Fully Heteroscedastic Count Regression with Deep Double Poisson Networks
Abstract
Neural networks capable of accurate, input-conditional uncertainty representation are essential for real-world AI systems. Deep ensembles of Gaussian networks have proven highly effective for continuous regression due to their ability to flexibly represent aleatoric uncertainty via unrestricted heteroscedastic variance, which in turn enables accurate epistemic uncertainty estimation. However, no analogous approach exists for count regression, despite many important applications. To address this gap, we propose the Deep Double Poisson Network (DDPN), a novel neural discrete count regression model that outputs the parameters of the Double Poisson distribution, enabling arbitrarily high or low predictive aleatoric uncertainty for count data and improving epistemic uncertainty estimation when ensembled. We formalize and prove that DDPN exhibits robust regression properties similar to heteroscedastic Gaussian models via learnable loss attenuation, and introduce a simple loss modification to control this behavior. Experiments on diverse datasets demonstrate that DDPN outperforms current baselines in accuracy, calibration, and out-of-distribution detection, establishing a new state-of-the-art in deep count regression.
1 Introduction
The pursuit of neural networks capable of learning accurate and reliable uncertainty representations has gained significant traction in recent years (Lakshminarayanan et al., 2017; Kendall & Gal, 2017; Gawlikowski et al., 2023; Dheur & Taieb, 2023). Input-dependent uncertainty is useful for detecting out-of-distribution data (Amini et al., 2020; Liu et al., 2020; Kang et al., 2023), active learning (Settles, 2009; Ziatdinov, 2024), reinforcement learning (Yu et al., 2020; Jenkins et al., 2022), and real-world decision-making under uncertainty (Abdar et al., 2021). While uncertainty quantification applied to regression on continuous outputs is well-studied, training neural networks to make probabilistic predictions over discrete counts has traditionally received less attention, despite multiple relevant applications. In recent years, neural networks have been trained to predict the size of crowds (Zhang et al., 2016; Lian et al., 2019; Zou et al., 2019; Luo et al., 2020; Zhang & Chan, 2020; Lin & Chan, 2023), the number of cars in a parking lot (Hsieh et al., 2017), traffic flow (Lv et al., 2014; Li et al., 2020; Liu et al., 2021), agricultural yields (You et al., 2017), inventory of product on shelves (Jenkins et al., 2023), and bacteria in microscopic images (Marsden et al., 2018).
Uncertainty is often decomposed into two quantities: epistemic, which refers to uncertainty due to misidentification of model parameters, and aleatoric, which is uncertainty due to observation noise (Der Kiureghian & Ditlevsen, 2009). In regression tasks, a popular and effective approach for capturing epistemic uncertainty is to use deep ensembles (DEs) (Lakshminarayanan et al., 2017) where a set of neural networks are independently trained from different initializations and combined to make predictions. Aleatoric uncertainty, meanwhile, is accounted for in each individual member, which outputs a distinct predictive distribution over the target. Aleatoric uncertainty can be categorized as homoscedastic, where the predictive uncertainty is constant for all inputs, and heteroscedastic, where predictive uncertainty varies as a function of the input. Existing work on DEs for regression trains each member of the ensemble to predict the mean and variance of a Gaussian distribution, . Each of the individual distributions are then combined into a single prediction.
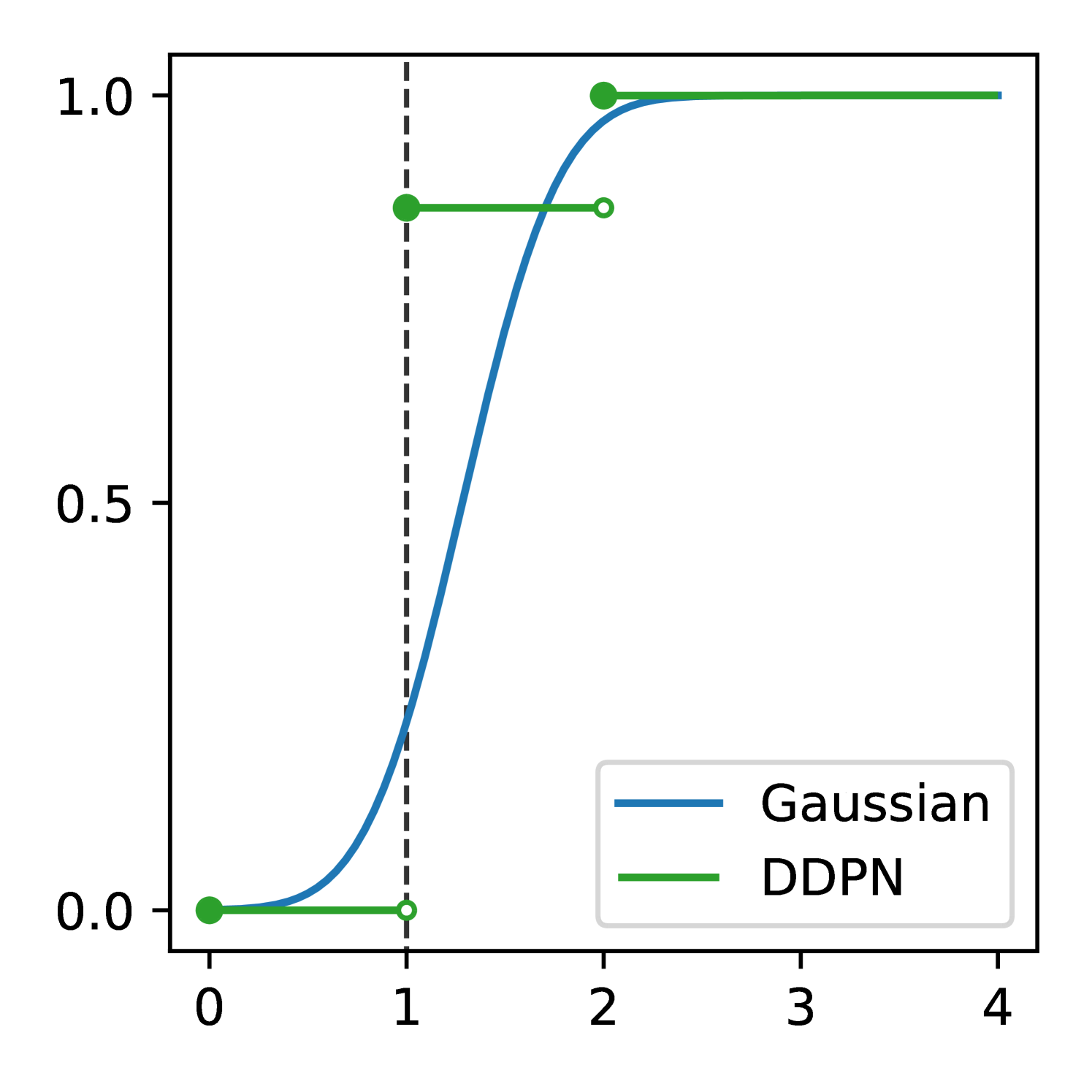
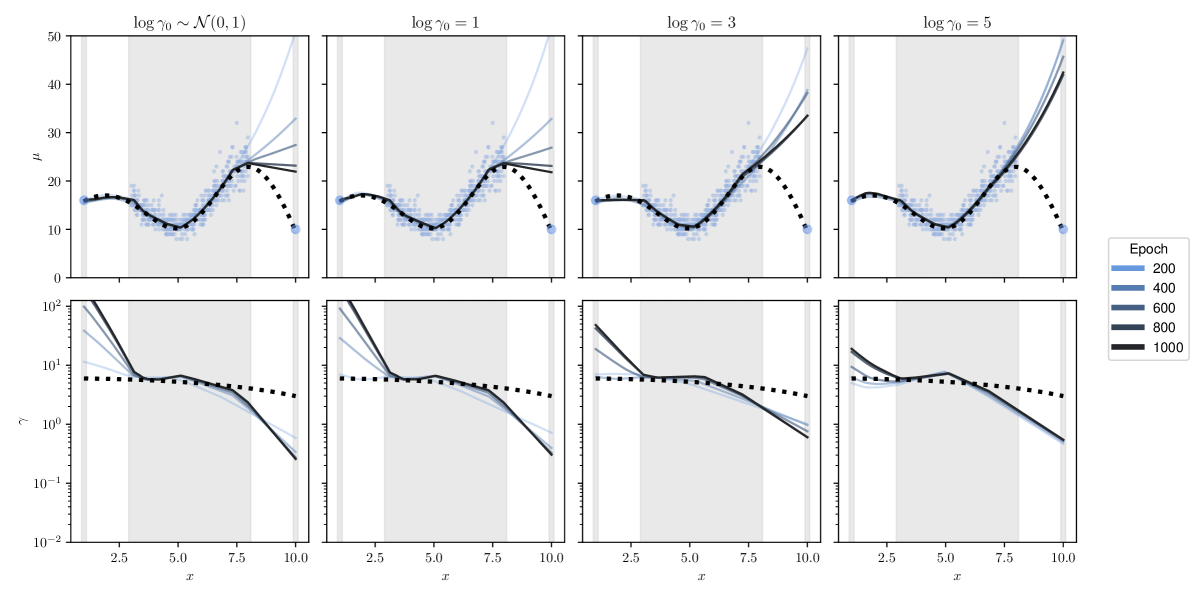
Full heteroscedasticity from unrestricted predictive variance is critical for DEs to produce calibrated output distributions. The total variance of an ensemble prediction can be described as , which is equal to the average aleatoric uncertainty of the members, plus the variance of the predicted means (Appendix C.6). If each member of the ensemble is not fully heteroscedastic (i.e., the regressor produces constrained variance predictions) the aleatoric term can be misspecified, which induces a miscalibrated predictive distribution of the ensemble. Additionally, recent work has shown that aleatoric and epistemic uncertainty are largely entangled in practice (Mucsányi et al., 2024), further compounding miscalibration. Consequently, poor aleatoric uncertainty quantification will likely also give rise to poor estimates of epistemic uncertainty. For a concrete example, see Figure 1. In this experiment we train three count regression DEs using a synthetic dataset and plot their predictive distributions, along with the estimated aleatoric and epistemic uncertainty decompositions. Two of these DEs, Poisson and Negative Binomial, are constituted of members that are not fully heteroscedastic (Proposition 2.3). This leads to overestimated aleatoric uncertainty and miscalibrated predictive distributions. We also note that such misspecification impacts epistemic uncertainty, which is high in these ensembles despite adequate training data.
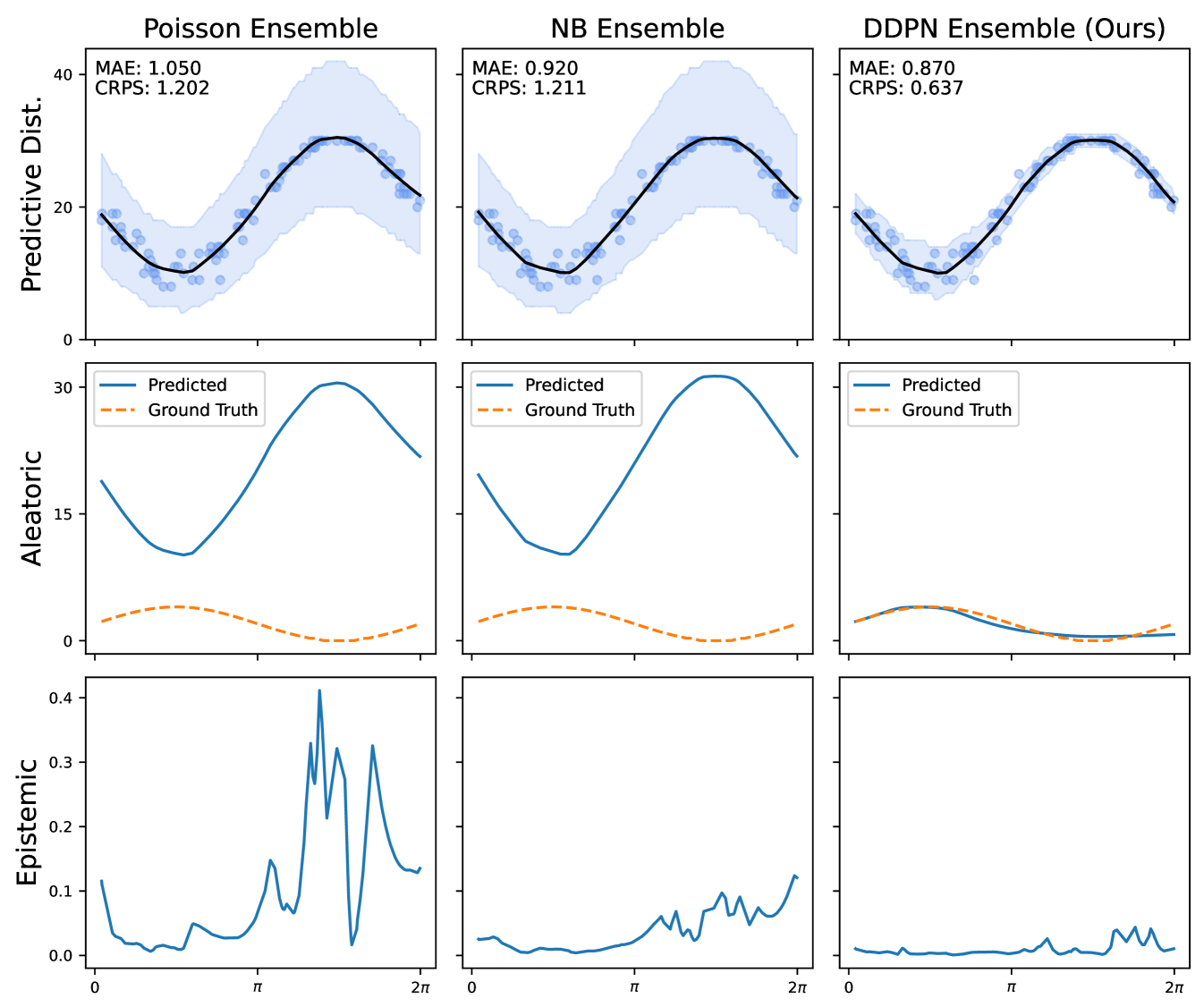
While full heteroscedasticity in deep regression on continuous outputs is well-studied (Nix & Weigend, 1994; Bishop, 1994), no such method exists for count data. Previous work trains a network to predict the parameter of a Poisson distribution and minimize its negative log likelihood (NLL) (Fallah et al., 2009). However, the Poisson parameterization of the neural network suffers from the equi-dispersion restriction: the predictive mean and variance are the same (). Another common alternative is to train the network to minimize Negative Binomial (NB) NLL (Xie, 2022). The Negative Binomial breaks equi-dispersion by introducing another parameter to the PMF. This helps disentangle the mean and variance, but suffers from the over-dispersion restriction: . Neither of these methods can produce unrestricted heteroscedastic variance.
A plausible alternative to introduce full heteroscedasticity to the count regression setting is to violate distributional assumptions and simply apply models with Gaussian likelihoods. However, this decision neutralizes a crucial inductive bias, since it outputs a probability density function, over a discrete output space, i.e. . This can impact both the accuracy and calibration of the predictive distribution, since the model is constrained to assign probability to infeasible real values and thus cannot maximally concentrate or center its predictions around the ground truth. Such a model will also exhibit various pathologies: 1) it will assign nontrivial probability to negative values (impossible for counting problems) when the predicted mean is small, and 2) the boundaries of its predictive intervals (i.e. highest density interval or 95% credible interval) are likely to fall between two valid integers, diminishing their interpretability and utility.
Our Contributions
To address these issues, we introduce the Deep Double Poisson Network (DDPN), a novel discrete neural regression model (see Figure 2). DDPN models aleatoric uncertainty by outputting the parameters of the Double Poisson distribution (Efron, 1986), a highly flexible predictive distribution over . Unlike existing count regression methods based on the Poisson and Negative Binomial distributions, DDPN exhibits full heteroscedasticity, allowing it to model a broader range of uncertainty patterns. At the same time, DDPN avoids the misspecification issues of Gaussian-based models on count data, enabling sharper, more reliable predictions. In addition to these desirable characteristics, we demonstrate that DDPN possesses robust regression properties akin to those of heteroscedastic Gaussian models. To do so, we propose a formal definition of learnable loss attenuation, a concept first studied by Kendall & Gal (2017) in which a model can adaptively modify its loss function to lower the impact of outlier points during training, and prove that DDPN satisfies this definition. Furthermore, we introduce a discrete analog of the -modification proposed by Seitzer et al. (2022), enabling controllable attenuation strength. Across a variety of datasets, our experiments show that DDPN (both individually and as an ensemble method) outperforms all baselines in terms of mean accuracy, calibration, and out-of-distribution detection, establishing a new state-of-the-art for deep count regression.
2 Modeling Predictive Uncertainty with Neural Networks
A large body of work has developed methods to represent both epistemic and aleatoric uncertainty in deep learning.
2.1 Epistemic Uncertainty
Epistemic uncertainty refers to uncertainty due to model misspecification. Modern neural networks tend to be significantly underspecified by the data, which introduces a high degree of uncertainty (Wilson & Izmailov, 2020). A variety of techniques have been proposed to explicitly represent epistemic uncertainty including Bayesian inference (Chen et al., 2014; Hoffman et al., 2014; Wilson & Izmailov, 2020), variational inference (Graves, 2011; Blundell et al., 2015), Laplace approximation (Daxberger et al., 2021), and Epistemic Neural Networks (Osband et al., 2023). Recently, deep ensembles have emerged as a simple and popular solution (Lakshminarayanan et al., 2017; D’Angelo & Fortuin, 2021; Dwaracherla et al., 2022). Other work connects Bayesian inference and ensembles by arguing the latter can be viewed as a Bayesian model average where the posterior is sampled at multiple local modes (Fort et al., 2019; Wilson & Izmailov, 2020). This approach has a number of attractive properties: 1) it generally improves predictive performance (Dietterich, 2000); 2) it can model more complex predictive distributions; and 3) it effectively represents uncertainty over learned weights, which leads to better calibration.
2.2 Aleatoric Uncertainty
Aleatoric uncertainty quantifies observation noise and generally cannot be reduced with more data (Der Kiureghian & Ditlevsen, 2009; Kendall & Gal, 2017). In practice, this uncertainty can be introduced by low resolution sensors, blurry images, or the intrinsic noise of a signal.
2.2.1 Heteroscedastic Regression in Deep Learning
Aleatoric noise is commonly modeled in deep learning by learning the parameters of a probability distribution over the label. This often takes the form of heteroscedastic regression, where the network learns an input-dependent dispersion parameter, , in addition to an estimate of the mean, (Nix & Weigend, 1994; Bishop, 1994). In the Gaussian case, . Recent work identifies issues with training such networks via Gaussian NLL due to the the influence of on the gradient of the mean, . Immer et al. (2024) reparameterize their model to output the natural parameters of the Gaussian distribution. Seitzer et al. (2022) propose a modified objective and introduce a hyperparameter, , which tempers the impact of on the gradient of and offers tunable control over the loss attenuation properties of the Gaussian NLL. Stirn et al. (2023) modify their architecture to include separate sub-networks for and , then use a stop gradient operation to neutralize the impact of on the sub-network. In the count setting, Poisson (Fallah et al., 2009) and Negative Binomial (Xie, 2022) likelihoods have been used to train heteroscedastic neural networks.
2.2.2 Heteroscedastic Regression with Generalized Linear Models
Historically, Generalized Linear Models (GLMs) have been used to model predictive uncertainty on tabular data. GLMs specify a conditional distribution, , where is a member of the exponential family, represents the natural parameter of , and is the dispersion term (McCullagh, 1989; Murphy, 2023). A link function, , is selected to specify a mapping between the natural parameter and the mean such that . The model is then fit by minimizing NLL. Many common models can be viewed under this general framework, including logistic regression, Poisson regression, and binomial regression (Fahrmeir et al., 2013). The Double Poisson distribution we employ in this work was originally developed in the context of GLMs and proposed a constrained dispersion term with an explicit dependence on the mean (Efron, 1986). More recent work employs Joint GLMs with separate covariates for mean and dispersion, allowing for more degrees of freedom (Aragon et al., 2018). All of these models are restricted to linear families of functions.
2.2.3 Full Heteroscedasticity
Because misspecification of aleatoric noise often corrupts overall estimates of uncertainty, regression models should be unconstrained in the range of variances they can output. We formalize this property as full heteroscedasticity, which ensures that a model’s predictive variance is both input-dependent and unconstrained in scale.
Definition 2.1.
A family of distributions , parametrized by , is said to have unrestricted variance if, for any random variable , if we condition on for any valid , for any there exists a setting of such that .
Definition 2.2.
A probabilistic regression model is called fully heteroscedastic if its predictive variance depends on the input and its output distribution family has unrestricted variance.
These definitions allow us to characterize existing methods through the lens of full heteroscedasticity.
Proposition 2.3.
Gaussian regressors are fully heteroscedastic, whereas Poisson and Negative Binomial regressors are not.
See Appendix C.1 for a proof. While Gaussian regressors provide the flexibility needed for uncertainty quantification in the continuous setting, existing methods for neural count regression place restrictions on their variance and thus lack full heteroscedasticity. This limitation reduces these models’ ability to capture the complex aleatoric noise present in real-world count data.
3 Deep Double Poisson Networks (DDPN)
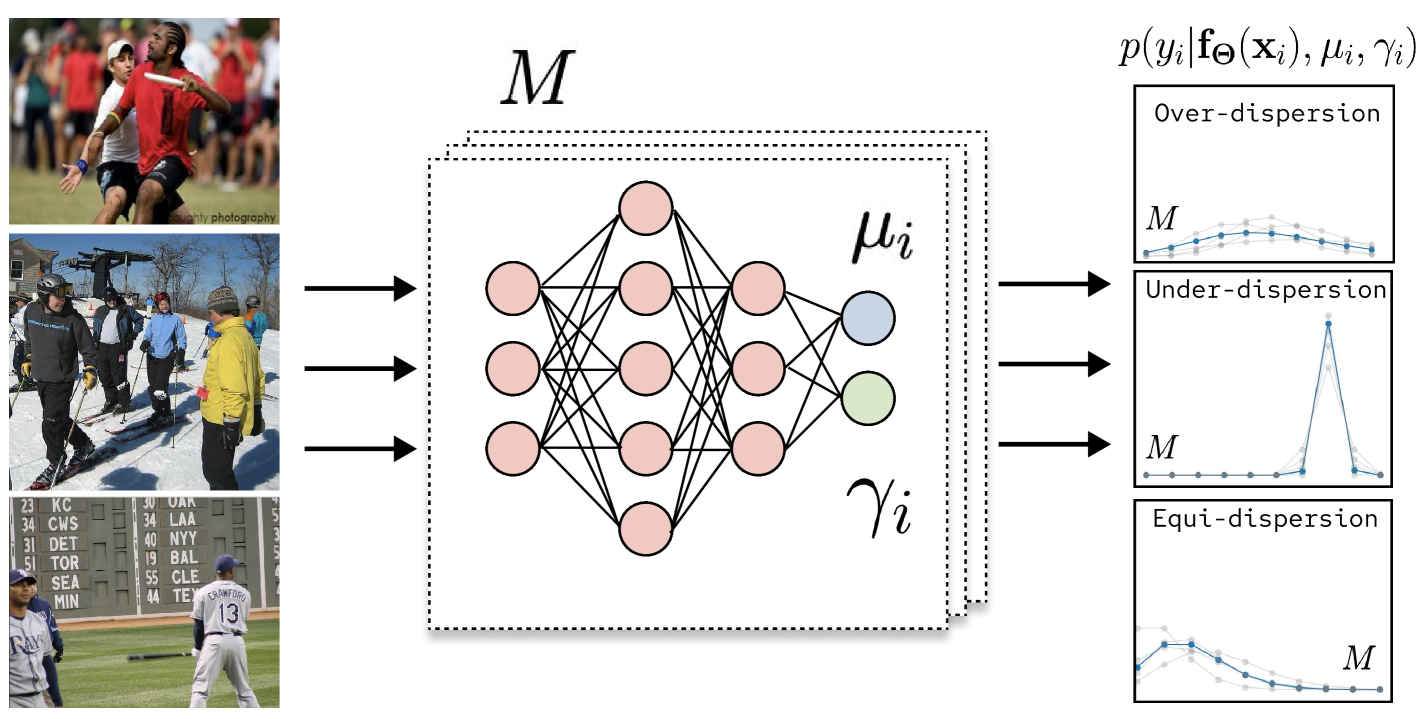
To address the limitations described in the previous section, we propose the Deep Double Poisson Network (DDPN), a state-of-the-art deep regression model that represents families of non-linear functions over complex, non-negative count data. DDPN outputs the parameters of the Double Poisson distribution (Efron, 1986), which results in a fully heteroscedastic predictive distribution under approximate moment assumptions (Proposition 3.1). We demonstrate that DDPN inherits robust regression properties through learnable loss attenuation, similar to Gaussian-based networks. Additionally, we introduce a discrete analog of the modification from Seitzer et al. (2022), allowing tunable control over self-attenuation to improve overall model fit.
We assume access to a dataset, , with training examples , where each is drawn from some unknown count distribution . Let denote the space of all possible inputs , let denote the space of all possible distributions over , and let denote a vector of parameters identifying a specific . We wish to model with a neural network with learnable weights (stacked into layers). In practice, we model . Given such a network, we obtain a predictive distribution, , for any input .
In particular, suppose that we restrict our output space to , the family of Double Poisson distributions over . Any distribution is uniquely parameterized by , with mean and inverse dispersion . The distribution function, , is defined as:
| (1) |
where is a normalizing constant. Let denote a random variable with a Double Poisson distribution function, then we say . In line with previous work (Zou et al., 2013; Aragon et al., 2018), we assume the moment approximations proposed by Efron (1986): and . We specify a model, 111For both and we apply the log “link” function to ensure positivity and numerical stability. We simply exponentiate whenever or are needed (i.e., to evaluate the P.M.F.) , as follows: let , be the -dimensional hidden representation of the input produced by the first layers of a neural network. We apply two separate affine transformations to this representation to obtain our distribution parameters: and .
The flexibility induced by the parameter in DDPN yields a powerful model with the capacity to represent any form of aleatoric noise. Referring back to Definition 2.2, we concretely state this property in the following proposition (with a proof in Appendix C.2):
Proposition 3.1.
DDPN regressors are fully heteroscedastic under approximate moment assumptions.
See Appendix A.3 for a thorough assessment of the quality of Efron’s moment approximations. In practice, we observe that these estimates are almost exact for nearly all relevant values of and (Figure 7).
3.1 DDPN Objective
To learn the weights of a DDPN, we minimize the following NLL objective (averaged across all prediction / target tuples in the dataset):
| (2) |
In accordance with convention, we define when (Cover, 1999). During training, we minimize iteratively via stochastic gradient descent (or common variants). Note that this objective drops the normalizing constant, . Prior work demonstrates that setting provides an accurate approximation of the Double Poisson density and is easier to optimize (Efron, 1986; Chow & Steenhard, 2009). We provide a full derivation of Equation 2 from the Double Poisson distribution function in Appendix A.1.
3.2 Loss Attenuation Dynamics of DDPN
Previous work (Kendall & Gal, 2017) states that Gaussian heteroscedastic regressors exhibit learnable loss attenuation, a property where predictive uncertainty in the NLL objective reduces the influence of outliers. We will demonstrate that the DDPN objective has this same property. To support this claim, we first introduce a formal definition of learnable attenuation — a concept that, to the best of our knowledge, has not been rigorously defined in prior literature:
Definition 3.2.
The loss function of a regressor , taking as input the predicted mean and dispersion , exhibits learnable attenuation if it admits the form , where , , and with equality holding iff . We call the dispersion penalty, the attenuation factor, and the residual penalty.
A key consequence of this formulation is that a model trained with such a loss can actively dampen the impact of certain data points—a phenomenon captured in the following proposition:
Proposition 3.3.
If a loss function exhibits learnable attenuation, then as .
This result (proved in Appendix C.3) reveals a fundamental mechanism of learnable attenuation: by increasing the predicted dispersion , a model can effectively nullify the residual penalty’s contribution to the total loss. This allows it to “ignore” high-error outliers, leading to a robust regressor with better overall accuracy. Meanwhile, the dispersion penalty in the loss discourages the model from universally inflating , ensuring that it does not suppress all errors.
The Gaussian NLL commonly used to train heteroscedastic regressors naturally satisfies Definition 3.2, as first observed by Kendall & Gal (2017). Specifically, if we set , we obtain , , and .
Proposition 3.4.
The DDPN objective in Equation 2 exhibits learnable attenuation of the form , , and .
3.3 -DDPN: Controllable Loss Attentuation
Seitzer et al. (2022) argue that the “learned loss attenuation” property of neural networks trained via Gaussian NLL can sometimes result in premature convergence due to inflated predicted variance in hard-to-fit regions of the training data, which in turn can give rise to suboptimal mean fit. The mechanism that drives this behavior is the presence of the predicted variance term in the partial derivative of the NLL with respect to the mean. We observe that these same phenomena exist with DDPN. Our loss has the following partial derivatives: and .
Notice that if the predicted inverse dispersion, , is sufficiently small (corresponding to large variance), it can completely zero out regardless of the current value of . Thus, during training, a neural network can converge to (and get “stuck” in) suboptimal solutions wherein poor mean fit is explained away via large uncertainty values. To remedy this behavior, we propose a modified loss function, , also called the Double Poisson -NLL:
| (3) |
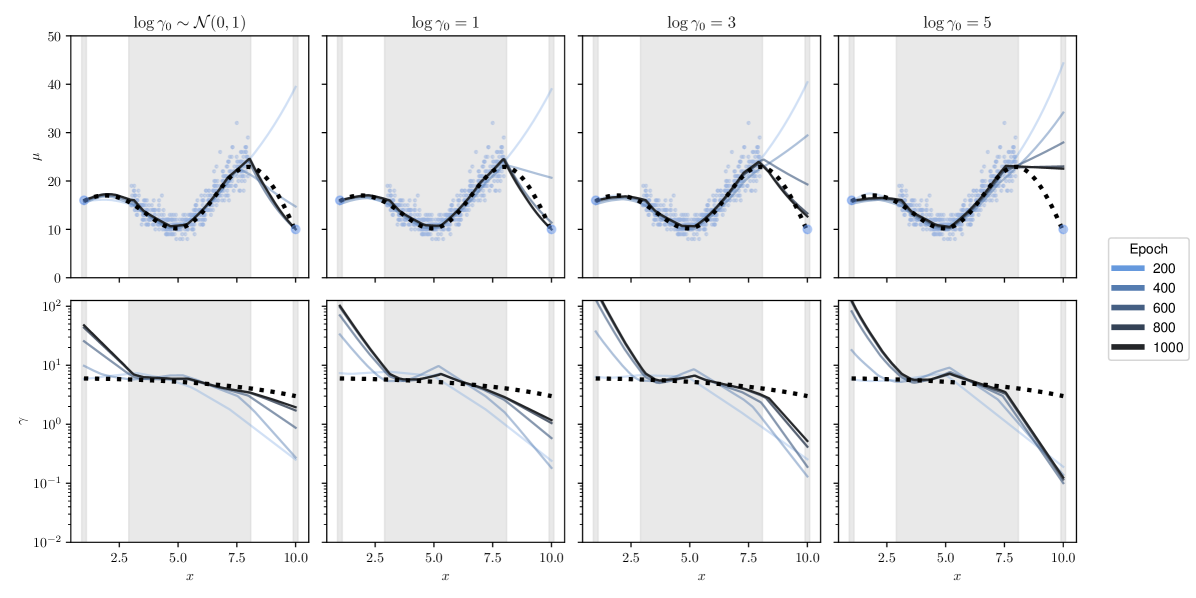
where denotes the stop-gradient operation and we once again average across all prediction / target tuples in the dataset. With this modification we can effectively temper the loss attenuation behavior of DDPN. We now have partial derivatives and . The Double Poisson -NLL is parameterized by , where recovers the original Double Poisson NLL and corresponds to fitting the mean, , with no respect to (while still performing normal weight updates to fit the value of ). Thus, we can consider the value of as providing a smooth interpolation between the natural DDPN likelihood and a more mean-focused loss. For an empirical demonstration of the impact of on DDPN, see Figure 6 in Section 4.5.
3.4 DDPN Ensembles
The formulation in the previous sections describes a network with a single forward pass. As noted in Section 2.1, multiple independently-trained neural networks can be combined to improve mean fit and distributional calibration. We create DDPN ensembles by combining the predictive distributions of distinct DDPNs in a uniform mixture as follows: Given settings of weights , we model as . Section 4 convincingly demonstrates that combining model predictions in this way yields the best overall performance.
4 Experiments
In our experiments, we aim to answer the following research questions: (1) Is DDPN flexible enough to fit any count distribution, even under known misspecification? (2) How does DDPN compare to existing deep regression methods as measured by accuracy and calibration? (3) Does the enhanced uncertainty quantification of DDPN from full heteroscedasticity combined with proper inductive biases of a discrete predictive distribution lead to better out-of-distribution detection? (4) What is the effect of the hyperparameter on the training dynamics of DDPN?
4.1 Evaluation Metrics
We evaluate each regression method along two key dimensions: accuracy, measured by mean fit, and calibration, which indicates the overall quality of the predictive distribution. Accuracy is quantified using the Mean Absolute Error (MAE). Calibration is assessed using the Continuous Ranked Probability Score (CRPS), a strictly proper scoring rule (Matheson & Winkler, 1976), with lower values signifying closer alignment between the predictive CDF and the observed label . Detailed explanations and definitions of these evaluation metrics are provided in Appendix B.2.
4.2 Misspecification Recovery
DDPN is trained by minimizing Double Poisson NLL, which makes a distributional assumption about the targets. In this section, we test whether DDPN is robust to violations of this assumption. To do so, we generate data from two processes: 1) ; and 2) ; neither of which conform to the assumptions in Section 3. For each dataset, we train both a DDPN and a model explicitly matched to the noise distribution of the data (a Poisson DNN for the first process and a Negative Binomial DNN for the second). Figures 3(a) and 3(b) compare the predictive distributions learned by these models. Within each figure, we report MAE and CRPS.
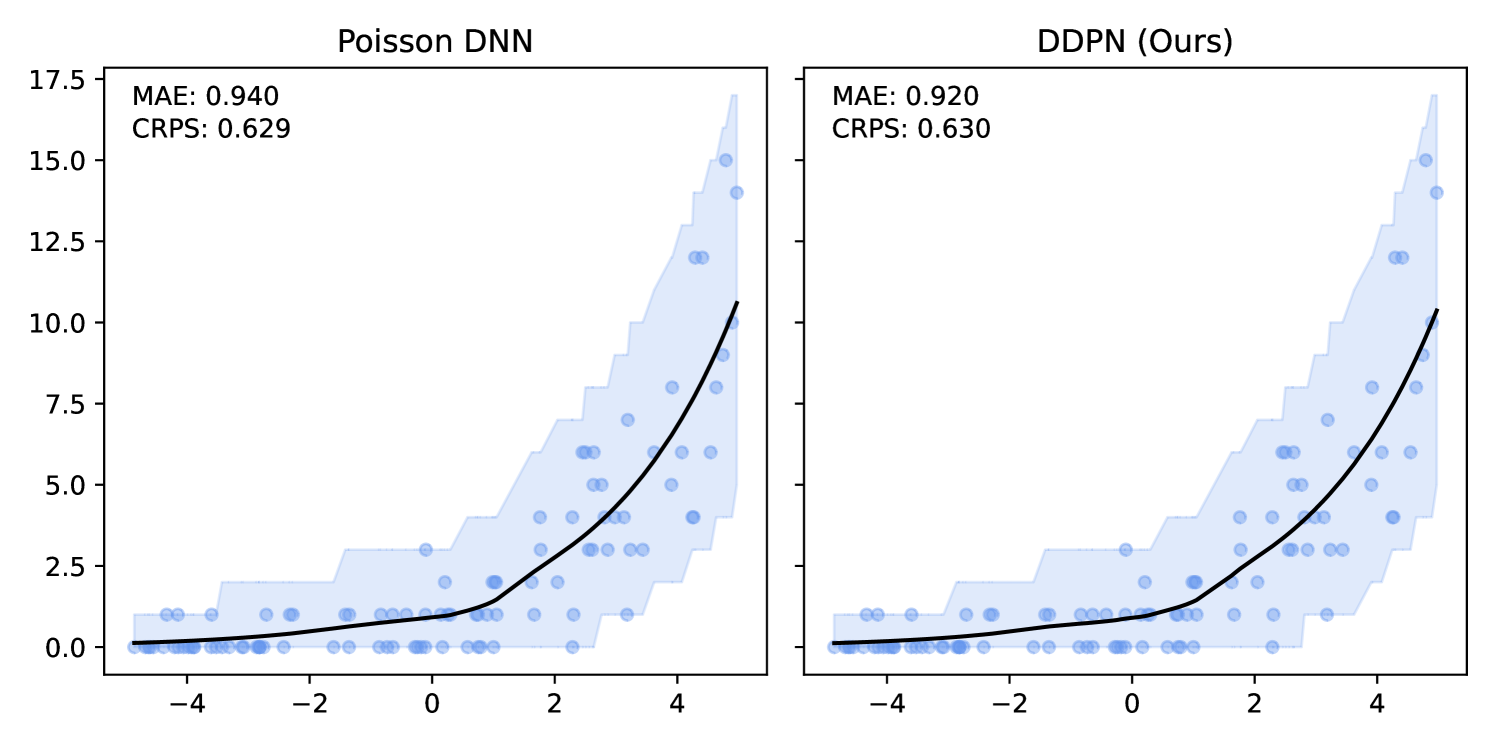
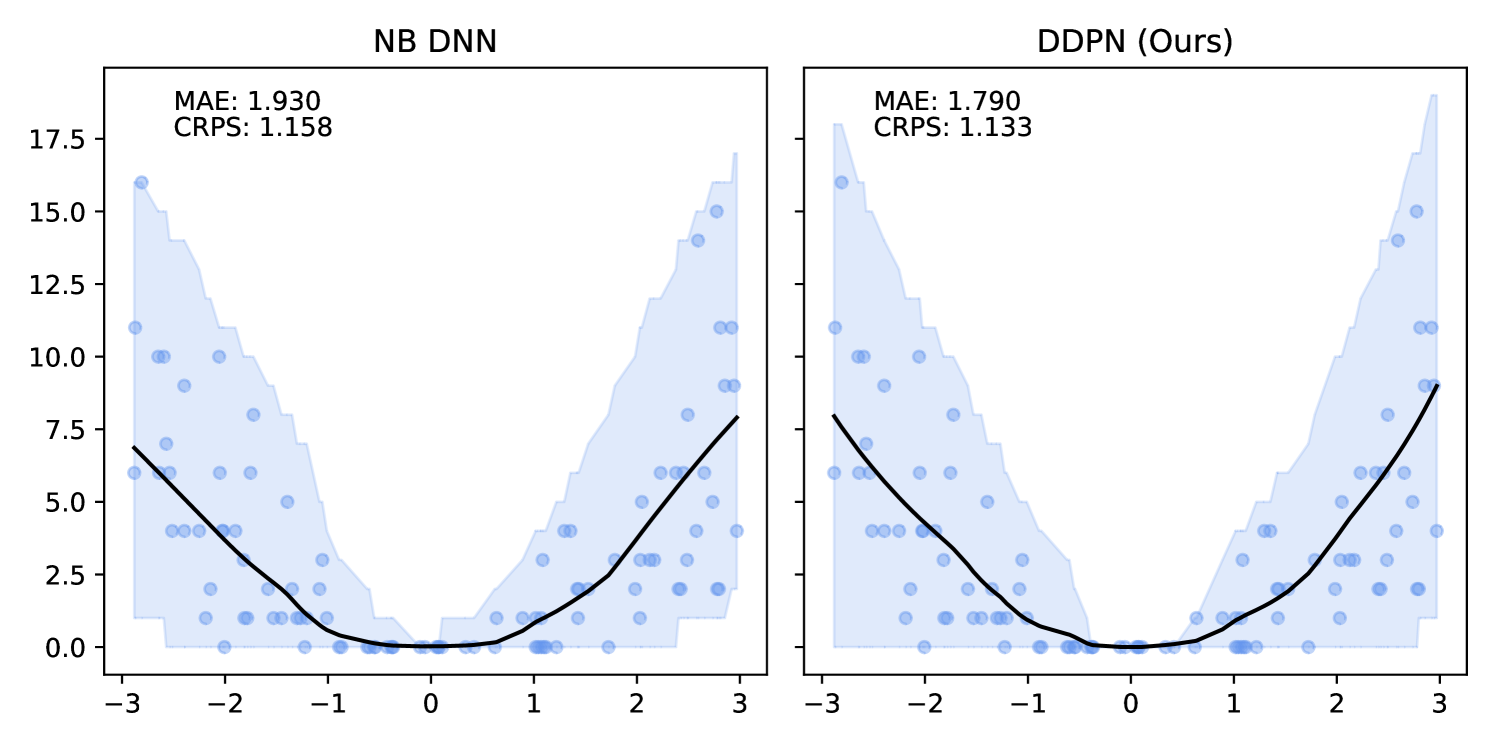
Remarkably, DDPN is flexible enough to accurately capture the aleatoric structure of the data in both experiments. It achieves performance that meets or exceeds models explicitly tailored to the true noise distribution. These results highlight the robustness of DDPN and suggest that it offers a reliable and versatile approach to neural count regression, even in the face of potential misspecification.
| Dataset | Modality | Backbone |
| Length of Stay | Tabular | MLP |
| COCO-People | Image | ViT-B-16 |
| Inventory | Point Cloud | CountNet3D |
| Reviews | Text | DistilBERT Base Cased |
4.3 Real-World Datasets
| Length of Stay | COCO-People | Inventory | Reviews | ||||||
| MAE () | CRPS () | MAE () | CRPS () | MAE () | CRPS () | MAE () | CRPS () | ||
| Aleatoric Only | Poisson DNN | 0.664 (0.01) | 0.553 (0.01) | 1.099 (0.02) | 0.851 (0.01) | 1.023 (0.04) | 0.706 (0.01) | 0.818 (0.01) | 0.559 (0.00) |
| NB DNN | 0.685 (0.00) | 0.570 (0.00) | 1.143 (0.05) | 0.867 (0.01) | 1.020 (0.04) | 0.708 (0.01) | 0.855 (0.01) | 0.562 (0.00) | |
| Gaussian DNN | 0.599 (0.01) | 0.453 (0.02) | 1.219 (0.12) | 0.866 (0.07) | 0.936 (0.01) | 0.659 (0.00) | 0.452 (0.01) | 0.323 (0.00) | |
| Faithful Gaussian | 0.582 (0.00) | 0.436 (0.01) | 1.082 (0.01) | 0.879 (0.01) | 0.959 (0.03) | 0.688 (0.02) | 0.428 (0.00) | 0.428 (0.00) | |
| Natural Gaussian | 0.597 (0.01) | 0.439 (0.01) | 1.157 (0.04) | 0.848 (0.02) | 0.958 (0.01) | 0.675 (0.01) | 0.428 (0.01) | 0.312 (0.00) | |
| -Gaussian | 0.600 (0.01) | 0.427 (0.01) | 1.055 (0.01) | 0.786 (0.00) | 0.935 (0.01) | 0.669 (0.01) | 0.420 (0.00) | 0.306 (0.00) | |
| -Gaussian | 0.646 (0.01) | 0.462 (0.01) | 1.085 (0.01) | 0.809 (0.00) | 0.923 (0.01) | 0.653 (0.01) | 0.458 (0.01) | 0.327 (0.00) | |
| DDPN (ours) | 0.502 (0.01) | 0.390 (0.04) | 1.135 (0.08) | 0.810 (0.03) | 0.906 (0.01) | 0.632 (0.01) | 0.392 (0.01) | 0.277 (0.00) | |
| -DDPN (ours) | 0.516 (0.01) | 0.370 (0.01) | 1.095 (0.03) | 0.782 (0.02) | 0.905 (0.02) | 0.635 (0.01) | 0.356 (0.01) | 0.268 (0.00) | |
| -DDPN (ours) | 0.558 (0.01) | 0.407 (0.01) | 1.006 (0.01) | 0.759 (0.01) | 0.909 (0.01) | 0.634 (0.01) | 0.356 (0.00) | 0.263 (0.00) | |
| Aleatoric + Epistemic (DEs) | Poisson DNN | 0.650 | 0.547 | 1.046 | 0.817 | 0.996 | 0.683 | 0.823 | 0.556 |
| NB DNN | 0.681 | 0.567 | 1.066 | 0.824 | 0.982 | 0.686 | 0.857 | 0.560 | |
| Gaussian DNN | 0.590 | 0.450 | 1.148 | 0.815 | 0.902 | 0.634 | 0.447 | 0.319 | |
| Faithful Gaussian | 0.571 | 0.429 | 1.042 | 0.841 | 0.909 | 0.643 | 0.424 | 0.324 | |
| Natural Gaussian | 0.582 | 0.428 | 1.090 | 0.800 | 0.916 | 0.643 | 0.423 | 0.307 | |
| -Gaussian | 0.591 | 0.420 | 1.019 | 0.740 | 0.879 | 0.619 | 0.414 | 0.302 | |
| -Gaussian | 0.633 | 0.453 | 1.050 | 0.765 | 0.887 | 0.624 | 0.455 | 0.324 | |
| DDPN (ours) | 0.485 | 0.361 | 1.024 | 0.744 | 0.861 | 0.604 | 0.373 | 0.268 | |
| -DDPN (ours) | 0.495 | 0.359 | 1.029 | 0.729 | 0.840 | 0.590 | 0.358 | 0.261 | |
| -DDPN (ours) | 0.543 | 0.393 | 0.959 | 0.712 | 0.859 | 0.597 | 0.344 | 0.257 | |
We compare DDPN to baselines on a number of real-world, complex count datasets. A summary of the datasets used and the corresponding backbone architectures is given in Table 1. Notably, we run experiments across various modalities, including tabular, image, point cloud, and text data.
