Game Level Blending using a Learned Level Representation
Abstract
Game level blending via machine learning, the process of combining features of game levels to create unique and novel game levels using Procedural Content Generation via Machine Learning (PCGML) techniques, has gained increasing popularity in recent years. However, many existing techniques rely on human-annotated level representations, which limits game level blending to a limited number of annotated games. Even with annotated games, researchers often need to author an additional shared representation to make blending possible. In this paper, we present a novel approach to game level blending that employs Clustering-based Tile Embeddings (CTE), a learned level representation technique that can serve as a level representation for unannotated games and a unified level representation across games without the need for human annotation. CTE represents game level tiles as a continuous vector representation, unifying their visual, contextual, and behavioral information. We apply this approach to two classic Nintendo games, Lode Runner and The Legend of Zelda. We run an evaluation comparing the CTE representation to a common, human-annotated representation in the blending task and find that CTE has comparable or better performance without the need for human annotation.
I Introduction
Procedural Content Generation via Machine Learning (PCGML) uses machine learning models trained on existing game content to generate various game elements, such as game items, characters, levels, and spaces [1]. Game level blending is one of the applications of PCGML that has been gaining increasing popularity in recent years [2]. It is the process of combining features from different game levels to create novel and unique game levels [3]. The most popular approach for game level blending in recent years has been using a generative model called a Variational Autoencoder (VAE), which consists of an encoder and decoder network. It attempts to learn a latent space distribution over the training data [4], encompassing levels from multiple games. By training a VAE on multiple games’ levels, we obtain a single, shared latent space distribution, and we can sample from the regions in between the existing games’ levels to output blended levels. However, despite advancements in game level blending approaches, most of them still use human-annotated level representations. In addition, these approaches require additional authoring of a unified level representation when dealing with multiple game domains. If we could find a representation for level blending that didn’t require human authoring or annotation we could greatly expand the set of game levels available for blending.
The Video Game Level Corpus (VGLC) has made a significant contribution to PCGML research by providing human-authored level representations for multiple classic game levels [5]. It offers a text-based tile level representation that assigns each in-game entity in a level to a character or “tile”, which is then mapped to the actual properties of that element in the game (e.g., “hazard” for enemies or other elements that can hurt the player). The VGLC and datasets with similar representations have been the default option for many game level blending projects [2]. This has been beneficial in terms of allowing for a great deal of research on blending the included game levels. However, it has also been limiting, since researchers can only blend between levels that have been annotated into this representation, which requires human labor.
Outside of the initial annotation of the dataset, when using representations like the VGLC, authors are required to come up with a unified level representation. This is because the characters represented in one game map to that game’s tile properties, and these aren’t necessarily shared by a second game. At times, the same character tile is even used to indicate different entities in different games. For instance, the character ‘B’ has the properties ‘Cannon top’, ‘Cannon’, ‘Solid’, and ‘Hazard’ in Super Mario Bros., but ‘Solid’ and ‘Breakable’ in MegaMan, and ‘Solid’ and ‘Ground’ in Lode Runner. Authors therefore must author a mapping that converts all of these tiles to a unified representation. This represents an additional human authoring burden, and one that must be undertaken every time one blends a unique set of games’ levels.
There has been a great variety of work exploring game level blending with VAEs [6], including controllable level blending [7], and sequential segment-based level blending [8]. While these works have proven effective at demonstrating the uses of VAEs for game level blending tasks, they rely on VGLC-like datasets. Due to the reasons outlined in the above paragraphs, these approaches therefore cannot be extended to new games without significant human effort.
In this paper, we introduce game level blending using Clustering-based Tile Embeddings (CTE). CTE is a learned, unified, domain-independent, and affordance-rich level representation. CTE represent game level tiles in a continuous vector representation, unifying their visual, contextual, and behavioral information. This makes it possible to represent levels from any tile-based game domains [9]. We investigate the use of CTE in VAEs for blending game levels of Lode Runner (LR) and The Legend of Zelda (LOZ). We trained a Convolutional Neural Network (CNN) VAE and a Fully Connected (FC) VAE using LR and LOZ game level segments with CTE representation, to compare their performance against baseline PCGML level blending representations. To the best of our knowledge, this is the first approach for game level blending that uses a learned-level representation. By investigating the application of CTE to game level blending, we open the possibility of using unannotated games in level blending. Additionally, this allows for blending without additional human authoring to obtain a unified level representation, thereby reducing a significant amount of human labor.
