General Munchausen Reinforcement Learning with Tsallis Kullback-Leibler Divergence
Abstract
Many policy optimization approaches in reinforcement learning incorporate a Kullback-Leilbler (KL) divergence to the previous policy, to prevent the policy from changing too quickly. This idea was initially proposed in a seminal paper on Conservative Policy Iteration, with approximations given by algorithms like TRPO and Munchausen Value Iteration (MVI). We continue this line of work by investigating a generalized KL divergence—called the Tsallis KL divergence. Tsallis KL defined by the -logarithm is a strict generalization, as corresponds to the standard KL divergence; provides a range of new options. We characterize the types of policies learned under the Tsallis KL, and motivate when could be beneficial. To obtain a practical algorithm that incorporates Tsallis KL regularization, we extend MVI, which is one of the simplest approaches to incorporate KL regularization. We show that this generalized MVI() obtains significant improvements over the standard MVI() across 35 Atari games.
1 Introduction
There is ample theoretical evidence that it is useful to incorporate KL regularization into policy optimization in reinforcement learning. The most basic approach is to regularize towards a uniform policy, resulting in entropy regularization. More effective, however, is to regularize towards the previous policy. By choosing KL regularization between consecutively updated policies, the optimal policy becomes a softmax over a uniform average of the full history of action value estimates (Vieillard et al., 2020a). This averaging smooths out noise, allowing for better theoretical results (Azar et al., 2012; Kozuno et al., 2019; Vieillard et al., 2020a; Kozuno et al., 2022).
Despite these theoretical benefits, there are some issues with using KL regularization in practice. It is well-known that the uniform average is susceptible to outliers; this issue is inherent to KL divergence (Futami et al., 2018). In practice, heuristics such as assigning vanishing regularization coefficients to some estimates have been implemented widely to increase robustness and accelerate learning (Grau-Moya et al., 2019; Haarnoja et al., 2018; Kitamura et al., 2021). However, theoretical guarantees no longer hold for those heuristics (Vieillard et al., 2020a; Kozuno et al., 2022). A natural question is what alternatives we can consider to this KL divergence regularization, that allows us to overcome some of these disadvantages while maintaining the benefits associate with restricting aggressive policy changes and smoothing errors.
In this work, we explore one possible direction by generalizing to Tsallis KL divergences. Tsallis KL divergences were introduced for physics (Tsallis, 1988, 2009) using a simple idea: replacing the use of the logarithm with the deformed -logarithm. The implications for policy optimization, however, are that we get quite a different form for the resulting policy. Tsallis entropy with has actually already been considered for policy optimization (Chow et al., 2018; Lee et al., 2018), by replacing Shannon entropy with Tsallis entropy to maintain stochasticity in the policy. The resulting policies are called sparsemax policies, because they concentrate the probability on higher-valued actions and truncate the probability to zero for lower-valued actions. Intuitively, this should have the benefit of maintaining stochasticity, but only amongst the most promising actions, unlike the Boltzmann policy which maintains nonzero probability on all actions. Unfortunately, using only Tsallis entropy did not provide significant benefits, and in fact often performed worse than existing methods. We find, however, that using a Tsallis KL divergence to the previous policy does provide notable gains.
We first show how to incorporate Tsallis KL regularization into the standard value iteration updates, and prove that we maintain convergence under this generalization from KL regularization to Tsallis KL regularization. We then characterize the types of policies learned under Tsallis KL, highlighting that there is now a more complex relationship to past action-values than a simple uniform average. We then show how to extend Munchausen Value Iteration (MVI) (Vieillard et al., 2020b), to use Tsallis KL regularization, which we call MVI(). We use this naming convention to highlight that this is a strict generalization of MVI: by setting , we exactly recover MVI. We then compare MVI() with MVI (namely the standard choice where ), and find that we obtain significant performance improvements in Atari.
Remark: There is a growing body of literature studying generalizations of KL divergence in RL (Nachum et al., 2019; Zhang et al., 2020). Futami et al. (2018) discussed the inherent drawback of KL divergence in generative modeling and proposed to use - and -divergence to allow for weighted average of sample contribution. These divergences fall under the category known as the -divergence (Sason and Verdú, 2016), commonly used in other machine learning domains including generative modeling (Nowozin et al., 2016; Wan et al., 2020; Yu et al., 2020) and imitation learning (Ghasemipour et al., 2019; Ke et al., 2019). In RL, Wang et al. (2018) discussed using tail adaptive -divergence to enforce the mass-covering property. Belousov and Peters (2019) discussed the use of -divergence. Tsallis KL divergence, however, has not yet been studied in RL.
