Fully Distributed Informative Planning for Environmental Learning with Multi-Robot Systems
Abstract
This paper proposes a cooperative environmental learning algorithm working in a fully distributed manner. A multi-robot system is more effective for exploration tasks than a single robot, but it involves the following challenges: i) online distributed learning of environmental map using multiple robots; ii) generation of safe and efficient exploration path based on the learned map; and iii) maintenance of the scalability with respect to the number of robots. To this end, we divide the entire process into two stages of environmental learning and path planning. Distributed algorithms are applied in each stage and combined through communication between adjacent robots. The environmental learning algorithm uses a distributed Gaussian process, and the path planning algorithm uses a distributed Monte Carlo tree search. As a result, we build a scalable system without the constraint on the number of robots. Simulation results demonstrate the performance and scalability of the proposed system. Moreover, a real-world-dataset-based simulation validates the utility of our algorithm in a more realistic scenario.
Index Terms:
Multi-Robot Systems, Distributed Systems, Informative Planning, Environmental Learning, Gaussian Process.I Introduction
Robotic sensor networks, which combine the local sensing capabilities of various sensors with the mobility of robots, can provide more versatility than conventional fixed sensor networks due to their capability to extend the sensing range and improve the resolution of sensory data maps [1]. These networks have been studied extensively in survey of global environment [2, 3, 4, 5], industrial environment perception [6], radio signal search [7], and so on.
To construct sensor networks, we first deploy many sensors in a working space. Then, we establish communication channels with the central server to collect and fuse data acquired from all sensors. Since the wireless communication range of sensors is limited, sensors usually make an indirect connection with the central server, such as a mesh network that connects all sensors and the central server by relay channels.
However, the relay network requires a routing table that must be rebuilt every time the robot network is reconfigured, which is cumbersome for robotic sensor networks. This problem is particularly noticeable in unmanned aerial vehicles (UAVs) or small robots since they need to use relatively weak communication modules to reduce power consumption.
Decentralizing the system can be a proper solution to network problems by removing the dependency of robots on the central server. For example, if a robot can infer the entire sensory map only from the local information directly provided by surrounding robots, the search task can be completed without the help of the central server. This paper applies decentralization to the environmental learning phase and the path planning phase, respectively. With an online information fusion algorithm, we build a distributed autonomous system of multiple robots to search and learn even dynamic environments that change over time.
I-A Literature Review
The first part of our work is multi-robot environmental learning in a distributed manner. For environmental learning, some useful techniques exist such as Gaussian mixture model (GMM) [8, 16, 17], finite element method (FEM) [9], and Gaussian process (GP) regression [4, 5, 7]. In particular, GP is a popular approach that derives a spatial relationship between sampled data using a kernel and performs Bayesian inference for prediction at an unknown region.
However, most GP-related researches focus on centralized systems, making it difficult to expand to large-scale multi-robot systems due to network resource limitations such as channel bandwidth and transmit power. Distributed multi-agent Gaussian regression is introduced in [12], which designs a finite-dimensional GP estimator by using Karhunen–Loève (KL) expansion [13]. In contrast to the decentralized GP presented in [10], the distributed GP provides a common copy of the global estimate to all agents by exchanging the estimated information with their neighbors. This paper extends [14], which shows that distributed GPs can construct environmental models using mobile robots in order to take the distributed path planning into account.
The second part of our work is informative path planning in a distributed multi-robot system. As an initial study of informative path planning, the problem of optimal sensor placement has been investigated to create an environmental map in a given space by properly placing a finite number of sensors [15, 16, 17]. Since then, by applying GPs and information theory, the research of optimal sensor placement has grown into the informative path planning research as presented in [5, 8, 18, 19, 20, 21, 22]. Some studies have combined GP with conventional planning algorithms such as rapidly-exploring random tree (RRT) [23], dynamic programming (DP) [20], or Monte Carlo tree search (MCTS) [24].
Besides the above approaches that mainly focus on informative path planning for single agents, many studies have applied informative planning for multi-robot systems. In [10, 7], although both studies deal with decentralized multi-robot exploration using GP, these algorithms are not scalable as they consider only two robots. [33] introduced the combination of the Kalman filter (KF) and the reduced value iteration (RVI) method for the parallelized active information gathering. While this technique is scalable to a large number of robots, it is noted that the environmental model has to be known, and only discrete environments can be represented since the model is expressed in KF. Considering the scalability for multi-robot systems, we extend the MCTS path planning in a distributed manner to be compatible with the distributed GP.
I-B Our Contribution
To achieve our goal of fully distributed multi-robot informative planning, we divide the whole process into two phases: environmental learning and path planning. During these phases, we focus on three main contributions as follows.
• We develop an online distributed GP algorithm for environmental learning through Karhunen–Loève expansion and an infinite impulse response filter. This algorithm is capable of learning a dynamic environment.
• We propose a distributed informative path planning algorithm using a distributed MCTS combined with GP. In addition, we introduce the trajectory merging method to consider predicted trajectories of other agents.
• We build a fully distributed exploration and learning architecture using only local peer-to-peer communication for system scalability, as shown in Table I.
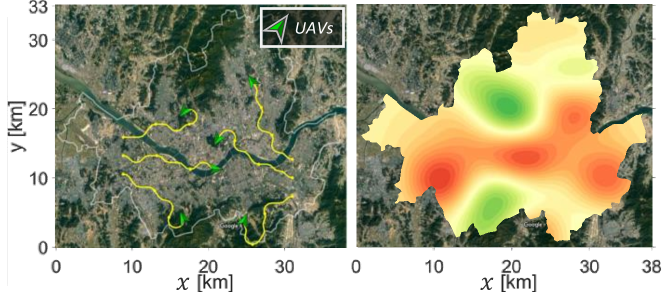
We perform a multi-robot exploration simulation with a virtual environment setting and real-world dataset [34] provided by the National Climate Data Center (NCDC) in South Korea as shown in Fig. 1.