II Related Work
II-A Level Blending
Game level blending is the process of combining different game levels to create levels approximating those from non-existant games. Approaches to game level blending include (1) Snodgrass and Ontañón’s domain adaptation, which used training data from some source game to approximate target game training data [10], (2) Guzdial and Riedl’s learned model blending, which employed the original conceptual blending algorithm to combine learned Bayesian networks [3], and (3) blending level design constraints from multiple games [11].
One popular level blending model in recent years is the Variational Autoencoder (VAE), which can be trained on multiple domains to obtain a single, shared latent space across training data. This means that the regions between different games’ levels output blended levels [7, 6, 8]. However, these approaches rely on human-annotated level representations and human-authored unified representations.
II-B Learned Level Representations
Learned-level representations are a recent area of PCGML research. This approach involves learning a new representation for game content rather than relying on human annotation or authoring. Approaches in learned-level representation include: (1) entity embeddings, which represent the entities of a game as 25-dimensional continuous vectors. This is achieved by training a Variational Autoencoder (VAE) on a joint representation of raw pixels and dynamic information, similar to tile embeddings [12]. Another approach is (2) to train a VQ-VAE on the raw pixels of game levels. A VQ-VAE learns a symbolic-like representation of the game levels by quantizing the input features to a fixed set, which allows users to run level generation approaches that require distinct classes [13].
(3) Tile embeddings represent game levels as tiles, with each tile represented as a 256-dimensional continuous vector. This is achieved by training an Autoencoder with a tile’s raw pixels and corresponding affordances as input [14]. Finally, (4) Clustering-based Tile Embeddings (CTE) are an extension to tile embeddings with the addition of edge information and a cluster-based loss to learn a more cohesive latent space [9].
All of these have proven effective as game level representations. However, only the entity embedding approach has been used in a blending task previously, and that was entity blending not level blending [15]. Thus, none of these learned level representations have been used for game level blending.
For this work, we chose to use a VAE approach with Clustering-based Tile Embeddings (CTE), a learned level representation. This approach could allow game-level blending researchers and developers to explore game-level blending across game domains that do not have an annotated dataset, without relying on a human-authored unified representation.
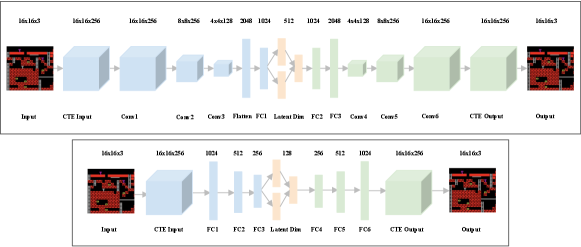
III System Overview
In this paper, we investigate the application of Clustering-based Tile Embedding (CTE), a learned level representation, to game level blending to determine whether we can avoid the labor involved in blending with hand-authored and annotated representations. We use CTE for our level representation and a Variational Autoencoder(VAE) approach for game level blending [7]. For our training set, we chose two classic Nintendo games: The Legend of Zelda (LOZ) and Lode Runner (LR). We trained two VAE variants on the CTE level representations for these two games, based on models utilized for level blending with hand-authored representations. Once trained, we used these two models to output blended game level segments.
III-A Clustering-based Tile Embedding (CTE)
We use the Clustering-based Tile Embedding (CTE) level representation because it outperforms tile embeddings [14] and accounts for affordances, unlike the VQ-VAE approach of Karth et al. [13]. CTE is a learned, tile-based level representation that combines the RGB tile pixels with that tile’s affordances (e.g., “Harmful”, “Solid”, etc.). Each tile embedding is represented by a 256-dimensional vector. This representation can be achieved by training an autoencoder that consists of three inputs: (1) a pixel input of a candidate tile and its neighbors () with the candidate tile () at the center, (2) a 13-dimensional one-hot affordance vector associated with the candidate tile, and (3) edge information for the candidate tile [9]. The second input (2) requires manual annotation, but the learned, unified affordances can be used for unannotated game levels [9]. A unified level representation can be obtained by training the CTE model with training data from multiple games. We specifically employ a pre-trained CTE supplied by Jadhav and Guzdial [9], as it was trained on a set of games’ levels including both LR and LOZ.
