Gauge invariant input to neural network for path optimization method
Abstract
We investigate the efficiency of a gauge invariant input to a neural network for the path optimization method. While the path optimization with a completely gauge-fixed link-variable input has successfully tamed the sign problem in a simple gauge theory, the optimization does not work well when the gauge degrees of freedom remain. We propose to employ a gauge invariant input, such as a plaquette, to overcome this problem. The efficiency of the gauge invariant input to the neural network is evaluated for the 2-dimensional gauge theory with a complex coupling. The average phase factor is significantly enhanced by the path optimization with the plaquette input, indicating good control of the sign problem. It opens a possibility that the path optimization is available to complicated gauge theories, including Quantum Chromodynamics, in a realistic setup.
I Introduction
Exploring the phase structure of gauge theories at finite temperature () and chemical potential () is an interesting and important subject not only in particle and nuclear physics but also in astrophysics. Quantitative understanding of heavy-ion experiments as well as the equation of state for neutron stars requires non-perturbative information of Quantum Chromodynamics (QCD) in the plane. It is, however, a difficult task due to the sign problem. Traditional Monte Carlo approaches work at low density, but fail in the middle and high density regions.
Recently, several new methods are developed to overcome the sign problem at high densities, e.g. . The complex Langevin method Klauder (1984); Parisi (1983) is a stochastic quantization with complexified variables. It is a non-Monte Carlo approach and thus free from the sign problem. The low computational cost allows us to apply it to 4-dimensional QCD at finite density Sexty (2014); Aarts et al. (2014); Fodor et al. (2015); Nagata et al. (2018); Kogut and Sinclair (2019); Sexty (2019); Scherzer et al. (2020); Ito et al. (2020). The tensor renormalization group method Levin and Nave (2007) is a coarse graining algorithm using a tensor network. It is also a non-Monte Carlo method. Although the computational cost is extremely high, it has been vigorously tested even in 4-dimensional theoretical models Akiyama et al. (2019, 2020, 2021a, 2021b). Recent improved algorithms considerably reduce the cost Kadoh and Nakayama (2019); Kadoh et al. (2021). The Lefschetz thimble method Witten (2011) is a Monte Carlo scheme that complexifies variables and determines the integration path by solving an anti-holomorphic flow equation from fixed points such that the imaginary part of the action is constant. Cauchy’s integral theorem ensures the integral is independent of a choice of the integration path, if the path is given as a result of continuous deformation from the original path Alexandru et al. (2016), crosses no poles, and the integral at infinity has no contribution. The numerical study has been started with Langevin algorithm Cristoforetti et al. (2012), Metropolis algorithm Mukherjee et al. (2013), and Hybrid Monte Carlo algorithm Fujii et al. (2013). The high computational cost is the main bottleneck of this method, but the algorithm development is overcoming it Fukuma and Matsumoto (2020); Fukuma et al. (2021). The path optimization method (POM) Mori et al. (2017, 2018), also referred to as the sign-optimized manifold Alexandru et al. (2018a), is an alternative approach that modifies the integration path by use of the machine learning via neural networks. The machine learning finds the best path on which the sign problem is maximally weakened. The POM successfully works for the complex theory Mori et al. (2017), the Polyakov-loop extended Nambu–Jona-Lasinio model Kashiwa et al. (2019a, b), the Thirring model Alexandru et al. (2018a, b), the dimensional bose gas Bursa and Kroyter (2018), the dimensional QCD Mori et al. (2019), the 2-dimensional gauge theory with complexified coupling constant Kashiwa and Mori (2020), as well as noise reduction in observables Detmold et al. (2021). The recent progress of the complexified path approaches is reviewed in Ref. Alexandru et al. (2020).
A key issue of the POM in gauge theories is control of the gauge degrees of freedom. In dimensional QCD at finite density Mori et al. (2019), the POM works with and without the gauge fixing. In higher dimensions, however, the gauge fixing is required for the neural networks to find an improved path. The effect of the gauge fixing is discussed in the 2-dimensional gauge theory with complexified coupling constant Kashiwa and Mori (2020). The average phase factor, an indicator of the sign problem, is never improved without the gauge fixing. As we reduce the gauge degrees of freedom by the gauge fixing, the average phase factor is enhanced better.
