GCP: Guarded Collaborative Perception with Spatial-Temporal Aware Malicious Agent Detection
Abstract
Collaborative perception significantly enhances autonomous driving safety by extending each vehicle’s perception range through message sharing among connected and autonomous vehicles. Unfortunately, it is also vulnerable to adversarial message attacks from malicious agents, resulting in severe performance degradation. While existing defenses employ hypothesis-and-verification frameworks to detect malicious agents based on single-shot outliers, they overlook temporal message correlations, which can be circumvented by subtle yet harmful perturbations in model input and output spaces. This paper reveals a novel blind area confusion (BAC) attack that compromises existing single-shot outlier-based detection methods. As a countermeasure, we propose GCP, a Guarded Collaborative Perception framework based on spatial-temporal aware malicious agent detection, which maintains single-shot spatial consistency through a confidence-scaled spatial concordance loss, while simultaneously examining temporal anomalies by reconstructing historical bird’s eye view motion flows in low-confidence regions. We also employ a joint spatial-temporal Benjamini-Hochberg test to synthesize dual-domain anomaly results for reliable malicious agent detection. Extensive experiments demonstrate GCP’s superior performance under diverse attack scenarios, achieving up to 34.69% improvements in AP@0.5 compared to the state-of-the-art CP defense strategies under BAC attacks, while maintaining consistent 5-8% improvements under other typical attacks. Code will be released at https://github.com/CP-Security/GCP.git.
Index Terms:
Connected and autonomous vehicle (CAV), collaborative perception, malicious agents, spatial-temporal detection.I Introduction
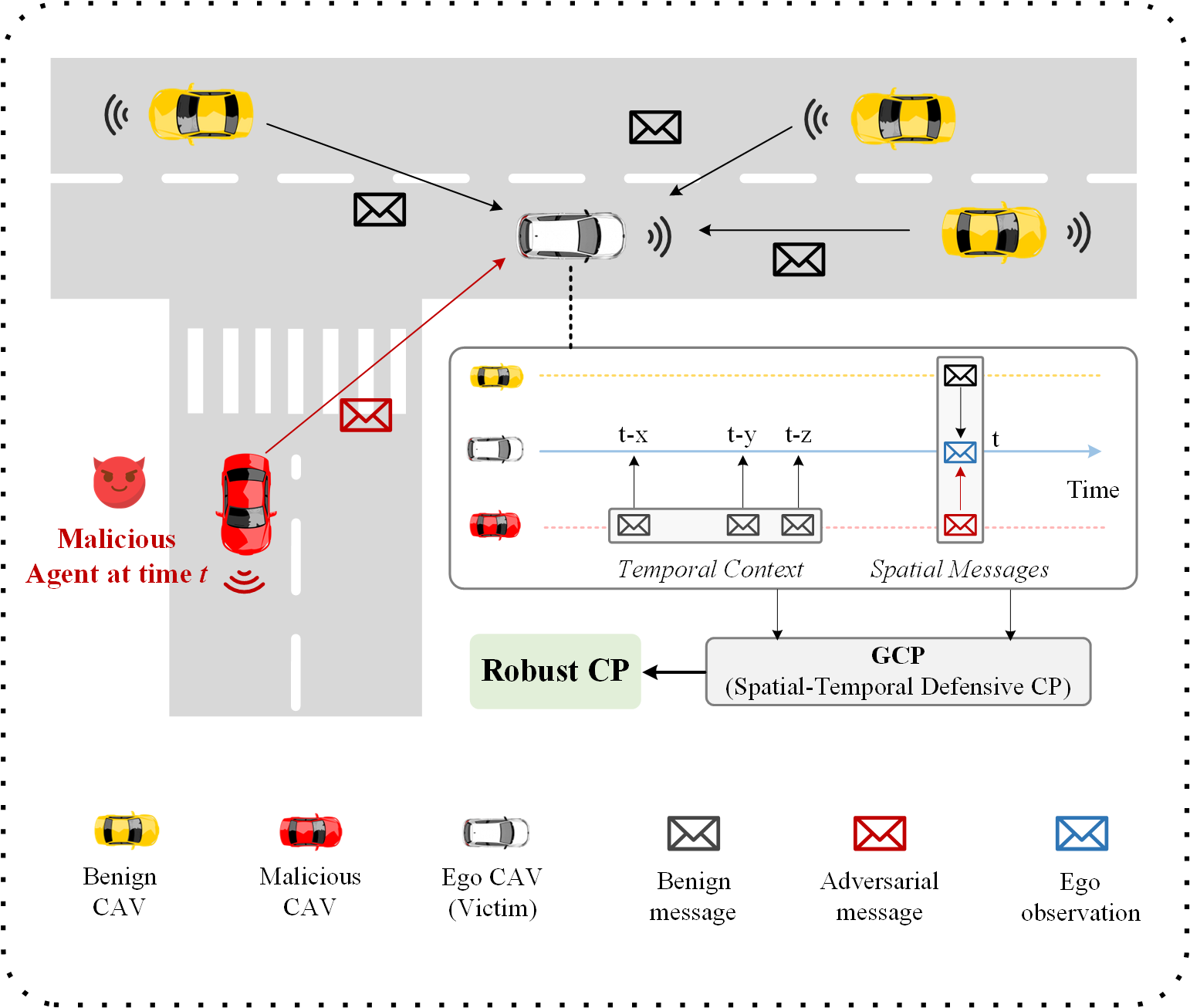
Collaborative perception (CP) supersedes single-agent perception by enabling information-sharing among multiple connected and autonomous vehicles (CAVs), substantially enlarging a vehicle’s perception scope and accuracy [1, 2, 3, 4, 5, 6, 7]. The extended perception helps an ego vehicle detect occluded objects that were originally difficult to recognize with single-vehicle perception due to physical occlusions, thereby boosting the safety of autonomous driving [8, 9, 10, 11, 12]. To collaborate, one simple way for an ego CAV to receive helps is to directly request early-stage raw data or late-stage detection results from the neighboring CAVs, and then combine this information with its own data to get the CP results. However, these methods are either bandwidth-consuming or vulnerable to perception noise or malicious message attacks. The recent development of deep learning has facilitated feature-level fusion, where the collaborative CAVs send an intermediate representation of deep neural network models to an ego CAV for aggregation, enhancing the performance-bandwidth trade-off in multi-agent perception.
Although CP has brought many benefits to CP systems, it is inevitably attracting adversarial attacks due to the openness of communication channels. While traditional authentication methods (e.g., message and/or source authentication) can verify message sources and data integrity, they cannot protect against compromised legitimate agents who possess valid credentials to share malicious messages. In an intermediate fusion-based CP system, a malicious collaborator could send an adversarial feature map with intricately crafted perturbation to an ego agent, causing significant CP performance degradation after fusion. This is particularly dangerous because the perturbed CP performance could drop far below the single-agent perception, consequently resulting in catastrophic driving decisions. Previous works have revealed diverse attacks that can fool a CP system [13, 14, 15, 16]. For example, Zhang et al.[16] introduced an online attack by optimizing a perturbation on the attacker’s feature map in each LiDAR cycle and reusing the perturbation over frames, which significantly lowers the performance of CP systems.
To guard CP systems, most existing works adopt outlier-based defense against malicious agents following a multi-round hypothesize-and-verify paradigm. In each round, ego agents first generate multiple hypothetical CP outcomes by assuming portion of the collaborators are benign based on prior knowledge and then verify the consistency between the ego agent’s single perception outcome and CP results. The iteration repeats until all malicious agents are identified. Following this idea, Li et al. [15] developed ROBOSAC, a random sample consensus-based method for detecting malicious agents. Besides, Zhao et al. [16] proposed MADE, a multi-test detection framework utilizing match and reconstruction losses to gauge consensus between the ego CAV and collaborative results. Despite its efficacy, the existing hypothesize-and-verify-based CP defense method merely compares the spatial outlier consistency in a single frame without considering the temporal contexts between consecutive frames. Meanwhile, the static outlier-based detection can be easily bypassed when the attacks are subtle yet dangerous in both model input and output. CP-Guard+ [17] proposed a feature-level defense by directly comparing the divergence of the spatial bird eye’s view (BEV) feature map of the ego agent and collaborators, effectively increasing the system’s scalability. However, all the above works only leverage independent spatial-domain information in a single time slot for malicious agent detection, without considering the temporal correlation of collaborators’ messages in different time slots, resulting in suboptimal defensive CP performance.
We strongly believe incorporating temporal knowledge is crucial for CP defense based on two key insights. First, adversarial attacks in real-world scenarios often exhibit distinct temporal patterns. When malicious agents inject perturbations intermittently to maintain stealth, these attacks manifest as anomalous variations in the temporal domain of CP results. For instance, both ROBOSAC [15] and MADE [16] observe that attackers typically alternate between sending malicious and benign messages across time slots to avoid detection. This temporal characteristic provides an additional verification dimension: beyond examining spatial consistency in the current frame, we can leverage historical clean messages from collaborators as reliable references to identify suspicious temporal deviations. Second, even when attackers continuously inject perturbations, their impact on CP results inevitably creates distinctive temporal patterns that differ from normal CP behaviors. These patterns manifest in various aspects, such as unnatural object motion trajectories, inconsistent detection confidence variations, or abrupt changes in spatial feature distributions across frames. Such temporal anomalies, while potentially subtle in individual frames, become more apparent when analyzed over extended long sequences.
To address the aforementioned challenges, in this paper, we first reveal a novel adversarial attack targeted at CP, namely, the blind area confusion (BAC) attack, which generates subtle and targeted perturbation in an ego CAV’s less confident areas to bypass the single-shot outlier-based detection methods. Besides, to overcome the limitations of previous malicious agent detection methods, we propose GCP, a defensive CP system against adversarial attackers based on knowledge from both the spatial and temporal domains. Specifically, GCP leverages a confidence-scaled spatial concordance loss and Long-short-term-memory autoencoder (LSTM-AE)-based BEV flow reconstruction to check the spatial and temporal consistency jointly. To sum up, our main contributions are three-fold:
-
•
We reveal a novel attack, dubbed as blind area confusion (BAC) attack, which is targeted at CP systems by generating subtle and dangerous perturbation in an an ego CAV’s less confident areas. The attack can significantly degrade existing state-of-the-art single-shot outlier-based malicious agent detection methods for CP systems.