Length of Stay (Microsoft, 2016) is a tabular dataset where the task is to forecast the number of days of a patient will spend in a hospital. The features consist of patient measurements and attributes of the healthcare facility. COCO-People (Lin et al., 2014) is an adaptation of the MS-COCO dataset, where the task is to predict the number of people in each image. Inventory (Jenkins et al., 2023) consists of point clouds that capture retail shelves. The goal is to predict the number of products in the point cloud. Finally, Reviews is taken from the “Patio, Lawn, and Garden” category of the Amazon Reviews dataset (Ni et al., 2019) . The goal is to predict the discrete 1-5 product rating from the text review.
4.3.1 Baselines
We compare to two discrete baselines: 1) Poisson DNN (Fallah et al., 2009) and 2) Negative Binomial DNN (Xie, 2022). We also include fully heteroscedastic continuous models in our experiments: 1) Gaussian DNN (Nix & Weigend, 1994), 2) -Gaussian (Seitzer et al., 2022), 3) Faithful Gaussian (Stirn et al., 2023), and 4) Natural Gaussian (Immer et al., 2024). For -Gaussian we use the prescribed values of and from Seitzer et al. (2022), and mirror this behavior for our discrete adaptation, -DDPN. A subscript marks the specific setting of (e.g. ).
We also evaluate ensembles for all methods to highlight the effects of modeling both aleatoric and epistemic uncertainty. Gaussian ensembles are produced according to the technique of Lakshminarayanan et al. (2017), while DDPN, Poisson, and Negative Binomial ensembles follow the prediction strategy outlined in Section 3.4. See Table 2 for results.
For each dataset, we generate train/val/test splits with a fixed random seed. We select models according to lowest average loss on the validation split and report results on the test split. We train and evaluate 5 models per technique and record the empirical mean and standard deviation of each metric. To form ensembles, these same 5 models are combined. All experiments are implemented in PyTorch (Paszke et al., 2017). Details related to data splits, network architecture, hardware, and hyperparameter selection are reported in Appendix B.3. Source code is available online222https://github.com/delicious-ai/ddpn.
4.3.2 Analysis of Empirical Results
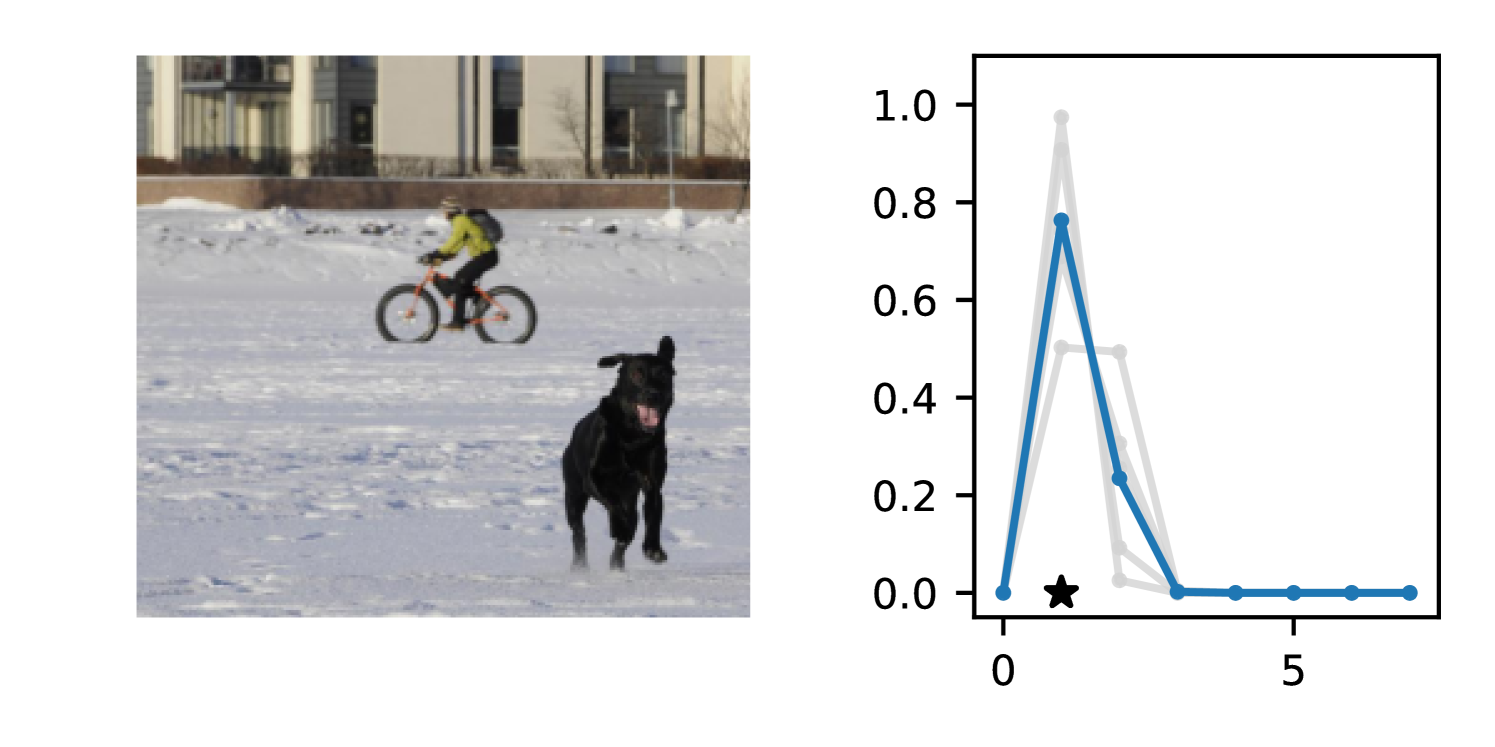
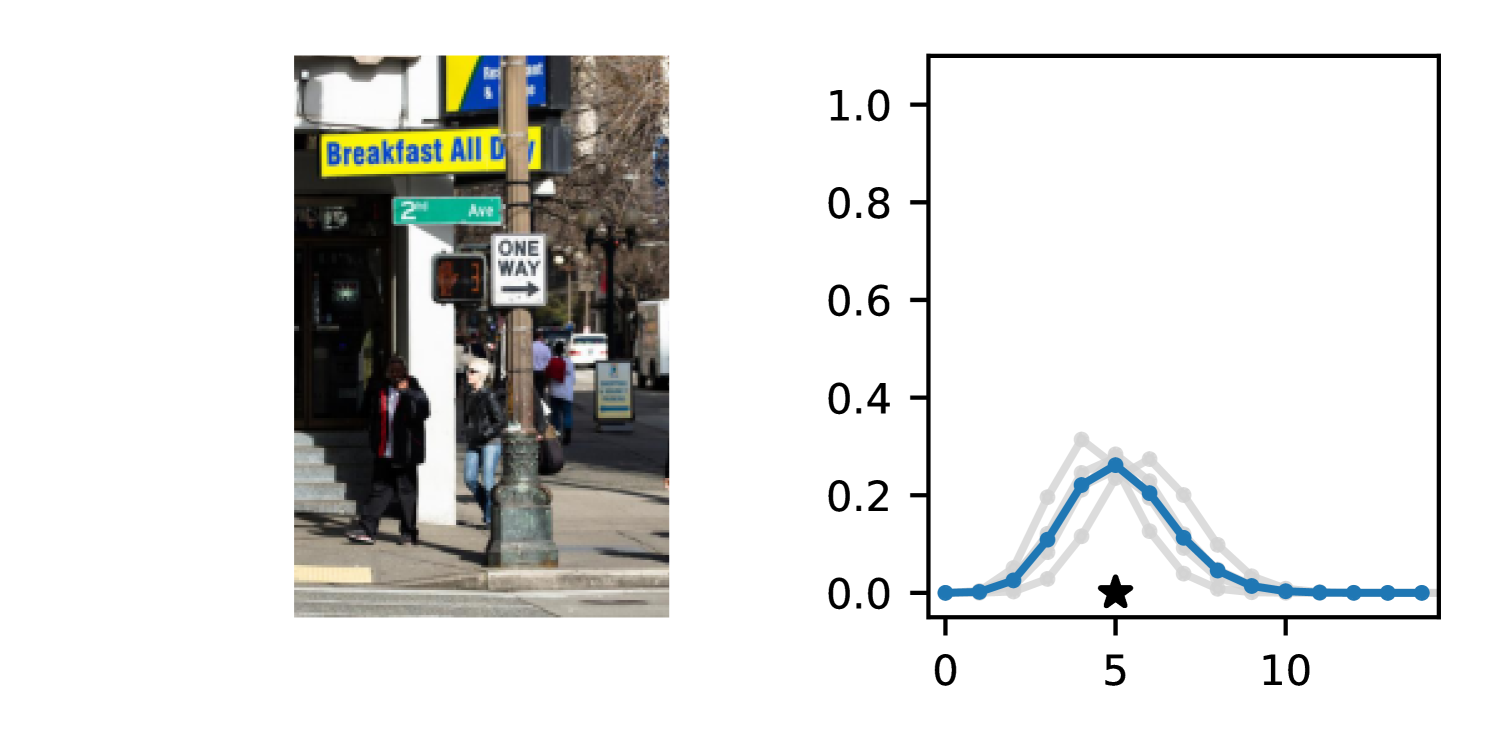
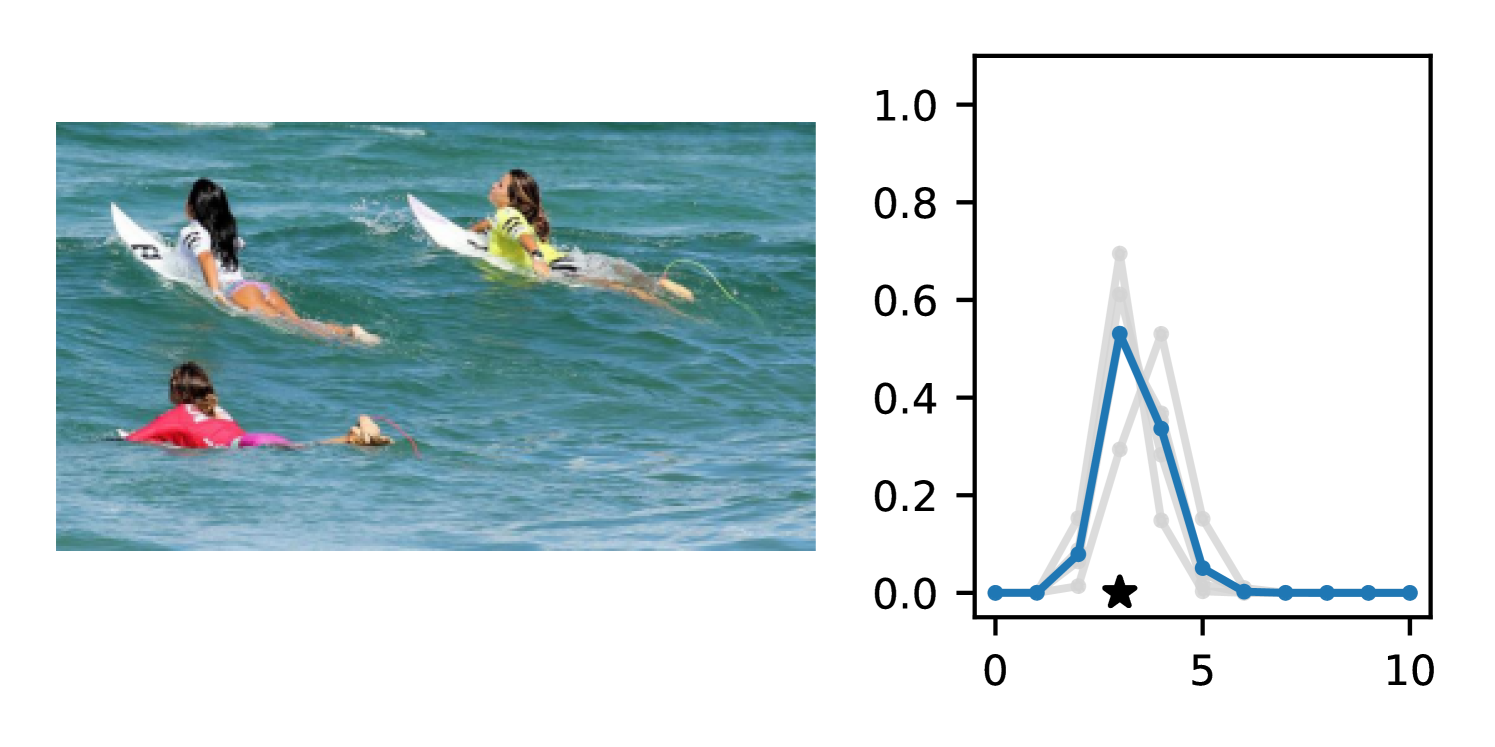
We observe that DDPN (or one of its variants) achieves the best accuracy and calibration on every task we benchmark. In almost all cases, the margin is substantial— across both individual models and ensembles, COCO-People is the only dataset in which a non-DDPN model (-Gaussian) even places in the top three. In line with previous results (Lakshminarayanan et al., 2017; Fort et al., 2019), we find that marginalizing over multiple plausible sets of weights through deep ensembles yields improvements in both mean fit and probabilistic alignment. Ensembled DDPN also outperforms all baselines in terms of accuracy and calibration.
On most datasets, we observe that Negative Binomial and Poisson DNNs struggle with fitting the mean in addition to uncertainty quantification. In contrast to Gaussian and DDPN models that can perform loss attenuation during training (see Section 3.2), Negative Binomial and Poisson regressors are limited in their ability to discount outliers. Whenever these models predict a high count, the equidispersion and overdispersion assumptions built into each respective distribution force a high uncertainty to be predicted as well. Thus, training data points are weighted according to their predicted labels without truly accounting for observation noise, and outliers are not properly tempered.
The gap in performance between Gaussian neural regressors and DDPN models, meanwhile, can largely be attributed to the lack of an inductive bias: Gaussian models naïvely assign probability mass to continuous values that are known a priori to be infeasible, while DDPNs concentrate their probabilities on discrete counts by explicit construction. This mismatch produces predictive CDFs that are more misaligned with observations compared to those produced by DDPNs. See Figure 5 for two illustrative examples from Length of Stay.
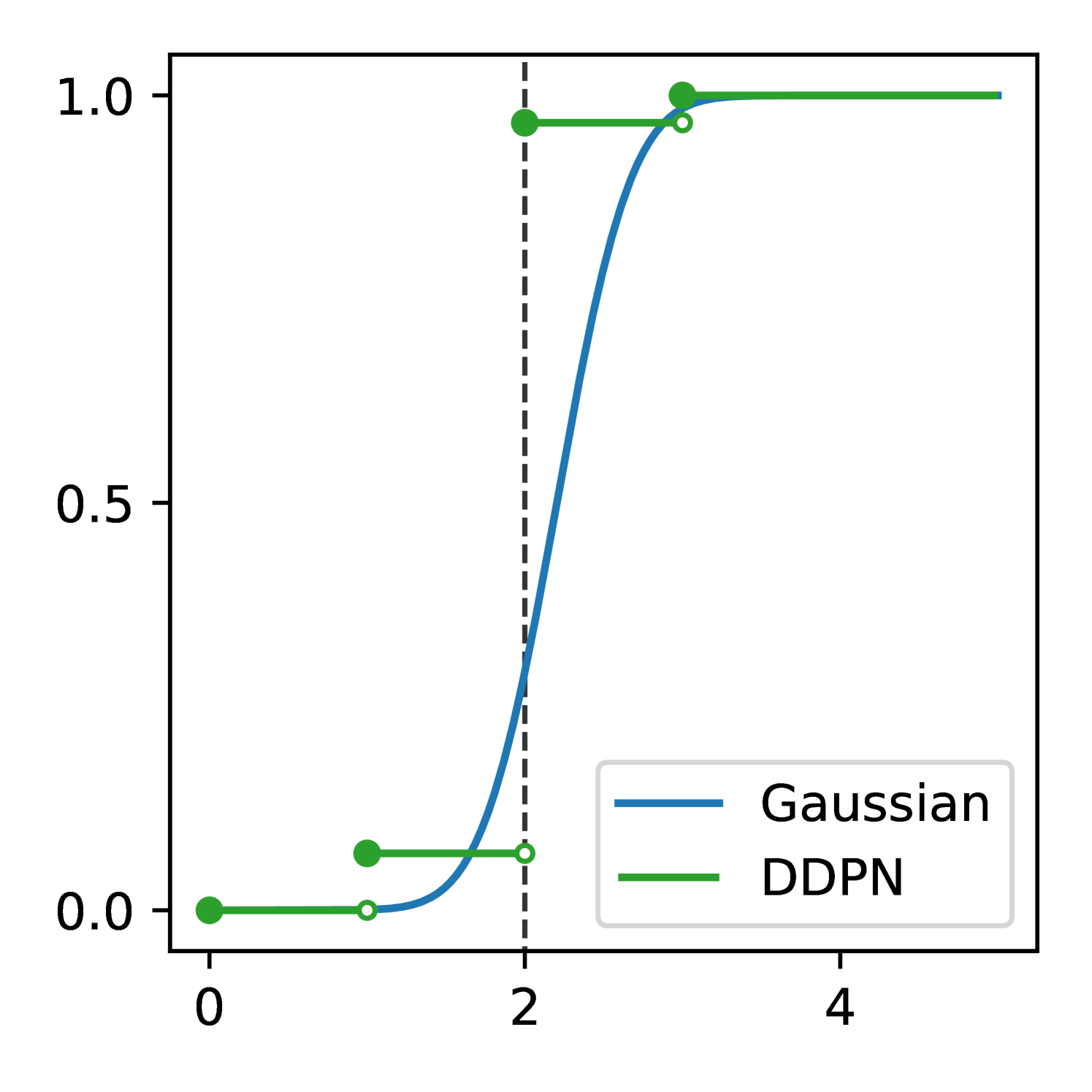
In Section 3.3, we explain how Seitzer et al. (2022)’s modification can be adapted to improve mean fit in the discrete heteroscedastic setting by defining -DDPN. Our results demonstrate that this adjustment to our training objective generally results in superior MAE, although the strength of the effect varies by dataset. We note that CRPS often improves alongside MAE, indicating that can simultaneously boost both accuracy and overall probabilistic fit.
4.4 Out-of-Distribution Detection
In this section, we investigate how DDPN models perform relative to baselines when their predictive distributions are used for out-of-distribution (OOD) detection. In accordance with common practice, we form scoring threshold-based OOD detectors and evaluate them in the binary classification setting (Hendrycks & Gimpel, 2016; Alemi et al., 2018; Ren et al., 2019). We define our in-distribution (ID) dataset to be Amazon Reviews and form our out-of-distribution dataset by compiling verses from the King James Version of the Holy Bible. We refer to the train and test splits of as and respectively.
We use the total variance of ensemble predictions as our OOD score, since both aleatoric and epistemic uncertainty are helpful OOD indicators (Wang & Aitchison, 2021). The OOD threshold is chosen such that we expect a false positive rate of on data drawn from . Specifically, we randomly select 20% of and define to be the quantile of the predictive uncertainties on that holdout set. Any inputs from (excluding the held-out data) or that produce a predictive variance above are classified as OOD, while the rest are marked as ID.
For each ensemble, we vary from 0 to 1 and report the resultant area under the ROC curve (AUROC), the area under the precision-recall curve (AUPR), and the false positive rate at the 80% true positive rate (FPR80). To account for variability due to randomness in the calculation of , we run each evaluation 10 times, re-sampling the holdout set with each iteration, and report the mean and standard deviation of each metric. Results are presented in Table 3.
| AUROC () | AUPR () | FPR80 () | |
| Poisson DNN | 0.330 (0.001) | 0.413 (0.000) | 0.793 (0.001) |
| NB DNN | 0.280 (0.001) | 0.397 (0.000) | 0.819 (0.002) |
| Gaussian DNN | 0.840 (0.001) | 0.812 (0.005) | 0.318 (0.002) |
| Faithful Gaussian | 0.731 (0.001) | 0.670 (0.001) | 0.380 (0.002) |
| Natural Gaussian | 0.836 (0.001) | 0.827 (0.002) | 0.317 (0.002) |
| -Gaussian | 0.829 (0.001) | 0.797 (0.004) | 0.323 (0.002) |
| -Gaussian | 0.817 (0.001) | 0.806 (0.002) | 0.338 (0.001) |
| DDPN (ours) | 0.854 (0.001) | 0.849 (0.003) | 0.269 (0.002) |
| -DDPN (ours) | 0.887 (0.001) | 0.875 (0.003) | 0.199 (0.001) |
| -DDPN (ours) | 0.870 (0.001) | 0.851 (0.002) | 0.236 (0.002) |
Our results demonstrate that uncertainties obtained from DDPN (and -DDPN) ensembles are the best-suited among all other models evaluated for identifying OOD inputs. This is strong evidence that uncertainty estimates obtained from DDPN models are robust, yielding important context for practitioners around how much an individual prediction can be trusted. For plots showing how distributions differ for ID / OOD data, see Appendix D.2. In particular, Figure 30 highlights the effective OOD behavior of DDPN.
4.5 The Effect of on DDPN Training Dynamics
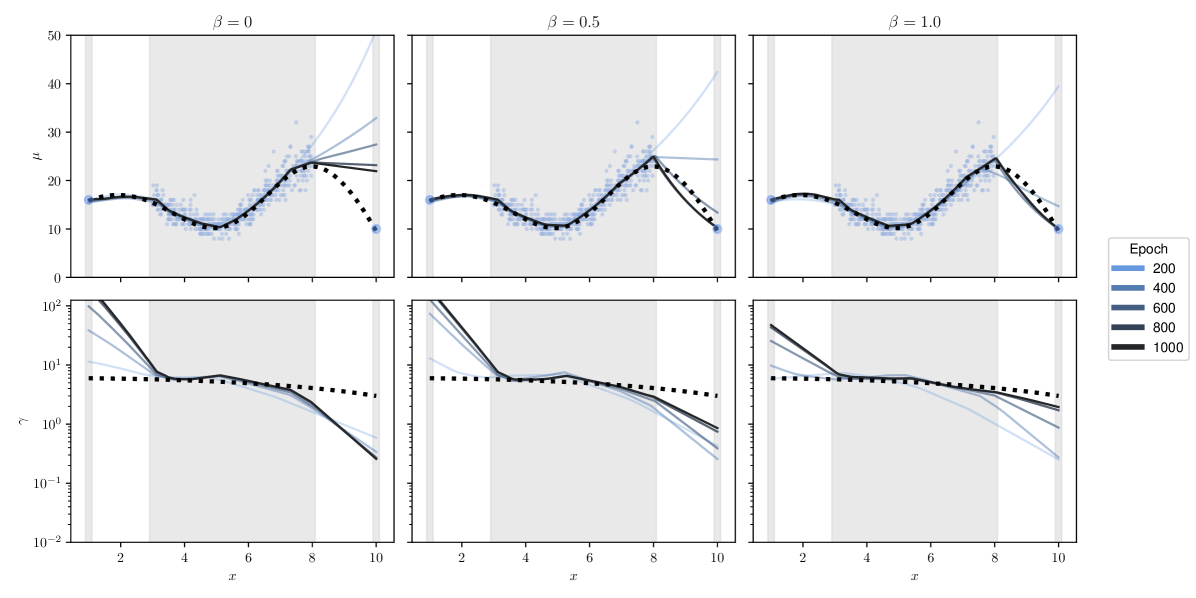
In this section, we study how the hyperparameter mediates the functional evolution of DDPN’s predictive distribution over the course of training. Figure 6 shows a one dimensional count regression problem with three settings of . We generate data from , where . We then produce a set of isolated points at and and concatenate them with the generated dataset. Since these points are relatively far from the rest of the training data, a neural network will struggle to initially fit them. If the network is heteroscedastic, it may downweight the contribution of these outlier points to the overall loss by assigning high uncertainty values (low values of for DDPN) to explain the poor fit. This is a consequence of the learnable loss attentuation property from Definition 3.2. This raises the possibility that model training converges without producing a function that fits the outlier points. We can temper the effect of such loss attenuation by training with -NLL. In Figure 6, we see that increasing the value of indeed addresses this behavior, with higher leading to faster convergence to the true mean fit. This matches the analysis performed by (Seitzer et al., 2022), who use to regularize the Gaussian NLL.
5 Conclusion
In this paper, we presented the Deep Double Poisson Network (DDPN) as a novel approach to enhance the quality of predictive distributions in deep count regression. DDPN achieves full heteroscedasticity through the unrestricted variance of its output distribution, allowing it to accurately capture aleatoric uncertainty of any form. This capability results in uncorrupted estimates of epistemic uncertainty when predictions are combined in an ensemble. In addition, we formally defined the concept of learnable loss attenuation and proved that DDPN exhibits this property. We also proposed the -DDPN modification, which enables control over the strength of this loss attenuation to further improve performance. Experiments on diverse datasets demonstrate that DDPN surpasses current baselines in accuracy, calibration, and out-of-distribution detection, establishing a new state-of-the-art in deep count regression.
Acknowledgments
The work was partially supported by NSF awards #2421839, NAIRR #240120. The views and conclusions contained in this paper are those of the authors and should not be interpreted as representing any funding agencies.
Impact Statement
By enabling robust uncertainty estimation on count data, DDPN improves the reliability and robustness of AI systems in high-stakes applications such as healthcare, finance, and environmental modeling. The ability to model both epistemic and aleatoric uncertainty enhances trustworthiness, particularly in safety-critical systems. However, as with any predictive modeling approach, there are ethical considerations regarding bias, misuse, and overreliance on model outputs. Ensuring that DDPN is used responsibly requires careful dataset curation, bias mitigation, and transparent reporting of model uncertainties.
References
- Abdar et al. (2021) Abdar, M., Pourpanah, F., Hussain, S., Rezazadegan, D., Liu, L., Ghavamzadeh, M., Fieguth, P., Cao, X., Khosravi, A., Acharya, U. R., et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information fusion, 76:243–297, 2021.
- Alemi et al. (2018) Alemi, A. A., Fischer, I., and Dillon, J. V. Uncertainty in the variational information bottleneck. arXiv preprint arXiv:1807.00906, 2018.
- Amini et al. (2020) Amini, A., Schwarting, W., Soleimany, A., and Rus, D. Deep evidential regression. Advances in neural information processing systems, 33:14927–14937, 2020.
- Aragon et al. (2018) Aragon, D. C., Achcar, J. A., and Martinez, E. Z. Maximum likelihood and bayesian estimators for the double poisson distribution. Journal of Statistical Theory and Practice, 12:886–911, 2018.
- Bishop (1994) Bishop, C. M. Mixture density networks. 1994.
- Błasiok et al. (2023) Błasiok, J., Gopalan, P., Hu, L., and Nakkiran, P. A unifying theory of distance from calibration. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, pp. 1727–1740, 2023.
- Blundell et al. (2015) Blundell, C., Cornebise, J., Kavukcuoglu, K., and Wierstra, D. Weight uncertainty in neural network. In International conference on machine learning, pp. 1613–1622. PMLR, 2015.
- Chen et al. (2014) Chen, T., Fox, E., and Guestrin, C. Stochastic gradient hamiltonian monte carlo. In Xing, E. P. and Jebara, T. (eds.), Proceedings of the 31st International Conference on Machine Learning, volume 32 of Proceedings of Machine Learning Research, pp. 1683–1691, Bejing, China, 22–24 Jun 2014. PMLR. URL https://proceedings.mlr.press/v32/cheni14.html.
- Chow & Steenhard (2009) Chow, N. and Steenhard, D. A flexible count data regression model using sas proc nlmixed. In SAS Global Forum: Statistics and Data Analysis, volume 250, pp. 1–14, 2009.
- Cover (1999) Cover, T. M. Elements of information theory. John Wiley & Sons, 1999.
- Cubuk et al. (2018) Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le, Q. V. Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501, 2018.
- D’Angelo & Fortuin (2021) D’Angelo, F. and Fortuin, V. Repulsive deep ensembles are bayesian. Advances in Neural Information Processing Systems, 34:3451–3465, 2021.
- Daxberger et al. (2021) Daxberger, E., Kristiadi, A., Immer, A., Eschenhagen, R., Bauer, M., and Hennig, P. Laplace redux-effortless bayesian deep learning. Advances in Neural Information Processing Systems, 34:20089–20103, 2021.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Der Kiureghian & Ditlevsen (2009) Der Kiureghian, A. and Ditlevsen, O. Aleatory or epistemic? does it matter? Structural safety, 31(2):105–112, 2009.
- Dheur & Taieb (2023) Dheur, V. and Taieb, S. B. A large-scale study of probabilistic calibration in neural network regression. In International Conference on Machine Learning, pp. 7813–7836. PMLR, 2023.
- Dietterich (2000) Dietterich, T. G. Ensemble methods in machine learning. In International workshop on multiple classifier systems, pp. 1–15. Springer, 2000.
- Dwaracherla et al. (2022) Dwaracherla, V., Wen, Z., Osband, I., Lu, X., Asghari, S. M., and Van Roy, B. Ensembles for uncertainty estimation: Benefits of prior functions and bootstrapping. arXiv preprint arXiv:2206.03633, 2022.
- Efron (1986) Efron, B. Double exponential families and their use in generalized linear regression. Journal of the American Statistical Association, 81(395):709–721, 1986.
- Fahrmeir et al. (2013) Fahrmeir, L., Kneib, T., Lang, S., Marx, B., Fahrmeir, L., Kneib, T., Lang, S., and Marx, B. Regression models, chapter 5. Springer, 2013.
- Fallah et al. (2009) Fallah, N., Gu, H., Mohammad, K., Seyyedsalehi, S. A., Nourijelyani, K., and Eshraghian, M. R. Nonlinear poisson regression using neural networks: A simulation study. Neural Computing and Applications, 18:939–943, 2009.
- Fort et al. (2019) Fort, S., Hu, H., and Lakshminarayanan, B. Deep ensembles: A loss landscape perspective. arXiv preprint arXiv:1912.02757, 2019.
- Fukushima (1969) Fukushima, K. Visual feature extraction by a multilayered network of analog threshold elements. IEEE Transactions on Systems Science and Cybernetics, 5(4):322–333, 1969.
- Gawlikowski et al. (2023) Gawlikowski, J., Tassi, C. R. N., Ali, M., Lee, J., Humt, M., Feng, J., Kruspe, A., Triebel, R., Jung, P., Roscher, R., et al. A survey of uncertainty in deep neural networks. Artificial Intelligence Review, 56(Suppl 1):1513–1589, 2023.
- Gneiting & Raftery (2007) Gneiting, T. and Raftery, A. E. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359–378, 2007.
- Gneiting et al. (2007) Gneiting, T., Balabdaoui, F., and Raftery, A. E. Probabilistic forecasts, calibration and sharpness. Journal of the Royal Statistical Society Series B: Statistical Methodology, 69(2):243–268, 2007.
- Graves (2011) Graves, A. Practical variational inference for neural networks. Advances in neural information processing systems, 24, 2011.
- Hendrycks & Gimpel (2016) Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136, 2016.
- Hill (2011) Hill, T. Conflations of probability distributions. Transactions of the American Mathematical Society, 363(6):3351–3372, 2011.
- Hoffman et al. (2014) Hoffman, M. D., Gelman, A., et al. The no-u-turn sampler: adaptively setting path lengths in hamiltonian monte carlo. J. Mach. Learn. Res., 15(1):1593–1623, 2014.
- Hsieh et al. (2017) Hsieh, M.-R., Lin, Y.-L., and Hsu, W. H. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE international conference on computer vision, pp. 4145–4153, 2017.
- Immer et al. (2024) Immer, A., Palumbo, E., Marx, A., and Vogt, J. Effective bayesian heteroscedastic regression with deep neural networks. Advances in Neural Information Processing Systems, 36, 2024.
- Jenkins et al. (2022) Jenkins, P., Wei, H., Jenkins, J. S., and Li, Z. Bayesian model-based offline reinforcement learning for product allocation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 12531–12537, 2022.
- Jenkins et al. (2023) Jenkins, P., Armstrong, K., Nelson, S., Gotad, S., Jenkins, J. S., Wilkey, W., and Watts, T. Countnet3d: A 3d computer vision approach to infer counts of occluded objects. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 3008–3017, 2023.
- Kang et al. (2023) Kang, K., Setlur, A., Tomlin, C., and Levine, S. Deep neural networks tend to extrapolate predictably. arXiv preprint arXiv:2310.00873, 2023.
- Kendall & Gal (2017) Kendall, A. and Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? Advances in neural information processing systems, 30, 2017.
- Kiefer & Wolfowitz (1952) Kiefer, J. and Wolfowitz, J. Stochastic estimation of the maximum of a regression function. The Annals of Mathematical Statistics, pp. 462–466, 1952.
- Kingma & Ba (2014) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Koren et al. (2009) Koren, Y., Bell, R., and Volinsky, C. Matrix factorization techniques for recommender systems. Computer, 42(8):30–37, 2009.
- Kuleshov et al. (2018) Kuleshov, V., Fenner, N., and Ermon, S. Accurate uncertainties for deep learning using calibrated regression. In International conference on machine learning, pp. 2796–2804. PMLR, 2018.
- Lakshminarayanan et al. (2017) Lakshminarayanan, B., Pritzel, A., and Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30, 2017.
- Li et al. (2020) Li, S., Chang, F., Liu, C., and Li, N. Vehicle counting and traffic flow parameter estimation for dense traffic scenes. IET Intelligent Transport Systems, 14(12):1517–1523, 2020.
- Lian et al. (2019) Lian, D., Li, J., Zheng, J., Luo, W., and Gao, S. Density map regression guided detection network for rgb-d crowd counting and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1821–1830, 2019.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, 2014.
- Lin & Chan (2023) Lin, W. and Chan, A. B. Optimal transport minimization: Crowd localization on density maps for semi-supervised counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21663–21673, 2023.
- Liu et al. (2021) Liu, C., Huynh, D. Q., Sun, Y., Reynolds, M., and Atkinson, S. A vision-based pipeline for vehicle counting, speed estimation, and classification. IEEE Transactions on Intelligent Transportation Systems, 22(12):7547–7560, 2021. doi: 10.1109/TITS.2020.3004066.
- Liu et al. (2020) Liu, W., Wang, X., Owens, J., and Li, Y. Energy-based out-of-distribution detection. Advances in neural information processing systems, 33:21464–21475, 2020.
- Loshchilov & Hutter (2016) Loshchilov, I. and Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- Loshchilov & Hutter (2017) Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Luo et al. (2020) Luo, A., Yang, F., Li, X., Nie, D., Jiao, Z., Zhou, S., and Cheng, H. Hybrid graph neural networks for crowd counting. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp. 11693–11700, 2020.
- Lv et al. (2014) Lv, Y., Duan, Y., Kang, W., Li, Z., and Wang, F.-Y. Traffic flow prediction with big data: A deep learning approach. Ieee transactions on intelligent transportation systems, 16(2):865–873, 2014.
- Marron & Wand (1992) Marron, J. S. and Wand, M. P. Exact mean integrated squared error. The Annals of Statistics, 20(2):712–736, 1992.
- Marsden et al. (2018) Marsden, M., McGuinness, K., Little, S., Keogh, C. E., and O’Connor, N. E. People, penguins and petri dishes: Adapting object counting models to new visual domains and object types without forgetting. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8070–8079, 2018.
- Marx et al. (2024) Marx, C., Zalouk, S., and Ermon, S. Calibration by distribution matching: trainable kernel calibration metrics. Advances in Neural Information Processing Systems, 36, 2024.
- Marzban (2004) Marzban, C. The roc curve and the area under it as performance measures. Weather and Forecasting, 19(6):1106–1114, 2004.
- Matheson & Winkler (1976) Matheson, J. E. and Winkler, R. L. Scoring rules for continuous probability distributions. Management science, 22(10):1087–1096, 1976.
- McCullagh (1989) McCullagh, P. Generalized linear models. Routledge, 1989.
- Microsoft (2016) Microsoft. r-server-hospital-length-of-stay, 2016. URL https://github.com/Microsoft/r-server-hospital-length-of-stay.
- Mnih & Salakhutdinov (2007) Mnih, A. and Salakhutdinov, R. R. Probabilistic matrix factorization. Advances in neural information processing systems, 20, 2007.
- Mucsányi et al. (2024) Mucsányi, B., Kirchhof, M., and Oh, S. J. Benchmarking uncertainty disentanglement: Specialized uncertainties for specialized tasks. arXiv preprint arXiv:2402.19460, 2024.
- Murphy (2023) Murphy, K. P. Probabilistic machine learning: Advanced topics, chapter 15. MIT press, 2023.
- Ni et al. (2019) Ni, J., Li, J., and McAuley, J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pp. 188–197, 2019.
- Nix & Weigend (1994) Nix, D. A. and Weigend, A. S. Estimating the mean and variance of the target probability distribution. In Proceedings of 1994 ieee international conference on neural networks (ICNN’94), volume 1, pp. 55–60. IEEE, 1994.
- Osband et al. (2023) Osband, I., Wen, Z., Asghari, S. M., Dwaracherla, V., Ibrahimi, M., Lu, X., and Van Roy, B. Epistemic neural networks. Advances in Neural Information Processing Systems, 36:2795–2823, 2023.
- Paszke et al. (2017) Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., and Lerer, A. Automatic differentiation in pytorch. 2017.
- Ren et al. (2019) Ren, J., Liu, P. J., Fertig, E., Snoek, J., Poplin, R., Depristo, M., Dillon, J., and Lakshminarayanan, B. Likelihood ratios for out-of-distribution detection. Advances in neural information processing systems, 32, 2019.
- Sanh et al. (2019) Sanh, V., Debut, L., Chaumond, J., and Wolf, T. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. ArXiv, abs/1910.01108, 2019.
- Seitzer et al. (2022) Seitzer, M., Tavakoli, A., Antic, D., and Martius, G. On the pitfalls of heteroscedastic uncertainty estimation with probabilistic neural networks. In International Conference on Learning Representations, April 2022. URL https://openreview.net/forum?id=aPOpXlnV1T.
- Settles (2009) Settles, B. Active learning literature survey. 2009.
- Song et al. (2019) Song, H., Diethe, T., Kull, M., and Flach, P. Distribution calibration for regression. In International Conference on Machine Learning, pp. 5897–5906. PMLR, 2019.
- Stirn et al. (2023) Stirn, A., Wessels, H., Schertzer, M., Pereira, L., Sanjana, N., and Knowles, D. Faithful heteroscedastic regression with neural networks. In International Conference on Artificial Intelligence and Statistics, pp. 5593–5613. PMLR, 2023.
- Toledo et al. (2022) Toledo, D., Umetsu, C. A., Camargo, A. F. M., and de Lara, I. A. R. Flexible models for non-equidispersed count data: comparative performance of parametric models to deal with underdispersion. AStA Advances in Statistical Analysis, 106(3):473–497, 2022.
- Wang & Aitchison (2021) Wang, X. and Aitchison, L. Bayesian ood detection with aleatoric uncertainty and outlier exposure. arXiv preprint arXiv:2102.12959, 2021.
- Wilson & Izmailov (2020) Wilson, A. G. and Izmailov, P. Bayesian deep learning and a probabilistic perspective of generalization. Advances in neural information processing systems, 33:4697–4708, 2020.
- Wu et al. (2020) Wu, B., Xu, C., Dai, X., Wan, A., Zhang, P., Yan, Z., Tomizuka, M., Gonzalez, J., Keutzer, K., and Vajda, P. Visual transformers: Token-based image representation and processing for computer vision, 2020.
- Xie (2022) Xie, S.-M. A neural network extension for solving the pareto/negative binomial distribution model. International Journal of Market Research, 64(3):420–439, 2022.
- You et al. (2017) You, J., Li, X., Low, M., Lobell, D., and Ermon, S. Deep gaussian process for crop yield prediction based on remote sensing data. In Proceedings of the AAAI conference on artificial intelligence, volume 31, 2017.
- Young & Jenkins (2024) Young, S. and Jenkins, P. On measuring calibration of discrete probabilistic neural networks, 2024.