III-B Dataset
To create our dataset, we first obtained a unified level representation for The Legend of Zelda (LOZ) and Lode Runner (LR) game levels by using the pre-trained CTE model [9], trained on both game domains. With LR levels represented with dimensions , where 22 is the height and 32 is the width of level and 256 is the CTE tile representation, and LOZ levels with dimensions of with is the height and is the width of level and 256 is the CTE tile representation. To train VAE models to achieve level blending using these two game domains, we needed consistent level dimensions, but the level dimensions varied for these two games. To address this problem, we chose the common strategy used in game level blending of splitting the game levels into consistent segments or chunks [7, 6, 8]. We chose as our segment dimensions, representing 16 by 16 tiles, given the similarity to common segment dimensions in the literature and due to our own perceived quality improvements [7, 6, 8].
For Lode Runner, all 150 game levels available in the VGLC have dimensions of tiles. So, we chose to take four segments per Lode Runner level, with each segment representing the top-right, top-left, bottom-right, and bottom-left. This meant our data had some overlapping rows between the top and bottom segments, as we felt this would aid generalization. For LOZ, the game levels, or dungeons in this case, vary significantly, but each room across these dungeons has the same dimensions of tiles. Therefore, we chose to take each room and apply vertical padding of three blank rows at the top and two blank rows at the bottom to obtain our required segment size. Using this representation, we obtained a total of 600 level segments for Lode Runner and 459 level segments for The Legend of Zelda, for a total of 1059 level segments. To train our model, we randomized the total level segments and divided them into three sets: 85% (900) level segments for training, 10% (105) level segments for testing, and 5% (52) level segments for validation. This is a common strategy for training machine learning models [4].
III-C Domains
We chose The Legend of Zelda (LOZ) and Lode Runner (LR) for this investigation for a number of reasons. First, these two games are included in the VGLC, and therefore PCGML researchers should have some familiarity with them [5]. Second, these two video games have a roughly equal number of level segments, which should benefit a VAE-based blending approach. Third, and most importantly, Lode Runner and the Legend of Zelda represent two very different types of games, with the former being a platformer and the latter a dungeon-crawl/adventure game (as in [2]). They also have largely distinct sets of mechanics, only sharing left and right movement. As such, we consider this blending task a “far transfer” task or a more difficult blend. With an easier blend (e.g., between two platformer games), we might not be able to get a clear picture of the impact of CTE representation on a level blending task.
III-D Model Architectures
A Variational Autoencoder (VAE) is a generative model that consists of an encoder and decoder network that attempts to learn a continuous latent space distribution over training data [4]. In this work, we developed two VAE varients: a Convolutional Neural Network VAE (CNN-VAE) [7] and a Fully Connected VAE (FC-VAE) [6].
III-D1 CNN-VAE
We visualize our CNN-VAE at the top of Figure 1. The CNN-VAE consists of convolutional layers in both the encoder and decoder networks of the VAE. The convolutional layers aim to learn local relationships between multidimensional data, such as images [16], which share similar 2D structural features to levels. For our model, the encoder network consists of three convolutional layers with 256 (), 256 (), and 128 () filters (filter size), each with a stride value of 2. This is followed by a flatten layer (2048), a fully connected(dense) layer (1024), and a latent sampling layer (512). The decoder network has the same architecture as the encoder network, but in reverse with transpose convolutional layers. Batch normalization and a ReLU activation function are applied after each layer. Batch normalization reduces internal covariance shift, which enables a higher learning rate and fewer training steps. It also acts as a regularizer, preventing overfitting [17]. This architecture was based around a theoretical understanding of CNN-VAEs given our data size, and then iterated on via visualizing the outputs.
III-D2 FC-VAE
We visualize our FC-VAE at the bottom of Figure 1. We used this second model to better compare the impact of employing a learned level representation against existing game level blending approaches with hand-authored/annotated representations [7, 6, 8]. The Fully Connected VAE (FC-VAE) consists of fully connected (dense) layers in both the encoder and decoder networks of the VAE. The encoder network consists of 4 fully connected layers with 1024, 512, 256, and 128 dimensions. The decoder network has the same architecture as the encoder network, but in reverse order. Each layer is followed by batch normalization and a ReLU activation function. This architecture was based on an existing VAE model used for level blending [6]. Notably, our goal is to not outperform this existing approach, but simply to demonstrate at least equivalent performance with our learned level representation. If we succeed, this will expand the possible game levels available for blending and decrease required human effort.
III-E Training
All models presented in this paper, including the baselines, were trained using the Adam optimizer [18] with a learning rate of 1e-5, following the training procedure outlined below.
