Fully Convolutional Scene Graph Generation
Abstract
This paper presents a fully convolutional scene graph generation (FCSGG) model that detects objects and relations simultaneously. Most of the scene graph generation frameworks use a pre-trained two-stage object detector, like Faster R-CNN, and build scene graphs using bounding box features. Such pipeline usually has a large number of parameters and low inference speed. Unlike these approaches, FCSGG is a conceptually elegant and efficient bottom-up approach that encodes objects as bounding box center points, and relationships as 2D vector fields which are named as Relation Affinity Fields (RAFs). RAFs encode both semantic and spatial features, and explicitly represent the relationship between a pair of objects by the integral on a sub-region that points from subject to object. FCSGG only utilizes visual features and still generates strong results for scene graph generation. Comprehensive experiments on the Visual Genome dataset demonstrate the efficacy, efficiency, and generalizability of the proposed method. FCSGG achieves highly competitive results on recall and zero-shot recall with significantly reduced inference time.
1 Introduction
Philosophers, linguists and artists have long wondered about the semantic content of what the mind perceives in images and speech [2, 9, 31, 45]. Many have argued that images carry layers of meaning [3, 47]. Considered as an engineering problem, semantic content has been modeled either as latent representations [12, 18, 27, 40], or explicitly as structured representations [39, 57, 60]. For a computer vision system to explicitly represent and reason about the detailed semantics, Johnson [26] et al.adopt and formalize scene graphs from computer graphics community. A scene graph serves as a powerful representation that enables many down-stream high-level reasoning tasks such as image captioning [63, 66], image retrieval [25, 26], Visual Question answering [22, 52] and image generation [25, 61].
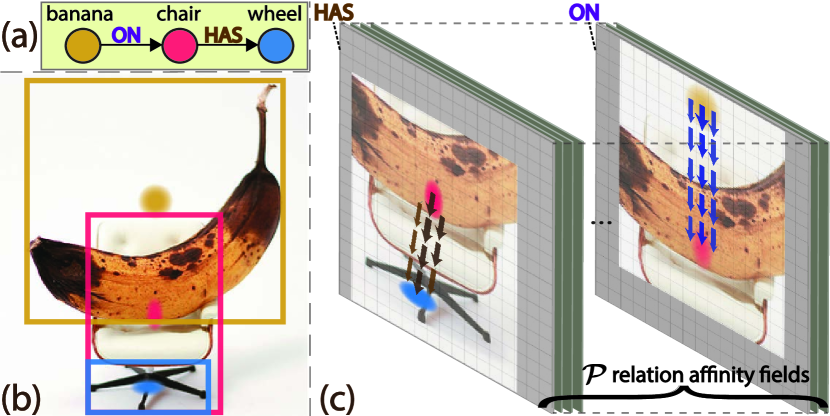
A scene graph is considered as an explicit structural representation for describing the semantics of a visual scene. The nodes in a scene graph represent the object classes and the edges represent the relationships between the objects. Figure 1(a) shows a simple example of a scene graph that represents the underlying semantics of an image. Each relationship between two objects is denoted as a triplet of <subject, PREDICATE, object> , i.e., banana chair and chair wheel in Figure 1(a). Most of the SGG work [6, 50, 51, 60, 70] is build as a two-stage pipeline: object detection then scene graph generation. For the first stage of object detection, existing object detectors, \ie, Fast/Faster R-CNN [13, 43], are used for object feature extraction from region proposals. For the second stage of scene graph generation, various approximation methods [51, 60, 70] for graph inference have been used. Some work [6, 67, 68, 69] have also investigated how to utilize external knowledge for improving the results. However, most previous work suffer from not only the long-tailed distribution of relationships [7, 11, 70], but also the highly biased prediction conditioned on object labels [16, 23, 28, 50]. Consequently, frequent predicates will prevail over less frequent ones, and unseen relationships can not be identified. Moreover, the extensibility and inference speed of a SGG framework is crucial for accelerating down-stream tasks. Although few researchers have studied the efficiency and scalability in SGG [14, 33, 62], the high computational complexity impedes the practicality towards real-world applications. A natural question that arises is: can we solve scene graph generation in a per-pixel prediction fashion? Recently, anchor-free object detectors [30, 53, 65, 72] have become popular due to their simplicity and low cost. These methods treat an object as a single or many, pre-defined or self-learned keypoints. Relating object detection to human pose estimation, if an object can be modeled as a point (human “keypoint”), is it possible to represent a binary relationship as vectors (human “limb”)?
In this paper, we propose a novel fully convolutional scene graph generation model, \ie, FCSGG, with state-of-the-art object detection results on Visual Genome dataset [29], as well as compelling SGG results compared with visual-only methods. We present a bottom-up representation of objects and relationships by modeling objects as points and relationships as vectors. Each relationship is encoded as a segment in a 2D vector field called relation affinity field (RAF). Figure 1(c) shows an illustration of RAFs for predicates ON and HAS. Both objects and relationships are predicted as dense feature maps without losing spatial information. For the first time, scene graphs can be generated from a single convolutional neural network (CNN) with significantly reduced model size and inference speed. Specifically, we make the following contributions:
-
•
We propose the first fully convolutional scene graph generation model that is more compact and computationally efficient compared to previous SGG models.
-
•
We introduce a novel relationship representation called relation affinity fields that generalizes well on unseen visual relationships. FCSGG achieves strong results on zero-shot recall.
-
•
Our proposed model outperforms most of the visual-only SGG methods, and achieves competitive results compared to methods boosted by external knowledge.
-
•
We conduct comprehensive experiments and benchmark our proposed method together with several previous work on model efficiency, and FCSGG achieves near real-time inference.
2 Related Work
We categorize the related work of SGG into the following directions: refinement of contextual feature, adaptation of external knowledge, and others.
Contextual feature refinement. Xu et al. [60] proposed an iterative message passing mechanism based on Gated Recurrent Units [8], where the hidden states are used for predictions. Followers [51, 70] studied better recurrent neural networks [21, 44, 48] for encoding object and edge context. Others trying to incorporate more spatial features into SGG. Li et al. [34] proposed the MSDN that merges features across multiple semantic levels, and later achieved message passing constrained on visual phrase [32]. Dai et al.[10] proposed a spatial module by learning from bounding box masks. Woo et al. [56] introduced the geometric embeddings by directly encoding the bounding box offsets between objects. Wang et al.[55] further studied the effects of relative positions between objects for extracting more discriminating features. Our method is fundamentally different from these methods as the relationships are grounded semantically and spatially directly into CNN features. Without any explicit iterative information exchange between nodes and edges, our model is able to predict objects and relationships in a single forward pass.
External knowledge adaptation. Beyond visual features, linguistic knowledge can serve as additional features for SGG [15, 39, 42, 67]. By adopting statistical correlations of objects, Chen et al. [6] utilized graph neural networks [46] to infer relationships. Gu et al. [17] and Zareian et al.[68, 69] explored the usefulness of knowledge or commonsense graphs for SGG. Tang et al. [50] proposed an de-biasing method by causal interventions of predictions. Lin et al. [38] investigated the graph properties and mitigated the long-tailed distributions of relationships. Compared with these methods, our proposed model relies only on visual features but still yields a strong performance.
Very few researchers have investigated alternatives either for object feature or relationship feature representations. Newell [41] and Zhang et al. [71] tried latent-space embeddings for relationship and achieved improvements. Different from most of the previous work, FCSGG reformulates and generalizes relationship representations from only visual-based features in near real-time, which is much faster than specifically designed SGG models for efficiency [33, 62].
3 Object Detection as Keypoint Estimation
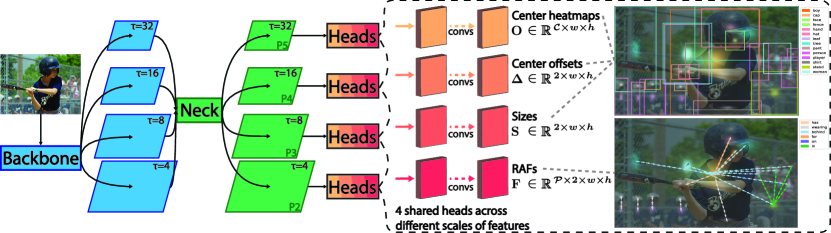
In this section, we provide the preliminaries of modeling object detection as keypoint estimation in a single-scale dense feature map prediction fashion.
Our model is built upon a one-stage anchor-free detector, namely CenterNet [72]. Different from commonly used anchor-based R-CNN approaches for generating object proposals and features, it predicts three dense features that represent centers of object bounding boxes, center offsets, and object sizes. More specifically, an input image will go through a backbone CNN generating feature maps of size where is the total stride until the last layer, and we set unless specified otherwise. Then these features will be fed into three prediction heads, each of which consists of several convolutional layers. The three heads are for predicting object center heatmaps where is the number of object classes in a dataset, object center offsets for recovering from downsampled coordinates, and object sizes , respectively (shown in the dashed block of Figure 2). We define the ground-truth (GT) objects in an image as where is the object of class , and denote the coordinates of the left-top and right-bottom corners of its bounding box. The center of the bounding box is defined as , and the size of the object is defined as . To obtain the ground-truth center heatmaps at feature level, we divide coordinates by the stride and add Gaussian-smoothed samples following Law [30] and Zhou et al. [72]. Formally, the object center will be modulated by a bivariate Gaussian distribution along x-axis and y-axis on . The value around is computed as
| (1) |
where and controls the spread of the distribution. When multiple objects of the same class contribute to , the maximum is taken as the ground truth. The center heatmaps are then supervised by Gaussian focal loss [30, 36, 72]. More details are provided in the supplementary file.
