Generalized Matrix Factor Model
Abstract
This article introduces a nonlinear generalized matrix factor model (GMFM) that allows for mixed-type variables, extending the scope of linear matrix factor models (LMFM) that are so far limited to handling continuous variables. We introduce a novel augmented Lagrange multiplier method, equivalent to the constraint maximum likelihood estimation, and carefully tailored to be locally concave around the true factor and loading parameters. This statistically guarantees the local convexity of the negative Hessian matrix around the true parameters of the factors and loadings, which is nontrivial in the matrix factor modeling and leads to feasible central limit theorems of the estimated factors and loadings. We also theoretically establish the convergence rates of the estimated factor and loading matrices for the GMFM under general conditions that allow for correlations across samples, rows, and columns. Moreover, we provide a model selection criterion to determine the numbers of row and column factors consistently. To numerically compute the constraint maximum likelihood estimator, we provide two algorithms: two-stage alternating maximization and minorization maximization. Extensive simulation studies demonstrate GMFM’s superiority in handling discrete and mixed-type variables. An empirical data analysis of the company’s operating performance shows that GMFM does clustering and reconstruction well in the presence of discontinuous entries in the data matrix.
Keywords: Matrix factor model; Mixed-type measurement; Penalized likelihood function.
1 Introduction
Matrix sequences appear in diverse areas, such as computer vision, recommending systems, social networks, economics, and management. It has the form of a three-way array consisting of a row dimension, a column dimension, and a third sequence limit dimension that might be a time domain. A natural question is “how are the entries generated?” In the high-dimensional scenario where both the numbers of rows and columns are large, an intuitive generative mechanism is that all rows and columns are formed by a latent low-rank structure. There are at least two parallel but seemingly equivalent streams of works that are learning the low-rank formation of the matrix-variate data. The first is via matrix (or tensor) regularization with low-rank penalization, e.g., rank constraint or nuclear norm penalty, with or without noise. These results in great success in wide applications like matrix completion, compressed sensing and image localization (Mao et al. (2019) and Mao et al. (2021)). The second line of work is the factor modeling which thinks all entries of a matrix observation are driven by a low-dimensional factor matrix, and the magnitude of each entry relies on the additive and/or interactive effect of the low-dimensional row features and column characteristics. In the present paper, we follow the factor modeling manner but a regularized optimization technique is used to adapt to the nonlinearity of our proposed model.
For ease of presentation, let be a matrix sequence (e.g., a matrix time series). There are also two ways to do matrix (or even tensor) factor analysis of . The first manner is to “flatten” each into a lengthy vector by stacking its columns or rows: the first step is learning the vector factor space with existing vector factor analysis methods (Bai and Ng (2002), Bai and Li (2012), Fan et al. (2013), Kong (2017), Pelger (2019), Trapani (2018), Barigozzi and Trapani (2022), Barigozzi et al. (2022)), and the second step is recovering the row and column factor spaces from the vectorized factor space with certain restriction, e.g. the Kronecker structure, c.f, Chen et al. (2024) and Chen et al. (2021b). The second collection of papers (Wang et al. (2019), Wang (2022), Chang et al. (2023), Yu et al. (2022), Yuan et al. (2023), He et al. (2022)) directly model each with carefully designed additive and/or interactive row and column effects. It is worth noticing that Wang et al. (2019) introduced the first matrix factor in the literature; Yu et al. (2022) provided a projection approach to estimate the twisted row and column factor spaces which has, so far to the best of our knowledge, the fastest convergence rates in the class of PCA procedures; Yuan et al. (2023) presented the first two-way additive matrix factor model and Zhang et al. (2024) combined the two-way additive and interactive components in generating the matrix entries recently; the seminal work of Chen et al. (2022) extends to the general tensor data.
However, the above works are limited to single-type continuous variables. In practical applications, such as social science and biology, high-dimensional data sets often involve mixed-type variables. For instance, in the context of corporate operational performance analysis, there are not only continuous variables, such as return on equity and fixed asset turnover, but also categorical variables like industry type, enterprise nature (e.g., state-owned or private enterprise), and regional classification. These categorical indicators are often used to depict the fundamental characteristics and background information of a company. There are also some binary indicators to measure each corporate’s social responsibility, such as whether the protection of employees’ rights and interests is disclosed, and whether environmental sustainable development is disclosed. Collectively, the discrete variables encompassed in a company’s economic indicators span multiple facets and play a pivotal role in portraying the company’s economic standing, analyzing market trends, and devising business strategies. In networks analysis (Jing et al. (2021), Jing et al. (2022), Chang et al. (2023) and Zhou et al. (2024)) like international trading, the weight on each edge could be the trading direction (binary variables indicating import or export), the number of traded products (e.g. shoes, clothes, food) that are measured either in counts (count variables) or kilograms (continuous variables). For non-continuous variables, nonlinear models are usually employed for modeling, where closed-form expressions for estimating factors and their loadings do not exist, in contrast to the explicit principal component solution with or without iteration to the linear two-way factor analysis, c.f., Chen and Fan (2023), Yu et al. (2022) and He et al. (2022). Moreover, with mixed-type variables, the nonlinear structure varies depending on the type of variables, posing challenges for statistical inference and computation. To the best of our knowledge, there is still a lack of study on a general nonlinear model with factor structure for matrix sequences with mixed-type variables. This is a motivation and will be the first contribution of the present paper.
The literature recently starts to pay attention to the latent factor structure with single or mixed type variables in vector factor modeling. Chen et al. (2021a) derived the asymptotic theory of the regression coefficients and the average partial effect for a class of generalized linear vector factor models that include logit, probit, ordered probit and Poisson models as special cases. Permitting general nonlinearity, Wang (2022) investigated the maximum likelihood estimation for the factors and loadings. Liu et al. (2023) proposed a canonical exponential family model with factor structure for mixed-type variables. However, the likelihood approach for these nonlinear vector factor models can not be trivially extended to the matrix sequences since the Hessian matrix jointly in the row and column loadings and the factors are more complex. Extra manipulation is needed to feasibly derive the convergence property of the parameters related to the factor structure, especially for the asymptotic normality of the estimates, see Section 2 for more details. This is a motivation and will be a second contribution to the present paper.
In this paper, we assume that each entry is generated by the following nonlinear generalized matrix factor model (GMFM):
| (1) |
where is an observed entry lying in the th row and th column in sample ; is some known probability (density or mass) function of allowed to vary across , and , permitting a mixture of distributions for each matrix; with being a dimensional vector of row loadings, being a dimensional vector of column loadings, and being a dimensional matrix of factors. Both factors and loadings are unobservable and and are the numbers of row and column factors, respectively. In the currently studied linear matrix factor model, represents the conditional mean of , while for non-continuous variables in the present paper, it might stand for the conditional log odds or log probabilities. Even for continuous variables, in model (1) can be a function of the conditional smoothly-winsorized-mean in the robust matrix factor model, c.f., He et al. (2024), which maps ’s to the Huber loss function. Thus model (1) is a quite flexible nonlinear matrix factor model. Certainly, to identify , one needs the identification constraints to form an identifiably feasible solution set.
In this paper, we consider the maximum (quasi-)likelihood estimation with rotational constraints for the factors and loadings of GMFM. We introduce a novel penalized likelihood function that not only covers the log-likelihood function and the identifiability restriction, but also includes an additional augmented Lagrangian term, which is carefully tuned to guarantee the local convexity of the negative Hessian matrix around the true parameters and hence a concave quasi-likelihood function with penalty in a neighborhood of the true parameters. This leads to a convenient derivation of the central limit theorems, and it is where the second contribution of the present paper comes from. This paper also establishes the convergence rates of the estimated factors and loadings. Our theory demonstrates that our estimators converge at rate in terms of the averaged Frobenius norm. This rate surpasses , the rate for generalized vector factor analysis achieved through vectorizing by Liu et al. (2023) and Wang (2022), particularly when the sequence length is relatively short. It is also no slower than the rate, , of the non-likelihood method -PCA in the seminal paper by Chen and Fan (2023), especially when the data matrix is not balanced. Furthermore, to consistently estimate the pair of numbers of the row and column factors, we present an information-type criterion under GMFM. This set of new results forms the third contribution of the present paper. Motivated by the challenges posed by nonlinear structures and mixed-type variables, we also present extended versions of the two-stage alternating maximization algorithm inspired by Liu et al. (2023) and the minorization maximization algorithm inspired by Chen et al. (2021a).
The rest of the paper is organized as follows. Section 2 introduces the set up and the estimation methodology. Section 3 presents the asymptotic theorems, and subsection 3.4 provides two computational algorithms. Section 4 is devoted to extensive simulation studies. Section 5 analyzes high-tech company’s operating performance. Section 6 concludes. All proofs are relegated to the supplementary materials.
