GANs May Have No Nash Equilibria
Abstract
Generative adversarial networks (GANs) represent a zero-sum game between two machine players, a generator and a discriminator, designed to learn the distribution of data. While GANs have achieved state-of-the-art performance in several benchmark learning tasks, GAN minimax optimization still poses great theoretical and empirical challenges. GANs trained using first-order optimization methods commonly fail to converge to a stable solution where the players cannot improve their objective, i.e., the Nash equilibrium of the underlying game. Such issues raise the question of the existence of Nash equilibrium solutions in the GAN zero-sum game. In this work, we show through several theoretical and numerical results that indeed GAN zero-sum games may not have any local Nash equilibria. To characterize an equilibrium notion applicable to GANs, we consider the equilibrium of a new zero-sum game with an objective function given by a proximal operator applied to the original objective, a solution we call the proximal equilibrium. Unlike the Nash equilibrium, the proximal equilibrium captures the sequential nature of GANs, in which the generator moves first followed by the discriminator. We prove that the optimal generative model in Wasserstein GAN problems provides a proximal equilibrium. Inspired by these results, we propose a new approach, which we call proximal training, for solving GAN problems. We discuss several numerical experiments demonstrating the existence of proximal equilibrium solutions in GAN minimax problems.
1 Introduction
Since their introduction in [1], generative adversarial networks (GANs) have gained great success in many tasks of learning the distribution of observed samples. Unlike the traditional approaches to distribution learning, GANs view the learning problem as a zero-sum game between the following two players: 1) generator aiming to generate real-like samples from a random noise input, 2) discriminator trying to distinguish ’s generated samples from real training data. This game is commonly formulated through a minimax optimization problem as follows:
| (1.1) |
Here, and are respectively the generator and discriminator function sets, commonly chosen as two deep neural nets, and denotes the minimax objective for generator and discriminator capturing how dissimilar the generated samples and training data are.
GAN optimization problems are commonly solved by alternating gradient methods, which under proper regularization have resulted in state-of-the-art generative models for various benchmark datasets. However, GAN minimax optimization has led to several theoretical and empirical challenges in the machine learning literature. Training GANs is widely known as a challenging optimization task requiring an exhaustive hyper-parameter and architecture search and demonstrating an unstable behavior. While a few regularization schemes have achieved empirical success in training GANs [2, 3, 4, 5], still little is known about the conditions under which GAN minimax optimization can be successfully solved by first-order optimization methods.
To understand the minimax optimization in GANs, one needs to first answer the following question: What is the proper notion of equilibrium in the GAN zero-sum game? In other words, what are the optimality criteria in the GAN’s minimax optimization problem? A classical notion of equilibrium in the game theory literature is the Nash equilibrium, a state in which no player can raise its individual gain by choosing a different strategy. According to this definition, a Nash equilibrium for the GAN minimax problem (1.1) must satisfy the following for every and :
| (1.2) |
As a well-known result, for a generator expressive enough to reproduce the distribution of observed samples, Nash equilibrium exists for the generator producing the data distribution [6]. However, such a Nash equilibrium would be of little interest from a learning perspective, since the trained generator merely overfits the empirical distribution of training samples [7]. More importantly, state-of-the-art GAN architectures [4, 5, 8, 9] commonly restrict the generator function through various means of regularization such as batch or spectral normalization. Such regularization mechanisms do not allow the generator to produce the empirical distribution of observed data-points. Since the realizability assumption does not apply to such regularized GANs, the existence of Nash equilibria will not be guaranteed in their minimax problems.
The above discussion motivates studying the equilibrium of GAN zero-sum games in the non-realizable settings where the generator cannot express the empirical distribution of training data. Here, a natural question is whether a Nash equilibrium still exists for the GAN minimax problem. In this work, we focus on this question and demonstrate through several theoretical and numerical results that:
-
Nash equilibrium may not exist in GAN zero-sum games.
We provide theoretical examples of well-known GAN formulations including the vanilla GAN [1], Wasserstein GAN (WGAN) [3], -GAN [10], and the second-order Wasserstein GAN (W2GAN) [11] where no local Nash equilibria exist in their minimax optimization problems. We further perform numerical experiments on widely-used GAN architectures which suggest that an empirically successful GAN training may converge to non-Nash equilibrium solutions.
Next, we focus on characterizing a new notion of equilibrium for GAN problems. To achieve this goal, we consider the Nash equilibrium of a new zero-sum game where the objective function is given by the following proximal operator applied to the minimax objective with respect to a norm on discriminator functions:
| (1.3) |
We refer to the Nash equilibrium of the new zero-sum game as the proximal equilibrium. Given the inherent sequential nature of GAN problems where the generator moves first followed by the discriminator, we consider a Stackelberg game for its representation and focus on the subgame perfect equilibrium (SPE) of the game as the right notion of equilibrium for such problems [12]. We prove that the proximal equilibrium of Wasserstein GANs provides an SPE for the GAN problem. This result applies to both the first-order and second-order Wasserstein GANs. In these cases, we show a proximal equilibrium exists for the optimal generator minimizing the distance to the data distribution.
Inspired by these theoretical results, we propose a proximal approach for training GANs, which we call proximal training, by changing the original minimax objective to the proximal objective in (1.3). In addition to preserving the optimal solution to the GAN minimax problem, proximal training can further enjoy the existence of Nash equilibrium solutions in the new minimax objective. We discuss numerical results supporting the proximal training approach and the role of proximal equilibrium solutions in various GAN problems.
2 Related Work
Understanding the minimax optimization in modern machine learning applications including GANs has been a subject of great interest in the machine learning literature. A large body of recent works [13, 14, 15, 16, 17, 18, 19, 20, 21] have analyzed the convergence properties of first-order optimization methods in solving different classes of minimax games.
In a related work, [12] proposes a new notion of local optimality, called local minimax, designed for general sequential machine learning games. Compared to the notion of local minimax, the proximal equilibrium proposed in our work gives a notion of global optimality, which as we show directly applies to Wasserstein GANs. [12] also provides examples of minimax problems where Nash equilibria do not exist; however, the examples do not represent GAN minimax problems. Some recent works [21, 22, 23] have analyzed the convergence of different optimization methods to local minimax solutions.
In another related work, [24] analyzes the stable points of the gradient descent ascent (GDA) and optimistic GDA [13] algorithms, proving that they will give strict supersets of the local saddle points. Regarding the stability of GAN algorithms, [25] proves that the GDA algorithm will be locally stable for the vanilla and regularized Wasserstein GAN problems. [11] shows the GDA algorithm is globally stable for W2GANs with linear generator and quadratic discriminator functions.
Regarding the equilibrium in GANs, [7] studies the Nash equilibrium of GAN minimax games in realizable settings. Also, [7, 26] develop methods for finding mixed strategy Nash equilibria. On the other hand, our results focus on the pure strategies in non-realizable settings. [27] empirically studies the equilibrium of GAN problems regularized via the gradient penalty, reporting positive results on the stability of regularized GANs. However, our focus is on the existence of pure Nash equilibrium solutions. [28] suggests a moment matching GAN formulation using the Sobolev norm. As a different direction, we use the Sobolev norm to analyze equilibrium in GANs. Finally, developing GAN architectures with improved equilibrium and stability properties has been studied in several recent works [2, 29, 30, 31, 32, 33, 34, 35].
3 An Initial Experiment on Equilibrium in GANs
To examine whether the Nash equilibrium exists in GAN problems empirically, we performed a simple numerical experiment. In this experiment, we applied three standard GAN implementations including the Wasserstein GAN with weight-clipping (WGAN-WC) [3], the improved Wasserstein GAN with gradient penalty (WGAN-GP) [4], and the spectrally-normalized vanilla GAN (SN-GAN) [5], to the two benchmark MNIST [36] and CelebA [37] databases. We used the convolutional architecture of the DC-GAN [38] optimized with the Adam [39] or RMSprop [40] (only for WGAN-WC) optimizers.