In addition to the supervision of center heatmaps, the center offset regression and object size regression are used to recover object detections. For mitigating discretization error due to downsampling, the offset target is , and regressed via L1 loss as at center locations. For object size regression , the target is feature-level object size , and the actual size can be recovered by multiplying the output stride. We also use L1 loss as at center locations. Both object size and offset regressors are class-agnostic such that there will be only one valid regression target at a particular location where . If two object centers collide onto the same location, we choose the smaller object for regression. The overall object detection objective is
| (2) |
where is the total number of objects in the image, and are hyper-parameters for weight balancing. We empirically set and for all experiments. Until here, object centers, offsets, and sizes are all represented in single-scale feature maps. We will discuss a multi-scale prediction approach reducing regression ambiguity effectively in section 4.2.
4 Relation Affinity Fields
Newell and Deng [41] model objects as center points, and ground edges at the midpoint of two vertices then construct the graph via associative embeddings. The midpoint serves as a confidence measurement of presence of relationships. However, false detections and ambiguities arise when there are crowded objects in a region, or the associated objects of a relation are far away from each other. Another limitation is that it still needs feature extraction and grouping that cause low inference speed. Inspired and from a bottom-up 2D human pose estimation work called OpenPose [4], we migrate the concept of part affinity fields into scene graph generation. Our proposed method grounds relationships onto CNN features pixel by pixel, and mitigates above mentioned limitations.
Our model is conceptually simple: in addition to the outputs that are produced by the object detection network described in Section 3, we add another branch that outputs a novel feature representation for relationships called relation affinity fields (RAFs). Specifically, the RAFs are a set of 2D vector fields , where and is the number of predicate classes in a dataset. Each 2D vector field represents the relationships among all the object pairs of predicate . Given our definition of objects as center points, the ground-truth RAFs are defined as vectors flow from the center of subject to the center of object. More formally, we define the binary relationships among objects in the input image as , where is the relationship triplet from subject to object with predicate . We define a “path” that “propagates” from subject center to object center . For a point , its ground-truth relation affinity field vector is given as
| (3) |
and the path is defined on a set of points between object centers forming a rectangular region:
| (4) |
where as the relationship “length” along the direction , and as the relationship “semi-width” along (orthogonal to ) being the minimum of object centers’ radii. Since vectors may overlap at the same point, the ground-truth RAF averages the fields computed for all the relationship triplets containing that particular predicate . It is given as , where is the number of non-zero vectors at point . With the definition of ground-truth RAFs, we can train our network to regress such dense feature maps. The RAF regression loss can be estimated using a normal regression losses such as L1, L2 or smooth L1 [13]. Given the predicted RAFs , the loss is defined as per-pixel weighted regression loss as
| (5) |
where is a pixel-wise weight tensor of the same shape of . The weights are determined and divided into three cases (Figure 3): a) if is exactly on the line segment between objects having the relationship b) if the distance between and the line segment is small and the value is negative correlated to the distance c) otherwise where . We provide ablation study on the choice of losses and the weight tensor in Section 5.3. Finally, the complete loss for training our proposed model can be written as .
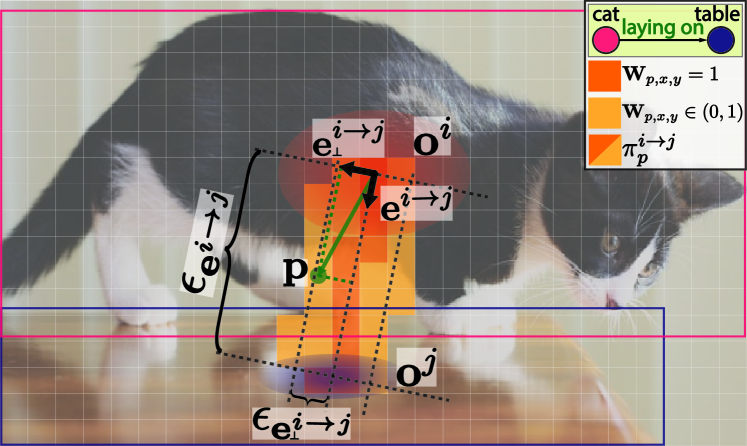
Our proposed RAFs encode rich information of both spatial and semantic features as dense feature maps, and enable end-to-end joint training of object detection and relation detection. To extract relationship from predictions, path integral over RAFs is performed which will be described below.
4.1 Inference
We compute path integrals over RAFs along the line segments connecting pairs of detected object centers as the scores of relationships. Specifically, for two candidate object centers and with predicted class scores and , we gather the predicted RAFs along the path between and , and compute the mean of their projections onto . The path integral scores are identified as the confidences of existence of relationships:
| (6) |
where is the number of points in . Since our RAFs are object-class-agnostic, we multiply the class scores of the objects and the path integral score as the overall classification score for the relationship predicate. The integral will be performed spatially for each predicate channel, so represents the confidences of predicted relationship triplet for all predicates. Note that the integral could be negative that indicates an opposite relationship of the object pairs, and those negative integral values can be simply negated as . Finally, both scores of and will be used for ranking the predicted relationships. We also experiment with a simple re-weighting step known as frequency bias [70] by multiplying with , where counts the occurrence of triplet in training set. The path integral procedure is presented in Algorithm 1. In practice, the operations are performed using matrix multiplication in stead of for loop for fast inference.
4.2 Multi-scale Prediction
Since object centers are downsampled to feature level, their centers could collide onto the same pixel location. Regression ambiguity may rise due to single-scale feature representations. In this subsection, we address this problem by utilizing multi-scale prediction and shared detection heads.
Though Zhou et al. [72] argued that only a very small fraction (<0.1% in COCO [37] dataset) of objects have center collision problem at stride of 4, the size and offset regression targets need better assignment strategy since there is only one valid target per pixel. We follow the work of FPN [35], RetinaNet [36] and FCOS [53], and assign the ground-truth bounding boxes to different levels based on scales. Building upon the backbone features, we construct multi-level feature maps where is of stride . We refer the network component of generating multi-scale features as the “neck” (the green box in Figure 2), such as FPN [35]. We define a valid range for objects in each scale, where is the maximum size of longer edge allowed for training and testing. Only bounding boxes of area within are qualified for the k-th scale training. We experiment different number of scale levels and input image size. For smaller input image of = 512, we build 4-scale features [35] (as shown in Figure 2) with valid ranges {[0, 322], [322, 642], [642, 1282], [1282, 5122]}; for larger input image of = 1024 (shorter edge is at least = 640), we use 5-scale features [36, 53] with area ranges {[0, 642], [642, 1282], [1282, 2562], [2562, 5122], [5122, 10242]}. If there is still more than one target at the same location, we simply choose the smallest object for regression.
In terms of the multi-scale RAFs training, the GT assignment is based on the distances between object centers. For high-level semantic features like P5, the feature map can capture large objects, as well as relationships among distant objects. We select the relationships of “length” as valid samples for training the k-th scale. The exact ranges for 4-scale or 5-scale RAFs are the same as the settings for bounding boxes. Finally, the weights of detection heads are shared across different feature scales for efficiencies and performance improvements. During inference, we gather outputs from each scale based on the corresponding valid range, then merge and rank all relationship triplets. Figure 2 illustrates the details of our proposed architecture using a four-scale feature setup as an example with shared detection heads. Our experiments (Section 5) show that the multi-scale GT and scale-aware training resolve the aforementioned ambiguity problem thus improve the results over single-scale prediction.