- Yu et al. (2020) Yu, T., Thomas, G., Yu, L., Ermon, S., Zou, J. Y., Levine, S., Finn, C., and Ma, T. Mopo: Model-based offline policy optimization. Advances in Neural Information Processing Systems, 33:14129–14142, 2020.
- Zhang & Chan (2020) Zhang, Q. and Chan, A. B. 3d crowd counting via multi-view fusion with 3d gaussian kernels. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp. 12837–12844, 2020.
- Zhang et al. (2016) Zhang, Y., Zhou, D., Chen, S., Gao, S., and Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 589–597, 2016.
- Zhu (2012) Zhu, F. Modeling time series of counts with com-poisson ingarch models. Mathematical and Computer Modelling, 56(9-10):191–203, 2012.
- Ziatdinov (2024) Ziatdinov, M. Active learning with fully bayesian neural networks for discontinuous and nonstationary data. arXiv preprint arXiv:2405.09817, 2024.
- Zou et al. (2013) Zou, Y., Geedipally, S. R., and Lord, D. Evaluating the double poisson generalized linear model. Accident Analysis & Prevention, 59:497–505, 2013.
- Zou et al. (2019) Zou, Z., Shao, H., Qu, X., Wei, W., and Zhou, P. Enhanced 3d convolutional networks for crowd counting. arXiv preprint arXiv:1908.04121, 2019.
Appendix A Deep Double Poisson Networks (DDPNs)
A.1 Derivation of the DDPN Objective
If we model our regression targets as , where , then the Double Poisson NLL for an individual prediction is obtained as follows:
Thus,
| (4) |
During training, we minimize this NLL on average across data points . N
A.2 Limitations
DDPNs are general, easy to implement, and can be applied to a variety of datasets. However, some limitations do exist. One limitation that might arise is on count regression problems of very high frequency (i.e., on the order of thousands or millions). In this paper, we don’t study the behavior of DDPN relative to existing benchmarks on high counts. In this scenario, it is possible that the choice of a Gaussian as the predictive distribution may offer a good approximation, even though the regression targets are discrete.
Although we follow precedent (Efron, 1986; Zou et al., 2013; Aragon et al., 2018) in employing the general approximations and for some in this work, these are not guaranteed to hold under all conditions. See Appendix A.3 for a detailed study of these approximations.
One difficulty that can sometimes arise when training a DDPN (or any model trained with NLL) is poor convergence of the model weights. In preliminary experiments for this research, we had trouble obtaining consistently high-performing solutions with the SGD (Kiefer & Wolfowitz, 1952) and Adam (Kingma & Ba, 2014) optimizers, thus AdamW (Loshchilov & Hutter, 2017) was used instead. Similar to Seitzer et al. (2022), we found that the -NLL exhibited greater stability across a wider variety of hyperparameter settings. Future researchers using the DDPN technique should be wary of this behavior.
In this paper, we performed a single out-of-distribution (OOD) experiment on Amazon Reviews. This experiment provided encouraging evidence of the efficacy of DDPN for OOD detection. However, the conclusions drawn from this experiment may be somewhat limited in scope since the experiment was performed on a single dataset and task. Future work should seek to build off of these results to more fully explore the OOD properties of DDPN on other count regression tasks.
A.3 Assessing the Quality of Efron’s Moment Approximations
In line with prior work, we use Efron’s approximations for the first two moments of the Double Poisson distribution in the proof of Proposition 3.1. An obvious question that arises is how reliable are these approximate moment assumptions. We introduce the concept of moment-deviation functions (MDFs) to assess this theoretically in Definition A.1.
Definition A.1.
Let be a family of univariate distributions parametrized by . Suppose we are given , which outputs a setting of parameters for , , such that the first moments of , , are nearly equal to target moments . Then for any pair , are moment-deviation functions if, for any valid , if , we have for all .
We focus on , (approximation error for the mean / variance of a distribution). If we can pick so that are small, it follows that is incredibly flexible, as there exists a setting of parameters that can roughly achieve any mean and variance. In the Gaussian case (), we have . The Double Poisson case (using Efron’s approximations for ), is handled in Proposition A.2.
Proposition A.2.
Let denote the Double Poisson family. Set . Letting , the MDFs for are:
where we have
Proof.
All we have to show is that the mean and variance of are within the provided and .
We first re-cast the Double Poisson PMF into canonical form, with natural parameters and :
where matches the form specified in the proposition, is the sufficient statistic, and is the cumulant function.
By properties of the canonical form, we then have , . Letting , we obtain
We first solve for . Recall that , or equivalently . Then
so, recalling that , we have
Thus, if , we have
This implies that
which trivially yields , as desired.
To evaluate , we must first compute the second derivative of :
We now have an expression for the variance:
So
which implies
yielding , as desired.
∎
Remark 1.
The MDFs in the proposition yield near-zero values for most target means and variances, implying that in most settings, the Double Poisson can be considered a distribution with unrestricted variance.
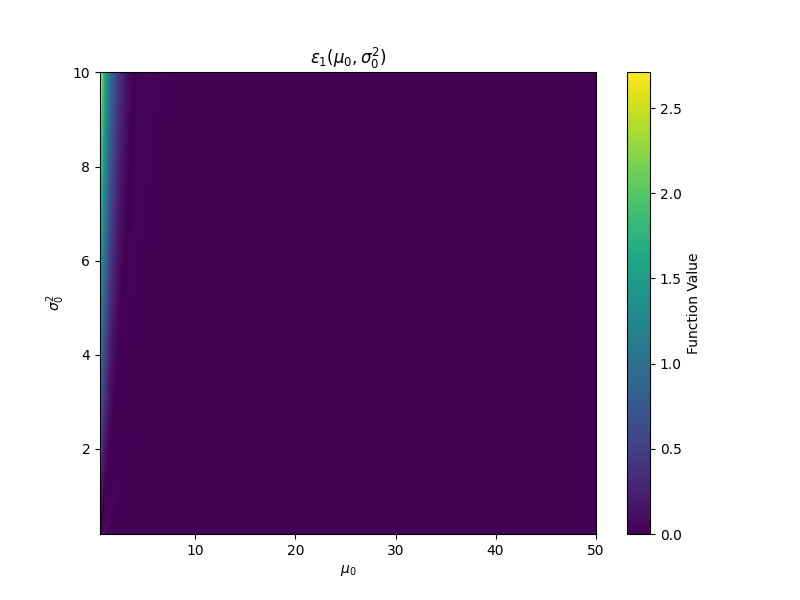
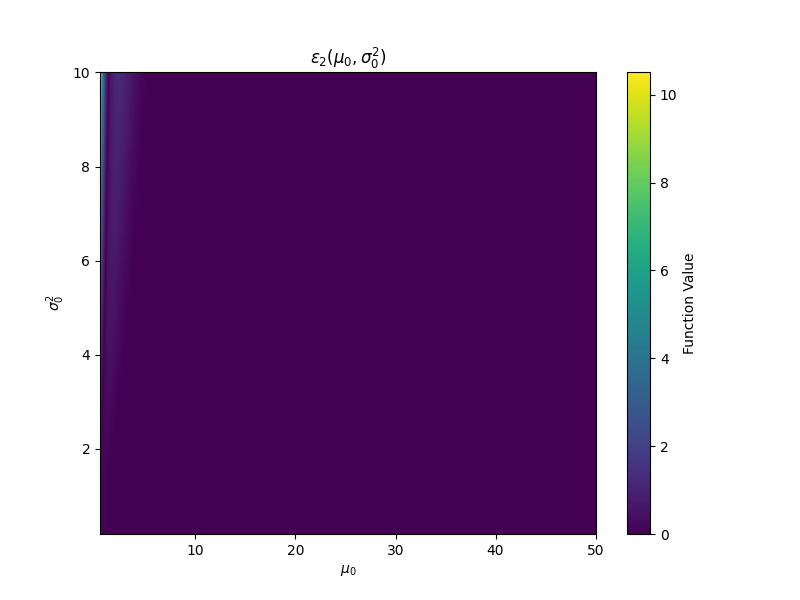
We now study the bounds obtained in Proposition A.2 empirically. In Figure 7 we plot the error, , incurred via Efron’s estimates on a grid of target means and variances, using 100th partial sums. Both and are effectively 0 for nearly all values of and . The only exception is for very small values of the target mean, ; when the target variance is subsequently large, we see an increase in both and . Under these rare conditions, the approximations begin to deteriorate.
A.4 The effect of initialization
