Generating and Weighting Semantically Consistent Sample Pairs for Ultrasound Contrastive Learning
Abstract
Well-annotated medical datasets enable deep neural networks (DNNs) to gain strong power in extracting lesion-related features. Building such large and well-designed medical datasets is costly due to the need for high-level expertise. Model pre-training based on ImageNet is a common practice to gain better generalization when the data amount is limited. However, it suffers from the domain gap between natural and medical images. In this work, we pre-train DNNs on ultrasound (US) domains instead of ImageNet to reduce the domain gap in medical US applications. To learn US image representations based on unlabeled US videos, we propose a novel meta-learning-based contrastive learning method, namely Meta Ultrasound Contrastive Learning (Meta-USCL). To tackle the key challenge of obtaining semantically consistent sample pairs for contrastive learning, we present a positive pair generation module along with an automatic sample weighting module based on meta-learning. Experimental results on multiple computer-aided diagnosis (CAD) problems, including pneumonia detection, breast cancer classification, and breast tumor segmentation, show that the proposed self-supervised method reaches state-of-the-art (SOTA). The codes are available at https://github.com/Schuture/Meta-USCL.
Computer aided diagnosis, neural networks, contrastive learning, meta-learning, medical ultrasound, pneumonia, COVID-19, breast tumor.
1 Introduction
Ultrasound (US) medical imaging system plays a vital role in computer-aided diagnosis (CAD) for its affordable cost [1] and being physically portable [2]. In previous literature, remarkable progress has been made in US image analysis [3, 4], primarily due to the increasingly powerful deep neural network (DNN) architectures and the growing amount of annotated medical datasets. However, most medical applications still lack sufficient data, resulting in the overfitting of complex DNNs [5]. Transfer learning [6], consisting of pre-training and fine-tuning, is an effective method to mitigate this problem. In the pre-training stage, DNNs learn generic visual representations from large datasets like ImageNet [7]. This process is called representation learning. In the fine-tuning stage, models adapt to the downstream tasks by reusing learned knowledge [8] and slightly updating pre-trained parameters. ImageNet contains millions of natural images, which makes it a widely-used pre-training dataset to learn abundant visual representations. Though effective, there is one problem that ImageNet pre-training usually meets when applied for medical applications, namely domain gap. Visual representations from the natural image domain of ImageNet would not necessarily be transferable to the downstream medical domains because they are quite dissimilar. The large domain gap between the source and target data will likely reduce the performance gain of transfer learning [5].
To narrow the domain gaps between pre-training and downstream medical tasks, many medical representation learning methods [9, 10, 11, 12, 13] were proposed. They learn representations directly from the same medical domains as the downstream tasks. With the recent development of self-supervised learning [14, 15, 16, 17], DNNs are able to exploit the existing unlabeled data from various sources to learn powerful representations. Medical models trained with self-supervised learning are shown to be highly transferable on a wide range of medical modalities like CT, MRI, and X-ray [11, 12, 13, 18]. There are also self-supervised methods proposed for the US, but they either require clear anatomical structures [19] or aligned video-speech correspondence [10] to train, which restricts their applications. A method that can be applied to any regular free-hand US videos [20] is needed.
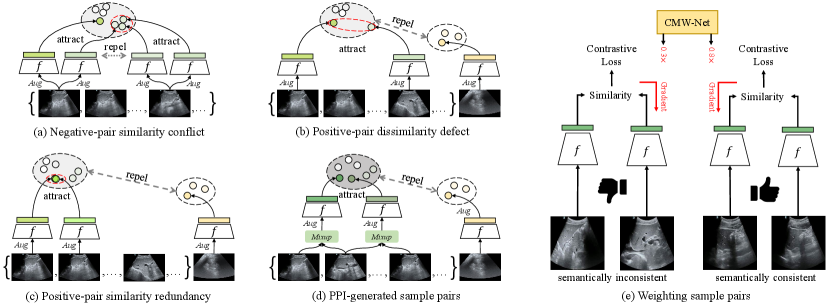
In this work, we regard contrastive learning [14, 16] as an ideal self-supervised learning baseline for US applications, because it shows promising performance in learning robust visual representations comparable to the supervised counterparts. The idea of contrastive learning is making two semantically similar samples (i.e., a positive sample pair) attract each other in the feature space while two dissimilar samples (i.e., a negative sample pair) repel each other. This work tries to utilize this idea, and tailor a contrastive learning algorithm to learn robust US representations from unlabeled videos. However, most previous contrastive methods (e.g., SimCLR [14], MoCo [16]) were proposed for image data, and they usually use an image to augment twice as a positive sample pair while two samples are generated from different images as a negative pair. Sample pairs generated in this way can hardly work well for US videos. We summarize three main problems of adapting contrastive learning for US videos: 1) Negative-pair similarity conflict (Fig. 1 (a)) appears when multiple positive pairs are generated from the same video. In this case, typical contrastive learning regards two samples generated from two frames as a negative pair, and their similarity may be higher than that between two randomly augmented positive samples. Pushing two negative samples with high semantic consistency apart misleads the training. It can be avoided by only generating one positive pair from a video. Moreover, considering a short US video clip usually contains the same lesion from the same patient, it is natural to take two frames from the same video as positive pair because they probably lead to similar diagnosis results. This improvement exploits the slight dissimilarity between frames as the natural perturbation, reaching the same goal as image augmentation, and enriches the feature diversity involved in a positive pair. 2) Positive-pair dissimilarity defect (Fig. 1 (b)) makes a positive pair no longer consistent in semantics, which is usually caused by too intense image transformation or significant frame differences. 3) Positive-pair similarity redundancy (Fig. 1 (c)) appears in the opposite case. When the random image transformation is too weak, or the frames only differ slightly, the appearance change of a positive pair teaches the DNN nothing because the model can obtain close features even if it does not have visual discriminative ability. The theory of contrastive learning [21] claims that what should be contrasted in contrastive learning should be the detailed appearance differences between a positive pair that do not affect their semantic meaning in common.
To tackle the positive-pair dissimilarity defect and similarity redundancy problems, we propose a Positive Pair Interpolation (PPI) module to generate positive pairs by interpolating frames from a video. Two image samples generated from PPI share common information of an “anchor” frame to remain semantically consistent, and randomly mix different appearances from the other two frames. The coefficients for mixing three frames are randomly sampled. This method reduces the risk of generating positive pairs that are too dissimilar (positive-pair dissimilarity defect) or similar (positive-pair similarity redundancy). It also enriches the feature of positive pairs by the multi-frame synthesis. A PPI-generated positive pair acts as two points with moderate distance in a semantic cluster (Fig. 1 (d)).
Although PPI mitigates positive-pair dissimilarity defect and positive-pair similarity redundancy, different randomly generated positive pairs will still be different w.r.t. their semantic consistency and appearance difference, resulting in different degrees of contribution to learning representations. For example, the positive pairs from videos with low motion, less informative regions (e.g., lung), or generated with extreme interpolation coefficients would contribute less or even do harm to learning semantically consistent mappings. This work proposes to make the training process focus more on beneficial positive pairs instead of the less helpful ones by training a meta-learning [22, 23, 24] driven weighting network, namely Contrastive Meta Weight Network (CMW-Net, Fig. 1 (e)). The whole training framework combining PPI and CMW-Net is called Meta UltraSound Contrastive Learning (Meta-USCL, see Fig. 2) in this work. The key idea of Meta-USCL is to properly generate and weight positive sample pairs with PPI and CMW-Net to make the contrastive learning benefit from learning the semantic consistency inherent in US videos.
This work is an extension of our previous USCL [25], a semi-supervised contrastive learning framework that achieves significantly better performance than ImageNet pre-training. This work extends and improves the previous work in the following ways: (i) We improve the USCL to Meta-USCL, which combines meta-learning with contrastive learning to overcome the bottleneck of sample pairs with uneven quality that USCL usually encounters. (ii) We provide the interpretability of meta-weighting through visualization, and attribute the benefit brought by CMW-Net to its ability to emphasize the positive pairs that teach the model more semantic consistency of US images. (iii) More extensive experiments and analyses are presented to validate the proposed Meta-USCL on various downstream applications.