2 Methodology and Set Up
2.1 Methodology
With model (1), the (quasi) log-likelihood function is
| (2) |
where with ; is a vector, is a vector, and with is a vector. The entries of can be continuous variables, count variables, binary variables, and so on. Representative examples are as follows.
Example 1 (Linear) is a likelihood function of Gaussian random variables and a quasi-likelihood function for other continuous random variables with homoscedasticity.
Example 2 (Poisson) as and .
Example 3 (Probit) , where is the cumulative distribution function of a standard normal random variable.
Example 4 (Logit) , where is the cumulative distribution function of the logistic distribution.
Example 5 (Tobit) Let where and is . , where is the indicator function.
Let be the row factor loading matrix, be the column factor loading matrix, be a common factor matrix. Denote the parameters of interest by the vector and their true values by , and , respectively. To well define a high-dimensional parameter space of , except the boundedness condition for each row of and and the factor matrix in Assumption 1, one needs constraints to identify the parameters. Note that for any , invertible matrix and , , and give the same likelihood as , and do. To uniquely determine , , and , without loss of generality, we impose the identifiability restriction as follows.
| (6) |
The conditions (3.1) and (3.2) are frequently used in the literature of matrix factor models, c.f., He et al. (2022). Without condition (3.3), results in factors and loadings can only be unambiguously determined up to a sign matrix (diagonal matrix with and on the diagonals) transformation. Then a naturally identified estimate of the vector of factor and loading parameters is the maximizer of (2) subject to the constraints in (6). It can be easily shown this constrained maximizer is equivalent to the solution to the following augmented Lagrange function up to the sign undeterminance:
| (7) | |||||
| (8) |
where
| (9) | |||||
| (10) | |||||
| (11) |
where , and are positive Lagrange multipliers. The penalty terms and are associated with the conditions (3.1) and (3.2). The additional augmented term is constructed to ensure a locally positive definite property of the negative Hessian matrix of the penalized likelihood function around the true parameter vector , by cleverly trading off the non-diagonal blocks of the scaled expectation of the Hessian matrix of . This property shows a desirable geometric concavity of the augmented Lagrange function and leads to an easy way to derive the second-order asymptotics, in particular the central limit theorems of the estimated parameters. Without this newly added term, simply introducing , might not result in a desirable landscape around the local minima of . In the sequel, we shall consider the estimated factors and loadings as the solution to maximizing and obtain the asymptotic results for matrix factor analysis. The equivalence between (2)-(6) and (7) is due to the non-positiveness of and the fact that is maximized if and only if .
Throughout the paper, means and going to infinity jointly, “w.p.a.1” is a short abbreviation of “with probability approaching ”. For vectors, denotes the Euclidean norm. For matrix , is its smallest eigenvalue, and , , , and denotes the spectral norm, Frobenius norm, -norm, infinity norm and max norm, respectively. When has rows, divide into blocks with each block containing rows, and let denote the th row in the th block and is the th block. Define .
2.2 Set Up Assumptions
In this section, we give some technical assumptions that are used to establish the asymptotic theories. In the sequel, will be a generic constant that might vary from line to line.
Assumption 1.
-
1.
, and for all and .
-
2.
with , and as for with . with , and as for with .
Assumption 1-1 indicates that are uniformly bounded. As explained in Wang (2022), the compactness of parameter space is a commonly encountered trait in nonlinear models, see more examples in Newey and McFadden (1986), Jennrich (1969) and Wu (1981). Assumption 1-2 assumes asymptotic distinct eigenvalues for and so that the eigenvectors can be uniquely determined. This is the same as Assumption B in Yu et al. (2022).
Let , and be the first, second and third order derivative of evaluated at , respectively. When these derivatives are evaluated at , we suppress the argument and simply write them as , and .
Assumption 2.
-
1.
is three times differentiable.
-
2.
There exists such that .
-
3.
within a compact space of .
Assumption 2-1 imposes a smoothness condition on the log-likelihood function. Assumptions 2-2 and 2-3 assume that the second-order derivative of the log-likelihood function is bounded from below and above, and the third-order derivative is bounded away from infinity. The boundedness of the second and the third-order derivative is used to control the remainder term in the expansion of the first-order condition. The boundedness from below of the second order derivative together with the boundedness of are used to show the consistency of the estimated factors and loadings. It can be easily verified that commonly used models, such as Linear, Logit, Probit, Poisson, and Tobit, satisfy Assumption 2.
Assumption 3.
-
1.
for some and all and .
-
2.
For any , .
-
3.
For every , ,
,
For every , .
Notice that for linear model, is the error term and is a constant. Many papers require to be conditionally independent for using the Hoeffding’s inequality in the proofs, such as He et al. (2023). This paper considers a more general situation: the distributions of are allowed to be heterogeneous over , and , and to have limited cross-row (-column) and cross-sample (e.g, serial) dependence of conditionally. Assumption 3 gives some moment conditions for . They are satisfied when, for example, are cross-sectionally and temporally weakly dependent conditional on .
Assumption 4.
For some ,
Assumption 4 is for the first derivatives of the log-likelihood function. Again, it is satisfied when are cross-sectionally and temporally weakly dependent conditional on . To present the next assumption on the moments of the second derivatives of the log-likelihood function, we introduce some more notations. Define
Assumption 5.
-
1.
Recall the notation for some matrix ,
-
2.
For any , and ,
,
,
,
,
,
.
-
3.
For any and some positive definite matrices and ,
For any and some positive definite matrices and ,
For any and some positive definite matrices and ,
Though cumbersome, it can be easily verified that Assumption 5 is also satisfied when are cross-sectionally and temporally weakly dependent conditional on .
Assumption 6.
, as .
Assumption 6 is sort of a balance condition for , and , meaning that each dimension size can not completely dominate the other two, which is controlled by and . It is weaker when and are larger. For example, when has subgaussian tails, can be arbitrarily large. And when ’s are conditionally Gaussian as a typical case in the linear model, can be arbitrarily large.
3 Asymptotic Theory
Let for some large enough, such that the true parameter lies in the interior of . Before stating the theoretical results, we give some more notations. Define , , and as the solution of maximizing within , where . Let , , , . Let , , and be the score functions. Let be the Hessian matrix. The decomposition of and the expression of each component is presented in Appendix A in the supplementary material. We suppress the argument when and are evaluated at , i.e. and .
3.1 Convergence Rates
We first provide a consistent result for the estimates of factors and loadings in terms of their average Euclidean norm (or equivalently the Frobenious norm of the estimated row and column factor loading matrices and the factor matrix).
To derive finer convergence rates and the limit distributions of the estimated parameters, we need to utilize the first-order condition . The following proposition demonstrates that w.p.a.1.
Proposition 2 is nontrivial because the dimension of increases with , and . In a fixed-dimensional parameter space, the consistency of the estimated parameters, coupled with the assumption that the true parameters lie in the interior of the parameter space, ensures that the estimated parameters also lie in the interior. Consequently, the first-order conditions are satisfied. However, when the dimension of the parameter space increases with , , and , the average consistency of as established in Proposition 1 is insufficient to ensure that remains an interior point of the parameter space. In this context, the uniform consistency of is required.
Note that and could be arbitrarily large in some examples as demonstrated below Assumption 6, and in such cases
Now we utilize the first-order conditions. Using the integral form of the mean value theorem for vector-valued functions to expand the first order conditions, we have , where . It shows that
| (15) |
where
It is straightforward to see that . Utilizing the local positive-definiteness of aided by the carefully designed augmented Lagrangian terms, we show in the supplementary material (Lemma A.3) that the largest eigenvalue of is in the neighborhood for some . Since lies in w.p.a.1, this implies that is . Then we have the following strengthened results.
Comparable outcomes have been established for continuous variables. For example, the averaged convergence rate of by the least square estimate given in He et al. (2023) and the PE estimate given in Yu et al. (2022), both reached . When the matrices are vectorized and the method for the generalized vector factor model is implemented as in Liu et al. (2023) and Wang (2022), the averaged convergence rate of estimating the loading space spanned by is , which is no faster than ours, especially in scenarios where outweighs . It is also no slower than the rate, , of the non-likelihood method -PCA in the seminal paper by Chen and Fan (2023), especially when the data matrix is not balanced. Yet extra effort has to be carried to separate and from their twisted Kronecker product.
3.2 Limit distributions
Now we proceed to the limit distributions of the estimated factors and loadings. Expanding the first-order conditions to a higher order, we have
where . , and are , and dimensional with element , and , respectively. , and are linear combinations of and . Thus
Utilizing the local landscape property of , we show in the supplementary material,
| (16) |
The intuition behind (16) is that is approximately block diagonal with the aid of the augmented Lagrangian terms , and also .
