Generating AI Literacy MCQs: A Multi-Agent LLM Approach
Abstract.
Artificial intelligence (AI) is transforming society, making it crucial to prepare the next generation through AI literacy in K-12 education. However, scalable and reliable AI literacy materials and assessment resources are lacking. To address this gap, our study presents a novel approach to generating multiple-choice questions (MCQs) for AI literacy assessments. Our method utilizes large language models (LLMs) to automatically generate scalable, high-quality assessment questions. These questions align with user-provided learning objectives, grade levels, and Bloom’s Taxonomy levels. We introduce an iterative workflow incorporating LLM-powered critique agents to ensure the generated questions meet pedagogical standards. In the preliminary evaluation, experts expressed strong interest in using the LLM-generated MCQs, indicating that this system could enrich existing AI literacy materials and provide a valuable addition to the toolkit of K-12 educators.
1. Introduction
AI is rapidly transforming our world, from the way we work to the way we interact with each other. To prepare the next generation for this AI-driven world, educational frameworks like AI4K12’s ”Five Big Ideas”(Touretzky et al., 2022) (Perception, Representation and Reasoning, Learning, Natural Interaction, and Natural Interaction) have been developed to integrate AI literacy into K-12 education.
However, as a relatively new subject area, there is a lack of learning materials in AI literacy instructional and assessment activities(Gardner-McCune et al., 2019). In addition, existing courses and assessment resources are often not scalable or reliable (Tseng et al., 2024). This shortage presents a significant challenge for teachers who must teach and assess students’ understanding of AI concepts while fostering critical thinking skills for responsible engagement with these technologies.
Leveraging Large Language Models (LLMs) to generate assessment questions (Doughty et al., 2024; Caines et al., 2023; Stamper et al., 2024) offers a potential solution. This method has shown promise in subjects like programming(Doughty et al., 2024), medicine(Indran et al., 2024), and language learning(Caines et al., 2023). The potential to apply these methods to AI literacy assessments could help bridge the gap for educators by providing accessible, scalable assessment resources.
This exploratory study, conducted as part of the active.ai111https://active-ai.vercel.app project, builds on previous research on MCQ generation (Doughty et al., 2024; Moore et al., 2023) and AI literacy (Touretzky et al., 2022). It seeks to address the following research question: Can LLM-powered multi-agent workflows effectively generate high-quality MCQs for AI literacy?
2. Methodology
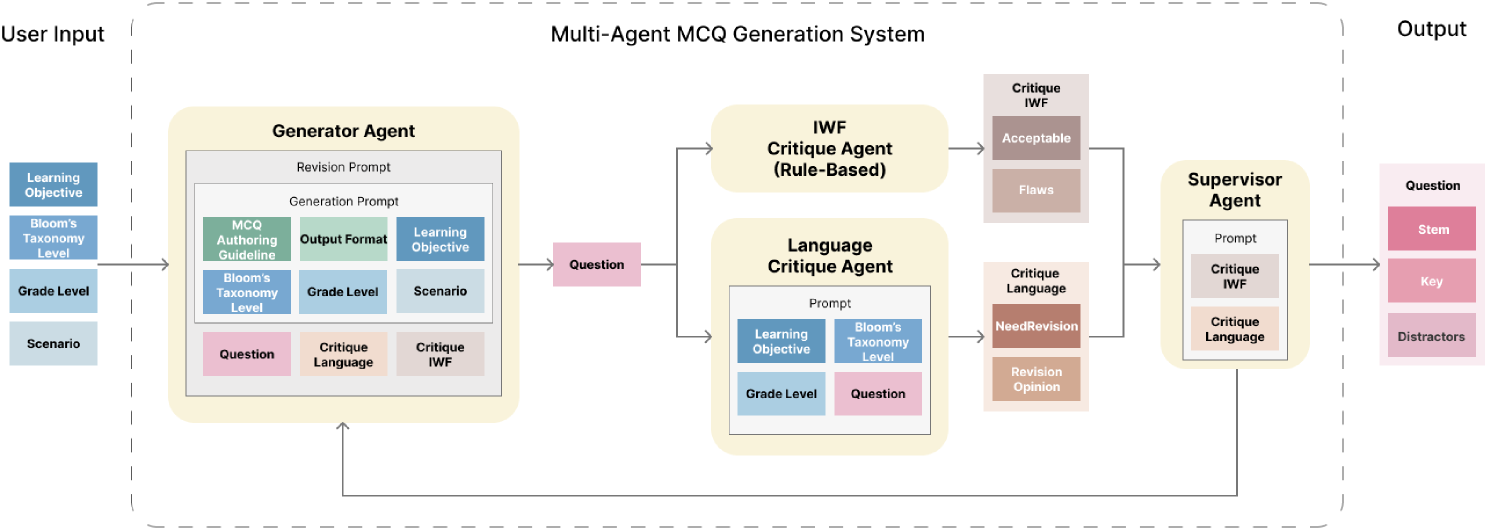
The Multi-Agent MCQ Generation System developed for this study generates and refines MCQs to assess AI literacy, using a workflow built on the LangGraph framework222https://www.langchain.com/langgraph, and OpenAI’s gpt-4o-mini-2024-07-18 model.