We performed each of the GAN experiments for 200,000 generator iterations to reach with and denoting the trained generator and discriminator parameters at the end of the 200,000 iterations. Our goal is to examine whether the solution pair represents a Nash equilibrium or not. To do this, we fixed the trained discriminator and kept optimizing the generator, i.e. continuing optimizing the generator without changing the discriminator . Here we solved the following optimization problem initialized at using the default first-order optimizer for the generator function for 10,000 iterations:
| (3.1) |
If the pair was in fact a Nash equilibrium, it would give a local saddle point to the minimax optimization and the above optimization could not make the objective any smaller than its initial value. Also, the image samples generated by the generator should have improved or at least preserved their initial quality during this optimization, since the discriminator would be the optimal discriminator against all generator functions.
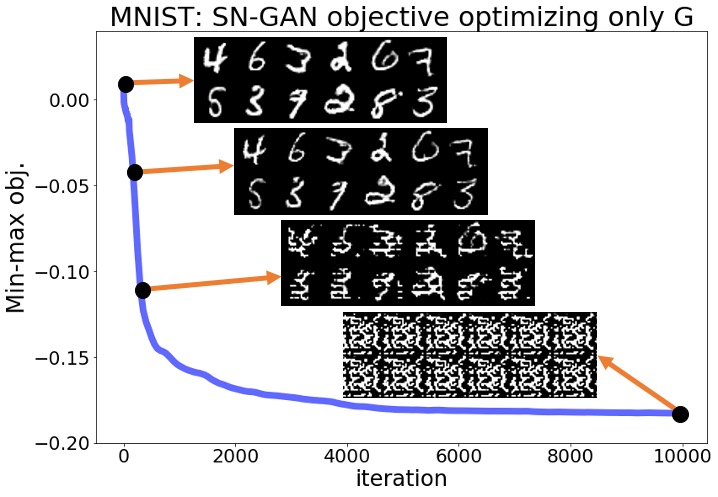
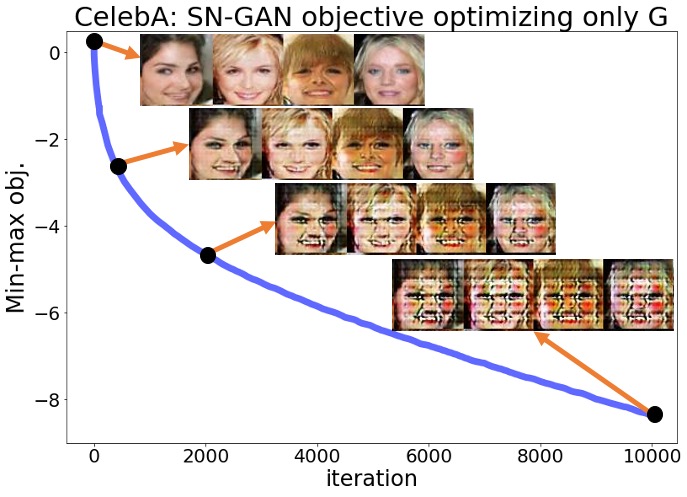
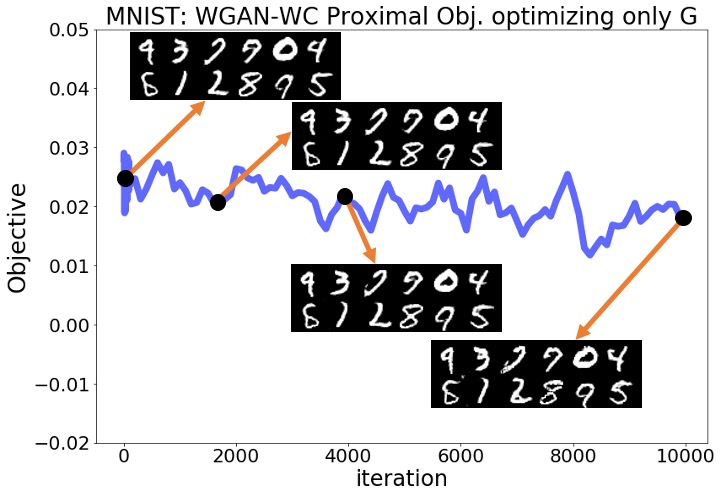
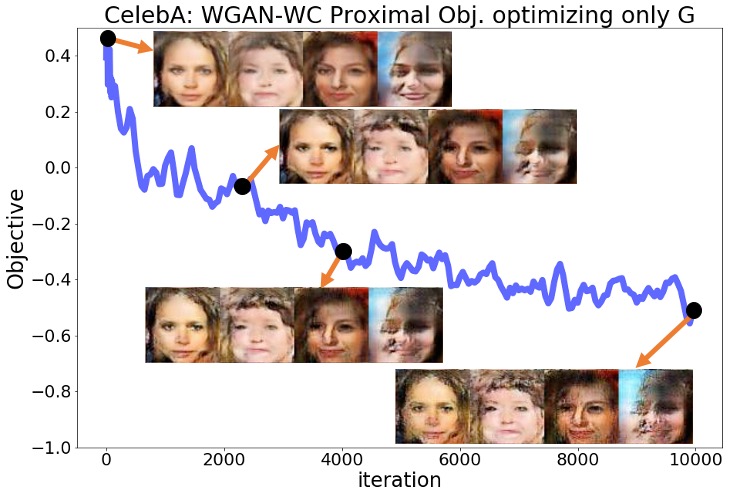
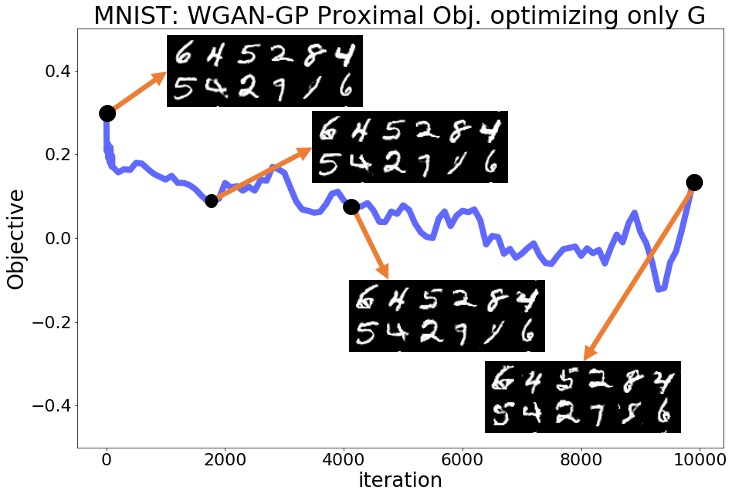
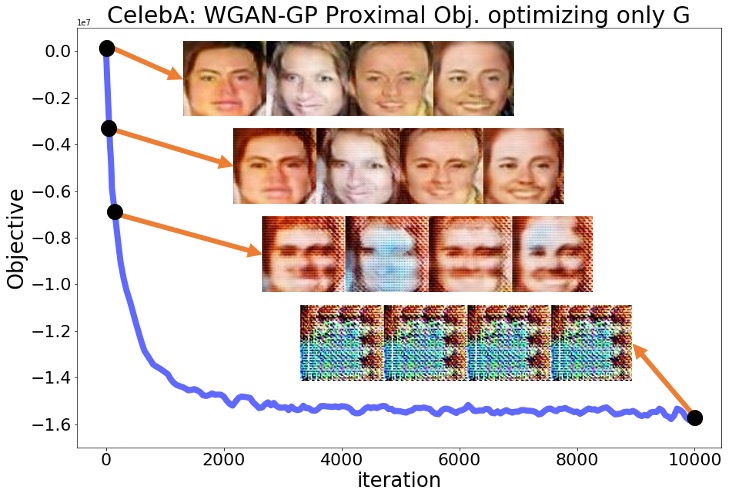
Despite the above predictions, we observed that none of the mentioned statements hold in reality for any of the six experiments with the three standard GAN implementations and the two datasets. The optimization objective decreased rapidly from the beginning of the optimization, and the pictures sampled from the generator completely lost their quality over this optimization. Figures 1(a), 1(b) show the objective for the SN-GAN experiments over the 10,000 steps of the above optimization. These figures also demonstrate the SN-GAN generated samples before and during the optimization, which shows the significant drop in the quality of generated pictures. We defer the results for the WGAN-WC and WGAN-GP problems to the Appendix.