2 Problem Setting
We focus on discrete-time discounted Markov Decision Processes (MDPs) expressed by the tuple , where and denote state space and finite action space, respectively. Let denote the set of probability distributions over . denotes the initial state distribution. denotes the transition probability function, and defines the reward associated with that transition. is the discount factor. A policy is a mapping from the state space to distributions over actions. We define the action value function following policy and starting from with action taken as . A standard approach to find the optimal value function is value iteration. To define the formulas for value iteration, it will be convenient to write the action value function as a matrix . For notational convenience, we define the inner product for any two functions over actions as .
We are interested in the entropy-regularized MDPs where the recursion is augmented with :
| (1) |
This modified recursion is guaranteed to converge if is concave in . For standard (Shannon) entropy regularization, we use . The resulting optimal policy has , where indicates proportional to up to a constant not depending on actions.
More generally, we can consider a broad class of regularizers known as -divergences (Sason and Verdú, 2016): , where is a convex function. For example, the KL divergence can be recovered by . In this work, when we say KL regularization, we mean the standard choice of setting , the estimate from the previous update. Therefore, serves as a penalty to penalize aggressive policy changes. The optimal policy in this case takes the form . By induction, we can show this KL-regularized optimal policy is a softmax over a uniform average over the history of action value estimates (Vieillard et al., 2020a): . Using KL regularization has been shown to be theoretically superior to entropy regularization in terms of error tolerance (Azar et al., 2012; Vieillard et al., 2020a; Kozuno et al., 2022; Chan et al., 2022).
The definitions of and rely on the standard logarithm and both induce softmax policies as an exponential (inverse function) over (weighted) action-values (Hiriart-Urruty and Lemaréchal, 2004; Nachum and Dai, 2020). Convergence properties of the resulting regularized algorithms have been well studied (Kozuno et al., 2019; Geist et al., 2019; Vieillard et al., 2020a). In this paper, we investigate Tsallis entropy and Tsallis KL divergence as the regularizer, which generalize Shannon entropy and KL divergence respectively.
3 Generalizing to Tsallis Regularization
We can easily incorporate other regularizers in to the value iteration recursion, and maintain convergence as long as those regularizers are strongly convex in . We characterize the types of policies that arise from using this regularizer, and prove the convergence of resulting regularized recursion.
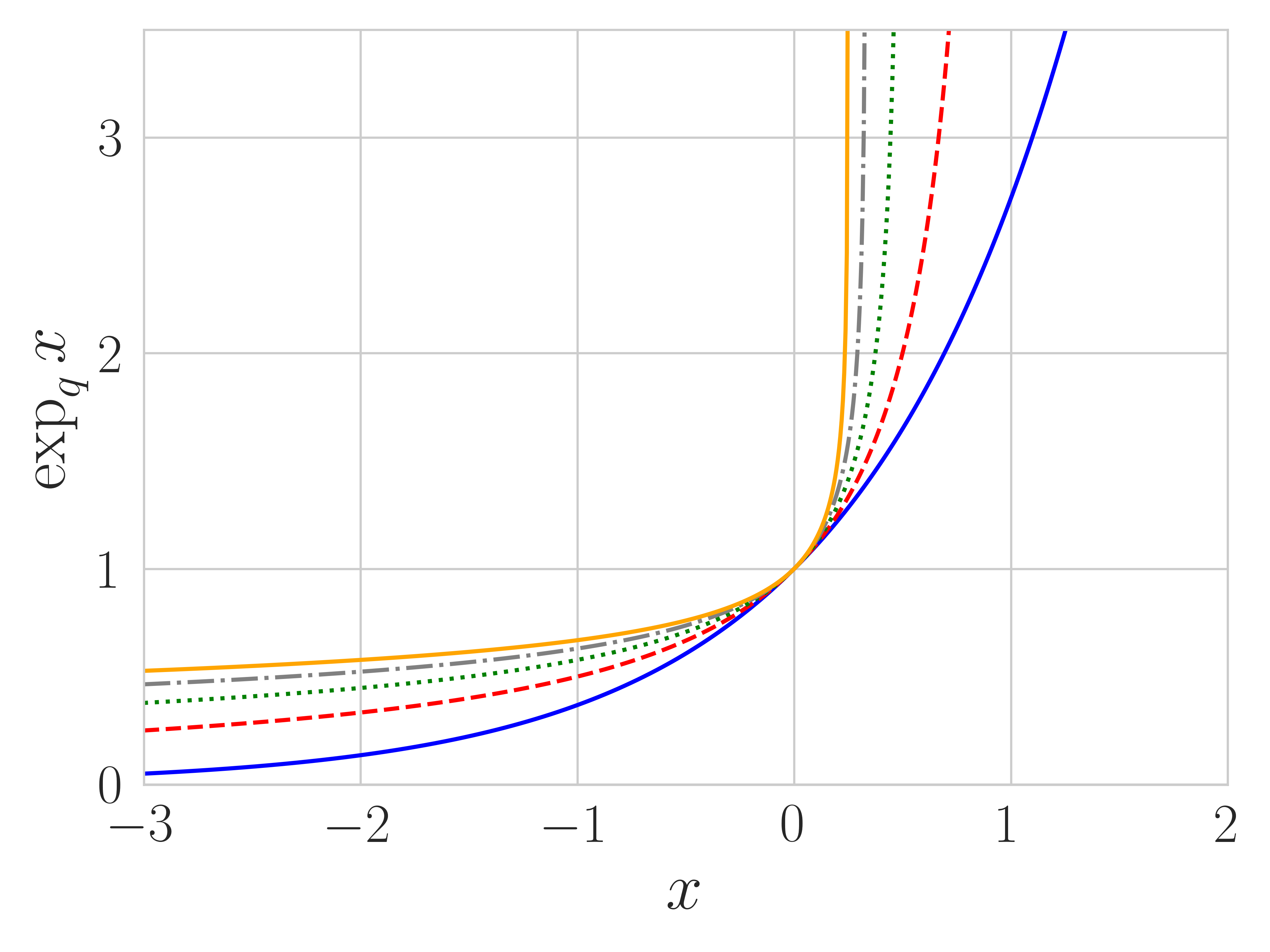
3.1 Tsallis Entropy Regularization
Tsallis entropy was first proposed by Tsallis (1988) and is defined by the -logarithm. The -logarithm and its unique inverse function, the -exponential, are defined as:
| (2) |
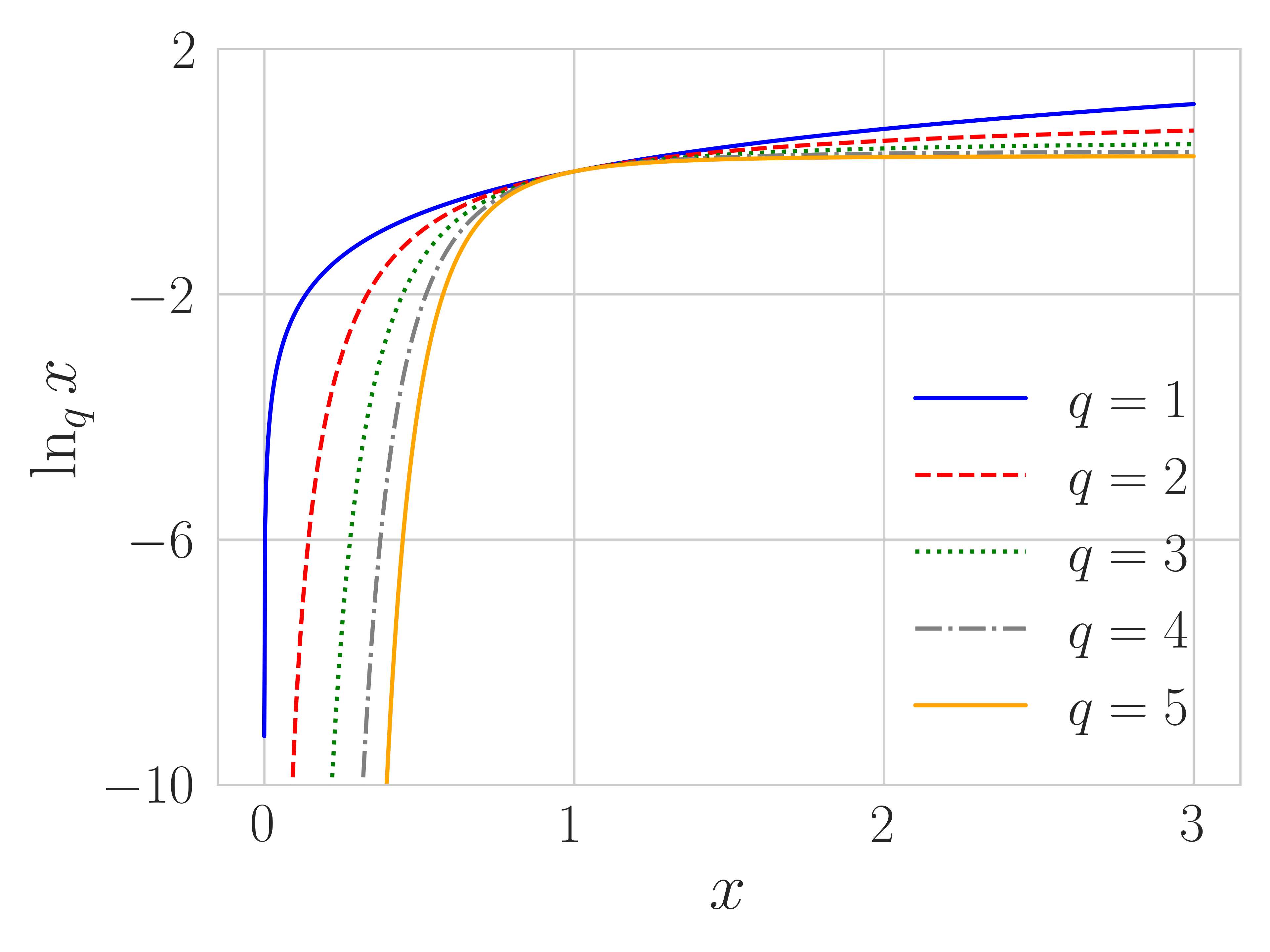
where . We define , as in the limit , the formulas in Eq. (2) approach these functions. Tsallis entropy can be defined by (Suyari and Tsukada, 2005). We visualize the -logarithm , -exponential and Tsallis entropy for different in Figure 1. As gets larger, -logarithm (and hence Tsallis entropy) becomes more flat and -exponential more steep111 The -logarithm defined here is consistent with the physics literature and different from prior RL works (Lee et al., 2020), where a change of variable is made. We analyze both cases in Appendix A. . Note that is only invertible for .
Tsallis policies have a similar form to softmax, but using the -exponential instead. Let us provide some intuition for these policies. When , , the optimization problem is known to be the Euclidean projection onto the probability simplex. Its solution is called the sparsemax (Martins and Astudillo, 2016; Lee et al., 2018) and has sparse support (Duchi et al., 2008; Condat, 2016; Blondel et al., 2020). is the unique function satisfying .
As our first result, we unify the Tsallis entropy regularized policies for all with the -exponential, and show that and are interchangeable for controlling the truncation.
Theorem 1.
Let in Eq. (1). Then the regularized optimal policies can be expressed:
| (3) | ||||
where . Additionally, for an arbitrary pair with , the same truncation effect (support) can be achieved using .
Proof.
See Appendix B for the full proof. ∎
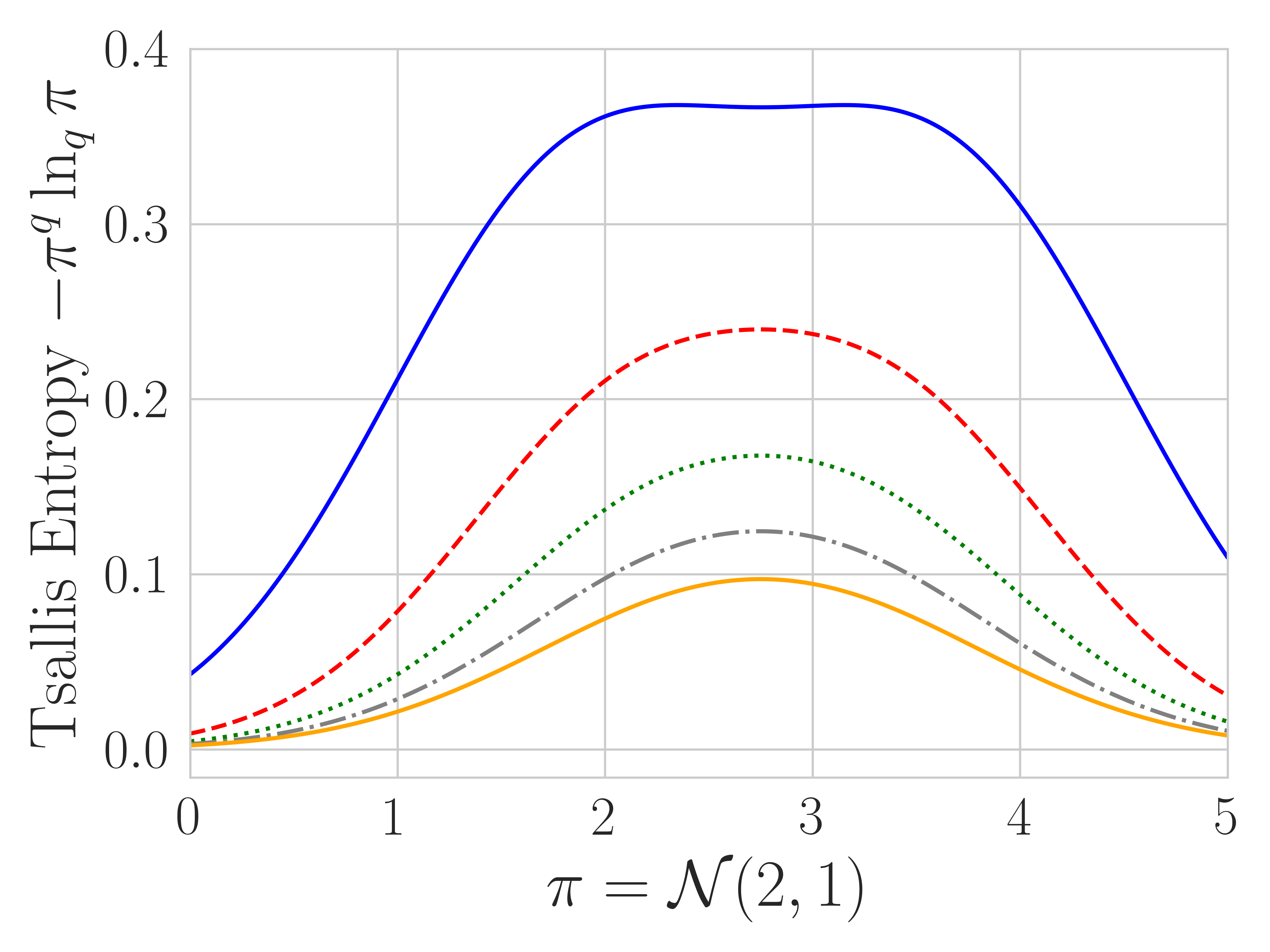
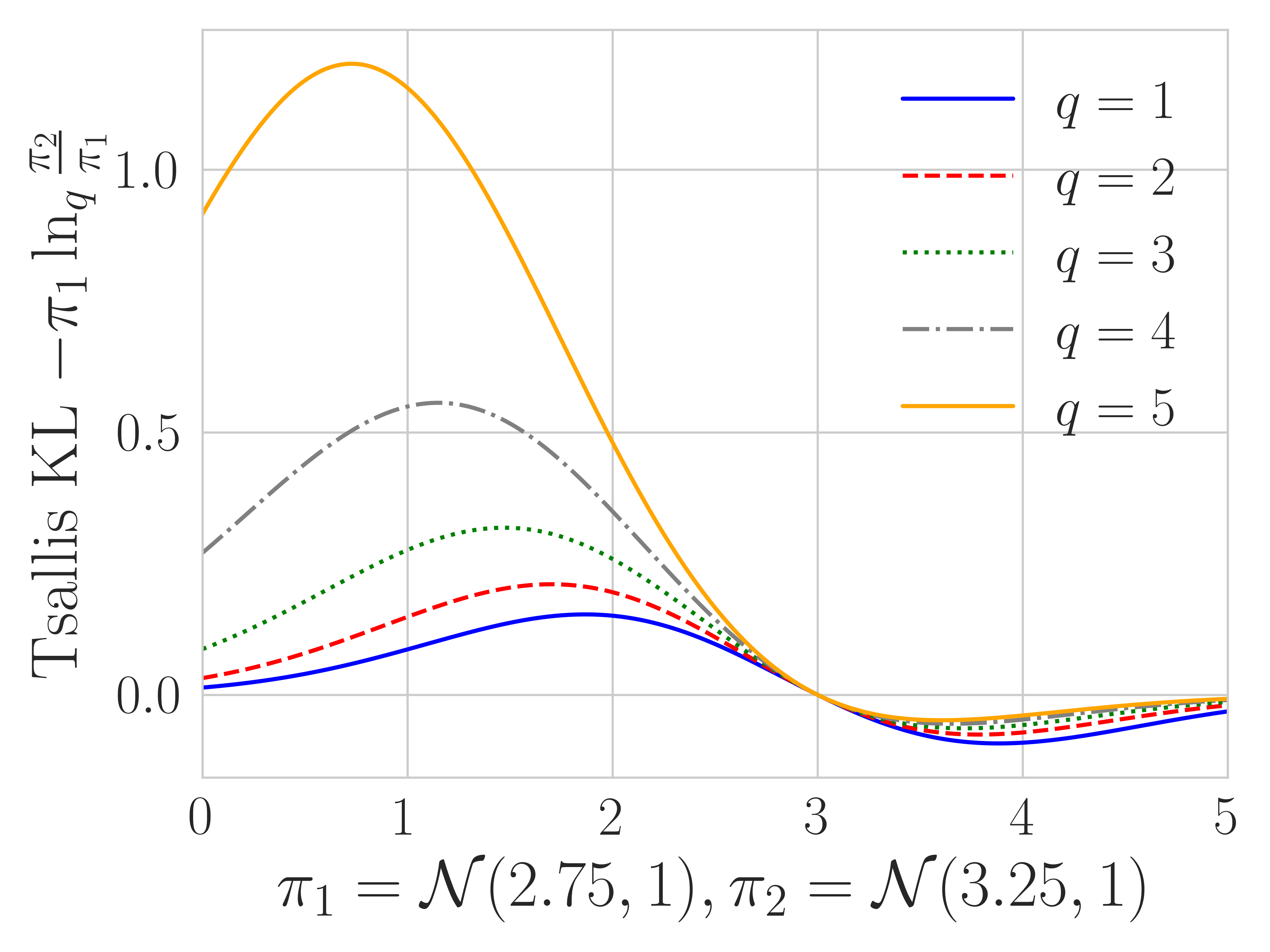
Theorem 1 characterizes the role played by : controlling the degree of truncation. We show the truncation effect when and in Figure 2, confirming that Tsallis policies tend to truncate more as gets larger. The theorem also highlights that we can set and still get more or less truncation using different , helping to explain why in our experiments is a generally effective choice.
