Functional Factor Modeling of Brain Connectivity
Abstract
Many fMRI analyses examine functional connectivity, or statistical dependencies among remote brain regions. Yet popular methods for studying whole-brain functional connectivity often yield results that are difficult to interpret. Factor analysis offers a natural framework in which to study such dependencies, particularly given its emphasis on interpretability. However, multivariate factor models break down when applied to functional and spatiotemporal data, like fMRI. We present a factor model for discretely-observed multidimensional functional data that is well-suited to the study of functional connectivity. Unlike classical factor models which decompose a multivariate observation into a “common” term that captures covariance between observed variables and an uncorrelated “idiosyncratic” term that captures variance unique to each observed variable, our model decomposes a functional observation into two uncorrelated components: a “global” term that captures long-range dependencies and a “local” term that captures short-range dependencies. We show that if the global covariance is smooth with finite rank and the local covariance is banded with potentially infinite rank, then this decomposition is identifiable. Under these conditions, recovery of the global covariance amounts to rank-constrained matrix completion, which we exploit to formulate consistent loading estimators. We study these estimators, and their more interpretable post-processed counterparts, through simulations, then use our approach to uncover a rich covariance structure in a collection of resting-state fMRI scans.
Keywords: functional data analysis, factor analysis, fMRI, functional connectivity, matrix completion
1 Introduction
There exist a number of imaging modalities that allow researchers to measure the physiological changes that accompany neuronal activation. Among the most widely used techniques is functional magnetic resonance imaging (fMRI). FMRI is based on the haemodynamic response wherein blood delivers oxygen to active brain regions at a greater rate than to inactive regions. Blood-oxygen-level-dependent (BOLD) imaging uses magnetic fields to measure relative oxygenation levels across the brain, allowing researchers to use BOLD signal as a proxy for neuronal activation. During an fMRI experiment, a subject is placed in a scanner that collects a temporal sequence of three-dimensional brain images. Each image is partitioned into a grid of three-dimensional volume elements, called voxels, and contains BOLD measurements at each voxel (Lindquist, 2008). The resulting data are both large and complex. The data from a single session typically contains hundreds of brain images, each with BOLD observations at more than 100,000 voxels; large fMRI datasets include hundreds of such scans. Moreover, these data exhibit spatiotemporal dependencies that complicate analysis.
A common goal of fMRI analyses is to characterize functional connectivity, or the statistical dependencies among remote neurophysiological events (Friston, 2011). This is of particular interest in resting-state fMRI, wherein subjects do not perform an explicit task while in the scanner. In this work, we study functional connectivity in resting-state data from the PIOP1 dataset of the Amsterdam Open MRI Collection (AOMIC) (Snoek, van der Miesen, Beemsterboer, van der Leij, Eigenhuis, and Steven Scholte, 2021), which contain six-minute scans collected from 210 subjects at rest. To do so, we develop a new approach that integrates two fields of statistics: factor analysis and functional data analysis.
Techniques used to study resting-state functional connectivity fall in two categories: seed methods and whole-brain methods. To conduct a seed-based connectivity analysis, researchers first select a seed voxel (or region), then correlate the time series of that seed with the time series of all other voxels (or regions), resulting in a functional connectivity map (Biswal, Zerrin Yetkin, Haughton, and Hyde, 1995). Although readily interpretable, these functional connectivity maps only describe dependencies of the selected seed region (Van Den Heuvel and Pol, 2010). Principal component analysis (PCA) is a rudimentary whole-brain approach to functional connectivity that finds the collection of orthogonal spatial maps (a.k.a., principal components) that maximally explains the variation – both between- and within-voxel – in a set of brain images (Friston et al., 1993). The orthogonality constraint, however, means that the low-order subspace is expressed by dense spatial maps containing many high-magnitude weights that complicate interpretation. Independent component analysis (ICA; Beckmann and Smith, 2004), perhaps the most popular whole-brain approach, offers a more parsimonious representation of this subspace. After computing the principal spatial components and associated temporal components from an fMRI scan, ICA rotates these components until the spatial set is maximally independent. Although the resulting spatial maps are typically more parsimonious than those of PCA, ICA may fragment broad areas of activation into multiple maps with highly correlated time courses in its pursuit to maximize spatial independence (Friston, 1998). This means ICA findings are not robust to dimension overspecification.
To address the shortcomings of the above approaches, we develop a method based on exploratory factor analysis. The goal of factor analysis is to describe the covariance relationships between many observed variables using a few unobserved random quantities. Classical factor analyses use the orthogonal factor model (OFM), which posits that zero-mean observed quantities having covariance are the sum of a common component, given by linear combinations of unobserved uncorrelated factors with zero-mean and unit variance, and an idiosyncratic component, given by a vector of uncorrelated errors with zero-mean. The loading matrix specifies the coefficients of these linear combinations in the common component:
If denotes the diagonal covariance matrix of , then decomposes as
The OFM is identifiable only up to an orthogonal rotation since, for and , where is a rotation matrix, we have the equivalences
Practitioners address this rotation problem by choosing from a suite of factor rotation algorithms, like quartimax (Neuhaus and Wrigley, 1954) and varimax (Kaiser, 1958) rotation, that bring the loading matrix closer to a so-called simple structure, where in (i) each variable has a high loading on a single factor but near-zero loadings on other factors, and (ii) each factor is described by only a few variables with high loadings on that factor while other variables have near-zero loadings on that factor. This structure provides a parsimonious representation of the common component and one can opt for a rotation procedure that is robust to dimension overspecification.
To grasp the value of factor analysis in functional connectivity, consider a naive application wherein an OFM is fit to a vector of voxel-wise BOLD observations. Used in conjunction with factor rotation, the OFM would provide simple spatial maps amenable to interpretation. This sparse and low-dimensional representation of the entire brain makes factor analysis an attractive alternative to seed and ICA methods which, respectively, are not whole-brain and lack such interpretable results. However, there is a problem; the OFM crucially assumes that its errors are uncorrelated, a condition violated in this application given that errors for nearby voxels will be correlated. Such autocorrelation may dissipate as grows, but this has two undesirable effects. First, the parsimony of the low-order model is lost. Second, a high-order common component will capture variation at small scales – possibly even between adjacent voxels – an outcome at odds with the purpose of functional connectivity studies: to study correlations between distant brain regions. In a more appropriate factor model, the common component would be low-rank and capture only large-scale variation while its error term would permit variation at a smaller scale.
To develop this better suited factor model, it helps to view fMRI data in the functional data analysis (FDA) framework. Data are said to be functional if we can naturally assume that they arise from some smooth curve. FDA is then the statistical analysis of sample curves in such data (Ramsay and Silverman, 2005; Wang et al., 2016; Kokoszka and Reimherr, 2017). Since it is reasonable to view BOLD observations of a brain image as noisy realizations from some smooth function over a three-dimensional domain, fMRI data is an example of multidimensional functional data. Though not widely adopted by the neuroimaging community, fMRI has been studied using FDA tools such as functional principal component analysis (FPCA; Viviani et al., 2005), functional regression (Reiss et al., 2015, 2017), and functional graphical models (Li and Solea, 2018). To adapt factor analytic techniques to fMRI data, we can extend classical factor methods to this functional setting.
Early extensions of the OFM come from studies of large-dimensional econometric panel data, in which time series (e.g., one time series per asset) are observed at the same points in time. When is large, traditionally reliable time series tools (e.g., vector autoregressive models) require estimation of too many parameters. Factor models are a practical alternative as they provide more parsimonious parameterizations. These factor models should, however, possess two characteristics to accommodate properties inherent to economic time series. First, they ought to be dynamic as problems involving time series are dynamic in nature. Second, they should permit correlated errors as uncorrelatedness is often unrealistic with large . Sargent and Sims (1977) and Geweke (1977) innovated on the OFM by making latent factors dynamic in their dynamic factor model (DFM). However, these early DFMs were exact in that they assumed uncorrelated errors. Factor models did not permit such error correlation until Chamberlain and Rothschild (1983) introduced their approximate factor model (AFM), which required only that the largest eigenvalue of the error covariance be bounded. Although this AFM was static, much subsequent study focused on factor models that were both approximate and dynamic (Forni et al., 2000; Stock and Watson, 2002; Bai, 2003).
Factor models are well-studied in large dimensions, but the literature on infinite-dimensional factor analysis is scarce. Hays et al. (2012) were the first to merge ideas from FDA with factor analysis in their dynamic functional factor model (DFFM) which they used to forecast yield curves. Liebl (2013) proposed a different DFFM which, unlike the model of Hays et al. (2012), placed no a priori constraints on the latent process of factor scores. Kowal et al. (2017) presented a Bayesian DFFM for modeling multivariate dependent functional data. None of these early functional factor models permit any degree of error dependence, a structure that certainly arises when representing potentially infinite-rank observations with low-rank objects. Otto and Salish (2022) were the first to address this issue using their approximate DFFM wherein the error covariance is left unrestricted. However, as this is a model for completely-observed functional data, one must either observe these data at infinite resolution (a practical impossibility) or obtain functional representations of discretely-observed sample curves via spline smoothing (Ramsay and Silverman, 2005) prior to model estimation.
Though spline smoothing (and other forms of pre-smoothing) may be an effective first step in many analyses of functional data, it is not in factor analysis. Analyses that begin by smoothing functional data assume that a functional observation is the sum of two uncorrelated components: a smooth signal and a white noise term whose covariance kernel is zero off the diagonal (or some infinitesimally narrow band). When observed at discrete points,
the smoothed curve is defined as
| (1) |
When is white noise, is a good approximation to . If, instead, the signal and the error are defined as in our theorized factor model – the former capturing only large-scale variation and the latter permitting small-scale variation – then minimizing the “uncorrelated” objective of (1) yields a smoothed curve contaminated by short-range variation of the error term, making it a poor approximation to . Using as a stand-in for in subsequent analyses is ill-advised. Thus, a factor model for functional data should not presume completely-observed sample curves, but rather deal directly with discretely-observed data.
As it turns out, an orthogonal factor structure indeed underlies discretely-observed functional data. Hörmann and Jammoul (2020) formalized this observation, noting, however, that the assumption of uncorrelated errors is rarely justified. They suggest that a more realistic factor model would permit error correlations that “taper to zero with increasing lag.” But this poses an identifiability question: is it possible to distinguish such error dependence from that residing in the common component? Descary and Panaretos (2019) show that this is, indeed, possible if one assumes the covariance of the common term is smooth with low rank and that of the error term is banded with potentially infinite rank. These assumptions give rise to a distinctly functional re-characterization of the common and idiosyncratic components of the OFM: the former becomes “global”, capturing dependencies between distant regions of the domain, while the latter becomes “local”, describing dependencies between nearby regions. As this is the precise perspective put forth by our theorized factor model for functional connectivity, we let the ideas of Descary and Panaretos (2019) guide the development of this model.
In this paper, we develop a factor analytic approach for discretely-observed multidimensional functional data that is well-suited to the study of functional connectivity in fMRI. Our methodology is inspired by the framework of Descary and Panaretos (2019), which we build upon in three key respects. First, we extend their conditions for identifying the global and local components of a full covariance to multidimensional functional data, and show that these conditions become less restrictive as the dimensionality grows. Second, we improve upon their global covariance estimator by incorporating a roughness penalty. Third, we develop a post-processing procedure – inspired by methods from classical factor analysis – that facilitates interpretation of global estimates. Using this new approach, we uncover a rich covariance structure in the 210 resting-state scans from the AOMIC-PIOP1 dataset.
The rest of this paper proceeds as follows. In Section 2, we introduce functional factor models for both completely- and discretely-observed functional data, and present identifiability conditions for both. In Section 3, we develop estimation methods for the discretely-observed functional factor model. We then take a brief detour, in Section 4, to review an ICA-based approach used throughout the neuroimaging community. In Section 5, we use simulations to compare our estimator to that of this ICA-based approach and several other comparators. Section 6 contains an application of our approach to the AOMIC resting-state data which we contrast with an application of the ICA-based estimator. We conclude, in Section 7, with some final remarks and future work.
2 The Functional Factor Model and its Identification
This section considers two data observation paradigms: (i) data observed completely (e.g., a brain image with infinite spatial resolution, making it a function), and (ii) data observed discretely on a grid (e.g., a brain image with finite spatial resolution, making it a tensor). Given that our methodology forgos the usual data smoothing step in many analyses of functional data, the completely-observed paradigm is not practically possible. We instead use this first paradigm as an intermediate step in the development of our theory for the second. Unless otherwise specified, let or denote scalars, or denote vectors, denote matrices, denote tensors, and denote operators.
2.1 Completely-Observed Data
In the completely-observed paradigm, we assume is a mean-zero random function in , which is endowed with the usual inner product and norm:
We may view , in the fMRI setting, as a 3-dimensional () brain image at infinite spatial resolution, an object conceivable only in theory. The covariance operator of is the integral operator with kernel
We say follows a functional factor model (FFM) with factors if
where and denote the th loading function and factor, respectively, and is the error function. In the spirit of classical factor models, this model assumes the are uncorrelated, mean-zero with unit variance, and independent of the mean-zero , and that the are linearly independent. In this functional setting, we want the components and to capture global and local variation in , respectively. If we assume the are sufficiently smooth (in a sense to be defined in Section 2.1.1), then , being a finite sum of these smooth functions, will contain the global variation in but fail to capture all of the function’s local variation. If we further assume has -banded covariance, i.e., when for some , , then the error function will contain only that local variation not captured by . When is an infinite-resolution brain image, this model decomposes into the sum of two images: one defined by a finite linear combination whose components (i.e., loading functions) describe dependencies between distant brain regions, and another that captures dependencies between nearby regions.
If the global component has covariance with kernel , and the local component has covariance with kernel , then
Moreover, being covariances, and admit the Mercer decompositions
Since the assumptions of the model also imply
the loading functions are equal to the scaled eigenfunctions of , , up to an orthogonal rotation. This makes it possible to impose smoothness on the loading functions through the eigenfunctions of , as we do in Section 2.1.1.
Like many latent models, the FFM is rotationally indeterminate. That is, if loading functions satisfy model constraints, then so do any orthogonal rotation of these functions (see Section 2 of Supplement A for a detailed explanation). In the fMRI context, this means there are infinitely many ways to express the global component via spatial map sets of size , and each set is a rotation away from the rest. Classical factor analysis addresses this rotation problem by bringing the loadings closer to a simple structure. We explore such approaches in Section 3.2.
2.1.1 Identification of from
Despite rotational indeterminacy of the loading functions, we may still hope to identify the global and local covariance components from . Thus far, we have imposed two critical conditions on this covariance decomposition: (i) has finite rank, and (ii) has banded covariance. These restrictions, however, do not sufficiently constrain the problem. Given , we know off the band, but it is not clear how to uniquely extend onto the band. Now, if were contaminated by only on its diagonal (i.e., is -banded), then we could simply assume to be continuous and smooth over this diagonal. However, this strategy does not suffice in the presence of a nontrivial band. Recall that in Section 2.1, we alluded to an additional assumption on the smoothness of the eigenfunctions of . In Theorem 1 from Section 3.1 of Supplement A, which extends Theorem 1 from Descary and Panaretos (2019), we formalize this condition through the notion of analyticity, showing that real analytic loading functions provide the formulation of smoothness needed to identify the covariance decomposition. To prove this result, we exploit the so-called analytic continuation property, which states that if a function is analytic over some domain, but is known only on an open subset of that domain, then the function extends uniquely to the rest of the domain. This property allows us to uniquely extend onto the band, thereby establishing a unique decomposition of the full covariance. When is an infinite-resolution brain image, this condition implies that the loading functions, which capture correlations between distant brain regions, are analytically smooth over the domain of the image.
2.2 Discretely-Observed Data
In practice, we can measure a function at only a finite number of locations. In fMRI, these locations are an evenly-spaced 3-dimensional grid of voxels. This manuscript assumes such a grid, although Section 3.2 of Supplement A presents theory for a more general discrete-observation framework. Let be an evenly-spaced grid where is the grid resolution and is the set of all -dimensional multi-indices with th component no greater than (i.e., ). In the case of the AOMIC dataset which contains brain images of dimension , we have resolution with dimension , and denotes the location of the voxel at grid position . Suppose we observe each of the samples of at the grid points,
If we summarize the functional terms in the model with the tensors
then we can compactly write the M-resolution functional factor model with factors as
Defining the covariance tensors
we can invoke the model’s assumptions, which carry over from the completely-observed setting, to decompose the covariance as
where denotes the usual tensor product, and the loading tensor is equal to the th scaled eigentensor of , , up to a rotation. For notational simplicity, we will often suppress the in the superscript when writing tensors. We will also say that tensors with dimension and simply have dimensions and , respectively. This allows us abbreviate and with and , respectively.
2.2.1 Identification of from
The rotation problem discussed in Section 2.1 extends to this finite resolution framework. That is, given , we can only identify the loading tensors up to a rotation. Yet we may still hope to identify (, ) from . This, however, is not obviously possible as analyticity, which was used to establish uniqueness in the completely-observed setting, is a property of functions, not of tensors. Descary and Panaretos (2019) showed that when this covariance decomposition is indeed unique at finite resolution and that analyticity plays a central role. In Theorem 4 from Section 3.2 of Supplement A, we extend their result to general , and show that the central identification condition becomes less restrictive as grows:
| (2) |
Condition (2) reveals that at finite resolution, identification depends crucially on the relationship between the bandwidth , resolution , and rank of the smooth operator . From a factor analytic perspective, for fixed and , this condition gives the maximum number of identifiable factors (up to a rotation). Figure 1 shows that these parameter constraints are not very restrictive. Of particular note is the order- polynomial growth of the maximal rank in . This means that in fMRI, where is typically large and , the functional -factor model will be identifiable up to a rotation for any practically reasonable .
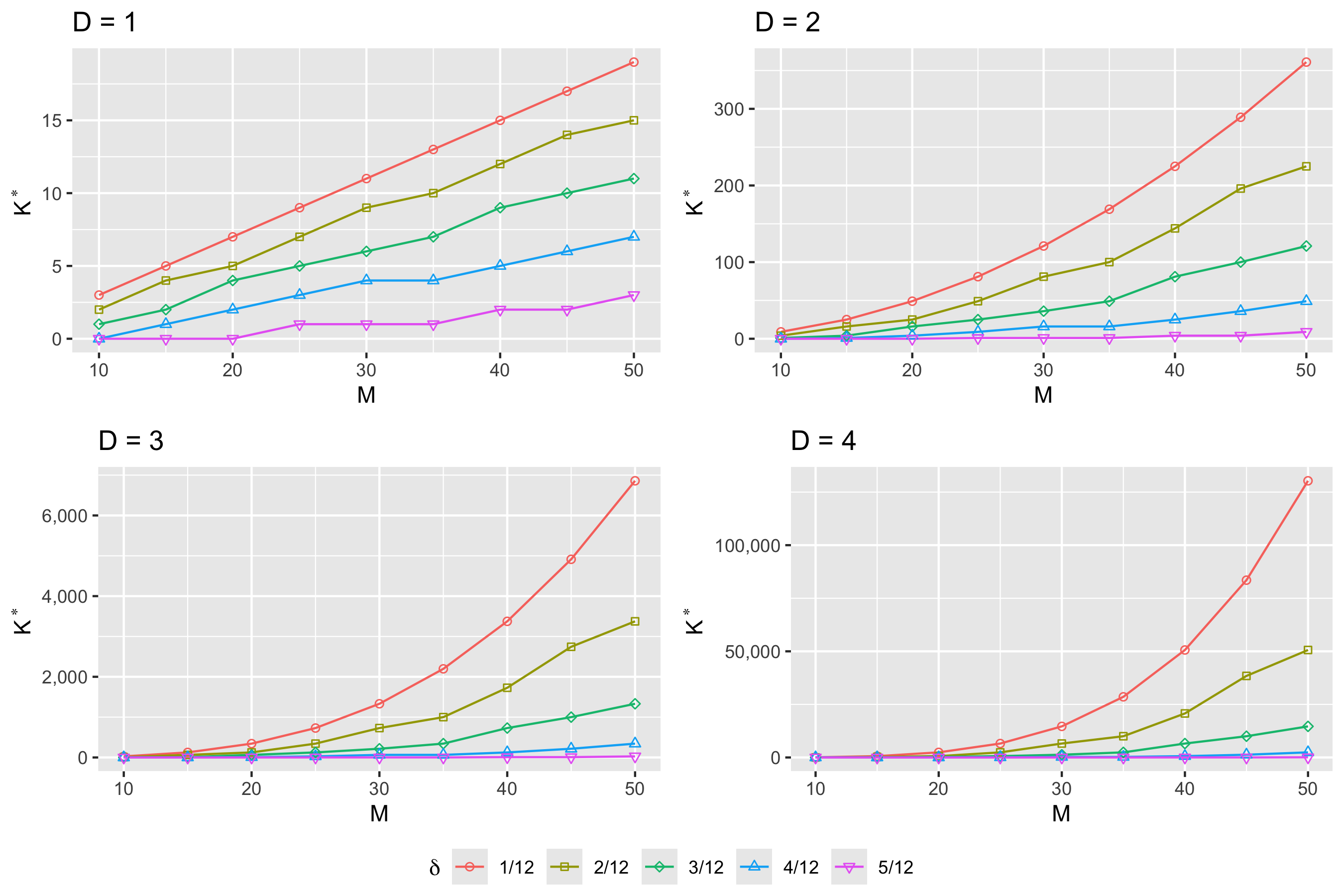
3 Estimation
In this section, we formulate estimation in the discrete observation paradigm. The methodology is split in two phases: initial loading estimation and post-processing. In the first phase, we define an estimator for , from which we derive estimates for the number of factors and the loading tensors . To estimate the through , we must assume that these are orthogonal. This, of course, is merely a mathematical convenience; there is no reason to suspect that a collection of brain maps describing connectivity structures is orthogonal. We depart from this assumption during post-processing, wherein the initial loading estimates are brought into a more interpretable form via rotation and shrinkage. This section emphasizes practical implementation of our method; Section 3.3 of Supplement A develops theory for these estimators and provides derivations of their asymptotic properties.
3.1 Initial Loading Estimation
Recall that when the data are observed at resolution , the covariance decomposes as
Two central goals of factor analysis are to estimate the number of factors and the loading tensors , , from the empirical covariance . Since loading tensors are only identifiable up to a rotation, we temporarily assume they are orthogonal so that the th loading tensor may be identified with the th scaled eigentensor of (i.e., , where is the th eigen-pair of ). In this section, we propose an estimator of from which we derive estimators for and the .
Given a sample of discretely-observed functions summarized by the tensors , our goal is to estimate the smooth covariance component from the empirical covariance defined by
| (3) |
where . We do so by finding a smooth low-rank covariance tensor that is a good approximation to off the band:
| (4) |
In the estimator of (4), is the space of covariance tensors satisfying constraints specified in Section 3.3 of Supplement A, is the “band-deleting” tensor defined by for , is some roughness-penalizing functional, is a roughness-penalizing parameter, and is a rank-penalizing parameter. Using , we define estimators for and the ,
| (5) |
, where and are the th scaled eigenvalue and eigentensor of , respectively.
To describe how one performs the optimization in (4), let us first assume we have already chosen a rank parameter and a smoothing parameter . Define the functional by . We then estimate as follows:
-
(a)
Solve the optimization problem
for , obtaining minimizers .
-
(b)
Compute the quantities and determine the furnishing the minimum quantity. Declare the corresponding to be the estimator .
Now consider selection of the penalty parameters, and (see Table 1 for a summary of information related to these parameters and others). Choice of the smoothing parameter depends on the roughness penalty . Although many choices for are possible, we use one that promotes smoothness via the eigentensors. In particular, we define where maps a tensor to its th scaled eigentensor, and is a roughness-penalizing functional defined by where is a generalization of the second difference matrix given by when , when , and otherwise. Here, denotes the vectorization of and is the square matricization of (see Section 1 of Supplement A for formal definitions of these tensor reshapings). As in smoothed functional principal component analysis, it may be satisfactory (or even preferable) to make the choice of subjectively based on visual inspection (Ramsay and Silverman, 2005, Section 9.3.3). For a discussion on automatic selection via cross-validation, see Section 3 of Supplement A.