The results of the above experiments show that practical GAN experiments may not converge to local Nash equilibrium solutions. After fixing the trained discriminator, the trained generator can be further optimized using a first-order optimization method to reach smaller values of the generator objective. More importantly, this optimization not only does not improve the quality of the generator’s output samples, but also totally disturbs the trained generator. As demonstrated in these experiments, simultaneous optimization of the two players is in fact necessary for the proper convergence and stability behavior in GAN minimax optimization. The above experiments suggest that practical GAN solutions are not local Nash equilibrium. In the upcoming sections, we review some standard GAN formulations and then show that there are examples of GAN minimax problems for which no Nash equilibrium exists. Those theoretical results will further support our observations in the above experiments.
4 Review of GAN Formulations
4.1 Vanilla GAN & -GAN
Consider samples observed independently from distribution . Our goal is to find a generator function where maps a random noise input from a known to an output distributed as , i.e., we aim to match the probability distributions and . To find such a generator function, [1] proposes the following minimax problem which is commonly referred to as the vanilla GAN problem:
| (4.1) |
Here and represent the set of generator and discriminator functions, respectively. In this formulation, the discriminator is optimized to map real samples from to larger values than the values assigned to generated samples from .
As shown in [1], the above minimax problem for an unconstrained containing all real-valued functions reduces to the following divergence minimization problem:
| (4.2) |
where denotes the Jensen-Shannon (JS) divergence defined in terms of KL-divergence as
-GANs extend the vanilla GAN problem by generalizing the JS-divergence to a general -divergence. For a convex function with , the -divergence corresponding to is defined as
| (4.3) |
Notice that the JS-divergence is a special case of -divergence with . [10] shows that generalizing the divergence minimization (4.2) to minimizing a -divergence results in the following minimax problem called -GAN:
| (4.4) |
where denotes the Fenchel-conjugate to defined as . The space implied by the f-divergence minimization will be the set of all functions, but a similar interpretation further applies to a constrained [41, 42]. Several examples of -GANs have been formulated and discussed in [10].
4.2 Wasserstein GANs
To resolve GAN training issues, [3] proposes to formulate a GAN problem by minimizing the optimal transport costs which unlike -divergences change continuously with the input distributions. Given a transportation cost for transporting to , the optimal transport cost is defined as
| (4.5) |
where denotes the set of all joint distributions on with marginally distributed as , respectively. An important special case is the first-order Wasserstein distance (-distance) corresponding to . In this special case, the Kantorovich-Rubinstein duality shows
| (4.6) |
Here denotes the expected value with respect to distribution and denotes the Lipschitz constant of function which is defined as the smallest satisfying for every . Formulating a GAN problem minimizing the -distance, [3] states the Wasserstein GAN (WGAN) problem as follows:
| (4.7) |
The above Wasserstein GAN problem can be generalized to a general optimal transport cost with arbitrary cost function . The generalization is as follows:
| (4.8) |
where the c-transform is defined as and a function is called c-concave if it is the c-transform of some valid function. In particular, the optimal transport GAN formulation with the quadratic cost results in the second-order Wasserstein GAN (W2GAN) problem which has been studied in several recent works [11, 43, 44, 45].
5 Existence of Nash Equilibrium Solutions in GANs
Consider a general GAN minimax problem (1.1) with a minimax objective . As discussed in the previous section, the optimal generator is defined to minimize the GAN’s target divergence to the data distribution. The following proposition is a well-known result regarding the Nash equilibrium of the GAN game in realizable settings where there exists a generator producing the data distribution.
Proposition 1.
Assume that generator results in the distribution of data, i.e., we have . Then, for each of the GAN problems discussed in Section 4 there exists a constant discriminator function which together with results in a Nash equilibrium to the GAN game, and hence satisfies the following for every and :
Proof.
This proposition is well-known for the vanilla GAN [46]. In the Appendix, we provide a proof for general -GANs and Wasserstein GANs. ∎
The above proposition shows that in a realizable setting with a generator function generating the distribution of observed samples, a Nash equilibrium exists for that optimal generator. However, the realizability assumption in this proposition does not always hold in real GAN experiments. For example, in the GAN experiments discussed in Section 3, we observed that the divergence estimate never reached the zero value because of regularizing the generator function. Therefore, the Nash equilibrium described in Proposition 1 does not apply to the trained generator and discriminator in such GAN experiments.
Here, we address the question of the existence of Nash equilibrium solutions for non-realizable settings, where no generator can produce the data distribution. Do Nash equilibria always exist in non-realizable GAN zero-sum games? The following theorem shows that the answer is in general no. Note that in this theorem denotes the maximum singular value, i.e., the spectral norm.
Theorem 1.
Consider a GAN minimax problem for learning a normally distributed with zero mean and scalar covariance matrix where . In the GAN formulation, we use a linear generator function where the weight matrix is spectrally-regularized to satisfy . Suppose that the Gaussian latent vector is normally distributed as with zero mean and identity covariance matrix. Then,
-
•
For the -GAN problem corresponding to an with non-decreasing over and an unconstrained discriminator where the dimensions of data and latent match, the f-GAN minimax problem has no Nash equilibrium solutions.
-
•
For the W2GAN problem with discriminator trained over -concave functions, where is the quadratic cost, the W2GAN minimax problem has no Nash equilibrium solutions. Also, given a quadratic discriminator parameterized by , the W2GAN problem has no local Nash equilibria.
-
•
For the WGAN problem with -dimensional and a discriminator trained over 1-Lipschitz functions, the WGAN minimax problem has no Nash equilibria.
Proof.
We defer the proof to the Appendix. Note that the condition on the -GAN holds for all -GAN examples in [10] including the vanilla GAN. ∎
The above theorem shows that under the stated assumptions the GAN zero-sum game does not have Nash equilibrium solutions. Consequently, the optimal divergence-minimizing generative model does not result in a Nash equilibrium. In contrast to Theorem 1, the following remark shows that the GAN zero-sum game in a non-realizable case may have Nash equilibrium solutions, of course if Theorem 1’s assumptions do not hold.
Remark 1.
Proof.
We defer the proof to the Appendix. ∎
The above remark explains that the phenomenon shown in Theorem 1 does not always hold in non-realizable GAN settings. As a result, we need other notions of equilibrium which consistently explain optimality in GAN games.
6 Proximal Equilibrium: A Relaxation of Nash Equilibrium
To define a proper notion of equilibrium for GANs, note that due to the sequential nature of GAN games the equilibrium notion should be flexible to allow to some extent the optimization of the discriminator around the equilibrium solution. This property is in fact consistent with the stability feature observed for the first-order GAN training methods where the alternating first-order method stabilizes around a certain solution. To this end, we consider the following objective for a GAN problem with minimax objective :
| (6.1) |
The above definition represents the application of a proximal operator to , which further optimizes the original objective in the proximity of discriminator . To keep the function variable close to , we penalize the distance among the two functions in the proximal optimization. Here the distance is measured using a norm on the discriminator function space.
To extend the notion of Nash equilibrium to general minimax problems, we propose considering the Nash equilibria of the defined .
Definition 1.
We call a -proximal equilibrium for if it represents a Nash equilibrium for , i.e. for every and
| (6.2) |
The next proposition provides necessary and sufficient conditions in terms of the original objective for the proximal equilibrium solutions.
Proposition 2.
is a -proximal equilibrium if and only if for every and we have
Therefore, if is a -proximal equilibrium it will give a global minimax solution, i.e., minimizes the worst-case objective, , with being its optimal solution.
Proof.
