GhostVec: A New Threat to Speaker Privacy of End-to-End Speech Recognition System
Abstract.
Speaker adaptation systems face privacy concerns, for such systems are trained on private datasets and often overfitting. This paper demonstrates that an attacker can extract speaker information by querying speaker-adapted speech recognition (ASR) systems. We focus on the speaker information of a transformer-based ASR and propose GhostVec, a simple and efficient attack method to extract the speaker information from an encoder-decoder-based ASR system without any external speaker verification system or natural human voice as a reference. To make our results quantitative, we pre-process GhostVec using singular value decomposition (SVD) and synthesize it into waveform. Experiment results show that the synthesized audio of GhostVec reaches 10.83% EER and 0.47 minDCF with target speakers, which suggests the effectiveness of the proposed method. We hope the preliminary discovery in this study to catalyze future speech recognition research on privacy-preserving topics.
1. Introduction
Automatic speech recognition (ASR) is a key technology in many speech-based applications, e.g., mobile communication devices and personal voice assistants, which typically require users to send their speech to the system for recognized text. Thanks to the development of deep learning and machine learning, ASR systems (Graves et al., 2006; Gulati et al., 2020; Dong et al., 2018; Schneider et al., 2019; Radford et al., 2022) have received a tremendous amount of attention and show excellent advantages over traditional ASR systems.
There is a problem that the performance of ASR can still degrade rapidly when their conditions of use differ from the training data. Many adaptive algorithms (speaker adaptation (Meng et al., 2019a; Shi et al., 2020; Li et al., 2018), domain adaptation (Hosseini-Asl et al., 2018; Meng et al., 2019b), accent adaptation (Yang et al., 2018; Turan et al., 2020), etc.) are used to alleviate the mismatch between the training data and test data. Speaker adaption, which adapts the system to a target speaker, is also one of the most popular forms of adaptation. Speaker adaptation attracts the attention of many researchers: it can explicitly model speaker characteristics and the speech context (Bell et al., 2020). Some researchers (Saon et al., 2013) directly extract speaker embeddings such as i-vectors in a manner independent of the model and concatenate them with acoustic input features. Instead of directly using speaker embedding as a speaker feature, some studies have proposed extracting low-dimensional embeddings from bottleneck layers in neural network models trained to distinguish between speakers (Shi et al., 2020) or across multiple layers followed by dimensionality reduction in a separate layer. Unlike the above speaker embedding approaches, some works do not use speaker information explicitly for ASR. (Tang et al., 2016; Kanda et al., 2020) used multi-task learning (MTL) to unify the training of transcribing speech and identifying speakers simultaneously by sharing the same speech feature extraction layers. Adversarial learning (AL) adopts a similar architecture to MTL but learns a speaker-invariant model to be more generalized to new speakers by reducing the effects of speaker variability (Meng et al., 2019a; Sun et al., 2018). Those methods, however, face the challenge of overfitting to targets seen in the adaptation data.
Recently, machine learning models have gained notoriety for exposing information about their training data, which can cause privacy leaks. Researchers (Yeom et al., 2018) view overfitting as a sufficient condition for privacy information leakage, and many attacks work by exploiting overfitting (Shokri et al., 2017; Carlini et al., 2021). An attacker (Shokri et al., 2017) can apply a member inference attack to predict the presence of some specific examples in the training data. In (Carlini et al., 2021), the authors also illustrate how large language models can be prodded to disgorge sensitive, personally identifying information picked up from their training data. As speech recognition algorithms increasingly have free access to everyone, attackers have more opportunities to extract private training data. Adversarial example (Goodfellow et al., 2014) is one of the well-known attack methods, and it is usually generated by adding some small perturbation to the example. Since almost all of the state-of-the-art ASR systems are based on the transformer-based model, it is necessary to investigate the leakage of speaker information in this model. This paper’s goal and our findings might serve as a warning in privacy-preserving speaker-adaptive ASR systems.