2 Related Works
The success of medical transfer learning is mainly attributed to the learned medical-related visual representations during the pre-training phase. In the following, we first review the works related to representation learning for medical applications, and then review the meta-weighting method, which is the key component for Meta-USCL.
2.1 Supervised Representation Learning for Medical Applications
For boosting the performance of DNNs on small datasets, representation learning in a supervised fashion is the earliest-developed method, among which ImageNet [7] pre-training is the most popular one. The effect of ImageNet pre-training is verified by various medical tasks such as dermatologist-level classification of skin cancer [26], recognition of Alzheimer’s disease [27], and abnormalities with X-ray [28].
Though the power of ImageNet transfer learning is robust for various medical applications [29], the transfer performance will be inevitably harmed by the large domain gap between natural images and medical images [5]. For example, transferring the ImageNet representations to glioma subtype identification will be less helpful since gliomas are highly heterogeneous tumors with variable 3D imaging phenotypes [9], which is hardly related to any images in ImageNet. When large-scale annotated medical datasets are available, supervised pre-training directly on medical domains becomes a preferred method to bridge the domain gaps. For example, Tajbakhsh et al.[30] designed a 2-channel image representation of emboli trained with voxel-level labeled pulmonary embolism data to better detect pulmonary embolism. Riasatian et al.[31] proposed to use weakly labeled whole slide images of formalin-fixed paraffin-embedded human pathology samples to learn histopathology image representations. Though frequently used and adopted by our previous conference paper [25], traditional label supervision is abandoned in this work for its apparent drawback: the high requirement of domain-specific annotation prohibits its further scaling.
2.2 Self-supervised Representation Learning for Medical Applications
In the medical field, unlabeled image data are far richer than labeled ones. Pre-training medical models with artificial labels, namely self-supervised representation learning, was verified to be an effective way to train with unlabeled data [32]. Self-supervised learning algorithms [33, 15, 34] surged recently in mainstream computer vision to learn generic visual representations since they show great potential to exploit the natural supervision inherent in the images themselves. Models Genesis [12], a perturbed auto-encoder framework, is the milestone of the medical self-supervised learning for its comparative transfer performance to ImageNet strongly supervised counterparts. Since then, from the technologies of frame order prediction [19], generative learning with Restricted Boltzmann Machine [35], Jigsaw game [36], image context restoration [33, 12] to more advanced contrastive learning [10], self-supervised representation learning boosted the medical models’ transferabilities to small datasets significantly.
Recently, contrastive learning [14] has been a dominating self-supervised method for its outstanding performance. It aims to pull semantically consistent positive samples together in the representation space, while pushing those dissimilar negative samples away. With the fast development of contrastive learning frameworks [16, 37], more and more works [13, 25] seek to combine properties inherent in medical data for learning better image representations. Since the US video clips are much different from individual images that contrastive learning was initially designed for, previous methods [19, 10] are not effective enough to learn powerful representations from them. We regard a key factor to the success of US contrastive learning to be mining semantic consistency from video clips to generate reasonable positive pairs. Previous works [21, 38] showed that an ideal positive pair should contain moderate appearance differences while keeping their semantics consistent. For this reason, this work considers the similarity between US frames as semantic continuity, and leverages this property to generate semantically similar samples from US videos.
2.3 Meta-learning for Weighting Samples
Sample weighting is an effective approach to improve the training performance when the data are diverse, e.g., free-hand US videos. It increases the effect of “good” samples’ gradients on the parameter updating and decreases the effect of those not good enough. In contrastive learning, “good” positive sample pairs denote those with higher appearance differences and lower semantic differences. Meta-weighting [23, 24], a meta-learning [39] technique, can achieve this target without any handcrafted weighting schemes. It is regarded as a bi-level optimization process [22], and aims at optimizing the weighting scheme (upper-level objective) for conducting a better learning process (lower-level objective). To learn a better weighting scheme, there are two main meta-learning frameworks. The first one [23] is assigning weights for each sample, and updating the weights based on the generalization error given by this weighting scheme. This method is easy-to-implement but converges slowly. The second one [24] is weighting the samples with a weighting module, which is usually a shallow network. The parameters of the weighting module are updated to minimize the generalization error with their validation gradients. The recent applications of meta-weighting contain the recognition of out-of-distribution samples [40], label noises, and training set biases [23]. In the medical field, similar problems are still common, but only a few pieces of literature use this method to boost training efficiency [41, 42]. Considering that some sample pairs in contrastive learning contribute more to learning desirable representations while some are not, we assign larger weights for those more helpful sample pairs. This work extends the idea of the meta-weighting module to the medical contrastive learning task, which is a novel application scenario.
3 Methods
3.1 Formulation of Meta-USCL
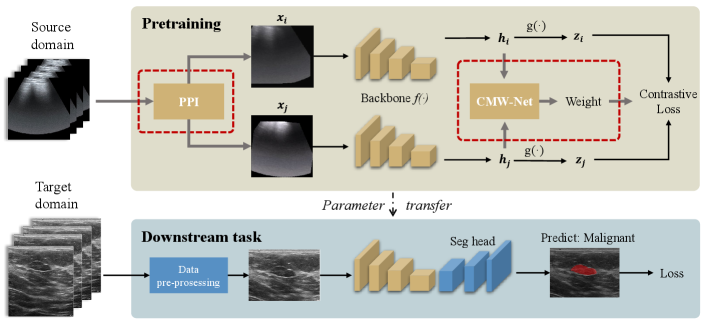
The core idea of contrastive learning methods [43, 10, 44, 18] is instance-level discrimination, which generates sample pairs from the original dataset and trains the neural networks by recognizing similar positive pairs against dissimilar negative pairs. Meta-USCL extends the core idea of contrastive learning from two aspects: 1) generating positive sample pairs from US videos by PPI module; 2) weighting the generated positive pairs with CMW-Net to make the training more efficient. The whole framework containing Meta-USCL pre-training and parameter transferring to downstream tasks is shown in Fig. 2.
The first part of Meta-USCL is generating positive sample pairs from videos. Given a raw video , we construct a frame set to discard overly redundant information, where is the number of extracted images. A simple way to do this is to sample several frames per second in a video. Then, the PPI module is used to generate a positive sample pair from the frame set.
After generating a sample pair , a DNN backbone encodes them to be a representation vector pair and . In a video batch of size , there are samples in total, where and indicate two samples generated from the video . Subsequently, the projection head (a two-layer MLP) maps the representations to be feature vectors specialized for contrastive learning. In this feature space, samples can better be pulled together or push apart with contrastive loss without affecting the representation quality for downstream tasks. In addition, the CMW-Net compares the representation pairs of each positive sample pair, and outputs quality scores (weights) for reweighting their contrastive losses.
The InfoNCE [45] is the most widely-used loss function for contrastive learning. It aims at minimizing the distances between positive pairs , and maximizing the distances between negative pairs in the mini-batch. This work modifies the InfoNCE to a weighted version, so that the loss for different positive sample pairs can update the model parameters differently:
| (1) |
where
| (2) |
and
| (3) |
denotes the cosine similarity of a feature vector pair . The indicator functon when , otherwise it equals to 0. And is a tuning temperature parameter.
Finally, the pre-training can be conducted with PPI-generated positive pairs and weighted InfoNCE loss. The contrastive training process learns the visual differences which would not affect the meaning of a US image. They act as the prior knowledge to assist the downstream classification or segmentation tasks.
3.2 Positive Pair Interpolation Module
The typical contrastive learning paradigm [14] generates positive pairs based on random augmentation and cannot perform well for US videos, because they were primarily designed for image datasets and will meet the three problems introduced in Sec. 1.