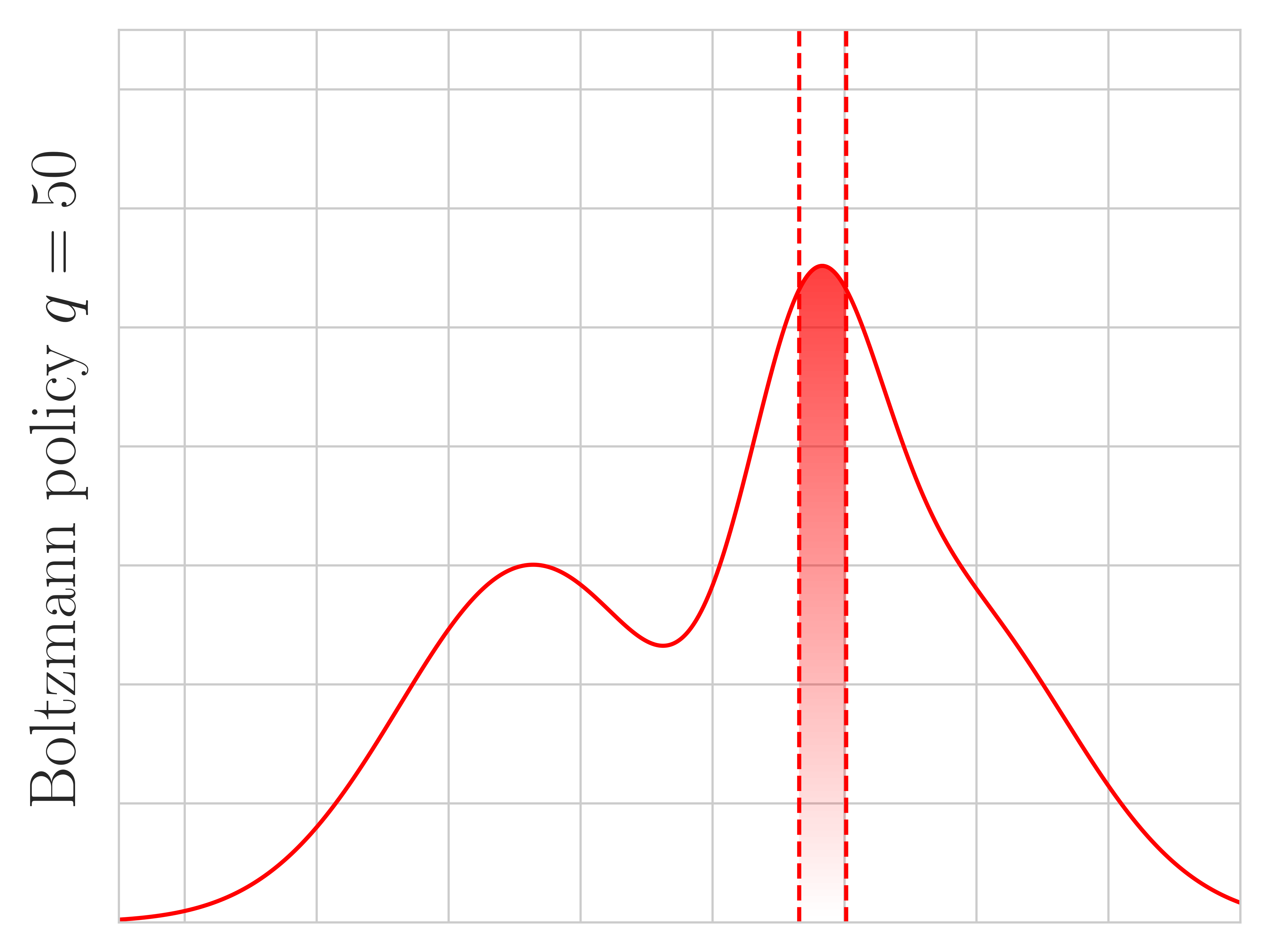
Unfortunately, the threshold (and ) does not have a closed-form solution for . Note that corresponds to Shannon entropy and to no regularization. However, we can resort to Taylor’s expansion to obtain approximate sparsemax policies.
Theorem 2.
For , we can obtain approximate threshold using Taylor’s expansion, and therefore an approximate policy:
| (4) |
is the set of highest-valued actions, satisfying the relation , where indicates the action with th largest action value. The sparsemax policy sets the probabilities of lowest-valued actions to zero: where . When , recovers .
Proof.
See Appendix B for the full proof. ∎
3.2 Tsallis KL Regularization and Convergence Results
The Tsallis KL divergence is defined as (Furuichi et al., 2004). It is a member of -divergence and can be recovered by choosing . As a divergence penalty, it is required that since should be convex. We further assume that to align with standard divergences; i.e. penalize large value of , since for the regularization would penalize instead. In practice, we find that tend to perform poorly. In contrast to KL, Tsallis KL is more mass-covering; i.e. its value is proportional to the -th power of the ratio . When is big, large values of are strongly penalized (Wang et al., 2018). This behavior of Tsallis KL divergence can also be found in other well-known divergences: the -divergence (Wang et al., 2018; Belousov and Peters, 2019) coincides with Tsallis KL when ; Rényi’s divergence also penalizes large policy ratio by raising it to the power , but inside the logarithm, which is therefore an additive extension of KL (Li and Turner, 2016). In the limit of , Tsallis entropy recovers Shannon entropy and the Tsallis KL divergence recovers the KL divergence. We plot the Tsallis KL divergence behavior in Figure 2.
Now let us turn to formalizing when value iteration under Tsallis regularization converges. The -logarithm has the following properties: Convexity: is convex for , concave for . When , both become linear. Monotonicity: is monotonically increasing with respect to . These two properties can be simply verified by checking the first and second order derivative. We prove in Appendix A the following similarity between Shannon entropy (reps. KL) and Tsallis entropy (resp. Tsallis KL). Bounded entropy: we have ; and . Generalized KL property: , . if and only if almost everywhere, and whenever and .
However, despite their similarity, a crucial difference is that is non-extensive, which means it is not additive (Tsallis, 1988). In fact, is only pseudo-additive:
| (5) |
Pseudo-additivity complicates obtaining convergence results for Eq. (1) with -logarithm regularizers, since the techniques used for Shannon entropy and KL divergence are generally not applicable to their counterparts. Moreover, deriving the optimal policy may be nontrivial. Convergence results have only been established for Tsallis entropy (Lee et al., 2018; Chow et al., 2018).
We know that Eq. (1) with , for any , converges for that make strictly convex (Geist et al., 2019). When , it is strongly convex, and so also strictly convex, guaranteeing convergence.
Theorem 3.
The regularized recursion Eq. (1) with when converges to the unique regularized optimal policy.
Proof.
See Appendix C. It simply involves proving that this regularizer is strongly convex. ∎
3.3 TKL Regularized Policies Do More Than Averaging
We next show that the optimal regularized policy under Tsallis KL regularization does more than uniform averaging. It can be seen as performing a weighted average where the degree of weighting is controlled by . Consider the recursion
| (6) |
where we dropped the regularization coefficient for convenience.
Theorem 4.
The greedy policy in Equation (6) satisfies
| (7) |
When , Eq. (6) reduces to KL regularized recursion and hence Eq. (7) reduces to the KL-regularized policy. When , Eq. (7) becomes:
i.e., Tsallis KL regularized policies average over the history of value estimates as well as computing the interaction between them .
Proof.
The form of this policy is harder to intuit, but we can try to understand each component. The first component actually corresponds to a weighted averaging by the property of the :
| (8) |
Eq. (8) is a possible way to expand the summation: the left-hand side of the equation is what one might expect from conventional KL regularization; while the right-hand side shows a weighted scheme such that any estimate is weighted by the summation of estimates before times (Note that we can exchange 1 and , see Appendix A). Weighting down numerator by the sum of components in the demoninator has been analyzed before in the literature of weighted average by robust divergences, e.g., the -divergence (Futami et al., 2018, Table 1). Therefore, we conjecture this functional form helps weighting down the magnitude of excessively large , which can also be controlled by choosing . In fact, obtaining a weighted average has been an important topic in RL, where many proposed heuristics coincide with weighted averaging (Grau-Moya et al., 2019; Haarnoja et al., 2018; Kitamura et al., 2021).
Now let us consider the second term with , therefore the leading vanishes. The action-value cross-product term can be intuitively understood as further increasing the probability for any actions that have had consistently larger values across iterations. This observation agrees with the mode-covering property of Tsallis KL. However, there is no concrete evidence yet how the average inside -exponential and the cross-product action values may work jointly to benefit the policy, and their benefits may depend on the task and environments, requiring further categorization and discussion. Empirically, we find that the nonlinearity of Tsallis KL policies bring superior performance to the uniform averaging KL policies on the testbed considered.
4 A Practical Algorithm for Tsallis KL Regularization
In this section we provide a practical algorithm for implementing Tsallis regularization. We first explain why this is not straightforward to simply implement KL-regularized value iteration, and how Munchausen Value Iteration (MVI) overcomes this issue with a clever implicit regularization trick. We then extend this algorithm to using a similar approach, though now with some approximation due once again to the difficulties of pseudo-additivity.