In practice, we do not explicitly choose the rank parameter invoked in Step (b). Since each implies a choice of rank , and thus some , we use the nonincreasing function to implicitly choose . Specifically, we identify the value of to be the smallest one such that for some threshold , then set to the corresponding minimizer (see Figure 2). We would like the threshold to be small enough that evaluated at the estimator is low, but not so small that the estimator has large rank. We thus select the rank of the estimator by identifying the elbow of the scree-type plot generated by the function .
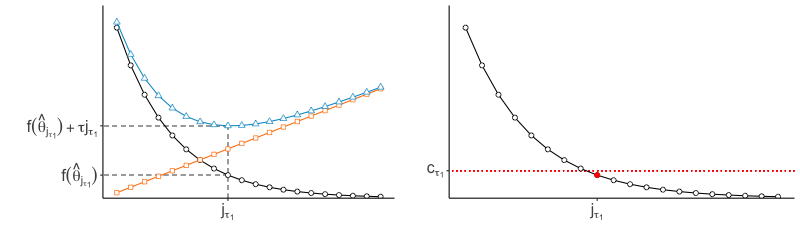
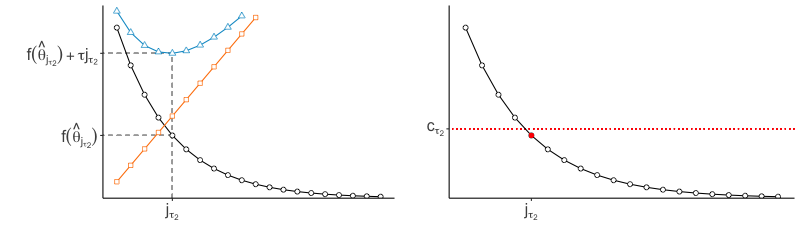
As shown in Section 3.3 of Supplement A, we can theoretically estimate using any for which each is less than 0.25. The choice of thus depends on how much small-scale variation one want to admit into the global component. In this sense, does not need to be tuned; rather, one needs to consider the purpose of the application in its selection. For instance, in the analysis of Section 6, we set for each , which demotes variation isolated to a radius of a few voxels to the local component. However, the optimization described in the next paragraph may be unstable when components of are near 0.25. For applications requiring wide bands, one may want to test a grid of bandwidths that increments to the desired bandwidth. If estimates change abruptly before reaching the final bandwidth, then algorithmic instability may be to blame.
| Parameter | Influence | Selection |
|---|---|---|
| increasing removes rough variation from | application-informed, testing for stability | |
| increasing yields smoother | subjective selection or cross-validation | |
| increasing lowers | implicitly chose via scree-type plots | |
| increasing produces sparser | cross-validation |
To solve the optimization problems in (a) we resort to approximate methods. In doing so, we note that any symmetric non-negative definite tensor with rank- has square matricization , , that may be written as , where . Note also that the columns of are equal to the vectorized scaled eigentensors of (up to a rotation), allowing us to impose smoothness on these eigentensors through the columns of . The optimization problems in (a) thus reduce to the factorized matrix completion problems
| (6) |
for , where when . For our choice of , we have where denotes the Frobenius inner product. As these problems are not convex in , no gradient descent-type algorithm is guaranteed to converge to the problems’ infinitely many global optima. In search of “good” local optima, we use MATLAB’s fminunc function, which implements the Broyden–Fletcher–Goldfarb–Shanno (BFGS; Broyden, 1970; Fletcher, 1970; Goldfarb, 1970; Shanno, 1970) algorithm or, for larger problems, the limited-memory BFGS (L-BFGS; Liu and Nocedal, 1989) algorithm. Indeed, when given a reasonable initialization, the simulations of Section 5 show that these routines are stable and quickly converge to suitable local optima. We use the initial value , where is the singular value decomposition of , is the matrix obtained by keeping the first columns of , and is the matrix obtained by keeping the rows and columns of .
3.2 Post-Processing: Rotation and Shrinkage
In Section 3.1, we assumed the loading tensors were equal to the scaled eigentensors of . Although mathematically convenient, we did not impose this constraint in the original model as there is no practical justification for orthogonal loadings. Unfortunately, without such an assumption, it is not possible to identify the from . We may still, however, hope to understand the latent factors that drive variation captured in the identifiable global component . For instance, interesting neurological phenomena, like visual processing, may contribute variation to the global component, and an effective factor analytic approach should help us discover these latent processes. However, such insights can be difficult to glean via the scaled eigentensors, which are often dense with many high-magnitude weights. In our two-step post-processing procedure, we transform the illegible eigentensors into loadings possessing simple structure. The resulting parsimony greatly facilitates interpretation of the underlying factors.
In the first post-processing step, we exploit the model’s rotational indeterminacy by rotating the scaled eigentensors of to a maximally-simple structure. We do so using varimax rotation (Kaiser, 1958) which solves the optimization problem
where is defined by , is an operator given by , and is the set of rotation matrices.
Although the rotated loading estimate may be sufficiently interpretable, it sometimes helps to shrink near-zero regions to zero. The second post-processing step accomplishes this systematically by adaptively soft-thresholding ,
| (7) |
where is a weight function with positive support (e.g., ), and the are shrinkage parameters, which may be tuned using the cross-validation procedure described in Section 3 of Supplement A. Beyond enhancing interpretability, we show in Section 5.3 that shrinkage can also correct an overspecified model by zeroing out “extra” loading estimates.
4 MELODIC Background
In Sections 5 and 6, we compare our approach to, among others, one based on ICA, the most popular whole-brain connectivity method. In doing so, we rely on the MELODIC function (Beckmann and Smith, 2004) of the FMRIB Software Library (FSL; Jenkinson et al., 2012), arguably ICA’s most widely used implementation for connectivity analyses. This section details the MELODIC model and its estimation.
FSL’s MELODIC function estimates the probabilistic ICA model which assumes that observations for each voxel are generated from a set of statistically independent non-Gaussian sources via a linear mixing process corrupted by additive Gaussian noise:
Here, denotes the -dimensional vector of observations at voxel , denotes the -dimensional vector of non-Gaussian sources, denotes the ()-dimensional mixing matrix, denotes the mean of the observations , and denotes Gaussian noise. The model assumes there are fewer sources than observations (i.e., ), and that the noise covariance is voxel-dependent (i.e., ).
The goal of estimation is to find the -dimensional unmixing matrix such that is a good approximation to for each voxel. Prior to invoking MELODIC, it is common to spatially smooth the data. We do so using the Gaussian filter of FSL’s FSLMATHS utility (Jenkinson et al., 2012), tuning the kernel width via cross-validation. Before estimation, MELODIC prepares the multi-session data by (i) temporally concatenating the preprocessed slices to form observation vectors for each voxel, (ii) temporally whitening each so that the noise covariance is isotropic at each voxel location, then (iii) normalizing each to zero mean and unit variance. By default, the utility also reduces the dimension of the concatenated data via MELODIC Incremental Group PCA (MIGP; Smith et al., 2014); however, we switch off this feature as Sections 5 and 6 consider datasets of sufficiently reduced sizes. After this preprocessing, one can show that the maximum likelihood (ML) mixing matrix estimate is
where and contain the first left singluar vectors and singular values of , the matrix of preprocessed data, and is some rotation matrix. From , the ML source estimates are obtained via generalized least squares,
where . Thus, to fix , one chooses the that maximizes the non-Gaussianity of the source estimates .
For a random variable , one measure of non-Gaussianity is negentropy,
where is the entropy of a random variable and is a Gaussian having the same variance (or covariance if is a random vector) as . Since a Gaussian random variable has the largest entropy among all random variables of equal variance, negentropy is a non-negative function that equals zero if and only if is Gaussian. As estimation of negentropy is difficult, it is often approximated using the contrast function
where is a standard normal and is a general non-quadratic function. To estimate the th source of the th voxel MELODIC uses a fixed-point iteration scheme (Hyvärinen and Oja, 2000) to choose the th row of so that is maximized for some domain-specific choice of . By default, MELODIC sets equal to the pow3 function. To estimate sources, the procedure is repeated times under the constraint that the vectors are mutually orthogonal.
5 Simulation Studies
To assess the efficacy of our methodology, we conduct three simulation studies. In the first, we compare the accuracy of the post-processed estimator of (4) (denoted by FFA) to that of four other estimators. In the second, we assess the relative interpretability of these estimators. In the third, which may be found in Section 4 of Supplement A, we explore how the scree plot approach for selecting the number of factors behaves in different settings. We begin, in Section 5.1, by describing the data generating procedure for these studies.
5.1 Data Simulation
To simulate data from an FFM (when ), we first generate i.i.d. mean-zero functions and i.i.d. mean-zero functions on an equally spaced lattice in , summarizing these discretely-observed functions with the order- tensors (i.e., matrices) and , respectively. We then sum these components to get the samples , and compute the empirical covariance tensor, . For simplicity, in all studies, we set and . Though these simulated “brain slices” are lower resolution than those of the AOMIC data whose axial slices have resolution , this simplification serves only to reduce compute time and has little impact on estimator performance.
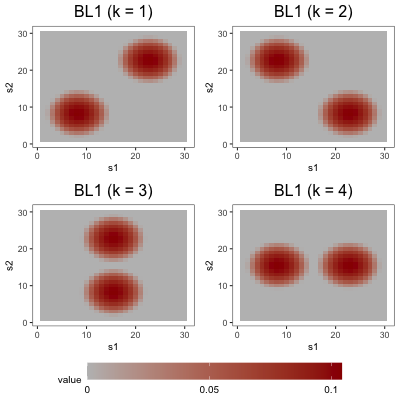
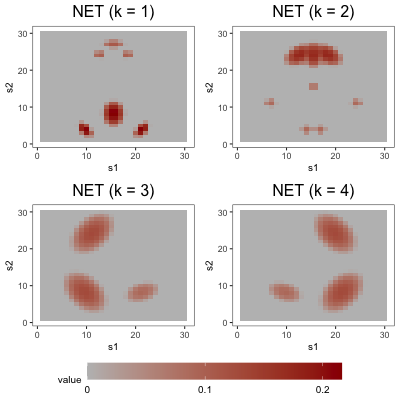
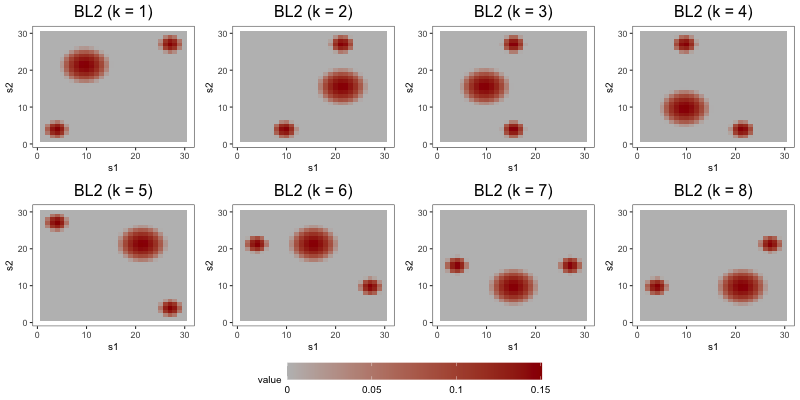
To simulate the functions , we set , where the are (possibly non-orthogonal) functions scaled to have unit norm, the are positive constants, and the factors are drawn from . We decompose the th loading function into its standardization and a scaling parameter to control the difficulty of the estimation problem. Also note that the are not necessarily equal to the eigen-pairs of , as we do not require the to be orthogonal. Across the three studies, we make use of three loading schemes, depicted in Figure 3. In the first loading scheme (denoted by BL1), each is defined piecewise with a bump function in two regions of its domain, and zero elsewhere. Each in the second loading scheme (denoted by NET) is also defined with piecewise bump functions, but these functions are arranged in the types of complex patterns one might expect to observe in a brain network. In the third loading scheme (denoted by BL2), each is defined by three bump functions, one of which is wider than the other two.
To generate the functions , we set , where the are (again, possibly non-orthogonal) functions with support on , the are positive constants, the are drawn i.i.d. from , and is large. As in the loading scheme framework, the may not be equal to the eigen-pairs of since the former need not be orthogonal. We consider two error schemes. Each defines functions with possibly overlapping supports on an equally-spaced grid of . In the first (denoted by BE), each is a two-dimensional bump function. In the second (denoted TRI), each is a two-dimensional triangle function.
5.2 Study 1: Accuracy Comparison
The aim of the first study is to compare the accuracy of the FFA estimator to that of five alternative estimators:
-
1.
Independent component analysis without smoothing (denoted by ICA): we estimate by extracting from the data an tensor of independent components via MELODIC, then computing where the matrix is the th estimated independent component. We skip variance normalization since the simulated data do not reproduce phenomena like scanner and physiological noise that lead to different levels of variability across different voxels. Omission of this step also ensures that ICA estimates are on the same scale as those derived from other estimators.
-
2.
Independent component analysis with smoothing (denoted by ICAS): we estimate using the same procedure as ICA but smooth the data with a Gaussian filter as described in Section 4.
-
3.
Principal component analysis (denoted by PCA): we estimate with a truncated eigen-decomposition of . Note that this approach corresponds with principal component estimation in multivariate factor analysis (Johnson and Wichern, 2002, Section 9.3).
- 4.
-
5.
Matrix completion approach with smoothing (denoted by DPS): we compute the estimator of (4) using , but omit post-processing.
We study these estimators in four scenarios, which are defined by the Cartesian product of two loading schemes (BL1 and NET) and the two error schemes: S1 for BL1 and BE, S2 for BL1 and TRI, S3 for NET and BE, and S4 for NET and TRI. Within each scenario, we consider 24 configurations, each of which is characterized by a sample size , a number of factors , a bandwidth , and a “regime” (R1 or R2). In both regimes, the are distributed uniformly in , while the are distributed uniformly in , and for R1 and R2, respectively. Consequently, the lower-signal R2 regime poses a more difficult estimation problem than the R1 regime. Note that in the multi-subject AOMIC analysis of Section 6, the sample size is the number of time points per subject multiplied by the number of subjects (). Accordingly, this simulation study evaluates our model in settings that are likely lower-signal than that of our application.
Per Section 3, FFA estimation – including initial loading estimation and post-processing – involves two levels of tuning. We consider a smoothing parameter and just one shrinkage parameter for all loading functions to lighten computation. Instead of conducting the expensive cross-validation procedures of Section 3 in Supplement A, we simply split the data into a training set (80%) and a test set (20%), then choose the (similarly, ) that minimizes the out-of-sample prediction error for the band-deleted empirical covariance. Throughout the study, we set for estimation procedures.
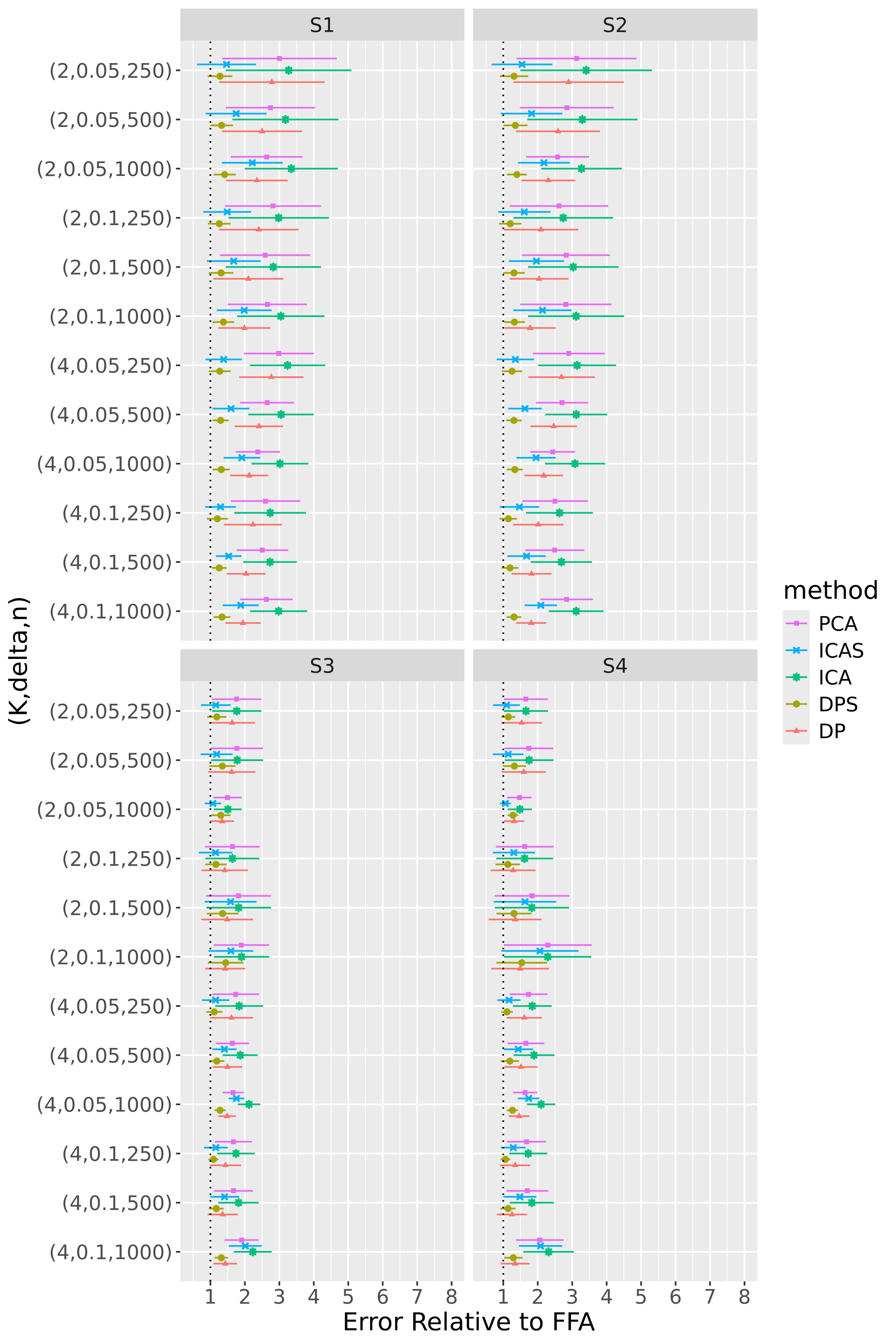
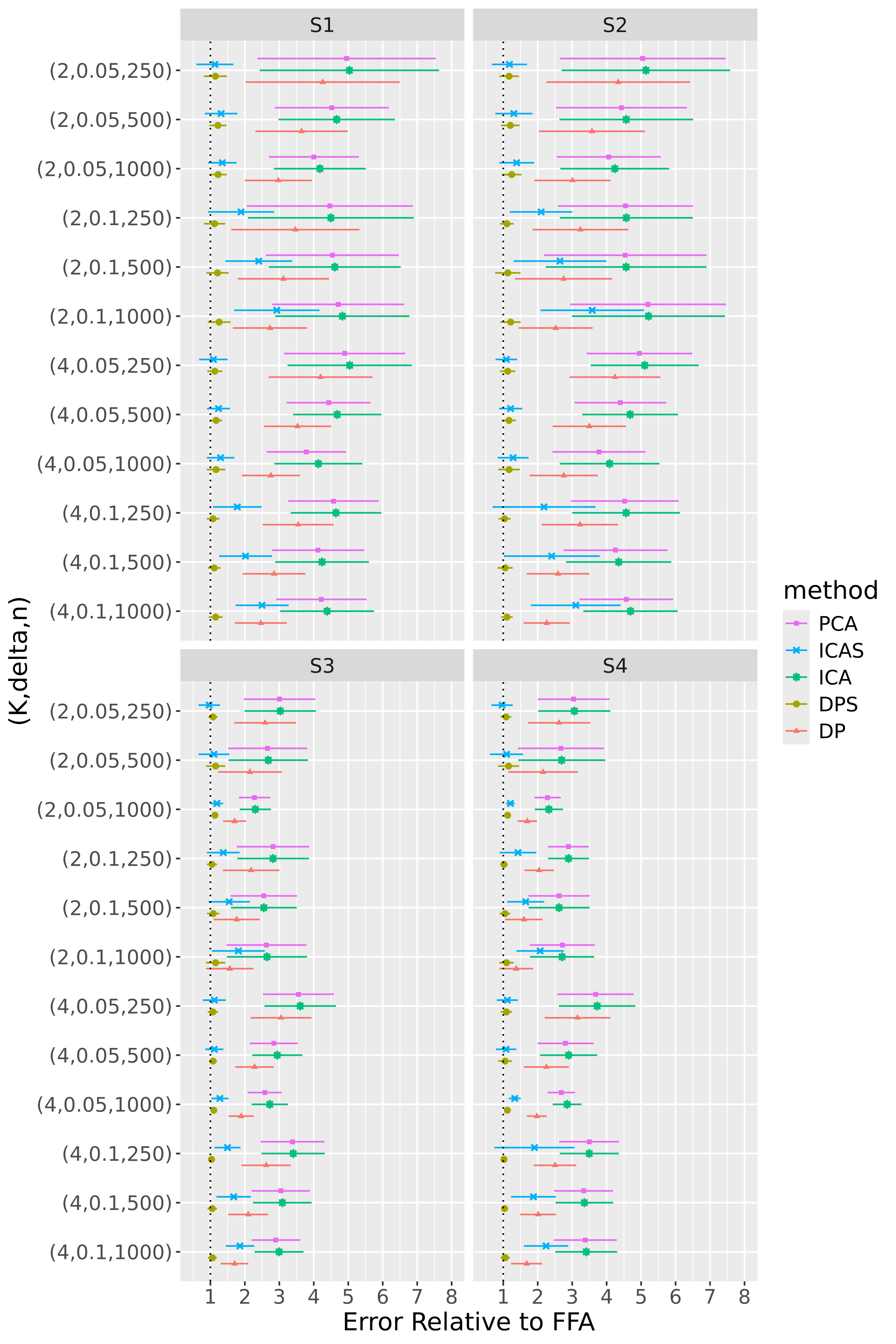
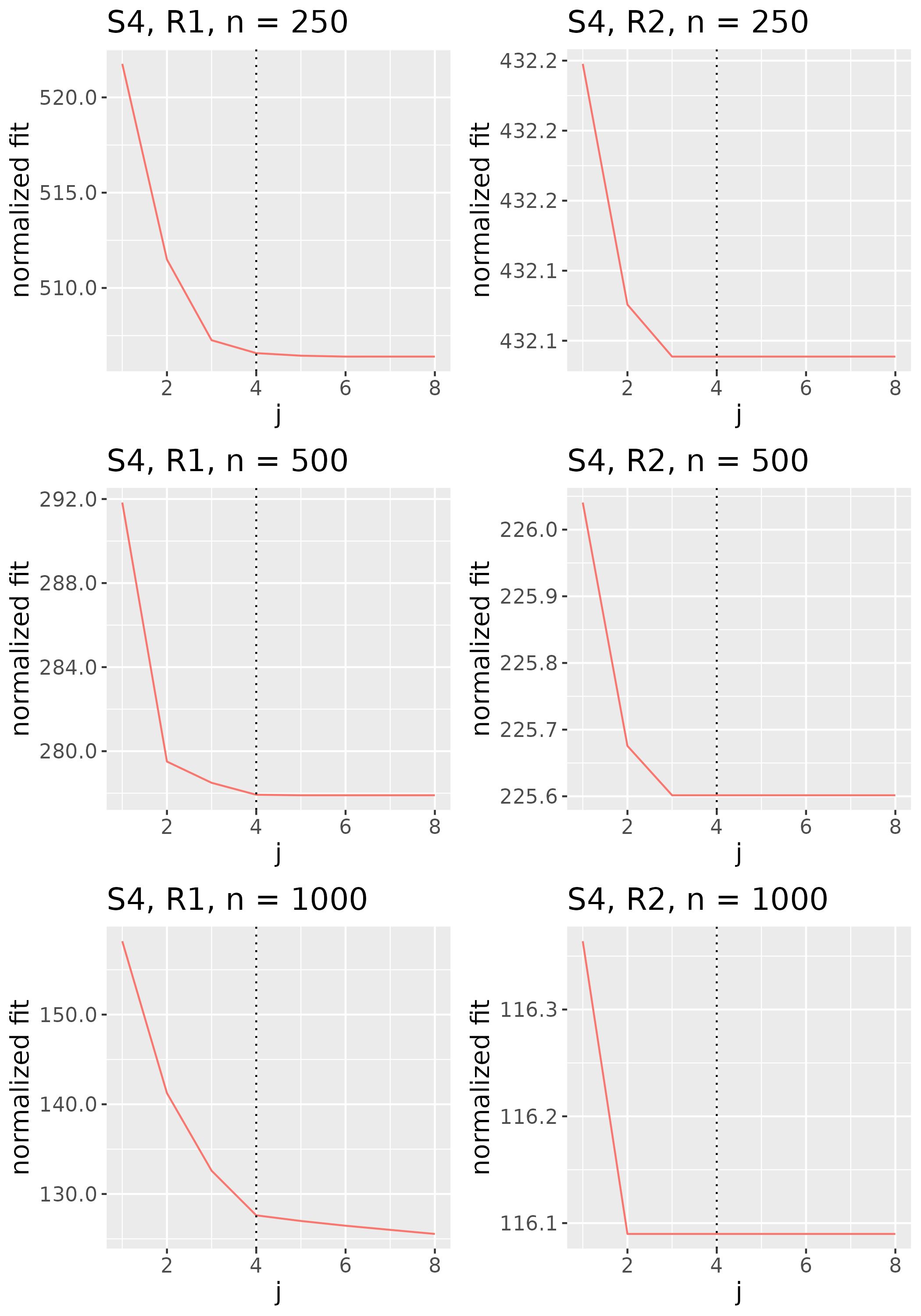
For 100 repetitions of each configuration, we compute the six estimators – FFA, DPS, DP, PCA, ICA, and ICAS – then calculate normalized errors by evaluating at each estimator. To assess the comparative accuracy of the FFA estimator, we form five relative errors by dividing the normalized errors for the DPS, DP, PCA, ICA, and ICAS estimators by that for the FFA estimator. Figures 4 and 5 display results for R1 and R2, respectively.