First, to prevent the negative-pair similarity conflict problem, the PPI module generates only one positive sample pair from one video. Secondly, it uses a mix-up [46] operation to generate semantically consistent positive pairs, which mitigates the positive-pair dissimilarity defect and similarity redundancy problems. The process of PPI is visualized in Fig. 3. In the first step, it randomly selects three frames in chronological order from the frame set of video . And then it regards the middle frame in temporal as an “anchor” frame, interpolates it with the other two perturbation frames respectively:
| (4) |
where , and are parameters of distribution. On the one hand, positive pairs are random offsets from the anchor image to the perturbation images, ensuring that they share the common semantic information from the anchor image, which overcomes the positive-pair dissimilarity defect problem. On the other hand, the sampling interval for a frame set results in low probability for PPI to sample three similar frames which are too close in appearance, which prevents the positive-pair similarity redundancy problem. The generated two positive samples would be further randomly augmented to gain more abundant visual differences.
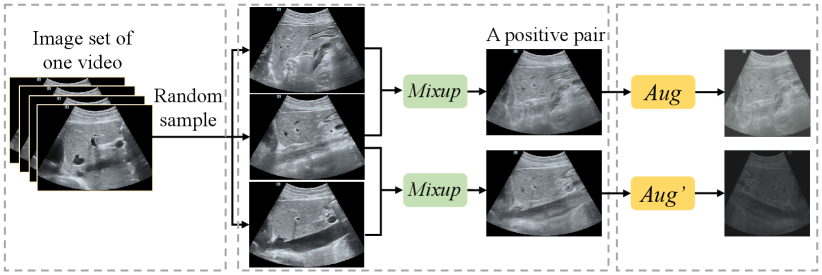
The PPI module generates positive pairs and regards samples from different videos as negative pairs. The benefits of the PPI can be summarized as follows: 1) Interpolation makes every point in the feature convex hull enclosed by the cluster boundary possible to be sampled, making the cluster cohesive as a whole; 2) Positive pairs generated with Eq. (4) have guaranteed semantic consistency and appearance discrepancies to make the training more stable and efficient.
| Sub-dataset | Organ | Image size | Depth | Frame rate | Videos | Images |
| Butterfly [47] | Lung | 658738 | - | 23Hz | 22 | 1533 |
| CLUST [48] | Liver | 434530 | - | 19Hz | 63 | 3150 |
| Liver Fibrosis | Liver | 600807 | 8cm | 28Hz | 611 | 27504 |
| COVID19-LUSMS | Lung | 747747 | 10cm | 17Hz | 670 | 6834 |
3.3 Learning to Weight Sample Pairs
For US videos that are too long, PPI may still generate dissimilar positive pairs due to the random mix-up coefficients of the distribution. In addition, videos collected by different sonographers from different organs have different sequential characteristics, making them contribute to the representation learning differently in quality. So it is challenging for PPI to solve the three problems thoroughly. Sample weighting with CMW-Net is a promising method to make the model learn more with desirable sample pairs and further mitigate these problems.
The CMW-Net is mainly inspired by [24], which proposed a sample weighting net to discover the important samples for training. This work extends this method and proposes to obtain weights for each positive pair in contrastive learning. Let denote the parameters of the main pre-training network and the CMW-Net, respectively. This weighting network takes the representation vectors of a positive pair as the input, and outputs corresponding quality score . The weighted training loss can be defined as Eq. 1 on the training set. The aim of representation learning is to minimize the weighted training loss w.r.t. the main network parameter given CMW-Net parameter .
| (5) |
Note that can be regarded as a function of since it acts as part of the learning scheme. The parameters decides how the weight of each sample pair is calculated. We use the validation loss as a guide for the CMW-Net to find parameters with better generalization. The updating of is based on the unweighted loss calculated on the validation sample pairs with optimal main network parameter :
| (6) |
The problem for deriving optimal parameters of the two networks can be understood as a nested optimization, where the lower-level objective is the minimization of training loss w.r.t. (Eq. 5) while the upper-level objective is the minimization of validation loss w.r.t. (Eq. 6).
Parameter Updating Procedure. To solve the above optimization problem, we design an online updating algorithm inspired by [24]. The core idea is to iteratively update the parameters of the two targets with the following three steps: (1) getting feedback about the current weights; (2) updating the weighting strategy; and (3) updating the network parameters. In the iteration , the algorithm first updates the main model parameters
| (7) |
with one step of gradient descent, where is the learning rate of the main model. This step is performed in a mini-batch of training data. Its function is to get feedback for the weights given by CMW-Net.
After taking the derivative of the meta (validation) loss w.r.t. the , we can take the second step to move the along the meta objective gradient on the validation data
| (8) |
with as the learning rate of the CMW-Net.
Finally, the updated is used to generate the weights of this batch of sample pairs, and obtain the updated main model parameters with the third step of gradient descent:
| (9) |
All these three steps are conducted in an iterative fashion. They update the parameters of CMW-Net and main model alternatively.
4 Experimental Setup
This section introduces the US-4 dataset for conducting meta-USCL, along with the implementation details of the pre-training and fine-tuning processes.
| Model | Params | MACs | Image size | From Scratch | ImageNet | Meta-USCL | |||||
| SimCLR | meta+SimCLR | (USCL) | meta+ | ||||||||
| ShuffleNet-v2 | 1.4M | 4.5M | |||||||||
| ShuffleNet-v2 | 2.3M | 13.2M | |||||||||
| ShuffleNet-v2 | 3.5M | 25.7M | |||||||||
| ShuffleNet-v2 | 7.4M | 50.4M | |||||||||
| ResNet18 | 11.7M | 149.2M | |||||||||
| ResNet34 | 21.8M | 300.5M | |||||||||
| ResNet50 | 25.6M | 338.4M | |||||||||
4.1 Pre-training Dataset: US-4
In this work, we construct a US pre-training dataset named US-4. It is collected from four convex probes [1] US video datasets involving two scan regions (i.e., lung and liver). The attributes (e.g., depth and frame rate) of the US-4 dataset are described in Tab. 1. Among the four sub-datasets, Liver Fibrosis and COVID19-LUSMS datasets are collected by our local sonographers [34, 49] with Resona 7T ultrasound system. The frequency is FH 5.0, and the pixel size is 0.101mm - 0.127mm. Butterfly [47] and CLUST [48] are two public sub-datasets. In order to generate a diverse and sufficiently large dataset, images are selected from original videos with a suitable sampling interval. We extract three samples per second for each video, ensuring the sampling interval so that US-4 contains sufficient but not redundant information about videos. This results in 1366 videos and 39,021 images. US-4 is relatively balanced regarding the number of images in each video, where most videos contain tens of US images.
4.2 Training Setup
Meta-USCL proposed in this work is implemented with PyTorch 1.8.0. The model training can be split into two parts: pre-training and fine-tuning. In the pre-training phase, 80% of data are used for training, and 20% are used for validation. The batch size of 32 is adopted to conduct the training. We conduct contrastive learning with images for the POCUS pneumonia detection and the UDIAT-B breast tumor segmentation tasks. For BUI breast cancer diagnosis, we use images. The key reason for using a small image size for transferring to this classification task is that the BUI dataset mainly contains small images, which will be elaborated on in Sec. 5.2. For the experiments without meta-learning, the optimizer is Adam, with a learning rate and an regularization (weight decay) strength of . The temperature parameter equals 0.5 as in [14]. For the experiments with meta-learning, the optimizer for the main model is replaced with SGD with a learning rate of . The learning rate for CMW-Net is as in the [24]. In each case, the images are augmented with random cropping followed by transformation to the initial size, random flipping, and random color jittering to make the model robust to different image appearances from different imaging systems. As important hyper-parameters, the batch size and the strengths for data augmentations are discussed in detail (see Sec. 5.3).