-
•
We develop GCP, a novel spatial-temporal aware CP defense framework, under which malicious agents can be jointly detected by utilizing a confidence-scaled spatial concordance loss and an LSTM-AE-based temporal BEV flow reconstruction. To the best of our knowledge, this is the first work to protect CP systems from joint spatial and temporal views.
-
•
We conduct comprehensive experiments on diverse attack scenarios with V2X-Sim dataset. The results demonstrate that GCP achieves the state-of-the-art performance, with up to 34.69% improvements in AP@0.5 compared to the existing state-of-the-art defensive CP methods under intense BAC attacks, while maintaining 5-8% advantages under other typical adversarial attacks targeting at CP systems.
II Related Work
II-A Collaborative Perception (CP)
To overcome the inherent limitations of single-agent perception systems, particularly their restricted field-of-view (FoV) and environmental occlusions, collaborative perception (CP) has emerged as a promising paradigm that leverages multi-agent data fusion to enhance perception comprehensiveness and accuracy [18, 19]. The evolution of CP systems has witnessed various fusion strategies, from early approaches like raw-data-level fusion [1] and output-level fusion [20], which faced significant challenges in communication overhead and perception quality due to their high bandwidth requirements and information loss, respectively, to more sophisticated intermediate-level feature fusion methods. Notable advances in intermediate fusion include DiscoNet [21], which employs a teacher-student framework to learn an optimized collaboration graph for efficient knowledge transfer, and V2VNet [22], which leverages graph neural networks for efficient neighboring vehicle information aggregation in dynamic traffic scenarios. Where2comm [4] further advances the field by introducing a confidence-aware attention mechanism that simultaneously optimizes communication efficiency and perception performance through selective information sharing. While these developments have improved performance-bandwidth trade-offs, they have exposed critical vulnerabilities in CP systems, particularly regarding robustness against adversarial attacks and system failures, which is the main focus of this paper.
II-B Adversarial CP
The vulnerabilities in CP systems can be broadly categorized into systematic and adversarial challenges, each presenting unique threats to system reliability and safety. On the system front, inherent issues such as communication delays, synchronization problems, and localization errors have been addressed by recent works. CoBEVFlow [23] introduced an asynchrony-robust CP system to compensate for relative motions to align perceptual information across different temporal states, while CoAlign [24] developed a comprehensive framework specifically targeting at unknown pose errors through adaptive feature alignment. However, beyond these system challenges lies a more insidious threat, namely, adversarial vulnerabilities introduced by malicious agents within the collaborative system. These adversaries can compromise system integrity by injecting subtle adversarial noise into shared intermediate representations, potentially causing catastrophic failures in critical scenarios. Initial investigations by Tu et al. [14] demonstrated how untargeted adversarial attacks could compromise detection accuracy in intermediate-fusion CP systems through feature perturbation. Zhang et al. [13] advanced this research by incorporating sophisticated perturbation initialization and feature map masking techniques for more realistic, targeted attacks in real-world settings. Nevertheless, these attack methods lack sophistication in attack region selection and output perturbation constraints, making them potentially detectable by conventional defense mechanisms while highlighting the need for more robust security measures.
II-C Defensive CP
In response to emerging threats, the research community has developed various defensive strategies, primarily focusing on output-level malicious agent detection through hypothesis-and-verification frameworks, each offering unique approaches to system security. ROBOSAC [15] employs an iterative approach with Hungarian matching to achieve perception consensus among collaborators, systematically identifying and excluding potentially malicious agents from the collaboration process. MADE [16] enhances this concept by introducing a comprehensive multi-test framework that leverages both match loss and collaborative reconstruction loss to ensure robust consistency verification among perception results. Zhang et al. [13] further contribute to this effort by utilizing occupancy maps for discrepancy detection, providing an additional layer of security through spatial consistency checking. While these outlier-based detection methods show promise in identifying obvious attacks, they remain vulnerable to sophisticated attacks that produce subtle yet dangerous perturbations in CP outputs, particularly in scenarios involving coordinated malicious activities. Recent advances have begun exploring intermediate feature-level inconsistency detection to improve both efficiency and detection accuracy [17]. However, existing approaches generally overlook the temporal dimension of collaborative messages and assume simplified intrusion models, limiting their effectiveness against advanced persistent threats. To address these limitations, we propose a comprehensive defense framework that considers both spatial and temporal aspects of malicious agent detection, offering a more robust and complete solution to the security challenges in CP systems.
III Attack Methodology
III-A Model of CP
Consider a scenario with CAVs, where the CAV set is denoted as . CAVs exchange collaboration messages with each other, and each CAV can maintain up to historical messages from its collaborators. For the -th CAV, we denote its raw observation at time as , and use to represent its pre-trained feature encoder that generates intermediate feature map . The collaboration message transmitted from the -th CAV to the -th CAV at time is denoted as . Based on the received messages at current timestamp and historical timestamps, the -th CAV uses a feature aggregator to fuse these feature maps and adopts a feature decoder to get the final CP output, which is expressed as:
| (1) |
where is the CP result of the -th CAV at time . There are two important notes in terms of the formulation described in Eq. 1: i) the times are not necessary to be equally distributed, and the time intervals between two consecutive times can be irregular. ii) When the length of historical times equals 0, the -th CAV outputs the CP results without referring to the temporal contexts of messages of collaborative CAVs, which degrades to the settings used in most existing works like ROBOSAC [15] and MADE [16].
III-B Adversarial Threat Model
The CP framework defined in Section III-A becomes vulnerable when malicious agents exist among the collaborative CAVs. At time , we denote the set of malicious agents as . We assume that malicious agents can request and transmit collaborative messages to benign agents before being identified, and their adversarial messages follow a specific time distribution (detailed in Section V-A). Once the victim CAV recognizes the malicious agents at a certain frame, it will discard the received messages from those malicious agents and cut off the connections with them until the next frame starts. Meanwhile, the malicious agents are assumed to have white-box access [25] to the model parameters since all agents in the CP system must share the same model architecture to enable feature-level cooperation. The malicious agents attack the CP system by transmitting perturbed feature maps to the victim CAV, resulting in its perception degradation. A general attack procedure can be described as follows.
-
1.
Observation Encoding: Each malicious agent encodes its raw observation at time into an initial feature map , preparing to combine with adversarial perturbations.
-
2.
Perturbation Generation: In general cases, the malicious agents generate perturbations [26, 27] by multi-step iterations, aiming to maximize the distance between CP results and ground truth (GT) while ensuring the input perturbation amplitude is lower than a certain value (using local prediction if GT is not available), which is represented by:
(2) where is the perturbation, is the maximum allowable input perturbation amplitude, is the Loss function, and represent the perturbed CP results and the ground truth at time , respectively. However, single-shot outlier-based detection can easily identify this general perturbation generation. Section III-C introduces a more elaborated attack targeted at CP systems.
-
3.
Attack Triggering: After multi-step iterations, the malicious agents generate intricately optimized perturbation and send it to the victim agent. Without defense, the victim agent will incorporate this adversarial message into the fusion based on Eq. 1, yielding attacked CP results with low accuracy.
III-C Blind Area Confusion Attack
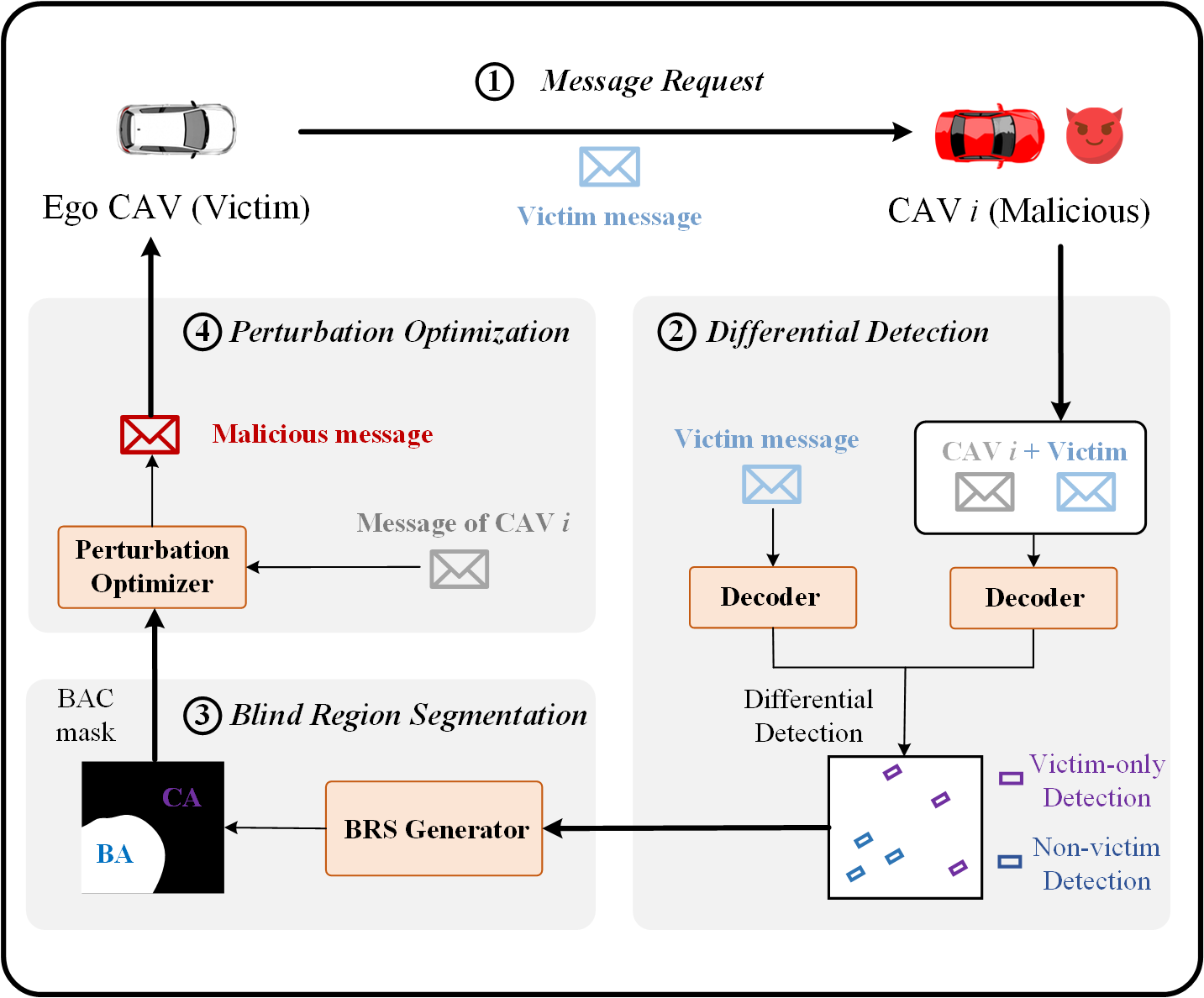
For previous outlier-based methods like ROBOSAC [15] and MADE [16], the core idea is to check the spatial consistency between ego CAV and CP outcomes. However, they only clip the perturbation at the input level, and the output detection errors are significant and randomly distributed, which can be easily detected by outlier-based defense methods. Intuitively, we want to emphasize that a good attack targeted at the CP system should satisfy two conditions: (i) both the input and output perturbation should not exceed a certain level; (ii) the output perturbation should be more distributed in the regions where the victim vehicle (i.e., agent or CAV) is less sensitive so that the victim vehicle can hardly discern whether the unseen detections could benefit from collaboration or just fake ones. Following the above ideas, we design a novel blind area confusion (BAC) attack as shown in Figure 2. The steps are elaborated below.