The elements within ’s diagonal blocks are significantly larger than those in its off-diagonal blocks. This structure of allows us to demonstrate that, in the expansion of , the additional terms resulting from the nonzero off-diagonal blocks collectively have an order of . Then combing with Theorem 1, we show in the supplement that
| (17) |
Thus if , would be and hence dominated by the first term on the right-hand side of (16).
From Proposition 4, we see that the convergence rate of each component of is the same as that of the least square estimator in LMFM by He et al. (2023), but slower than that of the PE estimator in Yu et al. (2022), except that one of dominates the others. This is because both the maximum likelihood and the least square estimation derive estimators of jointly, while the PE method estimates , and individually. Though the rate is not sharp, but enough for deriving the order of . Then we have the following central limit theorem.
Theorem 2.
Remark 1.
The asymptotic variances of , and can be consistently estimated, respectively, by
Theorem 2 generalizes Theorem 3.2 of Yu et al. (2022) allowing factors to be extracted from discrete or some other nonlinear models. And it allows the probability function to differ across rows, columns and samples. Thus the vast quantity of discrete data available in macroeconomic and financial studies can be effectively utilized, either by themselves or in combination with continuous data. An immediate consequence of Theorem 2 and Remark 1 is the following corollary.
3.3 Consistency in determining the number of factors
Under the linear matrix factor model, Yu et al. (2022) proposed an eigenvalue ratio test to consistently estimate the number of factors. While the eigenvalue ratio test is based on the ordered eigenvalues of the covariance matrix of , it is not suitable to describe the correlation of non-continuous random variables. In this article, we use the idea of information criterion to select the number of factors. The estimator of is similar to the penalized loss (PC) based estimator of Bai and Ng (2002), but is adaptive to the matrix observation and the likelihood function. Given the number of factors , let be the estimator of . Our PC-based estimator of is defined as
| (18) |
where is a prespecified penalty function. Theorem 3 below demonstrates that are consistent to by choosing a suitable .
In our simulation studies and real data analysis, we choose the penalty , which satisfies the conditions in Theorem 3 and is confirmed to work well.
3.4 Algorithms
We shall introduce two algorithms, the two-stage alternating maximization and the minorization maximization to numerically calculate the maximum likelihood estimator. The second one is computationally simpler, but so far it has been shown to be only applicable to Probit, Logit and Tobit models (Wang (2022)).
3.4.1 Two-stage alternating maximization (TSAM)
Let be an indicator set pertaining to a specific variable type in the -th column of with respect to , such that the cardinality of and are of comparable magnitude. Similarly, Let be an indicator set pertaining to a specific variable type in the -th row of with respect to , such that the number of elements in and are comparable. And let be an indicator set associated with a particular variable type in the -th sequence of relative to , where the cardinality of and are comparable in magnitude. Due to the finite number of variable types in , are well defined.
Algorithm 1. Step 1 (Initialization): Randomly generate the initial values of and .
Step 2 (Updating): For , calculate
Repeat the iteration until convergence and denote the derived estimators as and .
Step 3 (Correction): A second-stage update is then conducted based on the score function and Hessian matrix:
| (19) | ||||
| (20) | ||||
| (21) |
Step 4 (Repetition): Repeat step 1-step 3 a number of times. Take the one with the largest likelihood.
Step 5 (Normalization): Let , and be the estimators from step 4. To ensure the identification conditions in (6), a normalization step could be applied to the factor and loading matrices. Specifically, do singular value decomposition to and as follows.
Define
and hence the eigenvalue decompositions
Then, the normalized loading and factor score matrices are, respectively,
| (22) |
Liu et al. (2023) first proposed this algorithm for the generalized vector factor model, and the convergence of step 2 to a local maximum is given in their Proposition 2. To search for the global maximum, a common practice is to randomly choose the initial values multiple times and select the one with the highest likelihood among all local maxima. We generalize this approach to the matrix factor model setting. Although the computation for is simple, the efficiency may be lost since and are not obtained based on the log-likelihood function . To improve the efficiency, we then conduct a second-stage update in step 3, and the increase in efficiency from this one-step correction is validated in Section 4.5. The strength of this algorithm lies in its ability to perform estimations in parallel across all rows, columns and sequences, leveraging existing packages. This ensures straightforward programming and computation, enhancing efficiency and convenience.
3.4.2 Minorization maximization (MM)
Algorithm 2. Step 1 (Initialization): Randomly generate the initial values of , and .
Step 2 (Updating): For , first calculate for , , , then update as follows.
Iterate until error, where error is the level of numerical tolerance.
Step 3 (Repetition): Repeat step 1 and step 2 a number of times. Take the one with the largest likelihood.
Step 4 (Normalization): Similar to Algorithm 1, the solution in Step 3 is normalized by (22).
The Minorization Maximization (MM) algorithm does not require alternation. Instead, it only necessitates the matrix factorization in step 2, which can be performed quickly using standard software packages. Wang (2022) applies this algorithm to the generalized vector factor model and provides the proof of convergence for step 2 in their Appendix B. We are here extending it to the matrix factor models.
4 Numerical Studies
In Sections 4.1 and 4.2, we conduct simulation studies to assess the finite-sampling performance of the proposed method (GMFM) by comparing it with the linear matrix factor model (LMFM). The accuracy between the factor loadings and , evaluated by the smallest nonzero canonical correlation between them, denoted by ccor. Similarly, we also compute the smallest nonzero canonical correlation between and , denoted by ccor. Canonical correlation has been widely used to measure the performance in factor analysis; see for example Goyal et al. (2008), Doz et al. (2012), Bai and Li (2012), Liu et al. (2023)). In sections 4.3 and 4.4, we examine the performance of the information criterion for selecting the number of factors and verify the asymptotic normality in Theorem 2, separately. Section 4.5 investigates the efficiency gain of the second-stage correction in TSAM.
4.1 Simulation Setting
We generate the factor matrix sequence by an AR(1) model as where ’s are all generated from i.i.d. , . We draw the entries of and independently from the uniform distribution . We consider six settings with different variables and different combinations of , and .
Case 1 (Gaussian variables with homoscedasticity): , and .
Case 2 (Gaussian variables with heteroscedasticity): , , with and ’s are i.i.d from .
Case 3 (Poisson variables): and .
Case 4 (The mixture of binary and count variables): . For , , ; for , .
Case 5 (The mixture of continuous and count variables): . For , , ; for , .
Case 6 (The mixture of continuous, count and binary variables): . For , , ; for , , ; for , , ; for , , .
4.2 Comparison with the Linear Factor Models
Tables 1-2 report the average of ccor and ccor using the LMFM and GMFM based on 500 repetitions. The loadings and factors of GMFM are estimated and computed by our proposed TSAM algorithm, while the loadings and factors of LMFM are estimated by -PCA() in Chen and Fan (2023). Theoretically, under conditions of homoscedasticity, the LMFM and the GMFM are equivalent. This equivalence is reflected in the comparable results observed for Case 1 in Table 1. With heteroscedasticity, the GMFM demonstrates superior performance compared to the LMFM in case 2, as evident in Table 1. Moreover, it is evident that the precision of and increases as , and/or increases, which is consistent with our theoretical results in Theorems 1 and 2.
In case 3 of table 1, the performance of GMFM is significantly better than that of LMFM for the Poisson variables. Evidently, the LMFM is only effective for continuous variables, but performs poorly for discrete variables, and the estimation accuracy does not improve with increasing dimensionality. On the contrary, GMFM has a higher canonical correlation in estimating loadings for Poisson variables, showing a comparable accuracy to that of continuous variables.