5 Experiments
| Recall @K / | AP50 | Predicate Classification | Scene Graph Classification | Scene Graph Detection | ||||||||||||||||||||||||||||||||||
| No-graph Constraint Recall @K | R@20/50 /100 | ng-R@20/50/100 | R@20/50/100 | ng-R@20/50/100 | R@20/50/100 | ng-R@20/50/100 | ||||||||||||||||||||||||||||||||
| External Knowledge | VCTree [51] | - | 60.1 | / | 66.4 | / | 68.1 | - | 35.2 | / | 38.1 | / | 38.8 | - | 22.0 | / | 27.9 | / | 31.3 | - | ||||||||||||||||||
| KERN [6] | - | - | / | 65.8 | / | 67.6 | - | / | 81.9 | / | 88.9 | - | / | 36.7 | / | 37.4 | - | / | 45.9 | / | 49.0 | - | / | 27.1 | / | 29.8 | - | / | 30.9 | / | 35.8 | |||||||
| GPS-Net [38] | - | 67.6 | / | 69.7 | / | 69.7 | - | 41.8 | / | 42.3 | / | 42.3 | - | 22.3 | / | 28.9 | / | 33.2 | - | |||||||||||||||||||
| MOTIFS-TDE [50, 70] | 28.1 | 33.6 | / | 46.2 | / | 51.4 | - | 21.7 | / | 27.7 | / | 29.9 | - | 12.4 | / | 16.9 | / | 20.3 | - | |||||||||||||||||||
| GB-NET- [68] | - | - | / | 66.6 | / | 68.2 | - | / | 83.5 | / | 90.3 | - | / | 37.3 | / | 38.0 | - | / | 46.9 | / | 50.3 | - | / | 26.3 | / | 29.9 | - | / | 29.3 | / | 35.0 | |||||||
| Visual Only | VTransE⋆ [71] | - | - | - | - | - | - | / | 5.5 | / | 6.0 | - | ||||||||||||||||||||||||||
| FactorizableNet⋆ [33] | - | - | - | - | - | - | / | 13.1 | / | 16.5 | - | |||||||||||||||||||||||||||
| IMP† [60, 70] | 20.0 | 58.5 | / | 65.2 | / | 67.1 | - | 31.7 | / | 34.6 | / | 35.4 | - | 14.6 | / | 20.7 | / | 24.5 | - | |||||||||||||||||||
| Pixels2Graphs [41] | - | - | - | / | 68.0 | / | 75.2 | - | - | / | 26.5 | / | 30.0 | - | - | / | 9.7 | / | 11.3 | |||||||||||||||||||
| Graph R-CNN [62] | 23.0 | - | / | 54.2 | / | 59.1 | - | - | / | 29.6 | / | 31.6 | - | - | / | 11.4 | / | 13.7 | - | |||||||||||||||||||
| VRF [11] | - | - | / | 56.7 | / | 57.2 | - | - | / | 23.7 | / | 24.7 | - | - | / | 13.2 | / | 13.5 | - | |||||||||||||||||||
| CISC [55] | - | 42.1 | / | 53.2 | / | 57.9 | - | 23.3 | / | 27.8 | / | 29.5 | - | 7.7 | / | 11.4 | / | 13.9 | - | |||||||||||||||||||
| FCSGG (Ours) | HRNetW32-1S | 21.6 | 27.6 | / | 34.9 | / | 38.5 | 32.2 | / | 46.3 | / | 56.6 | 12.3 | / | 15.5 | / | 17.2 | 13.5 | / | 19.3 | / | 23.6 | 11.0 | / | 15.1 | / | 18.1 | 12.4 | / | 18.2 | / | 23.0 | ||||||
| HRNetW48-1S | 25.0 | 24.2 | / | 31.0 | / | 34.6 | 28.1 | / | 40.3 | / | 50.0 | 13.6 | / | 17.1 | / | 18.8 | 14.2 | / | 19.6 | / | 24.0 | 11.5 | / | 15.5 | / | 18.4 | 12.7 | / | 18.3 | / | 23.0 | |||||||
| ResNet50-4S-FPN | 23.0 | 28.0 | / | 35.8 | / | 40.2 | 31.6 | / | 44.7 | / | 54.8 | 13.9 | / | 17.7 | / | 19.6 | 14.8 | / | 20.6 | / | 25.0 | 11.4 | / | 15.7 | / | 19.0 | 12.2 | / | 18.0 | / | 22.8 | |||||||
| HRNetW48-5S-FPN | 28.5 | 28.9 | / | 37.1 | / | 41.3 | 34.0 | / | 48.1 | / | 58.4 | 16.9 | / | 21.4 | / | 23.6 | 18.6 | / | 26.1 | / | 31.6 | 13.5 | / | 18.4 | / | 22.0 | 15.4 | / | 22.5 | / | 28.3 | |||||||
| HRNetW48-5S-FPN-f | 28.5 | 33.4 | / | 41.0 | / | 45.0 | 37.2 | / | 50.0 | / | 59.2 | 19.0 | / | 23.5 | / | 25.7 | 19.6 | / | 26.8 | / | 32.1 | 16.1 | / | 21.3 | / | 25.1 | 16.7 | / | 23.5 | / | 29.2 | |||||||
| Mean Recall @K / | Predicate Classification | Scene Graph Classification | Scene Graph Detection | |||||||||||||||||||||||||||||||||
| Ng Mean Recall @K | mR@20/50/100 | ng-mR@20/50/100 | mR@20/50/100 | ng-mR@20/50/100 | mR@20/50/100 | ng-mR@20/50/100 | ||||||||||||||||||||||||||||||
| VCTree [51] | 14.0 | / | 17.9 | / | 19.4 | - | 8.2 | / | 10.1 | / | 11.8 | - | 5.2 | / | 6.9 | / | 8.0 | - | ||||||||||||||||||
| KERN [6] | - | / | 17.7 | / | 19.4 | - | - | / | 9.4 | / | 10.0 | - | - | / | 6.4 | / | 7.3 | - | ||||||||||||||||||
| GPS-Net [38] | - | / | - | / | 22.8 | - | - | / | - | / | 12.6 | - | - | / | - | / | 9.8 | - | ||||||||||||||||||
| MOTIFS-TDE [50, 70] | 18.5 | / | 25.5 | / | 29.1 | - | 9.8 | / | 13.1 | / | 14.9 | - | 5.8 | / | 8.2 | / | 9.8 | - | ||||||||||||||||||
| GB-NET- [68] | - | / | 22.1 | / | 24.0 | - | - | / | 12.7 | / | 13.4 | - | - | / | 7.1 | / | 8.5 | - | ||||||||||||||||||
| HRNetW32-1S | 4.0 | / | 5.5 | / | 6.3 | 5.4 | / | 9.7 | / | 13.6 | 1.9 | / | 2.5 | / | 2.8 | 2.7 | / | 4.4 | / | 6.2 | 1.7 | / | 2.4 | / | 2.9 | 2.2 | / | 3.6 | / | 4.9 | ||||||
| HRNetW48-1S | 3.7 | / | 5.2 | / | 6.1 | 5.2 | / | 9.5 | / | 14.7 | 2.2 | / | 2.9 | / | 3.4 | 3.5 | / | 6.3 | / | 9.4 | 1.8 | / | 2.6 | / | 3.1 | 2.7 | / | 4.7 | / | 6.9 | ||||||
| ResNet50-4S-FPN | 4.2 | / | 5.7 | / | 6.7 | 6.5 | / | 11.3 | / | 16.6 | 2.2 | / | 2.9 | / | 3.3 | 3.6 | / | 6.0 | / | 8.3 | 1.9 | / | 2.7 | / | 3.3 | 3.0 | / | 4.9 | / | 6.8 | ||||||
| HRNetW48-5S-FPN | 4.3 | / | 5.8 | / | 6.7 | 6.1 | / | 10.3 | / | 14.2 | 2.6 | / | 3.4 | / | 3.8 | 4.1 | / | 6.4 | / | 8.4 | 2.3 | / | 3.2 | / | 3.8 | 3.7 | / | 5.7 | / | 7.4 | ||||||
| HRNetW48-5S-FPN-f | 4.9 | / | 6.3 | / | 7.1 | 6.6 | / | 10.5 | / | 14.3 | 2.9 | / | 3.7 | / | 4.1 | 4.2 | / | 6.5 | / | 8.6 | 2.7 | / | 3.6 | / | 4.2 | 3.8 | / | 5.7 | / | 7.5 | ||||||
Dataset. We use the Visual Genome (VG) [29] dataset to train and evaluate our models. We followed the widely-used preprocessed subset of VG-150 [60] which contains the most frequent 150 object categories ( = 150) and 50 predicate categories ( = 50). The dataset contains approximately 108k images, with 70% for training and 30% for testing. Different from previous works [5, 51, 70], we do not filter non-overlapping triplets for evaluation.
General settings. We experiment on two settings, one for small input size ( = 512) and one for larger size ( = 1024). The model is trained end-to-end using SGD optimizer with the batch size of 16 for 120k iterations. The initial learning rate is set to 0.02 and decayed by the factor of 10 at 80k and 100k iteration. We adopt standard image augmentations of horizontal flip and random crop with multi-scale training. During testing, we keep the top 100 detected objects for path integral.
Metrics. We conduct comprehensive analysis following three standard evaluation tasks: Predicate Classification (PredCls), Scene Graph Classification (SGCls), and Scene Graph Detection (SGDet). We report results of recall@K (R@K) [39], no-graph constraint recall@K (ngR@K) [41, 70], mean recall@K (mR@K) [6, 51], no-graph constraint mean recall@K (ng-mR@K), zero-shot recall@K (zsR@K) [39] and no-graph constraint zero-shot recall@K (ng-zsR@K) [50] for all three evaluation tasks. We do not train separate models for different tasks.
5.1 Implementation Details
We conduct experiments on different backbone and neck networks. Each of the detection heads consists of four convolutions followed by batch normalization and ReLU, and one convolution with the desired number of output channels in all our experiments unless specified otherwise. For convenience, our models are named as backbone - # of output scales - neck - other options.
ResNet [20, 35]. We start by using ResNet-50 as our backbone and build a 4-scale FPN for multi-scale prediction. Since the tasks of object detection and RAFs prediction are jointly trained, the losses from the two tasks could compete with each other. We implement a neck named “FPN” with two parallel FPNs, such that one FPN is used for constructing features for object detection heads (center, size and offset), and the other is for producing features for RAFs. We name this model as ResNet50-4S-FPN.
HRNet [54]. We then experiment on a recent proposed backbone network called HRNet that consists of parallel convolution branches with information exchange across different scales. For single-scale experiments, we use HRNetV2-W32 and HRNetV2-W48; and for multi-scale prediction, we adopt its pyramid version called HRNetV2p. We omit their version number for the rest of the paper. We test several models: HRNetW32-1S, HRNetW48-1S and HRNetW48-5S-FPN. We also experiment on adding frequency bias for inference as discussed in Section B, and the model used is called HRNetW48-5S-FPN-f.
