Generalizable Implicit Neural Representation As a Universal Spatiotemporal Traffic Data Learner
Keywords: Implicit neural representations, Traffic data learning, Spatiotemporal traffic data, Traffic dynamics, Meta-learning
1 INTRODUCTION
The unpredictable elements involved in a vehicular traffic system, such as human behavior, weather conditions, energy supply and social economics, lead to a complex and high-dimensional dynamical transportation system. To better understand this system, Spatiotemporal Traffic Data (STTD) is often collected to describe its evolution over space and time. This data includes various sources such as vehicle trajectories, sensor-based time series, and dynamic mobility flow. The primary aim of STTD learning is to develop data-centric models that accurately depict traffic dynamics and can predict complex system behaviors.
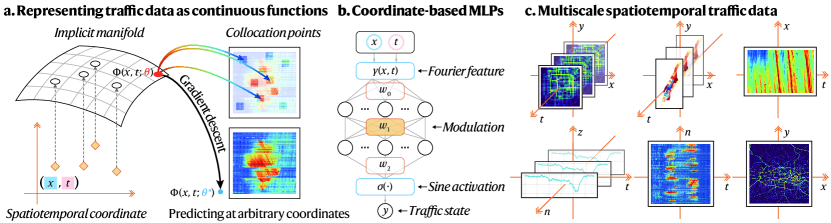
Despite its complexity, recent advances in STTD learning have found that the dynamics of the system evolve with some dominating patterns and can be captured by some low-dimensional structures. Notably, low-rankness is a widely studied pattern, and models based on it assist in reconstructing sparse data, detecting anomalies, revealing patterns, and predicting unknown system states. However, these models have two primary limitations: 1) they often require a grid-based input with fixed spatiotemporal dimensions, restricting them from accommodating varying spatial resolutions or temporal lengths; 2) the low-rank pattern modeling, fixed on one data source, may not generalize to different data sources. For instance, patterns identified in one data type, such as vehicle trajectories, may not be applicable to differently structured data, such as OD demand. These constraints mean that current STTD learning depends on data structures and sources. This limits the potential for a unified representation and emphasizes the need for a universally applicable method to link various types of STTD learning.
To address these limitations, we employ a novel technique called implicit neural representations (INRs) to learn the underlying dynamics of STTD. INRs use deep neural networks to discern patterns from continuous input (Sitzmann et al., , 2020, Tancik et al., , 2020). They function in a continuous space and take domain coordinates as input, predicting the corresponding quantity at queried coordinates. INRs learn patterns in implicit manifolds and fit processes that generate target data with functional representation. This differentiates them from low-rank models that depend on explicit patterns, enhancing their expressivity, and enabling them to learn dynamics implicitly. Consequently, they eliminate the need for fixed data dimensions and can adjust to traffic data of any scale or resolution, allowing us to model various STTD with a unified input. In this work, we exploit the advances of INRs and tailor them to incorporate the characteristics of STTD, resulting in a novel method that serves as a universal traffic data learner (refer to Fig. 1).
Our proof-of-concept has shown promising results through extensive testing using real-world data. The method is versatile, working across different scales - from corridor-level to network-level applications. It can also be generalized to various input dimensions, data domains, output resolutions, and network topologies. This study offers novel perspectives on STTD modeling and provides an extensive analysis of practical applications, contributing to the state-of-the-art. To our knowledge, this is the first time that INRs have been applied to STTD learning and have demonstrated effectiveness in a variety of real-world tasks. We anticipate this could form the basis for developing foundational models for STTD.
2 METHODOLOGY
To formalize a universal data learner, we let MLPs be the parameterization . Concretely, the function representation is expressed as a continuous mapping from the input domain to the traffic state of interest: , where is the spatial domain, is the temporal domain, and is the output domain. is a coordinate-based MLP (Fig. 1 (b)).
2.1 Encoding high-frequency components in function representation
High-frequency components can encode complex details about STTD. To alleviate the spectral bias of neural network towards low-frequency patterns, we adopt two advanced techniques to enable to learn high-frequency components. Given the spatial-temporal input coordinate , the frequency-enhanced MLP can be formulated as:
| (1) |
where are layerwise parameters, and is the predicted value. is the periodic activation function with frequency factor (Sitzmann et al., , 2020). is the concatenated random Fourier features (CRF) (Tancik et al., , 2020) with different Fourier basis frequencies sampled from the Gaussian :
| (2) |
By setting a large number of frequency features and a series of scale parameters , we can sample a variety of frequency patterns in the input domain. The combination of these two strategies achieves high-frequency, low-dimensional regression, empowering the coordinate-based MLPs to learn complex details with high resolution.
2.2 Factorizing spatial-temporal variability
Using a single to model entangled spatiotemporal interactions can be challenging. Therefore, we decompose the spatiotemporal process into two dimensions using variable separation:
| (3) |
where and are defined by Eq. (1). Eq. (3) is an implicit representation of matrix factorization model. But it can process data or functions that exist beyond the regular mesh grid of matrices. To further align the two components, we adopt a middle transform matrix to model their interactions in the hidden manifold, which yields: .