4.1 Implicit Regularization With MVI
Even for the standard KL, it is difficult to implement KL-regularized value iteration with function approximation. The difficulty arises from the fact that we cannot exactly obtain . This policy might not be representable by our function approximator. For , one needs to store all past which is computationally infeasible.
An alternative direction has been to construct a different value function iteration scheme, which is equivalent to the original KL regularized value iteration (Azar et al., 2012; Kozuno et al., 2019). A recent method of this family is Munchausen VI (MVI) (Vieillard et al., 2020b). MVI implicitly enforces KL regularization using the recursion
| (9) | ||||
We see that Eq. (9) is Eq. (1) with (blue) plus an additional red Munchausen term, with coefficient . Vieillard et al. (2020b) showed that implicit KL regularization was performed under the hood, even though we still have tractable :
| (10) |
where is the generalized action value function.
The implementation of this idea uses the fact that , where is the Boltzmann softmax operator.222Using is equivalent to the log-sum-exp operator up to a constant shift (Azar et al., 2012). In the original work, computing this advantage term was found to be more stable than directly using the log of the policy. In our extension, we use the same form.
4.2 MVI() For General
The MVI(q) algorithm is a simple extension of MVI: it replaces the standard exponential in the definition of the advantage with the -exponential. We can express this action gap as , where . When , it recovers . We summarize this MVI() algorithm in Algorithm B in the Appendix. When , we recover MVI. For , we get that is —no regularization—and we recover advantage learning (Baird and Moore, 1999). Similar to the original MVI algorithm, MVI() enjoys tractable policy expression with .
Unlike MVI, however, MVI() no longer exactly implements the implicit regularization shown in Eq. (10). Below, we go through a similar derivation as MVI, show why there is an approximation and motivate why the above advantage term is a reasonable approximation. In addition to this reasoning, our primary motivation for this extension of MVI to use was to inherit the same simple form as MVI as well as because empirically we found it to be effective.
Let us similarly define a generalized action value function . Using the relationship , we get
| (11) | |||
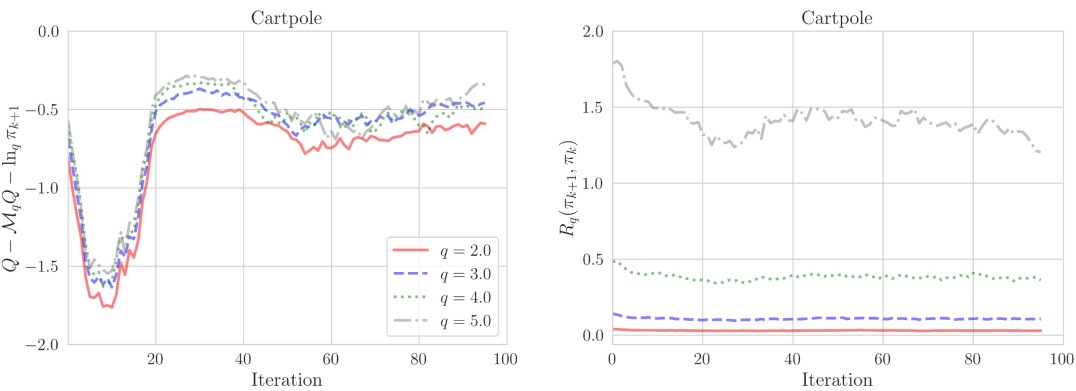
where we leveraged the fact that and defined the residual term . When , it is expected that the residual term remains negligible, but can become larger as increases. We visualize the trend of the residual for on the CartPole-v1 environment (Brockman et al., 2016) in Figure 3. Learning consists of steps, evaluated every steps (one iteration), averaged over 50 independent runs. It is visible that the magnitude of residual jumps from to , while remains negligible throughout.
A reasonable approximation, therefore, is to use and omit this residual term. Even this approximation, however, has an issue. When the actions are in the support, is the unique inverse function of and yields . However, for actions outside the support, we cannot get the inverse, because many inputs to can result in zero. We could still use as a sensible choice, and it appropriately does use negative values for the Munchausen term for these zero-probability actions. Empirically, however, we found this to be less effective than using the action gap.
Though the action gap is yet another approximation, there are clear similarities between using and the action gap . The primary difference is in how the values are centered. We can see as using a uniform average value of the actions in the support, as characterized in Theorem 2. , on the other hand, is a weighted average of action-values.
We plot the difference between and in Figure 3, again in Cartpole. The difference stabilizes around -0.5 for most of learning—in other words primarily just shifting by a constant—but in early learning is larger, across all . This difference in magnitude might explain why using the action gap results in more stable learning, though more investigation is needed to truly understand the difference. For the purposes of this initial work, we pursue the use of the action gap, both as itself a natural extension of the current implementation of MVI and from our own experiments suggesting improved stability with this form.
5 Experiments
In this section we investigate the utility of MVI() in the Atari 2600 benchmark (Bellemare et al., 2013). We test whether this result holds in more challenging environments. Specifically, we compare to standard MVI (), which was already shown to have competitive performance on Atari (Vieillard et al., 2020b). We restrict our attention to , which was generally effective in other settings and also allows us to contrast to previous work (Lee et al., 2020) that only used entropy regularization with KL regularization. For MVI(), we take the exact same learning setup—hyperparameters and architecture—as MVI() and simply modify the term added to the VI update, as in Algorithm 1.
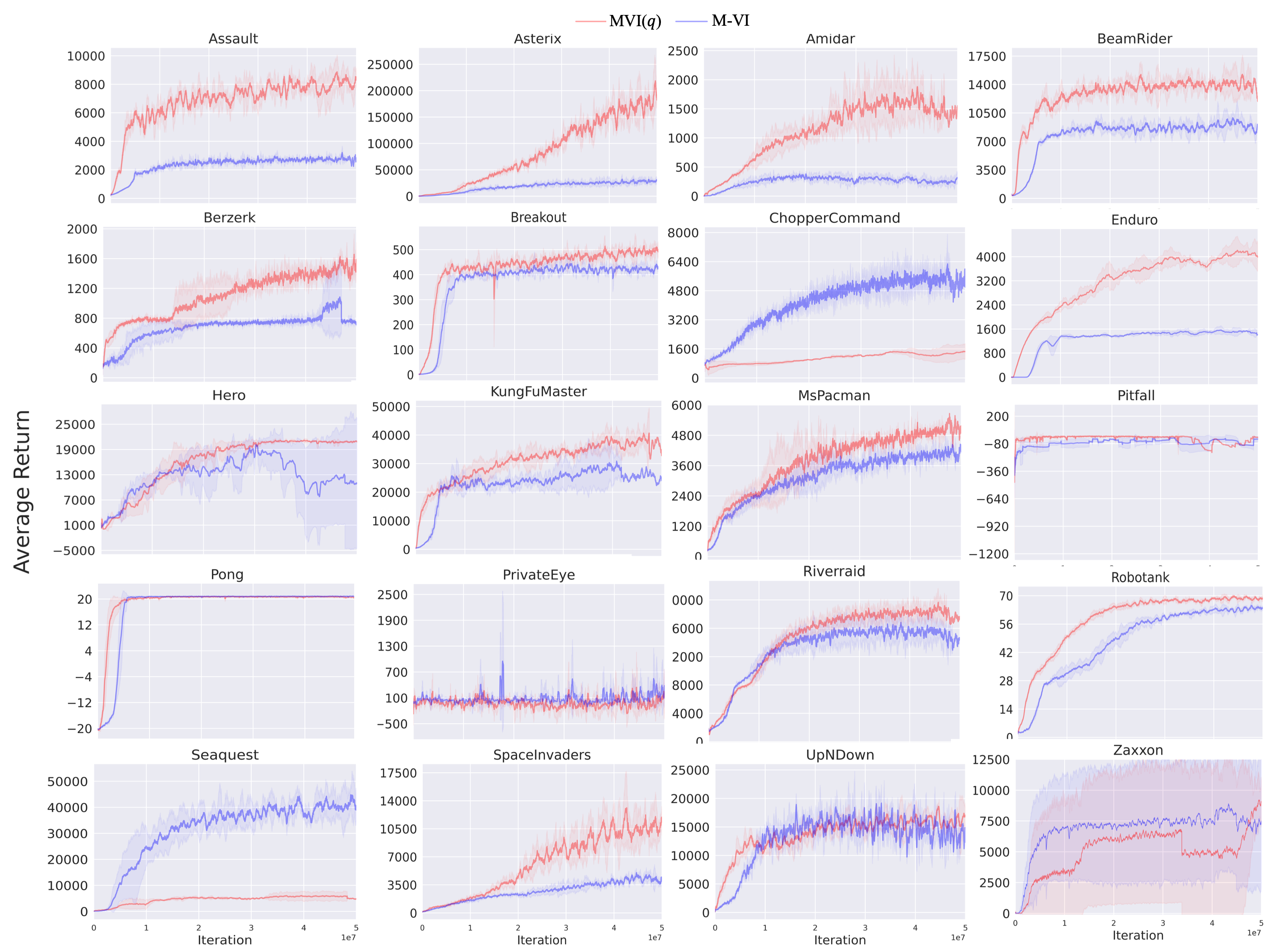
For the Atari games we implemented MVI(), Tsallis-VI and M-VI based on the Quantile Regression DQN (Dabney et al., 2018). We leverage the optimized Stable-Baselines3 architecture (Raffin et al., 2021) for best performance and average over 3 independent runs following (Vieillard et al., 2020b), though we run million frames instead of 200 million. From Figure 4 it is visible that MVI is stable with no wild variance shown, suggesting 3 seeds might be sufficient. We perform grid searches for the algorithmic hyperparameters on two environments Asterix and Seaquest: the latter environment is regarded as a hard exploration environment. MVI ; . Tsallis-VI . For MVI we use the reported hyperparameters in (Vieillard et al., 2020b). Hyperparameters can be seen from Table 2 and full results are provided in Appendix E.