We defer the proof to the Appendix. ∎
The following result shows the proximal equilibria provide a hierarchy of equilibrium solutions for different values.
Proposition 3.
Define to be the set of the -proximal equilibria for . Then, if ,
| (6.3) |
Proof.
We defer the proof to the Appendix. ∎
Note that as approaches infinity, tends to the original , implying that is the set of ’s Nash equilibria. In contrast, for the proximal objective becomes the worst-case objective . As a result, is the set of global minimax solutions described in Proposition 2.
Concerning the proximal optimization problem in (6.1), the following proposition shows that if the original minimax objective is a smooth function of the discriminator parameters, the proximal optimization can be solved efficiently and therefore one can efficiently compute the gradient of the proximal objective.
Proposition 4.
Consider the maximization problem in the definition of proximal objective (6.1) where generator and discriminator are parameterized by vectors , respectively. Suppose that
-
•
For the considered discriminator norm , is -strongly convex in for any function , i.e. for any :
-
•
For every , The GAN minimax objective is -smooth in , i.e. i.e. for any :
Under the above assumptions, if , the maximization objective in (6.1) is -strongly concave. Then, the maximization problem has a unique solution and if is differentiable with respect to we have
| (6.4) |
Proof.
We defer the proof to the Appendix. ∎
The above proposition suggests that under the mentioned assumptions, one can efficiently compute the optimal solution to the proximal maximization through a first-order optimization method. The assumptions require the smoothness of the GAN minimax objective with respect to the discriminator parameters, which can be imposed by applying norm-based regularization tools to neural network discriminators.
7 Proximal Equilibrium in Wasserstein GANs
As shown earlier, GAN minimax games may not have any Nash equilibria in non-realizable settings. As a result, we seek for a different notion of equilibrium which remains applicable to GAN problems. Here, we show the proposed proximal equilibrium provides such an equilibrium notion for Wasserstein GAN problems.
To define a proper proximal operator for defining proximal equilibria in Wasserstein GAN problems, we use the second-order Sobolev semi-norm averaged over the underlying distribution of data. Given the underlying distribution , we define the Sobolev semi-norm as
| (7.1) |
The above semi-norm is induced by the following semi-inner product and therefore leads to a semi-Hilbert space of functions:
| (7.2) |
Throughout our discussion, we consider a parameterized set of generators . For a GAN minimax objective , we define to be the optimal discriminator function for the parameterized generator :
| (7.3) |
The following theorem shows that the Wasserstein distance-minimizing generator function in the second-order Wasserstein GAN problem satisfies the conditions of a proximal equilibrium based on the Sobolev semi-norm defined in (7.1).
Theorem 2.
Proof.
We defer the proof to the Appendix. ∎
The above theorem shows that while, as demonstrated in Theorem 1, the W2GAN problem may have no local Nash equilibrium solutions, the proximal equilibrium exists for the W2GAN problem and holds at the Wasserstein-distance minimizing generator . The next theorem extends this result to the first-order Wasserstein GAN (WGAN) problem.
Theorem 3.
Consider the WGAN problem (4.7) minimizing the first-order Wasserstein distance. For each , define to be the magnitude of the resulted optimal transport map from to , i.e. shares the same distribution with .111Note that as shown in the proof such a mapping exists under mild regularity assumptions. Given these definitions, assume that
-
•
is a convex set,
-
•
for every and , holds for constant .
Then, for the Wasserstein distance-minimizing generator function provides an -proximal equilibrium with respect to the Sobolev norm in (7.1).
Proof.
We defer the proof to the Appendix. ∎
The above theorem shows that if the magnitude of optimal transport map is everywhere lower-bounded by , then the Wasserstein distance-minimizing generator in the WGAN problem yields a -proximal equilibrium.
8 Proximal Training
As shown for Wasserstein GAN problems, given the defined Sobolev norm and a small enough the proximal objective will possess a Nash equilibrium solution. This result motivates performing the minimax optimization for the proximal objective instead of the original objective . Therefore, we propose proximal training in which we solve the following minimax optimization problem:
| (8.1) |
with the proximal operator defined according to the Sobolev norm in (7.1).
In order to take the gradient of with respect to , Proposition 4 suggests solving the proximal optimization followed by computing the gradient of the original objective where the discriminator is parameterized with the optimal solution to the proximal optimization.
Algorithm 1 summarizes the main two steps of proximal training. At every iteration, the discriminator is optimized with an additive Sobolev norm penalty forcing the discriminator to remain in the proximity of the current discriminator. Next, the generator is optimized using a gradient descent method with the gradient evaluated at the optimal discriminator solving the proximal optimization. The stepsize parameter can be adaptively selected at every iteration . In practice, we can solve the proximal maximization problem via a first-order optimization method for a certain number of iterations. Assuming the conditions of Proposition 4 hold, the proximal optimization leads to the maximization of a strongly-concave objective which can be solved linearly fast through first-order optimization methods.
9 Numerical Experiments
To experiment the theoretical results of this work, we performed several experiments using the [4]’s implementation of Wasserstein GANs with the code available at the paper’s Github repository. In addition, we used the implementations of [5, 47] for applying spectral regularization to the discriminator network. In the experiments, we used the DC-GAN 4-layer CNN architecture for both the discriminator and generator functions [38] and ran each experiment for 200,000 generator iterations with 5 discriminator updates per generator update. We used the RMSprop optimzier [40] for WGAN experiments with weight clipping or spectral normalization and the Adam optimizer [39] for the other experiments.
9.1 Proximal Equilibrium in Wasserstein and Lipschitz GANs
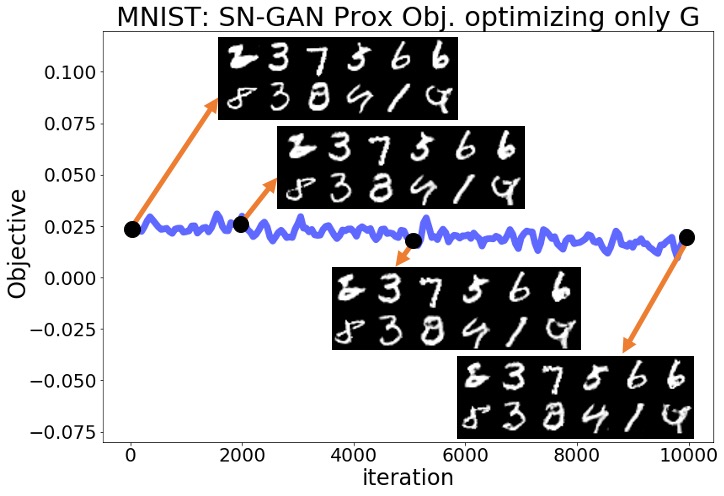
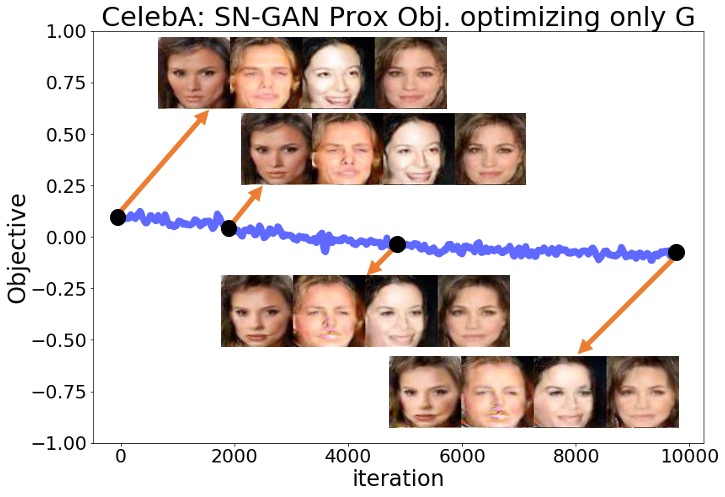
We examined whether the solutions found by Wasserstein and Lipschitz vanilla GANs represent proximal equilibria. Toward this goal, we performed similar experiments to Section 3’s experiments for the WGAN-WC [3], WGAN-GP [4], and SN-GAN [5] problems over the MNIST and CelebA datasets. In Section 3, we observed that after fixing the trained discriminator the GAN’s minimax objective kept decreasing when we optimized only the generator . In the new experiments, we similarly fixed the trained discriminator resulted from the 200,000 training iterations, but instead of optimizing the GAN minimax objective we optimized the proximal objective defined by the norm (7.1) with . Thus, we solved the following optimization problem initialized at which denotes the parameters of the trained generator:
| (9.1) |
We computed the gradient of the above proximal objective by applying the Adam optimizer for steps to approximate the solution to the proximal optimization (6.1) which at every iteration was initialized at . Figures 2(a) and 2(b) show that in the SN-GAN experiments the original minimax objective had only minor changes, compared to the results in Section 3, and the quality of generated samples did not change significantly during the optimization. We defer the similar numerical results of the WGAN-WC and WGAN-GP experiments to the Appendix. These numerical results suggest that while Wasserstein and Lipschitz GANs may not converge to local Nash equilibrium solutions as shown in Section 3, their found solutions can still represent a local proximal equilibrium.