Message Request. Following our threat model, a malicious CAV can participate in the CP system before being identified. During this initial phase, it masquerades as a benign agent to establish communication with the victim’s ego vehicle. Specifically, the malicious CAV requests feature messages from the victim’s ego agent at timestamp . These messages contain valuable information about the victim’s perception capabilities and limitations, which will be exploited in subsequent attack stages. Note that in our low frame rate setting (e.g., 10 FPS), the attack generation and feature fusion can be completed within the same frame, eliminating the need for temporal prediction compensation that would be required in high FPS scenarios.
Differential Detection. After obtaining a victim’s messages, the malicious CAV performs a comparative analysis between independent and CP results to infer the victim’s blind spots. The malicious CAV first generates two types of perception results: single perception using only the victim’s transmitted features, and CP using both local and the victim’s features. Let denote the matched bounding boxes between single and CP results. Based on this matching, the system partitions all detections into two categories: victim-only detections (marked in purple), and non-victim detections (marked in blue). This differential detection process reveals the spatial distribution of the victim’s unique detections, providing crucial insights into its perception strengths and potential blind spots, which form the foundation for subsequent targeted perturbation generation.
Blind Region Segmentation. The differential detection map is processed through an adaptive region growing algorithm to partition the BEV detection map into confident area (CA) and blind area (BA), as shown in Algorithm 1. The algorithm first uses to determine the victim grid by finding the grid point with the minimum total distance to all victim-detected objects, establishing a perception-centric coordinate system. It then initializes seed grids from as CA seeds (value 1) and as BA seeds (value -1). When is empty, which occurs in limited perception range scenarios, the grid farthest from is selected as the BA seed to reflect natural perception degradation with distance. The region growing process utilizes two priority queues (, ) to manage confident and blind area expansion. The function implements an adaptive neighbor selection mechanism:
| (3) |
where computes the Euclidean distance between grid and victim grid , is the normalization factor based on BEV detection map dimensions (height and width ), establishes a hexagonal-like growth pattern, and controls the decay rate. This distance-adaptive design ensures denser expansion near the victim and sparser expansion in distant regions, naturally modeling spatial perception reliability [28]. The algorithm expands both regions simultaneously through (which removes and returns the next grid point from the front of the queue) and (which adds a new grid point to the end of the queue) operations. The initial queues and are created using , which constructs priority queues containing all grid points that are labeled as confident area (1) or blind area (-1) respectively. These queue operations enable systematic breadth-first expansion of regions. As grid points are popped from either queue for processing, their unassigned neighbors receive the corresponding label (1 for CA, -1 for BA). They are appended to the appropriate queue for future expansion. The final binary mask is created by converting BA labels (-1) to 0, yielding a binary representation where 1 indicates confident areas and 0 represents blind areas. This region-growing process naturally forms boundaries between different perception zones, effectively capturing the spatial characteristics of the victim’s perception capabilities.
Perturbation Optimization. BAC perturbation optimization aims to make the perturbation mostly distributed in the victim-blind area of the BEV detection map while adaptively controlling the perturbation magnitude. This optimization problem can be formulated as:
| (4) | ||||
where denotes the optimization loss function, is the inverted confidence mask, is the sigmoid activation function, computes element-wise absolute values, bounds the input perturbation magnitude, bounds the output perturbation magnitude, and is a positive weighting parameter.
This optimization formulation incorporates several innovative design principles for effective and stealthy attacks. First, instead of a simple loss function, it employs a weighted loss function where denotes element-wise multiplication. The weight is carefully designed to guide the spatial distribution of perturbations, ensuring more targeted attacks. Second, the optimization adopts a dual-weight mechanism: the spatial guidance weight directs perturbations towards the victim’s blind areas, while the adaptive suppression weight automatically reduces weights when output perturbations become too large. The adaptive suppression is implemented through a sigmoid function, which provides smooth transitions when the prediction deviates from the ground truth beyond the threshold . This design ensures that the attack remains effective while avoiding generating easily detectable anomalies. Additionally, the input perturbation magnitude is constrained by to maintain physical feasibility and attack stealthiness. After the optimization, the malicious CAV incorporates the optimized perturbation into its intermediate BEV feature before transmission to the victim CAV.
Input:
-
•
, initial confidence mask (all-zero matrix).
-
•
, detected bounding boxes by victim vehicle.
-
•
, undetected bounding boxes by victim vehicle.
-
•
, the BEV detection map of CAV .
Output: , binary confidence mask.
IV GCP Framework
IV-A Overall Architecture
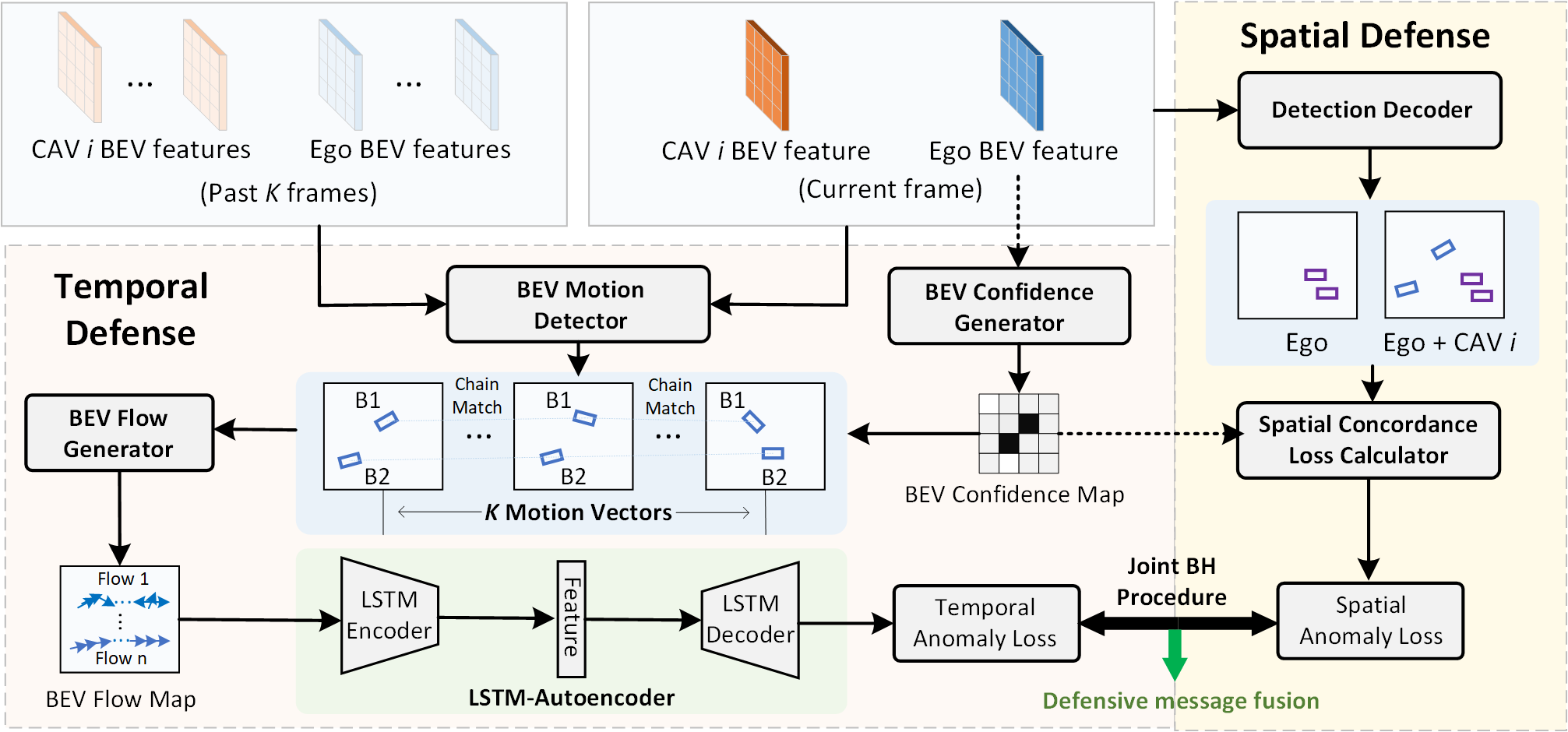
In this paper, we propose a robust framework to guard CP systems through spatial-temporal aware malicious agent detection. As illustrated in Fig. 3, GCP operates through a dual-domain verification process. First, it computes a confidence-scaled spatial concordance loss by estimating confidence scores for each grid cell in the BEV detection map, evaluating the consistency between the ego CAV’s observations and messages from the -th neighboring CAV at the current time slot. Second, it performs temporal verification by analyzing the past frames from both the ego CAV and the -th neighboring CAV to generate a BEV flow map for low-confidence detections, employing an LSTM-AE-based temporal reconstruction to verify motion consistency. The framework culminates in a comprehensive spatial-temporal multi-test that combines both consistency metrics to make final decisions on malicious agent detection. The following sections (IV-B to IV-D) provide the detailed descriptions of these core components.