Another potential method for avoiding the loss attenuation trap (see Section 3.3) is to initialize to some high value (via the initial bias in the output head). This essentially forces the network to begin training with low uncertainty values. We investigate the effectiveness of this method by initializing to various high values at the start of training. We train on the same dataset as in Figure 6. Results with differing initializations are presented in Figure 8. Rather than improve mean fit, we observe that this strategy actually hurts overall convergence to the true function. The best performance comes, in fact, when is initialized close to zero. Note that despite higher initialization of , the point to the far right of the data is still “explained” via low (high uncertainty). Interestingly, the modification can help us avoid the impact of such poor initialization. In Figure 9, we mirror the experimental setup of Figure 8 but set and train with -NLL. In all but the most extreme case (), allows us to recover the true function.
Appendix B Additional Experimental Details
B.1 Description of Datasets
In this section, we provide a brief description of each dataset used in our experiments and define the associated network architectures. For further details, we refer the reader to Appendix B.3 and our source code.
Length of Stay
Regression models on Length of Stay (Microsoft, 2016) are tasked with forecasting the number of days between initial admission and discharge for a given hospital patient, conditioned on a collection of health metrics and indicators about the specific facility providing the treatment. This is inherently a count prediction problem, since resource allocation and billing typically discretize time spent in a hospital. We train small MLPs to output the parameters of a predictive distribution over the number of days a patient is expected to stay.
COCO-People
We introduce an image regression task on the person class of MS-COCO (Lin et al., 2014), which we call COCO-People. In this dataset, the task is to predict the number of people in each image. Each model we evaluate on COCO-People is trained with a small MLP on top of the pooled output from a ViT-B-16 backbone (Wu et al., 2020)).
Inventory
This dataset comprises an inventory counting task (Jenkins et al., 2023), where the goal is to predict the number of objects on a retail shelf from an input point cloud (see Figure 32 in Appendix D.3 for an example). For this task, we adapt CountNet3D (Jenkins et al., 2023) for probabilistic regression.
Amazon Reviews
We model user ratings from the “Patio, Lawn, and Garden” split of a collection of Amazon reviews (Ni et al., 2019). The objective in this task is to predict the discrete review value (1-5 stars) from an input text sequence, which historically has been addressed with Gaussian NLL (Mnih & Salakhutdinov, 2007; Koren et al., 2009). All text regressors consist of a small MLP on top of a DistilBert backbone (Sanh et al., 2019).
B.2 Evaluation Metrics
In this section, we provide a detailed definition of each metric we employ for evaluation in our experiments. We also provide context for our choices around which metrics to use (when relevant).
B.2.1 Mean Absolute Error
The Mean Absolute Error (MAE) quantifies how closely a model’s point predictions align with the ground truth across a dataset. In the probabilistic setting, we use the mode of the predictive distribution as our point prediction. Given a dataset and model , the MAE is then computed as:
B.2.2 Continuous Ranked Probability Score
The Continuous Ranked Probability Score (CRPS) is a strictly proper scoring rule that quantifies how aligned predictive distributions (sometimes referred to as “forecasts”) are with ground-truth observations (Matheson & Winkler, 1976; Gneiting & Raftery, 2007). For a specific predictive cumulative density function (CDF), , and a ground-truth regression target with CDF , it is defined as follows:
Note that the second equality arises because , once observed, is deterministic (its probability density is a point mass at the observed value). When the predictive distribution is discrete, this integral further reduces to the summation:
CRPS can also be computed from deterministic forecasts (i.e. those obtained from models that output only a point prediction). In this case, it is a known fact that CRPS reduces to the mean absolute error (Gneiting & Raftery, 2007), which aids interpretability. In our experiments, when we report CRPS, we take the average value across all test points (since CRPS is defined point-wise).
B.2.3 Median Precision
Gneiting et al. (2007) observe that a good condition for a well-fit probabilistic model is “sharpness subject to calibration”. In other words, our model must produce forecasts that exhibit statistical consistency with observations while also concentrating as much mass as possible around the true value of a regression target. Although sharpness alone is not a useful metric for quantifying probabilistic fit, measuring this value can provide helpful insights into the typical shape of a model’s predictions. To quantify sharpness for a model/dataset pair, we use the Median Precision (MP), where precision is defined as . We employ the median instead of the mean as a summary statistic to increase robustness to outliers (when the predictive variance is very small, the precision value blows up). In Appendix B.4.1, we report MP values for each model benchmarked in Section 4.3.
B.2.4 On the Omission of Other Calibration Metrics
In this work, we choose not to quantify calibration via common metrics such as negative log likelihood (NLL) and expected calibration error (ECE). This is primarily due to the unique challenge of comparing probability forecasts across models with various distributional assumptions. NLLs obtained for continuous distributions are computed from probability densities, whereas discrete distributions output probability masses. These are fundamentally different quantities that cannot be directly compared. Meanwhile, the regression form of ECE (Kuleshov et al., 2018) has recently been shown to favor continuous models over discrete ones due to an implicit assumption about uniformity of the probability integral transform (Young & Jenkins, 2024). Other work suggests that ECE may not be a reliable indicator of true calibration in the first place, since it is a marginal measure (Song et al., 2019; Marx et al., 2024) and is sharply discontinuous as a function of the predictor — arbitrarily small perturbations to a model can cause large jumps in ECE (Błasiok et al., 2023).
We note that CRPS (see Appendix B.2.2), which is defined solely in terms of the distance between a predicted and ground-truth CDF and is a strictly proper scoring rule, overcomes the discrete vs. continuous comparison challenge and provides a reliable indicator of probabilistic fit. Thus, we include it as the main measure of calibration in our experiments (Section 4.3).
B.2.5 Out-of-Distribution Classification Metrics
