\ul
GaGSL: Global-augmented Graph Structure Learning via Graph Information Bottleneck
Abstract
Graph neural networks (GNNs) are prominent for their effectiveness in processing graph data for semi-supervised node classification tasks. Most works of GNNs assume that the observed structure accurately represents the underlying node relationships. However, the graph structure is inevitably noisy or incomplete in reality, which can degrade the quality of graph representations. Therefore, it is imperative to learn a clean graph structure that balances performance and robustness. In this paper, we propose a novel method named Global-augmented Graph Structure Learning (GaGSL), guided by the Graph Information Bottleneck (GIB) principle. The key idea behind GaGSL is to learn a compact and informative graph structure for node classification tasks. Specifically, to mitigate the bias caused by relying solely on the original structure, we first obtain augmented features and augmented structure through global feature augmentation and global structure augmentation. We then input the augmented features and augmented structure into a structure estimator with different parameters for optimization and re-definition of the graph structure, respectively. The redefined structures are combined to form the final graph structure. Finally, we employ GIB based on mutual information to guide the optimization of the graph structure to obtain the minimum sufficient graph structure. Comprehensive evaluations across a range of datasets reveal the outstanding performance and robustness of GaGSL compared with the state-of-the-art methods.
Index Terms:
Graph structure learning, graph neural networks, graph information bottleneck, robustnessI Introduction
Graph data is pervasive in a variety of real-world scenarios, including power networks [1], social media [2, 3], and computer graphics [4]. In these scenarios, each node with attributes represents an entity, while each edge represents the relationship between the entity pairs. For example, in social networks, each node represents a user or individual, and they may have attributes such as personal information, interests, and professions. The edge that connects different nodes represents a friendship or following relationship, and it can be either directed or undirected. In recent years, graph neural networks (GNNs) have emerged as a powerful approach for working with graph data [5, 6, 7, 8], and have been widely adopted for diverse network analysis tasks, including node classification [9, 10], link prediction [11, 12], and graph classification [13, 14].
Most existing GNNs rely on one basic assumption that the observed structure precisely represents the underlying node relationships. However, this assumption does not always hold in practice, as there are multiple factors that can lead to noisy graph structure: (1) Presence of noise and bias. Data can be collected and annotated from multiple sources. In the process of data collection and annotation, noisy connections and bias may be introduced by subjective human judgment or limitations in device precision. In some special cases (e.g., graph-enhanced applications [15] and visual navigation [16]), the data may lack inherent graph structure and require additional graph construction (e.g., NN) for representation learning. (2) Adversarial attacks on graph structure. The majority of current methods for adversarial attacks on graph data, including poisoning attacks [17] on graph structure, concentrate on altering the graph structure, especially adding/deleting/rewiring edges [18], and the original structure can be severely damaged. For instance, in credit card fraud detection, a fraudster might generate numerous transactions involving multiple high-credit users to conceal their identity and avoid detection by GNNs.
How does the model’s performance vary when the graph structure faces different levels of noise? And what is the impact on the graph structure when it is subjected to noise? To investigate the answer to this question, we simulated the noisy graph structure by introducing artificial edges into the graph at different proportions (i.e., 25%, 50%, and 75%) of the original number of edges (simulated noise), using the polblogs [19] dataset. Additionally, we calculate the probability matrices between communities for the original graph structure, as well as the graph structure with 75% additional edges, and draw them as heat maps. As illustrated in Fig. 1, the performance of GNNs models drops dramatically with the increase of edge addition rate, with SGC [20] exhibiting the most significant decline. This observation suggests that randomly adding edges has a detrimental effect on node classification performance. Further comparison of the middle and right plots reveals that randomly adding edges can result in connections between nodes from different communities. This inter-community connectivity decreases the distinguishing ability of nodes after GNN aggregates neighbor information, thereby leading to a decline in model performance. In summary, the effectiveness of GNNs is heavily dependent on the underlying graph structure, while real-world graphs often suffer from missing, meaningless, or even spurious edges. This structural noise may hinder message passing and limit the generalization ability of GNNs. Therefore, there is an urgent need to explore the optimal graph structure suitable for GNNs.
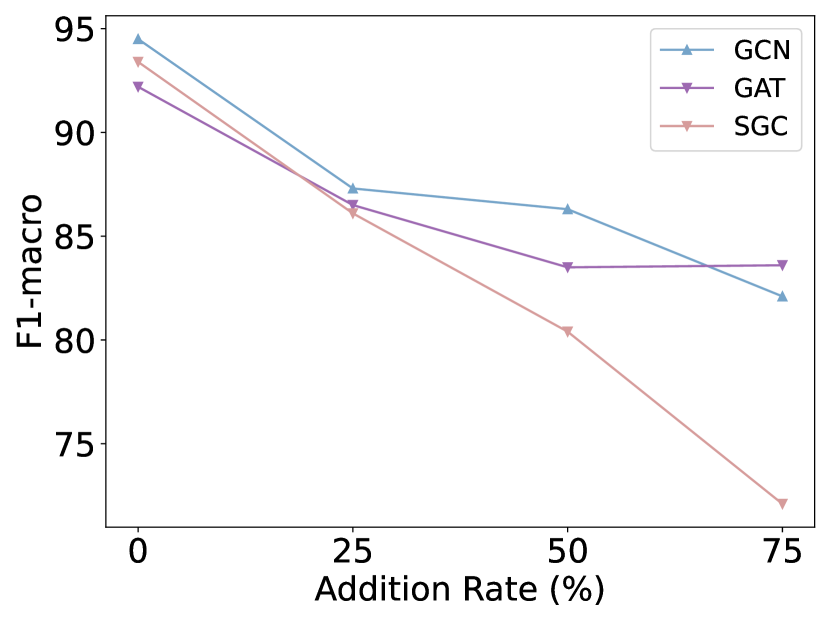
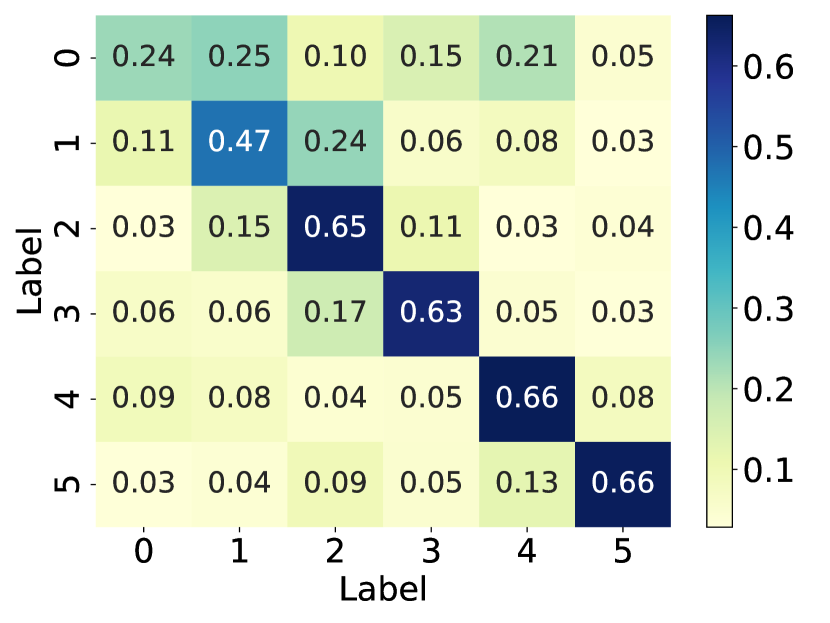
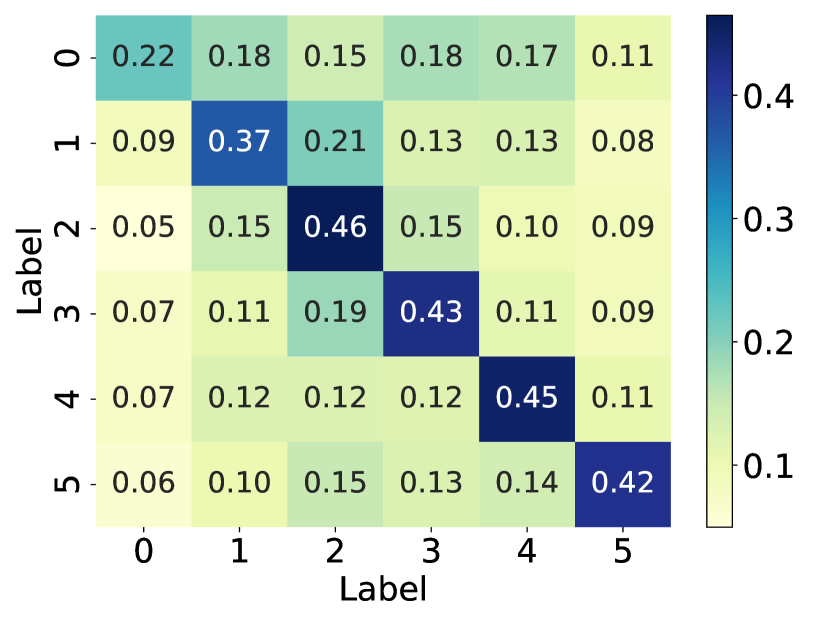
In recent years, various graph structure learning (GSL) methods [21] have emerged to handle the aforementioned problems, ensuring the performance and robustness of the models. Nevertheless, developing effective techniques to learn an optimal graph structure for GNNs represents a technically challenging task. (1) How can multifaceted information be introduced to provide a more comprehensive perspective? Relying on a single graph structure is inadequate to fully capture the complexity and diversity inherent in a graph [22]. Different perspectives of graph structure can shed light on various aspects and features within the graph. Therefore, it becomes imperative to integrate multi-perspective graph structure to acquire a more comprehensive and diverse graph structure. Most current methods for graph structure obtain the optimal graph structure from the single original structure [23, 24, 19]. There are also methods that obtain optimal graph structure based on multiple fundamental views [9, 25, 26, 22]. As an illustrative example, Chen et al. [25] constructed graph structure by incorporating both the normalized adjacency matrix and the node embedding similarity matrix. Nevertheless, it only considers feature similarity and fails to capture structural role information. (2) How to learn a clean graph structure for node classification tasks? In information theory, two key principles are Graph Information Bottleneck (GIB) [27, 28, 29] and Principle of Relevant Information (PRI) [30]. GIB and PRI represent distinct approaches to redundancy reduction and information preservation. Specifically, GIB offers an essential guideline for GSL: an optimal graph structure should contain the minimum sufficient information required for the downstream prediction task. For example, Sun et al. [28] advanced the GIB principle in graph classification by jointly optimizing the graph structure and graph representation. PRI views the issue of reducing redundancy and retaining information as a balancing act. This balance is struck between reducing the entropy of the representation and its relative entropy to the original data. For instance, a structure containing the most relevant yet least redundant information, quantified using von Neumann entropy and Quantum Jensen-Shannon divergence, was developed by Sun et al. [31]. However, exploring the learning of the optimal graph structure that strike a balance between performance and robustness in node classification tasks, based on information theory principle, remains an ongoing challenge.