The outline of this paper is as follows. Section \@slowromancapii@ briefly describes a multi-robot system setup and preliminaries. Section \@slowromancapiii@ presents a method for online distributed environmental learning. Section \@slowromancapiv@ combines environmental learning and MCTS in the distributed system. Simulations for the synthetic environment and real-world dataset are presented in Section \@slowromancapv@. Section \@slowromancapvi@ concludes the paper.
II Multi-Robot System Setup and Preliminaries
We focus on the environment learning problem in multi-robot systems by considering a target domain as a 3-dimensional compact set . Multiple robots (e.g., ground vehicles or UAVs with onboard sensors) explore an unknown area and estimate environmental information using both self-measurements and shared data received from neighbors. All robots can discover obstacles nearby using the range sensor and only communicate with adjacent robots within the communication distance.
II-A Multi-Robot System Setup
As depicted in Fig. 1, we consider robot agents exploring the environment. Each robot takes the measurement of an unknown environmental process in its position () at time which has the following relationship: {ceqn}
| (1) |
where the measurement of is corrupted by the additive white Gaussian noise .
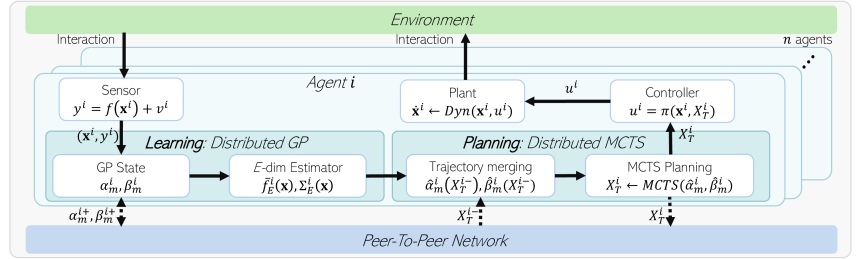
Each robot has its process modules, Distributed GP and Distributed MCTS, for the distributed monitoring task. During these processes, they share GP variables and predicted trajectories through a peer-to-peer communication network. This operation process is summarized in Fig. 2. The controller design process is not covered in this work.
To implement the communication network of robots, we define a set of neighbors for robot as , where is the index set of agents and is the communication range. means . For arbitrary variable , means , and means for brevity.
II-B Conventional Gaussian Process
GP regression, which is data-driven non-parametric learning, can provide Bayesian inference over the set , taking into account joint Gaussian probability distribution between the sampled dataset [27]. In (1), the unknown process model is assumed to follow a zero-mean Gaussian process as
| (2) |
is a kernel or covariance function for positions , and the original squared exponential (SE) kernel is defined as
| (3) |
where is the signal variance of , and is the length scale. The hyper parameters and can be determined by maximizaing the marginal likelihood [27].
Formally, let be the training dataset sampled by the robot , where is the sampling time. is the set of sampling time indices up to time . With the dataset of size , we can simply define the input data matrix as and the output data vector as . According to the test point , the posterior distribution over by robot is derived as follows: {ceqn}
| (4) |
where
| (5a) | ||||
| (5b) | ||||
is the kernel matrix whose -th element is for . is the column vector that is also obtained in the same way.
II-C Informative Path Planning
To obtain the better description of a spatial process model, robots perform informative path planning. It maximizes the information gain , which is the mutual information between the process and measurements :
| (6) |
where is the entropy of a random variable. Let be the possible trajectory of robot and be the possible trajectories of all robots. Then, the multi-robot team’s global objective function is defined as follows:
| (7) |
is the measurements corresponding to . As a result, the optimal trajectories for all agents are defined as follows:
III Environmental Learning: Distributed Gaussian Process
In this section, we expand the conventional GP in Section II-B to the distributed GP. The first step is to expand the conventional kernel (3) to be an infinite sum of eigenfunctions. Then, the expanded kernel is used to make a finite-dimensional GP estimator, and the estimator is reformulated to a distributed form. With a consecutive state update rule, the GP estimator works in a distributed manner.
III-A Karhunen–Loève (KL) Kernel Expansion
Let the usual GP consider robots. We can simply define the input data matrix for robots as . For simplicity, it is assumed that ’s are same for all robots, and we omit the subscript , so hereafter. With the matrix , the usual GP requires all the sampled data and inversion of with operations. These requirements are impractical when peer-to-peer communication is only used, and the computational burden also increases depending on the data size. For this reason, a new kernel method is needed. The kernel (3) can be expanded in terms of eigenfunctions and corresponding eigenvalues as follows [13]:
| (9) |
where . It is difficult to derive the kernel eigenfunctions in a closed-form, but the SE kernel expansion has already been obtained via Hermite polynomials, as mentioned in [28]. Then, the process model for the position is expanded as
| (12) |
where for . is the -dimensional model of where is a constant design parameter. This parameter can be tuned by the SURE strategies [12]. As shown in [28], the optimal -dimensional models can be obtained by a convex combination of the first -kernel eigenfunctions as the size of sampled dataset increases to infinity.