IV-B Confidence-Scaled Spatial Concordance Loss
Existing spatial consistency checking methods typically compare the difference between the ego CAV’s perception and CP without considering the ego CAV’s varying perception reliability across different spatial regions. This indiscrimination could result in mistaking true blindspot detection complemented by other CAVs as malicious signals. This occurs because the ego CAV’s perception reliability naturally decreases in occluded areas and at sensor range boundaries [28]. When other CAVs provide valid detections in these low-reliability regions, traditional methods may incorrectly flag them as inconsistencies by failing to account for the ego CAV’s spatially varying perception capabilities. To address this limitation, we propose a novel confidence-scaled spatial concordance loss (CSCLoss) that incorporates the ego CAV’s detection confidence when checking messages from the -th CAV at time . Let denote the ego CAV’s detected bounding boxes and represent the collaboratively detected bounding boxes at timestamp . We first construct a weighted bipartite graph between these two sets, where edges represent matching costs based on classification confidence and intersection-over-union (IoU) scores. Since may differ from , we pad the smaller set with empty boxes to ensure the one-to-one matching. The optimal matching is then obtained using the Kuhn-Munkres algorithm [29]. To compute the CSCLoss, we first estimate a spatial confidence map using the ego CAV’s feature map :
| (5) |
where is a detection decoder that generates confidence scores for each grid cell in the BEV map [4]. The CSCLoss is then calculated by combining the optimal matching and confidence map:
| (6) |
where is the confidence score for the grid cell containing bounding box , represents a prediction class, computes the matching cost between two boxes:
| (7) |
where and are the class posterior probabilities for boxes and , respectively, and are their spatial coordinates, and is a weighting coefficient. Typically, when temporal context is not applicable, a spatial anomaly can be assumed to be detected when exceeds a threshold .
IV-C Low-Confidence BEV Flow Matching
Bird’s Eye View (BEV) flow [23] represents the consecutive motion vectors of detected objects across consecutive frames in the top-down perspective. By observing the flow of bounding boxes in the BEV space over time, we can capture the temporal dynamics and motion patterns of objects in the scene. For computational efficiency, we only perform temporal matching on two specific types of low-confidence BEV flows: (i) those with low detection scores from ego CAV’s own view, and (ii) ego CAV’s unseen detections that the collaborative agents complement. While temporal matching could be applied to all detected boxes, focusing on these low-confidence cases is particularly crucial as it is difficult for an ego CAV to judge whether they represent true objects or perturbations caused by malicious agents merely through single-shot spatial checks, especially when the added perturbation is subtle. To address this challenge, we utilize temporal characteristics to analyze their anomaly patterns. We first match the detected low-confidence bounding boxes of to those in the past frames . In the BEV detection map, each detected bounding box can be represented as a set of 4 corner points:
| (8) |
where represents the locations of 4 corners of bounding box in BEV detection map. Given the current-frame low-confidence bounding boxes set , the ego CAV will generate BEV flow by iteratively matching the bounding boxes in each historical frame. As shown in Algorithm 2, the matching process is a chain-based process, which means that we first find the best-matched bounding boxes in for , then we keep searching for the best matched bounding boxes in for , until the -th frame has been matched. During this process, not all the bounding boxes in in can be matched up to the -th frame, we call the successfully matched bounding boxes as the candidate BEV flow . LSTM-AE is used to reconstruct it for further temporal consistency check. As for the unmatched BEV flow , they will result in additional time anomaly penalties. To maintain computational efficiency, we cache the historical matching chains for each tracked flow. This significantly reduces the computational complexity as previously established matches can be directly reused without re-computation, making the chain matching process highly efficient in practice. Note that consecutive frames are not always completely available for chain matching. There are two cases when the frame cache is not enough for chain matching.
-
•
Case 1: The ego CAV may have not collected up to frames of neighboring CAVs at the early stage. In this case, we only use spatial consistency to check the malicious agent until the cached messages are up to frames.
-
•
Case 2: Certain frames of neighboring CAVs have been identified as malicious messages and are thereby discarded. In this case, we use Kalman Filter (KF) [30] for interpolation (Please refer to Appendix A). We also set a maximum consecutive interpolation limit of to avoid the cumulative error. Once the consecutive interpolation frames exceed the limit , all the cached frames will be refreshed.
IV-D Temporal BEV Flow Reconstruction
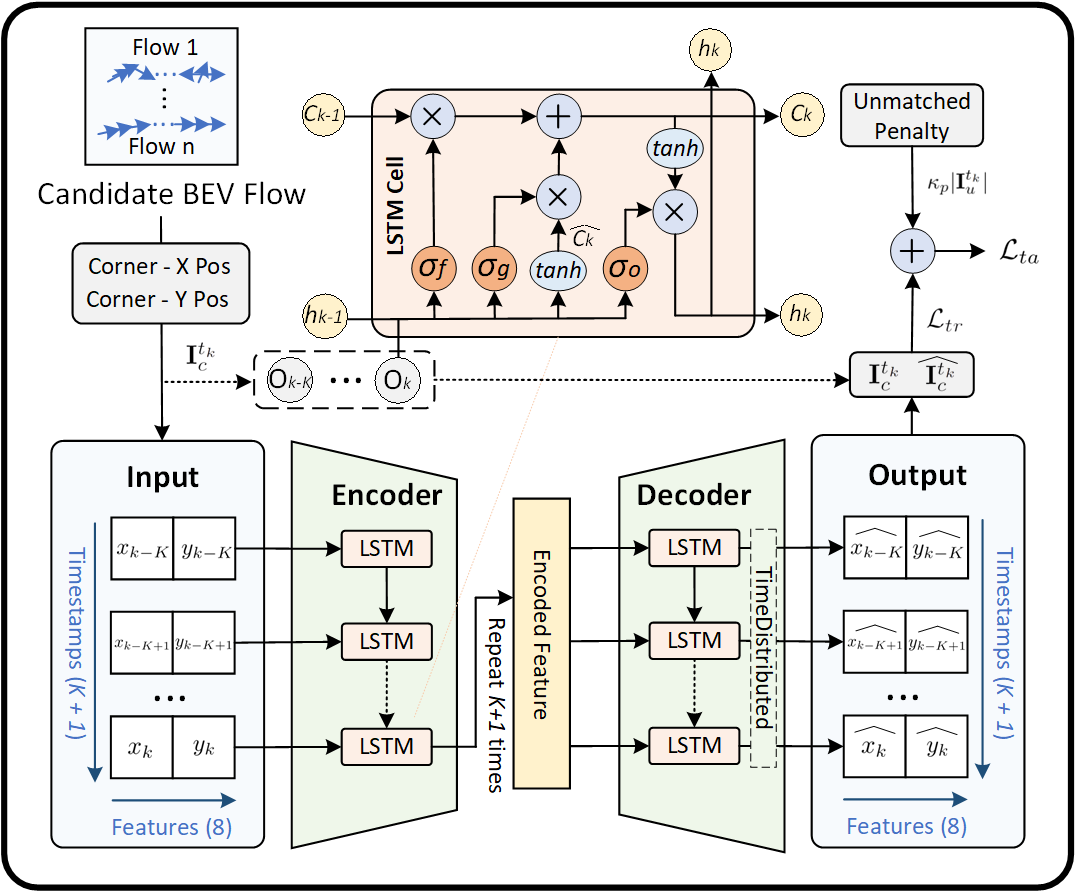
For the generated candidate BEV flow, we further analyze their temporal characteristics based on the current and past -frame messages from the -th CAV. As shown in Fig 3, there are three key components of BEV flow reconstruction: LSTM encoder, LSTM decoder, and temporal reconstruction loss estimator.
LSTM encoder. Each candidate BEV flow can be represented as , the LSTM encoder further encodes the high-dimensional input sequence into a low-dimensional hidden representation using the following equation:
| (9) |
where represents the output gate with activation function , weight , and bias . and represent the concatenation of the hidden state and the current input, respectively. represents the input gate calculated by:
| (10) |
| (11) |
where is the forget gate, , , represent the input gate. The output vector will be repeated times to yield the final encoded feature vector:
| (12) |
| (13) |
where is the latent encoded feature dimension, is the LSTM encoding network model containing computation units following Eq. 9 to Eq. 11, and represents the concatenation operation along the horizontal dimension.
LSTM decoder. The LSTM Decoder consists of a 3-layer network with LSTM cell units. Each LSTM cell processes each encoded feature. These LSTM units generate a output vector learned from the encoded feature, which is further multiplied with a vector output by a TimeDistributed (TD) layer [31]. The TimeDistributed layer maintains the temporal structure by applying a fully connected layer to each time step output. Finally, the LSTM decoder generates a reconstructed vector with the same size as the input vector following:
| (14) |
where is the LSTM decoding network model, represents the TimeDistributed Layer funciton.
Temporal reconstruction loss estimator. To evaluate the loss between the input vector and output vector, we use Mean Absolute Error (MAE) as a metric, given by:
| (15) |
where is the reconstructed BEV flow vector at time . The final temporal anomaly score is the sum of the candidate BEV flow reconstruction loss and the unmatched BEV flow penalty, given by:
| (16) |
where is a constant penalty coefficient for the unmatched BEV flow.