Table 2 shows the result in Cases 4-6, where are mixed variables including Poisson, binary, and normal variables. It is clear that the LMFM does not work on mixed variables containing discrete variables, while the GMFM remains reliable in Table 2. Particularly, the canonical correlation of GMFM for both and increases as , and/or increases, but that of LMFM does not.
| GMFM | LMFM | |||||||
| T | ||||||||
| Case 1 for Gaussian variables with homoscedasticity | ||||||||
| ccor | 0.9520 | 0.9677 | 0.9827 | 0.8792 | 09201 | 0.9509 | ||
| 0.9527 | 0.9690 | 0.9836 | 0.8882 | 0.9248 | 0.9590 | |||
| 0.9608 | 0.9718 | 0.9850 | 0.9316 | 0.9497 | 0.9724 | |||
| 0.9711 | 0.9833 | 0.9879 | 0.9204 | 0.9551 | 0.9725 | |||
| 0.9734 | 0.9845 | 0.9898 | 0.9475 | 0.9650 | 0.9763 | |||
| 0.9759 | 0.9845 | 0.9909 | 0.9590 | 0.9728 | 0.9840 | |||
| ccor | 0.9389 | 0.9573 | 0.9606 | 0.8284 | 0.8795 | 0.9305 | ||
| 0.9643 | 0.9669 | 0.9702 | 0.8779 | 0.9092 | 0.9427 | |||
| 0.9788 | 0.9819 | 0.9837 | 0.9340 | 0.9541 | 0.9693 | |||
| 0.9638 | 0.9718 | 0.9744 | 0.8973 | 0.9381 | 0.9563 | |||
| 0.9790 | 0.9813 | 0.9823 | 0.9268 | 0.9549 | 0.9694 | |||
| 0.9881 | 0.9898 | 0.9903 | 0.9592 | 0.9746 | 0.9816 | |||
| Case 2 for Gaussian variables with heteroscedasticity | ||||||||
| ccor | 0.9579 | 0.9771 | 0.9874 | 0.9341 | 0.9566 | 0.9740 | ||
| 0.9650 | 0.9809 | 0.9895 | 0.9457 | 0.9648 | 0.9809 | |||
| 0.9729 | 0.9814 | 0.9898 | 0.9619 | 0.9724 | 0.9844 | |||
| 0.9788 | 0.9881 | 0.9933 | 0.9618 | 0.9765 | 0.9859 | |||
| 0.9832 | 0.9892 | 0.9938 | 0.9725 | 0.9820 | 0.9884 | |||
| 0.9841 | 0.9905 | 0.9941 | 0.9775 | 0.9859 | 0.9912 | |||
| ccor | 0.6849 | 0.7969 | 0.8528 | 0.1692 | 0.1412 | 0.2050 | ||
| 0.7992 | 0.8821 | 0.9094 | 0.1881 | 0.1559 | 0.1996 | |||
| 0.9151 | 0.9345 | 0.9451 | 0.1850 | 0.1869 | 0.2097 | |||
| 0.8102 | 0.8924 | 0.9234 | 0.1670 | 0.1545 | 0.2479 | |||
| 0.9118 | 0.9376 | 0.9494 | 0.1698 | 0.1642 | 0.2730 | |||
| 0.9543 | 0.9662 | 0.9709 | 0.1956 | 0.1907 | 0.2650 | |||
| Case 3 for Possion variables | ||||||||
| ccor | 0.9663 | 0.9806 | 0.9882 | 0.3492 | 0.3393 | 0.3666 | ||
| 0.9697 | 0.9814 | 0.9890 | 0.2998 | 0.2521 | 0.3063 | |||
| 0.9720 | 0.9824 | 0.9891 | 0.2140 | 0.2165 | 0.2506 | |||
| 0.9808 | 0.9885 | 0.9931 | 0.3477 | 0.4054 | 0.4485 | |||
| 0.9827 | 0.9889 | 0.9933 | 0.3101 | 0.2969 | 0.2905 | |||
| 0.9836 | 0.9899 | 0.9941 | 0.2341 | 0.2528 | 0.2172 | |||
| ccor | 0.9504 | 0.9658 | 0.9687 | 0.2711 | 0.2624 | 0.2177 | ||
| 0.9699 | 0.9755 | 0.9806 | 0.2950 | 0.2836 | 0.2325 | |||
| 0.9852 | 0.9867 | 0.9876 | 0.2811 | 0.2738 | 0.1843 | |||
| 0.9732 | 0.9815 | 0.9830 | 0.3105 | 0.2304 | 0.1961 | |||
| 0.9830 | 0.9859 | 0.9879 | 0.3055 | 0.1895 | 0.1612 | |||
| 0.9905 | 0.9927 | 0.9934 | 0.2963 | 0.2441 | 0.2149 | |||
| GMFM | LMFM | |||||||
| T | ||||||||
| Case 4 for binary and count variables | ||||||||
| ccor | 0.9408 | 0.9666 | 0.9837 | 0.3900 | 0.3485 | 0.3704 | ||
| 0.9545 | 0.9718 | 0.9857 | 0.2693 | 0.2651 | 0.2580 | |||
| 0.9617 | 0.9767 | 0.9868 | 0.2708 | 0.2386 | 0.1882 | |||
| 0.9678 | 0.9819 | 0.9911 | 0.3961 | 0.4086 | 0.4384 | |||
| 0.9731 | 0.9847 | 0.9918 | 0.3098 | 0.3183 | 0.2968 | |||
| 0.9779 | 0.9864 | 0.9926 | 0.2823 | 0.2124 | 0.2362 | |||
| ccor | 0.7785 | 0.8926 | 0.9207 | 0.2160 | 0.1705 | 0.1533 | ||
| 0.9162 | 0.9350 | 0.9500 | 0.2126 | 0.1508 | 0.1405 | |||
| 0.9515 | 0.9627 | 0.9717 | 0.2079 | 0.1756 | 0.1412 | |||
| 0.8724 | 0.9382 | 0.9551 | 0.2194 | 0.1636 | 0.1041 | |||
| 0.9407 | 0.9604 | 0.9702 | 0.1982 | 0.1746 | 0.1517 | |||
| 0.9659 | 0.9787 | 0.9825 | 0.1941 | 0.1476 | 0.1375 | |||
| Case 5 for continuous and count variables | ||||||||
| ccor | 0.9624 | 0.9818 | 0.9913 | 0.5255 | 0.4910 | 0.5678 | ||
| 0.9705 | 0.9843 | 0.9917 | 0.3885 | 0.4213 | 0.4085 | |||
| 0.9791 | 0.9868 | 0.9929 | 0.2685 | 0.2784 | 0.2809 | |||
| 0.9814 | 0.9898 | 0.9946 | 0.5002 | 0.5464 | 0.6054 | |||
| 0.9849 | 0.9916 | 0.9954 | 0.4544 | 0.4507 | 0.4529 | |||
| 0.9875 | 0.9926 | 0.9961 | 0.3168 | 0.3032 | 0.3323 | |||
| ccor | 0.8882 | 0.9675 | 0.9766 | 0.2878 | 0.2077 | 0.1607 | ||
| 0.9596 | 0.9785 | 0.9850 | 0.2477 | 0.2497 | 0.1767 | |||
| 0.9843 | 0.9895 | 0.9912 | 0.3200 | 0.1805 | 0.1495 | |||
| 0.9473 | 0.9806 | 0.9867 | 0.2900 | 0.2060 | 0.1764 | |||
| 0.9745 | 0.9875 | 0.9914 | 0.2574 | 0.2566 | 0.1795 | |||
| 0.9902 | 0.9937 | 0.9950 | 0.3306 | 0.1877 | 0.1635 | |||
| Case 6 for continuous, count and binary variables | ||||||||
| ccor | 0.6565 | 0.8353 | 0.9498 | 0.2703 | 0.3290 | 0.2900 | ||
| 0.8167 | 0.9290 | 0.9777 | 0.2364 | 0.2423 | 0.2070 | |||
| 0.9493 | 0.9753 | 0.9880 | 0.1303 | 0.1690 | 0.1637 | |||
| 0.7052 | 0.8737 | 0.9620 | 0.3071 | 0.3589 | 0.3450 | |||
| 0.8969 | 0.9583 | 0.9849 | 0.1675 | 0.2789 | 0.2523 | |||
| 0.9662 | 0.9850 | 0.9930 | 0.1593 | 0.1828 | 0.1758 | |||
| ccor | 0.5365 | 0.7318 | 0.9250 | 0.2667 | 0.1670 | 0.1246 | ||
| 0.6170 | 0.8871 | 0.9621 | 0.1935 | 0.1428 | 0.1224 | |||
| 0.8769 | 0.9643 | 0.9848 | 0.2093 | 0.1545 | 0.1241 | |||
| 0.5823 | 0.8080 | 0.9544 | 0.2584 | 0.2362 | 0.1142 | |||
| 0.7168 | 0.9095 | 0.9768 | 0.2004 | 0.1887 | 0.1074 | |||
| 0.8829 | 0.9742 | 0.9896 | 0.1775 | 0.1606 | 0.1457 | |||
4.3 Model Selection
This section aims to verify the performance of the proposed methods for selecting the number of row and column factors. Table 3 reports the average of and based on repetitions, where the candidates of and are the integers from to . In Table 3, it can be seen that the PC-type information criterion (18) works well in all six cases considered with different and . We found that the LMFM using -PCA by Chen et al. (2022) and the projected estimation (PE) by Yu et al. (2022) both failed under the PC information criterion, which tends to choose in all the six cases.
| T | |||||||
| Case 1: | Case 2: | ||||||
| Case 3: | Case 4: | ||||||
| Case 5: | Case 6: | ||||||
4.4 Asymptotic distribution
In this section, we assess the adequacy of the asymptotic distributions in Theorem 2. We consider the case with and generate from i.i.d. . The generation and normalization of and are the same as Section 4.1. For the given , and , we consider three data generating processes (DGPs) for .