III-B Multi-Agent Distributed Gaussian Process
We apply -dimensional approximation to the GP estimator in (5) to derive the estimation of . According to -dimensional approximation, the kernel function (9) can be described as . For the input data matrix , kernel matrices included in (5) are defined by
| (13a) | ||||
| (13b) | ||||
where and . is the diagonal matrix of kernel eigenvalues.
| (15) |
where
| (16) |
Because each agent cannot obtain and in (15) without a fully connected network, we decompose the associated terms included in (16) as follows:
| (17a) | |||
| (17b) |
where and are GP states after the -th sensor measurements. Now (15) is reformulated in the following distributed form:
| (18) |
As the results of average consensus protocol [29], (18) converges to (15) after iterative communication. Similarly, the distributed form of in (5b) is expressed as
| (19) |
| (20) |
III-C Online Information Fusion by Moving Agents
If the -th new training dataset are obtained, and have to be discarded to include new data so that the consensus process must be restarted from scratch. To avoid repeated restarts and keep the continuity of environmental estimate, we introduce the online information fusion algorithm.
Let us assume that the sensor measurement frequencies of all agents are same for convenience. The update rule of and is defined as follows:
| (21) |
where and . This rule is an infinite impulse response (IIR) filter. If , The update rule reflects all dataset equally, so it is suitable for static environmental learning. If , this rule reflects more of the recent data, so it is suitable for dynamic environmental learning. Simulation results for each environmental learning are shown in Chapter V.
Theorem 1.
Proof.
See the Appendix in [14]. ∎
IV Path Planning: Distributed Monte Carlo Tree Search
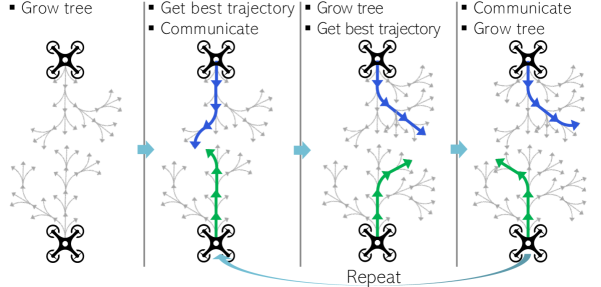
Using the distributed model learning discussed in the previous section, all agents create a local environmental map that converges to the global environmental map even in a distributed network. To find the most promising search trajectories with the learned map, all agents should consider every possible action. However, because the cardinality of possible action set grows exponentially with respect to the number of robots, the distributed planning strategy is needed in multi-robot path planning [33]. In [26], the decentralized MCTS approach is studied to alleviate the cardinality of possible action set from to , where represents the discrete action space of each robot. We apply this advantage to our GP-based informative planning of multiple robots. With the distributed MCTS, each robot calculates a promising trajectory by communication with neighboring agents only. This process is shown in Fig. 3. This section introduces the trajectory merging method to reflect the neighbor’s path in each agent’s tree search process. The contents of this section are summarized in Algorithm 1 and 2.
IV-A Trajectory merging
For each agent , denotes the predicted trajectory with the prediction length , or it can be represented by for brevity. Assuming that the agent receives the predicted trajectories of neighboring agents , we modify the GP sate as follows: {ceqn}
| (22) |
is the number of sensing points included in . With (22) and the -dimensional estimator in (20), we define the trajectory-merged GP estimator as follows:
| (23) |
In this way, predicted trajectories of neighboring agents are temporarily included in the acquired data set of the GP estimator. Because (22) and (23) are temporary values for tree search in distributed MCTS, they do not affect and disappear after getting new predicted trajectories. This process is summarized in the Distributed MCTS block of Fig. 2. With this result, the path planning process will be explained in the next section.
IV-B Informational reward function
As we mentioned in (7), the information gain is the objective function we have to maximize. With the definition in (8), the optimal trajectory considering neighboring paths is defined as follows.
| (24) |
and are the measurements corresponding to and , respectively. is the domain of possible trajectories for agent . As shown in (6), information gain is represented with entropies as follows:
| (25) |
Using the mesuarement model (1) and the entropy calculation for the normal distribution [32], conditional entropy becomes
| (26) |
is decomposed using conditional entropy, and it is obtained by calculating the entropy of GP as follows:
| (27) |
As a result, with the trajectory-merged GP estimator in (23), the optimal trajectory for agent is defined as follows:
| (28) |
We call the informational reward function, which is utilized in the tree search algorithm.
IV-C Tree Search with D-UCB Alogrithm
Using the informational reward function defined in IV-B, the tree search algorithm iteratively explores and evaluates predictive path candidates according to the discounted upper confidence bound (D-UCB) rule to find the optimal path. D-UCB rule assigns the probabilistic search priority to the action candidates.
The tree structure consists of nodes and edges for all legal actions . Each edge contains a set of variables where is the visit count, is the total action value, is the number of iterations for tree search (shown in line 5 of Algorithm 2), and is a closing variable which will be discussed. We follow the tree search process in Algorithm 1 and the distributed MCTS with GP in Algorithm 2. The MCTS process can be divided into four main steps as follows.
IV-C1 Selection
(lines 4, 12-22 of Algorithm 1) The selection phase focuses on finding a leaf node . Following the D-UCB rule, the selected action at node is defined as follows [32]:
| (29) |
where {ceqn}
| (30) |
The first term on the right-hand side of (29) means exploration term for the tree search, and the second term means exploitation term. As shown in Algorithm 2, each agent periodically receives the predicted trajectories of adjacent agents, which are utilized in the tree search process. It means that the tree, obtained by using previously given trajectories, may not be optimal when new neighboring trajectories are received. Therefore, adopting the discount factor makes the previously visited nodes less influential on the current UCB value.