We use standard binary classification metrics to characterize each model’s ability to identify out-of-distribution inputs, in line with Hendrycks & Gimpel (2016), Alemi et al. (2018), and Ren et al. (2019).
AUROC
The Area Under the Receiver Operating Characteristic Curve (AUROC) evaluates the performance of a binary classifier across a range of thresholds. In our out-of-distribution (OOD) experiment, we define these thresholds based on different expected false positive rates, i.e., . For each threshold, we plot the true positive rate (the percentage of true OOD samples correctly identified) against the false positive rate (the percentage of in-distribution samples mistakenly classified as OOD). This produces a curve whose integrated area provides a comprehensive measure of the classifier’s performance. In this context, the AUROC can be interpreted as the probability that, given a random in-distribution (ID) and OOD sample, the model assigns a higher predictive variance to the OOD sample than the ID sample. Thus, higher values of AUROC indicate more useful classifiers. A score of 0.5 corresponds to random guessing. For further details, see Marzban (2004).
AUPR
The Area Under the Precision-Recall Curve (AUPR) is another metric for evaluating classifier performance, analogous to AUROC, but tailored for imbalanced datasets. Like AUROC, it involves computing the integral under a curve parameterized by . This curve plots precision (the proportion of OOD classifications that were correct) against recall (the proportion of all true OOD instances that were correctly classified), illustrating the trade-off between these two metrics. Higher values are better. A model relying solely on class proportions in the data would achieve an AUPR equal to , which in our experiment is 0.224.
FPR80
The False Positive Rate at 80% True Positive Rate (FPR80) quantifies the proportion of in-distribution (ID) samples misclassified as out-of-distribution (OOD) when the classification threshold is set to achieve a True Positive Rate (TPR) of 80% (Ren et al., 2019). This metric highlights the classifier’s ability to minimize false positives while maintaining high sensitivity to OOD samples. Lower values indicate better performance, with a perfect classifier achieving an FPR80 of zero.
B.3 Training Details
In all experiments, instead of using the final set of weights achieved during training with a particular technique, we select the weights associated with the best average loss on a held-out validation set. This can be viewed as a form of early stopping.
The ReLU (Fukushima, 1969) activation is exclusively used for all MLPs. No dropout or batch normalization is applied. We employ the AdamW optimizer (Loshchilov & Hutter, 2017) for all training procedures, and anneal the initial learning rate to 0 following a cosine schedule (Loshchilov & Hutter, 2016).
The hyperparameter settings we report are chosen such that each model converges to a stable training loss basin with minimal overfitting (as quantified by validation loss). To ensure fairness across all models, we use one set of training hyperparameters (including choice of underlying architecure) for each specific dataset.
In addition to the details we provide in this section, we refer the reader to our source code 333https://github.com/delicious-ai/ddpn, where configuration files for each model benchmarked can be found. The corresponding author can be contacted for access to our pre-generated splits of each dataset.
B.3.1 Simulation Experiment (Introductory Figure)
To produce Figure 1, we generate a dataset with the following procedure: First, we sample from a uniform distribution, . Next, we draw an initial proposal for from a conflation (Hill, 2011) of five identical Poissons, each with rate parameterized by . We scale by and shift it by to achieve high dispersion at low counts and under-dispersion at high counts while maintaining nonnegativity. We generate 800 points from this process for the training split, as well as 100 for validation and 100 for evaluation.
The models that make up the ensembles we report in this figure are small MLPs (with layers of width [128, 128, 128, 64]). We train each network for 200 epochs on the CPU of a 2021 MacBook Pro with a batch size of 32 and an initial learning rate of . We set weight decay to .
B.3.2 Length of Stay
Each model benchmarked for Length of Stay is a small MLP with layer widths [128, 128, 128, 64]. Models are trained for 15 epochs on a 2021 MacBook Pro CPU with a batch size of 128, an initial learning rate of , and a weight decay value of .
The Length of Stay dataset has been open-sourced by Microsoft under the MIT license. It has 100,000 rows, which we divide into a 80/10/10 train/val/test split using a fixed random seed.
Licensing information for Length of Stay can be found at https://github.com/microsoft/r-server-hospital-length-of-stay/blob/master/Website/package.json.
The full dataset can be downloaded from https://raw.githubusercontent.com/microsoft/r-server-hospital-length-of-stay/refs/heads/master/Data/LengthOfStay.csv.
B.3.3 COCO-People
We train Vision Transformers (Wu et al., 2020) on COCO-People, passing their pooled patch representations to a two-layer MLP regression head with layer widths of [384, 256]. All weights are fine-tuned from the vit-base-patch16-224-in21k checkpoint (Deng et al., 2009). We set the initial learning rate to and use a weight decay of . We train with an effective batch size of 256 in a distributed fashion, using an on-prem machine with 2 Nvidia GeForce RTX 4090 GPUs. Images are normalized with the ImageNet (Deng et al., 2009) pixel means and standard deviations and augmented during training with the AutoAugment transformation (Cubuk et al., 2018). Training is done with BFloat 16 Mixed Precision.
The COCO dataset from which we form the COCO-People subset is distributed via the CCBY 4.0 license. It can be accessed at https://cocodataset.org/#home. Our subset has 64,115 images in total, which we divide into a 70/10/20 train/val/test split.
B.3.4 Inventory
For the Inventory task, we use a modified version of CountNet3D (Jenkins et al., 2023) that ouputs the parameters of a probability distribution instead of regressing the mean directly. We train models for 50 epochs with an effective batch size of 16, an initial learning rate of , and weight decay of . Training is performed on an internal cluster of 4 NVIDIA GeForce RTX 2080 Ti GPUs.
