Fusing multimodal neuroimaging data with a variational autoencoder
Abstract
Neuroimaging studies often involve the collection of multiple data modalities. These modalities contain both shared and mutually exclusive information about the brain. This work aims at finding a scalable and interpretable method to fuse the information of multiple neuroimaging modalities using a variational autoencoder (VAE). To provide an initial assessment, this work evaluates the representations that are learned using a schizophrenia classification task. A support vector machine trained on the representations achieves an area under the curve for the classifier’s receiver operating characteristic (ROC-AUC) of .
–
Clinical relevance – This work helps examine the complex interplay between multiple neuroimaging modalities and how that interplay affects mental disorders.
I INTRODUCTION
Multimodal neuroimaging data is abundantly available and although approaches that seek to combine these data, e.g., JointICA [1], and more recently multimodal subspace analysis [2] focus on linear decompositions, recent work on multimodal deep learning offers the benefits of additional flexibility which can also capture nonlinear relationships. Multimodal deep learning research mostly focuses on the relationship between audio, images, and/or text [3]. The exciting new direction of multimodal representation learning, together with growing evidence that deep learning representations can provide robust biomarkers [4], paves the way for multimodal representation learning in neuroimaging.
Just as with a puzzle, pieces that fit together will contain both shared information and mutually exclusive information. Fusing these pieces in terms of neuroimaging can lead to biomarkers that more robustly predict changes associated with mental illnesses [5]. An important downside to deep learning techniques is that their non-linear nature can present challenges to interpretation, which undermines their applicability to medical problems. Interpretability is, therefore, an important consideration in this work.
Recent work in multimodal deep learning applied to neuroimaging has focused on information maximization between representations extracted from two modalities [6, 7] or by translating between modalities [8]. This work aims to learn a continuous manifold of multiple modalities so that they are represented in a locally Euclidean space. The model architecture that is used is a variational autoencoder (VAE) [9], which maximizes a lower bound on the log-likelihood of the data’s marginal distribution. Other work on multimodal VAEs focuses on a factorization of shared and private subspaces [10] and uses a separate encoder for each modality. In this work, we intentionally force all of the modalities to inhabit the same shared subspace by using a single encoder-decoder pair for all modalities. This allows us to interpolate between modalities, similar to how VAEs have previously been used to interpolate between different digits in the MNIST dataset [9].
To provide an initial assessment of the potential for the unsupervised training of the VAE to produce robust biomarkers for complex mental illnesses, we evaluate our model and its representations on a schizophrenia classification task. Schizophrenia is a mental illness that is characterized by complex interconnected changes in dynamics and functional connectivity. To understand how the brains of patients with schizophrenia differ from controls it is imperative to piece together information from multiple modalities [5], such as structural MRI and functional MRI. In this work, we treat a structural MRI (sMRI) volume and each of the intrinsic functional brain networks that are extracted from resting-state functional MRI (rs-fMRI) data using NeuroMark [11] as separate modalities. An important consideration when choosing our method was that a VAE can decode locations in its latent space to brain space and provide insight as to what regions in the brain may differ between two groups. The regions that have in previous literature been linked to schizophrenia include the thalamus, cerebellum, caudate, superior temporal gyrus, most of the visual system (e.g., lingual gyrus, occipital gyrus [12]), and the supplementary motor area [13].
II Contributions
This work introduces an interpretable approach for fusing multiple neuroimaging modalities with the following properties:
-
•
It focuses on fusing multiple modalities and it scales in its number of parameters as with the number of modalities.
-
•
The model optimizes both an encoder and a decoder, the decoder makes it easier to interpret group differences in the latent space, because locations can be decoded back into brain space.
-
•
The framework forces the modalities to be represented in a shared locally Euclidean space, instead of learning two spaces and maximizing their similarity. This allows us to interpolate directly between multiple modalities.
