Gabor frames and deep scattering networks in audio processing
1 Abstract
This paper introduces Gabor scattering, a feature extractor based on Gabor frames and Mallat’s scattering transform. By using a simple signal model for audio signals, specific properties of Gabor scattering are studied. It is shown that, for each layer, specific invariances to certain signal characteristics occur. Furthermore, deformation stability of the coefficient vector generated by the feature extractor is derived by using a decoupling technique which exploits the contractivity of general scattering networks. Deformations are introduced as changes in spectral shape and frequency modulation. The theoretical results are illustrated by numerical examples and experiments. Numerical evidence is given by evaluation on a synthetic and a “real” dataset, that the invariances encoded by the Gabor scattering transform lead to higher performance in comparison with just using Gabor transform, especially when few training samples are available.
2 Introduction
During the last two decades, enormous amounts of digitally encoded and stored audio have become available. For various purposes, the audio data, be it music or speech, need to be structured and understood. Recent machine learning techniques, known as (deep) convolutional neural networks (CNN), have led to state of the art results for several tasks such as classification, segmentation or voice detection, cf. [1, 2]. CNNs were originally proposed for images [1], which may be directly fed into a network. Audio signals, on the other hand, commonly undergo some preprocessing to extract features that are then used as input to a trainable machine. Very often, these features consist of one or several two-dimensional arrays, such that the image processing situation is mimicked in a certain sense. However, the question about the impact of this very first processing step is important and it is not entirely clear whether a short-time Fourier transform (STFT), here based on Gabor frames, the most common representation system used in the analysis of audio signals, leads to optimal feature extraction. The convolutional layers of the CNNs can themselves be seen as feature extractors, often followed by a classification stage, either in the form of one or several dense network layers or classification tools such as support vector machine (SVM). Stéphane Mallat gave a first mathematical analysis of CNN as feature extractor, thereby introducing the so called scattering transform, based on wavelet transforms and modulus nonlinearity in each layer [3]. The basic structure thus parallels the one of CNNs, as these networks are equally composed of multiple layers of local convolutions, followed by a nonlinearity and, optionally, a pooling operator, cp., Section 2.1.
In the present contribution, we consider an approach inspired by Mallat’s scattering transform, but based on Gabor frames, respectively, Gabor transform (GT). The resulting feature extractor is called Gabor scattering (GS). Our approach is a special case of the extension of Mallat’s scattering transform proposed by Wiatowski and Bölcskei [4, 5], which introduces the possibility to use different semi-discrete frames, Lipschitz-continuous nonlinearities and pooling operators in each layer. In [3, 6, 7], invariance and deformation stability properties of the scattering transform with respect to operators defined via some group action were studied. In the more general setting of [4, 5], vertical translation invariance, depending on the network depth, and deformation stability for band-limited functions have been proved. In this contribution, we study the same properties of the GS and a particular class of signals, which model simple musical tones (Section 3.2).
Due to this concrete setting, we obtain quantitative invariance statements and deformation stability to specific, musically meaningful, signal deformations. Invariances are studied considering the first two layers, where the feature extractor extracts certain signal features of the signal model (i.e., frequency and envelope information), cp., Section 4.1.1. By using a low-pass filter and pooling in each layer, the temporal fine structure of the signal is averaged out. This results in invariance with respect to the envelope in the first and frequency invariance in the second layer output. To compute deformation bounds for the GS feature extractor, we assume more specific restrictions than band-limitation and use the decoupling technique, first presented in [4, 8]. Deformation stability is proven by only computing the robustness of the signal class w.r.t spectral shape and frequency modulation, see Section 4.1.2. The robustness results together with contractivity of the feature extractor, which is given by the networks architecture, yields deformation stability.
To empirically demonstrate the benefits of GS time-frequency representation for classification, we have conducted a set of experiments. In a supervised learning setting, where the main aim is the multiclass classification of generated sounds, we have utilized a CNN as a classifier. In these numerical experiments, we compare the GS to a STFT-based representation. We demonstrate the benefits of GS in a quasi-ideal setting on a self implemented synthetic dataset, and we also investigate if it benefits the performance on a real dataset, namely, GoodSounds [9]. Moreover we focus on comparing these two time-frequency representations in terms of performance on limited sizes of training data, see Section 5.
2.1 Convolutional Neural Networks (CNNs) and Invariance
CNNs are a specific class of neural network architectures which have shown extremely convincing results on various machine learning tasks in the past decade. Most of the problems addressed using CNNs are based on, often, big amounts of annotated data, in which case one speaks about supervised learning. When learning from data, the intrinsic task of the learning architecture is to gradually extract useful information and suppress redundancies, which always abound in natural data. More formally, the learning problem of interest may be invariant to various changes of the original data and the machine or network must learn these invariances in order to avoid overfitting. As, given a sufficiently rich architecture, a deep neural network can practically fit arbitrary data, cp. [10, 11], good generalization properties depend on the systematic incorporation of the intrinsic invariances of the data. Generalization properties hence suffer if the architecture is too rich given the amount of available data. This problem is often addressed by using data augmentation. Here, we raise the hypothesis that using prior representations which encode some potentially useful invariances will increase the generalization quality, in particular when using a restricted size of data set. The evaluation of the performance on validation data in comparison to the results on test data strengthens our hypothesis for the experimental problem presented in Section 5.
To understand the mathematical construction used within this paper, we briefly introduce the principal idea and structure of a CNN. We shall see that the scattering transforms, in general, and the GS, in particular, follow a similar concept of concatenating various processing steps, which ultimately leads to rather flexible grades of invariances in dependence on the chosen parameters. Usually, a CNN consists of several layers, namely, an input, several hidden (as we consider the case of deep CNN the number of hidden layers is supposed to be 2) and one output layer. A hidden layer consists of the following steps: first the convolution of the data with a small weighting matrix, often referred to as a kernel333We point out that the term kernel as used in this work always means convolutional kernels in the sense of filterbanks. Both the fixed kernels used in the scattering transform and the kernels used in the CNNs, whose size is fixed but whose elements are learned, should be interpreted as convolutional kernels in a filterbank. This should not be confused with the kernels used in classical machine learning methods based on reproducing kernel Hilbert spaces, e.g., the famous support vector machine, c.f. [12], which can be interpreted as localization of certain properties of the input data. The main advantage of this setup is that only the size and number of these (convolutional) kernels are fixed, but their coefficients are learned during training. So they reflect the structure of the training data in the best way w.r.t the task being solved. The next building block of the hidden layer is the application of a nonlinearity function, also called activation function, which signals if information of this neuron is relevant to be transmitted. Finally, to reduce redundancy and increase invariance, pooling is applied. Due to these building blocks, invariances to specific deformations and variations in the dataset are generated in dependence on the specific filters used, whether they are learned, as in the classical CNN case, or designed, as in the case of scattering transforms [13]. In this work, we will derive concrete qualitative statements about invariances for a class of music signals and will show by numerical experiments that these invariances indeed lead to a better generalization of the CNNs used to classify data.
Note that in a neural network, in particular in CNNs, the output, e.g., classification labels, is obtained after several concatenated hidden layers. In the case of scattering network, the outputs of each layer are stacked together into a feature vector, and further processing is necessary to obtain the desired result. Usually, after some kind of dimensionality reduction, cf. [14], this vector can be fed into a SVM or a dense NN, which performs the classification task.
2.2 Invarince Induced by Gabor Scattering
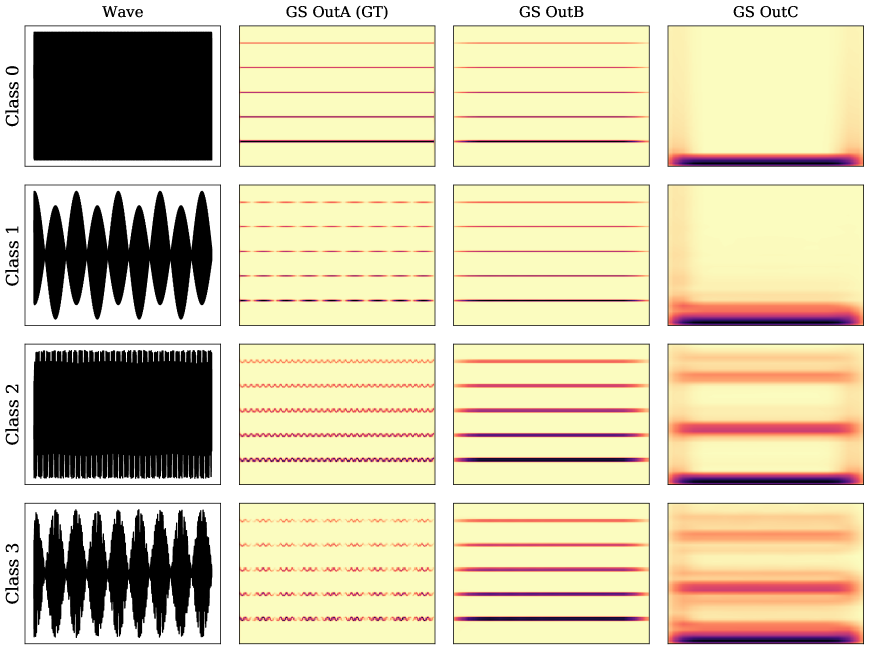
In this section, we give a motivation for the theory and underlying aim of this paper. In Figure 1, we see sound examples from different classes, where Class 0 is a pure tone with 5 harmonics, Class 1 is an amplitude modulated version thereof, Class 2 is the frequency modulated version, and Class 3 contains the amplitude and frequency modulated signal. So, we have classes with different amplitudes, as is clearly visible in the waveforms shown in the left-most plots. In this paper, we introduce GS, as a new feature extractor that introduces certain invariances. GS has several layers, denoted by OutA, OutB, and OutC, and each layer is invariant with respect to some features. The first layer, here OutA, is the spectrogram of the waveform. So, we see the time-frequency content of the four classes. OutB can be seen to be invariant with respect to amplitude changes, whereas the last layer, OutC, is invariant with respect to to frequency content while encoding the amplitude information. With GS it is therefore possible to separate different qualities of information contained in a spectrogram.