VAE loss consists of two loss terms: the reconstruction loss and the variational loss (also known as the KL loss). Although our training set represents a fairly equal number of segments, with 600 segments representing Lode Runner and 459 segments representing the Legend of Zelda, the Legend of Zelda segments had a more consistent segment representation compared to the Lode Runner segments, which have higher structural variance. This caused an imbalanced dataset issue. To address this problem, we employed a weighted loss [19] for our training, by weighting the reconstruction loss of Lode Runner segments with 0.57 (600/1059) and the Legend of Zelda segments with 0.43 (459/1059). In addition we multiplied the reconstruction loss by a constant value of 4, which we found improved the reconstruction accuracy during training.
For the variational loss, to overcome the issue of KL vanishing, we used cyclic annealing. We started with a value of 0 for the first cycle of 200 epochs to avoid the KL vanishing issue. Then, we used cyclic annealing for the variational loss weight rising from 0 to 0.01 for the first half cycle of 100 epochs, increasing by 0.0001 for each epoch. We then kept the variational loss weight at a constant value of 0.01 for the next half cycle of 100 epochs. This procedure continued for each cycle of 200 epochs [20].
We trained the models for a total of 4000 epochs. Although we could have employed a higher learning rate value due to the use of batch normalization in our models, we chose to use a learning rate of 1e-5 to achieve better generalization performance and to avoid local minima [21]. This is consistent with other PCGML approaches that train for long periods with low learning rates to deal with high variance level data [22].
III-F Model Usage
III-F1 Generation and Blending
After training a model, we can generate randomly blended or unblended level segments or blend existing level segments. To randomly generate blended or unblended novel level segments, we sample from the latent space. We pass this latent space sample to the decoder to obtain a novel level segment in the CTE representation [4]. Since this is a random sample, we cannot guarantee if the output level segment will be a mix of the games’ levels (blended) or not (unblended).
The procedure for blending existing level segments is similar to randomly blending game level segments. Instead of random input, we pass existing level segments (contained in the training data) that we want to blend to the trained encoder. This allows us to obtain their locations in the learned latent space. We can then sample from between these points to identify various blends between the existing level segments. This process is referred to as interpolation [23]. We can identify various points along this interpolation and pass them to the trained decoder to obtain a novel level segment that represents a blend between pairs of inputs.
III-F2 Visualizing Output
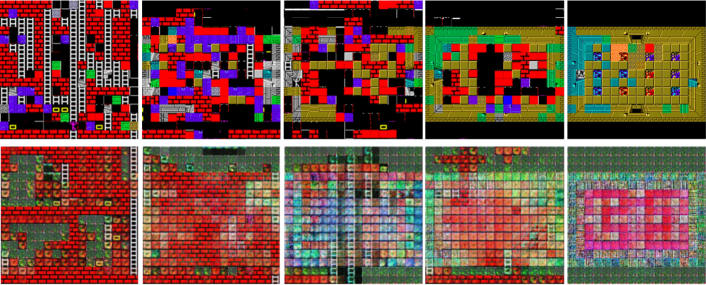
In our approach, we use CTE, a learned representation, as our level representation. CTE represents each pixel image as a tile, and each tile is represented as a 256-dimensional continuous vector. Once we train our VAE model on the CTE level representation, the output of our VAE model is also represented in the CTE representation. To obtain a graphical representation of the level segment, we can use two approaches: (1) nearest actual tile embedding or (2) CTE Decoder visualization. We visualize both approaches in Figure 2. In this paper, we primarily use the nearest actual tile embedding approach to evaluate our game blending approach.
The nearest actual tile embedding approach involves relying on the positions of the original training data in the learned latent space of the trained CTE model. By feeding the original inputs into the CTE model after training, we can extract a mapping of embeddings to pixels. After outputting a blend, we can then employ the Annoy Library to find the closest actual tile embedding and output the associated pixel representation. For the nearest actual tile embedding approach we employ the Manhattan distance to find the closest embedding from the training dataset. This has been the most common approach for visualizing the output of level generators trained with tile embeddings [14].
Visualizing the output with the CTE Decoder involves obtaining the trained VAE model output in the CTE representation, with each tile represented by a 256-dimensional continuous vector. By using the trained CTE decoder we can convert each of these 256-dimensional values to the CTE decoder output: pixels, a 13-length vector representing the affordances, and the edge information. This approach allows us not only to obtain pixels for each tile, but also to output novel tile visualizations and novel sets of affordances. Therefore this approach can allow us to move beyond the original tiles from the two games and to output novel tiles. To the best of our knowledge, this represents the first time novel tiles have been generated as part of a level blending approach. However, because of their novelty, its not possible to evaluate them against exiting tiles. In addition, as we demonstrate in Figure 2, these novel tiles do not match our human expectations in terms of pixel art quality at this time.
