions on Graphics 36 (4) (2017) 1–14.
- [18] J. Qin, H. Bai, Y. Zhao, Multi-level augmented inpainting network using spatial similarity, Pattern Recognition 126 (2022) 108547.
- [19] Y. Zeng, J. Fu, H. Chao, B. Guo, Learning pyramid-context encoder network for high-quality image inpainting, in: CVPR, 2019, pp. 1486–1494.
- [20] N. Wang, S. Ma, J. Li, Y. Zhang, L. Zhang, Multistage attention network for image inpainting, Pattern Recognit. 106 (2020) 107448.
- [21] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, T. S. Huang, Free-form image inpainting with gated convolution, in: CVPR, 2019, pp. 4471–4480.
- [22] C. Zheng, T.-J. Cham, J. Cai, Pluralistic image completion, in: CVPR, 2019, pp. 1438–1447.
- [23] L. Zhao, Q. Mo, S. Lin, Z. Wang, Z. Zuo, H. Chen, W. Xing, D. Lu, UCTGAN: diverse image inpainting based on unsupervised cross-space translation, in: CVPR, 2020, pp. 5740–5749.
- [24] H. Liu, Z. Wan, W. Huang, Y. Song, X. Han, J. Liao, PD-GAN: probabilistic diverse GAN for image inpainting, in: CVPR, 2021, pp. 9371–9381.
- [25] Y. Zeng, Y. Gong, J. Zhang, Feature learning and patch matching for diverse image inpainting, Pattern Recognit. 119 (2021) 108036.
- [26] J. Peng, D. Liu, S. Xu, H. Li, Generating diverse structure for image inpainting with hierarchical VQ-VAE, in: CVPR, 2021, pp. 10775–10784.
- [27] Y. Ren, X. Yu, R. Zhang, T. H. Li, S. Liu, G. Li, Structureflow: Image inpainting via structure-aware appearance flow, in: CVPR, 2019, pp. 181–190.
- [28] X. Guo, H. Yang, D. Huang, Image inpainting via conditional texture and structure dual generation, in: CVPR, 2021, pp. 14134–14143.
- [29] L. Liao, J. Xiao, Z. Wang, C. Lin, S. Satoh, Guidance and evaluation: Semantic-aware image inpainting for mixed scenes, in: ECCV, 2020, pp. 683–700.
- [30] G. E. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural network, CoRR abs/1503.02531 (2015).
- [31] M. Suin, K. Purohit, A. N. Rajagopalan, Distillation-guided image inpainting, in: ICCV, 2021, pp. 2461–2470.
- [32] E. Ben-Baruch, T. Ridnik, N. Zamir, A. Noy, I. Friedman, M. Protter, L. Zelnik-Manor, Asymmetric loss for multi-label classification, arXiv preprint arXiv:2009.14119 (2020).
- [33] A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikov, et al., The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale, arXiv preprint arXiv:1811.00982 (2018).
- [34] T. Karras, T. Aila, S. Laine, J. Lehtinen, Progressive growing of gans for improved quality, stability, and variation, in: ICLR, OpenReview.net, 2018.
- [35] C. Doersch, S. Singh, A. Gupta, J. Sivic, A. A. Efros, What makes paris look like paris?, Communications of the ACM 58 (12) (2015) 103–110.
- [36] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, A. Torralba, Places: A 10 million image database for scene recognition, IEEE Trans. Pattern Anal. Mach. Intell. 40 (6) (2017) 1452–1464.
- [37] Z. Liu, P. Luo, X. Wang, X. Tang, Deep learning face attributes in the wild, in: ICCV, 2015, pp. 3730–3738.
- [38] G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, B. Catanzaro, Image inpainting for irregular holes using partial convolutions, in: ECCV, 2018, pp. 85–100.
- [39] Y. Yu, F. Zhan, S. Lu, J. Pan, F. Ma, X. Xie, C. Miao, Wavefill: A wavelet-based generation network for image inpainting, in: ICCV, 2021, pp. 14114–14123.
- [40] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, S. Hochreiter, Gans trained by a two time-scale update rule converge to a local nash equilibrium, in: NeurIPS, 2017, pp. 6626–6637.
- [41] G. Jocher, et al., Yolov5, https://github.com/ultralytics/yolov5, accessed: 2020-12 (2020).
- [42] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft COCO: common objects in context, in: ECCV, Vol. 8693, 2014, pp. 740–755.
- [43] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang, W. Liu, B. Xiao, Deep high-resolution representation learning for visual recognition, IEEE Trans. Pattern Anal. Mach. Intell. 43 (10) (2021) 3349–3364.
- [44] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, A. Torralba, Scene parsing through ADE20K dataset, in: CVPR, 2017, pp. 5122–5130.
- [45] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al., Segment anything, arXiv preprint arXiv:2304.02643 (2023).