DGP 1 (Logit): is a binary random variable and , where .
DGP 2 (Probit): is a binary random variable and , where is the cumulative distribution function of standard normal distribution.
DGP 3(Mixed): For , , , ; for , , , is a binary random variable and ; for , , , is a binary random variable and .
Under such cases, by Theorem 2,
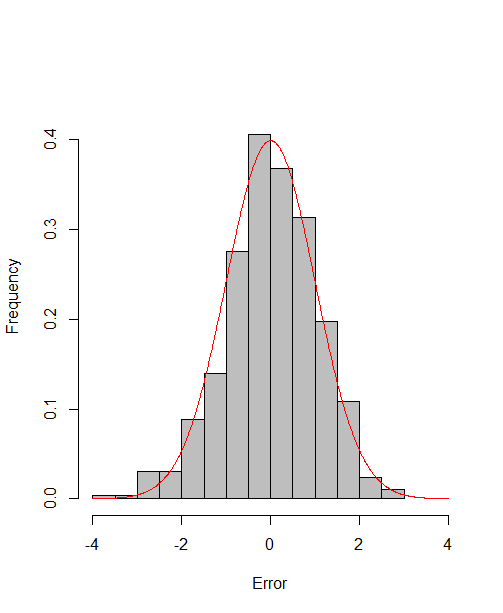
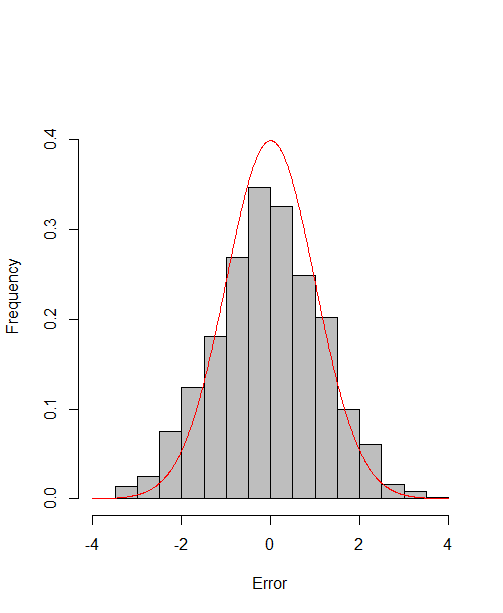
which reach the asymptotic efficiency bounds. Figure 1, 2 and 3 show the normalized histograms of and for DGP1-DGP3 by TSAM and MM separately, and the standard normal density curve is overlaid on them for comparison. As for the step 2 in MM, we choose for the Logit case and for the Probit case by the definition of in Section 2.2. The standard normal density curve clearly provides a good approximation across all subfigures.
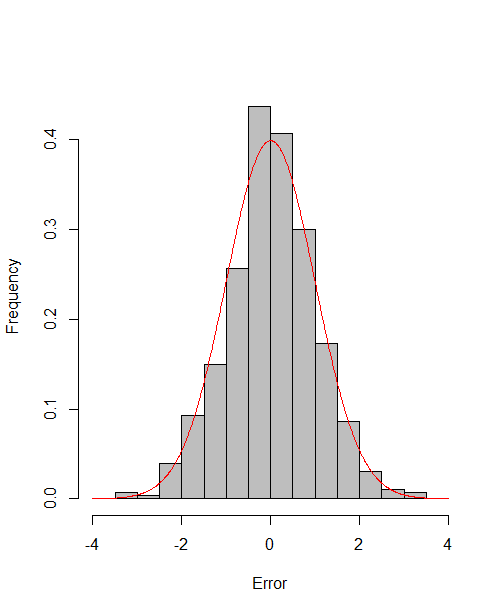
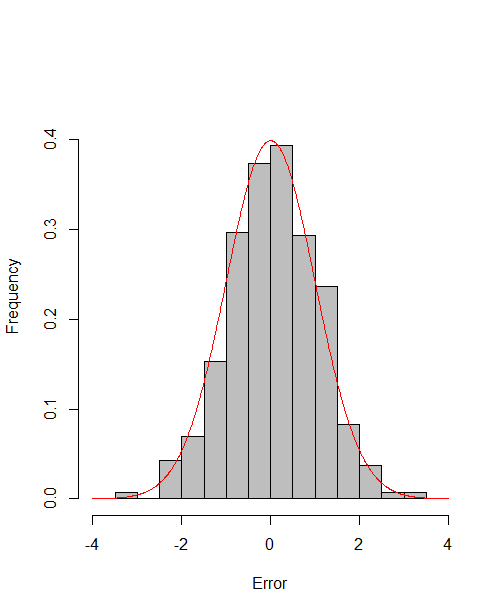
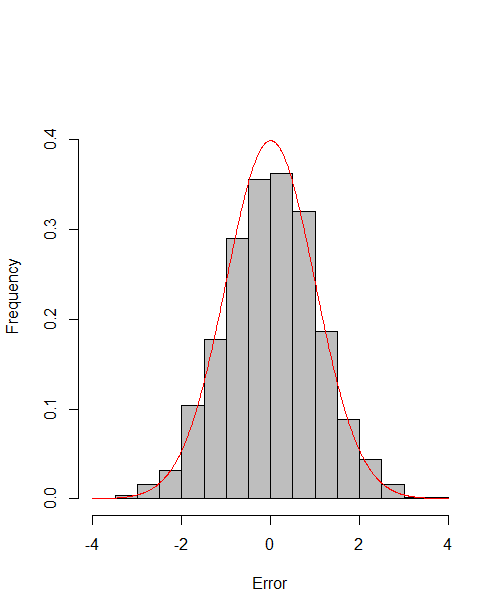
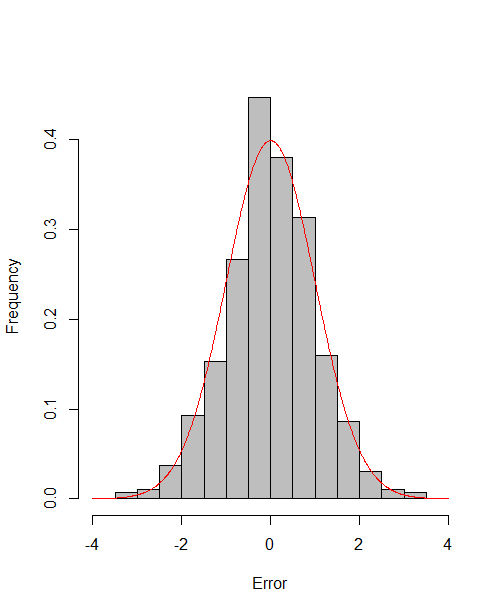
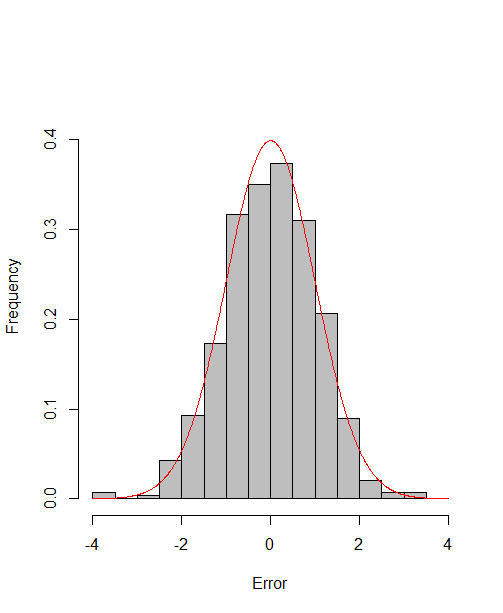
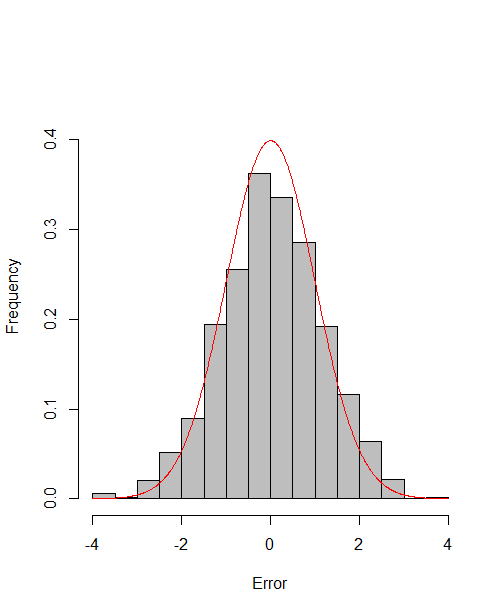
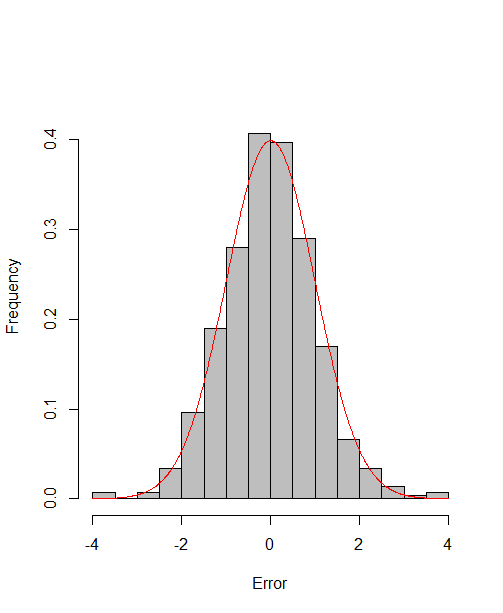
