GGP: A Graph-based Grouping Planner
for Explicit Control of Long Text Generation
Abstract.
Existing data-driven methods can well handle short text generation. However, when applied to the long-text generation scenarios such as story generation or advertising text generation in the commercial scenario, these methods may generate illogical and uncontrollable texts. To address these aforementioned issues, we propose a graph-based grouping planner (GGP) following the idea of first-plan-then-generate. Specifically, given a collection of key phrases, GGP firstly encodes these phrases into an instance-level sequential representation and a corpus-level graph-based representation separately. With these two synergic representations, we then regroup these phrases into a fine-grained plan, based on which we generate the final long text. We conduct our experiments on three long text generation datasets and the experimental results reveal that GGP significantly outperforms baselines, which proves that GGP can control the long text generation by knowing how to say and in what order.
1. Introduction
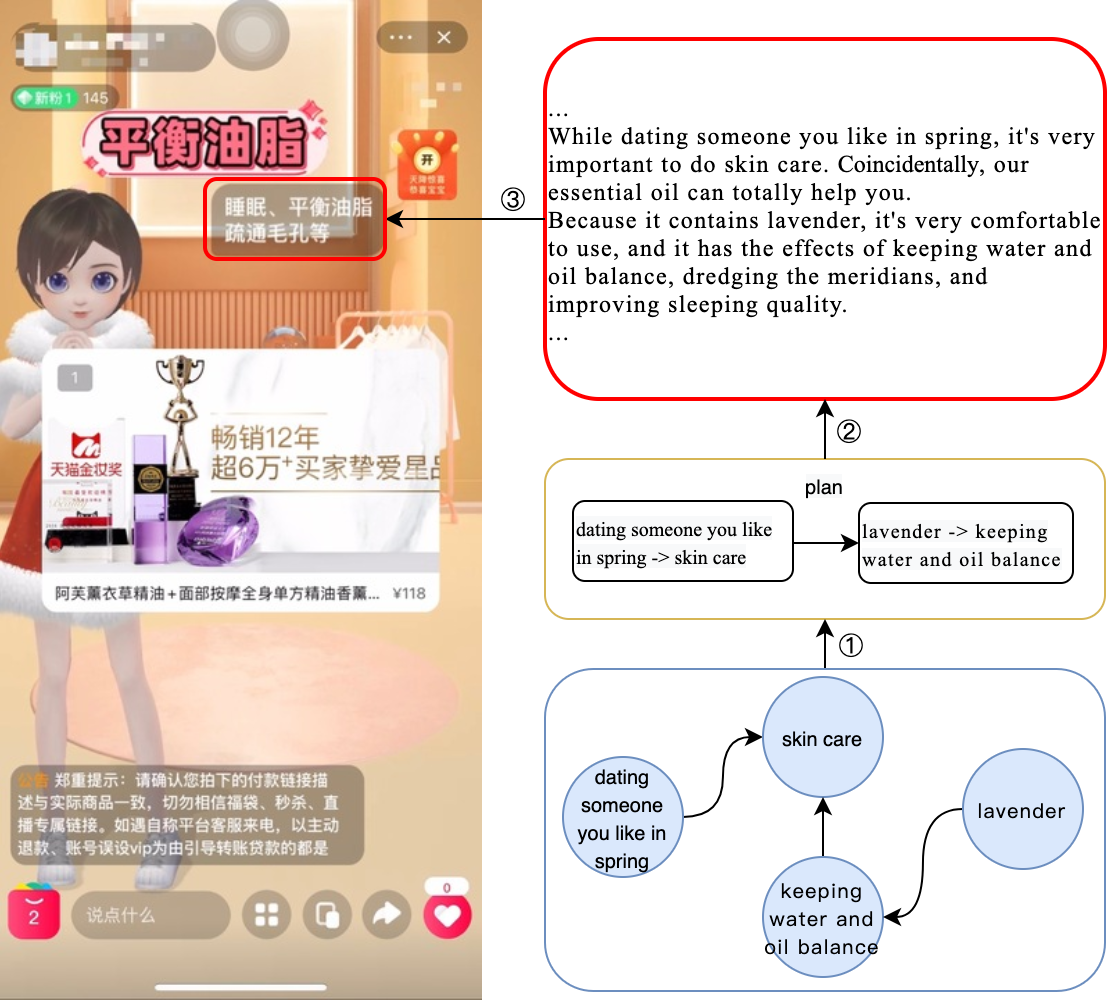
In recent years, live streaming is becoming an increasingly popular trend of sales in E-commerce. In live streaming, an anchor will attractively introduce the listed product items, and offer certain discounts or coupons, to facilitate user interaction and volume of transactions. However, script creation of product introduction is very time-consuming and requires professional sales experience. To alleviate this problem, we launched AliMe Avatar, an AI-powered Vtuber for automatically product broadcasting in the live-streaming sales scenario. Figure 1 reveals how our virtual avatar broadcasts products with scripts created by our proposed planning-based methods. In AliMe Avatar, the process of script creation is abstracted into a first-plan-then-generate data-to-text task. The task of data-to-text generation is to generate a natural language description for given structured data (Gatt and Krahmer, 2018). Data-to-text methods have a wide range of applications in domains like automatic generation of weather forecasting, game report and production description. Table 1 shows an example where the input data is a collection of key phrases, and the output texts are corresponding natural language descriptions generated from intermediate plans.