To address the aforementioned issues, in this paper, we propose a novel Global-augmented Graph Structure Learning (GaGSL) method to enhance the node classification performance and robustness based on the principle of GIB. GaGSL consists of global feature and structure augmentation, structure redefinition and GIB guidance. In global feature and structure augmentation, two different techniques used to obtain augmented features and augmented structure, respectively. Details are presented in subsection IV-B. In structure redefinition, we introduce a structure estimator to appropriately refine the graph structure. This involves reallocating weights to the graph adjacency matrix elements based on node similarity. Then, the redefined structures are integrated to form the final structure. More information is provided in subsection IV-C. In GIB guidance, we aim to maximize the mutual information (MI) between node labels and node embeddings based on the final graph structure, while simultaneously imposing constraints on the MI between and the node embeddings or based on the redefined structures. To effectively evaluate the MI, we employ an MI calculator based on the InfoNCE loss [32]. More elaboration is given in subsection IV-D. Finally, we employ a cyclic optimization scheme to iteratively update the model parameters. Details are presented in subsection IV-E. Our contributions can be summarized as follows:
-
•
We propose a Global-augmented GSL method, GaGSL, which is guided by GIB and aims at obtaining the most compact structure. This endeavor seeks to strike a finer balance between performance and robustness.
-
•
To alleviate the limitations of relying solely on a single graph structure, we integrate augmented features and augmented structure to obtain a more global and diverse graph structure.
-
•
The evaluation of our proposed GaGSL method is conducted on eight benchmark datasets, and the experimental findings convincingly showcase the effectiveness of GaGSL. Notably, GaGSL exhibits superior performance when contrasted to state-of-the-art GSL methods, and this advantage is particularly pronounced when the method is applied to datasets that have been subjected to attacks.
The rest of the paper is organized as follows. In section II we briefly introduce the related works. Before presenting our research methodology in Section IV, we give the relevant notations and backgrounds in Section III. In Section V, we present and discuss the results of our experiments on benchmark datasets. Finally, Section VI outlines the conclusions drawn from this work and discusses potential avenues for future research.
II Related works
Aligned with the focus of our study, we provide a concise review of the two research areas most pertinent to our work - Graph Neural Networks and graph structure learning.
II-A Graph Neural Networks
GNNs have emerged as a prominent approach due to their effectiveness in working with graph data. These GNN models can be broadly categorized into two main groups: spectral-based methods and spatial-based methods.
Spectral-based methods aim to identify graph patterns in the frequency domain, leveraging the sound mathematical precepts of Graph Signal Processing (GSP) [33, 34]. Bruna et al. [35] first extended the convolution to general graphs using a Fourier basis, treating the filter as a set of learnable parameters and considering graph signals with multiple channels. but eigendecomposition requires computational complexity. In order to reduce the computational complexity, Defferrard et al. [36] and Kipf et al. [10] made several approximations and simplifications. Defferrard et al. [36] defined fast localized convolutional filters on graphs based on Chebyshev polynomials. Kipf et al. [10] further simplified ChebNet via a localized first-order approximation of spectral graph convolutions. Despite being spectral-based, GCN can also be viewed through a spatial perspective. In this context, GCN operates by aggregating feature information from the local neighborhood of each node. Recent studies have progressively improved upon GCN [10] by exploring alternative symmetric matrices. For example, The adaptive Graph Convolution Network (AGCN) [37] proposed a Spectral Graph Convolution layer with graph Laplacian Learning (SGC-LL), which efficiently adapts the graph topology according to the data and learning task context. Dual Graph Convolutional Network (DGCN) [38] hamilton2017inductivedesigned a dual neural network structure to encode both local and global consistency. Other spectral graph convolutions have also been proposed. Graph Wavelet Neural Network (GWNN) [39] defines the convolution operator via wavelet transform, which avoids matrix eigendecomposition and provides good interpretability with its local and sparse graph wavelets. Simple Spectral Graph Convolution (S2GC)[40] derives a variant of GCN based on a modified Markov Diffusion Kernel. It achieves a balance between low- and high-pass filter bands to capture both global and local contexts of each node.
Conversely, spatial-based methods draw inspiration from the message passing mechanism employed in Recurrent Graph Neural Network (RecGNN) [41, 42]. They directly define graph convolution in the spatial domain as transforming and aggregating local information. The Neural Network for Graphs (NN4G) [43] is the first work towards spatial-based convolutional graph neural networks (ConvGNNs). Unlike RecGNNs, NN4G utilizes a combinatorial neural network architecture where each layer has independent parameters to learn the mutual dependencies of the graph. This method allows the extension of a node’s neighborhood through the progressive construction of the architecture. To identify a particularly effective variant of the general approach and apply it to the task of chemical property prediction, the message passing neural network (MPNN) [8] provides a unified model for spatial-based ConvGNNs. In this framework, graph convolutions are treated as a message-passing process, where information is directly transmitted between nodes along the edges. The graph isomorphism network (GIN) [14] identifies that previous methods based on MPNNs lack the ability to differentiate between distinct graph structures based on the embeddings they generate. To address this limitation, GIN proposed a theoretical framework for analyzing the expressive capabilities of GNNs to capture different graph structures. Obtaining the full size of a node’s neighborhood is inefficient since the number of neighbors a node has can span a wide range, from as few as one to possibly more than a thousand or more. Hamilton et al. [44] generated representations by sampling and aggregating features from a node’s local neighborhood. Velivckovic et al. [5] assumed that the contributions of neighboring nodes to the central node are neither identical as in GraphSage nor predetermined as in GCN. Velivckovic et al. [5] assigned distinct edge weights based on node features during aggregation process. GCN is primarily inspired by the latest deep learning methods and therefore may inherit unnecessary complexity and redundant computation. Wu et al. [20] reduced complexity and computation by successively removing nonlinearities and collapsing weight matrices between consecutive layers.
II-B Graph Structure Learning
GSL attempts to approximate a better structure for the original graph, which is not a newly emerged topic and has roots in prior works in network science [46, 47]. GSL methods can be generally classified into three categories: metric learning approaches, probabilistic modeling approaches and direct optimization approaches.
Metric learning methods polish the graph structure by learning a metric function that evaluates the similarity between pairs of node representations. For example, Zhang et al. [48] and Wang et al. [9] leveraged cosine similarity to model the edge weights. Zhang et al. [48] detected fake edges with different features and labels between nodes and mitigates their negative impact on prediction by removing these edges or reducing their weight in neural messaging. Wang et al. [9] employed a distinct method to derive the final node embeddings. It diffuses node features across the original graph and integrates the representations from both the generated feature graph and the original input graph using an attention mechanism. Note that Chen et al. [25] constructed the graph via a multi-head self-attention network, which is an end-to-end graph learning framework for iteratively optimizing graph structure and node embeddings. The core idea of IDGL [25] is that better node embedding is beneficial to capture better graph structure.
Probabilistic modeling approaches assume that graph is generated through a sampling process from certain distributions, and they use learnable parameters to model the probability of sampling edges. Franceschi et al. [23] modeled the edges between each pair of nodes by sampling from Bernoulli distributions with learnable parameters, and presented GSL as a two-layer programming problem, which was the first work in probabilistic modeling. The approach proposed by Zhang et al. [49] employed Monte Carlo dropout to sample the learnable model parameters multiple times for each generated graph. Meanwhile, the method developed by Wang et al. [22] processed multi-view information, such as multi-order neighborhood similarity, as observations of the optimal graph structure, and then derived the final graph structure based on Bayesian inference.
Direct optimization approaches consider the graph adjacency matrix as trainable parameters, which are tuned jointly alongside the primary GNN parameters. Yang et al. [50] aimed to leverage a given class label to both refine the graph structure and optimize the parameters of the GNN simultaneously. Jin et al. [19] focused on investigating key graph properties like sparsity, low rank, and feature smoothness, with the goal of designing more robust graph neural network models.
GSL methods can also be roughly split into single view and multiple fundamental views methods. However, these methods are insufficient to explore the theoretical guidance of learning optimal structure. A more comprehensive review of GSL can be found in a recent study [21].
III Notations and Backgrounds
In this section, we present the notations and backgrounds related to this paper.
III-A Notions
Let be a graph with adjacency matrix and node feature matrix , where denotes node set. Following the commonly adopted semi-supervised node classification setting, only a small portion of nodes, denoted as , have associated labels available, represented as , where corresponds to the label of node . denotes the normalized graph Laplacian matrix, where represents the identity matrix, and is a diagnoal degree matrix with .
Given an input graph and partial node labels , the objective of GSL for GNNs is to jointly learn an optimal graph structure and the GNN model parameters, with the aim of enhancing the node classification performance for unlabeled nodes. The main notations used in this paper are summarized in Table I.
III-B Graph Neural Network
Modern GNNs stack multiple graph convolution layers to learn high-level node representations. The convolution operation usually consists of two steps: aggregation and update, which are respectively represented as follows:
| (1) |
| (2) |
where and are the message vector and the hidden embedding of node at the l-th layer, respectively. The set consists of nodes that are adjacent to node . If , then . and are characterized by the specific model, respectively. In an L-layer network, the final embedding is fed to a linear fully connected layer for the classification task.
III-C Graph Information Bottleneck
Inspired by the Information Bottleneck (IB), Wu et al. [27] proposed GIB principle to optimize node-level representations to to capture the minimal sufficient information within the input graph data required for predicting the target . The objective is defined as the following optimization:
| (3) |
Intuitively, the first term encourages the representations to be maximally informative about the target (sufficient). The second term serves to prevent from obtaining extraneous information from the data that is not pertinent to predicting the target (minimal). The Lagrangian multiplier trading off sufficiency and minimality. Existing works based on GIB primarily focus on graph-level tasks [29, 51, 28]. In this paper, we specifically discuss GIB for node classification tasks.
| Notions | Descriptions |
|---|---|
| original structure | |
| the optimized original | |
| original features | |
| feature vector of node | |
| node set | |
| diagnoal degree matrix | |
| The th diagonal element of the degree matrix | |
| the optimized graph | |
| the redefined graph 1 | |
| the redefined graph 2 | |
| the embedding of node in graph | |
| the embedding of node in graph | |
| cosine similarity of and | |
| filter kerner | |
| the dimension of feature | |
| the number of nodes | |
| Lagrangian multiplier |
IV Methodology
In this section, we illustrate the proposed streamlined GSL model GaGSL guided by GIB. We begin with the overview of GaGSL in subsection IV-A. Subsequently, we will detail the 3 main parts of GaGSL (i.e., global feature and structure augmentation in subsection IV-B, structure redefinition in subsection IV-C, and GIB guidance in subsection IV-D). Finally, we detail the process of joint iterative optimization in subsection IV-E.
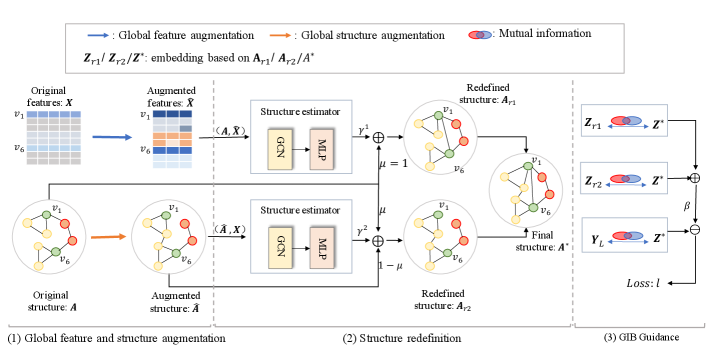
IV-A Overview
Most existing GNNs assume that the observed graph structure accurately reflects the true relationships between nodes. However, this assumption often fails in real-world scenarios where graphs are typically noisy. This pitfall in the observed graph can lead to a rapid decline in GNN performance. Thus, a natural and promising approach is to jointly optimize the graph structure and the GNN model parameters in an integrated manner. In this paper, the proposed GaGSL aims to learn compact and informative graph structure for node classification tasks guided by the principle of GIB. Fig. 2 provides an overview of the GaGSL model.