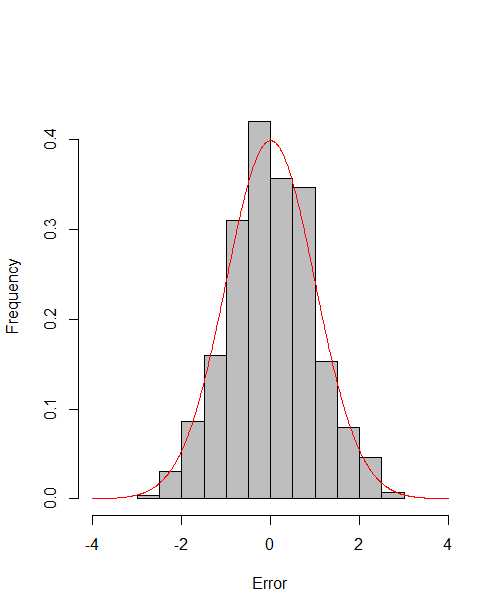
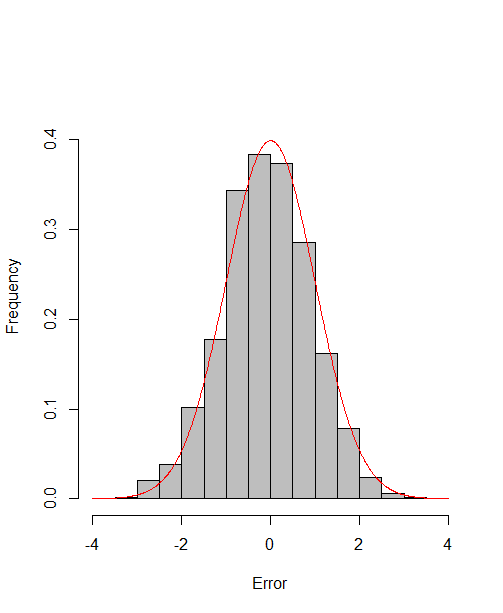
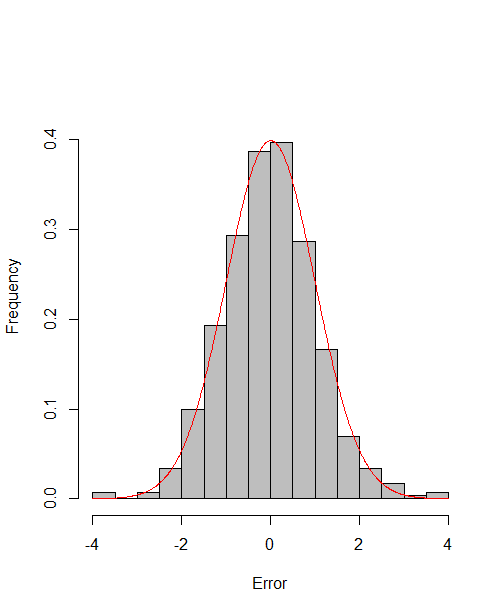
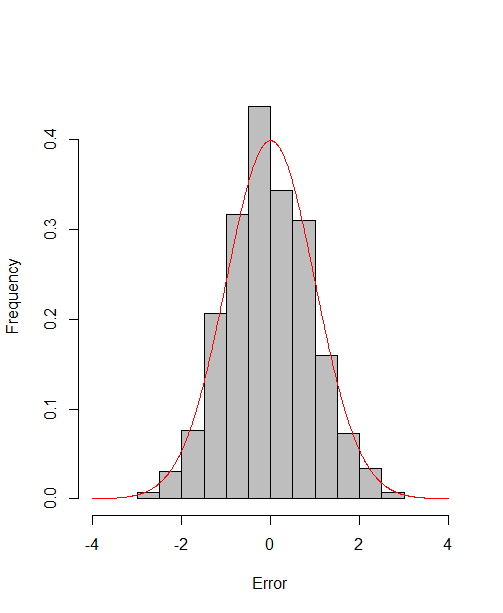
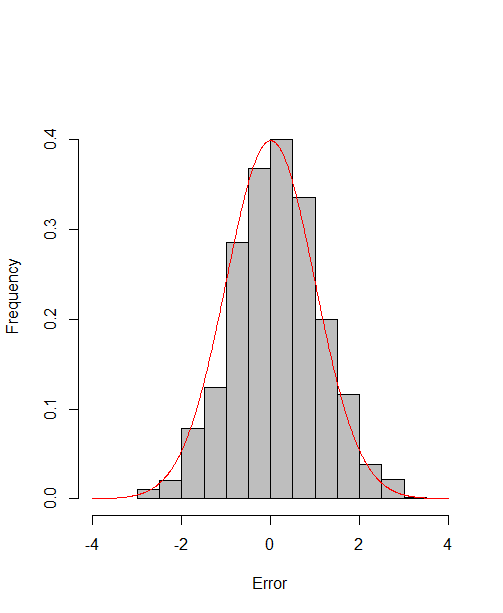
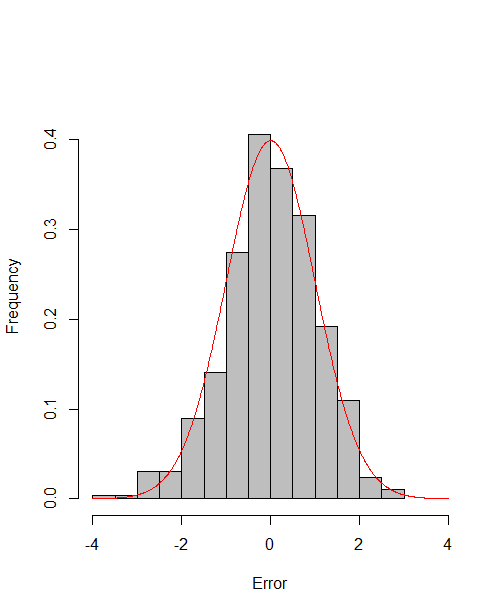
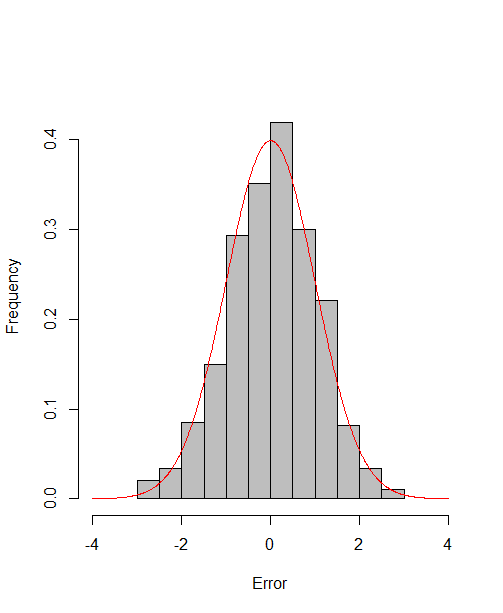
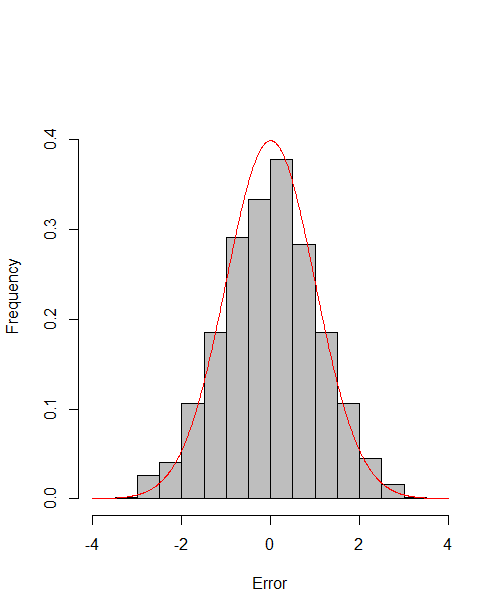
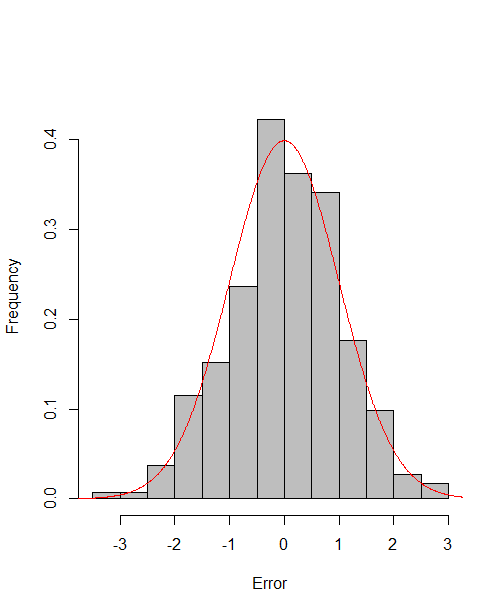
4.5 Efficiency Gain of the One-Step Correction in TSAM
To demonstrate the efficiency improvement from the second-stage update in TSAM, we illustrate the results using Case 5 with . In the first stage of TSAM, we obtain the estimator using continuous variables (S1N), count variables (S1P), and both (S1NP). As shown in Table 4, the performance of the first-stage estimators improves as , , and/or increase. Notably, S1NP demonstrates the best performance, while S1P and S1N exhibit similar levels of effectiveness. This aligns with our expectation since S1NP utilizes the most comprehensive information. The second-stage updating significantly enhances the performance of the estimators obtained from stage one, especially when the sample size is small.