Recently several published articles are inspired by the first-plan-then-generate pipeline (Kukich, 1983; Mei et al., 2015) which includes content planning, sentence planning and surface realization. Moryossef et al. (Moryossef et al., 2019) proposed a planning-based method to split the generation process into a symbolic text-planning stage followed by a neural generation stage. The text planner determines the information structure and expresses it unambiguously as a sequence of ordered trees from graph data. Puduppully et al. (Puduppully et al., 2019) also decomposed the generation task into two stages with end-to-end methods instead. Zhao et al. (Zhao et al., 2020) focused on planning from graph data and proposed a model named DualEnc. DualEnc is a dual encoding model that can not only incorporate the graph structure but can also cater to the linear structure of the output text. Considering the task of long text generation, Shao et al. (Shao et al., 2019) proposed a planning-based hierarchical variational model (PHVM) to generate long texts with plans.
However, these works ignore two points that are important in our scenarios: (1) Most of these works ignore the sentence planning process at the text planning stage and do not allow key phrase duplication. (2) The graph is extracted from the instance-level sample instead of the whole corpus, which is unable to learn regular patterns from a global perspective. Considering to overcome these shortcomings, we propose a GGP model. GGP combines sentence planning and text planning at the planning stage based on a corpus-level graph. Concretely, GGP can not only be aware of instance-level sequential representations but also corpus-level graph-based representations for each given key phrase. During the decoding process, GGP can regroup these encoded phrases into sentence-level plans and then paragraph-level plans in a fine-grained way. Finally, long texts are generated according to the generated plans. Moreover, recently Ribeiro et al. (Ribeiro et al., 2020) and Kale (Kale, 2020) reveal that large scale pre-trained language models are evidenced by large improvements on data-to-text tasks. So in this situation, we conduct our experiments based on pre-trained language models to further prove the effectiveness of our proposed methods.
Our contributions are summarized as follows:
-
•
We propose a grouping planner with a copy mechanism to first generate sentence-level plans and then paragraph-level plans in a fine-grained way with sentence planning and text planning together, in which key phrase duplication with any orders is allowed.
-
•
We combine the planner with graph neural networks to guide the plan generation with local instance-level information and global corpus-level knowledge learned from graphs.