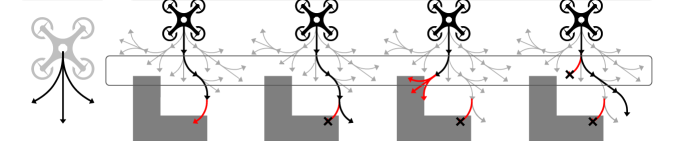
If the current node has no selectable actions because of path blockage, the node closes () and the algorithm returns to the parent node to restart the selection process. We call this process as node closing method illustrated in Fig. 4 and lines 15-21 of Algorithm 1.
IV-C2 Expansion
(line 5 of Algorithm 1) The expansion phase expands the selected node with uniformly sampled action from the action space if the depth of the selected node does not exceed the search depth . When the expanded node collides with an obstacle, the algorithm closes this edge () and returns to the selection phase.
IV-C3 Simulation
(lines 9, 23-27 of Algorithm 1) In the simulation phase, it calculates the informational reward of the selected trajectory. If the selected node’s depth is less than the search depth , it performs random walks. After that, the reward is calculated with the predicted trajectory as shown in Section IV-B.
IV-C4 Backpropagation
(line 10 of Algorithm 1) The edge variables are updated in a backward pass. The visit counts are incremented, , and the total action value is updated, . As described in the selection step, the discount factor is applied to reduce the weight of the previous value.
V Simulation Result
This section presents environmental learning simulations on the various situations. The first simulation is on a time-invariant synthetic environment, and the second is on a dynamic environment based on the real-world meteorological dataset. These environmental models are unknown a priori, and each robot obtains the sensory data from the current location. Furthermore, since the communication range is finite, some agents may not be able to communicate with each other.