IV-B Global Feature and Structure Augmentation
Most of the current research in GSL is predominantly conducted from a single structure. However, this single-structure approach is susceptible to biases that can result in an incomplete understanding of the entire graph structure, ultimately limiting the performance and robustness of the model. To mitigate this concern, we employ a two-pronged approach that combines global feature augmentation and global structure augmentation. This aims to comprehensively understand the graph structure from multiple perspectives.
IV-B1 Global Feature Augmentation
Nodes located in different regions of a graph may exhibit similar structural roles within their local network topology, and recognizing these roles is essential for understanding network organization. For example, nodes and in Fig. 2 exhibit similar structural roles despite being far apart in the graph. Following previous works [31, 52], we use spectral graph wavelets and empirical characteristic function to generate structural embedding for every node.
The filter kernel is characterized by a scaling parameter that controls the reach of the diffusion process, where greater promotes wider-ranging diffusion.
In this paper, we employ the heat kernel . The spectral graph wavelet centered around node is given by an -dimensional vector:
| (4) |
where and denote the eigenvalue and the eigenvector of the graph Laplacian , respectively. is the one-hot vector of node .
To address the node mapping problem, we regard the wavelets as probability distributions and describe them using empirical characteristic functions. Following [28], the empirical characteristic function of is:
| (5) |
Lastly, the structural embedding of node is obtained by sampling a 2-dimensional parametric function (as defined in Eq. (5)) at different points , and then concatenating the resulting values:
| (6) |
To effectively encode both the local and global structural roles of a node, we consider a set of different scales to integrate the information from different neighborhood radii to obtain a multi-scale structural role embedding:
| (7) |
We can construct an augmented features matrix by Eq. (7).
IV-B2 Global Structure Augmentation
In addition to structural role embeddings, we also augment structure from another perspective. Specifically, we employ the widely-used diffusion matrix to capture the global relationships between nodes. We utilize Personalized PageRank (PPR) [53], which provides a comprehensive representation of global structure. The PPR has a closed-form solution given as follows:
| (8) |
where, denotes the restart probability. Note that could be dense, thus we just keep 5 edges for each node on some datasets corresponding to the top 5 most affinity nodes on some datasets.
IV-C Structure Redefinition
Given two graph and , to further capture the complex associations and semantic similarities between nodes, we perform a structure estimator for each graph. Specifically, for graph , we conduct a layer of GCN [10] followed by a MLP layer:
| (9) |
| (10) |
where denotes the weight between node and node , and are the embeddings of node and node , respectively. Here, to mitigate resource consumption in terms of both space and time, we only estimate the -order neighbors of each node. Then, are normalized via sotfmax function to get the final weight:
| (11) |
We can construct a similarity matrix by Eq. (11). The original graph structure carries relatively rich information. Ideally, the learned graph structure can complement the original graph structure , creating an optimized graph for GNNs that enhances performance on the downstream task [25]. Thus, the matrix is combined with the similarity matrix to get the redefined structure :
| (12) |
where is combination coefficient. Similarly, we can obtain the redefined structure for graph :
| (13) |
where , are combination coefficients. Note that when using Eq. (11) based on the diffusion matrix, top- neighbors are selected for each node based on the PPR values.
After employing structure redefinition, we can obtain two corresponding graphs and .
IV-D GIB Guidance
In this section, the question we would like to answer is how to get the optimal structure for node classification tasks? And how to guide the training of so that it is the minimal sufficient? In order to avoid introducing new parameters and to simplify the model as much as possible, we obtain the final structure by applying the average function, with the inputs being two redefined structures:
| (14) |
Please review that we aims to learn minimum sufficient graph structure for node classification tasks. In other words, we want the learned representations based on to contain only labeled information, while filtering out label-irrelevant noise. To the end, we use GIB to guide the training of so that it is the minimal sufficient. We presume that no information is lost during this process, following the standard practice of MI estimation [54]. Therefore, we have and . For the sake of convenience in the following, we replace with and with . The objectives of GaGSL are as follows:
| (15) |
| (16) |
We can simplify Eq. (17) by letting :
| (18) |
where the first term is used to encourage to contain maximum information about the labels . The second term encourages to contain as little irrelevant information from and as possible, which is label-irrelevant for predicting the target.
The non-Euclidean nature of graph data makes it challenging to estimate the MI in Eq. (18) accurately [55]. Therefore, we introduce a variational upper bound of , and use the InfoNCE [56, 57] approximation to calculate and . First, we examine the prediction term .
Proposition 4.1 (Upper bound of ). Given graph with label and learned from , we have
| (19) |
where is the variational approximation of the . We have the following proof based on Sun et al. [28]:
| (20) | ||||
Since is intractable, let is the variational approximation of the true posterior . According to the non-negativity of Kullback Leiber divergence:
| (21) | ||||
Plug Eq. (20) into Eq. (21), then we have
| (22) | ||||
where is the entropy of label , which can be ignored in optimization procedure.
It is not trivial to compute the integral directly. To optimize the objective in Eq. (19), we approximate the integral by Monte Carlo sampling [58] of all training samples, so that we have:
| (23) | ||||
where represents the embedding of node and provides the label distribution of the learned graph , which can be modeled as a classifier. The classification loss, , is chosen to be the cross-entropy loss.
Then, we introduce how to approximate the mutual information and using InfoNCE. The InfoNCE loss [32] has been shown to maximize a lower bound of MI. Here, we design a MI calculator. Specifically, for we conduct a layer of GCN [10] followed by a shared two-layer MLP:
| (24) |
| (25) |
where and are the node representations obtained from GCN and MLP, respectively. Similarly, we can get the projected embedding and of and , respectively. For readability purposes, we represent the embedding of node in graph as , and the embedding of in graph as . Then, the InfoNCE loss of graph and graph is given following the GCA [59]:
| (26) |
where is the number of nodes that randomly sampled. The pairwise objective for each positive pair is defined as follows:
| (27) |
where is the cosine similarity and is temperature coefficient. Similarly, we can calculate loss .
IV-E Iterative Optimization
Optimizing the parameters of the structure estimator, of the MI calculator, and of the classifier simultaneously is challenging. The interdependence among them further complicates this process. In this study, we employ an alternating optimization approach to iteratively update , , and inspired by Wang et al. [22].
IV-E1 Update
IV-E2 Update
We can obtain the final learned structure by Eq. (14). Then we employ two-layer of GCN [10] to obtain node representations.
| (29) |
The parameters involved in Eq. (29) are collectively considered as the classifier’s parameters , and the cross-entropy loss is utilized for optimization:
| (30) |
IV-E3 Update
After training the classifier and MI calculator, we proceed with the continuous optimization of the structure estimator parameters . Guided by GIB, the resulting loss function is as follows:
| (31) |
where is a balance parameter trading off sufficiency and minimality. The first term is to motivate to contain maximal information about the labels in order to improve the performance on the predicted target. The intention of the second term is to minimize the information in from and that is label-irrelevant for predicting the target.
IV-E4 Training Algorithm
Based on the previously described update and inference rules, the training algorithm for GaGSL is outlined in Algorithm 1. Specifically, the algorithm begins by initializing all the parameters of GaGSL. In lines 4-8, GaGSL updates the parameters of structure estimator. In line 9, the redefined structures are combined. In lines 11-14, the parameter of the MI calculator is optimized. Finally, in lines 16-18, the classifier parameters are updated. Through this substitution and iterative updating, the graph structure and the better parameters promote each other.
V Experiments
In this section, we carry out a comprehensive evaluation to assess the effectiveness of the proposed GaGSL model. We first compare the performance of GaGSL against several state-of-the-art methods on the semi-supervised node classification task. Additionally, we perform an ablation study to verify the importance of each component within the GaGSL model. Then, we analyze the robustness of GaGSL. Finally, we present the graph structure visualization, hyper-parameter sensitivity and values in the learned structure.
V-A Experiment Setup
V-A1 Datasets
The eight datasets we employ consist of four academic networks (Cora, Citeseer, Wiki-CS, and MS Academic (MS)), three non-graph datasets (Wine, Breast Cancer (Cancer), and Digits) that are readily available in scikit-learn [60], and a blog graph dataset Polblogs. Table II provides a summary of the statistical information about these datasets. It is important to note that, for the non-graph datasets, we adopt the approach described in [25] and construct a NN graph as the original adjacency matrix.
| Dataset | #Nodes | #Edges | #Features | #Classes | #Train/#Val/#Test |
|---|---|---|---|---|---|
| Wine | 178 | 3560 | 13 | 3 | 10/20/148 |
| Cancer | 569 | 22760 | 30 | 2 | 10/20/539 |
| Digits | 1797 | 43128 | 64 | 10 | 50/100/1647 |
| Polblogs [19] | 1222 | 33428 | 1490 | 2 | 121/123/978 |
| Cora [10] | 2708 | 5429 | 1433 | 7 | 140/500/1000 |
| Citeseer [10] | 3327 | 9228 | 3703 | 6 | 120/500/1000 |
| Wiki-CS [61] | 11701 | 291039 | 300 | 10 | 200/500/1000 |
| MS [53] | 18333 | 163788 | 6850 | 15 | 300/500/1000 |
V-A2 Baselines
To demonstrate the effectiveness of our proposed method, we compare the proposed GaGSL with two categories of baselines: three classical GNN models (GCN [10], GAT [5], SGC [20]) and four GSL based methods (Pro-GNN [19], IDGL [25], GEN [22], PRI-GSL [31]). The details are given as follows.
a) GCN: It directly encodes the graph structure using a neural network, and trains on a supervised target for all labeled nodes. This neural network employs an efficient layer-wise propagation rule, which is derived from a first-order approximation of spectral graph convolutions.
b) GAT: It introduces an attention-based mechanism for classifying nodes in graph-structured data. By stacking layers, it enables nodes to incorporate features from their neighbors and implicitly assigns different weights to different nodes in the neighborhood. Additionally, this model can be directly applied to inductive learning problems.
c) SGC: It alleviates the excessive complexity of GCNs by iteratively eliminating nonlinearities between GCN layers and consolidating weights into a single matrix.
d) Pro-GNN: To defend against adversarial attacks, it iteratively eliminates adversarial structure by preserving the graph low rank, sparsity, and feature smoothness, while maintaining the intrinsic graph structure.
e) IDGL: Building on the principle that improved node embeddings lead to better graph structure, it introduces an end-to-end graph learning framework for the joint iterative learning of graph structure and embeddings. Additionally, it frames the graph learning challenge as a similarity metric learning problem and employs adaptive graph regularization to manage the quality of the learned graph.
f) GEN: It is a graph structure estimation neural network composed of two main components: the structure model and the observation model. The structure model characterizes the underlying graph generation process, while the observation model incorporates multi-order neighborhood information to accurately infer the graph structure using Bayesian inference techniques.
g) PRI-GSL: It is an information-theoretic framework for learning graph structure, grounded in the Principle of Relevant Information to manage structure quality. It incorporates a role-aware graph structure learner to develop a more effective graph that maintains the graph’s self-organization.