FFA is in league with or superior to the alternatives in nearly every configuration. DPS, however, consistently competes with FFA, indicating that post-processing leads to only modest accuracy gains (Section 5.3 considers the more noteworthy interpretability gains afforded by post-processing). The smoothing of FFA and DPS provides helpful de-noising in BL configurations – particularly in the low-signal regime and/or when is small – but is less effective in NET configurations. In the latter, over-smoothing occasionally forces the optimization procedure into bad local minima. This is likely because application of a single smoothing parameter to each loading tensor is more appropriate in the BL scheme, which has uniformly smooth loading tensors, than in the NET scheme, whose first and second loadings are spikier than its third and fourth loadings.
DP, PCA, ICA, and ICAS typically trail FFA and DPS. It is not surprising that the performances of ICA and PCA are in near lockstep, given that MELODIC projects the temporally whitened data onto the space spanned by the leading eigenvectors of , and that MELODIC’s temporal whitening has little effect on these i.i.d. data. The data smoothing of ICAS consistently improves upon ICA, most noticeably in regime R2. In this regime, ICAS performance even matches that of FFA and DPS when configurations, though it falls short in configurations where data smoothing smears more local variation into the global component. Contamination of the global component brought about by data smoothing is so pronounced that even DP, an estimator that does not explicitly encourage smooth loadings, outpaces ICAS in some of these configurations.
5.3 Study 2: Interpretability Comparison
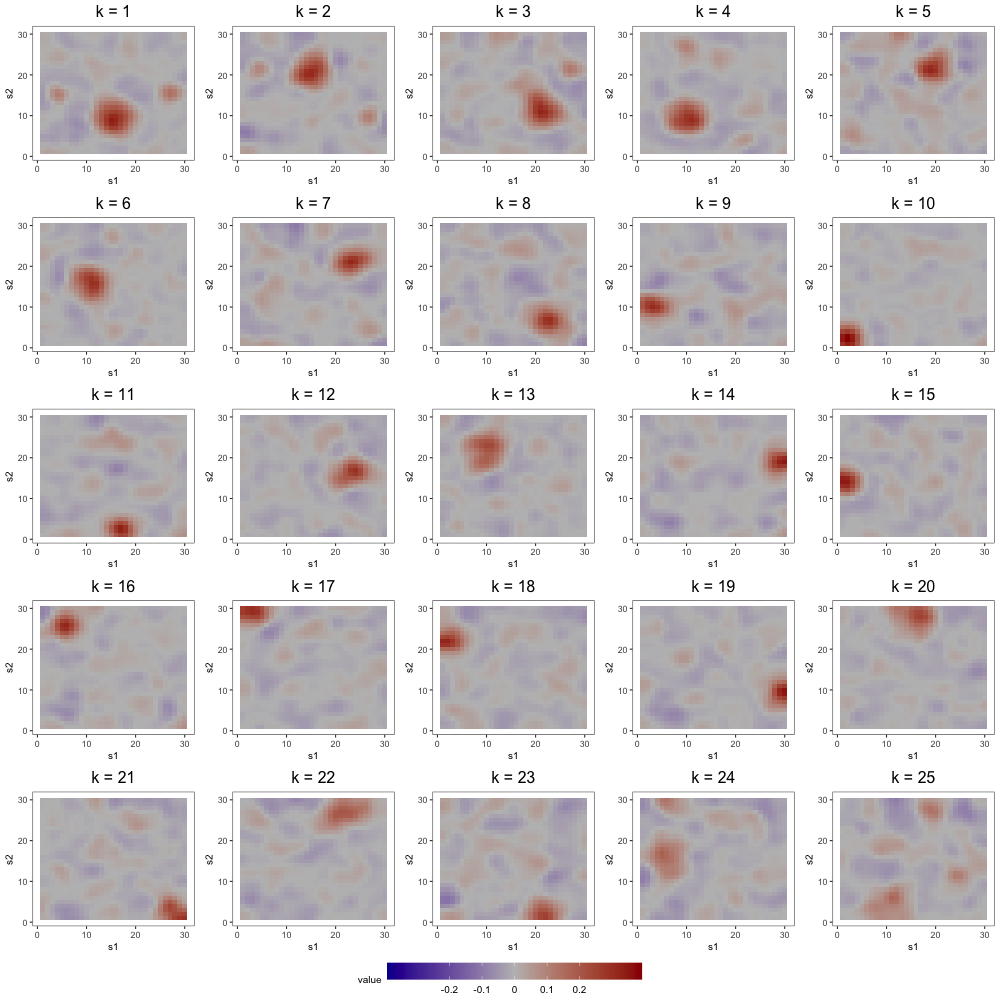
The aim of the second study is to compare the interpretability of FFA to that of DPS and ICAS, the two most competitive estimators from Section 5.2. To do so, we focus on output from a single repetition of a configuration with loading scheme BL2, error scheme BE, regime R2, set to 1000, set to 8, and set to 0.1. Consideration of only one repetition alleviates computational strains, allowing us to tune component-specific shrinkage parameters for the FFA estimator.
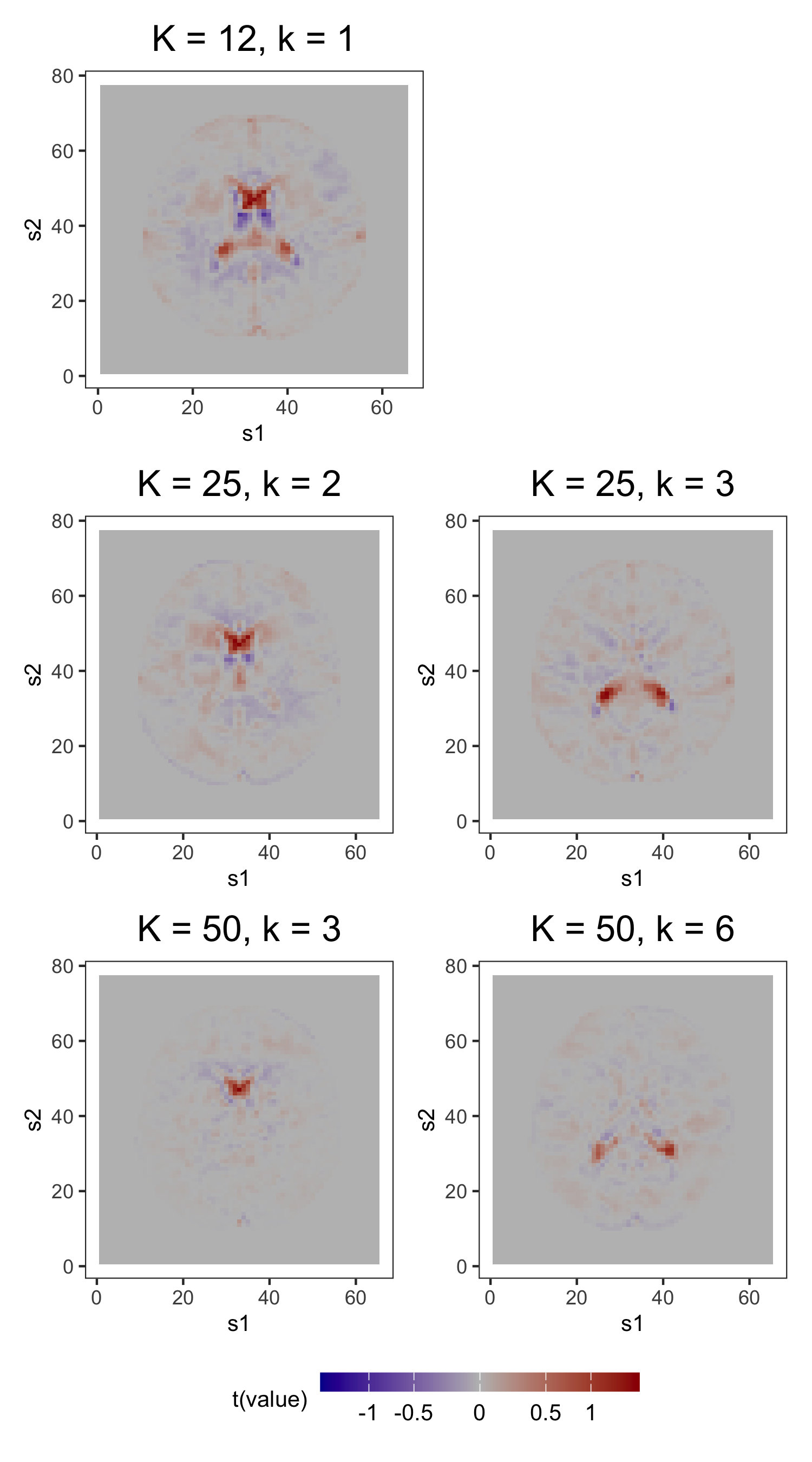
In the first part of this study, we correctly specify model order by estimating the three models with 8 components (see Figure 6). DPS fails to capture the simple structure of the true loadings. ICAS, on the other hand, largely accomplishes this, identifying 6 of the true loadings. However, it lacks the sparsity of FFA, which clearly capture 7 to 8 of the true loadings.
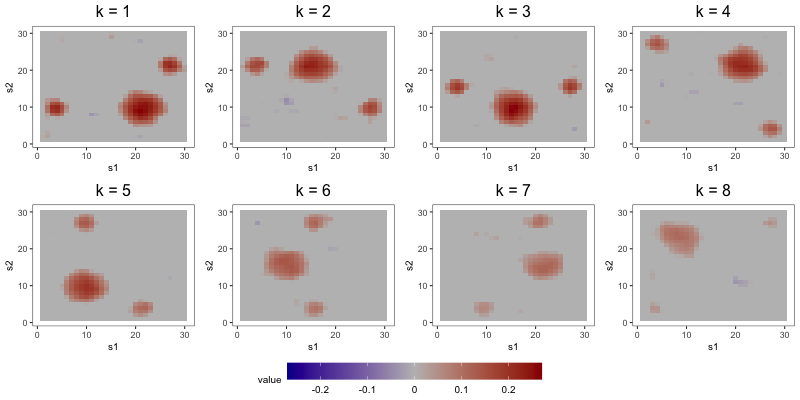
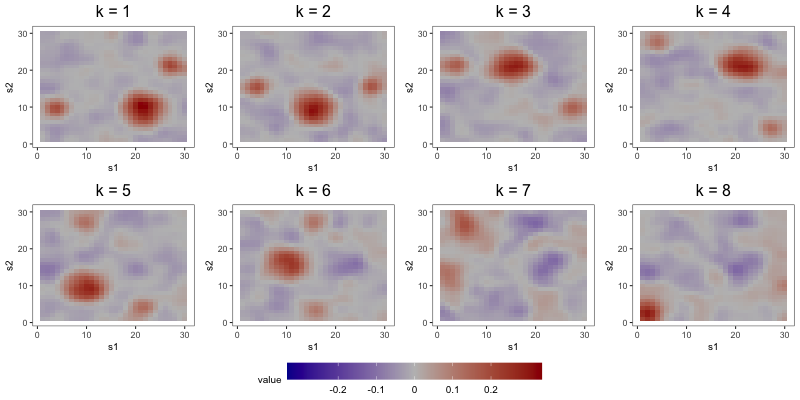
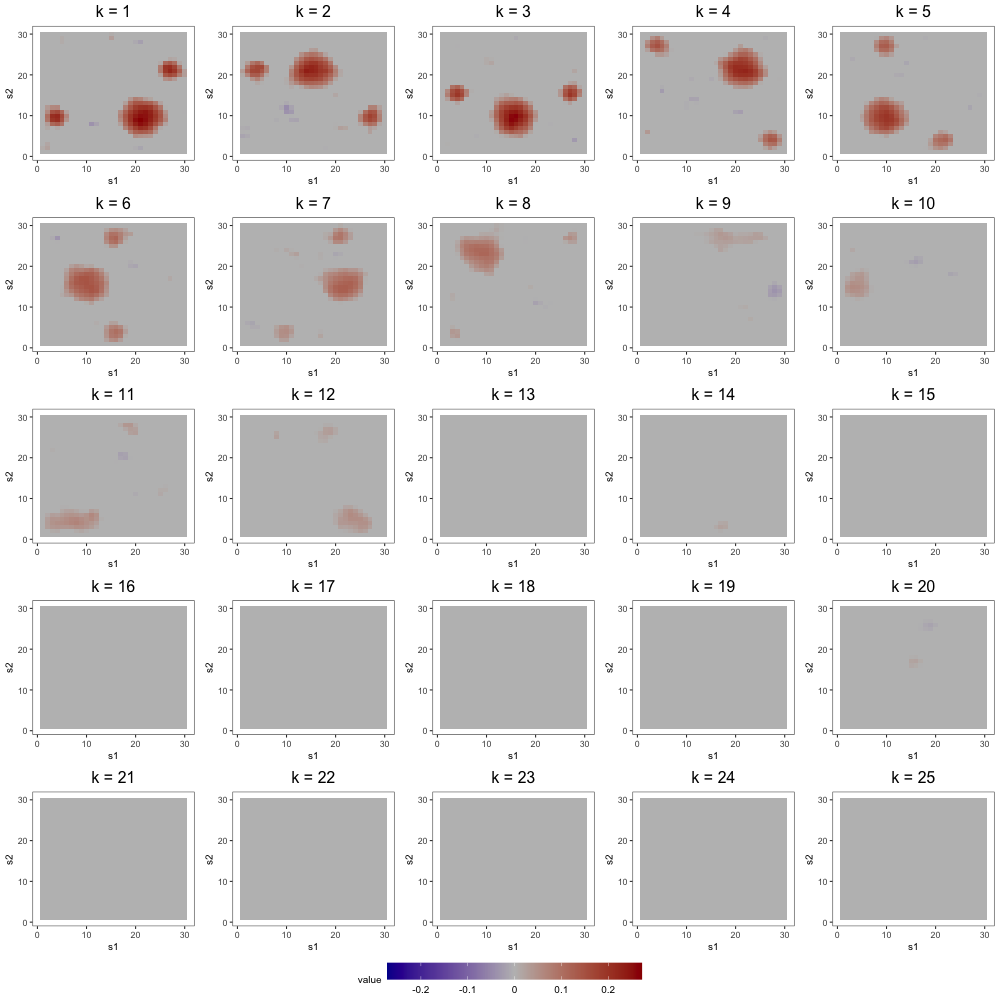
The most noteworthy difference, however, between FFA and ICAS is that ICAS results are less robust to dimension overspecification. That is, if we estimate two IC models, one with the true number of ICs and another with more, the latter will splinter structures found in single ICs of the former across multiple ICs. Such fragmentation does not occur in overspecified FFMs. To see this, consider output from order-25 FFA and ICAS models fit to these data (see Figures 7 and 8). The higher-order FFM preserves the 7 to 8 loadings of the lower-order FFM and even shrinks many of the other loadings to zero, effectively correcting overspecification. However, of the 6 true loadings captured in the 8-IC model, only two are preserved in the 25-IC model ( in Figure 8). Other structures in the 8-IC model are scattered across the remaining components of the higher-order model. This is because, in its search for maximally independent spatial maps, ICA fragments broad correlation structures across multiple maps (Friston, 1998). This splintering presents challenges to interpretation, particularly when the specified dimension far exceeds the true dimension. In contrast, varimax rotation in FFA does not fragment correlation structure. Moreover, shrinkage seems to have partially “corrected” the overspecification, zeroing out many of the extra loadings. This makes FFA an attractive approach when interpretation is the foremost goal and dimension overspecification is possible.
6 AOMIC Data Analysis
We now consider the AOMIC-PIOP1 dataset which includes six-minute resting-state scans for 210 healthy university students. Prior to each subject’s resting-state session, a structural image was acquired at a resolution of 1 mm isotropic while the functional image was acquired at a spatial resolution of 3 mm isotropic and a temporal resolution of 0.75 seconds (resulting in a single-subject data matrix with dimension ). Including all 300,000 voxels in this analysis would necessitate estimation and in-memory storage of a prohibitively large spatial covariance. We avoid this by focusing on one axial slice (at ). Preprocessing of anatomical and functional MRI were performed using a standard Fmriprep pipeline (Esteban et al., 2019), as detailed in Snoek et al. (2021).
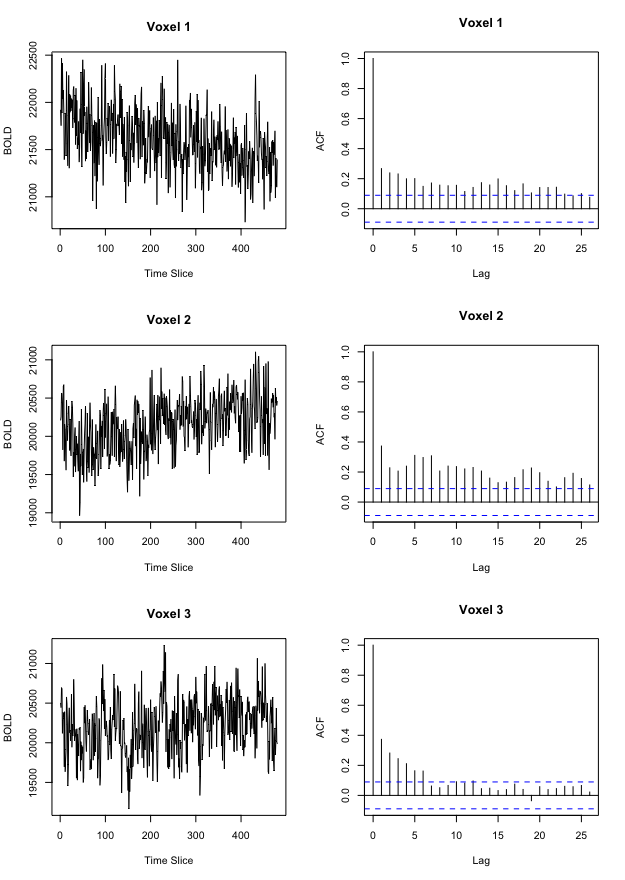
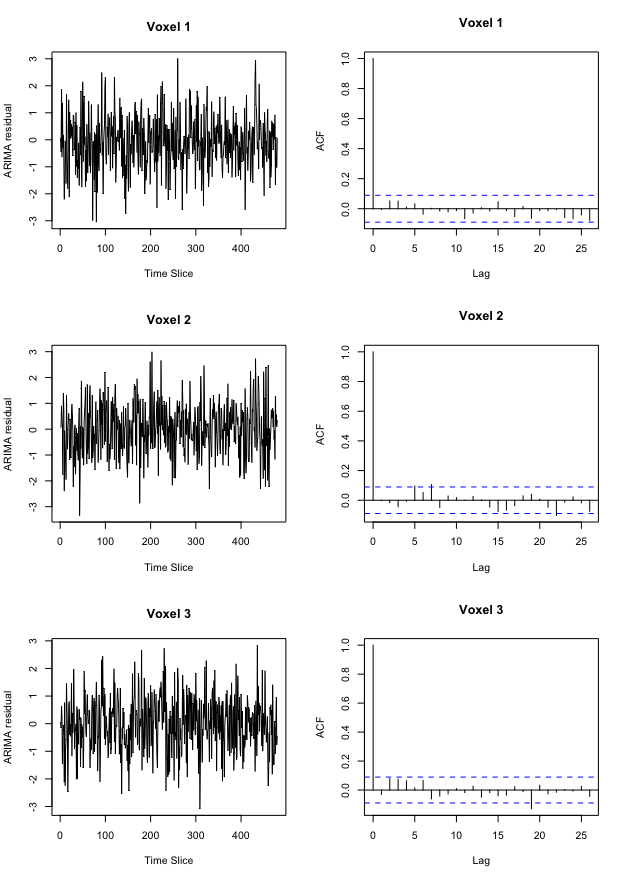
Our strategy for discovering the connectivity patterns present in these resting-state data was to prewhiten the voxel time courses in each subject’s preprocessed scan (which are, in general, nonstationary and autocorrelated), then treat the multi-subject collection of slices as an i.i.d. sample , , which we used to fit the FFM. Although fMRI data is inherently nonstationary and autocorrelated, many connectivity studies that correlate voxel time series skip this essential prewhitening step, risking the discovery of spurious correlations (Christova et al., 2011; Afyouni et al., 2019). Of course, prewhitening only addresses temporal correlation within voxel time courses, not between time courses. There are several ways to prewhiten voxel time courses, including those based on Fourier (Laird et al., 2004) and wavelet (Bullmore et al., 2001) decompositions. Taking another common approach, we performed prewhitening by fitting a non-seasonal AutoRegressive Integrative Moving Average (ARIMA) model to each voxel time course using the R function forecast::auto.arima (Hyndman and Khandakar, 2008), then extracting the residuals. Figure 5 from Section 6.1 of Supplement A demonstrates the effects of prewhitening on voxel time courses. Taking after Christova et al. (2011), we form samples from the scaled ARIMA residuals.