As for fine-tuning, we consider downstream classification and segmentation tasks. For classification tasks, we use a consistent batch size of 128 with the same image sizes as pre-training. The optimization method is set to be Adam with a learning rate of 0.01, training 30 epochs. Images are augmented with randomly cropping, resizing, and flipping. Please note that only the last three layers of pre-trained models are tuned in the fine-tuning phase of classification. For the segmentation task, we discard the final classification layer and use the pre-trained DNN backbone to construct a Mask-RCNN [50] model, and fine-tune it on the target dataset. The segmentation is trained with the batch size of 2 in the original image size. SGD method with learning rate , momentum 0.9, regularization strength is used for optimization. Only random flipping is used for data augmentation. All fine-tuning experiments are repeated 5 times. The mean and standard deviation of the results are reported to ensure the reliability of the results.
5 Experimental Results and Analysis
In this section, we start with validating each technique proposed in this work, including PPI and meta-weighting. And then, we continue with the comparative experiments for comparing the transferability of Meta-USCL pre-trained models to other representation learning methods. Finally, we explore some properties of Meta-USCL based on the US-4 dataset and show the potential to improve its performance further.
| Method | COVID-19 | Pneumonia | normal/abnormal | F1 | Accuracy | ||
| Sensitivity | Specificity | Sensitivity | Specificity | ||||
| From Scratch | |||||||
| ImageNet | |||||||
| US-4 supervised | |||||||
| SimCLR | |||||||
| MoCo v2 | |||||||
| Jiao et. al. | |||||||
| Meta+SimCLR | (***) | ||||||
| USCL | (***) | ||||||
| Meta-USCL | (***) | ||||||
5.1 Validation of Key Components
We first report the experimental results validating different components of Meta-USCL (Tab. 2). All pre-trained models are fine-tuned on the POCUS [1] pneumonia detection dataset. The POCUS is a widely used lung convex-probe US dataset for COVID-19 detection, consisting of 2116 frames from 140 videos for three classes (i.e., 655 frames from 58 videos for COVID-19, 349 frames from 24 videos for bacterial pneumonia, and 1112 frames from 58 frames for healthy controls). The video data were originally collected by Born et al. [1] from online websites and pre-processed for the subsequent algorithm development. We uniformly split POCUS into five folds w.r.t. videos in different classes and conduct a 5-fold cross-validation to ensure that the frames of a single video are present within a single fold only.
In this experiment, we test different DNN architectures (i.e., ResNet [51], ShuffleNet-v2 [52]) with different layers. First, ResNet is one of the most common network architectures for medical image analysis. Second, ShuffleNet-v2 is a practical choice for deploying DNN models to clinical US systems for its low memory footprint and high inference speed. All the architectures are chosen with increasing sizes (i.e., from 1M to 25M parameters). We also test 5 variants of Meta-USCL, namely SimCLR, , , , and meta+. “SimCLR” represents pure SimCLR trained with US-4 as an image dataset. Further, the variant only chooses one frame from a video and augments it twice to be a positive pair to avoid negative-pair similarity conflict, while chooses two frames from a video and augments them to gain richer visual features. Finally, (the USCL proposed by our preceding work [25]), is the method of using the PPI module to generate sample pairs with three frames in a video. Meta+ adds extra CMW-Net to for reweighting. As shown in Tab. 2, there are a few noteworthy results: 1) Training from scratch gives undesirable classification accuracy. 2) Transfer from ImageNet demonstrates consistent and significant improvements for ShuffleNet v2, but negative transfer appears for ResNet. This result is consistent with [1], indicating that not all pre-trained models are beneficial. 3) With more and more sophisticated design for contrastive learning (from SimCLR to ), representation learned with the US-4 dataset becomes more and more powerful, finally outperforms ImageNet pre-training significantly. 4) Meta-weighting improves both SimCLR and USCL, implicating that positive pairs in contrastive learning usually do not contribute to the model training equally.
This experiment demonstrates that the pre-training on ImageNet does not bring consistent and stable improvement for the downstream performance. However, it is also hard for simple medical adaptation of self-supervised methods like SimCLR to learn satisfying US medical visual representations because the US videos have different properties from individual images, and US-4 is far smaller than regular pre-training datasets of traditional natural images. Therefore, more targeted designs for the US are needed. From SimCLR to , the negative-pair similarity conflict problem is tackled. makes use of the semantic similarity between the video frames. It regards the appearance differences between frames as a perturbation, acting as a kind of natural data augmentation to promote the training process. uses the same idea as but further mitigates positive-pair similarity redundancy and positive-pair dissimilarity defect problems with PPI. The pre-training performances improve monotonically by solving negative-pair similarity conflict (), enriching features (), and solving positive-pair similarity redundancy and positive-pair dissimilarity defect () incrementally. In addition, the meta-learning module learns how important the positive sample pairs are by CMW-Net, and assigns different weights for different positive pairs in a batch. The experiment shows that the setting is still not perfect, and CMW-Net still improves by 0.3% to 3.0% with different DNN architectures. The reason why meta-weighting works will be elaborated in Sec. VI.
5.2 Comparative Experiments on Various Downstream Tasks
In comparative experiments, we select several supervised (ImageNet pre-training, supervised pre-training using the categorical labels of US-4) and self-supervised (SimCLR [14], MoCo v2 [53], Jiao et al. [19] ) methods to compare the transfer performance on CAD and segmentation tasks. All experiments are conducted with ResNet18. We use t-tests to evaluate the significance of performance improvement between our methods to ImageNet.
| Method | Precision | Recall | F1 | AUC | Accuracy |
| From Scratch | |||||
| ImageNet | |||||
| US-4 supervised | |||||
| SimCLR | |||||
| MoCo v2 | |||||
| Jiao et. al. | |||||
| Meta+SimCLR | (***) | (***) | |||
| USCL | (***) | (***) | |||
| Meta-USCL | (***) | (***) |
| Image size | |||
| Acc (%) |
POCUS Pneumonia Detection. We show the sensitivity and specificity of the two abnormalities in POCUS. It can be observed from Tab. 3 that the Meta-USCL achieves the highest sensitivities for both COVID-19 and Pneumonia. It is also the only method to reach the normal/abnormal and overall accuracy above 90%. In addition, some interesting results can be noticed. Firstly, training DNNs from scratch only gets 84.3% total accuracy and low sensitivity for COVID-19, but some pre-trained models even perform worse (e.g., ImageNet). This result is consistent with the previous literature [1], reporting that pre-training is not necessarily helpful in some cases. For ImageNet, its domain has a large gap to the POCUS dataset, which may lead to negative transfer. With Meta-USCL, we can achieve performance up to about 95%, which is higher than the 89% reported in [1] and 94% in [25]. The result shows that our method appears to be a new SOTA.
| Method | PPV | Sensitivity | Dice |
| From Scratch | |||
| ImageNet | |||
| US-4 supervised | |||
| SimCLR | |||
| MoCo v2 | |||
| Jiao et. al. | |||
| Meta+SimCLR | (n.s.) | ||
| USCL | (*) | ||
| Meta-USCL | (*) |
BUI Breast Cancer Classification. BUI [54] is a breast cancer dataset collected with linear US probes. In this task, we need to classify whether the breast tumor that an image contains is malignant or not. This dataset contains 250 breast cancer images, where 100 samples are benign, and the rest 150 are malignant. We use the metrics of binary classification (e.g., AUC) to evaluate the transferability of pre-trained models. The 5-fold cross-validation results are shown in Tab. 4. In the BUI dataset, there are fewer images than in the POCUS, thus it needs better visual representations to train DNNs for gaining generalization on this task. In addition, videos in US-4 are derived with convex probes. The domain gap between different kinds of probes doesn’t weaken the performance of Meta-USCL. Our results show that Meta-USCL reaches a similar performance improvement on BUI as POCUS (e.g., its accuracy improvements compared with training from scratch are 10.3% and 10.2%). We hypothesize that the general US representations learned by Meta-USCL lead to a more powerful adaptation ability on a small US dataset than other methods. Therefore, it makes up for the performance loss brought by the domain gap. This hypothesis is validated in the following Sec. 5.3. It is noteworthy that the BUI contains images with an average size of , making the pre-training and fine-tuning with smaller inputs even more stable and powerful (Tab. 5). This is because when pre-trained on small images of US-4, the learned basic pattern distribution is similar to the BUI dataset.