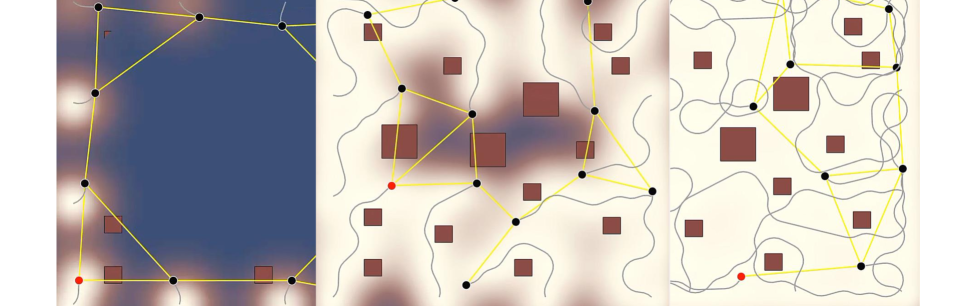
V-A Simulation 1 - synthetic environment learning
We perform the fully distributed informative planning simulation for multiple agents. They conduct exploration to obtain an estimate of the environmental map, considering collision avoidance and coordination. They can communicate only with neighbors within a range of 10 m (the map size is m m) and move at m/s constantly. We set and for the Gaussian kernel (3), and we set for -dimensional estimator (15) and (19).
The progress over time from to seconds is shown in Fig. 5. As shown in Figs. 5(a)-(b), twelve agents search the map together and generate the GP estimate presenting the ground truth model in 5(c). The agents scatter naturally and find the next locations to be updated based on the variance map. Also, as they avoid the places where the estimate is already reliable, they can minimize the redundant actions that can decrease the exploration efficiency. Through Fig. 5(b), it can be confirmed that the information of all agents is diffused through a communication link.
Although Figs. 5(a)-(b) show results from agent only, all the distributed GP estimates of each agent converge to the same by the average consensus as shown in Fig. 5(d). In other words, all agents do not simply use local information only in the exploration process but construct a global GP estimation map in a distributed manner.