User inputs, including learning objectives, Bloom’s taxonomy levels (Anderson and Krathwohl, 2001), grade level, and specific scenarios, guide the Generator Agent in producing an initial question with fields stem (question), key (correct option), and distractors (incorrect options). The question is independently reviewed by two critique agents: a Language Critique Agent, which evaluates readability and alignment with grade level, and an IWF (Item-Writing Flaw) Critique Agent (Moore et al., 2023), which applies rule-based checks (modified from (Moore et al., 2023)) for issues such as implausible distractors or absolute terms. A question with 0 or 1 flaw is considered acceptable. Based on feedback from these agents, the question is either approved by the Supervisor Agent or sent back to the Generator Agent for revision. This iterative process continues until the question meets quality standards or reaches the maximum number of revisions. We generated a total of 40 multiple choice questions for students in grades K7-9.
The following is an example of a generated question:
3. Results
Three experts with more than a year of K-12 AI Literacy teaching experiences, evaluated the quality of each of the 40 MCQs used a ten-item rubric (Table 1 modified from (Scaria et al., 2024)).
| Rubric Item | Definition and Response Option |
|---|---|
| Understandable | Could you understand what the question is asking? (yes/no) |
| LORelated | Is the question related to the learning objective? (yes/no) |
| Grammatical | Is the question grammatically well-formed? (yes/no) |
| Clear | Is it clear what the question asks for? (yes/more_or_less/no) |
| Rephrase | Could you rephrase the question to make it clearer and error-free? (yes/no) |
| Answerable | Can students answer the question with the information or context provided within? (yes/no) |
| Central | Do you think being able to answer the question is important to work on the topic given in the prompt? (yes/no) |
| WouldYouUseIt | If you were a teacher teaching the course topic would you use this question or the rephrased version in the course? (this/rephrased/both/neither) |
| Bloom’sLevel | Do you think the question is of the Bloom’s taxonomy level labeled? (yes/no) |