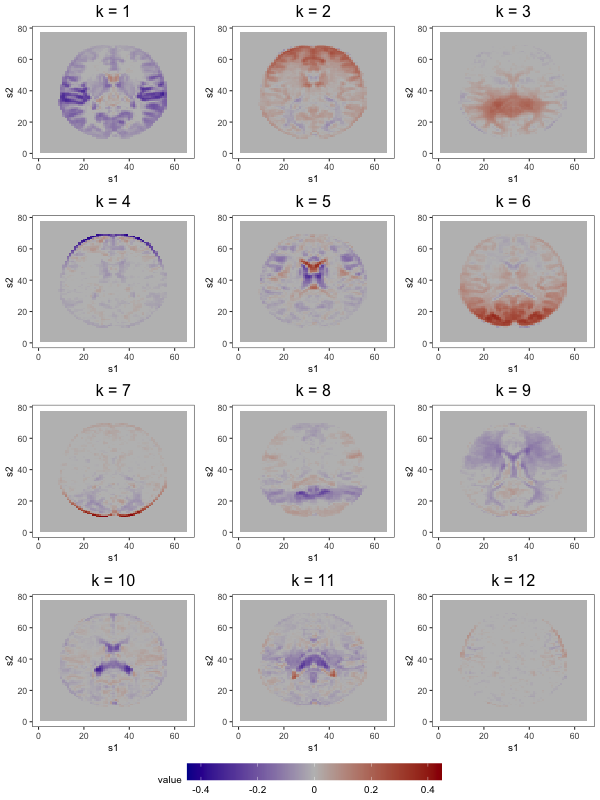
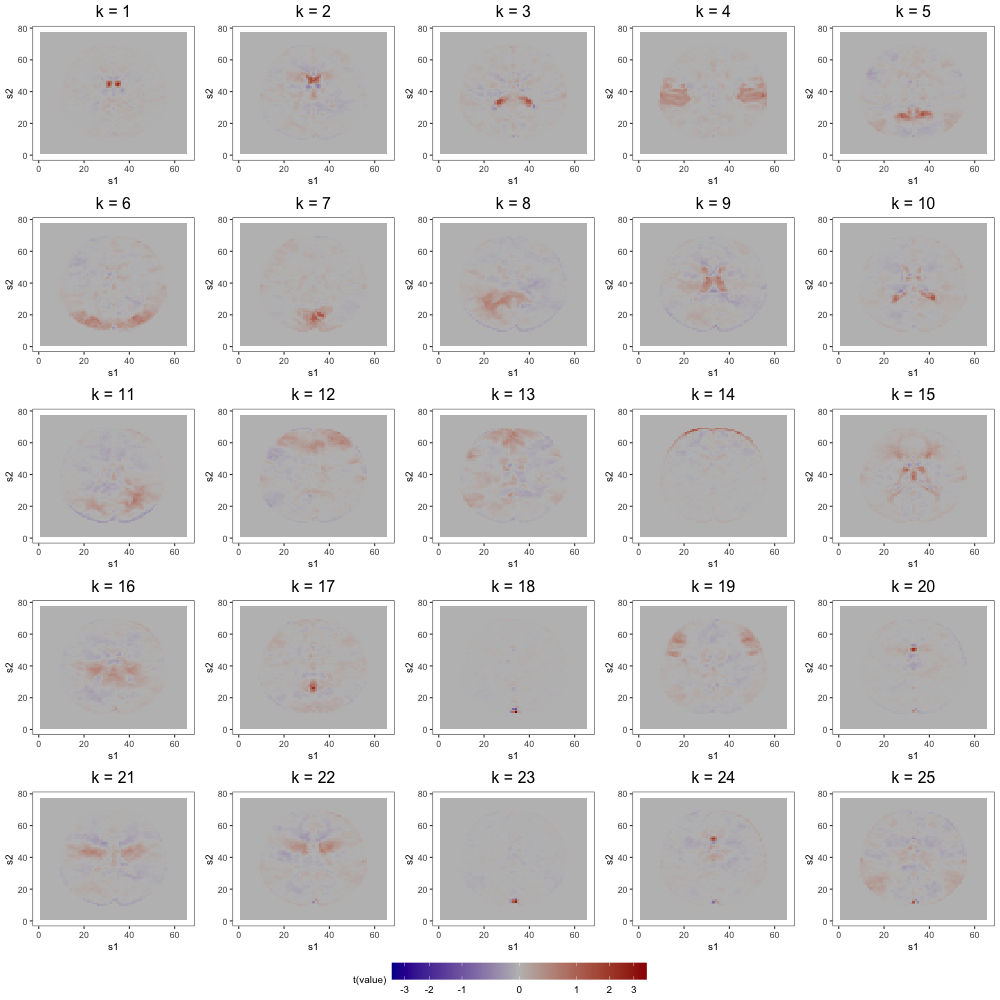
We begin analysis of these samples by computing the empirical covariance in equation (3). Based on visual inspection and the fact that the sample size is quite large, we opt not to smooth (i.e., we set ), then plot the non-increasing function for (see Figure 6 of Section 6.1 in Supplement A). Based on this plot, we set and use the corresponding as the initial loading estimates. To choose the shrinkage parameter used to compute the post-processed loadings , we define a manageable search grid then follow the tuning procedure described in Section 3 of Supplement A. Figure 9a displays the rich covariance structure captured by these post-processed loadings. In addition to anatomical segmentation (e.g., grey matter segmentation in loadings 1, 2, and 6; white matter segmentation in loadings 3 and 9; and ventricle segmentation in loadings 5 and 10), these 12 loadings contain known resting-state networks. The prominent bilateral structure in the first loading captures parts of the auditory resting-state network, including co-activation in Heschl’s gyrus and the posterior insular (see of Figure 1 in Smith et al., 2009). Next, frontal activation in the second loading includes areas associated with resting-state executive control, like the anterior cingulate (see of Figure 1 in Smith et al., 2014). Lastly, the sixth loading contains activation in the occipital lobe, an area associated with visual processing (see of Figure 1 in Smith et al., 2009).
To provide a methodological comparison, we also performed group ICA by temporally concatenating the preprocessed slices then running ICA on the resulting data to produce spatial maps common to all subjects (Calhoun et al., 2001). As in Section 5, we do so using FSL’s MELODIC function. For this analysis, we fit 12-, 25-, and 50-independent component (IC) models. Transformed components (for interpretability) for the 12-IC model are shown in Figure 9, and those for the 25- and 50-IC models are shown in Figures 8, 9, and 10 of Section 5.2 in Supplement A. To facilitate comparison with FFA, we also estimate the FFM with 25 and 50 factors (see Figures 5, 6, and 7 in Section 5.2 of Supplement A) even though the plots of Figure 6 in Section 6.1 of Supplement A suggest a smaller number of factors.
We first compare the 12-component models (see Figure 9). Several prominent structures are captured by both FFA and ICA: dorsal correlations appear in the 6th loading, and in the 4th and 9th ICs; frontal correlations appear in the 2nd loading and the 7th IC; bilateral correlations appear in the 1st loading and in the 8th IC; similar ventricle correlations appear in the 5th loading and in the 1st IC; and brain outlines appear in the 4th and 7th loadings, and in the 11th IC. Despite the many common features, there exist some discrepancies (e.g., the spikes of activation in the 10th and 12th IC do not display prominently in any single loading).
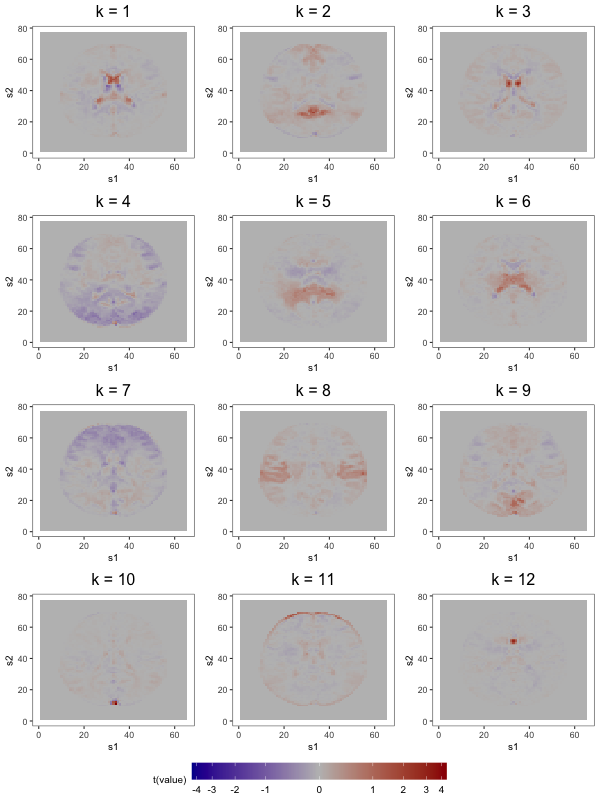
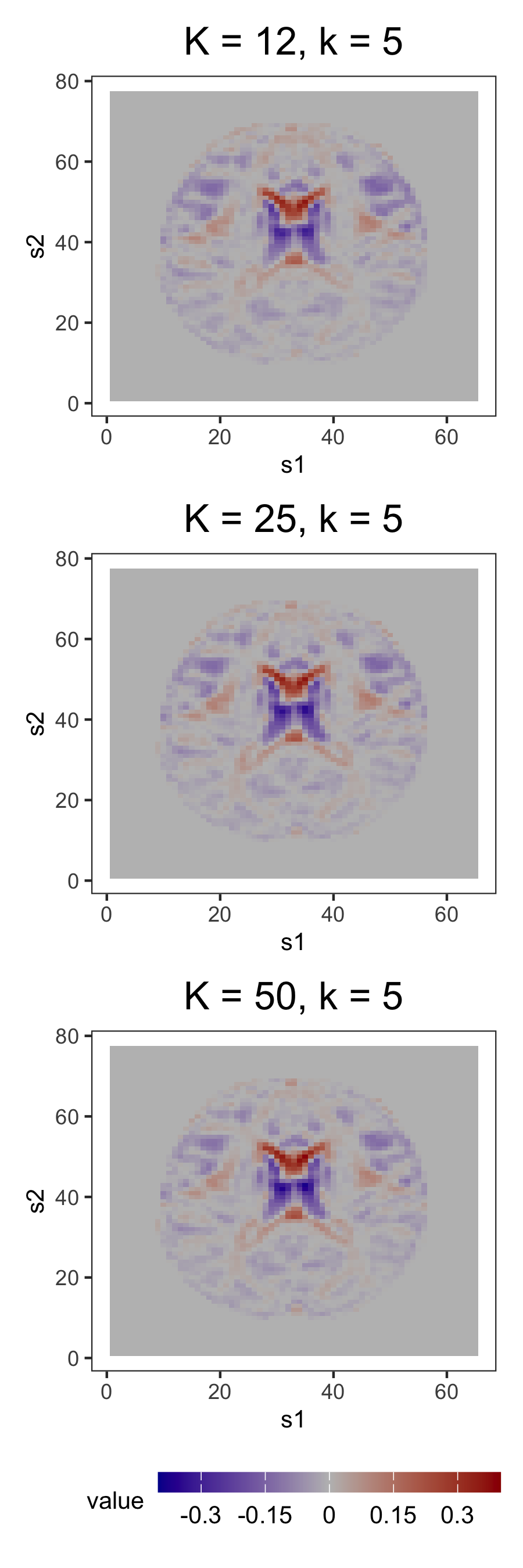
However, as observed in Section 5.3, the most practically meaningful difference is that MELODIC lacks FFA’s robustness to dimension misspecification. Consider, for instance, the similar ventricle correlations in loading 5 and IC 1 of the order-12 plots in Figures 10a and 10b. In the FFMs with 25 and 50 factors, this structure is preserved. However, this structure, captured in a single IC of the 12-IC model, is splintered across 2 ICs in both the 25- and 50-IC models, with the components of the latter containing less of the original structure than those of the former. Similar fragmentation occurs for other structures found in the 12-IC model.
One way to combat ICA’s instability is through multi-scale approaches. For example, Iraji et al. (2023) estimate common spatial maps by first generating 100 half-splits of their multi-subject dataset, then fitting IC models of order 25, 50, 75, 100, 125, 150, 175, and 200 to each data split. This produces 100 sets of 900 components from which they select the 900 with the highest average spatial similarity (calculated by Pearson correlation) across the 100 sets. They then identify those ICs among the 900 that are most distinct from each other (spatial similarity ¡ 0.8). In Section 6.2 of Supplement A, we adapt this procedure to the AOMIC data, showing that the final subset of estimated ICs does, in fact, preserve low-order structure. However, this requires more computing resources than a single-model ICA approaches. Moreover, this output lacks some of the interpretability afforded by that from a single-model approach: estimated ICs from this multi-scale algorithm are cherry-picked from many IC models, consequently collapsing the straightforward independence-based interpretation arising from the assumptions of a single IC model.
7 Discussion
This work recognizes the central contribution of Descary and Panaretos (2019) – a framework that decouples the global and local variation of a functional observation – as the proper scaffolding upon which to build a factor analytic approach for functional data. Our work extends their framework to multidimensional functional data, enhances the estimator of the global covariance via a roughness penalty, then appends a post-processing procedure that improves interpretability. The result is a factor analytic approach tailored to the study of functional connectivity in fMRI.
Three characteristics of our methodology make it uniquely suited to the study of functional connectivity. First, it outputs spatial maps possessing simple structure, which facilitates interpretation of the latent factors that drive correlations in the data. It is a hallmark of factor analytic methods and has, in fields like education and psychology, made multivariate factor analysis a popular alternative to less legible techniques, like PCA. We demonstrate the utility of this structure in the neuroimaging context. Second, our approach is not preceded by data smoothing like other functional connectivity methods. Given that connectivity studies aim to characterize correlations between distant brain regions, model estimation should exclude local variation, yet data smoothing forbids this. It smears local variation into the global signal, thereby corrupting subsequent attempts to estimate this signal. Third, our approach is robust to dimension overspecification. This model feature, not found in popular ICA-based methods, is critical in fMRI where it is difficult to correctly specify the dimension of the signal.
The limitations of our methodology present several opportunities for future work. One weakness of the approach is that its application does not consider all spatial information available in an fMRI scan. Although the model remains valid for 3-dimensional brain volumes, inclusion of a third spatial dimension renders the existing estimation method computationally impractical. Additionally, the model ignores the temporal information present in fMRI data. We attempted to mitigate the impact of these temporal dynamics in our analysis through prewhitening, but such dependencies ought to be acknowledged by the model. Future work on functional factor modeling of large-scale functional or spatiotemporal data should address these concerns.
Supplement A: Functional Factor Modeling of Brain Connectivity
1 Notation and Definitions
1.1 Tensor Reshaping
In the discrete observation paradigm, it is useful to define some tensor reshapings, or bijections between the set of indices of one tensor and that of another tensor. Denote the index set of by . Define a bijection so that the vectorization of is the vector
Next, define a symmetric bijection so that the square matricization of is the square matrix
Although there are many suitable selections for and , we choose these bijections to be consistent with the array reshaping operator in MATLAB.
1.2 Properties of Tensors
We use the tensor reshapings of Section 1.1 to define several properties of tensors. We say is symmetric if is symmetric, nonnegative definite if is nonnegative definite, and rank- if is rank-. Through square matricization and vectorization, it can be shown that any symmetric nonnegative definite tensor with rank- admits the eigendecomposition
where the are the nonnegative eigenvalues of and the orthonormal are the eigentensors of .
2 Rotational Indeterminacy
The FFM is identifiable up to an orthogonal rotation. To see this, let , defined by , be a set of loading functions indexed by . For a rotation matrix , define the rotation operator by . That is, rotates the loading functions by rotating the -dimensional vector by at each fixed . If is a vector of factors and is some rotation matrix, then the following equivalences hold:
and
Thus, when the global component and its covariance are known, it is impossible to distinguish the loading functions of from those of .
3 Theoretical Support
This section includes statements and proofs of results described in the manuscript, as well as those for auxiliary results that enrich our theory.
3.1 Identifiability in the Completely-Observed Paradigm
We begin with Theorem 3.1, which establishes conditions needed to identify the global covariance and the local covariance from the covariance in the complete-observation paradigm. The result is a straightforward extension of Theorem 1 from Descary and Panaretos (2019) to multidimensional functional data.
Theorem 3.1 (Identifiability).
Let be trace-class covariance operators of rank , respectively. Let be banded trace-class covariance operators whose bandwidths and , respectively, have components less than 1. If the eigenfunctions of and are real analytic, then we have the equivalence
By definition, a function defined on open is real analytic at if is equal to its Taylor expansion about in some neighborhood of . A function is real analytic on open if it is real analytic at each in . In the proof of the above result, we use an alternative characterization of real analyticity that generalizes to multivariable functions. The power of analyticity in our setting comes from the so-called analytic continuation property: if a function is analytic on an open interval , but is known only on open , then the function extends uniquely to . In the proof of Theorem 3.1, after showing that the kernel is real analytic on , we use this observation to uniquely extend to the on-band subset of its domain (contaminated by ) based on off-band values (uncontaminated by ).
Proof of Theorem 3.1.
Let denote the kernels of and , respectively. We begin by showing that (similarly, ) is analytic on . By Mercer’s Theorem (Hsing and Eubank, 2015), admits the decomposition
where we have assumed that each is analytic on . Equivalently, each has some real analytic extension to some open . Let and choose open and compact so that . Since each is real analytic on and is compact, there exists a positive constant such that for every multi-index ,
Define , , and . Then for every multi-index ,
for some sufficiently large . By symmetry, we also have
Thus, by Theorem 4.3.3 of (Krantz and Parks, 2002), is real analytic on , making (similarly ) real analytic on .
By Theorem 6.3.3 of (Krantz and Parks, 2002), the zero set of either kernel is at most -dimensional, provided the kernels are not uniformly zero. Since the result follows trivially if and are the zero operator, we assume that their kernels are not uniformly zero. Thus, if we can show that the two kernels coincide on an open (i.e., -dimensional) subset of , then by Corollary 1.2.6 of (Krantz and Parks, 2002), they will coincide on , and on by continuity.
Let be the maximum component across and , and define . Since , but on , it must be that on . This completes the proof. ∎
Despite this seemingly restrictive property, the assumption of analyticity is not overly prohibitive. There are many examples of analytic functions, including polynomials, the exponential and logarithmic functions, and trigonometric functions. Moreover, the class of real analytic functions is closed under addition, subtraction, multiplication, division (given a nonvanishing denominator), differentiation, and integration. In fact, Theorem 3.2 shows that any finite-rank covariance operator is well-approximated by finite-rank covariance operators having real analytic eigenfunctions.
Theorem 3.2 (Density).
Let be an -valued random function with a trace-class covariance of rank . Then, for any , there exists a random function whose covariance has analytic eigenfunctions and rank , such that
for the nuclear norm. If additionally has eigenfunctions on then we have the stronger result that for any , there exists a random function whose covariance has analytic eigenfunctions and rank , such that
where and are the kernels of and , respectively.
Proof.
Proposition 1 of Descary and Panaretos (2019) establishes this result for . The proof uses Fourier series approximations of the eigenfunctions of to establish each result. To extend these results to , we need only apply the same reasoning using a basis of that is composed of functions analytic on , and that yields approximations dense in under the sup-norm. One can show that these criteria are satisfied by the Fourier tensor product basis,
where is the -th function of the Fourier basis of . ∎
3.2 Identifiability in the Discretely-Observed Paradigm
Next, we turn to theory for the discrete-observation setting. We begin by describing an observation scheme that generalizes the evenly-spaced grid considered in the manuscript. Let be the partition of into cells of size , where and are defined as in the manuscript. Suppose we observe each of the samples of at the discrete points in where , and denote the set of all possible discrete point collections by . From here, we can follow the steps taken in the manuscript to define the M-resolution functional factor model with factors as
We denote the -resolution versions of by . These operators have kernels
which can be summarized using the tensors of dimension ,
As in the manuscript, the covariance decomposes as
Theorem 3.4 presents conditions needed to identify and from . Chief among them is the requirement from the complete-observation setting that be finite-rank with real analytic eigenfunctions. Theorem 3.3 is an intermediate result that links the functional assumption of analyticity to discretely-observed covariances.
Theorem 3.3.
Let have kernel with and real analytic eigenfunctions . If , then all order- minors of are nonzero, almost everywhere on .
Proof.
First, notice that from , we have that
where is the index set bijection that defines square matricization of . Thus, the the rank- matrix can be written as , where and . Note that any submatrix of can be written as
where and are matrices obtained by deleting rows of whose indices are not included in the cardinality- subsets , respectively. The condition that any order- minor of be nonzero is equivalent to the condition that
for any subsets of cardinality . By construction, , so the minor condition is then equivalent to requiring that for any subset of cardinality .
We will show that this is indeed the case almost everywhere on . Let denote the Lebesgue measure on and let , without loss of generality. Using the Leibniz formula, we have that can be written as the function
where is the symmetric group on elements and is the signature of the permutation . Note that the function is real analytic on , by virtue of each being real analytic on .
We will now proceed by contradiction. Assume that
Since is the Lebesque measure, it follows that the Hausdorff dimension of the set is equal to . However, since is analytic, Theorem 6.3.3 of (Krantz and Parks, 2002) implies the dichotomy: either is constant everywhere on , or the set is at most of dimension . Since the zero set of has positive measure and is thus of Hausdorff dimension , it must be that is everywhere zero on :
Now fix and apply (viewed as a function of only) the continuous linear functional . Then for all :
Applying iteratively to while keeping fixed then leads to
This last equality contradicts the fact that has norm one, and allows us to conclude that
∎
Theorem 3.4 (Identifiability at Finite Resolution).
Let and be covariance operators of rank , respectively, and assume without loss of generality that . Let and be banded continuous covariance operators whose bandwidths and , respectively, have components less than . If the eigenfunctions of and are real analytic, and
| (1) |
then we have the equivalence
almost everywhere on with respect to the Lebesgue measure.
Proof of Theorem 2 from the Manuscript.
Given our conditions, the tensors have bandwidths for and . Let for , and assume without loss of generality that . Let be the set of indices on which both and vanish:
From , we obtain that for all . Let and define
then equation (1) of the manuscript implies that , which in turn implies that the tensors and contain a common subtensor of dimension . Consequently, and contain a common submatrix of dimension , and, by equation (1) of the manuscript, a common submatrix of dimension .
Assume that all order- minors of are nonzero. Then the determinant of is nonzero. This implies that , which means and are two rank- tensors equal on .
Now, let be a tensor equal to on , but unknown at those indices not belonging to . We will now show that there exists a unique rank- completion of . Due to equation (1) of the manuscript, it is possible to find a submatrix of with dimension containing exactly one unobserved value, denoted . Using the fact that the determinant of any square submatrix of dimension larger than is zero, we obtain a linear equation of the form where is equal to to the determinant of a submatrix of of dimension . Since we have assumed that any minor of order is nonzero, we have that and the previous equation has a unique solution. It is then possible to impute the value of . Again, due to equation (1) of the manuscript, it is possible to apply this procedure iteratively until all missing entries are imputed, thereby allowing us to uniquely complete the tensor into a rank- tensor.
In summary, we have demonstrated that when all order- minors of are nonzero, it holds that , and hence . Theorem 3.3 ensures that indeed has nonvanishing minors of order almost everywhere on . So we conclude that and almost everywhere on . ∎
3.3 Estimation
We now present theory for the estimators of , , and discussed in Section 3 of the manuscript. To motivate the estimator of , we define an optimization problem for which is the unique solution. Let be the set of symmetric non-negative definite tensors with trace norm bounded by that of , whose own trace norm may be scaled to one. Next, define the functional by
where , is defined by for , and is a rank-penalizing parameter. The subsequent lemma shows how the functional is used to formulate two versions of the same optimization problem, both of which are solved uniquely by .
Lemma 3.1.
Let be a rank covariance operator with analytic eigenfunctions and kernel , and be a trace-class covariance operator with -banded kernel . For , let
and . Assume
| (2) |
Then for almost all grids in :
-
1.
The tensor is the unique solution to the optimization problem
-
2.
Equivalently, in penalized form,
for sufficiently small .
Proof.
We first show that is the unique solution to the constrained optimization problem. Note that a solution to the constrained problem must coincide with on
since . Then by condition (2) of the manuscript and Theorem 3.3, the square matricization of has a non-zero minor of order , implying that . Since satisfies the constraint and has rank , we have that . Using the iterative procedure from the proof of Theorem 2 of the manuscript, we can show that equals everywhere.
Next, we show that is the unique minimizer of for sufficiently small . First, consider some with . Since uniquely solves the constrained problem, we have that for all ,
Thus, does not minimize . Next, consider some with . Let , where the inequality holds since a minimizer of has rank bounded below by . Let . Then for all ,
Thus, does not minimize . ∎
In Lemma 3.1, we present constrained and penalized formulations of the same optimization problem. The constrained problem informs practical implementation of the estimator, while the penalized version motivates the formal estimator of . To make this estimation problem tractable, we assume that belongs to the subset defined by
where is some roughness-penalizing functional. On this space, define the functional by
where is a roughness-penalizing parameter. This functional, which may be viewed as a roughness-penalizing empirical analogue of , is used to define the estimator for .
Definition 3.1 (Estimator of ).
Suppose are an i.i.d. sample from a functional -factor model. Let and assume we observe
Let be the empirical covariance tensor of the tensors
We define the estimator of to be an approximate minimum of , where is sufficiently small, and as . By approximate minimum, we mean that satisfies
The rank and scaled eigentensors of the estimator in Definition 3.1 produce estimators for the number of factors and the loading tensors , respectively.