This paper focuses on a speaker-adaptive transformer-based ASR system, which includes massive speaker and acoustic information. It investigates the privacy leakage of speaker information from speaker-adapted ASR. Specifically, we propose GhostVec extract the target speaker’s voice from the existing ASR model by adversarial example. We process GhostVec to synthesize the target speaker’s voice to make the speaker information further distinguishable.
The main contributions can be summarized as follows. (1) We raise the concern of GhostVec, the adversarial speaker embedding. It can lead to speaker information leakage from speaker-adapted End-to-End ASR systems. (2) We also show a method to synthesize the targeted speaker voice from GhostVec.
2. Proposed Methods
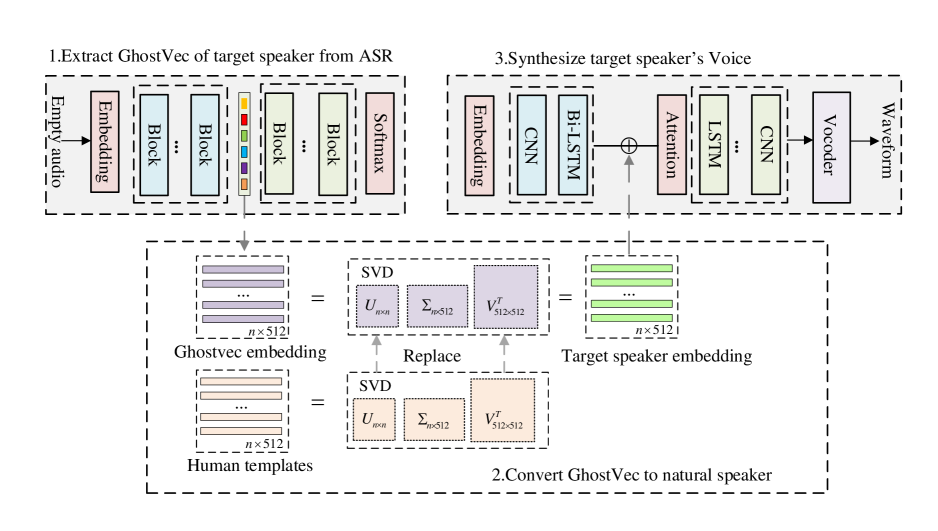
This work demonstrates that extracting speaker information from a trained speaker-adaptive ASR model is possible. This section discusses the proposed method, in which we first generate a target speaker’s GhostVec and further convert it to the target speaker’s voice. Fig.1 illustrates the flowchart of the proposed method. The following subsections are detailed descriptions.

| methods | MOS | DMOS |
| Genuine speaker | 3.91 | 3.84 |
| SVD-modified GhostVec (Our) | 3.73 | 2.78 |
| Enrolls | Trails | EER% (Snyder et al., 2018) | minDCF | ||
| min | act | ||||
| Target | Target | 1.50 | 0.32 | 0.07 | 0.71 |
| Target | GhostVec | 52.27 | 1.00 | 0.99 | 143.87 |
| Target | Our | 10.83 | 0.46 | 0.34 | 42.22 |
2.1. Extract GhostVec of the Target Speaker
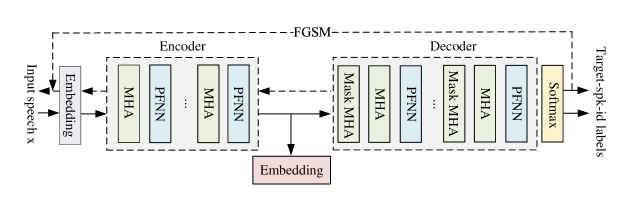
A speaker-adaptive ASR model, which adapts the system to a target speaker, can explicitly model speaker characteristics and the speech context (Bell et al., 2020). In this paper, as shown in Fig.2, we extract the information from this trained transformer-based speaker-adaptive ASR network, which includes two parts: an encoder and a decoder. The encoder is responsible for encoding the input speech feature sequence , and the decoder predicts the output sequence according to the decoding information from the encoder output . In previous studies(Huang and Zhang, 2019; Wang et al., 2021), random noise was used to learn the model information for success adversarial attacks. To eliminate the dependence on speech, we adopt empty audio, aka background noise, as the input to extract the speaker’s voice in this paper.