5.1 Comparing MVI() with to
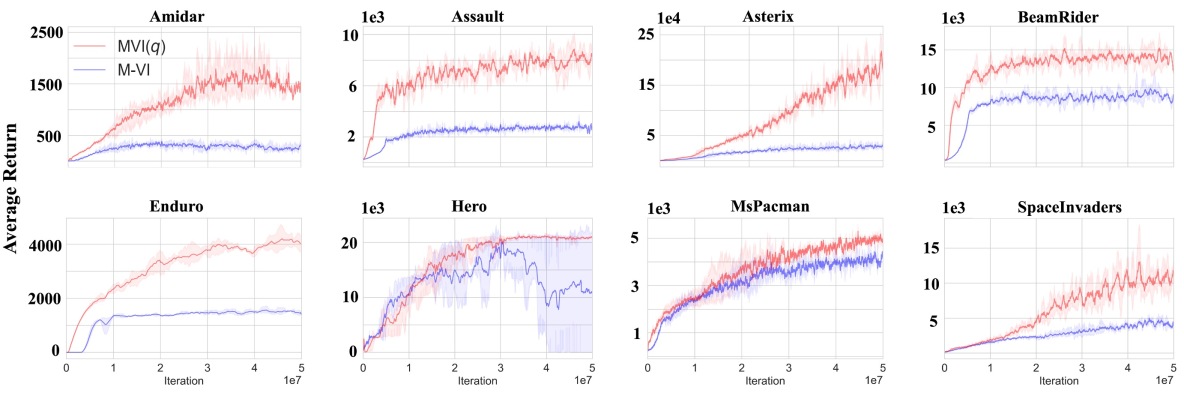
We provide the overall performance of MVI versus MVI() in Figure 5. Using provides a large improvement in about 5 games, about double the performance in the next 5 games, comparable performance in the next 7 games and then slightly worse performance in 3 games (PrivateEye, Chopper and Seaquest). Both PrivateEye and Seaquest are considered harder exploration games, which might explain this discrepancy. The Tsallis policy with reduces the support on actions, truncating some probabilities to zero. In general, with a higher , the resulting policy is greedier, with corresponding to exactly the greedy policy. It is possible that for these harder exploration games, the higher stochasticity in the softmax policy from MVI whre promoted more exploration. A natural next step is to consider incorporating more directed exploration approaches, into MVI(), to benefit from the fact that lower-value actions are removed (avoiding taking poor actions) while exploring in a more directed way when needed.
We examine the learning curves for the games where MVI() had the most significant improvement, in Figure 4. Particularly notable is how much more quickly MVI() learned with , in addition to plateauing at a higher point. In Hero, MVI() learned a stably across the runs, whereas standard MVI with clearly has some failures.
These results are quite surprising. The algorithms are otherwise very similar, with the seemingly small change of using Munchausen term instead of and using the -logarithm and -exponential for the entropy regularization and policy parameterization. Previous work using to get the sparsemax with entropy regularization generally harmed performance (Lee et al., 2018, 2020). It seems that to get the benefits of the generalization to , the addition of the KL regularization might be key. We validate this in the next section.
5.2 The Importance of Including KL Regularization
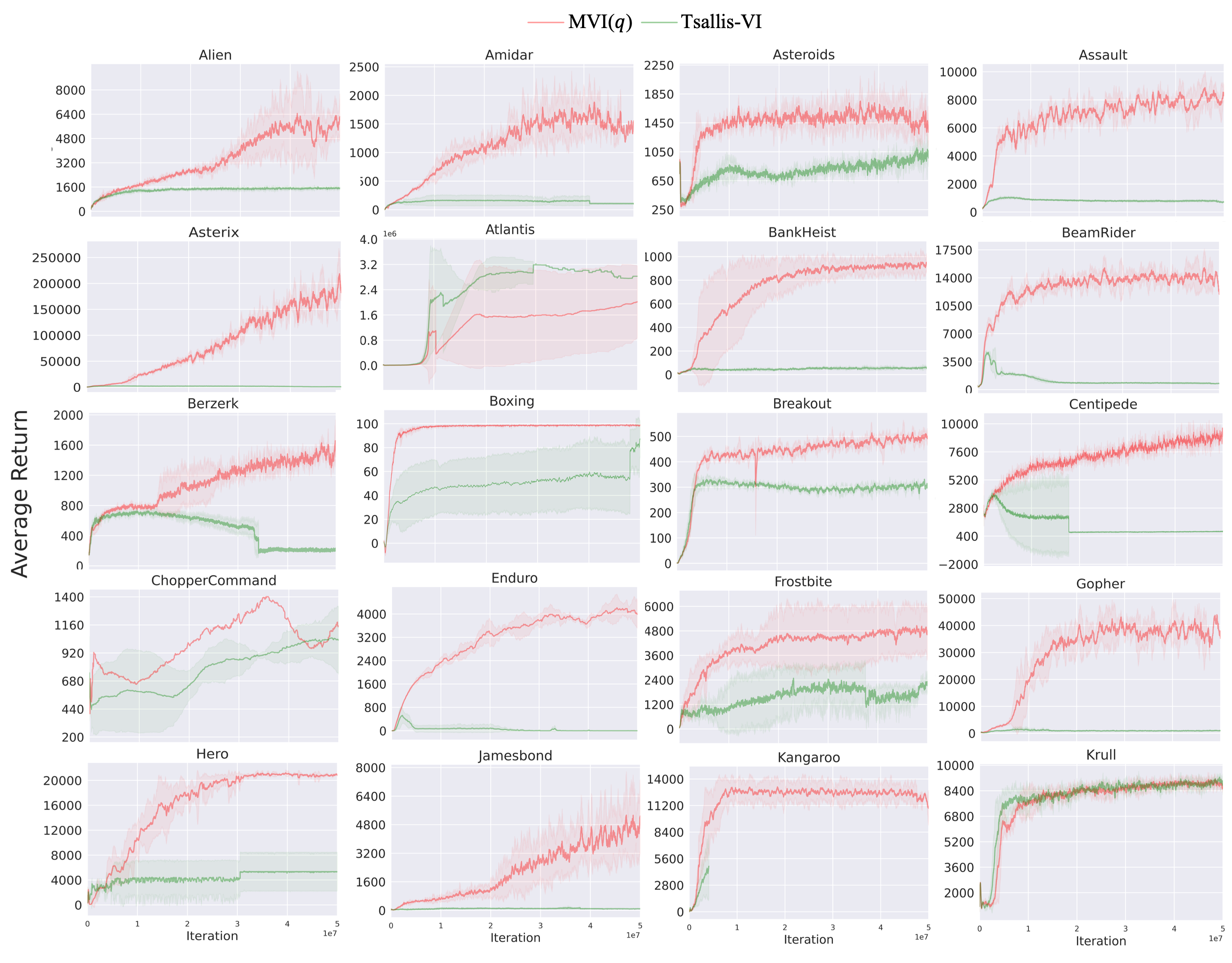
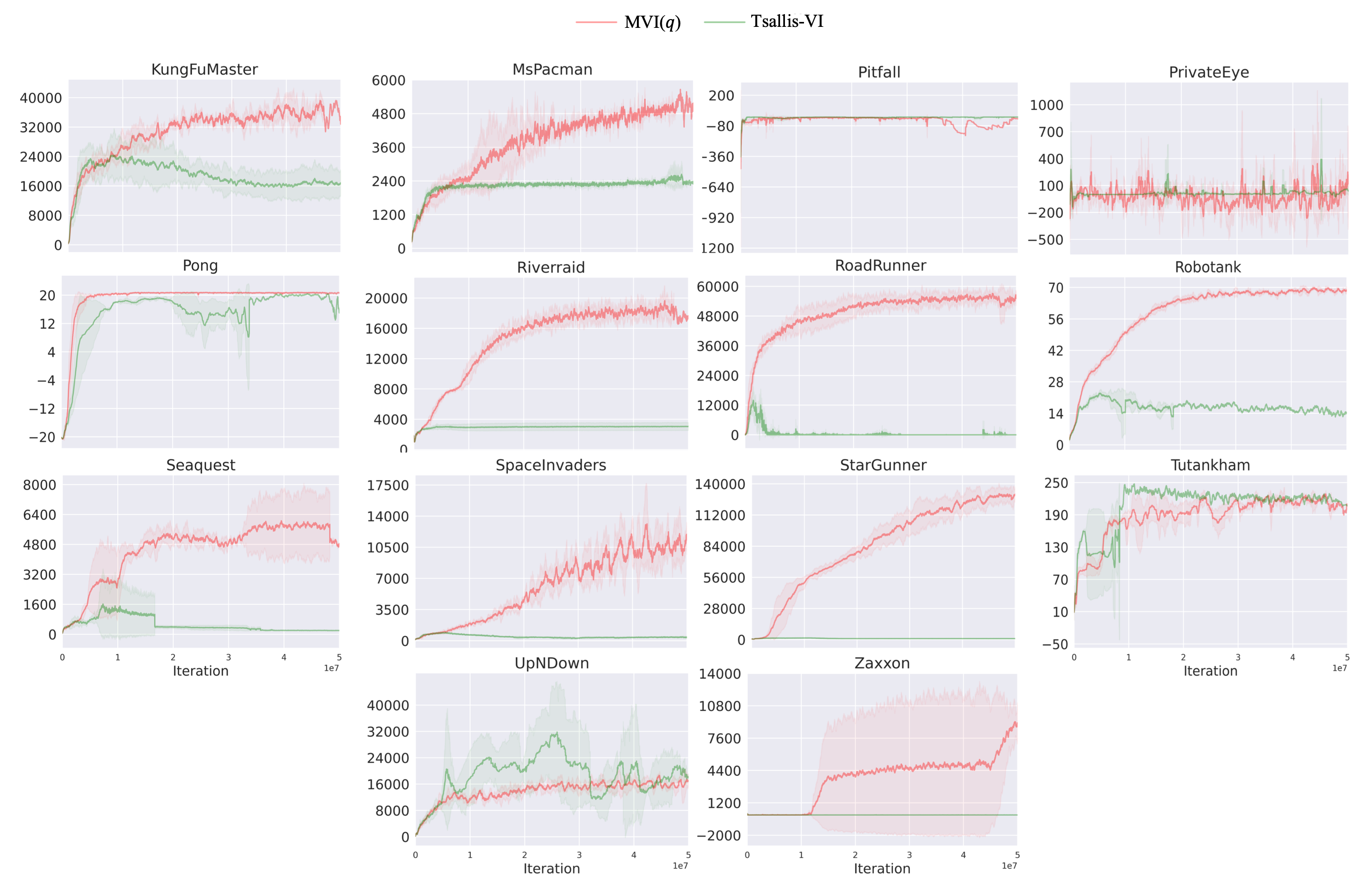
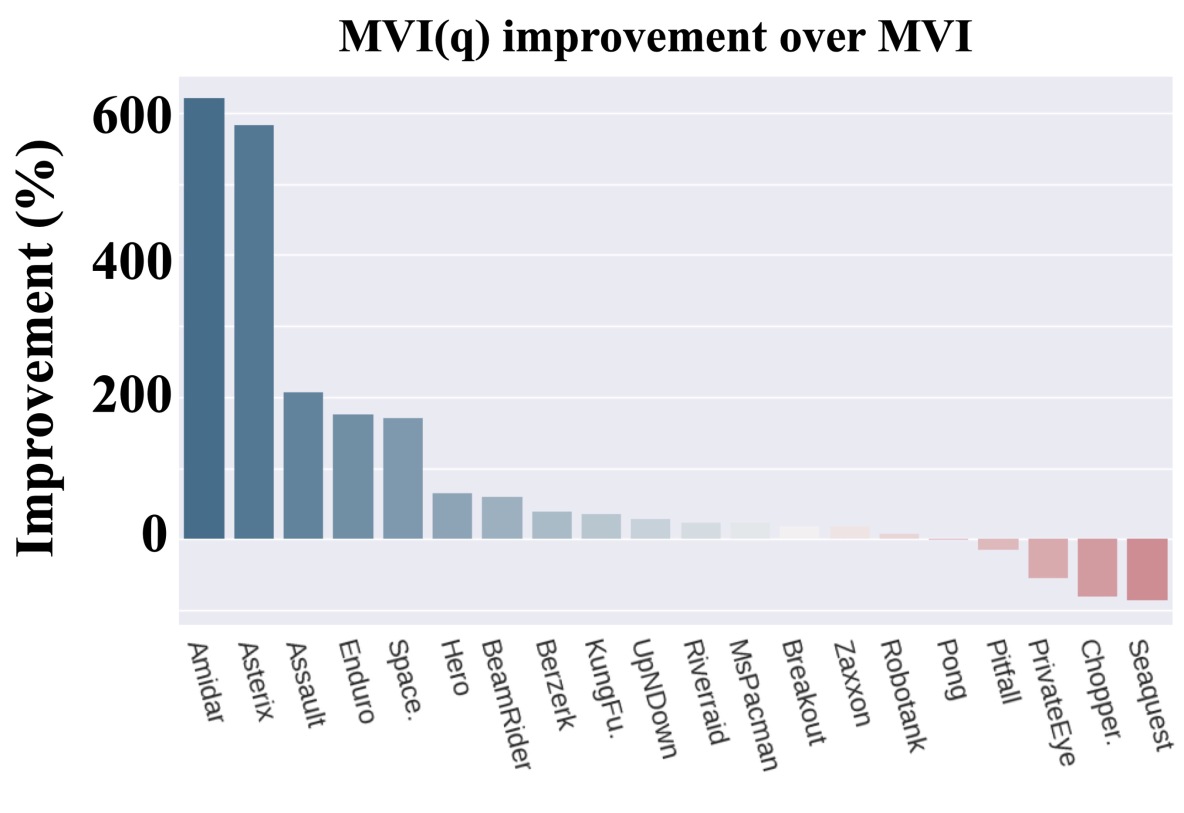
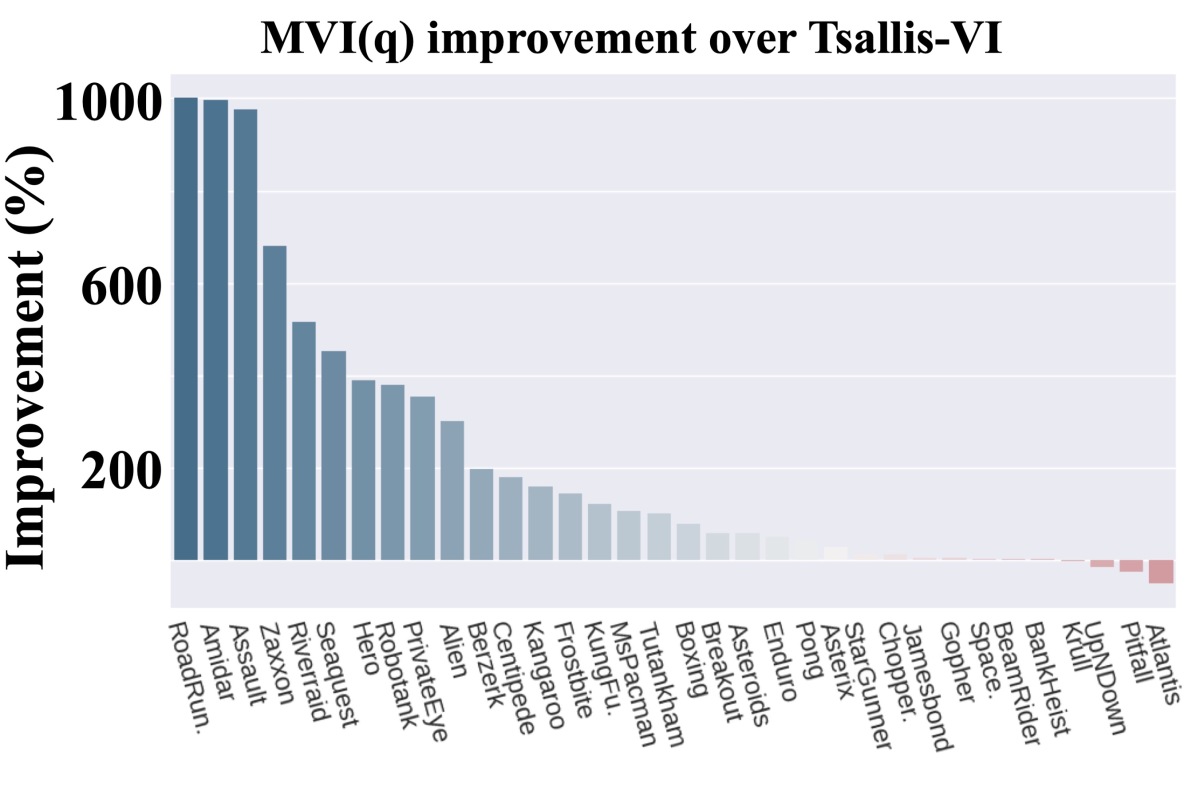
In the policy evaluation step of Eq. (11), if we set then we recover Tsallis-VI which uses regularization in Eq. (1). In other words, we recover the algorithm that incorporates entropy regularization using the -logarithm and the resulting sparsemax policy. Unlike MVI, Tsallis-VI has not been comprehensively evaluated on Atari games, so we include results for the larger benchmark set comprising 35 Atari games. We plot the percentage improvement of MVI() over Tsallis-VI in Figure 5.
The improvement from including the Munchausen term () is stark. For more than half of the games, MVI() resulted in more than 100% improvement. For the remaining games it was comparable. For 10 games, it provided more than 400% improvement. Looking more specifically at which games there was notable improvement, it seems that exploration may again have played a role. MVI() performs much better on Seaquest and PrivateEye. Both MVI() and Tsallis-VI have policy parameterizations that truncate action support, setting probabilities to zero for some actions. The KL regularization term, however, likely slows this down. It is possible the Tsallis-VI is concentrating too quickly, resulting in insufficient exploration.
6 Conclusion and Discussion
We investigated the use of the more general -logarithm for entropy regularization and KL regularization, instead of the standard logarithm (), which gave rise to Tsallis entropy and Tsallis KL regularization. We extended several results previously shown for , namely we proved (a) the form of the Tsallis policy can be expressed by -exponential function; (b) Tsallis KL-regularized policies are weighted average of past action-values; (c) the convergence of value iteration for and (d) a relationship between adding a -logarithm of policy to the action-value update, to provide implicit Tsallis KL regularization and entropy regularization, generalizing the original Munchausen Value Iteration (MVI). We used these results to propose a generalization to MVI, which we call MVI(), because for we exactly recover MVI. We showed empirically that the generalization to can be beneficial, providing notable improvements in the Atari 2600 benchmark.