III Method
III-A Problem setting
Let be a set of modalities with samples per modality and modalities. Sample index corresponds to a subject and each subject will have a sample for each modality. Instead of learning each modality with a separate decoder, we enforce a shared subspace. Further, to make this approach scalable to a large number of modalities and because we already use a shared decoder, we also only use one encoder for all modalities. This forces the features that are learned for each modality to be similar and makes sure the model scales well in terms of memory usage. Further, given that neuroimaging datasets are considered small compared to more commonly used deep learning datasets, using multiple encoders may lead to overfitting. The encoder decoder couple is optimized with respect to the log-likelihood of the marginal distribution of and each volume is treated as an independent sample. The integral over the marginal distribution of , is intractable. We therefore optimize the following evidence lower bound (ELBO) using a variational autoencoder (VAE) [9]:
| (1) | ||||
The objective function is calculated as a sum over each data point and can be split up into three parts, the first part is an encoder parameterized as a convolutional neural network (CNN) with parameters that estimates the latent variable . The second part is a decoder , also parameterized as a CNN with parameters , that reconstructs the original sample from the estimated latent variable . The last part of the loss is the KL-divergence between a prior of our choosing , which we choose to be a diagonal multivariate Gaussian centered at with a standard deviation of , and the estimated latent variable . The latent variable is sampled from a multivariate Gaussian as well, which in turn is parameterized by a mean and variance that is estimated by the encoder.
III-B Classification
To evaluate whether the fusion of modalities in the VAE’s latent space leads to robust biomarkers, we set up a classification task. The model is first trained using 10-fold cross-validation, where each fold of subjects is used as a test set once and the other 9 folds are used to train on. The validation set is randomly selected as a stratified 10% of the subjects in the training set. After training the VAE in an unsupervised manner, the weights in the VAE are frozen. The complete dataset is then embedded using the encoder , where instead of sampling from its estimated multivariate Gaussian, we use the estimated mean as our latent variable . This is to make sure there is no stochasticity in the inference process. The representations of the training and validation sets are stacked and used as input for a machine learning model, this model is then evaluated using the test set representations, as follows.
The estimated latent variable can be interpreted as a low-dimensional representation of a volume, with a dimensionality . Given that each subject has different modalities, each subject will also have representations . These representations can be concatenated for a subject to create a feature vector with a size of . The subject-by-feature matrix can be used as input for a classifier. In this case, we train a support vector machine (SVM)
to predict whether subjects in a held-out test set are patients with schizophrenia. Given that each modality is represented using features, we can extract the feature importance for all features and then sum the features for each modality, to get feature importance for each of the modalities. The feature importance information helps us understand how brain changes related to schizophrenia are jointly represented in multiple modalities.
The SVM classifier is evaluated by calculating the area under the curve (AUC) of their receiver operator characteristic (ROC). Given that the VAE is trained in an unsupervised manner and that parts of the training process are stochastic, we evaluate the model for different seeds to make sure the method is robust to its seed, these experiments are performed with a latent dimensionality of . To evaluate the effect of the number of latent dimensions on the classification performance, we set the seed to be and trained the model with four different latent dimensionalities , , , . We select the weights obtained during the first training fold for the model that performs the best. The best performance is determined by averaging the ROC-AUC over the 10 folds for each model. These encoder and decoder weights are used to create the figures and to determine the importance of each modality for the classification of schizophrenia.
III-C Data
The datasets used in this study are FBIRN, B-SNIP, and COBRE, each dataset was processed using NeuroMark [11] to obtain 53 independent component networks (ICNs). These 53 ICNs, together with a structural MRI scan for each subject are considered to be separate modalities, so . The sMRI data is preprocessed using SPM 12 in a Matlab 2016 environment. The data is then segmented into gray matter volume (GMV) with the help of a modulated algorithm, the GMV is then smoothed with a mm FWHM Gaussian kernel.
Each ICN is a volume with voxels, the sMRI volumes are resized to that same size using Scipy [14]. The values in each volume are then rescaled to [-1, 1] by dividing the values in a volume by their maximum, which is also sometimes referred to as maximum absolute scaling. The dataloader and transformations were implemented with the help of TorchIO [15].
III-D Implementation
The batches are constructed by loading the ICN volumes and an sMRI volume for a subject and concatenating them into a batch. Each volume is considered to be sampled independently during training, the reason the volumes are loaded per subject however is to minimize disk accesses. The ICNs for one subject are all saved in one file, so loading all of them into a batch leads to a smaller number of disk accesses and reduces training time. Further, because each modality is equally present in a mini-batch for which an optimizer step is performed, the loss calculated over each batch is balanced for the modalities.