Based on this result, we propose to adopt gauge invariant input for the optimization process. The link variables are no longer direct input to the neural network. We first construct a gauge invariant quantity and use it as the input. We employ the simplest gauge invariant input, plaquette, in this study. A similar idea is employed as a part of lattice gauge equivariant Convolutional Neural Networks Favoni et al. (2020). The performance of the POM with the gauge invariant input is demonstrated in the 2-dimensional gauge theory with a complex coupling. The sign problem originates from the imaginary part of the complex coupling. The above-mentioned several methods have been tested for this theory Kashiwa and Mori (2020); Pawlowski et al. (2021). Since the analytic result is available Wiese (1989); Rusakov (1990); Bonati and Rossi (2019), we can utilize it for verification of the simulation results.
II Formulation
II.1 -dimensional gauge action
The gauge action is Wilson’s plaquette action Wilson (1974) given by
| (1) |
where represents the lattice site, and is an overall constant consisting of the gauge coupling constant and the lattice spacing . () is the plaquette (its inverse). The definition is
| (2) |
where is a unit vector in -direction and with are the link variables. We impose a periodic boundary condition in each direction.
In addition to the plaquette, we measure expectation values of the topological charge defined on the lattice,
| (3) |
In the continuum limit, recovers the continuum form .
The analytic result of this theory has been obtained Wiese (1989); Rusakov (1990); Bonati and Rossi (2019). The partition function is represented through the modified Bessel function ,
| (4) | ||||
| (5) |
where is the volume factor with being the lattice size in -direction. Since is well-defined for all complex values of , the analytic solution is available over the whole domain of .
II.2 Path optimization method with plaquette and link input
The path optimization method utilizes complexified dynamical variables to tame the sign problem. In the case of the gauge theory, the plaquette and the link variable are extended as
| (6) | ||||
| (7) |
where . The modification of the integral path is represented by , originated from the imaginary part of , which is evaluated by a neural network consisting of the input, a single hidden, and the output layers, as follows. The neural network is a mathematical model inspired by a brain, which is often used for the machine learning McCulloch and Pitts (1943); Rosenblatt (1958); Hebb (2002); Hinton and Salakhutdinov (2006). A sufficient number of the hidden layer units with a non-linear function called an activation function reproduce any continuous function, as proven by the universal approximation theorem Cybenko (1989); Hornik (1991). The variables in the hidden layer nodes () and the output () are set as
| (8) | ||||
| (9) |
where with the number of the degree of freedom and , and are parameters of the neural network. An activation function defines a relation of data between two layers, the input and hidden layers as well as the hidden and output layers. The activation function is taken to be a tangent hyperbolic function in this work. Our choice of the input is the plaquette or the link variable.
| (10) | ||||
| (11) |
We compare (i) with (ii) in terms of the efficiency of the neural network. A schematic picture of our neural network with the plaquette input is given in Fig. 1.
The expectation value of a complexified observable is calculated by
| (12) |
where is the integration path that specifies the complexified link variables and the Jacobian . is the phase of . denotes the expectation value with the phase quenched Boltzmann weight. In contrast to the naive reweighting, Eq. (12) is evaluated on the modified integration path where the sign problem is maximally weakened by the machine learning without change of the expectation value guaranteed by Cauchy’s theorem. This is the advantage of the path optimization method.
The cost function controls optimization through the neural network. We apply the following cost function to minimize the sign problem,
| (13) |
We evaluate it by the exponential moving average (EMA) as in Ref. Kashiwa and Mori (2020). Using this cost function (13), the neural network finds the best path that enhances as much as possible.