We introduce GS mathematically in Section 3.1 and elaborate on the resulting invariances in different layers in Section 4.1.1. Numerical experiments, showing the benefit of GS, are discussed in Section 5.
3 Materials and Methods
3.1 Gabor Scattering
As Wiatowski and Bölcskei used general semi-discrete frames to obtain a wider class of window functions for the scattering transform (cp. [4, 5]), it seems natural to consider specific frames used for audio data analysis. Therefore, we use Gabor frames for the scattering transform and study corresponding properties. We next introduce the basics of Gabor frames, refer to [15] for more details. A sequence of elements in a Hilbert space is called frame if there exist positive frame bounds such that for all
| (1) |
If then we call a tight frame.
Remark 1.
In our context, the Hilbert space is either or
To define Gabor frames we need to introduce two operators, i.e., the translation and modulation operator.
-
•
The translation (time shift) operator:
-
–
for a function and is defined as for all
-
–
for a function and is defined as
-
–
-
•
The modulation (frequency shift) operator:
-
–
for a function and is defined as for all
-
–
for a function and is defined as
-
–
We use these operators to express the STFT of a function with respect to a given window function as To reduce redundancy, we sample on a separable lattice , where in case of , and with in case The sampling is done in time by and in frequency by The resulting samples correspond to the coefficients of with respect to a “Gabor system”.
Definition 1.
(Gabor System) Given a window function and lattice parameters , the set of time-frequency shifted versions of
is called a Gabor system.
This Gabor system is called Gabor frame if it is a frame, see Equation (1). We proceed to introduce a scattering transform based on Gabor frames. We base our considerations on [4] by using a triplet sequence where is associated to the -th layer of the network. Note that in this contribution, we will deal with Hilbert spaces or ; more precisely in the input layer, i.e., the th layer, we have and, due to the discretization inherent in the GT,
We recall the elements of the triplet:
-
•
with is a Gabor frame indexed by a lattice
-
•
A nonlinearity function (e.g., rectified linear units, modulus function, see [4]) is applied pointwise and is chosen to be Lipschitz-continuous, i.e., for all In this paper we only use the modulus function with Lipschitz constant for all
-
•
Pooling depends on a pooling factor which leads to dimensionality reduction. Mostly used are max- or average-pooling, some more examples can be found in [4]. In our context, pooling is covered by choosing specific lattices in each layer.
To explain the interpretation of GS as CNN, we write and have
| (2) |
Thus, the Gabor coefficients can be interpreted as the samples of a convolution.
We start by defining “paths” on index sets
Definition 2.
(Gabor Scattering) Let be a given triplet sequence. Then, the components of the -th layer of the GS transform are defined to be the output of the operator , :
| (3) |
where is some output-vector of the previous layer and The GS operator is defined as
Similar to [4], for each layer, we use one atom of the Gabor frame in the subsequent layer as output-generating atom, i.e., Note that convolution with this element corresponds to low-pass filtering 444In general, one could take As this element is the -th convolution, it is an element of the -th frame, but because it belongs to the -th layer, its index is .. We next introduce a countable set which is the union of all possible paths of the net and the space of sets of elements from Now we define the feature extractor of a signal as in ([4], Definition 3) based on chosen (not learned) Gabor windows.
Definition 3.
(Feature Extractor) Let be a triplet sequence and the output-generating atom for layer . Then the feature extractor is defined as
| (4) |
In the following section we are going to introduce the signal model which we consider in this paper.
3.2 Musical Signal Model
Tones are one of the smallest units and simple models of an audio signal, consisting of one fundamental frequency , corresponding harmonics , and a shaping envelope for each harmonic, providing specific timbre. Further, as our ears are limited to frequencies below 20 kHz, we develop our model over finitely many harmonics, i.e., .
The general model has the following form,
| (5) |
where and For one single tone we choose Moreover, we create a space of tones and assume
4 Theoretical Results
4.1 Gabor Scattering of Music Signals
4.1.1 Invariance
In [6], it was already stated that due to the structure of the scattering transform the energy of the signal is pushed towards low frequencies, where it is then captured by a low-pass filter as output-generating atom. The current section explains how GS separates relevant structures of signals modeled by the signal space . Due to the smoothing action of the output-generating atom, each layer expresses certain invariances, which will be illustrated by numerical examples in Section 4.2. In Proposition 1, inspired by [6], we add some assumptions on the analysis window in the first layer for some and
Proposition 1 (Layer ).
Let with For fixed j, for which such that can be found, we obtain
| (6) | |||
| (7) |
where is the indicator function.
Remark 2.
Equation (6) shows that for slowly varying amplitude functions , the first layer mainly captures the contributions near the frequencies of the tone’s harmonics. Obviously, for time sections during which the envelopes undergo faster changes, such as during a tone’s onset, energy will also be found outside a small interval around the harmonics’ frequencies and thus the error estimate Equation (7) becomes less stringent. The second term of the error in Equation (7) depends only on the window and its behavior is governed by the frequency decay of . Note that the error bound increases for lower frequencies, as the separation of the fundamental frequency and corresponding harmonics by the analysis window deteriorates.
Proof.
Step 1: Using the signal model for tones as input, interchanging the finite sum with the integral and performing a substitution we obtain
After performing a Taylor series expansion locally around
where the remainder can be estimated by
we have
Therefore, we choose set
| (8) | |||
| (9) |
and split the sum to obtain
Step 2: We bound the error terms, starting with Equation (8):
Using triangle inequality and the estimate for the Taylor remainder, we obtain, together with the assumption on the analysis window,
For the second bound, i.e., the bound of Equation (9), we use the decay condition on thus
Next we split the sum into and We estimate the error term for
| (10) |
As we have and, also, using we obtain
| (11) |
Further we estimate the error for
where we added and subtracted the term Due to the reverse triangle inequality and , we obtain
For convenience, we call and perform a little trick by adding and subtracting , so The reason for this steps will become more clear when putting the two sums back together. Now, we have
Shifting the sum, i.e., taking and using we get
| (12) |
Summing up the error terms, we obtain Equation (7).
∎
To obtain the GS coefficients, we need to apply the output-generating atom as in Equation (4).
Corollary 1 (Output of Layer ).
Let be the output-generating atom, then the output of the first layer is
where
Here is the error term of Proposition 1.
Remark 3.
Note that we focus here on an unmodulated Gabor frame element , and the convolution may be interpreted as a low-pass filter. Therefore, in dependence on the pooling factor , the temporal fine-structure of corresponding to higher frequency content is averaged out.
Proof.
For this proof, we use the result of Proposition 1. We show that the calculations for the first layer are similar to those of the second layer:
| (14) | |||
where
∎
We introduce two more operators, first the sampling operator
and second the periodization operator These operators have the following relation
In order to see how the second layer captures relevant signal structures, depending on the first layer, we propose the following Proposition 2. Recall that
Proposition 2 (Layer ).
Let and Then the elements of the second layer can be expressed as
| (15) |
where
Remark 4.
Note that, as the envelopes are expected to change slowly except around transients, their Fourier transforms concentrate their energy in the low frequency range. Moreover, the modulation term pushes the frequencies of down by , and therefore they can be captured by the output-generating atom in Corollary 2. In Section 4.2, we show, by means of the analysis of example signals, how the second layer output distinguishes tones that have a smooth onset (transient) from those that have a sharp attack, which leads to broadband characteristics of around this attack. Similarly, if undergoes an amplitude modulation, the frequency of this modulation can be clearly discerned, cf. Figure 5 and the corresponding example. This observation is clearly reflected in expression Equation (15).