V-A3 Implementation
For three classical GNN models (GCN, GAT, SGC), we use the corresponding Pytorch Geometric library implementations [62]. For four GSL based methods (Pro-GNN, IDGL, GEN, and PRI-GSL), we utilize the source codes provided by the authors and adhere to the settings outlined in their original papers, with careful tuning. For different datasets, we follow the original splits on training/validation/test. For the proposed GaGSL, we use Adam [63] optimizer and adopt 16 hidden dimensions. We set the learning rate for the classifier and the MI calculator to a fixed value of 0.01, while tuning it for the structure estimator across the values {0.1, 0.01, 0.001}. On the MS dataset we set combination coefficient to 0. On the other datasets we set to 1. We test the combination coefficients and in the range {0.1, 0.5}. The dropout for classifier is chosen form {0.3, 0.5, 0.7, 0.9}, and the dropout for MI calculator is turned amongst {0.2, 0.4, 0.6, 0.8}.
| Dataset | Metric | GCN | GAT | SGC | Pro-GNN | IDGL | GEN | PRI-GSL | GaGSL |
|---|---|---|---|---|---|---|---|---|---|
| Wine | AUC | 99.40.1 | 98.11.8 | 99.40.1 | \ul99.60.1 | 99.61.1 | 98.60.7 | 99.10.3 | 99.80.1 |
| F1-macro | \ul97.50.5 | 93.73.1 | 97.20.6 | 97.00.3 | 95.61.7 | 95.41.7 | 91.92.4 | 97.90.3 | |
| F1-micro | 97.40.5 | 93.44.2 | 97.20.7 | \ul97.50.3 | 95.31.8 | 95.11.9 | 91.52.5 | 97.90.3 | |
| Cancer | AUC | 96.70.4 | 95.81.4 | 97.40.2 | 97.80.2 | 97.90.9 | 97.80.3 | \ul98.40.2 | 98.80.2 |
| F1-macro | 91.50.7 | 89.32.1 | 91.30.4 | 93.30.5 | 91.92.7 | 93.50.3 | \ul94.20.6 | 94.60.3 | |
| F1-micro | 92.00.7 | 89.82.2 | 91.70.4 | 93.80.5 | 92.52.5 | 93.90.3 | \ul94.60.5 | 95.00.2 | |
| Digits | AUC | 98.51.7 | 99.00.2 | \ul99.20.1 | 98.10.2 | 98.90.4 | 98.80.4 | 98.30.3 | 99.50.1 |
| F1-macro | 88.91.9 | 90.20.7 | 89.40.2 | 89.70.3 | \ul90.41.2 | 92.00.5 | 90.30.8 | 92.70.4 | |
| F1-micro | 89.11.8 | 90.30.7 | 89.60.2 | 89.80.3 | 90.41.2 | \ul92.00.5 | 90.40.8 | 92.80.4 | |
| Polblogs | AUC | 98.40.0 | 97.21.3 | \ul98.50.0 | 98.10.2 | 98.00.5 | 98.00.5 | 98.40.1 | 98.60.1 |
| F1-macro | \ul95.30.3 | 92.02.6 | 94.80.0 | 94.60.7 | 94.41.6 | 95.20.8 | 95.10.4 | 95.90.2 | |
| F1-micro | 95.00.3 | 92.02.7 | 94.80.1 | 94.60.7 | 94.51.5 | \ul95.20.8 | 95.10.5 | 95.90.2 | |
| Cora | AUC | 93.70.7 | 92.50.7 | 96.10.1 | 96.90.9 | \ul97.00.3 | 94.01.9 | 95.80.3 | 97.30.3 |
| F1-macro | 74.31.8 | 70.30.9 | 78.40.2 | 78.82.6 | \ul80.41.3 | 80.11.3 | 75.00.4 | 82.31.1 | |
| F1-micro | 75.12.3 | 71.41.1 | 79.40.2 | 79.82.6 | \ul82.22.6 | 91.42.0 | 76.70.7 | 83.81.2 | |
| Citeseer | AUC | 87.51.2 | 89.40.2 | 89.90.2 | 88.50.3 | 91.40.4 | 90.11.7 | 88.60.2 | \ul90.60.5 |
| F1-macro | 63.20.4 | 63.31.2 | 66.40.5 | 63.10.7 | 69.40.4 | 69.41.4 | 64.50.4 | \ul68.80.9 | |
| F1-micro | 67.10.3 | 66.21.2 | 70.60.1 | 65.60.8 | 71.90.3 | 72.71.3 | 67.60.6 | \ul72.11.1 | |
| Wiki-CS | AUC | 91.30.5 | 91.00.6 | \ul94.00.0 | 93.30.3 | 91.80.2 | 92.61.2 | - | 96.12.7 |
| F1-macro | 62.51.7 | 62.01.7 | 67.50.2 | 64.82.0 | \ul69.11.1 | 68.40.3 | - | 73.62.4 | |
| F1-micro | 67.41.6 | 62.31.4 | 71.50.2 | 68.31.2 | \ul72.70.8 | 71.10.9 | - | 75.02.4 | |
| MS | AUC | 95.80.7 | 98.00.2 | \ul98.80.1 | - | 96.50.3 | 89.00.8 | - | 99.60.1 |
| F1-macro | 78.73.6 | 80.71.1 | 90.00.1 | - | 78.51.8 | 92.00.6 | - | \ul90.20.5 | |
| F1-micro | 80.83.4 | 83.40.8 | 91.90.2 | - | 82.90.9 | 98.80.3 | - | \ul92.30.4 |
| Methods | Cancer | Polblogs | Citeseer | MS |
|---|---|---|---|---|
| w/o FA | 93.90.3 | 95.60.2 | 67.81.7 | 89.90.2 |
| w/o SA | 93.60.4 | 94.00.6 | 65.63.0 | 890.5 |
| w/o SE | 93.80.5 | 95.30.3 | 67.71.8 | 89.10.4 |
| w/o GIB | 94.60.6 | 95.20.1 | 67.20.8 | 900.7 |
| GaGSL | 95.40.3 | 96.00.2 | 68.80.9 | 90.20.5 |
V-B Node Classification
In this section, we assess the proposed GaGSL on semi-supervised node classification, with the results presented in Table III. To conduct a comprehensive evaluation of our model, we utilize three widely-used performance metrics: F1-macro, F1-micro, and AUC. We report the mean and standard deviation of the results obtained over 10 independent trials with varying random seeds. Based on these evaluation results, we draw the following observations:
-
•
Compared with other baselines, the proposed GaGSL can obtain better or competitive results on all datasets, which shows that our cleverly designed GSL framework can effectively improve the node classification performance.
-
•
GaGSL demonstrates a significant performance improvement compared to the baseline GCN. Specifically, across all datasets, GaGSL achieves an AUC that is 0.4%-4.8% higher than GCN, an F1-macro score that is 0.4%-11.5% higher than GCN, and an F1-micro score that is 0.5%-11.5% higher than GCN. This observation suggests that GaGSL effectively mitigates the bias caused by a single perspective, enabling it to learn an appropriate graph structure by considering multi-perspective.
-
•
Our performance improvement compared to other GSL methods demonstrates the effectiveness of utilizing GIB for guiding GSL. The learned graph structure contains more valuable information and less noise, making it better suited for node classification tasks. Although GaGSL was the runner-up on the Citeseer dataset, it has an extremely weak disadvantage over the winner, possibly due to data imbalance or the presence of labeling noise.
V-C Ablation Study
Here, we describe the results of the ablation study for the different modules in the model. We report F1-macro and standard deviation results over 5 independent trials using different random seeds. According to the ablation study results presented in Table IV, the model’s performance exhibits a significant decline when the structure augmentation (SA) component is removed. The substantial drop in performance observed without the SA component suggests that the structure augmentation mechanism is highly important and plays a crucial role in enabling the model to effectively capture salient features. Notably, turning off any of the individual components results in a significant decrease in the model’s performance across all evaluated datasets, which underscores the effectiveness and importance of these components. Furthermore, the results highlight the benefits of leveraging GIB to guide the model training process.
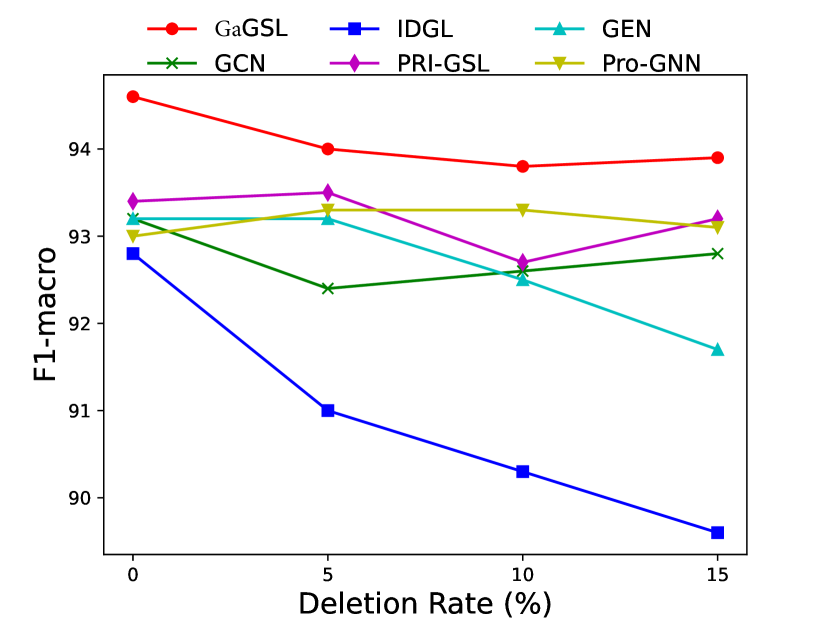
(a) Cancer
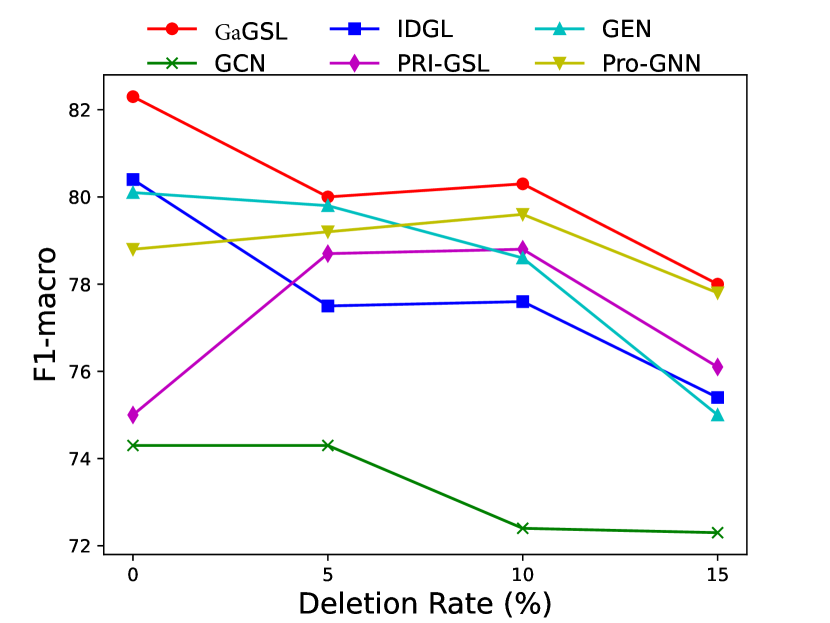
(b) Cora
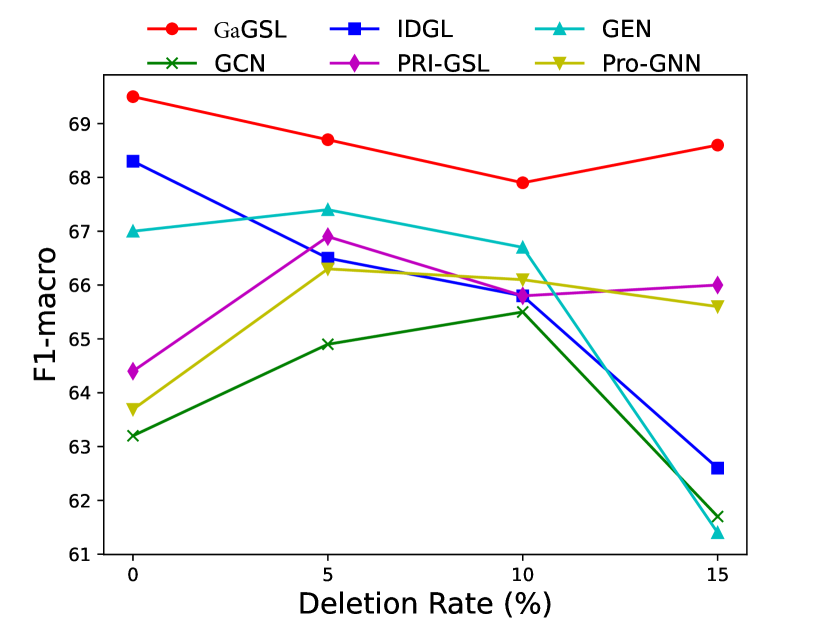
(c) Citeseer
(a) Cancer
(b) Cora
(c) Citeseer
(a) Cancer
(b) Cora
(c) Citeseer
V-D Defense Performance
In this section, we perform a careful evaluation of various methods, specifically focusing on comparing GSL models. These models exhibit the ability to adapt the original graph structure, making them more robust in comparison to other GNNs. To ensure a comprehensive evaluation, we conduct attacks on both edges and features, respectively.
