[figure]style=plain
Generic Identifiability of Linear Structural Equation Models by Ancestor Decomposition
Abstract.
Linear structural equation models, which relate random variables via linear interdependencies and Gaussian noise, are a popular tool for modeling multivariate joint distributions. These models correspond to mixed graphs that include both directed and bidirected edges representing the linear relationships and correlations between noise terms, respectively. A question of interest for these models is that of parameter identifiability, whether or not it is possible to recover edge coefficients from the joint covariance matrix of the random variables. For the problem of determining generic parameter identifiability, we present an algorithm that extends an algorithm from prior work by Foygel, Draisma, and Drton (2012). The main idea underlying our new algorithm is the use of ancestral subsets of vertices in the graph in application of a decomposition idea of Tian (2005).
Key words and phrases:
Half-trek criterion, structural equation models, identifiability, generic identifiability1. Introduction
It is often useful to model the joint distribution of a random vector in terms of a collection of noisy linear interdependencies. In particular, we may postulate that each is a linear function of and a stochastic noise term . Models of this type are called linear structural equation models and can be compactly expressed in matrix form as
| (1.1) |
where is a matrix, , and is a random vector of error terms. We will adopt the classical assumption that has a non-degenerate multivariate normal distribution with mean 0 and covariance matrix . With this assumption it follows immediately that has a multivariate normal distribution with mean and covariance matrix
| (1.2) |
where is the identity matrix. We refer the reader to the book by Bollen (1989) for background on these types of models.
We obtain a collection of interesting models by imposing different patterns of zeros among the coefficients in and . These models can then be naturally associated with mixed graphs containing both directed and bidirected edges. In particular, the graph will contain the directed edge when is not required to be zero and, similarly, will include the bidirected edge when is potentially non-zero. Representations of this type are often called path diagrams and were first advocated for in Wright (1921, 1934).
A natural question arising in the study of linear structural equations is that of identifiability; whether or not it is possible to uniquely recover the two parameter matrices and from the covariance matrix they define via (1.2). The most stringent version, known as global identifiability, amounts to unique recovery of every pair from the covariance matrix . This global property can be characterized efficiently (Drton et al., 2011). Often, however, a less stringent notion that we term generic identifiability is of interest. This property requires only that a generic (or randomly chosen) pair can be recovered from its covariance matrix. The computational complexity of deciding whether a given mixed graph defines a generically identifiable linear structural equation model is unknown. There are, however, a number of graphical criteria that are sufficient for generic identifiability and can be checked in polynomial time in the number of considered variables (or vertices of the graph). To our knowledge, the most widely applicable such criterion is the Half-Trek Criterion (HTC) of Foygel, Draisma, and Drton (2012a), which built on earlier work of Brito and Pearl (2006). The HTC also comes with a necessary condition for generic identifiability but in this paper our focus is on the sufficient condition. We remark that an extension of the HTC for identification of subsets of edge coefficients is given in Chen et al. (2014).
We begin with a brief review of background such as the formal connection between structural equation models and mixed graphs, and give a review of prior work in Section 2. In the main Section 3, we will demonstrate a simple method by which to infer generic identifiability of certain entries of by examining subgraphs of a given mixed graph that are induced by ancestral subsets of vertices. This will extend the applicability of the HTC in the case of acyclic mixed graphs after applying the decomposition techniques of Tian (2005). We leverage this extension in an efficient algorithmic form. In Section 4, we report on computational experiments demonstrating the applicability of our findings. A brief conclusion is given in Section 5.
2. Preliminaries
We assume that the reader is familiar with graphical representations of structural equation models and thus only provide a quick review of these topics. For a more in-depth treatment see, for instance, Pearl (2009) or Foygel et al. (2012a).
2.1. Mixed Graphs
For any , let . We define a mixed graph to be a triple where is a finite set of vertices and . The sets and correspond to the directed and the bidirected edges, respectively. When , we will write and if then we will write . Since edges in are bidirected the set is symmetric, that is, we have . We require that both the directed part and bidirected part contain no self loops so that for all . If the directed graph does not contain any cycles, so that there are no vertices such that , then we say that is acyclic; note, in particular, that being acyclic does not imply does not contain any (undirected) cycles.