The Inventory dataset is made available to us via an industry collaboration and is not publicly accessible.
B.3.5 Amazon Reviews
We fine-tune a DistilBert Base Cased (Sanh et al., 2019) backbone with a [384, 256] MLP regression head for the Amazon Reviews task. To avoid overfitting, we freeze all but the final transformer block in the backbone. The regression head is not frozen. All networks are trained for 10 epochs across 2 on-prem Nvidia GeForce RTX 4090 GPUs with an effective batch size of 2048. We use an initial learning rate of and a weight decay of , and run computations with BFloat 16 Mixed Precision.
Amazon Reviews is publicly available at https://cseweb.ucsd.edu/˜jmcauley/datasets/amazon_v2/. The “Patio, Lawn, and Garden” subset we employ in this work is hosted at https://datarepo.eng.ucsd.edu/mcauley_group/data/amazon_v2/categoryFilesSmall/Patio_Lawn_and_Garden.csv. Our subset contains 793,966 total reviews, which we divide into a 70/10/20 train/val/test split.
B.4 Additional Results
B.4.1 Sharpness
To provide a notion of the sharpness of predictive distributions produced by each model we benchmark, we measure and report the median precision (MP) across all datasets in Table 4. See Appendix B.2.3 for more details about how we compute this metric. Higher values correspond to sharper distributions (those with lower predictive variance). We note that sharpness alone is not an indication of good probabilistic fit; thus we do not mark “winners” in this metric. We simply provide sharpness values to facilitate improved understanding of each technique’s behavior on our datasets.
| Length of Stay | COCO-People | Inventory | Reviews | ||
| Aleatoric Only | Poisson DNN | 0.262 (0.00) | 0.437 (0.01) | 0.263 (0.01) | 0.211 (0.00) |
| NB DNN | 0.265 (0.00) | 0.392 (0.04) | 0.261 (0.01) | 0.211 (0.00) | |
| Gaussian DNN | 2.031 (0.09) | 0.913 (0.43) | 0.689 (0.02) | 3.833 (0.28) | |
| Faithful Gaussian | 1.258 (0.09) | 0.647 (0.05) | 1.072 (0.13) | 3.907 (0.04) | |
| Natural Gaussian | 1.456 (0.07) | 0.745 (0.20) | 0.713 (0.02) | 4.545 (0.29) | |
| -Gaussian | 2.125 (0.07) | 2.174 (0.18) | 1.011 (0.07) | 4.604 (0.45) | |
| -Gaussian | 1.646 (0.21) | 1.558 (0.09) | 0.814 (0.06) | 3.935 (0.04) | |
| DDPN (ours) | 2.663 (0.14) | 0.915 (0.30) | 0.680 (0.04) | 3.960 (0.13) | |
| -DDPN (ours) | 2.184 (0.14) | 1.006 (0.13) | 0.818 (0.04) | 3.642 (0.18) | |
| -DDPN (ours) | 1.565 (0.11) | 1.986 (0.04) | 0.690 (0.03) | 3.806 (0.04) | |
| Aleatoric + Epistemic | Poisson DNN | 0.261 | 0.413 | 0.253 | 0.210 |
| NB DNN | 0.263 | 0.354 | 0.252 | 0.210 | |
| Gaussian DNN | 1.933 | 0.548 | 0.631 | 3.643 | |
| Faithful Gaussian | 1.211 | 0.592 | 0.907 | 3.927 | |
| Natural Gaussian | 1.386 | 0.571 | 0.639 | 4.217 | |
| -Gaussian | 2.003 | 1.785 | 0.828 | 4.362 | |
| -Gaussian | 1.531 | 1.360 | 0.734 | 3.819 | |
| DDPN (ours) | 2.441 | 0.626 | 0.623 | 3.694 | |
| -DDPN (ours) | 2.046 | 0.821 | 0.709 | 3.645 | |
| -DDPN (ours) | 1.463 | 1.680 | 0.620 | 3.569 |
B.4.2 GLM Results on Length of Stay
Since Length of Stay is tabular, we may compare GLM baselines in addition to the neural networks benchmarked in Section 4.3. We train and evaluate a Poisson Generalized Linear Model (GLM), a Negative Binomial GLM, and a Double Poisson GLM (Efron, 1986; Zhu, 2012; Zou et al., 2013; Aragon et al., 2018; Toledo et al., 2022). As in Table 2, we train 5 independent models with each technique and report the mean and standard error of both MAE and CRPS across all trials under the “Aleatoric Only” header. We also provide the median precision values as in Table 4. Although GLMs are not deep networks, we may ensemble their predictions in a similar fashion as deep ensembles (DEs) to quantify epistemic uncertainty. We do so, and report these results under the “Aleatoric + Epistemic” header.
The limited flexibility of linear models appears to hinder the GLMs we evaluate, as they struggle with both mean fit and calibration when compared to their respective neural network counterparts.
| Aleatoric Only | Aleatoric + Epistemic | |||||
| MAE () | CRPS () | MP | MAE () | CRPS () | MP | |
| Poisson GLM | 1.284 (0.08) | 0.882 (0.06) | 0.319 (0.01) | 1.256 | 0.850 | 0.309 |
| NB GLM | 3.783 (0.27) | 1.692 (0.14) | 0.241 (0.00) | 3.906 | 1.685 | 0.239 |
| DP GLM | 1.320 (0.15) | 0.894 (0.08) | 0.543 (0.44) | 1.185 | 0.829 | 0.340 |
Appendix C Proofs and Derivations
In this section we provide full proofs of the propositions presented in the main body of the paper, along with derivations of key equations (excepting the Double Poisson NLL derivation, which is located in Appendix A.1)
C.1 Proof of Proposition 2.3
Proof.
We will first demonstrate that Gaussian regressors are fully heteroscedastic. Since they model both the predicted mean and variance conditionally, all we have to show is that the Normal distribution exhibits unrestricted variance. To see this, note that if is distributed normally, if we fix for any , then for an arbitrary , the parameter setting achieves . Thus the Normal distribution has unrestricted variance, and Gaussian regressors are indeed fully heteroscedastic.
To show that Poisson and Negative Binomial regressors are not fully heteroscedastic, we will prove that their respective output distributions do not have unrestricted variance, i.e. there exists at least one such that no setting of parameters can achieve this variance when the expected value is fixed.
If we say is Poisson, then for any , fixing requires , i.e. . For any , we see that there is no setting of such that , since . So the Poisson distribution does not have unrestricted variance.
The Negative Binomial case is similar. We employ the common parametrization, though other alternatives are possible. Recall that in this parametrization, is the number of successful trials until an experiment is stopped, and is the probability of success in each trial of the experiment. Pick any . If is Negative Binomial, then fixing means that must satisfy . Now choose any . For to be true, must satisfy . Noting that we chose such that , this implies . Multiplying both sides by the positive quantity yields . But by definition. Thus we have identified a range of values such that there exists no that can satisfy if . So the Negative Binomial distribution does not have unrestricted variance.
We conclude that any regression model outputting either the Poisson or Negative Binomial distribution is not fully heteroscedastic.
∎
C.2 Proof of Proposition 3.1
Proof.