IV Evaluation
The main aim of this paper is to investigate the use of learned level representations in game level blending, as opposed to traditional human-annotated level representations. We cannot employ the CTE Decoder visualization to evaluate our approach since it outputs novel tiles, making comparison impossible without a human evaluation or similar approach. Given that we want to run a large-scale evaluation with multiple comparisons between our learned representation and a human-authored level representation, a human subject study is infeasible. Therefore, for our evaluation, we employ the nearest actual tile embedding visualization and a series of metrics for the purpose of comparison.
For our evaluation, we used two common approaches [9, 8, 7] for PCGML level generation research: (1) tile-based metrics typically employed in expressive range analysis [22]: density, non-linearity, leniency, interestingness, and path proportions, and (2) a playability analysis, using A* agents to test the playability of the generated and blended game segments.
IV-A Baselines
For our baseline evaluation, we created a hand-authored unified level representation to represent the VGLC levels of both Lode Runner and Legend of Zelda games. This unified level representation was obtained using techniques similar to those used in previous game level blending approaches [7, 8]. We combined the repeated tile characters in both games and represented them as a single character that combined both games’ tile affordances, as shown in Table I.
| Tile Properties | Text |
|---|---|
| Solid, Ground, Block | ‘B’ |
| Solid, Diggable, Ground | ‘b’ |
| Passable, Empty | ‘.’ |
| Passable, Climable, Rope, Empty | ‘-’ |
| Passable, Climable, ladder | ‘#’ |
| Passable, Pickupable, Gold | ‘G’ |
| Damaging, Enemy | ‘E’ |
| Damaging, Spawn, Solid, Hazard | ‘M’ |
| Solid | ‘F’ |
| Element | ‘P’ |
| Element, Block | ‘I’ |
| Element, Solid | ‘O’ |
| Solid, Openable | ‘D’ |
| Passable, Climbable | ‘S’ |
| Solid, Wall | ‘W’ |
Hand-authoring this unified tile representation represents the standard approach in PCGML level blending research. To compare it to our choice of the CTE representation, we trained the same two VAE models presented in the system overview section, with the same training procedure. The only difference was in the reconstruction loss, where we employed Mean Square Error (MSE) for the CTE representation, but Cross-entropy Error for the baseline representation given baseline’s use of a one-hot encoding of tiles. With this setup, if our CTE approach has even equivalent performance to the hand-authored unified tile representation then we can safely argue that we can employ CTE for PCGML level blending. If so, this means we can avoid the requirement of human authoring or annotation to obtain a unified level representation for game level blending, and more unannotated games can be used in game level blending.
IV-B Tile-based Metrics
Tile-based metrics are the most commonly utilized approach to evaluate generated randomly blended and blended segments [9, 8]. Originally developed for expressive range analysis [24], they capture various properties of a distribution of levels and provide insights to developers and researchers. In this work, we use density, non-linearity, leniency, interestingness, and path-proportion as our tile-based metrics, which we adapt from prior work and describe in more detail below. In all cases we drew on existing implementations of these metrics.
IV-B1 Density
Measures the proportion of segments that are occupied by tiles that the player can stand on, such as solid ground(![]() ,
, ![]() ,
, ![]() ), blocks (
), blocks (![]() ), etc. [8].
), etc. [8].
IV-B2 Non-Linearity
IV-B3 Leniency
Measures the proportion of segments that are not occupied by tiles that have enemy ![]() or hazard
or hazard ![]() properties. This is a rough approximation of difficulty [8].
properties. This is a rough approximation of difficulty [8].
IV-B4 Interestingness
Measures the proportion of segments that are occupied by tiles that are interesting or otherwise unusual [22]. For Lode Runner and Legend of Zelda, the interesting tiles are gold ![]() , climbable (
, climbable (![]() ,
, ![]() ,
, ![]() ), door
), door ![]() , and elements
, and elements ![]() .
.
IV-B5 Path-Proportion
Measures the proportion of segments that are occupied by tiles the player can stand on or otherwise occupy [8]. In comparison to playability, which we also measure, this allows us to approximate the proportion of tiles the player can reach.
IV-C Playability Metrics
Playability is a metric that evaluates whether a player can move through a level segment. One of the core requirements of game level generation generally is to achieve playability, and A* pathfinding agents are often used to approximate it. However, blended and random blended levels have tiles from both games, each representing their own game affordances. This complicates the playability evaluation problem. Therefore, we developed two A* agents, an A* agent configured for each game: Lode Runner (LR) and The Legend of Zelda (LOZ). They are described in more detail below.