Definition 3.2 (Estimators of and ).
Consider the setting and estimator presented in Definition 3.1. We define estimators for the number of factors and the th loading function as
where and are the th eigenvalue and eigentensor of , respectively.
In Theorem 3.5, we show that , , and , are consistent for their population analogues.
Theorem 3.5 (Consistency).
Suppose is equal to the scaled eigentensor of for . Then for sufficiently small and , we have
-
(i)
,
-
(ii)
, and
-
(iii)
.
Proof.
In proving (i), we assume so that all tensors in the problem are matrices. For , simply square matricize each tensor then proceed as follows. By Corollary 3.2.3 from van der Vaart and Wellner (1996), the result follows after verifying that:
-
(a)
,
-
(b)
is lower semi-continuous on ,
-
(c)
has a unique minimum at , and
-
(d)
is uniformly tight.
Note that we already established (c) in the Lemma from the manuscript. After scaling to have unit trace norm, (d) holds as well. To verify (b), note that is continuous and is lower semi-continuous. Being the sum of a continuous and lower semi-continuous function is itself lower semi-continuous.
To check (a), note that for ,
where convergence follows from almost surely, and . This completes the proof of (i).
To prove (ii), we again assume and extend the proof to via square matricization. Proceeding by contradiction, suppose that (ii) does not hold. Then for some subsequence , there exist and such that for all . Consequently, there exists either
-
(e)
a subset such that for all , or
-
(f)
a subset such that for all .
Focusing on (e), the convergence of to in probability means there exists a subsequence such that almost surely. This means that on a set with probability at least , and for all . This is not possible since the set of matrices with rank at most is closed.
We thus focus on (f). Again, since converges to in probability, there exists a subsequence for which almost surely. This means that on a set with probability at least , and for all . Working on this set, for all ,
| (3) | ||||
| (4) |
where line (3) follows because is a minimizer of . From the proof of (i), we have that
| (5) |
which implies
| (6) |
Moreover, since is continuous and almost surely, by continuous mapping we have
| (7) |
Combining the results of lines (6) and (7) gives
| (8) |
Now, note that on the set the are equi-Lipschitz continuous. From this and the uniform convergence in line (5), we have
| (9) |
By the inequality in line (4) and the results in lines (8) and (9), we derive the contradiction that . This proves (ii).
Finally, (iii) follows immediately from (i), thus completing the proof. ∎
4 Tuning Procedures