UDIAT-B Breast Tumor Segmentation. The UDIAT-B [55] consists of 163 linear US probe breast tumor images from different women with a mean image size of pixels. Each images presents one lesion with pixel-wise mask annotation. We choose this dataset to evaluate the model transferability for the downstream segmentation task. Of the 163 images, 53 are cancerous masses, and the other 110 are benign lesions. We randomly select 113 images for training and the other 50 images for validation. Since the segmentation task needs precise discrimination for pixels, we compare different methods with pre-training image size for better detail resolving ability.
For segmentation, our main concern is the true positive (TP) region, which is the overlapped region between the ground-truth mask and the prediction. The importance of TP in clinical scenarios is primarily due to the low tolerance of missing any important lesion. Therefore, the three metrics , , and are chosen to evaluate the segmentation performance, where TN, FP, FN are the number of true negative, false positive ,and false negative pixels. The final results are shown in Tab. 6. We can see that the Meta-USCL outperforms all other counterparts in this pixel-level prediction task. Note that both domain (linear/convex probe) and the task (segmentation/instance discrimination) between the downstream task and pre-training task are different, and the number of samples is also limited. The medical pre-training methods with contrastive image operations, including Meta+SimCLR and Meta-USCL, show the best performance compared with other supervised or unsupervised methods. This phenomenon indicates that: 1) instance-wise discrimination learns more pixel-level prediction ability than class-wise discrimination due to the semantic-invariant appearance discrepancies; 2) Meta-USCL reaches a significantly higher performance (3.1%, ) compared to ImageNet, showing the potential for specialized representation learning methods to beat general pre-trained models on segmentation applications.
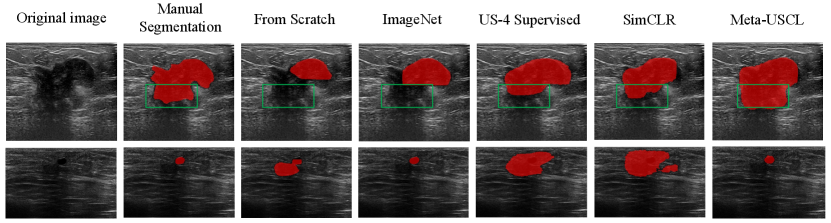
In addition, we visualize the segmentation results in Fig. 4. The first row illustrates that Meta-USCL pre-trained model can distinguish the edge of a large tumor well. The upper half of this lesion is quite clear, resulting in consistent segmentation results of all methods. However, the lower half (see green rectangles in Fig. 4) becomes blurred, so better semantic understandings of the tumors are needed, where Meta-USCL performs the best. The second row shows that the Meta-USCL pre-trained model can localize a small lesion region precisely. Given an inconspicuous tumor, its outline is hard to distinguish from the black background area, making the detection of small lesions even more challenging than segmenting the edges of large lesions. Only ImageNet pre-training and Meta-USCL pre-training work well in this case.

5.3 Property Analysis and Visualization
This subsection first explores the hyper-parameter tuning procedure. And then, how and why Meta-USCL works well is discussed through visualization of the knowledge that CMW-Net and the main model learn. Finally, we use quantitative analysis to reveal the performance w.r.t. the data amount of pre-training and fine-tuning.
Hyper-parameter Tuning. Previous works have shown that hyper-parameters are critical for contrastive learning to achieve desirable performance [14, 16]. Proper data augmentation and batch size are two of the most important factors that highly affect the transferabilities of learned image representations. Following SimCLR [14], we try image cropping, color jittering, and Gaussian blurring in our experiments. The results are shown in Tab. 7. For both image cropping and color distortion, there are optimal parameters of moderate strengths. However, the Gaussian blurring does not show any performance gain for ultrasound contrastive learning. We conjecture that the imaging sharpness of the US systems is lower than the regular optical lens. The blurring leads to more unsatisfying image quality for US images than natural images. Therefore, Gaussian blurring is less helpful for models to learn transformation invariants since it cannot guarantee semantic consistency. For SimCLR, it was proved that the larger batch size improves the performance to a larger extent. But this conclusion does not hold for Meta-USCL (see Tab. 8). The batch size of 32 is the best for Meta-USCL, and the larger batch size even brings an evident drop in transfer learning performance. This phenomenon may be caused by the high similarity of frames from different US videos. Compared with natural images, US videos are far more similar to each other. Larger batch size increases the probability of sampling similar videos from the pre-training dataset, which may lead to the negative-pair similarity conflict problem.
| Cropping | 0.6 | 0.7 | 0.8 | 0.85 | 0.9 |
| Acc (%) | 92.3 | 93.5 | 94.1 | 94.6 | 94.3 |
| Color jittering | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 |
| Acc (%) | 92.8 | 94.3 | 94.6 | 93.8 | 92.7 |
| Gaussian blurring | Yes | No | |||
| Acc (%) | 93.8 | 94.6 |
| Batch size | 8 | 16 | 32 | 64 | 128 |
| Acc (%) | 87.5 | 89.5 | 94.6 | 91.6 | 89.7 |
Visualization of CMW-Net Learned Weights. We visualize the sample pairs and the corresponding weights to verify that the meta-knowledge learned by CMW-Net can judge whether a positive pair is beneficial or not. As shown in Fig. 5, we use frames of a lung US video without any augmentation to obtain weights of sample pairs with CMW-Net. The leftmost image is the first frame of the video, and the following frames present descending cosine similarities to the first one. The resulting weights between the initial frame and the rest show a trend of rising and falling w.r.t. image similarities because the semantic marks are disappearing and the textural dissimilarities are becoming larger. The ideal sample pairs should have small semantic distances and appropriate texture information gaps between the two samples, which turns out to be moderately inconsistent (e.g., the third frame and the initial frame in Fig. 5).