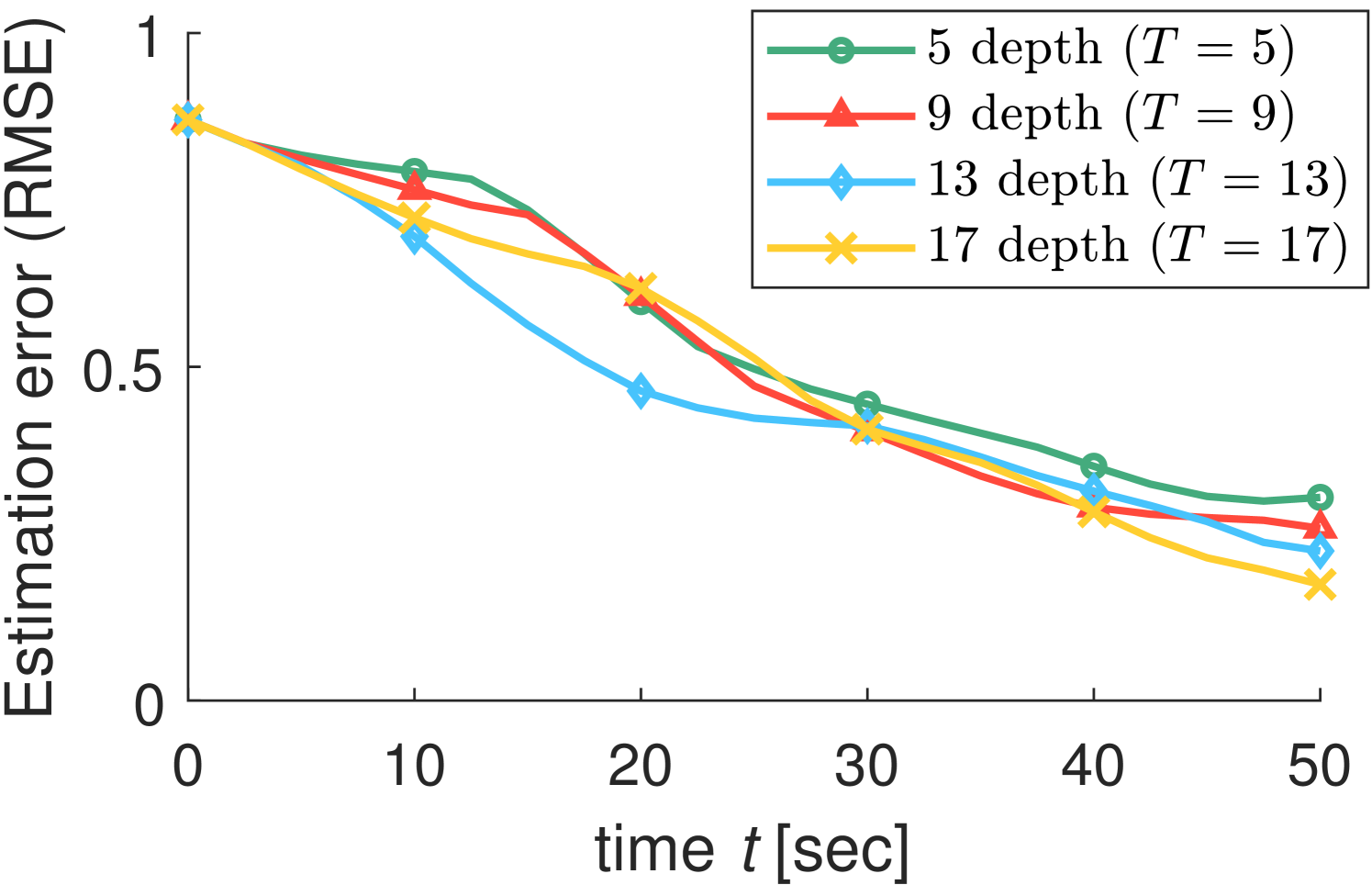
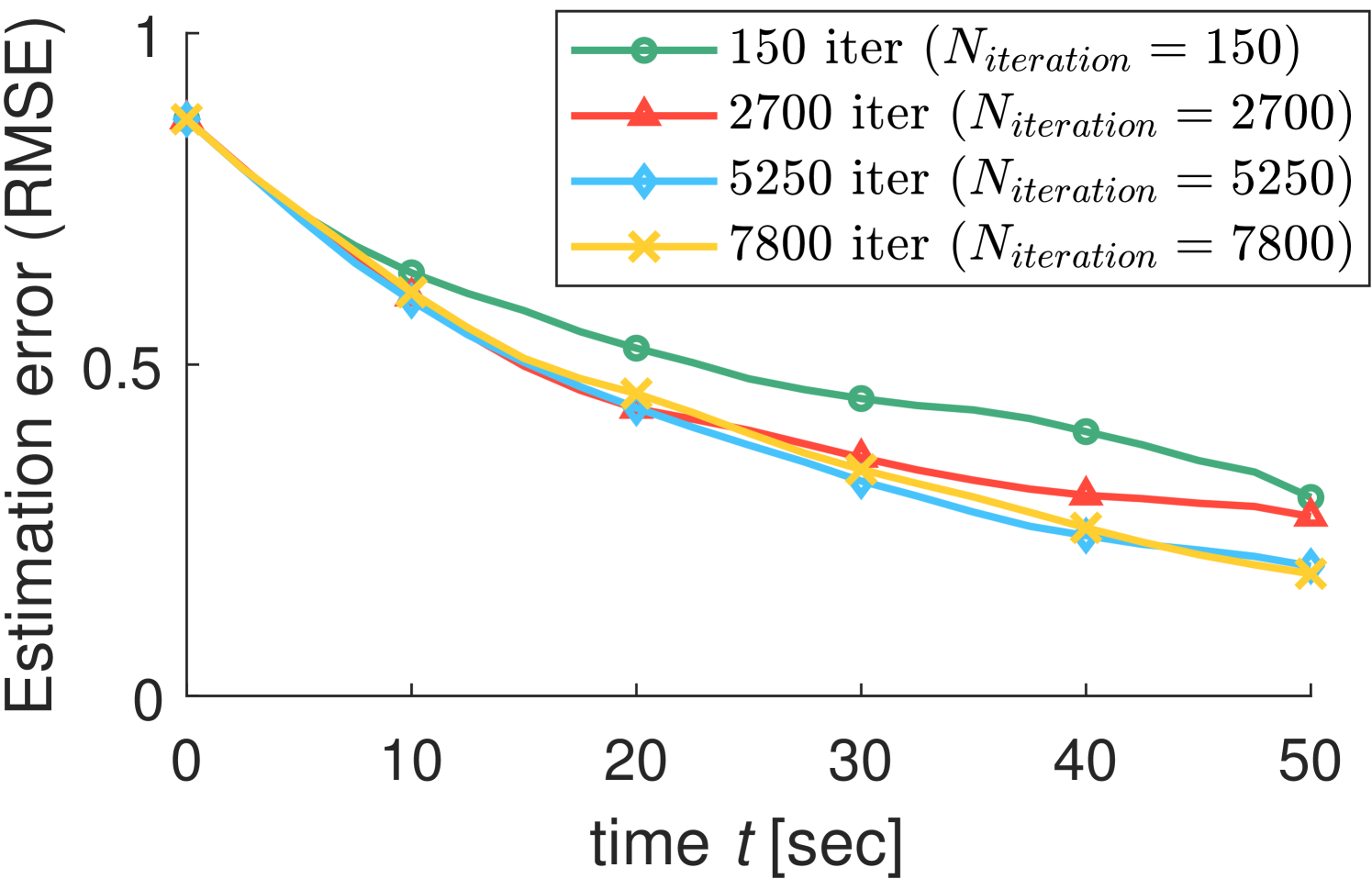
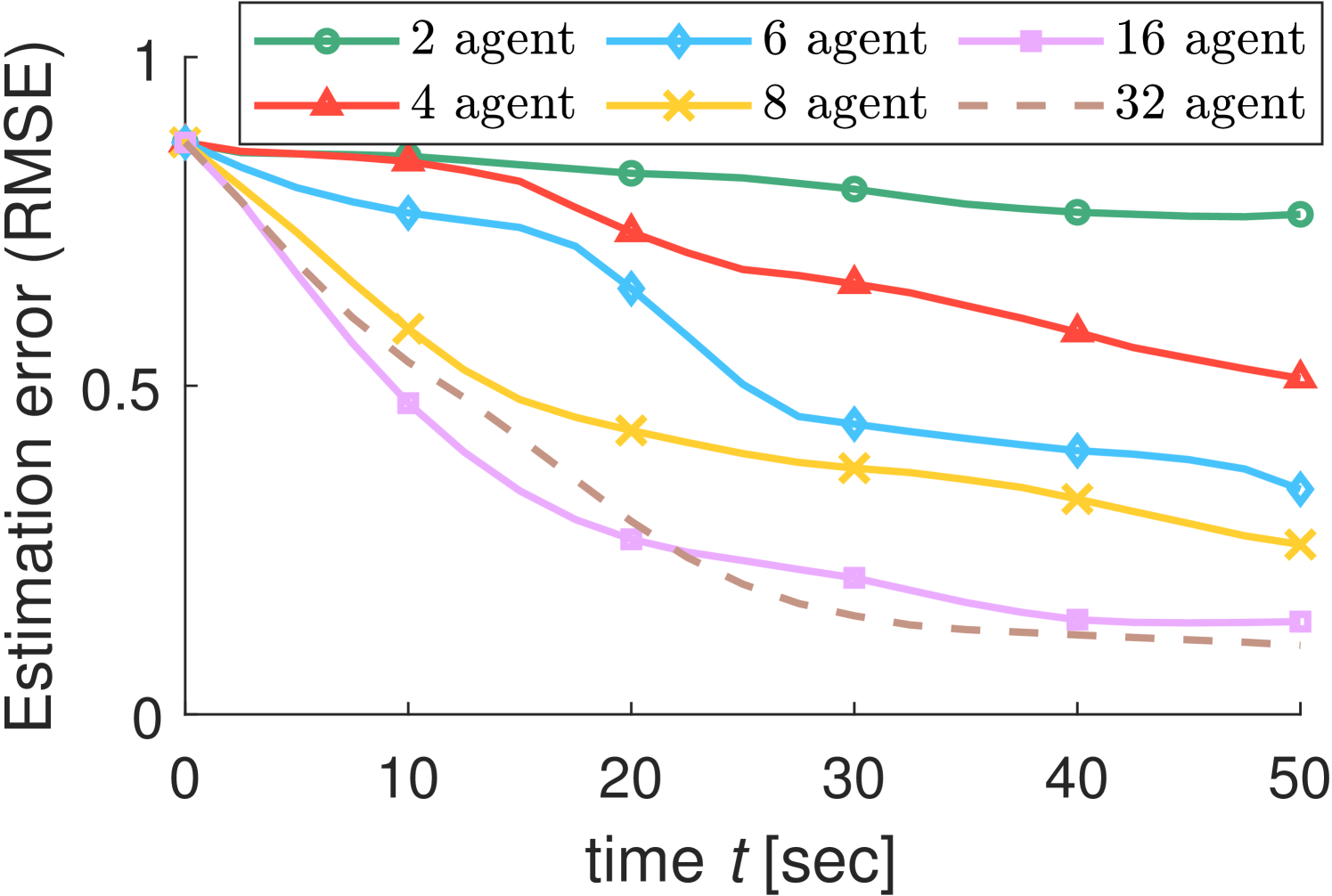
We conduct more simulations in various environments to investigate the factors that affect search performance. In the tree search algorithm, the search depth and the number of iterations are the factors that directly affect the search result. The simulation results in Figs. 6(a)-(b) show that the search performance is proportional to both and . The deeper the search, the more distant paths are considered. As the number of searching iterations increases, the probability of finding an optimal route increases. Fig. 6(c) shows that the search performance can be improved as the number of agents increases through a distributed algorithm. From these results, we can see that our algorithm is scalable for a large number of robots as well.
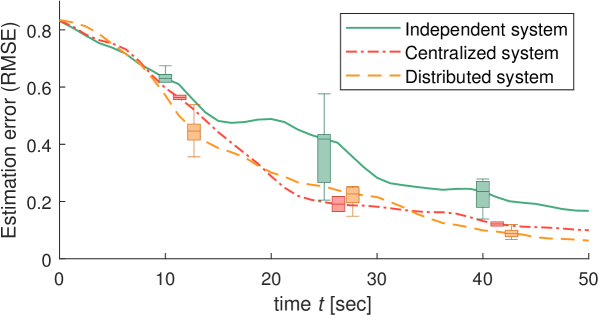
Fig. 7 compares the search performance of distributed systems, centralized systems, and independent systems. In the independent system, agents explore the area without communication. The centralized system has a central server that gathers all the information regardless of the communication range, and the server calculates paths for all agents. Because the action space of centralized system is much bigger than that of distributed system , we set about 22 times more for the centralized system than the distributed system. Even with limited communication and much fewer iterations, the distributed system performs similarly to the centralized system.