9.2 Proximal Training Improves Lipschitz GANs
| GAN Problem | Ordinary | Proximal |
|---|---|---|
| WGAN-WC (DIM=64) | ||
| WGAN-WC (DIM=128) | ||
| SN-GAN (DIM=64) | ||
| SN-GAN (DIM=128) |
We applied the proximal training in Algorithm 1 to the WGAN-WC and SN-GAN problems. To compute the gradient of the proximal minimax objective, we solved the maximization problem in the Algorithm 1’s first step in the for loop by applying steps of Adam optimization initialized at the discriminator parameters at that iteration. Applying the proximal training to MNIST, CIFAR-10, and CelebA datasets, we qualitatively observed slightly visually better generated pictures. We postpone the generated samples to the Appendix.
To quantitatively compare the proximal and ordinary non-proximal GAN training, we measured the Inception scores of the samples generated in the CIFAR-10 experiments. As shown in Table 1, proximal training results in an improved inception score. In this table, DIM stands for the dimension parameter of the DC-GAN’s CNN networks.
References
- [1] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- [2] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Advances in neural information processing systems, pages 2234–2242, 2016.
- [3] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017.
- [4] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans. In Advances in neural information processing systems, pages 5767–5777, 2017.
- [5] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018.
- [6] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning, volume 1. MIT Press, 2016.
- [7] Sanjeev Arora, Rong Ge, Yingyu Liang, Tengyu Ma, and Yi Zhang. Generalization and equilibrium in generative adversarial nets (gans). In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 224–232, 2017.
- [8] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318, 2018.
- [9] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
- [10] Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. f-gan: Training generative neural samplers using variational divergence minimization. In Advances in neural information processing systems, pages 271–279, 2016.
- [11] Soheil Feizi, Farzan Farnia, Tony Ginart, and David Tse. Understanding gans: the lqg setting. arXiv preprint arXiv:1710.10793, 2017.
- [12] Chi Jin, Praneeth Netrapalli, and Michael I Jordan. Minmax optimization: Stable limit points of gradient descent ascent are locally optimal. arXiv preprint arXiv:1902.00618, 2019.
- [13] Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, and Haoyang Zeng. Training gans with optimism. arXiv preprint arXiv:1711.00141, 2017.
- [14] Maher Nouiehed, Maziar Sanjabi, Tianjian Huang, Jason D Lee, and Meisam Razaviyayn. Solving a class of non-convex min-max games using iterative first order methods. In Advances in Neural Information Processing Systems, pages 14905–14916, 2019.
- [15] Aryan Mokhtari, Asuman Ozdaglar, and Sarath Pattathil. A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: Proximal point approach. arXiv preprint arXiv:1901.08511, 2019.
- [16] Kiran K Thekumparampil, Prateek Jain, Praneeth Netrapalli, and Sewoong Oh. Efficient algorithms for smooth minimax optimization. In Advances in Neural Information Processing Systems, pages 12659–12670, 2019.
- [17] Kaiqing Zhang, Zhuoran Yang, and Tamer Basar. Policy optimization provably converges to nash equilibria in zero-sum linear quadratic games. In Advances in Neural Information Processing Systems, pages 11598–11610, 2019.
- [18] Eric V Mazumdar, Michael I Jordan, and S Shankar Sastry. On finding local nash equilibria (and only local nash equilibria) in zero-sum games. arXiv preprint arXiv:1901.00838, 2019.
- [19] Tanner Fiez, Benjamin Chasnov, and Lillian J Ratliff. Convergence of learning dynamics in stackelberg games. arXiv preprint arXiv:1906.01217, 2019.
- [20] Yisen Wang, Xingjun Ma, James Bailey, Jinfeng Yi, Bowen Zhou, and Quanquan Gu. On the convergence and robustness of adversarial training. In International Conference on Machine Learning, pages 6586–6595, 2019.
- [21] Tianyi Lin, Chi Jin, and Michael I Jordan. On gradient descent ascent for nonconvex-concave minimax problems. arXiv preprint arXiv:1906.00331, 2019.
- [22] Qi Lei, Jason D Lee, Alexandros G Dimakis, and Constantinos Daskalakis. Sgd learns one-layer networks in wgans. arXiv preprint arXiv:1910.07030, 2019.
- [23] Yuanhao Wang, Guodong Zhang, and Jimmy Ba. On solving minimax optimization locally: A follow-the-ridge approach. In International Conference on Learning Representations, 2020.
- [24] Constantinos Daskalakis and Ioannis Panageas. The limit points of (optimistic) gradient descent in min-max optimization. In Advances in Neural Information Processing Systems, pages 9236–9246, 2018.
- [25] Vaishnavh Nagarajan and J Zico Kolter. Gradient descent gan optimization is locally stable. In Advances in neural information processing systems, pages 5585–5595, 2017.
- [26] Ya-Ping Hsieh, Chen Liu, and Volkan Cevher. Finding mixed nash equilibria of generative adversarial networks. arXiv preprint arXiv:1811.02002, 2018.
- [27] William Fedus, Mihaela Rosca, Balaji Lakshminarayanan, Andrew M Dai, Shakir Mohamed, and Ian Goodfellow. Many paths to equilibrium: Gans do not need to decrease a divergence at every step. arXiv preprint arXiv:1710.08446, 2017.
- [28] Youssef Mroueh, Chun-Liang Li, Tom Sercu, Anant Raj, and Yu Cheng. Sobolev gan. arXiv preprint arXiv:1711.04894, 2017.
- [29] David Berthelot, Thomas Schumm, and Luke Metz. Began: Boundary equilibrium generative adversarial networks. arXiv preprint arXiv:1703.10717, 2017.
- [30] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in neural information processing systems, pages 6626–6637, 2017.
- [31] Lars Mescheder, Sebastian Nowozin, and Andreas Geiger. The numerics of gans. In Advances in Neural Information Processing Systems, pages 1825–1835, 2017.
- [32] Kevin Roth, Aurelien Lucchi, Sebastian Nowozin, and Thomas Hofmann. Stabilizing training of generative adversarial networks through regularization. In Advances in neural information processing systems, pages 2018–2028, 2017.
- [33] Naveen Kodali, Jacob Abernethy, James Hays, and Zsolt Kira. On convergence and stability of gans. arXiv preprint arXiv:1705.07215, 2017.
- [34] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? arXiv preprint arXiv:1801.04406, 2018.
- [35] Zhiming Zhou, Jiadong Liang, Yuxuan Song, Lantao Yu, Hongwei Wang, Weinan Zhang, Yong Yu, and Zhihua Zhang. Lipschitz generative adversarial nets. arXiv preprint arXiv:1902.05687, 2019.
- [36] Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- [37] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015.
- [38] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
- [39] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [40] Geoffrey Hinton, Nitish Srivastava, and Kevin Swersky. Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. 14(8), 2012.