III Numerical setup and result
III.1 Setup
We evaluate performance of the POM for –. The sign problem is originated from the imaginary part of . We generate gauge configurations by the Hybrid Monte-Carlo algorithm in the POM. The total number of configurations is . Statistical errors are estimated by the Jackknife method with the bin size of . The neural network utilizes ADADELTA optimizer Zeiler (2012) combined with the Xavier initialization Glorot and Bengio (2010). The parameters in Eqs.(8) and (9) are optimized during learning. The flow chart is displayed in Ref. Kashiwa and Mori (2020). We set the learning rate to 1 and the decay constant 0.95, combined with the batch size of 10. The number of units in the input layer reflects our choice of in Eqs. (10), (11) as
| (14) | ||||
| (15) |
where and . The number of units in the output layer is common to (i) and (ii), . We employ a single hidden layer with hidden units on lattice, on lattice, and on lattice, respectively. As we set the proportional to the volume, the cost of the neural network is and is for the Jacobian.
III.2 Result
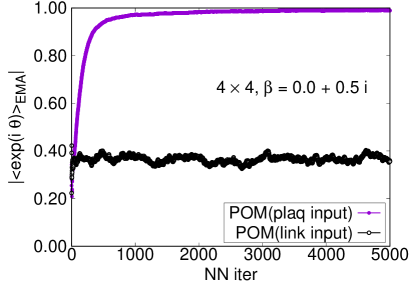
Figure 2 exhibits the neural-network–step-number dependence of the exponential moving average of the average phase factor at on a lattice as a typical example. The path optimization with the plaquette input successfully enhances , while that with the link variable input does not. Similar behavior is also observed at other values of on and lattices. Our result verifies the advantage of the gauge invariant input to the neural network for the 2-dimensional gauge theory with the complex coupling.
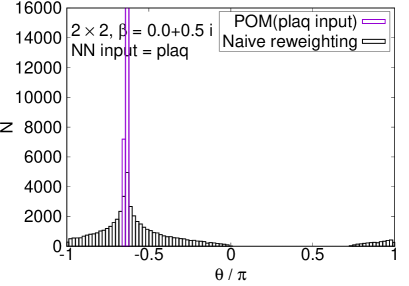
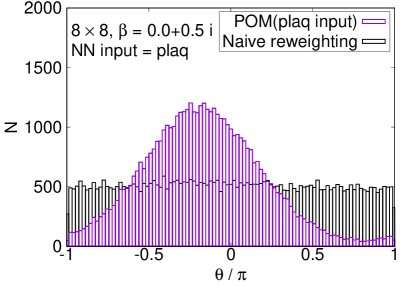
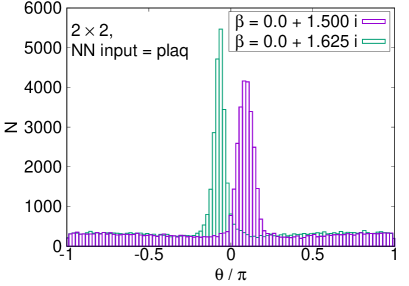
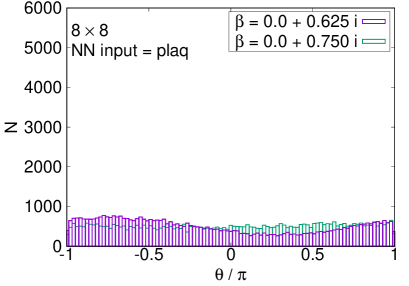
The enhancement with the plaquette input is confirmed in the histogram of the phases, shown in Fig. 3. While the naive reweighting gives a broad distribution of the phase factor, the path optimization significantly sharpens the peak structure. We stress that the POM works even on the lattice, where the sign problem is severer. Although the naive reweighting has almost flat dependence on the phase, the POM can still extract a peak structure around .
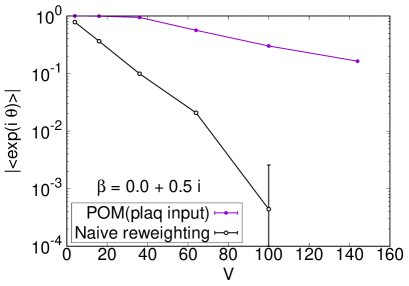
Figure 4 represents the volume dependence of the average phase factor at with additional simulation results on , and lattices. The naive reweighting leads to steep exponential fall-off as a function of the volume. The sign problem becomes extremely severer toward the infinite volume limit. The path optimization evidently changes the volume dependence of the average phase factor to be milder. It indicates better control of the sign problem.