A path from to is any sequence of edges from or beginning at and ending with , here edges need not obey direction and loops are allowed. A directed path from to is then any path from to all of whose edges are directed and pointed in the same direction, away from and towards . Finally, a trek from a source to a target is any path that has no colliding arrowheads, that is, must be of the form
or
where , , and we call the top node. If is as in the first case then we let and , if is as in the second case then we let and . Note that, in the second case, is included in both and . A trek is called a half-trek if so that is of the form
or
It will be useful to reference the local neighborhood structure of the graph. For this purpose, for all , we define the two sets
| (2.1) | |||
| (2.2) |
The former comprises the parents of , and the latter contains the siblings of .
We associate a mixed graph to a linear structural equation model as follows. Let be the set of real matrices with support , i.e., . Let be the cone of positive definite matrices . Define to be the subset of positive definite matrices with support , i.e. for , .
In this paper, we focus on acyclic graphs . If is acyclic then the matrix is invertible for all . In other words, the equation system from (1.1) can always be solved uniquely for . We are led to the following definition.
Definition 2.1.
The linear structural equation model given by an acyclic mixed graph with is the collection of all -dimensional normal distributions with covariance matrix
for a choice of and .
2.2. Prior Work and the HTC
For a fixed acyclic mixed graph , let be the parameter space and be the map
| (2.3) |
Then the question of identifiability is equivalent to asking whether the fiber
equals the singleton . We note that the above notions are well-defined also when is not acyclic but, in that case, should be restricted to contain only matrices with invertible.
When for all , so that is injective on , then is said to be globally identifiable. Global identifiability is, however, often too strong a condition. So-called instrumental variable problems, for instance, give rise to graphs that would not be globally identifiable but for which the set of on which identifiability fails has measure zero; see the example in the introduction of Foygel et al. (2012a). Instead, we will be concerned with the question of generic identifiability.
Definition 2.2.
A mixed graph is said to be generically identifiable if there exists a proper algebraic subset so that is identifiable on .
Here, as usual, an algebraic set is defined as the zero-set of a collection of polynomials. We again refer the reader to the introduction of Foygel et al. (2012a) for an in-depth exposition on why generic identifiability is an often appropriate weakening of global identifiability.
Now there will be cases when we are interested in understanding the generic identifiability of certain coefficients of a mixed graph rather than all coefficients simultaneously. In these cases we say that the coefficient (or ), for , is generically identifiable in if the projection of the fiber onto (or ) is a singleton for all where is a proper algebraic set.
Let and be matrices of indeterminates as in Equation (1.2) with zero pattern corresponding to . Then, by the Trek Rule of Wright (1921), see also Spirtes, Glymour, and Scheines (2000), the covariance can be represented as a sum of monomials corresponding to treks between and in . To state the Trek Rule formally, let be the set of all treks from to in . Then for any , if contains no bidirected edge and has top node , we define the trek monomial as
and if contains a bidirected edge connecting then we define the trek monomial as
We may then state the rule as follows.
Proposition 2.3 (Trek Rule).
For all , the covariance matrix corresponding to a mixed graph satisfies
Before giving the statement of the HTC, we must first define what is meant by a half-trek system. Let be a collection of treks with each having source and target , then is called a system of treks from to if so that all sources as well as all targets are pairwise distinct. If each is a half-trek, then is a system of half-treks. Moreover, a collection of treks is said to have no sided intersection if
Let be the collection of vertices for which there is a half-trek from to , these are called half-trek reachable from . We have the following definition and result of Foygel et al. (2012a).
Definition 2.4.
A set of nodes satisfies the half-trek criterion with respect to a node if
-
(i)
,
-
(ii)
, and
-
(iii)
there is a system of half-treks with no sided intersection from to .
Theorem 2.5 (HTC-identifiability).
Let be a family of subsets of the vertex set of a mixed graph . If, for each node , the set satisfies the half-trek criterion with respect to , and there is a total ordering on the vertex set such that whenever , then is rationally identifiable.
The assertion that is rationally identifiable means that the inverse map can be represented as a rational function on where is some proper algebraic subset of . Clearly, rational identifiability is a stronger condition than generic identifiability. If a graph satisfies Theorem 2.5 we will say that is HTC-identifiable (HTCI). In a similar vein, Theorem 2 of Foygel et al. (2012a) gives sufficient conditions for a graph to be generically unidentifiable (with generically infinite fibers of ), and we will call such graphs HTC-unidentifiable (HTCU). Graphs that are neither HTCI or HTCU are called HTC-inconclusive, these are the graphs on which progress is left to be made.