- [41] Shuang Liu, Olivier Bousquet, and Kamalika Chaudhuri. Approximation and convergence properties of generative adversarial learning. In Advances in Neural Information Processing Systems, pages 5545–5553, 2017.
- [42] Farzan Farnia and David Tse. A convex duality framework for gans. In Advances in Neural Information Processing Systems, pages 5248–5258, 2018.
- [43] Tim Salimans, Han Zhang, Alec Radford, and Dimitris Metaxas. Improving gans using optimal transport. arXiv preprint arXiv:1803.05573, 2018.
- [44] Maziar Sanjabi, Jimmy Ba, Meisam Razaviyayn, and Jason D Lee. On the convergence and robustness of training gans with regularized optimal transport. In Advances in Neural Information Processing Systems, pages 7091–7101, 2018.
- [45] Amirhossein Taghvaei and Amin Jalali. 2-wasserstein approximation via restricted convex potentials with application to improved training for gans. arXiv preprint arXiv:1902.07197, 2019.
- [46] Ian Goodfellow. Nips 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160, 2016.
- [47] Farzan Farnia, Jesse Zhang, and David Tse. Generalizable adversarial training via spectral normalization. In International Conference on Learning Representations, 2019.
- [48] Stephen Boyd and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004.
- [49] Cédric Villani. Optimal transport: old and new, volume 338. Springer Science & Business Media, 2008.
- [50] Dimitri P Bertsekas. Nonlinear programming. Journal of the Operational Research Society, 48(3):334–334, 1997.
- [51] Luigi Ambrosio and Nicola Gigli. A user’s guide to optimal transport. In Modelling and optimisation of flows on networks, pages 1–155. Springer, 2013.
Appendix A Numerical Results for Section 3
Here, we provide the complete numerical results for the experiments discussed in Section 3 of the main text. Regarding the plots shown in Section 3 for the SN-GAN implementation, here we present the same plots for the Wasserstein GAN with weight clipping (WGAN-WC) and with gradient penalty (WGAN-GP) problems. Figures 3(a)-4(b) repeat the experiments of Figures 1,2 in the main text for the WGAN-WC and WGAN-GP problems. These plots suggest that a similar result also holds for the WGAN-WC and WGAN-GP problems, where the objective and the generated samples’ quality were decreasing during the generator optimization. For a larger set of generated samples in the main text’s Figures 1,2 and Figures 3(a)-4(b), we refer the readers to Figures 5(a)-7(b).
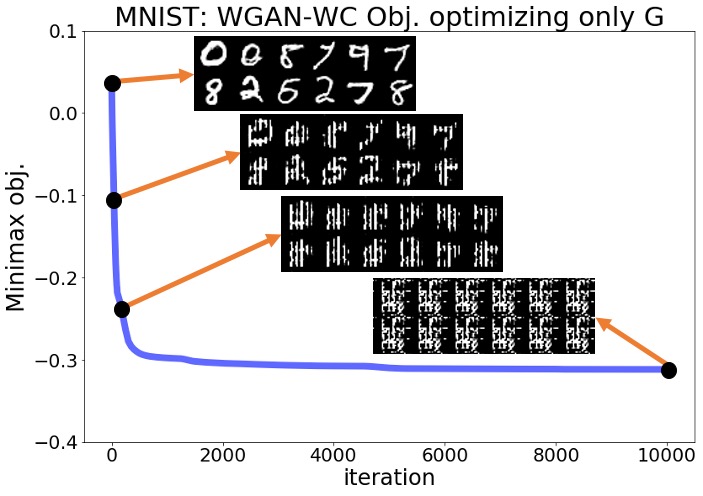
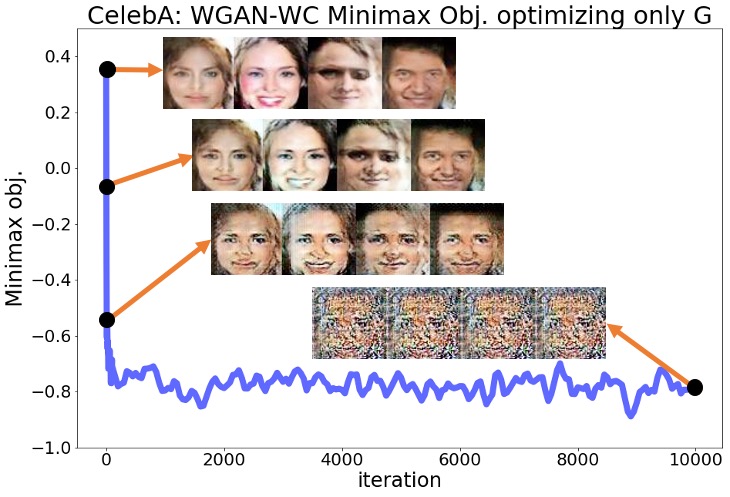
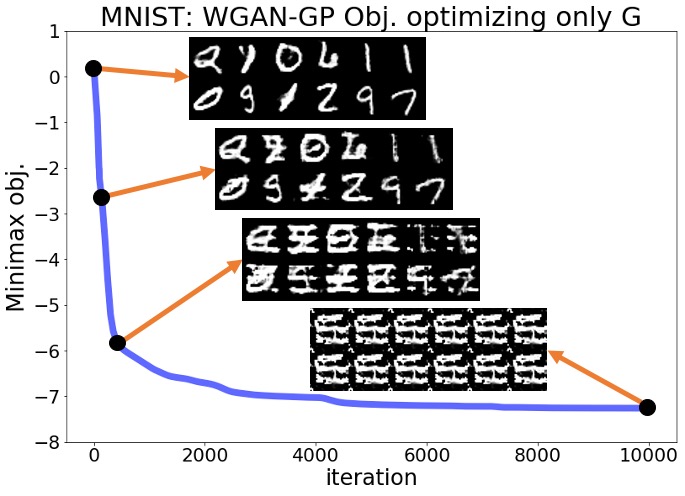
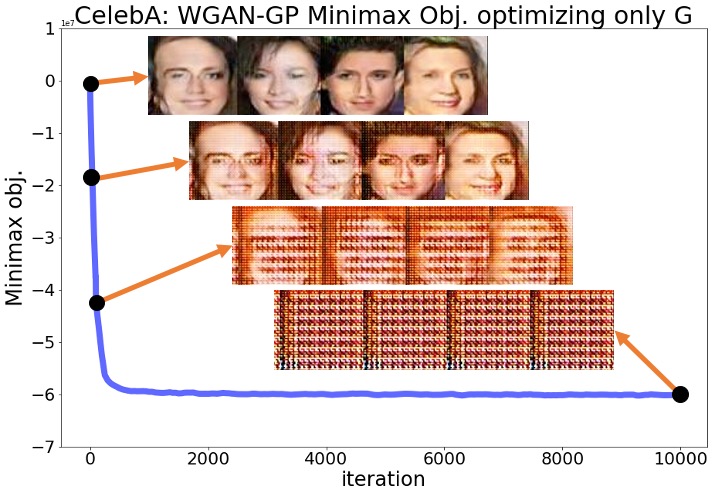






Appendix B Numerical Results for Section 9
Here, we present the complete numerical results for the experiments of Section 9 in the main text. Figures 8(a)-9(b) demonstrate the results of the main text’s Figures 3,4 for the WGAN-WC and WGAN-GP problems. Here, except the WGAN-GP experiment on the CelebA dataset, we observed that the objective and the generated samples’ quality did not significantly decrease over the generator optimization. Even for the WGAN-GP experiment on the CelebA data, we observed that the objective value decreased three times less than in minimizing the original objective rather than the proximal objective. These experiments suggest that the Wasserstein and Lipschitz GAN problems can converge to local proximal equilibrium solutions. We also show a larger group of generated samples at the beginning and final iterations of Figures 3,4 in the main text and Figures 8(a)-9(b) in Figures 10(a)-12(b).