-
•
We achieve state-of-the-art results on all planning related metrics on three public data-to-text datasets which are required to generate long texts, including the Advertising Text Generation(ATG) dataset from Shao et al. (Kale, 2020), the Now You’re Cooking dataset from Kiddon et al. (Kiddon et al., 2016) and the preprocessed Tao Describe (TaoDesc) dataset from Chen et al. (Chen et al., 2019).
| data | figure-flattering, aesthetic plaid, youthful, pure cotton, fresh, high-rise, irregular flounce, skirt |
|---|---|
| plan | skirt, pure cotton; fresh, aesthetic plaid; figure-flattering, high-rise; irregular flounce, youthful |
| text | This skirt is made of pure cotton, which is comfortable and breathable. The fresh and aesthetic plaid brings about lovely preppy style. The figure-flattering design, in particular, the high-rise design, heightens your waistline and perfects your body shape. The irregular flounce is youthful, making you look a bit more free and easy. |
2. Model
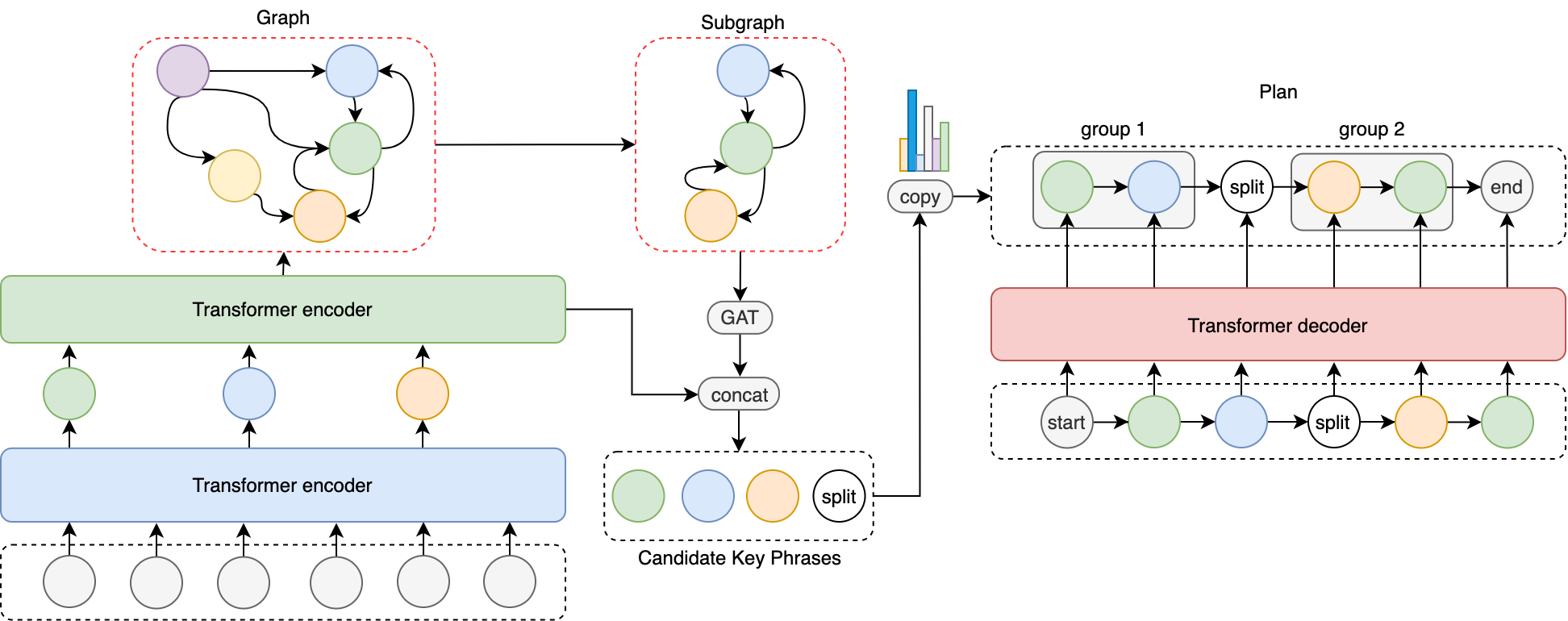
2.1. Model Overview
Given a collection of key phrases , represents a possible key phrase which consists of several tokens, in other words, . Our goal is to generate a context which can represent the content of the key phrase. Instead of the conventional straightforward first-plan-then-generate approach, we adopt a graph-based grouping approach: (1) Encoding key phrases from the input into a combination of sequential representations and graph-based representations; (2) A plan is generated by picking and regrouping key phrases from instead of reordering these phrases only. For each , it means the key phrase is chosen as the element of the group. For example, in the ATG dataset, given a collection of key phrases ={figure-flattering, aesthetic plaid, youthful, pure cotton, fresh, high-rise, irregular flounce, skirt}, it’s required to generate a plan according to this key phrase list. In this case, the plan can be generated like c={skirt, pure cotton; fresh, aesthetic plaid; figure-flattering, high-rise; irregular flounce, youthful}, where =skirt, and ’;’ means the group boundary. Finally the story is generated according to this plan.