Proof.
Using the outcome of Proposition 1, we obtain
For the error , we use the global estimate Moreover, using the notation above and ignoring the constant term , we proceed as follows,
| (16) |
As is concentrated around , the right-hand term in Equation (16) can only contain significant values if has frequency-components concentrated around therefore we consider the case separately and obtain
| (17) |
It remains to bound the sum of aliases, i.e., the second term of Equation (17):
| (18) |
Using the assumption and also the assumption on the analysis window namely, the fast decay of , we obtain
| (19) |
Remark 5.
For sufficiently big the sum decreases fast, e.g., taking the sum is approximately
The second layer output is obtained by applying the output-generating atom as in Equation (4).
Corollary 2 (Output of Layer ).
Let then the output of the second layer is
where
Here is the error of Proposition 2.
Remark 6.
Note that in the second layer, applying the output-generating atom removes the fine temporal structure, and thus the second layer output reveals information contained in the envelopes .
Proof.
Proof is similar to the first layer output, see Corollary 1.
∎
4.1.2 Deformation Stability
In this section, we study the extent to which GS is stable with respect to certain, small deformations. This question is interesting, as we may often intuitively assume that the classification of natural signals, be it sound or images, is preserved under mild and possibly local deformations. For the signal class , we consider musically meaningful deformations and show stability of GS with respect to these deformations. We consider changes in spectral shape as well as frequency modulations. Note that, as opposed to the invariance properties derived in Section 4.1.1 for the output of specific layers, the derived stability results pertain to the entire feature vector obtained from the GS along all included layers, cp. the definition and derivation of deformation stability in [3]. The method we apply is inspired by the authors of [8] and uses the decoupling technique, i.e., to prove stability of the feature extractor we first take the structural properties of the signal class into account and search for an error bound of deformations of the signals in In combination with the contractivity property of , see ([4] Proposition 4), which follows from where is the upper frame bound of the Gabor frame this yields deformation stability of the feature extractor.
Simply deforming a tone would correspond to deformations of the envelope This corresponds to a change in timbre, for example, by playing a note on a different instrument. Mathematically this can be expressed as
Lemma 1 (Envelope Changes).
Let and for constants and Moreover let Then
for depending only on
Proof.
Setting , we obtain
We apply the mean value theorem for a continuous function and get
Applying the norm on and the assumption on we obtain
Splitting the integral into and , we obtain
Using the monotonicity of and in order to remove the supremum, by shifting we have
Moreover for we have This leads to
Performing a change of variables, i.e., with we obtain
Setting and summing up we obtain
∎
Remark 7.
Harmonics’ energy decreases with increasing frequency, hence hence the sum can be expected to be small.
Another kind of sound deformation results from frequency modulation of This corresponds to, for example, playing higher or lower pitch, or producing a vibrato. This can be formulated as
Lemma 2 (Frequency Modulation).
Let Moreover let Then,
Proof.
We have
with . Computing the norm of , we obtain
We rewrite
Setting this term gets small if Using the assumptions of our signal model on the envelopes, i.e., we obtain
∎
Proposition 3 (Deformation Stability).
Let and for constants and Moreover let and Then the feature extractor is deformation stable with respect to
-
•
envelope changes
for depending only on
-
•
frequency modulation
4.2 Visualization Example
In this section, we present some visualizations based on two implementations, one in Matlab, which we call the GS implementation, and the other one in Python, which is the channel averaged GS implementation. The main difference between these implementations is an averaging step of Layer 2 in the case of the Python implementation; averaging over channels is introduced in order to obtain a 2D representation in each layer. Furthermore, the averaging step significantly accelerates the computation of the second layer output.
Referring to Figure 2, the following nomenclature will be used. Layer 1 (L1) is the GT, which, after resampling to the desired size, becomes Out A. Output 1 (O1) is the output of L1, i.e., after applying the output-generating atom. Recall that this is done by a low-pass filtering step. Again, Out B is obtained by resampling to the desired matrix size.
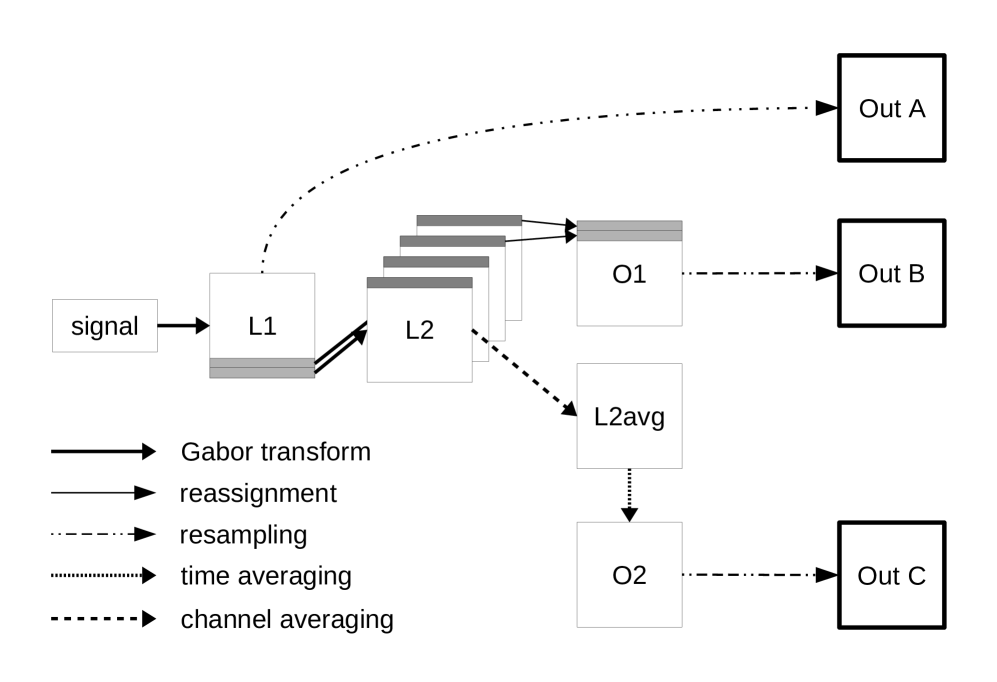
Layer 2 (L2) is obtained by applying another GT for each frequency channel. In the Matlab code, Output 2 (O2) is then obtained by low-pass filtering the separate channels of each resulting spectrogram. In the case of Python implementation (see Figure 2), we average all the GT of L2 to one spectrogram (for the sake of speed) and then apply a time averaging step in order to obtain O2. Resampling to the desired size yields Out C.
As input signal for this section we generate single tones following the signal model from Section 3.2.
4.2.1 Visualization of Different Frequency Channels within the GS Implementation
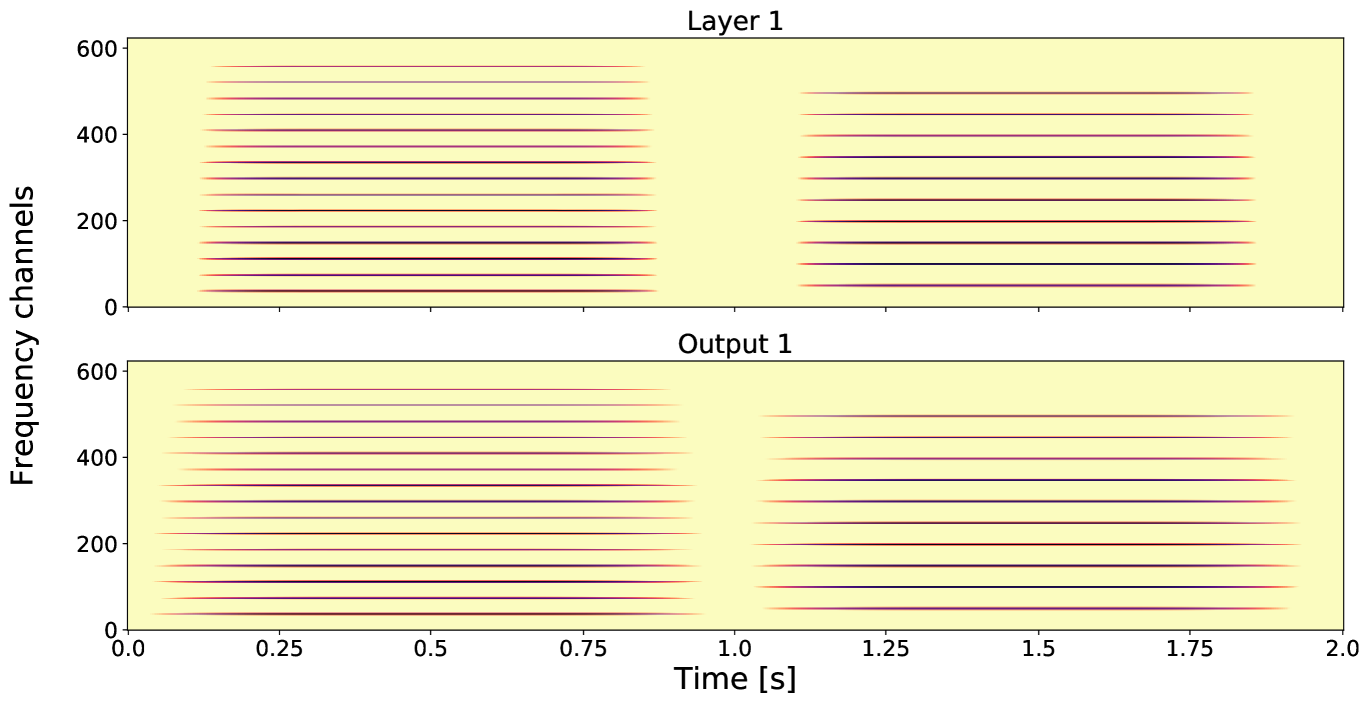
Figures 3 and 4 show two tones, both having a smooth envelope but different fundamental frequencies and number of harmonics. The first tone has fundamental frequency and harmonics, and the second tone has fundamental frequency and harmonics.