The code for the model, inference, and training was implemented using PyTorch [16], Catalyst [17], and NumPy [18]. The VAE uses a convolutional encoder and decoder pair, each of the layers uses a -voxel kernel, a stride of and -voxel padding. The channel sizes in the encoder are and in the decoder, the last layer in the decoder uses stride and no bias parameters. Each convolutional layer uses a ReLU [19] as its activation function, except for the last layer in the decoder, which uses a hyperbolic tangent function to map the output between [-1, 1] to match the input range. The last convolutional layer in the encoder produces an output with shape: and channels, this output is flattened and mapped to the mean and variance , which are used to construct a diagonal multivariate Gaussian from which is sampled. To make sure the VAE is fully differentiable, we use the reparameterization trick to train it [9]. The classification evaluations in the latent space are implemented using RAPIDS AI [20] to make sure highly parallelizable computations are performed on the GPU and to minimize costly CPUGPU and GPUCPU data transfers. The experiments were performed on an NVIDIA DGX-1 V100.
III-E Latent structure
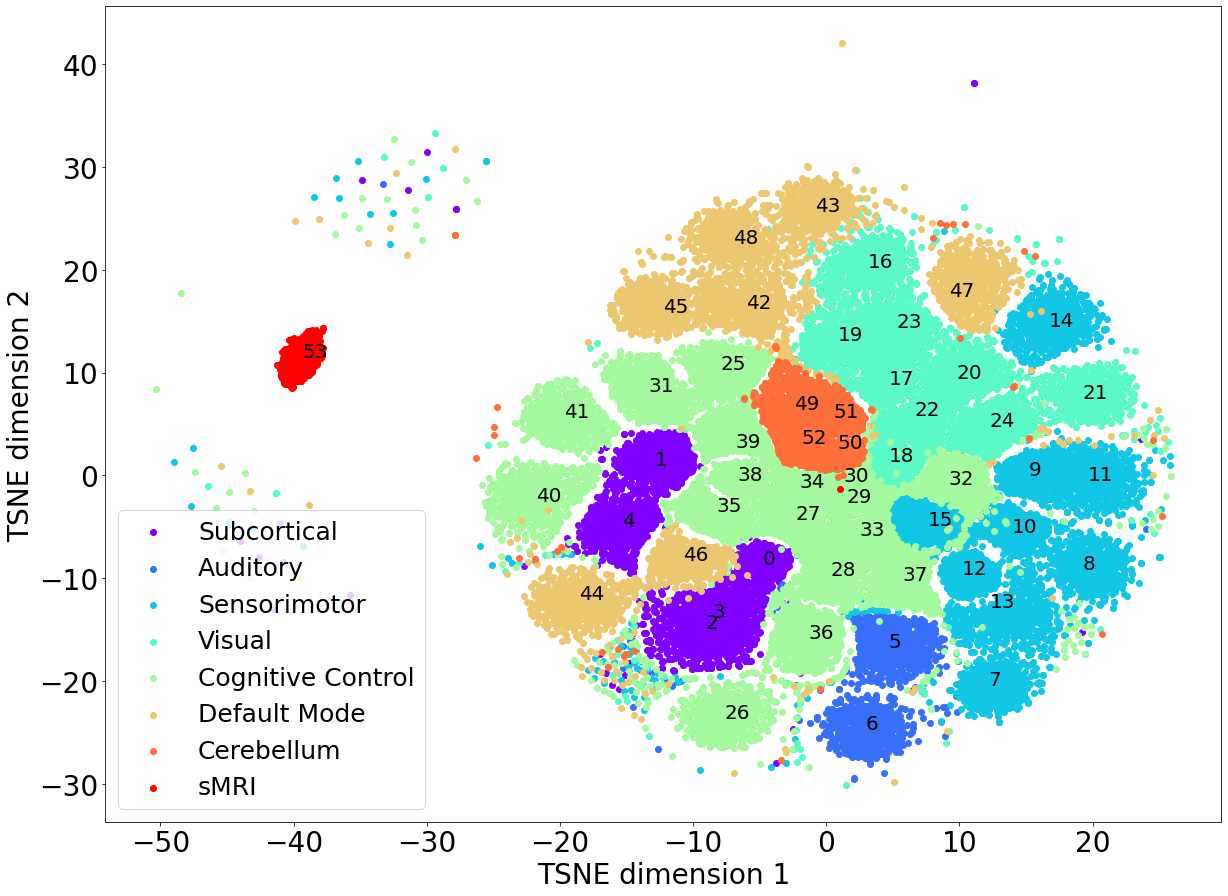
Most of the modalities that are used in this paper are intrinsic networks, which are obtained through independent component analysis (ICA). The independence in the spatial volumes for those components leads to a latent space that clusters modalities, which is shown in Figure 1. The plot depicts a T-SNE projection of a -dimensional space that preserves the latent structure in a 2D image. Interestingly, the ICNs that belong to the same domain are generally clustered together, such as ICNs in the cerebellum. It is also clear from Figure 1 that the sMRI cluster is located relatively farther away from the other modalities in the latent space. The ICNs are all localized spatial ICA maps, whereas the sMRI volume represents all of the structures in the brain. There is more inter-subject variance to be modeled for the sMRI volumes than for the spatially localized ICNs which likely contributes to the sMRI cluster being further away from the latent space ICN clusters.