| S1N | S1P | S1NP | S1N | S1P | S1NP | S1N | S1P | S1NP | |
| ccorR | 0.9328 | 0.9388 | 0.9702 | 0.9502 | 0.9583 | 0.9787 | 0.9703 | 0.9776 | 0.9879 |
| ccorC | 0.8930 | 0.8612 | 0.9470 | 0.9055 | 0.9533 | 0.9652 | 0.9699 | 0.9695 | 0.9764 |
| OSN | OSP | OSNP | OSN | OSP | OSNP | OSN | OSP | OSNP | |
| ccorR | 0.9692 | 0.9701 | 0.9753 | 0.9761 | 0.9761 | 0.9791 | 0.9872 | 0.9877 | 0.9883 |
| ccorC | 0.9456 | 0.9424 | 0.9542 | 0.9500 | 0.9689 | 0.9699 | 0.9766 | 0.9766 | 0.9769 |
5 Real Data Analysis
In this section, we analyze the operating performance of the listed high-tech manufacturing companies in China. These comprehensive datasets are sourced from various reliable resources, encompassing publicly accessible financial reports, corporate social responsibility statements, and stock exchange-released trading data. The data can be downloaded from https://data.csmar.com. This dataset encompasses 22 indicators for 12 manufacturing companies, spanning a total of 68 quarters from 2007-Q1 to 2023-Q2. It is worth noting that, unlike in the general LMFM literature (Wang et al. (2019),Chen et al. (2022),Yu et al. (2022)), in addition to 18 continuous variables, there are four binary variables. These binary variables represent corporate social responsibility, such as the protection of employees’ rights and interests, environmental and sustainable development initiatives, as well as public relations and social welfare undertakings. Indicator disclosure is marked as , while non-disclosure is marked as . Furthermore, the economic indicators of these companies can be categorized into four main groups: profitability, development ability, operational ability, and solvency. A detailed list of these indicators is presented in the supplementary material. The enterprises belong to three high-tech industries: pharmaceutical manufacturing, electronic equipment manufacturing, and transportation manufacturing.
The missing rate is low in this data set (), and we use simple linear interpolation to fill in the missing values. Each original univariate time series is transformed by taking the second difference. We also standardize each of the transformed series to avoid the effects of non-zero mean or disparate variances.
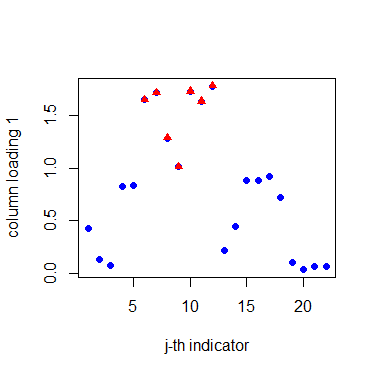
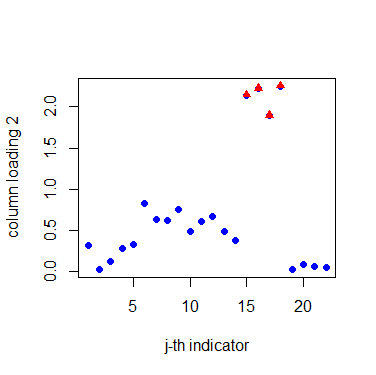
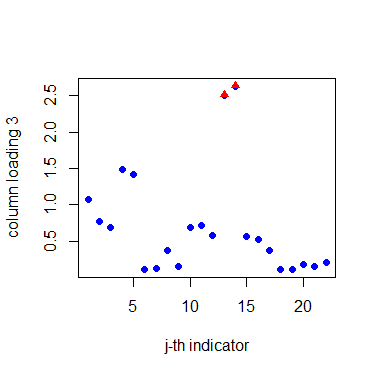
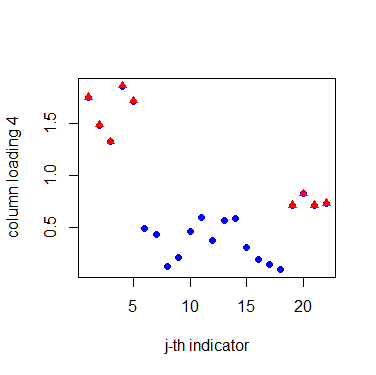
Before the estimation of matrix factors and matrix loadings, we need to determine the numbers of row and column factors first. Our proposed criterion suggests taking , . For the row factors, Table 5 shows that they are closely related to the industry classification. Companies in the same industry often have similar loadings on the factors. These 12 companies are naturally divided into three groups, namely pharmaceutical manufacturing (P1, P2, P3, P4), electronic equipment manufacturing (E1, E2, E3, E4, E5), and transportation manufacturing (T1, T2, T3). For the column factors, Figure 4 divides the indicators into four groups: profitability (G1), operational ability (G2), solvency (G3), and development ability (G4). Notably, the disclosure of social responsibility has been incorporated into the indicators of development capability. A company with a strong sense of social responsibility generally tends to have better development prospects. This categorization aligns with economic explanations. The detailed grouping of these indicators is clearly outlined in the supplementary material.
| Row Factor | E1 | E2 | E3 | E4 | E5 | P1 | P2 | P3 | P4 | T1 | T2 | T3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | -5 | -3 | 2 | 0 | -2 | -21 | -20 | -16 | -9 | 0 | -2 | 1 |
| F2 | -3 | -5 | 0 | -8 | -6 | 1 | 1 | 0 | 3 | 20 | 17 | 20 |
| F3 | -17 | -13 | -10 | -20 | -13 | 2 | 1 | 0 | 5 | -5 | -6 | -8 |
The canonical correlation of (resp. ) for LMFM (estimating by -PCA with ) and GMFM is 0.76 ( resp. 0.70) respectively, showing that the loading estimators of LMFM are different from those of GMFM. In addition, we calculated the negative scaled log-likelihood for GMFM and LMFM to measure the goodness of fit ( and for GMFM and LMFM, respectively, with ). Clearly, GMFM has a higher goodness of fit for the data.