Recall from Section 3.1.1 of the manuscript that we must choose values for the smoothing parameter before estimating . We find that subjective selection is often preferable, but there are some settings (e.g., a simulation study) that require automatic selection. One may do so using V-fold cross-validation, as follows:
-
(1a)
Partition the sample into folds of equal (or near equal) size.
-
(1b)
For a given , let be the solution to the optimization problem
where denotes the empirical covariance of all samples except those in the th fold, and is the maximal rank of . That is, is the maximal-rank version of the estimator in Definition 1 of the manuscript for the sample excepting the th fold.
-
(1c)
Compute the cross-validation scores
where is the empirical covariance of samples in the th fold.
-
(1d)
Minimize to provide the choice of smoothing parameters.
One might wonder if we could use the above procedure to tune a vector of smoothing parameters that applies a different level of smoothing to each eigentensor. We do not recommend this for the following reason. Recall that we solve the problem in (1b) by re-framing it as a factorized matrix completion problem like equation (4) of the manuscript that optimizes over , . For fixed , the error term in equation (4) of the manuscript is constant for any while the penalty term varies as we rotate . This means that rough loading tensors can avoid penalization by “hiding” from larger in some rotation of , making it difficult to target a specific loading tensor with a particular roughness penalty.
Next, recall from Section 3.2 of the manuscript that some tuning procedure is needed to systematically choose the shrinkage parameter . One option is to choose using -fold cross-validation, as follows:
-
(2a)
Apply a varimax rotation to the initial estimate to obtain .
-
(2b)
Partition the sample into folds of equal (or near equal) size.
-
(2c)
Using the tuned smoothing parameter , compute as in step (b) of the estimation procedure for (see Section 3.1.1 of the manuscript), setting . We suppress from here forward.
-
(2d)
Rotate each towards the target (using GPArotation::targetT from Bernaards et al. (2015)) to get .
-
(2e)
For a given , adaptively soft-threshold as in equation (5) of the manuscript to get .
-
(2f)
Compute the cross-validation scores
where , and is the empirical covariance of samples in the th fold.
-
(2g)
Minimize to provide the choice of shrinkage parameter.
5 Rank Simulation Study
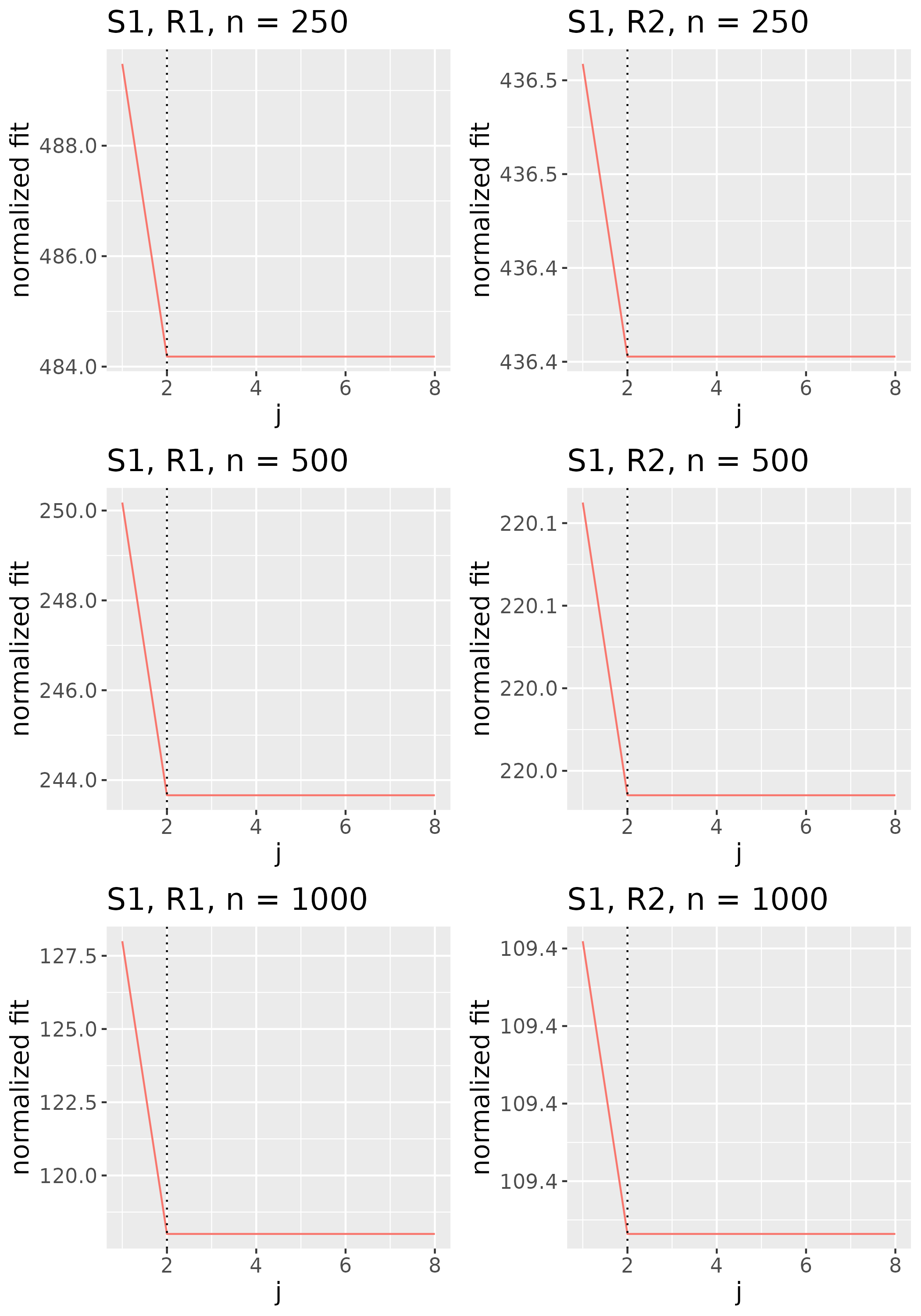
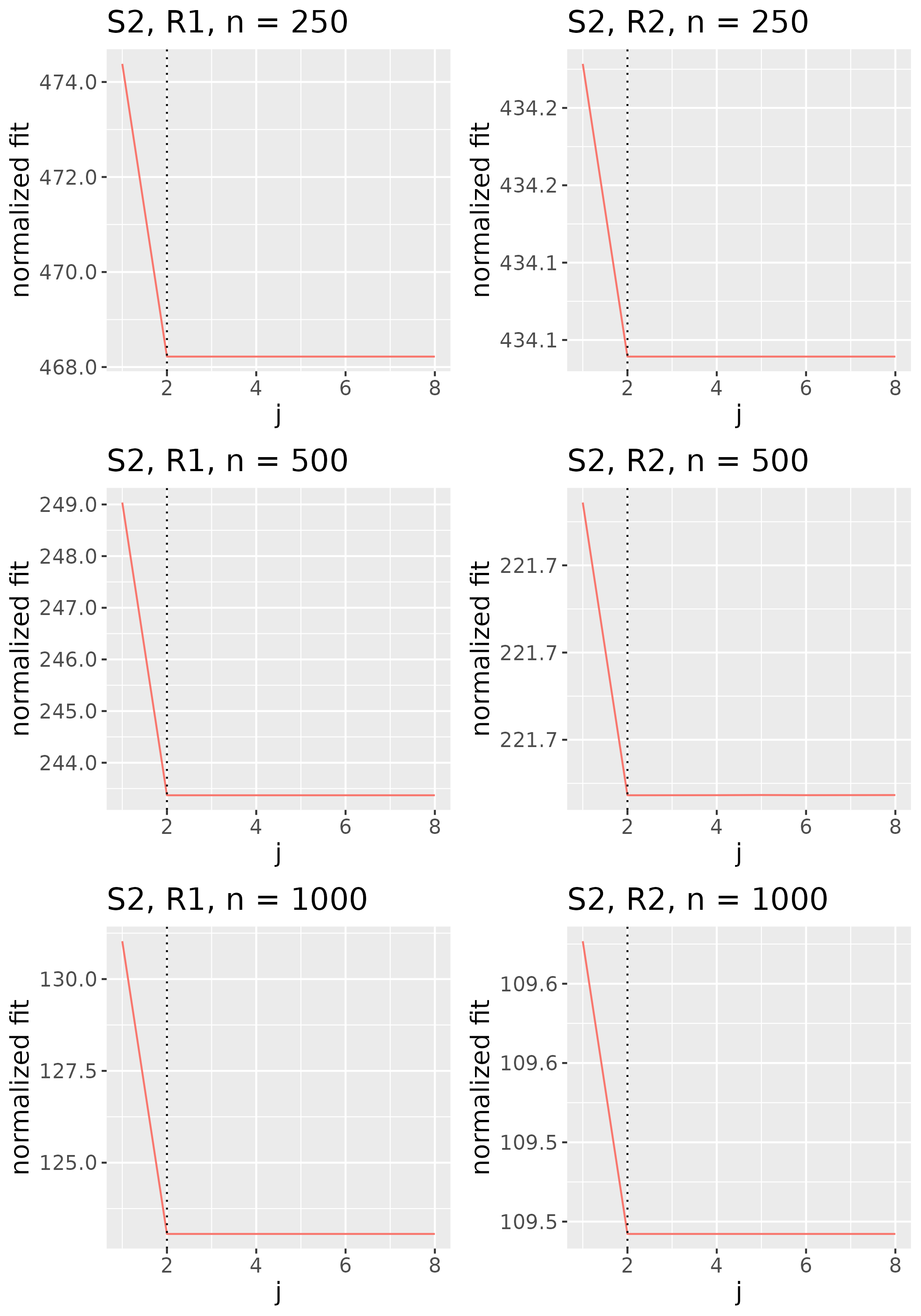
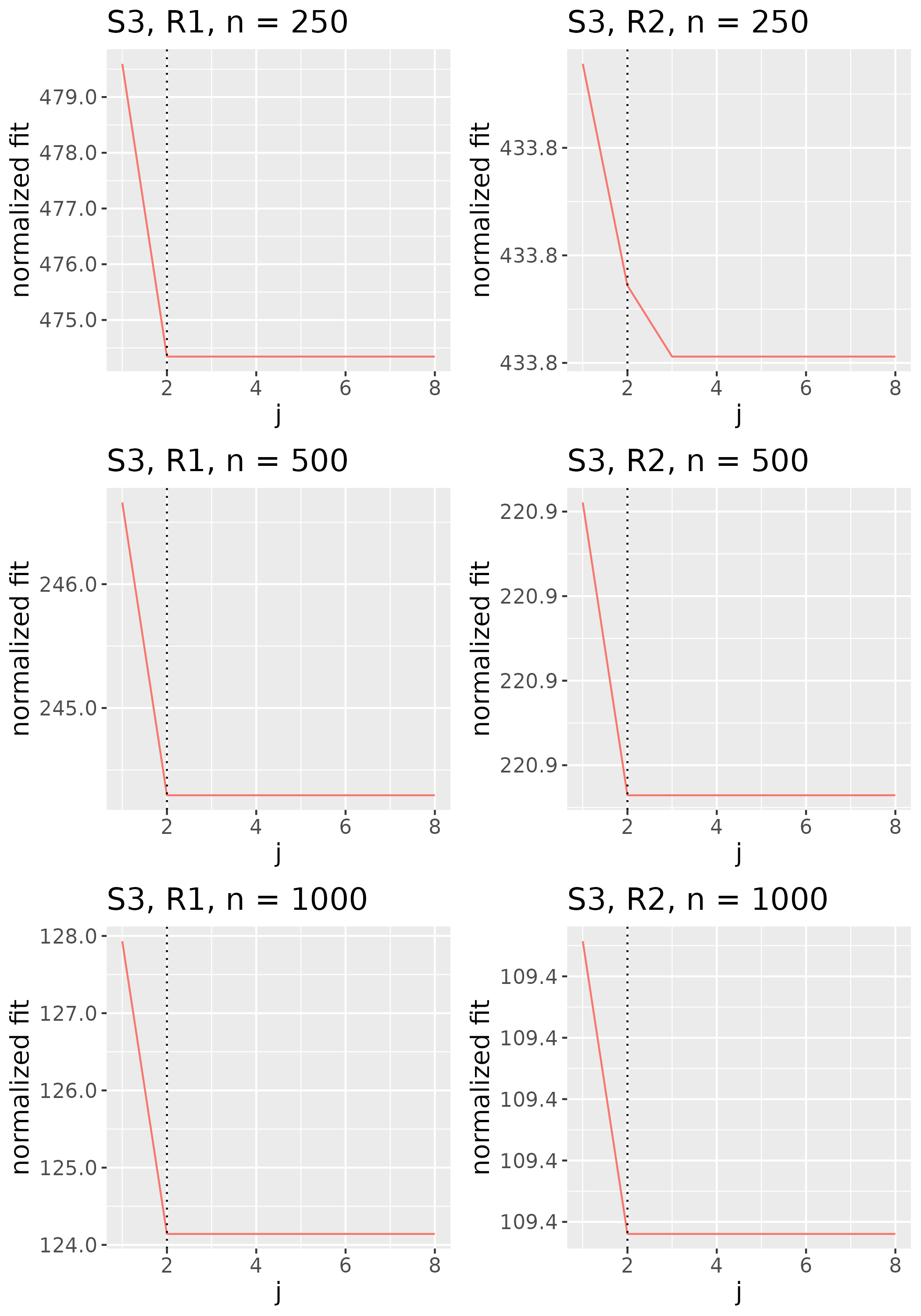
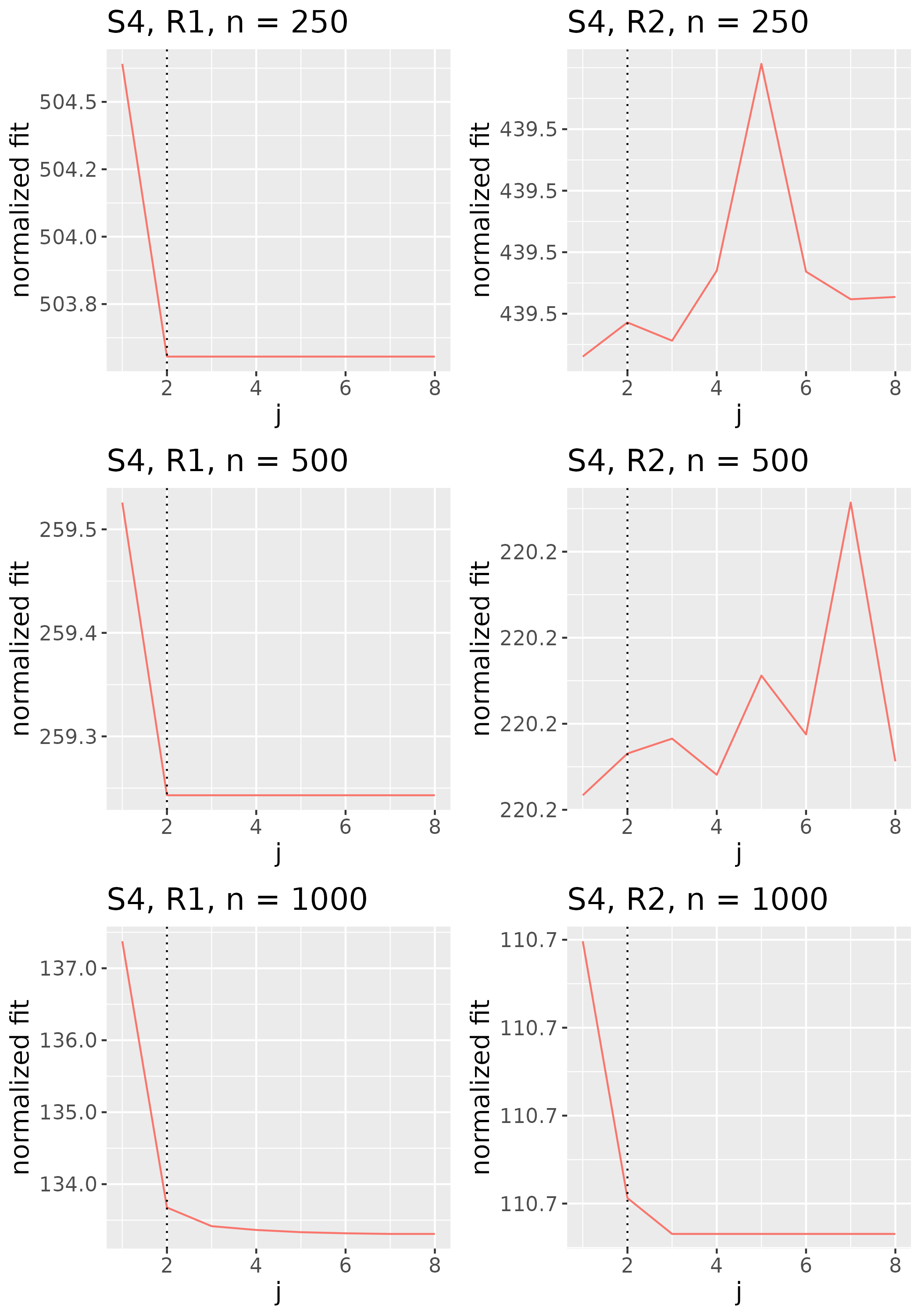
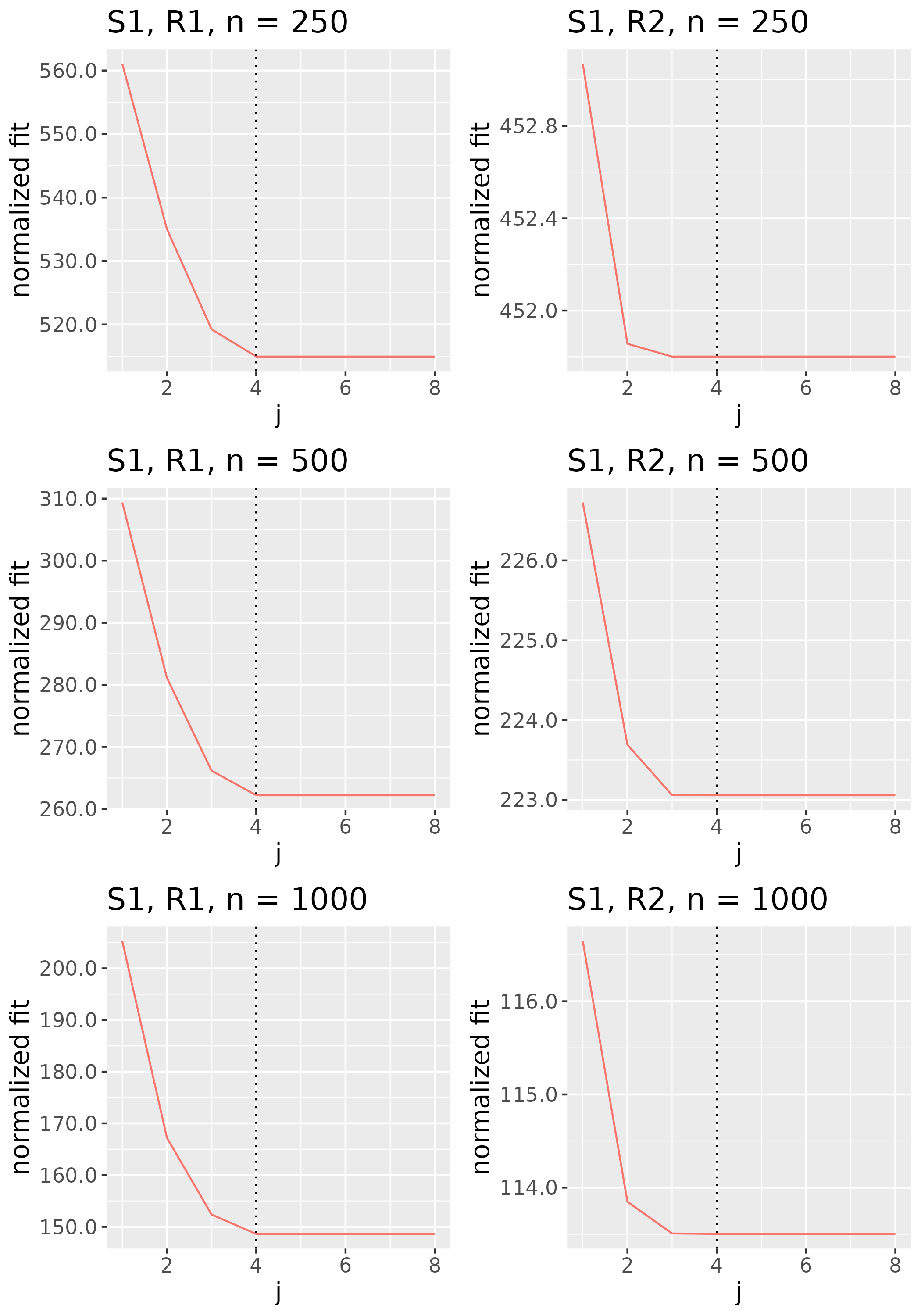
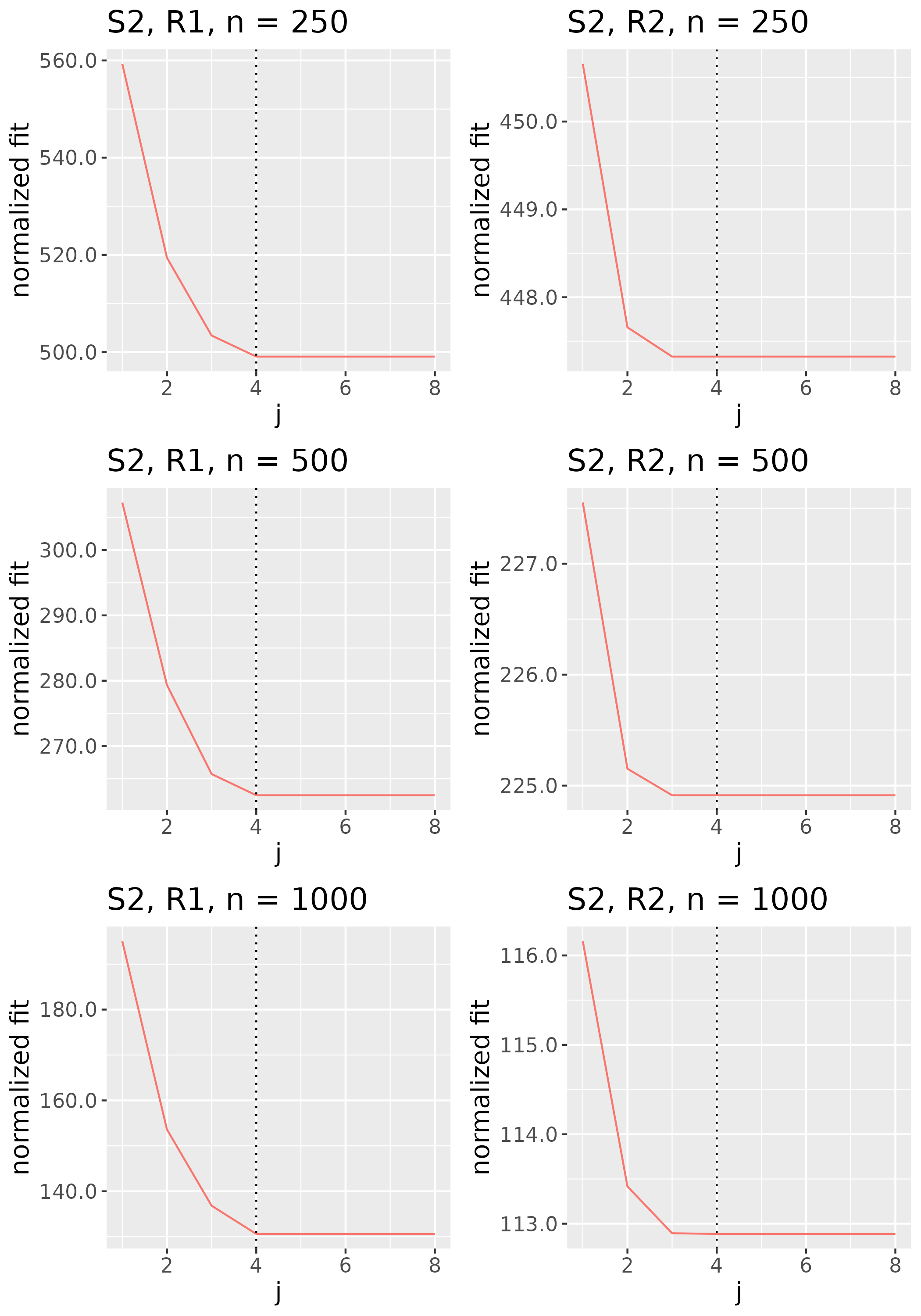
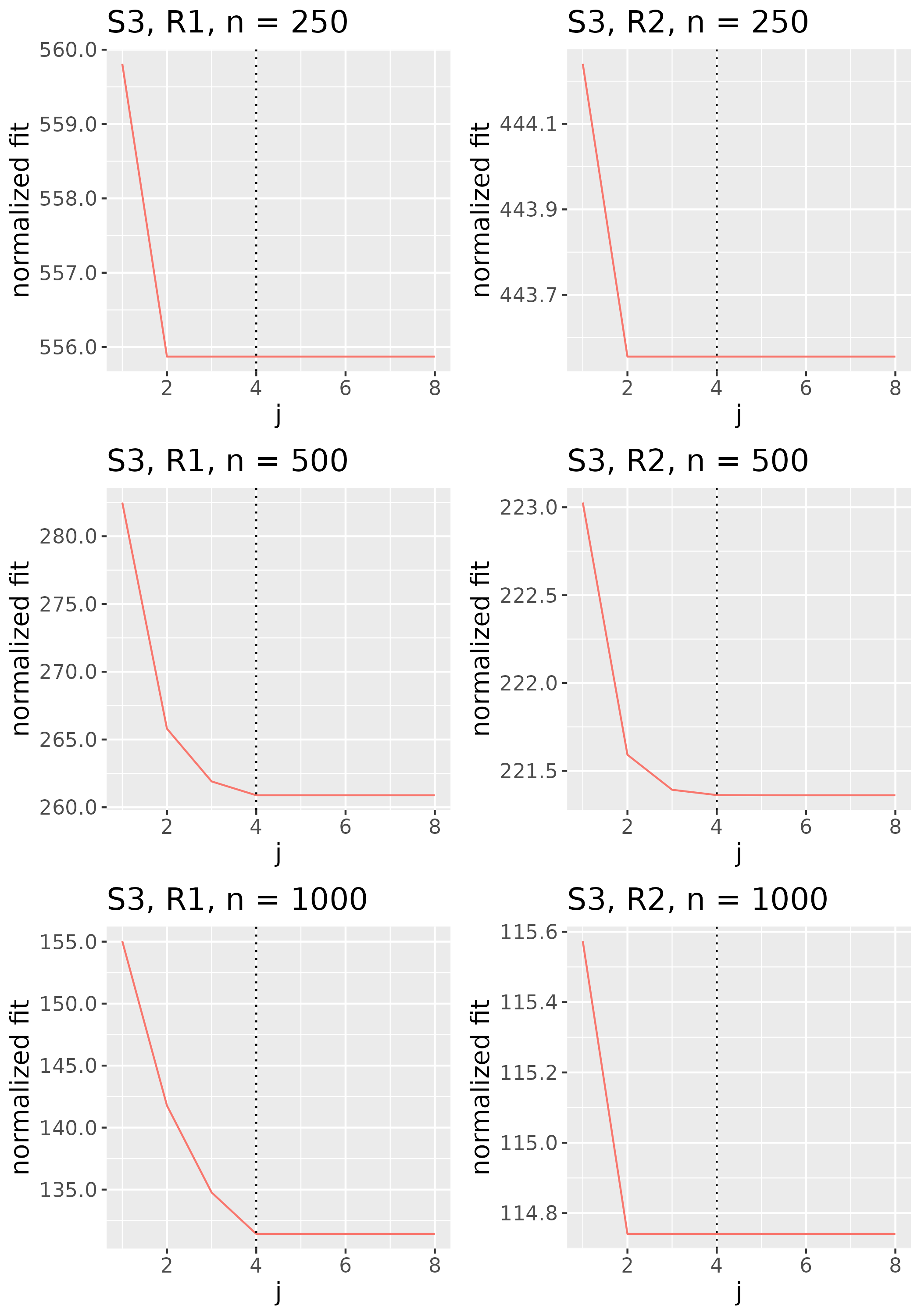