IV Results
IV-A Classification
The average ROC-AUC for the five models trained with a latent dimensionality of and multiple different seeds is , with a standard deviation of . This shows that the model robustly learns a latent space, where patients with schizophrenia and controls are linearly separable.
The experiment involving an increasing number of latent dimensions shows that the ROC-AUC increases with the number of latent dimensions up to a certain point. The ROC-AUC is for dimensions, for dimensions, for dimensions and for dimensions. These results show that the model is not learning to represent each modality using a single latent dimension, but rather that the variance that is modeled across a latent dimension is shared among multiple modalities or that multiple latent dimensions are used to model a single modality.
The best model, and latent dimensions were used to calculate the feature importance for each modality. The 10 modalities with the highest feature importance are shown in Figure 2, where the rightmost modality is the most important and the leftmost modality is the 10th most important. sMRI shows the lowest performance in terms of feature importance. This is likely due to the trade-off in the loss function for the VAE. The KL-divergence pulls the latent variables closer to a zero-mean unit-norm Gaussian, while the reconstruction loss tries to make sure every modality is reconstructed correctly. The number of different modalities and the KL-divergence likely limit variance that can be modeled to represent the sMRI volumes. The variations that are modeled for sMRI do not help linearly separate patients from controls.
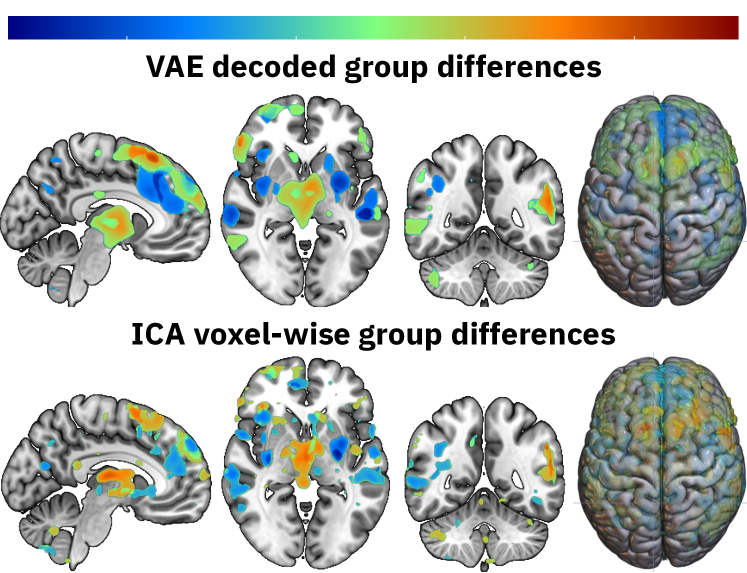
The group differences that the VAE has learned can be interpreted by visualizing the group centers in the latent space. Group centers can be calculated for each modality by averaging the locations of subjects within that group. The latent center for SZ patients can then be decoded and subtracted from the decoded latent center for HC to show the group differences. The differences of the top five most important features from Figure 2 are calculated, then thresholded at the 99th quantile highest values for each modality, and then summed to create Figure 3. The figure compares the learned differences with the voxelwise differences of the spatial ICA components that correspond to the five most important modalities. The results are remarkably similar, which proofs that VAEs yield interpretable results in their latent space. As future work fuses modalities more, the results will likely differ more from the voxelwise differences.
V Conclusion
When the number of modalities increases for multimodal learning, it may not be feasible or optimal to learn a separate encoder-decoder pair for each modality. This is especially true for small datasets that models may easily overfit on due to overparameterization. This work takes the approach of joint multimodal representation learning by modeling the marginal distribution of all the modalities together. The VAE learns subspaces in the latent space that can linearly separate HC from patients with SZ. The VAE framework is easy to generalize to more modalities, although modalities like functional connectivity will require some engineering because the network expects a 53x52x63 volume as input right now.
VI Future work
The independence of spatial ICA components is reflected in the latent space of our model, which leads us to believe that unprocessed volumes may be an important direction for fusing modality representations. Another way to tackle this problem is to enforce additional losses in the latent space or create an inductive bias in the architecture of the model. Furthermore, computing joint features (early fusion) and using those as inputs for the model may also increase multimodal fusion in the latent space.