We assume the first and second moment approximations proposed by Efron (1986): and . To see that DDPN is fully heteroscedastic, note that for any input , DDPN predicts , where is a neural network’s input-conditional hidden representation of . Since DDPN’s predictive variance directly depends on (which we just showed depends on ), all we have left to demonstrate is that the Double Poisson distribution has unrestricted variance. To see this, note that if is Double Poisson with expectation (where ), then for any , choosing implies . Thus, DDPN is fully heteroscedastic. ∎
C.3 Proof of Proposition 3.3
C.4 Proof of Proposition 3.4
Proof.
To see that DDPN exhibits learnable loss attenuation and conforms with Definition 3.2, recall the loss function from Equation 2:
| (5) |
Because DDPN is expressed in terms of inverse dispersion, , we can substitute in for to re-parameterize the loss function in terms of dispersion:
| (6) |
We can rearrange terms to put in the standard form with dispersion penalty , attenuation factor , and residual penalty :
Let , , and . We have . Clearly, is monotonically increasing w.r.t and is both monotonically decreasing w.r.t and bounded from below by 0 (since .
All that is left to show is that (i) and (ii) is nonnegative:
-
(i)
We first show that . To see this, note that when , both the terms in our residual penalty, and , are 0. So their difference, , must be 0.
To see that , we handle the case of and separately:
Case 1
If , then . But cancels the second term in this difference, leaving us with .
Case 2
If , we can make the substitution and rewrite the residual penalty: . Since , this yields . We now claim that . To see this, note that is negative when and positive when . Since when , strictly increasing to the right of , and strictly decreasing to the left of , is uniquely achieved by at . So . Thus, .
In either case, we have . Since we have proved both directions, we conclude that .
-
(ii)
We separately handle the cases of and , and may now assume (by virtue of the iff) that :
Case 1
If , then , where the last inequality comes from the restrictions on the parameters of a Double Poisson distribution.
Case 2
If , then substituting as before yields , which is positive if is positive. Recall that iff , and that is strictly decreasing to the left of and strictly increasing to the right of . Since , this implies (by the first derivative test) that is the unique minimizer of , with . But we only have if , which we can assume is not the case because of (i). So .
In both cases, we are guaranteed that .
∎
C.5 Computing the Mean and Variance of a Mixture Model
In Section 3.4 we describe how the ensembled predictive distribution is a uniform mixture of the members of the ensemble: .
Letting and , we can get the mean and variance of the predictive distribution as and .
We note that the ensembling technique used throughout our work can be applied to form an ensemble from any collection of neural networks outputting a probability distribution, regardless of the specific parametric form (Marron & Wand, 1992).
C.6 Decomposing the Predictive Variance of a Mixture Model
For the mixture model described above, we can decompose the predictive variance for a single regression target as follows:
The first term in this sum, , is the average predictive variance of each ensemble member and is often considered to be a proxy for aleatoric uncertainty, while represents the amount of disagreement between ensemble members regarding the predicted mean and is interpreted as epistemic uncertainty (Kendall & Gal, 2017).
Appendix D Additional Case Studies
D.1 Example Predictive Distributions on COCO-People
For each baseline, Figures 10-19 depict the predictive distributions of one model trained under that framework on COCO-People, while 20-29 show the combined predictions of a 5-model ensemble. We select 3 instances from the test split and visualize outputs on each. A black star indicates the true count of people in the image.
D.1.1 Individual Models
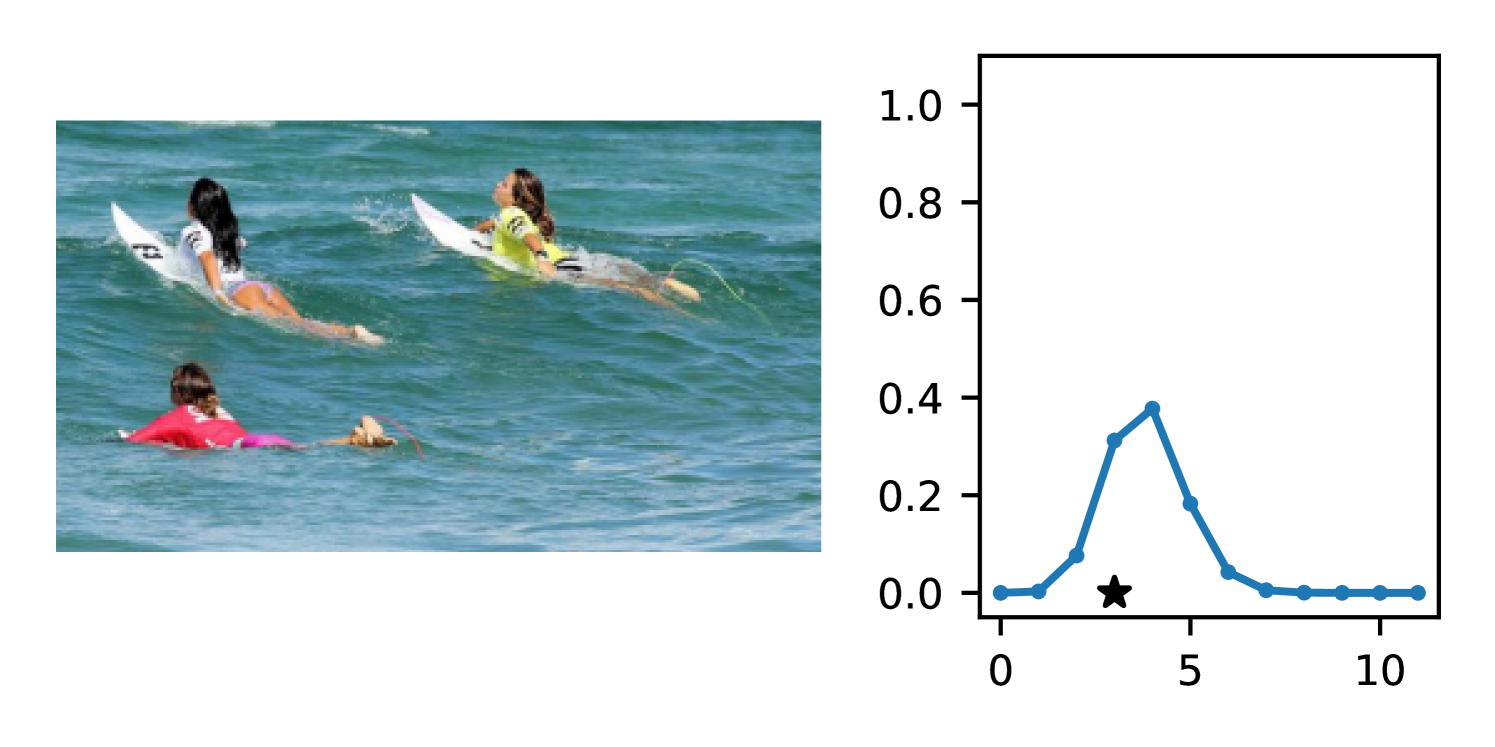
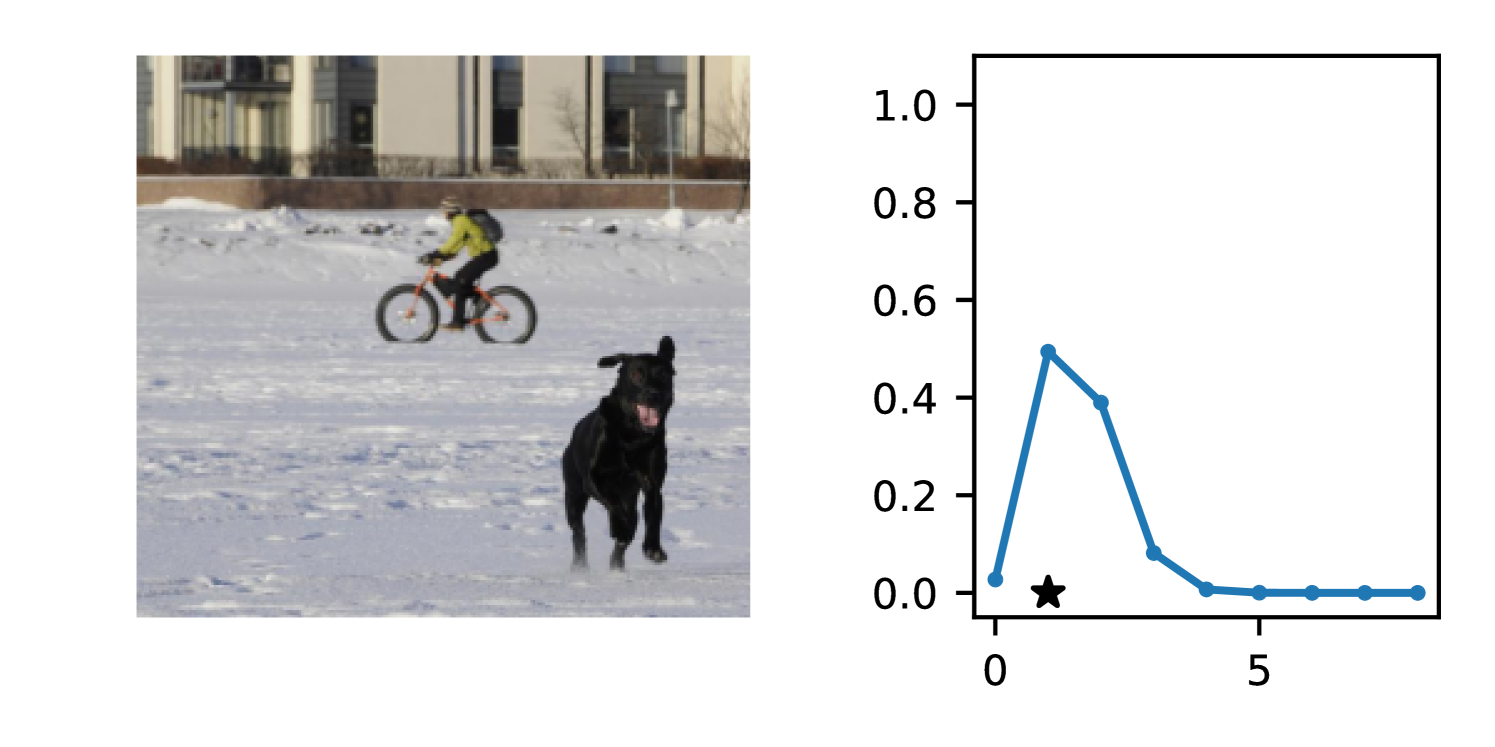
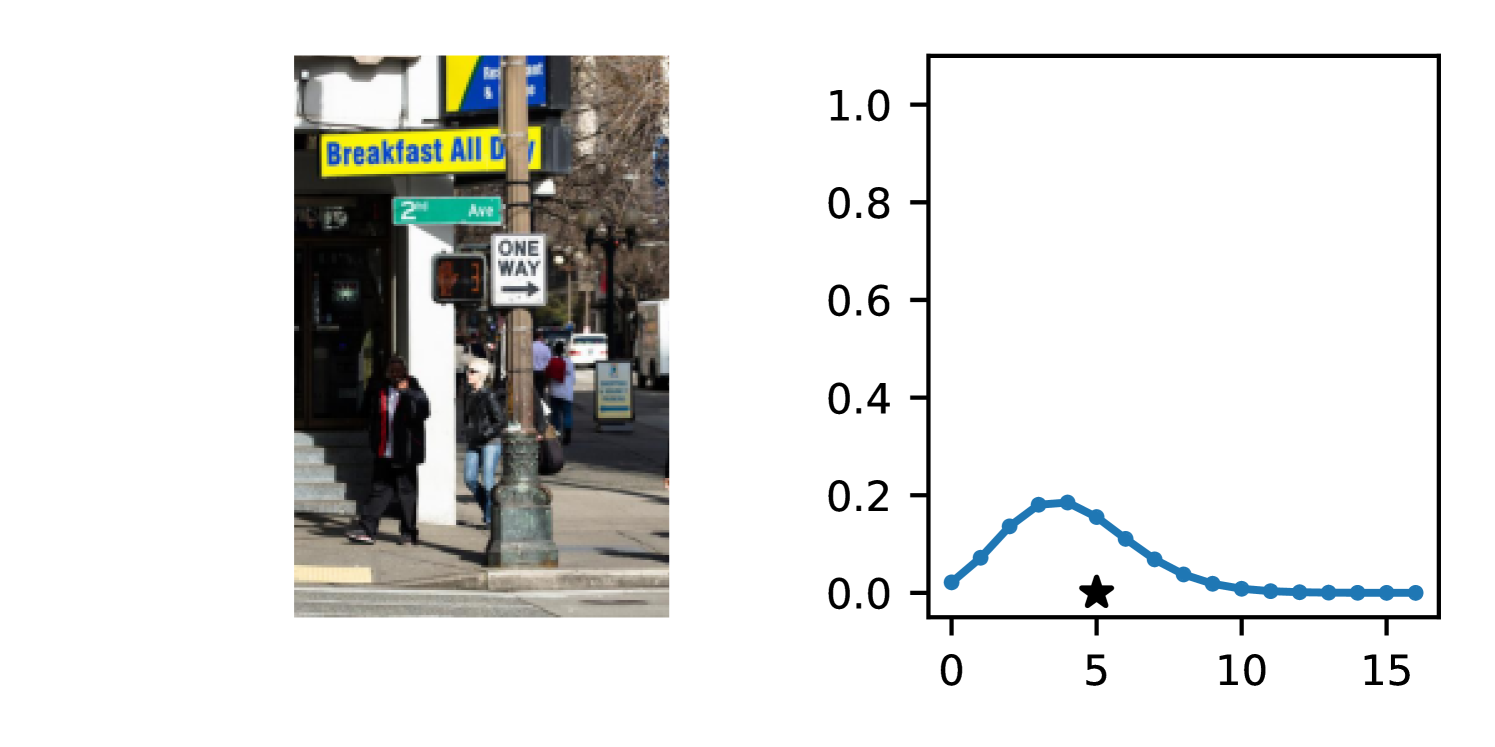
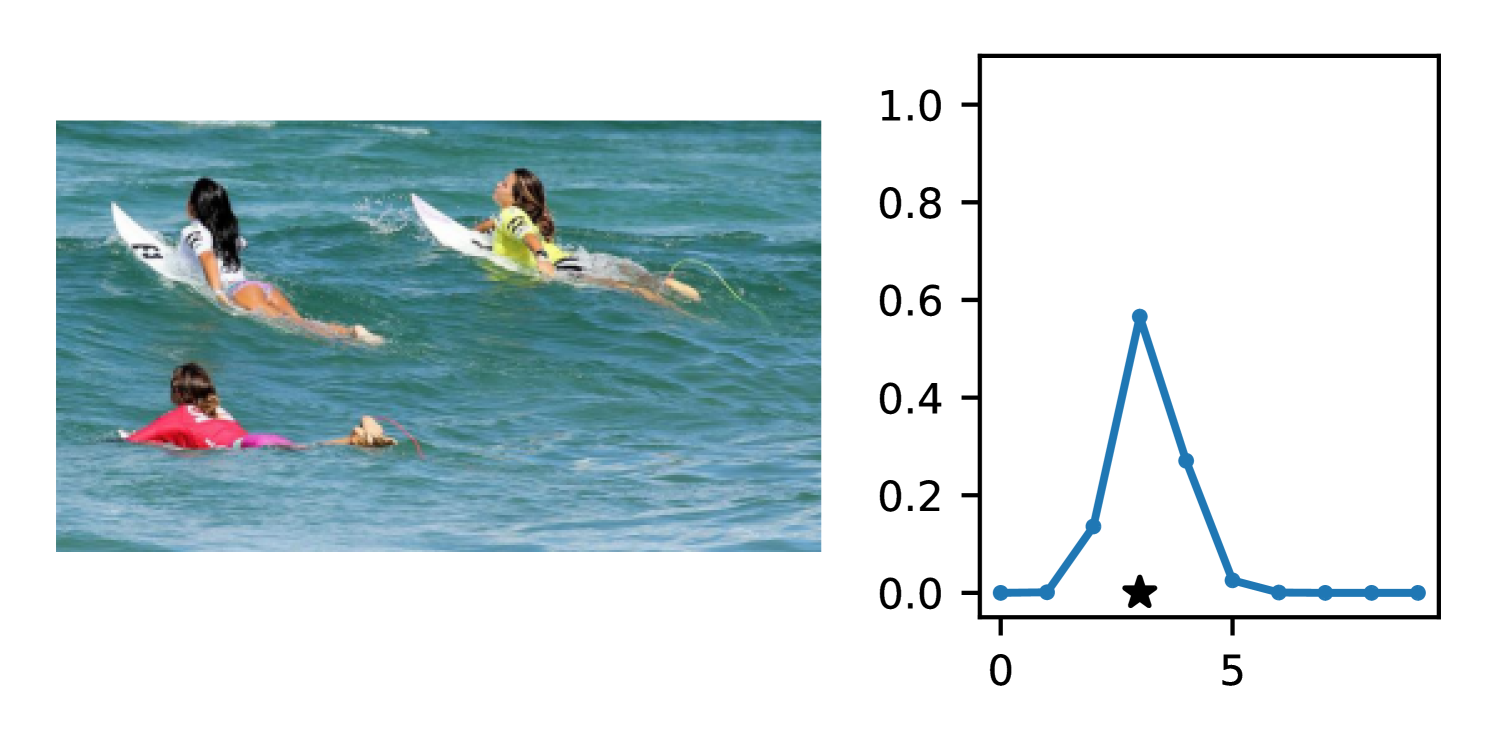
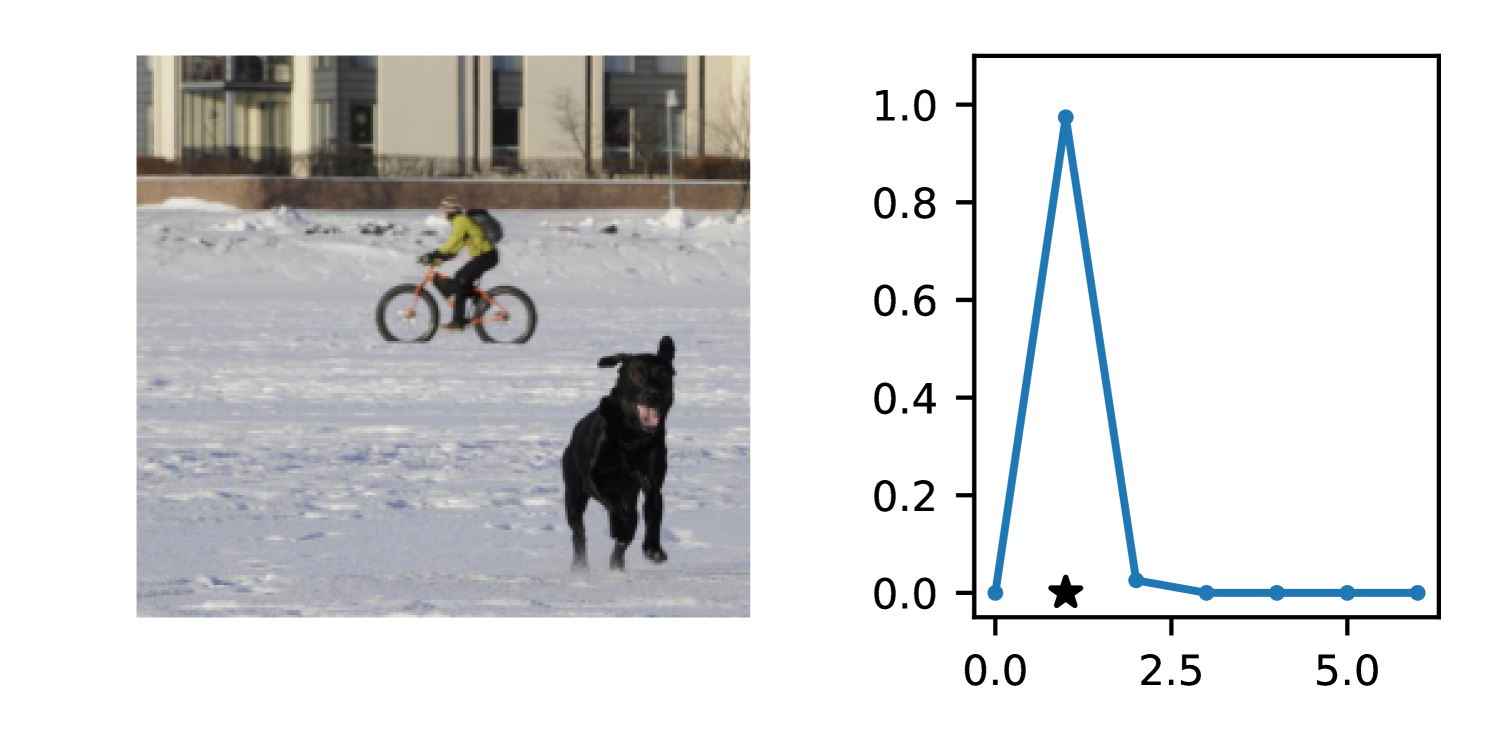
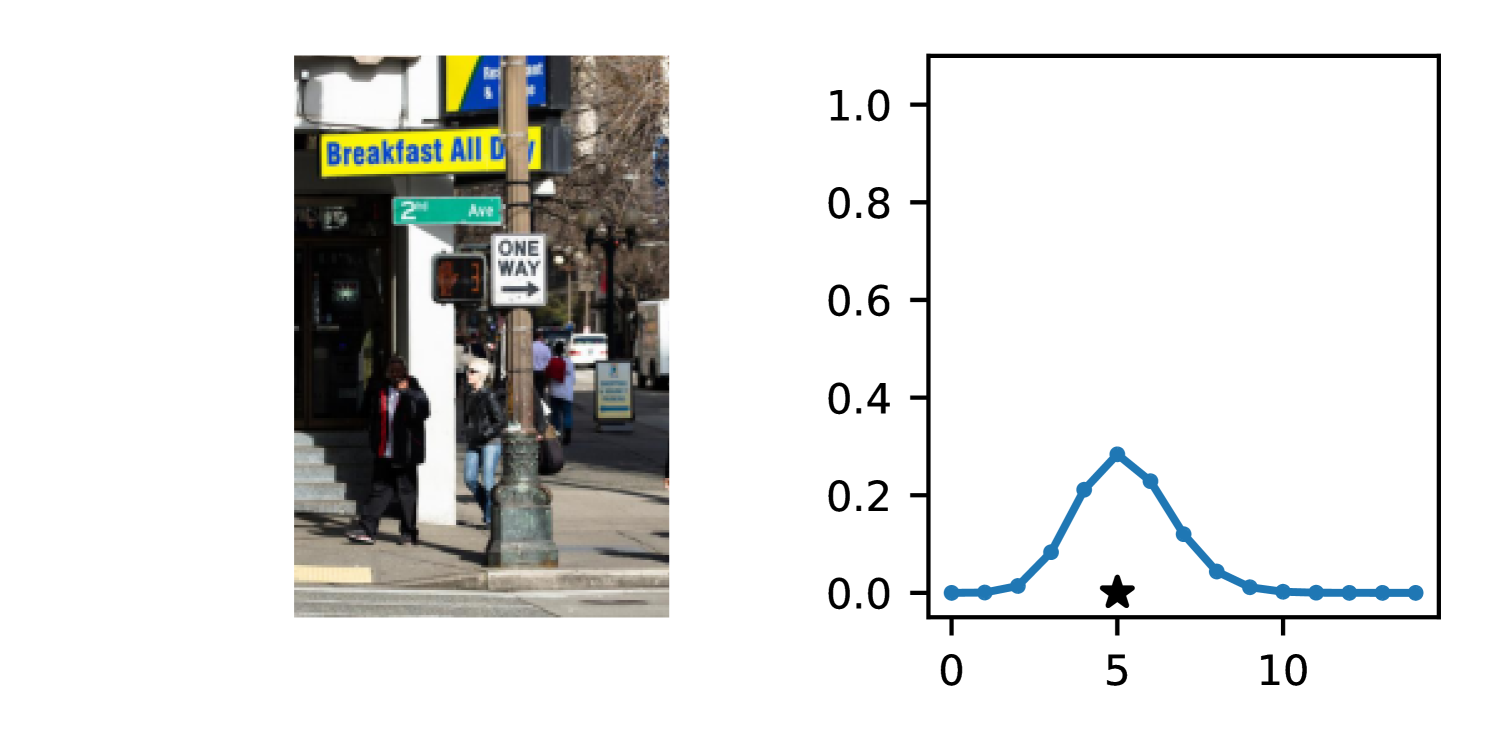
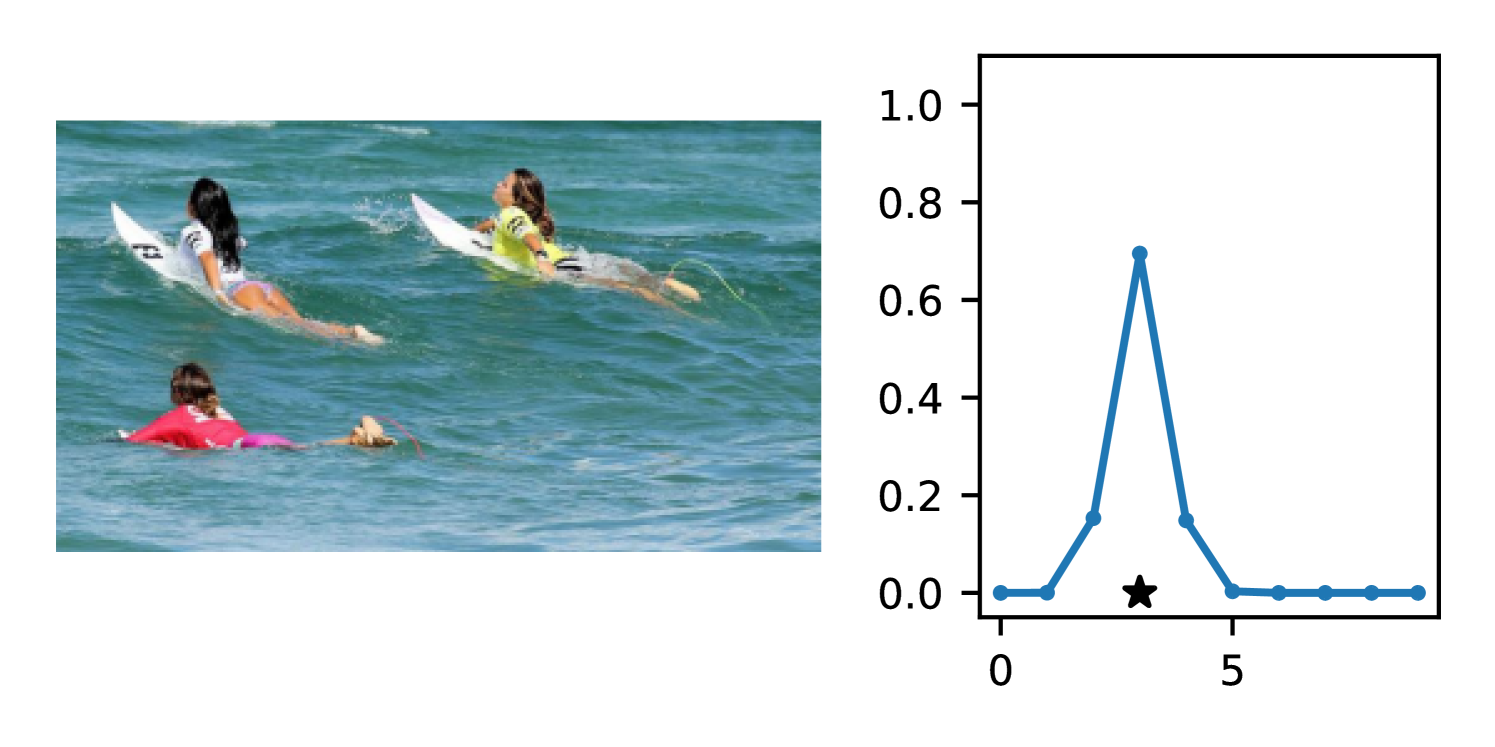
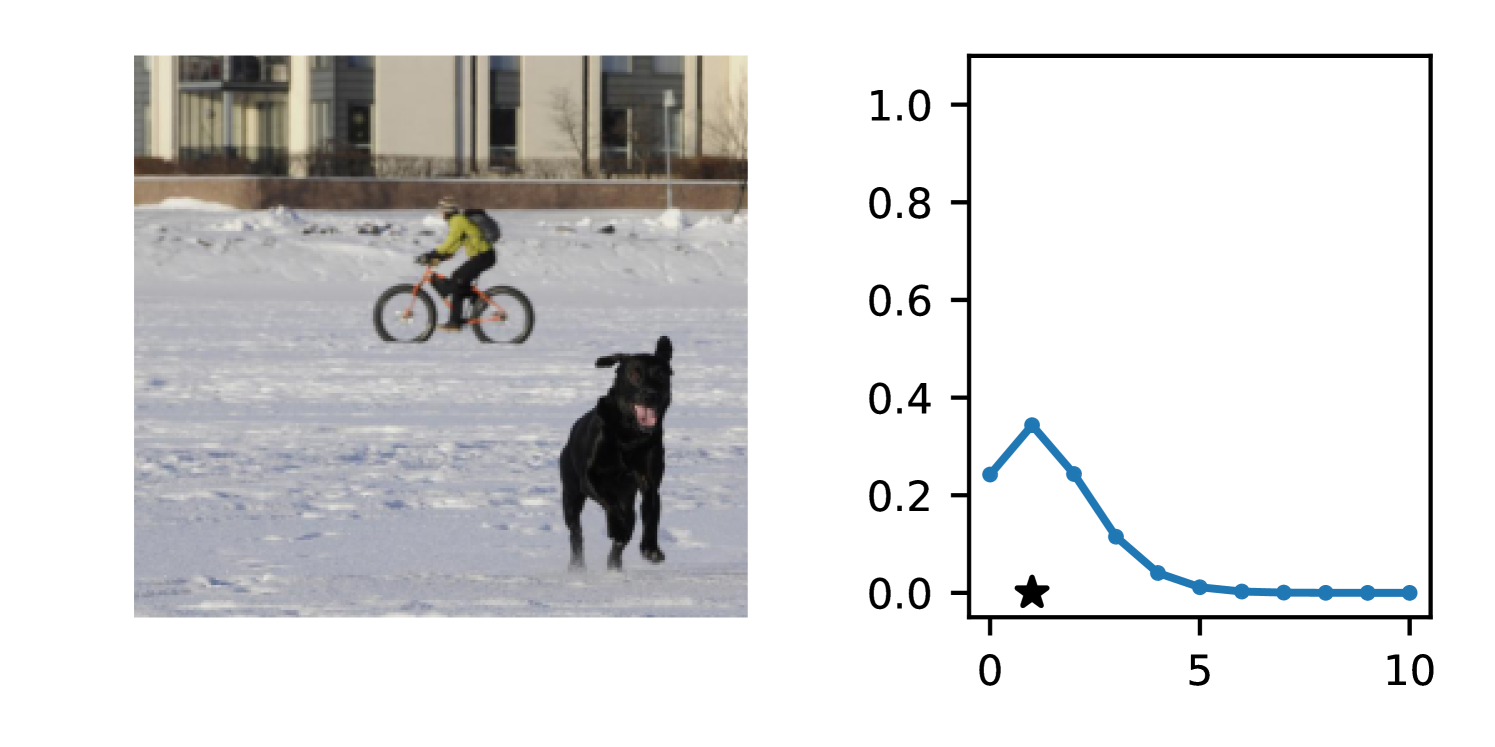
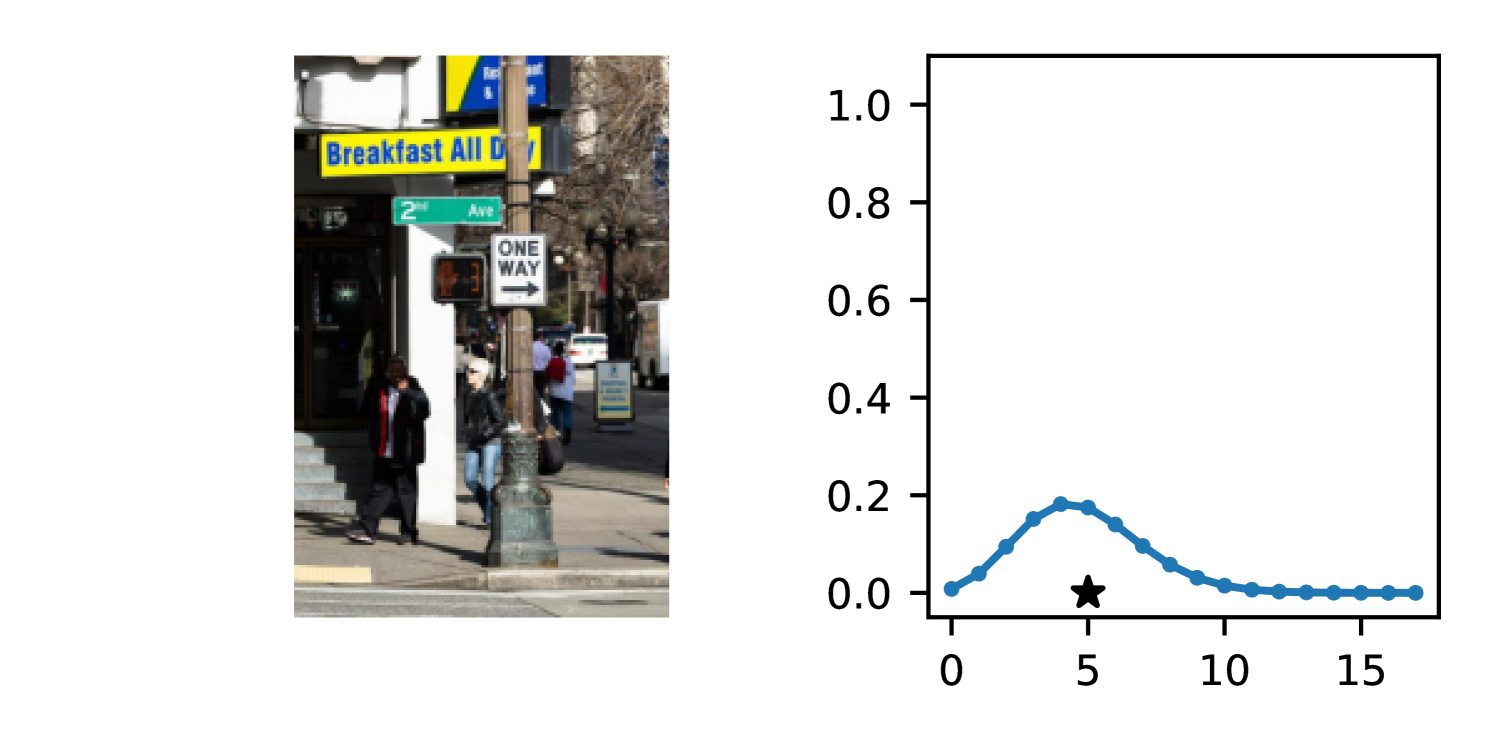
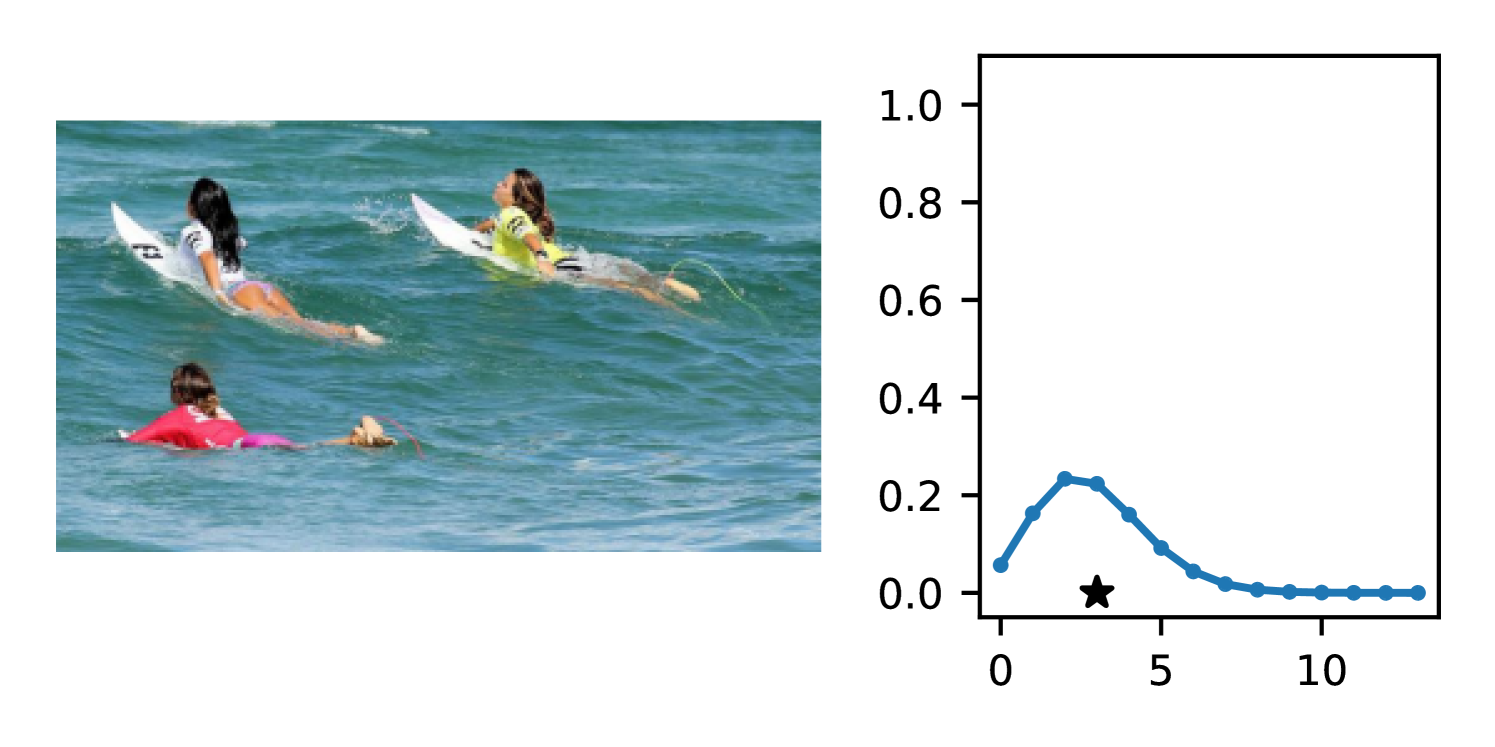
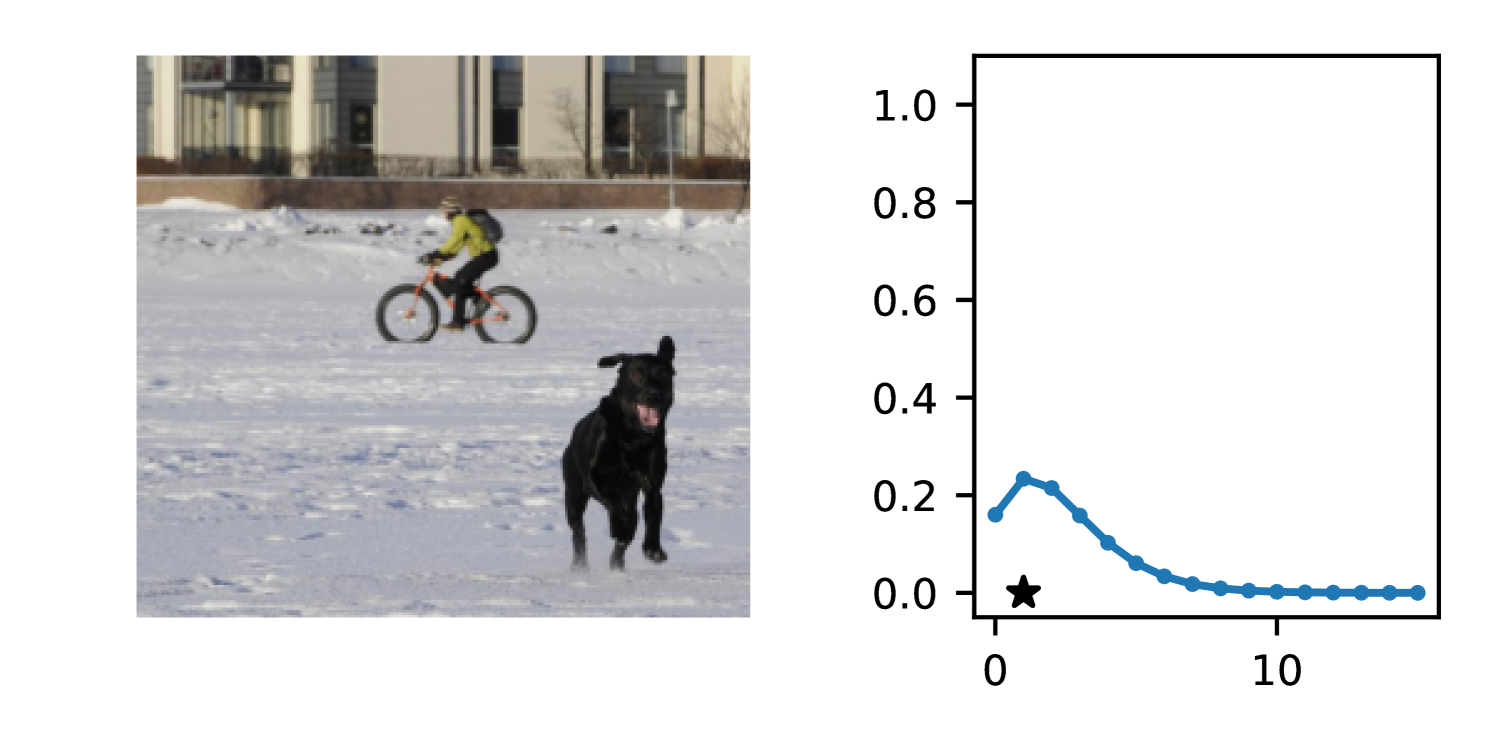
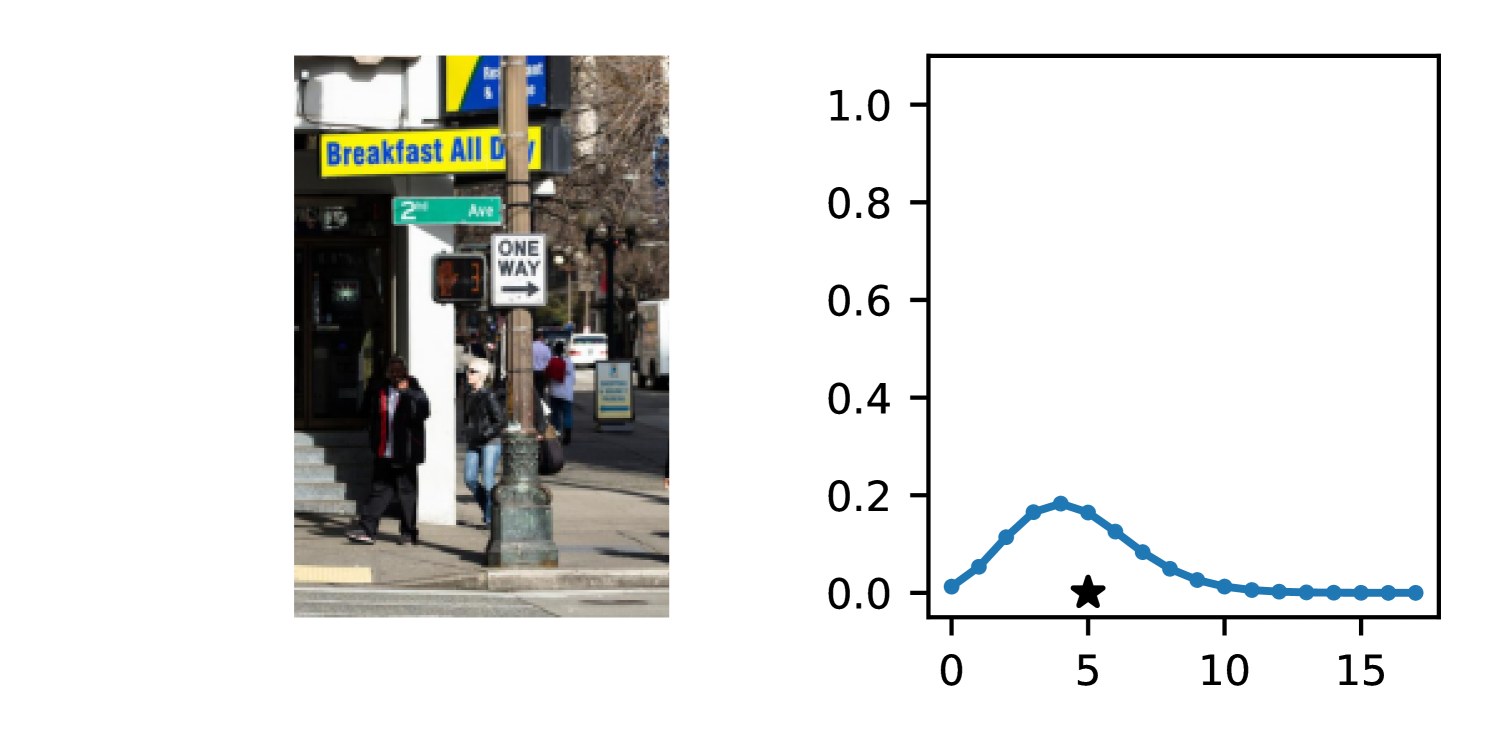
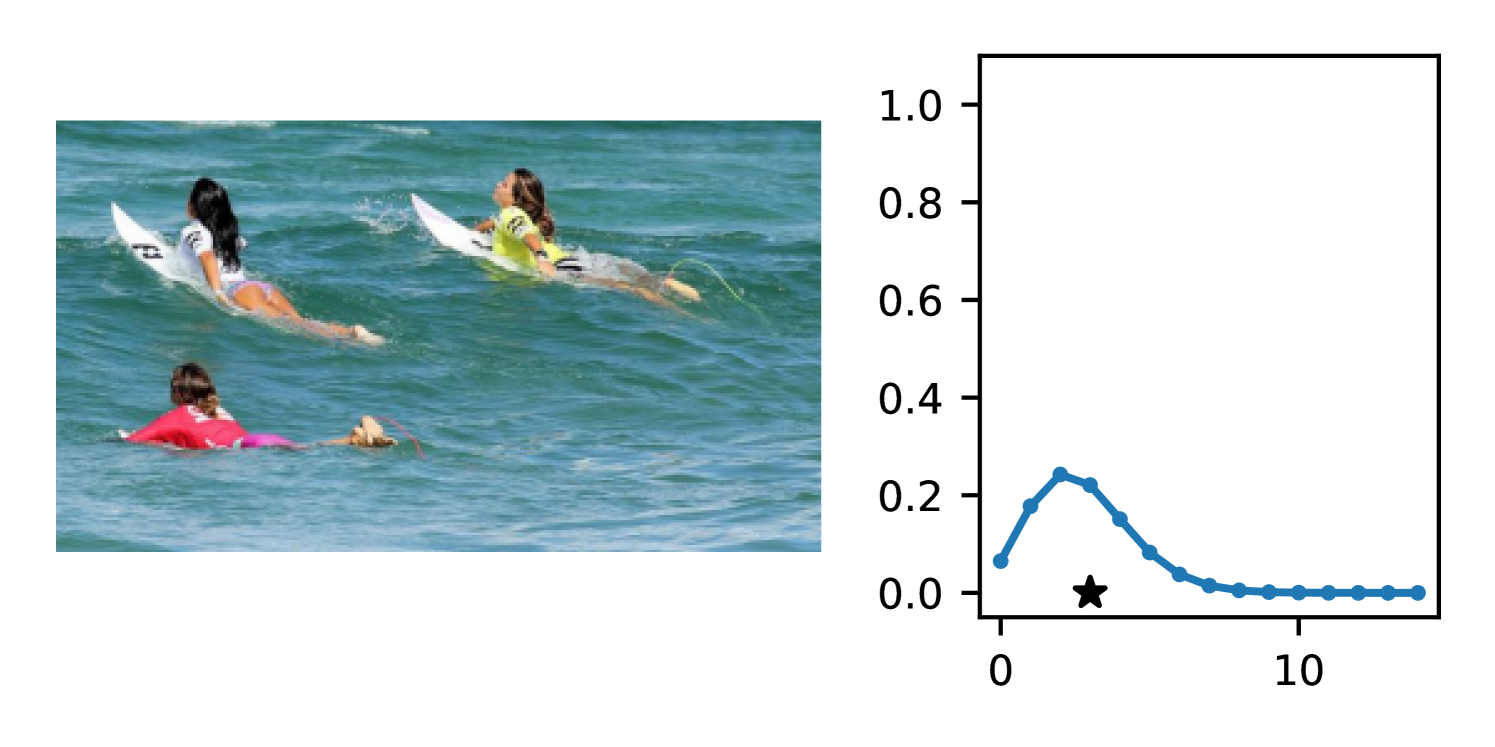
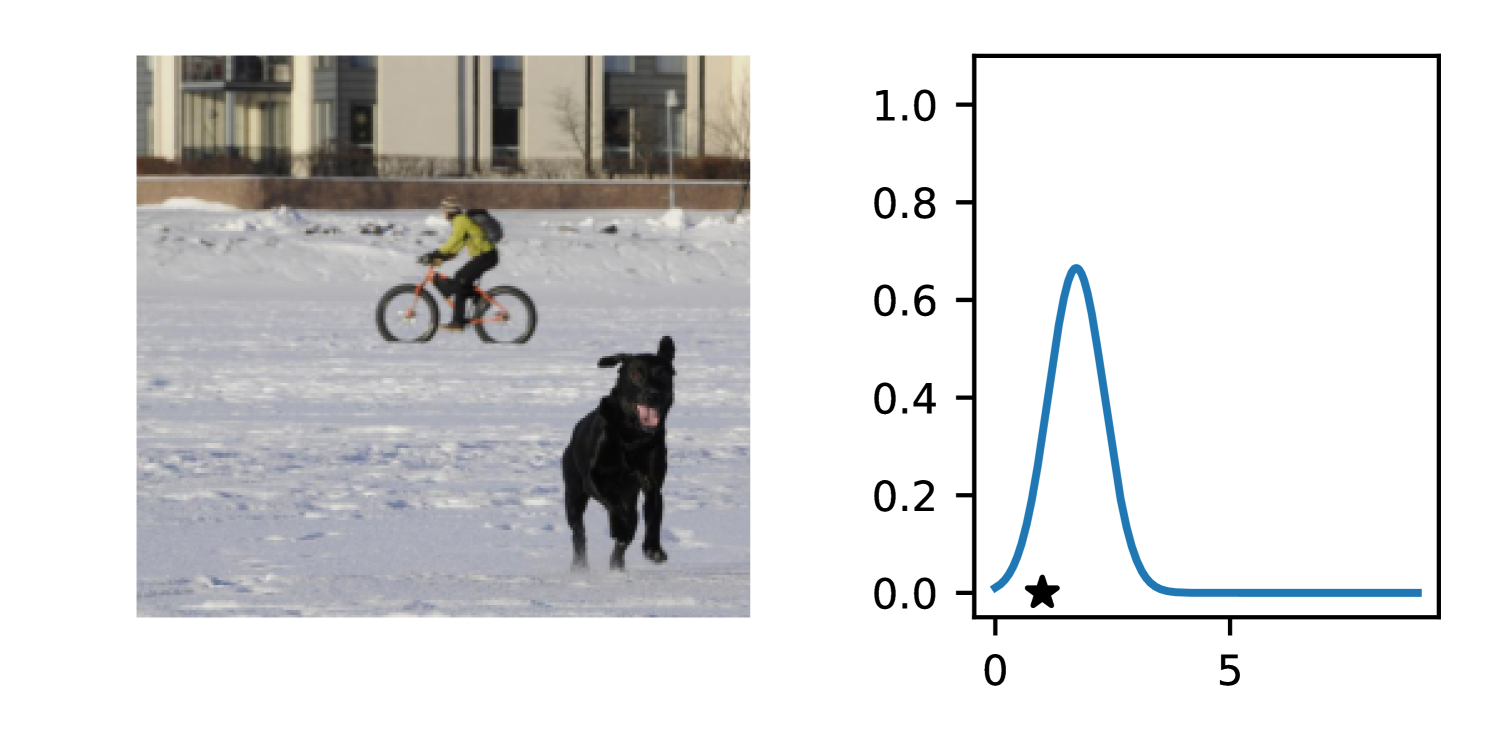
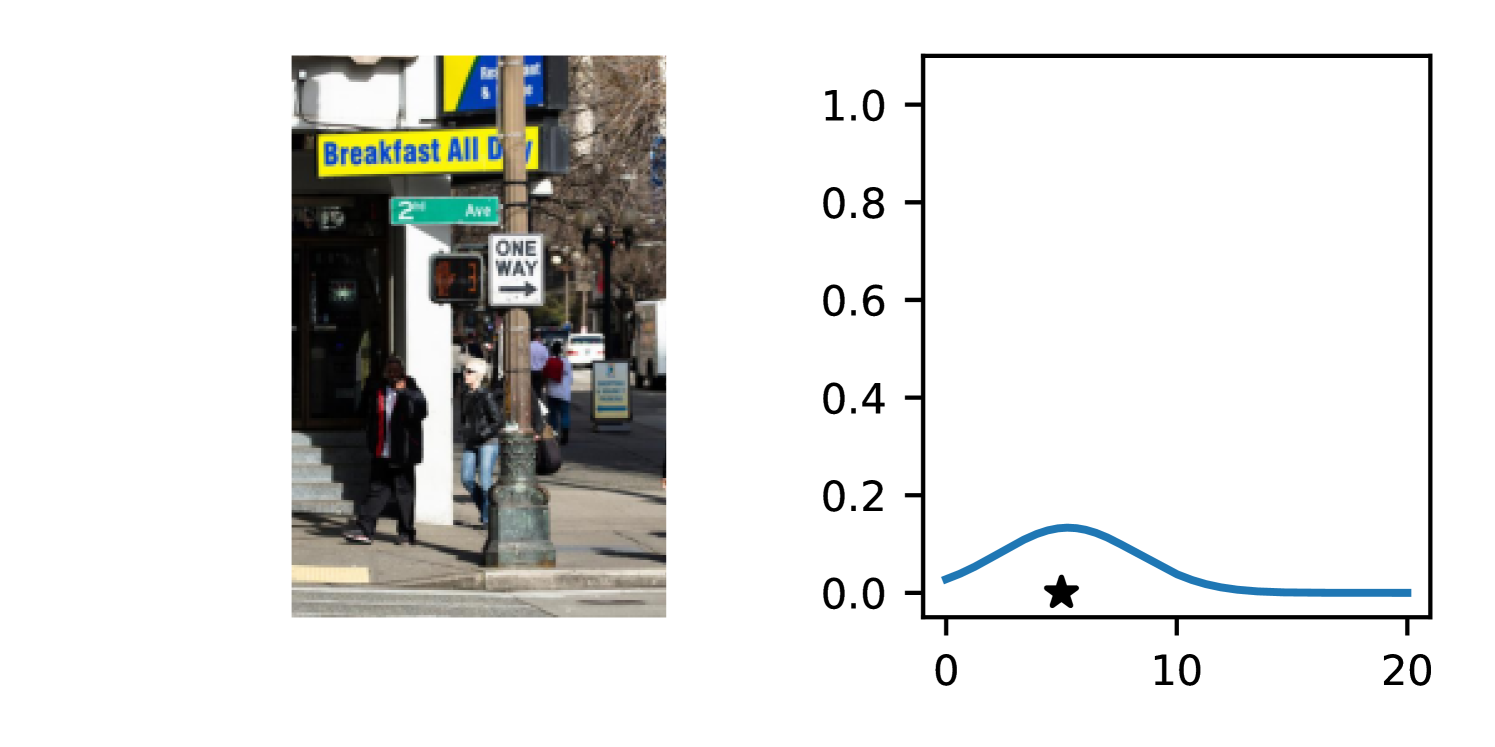
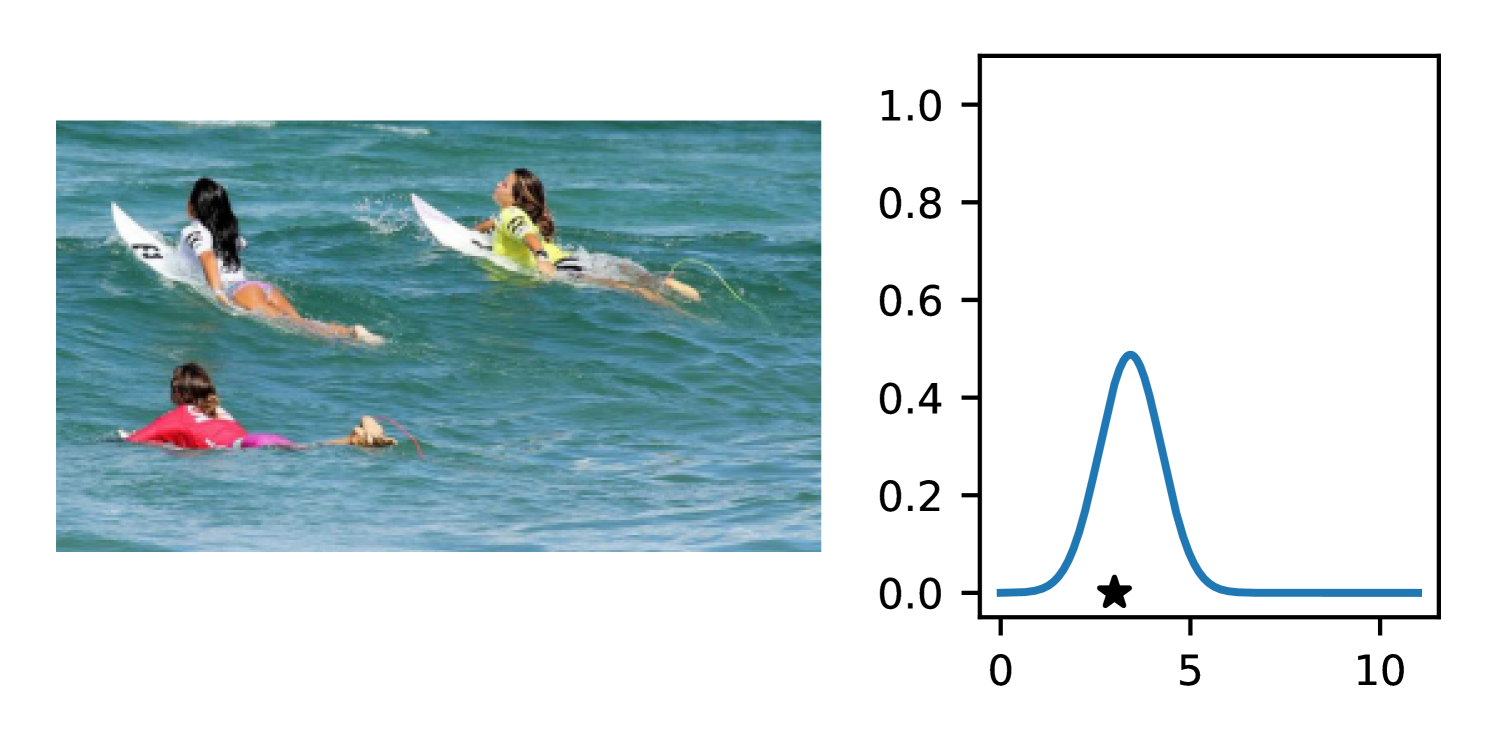
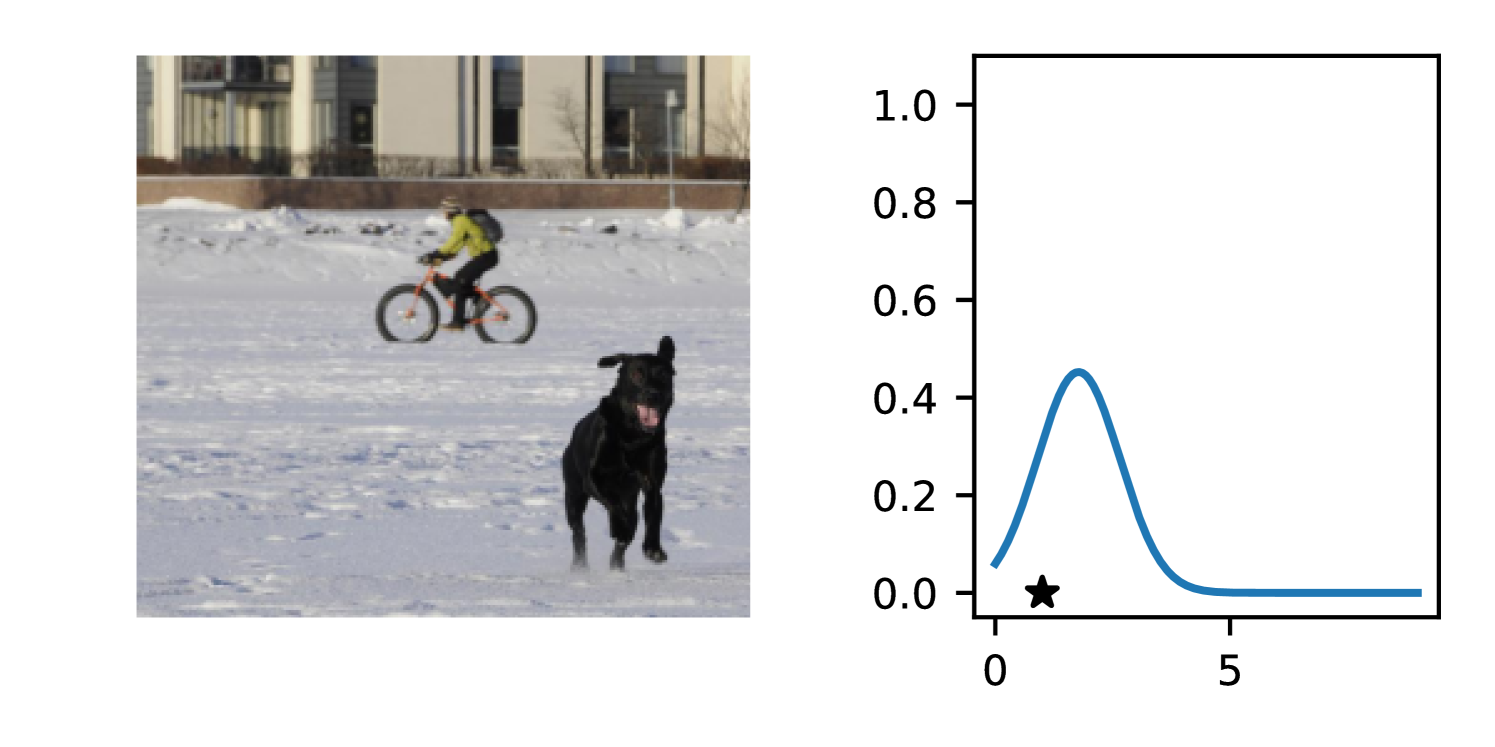
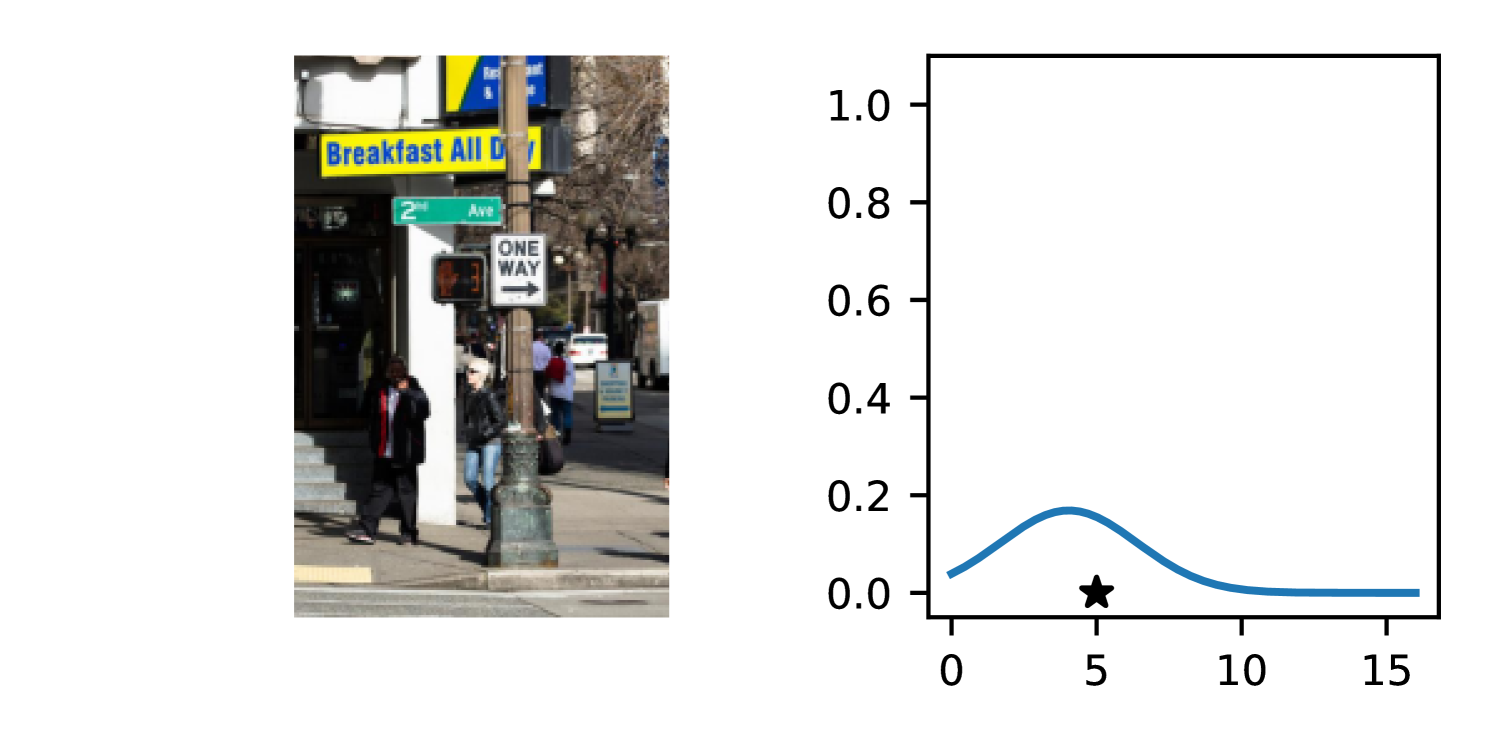
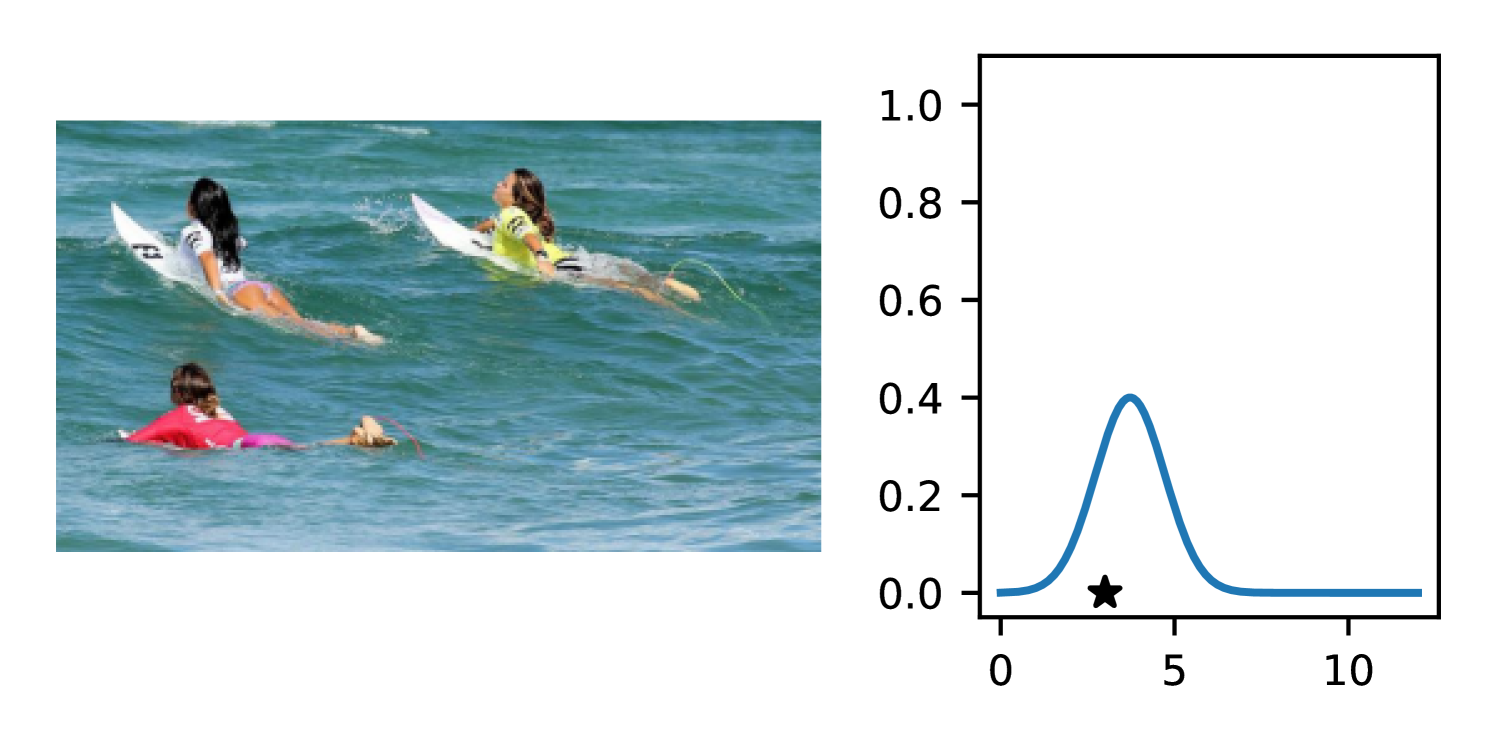
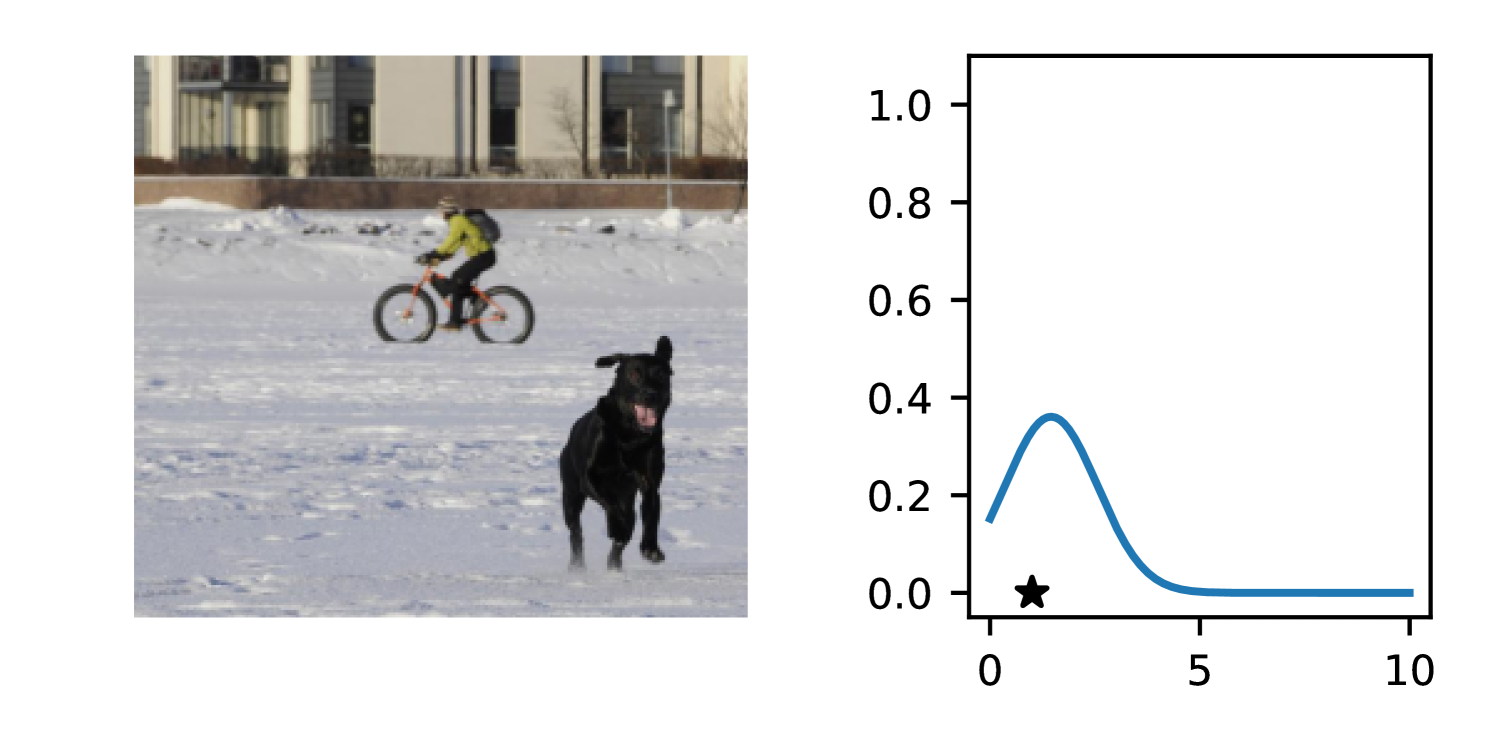
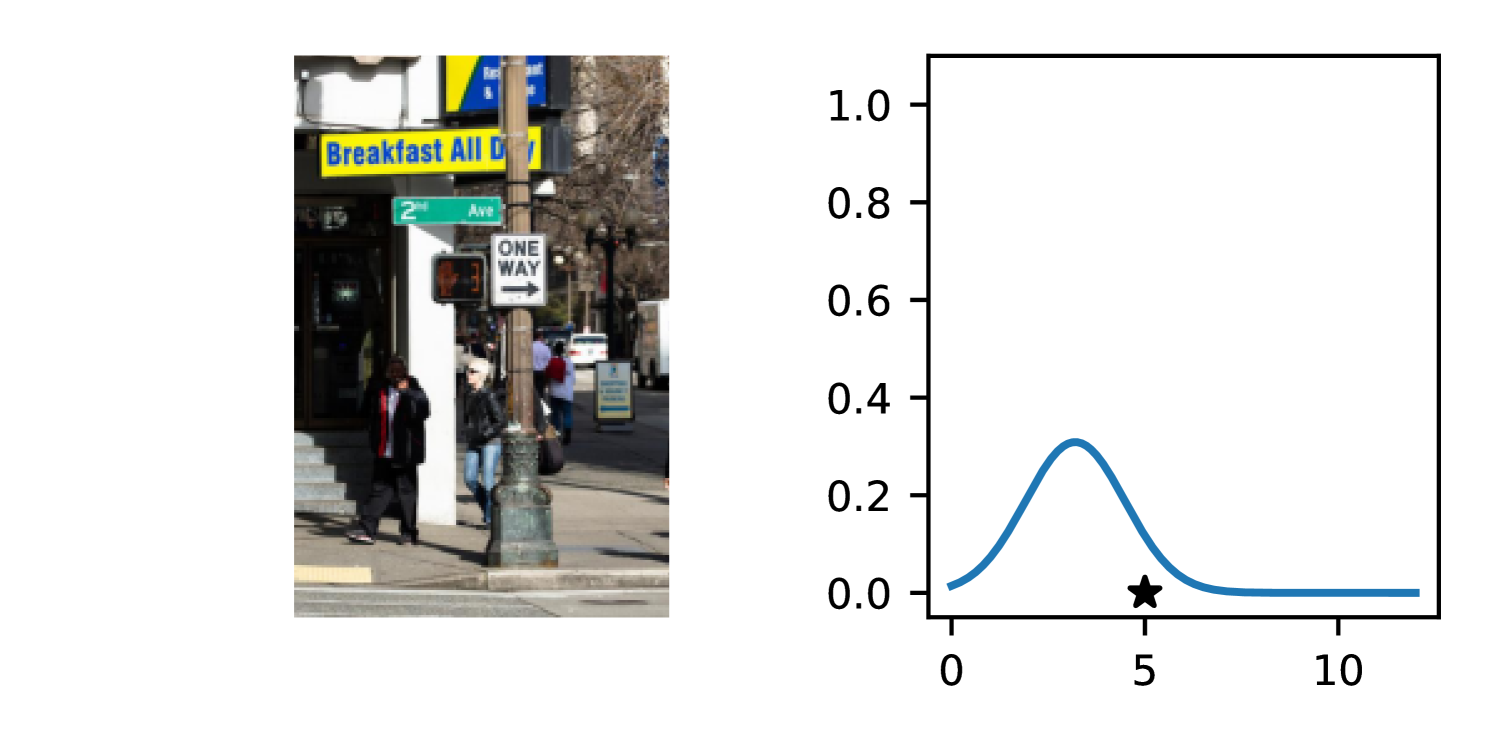
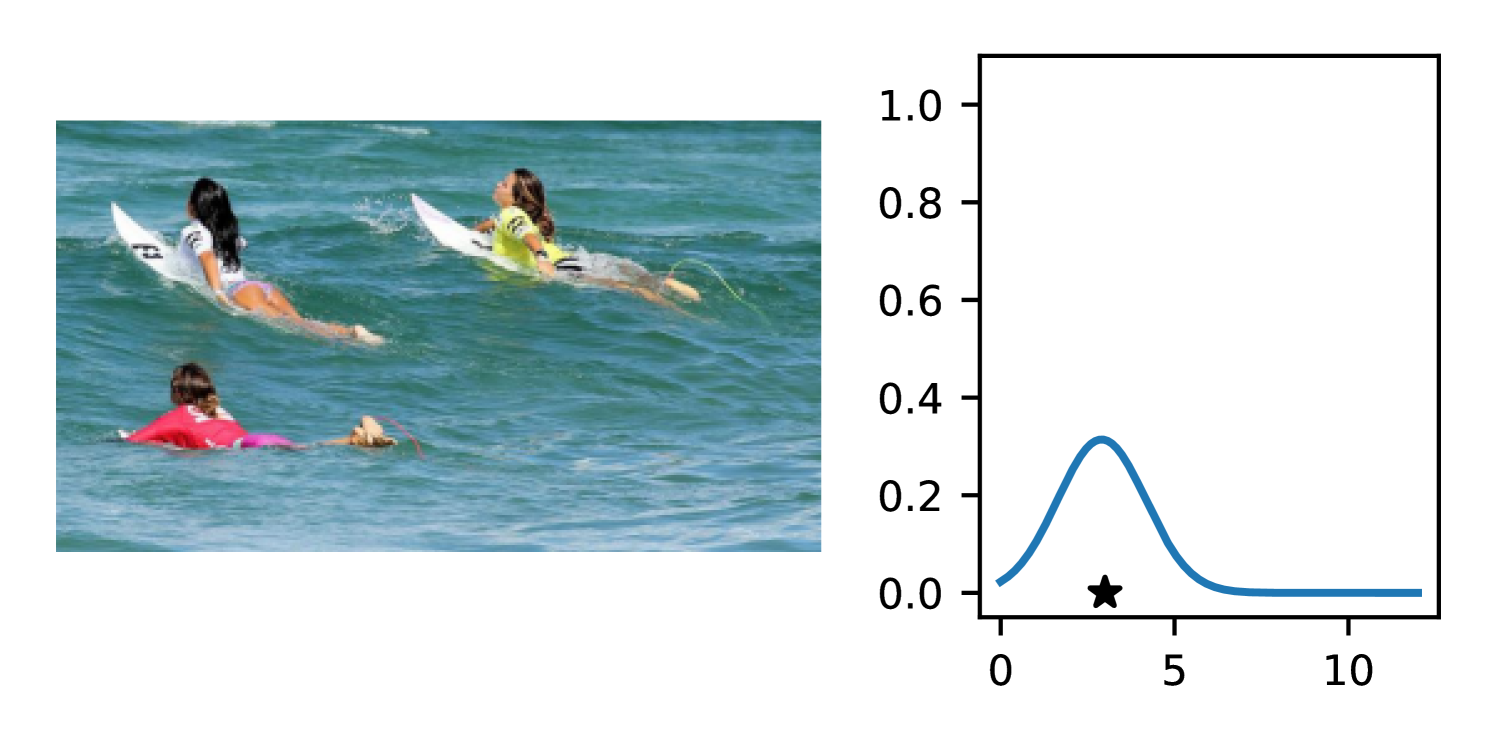
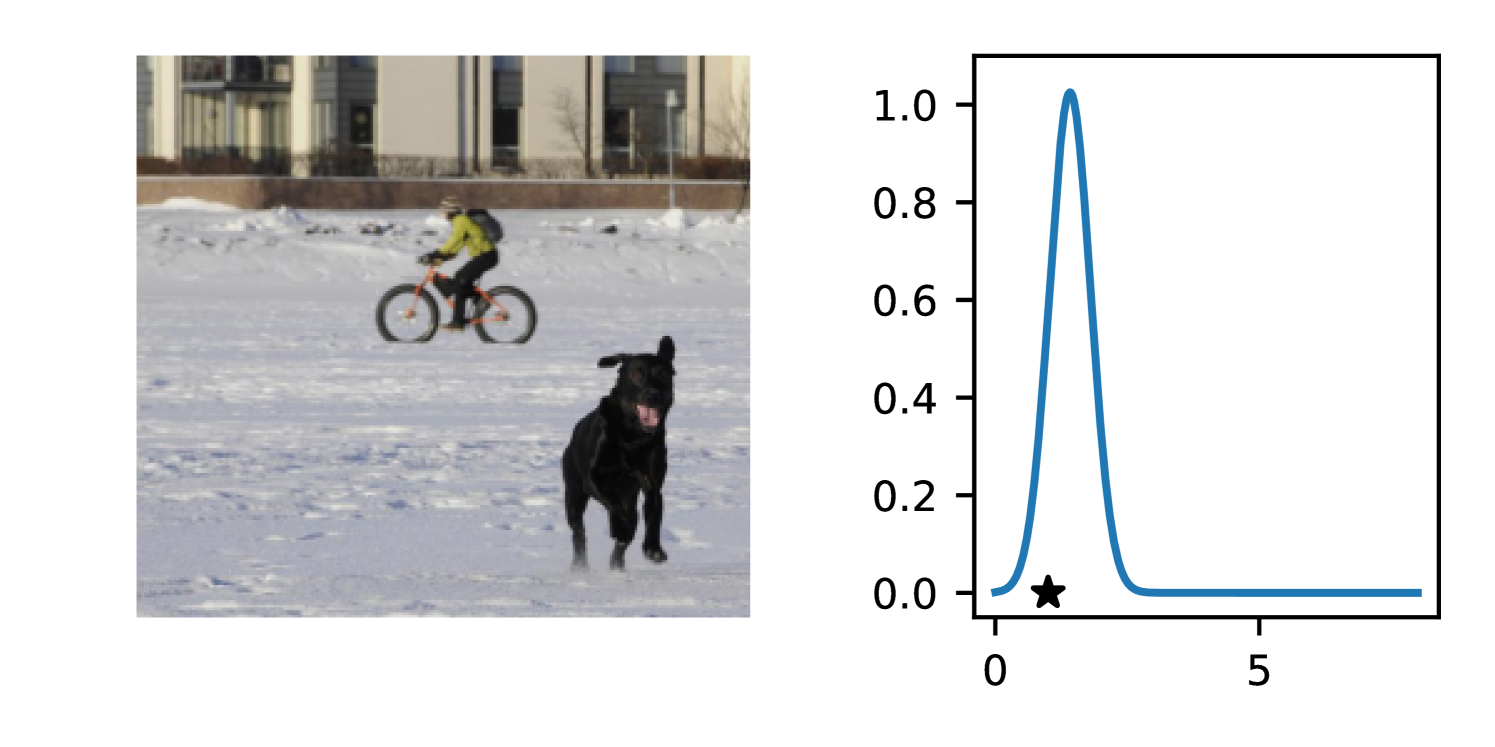
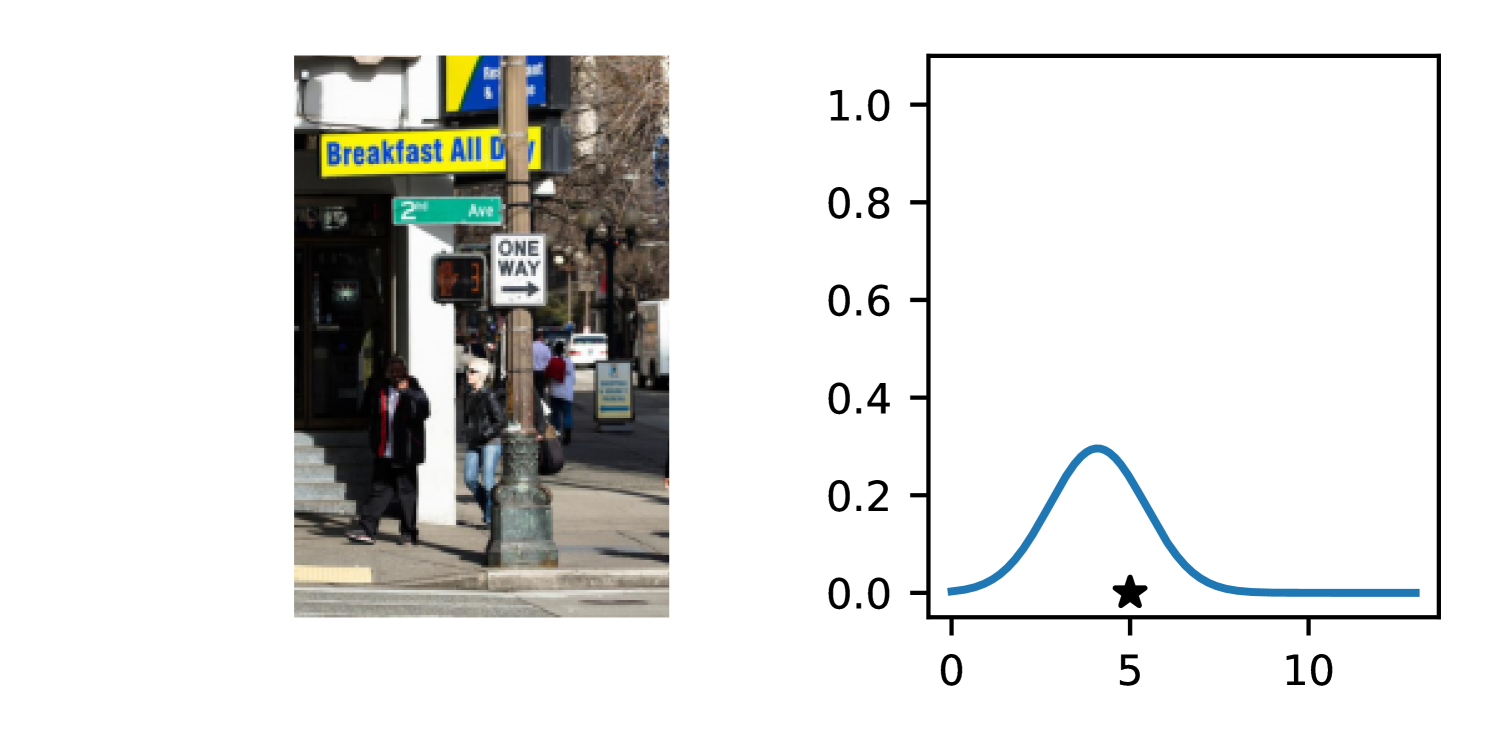
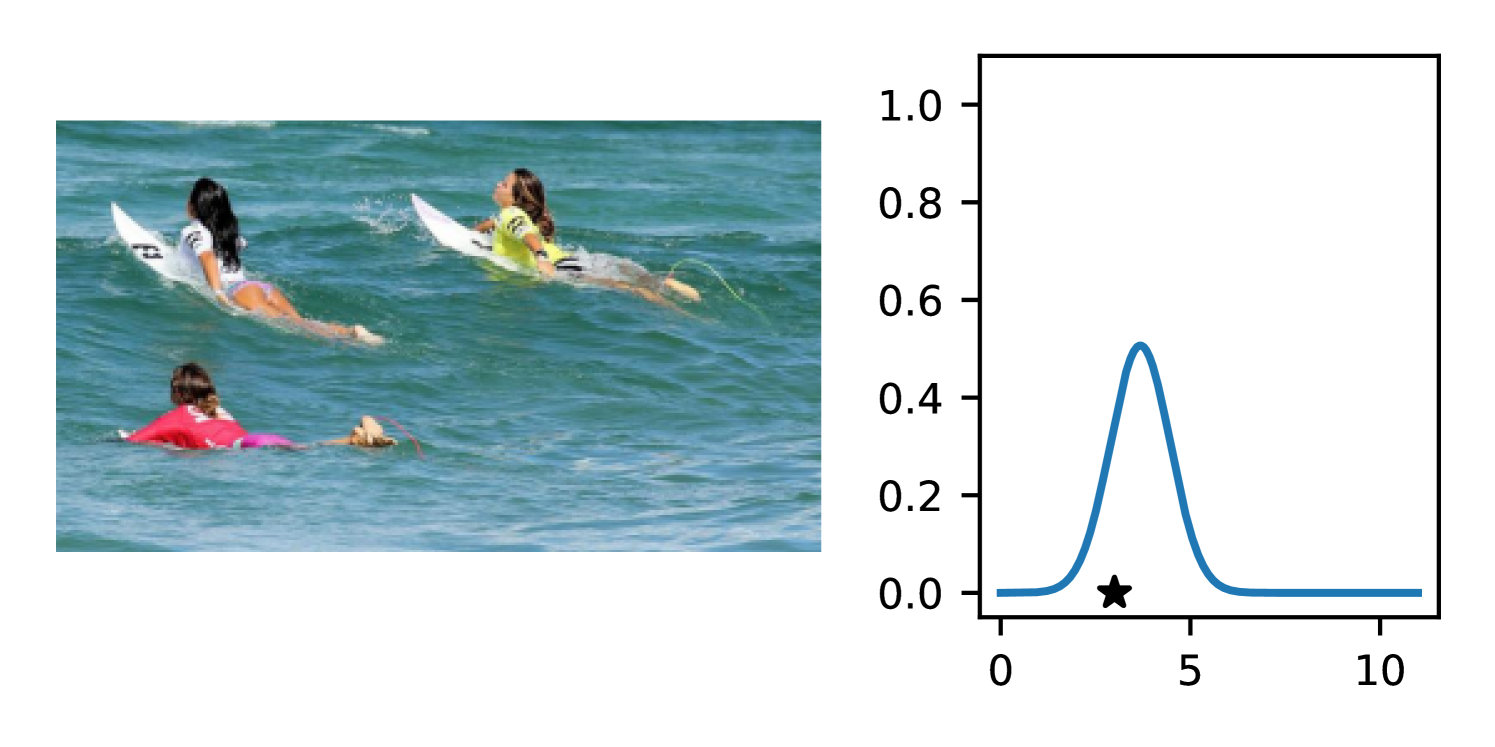
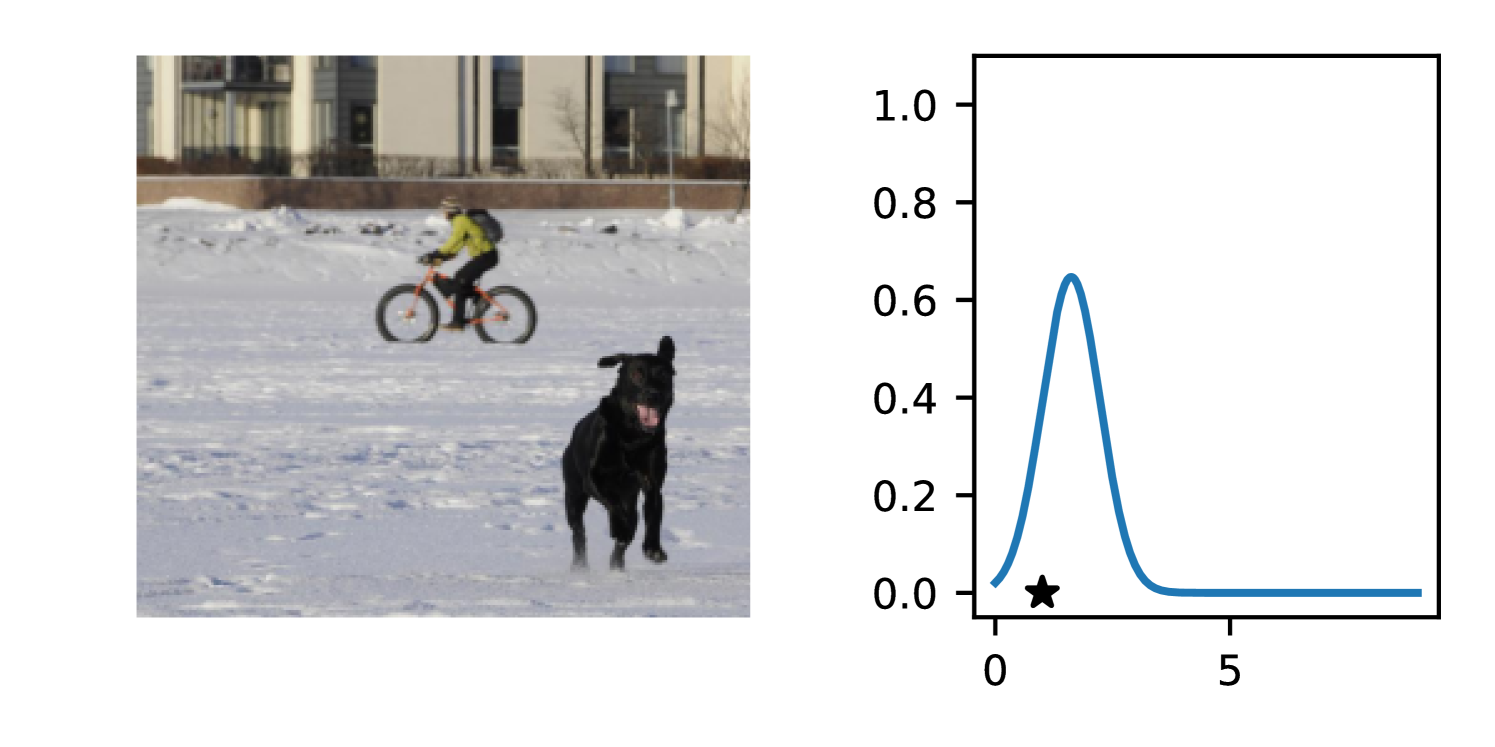
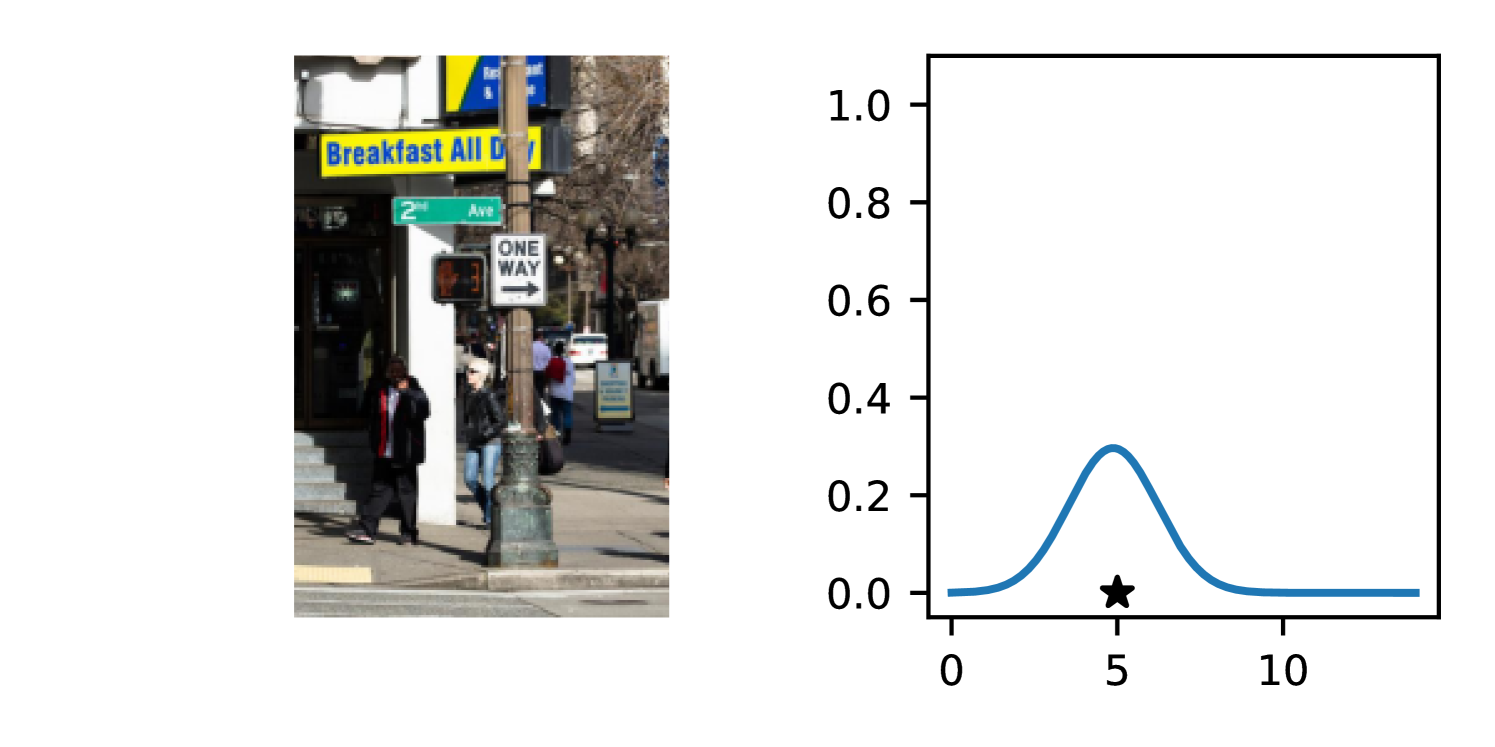
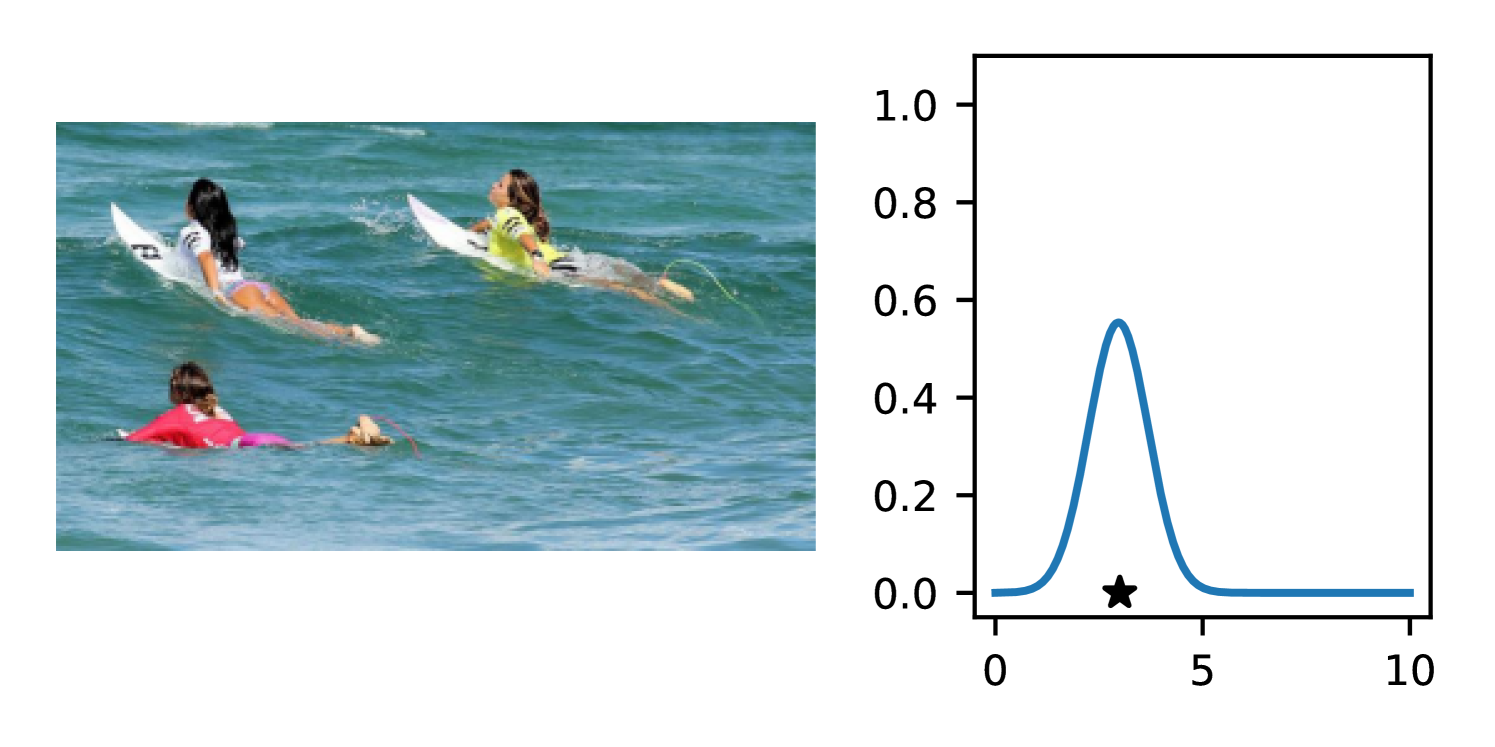
D.1.2 Ensembles
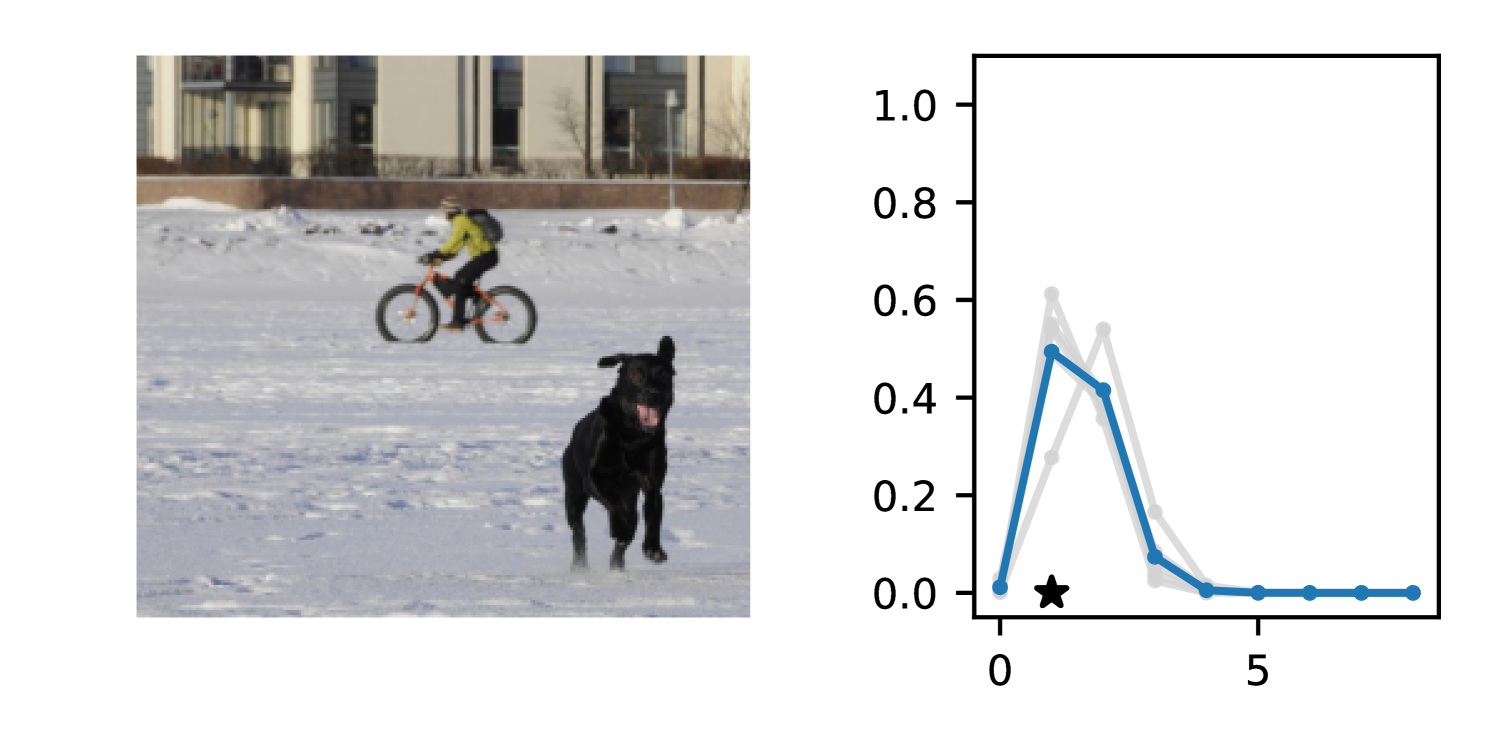
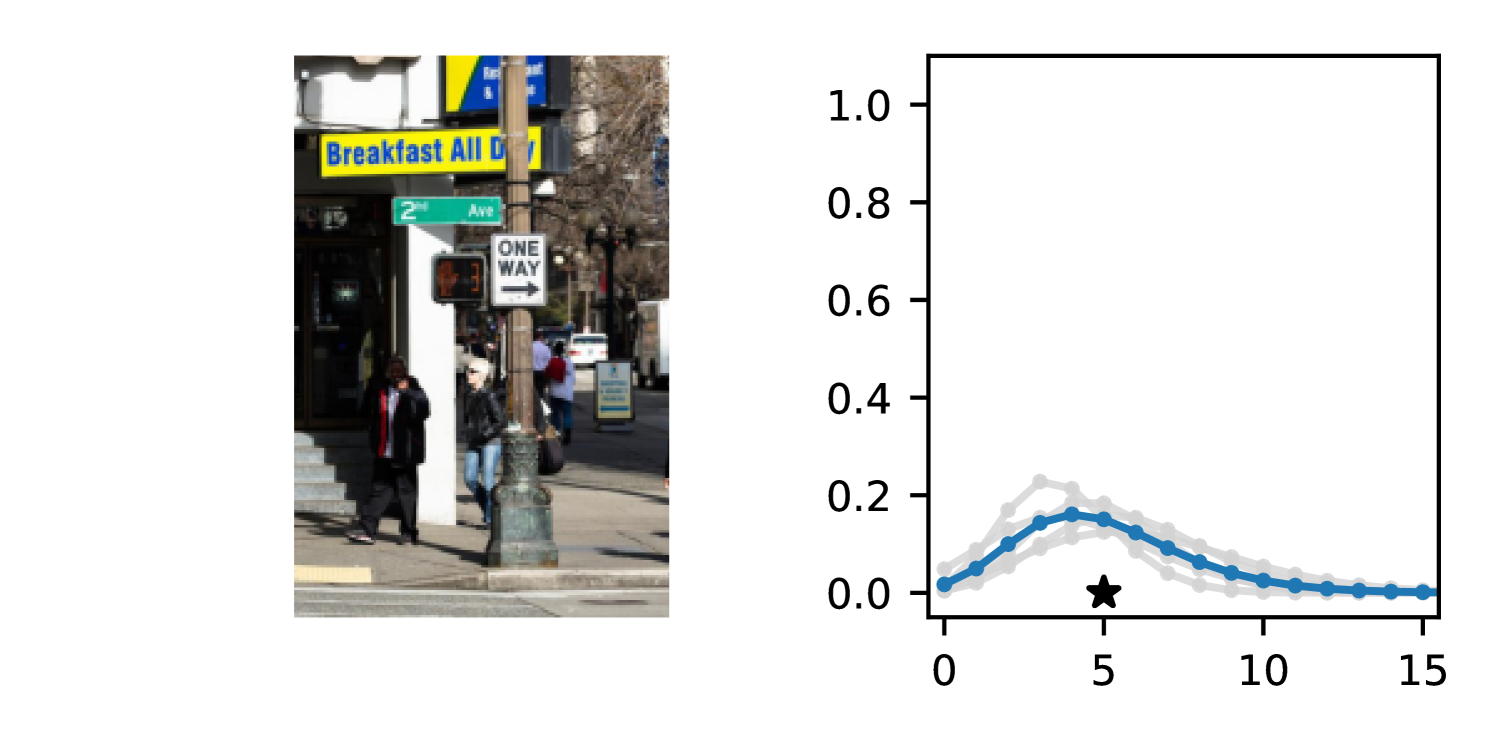
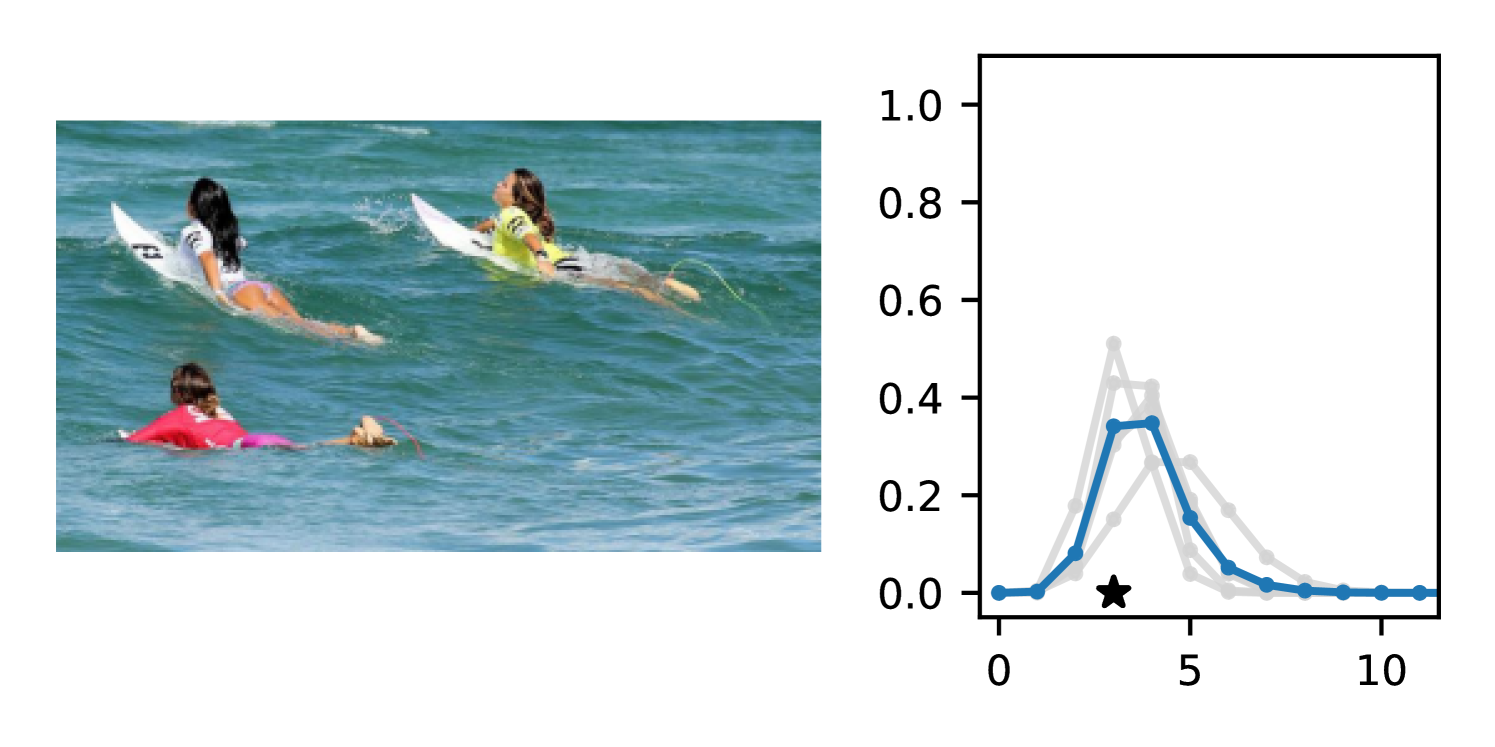
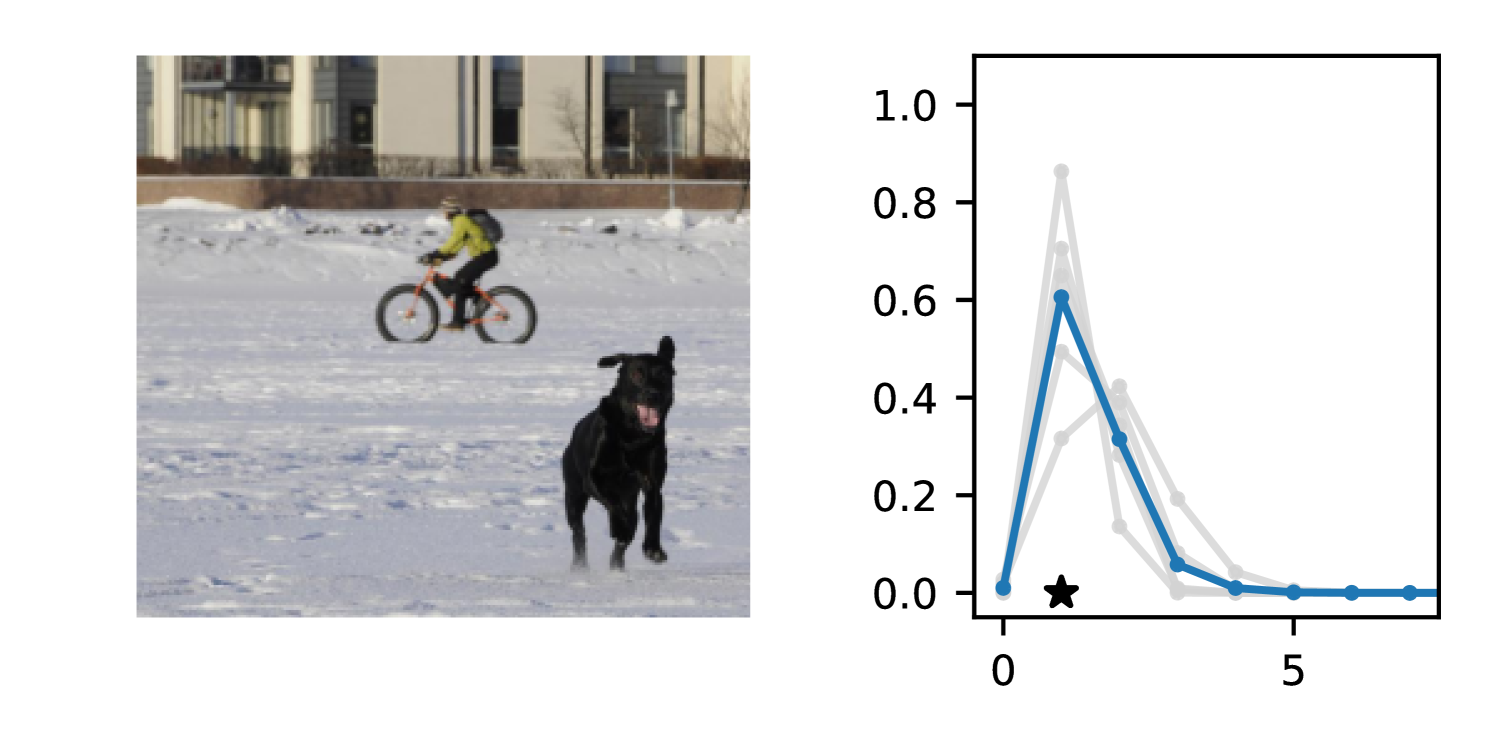
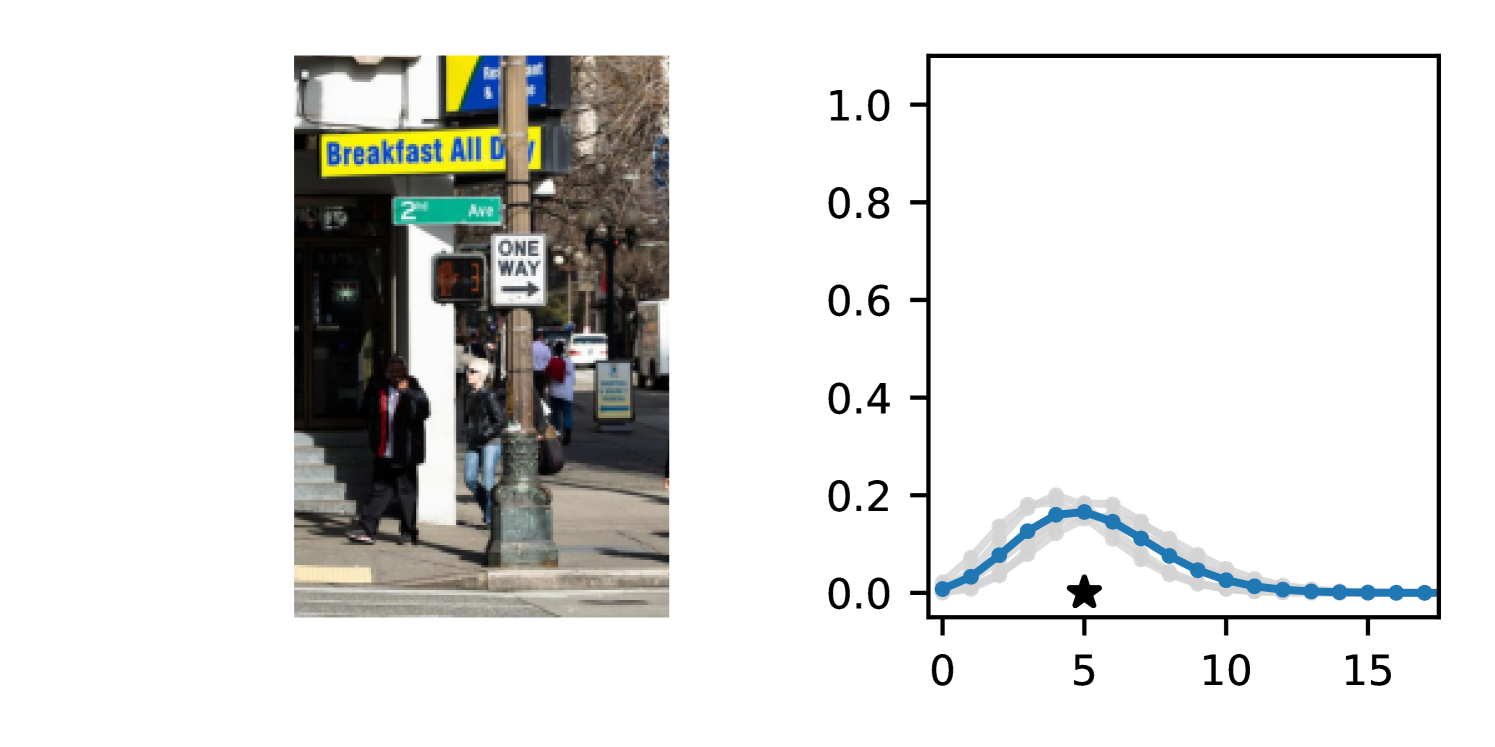
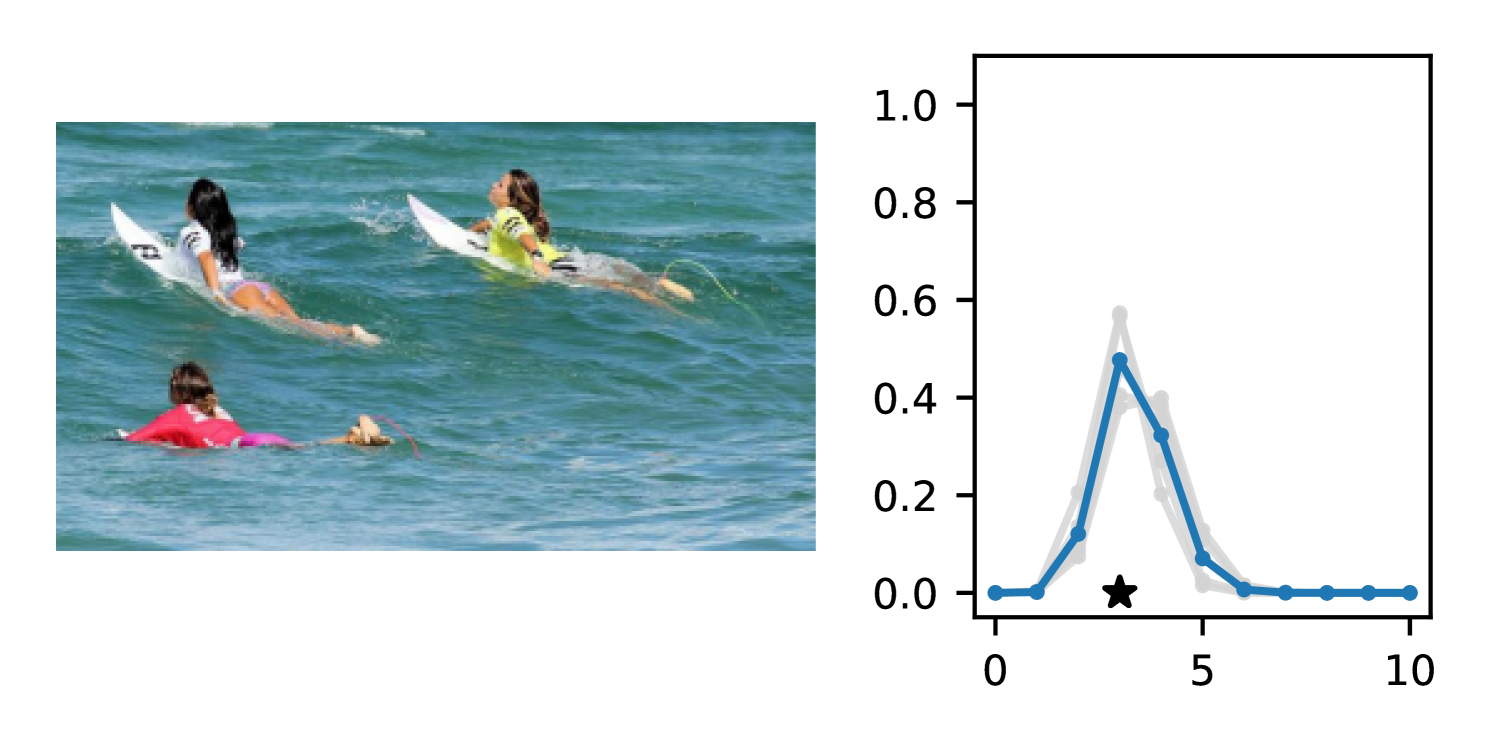
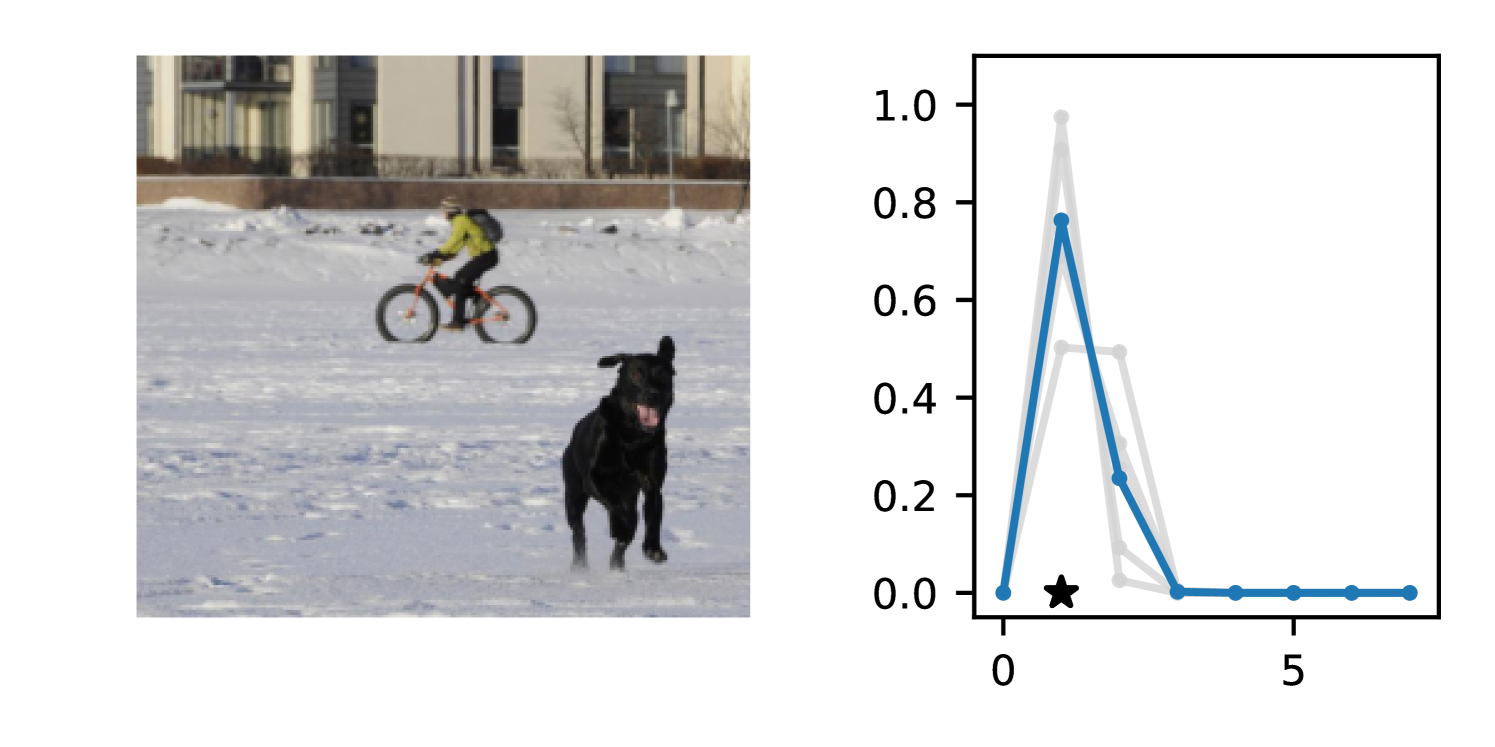
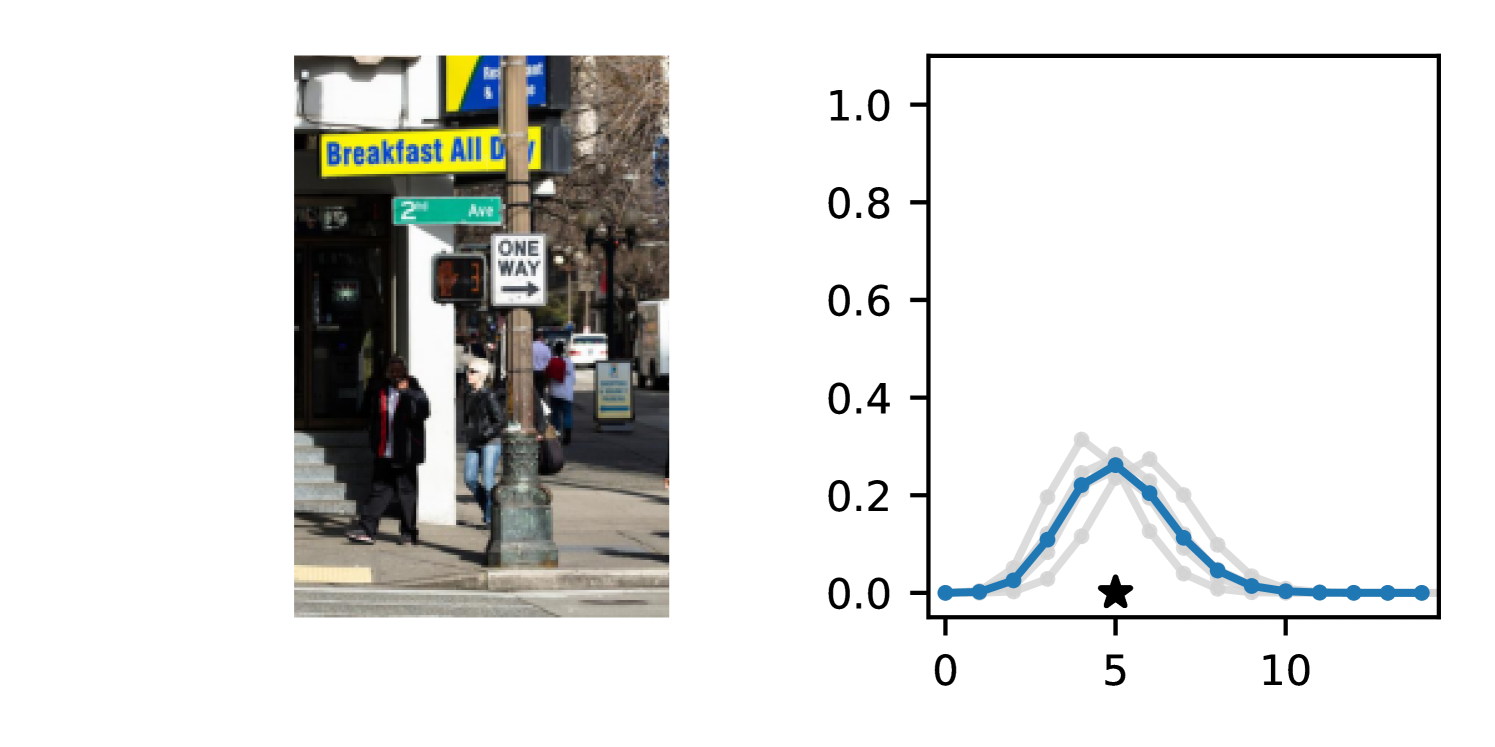
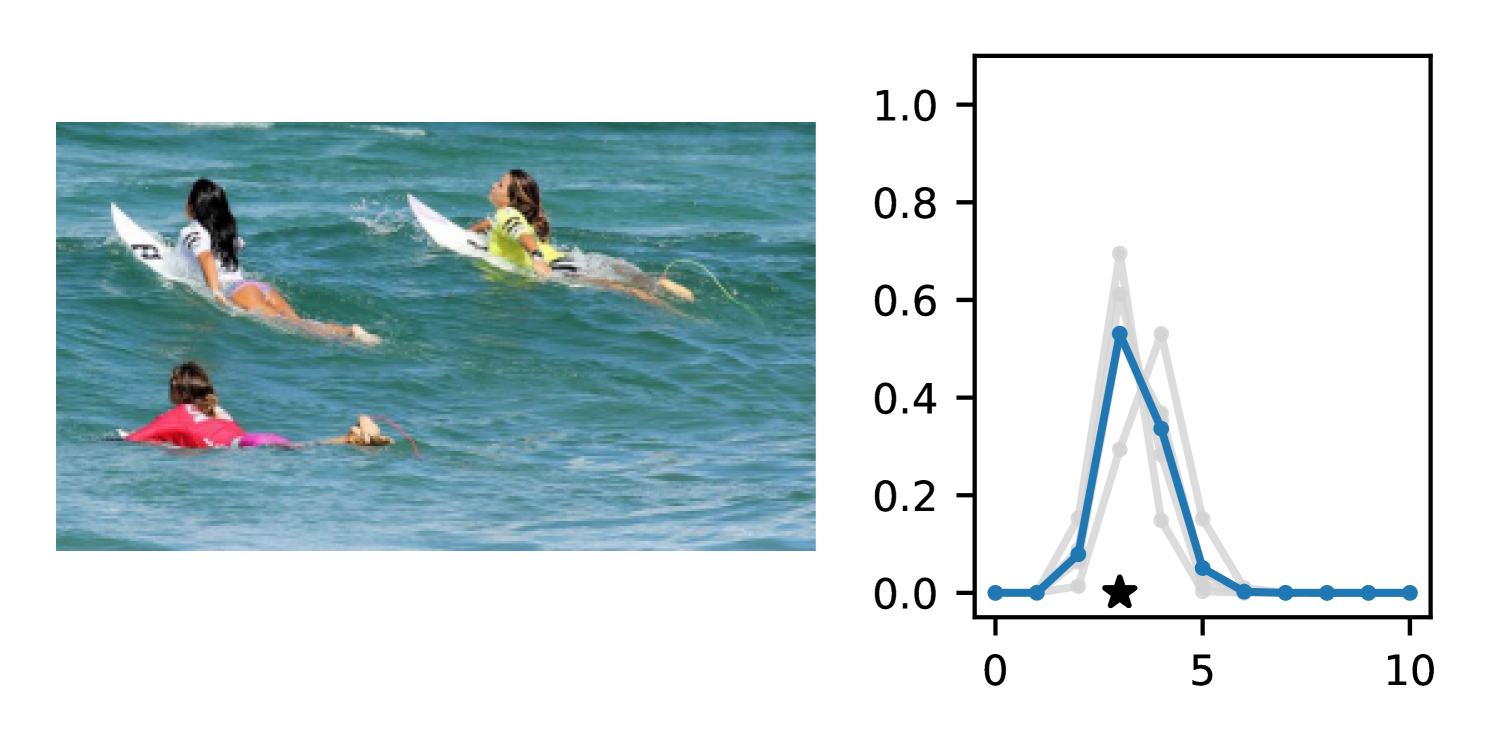
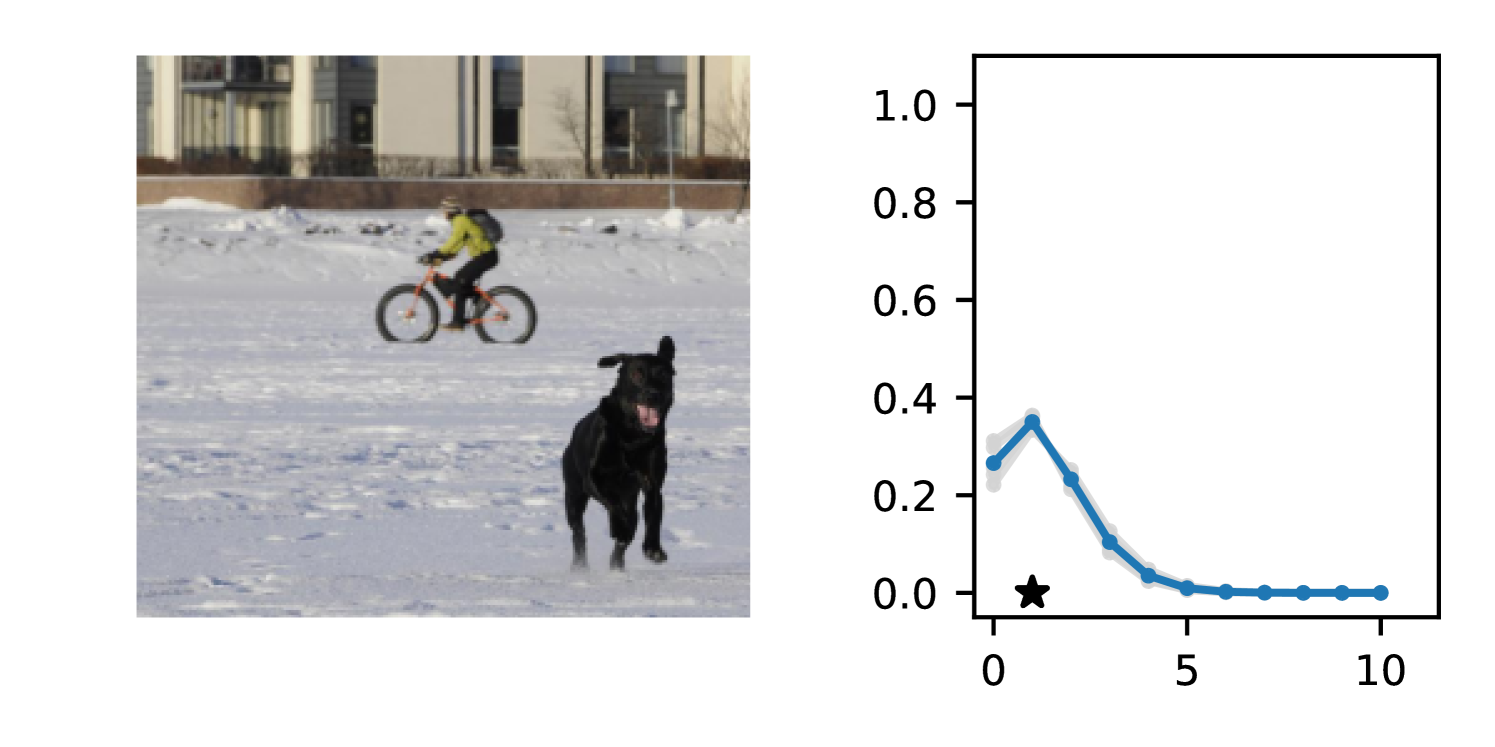
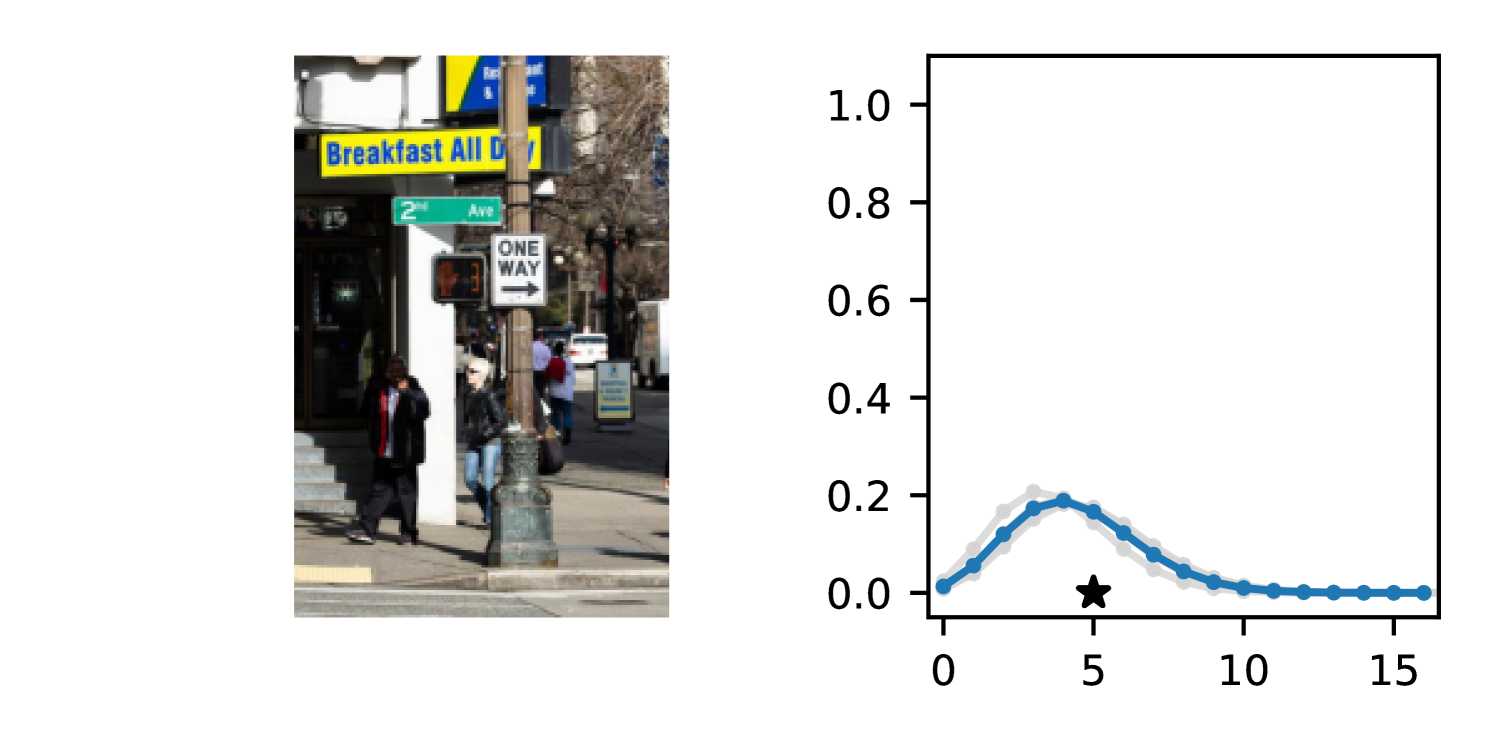
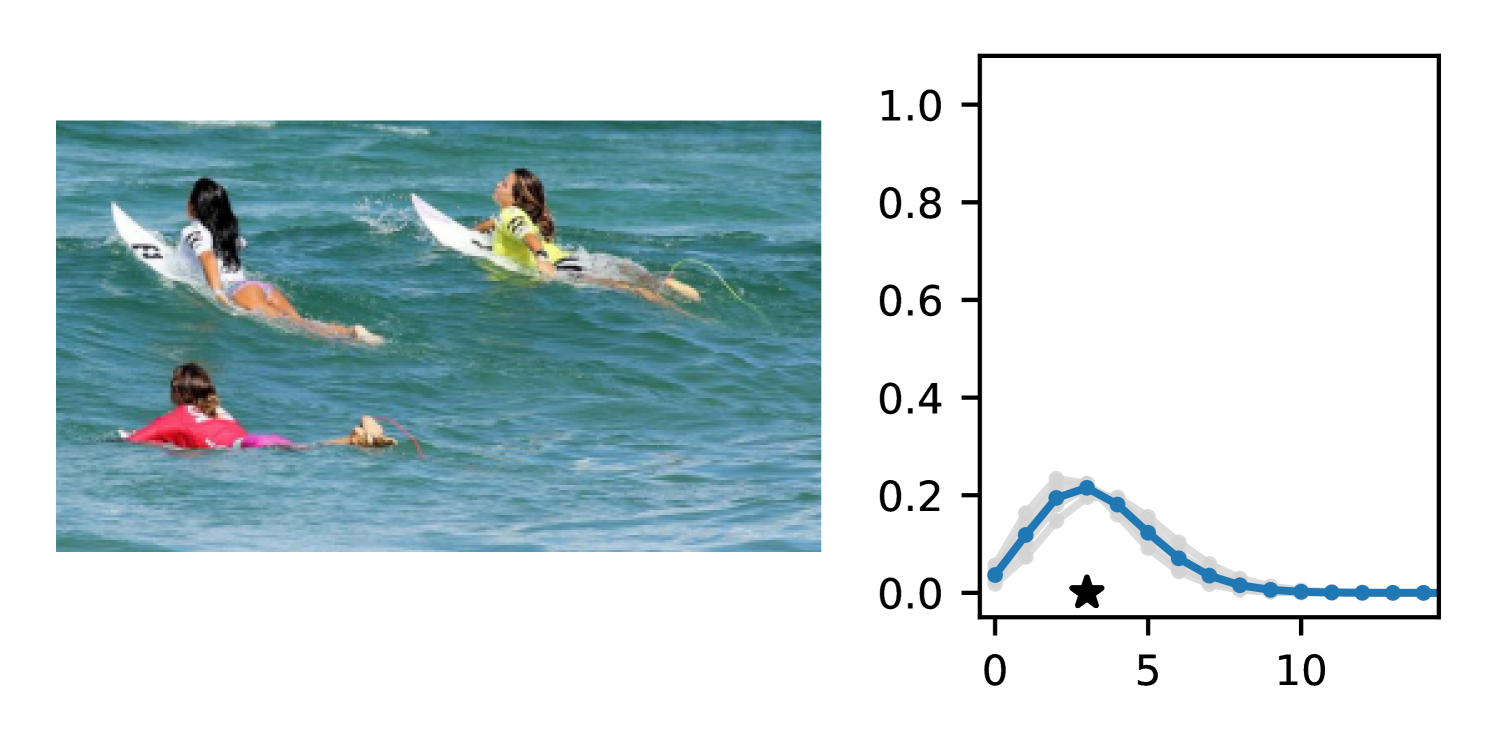
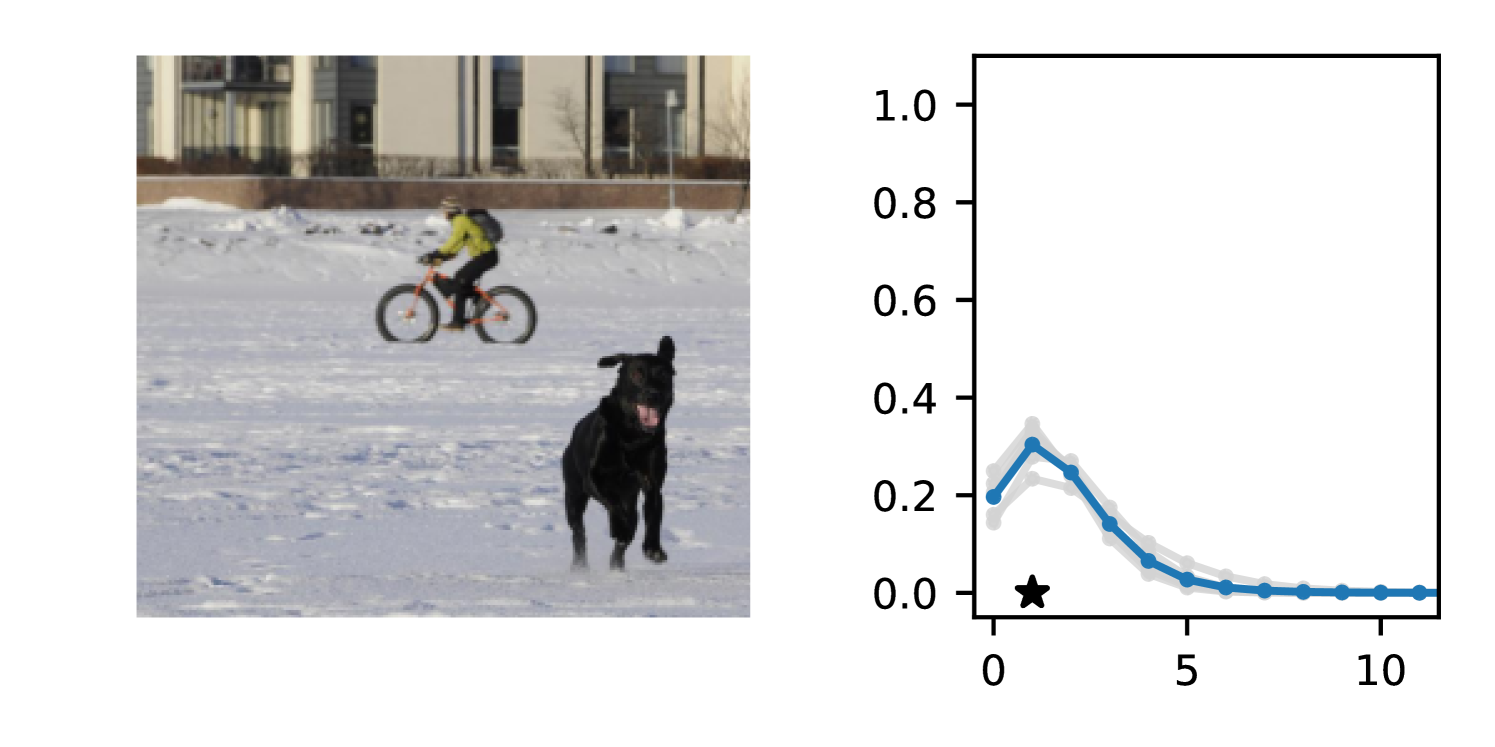
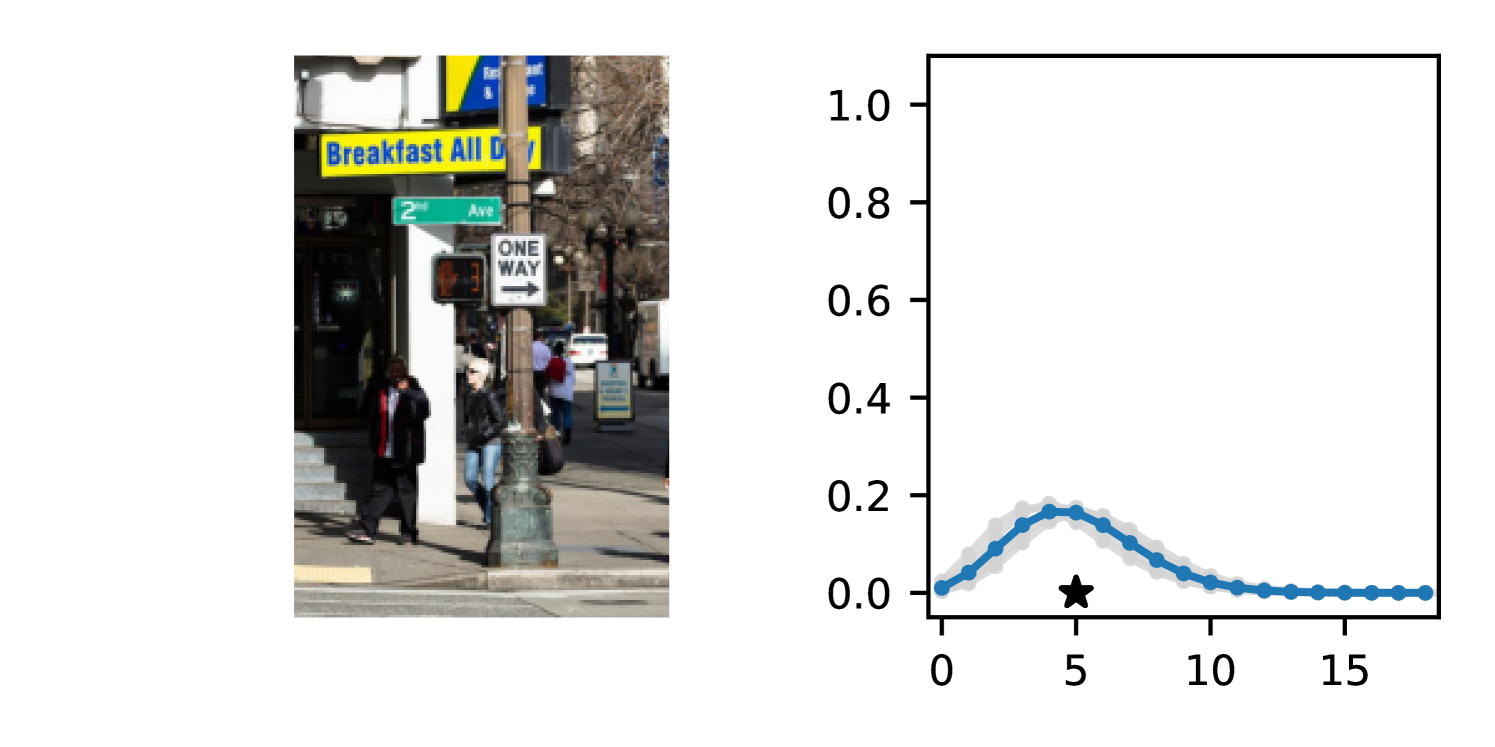
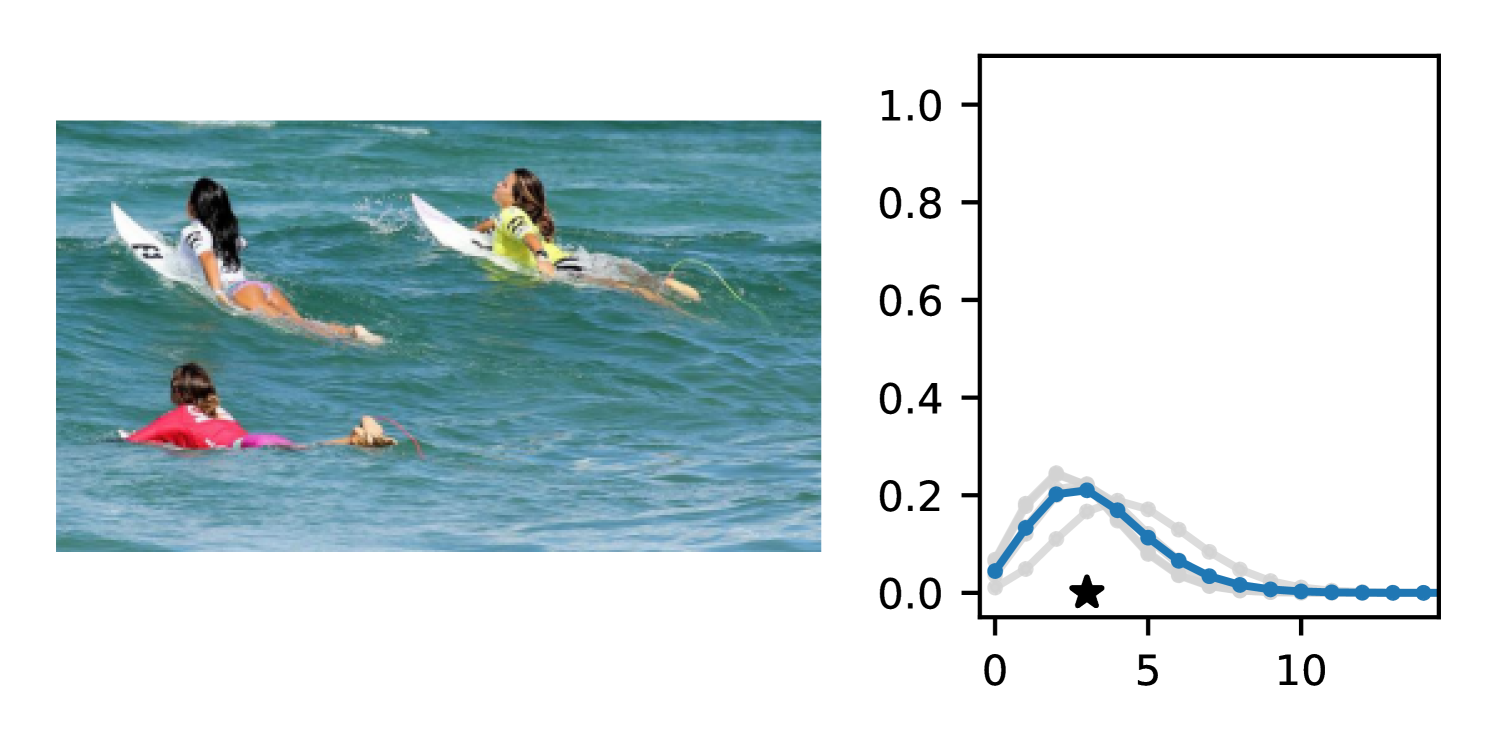
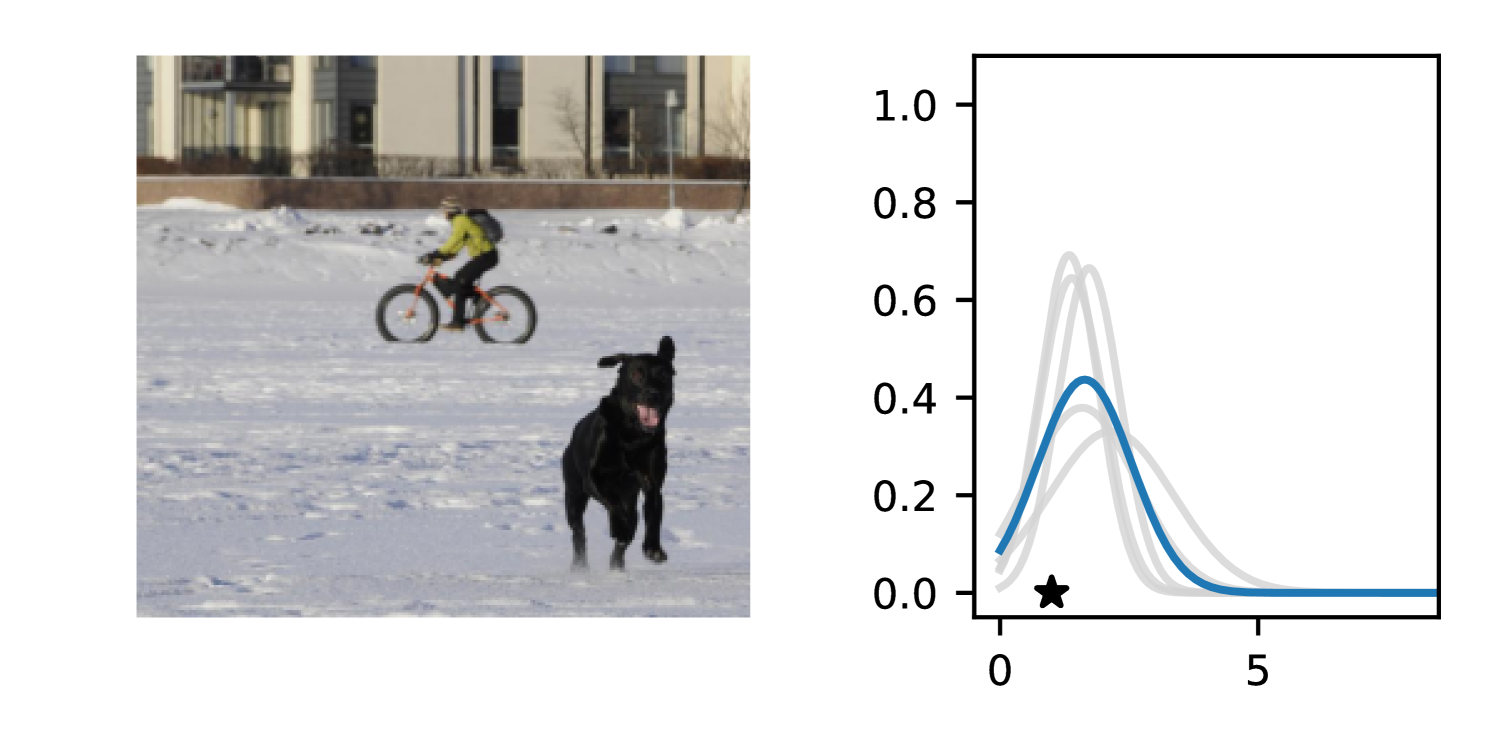
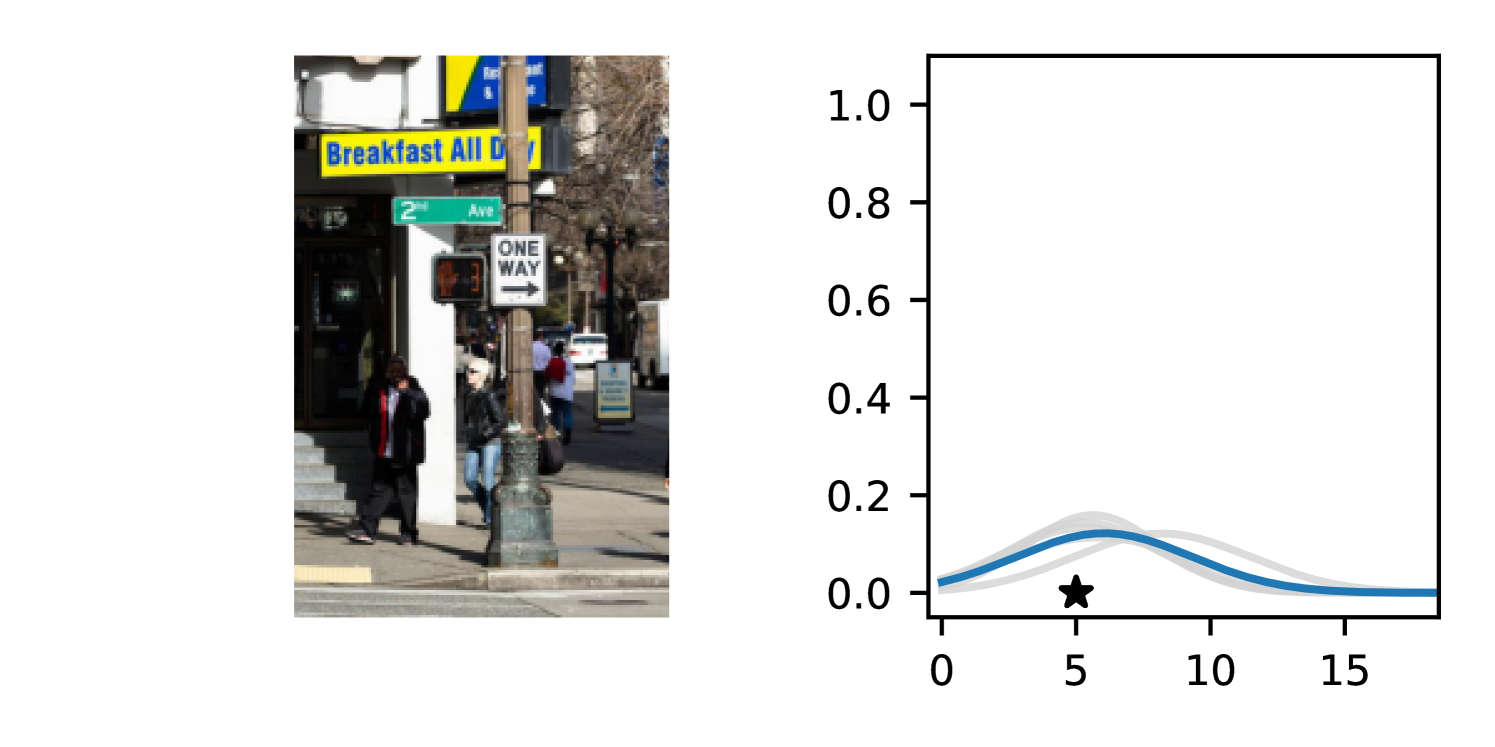
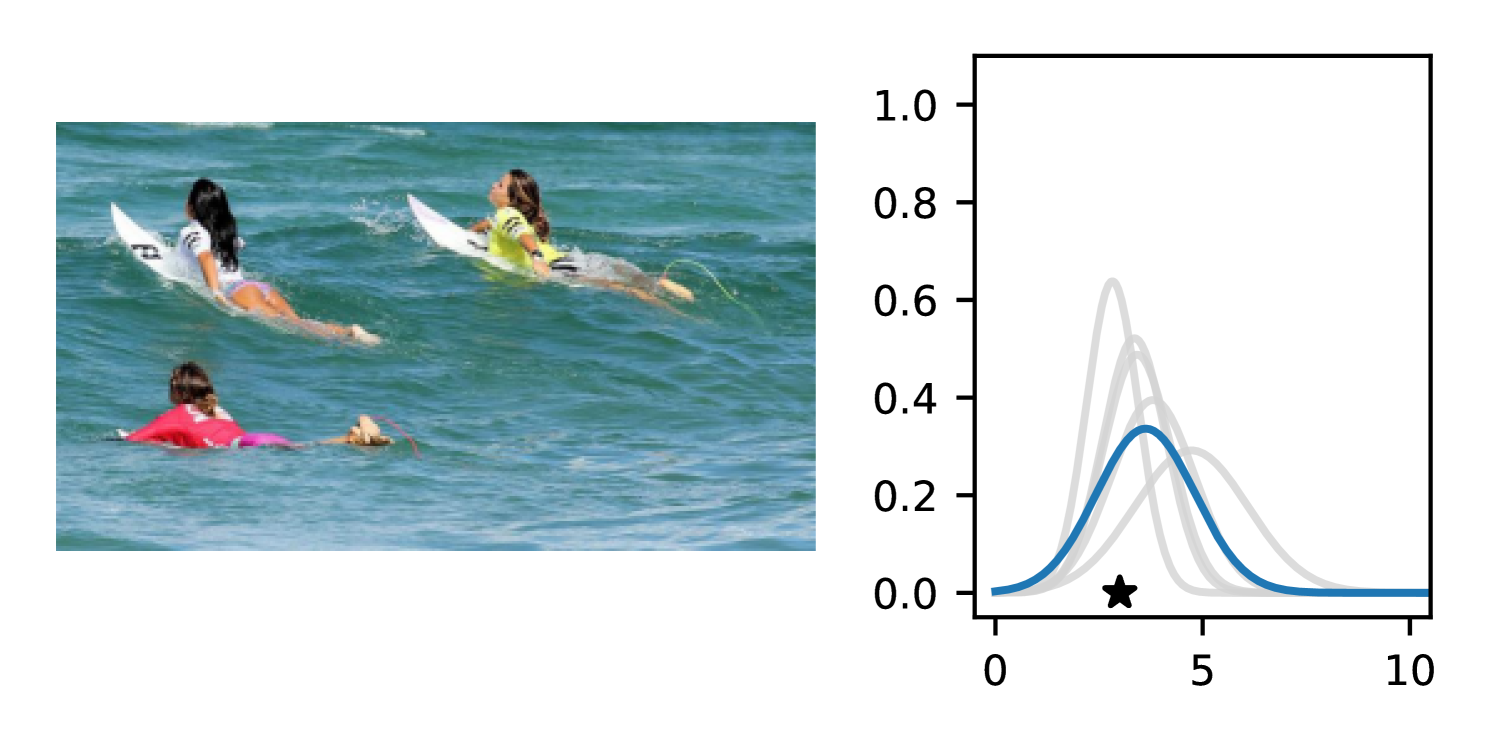
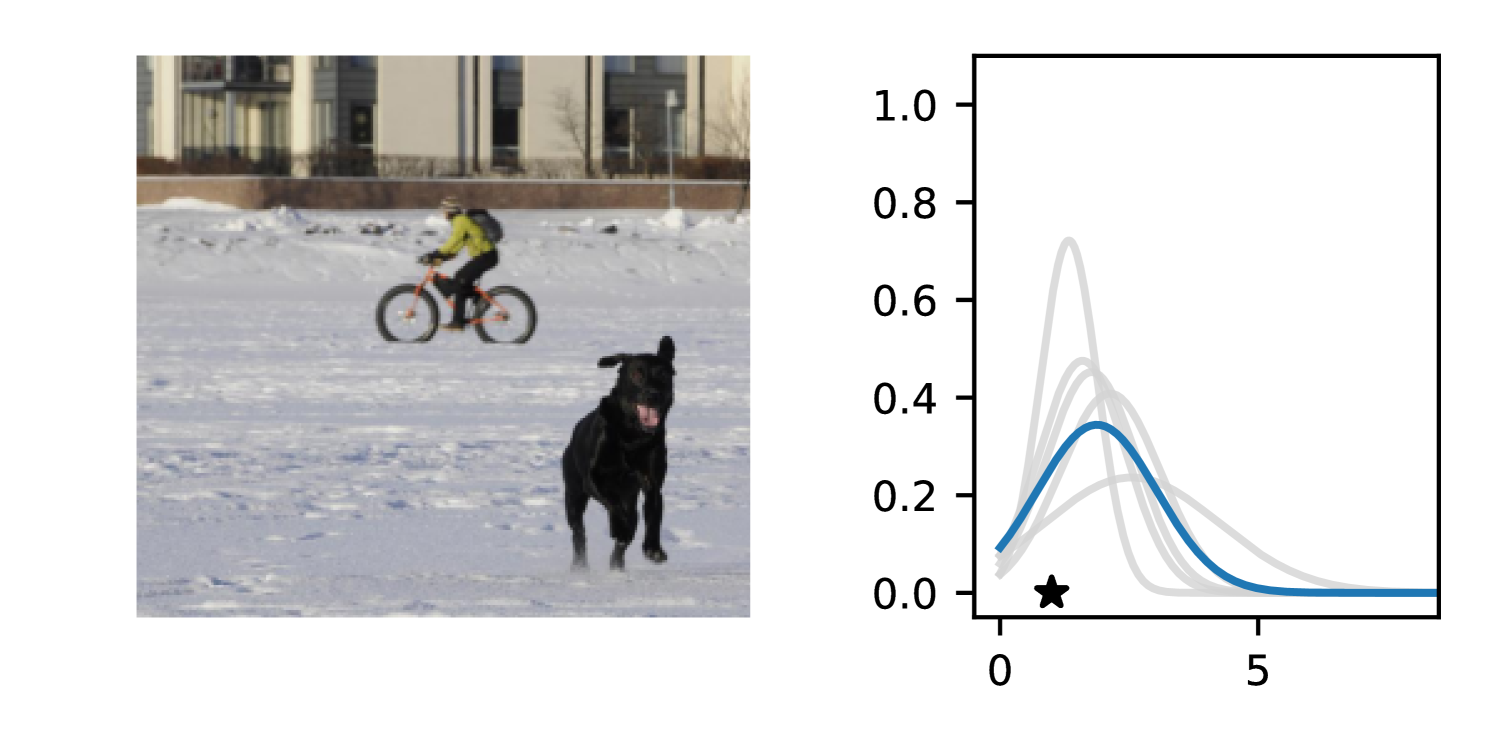
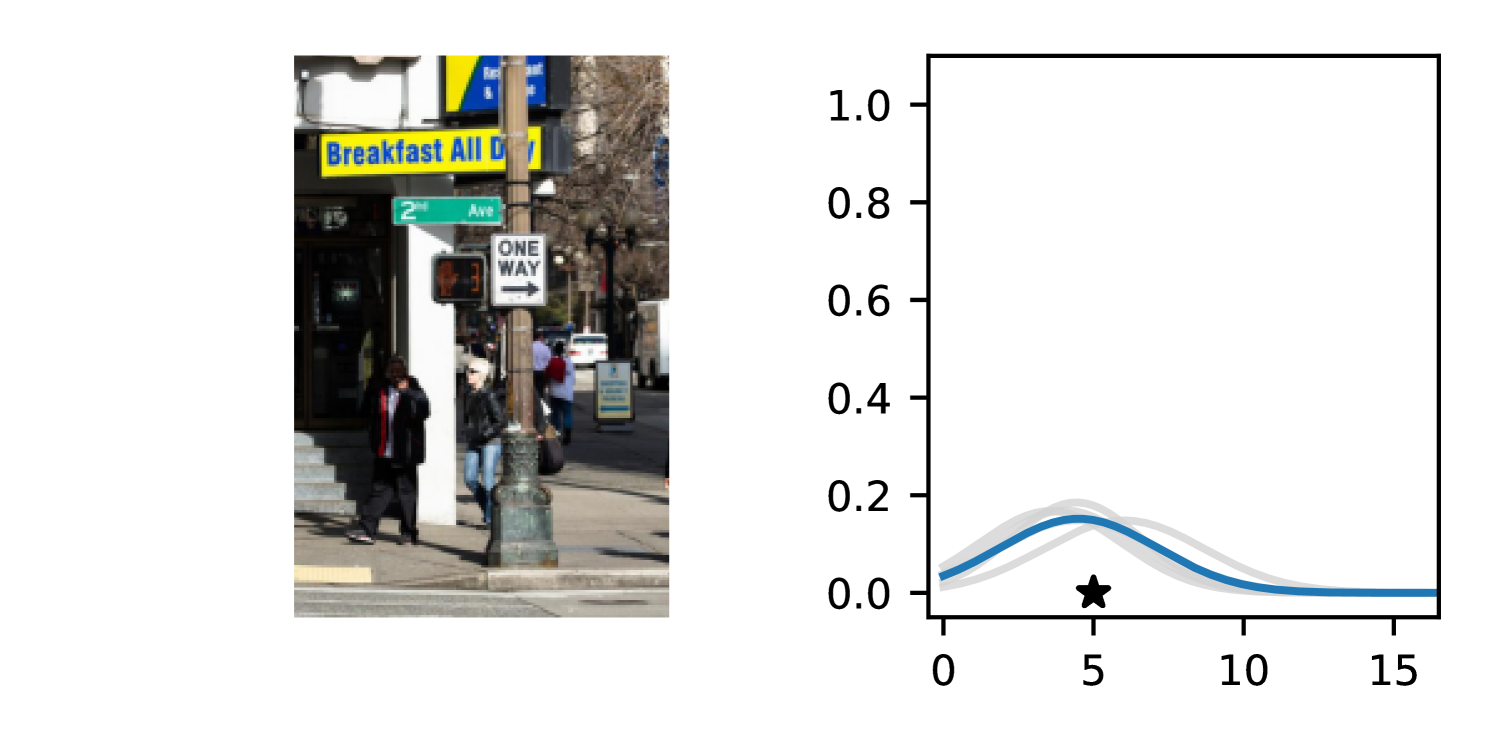
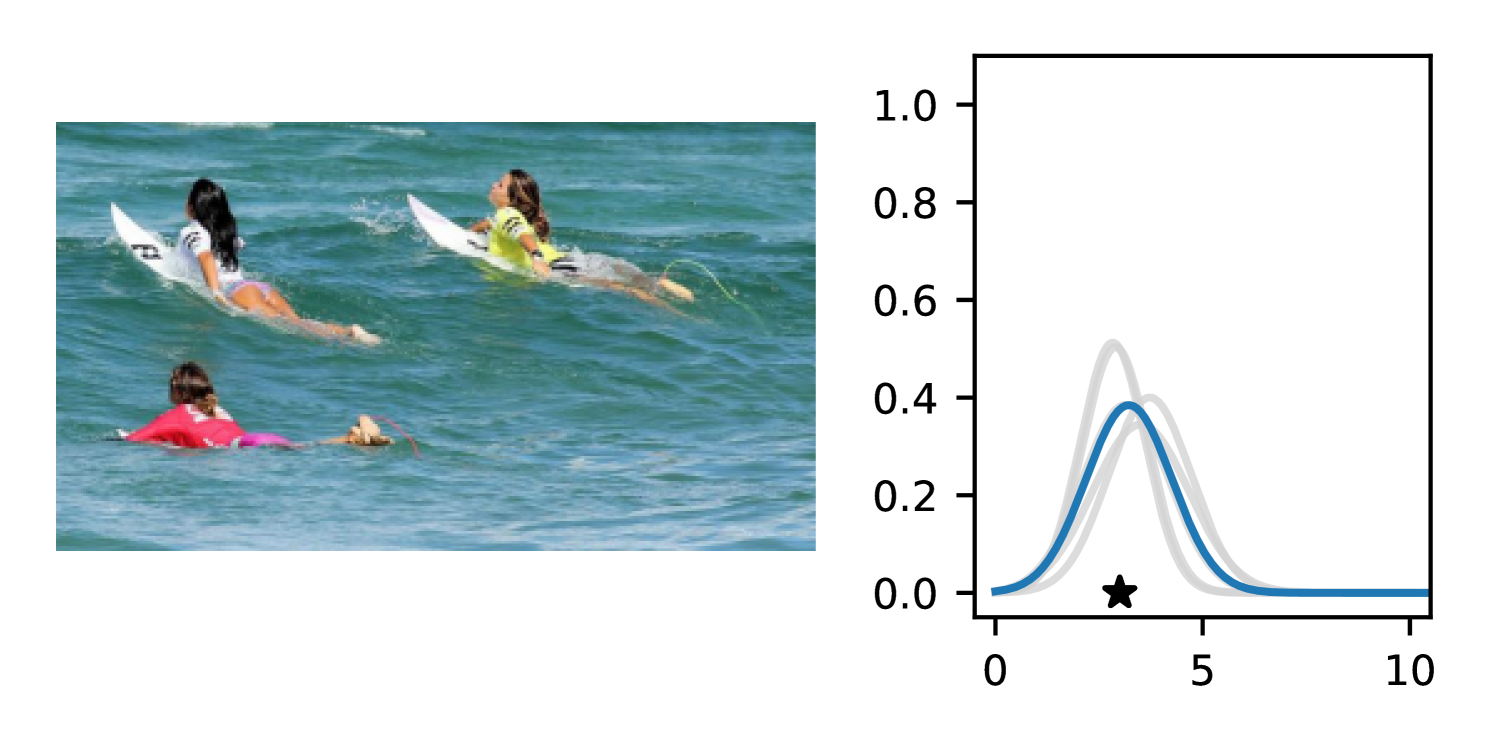
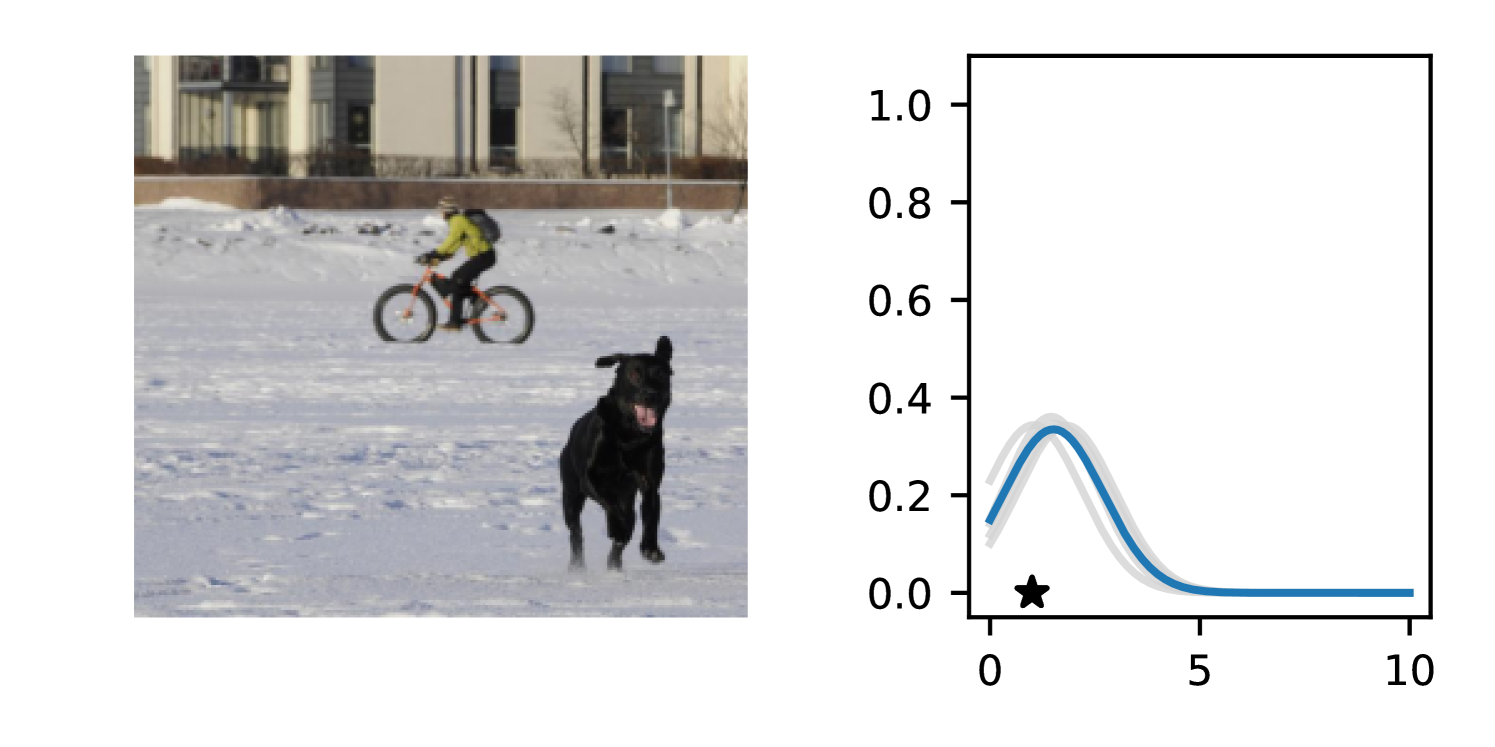
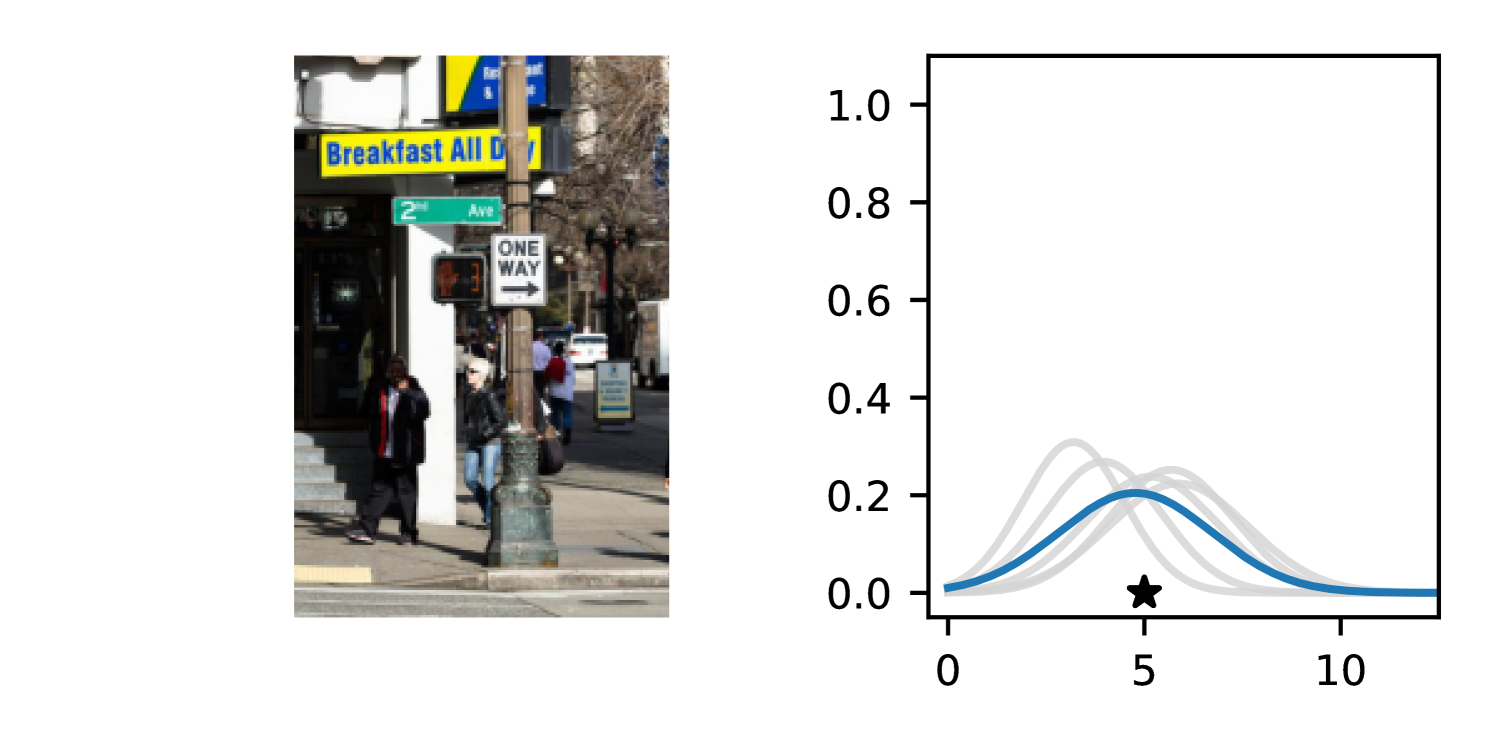
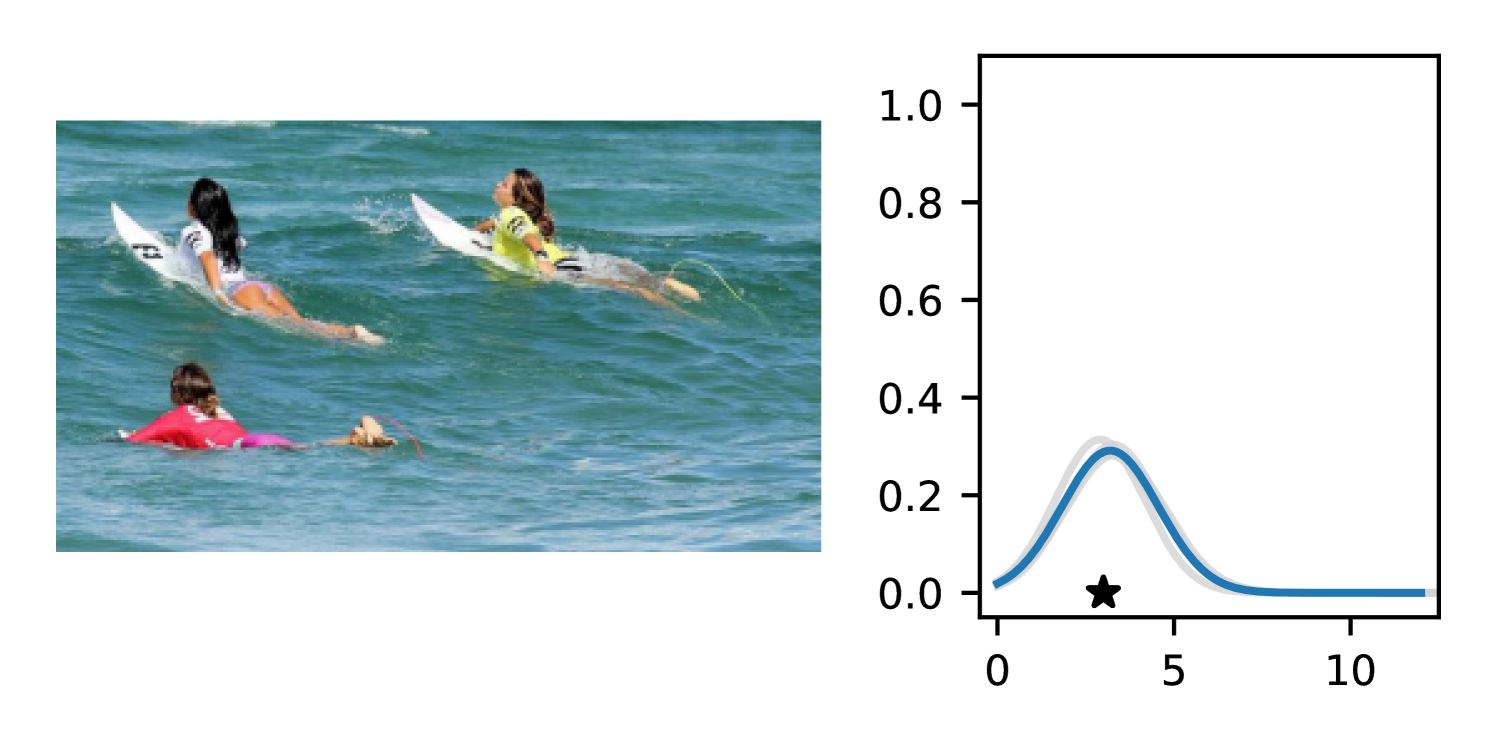
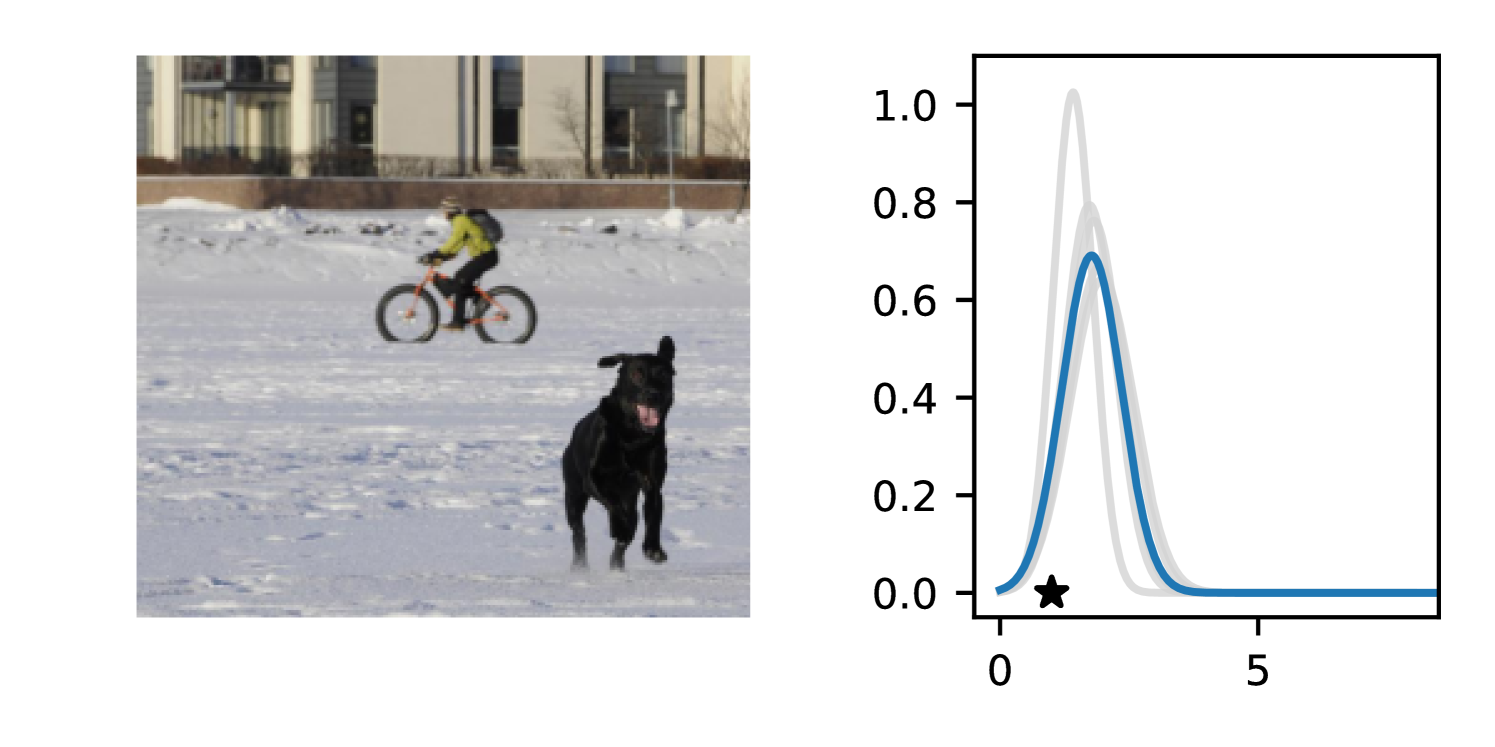
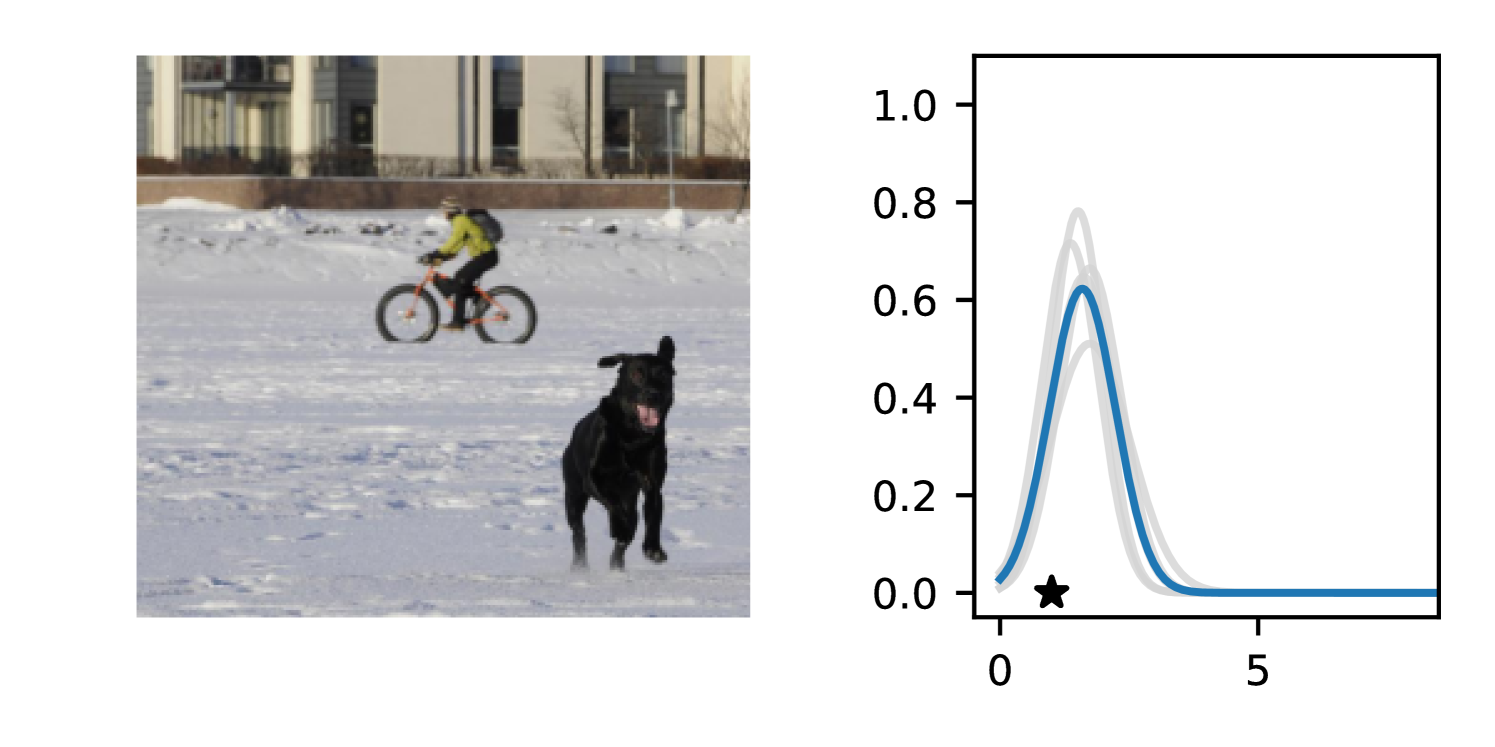
D.2 ID / OOD Predictive Distributions on Amazon Reviews
Figures 30 and 31 visualize the difference (or lack thereof) between ensemble predictions on in-distribution data (in this case, the test split of Amazon Reviews) and out-of-distribution data (verses from the King James Bible). We include predictive distributions for each ensemble baseline presented in Section 4.3.