-
•
Layer 1: The first spectrogram of Figure 3 shows the GT. Observe the difference in the fundamental frequencies and that these two tones have a different number of harmonics, i.e., tone one has more than tone two.
-
•
Output 1: The second spectrogram of Figure 3 shows Output 1, which is is time averaged version of Layer 1.
-
•
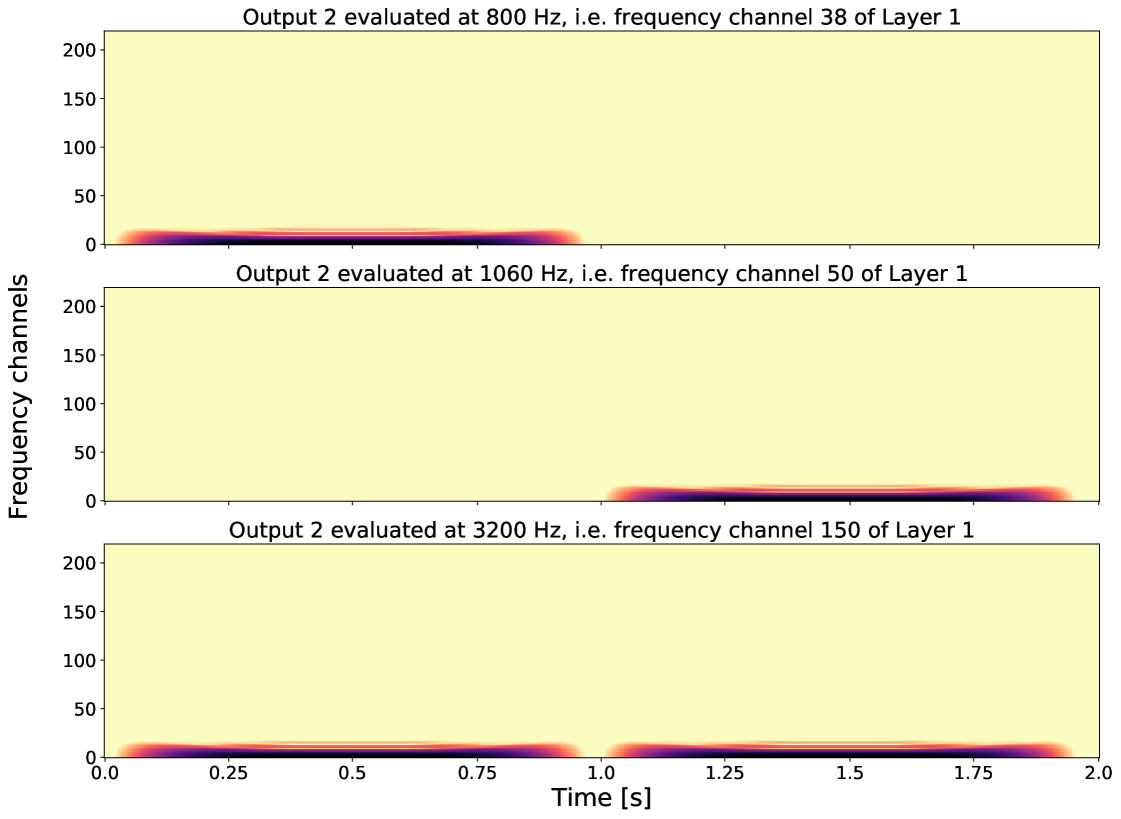
Output 2: For the second layer output (see Figure 4), we take a fixed frequency channel from Layer 1 and compute another GT to obtain a Layer 2 element. By applying an output-generating atom, i.e., a low-pass filter, we obtain Output 2. Here, we show how different frequency channels of Layer 1 can affect Output 2. The first spectrogram shows Output 2 with respect to, the fundamental frequency of tone one, i.e., Therefore no second tone is visible in this output. On the other hand, in the second spectrogram, if we take as fixed frequency channel in Layer 1 the fundamental frequency of the second tone, i.e., in Output 2, the first tone is not visible. If we consider a frequency that both share, i.e., , we see that for Output 2 in the third spectrogram both tones are present. As GS focuses on one frequency channel in each layer element, the frequency information in this layer is lost; in other words, Layer 2 is invariant with respect to frequency.
4.2.2 Visualization of Different Envelopes within the GS Implementation
Here, Figure 5 shows two tones, played sequentially, having the same fundamental frequency and harmonics, but different envelopes. The first tone has a sharp attack, maintains and goes softly to zero, the second starts with a soft attack and has some amplitude modulation. An amplitude modulated signal would, for example, correspond to ; here, the signal is modulated by The GS output of these signals are shown in Figure 5.
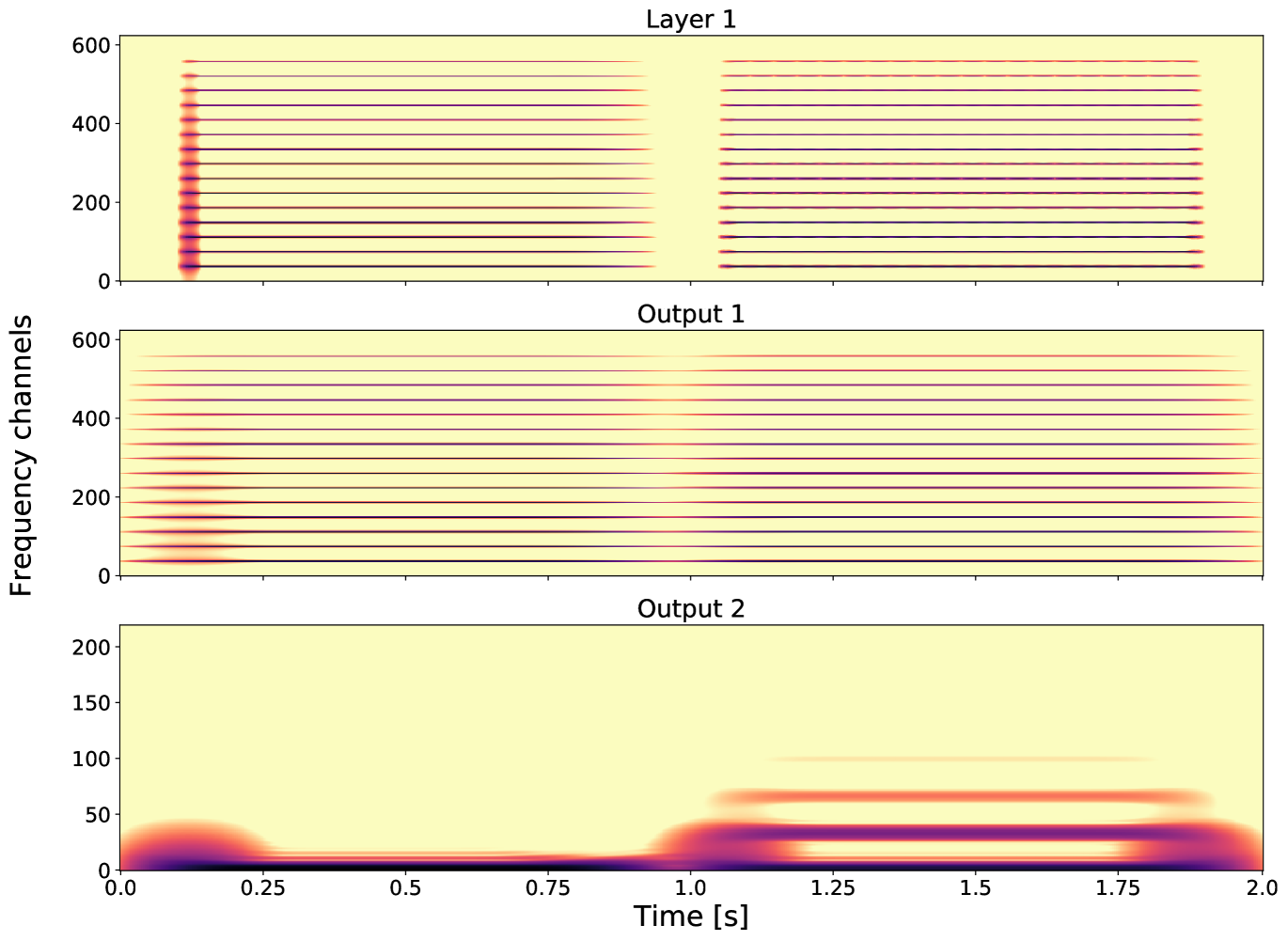
-
•
Layer 1: In the spectrogram showing the GT, we see the difference between the envelopes and we see that the signals have the same pitch and the same harmonics.