As is noted in Section 8 in Foygel et al. (2012a) we may extend the power of the HTC by using the graph decomposition techniques of Tian (2005). Let be the unique partitioning of where if and only if there exists a (possibly empty) path from to composed of only bidirected edges. In other words, are the connected components of , the bidirected part of . For , let
Then the mixed graphs are called the mixed components of . From the work of Tian (2005), Foygel et al. (2012a) present the following theorem.
Theorem 2.6 (Tian Decomposition).
For an acyclic mixed graph with mixed components , the following holds:
-
(i)
is rationally (or generically) identifiable if and only if all components
are rationally (or generically) identifiable; -
(ii)
is generically infinite-to-one if and only if there exists a component that is generically infinite-to-one;
-
(iii)
if each is generically -to-one with , then is generically -to-one with .
We remark that this decomposition also plays a role in non-linear models; see, for instance, the paper of Shpitser et al. (2014) and the references given therein.
3. Ancestral Decomposition
For a later strengthening of the HTC, we will show that the generic identification of certain subgraphs of an acyclic mixed graph implies the generic identification of their associated edge coefficients in the larger graph . This result is straightforward and is well known in other forms. Surprisingly, however, this simple idea can extend the applicability of the HTC when combined with the decomposition from Theorem 2.6. We will first define what we mean by an ancestral subset and an induced graph,
Definition 3.1.
Let be a subset of vertices. The ancestors of form the set
where we consider the empty path to be directed so that . If , then we call ancestral.
Definition 3.2.
Let be again a subset of vertices. The subgraph of induced by is the mixed graph with
We now have the following simple fact.
Theorem 3.3.
Let be a mixed graph, and let be an ancestral subset of . If the induced subgraph is generically (or rationally) identifiable then so are all the corresponding edge coefficients in .
Proof..
Let the covariance matrix correspond to , that is, and . Let and denote the submatrices of and , respectively, and let where is the identity matrix. For ease of notation, write .
Recall that for any , the set comprises all treks between and in . Similarly, write for the set of treks between and in . Since is ancestral, it holds that for all . Thus, by Proposition 2.3, we have that for any
Now suppose that is generically (or rationally) identifiable. Then can be generically (or rationally) recovered from . As we have just shown that for all , we have that the entries of corresponding to can be recovered from generically (or rationally). ∎
We may generalize the above theorem so that we do not have to consider the identifiability of all of and instead only look at certain edges in .
Corollary 3.4.
Let be a mixed graph, and let be an ancestral subset of . If an edge coefficient of is generically (or rationally) identifiable then so is the corresponding coefficient in .
Proof..
This follows exactly as in the proof of Theorem 3.3 by only considering a single generically (or rationally) identifiable coefficient of at a time. ∎
We give an example as to how Theorem 3.3 strengthens the HTC.
Example 3.5.
It is straightforward to check that the graph from Figure 1(a) is HTC-inconclusive using Algorithm 1 from Foygel et al. (2012a). We direct the reader who does not want to perform this computation by hand to the R package SEMID (Foygel and Drton, 2013; R Core Team, 2014). Moreover, cannot be decomposed as its bidirected part is connected.
Now the set is ancestral in , so we may apply Theorem 3.3 to the induced subgraph . While remains HTC-inconclusive, the Tian decomposition of Theorem 2.6 is applicable. After decomposing into its mixed components, see Figure 1(c), we find that each component is HTC-identifiable and thus itself is generically identifiable. To show generic identifiability of , we are left to show that all the coefficients on the directed edges between and 6 are generically identifiable. Since satisfies the HTC with respect to it follows, by Lemma 3.6 below, that is generically identifiable. Hence, the entire matrix is generically identifiable, and since , this implies generic identifiability of . We conclude that is generically identifiable despite being HTC-inconclusive.
Lemma 3.6.
Let be a mixed graph, and let . If satisfies the HTC with respect to and for each we have that is generically (or rationally) identifiable, then is generically (or rationally) identifiable.
Proof..