IV-E Joint Spatial-Temporal Benjamini-Hochberg Test
To jointly utilize spatial and temporal anomaly results for malicious agent detection, we employ the Benjamini-Hochberg (BH) procedure [32, 16]. The BH procedure effectively controls the False Discovery Rate (FDR) - the expected proportion of false positives among all rejected null hypotheses, which is crucial in CP where false accusations can severely impact system reliability. For each CAV under inspection, we first compute a weighted combination of spatial and temporal scores:
| (17) |
where and are learnable weights. The BH procedure controls FDR through a step-up process that adapts its rejection threshold based on the distribution of observed p-values. Unlike traditional single hypothesis testing, the BH procedure maintains FDR control at level even under arbitrary dependencies between tests, making it particularly suitable for CP where agents’ behaviors may be correlated due to shared environmental factors or coordinated attacks. We formulate the hypothesis test , where represents the null hypothesis that the combined score follows the distribution of normal agents, and represents the alternative hypothesis. Since this distribution is typically intractable, we compute conformal p-values using the calibration set :
| (18) |
where represents the cardinality of the set. Following the BH procedure, we sort the p-values in ascending order for hypothesis tests. Let be the largest index satisfying:
| (19) |
Then, agent is classified as malicious when its p-value is less than or equal to , where controls the desired false detection rate.
Input:
-
•
, low-confidence detections at current frame
-
•
, cached detections from past frames
Output: , (candidate and unmatched BEV flows)
V Experiments
In this section, we first describe the experimental setup, including dataset, attack and defense settings, and implementation details. After that, both the quantitative and qualitative results are introduced.
V-A Experimental Setup
Datasets. We conduct experiments using two data sets, namely, V2X-Sim dataset [2] and V2X-Flow dataset. V2X-Sim dataset is used for training and evaluating different CP models and CP defense methods, while V2X-Flow dataset is used for pre-training LSTM-AE in our GCP.
-
•
V2X-Sim Dataset. V2X-Sim [2] is a simulated dataset generated by the CARLA simulator [33]. The dataset contains 10,000 frames of synchronized multi-view data captured from 6 different connected agents (5 vehicles and 1 RSU), including LiDAR point clouds (32-beam, 70m range) and RGB images, along with 501,000 annotated 3D bounding boxes containing object attributes. The data is split into training, validation, and test sets with a ratio of 8:1:1.
-
•
V2X-Flow Dataset. To facilite the pre-training of LSTM-AE used in our GCP, we construct a V2X-Flow dataset based on V2X-Sim. We separate the annotations of the V2X-Sim dataset to generate the BEV flow of each bounding box using the chain-based BEV flow matching method mentioned in Section IV-C. The dataset split of V2X-Flow is the same as V2X-Sim.
Attack Settings. To simulate realistic attack scenarios in vehicular networks, we consider that malicious agents would adopt stealthy strategies instead of continuously launching attacks. The temporal patterns of such attacks can be modeled with different distributions. Given the total number of collaborative agents , the time horizon , the number of malicious agents , and an attack ratio (the proportion of malicious messages to the total messages from all agents over the time horizon), we evaluate three representative time series attack modes. For all modes, the total malicious messages are distributed among malicious agents following a truncated normal distribution to simulate varying attack capabilities while maintaining reasonable attack intensities:
- •
-
•
Poisson attack process (P-mode) [34]. This mode models bursty attack patterns (e.g., DDoS attacks) in which intense activities occur in short durations. At each time step , the number of malicious messages follows a Poisson distribution:
(20) where denotes the number of malicious messages at time step , and represents the mean rate.
-
•
Susceptible-Infectious process (S-mode) [35]. This mode simulates progressive attack scenarios where malicious behaviors spread through the network over time, similar to virus propagation. The evolution of the number of malicious messages follows:
(21) where represents the propagation rate.
For adversarial perturbation generation, we evaluate our method against three representative white-box attacks: Projected Gradient Descent (PGD) [36], Carlini & Wagner (C&W) [37], and Basic Iterative Method (BIM) (Please refer to Appendix B for implementation details). Moreover, we introduce our proposed BAC attack to exploit the vulnerabilities in CP systems specifically. To maintain real-time attack capability, the BAC mask generation adopts a slow update strategy without requiring per-frame updates. In our experiments, we set the mask update rate to 0.5 FPS.
Implementation Details. Our GCP is implemented with PyTorch. Each agent’s locally captured LiDAR or camera data is first encoded into a BEV feature map with size and 512 channels. The encoder network adopts a ResNet-style architecture with 5 layers of feature encoding, with output feature dimensions progressively increasing from 32 to 512 channels while spatial dimensions decrease from 256 to 16. The decoder consists of three convolutional blocks with channel dimensions progressively decreasing from 512 to 64. The detection head follows a two-branch design (classification and regression) with standard convolutional layers, batch normalization, and ReLU activation. It uses an anchor-based detection decoder [38] with multiple anchor sizes per location. The fusion method is V2VNet [22]. The LSTM-AE model consists of 2 LSTM layers with hidden dimension 32. We train the model using Adam optimizer (lr=0.001) with the default history sequence length 5. All experiments are conducted on a server with 2 Intel(R) Xeon(R) Silver 4410Y CPUs, 4 NVIDIA RTX A5000 GPUs, and 512 GB RAM.
Baselines and Evaluation Metrics. We compare our method with two state-of-the-art CP defense baselines: ROBOSAC [15] and MADE [16]. We also include three reference settings: (1) Upper-bound - CP without malicious agents, representing the optimal performance; (2) Lower-bound - ego vehicle’s local perception only; and (3) No defense - CP with malicious agents but without any defense measures. To validate the effectiveness of our spatial-temporal design, we also evaluate two variants of GCP: spatial-only defense (GCP-S) and temporal-only defense (GCP-T). The performance of all methods is evaluated using both accuracy and efficiency metrics: average precision at 0.5 IoU (AP@0.5) and 0.7 IoU (AP@0.7) for detection accuracy and Frames Per Second (FPS) for computational efficiency.
V-B Quantitative Results
| Method | Mode | PGD attack | C&W attack | BIM attack | BAC attack | ||||
| AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | ||
| Upper-bound | — | 80.52 | 78.65 | 80.52 | 78.65 | 80.52 | 78.65 | 80.52 | 78.65 |
| GCP (Ours) | Average | 77.54 | 76.51 | 76.81 | 75.56 | 77.40 | 76.46 | 76.64 | 75.64 |
| R | 76.88 | 75.78 | 76.90 | 75.16 | 76.72 | 75.74 | 75.80 | 74.96 | |
| P | 77.37 | 76.34 | 77.13 | 76.20 | 77.38 | 76.43 | 76.29 | 75.09 | |
| S | 78.36 | 77.41 | 76.41 | 75.32 | 78.11 | 77.22 | 77.82 | 76.87 | |
| MADE [16] | Average | 77.07 | 75.75 | 76.28 | 74.87 | 76.61 | 75.06 | 64.00 | 54.48 |
| R | 76.67 | 75.56 | 75.81 | 74.28 | 76.82 | 75.28 | 65.63 | 56.92 | |
| P | 76.76 | 75.04 | 76.29 | 74.81 | 76.96 | 75.88 | 65.11 | 55.95 | |
| S | 77.79 | 76.66 | 76.39 | 75.42 | 76.06 | 74.01 | 61.28 | 50.58 | |
| ROBOSAC [15] | Average | 73.31 | 71.54 | 73.90 | 72.16 | 73.48 | 71.70 | 68.11 | 64.77 |
| R | 74.64 | 72.93 | 74.52 | 72.78 | 74.67 | 73.19 | 68.68 | 64.82 | |
| P | 73.98 | 72.84 | 73.63 | 72.45 | 73.63 | 72.07 | 67.25 | 65.48 | |
| S | 71.31 | 68.84 | 73.54 | 71.26 | 72.14 | 69.85 | 68.40 | 64.02 | |
| No Defense | Average | 36.65 | 35.92 | 17.70 | 15.14 | 38.27 | 37.28 | 54.83 | 45.11 |
| R | 36.50 | 35.64 | 18.03 | 15.52 | 37.07 | 36.18 | 55.19 | 43.99 | |
| P | 39.01 | 38.35 | 18.92 | 16.23 | 36.59 | 35.47 | 55.03 | 45.07 | |
| S | 34.45 | 33.78 | 16.14 | 13.66 | 41.16 | 40.19 | 54.26 | 46.28 | |
| Lower-bound | — | 64.08 | 61.99 | 64.08 | 61.99 | 64.08 | 61.99 | 64.08 | 61.99 |
Comparative results against different attacks. As shown in Table I, we evaluate our proposed GCP against various attack methods and time series modes on the V2X-Sim dataset. First, all defense methods demonstrate varying degrees of effectiveness compared to the no-defense baseline, which suffers severe performance degradation under all attack scenarios, especially for C&W attacks. While baseline methods show some defense capability, with MADE performing slightly better than ROBOSAC against conventional attacks (PGD, C&W, and BIM), they both exhibit significant vulnerability to our proposed BAC attack. Our proposed GCP consistently performs better across all attack scenarios and time series modes. For conventional attacks, GCP outperforms existing methods with consistent improvements (0.47%-0.79% in AP@0.5) across PGD, C&W, and BIM attacks. The advantage becomes more pronounced under our challenging BAC attack, where GCP significantly surpasses MADE and ROBOSAC by 12.64% and 8.53% in AP@0.5, respectively, while maintaining performance close to the upper bound with only 3.88% degradation. Across different time series attack modes (R-Mode, P-Mode, and S-Mode), GCP demonstrates consistent robustness, maintaining stable performance where baseline methods show varying degrees of degradation. These results validate the effectiveness of our spatial-temporal defense mechanism in handling diverse attack patterns in CP systems.