V-D1 Attacks on edges
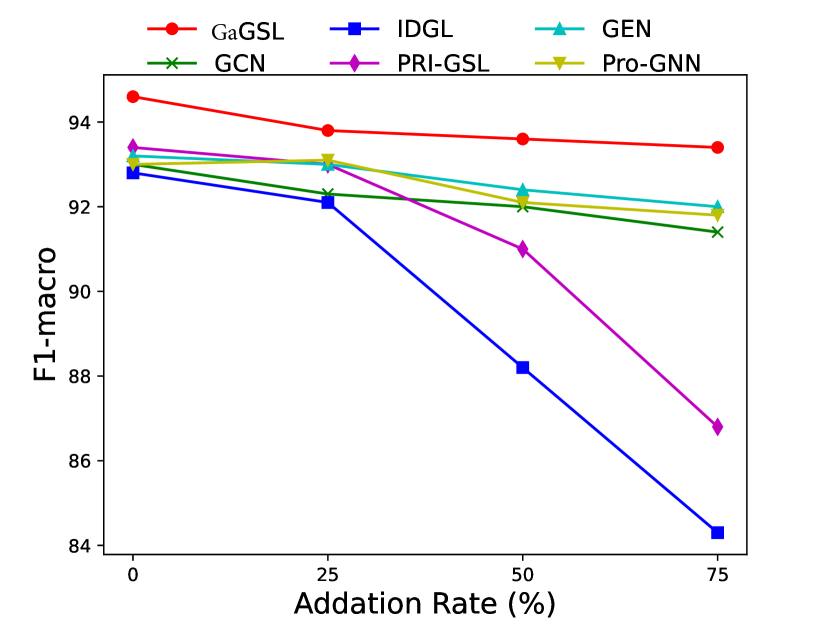
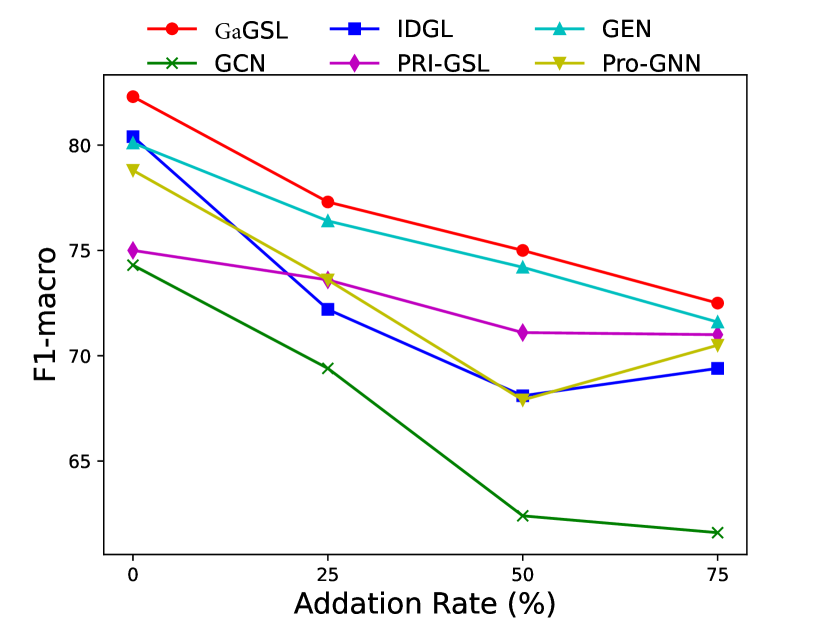
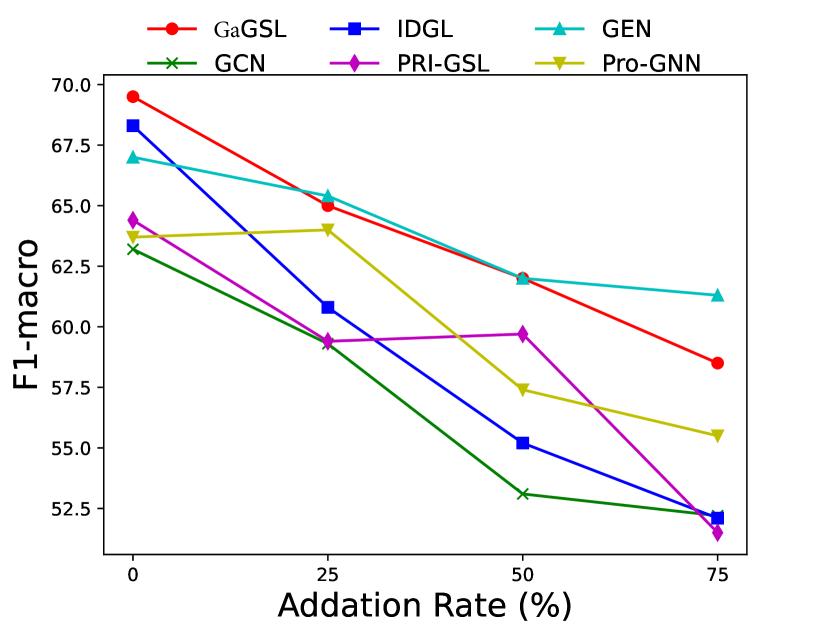
To attack edges, we generate synthetics dataset by deleting or adding edges on Cancer, Cora, and Citeseer following [25]. Specifically, for each graph in the dataset, we randomly remove 5%, 10%, 15% edges or randomly inject 25%, 50%, 75% edges. We select the poisoning attack [64] and first generate the attacked graphs and subsequently train the model using these graphs. The experimental results are displayed in Figs. 3 and 4.
As can be seen in Figs. 3 and 4, GaGSL consistently outperforms all other baselines as the perturbation rate increases. On the Cancer and Citeseer datasets, the performance of GaGSL fluctuates lightly under different perturbation rates. On the Cora dataset, although GaGSL’s performance declines with increasing perturbation rates, it still outperforms other baselines. Specifically, our model improves over vanilla GCN by 12.6% and over other GSL methods by 0.8%-11% when 50% edges are added randomly on Cora. This suggests that our method is more effective against robust attacks. We also find that the GSL method (i.e. Pro-GNN [19], IDGL [25], GEN [22], PRI-GSL [31]) outperforms vanilla GCN at different perturbation rates on both the Cancer and Citeseer datasets, but on the Cancer dataset, IDGL is not as robust to attacks as vanilla GCN. The possible reason for this is the presence of labeling imbalances or outliers in the data, which may interfere with the model’s ability to learn the correct graph structure and lead to performance degradation.
V-D2 Attacks on feature
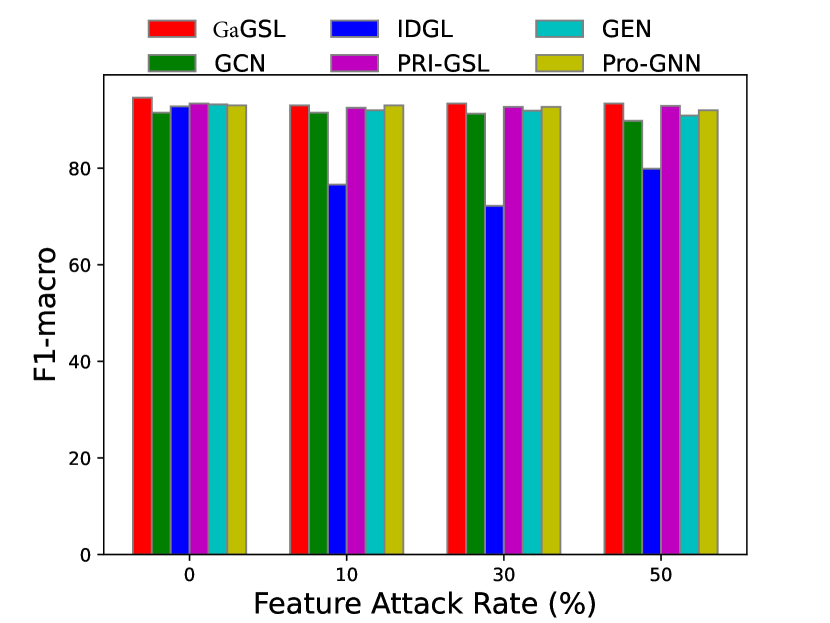
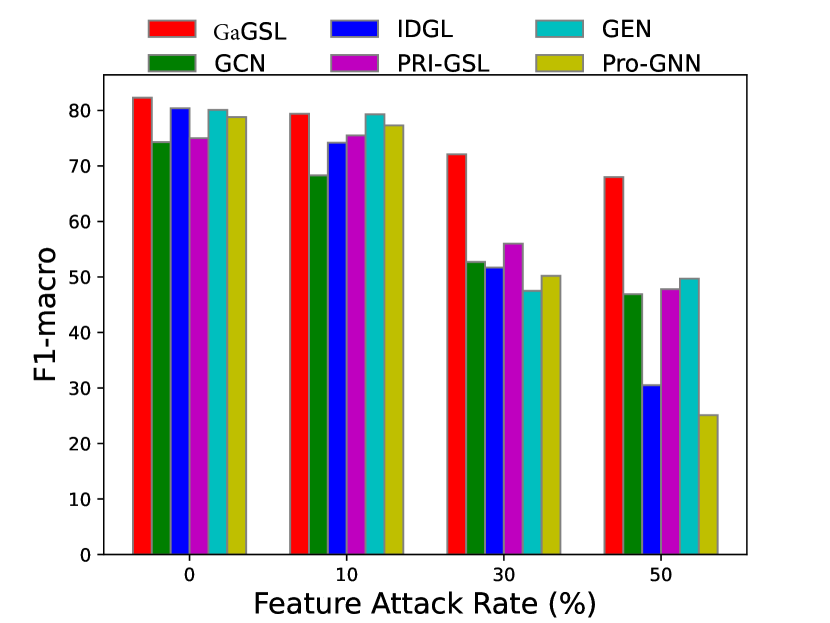
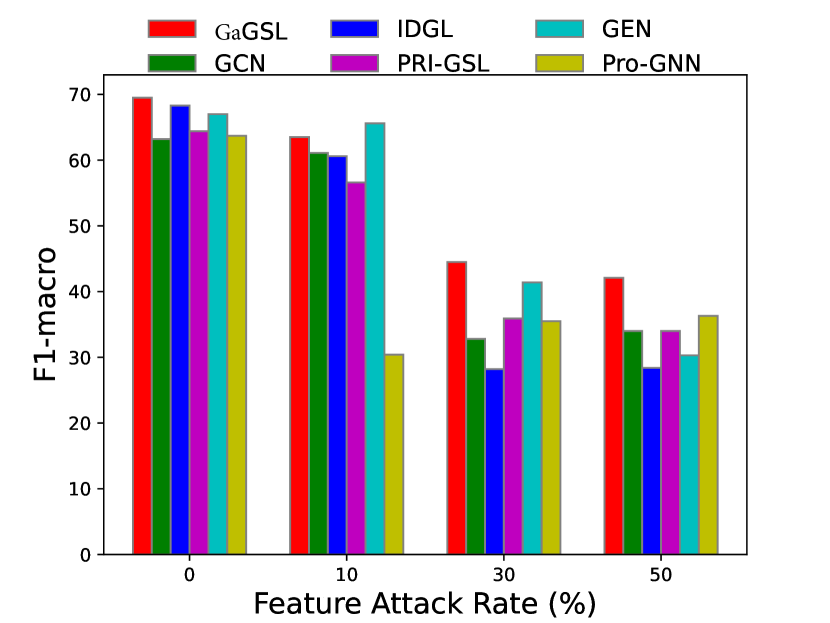
To attack feature, we introduce independent Gaussian noise to features following [27]. Specifically, we employ the mean of the maximum value of each node’s feature as the reference amplitude , and for every feature dimension of each node we introduce Gaussian noise , where is the feature noise ratio, and . We evaluate the models’ performance with . Additionally, we perform poisoning experiments and present the results in Fig. 5.