Suppose vertex has parents, and let . Since satisfies the HTC for , we must have . Thus we may enumerate the set as . Define a matrix with entries
and define a vector with entries
Both and are generically identifiable because we have assumed that is generically identifiable for every . Now, from the proof of Theorem 1 in Foygel et al. (2012a), we have , and from Lemma 2 of Foygel et al. (2012a) we deduce that is generically invertible. It follows that generically so that is generically identifiable. ∎
Algorithm 1 from Foygel et al. (2012a) (hereafter called the HTC-algorithm) determines whether or not a mixed graph satisfies the conditions of Theorem 2.5 and and thus checks if the graph is HTCI. The HTC-algorithm operates by iteratively looping through the nodes and attempting to find a half-trek system to with having sources which are in a set of “allowed” nodes . Here, a node is allowed if or if was previously shown to be generically identifiable in the sense that all coefficients on directed edges were shown to be generically identifiable. If such a half-trek system is found for node then Foygel et al. (2012a) show that this implies that is generically identifiable, and thus may be added to the set of allowed nodes for the remaining iterations. The algorithm terminates when all nodes have been shown to be generically identifiable or once it has iterated through all vertices and has been unable to show the generic identifiability of any new nodes. To find a half-trek system between a suitable subset of the set of allowed nodes and , the HTC-algorithm solves a Max Flow problem on an auxiliary network , and this step takes time when is acyclic. If in one can find a flow of size then the half-trek system exists. See Section 6 of Foygel et al. (2012a) for more details about how is defined. Finally, for an acyclic mixed graph , the HTC-algorithm has a worst case running time of .
Algorithm 1 presents a simple modification of the HTC-algorithm to leverage Corollary 3.4 extending the ability of the HTC to determine the generic identifiability of acyclic mixed graphs. We emphasize that this algorithm considers only certain ancestral subsets and, as such, we do not necessarily expect the algorithm to reach a conclusion in all cases in which Corollary 3.4 may be applicable.
Proposition 3.7.
Proof..
The fact that Algorithm 1 only returns “yes” if is generically identifiable follows from Theorem 7 in Foygel et al. (2012a, b) and our Corollary 3.4. That Algorithm 1 returns “yes” whenever the HTC-algorithm does can be argued as follows:
If, for a set of allowed nodes and , there exists satisfying the HTC for then we must have that and satisfies the HTC for in . Lemma 4 of Foygel et al. (2012b) then yields that there exists a set of allowed nodes which satisfies the HTC for in the mixed component of containing . Hence, if is added to the set of solved nodes in the HTC-algorithm it will also be added to the set of solved nodes in Algorithm 1. From this it follows that if the HTC-algorithm outputs “yes” then so will Algorithm 1.
It is straightforward to check that Algorithm 1 returns “yes” for the graph in Figure 1(a) and, thus, it remains only to argue that the time complexity is at most . Note that the Max Flow algorithm for this problem has a running time of since is acyclic, see Foygel et al. (2012a) for details. It is easy to see that this running time dominates on each iteration. Moreover, since at the end of each iteration through the nodes of the graph, the algorithm must either terminate or add at least one vertex to the set of solved nodes, it follows that there are at most iterations. We conclude that the maximum run time of the algorithm is . ∎
Remark 3.8.
One might expect that lines 18 to 22 in Algorithm 1 are superfluous. This is, however, false, and indeed we have found examples of graphs on 10 nodes for which Algorithm 1 returns “yes” but the corresponding algorithm with lines 18 to 22 removed returns “no.” As these examples are fairly large we have chosen to not display them here.
4. Computational Experiments
We now run a simulation study to examine the effect of applying Algorithm 1 to HTC-inconclusive graphs. All code is written in , and we use the SEMID package to determine HTC-identifiability and HTC-unidentifiability (R Core Team, 2014; Foygel and Drton, 2013).
For each combination of , , and we perform the following steps:
-
(i)
Use Algorithm 2 with probability parameters and to generate random acyclic mixed graphs with connected bidirected part on nodes, until we have found 1000 graphs which are HTC-inconclusive.
-
(ii)
For each of the 1000 HTC-inconclusive graphs , use Algorithm 1 to test the generic identifiability of .
-
(iii)
Record the proportion of the 1000 graphs that are shown to be generically identifiable by Algorithm 1. Call this proportion .