Comparative results with dynamic attack intensities. Table II shows the performance comparison under different perturbation budgets and attack intensities. All methods show performance degradation with more intense attacks (, ), where MADE exhibits the largest drops (13.69%-15.68% in AP@0.5) while GCP maintains relatively stable performance with only 5.46%-5.74% degradation. For perturbation budget settings, we observe that larger output perturbation () enables more effective defense than smaller ones (). Increasing input perturbation () significantly impacts baseline methods, with ROBOSAC showing 4.56% drop in AP@0.5 even under moderate attacks. In contrast, GCP maintains consistent performance across all settings (less than 0.5% variation in AP@0.5). Overall, our proposed GCP outperforms baselines by 7.12%-18.29% in AP@0.5, with advantages more pronounced under intense attacks and large perturbation budgets. These results demonstrate our spatial-temporal defense mechanism’s strong adaptability and robustness against varying attack parameters.
| Method | BAC Attack | ||||||||
| AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | ||
| Upper-bound | — | 80.52 | 78.65 | 80.52 | 78.65 | 80.52 | 78.65 | 80.52 | 78.65 |
| GCP (Ours) | Moderate | 75.80 | 74.96 | 75.23 | 74.02 | 75.58 | 74.28 | 75.51 | 74.69 |
| Intense | 70.22 | 68.57 | 70.03 | 68.36 | 70.07 | 68.59 | 69.77 | 68.20 | |
| MADE [16] | Moderate | 65.63 | 56.92 | 65.80 | 57.26 | 65.39 | 55.56 | 66.93 | 56.79 |
| Intense | 51.94 | 40.87 | 54.22 | 41.38 | 53.21 | 40.61 | 51.04 | 36.25 | |
| ROBOSAC [15] | Moderate | 68.68 | 64.82 | 66.26 | 62.38 | 64.12 | 58.08 | 65.64 | 61.42 |
| Intense | 60.09 | 54.88 | 61.20 | 55.07 | 59.08 | 51.14 | 61.02 | 53.87 | |
| No Defense | Moderate | 55.19 | 43.99 | 65.05 | 55.44 | 55.92 | 42.91 | 59.54 | 47.27 |
| Intense | 35.63 | 25.35 | 47.82 | 32.55 | 33.40 | 17.98 | 41.85 | 23.24 | |
Ablation studies. To evaluate the effectiveness of our proposed GCP, we compare it with its variants that use only spatial or temporal defense mechanisms. As shown in Table III, both components contribute to the overall defense performance but with different strengths against different attacks. For conventional PGD attacks, the spatial component plays a dominant role, with GCP-S achieving comparable performance (77.21% AP@0.5) to the full model (77.54% AP@0.5), while GCP-T shows limited effectiveness (70.16% AP@0.5). However, for our challenging BAC attack, neither component alone can maintain robust performance, with significant drops in GCP-S (7.41% decrease in AP@0.5) and GCP-T (10.63% decrease in AP@0.5) compared to the full model. This demonstrates the necessity of combining both spatial and temporal consistency checks for effective defense against sophisticated attacks in CP systems. Notably, despite using a lighter architecture, GCP-S maintains better performance than ROBOSAC [15] and MADE [16], validating the effectiveness of our CSCLoss design proposed in Section 4.2.
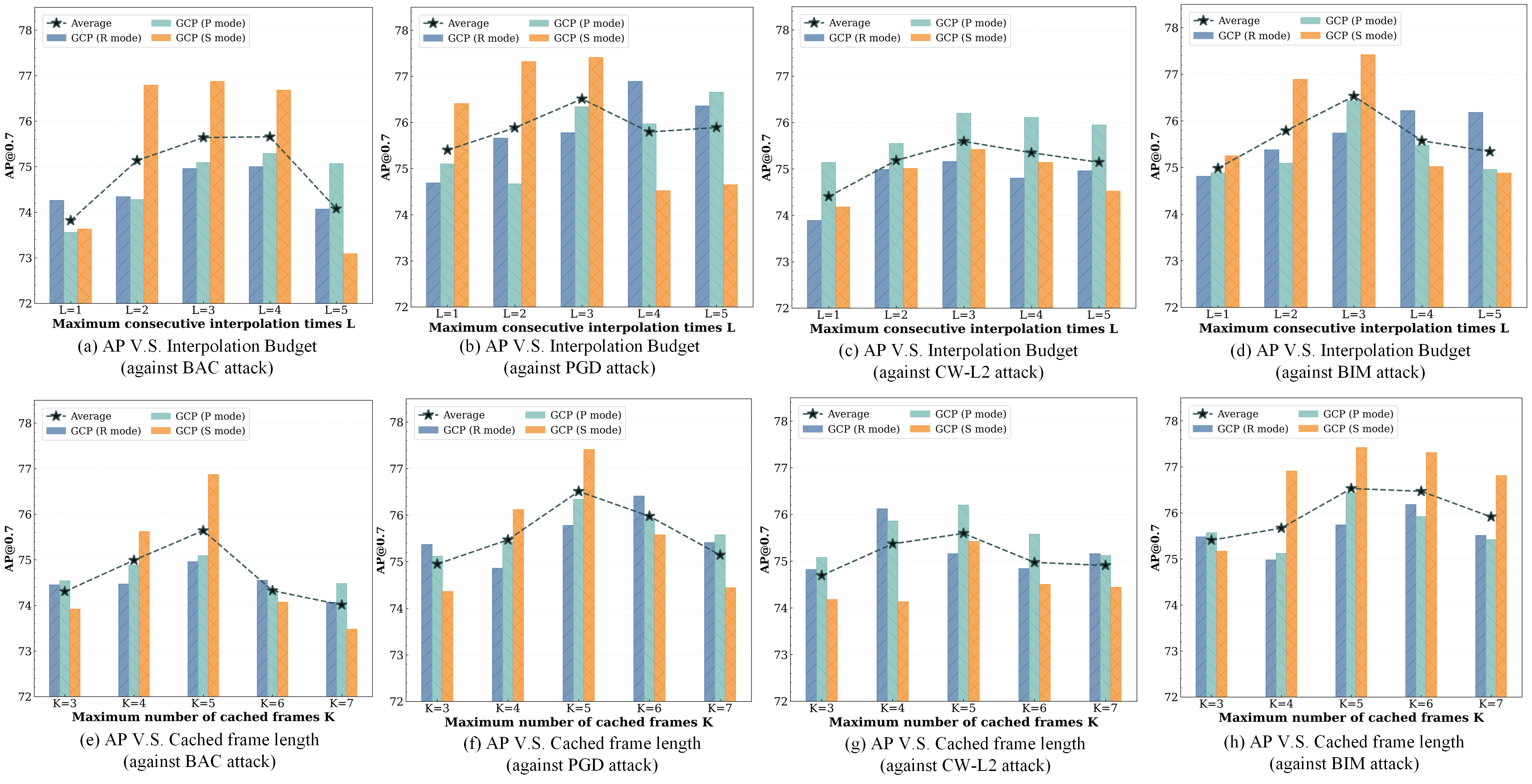
Effect of the frame cache length and KF interpolation times. We analyze two key hyperparameters in GCP: the maximum cached frame length () and the maximum allowed consecutive KF interpolation times (). As shown in Fig. 5, moderate values for both parameters generally yield better performance across different attack modes. The optimal value for cache size is consistently around . Under BAC attack, S-mode performance peaks at with AP@0.5 of 76.87%, while smaller (, 73.92%) and larger (, 73.48%) sizes degrade performance. This suggests a moderate cache balances sufficient temporal context and avoids noise from distant frames. For consecutive KF interpolation times , optimal performance is typically achieved at or . For BIM attacks, S-mode AP@0.5 reaches 77.42% when, dropping to 73.09% when increases to 5. This indicates that while KF interpolation aids temporal consistency, excessive consecutive interpolation may introduce cumulative errors, affecting detection accuracy.
Quantitative analysis of attack and defense speeds. As shown in Table IV, we analyze computation speeds across different attack and defense methods. For attacks, the reported FPS values represent single-iteration performance. With 3-5 iterations typically sufficient for effective attacks, all methods can enable real-time attacks in low frame rate scenarios (10-15 FPS). Our BAC attack shows slightly lower speed than PGD (22.4 vs 25.3 FPS) due to mask generation but maintains efficiency through a low-frequency mask update strategy (0.5 FPS). On the defense side, while baseline methods MADE and ROBOSAC show higher speeds against BAC attack (82.8 and 44.6 FPS), this actually indicates that their detection mechanisms are bypassed. In contrast, our GCP maintains robust defense speeds (30.2-47.6 FPS) with only 3.88% performance degradation under BAC attack. These results validate that both our attack and defense methods meet the real-time requirements for practical deployment, demonstrating the potential for seamless integration into existing CP systems without compromising efficiency.
| Method | PGD attack | BAC attack | ||
| AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | |
| Upper-bound | 80.52 | 78.65 | 80.52 | 78.65 |
| GCP (Ours) | 77.54 | 76.51 | 76.64 | 75.64 |
| GCP-S | 77.21 | 76.10 | 69.23 | 62.38 |
| GCP-T | 70.16 | 67.33 | 66.01 | 58.79 |
| No Defense | 36.65 | 35.92 | 54.83 | 45.11 |
| Attack Method | Attack | Defense Speed (FPS) | ||
| Speed (FPS) | MADE | ROBOSAC | GCP | |
| PGD attack | 25.3 | 55.8 | 27.1 | 38.6 |
| C&W attack | 18.2 | 38.5 | 21.6 | 30.2 |
| BIM attack | 24.8 | 54.6 | 28.7 | 37.5 |
| BAC attack | 22.4 | 82.8 | 44.6 | 47.6 |
V-C Qualitative Results
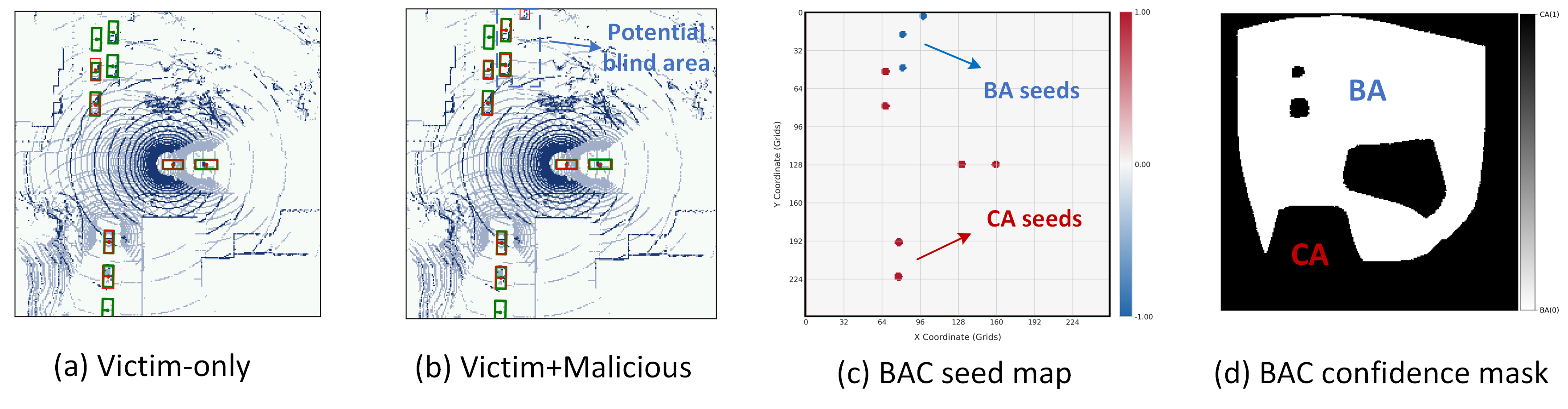
Visualization of BAC attack process. As shown in Fig. 6, the complete pipeline of BAC attack on V2X-Sim dataset is visualized. First, the malicious agent analyzes the detection results using only the victim vehicle’s local perception (Fig. 6(a)) to identify its inherent blind spots and perception limitations. Then, by comparing with the CP results (Fig. 6(b)), the attacker can identify regions where the victim heavily relies on collaborative messages for object detection. This differential analysis enables the malicious agent to generate an initial BAC seed map (Fig. 6(c)) that highlights these perception-dependent areas. Finally, through the proposed blind region segmentation algorithm, the attacker obtains a refined BAC confidence mask (Fig. 6(d)) that precisely delineates the victim’s vulnerable regions, providing targeted guidance for adversarial perturbation generation.