Similarly, we can observe from Fig. 5 that in most cases, GaGSL consistently surpasses all other baselines and successfully resists feature attacks. As the feature attack rate increases, the performance of most methods decreases, but the decline rate of GaGSL is the slowest. For example, on the Cora dataset, as the perturbation rate increases from 0 to 50%, the performance of GaGSL decreases by 13.3%, while the performance of GCN decreases by 27.4%. In addition, we observed that under various feature attack scenarios, GaGSL consistently maintained top performance, whereas the rankings of other methods fluctuated. For example, on the Cora dataset, IDGL ranked second when the perturbation rate was 0%, but dropped to fifth, fourth, and fifth at perturbation rates of 10%, 30%, and 50%, respectively. Even more concerning, IDGL’s performance was worse than that of GCN at perturbation rates of 30% and 50%. This further demonstrates the strong robustness of GaGSL against feature attacks. Combining the observations from Figs. 3 and 4, we can conclude that GaGSL is able to approach the minimal sufficient structure, and thus demonstrates the capacity to withstand attacks on both graph edges and node features.
(a) Original graph
(b) Perturbed graph
(c) Learned graph
(a) Polblogs
(b) Cora
(a) Polblogs
(b) Cora
V-E Graph Structure Visualization
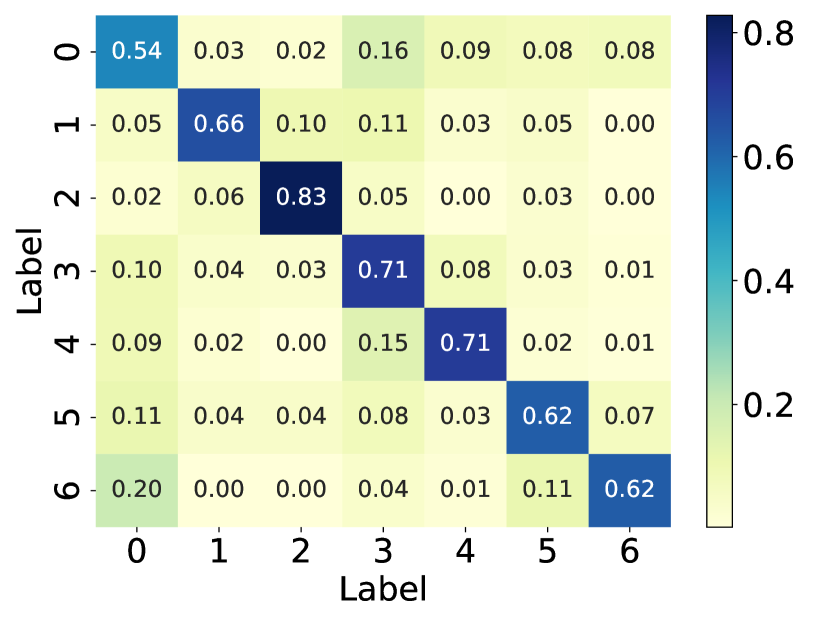
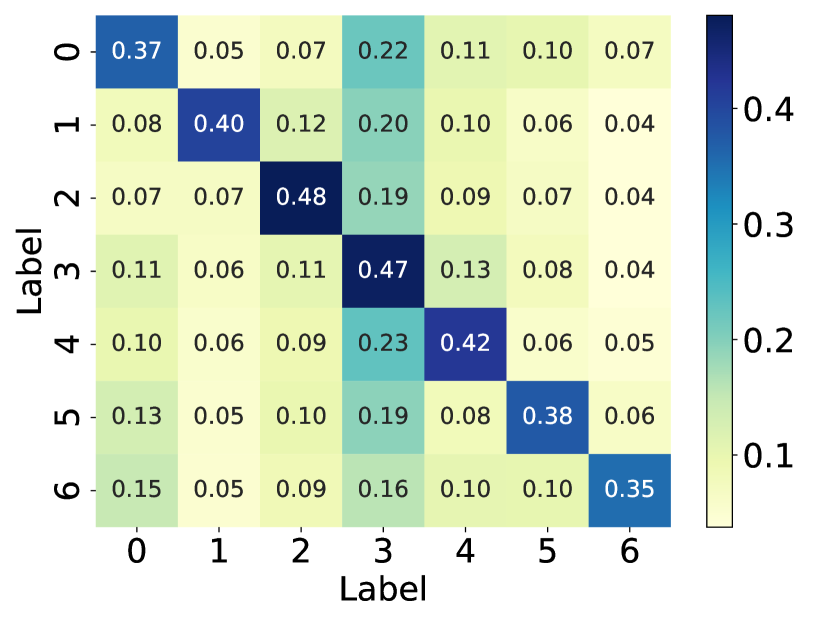
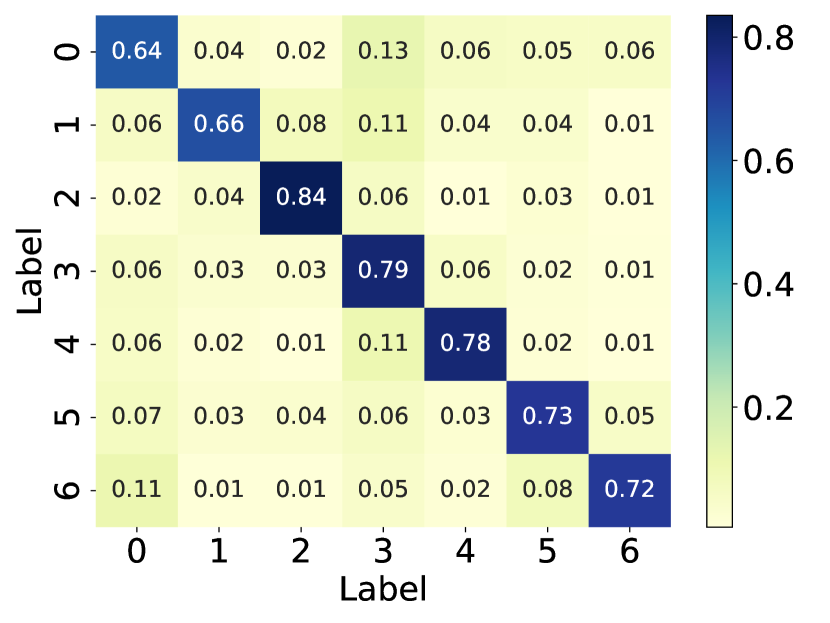
Here, we visualize the probability matrices of the original graph structure, the perturbed graph structure, and the graph structure learned by GaGSL and draw them in Fig. 6.
From the visualization, we can observe that in the perturbed graph structure, there exist noisy connections, as indicated by the higher probability of edges between different communities compared to the original graph structure. These noisy connections degrade the quality of the graph structure, thereby reducing the performance of GNNs. Additionally, we observed that, in contrast to the perturbed graph, the learned graph structure weakens the connections between communities and strengthens the connections within communities.
This observation is expected because GaGSL is optimized based on the GIB principle. The GIB optimization allows GaGSL to effectively capture information in the graph structure that contributes to accurate node classification while constraining information that is label-irrelevant. This optimization process ensures that the learned graph structure is robust against noisy connections and focuses on preserving the most informative aspects of the graph for the task at hand.