-
•
Output 1: The output of the first layer is invariant with respect to the envelope of the signals. This is due to the output-generating atom and the subsampling, which removes temporal information of the envelope. In this output, no information about the envelope (neither the sharp attack nor the amplitude modulation) is visible, therefore the spectrogram of the different signals look almost the same.
-
•
Output 2: For the second layer output we took as input a time vector at fixed frequency of 800 Hz (i.e., frequency channel 38) of the first layer. Output 2 is invariant with respect to the pitch, but differences on larger scales are captured. Within this layer we are able to distinguish the different envelopes of the signals. We first see the sharp attack of the first tone and then the modulation with a second frequency is visible.
The source code of the Matlab implementation and further examples can be found in [16].
4.2.3 Visualization of How Frequency and Amplitude Modulations Influence the Outputs Using the Channel Averaged Implementation
To visualize the resampled transformation in a more structured way, we created an interactive plot (see Figure 6), which shows 25 different synthetic audio signals side by side, transformed into Out A, Out B, and Out C with chosen GS parameters. Each signal consists of one or more sine waves modulated in amplitude and frequency with 5 Hz steps.
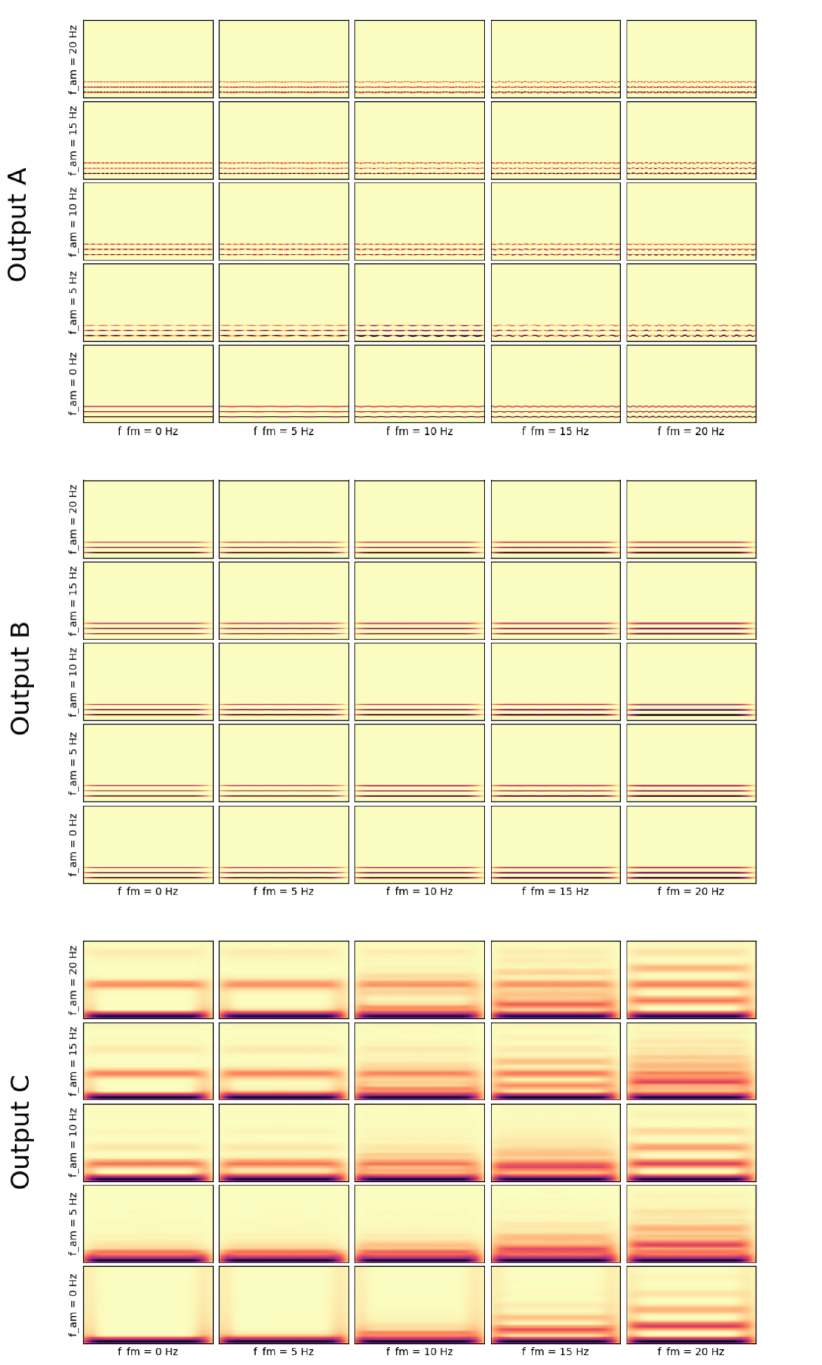
The parameters can be adjusted by sliders and the plot is changed accordingly. The chosen parameters to be adjusted were number of frequency channels in Layer 1, number of frequency channels in Layer 2, sampling rate, and number of harmonics of the signal. The code for the interactive plot is available as a part of the repository [16].
5 Experimental Results
In the numerical experiments, we compare the GS to a GT representation, which is one of the standard time-frequency representations used in a preprocessing phase for training neural networks applied to audio data. We compare these two time-frequency representations with respect to the performance on limited size of the training dataset.
To convert the raw waveform into the desired representations (GS and GT), we have used the Gabor-scattering v0.0.4 library [17], which is our Python implementation of the GS transform based on the Scipy v1.2.1 [18, 19, 20] implementation of STFT.
To demonstrate the beneficial properties of GS, we first create synthetic data in which we have the data generation under a full control. In this case, we generate four classes of data that reflect the discriminating properties of GS. Second, we investigate whether the GS representation is beneficial when using a “real” dataset for training. For this purpose, we have utilized the GoodSounds dataset [9].
5.1 Experiments with Synthetic Data
In the synthetic dataset, we created four classes containing s long signals, sampled at kHz with bit precision. All signals consist of a fundamental sine wave and four harmonics. The whole process of generating sounds is controlled by fixed random seeds for reproducibility.
5.1.1 Data
We describe the sound generator model for one component of the final signal by the following equation,
| (21) |
where is the frequency modulation and is the amplitude modulation. Here, is the amplitude, denotes the frequency and denotes the phase. Furthermore, the amplitude, frequency, and phase of the frequency modulation carrier wave is denoted by , , and , respectively, and for the case of amplitude modulation carrier wave we have , , and
To generate five component waves using the sound generator described above, we needed to decide upon the parameters of each component wave. We started by randomly generating the frequencies and phases of the signal and the carrier waves for frequency and amplitude modulation from given intervals. These parameters describe the fundamental sine wave of the signal. Next we create harmonics by taking multiples (from 2 to 5) of the fundamental frequency where of each next harmonic is divided by a factor. Afterwards, by permuting the two parameters, namely, by turning the amplitude modulation and frequency modulation on and off, we defined four classes of sound. These classes are indexed starting from zero. The class has neither amplitude nor frequency modulation. Class 1 is just amplitude modulated, Class 2 is just modulated in frequency, and Class 3 is modulated in both amplitude and frequency, as seen in Table 1. At the end, we used those parameters to generate each harmonic separately and then summed them together to obtain the final audio file.
| = 0 | = 1 | |
|---|---|---|
| class 0 | class 1 | |
| = 1 | class 2 | class 3 |
The following parameters were used to obtain GS; n_fft = 500—number of frequency channels, n_perseg = 500—window length, n_overlap = 250—window overlap were taken for Layer 1, i.e., GT, n_fft = 50, n_perseg = 50, n_overlap = 40 for Layer 2, window_length of the time averaging window for Output 2 was set to 5 with mode set to “same”. All the shapes for Output A, Output B, and Output C were . Bilinear resampling [21] was used to adjust the shape if necessary. The same shape of all of the outputs allows the stacking of matrices into shape , which is convenient for CNN, because it can be treated as a 3-channel image. Illustration of the generated sounds from all four classes transformed into GT and GS can be seen in Section 2.2 and Figure 1.