5.2 Quantitative Results
| Zero-shot Recall @K | PredCls | SGCls | SGDet | |||
|---|---|---|---|---|---|---|
| Method | zsR@50/100 | zsR@50/100 | zsR@ 50/100 | |||
| MOTIFS-TDE [50] | 14.4 / 18.2 | 3.4 / 4.5 | 2.3 / 2.9 | |||
| VTransE-TDE [50] | 13.3 / 17.6 | 2.9 / 3.8 | 2.0 / 2.7 | |||
| VCTree-TDE [50] | 14.3 / 17.6 | 3.2 / 4.0 | 2.6 / 3.2 | |||
| Knyazev et al.[28] | - / 21.5 | - / 4.2 | - / - | |||
| FCSGG (Ours) | zsR | ng-zsR | zsR | ng-zsR | zsR | ng-zsR |
| @50/100 | @50/100 | @50/100 | @50/100 | @50/100 | @50/100 | |
| HRNetW32-1S | 8.3 / 10.7 | 12.9 / 19.2 | 1.0 / 1.2 | 2.3 / 3.5 | 0.6 / 1.0 | 1.2 / 1.6 |
| HRNetW48-1S | 8.6 / 10.9 | 12.8 / 19.6 | 1.7 / 2.1 | 2.9 / 4.4 | 1.0 / 1.4 | 1.8 / 2.7 |
| ResNet50-4S-FPN | 8.2 / 10.6 | 11.7 / 18.1 | 1.3 / 1.7 | 2.4 / 3.8 | 0.8 / 1.1 | 1.0 / 1.7 |
| HRNetW48-5S-FPN | 7.9 / 10.1 | 11.5 / 17.7 | 1.7 / 2.1 | 2.8 / 4.8 | 0.9 / 1.4 | 1.4 / 2.4 |
| HRNetW48-5S-FPN-f | 7.8 / 10.0 | 11.4 / 17.6 | 1.6 / 2.0 | 2.8 / 4.8 | 0.8 / 1.4 | 1.4 / 2.3 |
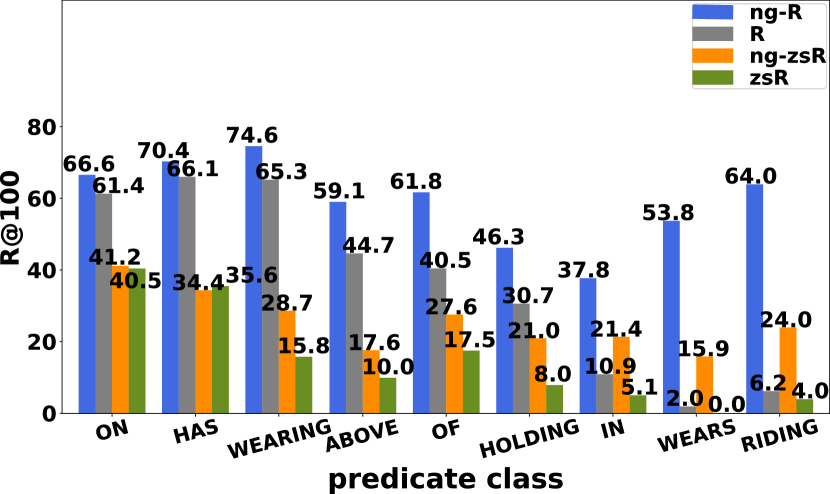
We first compare results of R@K and ng-R@K with various of state-of-the-art (SOTA) models, and divide them into two categories: 1) models that only use visual features derived from the input image like our proposed model 2) models that not only use visual features, but also use features like language embeddings, dataset statistics or counterfactual causality, \etc The results are shown in Table 1. Our best model achieves 28.5 average precision at IoU = 0.5 () for object detection. Though our SGG results do not outperform the SOTA approaches, we achieve the best scene graph detection results among visual-only models. Specifically, Pixels2Graphs [41] and our models are the only models without using Faster R-CNN [43] as object detector, and we achieves 13.8 / 17.9 gain on SGDet ng-R@50 / 100 compared with their results using RPN [43]. We then report mean recall and no-graph constraint mean recall results shown in Table 2. We still obtain competitive results, especially on ng-mR. By comparing (m) R@K and ng-(m) R@K directly, we observe more gain on our results than other methods’.
Zero-shot recall (zsR) [16, 23, 28, 39, 42, 50, 64] is a proper metric for evaluating the model’s robustness and generalizability for generating scene graphs. It computes recall on those subject-predicate-object triplets that do not present during training. There are in total of 5971 unique zero-shot triplets from the testing set of VG-150. The results and comparisons are listed in Table 5. We also compute the per-predicate recall@100 for predicate classification task using HRNetW48-5S-FPN-f, and show the comparisons in Figure 5. We observe similar behavior with our results on recall, such that the results on no-graph constraint zero-shot recall are significantly better than zero-shot recall. Even for unseen triplets, purely based on visual features, FCSGG is still capable of predicting meaningful RAFs which proves its generalization capability. In other words, when constructing scene graphs from RAFs, our approach does not highly depend on the object classes but only focuses on the context features between the objects. When comparing with other reported results on zsR, we achieve slightly lower results than those much larger models. For example of PredCls task, ResNet50-4S-FPN achieves 10.6 zsR@100 with only 36 million (M) number of parameters and inference time of 40 milliseconds (ms) per image, while VCTree-TDE [50] achieves 17.6 zsR@100 with 360.8M number of parameters and inference time of 1.69 s per image. For comparison, ResNet50-4S-FPN is 10 times smaller and 42 times faster than VCTree-TDE.
Limitations. It should be noticed that FCSGG also has some “disadvantages” over Faster R-CNN-based methods on easier tasks such as PredCls and SGCls. During evaluations with given GT bounding boxes or classes, our RAFs features will not change, while R-CNN extracted object/union-box features will change which leads to better results. When using visual-only representation of relationships, it is hard for the network to distinguish predicates between WEARS / WEARING (by comparing R and ng-R in Figure 5) or LAYING ON / LYING ON, which is common in VG dataset. In this sense, incorporating external knowledge gives FCSGG a large potential in improving results. Comparing the model HRNetW48-5S-FPN and its frequency-biased counterpart HRNetW48-5S-FPN-f, we find noticeable improvement by using training set statistics. This simple cost-free operation can improve R@20 by 2.6, and we expect better results from fine-tuning hyper-parameters. However, the focus of this work is not perfectly fitting on a dataset, but improving generalization of relationship based on visual features. More sophisticated ensemble methods or extensions are beyond the scope of this paper.
5.3 Ablation Study
5.3.1 RAF regression Loss
We experience the same difficulty of training from sparsely annotated scene graphs as discussed by Newell et al. [41]. The network has the potential of generating reasonable triplets not covered in the ground-truth, and our results on zero-shot recall prove the argument. To reduce the penalty on these detections, we investigate the design methodology of RAF regression loss (Equation 5).
| R@50 | zR@50 | mR@50 | |||
|---|---|---|---|---|---|
| L1 | 0 | 21.57 | 6.22 | 0.40 | 2.28 |
| L1 | 1 | 21.52 | 9.80 | 0.56 | 2.33 |
| L1 | 10 | 21.56 | 15.05 | 0.60 | 2.36 |
| Smooth L1 | 0 | 20.15 | 5.00 | 0.30 | 2.51 |
| Smooth L1 | 1 | 19.65 | 7.46 | 0.57 | 2.45 |
| Smooth L1 | 10 | 20.63 | 11.82 | 0.61 | 2.83 |
| L2 | 0 | 19.62 | 4.82 | 0.26 | 2.34 |
| L2 | 1 | 21.60 | 10.76 | 0.68 | 2.57 |
| L2 | 10 | 21.62 | 2.89 | 0.57 | 2.50 |
We refer the loss applied at locations having GT RAFs defined as positive loss , and we test different regression losses. As for locations where , we apply so called negative loss using L1 for regression. will be multiplied by a factor for adjusting the penalty. Spatially, can be re-written as . Table 3 shows the effects of different losses and penalty factor on the performance. We observe better performance using L1 and = 10. However, when only supervise on loss, the model has comparable mean recall results and it can detect more semantic and rare relationships. On the other hand, adding loss will push the model more biased to dominating predicates like ON and HAS.