2.2. Hierarchical Sequential Encoding
Given key phrases, a hierarchical transformer-based encoder (Vaswani et al., 2017) is used to encode key phrases into a sequence of vector representations, and then these vectors are encoded again with another transformer to learn inter-relation among these key phrases. means the raw input tokens of each key phrase . is the final key phrase representation after being encoded with the hierarchical sequential encoder.
| (1) |
| (2) |
2.3. Graph Encoding
To learn the graph-based representation, we first build a probability transition graph obtained from the statistics of the entire corpus, in which each node represents a key phrase. Then for each sample, we can build a subgraph according to the given key phrases. The nodes in this subgraph are encoded with a graph neural network. In our setting, we choose Graph Attention Networks (GAT) (Veličković et al., 2018) instead of Graph Convolutional Networks (GCN) (Kipf and Welling, 2017) as GAT performs slightly better in our experiments than GCN does. Let be the relation matrix of the current data input.
| (3) |
2.4. Grouping Copynet
The graph-based representation may not preserve the original sequential information. In this way, we combine two representations from the graph encoder and the sequential encoder together. Specifically, given the graph-based representation and the sequential representation , we merge these two vectors into one vector with MLPs:
| (4) |
Suppose there are key phrases in the key phrase list, a transformer-based decoder (Vaswani et al., 2017) with a copy mechanism is used to pick key phrases from the input, and the generated plan is a sequence of groups. The white node in Figure 2 represents the group boundary, and each group represents the plan of each sentence. For every decoding step, the decoder is required to discriminate whether it should be separated as a group boundary or pick a key phrase from the input collections.
| (5) |
Finally, the loss function is calculated as cross entropy for each decoding step.
3. Experiments
3.1. Dataset
-
•
Advertising Text Generation (ATG) (Shao et al., 2019): we used the same dataset from Shao et al. (Shao et al., 2019), which consists of 119K pairs of Chinese advertising text.
-
•
Now You’re Cooking (Cooking) (Kiddon et al., 2016): we used the same dataset and pre-processing process from Kiddon et al. (Kiddon et al., 2016). In the training set, the average recipe length is 102 tokens, and the vocabulary size of recipe text is 14,103.
-
•
Tao Describe (TaoDesc) (Chen et al., 2019): TaoDesc dataset is from Chen et al. (Chen et al., 2019). This dataset contains 2.1M pairs of product descriptions created by shop owners. We extract key phrases from these descriptions with our sequence labeling model. The format of this dataset is the same as the format of the ATG dataset.
3.2. Baselines
We compared our model with four strong baselines, including a pre-trained language model baseline, BART(Lewis et al., 2019), and three planning-based baselines, PHVM, Step-By-Step and DualEnc.
-
•
BART (Lewis et al., 2019): a pre-trained autoencoder whose input is a collection of key phrases or the generated plan, and output is the generated text in our settings.
-
•
PHVM (Shao et al., 2019): this model achieves state-of-the-art results on ATG. In our experiments, we use the exact implementation in Shao et al. (Shao et al., 2019) as a strong baseline on ATG.
-
•
Random Planner (RP): it chooses the key phrases from the phrase list randomly as a plan.
-
•
Step-By-Step (SBS) (Moryossef et al., 2019): this method captures the division of facts into sentences and the ordering of the sentences. Again we use the exact implementation in Moryossef et al. (Moryossef et al., 2019) on our datasets.