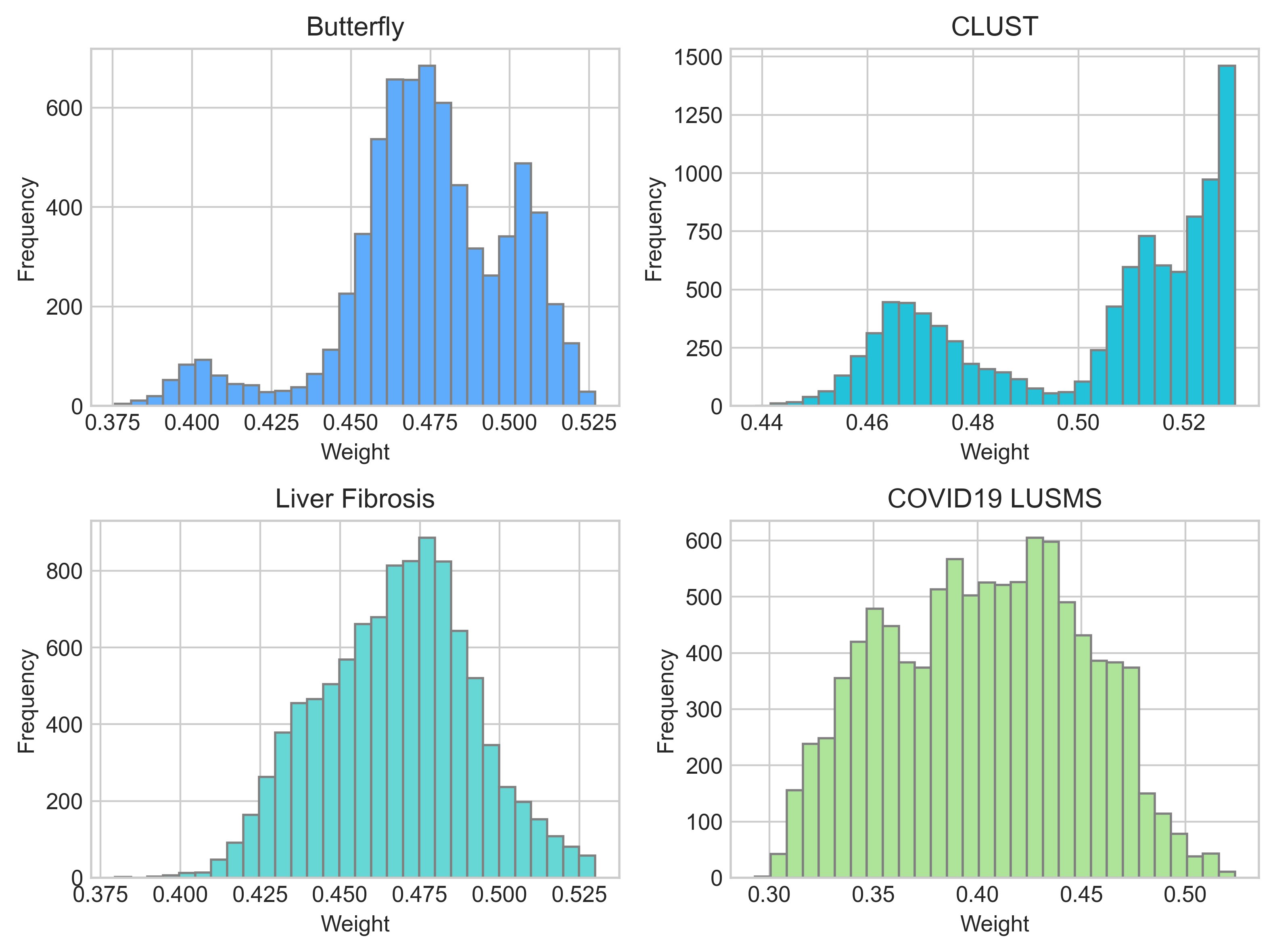
In addition to different weights between positive pairs from a video, we also observe different weight distributions between different sub-datasets of US-4 (Fig. 6), indicating that different US domains do not contribute their medical visual representations equally. For example, about half the sample pairs of the COVID19-LUSMS sub-dataset have weights below 0.4, meaning they may be less important for pre-training. We infer that the different distributions are caused by the CMW-Net’s target, minimizing the overall validation loss. The imbalanced US videos of different organs may make some patterns (i.e., lesions) faster to be recognized, while the minority patterns are less focused. This results in the validation sample pairs of minority classes having higher loss values. For example, the COVID19-LUSMS sub-dataset has the most abundant videos among the four sub-datasets. Therefore, CMW-Net assigns lower weights to it so the model can learn more from smaller subsets to reduce the overall validation loss. It is also noticeable that the differences between sub-datasets do not exactly match the number of videos per subset. We conjecture that the meta-reweighting network does not only consider the number of videos of different subsets. It is also affected by other factors such as the organ and lesion distributions, video lengths, and frame similarities (e.g., the frame similarity of a CLUST video is higher than that of other sub-datasets, which leads to a lower probability of positive-pair dissimilarity defect and may be a reason for its higher overall weights).
All in all, CMW-Net makes contrastive learning work better by 1) emphasizing more on the sample pairs that help the model learn better semantic consistency; 2) balancing the sample pairs from different sample sub-domains to decrease the overall validation loss.
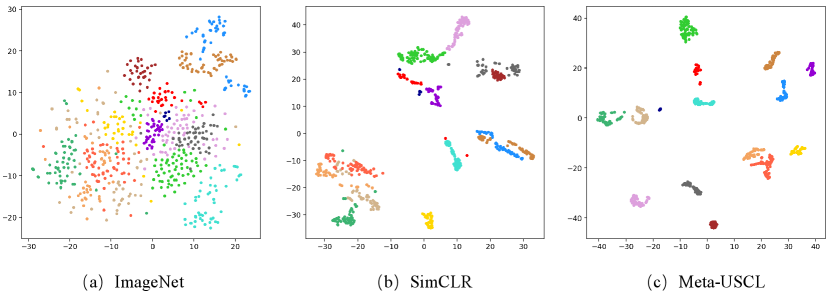
Visualization of Representations Learned by Meta-USCL. We use tSNE to visualize the feature space of the ImageNet, SimCLR, and Meta-USCL pre-training. Fig. 7 shows the feature distribution of randomly selected 15 US videos in the frame level. The ImageNet pre-trained DNNs are insensitive to US textures, resulting in scattered feature vectors. The reason may be that ImageNet pre-training does not involve sufficient US-related images, leading to the poor discriminative ability of US data. Using SimCLR to learn representations on US-4 can mitigate this issue. But the similarity defect problem makes the features from a video distributed on a broader range than Meta-USCL. This may be because SimCLR pushes two similar frames apart when they are sampled as a negative pair. However, Meta-USCL pre-training takes advantage of the characteristics of US videos to learn better feature representations, making all representations from a video distributed in a cluster. Overall, the performance advantage of Meta-USCL is due to two factors: (1) the pre-adaptation to the US domain and (2) its reasonable positive pair generating and weighting scheme.
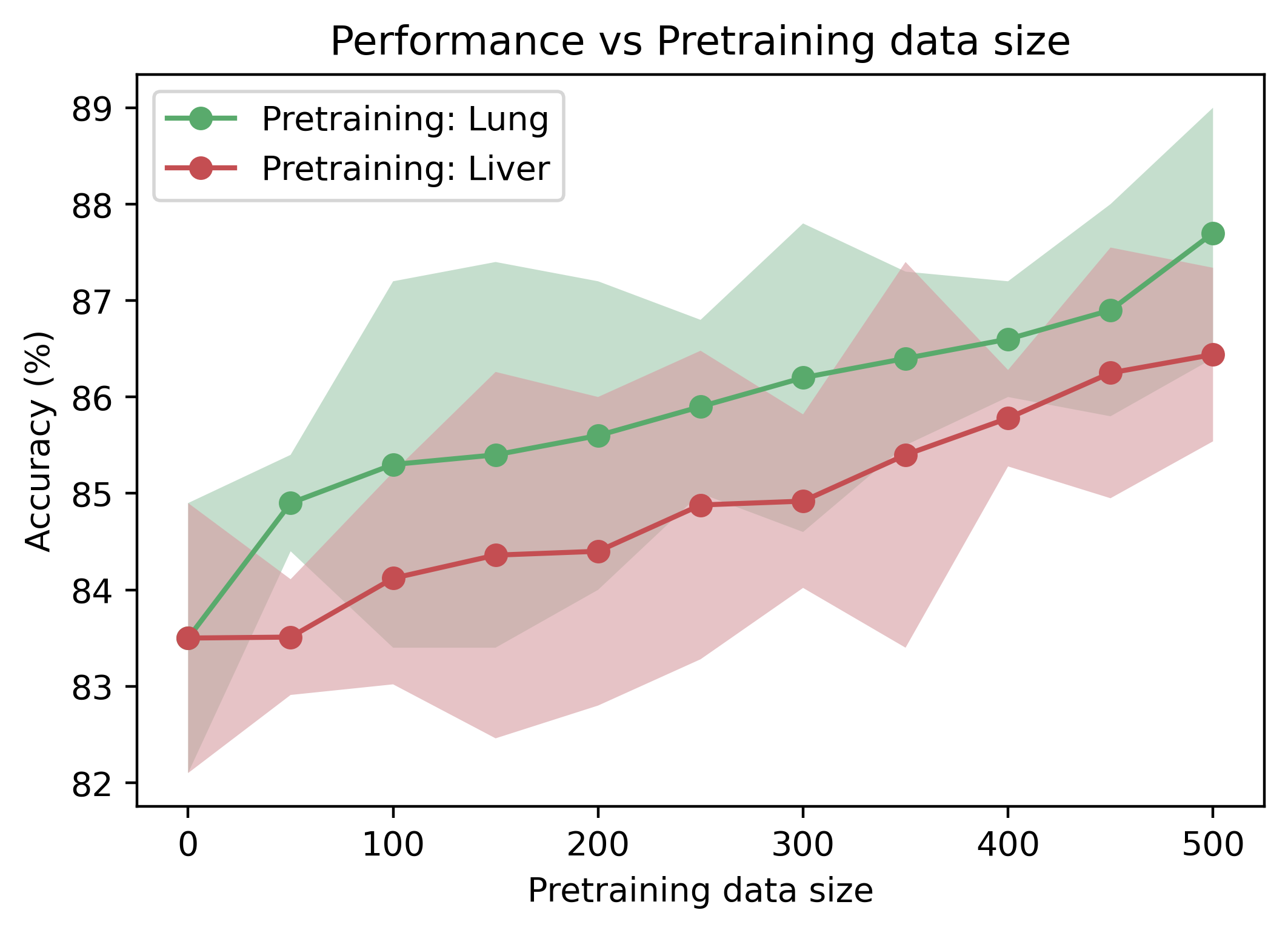
The Relationship between Pre-training Data Amount and Transfer Learning Performance. Unlike ImageNet, US-4 is a video dataset of US containing only 1300 videos. Therefore, it is very likely that the increasing amount of pre-training data can improve the pretraining performance. As illustrated in Fig. 8, we only use one sub-dataset (i.e., COVID19-LUSMS or Liver Fibrosis, which both have above 600 videos) to investigate the pre-training performance w.r.t. data amount and data domain. The pre-trained models consistently perform better on the POCUS pneumonia detection task with increased video amount. Moreover, we find that the uptrend seems far from saturated when the video amount reaches 500, which means the larger US video dataset can further promote the pre-training performance. In addition, the performance curve of lung pre-training is nearly always higher than liver pre-training, which might suggest that: 1) pre-training with Meta-USCL on the same domain gains more benefits than on a different domain; 2) pre-training in a different domain can also boost the performance of downstream tasks, though it is not an ideal solution.