V-F Hyper-parameter Sensitivity
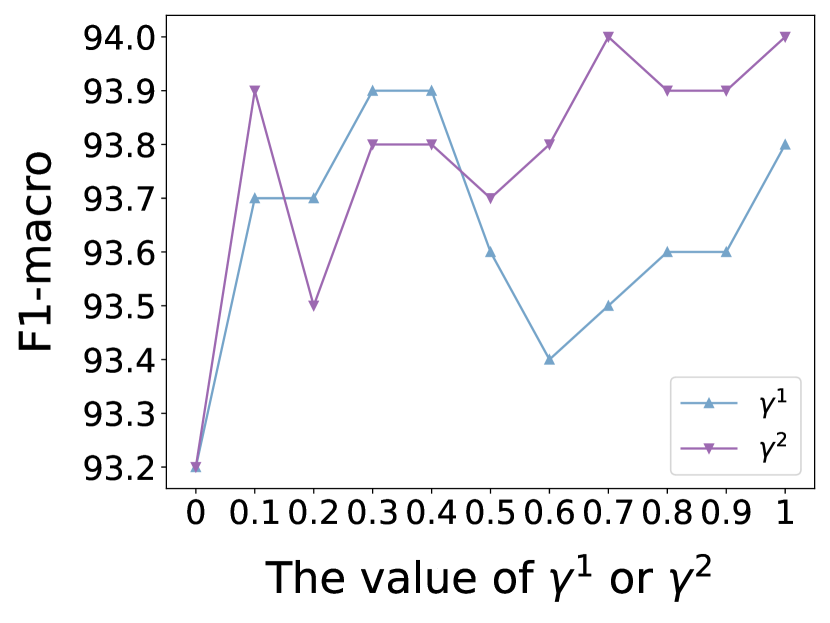
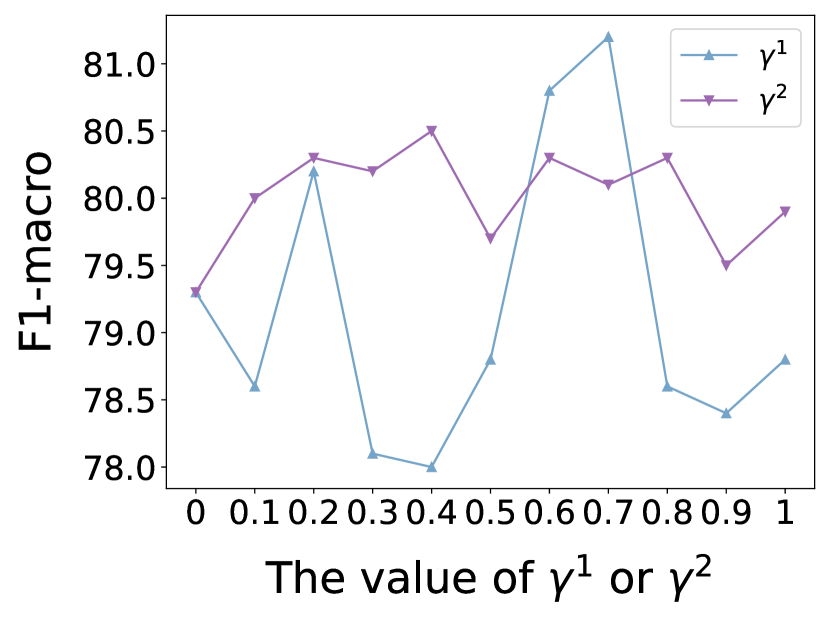
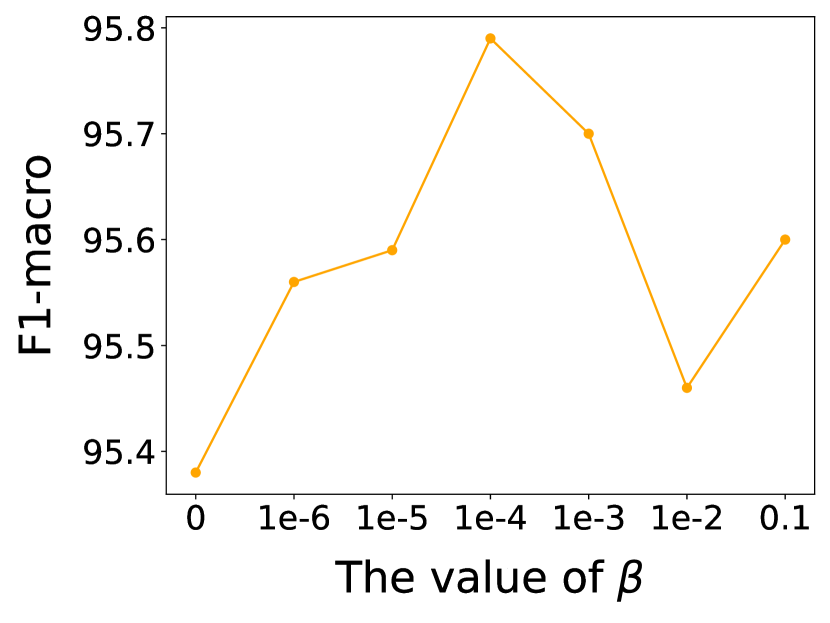
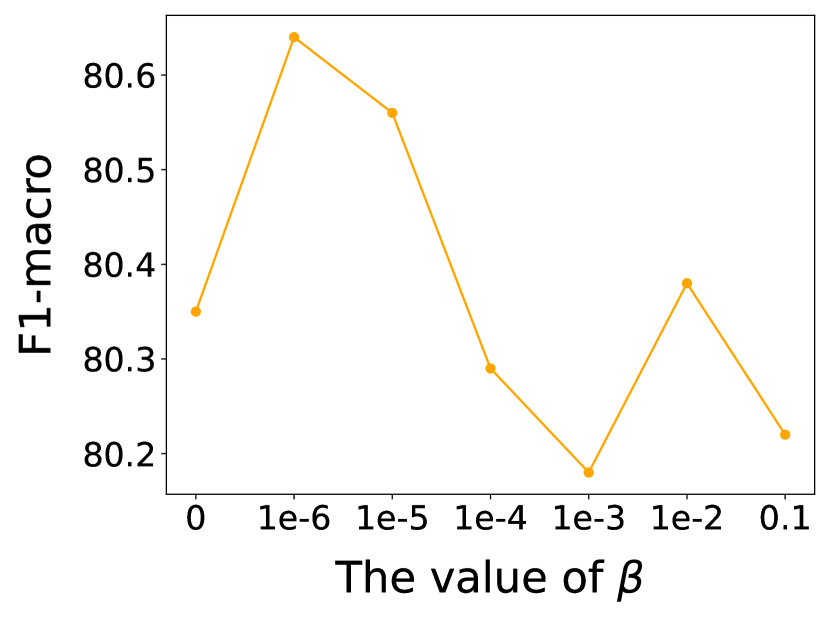
In this subsection, we investigate the sensitivity of key hyper-parameters: combination coefficient in Eq. (12), in Eq. (13), as well as the balance parameter in Eq. (31). More concretely, we vary the value of , and to analyze their impact on the performance of our proposed model. We vary or or from 0 to 1, and from 0 to 0.1. For clarity, we report the node classification results on Cora and Polblogs datasets, as similar trends are observed across other datasets. The results are presented in Figs. 7 and 8.
As can be observed from Fig. 7, by tuning the value of (or ), we can achieve better node classification performance compared to when (or ) is set to 0. This precisely demonstrates that our designed structure estimator is capable of capturing the complex correlations and semantic similarities between nodes.
Observing Fig. 8, it is evident that as the value of increases, the performance of GaGSL first rises to a peak and then declines. When is small, has a minimal impact on the total loss function , and dominates the model’s training. At this stage, increasing enhances the influence of , thereby helping the model better constrain the label-irrelevant information from and in , thus improving performance. However, if becomes too large, the model may excessively focus on and neglect during training, leading to a decline in performance. Overall, an appropriate value of can effectively balance the influence of and , thereby enhancing the model’s performance.
(a) Citeseer
(b) Polblogs
V-G Values in Learned Structure
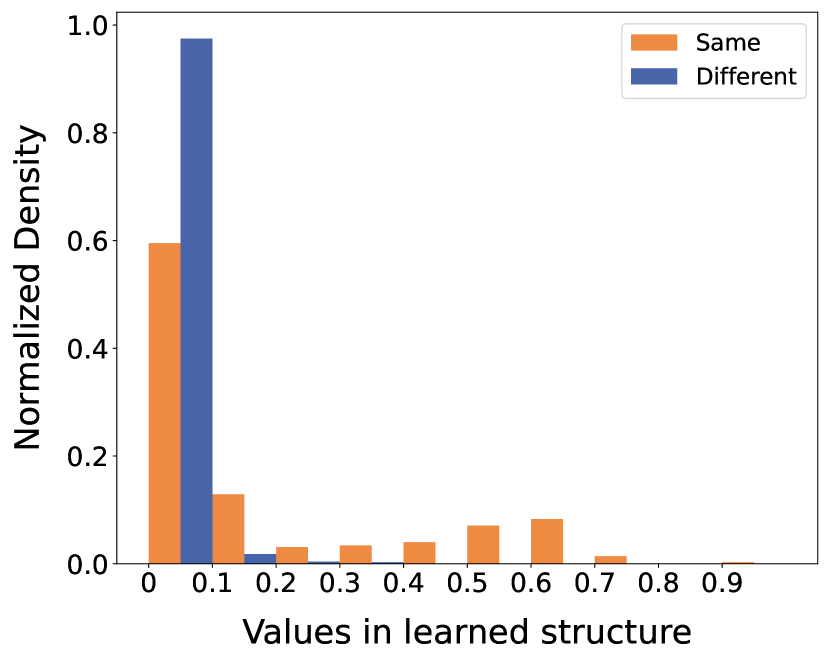
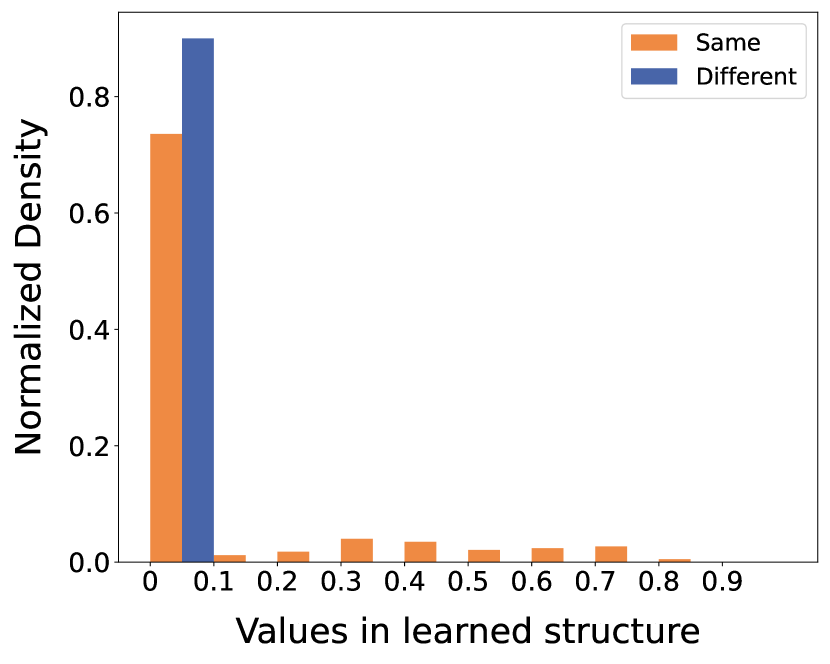
To further elucidate the distribution of edge weights between community nodes, we categorize the edges into two teams: edges connecting nodes within the same communities and edges connecting nodes across different communities. In Fig. 9, we showcase the normalized histograms of the learned structure values (weights) on Citeseer and Polblogs datasets.
From the histograms, it is apparent that the weights of edges between different communities are predominantly concentrated in the first bin (less than 0.1). In contrast, the weights of edges within the same communities are distributed not only in the first interval but also in higher bins. This distribution demonstrates that GaGSL effectively differentiates between inter-community and intra-community edges when assigning weights. Consequently, this ability to assign appropriate weights enhances the performance and robustness of graph representations.
VI Conclusion
In this paper, we proposed a novel GSL method GaGSL, which tackles the challenge of learning a graph structure for node classification tasks guided by the GIB principle. The GaGSL method consists of three parts: global feature and structure augmentation, structure redefinition, and GIB guidance. We first mitigate the inherent bias of relying solely on a single original structure by global feature and structure augmentation. Subsequently, we design the structure estimator with different parameters to refine and optimize the graph structure. Finally, The optimization of the final graph structure is guided by the GIB principle. Experimental results on various datasets validate the superior effectiveness and robustness of GaGSL in learning compact and informative graph structure.