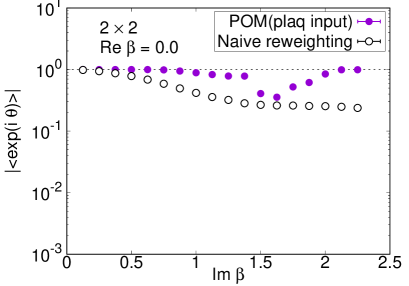
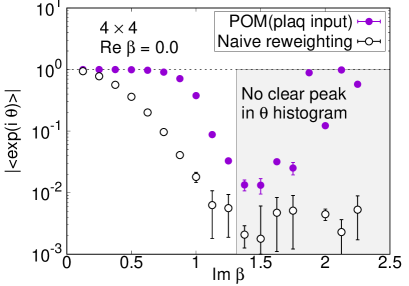
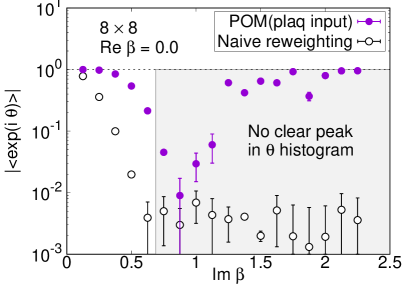
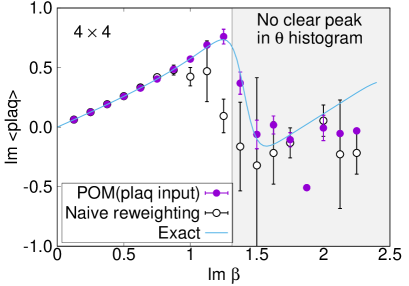
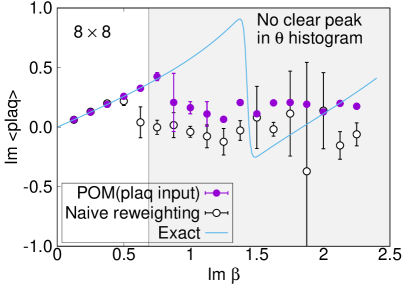
We plot the average phase factors with and without the path optimization as functions of in Fig. 5. The average phase factors are enhanced by factors of up to 4 on , 21 on , and 27 on lattices, respectively. The enhancement decreases, however, as we approach the critical coupling where the partition function becomes zero, corresponding to the Lee-Yang zero. While clear peaks are still visible in the histogram of the phases by the path optimization even at on lattice, no clear peak is obtained and the neural network eventually becomes unstable around on and lattices, as displayed in Fig. 6. We need further improvement of the POM around on large lattices.
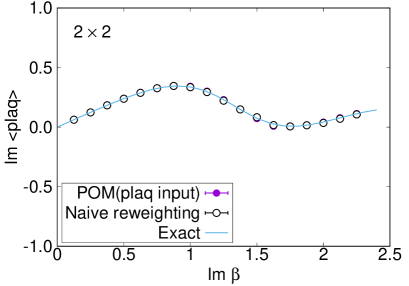
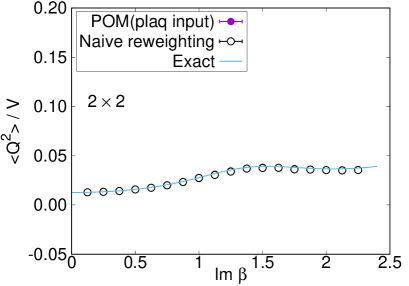
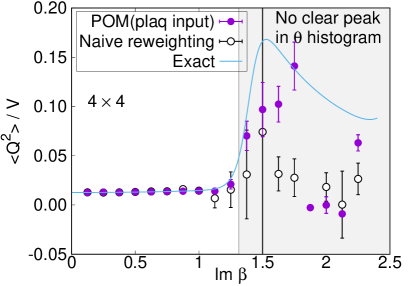
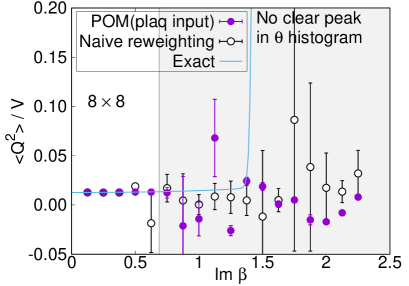
Comparison with the exact solution (4) is accomplished for the expectation values of the plaquette and the topological charge. The result for the plaquette is plotted in Fig. 7 and for the topological charge in Fig. 8. The naive reweighting works in a small region but starts to deviate from the exact value with uncontrolled errors as becomes larger. Our data using the POM agree with the exact solution, as long as we find a peak in the histogram of the phases. The valid region of the POM is definitely extended to larger . Deviations from the exact solution are also observed by the path optimization case, if we have no clear peak in the histogram of the phases, where enhancement of the phase factor by the path optimization is still limited to be small or the path optimization is unstable. One reason of the failure is a restriction of the statistics. The machine learning requires more data to find the best path especially for a system with a large degrees of freedom. Another possibility is the effect of the multimodality. Though there can be several regions contributing to the integral (relevant thimbles), the optimized path may emphasize only a part of them. Quantitative evaluation of the systematic errors of the POM result is still difficult and is beyond the scope of this paper. It is an important future work. Nevertheless, these results demonstrate the superiority of the POM over the naive reweighting for the analysis of the gauge theory with the complex .