-
•
DualEnc (DE) (Zhao et al., 2020): this is a dual encoding model that can not only incorporate the graph structure but also can cater to the linear structure of the output text to extract plans. Our implementation is according to Zhao et al. (Zhao et al., 2020) on our datasets.
| Dataset | Method | BLEU-4 | PB-4 | PR-L |
| ATG | PHVM | 2.9 | 13.8 | 64.7 |
| BART | 4.0 | 17.5 | 66.3 | |
| RP + BART | 2.6 | 5.9 | 52.8 | |
| SBS + BART | 1.7 | 2.9 | 47.1 | |
| DE + BART | 2.7 | 9.4 | 58.5 | |
| GGP + BART | 4.3 | 20.8 | 68.7 | |
| Cooking | BART | 7.3 | 17.7 | 73.1 |
| RP + BART | 0.6 | 4.6 | 58.7 | |
| SBS + BART | 0.5 | 4.4 | 45.1 | |
| DE + BART | 1.4 | 12.0 | 55.7 | |
| GGP + BART | 7.5 | 19.5 | 74.1 | |
| TaoDesc | BART | 14.6 | 13.7 | 59.4 |
| RP + BART | 13.0 | 5.6 | 51.8 | |
| SBS + BART | 3.6 | 1.7 | 44.2 | |
| DE + BART | 13.2 | 12.9 | 59.5 | |
| GGP + BART | 16.8 | 16.8 | 61.6 |
3.3. Automatic Evaluation Metrics
We adopted the following automatic metrics to evaluate the quality of generated outputs: (1) BLEU-4 (Papineni et al., 2002). (2)PLAN BLEU-4 (PB-4) (Papineni et al., 2002): this metric is exactly BLEU-4, but hypotheses and references are generated plans and golden plans individually. (3) PLAN ROUGE-L (PR-L) (Lin, 2004): the same as PLAN BLEU-4, but the metric is ROUGE-L instead of BLEU-4. PLAN BLEU-4 and PLAN ROUGE-L measure the quality of generated plans while BLEU-4 focuses on measuring the generated text.
3.4. Experimental Results
| Method | BLEU-4 | PB-4 | PR-L |
|---|---|---|---|
| GGP + BART | 4.3 | 20.8 | 68.7 |
| w/o graph networks | 4.2 | 20.8 | 67.9 |
| w/o grouping copynet | 4.0 | 16.7 | 64.8 |
Table 2 reveals our experimental results. Our model outperforms the baselines in terms of BLEU-4, PLAN BLEU-4 and PLAN ROUGE-L on three datasets, which indicates that our proposed method can better make the plan according to the given key phrase list without missing important input items in a long text. The most competitive baseline on ATG is PHVM, but BART performs a better result than PHVM. With GGP, it outperforms PHVM by 1.4% on BLEU-4, 7.0% on PLAN BLEU-4 and 4.0% on PLAN ROUGE-L, indicating the effectiveness of our planner. As for Now You’re Cooking and TaoDesc, DualEnc achieves state-of-the-art results on WebNLG (Castro Ferreira et al., 2018). However, it performs even worse than Random Planner on PLAN ROUGE-L on Now You’re Cooking and much worse than BART on all metrics as it only considers instance-level information of a sentence. However, our GGP considers constructing plans from the current instance and the corpus perspective. On Now You’re Cooking, our GGP outperforms DualEnc by 6.1% on BLEU-4, 7.5% on PLAN BLEU-4 and 18.4% on PLAN ROUGE-L. And on TaoDesc, our proposed GGP outperforms DualEnc by 3.6% on BLEU-4, 3.9% on PLAN BLEU-4 and 2.1% on PLAN ROUGE-L. In conclusion, GGP significantly outperforms baselines on PB-4 and PR-L on all of these three long text generation datasets, which proves that GGP can better control the long text generation process according to the given plan.
3.5. Ablation Study
To further investigate the effectiveness of graph networks and grouping copynet, we conduct ablation experiments on GGP. Table 3 reveals that graph networks can improve PLAN ROUGE-L by 0.8%. And with grouping copynet, PLAN BLEU-4 is improved by 4.1% while PLAN ROUGE-L is improved by 3.9%, and there is almost no effect on BLEU-4 which is exploited to measure generated texts. It can be analyzed from the results that grouping copynet can learn plans well from the whole corpus and graph information can slightly help improve the results. The reason is that copynet can directly extract phrases from source data which are also revealed in generated plans. However, the model is more flexible with the graph structure as we can use the knowledge graph or the graph extracted from other corpora in our future work.