IV-C1 Lode Runner (LR) A* Agent
The LR A* agent is configured to take all the possible actions a real-world player can take in LR, with gravity taken into consideration. The actions include (1) Moving left or right when there are ground tiles and the neighboring tiles are empty and passable. (2) Falling down from an action of moving left or right when the neighboring tile is empty or passable but there is no ground tiles below. (3) Digging through the breakable tiles, and (4) Climbing the ladder to move up or down and using the rope to move left or right.
IV-C2 Legend of Zelda (LOZ) A* Agent
Our LOZ A* agent is configured to take all the possible actions that a real-world player can take in LOZ. By default, we assume the player doesn’t have a ladder to cross the element tiles ![]() .
.
IV-C3 Playability Evaluation
For our playability evaluations, as we mentioned earlier, blended level segments have tiles from both games, each representing their own game affordances. Therefore, we measured the playability of the given set of segments for both the LR A* agent and LOZ A* agent configured as outlined above.
For the LR A* agent playability evaluation, a given level segment might represent either a more LR-like segment or a more LOZ-like segment. To address this problem, we categorized the set of level segments into two categories: either LR-like segments or LOZ-like segments, based on the tiles represented in the segments. A segment with a majority of the tiles representing LR tiles is categorized as a LR-like segment, and a segment with a majority of the tiles representing LOZ tiles is categorized as a LOZ-like segment.
We then ran our configured LR A* agent on all the LR-like level segments with the goal of collecting the gold presented in the level segment, as it’s the main way we can evaluate the playability of a LR level segment, since that’s the game’s goal. We gave two starting positions towards this goal because we found during our evaluation that the LR A* agent could get stuck between blocks on some of the LR-like segments if we only had one starting position from the top of the level segment. Therefore, we also gave a second starting position from the bottom and found that this solved the issue. We consider an LR-like segment to be playable by an LR A* agent if the agent can collect at least half of the gold tiles presented in the level segments from either starting position. These simplifications were included since each segment is only a subsection of an LR level, and we could therefore imagine other paths “offscreen”.
We also ran our configured LR A* agent on all the LOZ-like level segments. For these, we gave four start and goal positions. The four starting positions and corresponding goal positions were: (1) starting from the bottom-left of the room segment with a goal to reach the top-right, (2) starting from the bottom-right with a goal to reach the top-left, (3) starting from the top-left with a goal to reach the bottom-right, and (4) starting from the top-right with a goal to reach the bottom-left. We consider a segment to be playable if there is a path between at least two of the above four goals because, if any two of the above goals are satisfied, this indicates that the agent can move through the room, which satisfies the player goals for LOZ. We didn’t just use the door sprites as our start and goal locations as there was no guarantee a LOZ-like segment would include doors at particular positions.
| Metrics | CTE FC-VAE | VGLC FC-VAE | CTE CNN-VAE | VGLC CNN-VAE |
| Density | ||||
| Non-linearity | ||||
| Leniency | ||||
| Interestingness | ||||
| Path Proportion | ||||
| E-Distance | 0.04016 | 0.1755 | 0.07036 | 0.1930 |
| LR A* | 33.5 | 32.0 | 32.0 | 31.5 |
| LOZ A* | 79.0 | 79.5 | 81.5 | 79 |
For the LOZ A* agent playability evaluation, we didn’t need to categorize the set of segments into two categories because the LOZ A* agent doesn’t have a gravitational constraint and can move freely through the level segments. Therefore, we evaluated it with the same four start and goal positions as in the LR A* agent playability evaluation for LOZ-like segments but with the LOZ A* agent.
V Results
Table II presents the results for 1000 randomly blended novel level segments for each of the approaches we presented in this paper, labeled as ‘CTE FC-VAE’: our Fully connected VAE trained using the CTE representation, ‘VGLC FC-VAE’: the Fully connected VAE trained using VGLC representation, ‘CTE CNN-VAE’: our CNN-VAE trained using the CTE representation, and ‘VGLC CNN-VAE’: the CNN-VAE trained using the VGLC representation. It contains three different groups of evaluation metrics: (1) the Tile-based results presented in the evaluation section, represented as mean standard deviation values over the 1000 randomly blended segments. (2) the E-distance between the 1000 randomly blended segments and the training segments for the presented metrics [22]. (3) the Playability results of the 1000 segments for each A* agent, labeled ‘LR A*’: for the Lode Runner A* agent, and ‘LOZ A*’: for The Legend of Zelda A*.