With the aforementioned parameters, the mean time necessary to compute the GS was 17.4890 ms, whereas the mean time necessary to compute the GT was 5.2245 ms, which is approximately times less. Note that such comparison is only indicative, because the time is highly dependent on chosen parameters, hence the final time depends on the specific settings.
5.1.2 Training
To compare the discriminating power of both GS and GT, we have generated 10,000 training samples ( from each class) and 20,000 ( from each class) validation samples. As the task at hand is not as challenging as some real-world datasets, we assume these sizes to be sufficient for both time-frequency representations to converge to very good performances. To compare the performance of GS and GT on a limited set of training data, we have altogether created four scenarios in which the training set was limited to , and 10,000 samples. In all of these scenarios, the size of the validation set remained at its original size of 20,000 samples and we have split the training set into smaller batches each containing 100 samples with the same number of samples from each class. Batches were used to calculate the model error based on which the model weights were updated.
The CNN consisted of the batch normalization layer, which acted upon the input data separately for each channel of the image (we have three channels, namely Out A, Out B, and Out C), followed by four stacks of 2D convolution with average pooling. The first three convolutional layers were identical in the number of kernels, which was set to 16 of the size with stride . The last convolutional layer was also identical apart from using just 8 kernels. Each convolutional layer was initialized by a Glorot uniform initialization [22], and followed by a ReLu nonlinearity [23] and an average pooling layer with a pool size. After the last average pooling the feature maps were flattened and fully connected to an output layer with neurons and a softmax activation function [24]. For more details about the networks architecture, the reader should consult the repository [16]. There one also finds the exact code in order to reproduce the experiment.
The network’s categorical cross-entropy loss function was optimized using the Adam optimizer [25] with = 0.001, = 0.9, and = 0.999. To have a fair comparison, we limit each of the experiments in terms of computational effort as measured by a number of weight updates during the training phase. One weight update is made after each batch. Each experiment with synthetic data was limited to 2000 weight updates. To create the network, we used Python 3.6 programming language with Keras framework v2.2.4 [26] on Tensorflow backend v1.12.0 [27]. To train the models, we used two GPUs, namely, NVIDIA Titan XP and NVIDIA GeForce GTX 1080 Ti, on the OS Ubuntu 18.04 based system. Experiments are fully reproducible and can be obtained by running the code in the repository [16].
5.1.3 Results
The results are shown in Table 2, listing the accuracies of the model’s best weight update on training and validation sets. The best weight update was chosen based on the performance on the validation set. More detailed tables of the results can be found in the aforementioned repository. In this experiment, we did not use any testing set, because of the synthetic nature of the data. Accuracy is computed as a fraction of correct predictions to all predictions.
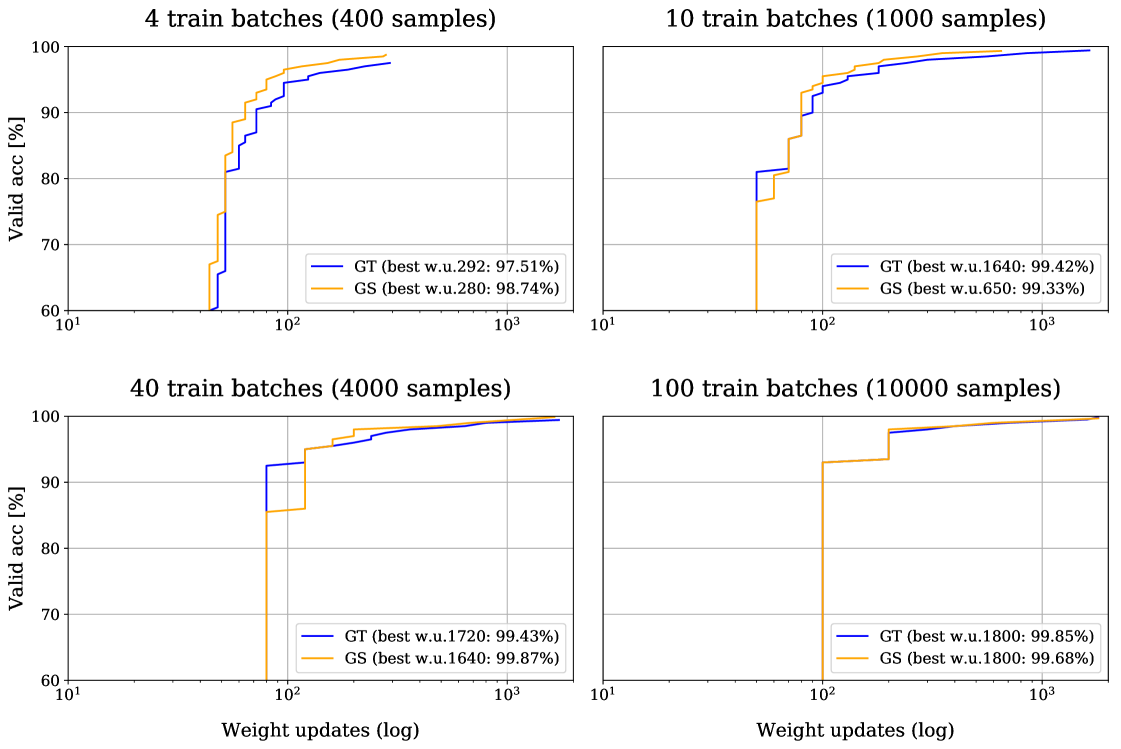
The most important observation is visible in Figure 7, where it is shown that in the earlier phases of the training, GS reaches higher accuracies after less weight updates than GT. This effect diminishes with bigger training sets and vanishes completely in case of 100 training batches. In case of very limited data, i.e., with only 400 training samples, the results show that GS even outperformed GT. With more training samples, i.e., 1000 and 4000, the best performances of GT and GS are nearly the same. In this case we could hypothesize that the prior knowledge of the intrinsic properties of a time series signal shown by GS (in the invariances of Layer 1 and Layer 2) is not needed anymore and the network is able to learn the necessary transformation itself.
| TF | N Train | N Valid | BWU | Train | Valid |
|---|---|---|---|---|---|
| GS | 400 | 20,000 | 280 | 1.0000 | 0.9874 |
| GT | 400 | 20,000 | 292 | 1.0000 | 0.9751 |
| GS | 1000 | 20,000 | 650 | 0.9990 | 0.9933 |
| GT | 1000 | 20,000 | 1640 | 1.0000 | 0.9942 |
| GS | 4000 | 20,000 | 1640 | 0.9995 | 0.9987 |
| GT | 4000 | 20,000 | 1720 | 0.9980 | 0.9943 |
| GS | 10,000 | 20,000 | 1800 | 0.9981 | 0.9968 |
| GT | 10,000 | 20,000 | 1800 | 0.9994 | 0.9985 |
| Table notation: TF—Time-frequency representation. N train and N valid—Number of samples in training and validation sets. BWU—Weight update after which the highest performance was achieved on the validation set. Train and valid—accuracy on training and validation sets. |
5.2 Experiments with GoodSounds Data
In the second set of experiments, we used the GoodSounds dataset [9]. It contains monophonic audio recordings of single tones or scales played by 12 different musical instruments. The main purpose of this second set of experiments is to investigate whether GS shows superior performance to GT in a classification task using real-life data.
5.2.1 Data
To transform the data into desired form for training, we removed the silent parts using the SoX v14.4.2 library [28, 29]; next, we split all files into 1 s long segments sampled at a rate of 44.1 kHz with 16 bit precision. A Tukey window was applied to all segments to smooth the onset and the offset of each with the aim to prevent undesired artifacts after applying the STFT.
The dataset contains h of recordings, which is a reasonable amount of audio data to be used in training of Deep Neural Networks considering the nature of this task. Unfortunately, the data are distributed into classes unevenly, half of the classes are extremely underrepresented, i.e., half of the classes together contain only 12.6% of all the data. In order to alleviate this problem, we decided upon an equalization strategy by variable stride.