References
- Azar et al. [2012] M. G. Azar, V. Gómez, and H. J. Kappen. Dynamic policy programming. Journal of Machine Learning Research, 13(1):3207–3245, 2012.
- Baird and Moore [1999] L. Baird and A. Moore. Gradient descent for general reinforcement learning. In Proceedings of the 1998 Conference on Advances in Neural Information Processing Systems II, page 968–974, 1999.
- Bellemare et al. [2013] M. G. Bellemare, Y. Naddaf, J. Veness, and M. Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47(1):253–279, 2013. ISSN 1076-9757.
- Belousov and Peters [2019] B. Belousov and J. Peters. Entropic regularization of markov decision processes. Entropy, 21(7), 2019.
- Blondel et al. [2020] M. Blondel, A. F. Martins, and V. Niculae. Learning with fenchel-young losses. Journal of Machine Learning Research, 21(35):1–69, 2020.
- Brockman et al. [2016] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- Chan et al. [2022] A. Chan, H. Silva, S. Lim, T. Kozuno, A. R. Mahmood, and M. White. Greedification operators for policy optimization: Investigating forward and reverse kl divergences. Journal of Machine Learning Research, 23(253):1–79, 2022.
- Chen et al. [2018] G. Chen, Y. Peng, and M. Zhang. Effective exploration for deep reinforcement learning via bootstrapped q-ensembles under tsallis entropy regularization. arXiv:abs/1809.00403, 2018. URL http://arxiv.org/abs/1809.00403.
- Chow et al. [2018] Y. Chow, O. Nachum, and M. Ghavamzadeh. Path consistency learning in Tsallis entropy regularized MDPs. In International Conference on Machine Learning, pages 979–988, 2018.
- Condat [2016] L. Condat. Fast projection onto the simplex and the l1 ball. Mathematical Programming, 158:575–585, 2016.
- Cover and Thomas [2006] T. M. Cover and J. A. Thomas. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing). Wiley-Interscience, USA, 2006.
- Dabney et al. [2018] W. Dabney, M. Rowland, M. Bellemare, and R. Munos. Distributional reinforcement learning with quantile regression. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, pages 2892–2899, 2018.
- Duchi et al. [2008] J. Duchi, S. Shalev-Shwartz, Y. Singer, and T. Chandra. Efficient projections onto the l1-ball for learning in high dimensions. In Proceedings of the 25th International Conference on Machine Learning, page 272–279, 2008.
- Furuichi et al. [2004] S. Furuichi, K. Yanagi, and K. Kuriyama. Fundamental properties of tsallis relative entropy. Journal of Mathematical Physics, 45(12):4868–4877, 2004.
- Futami et al. [2018] F. Futami, I. Sato, and M. Sugiyama. Variational inference based on robust divergences. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84, pages 813–822, 2018.
- Geist et al. [2019] M. Geist, B. Scherrer, and O. Pietquin. A theory of regularized Markov decission processes. In 36th International Conference on Machine Learning, volume 97, pages 2160–2169, 2019.
- Ghasemipour et al. [2019] S. K. S. Ghasemipour, R. S. Zemel, and S. S. Gu. A divergence minimization perspective on imitation learning methods. In Conference on Robot Learning, pages 1–19, 2019.
- Grau-Moya et al. [2019] J. Grau-Moya, F. Leibfried, and P. Vrancx. Soft q-learning with mutual-information regularization. In International Conference on Learning Representations, pages 1–13, 2019.
- Haarnoja et al. [2018] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, pages 1861–1870, 2018.
- Hiriart-Urruty and Lemaréchal [2004] J. Hiriart-Urruty and C. Lemaréchal. Fundamentals of Convex Analysis. Grundlehren Text Editions. Springer Berlin Heidelberg, 2004.
- Ke et al. [2019] L. Ke, S. Choudhury, M. Barnes, W. Sun, G. Lee, and S. Srinivasa. Imitation learning as -divergence minimization, 2019. URL https://arxiv.org/abs/1905.12888.