To gain the speaker information from the model, the concept of adversarial example is adapted to find information by extracting speaker embedding . We add small and purposed adversarial perturbation to the empty input, and is trained to find the speaker information in this speaker-adaptive ASR model. The output of encoder represents the speaker information. We call the embedding that contains the speaker’s information as GhostVec. As shown in Fig.2, the process of extracting GhostVec is , , , where x is the input feature of speech, is the recognition result of the target speaker, which contains the speaker-id; the likelihood of each output token is given by softmax, is the speaker id of the target speaker; and is the generated adversarial perturbation by model.
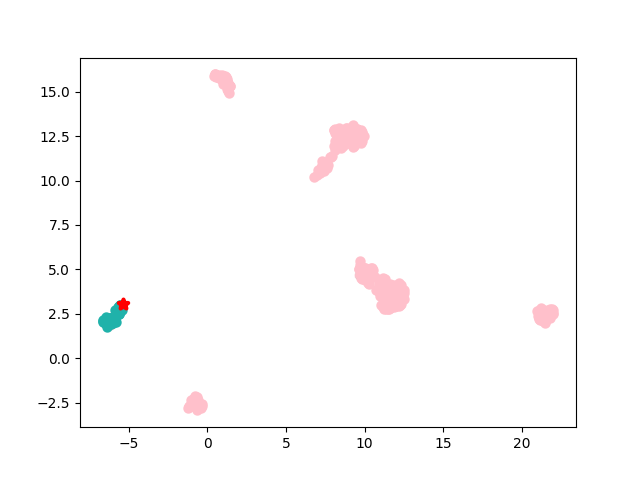
To extract the speaker information , is optimized to help empty input to obtain the speaker information from the model. In this paper, is updated by the fast gradient sign method (FGSM)(Szegedy et al., 2013) and is formulated as: , where is the ASR model’s parameter and is frozen in this paper; is a hyperparameter to constrain with a small value; y satisfies and is the correct output of x; and is the loss function used in the trained model. Considering that speech content is not the aim of this paper, we only focus on the result of speaker id . So, extracting the speaker information has a target speaker id, and is optimized until the output is a target speaker id. Embeddings from the same speaker are close in the embedding vector space, and we observe GhostVec in low dimensions. As shown in Figure 3, we show the clustering effect of GhostVec with six speakers in low dimensions. GhostVec can be clustered into the same class with the target speaker in low dimensions and distanced from the non-target speaker. We think the speaker information has been extracted.
2.2. Converting GhostVec to Waveform
GostVec has a specific and detailed meaning for the model, but humans cannot intuitively comprehend it from the embedding perspective. The authors in (Wu et al., 2022) prove that the vocoder’s preprocessing will not affect the ASV scores of genuine samples too much. To further make our results quantitative, we utilize the text-to-speech system (TTS) to convert GhostVec to a waveform, which is a human-comprehensible form. The TTS model synthesizes waveforms given text, and multi-speaker TTS can generate natural speech for various speakers by speaker embedding. In particular, given conditional text , the TTS model aims to build the mapping , viz., = , where is the speaker embedding that controls the audio styles with the speaker identity, and is the synthesized waveform, which is the output of the TTS model. Therefore, different speaker embeddings have different representations of the synthesized speech.