To avoid extensive equalization techniques, we have discarded all classes that spanned less than 10% of the data. In total we used six classes, namely, clarinet, flute, trumpet, violin, sax alto, and cello. To equalize the number of segments between these classes, we introduced the aforementioned variable stride when creating the segments. The less data a particular class contains, the bigger is the overlap between segments, thus more segments are generated and vice versa. The whole process of generating sounds is controlled by fixed random seeds for reproducibility. Detailed information about the available and used data, stride settings for each class, obtained number of segments and their split can be seen in Table 3.
| All Available Data | Obtained Segments | |||||||
| Class | Files | Dur | Ratio | Stride | Train | Valid | Test | |
| Used | Clarinet | 3358 | 369.70 | 21.58% | 37,988 | 12,134 | 4000 | 4000 |
| Flute | 2308 | 299.00 | 17.45% | 27,412 | 11,796 | 4000 | 4000 | |
| Trumpet | 1883 | 228.76 | 13.35% | 22,826 | 11,786 | 4000 | 4000 | |
| Violin | 1852 | 204.34 | 11.93% | 19,836 | 11,707 | 4000 | 4000 | |
| Sax alto | 1436 | 201.20 | 11.74% | 19,464 | 11,689 | 4000 | 4000 | |
| Cello | 2118 | 194.38 | 11.35% | 15,983 | 11,551 | 4000 | 4000 | |
| Not used | Sax tenor | 680 | 63.00 | 3.68% | ||||
| Sax soprano | 668 | 50.56 | 2.95% | |||||
| Sax baritone | 576 | 41.70 | 2.43% | |||||
| Piccolo | 776 | 35.02 | 2.04% | |||||
| Oboe | 494 | 19.06 | 1.11% | |||||
| Bass | 159 | 6.53 | 0.38% | |||||
| Total | 16,308 | 1713.23 | 100.00% | 70,663 | 24,000 | 24,000 | ||
| Table notation: Files—Number of available audio files. Dur—Duration of all recordings within one class in minutes. Ratio—Ratio of the duration to total duration of all recordings in the dataset. Stride—Step size (in samples) used to obtain segments of the same length. Train, Valid, Test—Number of segments used to train (excluding the leaking segments), validate, and test the model. |
As seen from the table, the testing and validation sets were of the same size comprising the same number of samples from each class. The remaining samples were used for training. To prevent leaking of information from validation and testing sets into the training set, we have excluded all the training segments originating from the audio excerpts, which were already used in validation or testing set. More information can be found in the repository [16].
The following parameters were used to obtain GS; n_fft = 2000—number of frequency channels, n_perseg = 2000—window length, n_overlap = 1750—window overlap were taken for Layer 1, i.e., GT, n_fft = 25, n_perseg = 25, n_overlap = 20 for Layer 2, window_length of the time averaging window for Output 2 was set to 5 with mode set to ‘same’. All the shapes for Output A, Output B and Output C were . Bilinear resampling [21] was used to adjust the shape if necessary. The same shape of all the outputs allows the stacking of matrices into shape . Illustration of the sounds from all six classes of musical instruments transformed into GT and GS can be found in the repository [16].
5.2.2 Training
To make the experiments on synthetic data and the experiments on GoodSounds data comparable, we again used the CNN as a classifier trained in a similar way as described in Section 5.1.2. We have also preprocessed the data, so the audio segments are of the same duration and sampling frequency. However, musical signals have different distribution of frequency components than the synthetic data, therefore we had to adjust the parameters of the time-frequency representations. This led to a change in the input dimension to . These changes and the more challenging nature of the task led to slight modification of the architecture in comparison to the architecture in the experiment with synthetic data:
The number of kernels in the first three convolutional layers was raised to 64. The number of kernels in the last convolutional layer was raised to 16. The output dimension of this architecture was set to 6, as this was the number of classes. The batch size changed to 128 samples per batch. The number of weight updates was set to 11,000. To prevent unnecessary training, this set of experiments was set to terminate after 50 consecutive epochs without an improvement in validation loss as measured by categorical cross-entropy. The loss function and optimization algorithm remained the same as well as the used programming language, framework, and hardware. Experiments are fully reproducible and can be obtained by running the code in the repository [16]. Consider this repository also for more details about the networks architecture.
In this set of experiments, we have trained 10 models in total with five scenarios with limited training set (5, 11, 55, 110, and 550 batches each containing 128 samples) for each time-frequency representation. In all of these scenarios, the sizes of the validation and testing sets remained at their full sizes each consisting of 188 batches containing 24,000 samples.
5.2.3 Results
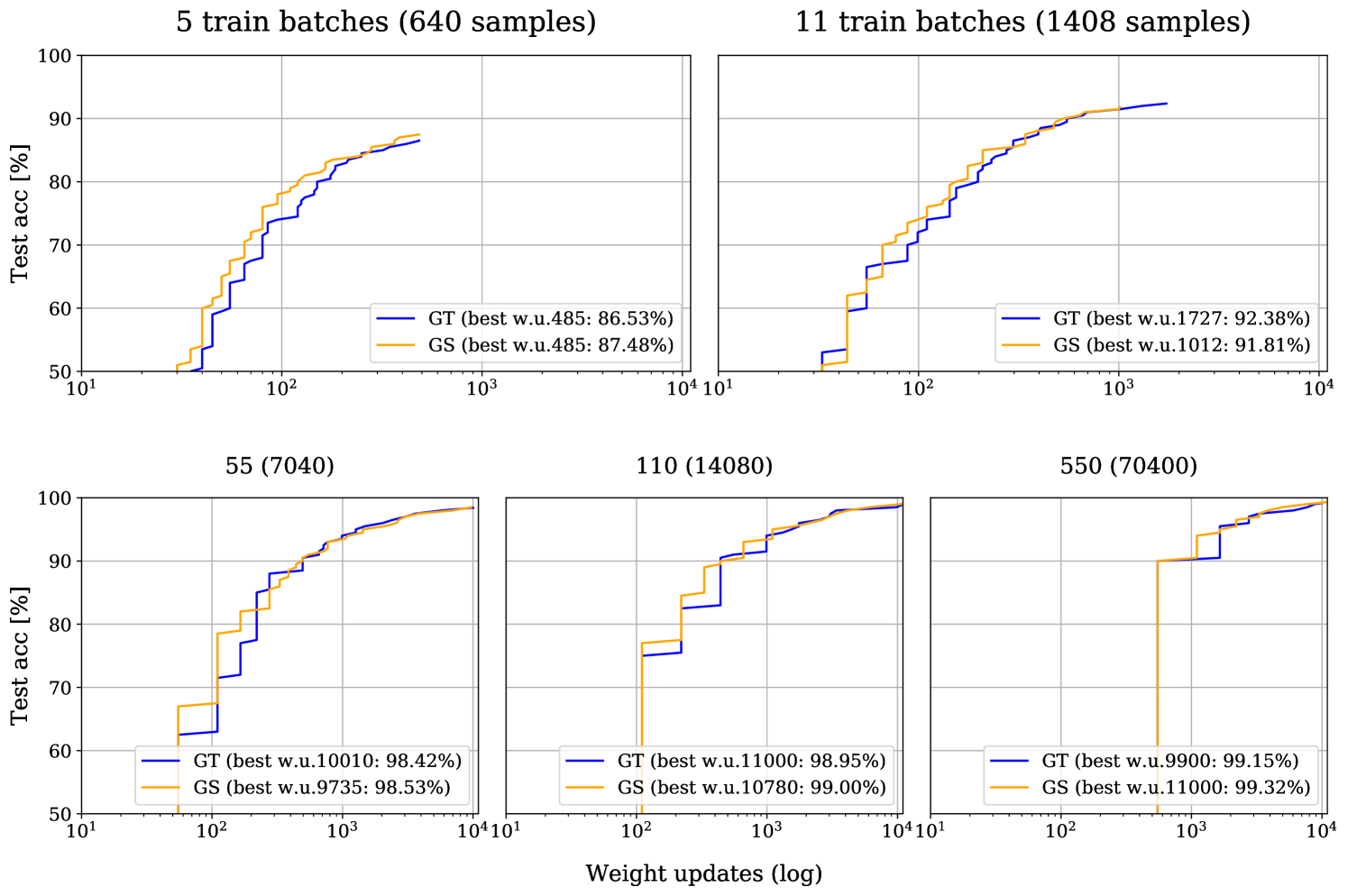
Table 4 shows the accuracies of the model’s best weight update on training, validation, and testing sets. The best weight update was chosen based on the performance on the validation set. As before, more details can be found in the aforementioned repository. In this experiment using GoodSounds data, a similar trend as for the synthetic data is visible. GS performs better than GT if we are limited in training set size, i.e., having 640 training samples, the GS outperformed GT.
| TF | N Train | N Valid | N Test | BWU | Train | Valid | Test |
|---|---|---|---|---|---|---|---|
| GS | 640 | 24,000 | 24,000 | 485 | 0.9781 | 0.8685 | 0.8748 |
| GT | 640 | 24,000 | 24,000 | 485 | 0.9766 | 0.8595 | 0.8653 |
| GS | 1408 | 24,000 | 24,000 | 1001 | 0.9773 | 0.9166 | 0.9177 |
| GT | 1408 | 24,000 | 24,000 | 1727 | 0.9943 | 0.9194 | 0.9238 |
| GS | 7040 | 24,000 | 24,000 | 9735 | 0.9996 | 0.9846 | 0.9853 |
| GT | 7040 | 24,000 | 24,000 | 8525 | 0.9999 | 0.9840 | 0.9829 |
| GS | 14,080 | 24,000 | 24,000 | 10,780 | 0.9985 | 0.9900 | 0.9900 |
| GT | 14,080 | 24,000 | 24,000 | 9790 | 0.9981 | 0.9881 | 0.9883 |
| GS | 70,400 | 24,000 | 24,000 | 11,000 | 0.9963 | 0.9912 | 0.9932 |
| GT | 70,400 | 24,000 | 24,000 | 8800 | 0.9934 | 0.9895 | 0.9908 |
| Table notation: TF—Time-frequency representation. N train, N valid and N test—Number of samples in training, validation and testing sets. BWU—Weight update after which the highest performance was achieved on the validation set. Train, valid and test—accuracy on training, validation, and testing sets. |
In Figure 8, we again see that in earlier phases of the training, GS reaches higher accuracies after less weight updates than GT. This effect diminishes with bigger training sets and vanishes in case of 550 training batches.