- Kitamura et al. [2021] T. Kitamura, L. Zhu, and T. Matsubara. Geometric value iteration: Dynamic error-aware kl regularization for reinforcement learning. In Proceedings of The 13th Asian Conference on Machine Learning, volume 157, pages 918–931, 2021.
- Kozuno et al. [2019] T. Kozuno, E. Uchibe, and K. Doya. Theoretical analysis of efficiency and robustness of softmax and gap-increasing operators in reinforcement learning. In Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89, pages 2995–3003, 2019.
- Kozuno et al. [2022] T. Kozuno, W. Yang, N. Vieillard, T. Kitamura, Y. Tang, J. Mei, P. Ménard, M. G. Azar, M. Valko, R. Munos, O. Pietquin, M. Geist, and C. Szepesvári. Kl-entropy-regularized rl with a generative model is minimax optimal, 2022. URL https://arxiv.org/abs/2205.14211.
- Lee et al. [2018] K. Lee, S. Choi, and S. Oh. Sparse markov decision processes with causal sparse tsallis entropy regularization for reinforcement learning. IEEE Robotics and Automation Letters, 3:1466–1473, 2018.
- Lee et al. [2020] K. Lee, S. Kim, S. Lim, S. Choi, M. Hong, J. I. Kim, Y. Park, and S. Oh. Generalized tsallis entropy reinforcement learning and its application to soft mobile robots. In Robotics: Science and Systems XVI, pages 1–10, 2020.
- Li and Turner [2016] Y. Li and R. E. Turner. Rényi divergence variational inference. In Advances in Neural Information Processing Systems, volume 29, 2016.
- Martins and Astudillo [2016] A. F. T. Martins and R. F. Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label classification. In Proceedings of the 33rd International Conference on Machine Learning, page 1614–1623, 2016.
- Nachum and Dai [2020] O. Nachum and B. Dai. Reinforcement learning via fenchel-rockafellar duality. 2020. URL http://arxiv.org/abs/2001.01866.
- Nachum et al. [2019] O. Nachum, B. Dai, I. Kostrikov, Y. Chow, L. Li, and D. Schuurmans. Algaedice: Policy gradient from arbitrary experience. arXiv preprint arXiv:1912.02074, 2019.
- Naudts [2002] J. Naudts. Deformed exponentials and logarithms in generalized thermostatistics. Physica A-statistical Mechanics and Its Applications, 316:323–334, 2002.
- Nowozin et al. [2016] S. Nowozin, B. Cseke, and R. Tomioka. f-gan: Training generative neural samplers using variational divergence minimization. In Advances in Neural Information Processing Systems, volume 29, pages 1–9, 2016.
- Prehl et al. [2012] J. Prehl, C. Essex, and K. H. Hoffmann. Tsallis relative entropy and anomalous diffusion. Entropy, 14(4):701–716, 2012.
- Raffin et al. [2021] A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann. Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 22(268):1–8, 2021.
- Sason and Verdú [2016] I. Sason and S. Verdú. f-divergence inequalities. IEEE Transactions on Information Theory, 62:5973–6006, 2016.
- Suyari and Tsukada [2005] H. Suyari and M. Tsukada. Law of error in tsallis statistics. IEEE Transactions on Information Theory, 51(2):753–757, 2005.
- Suyari et al. [2020] H. Suyari, H. Matsuzoe, and A. M. Scarfone. Advantages of q-logarithm representation over q-exponential representation from the sense of scale and shift on nonlinear systems. The European Physical Journal Special Topics, 229(5):773–785, 2020.
- Tsallis [1988] C. Tsallis. Possible generalization of boltzmann-gibbs statistics. Journal of Statistical Physics, 52:479–487, 1988.
- Tsallis [2009] C. Tsallis. Introduction to Nonextensive Statistical Mechanics: Approaching a Complex World. Springer New York, 2009. ISBN 9780387853581.
- Vieillard et al. [2020a] N. Vieillard, T. Kozuno, B. Scherrer, O. Pietquin, R. Munos, and M. Geist. Leverage the average: an analysis of regularization in rl. In Advances in Neural Information Processing Systems 33, pages 1–12, 2020a.
- Vieillard et al. [2020b] N. Vieillard, O. Pietquin, and M. Geist. Munchausen reinforcement learning. In Advances in Neural Information Processing Systems 33, pages 1–11. 2020b.
- Wan et al. [2020] N. Wan, D. Li, and N. Hovakimyan. f-divergence variational inference. In Advances in Neural Information Processing Systems, volume 33, pages 17370–17379, 2020.
- Wang et al. [2018] D. Wang, H. Liu, and Q. Liu. Variational inference with tail-adaptive f-divergence. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, page 5742–5752, 2018.
- Yamano [2002] T. Yamano. Some properties of q-logarithm and q-exponential functions in tsallis statistics. Physica A: Statistical Mechanics and its Applications, 305(3):486–496, 2002.
- Yu et al. [2020] L. Yu, Y. Song, J. Song, and S. Ermon. Training deep energy-based models with f-divergence minimization. In Proceedings of the 37th International Conference on Machine Learning, ICML’20, pages 1–11, 2020.
- Zhang et al. [2020] R. Zhang, B. Dai, L. Li, and D. Schuurmans. Gendice: Generalized offline estimation of stationary values. In International Conference on Learning Representations, 2020.
Appendix A Basic facts of Tsallis KL divergence
We present some basic facts about -logarithm and Tsallis KL divergence.
We begin by introducing the duality for Tsallis statistics. Recall that the -logarithm and Tsallis entropy defined in the main paper are:
In the RL literature, another definition is more often used [Lee et al., 2020]. This is called the duality [Naudts, 2002, Suyari and Tsukada, 2005], which refers to that the Tsallis entropy can be equivalently defined as:
By the duality we can show [Suyari and Tsukada, 2005, Eq.(12)]:
i.e. the duality between logarithms and allows us to define Tsallis entropy by an alternative notation that eventually reaches to the same functional form.
We now come to examine Tsallis KL divergence (or Tsallis relative entropy) defined in another form: [Prehl et al., 2012]. In the main paper we used the definition [Furuichi et al., 2004]. We show they are equivalent by the same logic:
| (12) |
The equivalence allows us to work with whichever of and that makes the proof easier to work out the following useful properties of Tsallis KL divergence:
Nonnegativity : since the function is convex, by Jensen’s inequality
Conditions of : directly from the above, in Jensen’s inequality the equality holds only when almost everywhere, i.e. implies almost everywhere.
Conditions of : To better align with the standard KL divergence, let us work with , following [Cover and Thomas, 2006], let us define
We conclude that whenever and .
Bounded entropy : let , by the nonnegativity of Tsallis KL divergence:
Notice that and , we conclude
Appendix B Proof of Theorem 1 and 2
We structure this section as the following three parts:
General expression for Tsallis entropy regularized policy. The original definition of Tsallis entropy is . Note that similar to Appendix A, we can choose whichever convenient of and , since the domain of the entropic index is . To obtain the Tsallis entropy-regularized policies we follow [Chen et al., 2018]. The derivation begins with assuming an actor-critic framework where the policy network is parametrized by . It is well-known that the parameters should be updated towards the direction specified by the policy gradient theorem:
| (13) |
Recall that denotes the Shannon entropy and is the coefficient. are the Lagrange multipliers for the constraint . In the Tsallis entropy framework, we replace with . We can assume to ease derivation, which is the case for sparsemax.
We can now explicitly write the optimal condition for the policy network parameters:
| (14) | ||||
where we leveraged in the second step and absorbed terms into the expectation in the last step. denotes the adjusted Lagrange multipliers by taking inside the expectation and modifying it according to the discounted stationary distribution.
Now it suffices to verify either or
| (15) | ||||
where we changed the entropic index from to . Clearly, the root does not affect truncation. Consider the pair , then the same truncation effect can be achieved by choosing . The same goes for . Therefore, we conclude that and are interchangeable for the truncation, and we should stick to the analytic choice .
Tsallis policies can be expressed by -exponential. Given Eq. (15), by adding and subtracting , we have:
where we defined . Note that this expression is general for all , but whether has closed-form expression depends on the solvability of .
Let us consider the extreme case . It is clear that . Therefore, for any we must have ; i.e., there is only one action with probability 1, with all others being 0. This conclusion agrees with the fact that as : hence the regularized policy degenerates to .
A computable Normalization Function. The constraint is exploited to obtain the threshold for the sparsemax [Lee et al., 2018, Chow et al., 2018]. Unfortunately, this is only possible when the root vanishes, since otherwise the constraint yields a summation of radicals. Nonetheless, we can resort to first-order Taylor’s expansion for deriving an approximate policy. Following [Chen et al., 2018], let us expand Eq. (15) by the first order Taylor’s expansion , where we let , , , . So that the unnormalized approximate policy has
| (16) | ||||
Therefore it is clear as . This concords well with the limit case where degenerates to . With Eq. (16), we can solve for the approximate normalization by the constraint :
In order for an action to be in , it has to satisfy . Therefore, the condition of satisfies:
Therefore, we see the approximate threshold . When or , recovers and hence recovers the exact sparsemax policy.
Appendix C Proof of convergence of when
Let us work with from Appendix A and define as the -norm. The convergence proof for when comes from that is strongly convex in :
| (17) |
Similarly, the negative Tsallis sparse entropy is also strongly convex. Then the propositions of [Geist et al., 2019] can be applied, which we restate in the following:
Lemma 1 ([Geist et al., 2019]).
Define regularized value functions as:
If is strongly convex, let denote the Legendre-Fenchel transform of , then
-
•
is Lipschitz and is the unique maximizer of .
-
•
is a -contraction in the supremum norm, i.e. . Further, it has a unique fixed point .
-
•
The policy is the unique optimal regularized policy.
Note that in the main paper we dropped the subscript for both the regularized optimal policy and action value function to lighten notations. It is now clear that Eq. (6) indeed converges for entropic indices that make strongly convex. But we mostly consider the case .
Appendix D Derivation of the Tsallis KL Policy
This section contains the proof for the Tsallis KL-regularized policy (7). Section D.1 shows that a Tsallis KL policy can also be expressed by a series of multiplications of ; while Section D.2 shows its more-than-averaging property.
D.1 Tsallis KL Policies are Similar to KL
We extend the proof and use the same notations from [Lee et al., 2020, Appendix D] to derive the Tsallis KL regularized policy. Again let us work with from Appendix A. Define state visitation as and state-action visitaion . The core of the proof resides in establishing the one-to-one correspondence between the policy and the induced state-action visitation . For example, Tsallis entropy is written as
This unique correspondence allows us to replace the optimization variable from to . Indeed, one can always restore the policy by .
Let us write Tsallis KL divergence as by replacing the policies with their state-action visitation . One can then convert the Tsallis MDP problem into the following problem:
| (18) | ||||
where is the initial state distribution. Eq. (18) is known as the Bellman Flow Constraints [Lee et al., 2020, Prop. 5] and is concave in since the first term is linear and the second term is concave in . Then the primal and dual solutions satisfy KKT conditions sufficiently and necessarily. Following [Lee et al., 2020, Appendix D.2], we define the Lagrangian objective as
where and are dual variables for nonnegativity and Bellman flow constraints. The KKT conditions are:
The dual variable can be shown to equal to the optimal state value function following [Lee et al., 2020], and whenever .