GhostVec is nonrobust and adversarial (Ilyas and et al., 2019). We adopt SVD to preprocess GhostVec to a robust embedding. SVD can find the essential dimension of a matrix. We expect audio with real human intelligibility and naturalness by modifying GhostVec’s decomposed matrices. Generally, for an arbitrary matrix , SVD can be expressed as: , where and are the orthogonal matrices, is a diagonal matrix, so that is rectangular with the same dimensions as . The diagonal entries of that is , can be arranged to be nonnegative and in order of decreasing magnitude. We interpreted as low-dimensional speaker information directly reflected in speaker clustering (as shown in Fig. 3). and reflect the intrinsic characteristics of human voices or adversarial audios.
As shown in Fig. 1, we replaced the and of the GhostVec with the and from template human voices, which is a nearest human template of target speaker in the speaker embedding spaces. In this paper, we truncate the GhostVecs for the same target speaker with different utterances (100 sentences) to organize a matrix, and then we use SVD to decompose this matrix. The distance between embeddings is measured by cosine distance.
3. Experiment Setup
Datasets: All datasets utilized in the ASR model were based on the 100 hours of Librispeech dataset (train-clean-100) (Panayotov et al., 2015). The input feature was 120-dimensional log Mel-filterbank (40-dim static, +, and +). The synthesizer of multi-speaker TTS used 100 hours of train-clean-100, and the vocoder was trained using VCTK (Yamagishi et al., 2019) datasets. Librispeech TTS train-clean-500 is used as template human embedding during pre-processing GhostVec.
| methods | CER% |
| Baseline (Li et al., 2019) | 9.80 |
| SVD-modified GhostVec (Our) | 15.42 |
ASR model setting: We adopt the transformer-based speaker-adapted speech recognition model (ASRspk). In this paper, the ASRspk model required for embedding extraction is trained on the LibriSpeech train-clean-100 but based on the multitask training method following (Li et al., 2019; Vaswani et al., 2017) with the speaker-id and label. The character error rate (CER%) was approximately 9.0%, which is our proposed method’s baseline. The speaker-id was explicitly added as the label during training (Li et al., 2019; Vaswani et al., 2017). The training labels are organized as “SOS speaker-id labels EOS”. We augment target speaker IDs to ground truth labels in training GhostVec.
TTS system setting: Synthesizing the target speaker’s voice is based on an End-to-End multispeaker TTS system (Liu et al., 2021). This system extracts speech embeddings from an ASR encoder(Li et al., 2019) to improve the multispeaker TTS quality, especially for speech naturalness. We trained the synthesizer and vocoder separately. For the synthesizer, we train based on the LibriSpeech train-clean-100 and embeddings from the ASRspk model (Li et al., 2019). We trained the vocoder using VCTK.
4. Experiment Results
4.1. The quality of synthesized audio
4.1.1. Subjective evaluations
: We first show that synthesized speech from our proposed method is natural and understandable. In this paper, we adopt the mean opinion score (MOS) for speech naturalness and the differential MOS (DMOS) (Kinnunen et al., 2018) for similarity. Specifically, we invited 21 participants who used headphones for listening tests. For the naturalness evaluation, all listeners completed 120 audio tasks 111Audio samples are available at https://demoghostvec.github.io. Additionally, all listeners completed 60 pairs of audio tasks for the similarity evaluation. The reference sentences were synthesized using 12 speakers (6 male and 6 female). Table 1 shows the average MOS and DMOS scores with 95 % confidence intervals. We use the genuine waveform of the target speaker as the baseline. As shown in Table 1, the MOS of the proposed SVD-modified GhostVec has expected performance in speech naturalness. Furthermore, there is still some gap in DMOS scores, and the difference between the two groups deals with the adversarial factors in the GhostVec. We must remove the adversarial factors of GhostVec for higher-quality TTS.