| Video ratio | ImageNet | Meta-USCL |
| 10% | ||
| 20% | ||
| 30% | ||
| 40% | ||
| 50% | ||
| 60% | ||
| 70% | ||
| 80% | ||
| 90% | ||
| 100% |
The Relationship between Fine-tuning Data Amount and Transfer Performance. It was shown in Sec. 5.2 that Meta-USCL pre-trained models gain comparative or even greater advantages when fine-tuned on smaller datasets than ImageNet pre-training. We demonstrate fine-tuning results with different video ratios of the POCUS dataset in Tab. 9. As the data ratio decreases from 100% to 10%, the ImageNet pre-trained model has a 17.5% performance drop, but Meta-USCL only shows a 12.7% difference. The result indicates that when fine-tuning on a small amount of data, Meta-USCL pre-trained models generalize the pattern of downstream tasks better since they are pre-trained on the US video domains themselves. The network parameters of these pre-trained networks can be regarded as closer to optimal points of different downstream tasks than ImageNet pre-training, leading to easier generalization.
6 Conclusion
In this work, we propose a novel visual representation learning method, Meta-USCL, especially for US downstream tasks. Meta-USCL generates sample pairs with the PPI module to learn rich feature representations from the limited US video datasets. Moreover, it uses CMW-Net to choose positive sample pairs with more visual contrastive information. We conduct extensive experiments to validate the superiority of Meta-USCL to other existing representation learning methods, including ImageNet pre-training. Its outstanding performance on small-size target datasets makes us envision that Meta-USCL may serve as a primary source of transfer learning for US applications. Therefore, we make the Meta-USCL framework an open resource and encourage researchers all around the field to contribute to its improvements and further explorations.
References
- [1] J. Born, N. Wiedemann, M. Cossio, C. Buhre, G. Brändle, K. Leidermann, A. Aujayeb, M. Moor, B. Rieck, and K. Borgwardt, “Accelerating detection of lung pathologies with explainable ultrasound image analysis,” Applied Sciences, vol. 11, no. 2, p. 672, 2021.
- [2] K. E. Thomenius, “Miniaturization of ultrasound scanners,” Ultrasound clinics, vol. 4, no. 3, pp. 385–389, 2009.
- [3] A. Singal, M. Volk, A. Waljee, R. Salgia, P. Higgins, M. Rogers, and J. Marrero, “Meta-analysis: surveillance with ultrasound for early-stage hepatocellular carcinoma in patients with cirrhosis,” Alimentary pharmacology & therapeutics, vol. 30, no. 1, pp. 37–47, 2009.
- [4] J. Chi, E. Walia, P. Babyn, and et al., “Thyroid nodule classification in ultrasound images by fine-tuning deep convolutional neural network,” Journal of digital imaging, vol. 30, no. 4, pp. 477–486, 2017.
- [5] N. Tajbakhsh, J. Y. Shin, S. R. Gurudu, R. T. Hurst, C. B. Kendall, M. B. Gotway, and J. Liang, “Convolutional neural networks for medical image analysis: Full training or fine tuning?” IEEE TMI, vol. 35, no. 5, pp. 1299–1312, 2016.
- [6] A. Sharif Razavian, H. Azizpour, J. Sullivan, and S. Carlsson, “Cnn features off-the-shelf: an astounding baseline for recognition,” in CVPR workshop, 2014, pp. 806–813.
- [7] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in CVPR, 2009, pp. 248–255.
- [8] C. Matsoukas, J. F. Haslum, M. Sorkhei, M. Söderberg, and K. Smith, “What makes transfer learning work for medical images: Feature reuse & other factors,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 9225–9234.
- [9] Z. Ning, C. Tu, X. Di, Q. Feng, and Y. Zhang, “Deep cross-view co-regularized representation learning for glioma subtype identification,” Medical Image Analysis, vol. 73, p. 102160, 2021.
- [10] J. Jiao, Y. Cai, M. Alsharid, L. Drukker, A. T.Papageorghiou, and J. A. Noble, “Self-supervised contrastive video-speech representation learning for ultrasound,” in MICCAI. Springer, 2020, pp. 534–543.
- [11] X.-B. Nguyen, G. S. Lee, S. H. Kim, and H. J. Yang, “Self-supervised learning based on spatial awareness for medical image analysis,” IEEE Access, vol. 8, pp. 162 973–162 981, 2020.
- [12] Z. Zhou, V. Sodha, M. M. R. Siddiquee, and et al., “Models genesis: Generic autodidactic models for 3d medical image analysis,” in MICCAI, 2019, pp. 384–393.
- [13] H.-Y. Zhou, S. Yu, C. Bian, Y. Hu, K. Ma, and Y. Zheng, “Comparing to learn: Surpassing imagenet pretraining on radiographs by comparing image representations,” in MICCAI, 2020, pp. 398–407.
- [14] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in ICML. PMLR, 2020, pp. 1597–1607.
- [15] T. Chen, S. Kornblith, K. Swersky, M. Norouzi, and G. E. Hinton, “Big self-supervised models are strong semi-supervised learners,” NeurIPS, vol. 33, pp. 22 243–22 255, 2020.
- [16] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in CVPR, 2020, pp. 9729–9738.
- [17] F. C. Ghesu, B. Georgescu, A. Mansoor, Y. Yoo, D. Neumann, P. Patel, R. Vishwanath, J. M. Balter, Y. Cao, S. Grbic et al., “Self-supervised learning from 100 million medical images,” arXiv preprint arXiv:2201.01283, 2022.
- [18] H. Sowrirajan, J. Yang, A. Y. Ng, and P. Rajpurkar, “Moco pretraining improves representation and transferability of chest x-ray models,” in Medical Imaging with Deep Learning. PMLR, 2021, pp. 728–744.