To study the behavior of the scree plot approach, we simulated a single instance of each configuration, then plotted the quantities for . Figures 1, 2, 3, and 4 display the resulting scree plots. As expected, R2 presents a harder problem than R1, while rank selection generally becomes easier as grows. Post-hoc analysis of some selection failures – for instance, when the scree plot appears non-decreasing or under-selects the rank – reveals that over-smoothing can force optimization into bad local optima, and that such optima may sometimes be avoided with a more conservative choice of the smoothing parameter. In particular, for several R2 configurations, the scree plot approach fails more frequently for the NET loading scheme than for the BL scheme. As discussed in Section 4.1 of the manuscript, this is likely due to the application of a single smoothing parameter to the loading tensors of NET which exhibit varying degrees of smoothness. Despite these occasional failures, our simulation study supports the scree plot approach as a viable rank selection method.
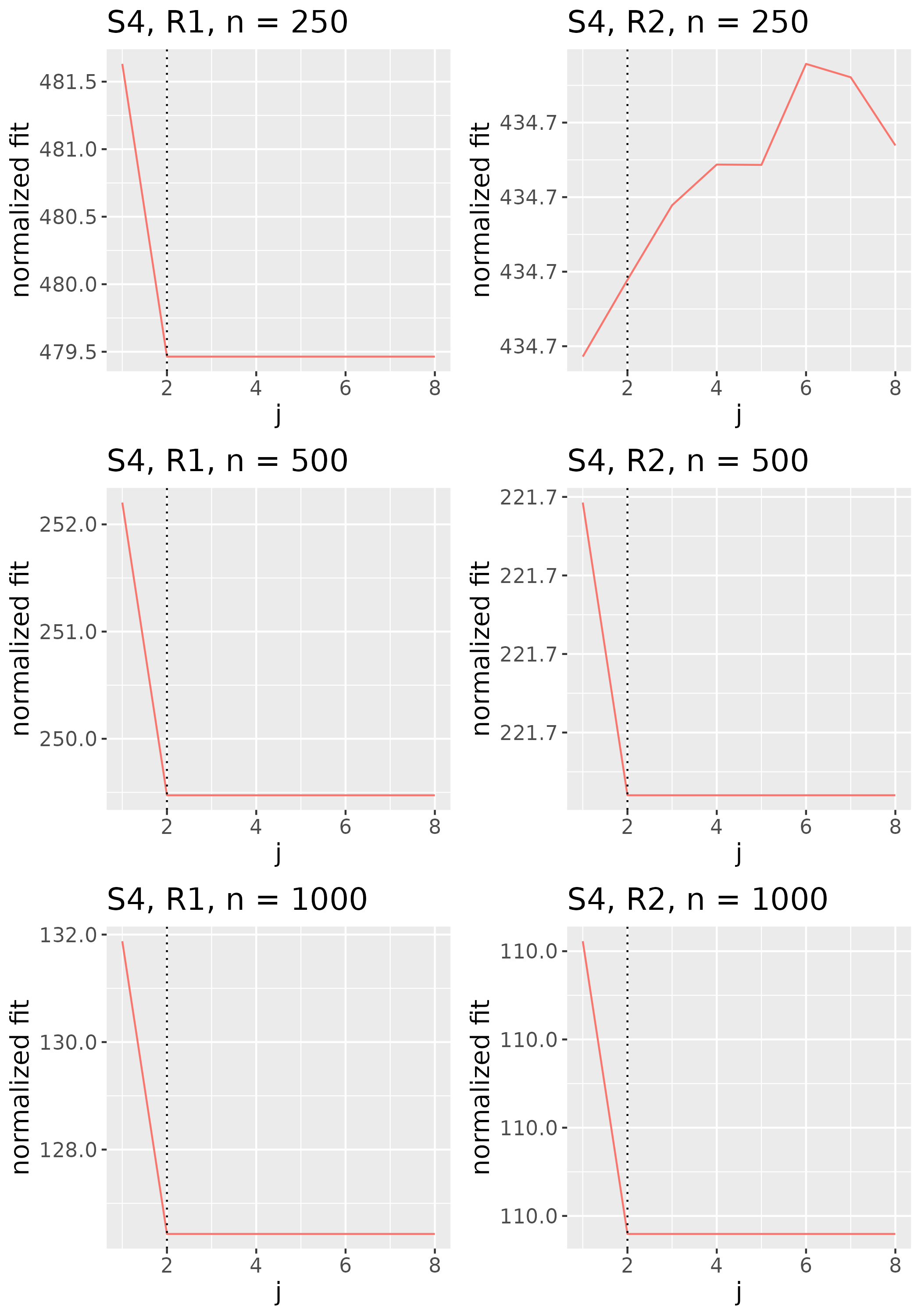
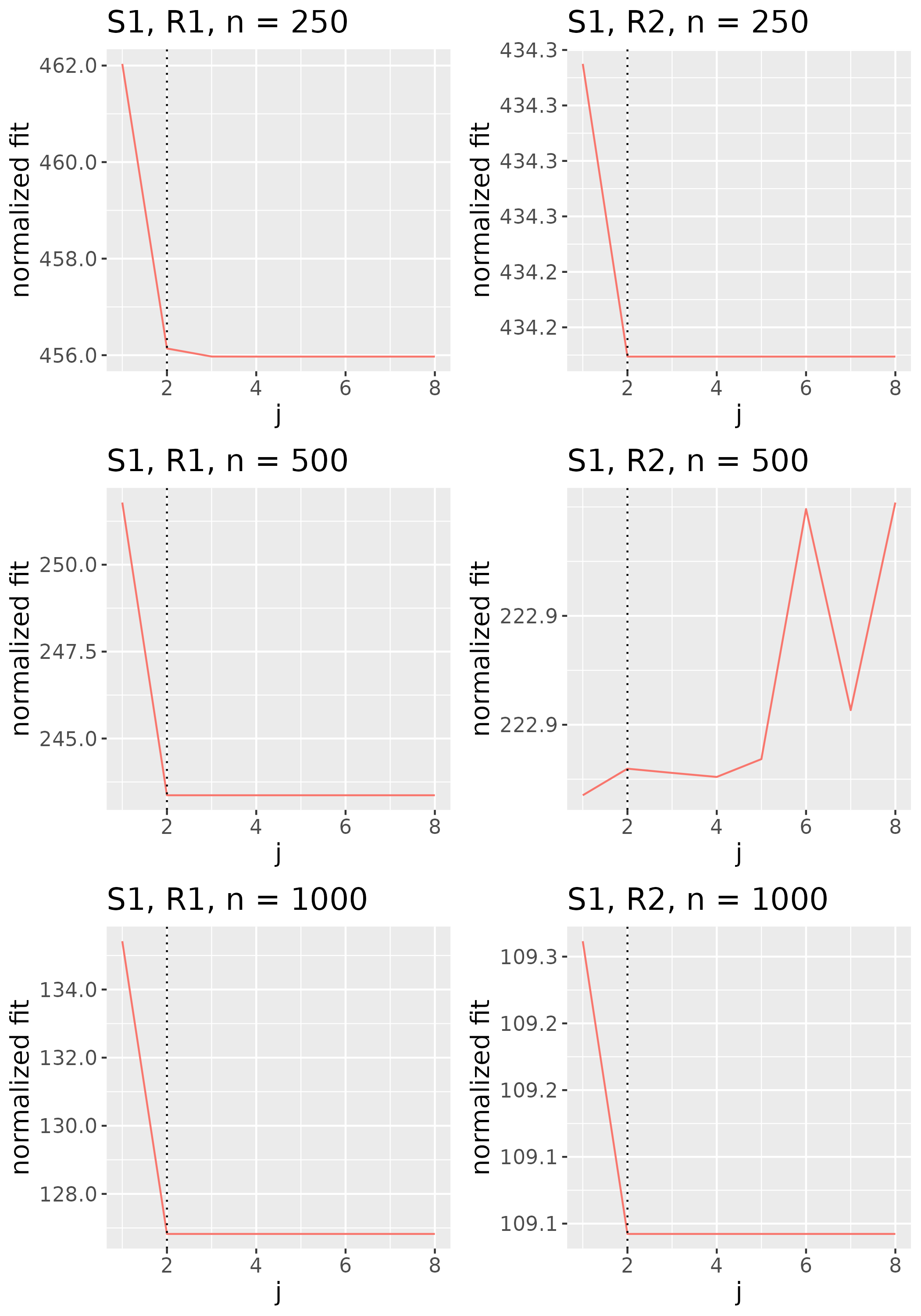
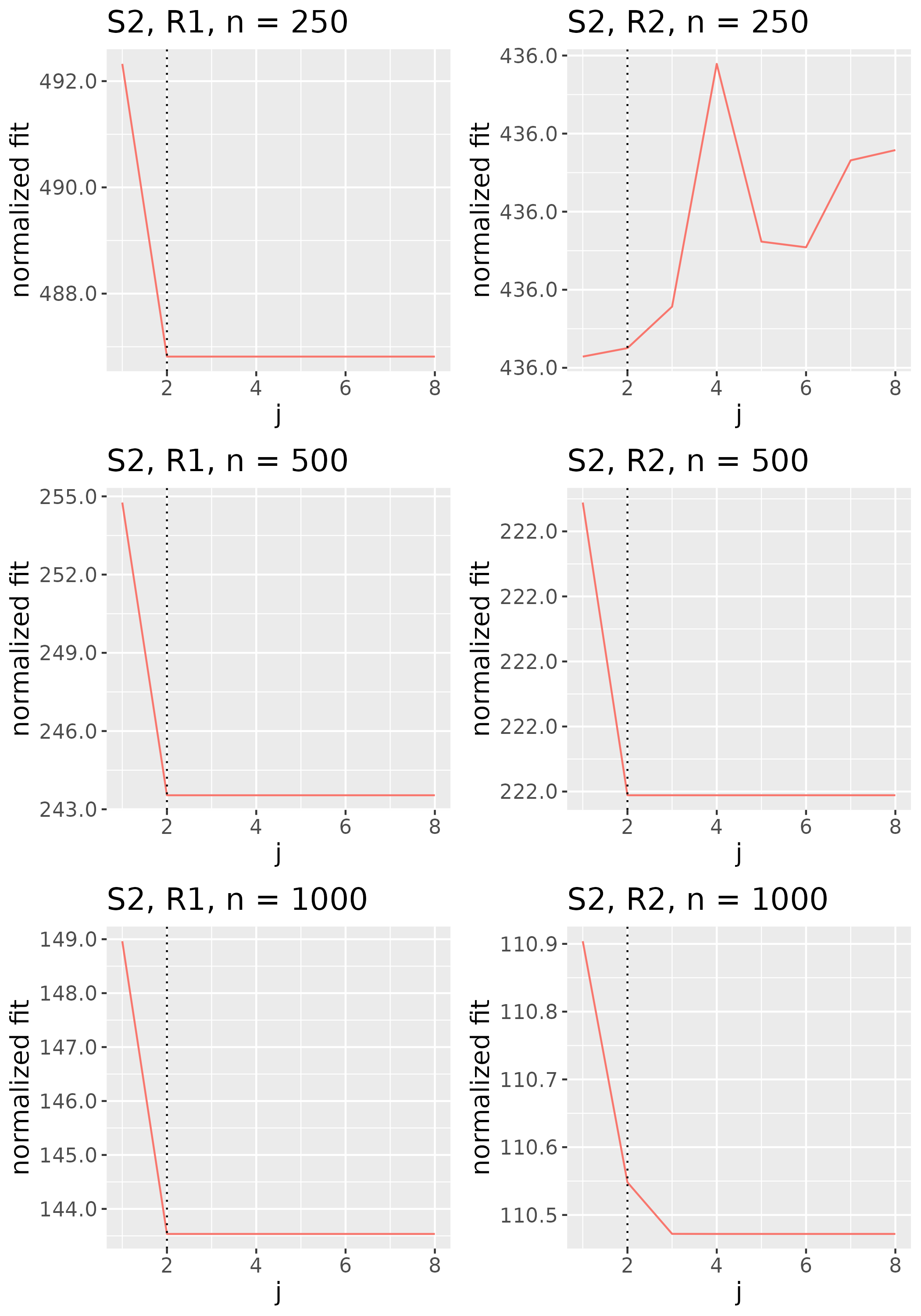
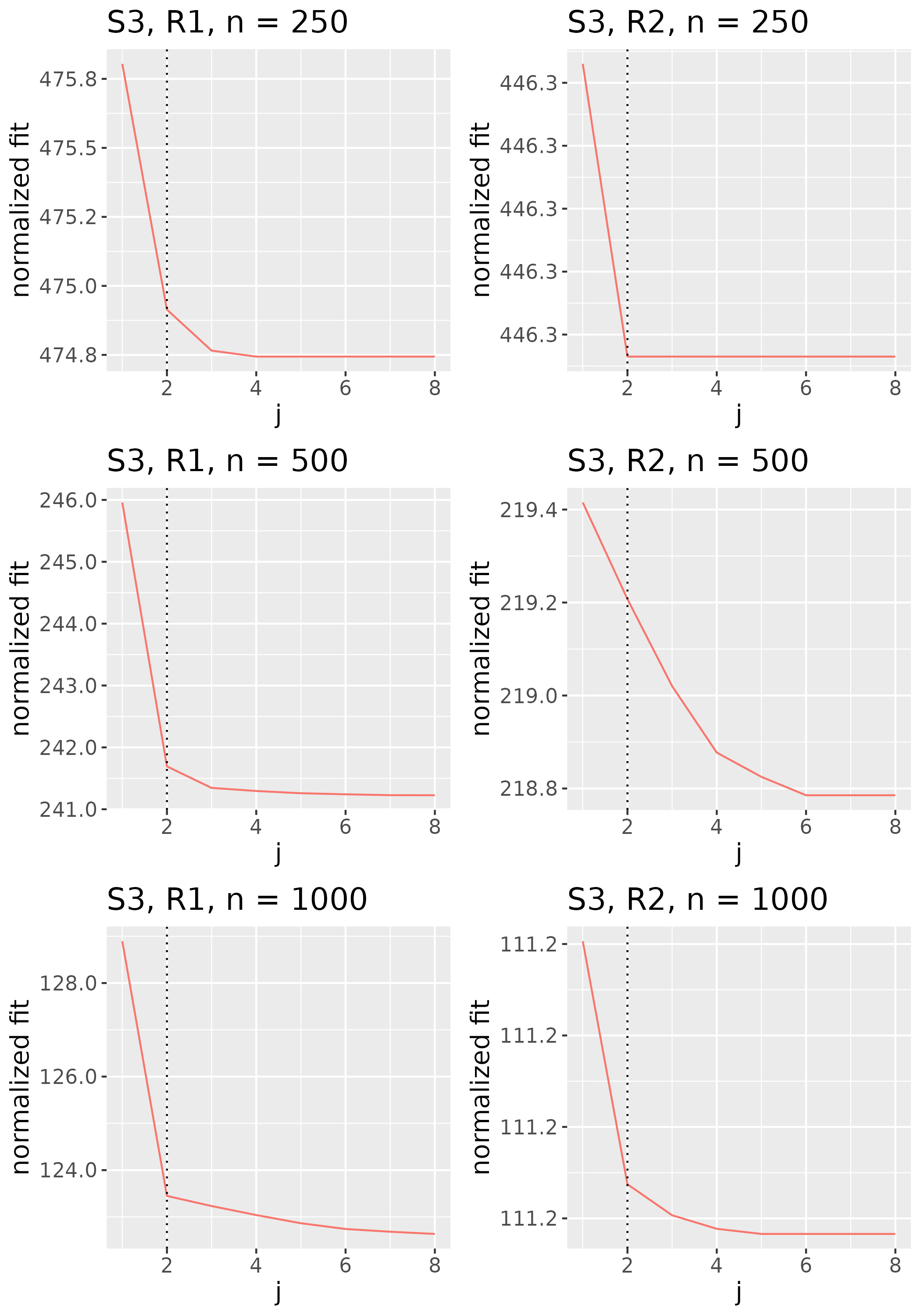
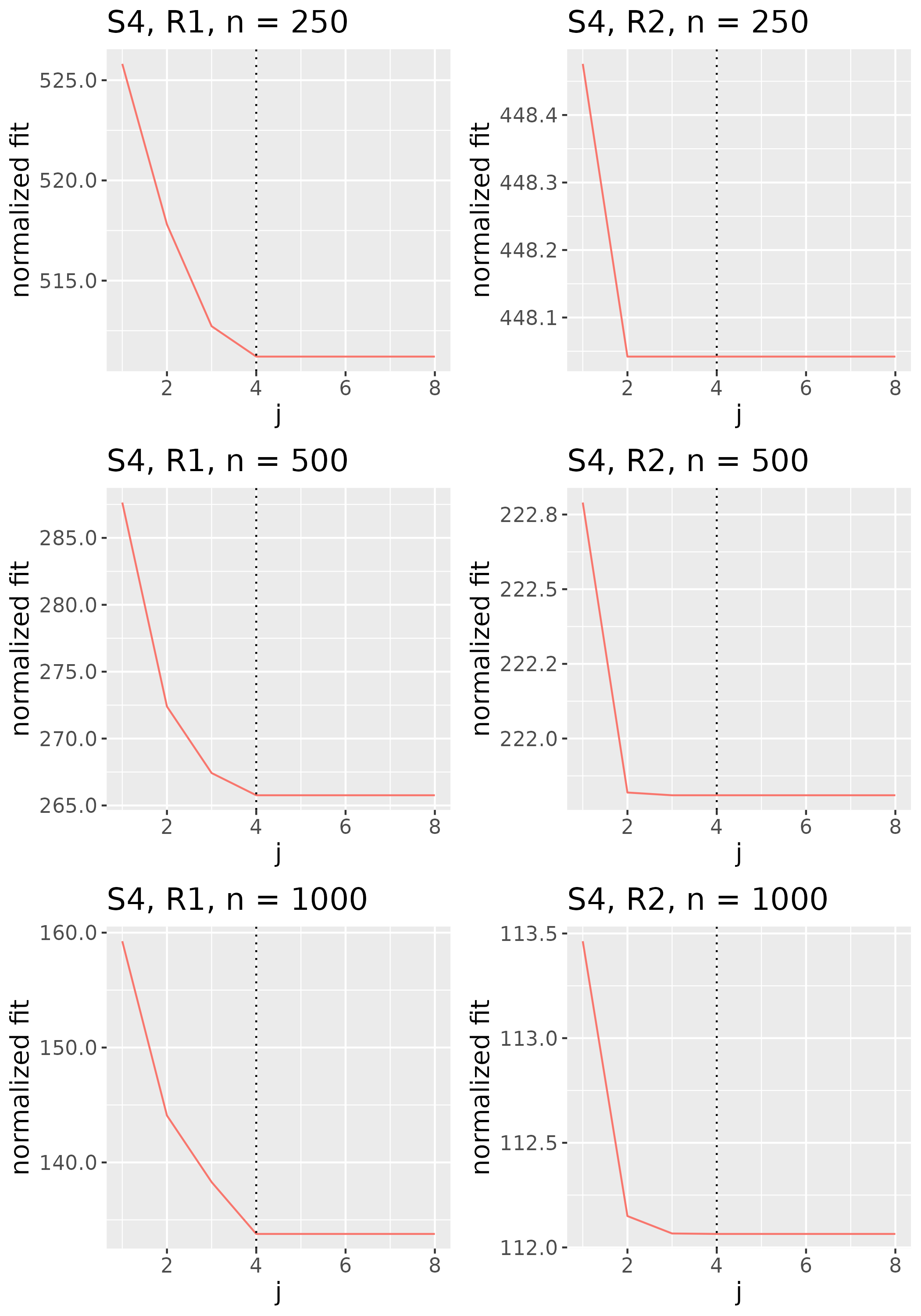
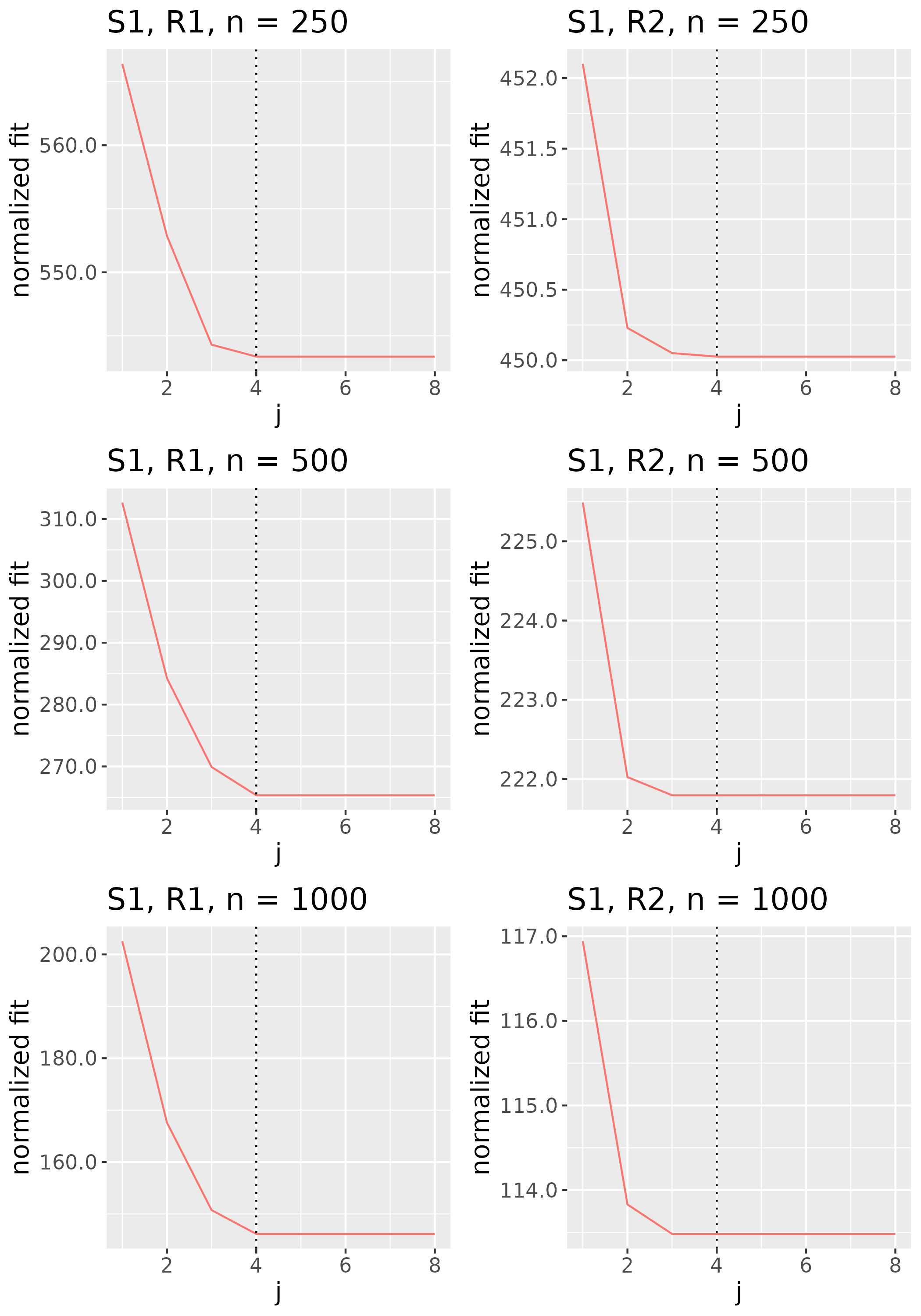
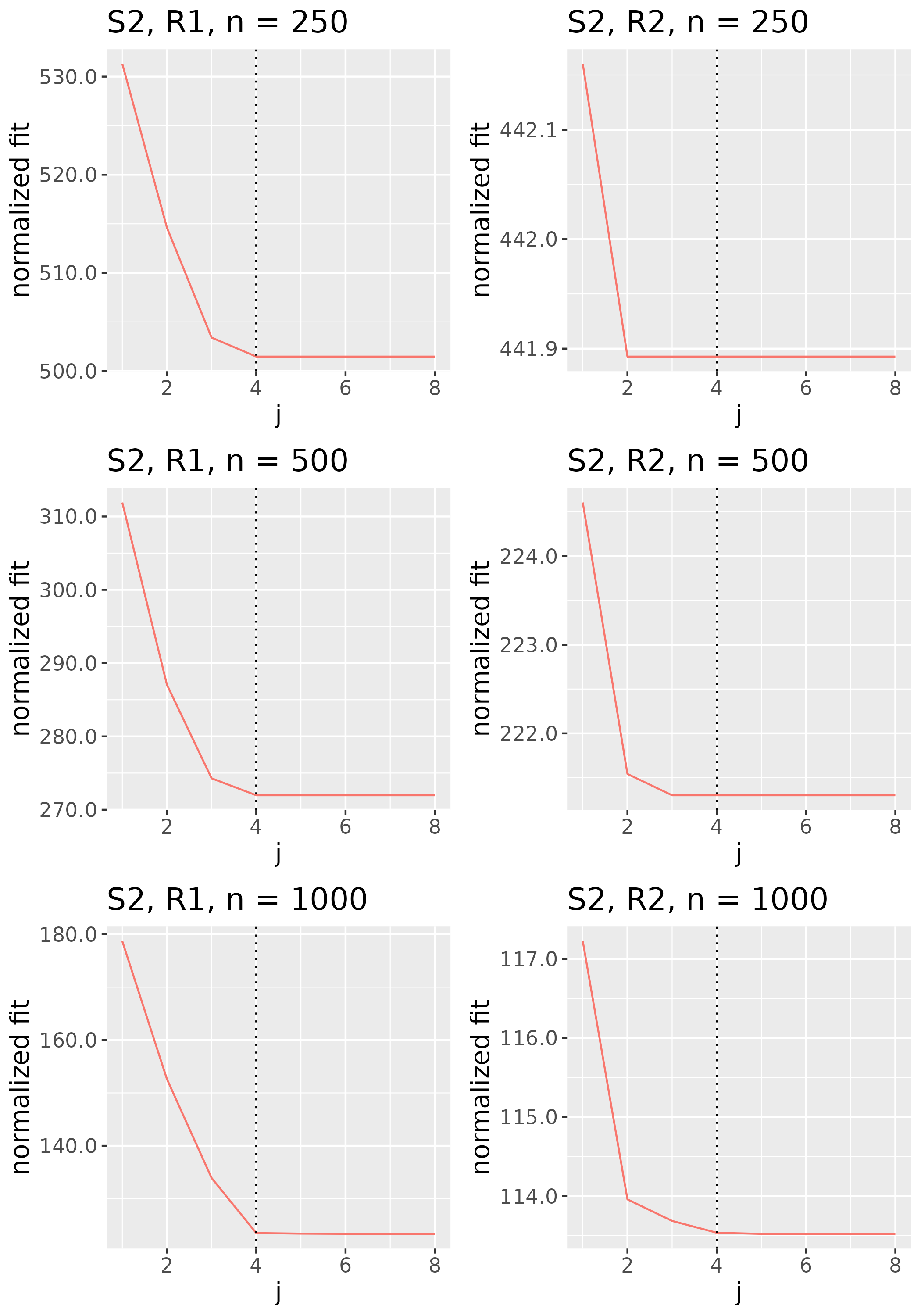
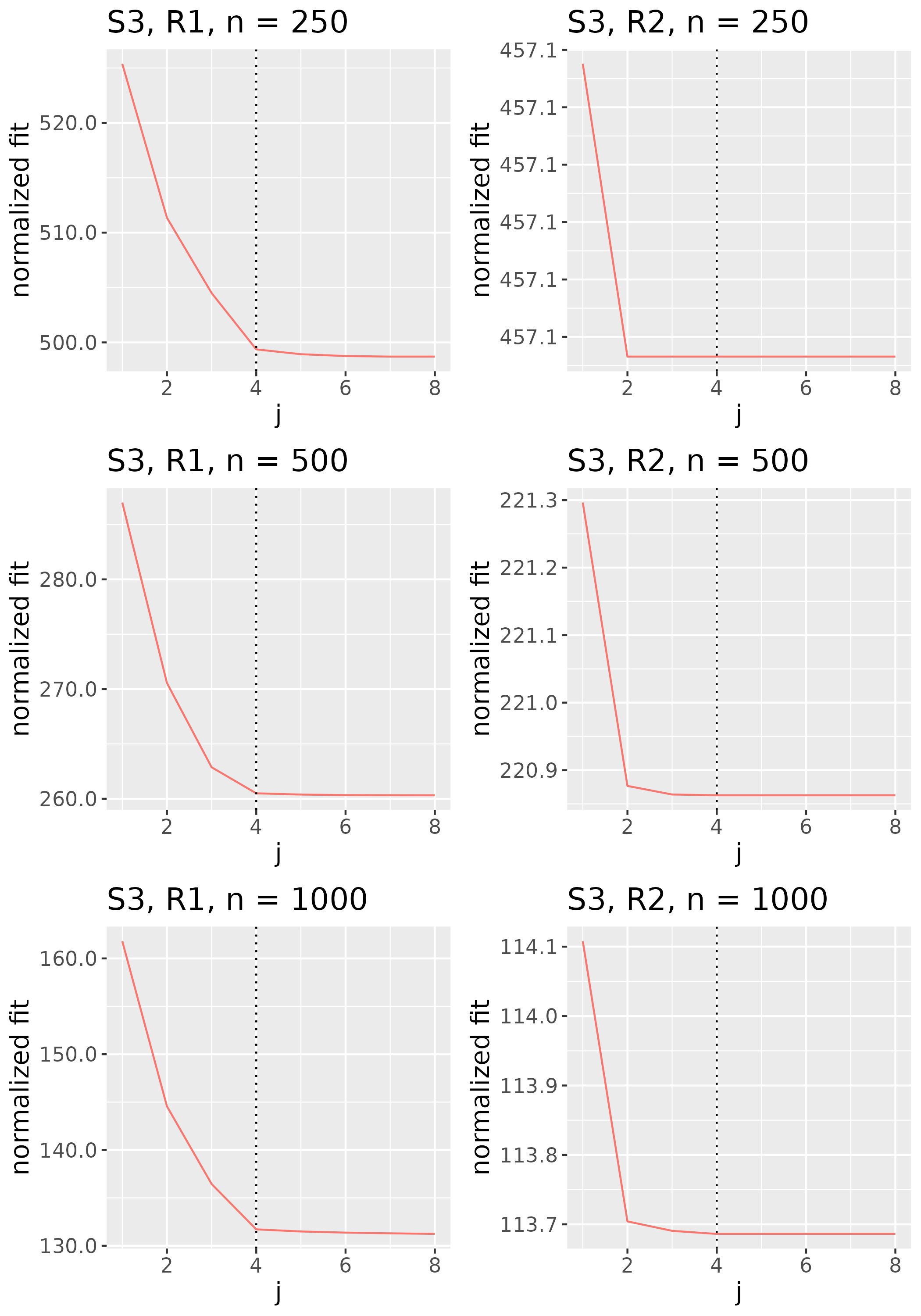
6 AOMIC Data Analysis
6.1 Output from Higher-Order Models
This section contains supplementary figures from the analysis of resting-state data from the Amsterdam Open MRI Collection (AOMIC) PIOP1 dataset in Section 5 of the manuscript.
Figure 5 demonstrates the effect of prewhitening on voxel time courses. Figure 5a shows a time course and corresponding autocorrelation function (acf) for three example voxels from one subject’s preprocessed data, while Figure 5b displays each time course’s ARIMA residuals scaled to unit variance with accompanying acf.
The left-hand plot of Figure 6 displays the non-increasing function for . To aid in identification of this plot’s elbow, we also plot the ratios for in Figure 6. The estimated number of factors should be the at which levels off or, equivalently, the at which becomes a constant close to 1. As discussed in Section 6 of the manuscript, we set .
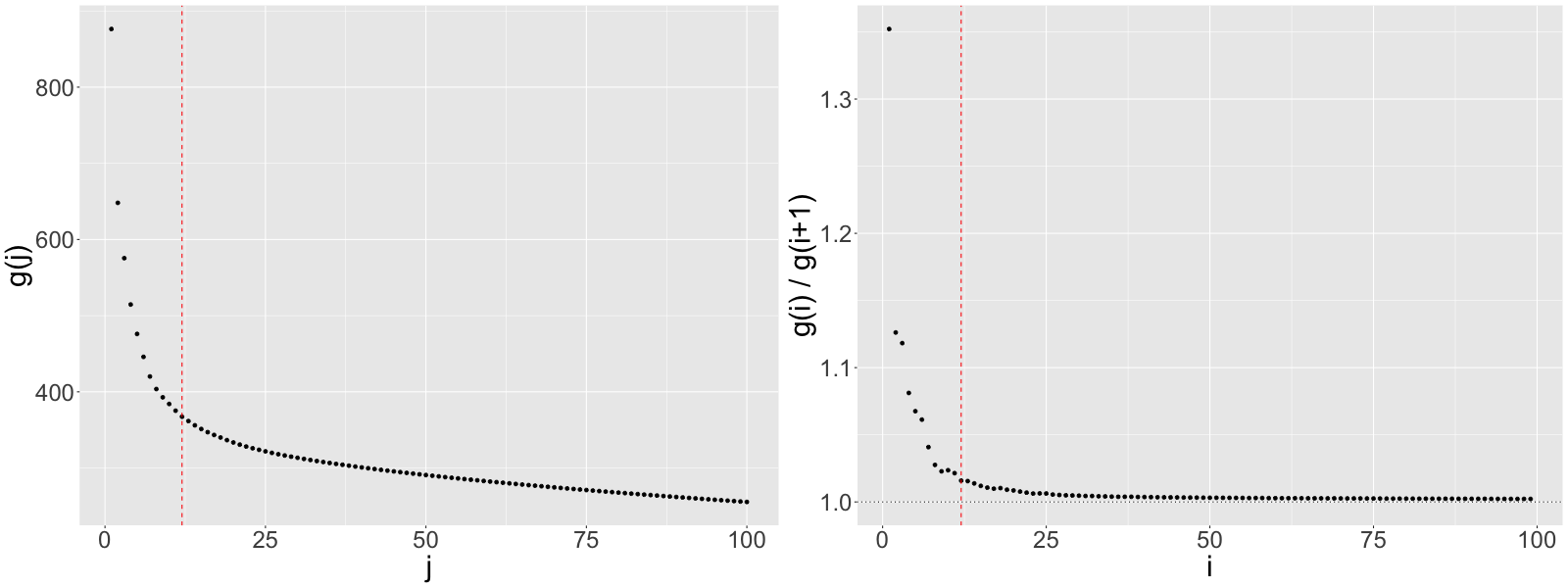
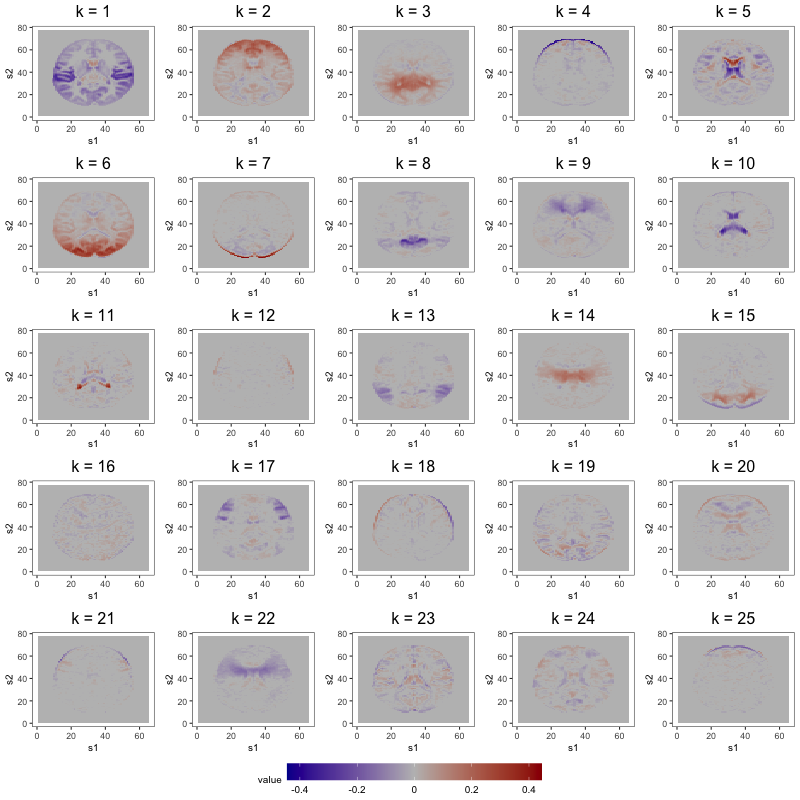
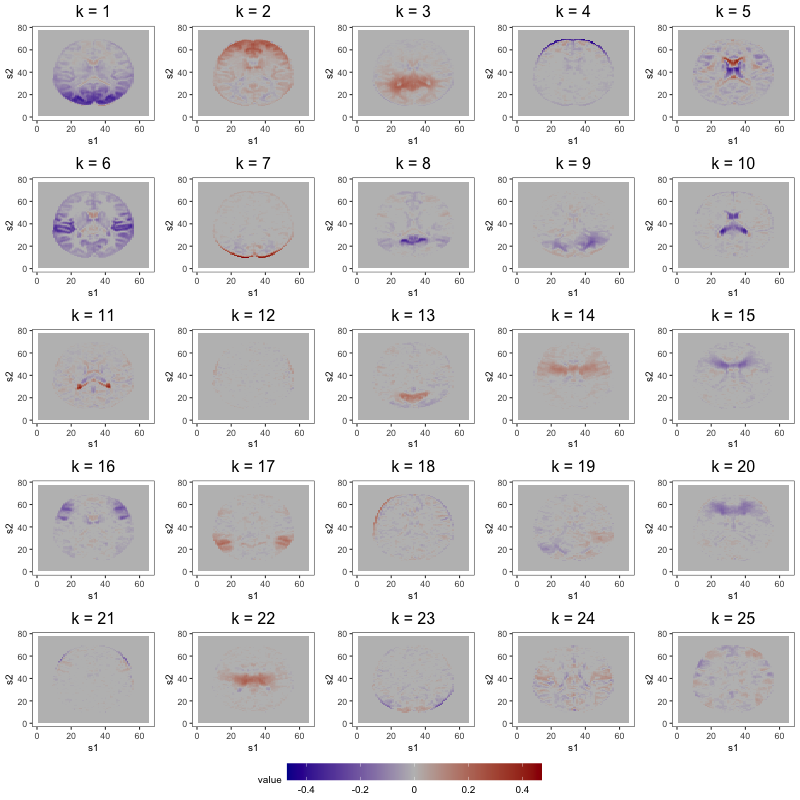
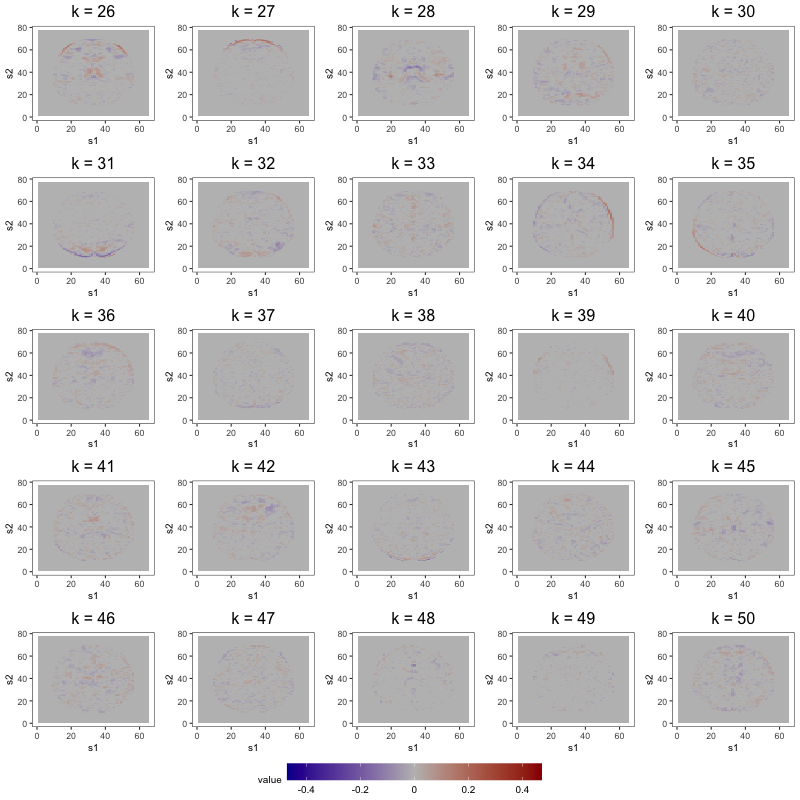
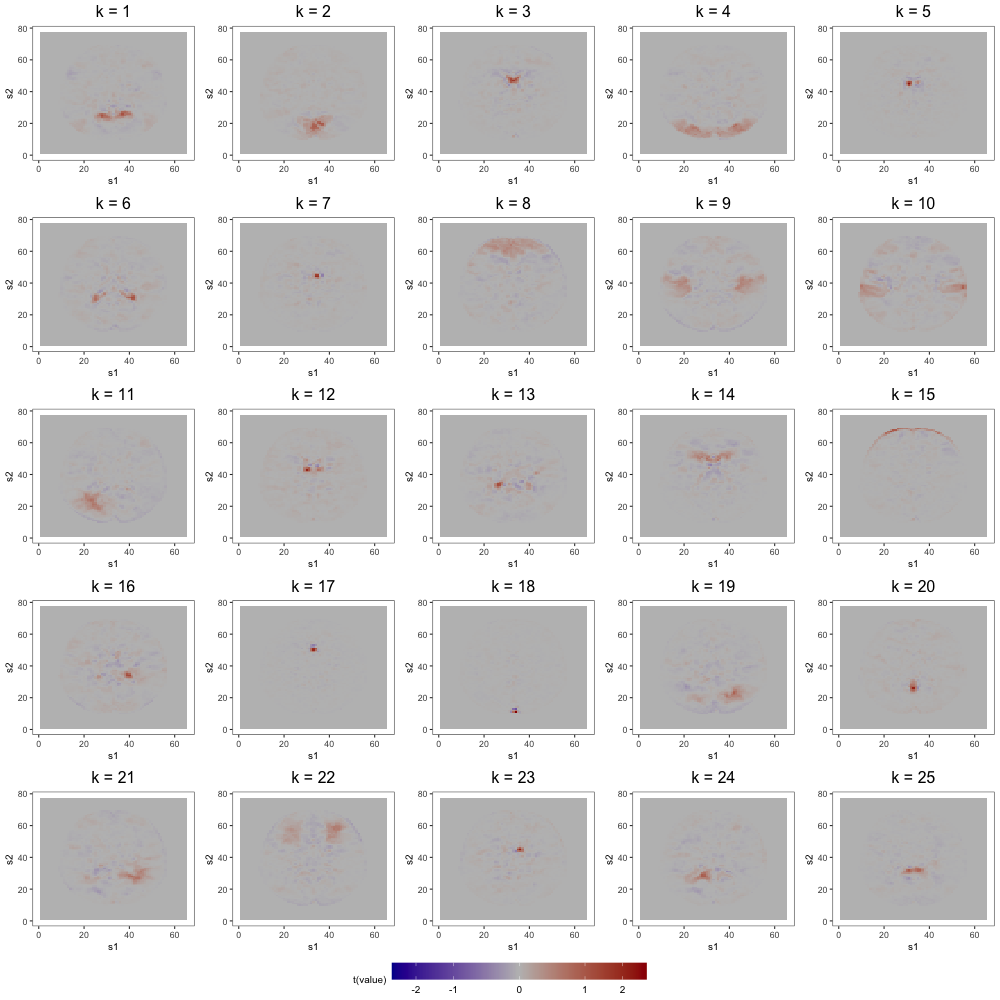
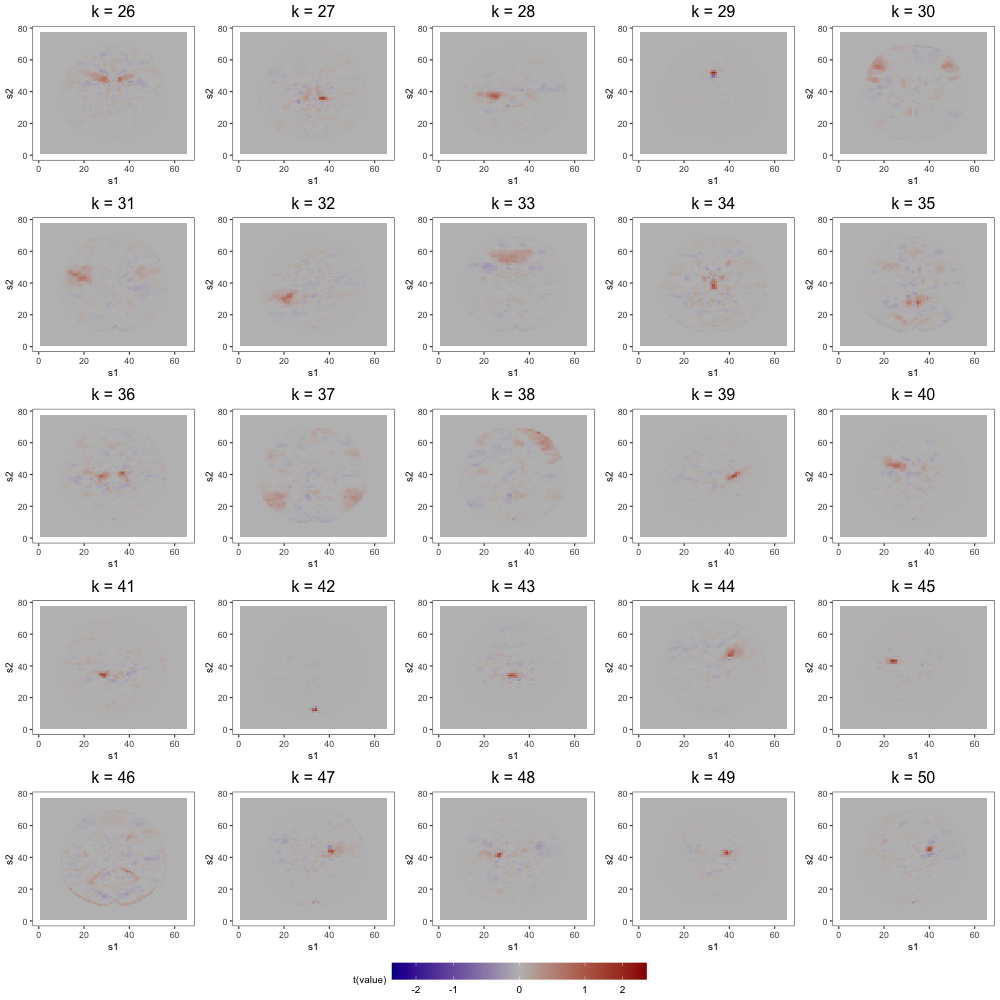
Figure 7 displays loading estimates from the 25-factor FFM while Figures 8 and 9 show those from the 50-factor FFM. Figure 10 displays independent component (IC) estimates from the 25-IC model while Figures 11 and 12 show those from the 50-IC model.