IV Summary
We established the efficiency of gauge invariant input in the POM for the 2-dimensional gauge theory with a complex coupling. While the path optimization using the link variable input without gauge fixing shows no gain, the optimization with the gauge invariant input shows a clear increase in the average phase factor through the neural network process. The gain is up to 4 on , 21 on , and 27 on lattices. Even on lattice at , the POM using the gauge invariant input successfully identifies a peak structure in the histogram of the phases, where the naive reweighting shows no peak in the histogram. We confirm the volume dependence of the average phase factor becomes much milder by the POM with the gauge invariant input. We also calculated expectation values of the plaquette and the topological charge for comparison with their exact solutions. Our results agree with the analytical values, as long as we find a peak in the histogram of the phases. The valid region is clearly enlarged to larger , compared with that by the naive reweighting method. It is encouraging toward the POM analysis in more realistic cases.
In the severer sign problem region near the critical point on the large volume, the gain of the POM is less clear. Further improvement of the POM is required. One possible direction is the incorporation of larger Wilson loops and the Polyakov lines as input to the neural network. Another direction is the adoption of novel approaches which respect the gauge symmetry in the neural network, such as the lattice gauge equivariant convolutional neural networks Favoni et al. (2020) and the gauge covariant neural network Tomiya and Nagai (2021). In addition, there is a different approach that modifies the action instead of the integral path Tsutsui and Doi (2016); Doi and Tsutsui (2017); Lawrence (2020). The combination of the modifications of the action and the integral path seems to be interesting.
Acknowledgements.
Our code is in part based on LTKf90 Choe et al. (2002). This work is supported by JSPS KAKENHI Grant Numbers JP18K03618, JP19H01898, and JP21K03553.References
- Klauder (1984) J. R. Klauder, Phys. Rev. A 29, 2036 (1984).
- Parisi (1983) G. Parisi, Phys. Lett. B 131, 393 (1983).
- Sexty (2014) D. Sexty, Phys. Lett. B 729, 108 (2014), arXiv:1307.7748 [hep-lat] .
- Aarts et al. (2014) G. Aarts, E. Seiler, D. Sexty, and I.-O. Stamatescu, Phys. Rev. D 90, 114505 (2014), arXiv:1408.3770 [hep-lat] .
- Fodor et al. (2015) Z. Fodor, S. D. Katz, D. Sexty, and C. Török, Phys. Rev. D 92, 094516 (2015), arXiv:1508.05260 [hep-lat] .
- Nagata et al. (2018) K. Nagata, J. Nishimura, and S. Shimasaki, Phys. Rev. D 98, 114513 (2018), arXiv:1805.03964 [hep-lat] .
- Kogut and Sinclair (2019) J. B. Kogut and D. K. Sinclair, Phys. Rev. D 100, 054512 (2019), arXiv:1903.02622 [hep-lat] .
- Sexty (2019) D. Sexty, Phys. Rev. D 100, 074503 (2019), arXiv:1907.08712 [hep-lat] .