For the tile-based results presented in Table II, all the results are similar for CTE FC-VAE and VGLC FC-VAE.However, the results vary slightly for our CTE CNN-VAE and the VGLC CNN-VAE, with the main difference being in interestingness, non-linearity and density. The higher mean range indicates that the CTE CNN-VAE has more tiles representing each metric compared to the VGLC CNN-VAE. All of the remaining results were similar, suggesting that both VAE variants have similar performance in terms of tile-based metrics between the CTE and VGLC representations. This implies the CTE representation could be used instead of human annotated level representations without negatively impacting blending results.
E-distance is a measure of similarity between different distributions [25] and has been used as an evaluation metric for generative models [26]. A lower E-distance value indicates that the measured distributions are more similar. In this work, E-distance is measured for the 1000 randomly blended segments for each approach against the training segments, and the results are bolded for the best values in Table II. The E-distance results vary between the CTE and VGLC representations for the two variants. The CTE FC-VAE and CTE CNN-VAE both have lower E-distance values compared to the VGLC FC-VAE and VGLC CNN-VAE, suggesting that the models trained on CTE have outputs more similar to the training segments.
Finally, in general, the playability results are similar for all the approaches. The playability is better in all cases for the LOZ A* agent, since it doesn’t have gravity constraints. Whereas for the LR A* agent, the playability score is approximately 32%, since it has more constraints. That said, the CTE approaches have a slightly better playability than the VGLC approaches, which further supports the E-distance results.

VI Discussion and Future Work
Our results from Table II support that our approach, which uses CTE and doesn’t require human annotation or authoring, is largely similar and, in some cases, better (as measured by E-distance and playability) than using VGLC, which did require human annotation or authoring. In addition to the results from Table II, we have also included tile-based metric results for level blending with different percentages of each level segment type as line graph in our supplementary material. These graphs further support the results from Table II for level blending, showing a similar tread for each metric.
Our initial motivation for this work was to use unannotated game domains with the CTE representation for game blending. However, the CTE representation has never been used for game blending before, and therefore has never been evaluated. In addition, we are unable to evaluate unannotated game domains in the same manner as the above as there is no ground truth available. Therefore, for this work, we chose to use CTE representation for game domains that had annotated datasets available. But as we outlined in our introduction, using CTE would expand the available game domains since it can be used with unannotated game domains, which is one of our long-term goals. As proof of concept, we also included random blend level segments in Figure 3. These were trained on Bugs Bunny Crazy Castle (an unannotated game) and Lode Runner using the CNN-VAE model with the CTE representation, following the same training procedure outlined in our training section. The results included in Figure 3 further show that the model is capable of producing random blended segments that are similar to Lode Runner (the left segment of the figure) and similar to Bugs Bunny Crazy Castle (the right segment of the figure), as well as the in-between blended segments (the middle segments of the figure). This demonstrates the possibility of game blending for an unannotated dataset using the CTE representation.
There are many avenues we hope to explore in future work. One clear vector is evaluating the use of the CTE decoder as the visualization approach, since it provides blended game levels with a blended tile representation that includes blended affordances as shown in Figure 2. This could potentially lead to novel game levels that implicitly encode novel gameplay mechanics, through extending the approaches developed by Summerville et al. [27]. Another possible area would be to evaluate our approach for game domains without annotated datasets. This could allow us to approximate target game levels for games without any level training data available, such as in-development games. Another possible area would be further exploring the possibility of CTE by increasing the number of game domains beyond just two game domains, since our approach doesn’t require human annotation/authoring to achieve a uniform/unified level representation. Although we used a VAE as our game blending approach in this work, further experiments need to be conducted to further test CTE with other game blending approaches in order to determine what models best support CTE-based level blending.
VII Conclusions
In this paper, we introduce a novel approach to game level blending that uses Clustering-based Tile Embeddings (CTE). CTE is a learned level representation that can be used for unannotated game domains and does not require human annotation or authoring to achieve a unified level representation for game level blending. We provide an evaluation of this approach against a baseline game level blending representation and show that it performs equivalently to or better than this baseline without the need for human annotation. We also provide examples of blended levels that include novel, blended tiles and blended levels between annotated and unannotated games. This work has greatly expanded the domains available for level blending while decreasing required human labor.
References
- [1] A. Summerville, S. Snodgrass, M. Guzdial, C. Holmgård, A. K. Hoover, A. Isaksen, A. Nealen, and J. Togelius, “Procedural content generation via machine learning (pcgml),” IEEE Transactions on Games, vol. 10, no. 3, pp. 257–270, 2018.