6.2 Multi-Scale ICA
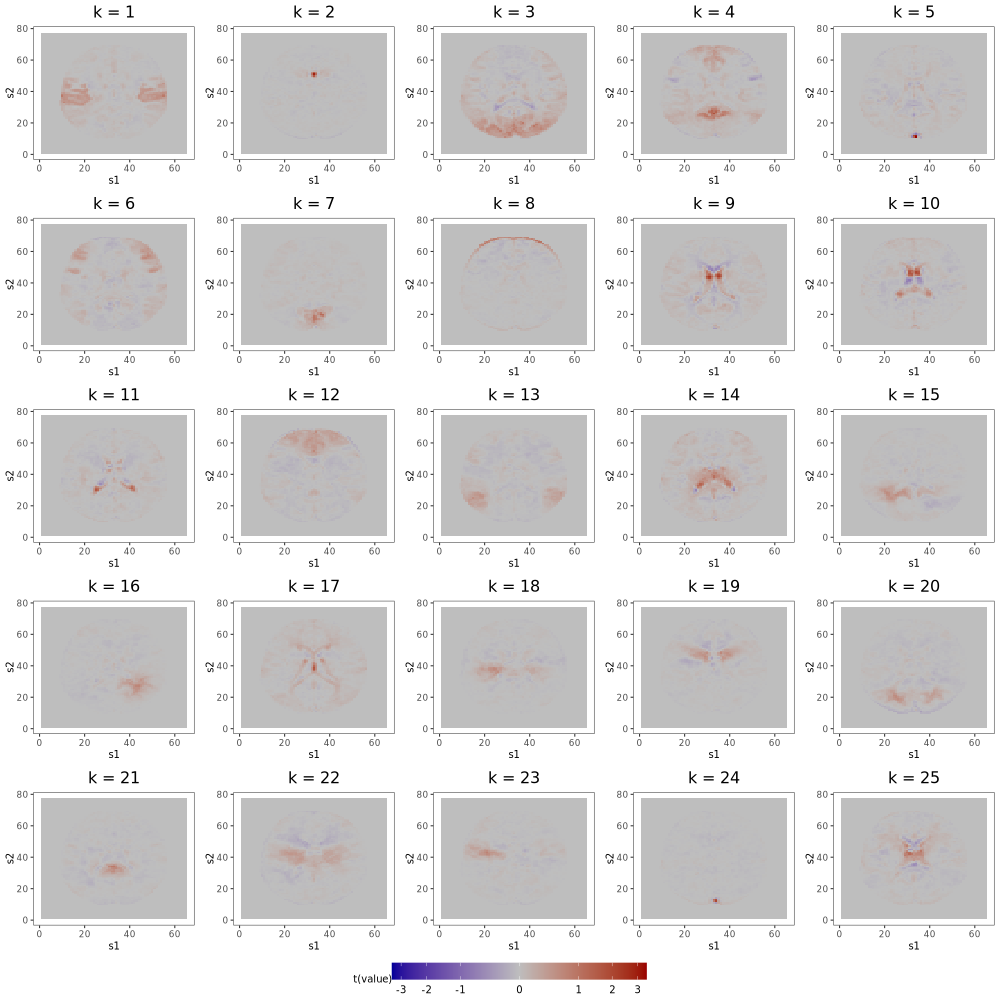
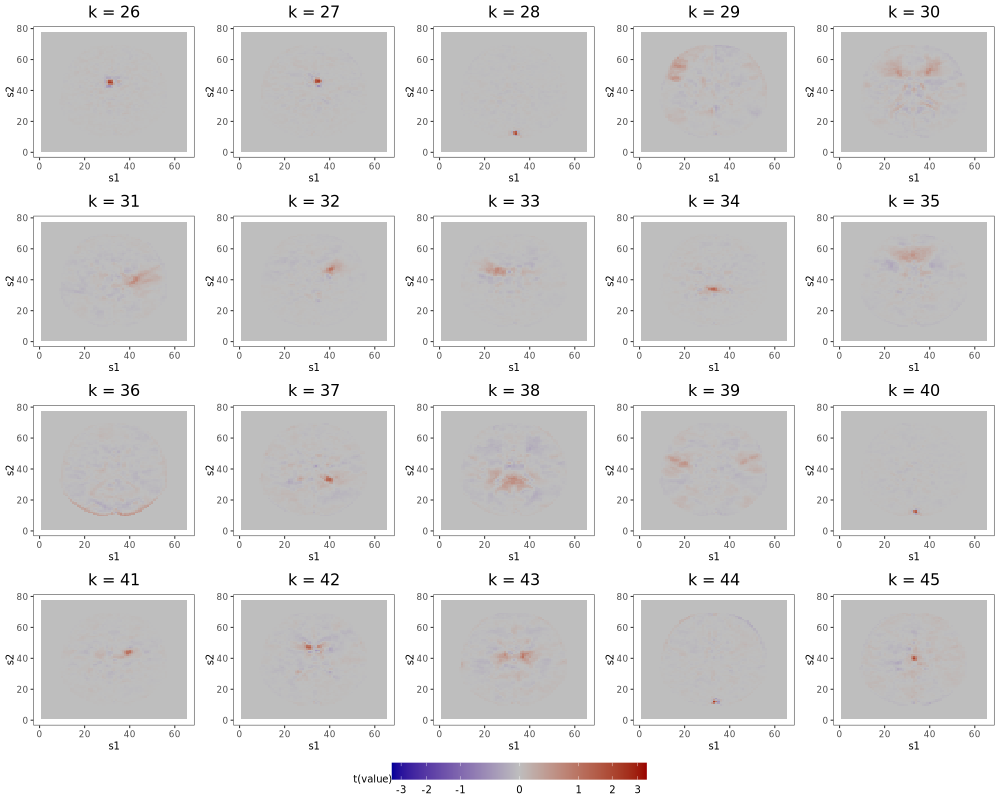
As described in Section 6 of the manuscript, multi-scale approaches, like that of Iraji et al. (2023), can remedy ICA’s sensitivity to dimension misspecification. Adapting the method of Iraji et al. (2023) to the AOMIC data, we first independently generate 25 random subsets of the full dataset, each containing the scans of 150 subjects. Next, we fit IC models of order 10, 20, 30, 40, and 50 to each subset, yielding 25 sets of 150 components. From the collection of all components, we select the 150 with the highest average spatial similarity (calculated by Pearson correlation) across the 25 sets, then identify the components among the 150 that are most distinct from each other (spatial similarity ¡ 0.5). The final 45 components are displayed in Figures 13 and 14. Among this final set is a single component () containing the ventricle correlations of the first component from the 12-IC model, a structure splintered across several components of higher-order IC models. Comparing Figure 9b of the manuscript to Figures 13 and 14 confirms that other low-order structures are similarly preserved. As discussed in Section 6 of the manuscript, this solution to the fragmentation problem comes at the cost of additional computational resources and an interpretation more convoluted than that of approaches based on single IC models.
References
- Afyouni et al. [2019] Soroosh Afyouni, Stephen M Smith, and Thomas E Nichols. Effective degrees of freedom of the pearson’s correlation coefficient under autocorrelation. NeuroImage, 199:609–625, 2019.
- Bai [2003] Jushan Bai. Inferential theory for factor models of large dimensions. Econometrica, 71(1):135–171, 2003. doi: https://doi.org/10.1111/1468-0262.00392. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/1468-0262.00392.
- Beckmann and Smith [2004] Christian F Beckmann and Stephen M Smith. Probabilistic independent component analysis for functional magnetic resonance imaging. IEEE transactions on medical imaging, 23(2):137–152, 2004.
- Bernaards et al. [2015] Coen Bernaards, Robert Jennrich, and Maintainer Paul Gilbert. Package ‘gparotation’. Retrieved February, 19:2015, 2015.
- Biswal et al. [1995] Bharat Biswal, F Zerrin Yetkin, Victor M Haughton, and James S Hyde. Functional connectivity in the motor cortex of resting human brain using echo-planar mri. Magnetic resonance in medicine, 34(4):537–541, 1995.
- Broyden [1970] Charles George Broyden. The convergence of a class of double-rank minimization algorithms 1. general considerations. IMA Journal of Applied Mathematics, 6(1):76–90, 1970.
- Bullmore et al. [2001] Ed Bullmore, Chris Long, John Suckling, Jalal Fadili, Gemma Calvert, Fernando Zelaya, T Adrian Carpenter, and Mick Brammer. Colored noise and computational inference in neurophysiological (fmri) time series analysis: resampling methods in time and wavelet domains. Human brain mapping, 12(2):61–78, 2001.
- Calhoun et al. [2001] Vince D Calhoun, Tulay Adali, Godfrey D Pearlson, and James J Pekar. A method for making group inferences from functional mri data using independent component analysis. Human brain mapping, 14(3):140–151, 2001.
- Chamberlain and Rothschild [1983] Gary Chamberlain and Michael Rothschild. Arbitrage, factor structure, and mean-variance analysis on large asset markets. Econometrica, 51(5):1281–1304, 1983. ISSN 00129682, 14680262. URL http://www.jstor.org/stable/1912275.
- Christova et al. [2011] P Christova, SM Lewis, TA Jerde, JK Lynch, and Apostolos P Georgopoulos. True associations between resting fmri time series based on innovations. Journal of neural engineering, 8(4):046025, 2011.
- Descary and Panaretos [2019] Marie-Hélène Descary and Victor M. Panaretos. Functional data analysis by matrix completion. The Annals of Statistics, 47(1):1 – 38, 2019. doi: 10.1214/17-AOS1590. URL https://doi.org/10.1214/17-AOS1590.
- Esteban et al. [2019] Oscar Esteban, Christopher J Markiewicz, Ross W Blair, Craig A Moodie, A Ilkay Isik, Asier Erramuzpe, James D Kent, Mathias Goncalves, Elizabeth DuPre, Madeleine Snyder, et al. fmriprep: a robust preprocessing pipeline for functional mri. Nature methods, 16(1):111–116, 2019.
- Fletcher [1970] Roger Fletcher. A new approach to variable metric algorithms. The computer journal, 13(3):317–322, 1970.
- Forni et al. [2000] Mario Forni, Marc Hallin, Marco Lippi, and Lucrezia Reichlin. The Generalized Dynamic-Factor Model: Identification and Estimation. The Review of Economics and Statistics, 82(4):540–554, 11 2000. ISSN 0034-6535. doi: 10.1162/003465300559037. URL https://doi.org/10.1162/003465300559037.
- Friston [1998] Karl J Friston. Modes or models: a critique on independent component analysis for fmri. Trends in cognitive sciences, 2(10):373–375, 1998.
- Friston [2011] Karl J Friston. Functional and effective connectivity: a review. Brain connectivity, 1(1):13–36, 2011.
- Friston et al. [1993] Karl J Friston, Chris D Frith, Peter F Liddle, and Richard SJ Frackowiak. Functional connectivity: the principal-component analysis of large (pet) data sets. Journal of Cerebral Blood Flow & Metabolism, 13(1):5–14, 1993.
- Geweke [1977] John Geweke. The dynamic factor analysis of economic time series. Latent variables in socio-economic models, pages 365 – 383, 1977.
- Goldfarb [1970] Donald Goldfarb. A family of variable-metric methods derived by variational means. Mathematics of computation, 24(109):23–26, 1970.
- Hays et al. [2012] Spencer Hays, Haipeng Shen, and Jianhua Z. Huang. Functional dynamic factor models with application to yield curve forecasting. The Annals of Applied Statistics, 6(3):870 – 894, 2012. doi: 10.1214/12-AOAS551. URL https://doi.org/10.1214/12-AOAS551.
- Hsing and Eubank [2015] Tailen Hsing and Randall Eubank. Theoretical foundations of functional data analysis, with an introduction to linear operators, volume 997. John Wiley & Sons, 2015.
- Hyndman and Khandakar [2008] Rob J Hyndman and Yeasmin Khandakar. Automatic time series forecasting: the forecast package for r. Journal of statistical software, 27:1–22, 2008.
- Hyvärinen and Oja [2000] Aapo Hyvärinen and Erkki Oja. Independent component analysis: algorithms and applications. Neural networks, 13(4-5):411–430, 2000.
- Hörmann and Jammoul [2020] Siegfried Hörmann and Fatima Jammoul. Preprocessing noisy functional data: a multivariate perspective, 2020.
- Iraji et al. [2023] Armin Iraji, Z Fu, Ashkan Faghiri, M Duda, Jiayu Chen, Srinivas Rachakonda, Thomas DeRamus, Peter Kochunov, BM Adhikari, A Belger, et al. Identifying canonical and replicable multi-scale intrinsic connectivity networks in 100k+ resting-state fmri datasets. Human brain mapping, 44(17):5729–5748, 2023.
- Jenkinson et al. [2012] Mark Jenkinson, Christian F Beckmann, Timothy EJ Behrens, Mark W Woolrich, and Stephen M Smith. Fsl. Neuroimage, 62(2):782–790, 2012.
- Johnson and Wichern [2002] Wichern A Johnson and Dean W. Wichern. Applied Multivariate Statistical Analysis. Prentice Hall, Upper Saddle River, 2002.
- Kaiser [1958] Henry F Kaiser. The varimax criterion for analytic rotation in factor analysis. Psychometrika, 23(3):187–200, 1958.
- Kokoszka and Reimherr [2017] Piotr Kokoszka and Matthew Reimherr. Introduction to functional data analysis. CRC press, 2017.
- Kowal et al. [2017] Daniel R. Kowal, David S. Matteson, and David Ruppert. A bayesian multivariate functional dynamic linear model. Journal of the American Statistical Association, 112(518):733–744, 2017. doi: 10.1080/01621459.2016.1165104. URL https://doi.org/10.1080/01621459.2016.1165104.
- Krantz and Parks [2002] Steven G Krantz and Harold R Parks. A primer of real analytic functions. Springer Science & Business Media, 2002.
- Laird et al. [2004] Angela R Laird, Baxter P Rogers, and M Elizabeth Meyerand. Comparison of fourier and wavelet resampling methods. Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine, 51(2):418–422, 2004.
- Li and Solea [2018] Bing Li and Eftychia Solea. A nonparametric graphical model for functional data with application to brain networks based on fmri. Journal of the American Statistical Association, 113(524):1637–1655, 2018.
- Liebl [2013] Dominik Liebl. Modeling and forecasting electricity spot prices: A functional data perspective. The Annals of Applied Statistics, 7(3):1562 – 1592, 2013. doi: 10.1214/13-AOAS652. URL https://doi.org/10.1214/13-AOAS652.
- Lindquist [2008] Martin A Lindquist. The statistical analysis of fmri data. Statistical science, 23(4):439–464, 2008.
- Liu and Nocedal [1989] Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45(1-3):503–528, 1989.
- Neuhaus and Wrigley [1954] Jack O Neuhaus and Charles Wrigley. The quartimax method: An analytic approach to orthogonal simple structure 1. British Journal of Statistical Psychology, 7(2):81–91, 1954.
- Otto and Salish [2022] Sven Otto and Nazarii Salish. Dynamic factor model for functional time series: Identification, estimation, and prediction, 2022.
- Ramsay and Silverman [2005] J. O. Ramsay and B. W. Silverman. Functional Data Analysis. Springer, 2005. ISBN 9780387400808. URL http://www.worldcat.org/isbn/9780387400808.
- Reiss et al. [2015] Philip T Reiss, Lan Huo, Yihong Zhao, Clare Kelly, and R Todd Ogden. Wavelet-domain regression and predictive inference in psychiatric neuroimaging. The annals of applied statistics, 9(2):1076, 2015.
- Reiss et al. [2017] Philip T Reiss, Jeff Goldsmith, Han Lin Shang, and R Todd Ogden. Methods for scalar-on-function regression. International Statistical Review, 85(2):228–249, 2017.
- Sargent and Sims [1977] Thomas Sargent and Christopher Sims. Business cycle modeling without pretending to have too much a priori economic theory. Working Papers 55, Federal Reserve Bank of Minneapolis, 1977. URL https://EconPapers.repec.org/RePEc:fip:fedmwp:55.
- Shanno [1970] David F Shanno. Conditioning of quasi-newton methods for function minimization. Mathematics of computation, 24(111):647–656, 1970.
- Smith et al. [2009] Stephen M Smith, Peter T Fox, Karla L Miller, David C Glahn, P Mickle Fox, Clare E Mackay, Nicola Filippini, Kate E Watkins, Roberto Toro, Angela R Laird, et al. Correspondence of the brain’s functional architecture during activation and rest. Proceedings of the national academy of sciences, 106(31):13040–13045, 2009.
- Smith et al. [2014] Stephen M Smith, Aapo Hyvärinen, Gaël Varoquaux, Karla L Miller, and Christian F Beckmann. Group-pca for very large fmri datasets. Neuroimage, 101:738–749, 2014.
- Snoek et al. [2021] Lukas Snoek, Maite M van der Miesen, Tinka Beemsterboer, Andries van der Leij, Annemarie Eigenhuis, and H Steven Scholte. The amsterdam open mri collection, a set of multimodal mri datasets for individual difference analyses. Scientific Data, 8(1):1–23, 2021.
- Stock and Watson [2002] James H. Stock and Mark W. Watson. Forecasting using principal components from a large number of predictors. Journal of the American Statistical Association, 97(460):1167–1179, 2002. ISSN 01621459. URL http://www.jstor.org/stable/3085839.
- Van Den Heuvel and Pol [2010] Martijn P Van Den Heuvel and Hilleke E Hulshoff Pol. Exploring the brain network: a review on resting-state fmri functional connectivity. European neuropsychopharmacology, 20(8):519–534, 2010.
- van der Vaart and Wellner [1996] Aad W van der Vaart and Jon A Wellner. Weak Convergence and Empirical Processes with Applications to Statistics. Springer, 1996.
- Viviani et al. [2005] Roberto Viviani, Georg Grön, and Manfred Spitzer. Functional principal component analysis of fmri data. Human brain mapping, 24(2):109–129, 2005.
- Wang et al. [2016] Jane-Ling Wang, Jeng-Min Chiou, and Hans-Georg Müller. Functional data analysis. Annual Review of Statistics and Its Application, 3(1):257–295, 2016. doi: 10.1146/annurev-statistics-041715-033624. URL https://doi.org/10.1146/annurev-statistics-041715-033624.