- Scherzer et al. (2020) M. Scherzer, D. Sexty, and I. O. Stamatescu, Phys. Rev. D 102, 014515 (2020), arXiv:2004.05372 [hep-lat] .
- Ito et al. (2020) Y. Ito, H. Matsufuru, Y. Namekawa, J. Nishimura, S. Shimasaki, A. Tsuchiya, and S. Tsutsui, JHEP 10, 144 (2020), arXiv:2007.08778 [hep-lat] .
- Levin and Nave (2007) M. Levin and C. P. Nave, Phys. Rev. Lett. 99, 120601 (2007), arXiv:cond-mat/0611687 .
- Akiyama et al. (2019) S. Akiyama, Y. Kuramashi, T. Yamashita, and Y. Yoshimura, Phys. Rev. D 100, 054510 (2019), arXiv:1906.06060 [hep-lat] .
- Akiyama et al. (2020) S. Akiyama, D. Kadoh, Y. Kuramashi, T. Yamashita, and Y. Yoshimura, JHEP 09, 177 (2020), arXiv:2005.04645 [hep-lat] .
- Akiyama et al. (2021a) S. Akiyama, Y. Kuramashi, T. Yamashita, and Y. Yoshimura, JHEP 01, 121 (2021a), arXiv:2009.11583 [hep-lat] .
- Akiyama et al. (2021b) S. Akiyama, Y. Kuramashi, and Y. Yoshimura, (2021b), arXiv:2101.06953 [hep-lat] .
- Kadoh and Nakayama (2019) D. Kadoh and K. Nakayama, (2019), arXiv:1912.02414 [hep-lat] .
- Kadoh et al. (2021) D. Kadoh, H. Oba, and S. Takeda, (2021), arXiv:2107.08769 [cond-mat.str-el] .
- Witten (2011) E. Witten, AMS/IP Stud. Adv. Math. 50, 347 (2011), arXiv:1001.2933 [hep-th] .
- Alexandru et al. (2016) A. Alexandru, G. Basar, P. F. Bedaque, G. W. Ridgway, and N. C. Warrington, JHEP 05, 053 (2016), arXiv:1512.08764 [hep-lat] .
- Cristoforetti et al. (2012) M. Cristoforetti, F. Di Renzo, and L. Scorzato (AuroraScience), Phys. Rev. D 86, 074506 (2012), arXiv:1205.3996 [hep-lat] .
- Mukherjee et al. (2013) A. Mukherjee, M. Cristoforetti, and L. Scorzato, Phys. Rev. D 88, 051502 (2013), arXiv:1308.0233 [physics.comp-ph] .
- Fujii et al. (2013) H. Fujii, D. Honda, M. Kato, Y. Kikukawa, S. Komatsu, and T. Sano, JHEP 10, 147 (2013), arXiv:1309.4371 [hep-lat] .
- Fukuma and Matsumoto (2020) M. Fukuma and N. Matsumoto, (2020), 10.1093/ptep/ptab010, arXiv:2012.08468 [hep-lat] .
- Fukuma et al. (2021) M. Fukuma, N. Matsumoto, and Y. Namekawa, (2021), arXiv:2107.06858 [hep-lat] .
- Mori et al. (2017) Y. Mori, K. Kashiwa, and A. Ohnishi, Phys. Rev. D 96, 111501 (2017), arXiv:1705.05605 [hep-lat] .
- Mori et al. (2018) Y. Mori, K. Kashiwa, and A. Ohnishi, PTEP 2018, 023B04 (2018), arXiv:1709.03208 [hep-lat] .
- Alexandru et al. (2018a) A. Alexandru, P. F. Bedaque, H. Lamm, and S. Lawrence, Phys. Rev. D 97, 094510 (2018a), arXiv:1804.00697 [hep-lat] .
- Kashiwa et al. (2019a) K. Kashiwa, Y. Mori, and A. Ohnishi, Phys. Rev. D 99, 014033 (2019a), arXiv:1805.08940 [hep-ph] .
- Kashiwa et al. (2019b) K. Kashiwa, Y. Mori, and A. Ohnishi, Phys. Rev. D 99, 114005 (2019b), arXiv:1903.03679 [hep-lat] .