| GradeLevel | Do you think the question is appropriate for K7-9? (yes/no) |
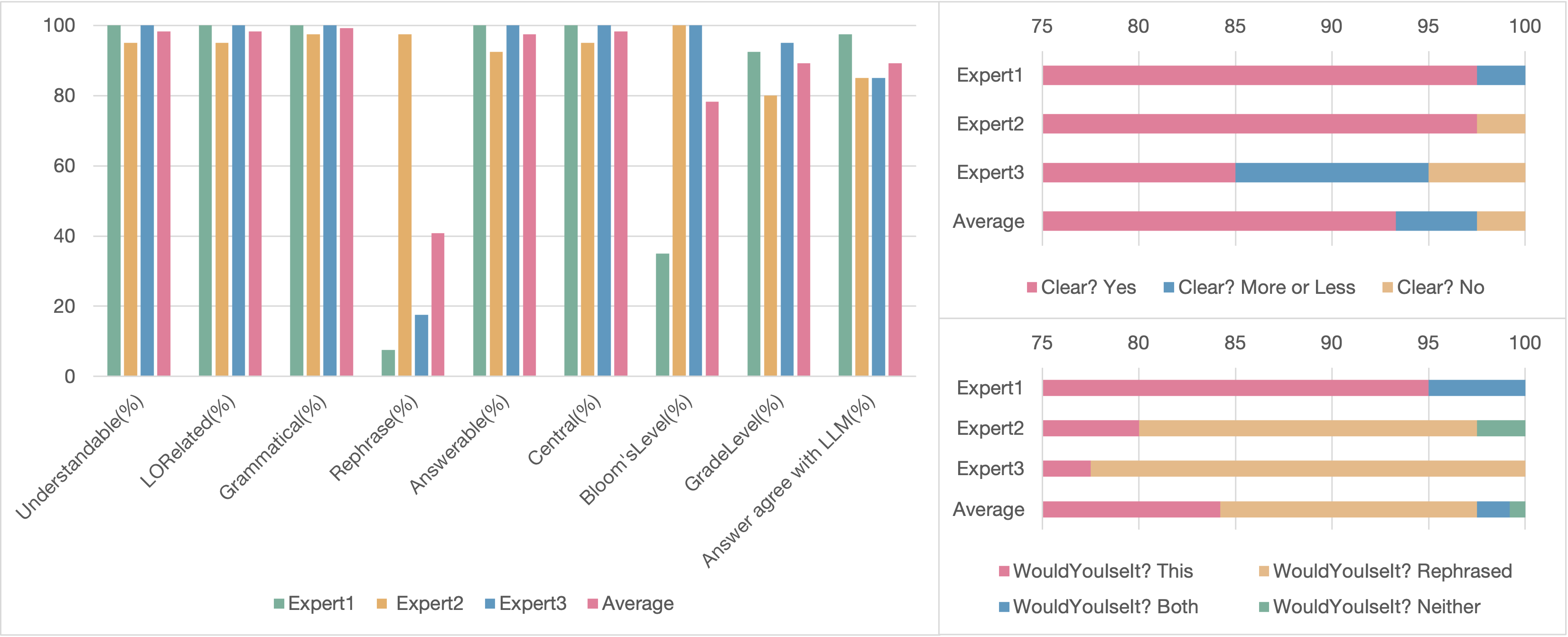
Experts 1, 2, and 3 agreed with the system on 97.5%, 85%, and 85% of the correct answers, respectively. This suggests that the system generally produces correct answers that align with expert judgments. Although rare, there are also occasional misalignments between the system’s generated answers and expert evaluations.
There was strong agreement among experts on syntactical correctness, with high ”Yes” responses for criteria such as Understandable, Answerable, Grammatical, and Clear, with average percentages ranging from 93.3% to 99.2%. This suggests that the questions generated by the multi-agent approach are well-formed and clear. Additionally, experts agreed that the questions were highly relevant to the learning objectives (LORelated 98.3%) and central to the topics being assessed (Central 98.3%).
There was noticeable disagreement among the experts in criterion Rephrase, Bloom’sLevel, and GradeLevel. Expert 2 was stricter, suggesting that 97.5% of the questions needed rephrasing, while Experts 1 and 3 flagged fewer questions (7.5% and 17.5%). The same trend is seen with the GradeLevel, where Expert 2 marked 20% of the questions as inappropriate, compared to Expert 1 at 7.5% and Expert 3 at 5%. These discrepancies likely arise from varying interpretations of the rubric or differences in pedagogical approaches. Expert 1 significantly differed from Experts 2 and 3 on the Bloom’sLevel criterion, marking only 35% of the questions as appropriate for the intended cognitive level, while the other two experts rated all questions as aligned with the correct Bloom’s level.
Finally, there was moderate agreement on the WouldYouUseIt criterion, with expert responses ranging from 77.5% to 95% (average 84.2%). This indicates that a significant majority of the questions were seen as suitable for classroom use, demonstrating that the multi-agent system can produce questions that are not only well-formed but also useful in practical educational settings. However, the diverse responses suggest that individual preferences or teaching styles influence the willingness to use certain questions.