4.1.2. Objective Evaluation
As for the actual similarity measurement of synthesized audio and reference audio, we use three evaluation metrics to report the system performance: Equal Error Rate (EER), minimum Detection Cost Function (minDCF) with ptarget= 0.01 and the log-likelihood ratio (LLR) based costs , which can be decomposed into a discrimination loss () and a calibration loss(). A total of 120 sentences generated by the proposed method and the same number of audios from the different target GhostVec are also provided. Moreover, the value of EER% from speaker verification (SV) (Snyder et al., 2018) was used to evaluate similarity as the objective evaluation of the proposed method in Table 2. The results in Table 2 show that our synthesized waveform effectively demonstrates target speaker characteristics. The proposed SVD-modified GhostVec method achieves better performance, effectively surpassing the GhostVec. The results suggest that the speaker’s identity has been hidden, while the GhostVec is directly conveyed to the TTS system. The proposed SVD-modified GhostVec method successfully represents the target speaker identity.
4.2. Automatic Speech Recognition evaluation
The above experimental results indicate that the speech synthesized by SVD-modified GhostVec has a unique speaking voice and an acceptable difference from genuine speech audio. These two conclusions motivate us to explore the practical implications of our synthetic audio. We mainly verify from the perspective of ASR.
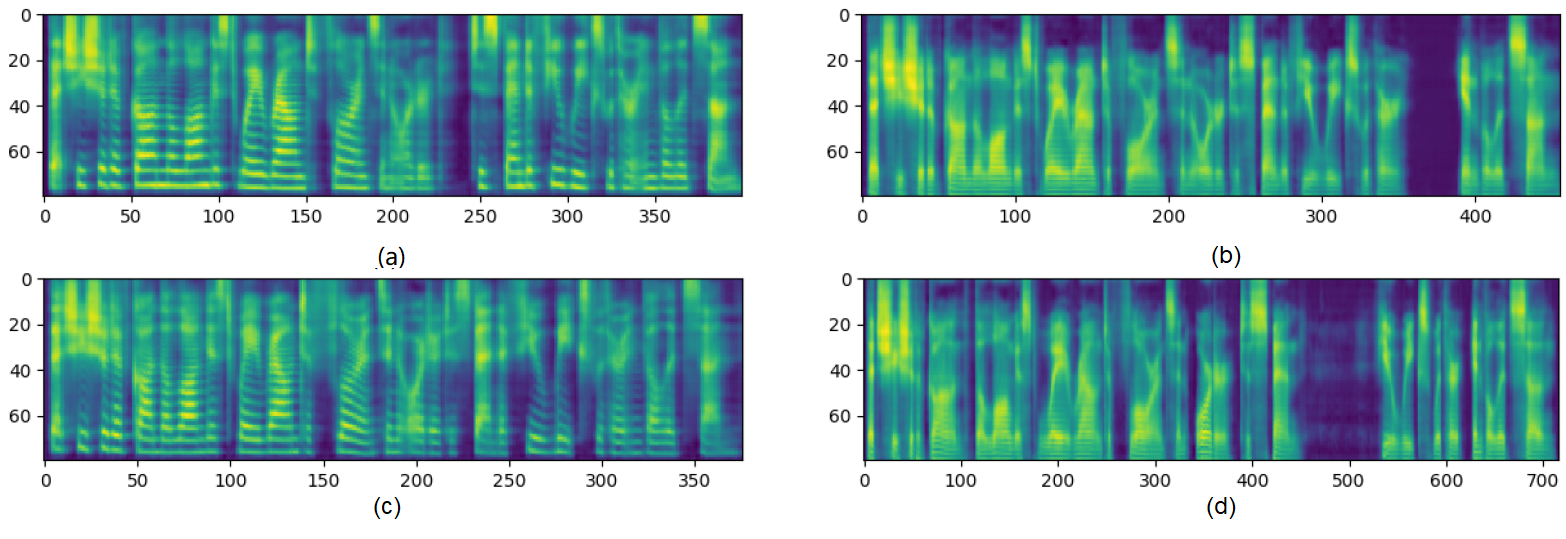
Firstly, we observe the Mel-spectrum of different embeddings. Figure 4 shows the spectrum from different genders and various speaker embeddings. The results show that some adversarial elements in the spectrum still influence the length and position of silent frames. In objective evaluation on section 4.1.2, we found that the synthesized audios contained sufficient target speaker information. Therefore, we convey those audios to the ASR systems. The objective intelligibility evaluation in terms of CER in Table 3 shows the quality of the speech content. We synthesize the same text as the baseline and get similar scores. The difference in scores may be due to the residual adversarial elements. That is exactly what is so special about GhostVec’s synthetic audio. The experimental results also directly reflect that the audio synthesized in this paper can be used as valid audio. It is possible to improve the model’s robustness further.