By noticing that , we can show that . Substituting , , into the above KKT condition and leverage the equality we have:
By comparing it to the maximum Tsallis entropy policy [Lee et al., 2020, Eq.(49)] we see the only difference lies in the baseline term , which is expected since we are exploiting Tsallis KL regularization. Let us define the normalization function as
then we can write the policy as
In a way similar to KL regularized policies, at -th update, take and , we write since the normalization function does not depend on actions. We ignored the scaling constant and regularization coefficient. Hence one can now expand Tsallis KL policies as:
which proved the first part of Eq. (7).
D.2 Tsallis KL Policies Do More than Average
We now show the second part of Eq. (7), which stated that the Tsallis KL policies do more than average. This follows from the following lemma:
Lemma 2 (Eq. (25) of [Yamano, 2002]).
| (19) | ||||
However, the mismatch between the base and the exponent is inconvenient. We exploit the duality to show this property holds for as well:
Now since we proved the two-point property for , by the same induction steps in [Yamano, 2002, Eq. (25)] we conclude the proof. The weighted average part Eq. (8) comes immediately from [Suyari et al., 2020, Eq.(18)].
Appendix E Implementation Details
We list the hyperparameters for Gym environments in Table 1. The epsilon threshold is fixed at from the beginning of learning. FC refers to the fully connected layer with activation units.
The Q-network uses 3 convolutional layers. The epsilon greedy threshold is initialized at 1.0 and gradually decays to 0.01 at the end of first 10% of learning. We run the algorithms with the swept hyperparameters for full steps on the selected two Atari environments to pick the best hyperparameters.
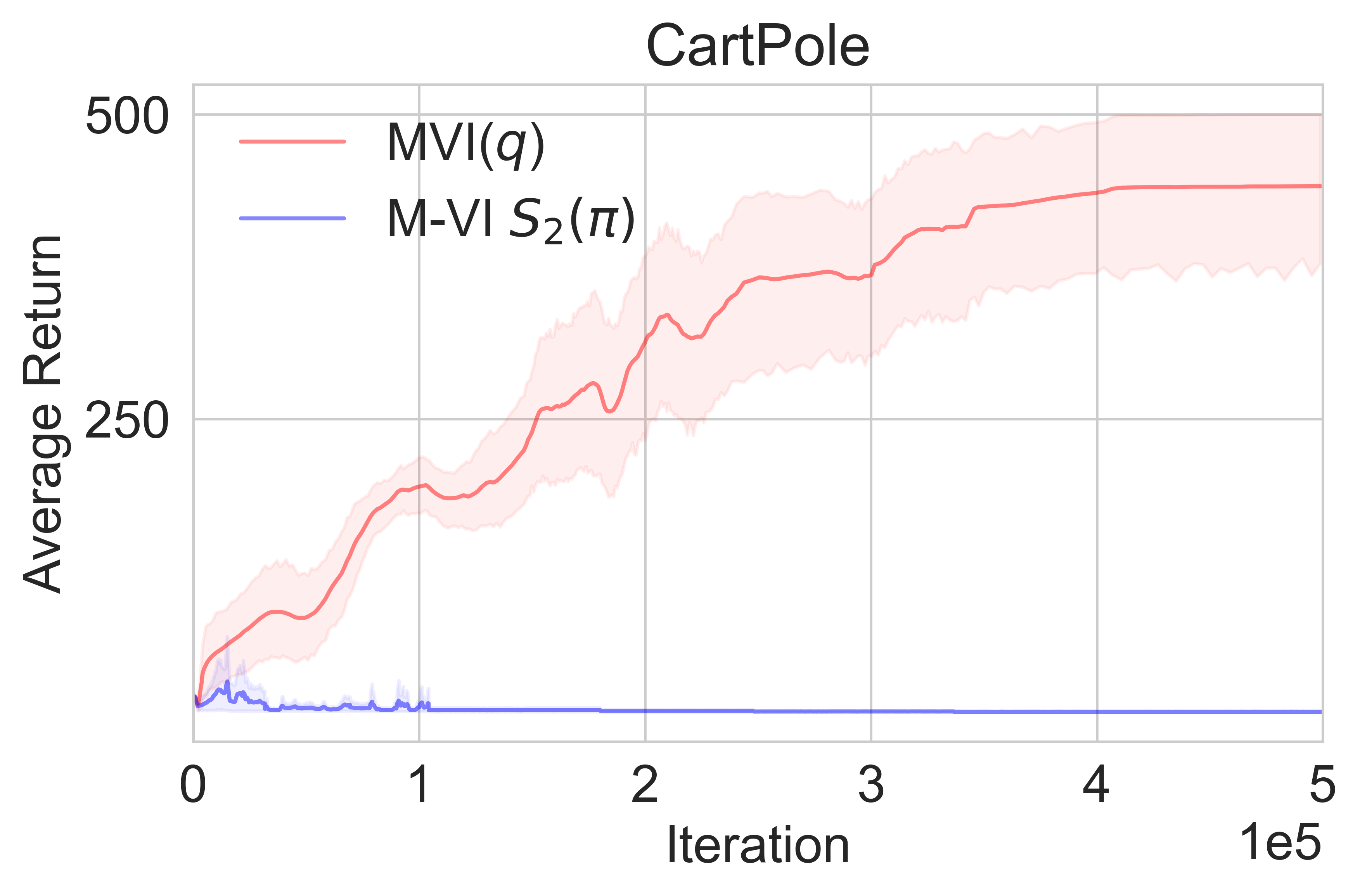
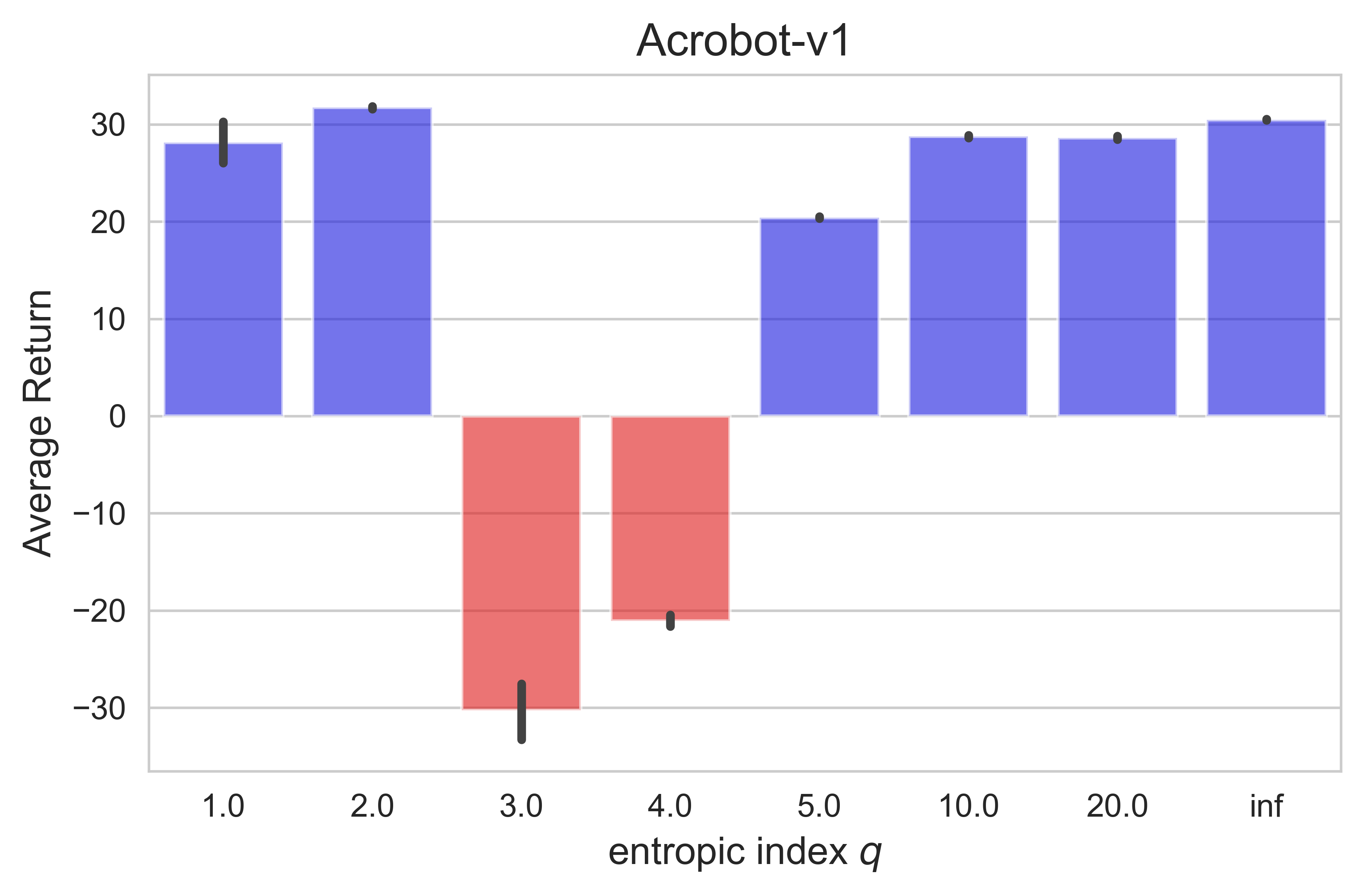
We show in Figure 6 the performance of MVI on Cartpole-v1 and Acrobot-v1, and the full learning curves of MVI() on the Atari games in Figure 7. Figures 8 and 9 show the full learning curves of Tsallis-VI.
| Network Parameter | Value | Algorithm Parameter | Value |
|---|---|---|---|
| (total steps) | (discount rate) | 0.99 | |
| (interaction period) | 4 | (epsilon greedy threshold) | 0.01 |
| (buffer size) | (Tsallis entropy coefficient) | ||
| (batch size) | 128 | (advantage coefficient) | |
| (update period) | (Car.) / (Acro.) | ||
| Q-network architecture | FC512 - FC512 | ||
| activation units | ReLU | ||
| optimizer | Adam | ||
| optimizer learning rate |
| Network Parameter | Value | Algorithmic Parameter | Value |
|---|---|---|---|
| (total steps) | (discount rate) | 0.99 | |
| (interaction period) | 4 | ( MVI() entropy coefficient) | 10 |
| (buffer size) | ( MVI() advantage coefficient) | 0.9 | |
| (batch size) | 32 | (Tsallis-VI entropy coef.) | 10 |
| (update period) | (M-VI advantage coefficient) | 0.9 | |
| activation units | ReLU | (M-VI entropy coefficient) | 0.03 |
| optimizer | Adam | (epsilon greedy threshold) | |
| optimizer learning rate | |||
| Q-network architecture | |||
| - - - FC512 - FC | |||