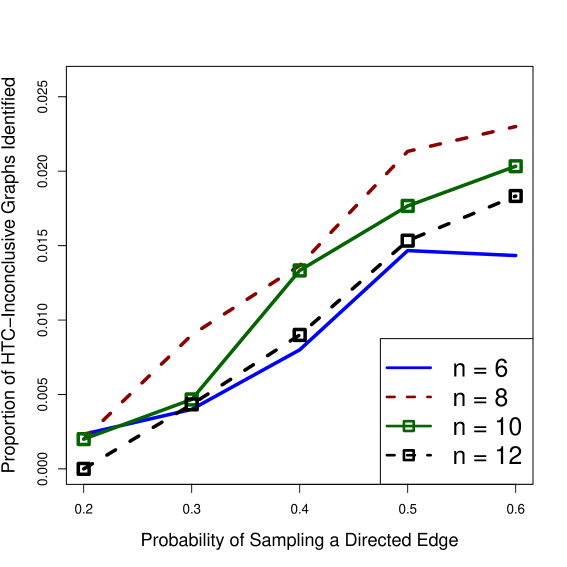
To summarize our findings we compute, for each pair , the average . We then plot the values of in Figure 2. According to this figure, Algorithm 1 provides a modest increase in the number of graphs that are generically identifiable. This improvement is seen to be largest when is large, that is, the directed part of the mixed graph is dense.
5. Conclusion
We have shown how the generic identifiability of a subgraph of a mixed graph induced by an ancestral subset of vertices implies the generic identifiability of the corresponding edge coefficients in (Theorem 3.3 and Corollary 3.4). We then provided, in Algorithm 1, one specific way of how to leverage this result by using the HTC of Foygel et al. (2012a) and the decomposition techniques of Tian (2005). Our new algorithm provides a modest strengthening of the HTC while not increasing the algorithmic complexity of the HTC-algorithm of Foygel et al. (2012a).
When saying above that Algorithm 1 constitutes one way of leveraging, we mean that the algorithm considers only certain ancestral subsets. While we do not have any examples to report, it is possible that there are acyclic mixed graphs for which Algorithm 1 does not return “yes” but which could be proven generically identifiable by a combination of Corollary 3.4, the Tian decomposition, and the HTC-algorithm. This said, it is not clear to us that all ancestral subsets can be considered in an algorithm with polynomial run time. Clarifying this issue would be an interesting topic for future work.
Acknowledgments
We would like to thank Thomas Richardson whose questions following a seminar talk started this project. This work was partially supported by the U.S. National Science Foundation (DMS-1305154) and National Security Agency (H98230-14-1-0119).
References
- Bollen (1989) K. A. Bollen. Structural equations with latent variables. Wiley Series in Probability and Mathematical Statistics: Applied Probability and Statistics. John Wiley & Sons, Inc., New York, 1989. A Wiley-Interscience Publication.
- Brito and Pearl (2006) C. Brito and J. Pearl. Graphical condition for identification in recursive SEM. In Proceedings of the Twenty-Second Annual Conference on Uncertainty in Artificial Intelligence (UAI-06), pages 47–54. AUAI Press, 2006.
- Chen et al. (2014) B. Chen, J. Tian, and J. Pearl. Testable implications of linear structural equations models. In C. E. Brodley and P. Stone, editors, Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, pages 2424–2430. AAAI Press, 2014.
- Drton et al. (2011) M. Drton, R. Foygel, and S. Sullivant. Global identifiability of linear structural equation models. Ann. Statist., 39(2):865–886, 2011.
- Foygel and Drton (2013) R. Foygel and M. Drton. SEMID: Identifiability of linear structural equation models, 2013. R package version 0.1.
- Foygel et al. (2012a) R. Foygel, J. Draisma, and M. Drton. Half-trek criterion for generic identifiability of linear structural equation models. Ann. Statist., 40(3):1682–1713, 2012a.
- Foygel et al. (2012b) R. Foygel, J. Draisma, and M. Drton. Supplement to “half-trek criterion for generic identifiability of linear structural equation models. Ann. Statist., 40(3), 2012b.
- Pearl (2009) J. Pearl. Causality. Cambridge University Press, Cambridge, second edition, 2009. Models, reasoning, and inference.
- R Core Team (2014) R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria, 2014.
- Shpitser et al. (2014) I. Shpitser, R. J. Evans, T. S. Richardson, and J. M. Robins. Introduction to nested Markov models. Behaviormetrika, 41(1):3–39, 2014.
- Spirtes et al. (2000) P. Spirtes, C. Glymour, and R. Scheines. Causation, prediction, and search. MIT press, Cambridge, MA, 2nd edition, 2000.
- Tian (2005) J. Tian. Identifying direct causal effects in linear models. In Proceedings of the National Conference on Artificial Intelligence (AAAI), pages 346–352. AAAI Press/The MIT Press, 2005.
- Wright (1921) S. Wright. Correlation and causation. J. Agricultural Research, 20:557–585, 1921.
- Wright (1934) S. Wright. The method of path coefficients. Ann. Math. Statist., 5:161–215, 1934.