5. Conclusions
This paper shows a new threat to speaker privacy from an End-to-End ASR system. In this paper, we use adversarial examples to extract a target speaker embedding, GhostVec, from the ASR model without using any reference speech. The target speaker’s voice is further synthesized using SVD-modified GhostVec. The experimental results show the effectiveness of our method in terms of both the synthesized audio quality and the speaker characteristics in audio. Moreover, the intelligibility of synthesized audio also confirms that audio synthesized by our proposed model can serve as legitimate audio samples. We hope the discovery in this study will catalyze future downstream research on speaker and speech privacy preservation topics.
References
- (1)
- Bell et al. (2020) Peter Bell, Joachim Fainberg, Ondrej Klejch, Jinyu Li, Steve Renals, and Pawel Swietojanski. 2020. Adaptation algorithms for neural network-based speech recognition: An overview. IEEE Open Journal of Signal Processing 2 (2020), 33–66.
- Carlini et al. (2021) Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom B Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting Training Data from Large Language Models.. In USENIX Security Symposium, Vol. 6.
- Dong et al. (2018) Linhao Dong, Shuang Xu, and Bo Xu. 2018. Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 5884–5888.
- Goodfellow et al. (2014) Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).
- Graves et al. (2006) Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber. 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning. 369–376.
- Gulati et al. (2020) Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, et al. 2020. Conformer: Convolution-augmented transformer for speech recognition. arXiv preprint arXiv:2005.08100 (2020).
- Hosseini-Asl et al. (2018) Ehsan Hosseini-Asl, Yingbo Zhou, Caiming Xiong, and Richard Socher. 2018. Augmented cyclic adversarial learning for low resource domain adaptation. arXiv preprint arXiv:1807.00374 (2018).
- Huang and Zhang (2019) Zhichao Huang and Tong Zhang. 2019. Black-box adversarial attack with transferable model-based embedding. arXiv preprint arXiv:1911.07140 (2019).
- Ilyas and et al. (2019) A. Ilyas and et al. 2019. Adversarial examples are not bugs, they are features. In Proc. NeurlPS, Vol. 32.
- Kanda et al. (2020) Naoyuki Kanda, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Zhuo Chen, Tianyan Zhou, and Takuya Yoshioka. 2020. Joint speaker counting, speech recognition, and speaker identification for overlapped speech of any number of speakers. arXiv preprint arXiv:2006.10930 (2020).
- Kinnunen et al. (2018) Tomi Kinnunen, Jaime Lorenzo-Trueba, Junichi Yamagishi, Tomoki Toda, Daisuke Saito, Fernando Villavicencio, and Zhenhua Ling. 2018. A spoofing benchmark for the 2018 voice conversion challenge: Leveraging from spoofing countermeasures for speech artifact assessment. arXiv preprint arXiv:1804.08438 (2018).
- Li et al. (2018) Ke Li, Jinyu Li, Yong Zhao, Kshitiz Kumar, and Yifan Gong. 2018. Speaker adaptation for end-to-end CTC models. In 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE, 542–549.
- Li et al. (2019) S. Li, R. Dabre, X. Lu, P. Shen, T. Kawahara, and H. Kawai. 2019. Improving Transformer-based Speech Recognition Systems with Compressed Structure and Speech Attributes Augmentation. In Proc. INTERSPEECH.