Visualization of collaborative 3D detection. As shown in Fig. 7, we visualize the detection performance under different attack and defense scenarios on V2X-Sim dataset. While conventional attacks (PGD, C&W, BIM) generate obvious perturbations that baseline methods can easily detect, our BAC attack demonstrates superior stealthiness by optimizing output-space perturbations, specifically in blind regions. This makes it particularly challenging for existing methods like ROBOSAC and MADE to defend against, as evidenced by their significant performance degradation. In contrast, our proposed GCP framework maintains robust detection performance through effective spatial-temporal consistency verification, achieving results that approach the upper bound of CP. The visualization clearly shows that GCP successfully preserves accurate object detection even under sophisticated BAC attacks, while baseline methods struggle to maintain reliable performance.
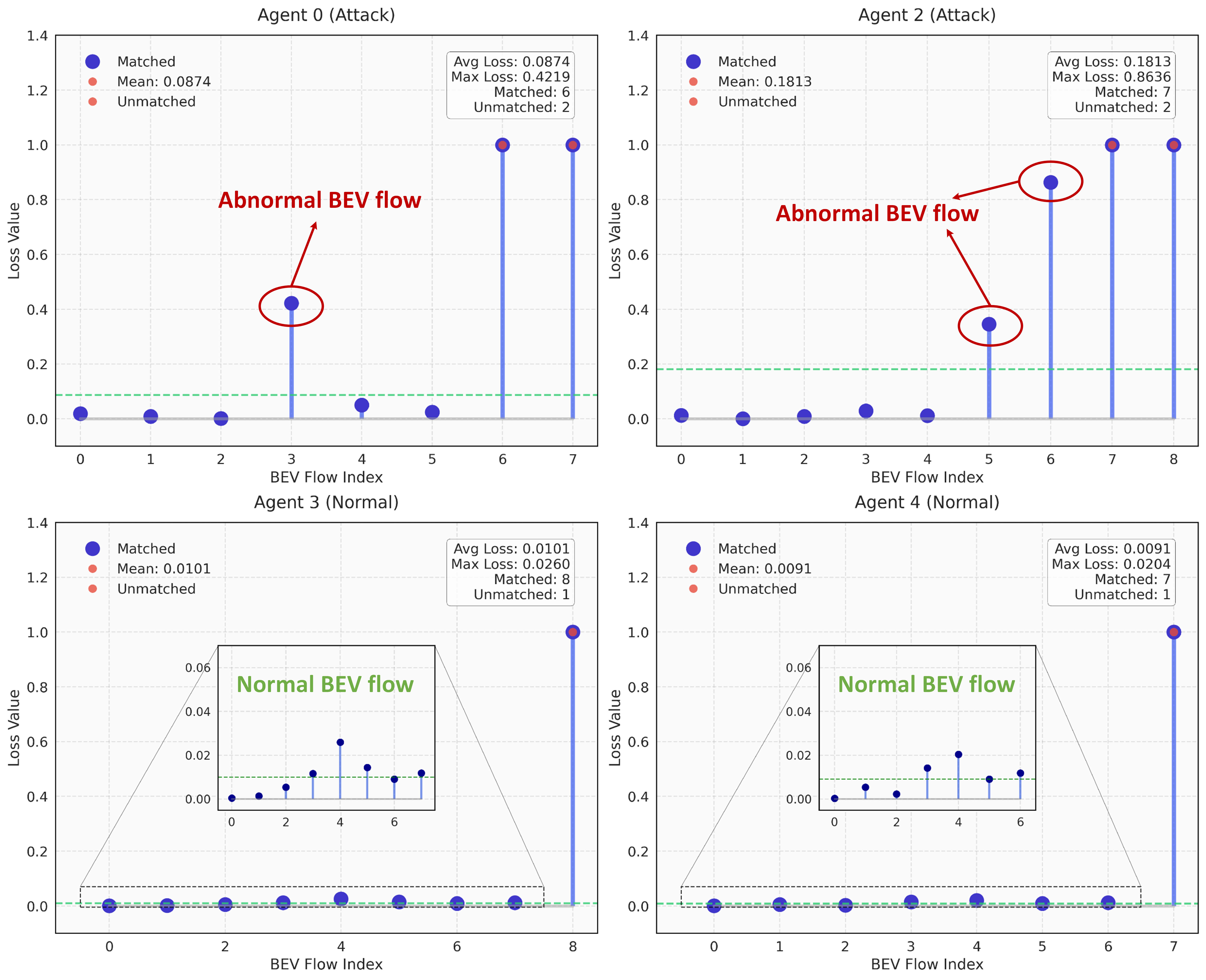
Visualization of BEV flow reconstruction loss distribution. Fig. 8 illustrates the distribution of BEV flow reconstruction losses across different agents. Normal agents (Agent 3 and 4) exhibit consistently low losses (mean: 0.0101 and 0.0091) with minimal variance and only one unmatched flow each, indicating stable temporal consistency. In contrast, agents under BAC attack (Agent 0 and 2) show significantly higher maximum losses (0.4219 and 0.8636) with greater variance and more unmatched flows (2 each), revealing temporal inconsistencies introduced by the attack. While some flows from malicious agents maintain low losses due to the stealthy nature of BAC attacks, the combination of high-loss outliers and increased unmatched flows provides reliable indicators for attack detection.
VI Conclusion
In this paper, we have devised a novel blind area confusion (BAC) attack to show that collaborative perception (CP) systems are vulnerable to malicious attacks even with existing outlier-based CP defense mechanisms. The key innovation of the BAC attack lies in the blind region segmentation-based local perturbation optimization. To counter such attacks, we have proposed our GCP, a robust CP defense framework utilizing spatial and temporal contextual information through confidence-scaled spatial concordance loss and LSTM-AE-based temporal BEV flow reconstruction. These components are integrated via a spatial-temporal Benjamini-Hochberg test to generate reliable anomaly scores for malicious agent detection. Extensive experiments have demonstrated the superior robustness of our framework against various attacks while maintaining high detection performance. The effectiveness of our approach across different attack scenarios and perturbation settings highlights the potential of spatial-temporal analysis to guard CP systems. Looking forward, our work provides valuable insights into developing secure and reliable CP systems in autonomous driving, paving the way to robust multi-agent collaboration in real-world applications.
References
- [1] Q. Chen, S. Tang, Q. Yang, and S. Fu, “Cooper: Cooperative Perception for Connected Autonomous Vehicles Based on 3D Point Clouds ,” in IEEE International Conference on Distributed Computing Systems (ICDCS), Jul. 2019, pp. 514–524.
- [2] Y. Li, D. Ma, Z. An, Z. Wang, Y. Zhong, S. Chen, and C. Feng, “V2X-Sim: Multi-Agent Collaborative Perception Dataset and Benchmark for Autonomous Driving,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 914–10 921, 2022.
- [3] S. Hu, Z. Fang, H. An, G. Xu, Y. Zhou, X. Chen, and Y. Fang, “Adaptive Communications in Collaborative Perception with Domain Alignment for Autonomous Driving,” arXiv:2310.00013, 2024.
- [4] Y. Hu, S. Fang, Z. Lei, Y. Zhong, and S. Chen, “Where2comm: Communication-Efficient Collaborative Perception via Spatial Confidence Maps,” in Advances in Neural Information Processing Systems (NeurIPS), 2022.
- [5] S. Hu, Z. Fang, Y. Deng, X. Chen, Y. Fang, and S. Kwong, “Towards Full-scene Domain Generalization in Multi-agent Collaborative Bird’s Eye View Segmentation for Connected and Autonomous Driving,” arXiv:2311.16754, 2024.
- [6] Z. Fang, S. Hu, H. An, Y. Zhang, J. Wang, H. Cao, X. Chen, and Y. Fang, “PACP: Priority-Aware Collaborative Perception for Connected and Autonomous Vehicles,” IEEE Transactions on Mobile Computing, vol. 23, no. 12, pp. 15 003–15 018, 2024.
- [7] Y. Tao, S. Hu, Z. Fang, and Y. Fang, “Direct-CP: Directed Collaborative Perception for Connected and Autonomous Vehicles via Proactive Attention,” arXiv:2409.08840, 2024.
- [8] S. Hu, Z. Fang, Z. Fang, Y. Deng, X. Chen, and Y. Fang, “AgentsCoDriver: Large Language Model Empowered Collaborative Driving with Lifelong Learning,” arXiv:2404.06345, Apr. 2024.