6 Discussion and Future Work
In the current contribution, a scattering transform based on Gabor frames has been introduced, and its properties were investigated by relying on a simple signal model. Thereby, we have been able to mathematically express the invariances introduced by GS within the first two layers.
The hypothesis raised in Section 2.1, that explicit encoding of invariances by using an adequate feature extractor is beneficial when a restricted amount of data is available, was substantiated in the experiments presented in the previous section. It was shown that in the case of a limited dataset the application of a GS representation improves the performance in classification tasks in comparison to using GT.
In the current implementation and with parameters described in Section 5.1.1, the GS is approximately 3 times more expensive to compute than GT. However, this transformation needs to be done only once—in the preprocessing phase. Therefore, the majority of computational effort is still spent during training, e.g., in the case of the GoodSounds experiment, the training with GS is 2.5 times longer than with GT. Note that this is highly dependent on the used data handling pipeline, network architecture, software framework, and hardware, which all can be optimized to alleviate this limitation. Although GS is more computationally-expensive, the obtained improvement justifies its use in certain scenarios; in particular, for classification tasks which can be expected to benefit from the invariances introduced by GS. In these cases, the numerical experiments have shown that by using GS instead of GT a negative effect of a limited dataset can be compensated.
Hypothetically, with enough training samples, both GS and GT should perform equally assuming sufficient training, i.e., performing enough weight updates. This is shown in the results of both numerical experiments presented in this article (see Tables 2 and 4). This is justified by the fact that GS comprises exclusively the information contained within GT, only separated into three different channels. We assume it is easier for the network to learn from such a separated representation. The evidence to support this assumption is visible in the earlier phases of the training, where GS reaches higher accuracies after less weight updates than GT (see Figures 7 and 8). This effect increases with smaller datasets while with very limited data GS even surpasses GT in performance. This property can be utilized in restricted settings, e.g., in embedded systems with limited resources or in medical applications, where sufficient datasets are often too expensive or impossible to gather, whereas the highest possible performance is crucial.
We believe that GT would eventually reach the same performance as GS, even on the smallest feasible datasets, but the network would need more trainable parameters, i.e., more complex architecture to do the additional work of finding the features that GS already provides. Unfortunately, in such a case, it remains problematic to battle the overfitting problem. This opens a new question—whether the performance boost of GS would amplify on lowering the number of trainable parameters of the CNN. This is out of the scope of this article and will be addressed in the future work.
In another paper [30], we extended GS to mel-scattering (MS), where we used GS in combination with a mel-filterbank. This MS representation reduces the dimensionality, and therefore it is computationally less expensive compared to GS.
It remains to be said that the parameters in computing GS coefficients have to be carefully chosen to exploit the beneficial properties of GS by systematically capturing data-intrinsic invariances.
Future work will consist of implementing GS on the GPU, to allow for fast parallel computation. At the same time, more involved signal models, in particular, those concerning long-term correlations, will be studied analytically to the end of achieving results in the spirit of the theoretical results presented in this paper.
Acknowledgment
This work was supported by the Uni:docs Fellowship Programme for Doctoral Candidates in Vienna, by the Vienna Science and Technology Fund (WWTF) project SALSA (MA14-018), by the International Mobility of Researchers (CZ.02.2.69/0.0/0.0/16 027/0008371), and by the project LO1401. Infrastructure of the SIX Center was used for computation.
References
- [1] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1097–1105. Curran Associates, Inc., 2012.
- [2] Thomas Grill and Jan Schlüter. Music Boundary Detection Using Neural Networks on Combined Features and Two-Level Annotations. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, 2015.
- [3] S. Mallat. Group Invariant Scattering. Comm. Pure Appl. Math., 65(10):1331–1398, 2012.
- [4] Thomas Wiatowski and Helmut Bölcskei. A mathematical theory of deep convolutional neural networks for feature extraction. CoRR, abs/1512.06293, 2015.
- [5] T. Wiatowski and H. Bölcskei. Deep Convolutional Neural Networks Based on Semi-Discrete Frames. In Proc. of IEEE International Symposium on Information Theory (ISIT), pages 1212–1216, june 2015.
- [6] J. Andén and S. Mallat. Deep scattering spectrum. IEEE Transactions on Signal Processing, 62(16):4114–4128, 2014.
- [7] J. Andén, V. Lostanlen, and S. Mallat. Joint time-frequency scattering for audio classification. In 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), pages 1–6, 2015.
- [8] P. Grohs, T. Wiatowski, and H. Bölcskei. Deep convolutional neural networks on cartoon functions. In 2016 IEEE International Symposium on Information Theory (ISIT), pages 1163–1167, July 2016.
- [9] Oriol Romani Picas, Hector Parra Rodriguez, Dara Dabiri, Hiroshi Tokuda, Wataru Hariya, Koji Oishi, and Xavier Serra. A real-time system for measuring sound goodness in instrumental sounds. In Audio Engineering Society Convention 138. Audio Engineering Society, 2015.
- [10] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. 2017.
- [11] Kenji Kawaguchi, Leslie Pack Kaelbling, and Yoshua Bengio. Generalization in deep learning. arXiv preprint arXiv:1710.05468, 2017.
- [12] T. Hofmann, B. Schölkopf, and AJ. Smola. Kernel methods in machine learning. Annals of Statistics, 36(3):1171–1220, June 2008.
- [13] Stéphane Mallat. Understanding deep convolutional networks. Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, 374(2065), 2016.
- [14] T. Wiatowski, M. Tschannen, A. Stanic, P. Grohs, and H. Bölcskei. Discrete deep feature extraction: A theory and new architectures. In Proc. of International Conference on Machine Learning (ICML), june 2016.
- [15] Karlheinz Gröchenig. Foundations of time-frequency analysis. Applied and numerical harmonic analysis. Birkhäuser, Boston, Basel, Berlin, 2001.
- [16] P. Harar and R. Bammer. gs-gt. https://gitlab.com/hararticles/gs-gt, 2019. [Online; accessed 2019-06-20].
- [17] P. Harar. Gabor scattering v0.0.4. https://gitlab.com/paloha/gabor-scattering, 2019. [Online; accessed 2019-06-20].
- [18] Eric Jones, Travis Oliphant, Pearu Peterson, et al. SciPy: Open source scientific tools for Python. http://www.scipy.org/, note = [Online; accessed 2019-02-01], 2001–.
- [19] Alan V Oppenheim. Discrete-time signal processing. Pearson Education India, 1999.
- [20] Daniel Griffin and Jae Lim. Signal estimation from modified short-time fourier transform. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(2):236–243, 1984.
- [21] Earl J Kirkland. Bilinear interpolation. In Advanced Computing in Electron Microscopy, pages 261–263. Springer, 2010.
- [22] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Aistats, volume 9, pages 249–256, 2010.
- [23] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In The IEEE International Conference on Computer Vision (ICCV), December 2015.
- [24] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
- [25] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [26] François Chollet et al. Keras. https://keras.io, 2015. [Online; accessed 2019-08-19].
- [27] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, …, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
- [28] Chris Bagwell. SoX - Sound Exchange the swiss army knife of sound processing. https://launchpad.net/ubuntu/+source/sox/14.4.1-5. Accessed: 2018-10-31.
- [29] Jason Navarrete. The SoX of Silence tutorial. https://digitalcardboard.com/blog/2009/08/25/the-sox-of-silence. Accessed: 2018-10-31.
- [30] Pavol Harar, Roswitha Bammer, Anna Breger, Monika Dörfler, and Zdenek Smékal. Machines listening to music: the role of signal representations in learning from music. CoRR, abs/1903.08950, 2019.