3.6. Case Study
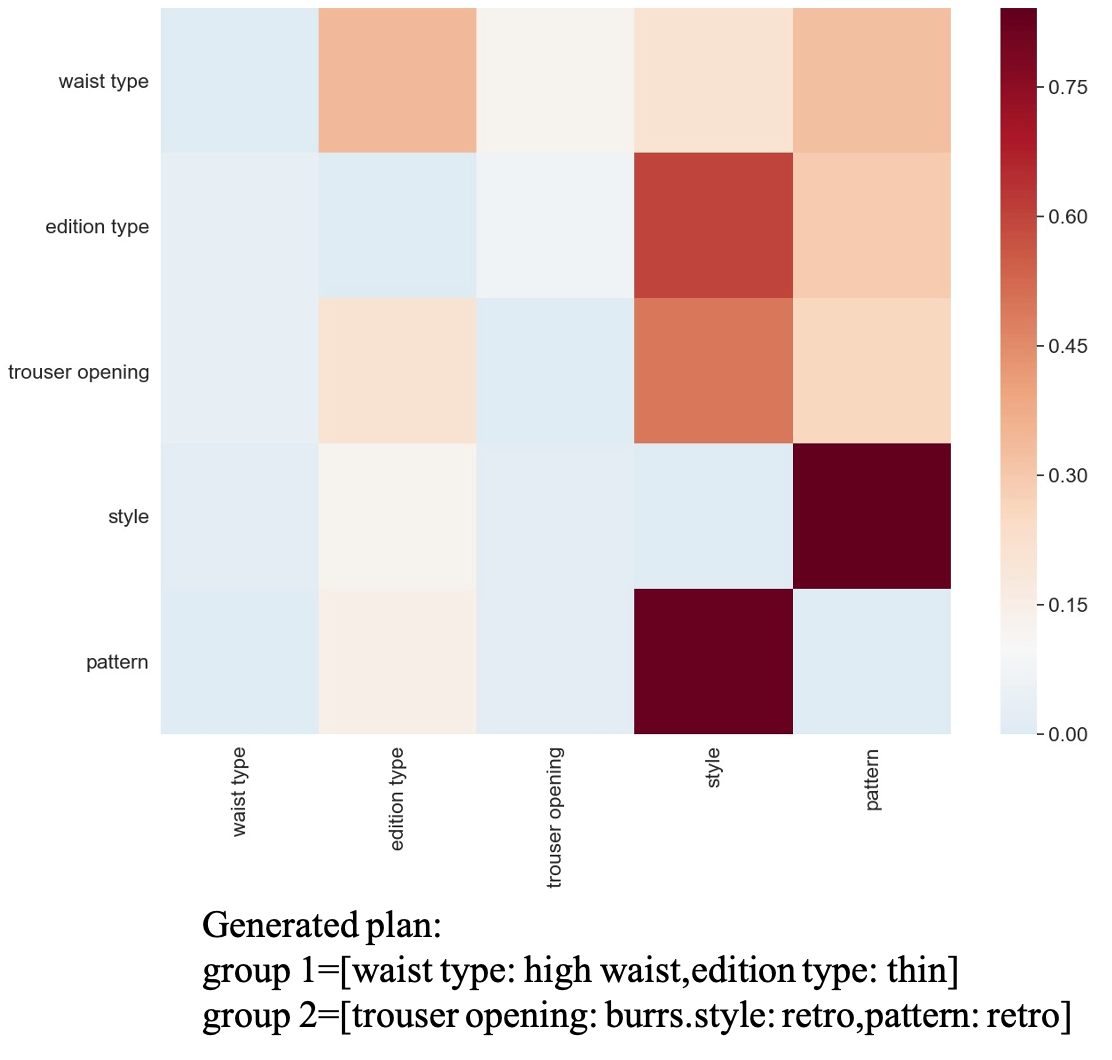
To observe how graph-based representations affect the planning process, we extract the graph attention from GAT and the corresponding generated plan from the ATG dataset. Figure 3 reveals that attention scores in the same row are relatively high from ”waist type” to ”edition type”, from ”trouser opening” to ”style” and from ”style” to ”pattern”, which is how the first group and the second group are generated and both of them are combined into the final plan.