- Liu et al. (2021) Dawei Liu, Longbiao Wang, Sheng Li, Haoyu Li, Chenchen Ding, Ju Zhang, and Jianwu Dang. 2021. Exploring Effective Speech Representation via ASR for High-Quality End-to-End Multispeaker TTS. In International Conference on Neural Information Processing. Springer, 110–118.
- McInnes et al. (2018) Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018).
- Meng et al. (2019b) Zhong Meng, Jinyu Li, Yashesh Gaur, and Yifan Gong. 2019b. Domain adaptation via teacher-student learning for end-to-end speech recognition. In 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 268–275.
- Meng et al. (2019a) Zhong Meng, Jinyu Li, and Yifan Gong. 2019a. Adversarial speaker adaptation. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 5721–5725.
- Panayotov et al. (2015) Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Librispeech: An ASR corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 5206–5210. https://doi.org/10.1109/ICASSP.2015.7178964
- Radford et al. (2022) Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022. Robust speech recognition via large-scale weak supervision. arXiv preprint arXiv:2212.04356 (2022).
- Saon et al. (2013) George Saon, Hagen Soltau, David Nahamoo, and Michael Picheny. 2013. Speaker adaptation of neural network acoustic models using i-vectors. In 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. IEEE, 55–59.
- Schneider et al. (2019) Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. 2019. wav2vec: Unsupervised pre-training for speech recognition. arXiv preprint arXiv:1904.05862 (2019).
- Shi et al. (2020) Yanpei Shi, Qiang Huang, and Thomas Hain. 2020. H-vectors: Utterance-level speaker embedding using a hierarchical attention model. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 7579–7583.
- Shokri et al. (2017) Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP). IEEE, 3–18.
- Snyder et al. (2018) David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur. 2018. X-vectors: Robust dnn embeddings for speaker recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 5329–5333.
- Sun et al. (2018) Sining Sun, Ching-Feng Yeh, Mei-Yuh Hwang, Mari Ostendorf, and Lei Xie. 2018. Domain adversarial training for accented speech recognition. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 4854–4858.
- Szegedy et al. (2013) Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2013. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 (2013).
- Tang et al. (2016) Zhiyuan Tang, Lantian Li, and Dong Wang. 2016. Multi-task recurrent model for speech and speaker recognition. In 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA). IEEE, 1–4.
- Turan et al. (2020) Mehmet Ali Tuğtekin Turan, Emmanuel Vincent, and Denis Jouvet. 2020. Achieving multi-accent ASR via unsupervised acoustic model adaptation. In INTERSPEECH 2020.
- Vaswani et al. (2017) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, and I. Polosukhin. 2017. Attention Is All You Need. In CoRR abs/1706.03762.
- Wang et al. (2021) Wenxuan Wang, Bangjie Yin, Taiping Yao, Li Zhang, Yanwei Fu, Shouhong Ding, Jilin Li, Feiyue Huang, and Xiangyang Xue. 2021. Delving into data: Effectively substitute training for black-box attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4761–4770.
- Wu et al. (2022) Haibin Wu, Po-chun Hsu, Ji Gao, Shanshan Zhang, Shen Huang, Jian Kang, Zhiyong Wu, Helen Meng, and Hung-yi Lee. 2022. Adversarial sample detection for speaker verification by neural vocoders. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 236–240.
- Yamagishi et al. (2019) Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. 2019. CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit (version 0.92). https://doi.org/10.7488/ds/2645
- Yang et al. (2018) Xuesong Yang, Kartik Audhkhasi, Andrew Rosenberg, Samuel Thomas, Bhuvana Ramabhadran, and Mark Hasegawa-Johnson. 2018. Joint modeling of accents and acoustics for multi-accent speech recognition. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5.
- Yeom et al. (2018) Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. Privacy risk in machine learning: Analyzing the connection to overfitting. In 2018 IEEE 31st computer security foundations symposium (CSF). IEEE, 268–282.