5.3.2 Architecture Choices
| Neck | Norm | R@50 | zR@50 | mR@50 | |
|---|---|---|---|---|---|
| FPN | GN | 22.75 | 11.29 | 0.71 | 2.95 |
| FPN | MS-BN | 22.10 | 13.23 | 0.75 | 2.67 |
| FPN | GN | 22.74 | 11.96 | 0.78 | 3.00 |
| FPN | MS-BN | 22.60 | 12.01 | 0.80 | 2.88 |
By comparing our results between single-scale and multi-scale models, we see substantial performance gain on both object detection and scene graph generation from Table 1 2 5. We also observe HRNet has better results over ResNet due to its multi-scale feature fusions. For investigating the entanglement of object features and contextual features producing RAFs, we compare the results of FPN and FPN using ResNet-50 as backbone shown in Table 4. As observed in [53], the regression range differs across different levels. Therefore, to improve the performance of shared fully-convolutional heads, we replace each batch normalization (BN) [24] layer in the head with a set of BN layers, each of which is only applied for the corresponding scale. We name this modified BN as multi-scale batch normalization (MS-BN). We also experiment on group normalization (GN) [58] which stabilizes the training as well. We show the comparisons of MS-BN and GN (Section 4.2) in the same table. We observe better mR by using FPN and better recall and zsR by using MS-BN. We expect more performance improvement if using larger batch size with MS-BN.
| Method | #Params (M) | Input Size | s / image |
| Pixels2Graphs [71] | 94.8 | 3.55 | |
| VCTree-TDE [50] | 360.8 | 1.69 | |
| MOTIFS-TDE [50] | 369.5 | 0.87 | |
| KERN [6] | 405.2 | 0.79 | |
| MOTIFS [50] | 367.2 | 0.66 | |
| FactorizableNet [33] | 40.4 | 0.59 | |
| VTransE-TDE [50] | 311.6 | 0.55 | |
| GB-NET- [68] | 444.6 | 0.52 | |
| Graph R-CNN [62] | 80.2 | 0.19 | |
| FCSGG (Ours) | |||
| HRNetW32-1S | 47.3 | 0.07 | |
| HRNetW48-1S | 86.1 | 0.08 | |
| ResNet50-4S-FPN | 36.0 | 0.04 | |
| HRNetW48-5S-FPN | 87.1 | 0.12 | |
| HRNetW48-5S-FPN-f | 87.1 | 0.12 | |
5.3.3 Model Size and Speed
We also conduct experiments on the model size and inference speed. Few work benchmarked on efficiency of scene graph generation previously [33, 68]. Though scene graphs are powerful, it is almost not possible to perform SGG and down-stream tasks in real-time due to significantly increased model complexity. FCSGG alleviates the computational complexity effectively. Our experiments are performed on a same NVIDIA GeForce GTX 1080 Ti GPU with inference batch size of 1. For comparisons, we include several previous work by running corresponding open-source codes under the same settings. The results are shown in Table 5. Both the number of parameters and inference time are considerably lower for FCSGG models. It is worth noting that the computation overhead is from the backbone network. The path integral (Algorithm. 1) is performed pair-wisely for all 100 kept objects across five scales, which results in maximum number of candidate relationships for an image. The inference time for path integral is almost invariant over the number of instances as analyzed by Cao et al. [4]. We believe that object relationships exist universally, especially geometric ones. By grounding the full graph in RAFs as intermediate features, richer semantics can be retained for down-stream tasks. More importantly, convolution is hardware-friendly, and the model size is kept small for deployment on edge devices. We anticipate that real-time mobile SGG can be performed in the near future.
6 Conclusions
Scene graph generation is a critical pillar for building machines to visually understand scenes and perform high-level vision and language tasks. In this paper, we introduce a fully convolutional scene graph generation framework that is simple yet effective with fast inference speed. The proposed relation affinity fields serve as a novel representation for visual relationship and produce strong generalizability for unseen relationships. By only using visual features, our exploratory method achieves competitive results over object detection and SGG metrics on the VG dataset. We expect that FCSGG can serve as a general and strong baseline for SGG task, as well as a vital building block extending to down-stream tasks.
Acknowledgement
This work was partially supported by Bourns Endowment funds at the University of California, Riverside.
References
- [1] Simon Baker, Daniel Scharstein, JP Lewis, Stefan Roth, Michael J Black, and Richard Szeliski. A database and evaluation methodology for optical flow. International journal of computer vision, 92(1):1–31, 2011.
- [2] W. Benjamin and E. Leslie. On Photography. Reaktion Books, 2015.
- [3] J. Berger. Ways of Seeing. Penguin Modern Classics. Penguin Books Limited, 2008.
- [4] Zhe Cao, Gines Hidalgo Martinez, Tomas Simon, Shih-En Wei, and Yaser A Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
- [5] Long Chen, Hanwang Zhang, Jun Xiao, Xiangnan He, Shiliang Pu, and Shih-Fu Chang. Counterfactual critic multi-agent training for scene graph generation. In Proceedings of the IEEE International Conference on Computer Vision, pages 4613–4623, 2019.
- [6] Tianshui Chen, Weihao Yu, Riquan Chen, and Liang Lin. Knowledge-embedded routing network for scene graph generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6163–6171, 2019.
- [7] Vincent S Chen, Paroma Varma, Ranjay Krishna, Michael Bernstein, Christopher Re, and Li Fei-Fei. Scene graph prediction with limited labels. In Proceedings of the IEEE International Conference on Computer Vision, pages 2580–2590, 2019.
- [8] Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder–decoder approaches. Syntax, Semantics and Structure in Statistical Translation, page 103, 2014.
- [9] Noam Chomsky. Language and Mind. Cambridge University Press, 3 edition, 2006.
- [10] Bo Dai, Yuqi Zhang, and Dahua Lin. Detecting visual relationships with deep relational networks. In Proceedings of the IEEE conference on computer vision and Pattern recognition, pages 3076–3086, 2017.
- [11] Apoorva Dornadula, Austin Narcomey, Ranjay Krishna, Michael Bernstein, and Fei-Fei Li. Visual relationships as functions: Enabling few-shot scene graph prediction. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 0–0, 2019.
- [12] Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, Marc’Aurelio Ranzato, and Tomas Mikolov. Devise: A deep visual-semantic embedding model. In Advances in neural information processing systems, pages 2121–2129, 2013.
- [13] Ross Girshick. Fast r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 1440–1448, 2015.
- [14] Nikolaos Gkanatsios, Vassilis Pitsikalis, Petros Koutras, and Petros Maragos. Attention-translation-relation network for scalable scene graph generation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 0–0, 2019.
- [15] Nikolaos Gkanatsios, Vassilis Pitsikalis, Petros Koutras, and Petros Maragos. Attention-translation-relation network for scalable scene graph generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Oct 2019.
- [16] Nikolaos Gkanatsios, Vassilis Pitsikalis, and Petros Maragos. From saturation to zero-shot visual relationship detection using local context. In Proceedings of the British Machine Vision Conference, 2020.
- [17] Jiuxiang Gu, Handong Zhao, Zhe Lin, Sheng Li, Jianfei Cai, and Mingyang Ling. Scene graph generation with external knowledge and image reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1969–1978, 2019.
- [18] David Harwath, Wei-Ning Hsu, and James Glass. Learning hierarchical discrete linguistic units from visually- grounded speech. In International Conference on Learning Representations, 2020.
- [19] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- [20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [21] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [22] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6700–6709, 2019.
- [23] Zih-Siou Hung, Arun Mallya, and Svetlana Lazebnik. Contextual translation embedding for visual relationship detection and scene graph generation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [24] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, pages 448–456, 2015.
- [25] Justin Johnson, Agrim Gupta, and Li Fei-Fei. Image generation from scene graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1219–1228, 2018.
- [26] Justin Johnson, Ranjay Krishna, Michael Stark, Li-Jia Li, David Shamma, Michael Bernstein, and Li Fei-Fei. Image retrieval using scene graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3668–3678, 2015.
- [27] Andrej Karpathy and Li Fei-Fei. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3128–3137, 2015.
- [28] Boris Knyazev, Harm de Vries, Cătălina Cangea, Graham W Taylor, Aaron Courville, and Eugene Belilovsky. Graph density-aware losses for novel compositions in scene graph generation. arXiv preprint arXiv:2005.08230, 2020.
- [29] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123(1):32–73, 2017.
- [30] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), pages 734–750, 2018.
- [31] C.D. Lewis. The Poetic Image (Clark Lectures). Cambridge, 1946.
- [32] Yikang Li, Wanli Ouyang, Xiaogang Wang, and Xiao’ou Tang. Vip-cnn: Visual phrase guided convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1347–1356, 2017.
- [33] Yikang Li, Wanli Ouyang, Bolei Zhou, Jianping Shi, Chao Zhang, and Xiaogang Wang. Factorizable net: an efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 335–351, 2018.
- [34] Yikang Li, Wanli Ouyang, Bolei Zhou, Kun Wang, and Xiaogang Wang. Scene graph generation from objects, phrases and region captions. In Proceedings of the IEEE International Conference on Computer Vision, pages 1261–1270, 2017.
- [35] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- [36] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
- [37] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- [38] Xin Lin, Changxing Ding, Jinquan Zeng, and Dacheng Tao. Gps-net: Graph property sensing network for scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3746–3753, 2020.
- [39] Cewu Lu, Ranjay Krishna, Michael Bernstein, and Li Fei-Fei. Visual relationship detection with language priors. In European conference on computer vision, pages 852–869. Springer, 2016.
- [40] Masood Mortazavi. Speech-image semantic alignment does not depend on any prior classification tasks. In Proceedings of InterSpeech, 2020.
- [41] Alejandro Newell and Jia Deng. Pixels to graphs by associative embedding. In Advances in neural information processing systems, pages 2171–2180, 2017.
- [42] Bryan A Plummer, Arun Mallya, Christopher M Cervantes, Julia Hockenmaier, and Svetlana Lazebnik. Phrase localization and visual relationship detection with comprehensive image-language cues. In Proceedings of the IEEE International Conference on Computer Vision, pages 1928–1937, 2017.
- [43] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015.
- [44] David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
- [45] Gilbert Ryle. The Concept of Mind. U of Chicago Press, 1949.
- [46] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1):61–80, 2008.
- [47] S. Sontag. On Photography. Kushiel’s Legacy. Picador, 2001.