4. Conclusion and Future Work
In this work, we present a graph-based grouping planner (GGP) for sentence planning and content planning together with graph-based information to explicitly control the process of long text generation. GGP combines the grouping copynet with graph neural networks to better capture the global information from the whole corpus and it can regroup plans from sentence-level to paragraph level. Experiments on three data-to-text corpora reveal that our model is more competitive to extract plans than state-of-the-art baselines. In the future, we will conduct more experiments on plan generation with the knowledge graph or graphs constructed from human live streaming corpus, and further apply it to our industrial scenarios.
References
- (1)
- Castro Ferreira et al. (2018) Thiago Castro Ferreira, Diego Moussallem, Emiel Krahmer, and Sander Wubben. 2018. Enriching the WebNLG corpus. In Proceedings of the 11th International Conference on Natural Language Generation. Association for Computational Linguistics, Tilburg University, The Netherlands, 171–176. https://doi.org/10.18653/v1/W18-6521
- Chen et al. (2019) Qibin Chen, Junyang Lin, Yichang Zhang, Hongxia Yang, Jingren Zhou, and Jie Tang. 2019. Towards knowledge-based personalized product description generation in e-commerce. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 3040–3050.
- Gatt and Krahmer (2018) Albert Gatt and Emiel Krahmer. 2018. Survey of the state of the art in natural language generation: Core tasks, applications and evaluation. Journal of Artificial Intelligence Research 61 (2018), 65–170.
- Kale (2020) Mihir Kale. 2020. Text-to-text pre-training for data-to-text tasks. arXiv preprint arXiv:2005.10433 (2020).
- Kiddon et al. (2016) Chloé Kiddon, Luke Zettlemoyer, and Yejin Choi. 2016. Globally coherent text generation with neural checklist models. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 329–339.
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. arXiv:1609.02907 [cs.LG]
- Kukich (1983) Karen Kukich. 1983. Design of a knowledge-based report generator. In 21st Annual Meeting of the Association for Computational Linguistics. 145–150.
- Lewis et al. (2019) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv:1910.13461 [cs.CL]
- Lin (2004) Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out. 74–81.
- Mei et al. (2015) Hongyuan Mei, Mohit Bansal, and Matthew R Walter. 2015. What to talk about and how? selective generation using lstms with coarse-to-fine alignment. arXiv preprint arXiv:1509.00838 (2015).
- Moryossef et al. (2019) Amit Moryossef, Yoav Goldberg, and Ido Dagan. 2019. Step-by-step: Separating planning from realization in neural data-to-text generation. arXiv preprint arXiv:1904.03396 (2019).
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318.
- Puduppully et al. (2019) Ratish Puduppully, Li Dong, and Mirella Lapata. 2019. Data-to-text generation with content selection and planning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 6908–6915.
- Ribeiro et al. (2020) Leonardo FR Ribeiro, Martin Schmitt, Hinrich Schütze, and Iryna Gurevych. 2020. Investigating pretrained language models for graph-to-text generation. arXiv preprint arXiv:2007.08426 (2020).
- Shao et al. (2019) Zhihong Shao, Minlie Huang, Jiangtao Wen, Wenfei Xu, and Xiaoyan Zhu. 2019. Long and diverse text generation with planning-based hierarchical variational model. arXiv preprint arXiv:1908.06605 (2019).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. arXiv:1706.03762 [cs.CL]
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. arXiv:1710.10903 [stat.ML]
- Zhao et al. (2020) Chao Zhao, Marilyn Walker, and Snigdha Chaturvedi. 2020. Bridging the structural gap between encoding and decoding for data-to-text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2481–2491.