For the proximal training experiments, Figures 13-15(b) show the samples generated by the SN-GAN and WGAN-WC proximally trained on CIFAR-10 and CelebA data with the results for the baseline regular training on the top of the figure and the results for proximal training on the bottom. We observed a somewhat improved quality achieved by proximal training, which was further supported by the inception scores for the CIFAR-10 experiments reported in the main text.










Appendix C Proofs
C.1 Proof of Proposition 1
Proof for -GANs:
Consider the following -GAN minimax problem corresponding to the convex function :
| (C.1) |
Due to the realizability assumption, given we assume that the data distribution and the generative model are identical, i.e., . Then, the minimax objective for reduces to
| (C.2) |
The above objective decouples across outcomes. As a result, the maximizing discriminator will be a constant function where the constant value follows from the optimization problem:
| (C.3) |
Note that the objective is a concave function of whose derivative is zero at , because the Fenchel-conjugate of a convex satisfies .
So far we have proved that the constant function provides the optimal discriminator for generator . Therefore, for every discriminator we have
| (C.4) |
where denotes the -GAN’s minimax objective. Moreover, note that for a constant the value of the minimax objective does not change with generator . As a result, for every
| (C.5) |
Then, (C.4) and (C.5) collectively prove that for every and we have
which completes the proof for -GANs.
Proof for Wasserstein GANs:
Consider a general Wasserstein GAN problem with a cost function satisfying for every . Notice that this property holds for all Wasserstein distance measures corresponding to cost function for . The generalized Wasserstein GAN minimax problem is as follows:
| (C.6) |
Due to the realizability assumption, a generator function results in the data distribution such that . Then, the above minimax objective for reduces to
| (C.7) |
Since the cost is assumed to take a zero value given identical inputs, we have:
As a result, holds for every . Hence, the objective in (C.7) will be non-positive and takes its maximum zero value for any constant function , which by definition satisfies -concavity. Therefore, letting denote the GAN minimax objective, for every we have
| (C.8) |
We also know that for a constant discriminator the value of the minimax objective is independent from the generator function. Therefore, for every we have
| (C.9) |
As a result, (C.8) and (C.9) together show that for every and
| (C.10) |
which makes the proof complete for Wasserstein GANs.
C.2 Proof of Theorem 1 & Remark 1
Proof for -GANs:
Lemma 1.
Consider two random vectors with probability density functions , respectively. Suppose that are non-zero everywhere. Then, considering the following variational representation of ,
| (C.11) |
the optimal solution will satisfy
| (C.12) |
Proof.
Let us rewrite the -divergence’s variational representation as
where the last equality holds, since the maximization objective decouples across values. It can be seen that the inside optimization problem for each is maximizing a concave objective in which by setting the derivative to zero we obtain
| (C.13) |
As a property of the Fenchel-conjugate of a convex , we know which combined with the above equation implies that
| (C.14) |
The above result completes Lemma 1’s proof. ∎
Consider the -GAN problem with the generator function specified in the theorem:
| (C.15) |
Note that and . Notice that if was not full-rank, the maximized discriminator objective would be achieved by a assigning an infinity value to the points not included in the rank-constrained support set of generator . This will not result in a solution to the -GAN problem, because we assume that the dimensions of and match each other and hence there exists a full-rank with a finite maximized objective, i.e. -divergence value. Therefore, in a Nash equilibrium of the -GAN problem, the solution must be full-rank and invertible.
Lemma 1 results in the following equation for the optimal discriminator given generator parameters :
As a result, the function appearing in the -GAN’s minimax objective will be
Claim: is a strictly convex function of .
To show this claim, note that the following expression is a strongly-convex quadratic function of , since we have assumed that the spectral norm of is bounded as :
For simplicity, we denote the above strongly-convex function with and define the function as
According to the above definitions, is the composition of and strongly-convex . Note that is a monotonically increasing function, since defining we have
| (C.16) |
which follows from the equality
that is a consequence of the definition of Fenchel-conjugate, implying that for the convex . Note that holds everywhere, because is assumed to be strictly convex. This proves that is strictly increasing. Furthermore, is a convex function, because is non-decreasing due to the assumption that is non-decreasing over . As a result, is an increasing convex function.
Therefore, is a composition of a strongly-convex and an increasing convex . Therefore, as a well-known result in convex optimization [48], the claim is true and is a strictly convex function of .
We showed that the claim is true for every feasible . Now, we prove that the pair will not be a local Nash equilibrium for any feasible . If the pair was a local Nash equilibrium, would be a local minimum for the following minimax objective where is fixed to be :
| (C.17) |
However, as shown earlier, for any feasible , is a strictly-convex function of , which in turn shows that (C.17) is a strictly-concave function of variable . This consequence proves that the objective has no local minima for the unconstrained variable . Due to the shown contradiction, a pair with the form cannot be a local Nash equilibrium in parameters . Consequently, the minimax problem has no pure Nash equilibrium solutions, since in a pure Nash equilibrium the discriminator will be by definition optimal against the choice of generator.
Proof for W2GANs:
Consider the W2GAN problem with the assumed generator function:
| (C.18) |
where the c-transform is defined for the quadratic cost function . Similar to the -GAN case, define to be the optimal discriminator for the generator function parameterized by . Note that and .
According to the Brenier’s theorem [49], the optimal transport from the Gaussian data distribution to the Gaussian generative model will be
As a well-known result regarding the second-order optimal transport map between two Gaussian distributions, the optimal transport will be a linear transformation as . This result shows that
| (C.19) |
Note that the c-transform for cost satisfies where denotes ’s Fenchel-conjugate. For general convex quadratic function we have where denotes ’s Moore Penrose pseudoinverse. Therefore, for the c-transform of the optimal discriminator we will have
Since every feasible satisfies the bounded spectral norm condition as , the optimal will be a quadratic function whose Hessian has at least one strictly positive eigenvalue along the principal eigenvector of . The positive eigenvalue exists in general case where ’s dimension can be even smaller than ’s dimension. If we had the stronger assumption that the two dimensions exactly match, similar to the f-GAN problem considered, then the pseudo-inverse would be the same as the inverse resulting in a strongly-convex quadratic . Nevertheless, as we prove here, the theorem’s result on W2GAN holds in the general case and does not necessarily require the same dimension between and .
Consider the W2GAN minimax objective for the pair where is fixed to be the optimal :
| (C.20) |
If was a local Nash equilibrium, the variables would provide a local minimum to the above objective. However, since is shown to be a quadratic function with a Hessian possessing positive eigenvalues, the above minimax objective will not have a local minimum in the unconstrained variable . Therefore, the minimax problem possesses no local Nash equilibrium solutions with the form and therefore no pure Nash equilibrium solutions.
For the parameterized case with a quadratic discriminator , first of all note that as shown in the proof the optimal discriminator for any generator parameter will be a -concave quadratic function. Therefore, the optimal solution for the discriminator does not change because of the new quadratic constraint. Furthermore, the discriminator optimization problem has a concave objective in parameters . This is because the discriminator is a linear function in terms of , and is a convex function of as the supremum of some affine functions is convex.
As a result, the discriminator optimization reduces to maximizing a concave objective of constrained to a convex set which is equivalent to the -concave constraint on the quadratic . Hence, any local solution to this optimization problem will also be a global solution. This result implies that any local Nash equilibrium for the new parameterized minimax problem will have the form , which as we have already shown does not exist under the theorem’s assumptions.
Proof for the 1-dimensional WGAN:
Consider the 1-dimensional Wasserstein GAN problem for the assumed linear generator function:
| (C.21) |
The inner maximization problem can be rewritten as
| (C.22) |
Here we have
Since , it can be seen that the above difference will be positive everywhere except over an interval , where are the two solutions to the quadratic equation:
| (C.23) |
Note that the above quadratic equation has two distinct solutions , since and leading to the positive discriminant:
| (C.24) |
As the function in the maximization problem (C.22) is only constrained to be 1-Lipschitz, the optimal ’s slope must be equal to over and equal to over , in order to allow the maximum increase in the maximization objective. Over the interval , we claim that for the optimal is a convex function, because otherwise its double Fenchel-conjugate , which is by definition convex, achieves a higher value.