- [48] Kai Sheng Tai, Richard Socher, and Christopher D Manning. Improved semantic representations from tree-structured long short-term memory networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1556–1566, 2015.
- [49] Mingxing Tan, Ruoming Pang, and Quoc V Le. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10781–10790, 2020.
- [50] Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and Hanwang Zhang. Unbiased scene graph generation from biased training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3716–3725, 2020.
- [51] Kaihua Tang, Hanwang Zhang, Baoyuan Wu, Wenhan Luo, and Wei Liu. Learning to compose dynamic tree structures for visual contexts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6619–6628, 2019.
- [52] Damien Teney, Lingqiao Liu, and Anton van Den Hengel. Graph-structured representations for visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2017.
- [53] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE international conference on computer vision, pages 9627–9636, 2019.
- [54] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, et al. Deep high-resolution representation learning for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 2020.
- [55] Wenbin Wang, Ruiping Wang, Shiguang Shan, and Xilin Chen. Exploring context and visual pattern of relationship for scene graph generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8188–8197, 2019.
- [56] Sanghyun Woo, Dahun Kim, Donghyeon Cho, and In So Kweon. Linknet: Relational embedding for scene graph. In Advances in Neural Information Processing Systems, pages 560–570, 2018.
- [57] Hao Wu, Jiayuan Mao, Yufeng Zhang, Yuning Jiang, Lei Li, Weiwei Sun, and Wei-Ying Ma. Unified visual-semantic embeddings: Bridging vision and language with structured meaning representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6609–6618, 2019.
- [58] Yuxin Wu and Kaiming He. Group normalization. In Proceedings of the European conference on computer vision (ECCV), pages 3–19, 2018.
- [59] Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2. https://github.com/facebookresearch/detectron2, 2019.
- [60] Danfei Xu, Yuke Zhu, Christopher B Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5410–5419, 2017.
- [61] Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1316–1324, 2018.
- [62] Jianwei Yang, Jiasen Lu, Stefan Lee, Dhruv Batra, and Devi Parikh. Graph r-cnn for scene graph generation. In Proceedings of the European conference on computer vision (ECCV), pages 670–685, 2018.
- [63] Xu Yang, Kaihua Tang, Hanwang Zhang, and Jianfei Cai. Auto-encoding scene graphs for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10685–10694, 2019.
- [64] Xu Yang, Hanwang Zhang, and Jianfei Cai. Shuffle-then-assemble: Learning object-agnostic visual relationship features. In Proceedings of the European conference on computer vision (ECCV), pages 36–52, 2018.
- [65] Ze Yang, Shaohui Liu, Han Hu, Liwei Wang, and Stephen Lin. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9657–9666, 2019.
- [66] Ting Yao, Yingwei Pan, Yehao Li, and Tao Mei. Exploring visual relationship for image captioning. In Proceedings of the European conference on computer vision (ECCV), pages 684–699, 2018.
- [67] Ruichi Yu, Ang Li, Vlad I Morariu, and Larry S Davis. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE international conference on computer vision, pages 1974–1982, 2017.
- [68] Alireza Zareian, Svebor Karaman, and Shih-Fu Chang. Bridging knowledge graphs to generate scene graphs. arXiv preprint arXiv:2001.02314, 2020.
- [69] Alireza Zareian, Haoxuan You, Zhecan Wang, and Shih-Fu Chang. Learning visual commonsense for robust scene graph generation. arXiv preprint arXiv:2006.09623, 2020.
- [70] Rowan Zellers, Mark Yatskar, Sam Thomson, and Yejin Choi. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5831–5840, 2018.
- [71] Hanwang Zhang, Zawlin Kyaw, Shih-Fu Chang, and Tat-Seng Chua. Visual translation embedding network for visual relation detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5532–5540, 2017.
- [72] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. Objects as points. arXiv preprint arXiv:1904.07850, 2019.
Appendix
Appendix A Training
We defined the center heatmaps in Equation 1 from the paper such that the centers are converted into 2D Gaussian masks. The standard deviations and are computed based on the desired radii and along x-axis and y-axis, respectively:
| (7) |
The values of and are determined by Eq.(7) such that for any point within the ellipse region of radii and , when using it as a center to create a bounding box of object size , the bounding box has at least 0.5 intersection over union (IoU) with the GT bounding box.
Then the prediction of center heatmaps can be supervised by forms of distance losses such as Gaussian focal loss [30, 36, 72] with hyper-parameters and for weight balancing. Let be the predicted center heatmap, then the pixel-wise loss is defined as:
|
|
(8) |
Appendix B Inference
In this section, we provide more details on inference and post-processing of our proposed fully convolutional scene graph generation (FCSGG). Our model outputs four dense feature maps: center heatmaps , center offsets , object sizes and relation affinity fields (RAFs) . To get the object centers, we follow the same step in [72]. Specifically, a in-place sigmoid function is applied to the predicted center heatmaps such that their values are mapped into the range of . Then a max pooling is applied to center heatmaps for filtering duplicate detections. For a point , the value of is considered as the measurement of the center detection score for object class . Then peaks in center heatmaps are extract for each object class independently. We keep the top 100 peaks by their scores and get a set of object centers with object classes .
To get the corresponding center offset and object size given a detected object center , we simply gather the values from and at . We can get the center offset , and the object size . Finally, the bounding box of object can be recovered by
| (9) |
where is the stride of the output features.
As for multi-scale prediction, we gather the top 100 detected objects for each scale, then perform a per-class non-maximum suppression (NMS) and keep the top 100 boxes from all the detections, \eg, if there are 5 scales, we will keep the top 100 boxes from the 500 boxes across all the five scales.
B.1 Path Integral
For multi-scale RAFs, we select the valid object pairs from the kept 100 detections following the rule defined in Section 4.2 from the paper. For example, we define the predicted 5-scale RAFs as . If the distance between and is within , then the path integral from to will be only performed on . We gather the top 100 relationships from each scale, and keep the top 100 relationships across all scales for evaluation.
Mentioned in the paper, the path integral is performed using matrix multiplication in practice. Specifically, we determine the longest integral “length” among the predicted object centers . In other words, there will be sampled points along the integral path for each pair of object centers regardless of their distance.
B.2 Performance Upper Bound
One may concern the relation affinity field representation can actually work and reconstruct relationship successfully by path integral. We analyze the performance upper bound by using the ground-truth of objects and RAFs for evaluation on the test set. It achieves 91.13 R@20 and 86.85 mR@20, which proves that our proposed method is capable of recovering scene graphs from our definition of RAFs. It is worth noting that it is not possible to get 100% re-call since there exist multiple edges between nodes in some ground-truth annotations.
Appendix C Detailed Architectures
| FCSGG | Backbone | #Params | Neck | #Params | Object detection heads | Relation detection head | #Params |
|---|---|---|---|---|---|---|---|
| HRNetW32-1S | Figure 6(b), C=32 | 29.3M | Figure 2c | 0.0M | 256 - 256 - 256 - 256 | 512 - 512 - 512 - 512 - | 18.0M |
| HRNetW48-1S | Figure 6(b), C=48 | 65.3M | Figure 2c | 0.0M | 256 - 256 - 256 - 256 | 512 - 512 - 512 - 512 - | 20.8M |
| ResNet50-4S-FPN | Figure 6(a), C=256 | 23.6M | Figure 2a | 11.4M | 64 - 64 - 64 - 64 | 64 - 64 - 64 - 64 | 1.1M |
| HRNetW48-5S-FPN | Figure 6(b), C=48 | 65.3M | Figure 2b | 6.3M | 256 - 256 - 256 - 256 | 512 - 512 - 512 - 512 | 15.5M |
In this section, we provide more details of the proposed fully convolutional scene graph generation model. Our codebase is based on Detectron2 [59] and Tang et al. [50]. We list the models mentioned in the paper in Table 1 again for convenience. The number of parameters (#Params) of each network module is also listed in Table 6. As shown in the table, the backbone network has the largest number of parameters while the heads are relatively small.