ACKNOWLEDGMENT
References
- [1] Calhoun, V. D., Adali, T., Pearlson, G. D., & Kiehl, K. A. (2006). Neuronal chronometry of target detection: fusion of hemodynamic and event-related potential data. Neuroimage, 30(2), 544-553.
- [2] Silva, R. F., Plis, S. M., Adalı, T., Pattichis, M. S., & Calhoun, V. D. (2020). Multidataset Independent Subspace Analysis with Application to Multimodal Fusion. IEEE Transactions on Image Processing, 30, 588-602.
- [3] Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., & Ng, A. Y. (2011, January). Multimodal deep learning. In ICML.
- [4] Abrol, A., Fu, Z., Salman, M., Silva, R., Du, Y., Plis, S., & Calhoun, V. (2021). Deep learning encodes robust discriminative neuroimaging representations to outperform standard machine learning. Nature communications, 12(1), 1-17.
- [5] Calhoun, V. D., & Sui, J. (2016). Multimodal fusion of brain imaging data: a key to finding the missing link (s) in complex mental illness. Biological psychiatry: cognitive neuroscience and neuroimaging, 1(3), 230-244.
- [6] Fedorov, A., Geenjaar, E., Wu, L., DeRamus, T. P., Calhoun, V. D., & Plis, S. M. (2021). Tasting the cake: evaluating self-supervised generalization on out-of-distribution multimodal MRI data. arXiv preprint arXiv:2103.15914.
- [7] Fedorov, A., Sylvain, T., Geenjaar, E., Luck, M., Wu, L., DeRamus, T. P., … & Plis, S. M. (2020). Self-Supervised Multimodal Domino: in Search of Biomarkers for Alzheimer’s Disease. arXiv preprint arXiv:2012.13623.
- [8] Plis, S. M., Amin, M. F., Chekroud, A., Hjelm, D., Damaraju, E., Lee, H. J., … & Calhoun, V. D. (2018). Reading the (functional) writing on the (structural) wall: Multimodal fusion of brain structure and function via a deep neural network based translation approach reveals novel impairments in schizophrenia. NeuroImage, 181, 734-747.
- [9] Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- [10] Shi, Y., Siddharth, N., Paige, B., & Torr, P. H. (2019). Variational mixture-of-experts autoencoders for multi-modal deep generative models. arXiv preprint arXiv:1911.03393.
- [11] Du, Y., Fu, Z., Sui, J., Gao, S., Xing, Y., Lin, D., … & Alzheimer’s Disease Neuroimaging Initiative. (2019). NeuroMark: an adaptive independent component analysis framework for estimating reproducible and comparable fMRI biomarkers among brain disorders. MedRxiv, 19008631.
- [12] Salman, M. S., Du, Y., Lin, D., Fu, Z., Fedorov, A., Damaraju, E., … & Calhoun, V. D. (2019). Group ICA for identifying biomarkers in schizophrenia:‘Adaptive’networks via spatially constrained ICA show more sensitivity to group differences than spatio-temporal regression. NeuroImage: Clinical, 22, 101747.
- [13] Schröder, J., Wenz, F., Schad, L. R., Baudendistel, K., & Knopp, M. V. (1995). Sensorimotor cortex and supplementary motor area changes in schizophrenia. The British Journal of Psychiatry, 167(2), 197-201.
- [14] Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., … & van Mulbregt, P. (2020). SciPy 1.0: fundamental algorithms for scientific computing in Python. Nature methods, 17(3), 261-272.
- [15] Pérez-García, F., Sparks, R., & Ourselin, S. (2020). TorchIO: a Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. arXiv preprint arXiv:2003.04696.
- [16] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., … & Chintala, S. (2019). Pytorch: An imperative style, high-performance deep learning library. arXiv preprint arXiv:1912.01703.
- [17] Kolesnikov, S. (2018). Accelerated deep learning R&D. GitHub.
- [18] Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., … & Oliphant, T. E. (2020). Array programming with NumPy. Nature, 585(7825), 357-362.
- [19] Glorot, X., Bordes, A., & Bengio, Y. (2011, June). Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics (pp. 315-323). JMLR Workshop and Conference Proceedings.
- [20] Team, R. D. (2018). RAPIDS: Collection of Libraries for End to End GPU Data Science. NVIDIA, Santa Clara, CA, USA.