First of all, note that the double Fenchel-conjugate will not be different from outside the interval, because is defined to provide the largest convex function satisfying , and is supposed to be -Lipschitz taking its minimum derivative on and its maximum derivative over . Next, since lower-bounds , it results in a non-smaller integral value over the interval as takes negative values over . If is not convex, then provides a strict lower-bound for which matches over . Therefore, the convex -Lipschitz results in a greater objective that is a contradiction to ’s optimality. This contradiction proves that the optimal discriminator is a convex function.
Therefore, for every feasible , there exists an optimal solution for (C.22) that is a non-constant convex function. This result proves that the WGAN problem has no local Nash equilibiria with the form , because if was a local Nash equilibrium then would be a local minimum for the following objective where is fixed to be :
| (C.25) |
However, the above objective is a non-constant concave function of the unconstrained variable and hence does not have a local minimum in . This shows that the WGAN problem does not have a Nash equilibrium and completes the proof for the WGAN case.
Remark.
Proof.
Proof for the W2GAN:
For the W2GAN case, note that if we repeat the same steps as in the proof of Theorem 1, we can show
which is a concave quadratic function of , since the assumptions imply that . Here is supposed to be a full-rank square matrix as its minimum singular value is assumed to be positive and has the same dimension as .
We claim that for the feasible choice and , the pair results in a Nash equilibrium of the minimax problem. Considering the definition of the optimal discriminator , its optimlaity for directly follows. Moreover, (C.2) implies that
| (C.26) |
As a result, fixing the above discriminator function the minimax objective will be
which is minimized at and over the specified feasible set, as we know the Frobenius norm-squared, , is the sum of the squared of ’s singular values. Therefore, the claim holds and the choice and results in the optimal solution and a Nash equilibrium.
Proof for the 1-dimensional Wasserstein GAN:
Here we select the parameters , . We claim that the optimal discriminator function for this choice is the negative absolute value function . Note that the optimal 1-Lipschitz solves the following problem:
| (C.27) |
In the above objective given , the function is positive over and negative elsewhere. Therefore, the optimal should get the maximum derivative over and the minimum derivative over . Because of the even structure of , there exists an even optimal because remains -Lipschitz and optimal for any optimal -Lipschitz discriminator . The optimal even should further be continuous as a -Lipschitz function, implying that such a is decreasing over and increasing over . Enforcing the maximum derivative over the two interval results in the optimal .
Therefore, provides an optimal discriminator for . Also, for this the minimax objective of the Wasserstein GAN will be
In the above equation, , showing that the above objective is minimized at considering the assumed feasible set where . As a result, the pair provides a Nash equilibrium to the WGAN minimax game. ∎
C.3 Proof of Proposition 2
Proof of the direction:
Assume that is a -proximal equilibrium. According to the definition of the proximal equilibrium, the following holds for every and :
| (C.28) |
Claim: .
To show this claim, note that
| (C.29) |
In this optimization, the optimal solution is itself. Otherwise, for the optimal we have and as a result
| (C.30) |
which is a contradiction given that is a -proximal equilibrium. Therefore, optimizes the proximal optimization, which shows the claim is valid and we have . Knowing that holds for every , we have
Furthermore,
| (C.31) | ||||
| (C.32) | ||||
Therefore, the proof is complete.
Proof of the direction:
Suppose that for the following holds for every and :
| (C.33) |
We claim that . To show this claim, consider the definition of the -proximal equilibrium:
| (C.34) |
Here maximizes the objective because we have assumed that holds for every . Therefore, the claim is valid and .
Also, note that for every the solution in the proximal optimization satisfies . Combining these results with (C.33), we obtain the following inequalities which hold for every and :
| (C.35) |
The above equation shows that the pair is a -proximal equilibrium.
C.4 Proof of Proposition 3
Consider a -proximal equilibrium . As a result of Proposition 2, for every and we have
Since , the following holds
which shows that
Due to Proposition 2, will be a -proximal equilibrium as well. Hence, the proof is complete and we have
| (C.36) |
C.5 Proof of Proposition 4
Consider the definition of a -proximal equilibrium in the parameterized space:
| (C.37) |
In the above optimization problem, the first term is assumed to be -smooth in , while the second term will be -strongly convex in . As a result, the sum of the two terms will be -strongly concave if holds. Since the objective function is strongly-concave in , it will be maximized by a unique solution . Moreover, applying the Danskin’s theorem [50] implies that the following holds at the optimal :
| (C.38) |
C.6 Proof of Theorem 2
Lemma 2.
Suppose that is a -strongly convex function according to norm , i.e. for any and we have
| (C.39) |
Consider the following optimization problem where the feasible set is a convex set and is the optimal solution,
| (C.40) |
Then, for every we have
| (C.41) |
Proof.
Based on Proposition 2 and the definition of , we only need to show that for the W2GAN’s objective, which we denote by , the following holds for every :
| (C.46) |
To show the above inequality, it suffices to prove the following inequality
| (C.47) |
Claim: For the W2GAN problem, we have
To show this claim, note that according to the W2GAN’s formulation we have where is the second-order cost function specified in the theorem. We start by proving this result for . In this case, the Brenier theorem [51] proves that the optimal transport map from the data variable to the generative model can be derived from the gradient of the optimal as follows
| (C.48) |
which plugged into the optimal transport objective proves that
The above equation proves the result holds for . For a general , note that applying a simple change of variable in the Kantorovich duality representation and solving the dual problem for shows that transport samples from the data domain to the generative model. This is due to the fact that after applying this change of variable the Kantorovich duality reduces to multiplied to the dual problem for . As a result, applying the transport map to the definition of the optimal transport cost shows that
proving the claim holds for any .
Substituting the discriminator maximization with the result in the above claim, the W2GAN problem reduces to the following problem:
| (C.49) |
Here we can equivalently optimize for instead of minimizing over the variable , obtaining
| (C.50) |
Note that the term reduces to the squared of the defined Sobolev norm in a semi-Hilbert space, which results in a -strongly convex function according to with strong convexity defined as in (C.39). As a result, the objective in (C.50) is -strongly convex according to the Sobolev norm . In addition, this objective is minimized over a convex feasible set , due to the theorem’s assumption. Therefore, Lemma 2 shows that the optimal satisfies the following inequality for every :
The above result implies that
| (C.51) |
which completes the proof.
C.7 Proof of Theorem 3
Lemma 3.
Consider two vectors with equal Euclidean norms . Then for every , we have
| (C.52) |
Proof.
Note that
The above holds as we have assumed that implying and since the two vectors share the same Euclidean norm
Hence, Lemma 3’s proof is complete. ∎
As shown by the Kantorovich duality [49], for the optimal and the optimal coupling the following holds with probability for every joint sample drawn from the optimal coupling ,
| (C.53) |
Knowing that is 1-Lipschitz, for every convex combination we must have
This will imply that there definitely exists such that the transport map described in the theorem maps the data distribution to the generative model. Plugging this transport map into the definition of the first-order Wasserstein distance, we obtain
where the last equality holds since the Euclidean norm of has a unit Euclidean norm with probability over the data distribution as we proved holds for every including .
As a result, the Wasserstein GAN problem reduces to the following optimization problem
| (C.54) |
Defining , is -strongly convex with respect to the norm function
that is induced by the following inner product and results in a Hilbert space
Therefore, for the minimizing the objective in (C.54) over the assumed convex set , Lemma 2 implies that
Here the last inequality follows from Lemma 3 since every has a unit-norm gradient with probability according to the data distribution . Therefore, we have proved that
| (C.55) |
The above inequality results in the following for every feasible
| (C.56) |
Hence, according to Proposition 2, we have shown that the pair is an -proximal equilibrium with respect to the Sobolev norm .