V-B Simulation 2 - real-world dataset environmental learning
This section presents simulation result for the exploration in a dynamic environment (Fig. 1), using a real-world meteorological dataset. The simulation uses temperature data collected from weather stations in Seoul, South Korea [34]. The reason we choose the weather data for Seoul is that weather stations are densely distributed (the area of Seoul is ). We create a heat map for a ground truth based on the data measured from 0 am to 5 am on July 16th, 2020.
In this scenario, a team of UAVs flies over the search area and gathers temperature data from the current UAV’s location. They fly at a constant velocity of 20 km/h. Because their communication distance is limited to 20 km, sometimes they can be disconnected from one another.
Some snapshots taken during the simulation are shown in Fig. 8. The ground truth over time is shown in Fig. 8(a), and the GP estimation is shown in Fig. 8(b). After 1.7 hours, the estimation result is similar to the ground truth. After that, the results track the true value continuously even when the actual environment changes.
VI Conclusions
This paper presents fully distributed robotic sensor networks to obtain a global environmental model estimate. We combine the Gaussian process with the Monte Carlo tree search in a distributed manner for peer-to-peer communication. Our method allows multiple robots to collaboratively perform exploration, taking into account collision avoidance and coordination. We validate our algorithm in various environments, including a time-varying temperature monitoring task using a real-world dataset. The results confirm that multiple agents can successfully explore the environment, and it is scalable with the increasing number of agents in the distributed network.
References
- [1] F. Deng, S. Guan, X. Yue, X. Gu, and J. Chen, “Energy-Based Sound Source Localization with Low Power Consumption in Wireless Sensor Networks,” in IEEE Trans. Industrial Electronics, 2017.
- [2] C. Matthew, W.-H. Chen, and C. Liu, “Boustrophedon Coverage Path Planning for UAV Aerial Surveys in Wind,” in Proc. Int. Conf. Unman. Air. Sys., 2017.
- [3] Q. Feng, H. Cai, Y. Yang, J. Xu, M. Jiang, F. Li, X. Li, and C. Yan, “An Experimental and Numerical Study on a Multi-Robot Source Localization Method Independent of Airflow Information in Dynamic Indoor Environments,” Sust. Cit. Soc., 2020.
- [4] J. Patrikar, B. G. Moon, and S. Scherer, “Wind and the City: Utilizing UAV-Based In-Situ Measurements for Estimating Urban Wind Fields,” in Proc. IEEE/RSJ Int. Conf. on Int. Robot. Sys., 2020.
- [5] K.-C. Ma, L. Liu, and G. S. Sukhatme, “An Information-driven and Disturbance-Aware Planning Method for Long-Term Ocean Monitoring,” in Proc. IEEE/RSJ Int. Conf. on Int. Robot. Sys., 2016.
- [6] J. Zhang, R. Liu, K. Yin, Z. Wang, M. Gui, and S. Chen,“Intelligent Collaborative Localization Among Air-Ground Robots for Industrial Environment Perception,” in IEEE Trans. Industrial Electronics, 2019.
- [7] A. Q. Li, P. K. Penumarthi, J. Banfi, N. Basilico, J. M. O’Kane, I. Rekleitis, S. Nelakuditi, and F. Amigoni, “Multi-Robot Online Sensing Strategies for the Construction of Communication Maps,” Auton. Robots, 2020.
- [8] Y. Shi, N. Wang, J. Zheng, Y. Zhang, S. Yi, W. Luo, and K. Sycara, “Adaptive Informative Sampling with Environment Partitioning for Heterogeneous Multi-Robot Systems,” in Proc. IEEE/RSJ Int. Conf. on Int. Robot. Sys., 2020.
- [9] M. L. Elwin, R. A. Freeman, and K. M. Lynch, “Distributed Environmental Monitoring With Finite Element Robots,” IEEE Trans. Robot., 2020.
- [10] A. Viseras, T. Wiedemann, C. Manss, L. Magel, J. Mueller, D. Shutin, and L. Merino, “Decentralized Multi-Agent Exploration with Online-Learning of Gaussian Processes,” in Proc. IEEE Int. Conf. Robot. Autom., 2016.
- [11] B. Kartal, E. Nunes, J. Godoy, and M. Gini, “Monte carlo tree search for multi-robot task allocation,” in Proc. AAAI Conf. Art. Intell., 2016.
- [12] G. Pillonetto, L. Schenato, and D. Varagnolo, “Distributed Multi-Agent Gaussian Regression via Finite-Dimensional Approximations,” IEEE Trans. Pattern Anal. Mach. Intell., 2019.
- [13] B.C. Levy, “Karhunen Loève Expansion of Gaussian Processes,” Principles of Signal Detection and Parameter Estimation, Springer, 2008.
- [14] D. Jang, J. Yoo, C. Y. Son, D. Kim, and H. J. Kim, “Multi-Robot Active Sensing and Environmental Model Learning With Distributed Gaussian Proces,” IEEE Robot. Autom. Lett., 2020.
- [15] A. Krause, A. Singh, and C. Guestrin, “Near-Optimal Sensor Placements in Gaussian Processes: Theory, Efficient Algorithms and Empirical Studies,” J. Mach. Learn. Res., 2008.
- [16] W. Luo, C. Nam, G. Kantor, and K. Sycara, “Distributed Environmental Modeling and Adaptive Sampling for Multi-Robot Sensor Coverage,” in Proc. Int. Conf. Auton. Agents Multiagent Sys., 2019.