- Alexandru et al. (2018b) A. Alexandru, P. F. Bedaque, H. Lamm, S. Lawrence, and N. C. Warrington, Phys. Rev. Lett. 121, 191602 (2018b), arXiv:1808.09799 [hep-lat] .
- Bursa and Kroyter (2018) F. Bursa and M. Kroyter, JHEP 12, 054 (2018), arXiv:1805.04941 [hep-lat] .
- Mori et al. (2019) Y. Mori, K. Kashiwa, and A. Ohnishi, PTEP 2019, 113B01 (2019), arXiv:1904.11140 [hep-lat] .
- Kashiwa and Mori (2020) K. Kashiwa and Y. Mori, Phys. Rev. D 102, 054519 (2020), arXiv:2007.04167 [hep-lat] .
- Detmold et al. (2021) W. Detmold, G. Kanwar, H. Lamm, M. L. Wagman, and N. C. Warrington, (2021), arXiv:2101.12668 [hep-lat] .
- Alexandru et al. (2020) A. Alexandru, G. Basar, P. F. Bedaque, and N. C. Warrington, (2020), arXiv:2007.05436 [hep-lat] .
- Favoni et al. (2020) M. Favoni, A. Ipp, D. I. Müller, and D. Schuh, (2020), arXiv:2012.12901 [hep-lat] .
- Pawlowski et al. (2021) J. M. Pawlowski, M. Scherzer, C. Schmidt, F. P. G. Ziegler, and F. Ziesché, Phys. Rev. D 103, 094505 (2021), arXiv:2101.03938 [hep-lat] .
- Wiese (1989) U. J. Wiese, Nucl. Phys. B 318, 153 (1989).
- Rusakov (1990) B. E. Rusakov, Mod. Phys. Lett. A 5, 693 (1990).
- Bonati and Rossi (2019) C. Bonati and P. Rossi, Phys. Rev. D 99, 054503 (2019), arXiv:1901.09830 [hep-lat] .
- Wilson (1974) K. G. Wilson, Phys. Rev. D 10, 2445 (1974).
- McCulloch and Pitts (1943) W. S. McCulloch and W. Pitts, The bulletin of mathematical biophysics 5, 115 (1943).
- Rosenblatt (1958) F. Rosenblatt, Psychological review 65, 386 (1958).
- Hebb (2002) D. O. Hebb, The organization of behavior: A neuropsychological theory (Psychology Press, 2002).
- Hinton and Salakhutdinov (2006) G. E. Hinton and R. R. Salakhutdinov, Science 313, 504 (2006), https://www.science.org/doi/pdf/10.1126/science.1127647 .
- Cybenko (1989) G. Cybenko, Mathematics of Control, Signals, and Systems (MCSS) 2, 303 (1989).
- Hornik (1991) K. Hornik, Neural Networks 4, 251 (1991).
- Zeiler (2012) M. D. Zeiler, CoRR abs/1212.5701 (2012), arXiv:1212.5701 .
- Glorot and Bengio (2010) X. Glorot and Y. Bengio, in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, Vol. 9, edited by Y. W. Teh and M. Titterington (PMLR, Chia Laguna Resort, Sardinia, Italy, 2010) pp. 249–256.
- Tomiya and Nagai (2021) A. Tomiya and Y. Nagai, (2021), arXiv:2103.11965 [hep-lat] .
- Tsutsui and Doi (2016) S. Tsutsui and T. M. Doi, Phys. Rev. D 94, 074009 (2016), arXiv:1508.04231 [hep-lat] .
- Doi and Tsutsui (2017) T. M. Doi and S. Tsutsui, Phys. Rev. D 96, 094511 (2017), arXiv:1709.05806 [hep-lat] .
- Lawrence (2020) S. Lawrence, Phys. Rev. D 102, 094504 (2020), arXiv:2009.10901 [hep-lat] .
- Choe et al. (2002) S. Choe, S. Muroya, A. Nakamura, C. Nonaka, T. Saito, and F. Shoji, Nucl. Phys. B Proc. Suppl. 106, 1037 (2002).