Overall, while some refinement is necessary to accommodate diverse educational contexts, the multi-agent approach demonstrates strong potential to generate pedagogically sound and scalable high-quality assessment questions for AI literacy in K-12 education.
4. Limitations and Future Work
One avenue for future work is to conduct classroom trials to evaluate student learning outcomes and teacher usability. While our multi-agent system successfully generated AI literacy MCQs, it has not been tested in real-world classrooms, so its effectiveness in diverse learning environments is still uncertain. Another important direction for future research is to explore additional methods for evaluating question quality beyond expert assessments, such as leveraging student performance data, crowd-sourced feedback, and automated analysis to provide a more comprehensive and objective evaluation. Our current evaluation relied on expert judgments, which introduces potential subjectivity. Key priorities include expanding the system’s adaptability to more grade levels, Bloom’s Taxonomy levels, and subjects beyond AI literacy, as well as integrating diverse assessment formats (e.g., open-ended, project-based questions) to enhance its practical utility. Finally, the tool can help teachers design AI literacy courses using a backward design approach, aligning assessments with learning objectives.
References
- (1)
- Anderson and Krathwohl (2001) Lorin W. Anderson and David R. Krathwohl (Eds.). 2001. A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives (complete ed ed.). Longman, New York.
- Caines et al. (2023) Andrew Caines, Luca Benedetto, Shiva Taslimipoor, Christopher Davis, Yuan Gao, Oeistein Andersen, Zheng Yuan, Mark Elliott, Russell Moore, Christopher Bryant, et al. 2023. On the application of large language models for language teaching and assessment technology. arXiv preprint arXiv:2307.08393 (2023).
- Doughty et al. (2024) Jacob Doughty, Zipiao Wan, Anishka Bompelli, Jubahed Qayum, Taozhi Wang, Juran Zhang, Yujia Zheng, Aidan Doyle, Pragnya Sridhar, Arav Agarwal, et al. 2024. A comparative study of AI-generated (GPT-4) and human-crafted MCQs in programming education. In Proceedings of the 26th Australasian Computing Education Conference. 114–123.
- Gardner-McCune et al. (2019) Christina Gardner-McCune, David Touretzky, Fred Martin, and Deborah Seehorn. 2019. AI for K-12: Making room for AI in K-12 CS curricula. In Proceedings of the 50th ACM Technical Symposium on Computer Science Education. 1244–1244.
- Indran et al. (2024) Inthrani Raja Indran, Priya Paranthaman, Neelima Gupta, and Nurulhuda Mustafa. 2024. Twelve tips to leverage AI for efficient and effective medical question generation: a guide for educators using Chat GPT. Medical Teacher (2024), 1–6.
- Moore et al. (2023) Steven Moore, Huy A Nguyen, Tianying Chen, and John Stamper. 2023. Assessing the quality of multiple-choice questions using gpt-4 and rule-based methods. In European Conference on Technology Enhanced Learning. Springer, 229–245.
- Scaria et al. (2024) Nicy Scaria, Suma Dharani Chenna, and Deepak Subramani. 2024. Automated Educational Question Generation at Different Bloom’s Skill Levels Using Large Language Models: Strategies and Evaluation. In International Conference on Artificial Intelligence in Education. Springer, 165–179.
- Stamper et al. (2024) John Stamper, Ruiwei Xiao, and Xinying Hou. 2024. Enhancing llm-based feedback: Insights from intelligent tutoring systems and the learning sciences. In International Conference on Artificial Intelligence in Education. Springer, 32–43.
- Touretzky et al. (2022) David S. Touretzky, Christina Gardner-Mccune, and Deborah W. Seehorn. 2022. Machine Learning and the Five Big Ideas in AI. International Journal of Artificial Intelligence in Education 33 (2022), 233–266.
- Tseng et al. (2024) Ying-Jui Tseng, Ruiwei Xiao, Christopher Bogart, Jaromir Savelka, and Majd Sakr. 2024. Assessing the Efficacy of Goal-Based Scenarios in Scaling AI Literacy for Non-Technical Learners. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 2. 1842–1843.