- [17] D. Gu, “Distributed EM Algorithm for Gaussian Mixtures in Sensor Networks,” IEEE Trans. Neural Netw., 2008.
- [18] G. Flaspohler, V. Preston, A. P. M. Michel, Y. Girdhar, and N. Roy, “Information-Guided Robotic Maximum Seek-and-Sample in Partially Observable Continuous Environments.” IEEE Robot. Autom. Lett., 2019.
- [19] P. R. Silveria, D. F. Naiff, C. M.N.A. Pereira, and R. Schirru, “Reconstruction of Radiation Dose Rate Profiles by Autonomous Robot with Active Learning and Gaussian Process Regression,” Ann. Nuc. Energy, 2018.
- [20] K. C. Ma, L. Liu, and G. S. Sukhatme, “Informative Planning and Online Learning with Sparse Gaussian Processes,” in Proc. IEEE Int. Conf. Robot. Autom., 2017.
- [21] A. Meliou, A. Krause, C. Guestrin, and J. M. Hellerstein, “Nonmyopic Informative Path Planning in Spatio-Temporal Models,” Assoc. Adv. Art. Intell., 2007.
- [22] L. Bottarelli, M. Bicego, J. Blum, and A. Farinelli, “Orienteering-Based Informative Path Planning for Environmental Monitoring,” Eng. App. Art. Intell., 2019.
- [23] K. Yang, S. K. Gan, and S. Sukkarieh, “A Gaussian Process Based RRT Planner for the Exploration of an Unknown and Cluttered Environment with a UAV,” Advanced Robotics, 2013.
- [24] W. Chen, and L. Liu, “Pareto Monte Carlo Tree Search for Multi-Objective Informative Planning,” in Proc. Robot.: Sci. Sys., 2019.
- [25] J. Choi, S. Oh, and R. Horowitz, “Distributed Learning and Cooperative Control for Multi-Agent Systems,” Automatica, 2009.
- [26] G. Best, O. M Cliff, T. Patten, R. R Mettu, and R. Fitch, “Dec-MCTS: Decentralized Planning for Multi-Robot Active Perception,” Int. J. Robot. Res., 2019.
- [27] C. E. Rasmussen, “Gaussian Processes in Machine Learning,” Advanced Lectures on Machine Learning, Springer, 2003.
- [28] H. Zhu, C. K. I. Williams, R. Rohwer, and M. Morciniec, “Gaussian Regression and Optimal Finite Dimensional Linear Models,” Tech. Rep., Aston University, 1997.
- [29] R. O. Saber, and R. M. Murray, “Consensus Protocols for Networks of Dynamic Agents,” in Proc. Amer. Cont. Conf., 2003.
- [30] D. H. Wolpert, S. R. Bieniawski, and D. G. Rajnarayan, “Probability Collectives in Optimization,” Handbook of Statistics 31, 2013.
- [31] A. Garivier, and E. Moulines, “On Upper-Confidence Bound Policies for Switching Bandit Problems,” in Proc. Int. Conf. Alg. Learning Theory, 2011.
- [32] N. Srinivas, A. Krause, S. M. Kakade, and M. W. Seeger, “Information-Theoretic Regret Bounds for Gaussian Process Optimization in the Bandit Setting,” IEEE Trans. Info. Theory, 2012.
- [33] B. Du, K. Qian, C. Claudel, and D. Sun, “Parallelized Active Information Gathering Using Multisensor Network for Environment Monitoring,” IEEE Trans. Cont. Sys. Tech., 2021.
- [34] https://data.kma.go.kr/
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d2960c79-837e-470f-97c8-da1ebaa0baf3/x11.png) |
Dohyun Jang received the B.S. degree in Electrical Engineering from Korea University in 2017, and the M.S. degree in Mechanical and Aerospace Engineering from Seoul National University, Seoul, in 2019. He is currently a Ph.D. Candidate in the School of Aerospace Engineering, SNU. His research interests include distributed systems, networked systems, machine learning, and robotics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d2960c79-837e-470f-97c8-da1ebaa0baf3/x12.png) |
Jaehyun Yoo received the Ph.D. degree in the School of Mechanical and Aerospace Engineering, Seoul National University, Seoul, in 2016. He was a postdoctoral researcher at the School of Electrical Engineering and Computer Science, KTH Royal Institute of Technology, Stockholm, Sweden. He is currently a Professor at the School of AI,
Sungshin Women’s University. His research interests include machine learning, indoor localization, automatic control, and robotic systems.
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d2960c79-837e-470f-97c8-da1ebaa0baf3/x13.png) |
Clark Youngdong Son Clark Youngdong Son received the B.S. degree in Mechanical Engineering from Sungkyunkwan University, and the Ph.D. degree in Mechanical and Aerospace Engineering from Seoul National University, in 2015 and 2021, respectively. He is currently a Staff Engineer at Mechatronics R&D Center, Samsung Electronics. His research interests include robotics, path planning, and optimal control. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d2960c79-837e-470f-97c8-da1ebaa0baf3/x14.png) |
H. Jin Kim received the B.S. degree from Korea Advanced Institute of Technology (KAIST) in 1995, and the M.S. and Ph.D. degrees in Mechanical Engineering from University of California, Berkeley, in 1999 and 2001, respectively.
From 2002 to 2004, she was a Postdoctoral Researcher in Electrical Engineering and Computer Science, UC Berkeley. In 2004, she joined the Department of Mechanical and Aerospace Engineering at Seoul National University as an Assistant Professor, where she is currently a Professor. Her research interests include intelligent control of robotic systems and motion planning.
|