- [2] A. Sarkar, Z. Yang, and S. Cooper, “Conditional level generation and game blending,” in Proceedings of the Experimental AI in Games (EXAG) Workshop at AIIDE, 2020.
- [3] M. Guzdial and M. Riedl, “Learning to blend computer game levels,” arXiv preprint arXiv:1603.02738, 2016.
- [4] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [5] A. J. Summerville, S. Snodgrass, M. Mateas, and S. Ontanón, “The vglc: The video game level corpus,” arXiv preprint arXiv:1606.07487, 2016.
- [6] A. Sarkar, A. Summerville, S. Snodgrass, G. Bentley, and J. Osborn, “Exploring level blending across platformers via paths and affordances,” in Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 16, no. 1, 2020, pp. 280–286.
- [7] A. Sarkar, Z. Yang, and S. Cooper, “Controllable level blending between games using variational autoencoders,” arXiv preprint arXiv:2002.11869, 2020.
- [8] A. Sarkar and S. Cooper, “Sequential segment-based level generation and blending using variational autoencoders,” in Proceedings of the 15th International Conference on the Foundations of Digital Games, 2020, pp. 1–9.
- [9] M. Jadhav and M. Guzdial, “Clustering-based tile embedding (cte): A general representation for level design with skewed tile distributions,” arXiv preprint arXiv:2210.12789, 2022.
- [10] S. Snodgrass and S. Ontanon, “An approach to domain transfer in procedural content generation of two-dimensional videogame levels,” in Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 12, no. 1, 2016, pp. 79–85.
- [11] S. Cooper, “Constraint-based 2d tile game blending in the sturgeon system,” in Proceedings of the Experimental AI in Games Workshop, 2022.
- [12] N. Y. Khameneh and M. Guzdial, “Entity embedding as game representation,” arXiv preprint arXiv:2010.01685, 2020.
- [13] I. Karth, B. Aytemiz, R. Mawhorter, and A. M. Smith, “Neurosymbolic map generation with vq-vae and wfc,” in Proceedings of the 16th International Conference on the Foundations of Digital Games, 2021, pp. 1–6.
- [14] M. Jadhav and M. Guzdial, “Tile embedding: a general representation for level generation,” in Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 17, no. 1, 2021, pp. 34–41.
- [15] N. Y. Khameneh and M. Guzdial, “World models with an entity-based representation,” in Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 18, no. 1, 2022, pp. 215–222.
- [16] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
- [17] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in International conference on machine learning. pmlr, 2015, pp. 448–456.
- [18] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [19] S. Wang, W. Liu, J. Wu, L. Cao, Q. Meng, and P. J. Kennedy, “Training deep neural networks on imbalanced data sets,” in 2016 international joint conference on neural networks (IJCNN). IEEE, 2016, pp. 4368–4374.
- [20] H. Fu, C. Li, X. Liu, J. Gao, A. Celikyilmaz, and L. Carin, “Cyclical annealing schedule: A simple approach to mitigating kl vanishing,” arXiv preprint arXiv:1903.10145, 2019.
- [21] L. N. Smith, “Cyclical learning rates for training neural networks,” in 2017 IEEE winter conference on applications of computer vision (WACV). IEEE, 2017, pp. 464–472.
- [22] A. Summerville, J. R. Mariño, S. Snodgrass, S. Ontañón, and L. H. Lelis, “Understanding mario: an evaluation of design metrics for platformers,” in Proceedings of the 12th international conference on the foundations of digital games, 2017, pp. 1–10.
- [23] V. Dumoulin, I. Belghazi, B. Poole, O. Mastropietro, A. Lamb, M. Arjovsky, and A. Courville, “Adversarially learned inference,” arXiv preprint arXiv:1606.00704, 2016.
- [24] G. Smith and J. Whitehead, “Analyzing the expressive range of a level generator,” in Proceedings of the 2010 workshop on procedural content generation in games, 2010, pp. 1–7.
- [25] G. J. Székely and M. L. Rizzo, “Energy statistics: A class of statistics based on distances,” Journal of statistical planning and inference, vol. 143, no. 8, pp. 1249–1272, 2013.
- [26] A. Summerville, “Expanding expressive range: Evaluation methodologies for procedural content generation,” in Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 14, no. 1, 2018, pp. 116–122.
- [27] A. Summerville, A. Sarkar, S. Snodgrass, and J. C. Osborn, “Extracting physics from blended platformer game levels.” in AIIDE Workshops, 2020.