- [19] J. Jiao, R. Droste, L. Drukker, A. T. Papageorghiou, and J. A. Noble, “Self-supervised representation learning for ultrasound video,” in ISBI, 2020, pp. 1847–1850.
- [20] C. F. Baumgartner, K. Kamnitsas, J. Matthew, T. P. Fletcher, S. Smith, L. M. Koch, B. Kainz, and D. Rueckert, “Sononet: real-time detection and localisation of fetal standard scan planes in freehand ultrasound,” IEEE TMI, vol. 36, no. 11, pp. 2204–2215, 2017.
- [21] Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, “What makes for good views for contrastive learning?” NeurIPS, vol. 33, pp. 6827–6839, 2020.
- [22] L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil, “Bilevel programming for hyperparameter optimization and meta-learning,” in ICML. PMLR, 2018, pp. 1568–1577.
- [23] M. Ren, W. Zeng, B. Yang, and R. Urtasun, “Learning to reweight examples for robust deep learning,” in ICML. PMLR, 2018, pp. 4334–4343.
- [24] J. Shu, Q. Xie, L. Yi, Q. Zhao, S. Zhou, Z. Xu, and D. Meng, “Meta-weight-net: Learning an explicit mapping for sample weighting,” NeurIPS, vol. 32, 2019.
- [25] Y. Chen, C. Zhang, L. Liu, C. Feng, C. Dong, Y. Luo, and X. Wan, “Uscl: Pretraining deep ultrasound image diagnosis model through video contrastive representation learning,” in MICCAI. Springer, 2021, pp. 627–637.
- [26] A. Esteva, B. Kuprel, R. A. Novoa, J. Ko, S. M. Swetter, H. M. Blau, and S. Thrun, “Dermatologist-level classification of skin cancer with deep neural networks,” Nature, vol. 542, no. 7639, pp. 115–118, 2017.
- [27] Y. Ding, J. H. Sohn, M. G. Kawczynski, H. Trivedi, R. Harnish, N. W. Jenkins et al., “A deep learning model to predict a diagnosis of alzheimer disease by using 18f-fdg pet of the brain,” Radiology, vol. 290, no. 2, pp. 456–464, 2019.
- [28] S. Guendel, S. Grbic, B. Georgescu, S. Liu, A. Maier, and D. Comaniciu, “Learning to recognize abnormalities in chest x-rays with location-aware dense networks,” in Iberoamerican Congress on Pattern Recognition. Springer, 2018, pp. 757–765.
- [29] H.-C. Shin, H. R. Roth, M. Gao, L. Lu, Z. Xu, I. Nogues, J. Yao, D. Mollura, and R. M. Summers, “Deep convolutional neural networks for computer-aided detection: Cnn architectures, dataset characteristics and transfer learning,” IEEE TMI, vol. 35, no. 5, pp. 1285–1298, 2016.
- [30] N. Tajbakhsh, M. B. Gotway, and J. Liang, “Computer-aided pulmonary embolism detection using a novel vessel-aligned multi-planar image representation and convolutional neural networks,” in MICCAI. Springer, 2015, pp. 62–69.
- [31] A. Riasatian, M. Babaie, D. Maleki, S. Kalra, M. Valipour, S. Hemati, M. Zaveri, A. Safarpoor, S. Shafiei, M. Afshari et al., “Fine-tuning and training of densenet for histopathology image representation using tcga diagnostic slides,” Medical Image Analysis, vol. 70, p. 102032, 2021.
- [32] N. Tajbakhsh, Y. Hu, J. Cao, X. Yan, Y. Xiao, Y. Lu, J. Liang, D. Terzopoulos, and X. Ding, “Surrogate supervision for medical image analysis: Effective deep learning from limited quantities of labeled data,” in ISBI. IEEE, 2019, pp. 1251–1255.
- [33] L. Chen, P. Bentley, K. Mori, K. Misawa, M. Fujiwara, and D. Rueckert, “Self-supervised learning for medical image analysis using image context restoration,” Medical image analysis, vol. 58, p. 101539, 2019.
- [34] X. Li, M. Jia, M. T. Islam, L. Yu, and L. Xing, “Self-supervised feature learning via exploiting multi-modal data for retinal disease diagnosis,” IEEE TMI, vol. 39, no. 12, pp. 4023–4033, 2020.
- [35] G. van Tulder and M. de Bruijne, “Combining generative and discriminative representation learning for lung ct analysis with convolutional restricted boltzmann machines,” IEEE TMI, vol. 35, no. 5, pp. 1262–1272, 2016.
- [36] F. Navarro, C. Watanabe, S. Shit, A. Sekuboyina, J. C. Peeken, S. E. Combs, and B. H. Menze, “Evaluating the robustness of self-supervised learning in medical imaging,” arXiv preprint arXiv:2105.06986, 2021.
- [37] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” NeurIPS, vol. 33, pp. 21 271–21 284, 2020.
- [38] T. Xiao, X. Wang, A. A. Efros, and T. Darrell, “What should not be contrastive in contrastive learning,” in ICLR, 2020.
- [39] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in ICML. PMLR, 2017, pp. 1126–1135.
- [40] L.-Z. Guo, Z.-Y. Zhang, Y. Jiang, Y.-F. Li, and Z.-H. Zhou, “Safe deep semi-supervised learning for unseen-class unlabeled data,” in ICML. PMLR, 2020, pp. 3897–3906.
- [41] Y. Lei, H. Shan, and J. Zhang, “Meta ordinal weighting net for improving lung nodule classification,” in ICASSP. IEEE, 2021, pp. 1210–1214.
- [42] J. Wang, S. Zhou, C. Fang, L. Wang, and J. Wang, “Meta corrupted pixels mining for medical image segmentation,” in MICCAI. Springer, 2020, pp. 335–345.
- [43] Y. N. T. Vu, R. Wang, N. Balachandar, C. Liu, A. Y. Ng, and P. Rajpurkar, “Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation,” in Machine Learning for Healthcare Conference. PMLR, 2021, pp. 755–769.
- [44] Y. Zhang, H. Jiang, Y. Miura, C. D. Manning, and C. P. Langlotz, “Contrastive learning of medical visual representations from paired images and text,” arXiv:2010.00747, 2020.
- [45] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
- [46] Z. Hongyi, C. Moustapha, N. D. Yann, and L.-P. David, “mixup: Beyond empirical risk minimization,” in ICLR, 2018.
- [47] “Butterfly videos,” https://www.butterflynetwork.com/covid19/covid-19-ultrasound-gallery, accessed September 20, 2020.
- [48] O. Somphone, S. Allaire, B. Mory, and C. Dufour, “Live feature tracking in ultrasound liver sequences with sparse demons,” in MICCAI Workshop, 2014, pp. 53–60.
- [49] L. Liu, W. Lei, X. Wan, L. Liu, Y. Luo, and C. Feng, “Semi-supervised active learning for covid-19 lung ultrasound multi-symptom classification,” in ICTAI. IEEE, 2020, pp. 1268–1273.
- [50] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask r-cnn,” IEEE TPAMI, vol. 42, no. 2, pp. 386–397, 2020.
- [51] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
- [52] N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “Shufflenet v2: Practical guidelines for efficient cnn architecture design,” in ECCV, 2018, pp. 116–131.
- [53] X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with momentum contrastive learning,” arXiv:2003.04297, 2020.
- [54] P. S. Rodrigues, “Breast ultrasound image,” Mendeley Data, V1, doi: 10.17632/wmy84gzngw.1, 2018.
- [55] M. H. Yap, G. Pons, J. Martí, S. Ganau, M. Sentís, R. Zwiggelaar, A. K. Davison, and R. Marti, “Automated breast ultrasound lesions detection using convolutional neural networks,” IEEE journal of biomedical and health informatics, vol. 22, no. 4, pp. 1218–1226, 2017.