C.1 Backbone
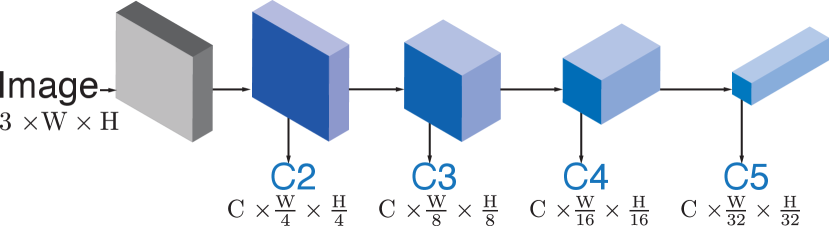
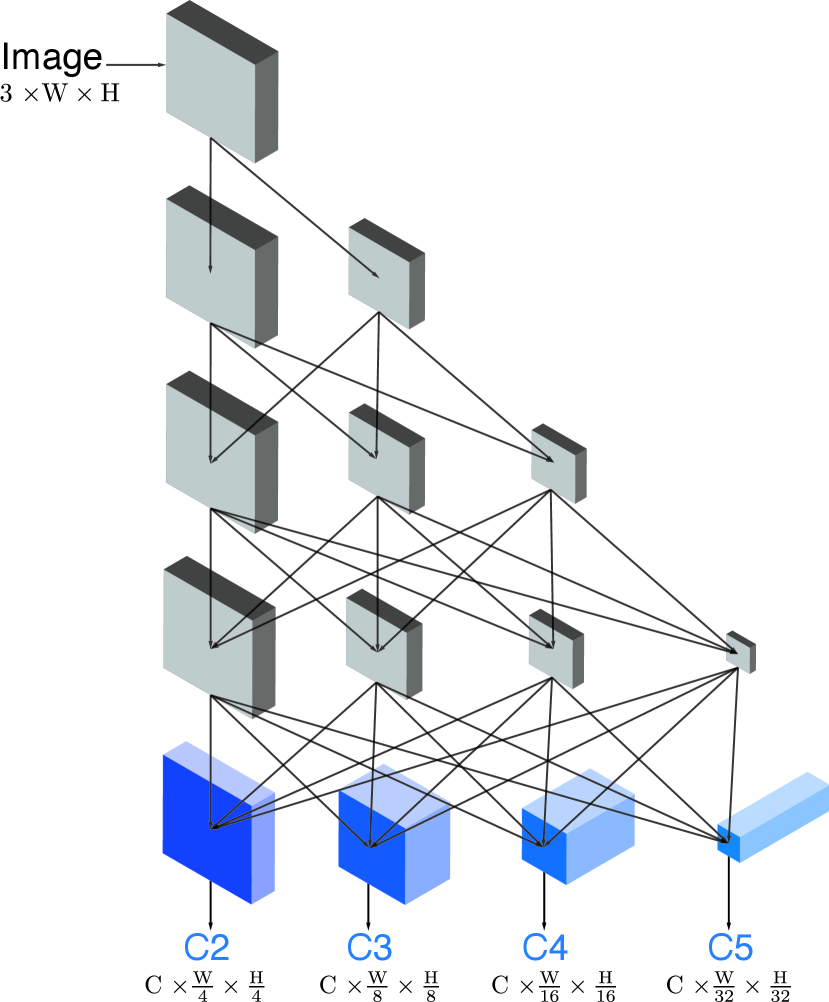
The backbone network serves as a feature extraction module in most of the deep learning applications. We choose the widely used network ResNet [20] and a recent successful alternative named HRNet [54]. ResNet is a representative of deep networks such that the resolution of the feature maps is downsampled while the number of channels is increased, sequentially. ResNet can be divided into stages after the “stem” (first several convolutional layers of the backbone), and the output features of each stage is named as C2, C3, C4, and C5 respectively. On the other hand, HRNet maintains a higher feature resolution all the way to the network output, and constructs several branches of features with lower resolutions. Features from each branch will be fused for exchanging information repeatedly. The output features of each branch are named as C2, C3, C4, and C5 respectively for convenience. The conceptual architecture diagrams of ResNet and HRNet are shown in the figure 1. We do not change the architecture and hyper-parameters of the backbone network with respect to the original papers [20, 54].
C.2 Neck
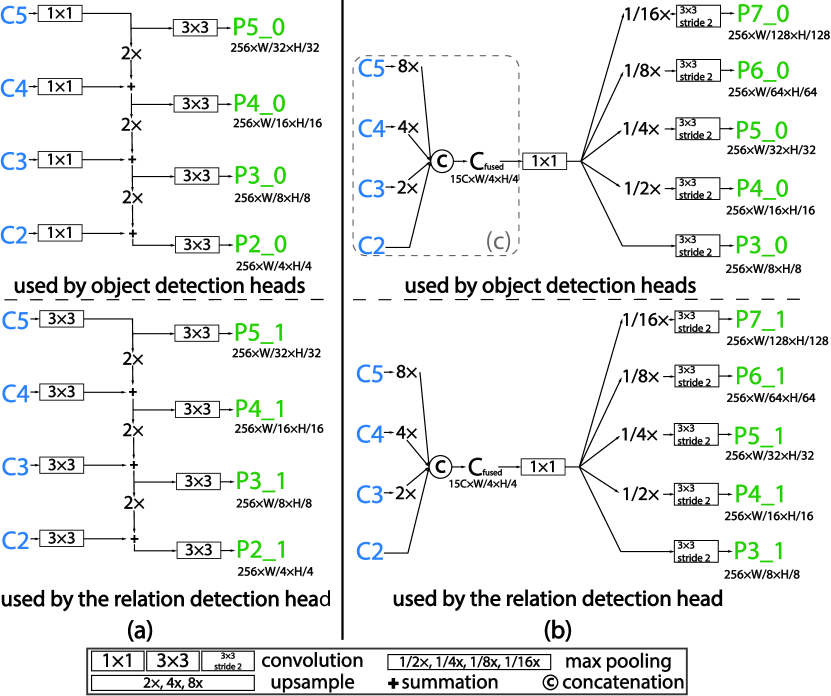
As presented in the paper, the neck networks serves as a module for constructing multiple scales of features that can be used for later predictions. We use feature pyramid network (FPN) [35] as the neck for ResNet, which is widely used for object detection [19, 36, 53]. FPN allows information exchange across different scales of features after backbone feature extraction. By up-sampling higher level of features (\egC5) then summing with lower level of features (\egoutput features from C4 after a 1 convolution) consecutively, a pyramid of feature maps (with the same number of channels) is built and called {P2, P3, P4, P5}. For ResNet50-4S-FPN×2, we use a modified version of FPN called bidirectional FPN (BiFPN [49]) which allows more connections among each scale. A detailed illustration of FPN as a neck is shown in Figure 2a.
As for HRNet as backbone, we follow Wang et al. [54] and use the HRNetV2 for single-scale prediction, and HR-NetV2p network for multi-scale feature representations. It should be addressed that even for single-scale models like HRNetW32-1S and HRNetW48-1S, a neck is applied for merging features from all branches. In this case, the neck is simply a feature fusion module without any trainable parameters. Features of C2, C3, C4, and C5 will be upsampled to the resolution of C2 via bilinear interpolation then concatenated. We name the fused features as . Different from HRNetV2 [54], we did not use convolution after fusion, and the resulting features will be fed into the heads. As for HRNetV2p, the first step is the same as HRNetV2, then a max pooling and a convolution are applied on with different strides to construct multiple scales of feature maps. The designs of necks for HRNet are shown in Figure 2b.
C.3 Heads
There are in total of four heads, and each head is responsible for the task of predicting center heatmaps, center off-sets, object size and relation affinity fields respectively. We name the first three heads as object detection heads, and the last one as the relation detection head. As stated in the paper, all heads are small network with four convolutional blocks, each of which consists of a convolution, a normalization layer of choice such as group normalization (GN), batch normalization (BN) or multi-scale batch normalization (MS-BN), and a ReLU activation layer. Then, for each head, there is a convolution as the output layer, and the number of channels is , 2, 2 and respectively. The number of channels are the same among object detection heads except the output layer, while we increase the number of channels for relation detection head in some models. We list the number of channels in each block for object detection heads and relation detection head as shown in Table 6 (the output convolution is omitted).
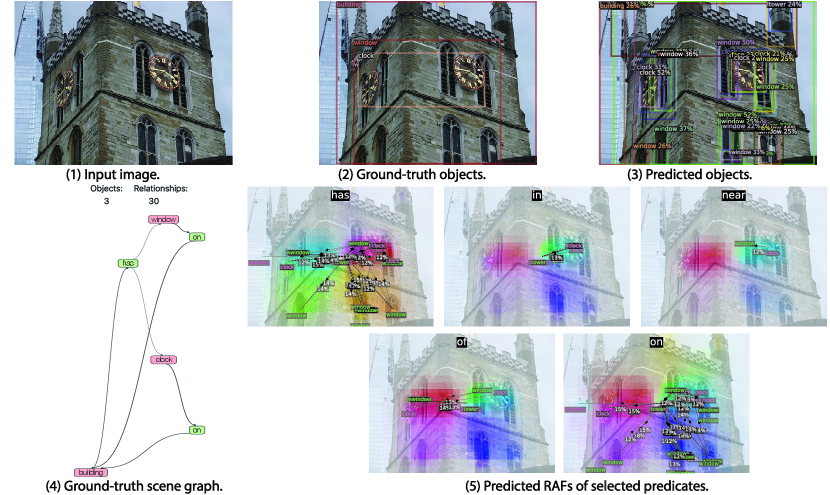
Appendix D Qualitative Results


We adopt the visualization method for optical flow [1] on visualizing relation affinity fields. Shown in Figure 8, the vector orientation is represented by color hue while the vector length is encoded by color saturation. We only visualize the bounding boxes with predicted scores over 0.2, and relationships with scores over 0.1.