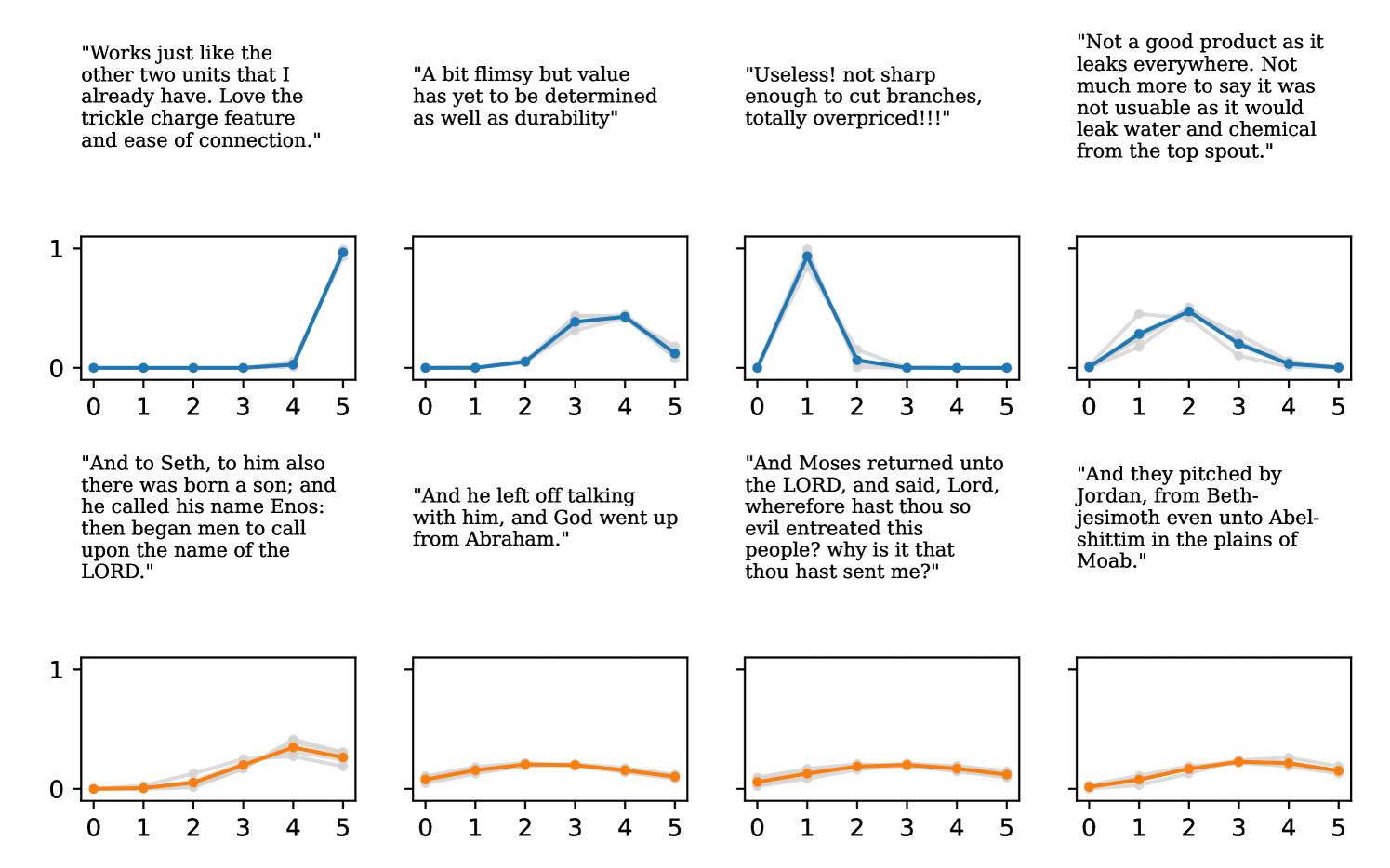
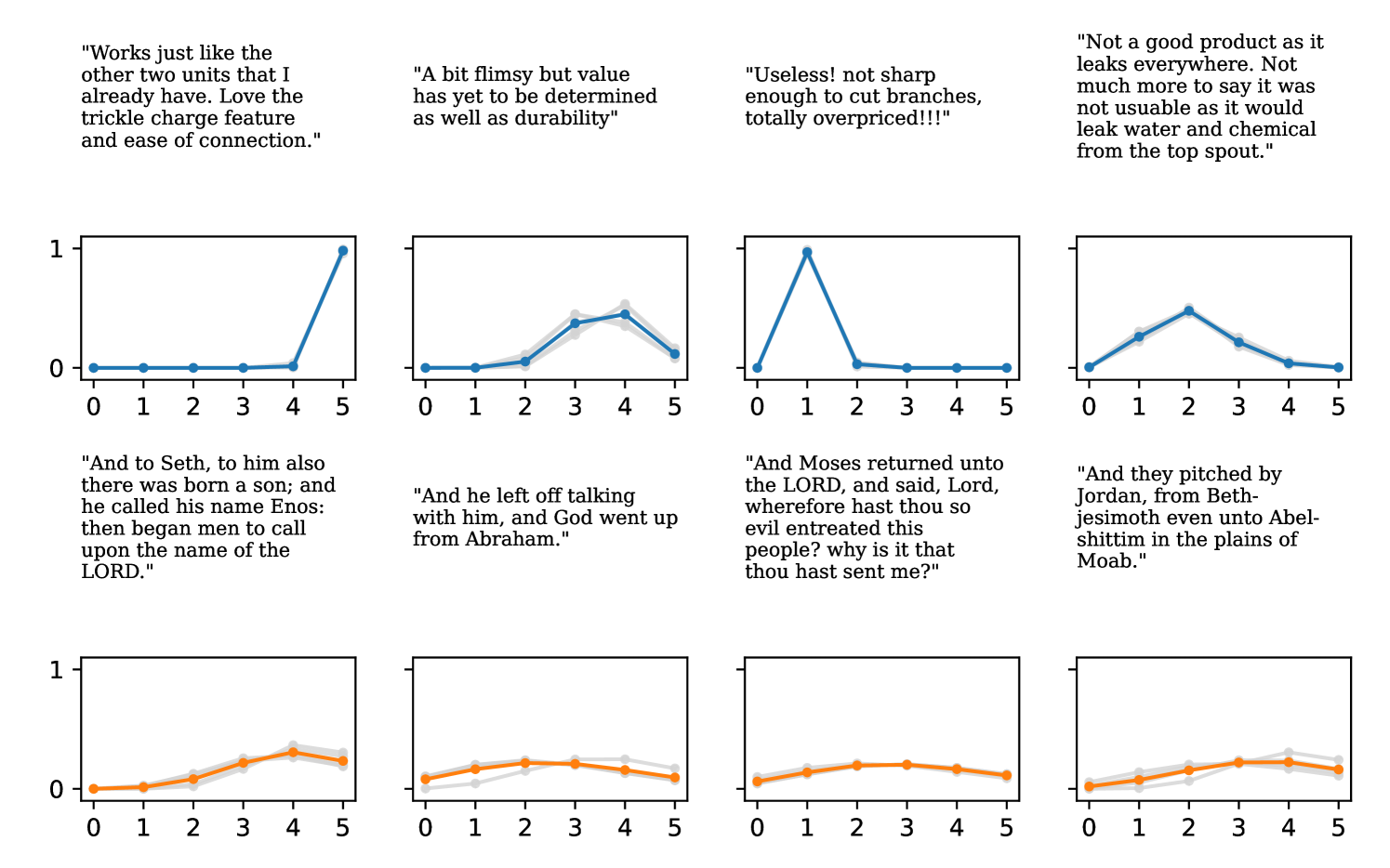
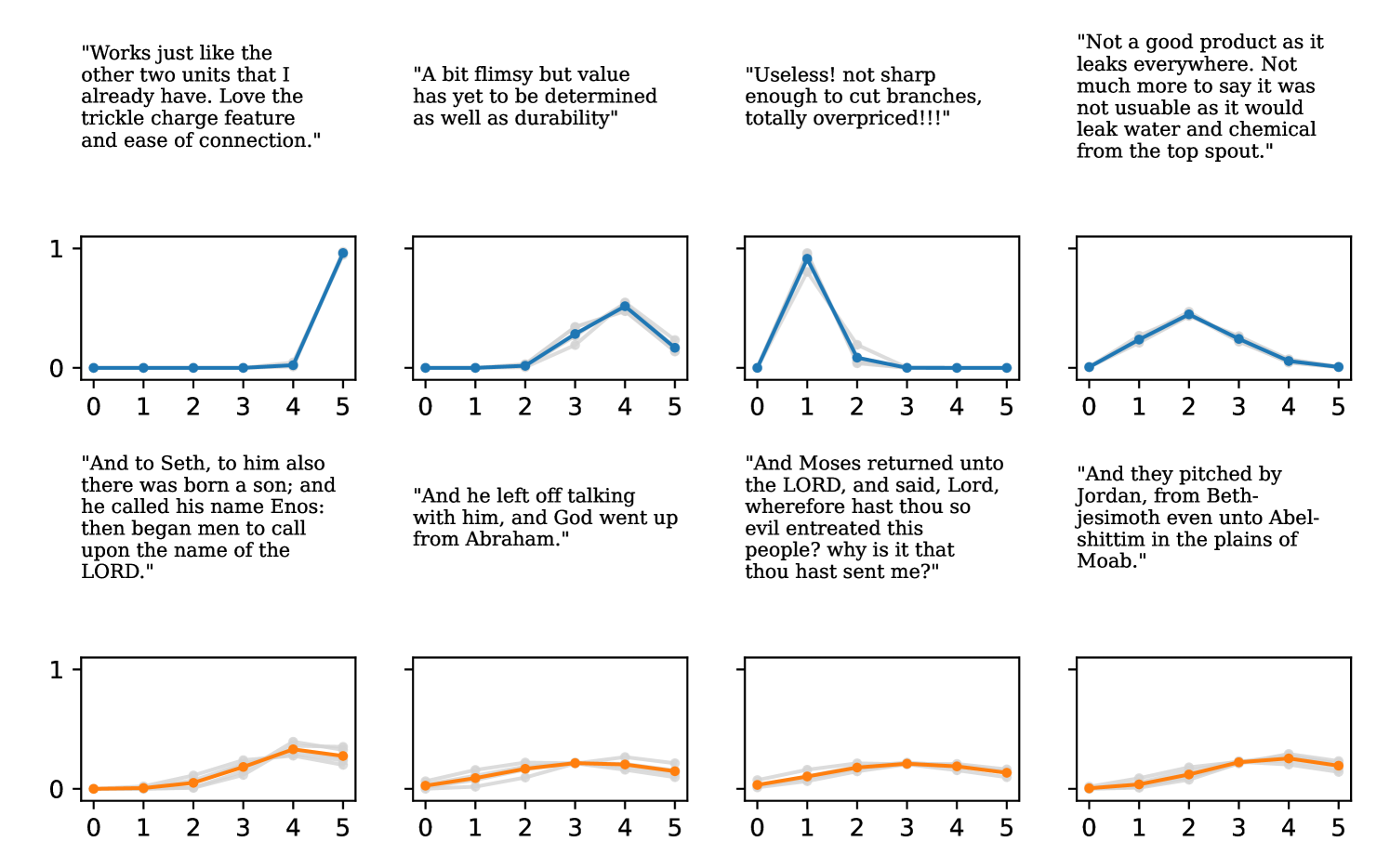
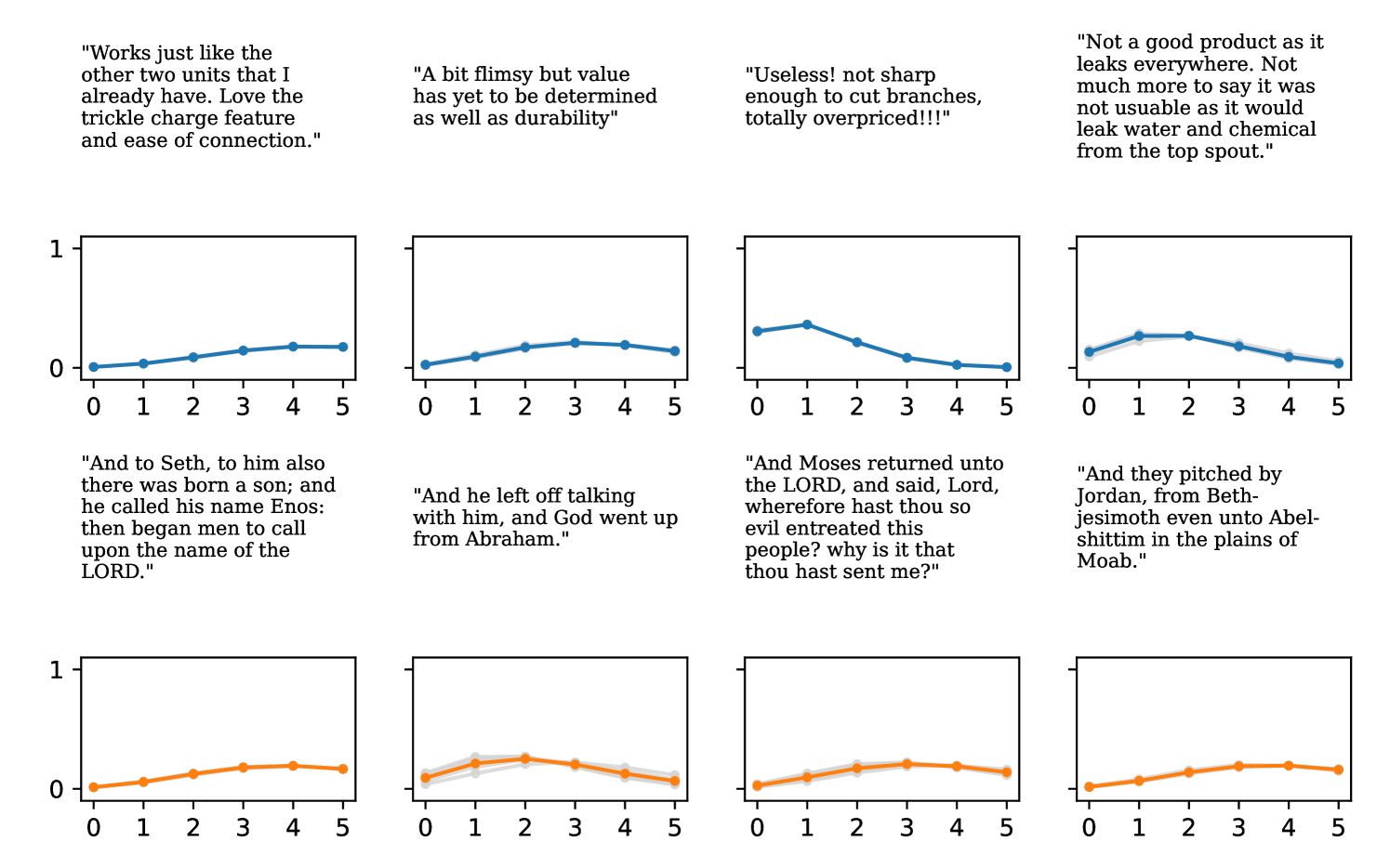
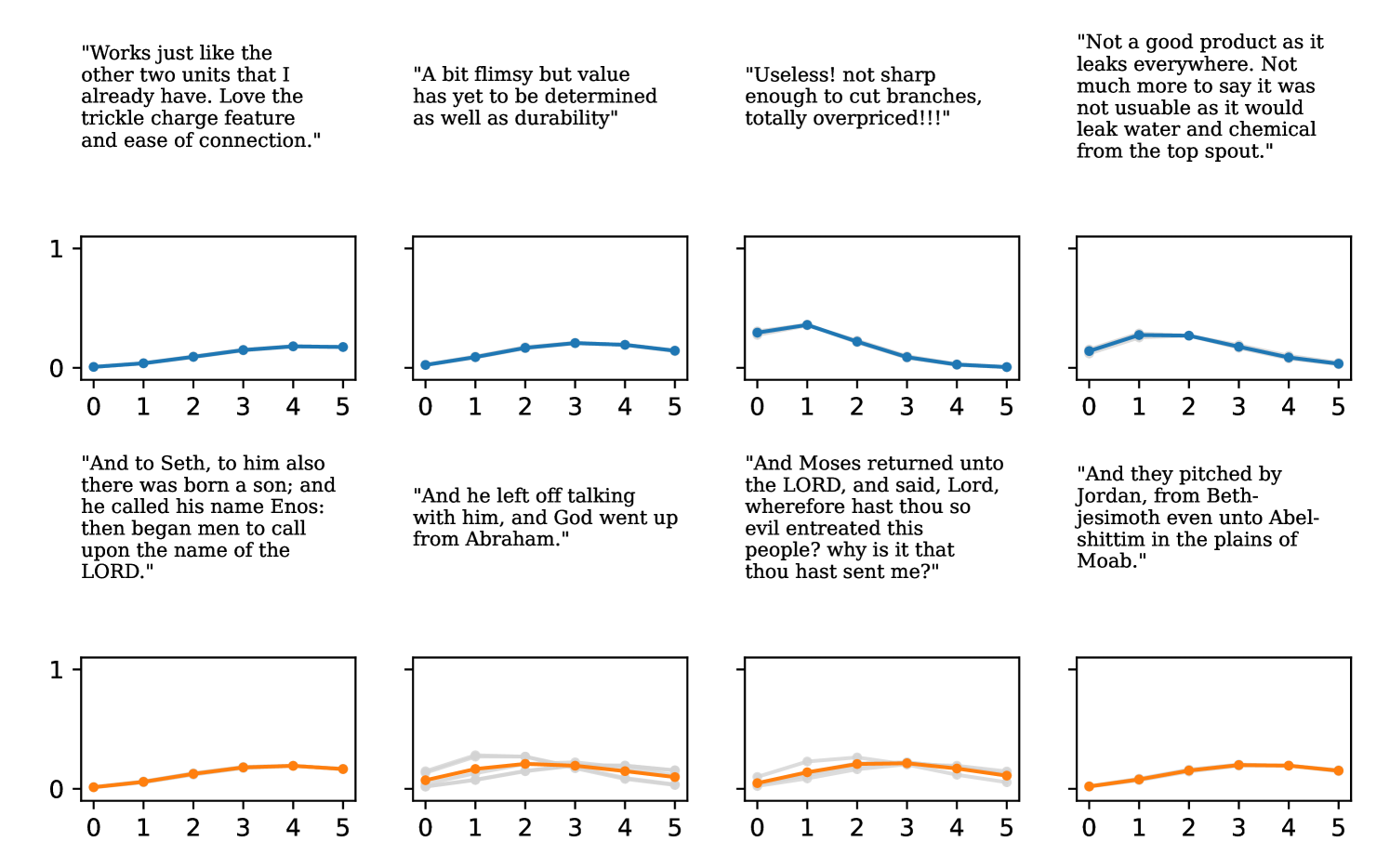
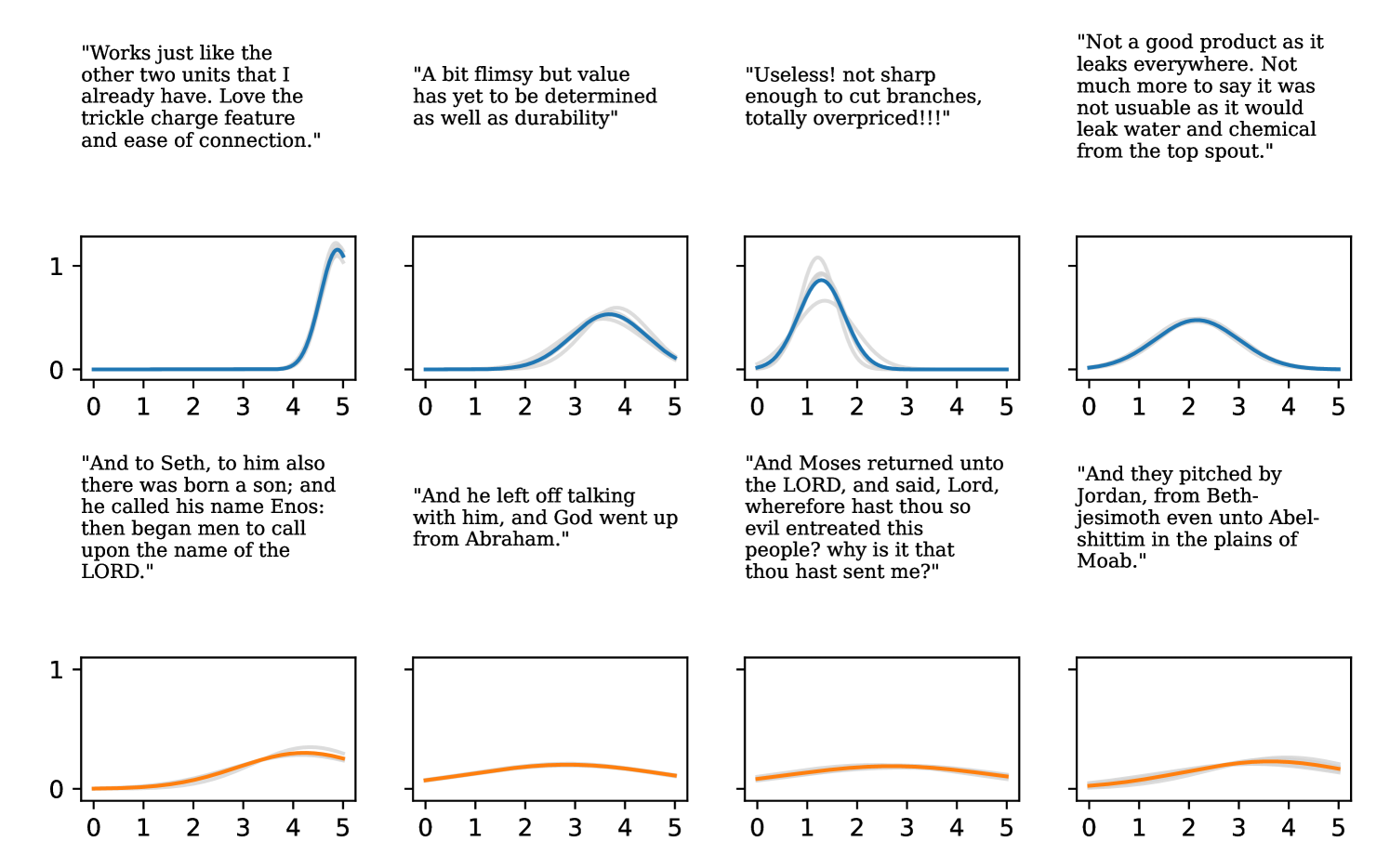
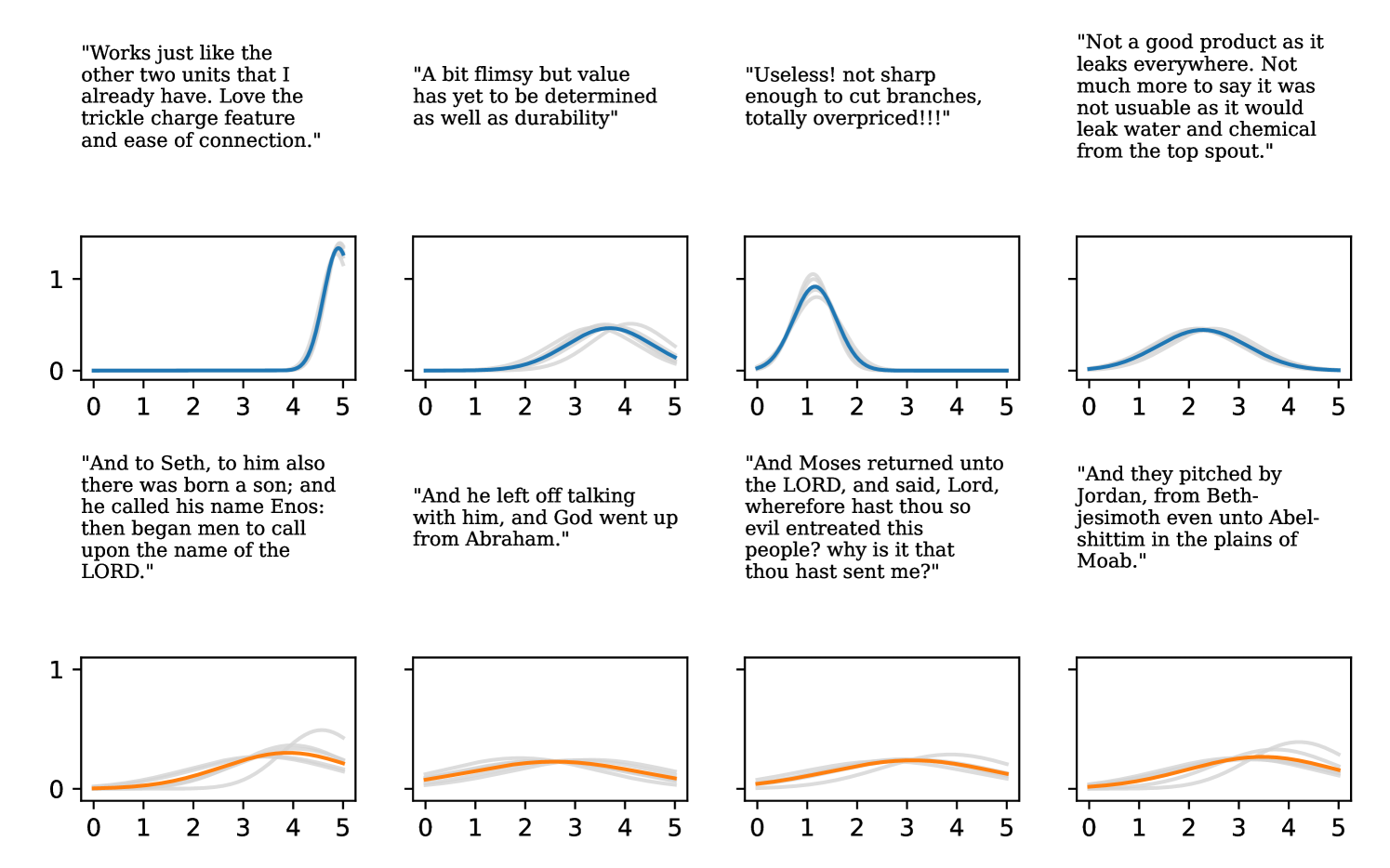
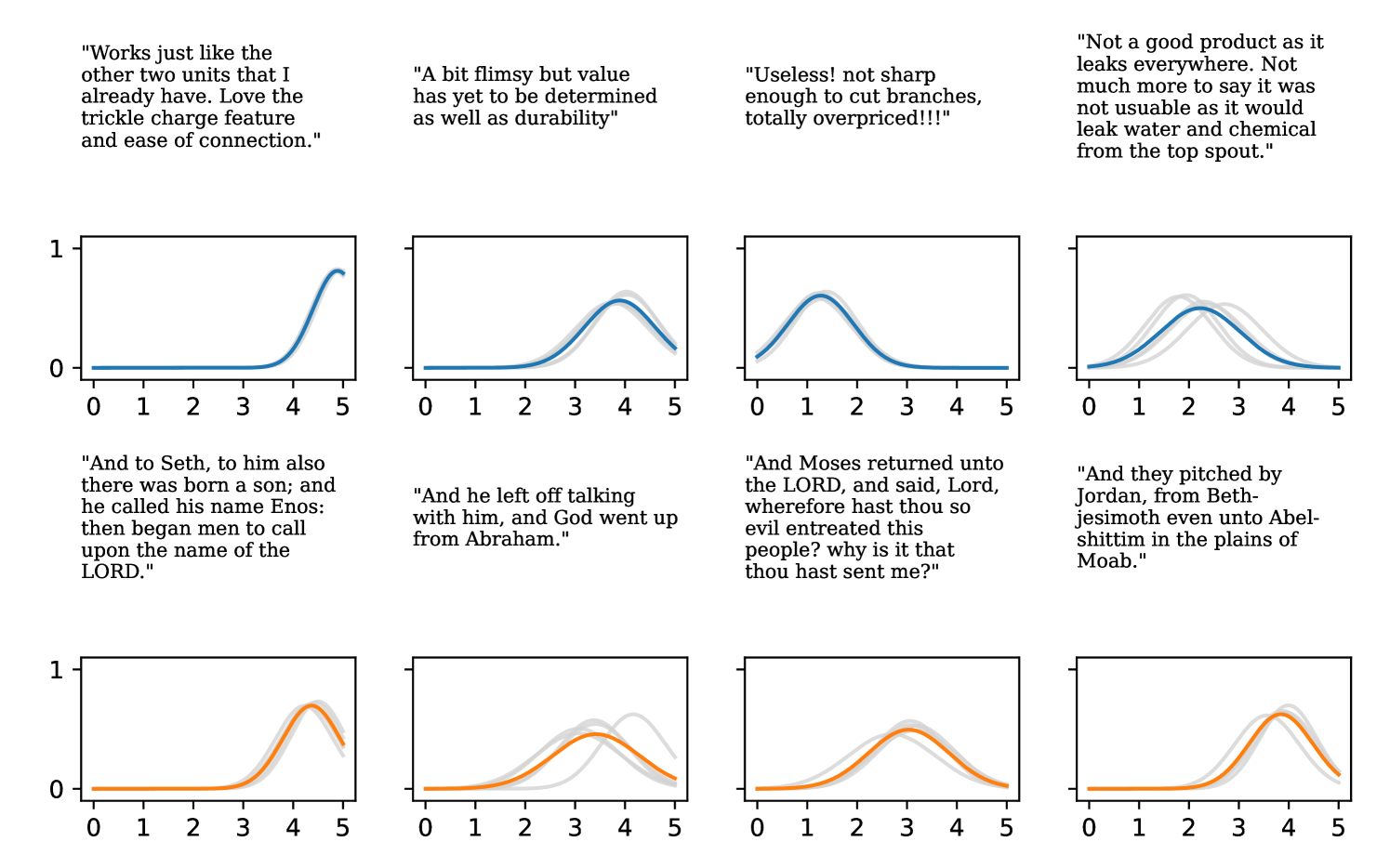
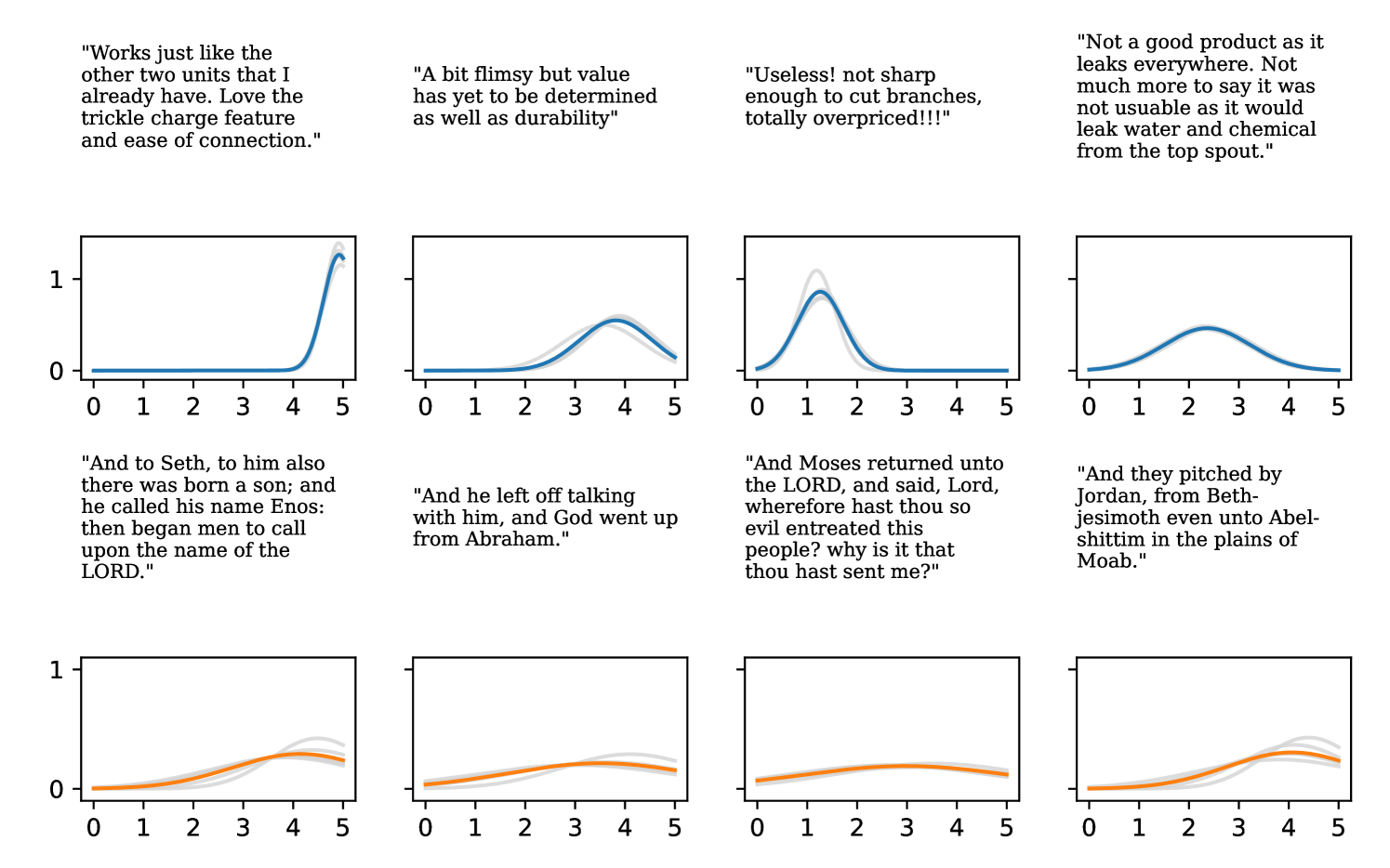
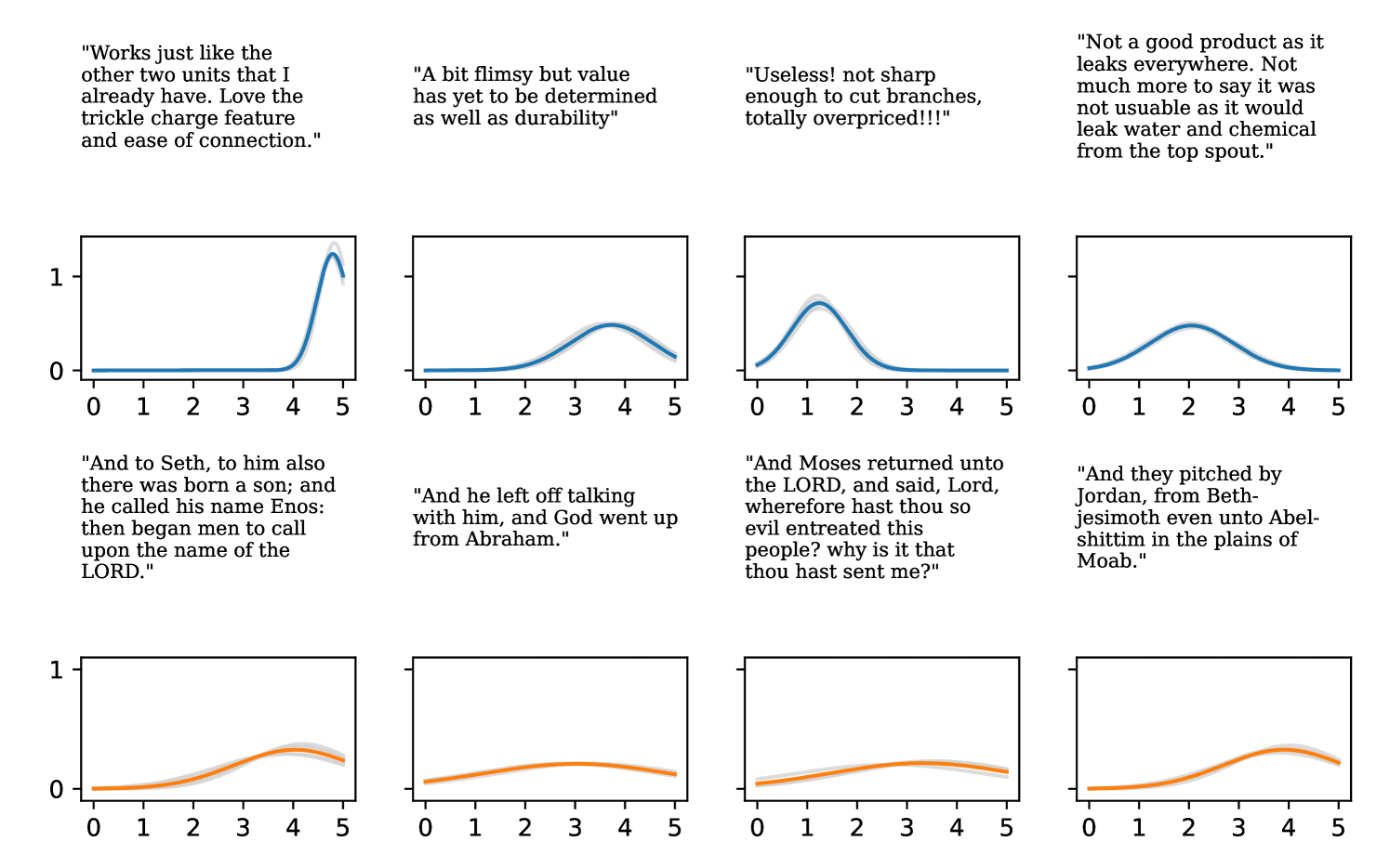
D.3 Example Point Cloud from Inventory
In Figure 32, we provide an example point cloud from the Inventory dataset used in the experiments of Section 4.3. Further examples can be viewed in Jenkins et al. (2023).