Future work will delve into further optimizing the GaGSL model to address label noise and data imbalance. Although this paper effectively mitigates structural noise, challenges posed by label noise and data imbalance remain unresolved. Therefore, upcoming research will concentrate on devising robust strategies to manage label noise and handle data imbalance issues. By tackling these challenges, we aim to ensure that the model achieves enhanced performance and robustness in real-world scenarios.
References
- [1] Å. J. Holmgren, “Using graph models to analyze the vulnerability of electric power networks,” Risk analysis, vol. 26, no. 4, pp. 955–969, 2006.
- [2] B. Krishnamurthy, P. Gill, and M. Arlitt, “A few chirps about twitter,” in Proceedings of the first workshop on Online social networks, 2008, pp. 19–24.
- [3] Y. Zhang, Y. Fan, W. Song, S. Hou, Y. Ye, X. Li, L. Zhao, C. Shi, J. Wang, and Q. Xiong, “Your style your identity: Leveraging writing and photography styles for drug trafficker identification in darknet markets over attributed heterogeneous information network,” in The World Wide Web Conference, 2019, pp. 3448–3454.
- [4] G. Taubin, T. Zhang, and G. Golub, “Optimal surface smoothing as filter design,” in Computer Vision—ECCV’96: 4th European Conference on Computer Vision Cambridge, UK, April 15–18, 1996 Proceedings, Volume I 4. Springer, 1996, pp. 283–292.
- [5] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” arXiv preprint arXiv:1710.10903, 2017.
- [6] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y. Philip, “A comprehensive survey on graph neural networks,” IEEE transactions on neural networks and learning systems, vol. 32, no. 1, pp. 4–24, 2020.
- [7] L. Wu, P. Cui, J. Pei, L. Zhao, and X. Guo, “Graph neural networks: foundation, frontiers and applications,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 4840–4841.
- [8] J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl, “Neural message passing for quantum chemistry,” in International conference on machine learning. PMLR, 2017, pp. 1263–1272.
- [9] X. Wang, M. Zhu, D. Bo, P. Cui, C. Shi, and J. Pei, “Am-gcn: Adaptive multi-channel graph convolutional networks,” in Proceedings of the 26th ACM SIGKDD International conference on knowledge discovery & data mining, 2020, pp. 1243–1253.
- [10] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [11] M. Zhang, “Graph neural networks: link prediction,” Graph Neural Networks: Foundations, Frontiers, and Applications, pp. 195–223, 2022.
- [12] M. Zhang and Y. Chen, “Weisfeiler-lehman neural machine for link prediction,” in Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 2017, pp. 575–583.
- [13] J. Zeng and P. Xie, “Contrastive self-supervised learning for graph classification,” in Proceedings of the AAAI conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 10 824–10 832.
- [14] K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?” arXiv preprint arXiv:1810.00826, 2018.
- [15] Q. Li, H. Peng, J. Li, C. Xia, R. Yang, L. Sun, P. S. Yu, and L. He, “A survey on text classification: From shallow to deep learning,” arXiv preprint arXiv:2008.00364, 2020.
- [16] C. Gao, J. Chen, S. Liu, L. Wang, Q. Zhang, and Q. Wu, “Room-and-object aware knowledge reasoning for remote embodied referring expression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3064–3073.
- [17] A. Demontis, M. Melis, M. Pintor, M. Jagielski, B. Biggio, A. Oprea, C. Nita-Rotaru, and F. Roli, “Why do adversarial attacks transfer? explaining transferability of evasion and poisoning attacks,” in 28th USENIX security symposium (USENIX security 19), 2019, pp. 321–338.
- [18] H. Xu, Y. Ma, H.-C. Liu, D. Deb, H. Liu, J.-L. Tang, and A. K. Jain, “Adversarial attacks and defenses in images, graphs and text: A review,” International journal of automation and computing, vol. 17, pp. 151–178, 2020.
- [19] W. Jin, Y. Ma, X. Liu, X. Tang, S. Wang, and J. Tang, “Graph structure learning for robust graph neural networks,” in Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 66–74.
- [20] F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Simplifying graph convolutional networks,” in International conference on machine learning. PMLR, 2019, pp. 6861–6871.
- [21] Y. Zhu, W. Xu, J. Zhang, Q. Liu, S. Wu, and L. Wang, “Deep graph structure learning for robust representations: A survey,” arXiv preprint arXiv:2103.03036, vol. 14, pp. 1–1, 2021.
- [22] R. Wang, S. Mou, X. Wang, W. Xiao, Q. Ju, C. Shi, and X. Xie, “Graph structure estimation neural networks,” in Proceedings of the web conference 2021, 2021, pp. 342–353.
- [23] L. Franceschi, M. Niepert, M. Pontil, and X. He, “Learning discrete structures for graph neural networks,” in International conference on machine learning. PMLR, 2019, pp. 1972–1982.
- [24] B. Jiang, Z. Zhang, D. Lin, J. Tang, and B. Luo, “Semi-supervised learning with graph learning-convolutional networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 11 313–11 320.
- [25] Y. Chen, L. Wu, and M. Zaki, “Iterative deep graph learning for graph neural networks: Better and robust node embeddings,” Advances in neural information processing systems, vol. 33, pp. 19 314–19 326, 2020.
- [26] H. Pei, B. Wei, K. C.-C. Chang, Y. Lei, and B. Yang, “Geom-gcn: Geometric graph convolutional networks,” arXiv preprint arXiv:2002.05287, 2020.
- [27] T. Wu, H. Ren, P. Li, and J. Leskovec, “Graph information bottleneck,” Advances in Neural Information Processing Systems, vol. 33, pp. 20 437–20 448, 2020.
- [28] Q. Sun, J. Li, H. Peng, J. Wu, X. Fu, C. Ji, and S. Y. Philip, “Graph structure learning with variational information bottleneck,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 4, 2022, pp. 4165–4174.
- [29] J. Yu, T. Xu, Y. Rong, Y. Bian, J. Huang, and R. He, “Graph information bottleneck for subgraph recognition,” arXiv preprint arXiv:2010.05563, 2020.
- [30] J. C. Principe, Information theoretic learning: Renyi’s entropy and kernel perspectives. Springer Science & Business Media, 2010.
- [31] Q. Sun, J. Li, B. Yang, X. Fu, H. Peng, and S. Y. Philip, “Self-organization preserved graph structure learning with principle of relevant information,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 4, 2023, pp. 4643–4651.
- [32] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
- [33] D. K. Hammond, P. Vandergheynst, and R. Gribonval, “Wavelets on graphs via spectral graph theory,” Applied and Computational Harmonic Analysis, vol. 30, no. 2, pp. 129–150, 2011.
- [34] Z. Qiao, Y. Fu, P. Wang, M. Xiao, Z. Ning, D. Zhang, Y. Du, and Y. Zhou, “Rpt: toward transferable model on heterogeneous researcher data via pre-training,” IEEE Transactions on Big Data, vol. 9, no. 1, pp. 186–199, 2022.
- [35] J. Bruna, W. Zaremba, A. Szlam, and Y. LeCun, “Spectral networks and locally connected networks on graphs,” arXiv preprint arXiv:1312.6203, 2013.
- [36] M. Defferrard, X. Bresson, and P. Vandergheynst, “Convolutional neural networks on graphs with fast localized spectral filtering,” Advances in neural information processing systems, vol. 29, 2016.
- [37] R. Li, S. Wang, F. Zhu, and J. Huang, “Adaptive graph convolutional neural networks,” in Proceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018.
- [38] C. Zhuang and Q. Ma, “Dual graph convolutional networks for graph-based semi-supervised classification,” in Proceedings of the 2018 world wide web conference, 2018, pp. 499–508.
- [39] B. Xu, H. Shen, Q. Cao, Y. Qiu, and X. Cheng, “Graph wavelet neural network,” arXiv preprint arXiv:1904.07785, 2019.
- [40] H. Zhu and P. Koniusz, “Simple spectral graph convolution,” in International conference on learning representations, 2021.
- [41] C. Gallicchio and A. Micheli, “Graph echo state networks,” in The 2010 international joint conference on neural networks (IJCNN). IEEE, 2010, pp. 1–8.
- [42] H. Dai, Z. Kozareva, B. Dai, A. Smola, and L. Song, “Learning steady-states of iterative algorithms over graphs,” in International conference on machine learning. PMLR, 2018, pp. 1106–1114.
- [43] A. Micheli, “Neural network for graphs: A contextual constructive approach,” IEEE Transactions on Neural Networks, vol. 20, no. 3, pp. 498–511, 2009.
- [44] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” Advances in neural information processing systems, vol. 30, 2017.
- [45] J. Zhou, G. Cui, S. Hu, Z. Zhang, C. Yang, Z. Liu, L. Wang, C. Li, and M. Sun, “Graph neural networks: A review of methods and applications,” AI open, vol. 1, pp. 57–81, 2020.
- [46] D. Lusher, J. Koskinen, and G. Robins, Exponential random graph models for social networks: Theory, methods, and applications. Cambridge University Press, 2013.
- [47] T. Martin, B. Ball, and M. E. Newman, “Structural inference for uncertain networks,” Physical Review E, vol. 93, no. 1, p. 012306, 2016.
- [48] X. Zhang and M. Zitnik, “Gnnguard: Defending graph neural networks against adversarial attacks,” Advances in neural information processing systems, vol. 33, pp. 9263–9275, 2020.
- [49] Y. Zhang, S. Pal, M. Coates, and D. Ustebay, “Bayesian graph convolutional neural networks for semi-supervised classification,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 5829–5836.
- [50] L. Yang, Z. Kang, X. Cao, D. J. 0001, B. Yang, and Y. Guo, “Topology optimization based graph convolutional network.” in IJCAI, 2019, pp. 4054–4061.
- [51] J. Yu, J. Cao, and R. He, “Improving subgraph recognition with variational graph information bottleneck,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 19 396–19 405.
- [52] C. Donnat, M. Zitnik, D. Hallac, and J. Leskovec, “Learning structural node embeddings via diffusion wavelets,” in Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 1320–1329.
- [53] J. Gasteiger, A. Bojchevski, and S. Günnemann, “Predict then propagate: Graph neural networks meet personalized pagerank,” arXiv preprint arXiv:1810.05997, 2018.
- [54] Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, “What makes for good views for contrastive learning?” Advances in neural information processing systems, vol. 33, pp. 6827–6839, 2020.
- [55] L. Paninski, “Estimation of entropy and mutual information,” Neural computation, vol. 15, no. 6, pp. 1191–1253, 2003.
- [56] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597–1607.
- [57] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738.
- [58] A. Shapiro, “Monte carlo sampling methods,” Handbooks in operations research and management science, vol. 10, pp. 353–425, 2003.
- [59] Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Graph contrastive learning with adaptive augmentation,” in Proceedings of the Web Conference 2021, 2021, pp. 2069–2080.
- [60] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg et al., “Scikit-learn: Machine learning in python,” the Journal of machine Learning research, vol. 12, pp. 2825–2830, 2011.
- [61] P. Mernyei and C. Cangea, “Wiki-cs: A wikipedia-based benchmark for graph neural networks,” arXiv preprint arXiv:2007.02901, 2020.
- [62] M. Fey and J. E. Lenssen, “Fast graph representation learning with pytorch geometric,” arXiv preprint arXiv:1903.02428, 2019.
- [63] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [64] D. Zügner, A. Akbarnejad, and S. Günnemann, “Adversarial attacks on neural networks for graph data,” in Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 2847–2856.