2.3 Generalizable representation with meta-learning
Given a STTD instance, we can sample a set containing data pairs where is the input coordinate and is the traffic state value. Then we can learn an INR using gradient descent over the loss . As can be seen, a single INR encodes a single data domain, but the learned INR cannot be generalized to represent other data instances and requires per-sample retraining. Given a series of data instances , we set a series of latent codes for each instance to account for the instance-specific data pattern and make a base network conditional on the latent code (Dupont et al., , 2022). We then perform per-sample modulations to the middle INR layers:
| (4) |
where is the shift modulation of instance at layer , and is a shared linear hypernetwork layer to map the latent code to layerwise modulations. Then, the loss function of the generalizable implicit neural representations (GINRs) is given as:
| (5) |
To learn all codes, we adopt the meta-learning strategy to achieve efficient adaptation and stable optimization. Since conditional modulations are processed as functions of , and each represents an individual instance, we can implicitly obtain these codes using an auto-decoding mechanism. For data , this is achieved by an iterative gradient descent process: , where is the learning rate, and the above process is repeated in several steps. To integrate the auto-decoding into the meta-learning procedure, inner-loop and outer-loop iterations are considered to alternatively update , and .
3 RESULTS
We conduct extensive experiments on real-world STTD covering scales from corridor to network, specifically including: (a) Corridor-level application: Highway traffic state estimation; (b-c) Grid-level application: Urban mesh-based flow estimation; and (d-f) Network-level application: Highway and urban network state estimation. We compare our model with SOTA low-rank models and evaluate its generalizability in different scenarios, such as different input domains, multiple resolutions, and distinct topologies. We also find that the encoding of high-frequency components is crucial for learning complex patterns (g-h). Fig. 2 briefly summarizes our results.
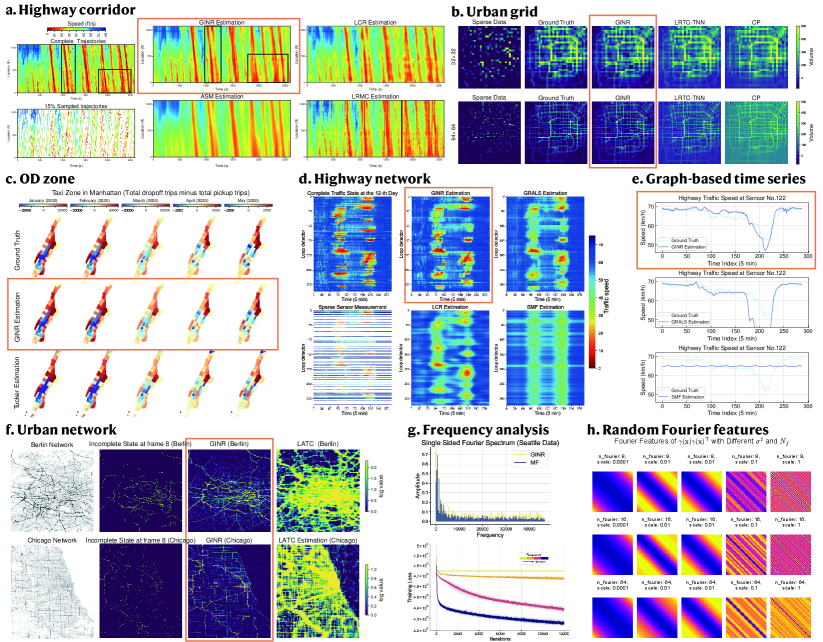
4 SUMMARY
We have developed a new method for learning spatiotemporal traffic data (STTD) using implicit neural representations. This involves parameterizing STTD as deep neural networks, with INRs trained to map coordinates directly to traffic states. The versatility of this representation allows it to model various STTD types, including vehicle trajectories, origin-destination flows, grid flows, highway networks, and urban networks. Thanks to the meta-learning paradigm, this approach can be generalized to a range of data instances. Experimental results from various real-world benchmarks show that our model consistently surpasses conventional low-rank models. It also demonstrates potential for generalization across different data structures and problem contexts.
References
- Dupont et al., (2022) Dupont, Emilien, Kim, Hyunjik, Eslami, SM, Rezende, Danilo, & Rosenbaum, Dan. 2022. From data to functa: Your data point is a function and you can treat it like one. arXiv preprint arXiv:2201.12204.
- Nie et al., (2024) Nie, Tong, Qin, Guoyang, Ma, Wei, & Sun, Jian. 2024. Spatiotemporal Implicit Neural Representation as a Generalized Traffic Data Learner. arXiv preprint arXiv:2405.03185.
- Sitzmann et al., (2020) Sitzmann, Vincent, Martel, Julien, Bergman, Alexander, Lindell, David, & Wetzstein, Gordon. 2020. Implicit neural representations with periodic activation functions. Advances in Neural Information Processing Systems, 33, 7462–7473.
- Tancik et al., (2020) Tancik, Matthew, Srinivasan, Pratul, Mildenhall, Ben, Fridovich-Keil, Sara, Raghavan, Nithin, Singhal, Utkarsh, Ramamoorthi, Ravi, Barron, Jonathan, & Ng, Ren. 2020. Fourier features let networks learn high frequency functions in low dimensional domains. Advances in Neural Information Processing Systems, 33, 7537–7547.