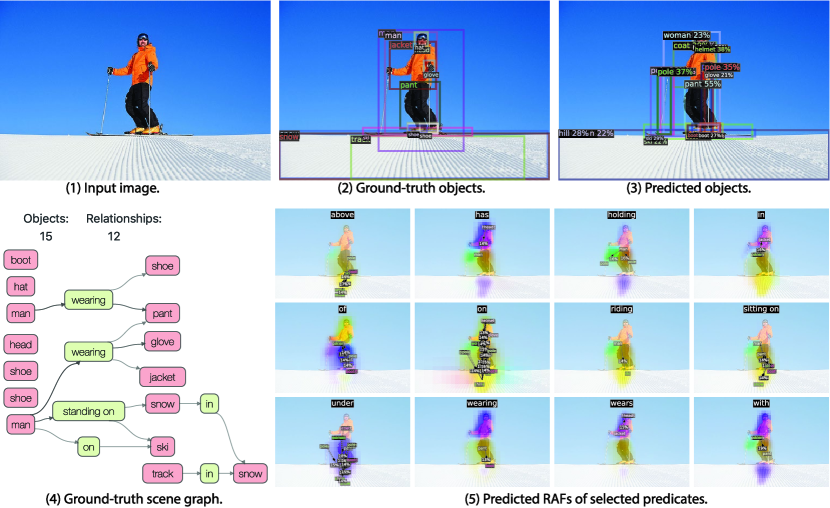
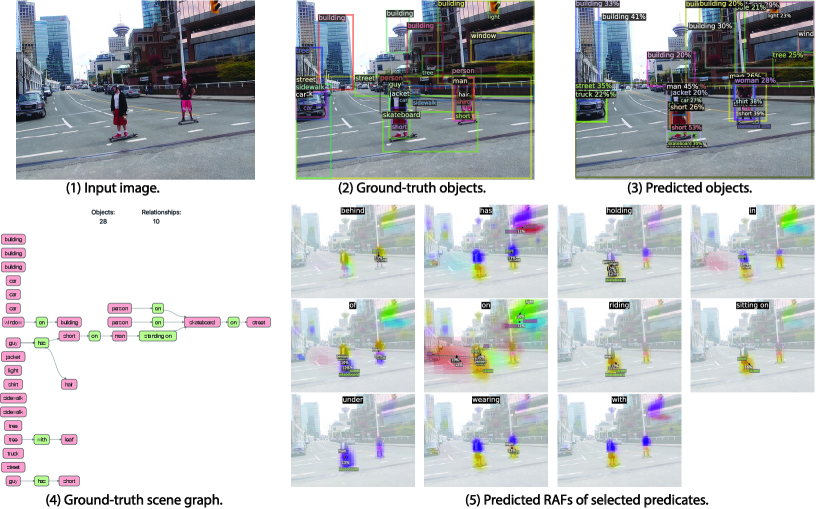
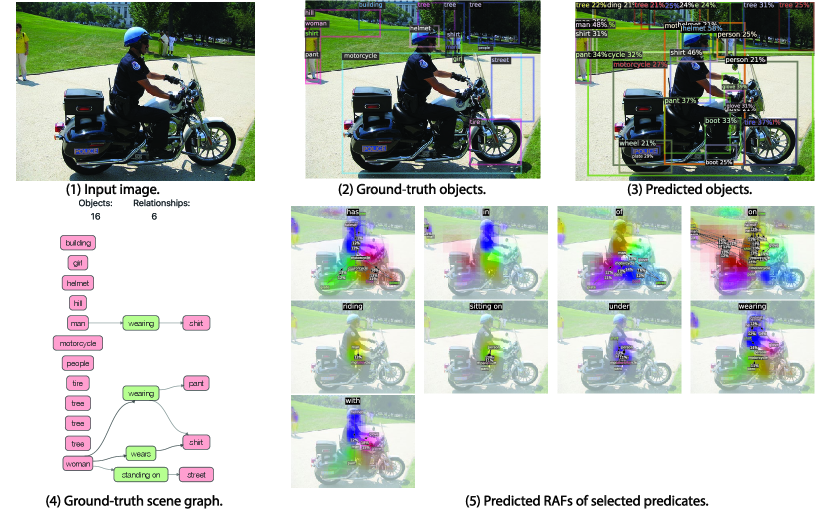
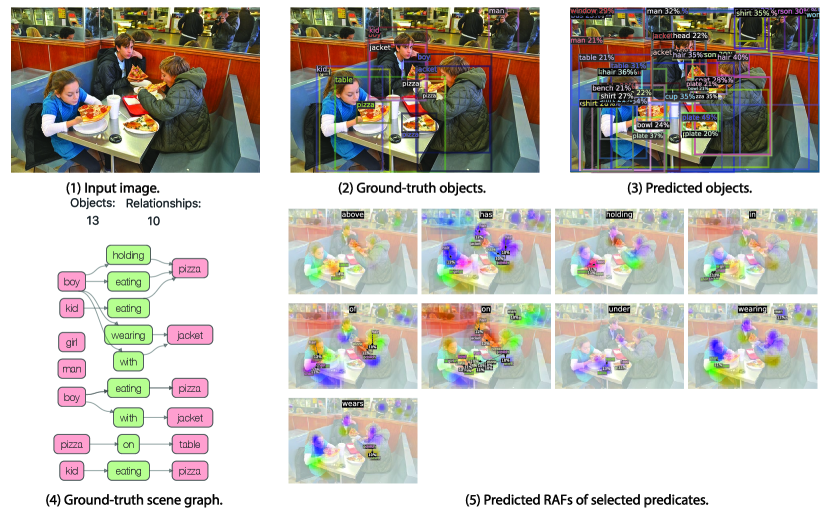
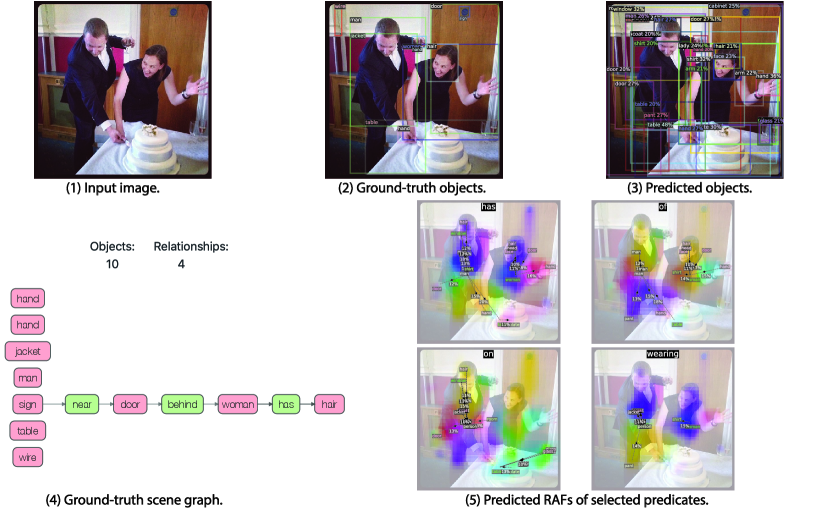
The visualizations of scene graph detection (SGDet) results for several test images from Visual Genome dataset [29] are shown in Figure 12. From the figure, FCSGG has strong object detection performance, especially on the localization of bounding boxes. In Figure 10(a), pole can be recognized even though it is not annotated in the ground-truth. In Figure 12(b), FCSGG detects more and accurate objects compared to the ground-truth.
However, there are two challenges for training on Visual Genome dataset: object class ambiguity and predicate ambiguity. For the first challenge, as an example of Figure 10(a), Jacket is misclassified as coat which is reasonable since the semantic difference between the two is subtle. Meanwhile, it also detects the person instance with even better bounding box than the ground-truth. However, it misclassified man as woman. As a result, all the relationships associated with man will be false detections. Similarly in Figure 12(a), woman is misclassified as lady. We argue that these person-centric relationships take a large proportion in the Visual Genome dataset, and it is difficult to visually distinguish among person entities of similar semantics such as woman / lady, boy / kid, man / men, and person / people. Even though, FCSGG achieves superior object detection performance on Visual Genome dataset.
The other challenge is the predicate ambiguity. Even though VG-150 only keeps the top 50 frequent predicates, there are still predicates with similar semantics (\egOF / PART OF, WEARING / WEARS, LAYING ON / LYING ON), or with vague and trivial meanings (\egOF, TO, NEAR, WITH). FCSGG is still able to capture similar semantics with similar responses. For example, we see similar RAFs predictions between WEARING and WEARS (Figure 10(a) and 11(b)). Since we do not add any predicate-specific hyper-parameters or statistic bias during training, there will always be some loss contributed by the predicate ambiguities that causes the training even harder. However, FCSGG achieves strong generalization on relationship prediction. In Figure 11(a), it predicts <man, RIDING ,motorcycle>, <person, SITTTING ON, motorcycle>, and motorcycle, UNDER, person> concurrently though neither of these are annotated in the dataset.
It should be addressed that multiple predicates could be all valid for a pair of objects, \egboth <person, ON, street> and <person, STANDING ON, street> can represent the correct relationship. Our proposed RAFs are suitable for multi-class problem so that our no-graph constraint results are much improved. More importantly, <street, UNDER, person> is actually true even though we rarely describe this way due to language bias. Interestingly, FCSGG generalizes the relationships and learns the reciprocal correlations between predicates. From the visualizations in Figure 10(a) and 11(b), ABOVE and UNDER will have responses with similar vector magnitudes but opposite directions. We can also see the similar pattern between OF and HAS.

We then tested on wild images for examining the applicability of our approach. For testing predicate WEARING, we downloaded 3 online images containing jacket shown in Figure 9 but in different scenarios: a product photo of jacket (4a); man WEARING jacket (4b); jacket ON bed (4c). The RAF predictions for WEARING are visualized, and the maximum unnormalized RAF vector norm is , , and for 4a, 4b, and 4c, respectively. The predicate WEARING gets the strongest response in Figure 4b among the three images, demonstrating that RAFs successfully capture the semantics. It also exposes the problem of learning bias, such that even no person presents in 4a and 4c, there are responses of WEARING since jacket and WEARING often coexist.