- [9] S. Hu, Z. Fang, Z. Fang, Y. Deng, X. Chen, Y. Fang, and S. Kwong, “AgentsCoMerge: Large Language Model Empowered Collaborative Decision Making for Ramp Merging,” arXiv:2408.03624, Aug. 2024.
- [10] S. Hu, Z. Fang, Y. Deng, X. Chen, Y. Fang, and S. Kwong, “Toward Full-Scene Domain Generalization in Multi-Agent Collaborative Bird’s Eye View Segmentation for Connected and Autonomous Driving,” IEEE Transactions on Intelligent Transportation Systems, pp. 1–14, 2024.
- [11] S. Hu, Y. Tao, G. Xu, Y. Deng, X. Chen, Y. Fang, and S. Kwong, “CP-Guard: Malicious Agent Detection and Defense in Collaborative Bird’s Eye View Perception,” arXiv:2412.12000, Dec. 2024.
- [12] Z. Fang, J. Wang, Y. Ma, Y. Tao, Y. Deng, X. Chen, and Y. Fang, “R-ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,” arXiv:2410.04168, 2024.
- [13] Q. Zhang, S. Jin, R. Zhu, J. Sun, X. Zhang, Q. A. Chen, and Z. M. Mao, “On Data Fabrication in Collaborative Vehicular Perception: Attacks and Countermeasures,” in 33rd USENIX Security Symposium, Aug. 2024, pp. 6309–6326.
- [14] J. Tu, T. Wang, J. Wang, S. Manivasagam, M. Ren, and R. Urtasun, “Adversarial Attacks On Multi-Agent Communication,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 7748–7757.
- [15] Y. Li, Q. Fang, J. Bai, S. Chen, F. Juefei-Xu, and C. Feng, “Among Us: Adversarially Robust Collaborative Perception by Consensus,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 186–195.
- [16] Y. Zhao, Z. Xiang, S. Yin, X. Pang, S. Chen, and Y. Wang, “Malicious Agent Detection for Robust Multi-Agent Collaborative Perception,” arXiv:2310.11901, 2024.
- [17] Anonymous, “CP-Guard+: A New Paradigm for Malicious Agent Detection and Defense in Collaborative Perception,” in Submitted to The Thirteenth International Conference on Learning Representations (ICLR), 2024, under review.
- [18] Y. Han, H. Zhang, H. Li, Y. Jin, C. Lang, and Y. Li, “Collaborative Perception in Autonomous Driving: Methods, Datasets and Challenges,” IEEE Intelligent Transportation Systems Magazine, vol. 15, no. 6, pp. 131–151, Nov. 2023, arXiv:2301.06262 [cs].
- [19] S. Hu, Z. Fang, Y. Deng, X. Chen, and Y. Fang, “Collaborative Perception for Connected and Autonomous Driving: Challenges, Possible Solutions and Opportunities,” Jan. 2024, arXiv:2401.01544.
- [20] W. Zeng, S. Wang, R. Liao, Y. Chen, B. Yang, and R. Urtasun, “DSDNet: Deep Structured Self-driving Network,” in European Conference on Computer Vision (ECCV), 2020, pp. 156–172.
- [21] Y. Li, S. Ren, P. Wu, S. Chen, C. Feng, and W. Zhang, “Learning Distilled Collaboration Graph for Multi-Agent Perception,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 29 541–29 552.
- [22] T.-H. Wang, S. Manivasagam, M. Liang, B. Yang, W. Zeng, and R. Urtasun, “V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction,” in European Conference on Computer Vision (ECCV), 2020, pp. 605–621.
- [23] S. Wei, Y. Wei, Y. Hu, Y. Lu, Y. Zhong, S. Chen, and Y. Zhang, “Asynchrony-Robust Collaborative Perception via Bird’s Eye View Flow,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023, pp. 28 462–28 477.
- [24] Y. Lu, Q. Li, B. Liu, M. Dianati, C. Feng, S. Chen, and Y. Wang, “Robust Collaborative 3d Object Detection in Presence of Pose Errors,” in IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 4812–4818.
- [25] H. An, G. Hua, Z. Lin, and Y. Fang, “Box-Free Model Watermarks Are Prone to Black-Box Removal Attacks,” arXiv:2405.09863, 2024.
- [26] H. Cao, L. Yuan, G. Xu, Z. He, Z. Fang, and Y. Fang, “Secure Traffic Sign Recognition: An Attention-Enabled Universal Image Inpainting Mechanism against Light Patch Attacks,” arXiv:2409.04133, 2024.
- [27] H. Cao, W. Huang, G. Xu, X. Chen, Z. He, J. Hu, H. Jiang, and Y. Fang, “Security Analysis of WiFi-based Sensing Systems: Threats from Perturbation Attacks,” arXiv:2404.15587, 2024.
- [28] J. Yin, J. Shen, C. Guan, D. Zhou, and R. Yang, “LiDAR-Based Online 3D Video Object Detection With Graph-Based Message Passing and Spatiotemporal Transformer Attention,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11 492–11 501.
- [29] X. Gao, Z. Chen, J. Pan, F. Wu, and G. Chen, “Energy Efficient Scheduling Algorithms for Sweep Coverage in Mobile Sensor Networks,” IEEE Transactions on Mobile Computing, vol. 19, no. 6, pp. 1332–1345, 2020.
- [30] J. Liu, Y. Zhang, X. Zhao, Z. He, W. Liu, and X. Lv, “Fast and Robust LiDAR-Inertial Odometry by Tightly-Coupled Iterated Kalman Smoother and Robocentric Voxels,” IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 10, pp. 14 486–14 496, 2024.
- [31] Y. Wei, J. Jang-Jaccard, F. Sabrina, W. Xu, S. Camtepe, and A. Dunmore, “Reconstruction-based LSTM-Autoencoder for Anomaly-based DDoS Attack Detection over Multivariate Time-Series Data,” arXiv:2305.09475, 2023.
- [32] Y. Benjamini and Y. Hochberg, “Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing,” Journal of the Royal statistical society: series B (Methodological), vol. 57, no. 1, pp. 289–300, 1995.
- [33] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An open urban driving simulator,” in Proceedings of the 1st Annual Conference on Robot Learning, 2017, pp. 1–16.
- [34] Y. Xiang, K. Li, and W. Zhou, “Low-Rate DDoS Attacks Detection and Traceback by Using New Information Metrics,” IEEE Transactions on Information Forensics and Security, vol. 6, no. 2, pp. 426–437, 2011.
- [35] H. Ahn, J. Choi, and Y. H. Kim, “A Mathematical Modeling of Stuxnet-Style Autonomous Vehicle Malware,” IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 1, pp. 673–683, 2023.
- [36] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards Deep Learning Models Resistant to Adversarial Attacks,” in International Conference on Learning Representations (ICLR), 2018.
- [37] N. Carlini and D. Wagner, “Towards Evaluating the Robustness of Neural Networks,” in IEEE Symposium on Security and Privacy (SP), May 2017, pp. 39–57.
- [38] W. Luo, B. Yang, and R. Urtasun, “Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2018, pp. 3569–3577.
- [39] A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” arXiv:1607.02533, 2017.
Appendix A KF-based BEV Flow Interpolation
Given the state transition equations for intermittent BEV flow, we can directly apply these to the Kalman filter (KF) framework for both prediction and state update, and thereby interpolate the missing values. Assume that system state and observation noises are additive white Gaussian noises and that the state transition and observation models are linear, we first define the state vector and the state transition matrix of BEV flow:
| (22) |
where represents the BEV flow state vector, containing 4 corner points of a bounding box in the BEV detection map, with being the coordinates of the -th corner point. Then, the state transition equation can be represented as:
| (23) |
where is the state transition matrix constructed based on the equations provided, assuming no external control inputs besides the physical model-based linear relationships:
| (24) |
where represents identity matrix, is zero matrix, and is the time difference between frame and frame . Based on the state transition matrix above, there are two stages for KF, namely, the prediction stage and the update stage. In the prediction stage, both the state and the error covariance are predicted, given as:
| (25) |
| (26) |
where is the process noise covariance matrix, which needs to be set based on practical scenarios. In the update stage, assuming the observation vector directly reflects all state variables, we have the observation model as follows:
| (27) |
where is the observation matrix, which can be simplified to the identity matrix , if all state variables are directly observable. The KF update process includes updating Kalman gain, state estimate, and error covariance as follows:
| (28) |
| (29) |
| (30) |
where is the Kalman gain, is the state estimate, is the error covariance, and is the observation noise covariance matrix.
Appendix B Implementation of Adversarial Attacks
In this paper, we evaluate our proposed GCP and other baselines by implementing two adversarial attacks:
-
•
Projected Gradient Descent (PGD) Attack [36]: PGD attack introduces a random initialization step to the adversarial example generation process. The mathematical expression for PGD is initiated by adding uniformly distributed noise to the original input:
(31) where is a predefined perturbation limit. Subsequent iterations adjust the adversarial example by moving in the direction of the gradient of the loss function:
(32) where denotes the iteration index, is the step size and represents the projection operation that confines the perturbation within the allowable range. This procedure is typically repeated for a predefined number of iterations, with settings such as and often used.
-
•
Carini & Wagner (C&W) Attack [37]: The C&W attack focuses on identifying the minimal perturbation that leads to a misclassification, formulated as the following optimization problem:
(33) where the function measures the size of the perturbation using the norm, while is a scaling constant that adjusts the weight of the misclassification function , which is designed to increase the likelihood of misclassification:
(34) where outputs the logits from the model for the perturbed input, with indicating the target class, and serving as a confidence parameter to ensure robustness in the adversarial example.
-
•
Basic Iterative Method (BIM) Attack [39]: The BIM attack incrementally adjusts an initial input by applying small but cumulative perturbations, based on the sign of the gradient of the loss function with respect to the input, aiming to maximize the prediction error in a model while ensuring the perturbations remain within specified bounds:
(35) where represents the iteration index, is the size of the step, defines the maximum allowable perturbation, and is a function that restricts the values within a boundary around the original features . The initial setting is . This procedure is iterated either a preset number of times or until a specific stopping condition is reached.