To further compare the GMFM and LMFM, we employ a rolling-validation procedure as in Yu et al. (2022). For each year from 2007 to 2022, we repeatedly use the (bandwidth) years observations before to fit the matrix-variate factor model and estimate the two loading matrices. The loadings are then used to estimate the factors and corresponding residuals of the quarters in the current year. Specifically, let and be the observed and estimated performance matrix of quarter in year . Define
as the mean squared error (MSE) and unexplained proportion of total variances, respectively. Let and be the mean MSE and the mean unexplained proportion of total variances, respectively. For LMFM, the ’s are reconstructed by the projected estimator (PE) in Yu et al. (2022) and the -PCA method with (-PCA) in Chen et al. (2020a).
| n | LMFM | LMFM | GMFM | GVFM | LMFM | LMFM | GMFM | GVFM | |
| (-PCA) | (PE) | (-PCA) | (PE) | ||||||
| 1 | 0.97 | 0.99 | 0.93 | 1.20 | 1.21 | 1.13 | |||
| 5 | 2 | 0.90 | 0.91 | 0.91 | 1.11 | 1.10 | 1.12 | ||
| 5 | 3 | 0.81 | 0.80 | 0.88 | 0.99 | 0.96 | 1.07 | ||
| 10 | 1 | 0.96 | 0.96 | 1.21 | 1.19 | 1.13 | |||
| 10 | 2 | 0.88 | 0.87 | 0.89 | 1.10 | 1.08 | 1.14 | ||
| 10 | 3 | 0.79 | 0.77 | 0.88 | 0.97 | 1.08 | |||
Table 6 presents the average values of MSE and obtained from various estimation methods: LMFM (-PCA), LMFM (PE), GMFM and the generalized vector factor model (GVFM) with factor numbers by Liu et al. (2023). A comprehensive comparison is made across different combinations of bandwidth () and the number of factors (). From Table 6, our proposed GMFM outperforms other methods across the board. Specifically, when k=1, GMFM and GVFM display comparable MSEs. Nevertheless, as k rises, the MSE of GMFM notably decreases, whereas the decline for GVFM is gradual. Moreover, the two estimation methods for LMFM demonstrate comparable behavior, both worse than GMFM.
6 Conclusion
This paper provides a general theory for matrix factor analysis of a high-dimensional nonlinear model. Given certain regularity conditions, we have established the consistency and convergence rates of the estimated factors and loadings. Meanwhile, the asymptotic normality of the estimated loadings is derived. Furthermore, we develop a criterion based on a penalized loss to consistently estimate the number of row factors and column factors within the framework of the GMFM. Computationally, We have proposed two algorithms to compute the factors and loadings from the GMFM. To justify our theory, we conduct extensive simulation studies and applied GMFM to the analysis of a business performance dataset.
Supplementary Material
The Supplementary Material contains the detailed technical proof of the main theorems, as well as some technical lemmas that are of their own interests, in addition to details of the data set.
References
- Bai and Li (2012) Bai, J., Li, K., 2012. Statistical analysis of factor models of high dimension. The Annals of Statistics 40, 436–465.
- Bai and Ng (2002) Bai, J., Ng, S., 2002. Determining the number of factors in approximate factor models. Econometrica 70, 191–221.
- Barigozzi et al. (2022) Barigozzi, M., He, Y., Li, L., Trapani, L., 2022. Statistical inference for large-dimensional tensor factor model by iterative projections. arXiv:2206.09800 .
- Barigozzi and Trapani (2022) Barigozzi, M., Trapani, L., 2022. Testing for common trends in nonstationary large datasets. Journal of Business & Economic Statistics 40, 1107–1122.
- Chang et al. (2023) Chang, J., He, J., Yang, L., Yao, Q., 2023. Modelling matrix time series via a tensor cp-decomposition. Journal of the Royal Statistical Society Series B: Statistical Methodology 85, 127–148.
- Chen et al. (2024) Chen, E., Fan, J., Zhu, X., 2024. Factor augmented matrix regression. arXiv:2405.17744 .
- Chen and Fan (2023) Chen, E.Y., Fan, J., 2023. Statistical inference for high-dimensional matrix-variate factor models. Journal of the American Statistical Association 118, 1038–1055.
- Chen et al. (2021a) Chen, M., Fern¨¢ndez-Val, I., Weidner, M., 2021a. Nonlinear factor models for network and panel data. Journal of Econometrics 220, 296–324.
- Chen et al. (2021b) Chen, R., Xiao, H., Yang, D., 2021b. Autoregressive models for matrix-valued time series. Journal of Econometrics 222, 539–560.
- Chen et al. (2022) Chen, R., Yang, D., Zhang, C.H., 2022. Factor models for high-dimensional tensor time series. Journal of the American Statistical Association 117, 94–116.
- Doz et al. (2012) Doz, C., Giannone, D., Reichlin, L., 2012. A quasi-maximum likelihood approach for large, approximate dynamic factor models. The Review of Economics and Statistics 94, 1014–1024.
- Fan et al. (2013) Fan, J., Liao, Y., Mincheva, M., 2013. Large covariance estimation by thresholding principal orthogonal complements. Journal of the Royal Statistical Society Series B: Statistical Methodology 75, 603–680.
- Goyal et al. (2008) Goyal, A., P¨¦rignon, C., Villa, C., 2008. How common are common return factors across the nyse and nasdaq? Journal of Financial Economics 90, 252–271.
- He et al. (2022) He, Y., Wang, Y., Yu, L., Zhou, W., Zhou, W., 2022. Matrix kendall’s tau in high-dimensions: A robust statistic for matrix factor model. arXiv: 2207.09633 .
- He et al. (2023) He, Y., Zhao, R., Zhou, W., 2023. Iterative alternating least square estimation for large-dimensional matrix factor model. arXiv:2301.00360 .
- Jennrich (1969) Jennrich, R.I., 1969. Asymptotic properties of non-linear least squares estimators. The Annals of Mathematical Statistics 40, 633–643.
- Jing et al. (2021) Jing, B., Li, T., Lyu, Z., Xia, D., 2021. Community detection on mixture multilayer networks via regularized tensor decomposition. Annals of Statistics 49, 3181–3205.
- Jing et al. (2022) Jing, B., Li, T., Ying, N., Yu, X., 2022. Community detection in sparse networks using the symmetrized laplacian inverse matrix (slim). Statistica Sinica 32, 1–22.
- Kong (2017) Kong, X., 2017. On the number of common factors with high-frequency data. Biometrika 104, 397–410.
- Liu et al. (2023) Liu, W., Lin, H., Zheng, S., Liu, J., 2023. Generalized factor model for ultra-high dimensional correlated variables with mixed types. Journal of the American Statistical Association 118, 1385–1401.
- Mao et al. (2019) Mao, X., Chen, S., Wong, R.K.W., 2019. Matrix completion with covariate information. Journal of the American Statistical Association 114, 198–210.
- Mao et al. (2021) Mao, X., Wong, R.K.W., Chen, S., 2021. Matrix completion under low-rank missing mechanism. Statistica Sinica 31, 2005–2030.
- Newey and McFadden (1986) Newey, W., McFadden, D., 1986. Large sample estimation and hypothesis testing. Handbook of Econometrics 4, 2111–2245.
- Pelger (2019) Pelger, M., 2019. Large-dimensional factor modeling based on high-frequency observations. Journal of Econometrics 208, 23–42.
- Trapani (2018) Trapani, L., 2018. A randomized sequential procedure to determine the number of factors. Journal of the American Statistical Association 113, 1341–1349.
- Wang et al. (2019) Wang, D., Liu, X., Chen, R., 2019. Factor models for matrix-valued high-dimensional time series. Journal of Econometrics 208, 231–248.
- Wang (2022) Wang, F., 2022. Maximum likelihood estimation and inference for high dimensional generalized factor models with application to factor-augmented regressions. Journal of Econometrics 229, 180–200.
- Wu (1981) Wu, C.F., 1981. Asymptotic theory of nonlinear least squares estimation. The Annals of Statistics 9, 501–513.
- Yu et al. (2022) Yu, L., He, Y., Kong, X., Zhang, X., 2022. Projected estimation for large-dimensional matrix factor models. Journal of Econometrics 229, 201–217.
- Yuan et al. (2023) Yuan, C., Gao, Z., He, X., Huang, W., Guo, J., 2023. Two-way dynamic factor models for high-dimensional matrix-valued time series. Journal of the Royal Statistical Society Series B: Statistical Methodology 85, 1517–1537.
- Zhang et al. (2024) Zhang, X., Liu, C.C., Guo, J., Yuen, K.C., Welsh, A.H., 2024. Modeling and learning on high-dimensional matrix-variate sequences. Journal of the American Statistical Association 0, 1–16. URL: https://doi.org/10.1080/01621459.2024.2344687.
- Zhou et al. (2024) Zhou, T., Pan, R., Zhang, J., Wang, H., 2024. An attribute-based node2vec model for dynamic community detection on co-authorship network. Computational Statistics , 1–28.