11email: {wangshujun.wsj,dengcheng.hedc}@alibaba-inc.com
puling.tyq@taobao.com
gMeta: Template-based Regular Expression Generation over Noisy Examples
Abstract
Regular expressions (regexes) are widely used in different fields of computer science, such as programming languages, string processing, and databases. However, existing tools for synthesizing or repairing regexes always assume that the input examples are faultless. In real industrial scenarios, this assumption does not entirely hold. Thus, this paper presents a simple but effective templated-based approach to generate regular expressions over noisy examples. Specifically, we present a data model (i.e., MetaParam) to extract features of strings for clustering all examples. Then, we propose a practical dynamic thresholding scheme to filter out anomalous examples via detecting knee points on CDF graphs. Finally, we design a template-based algorithm to translate a finite of positve examples to regular expression, which is efficient, interpretable, and extensible. We performed an experimental evaluation on four different extraction tasks applied to real-world datasets and obtained promising results in terms of F-measure. Moreover, gMeta achieves excellent results in real industrial scenarios.
Keywords:
Regular Expression, Template, CDF, Knee Point1 Introduction
A regular expression is a means for specifying string patterns concisely. A specialized engine may use such a specification for extracting the strings matching the specification from a data stream. Regular expressions are a long-established technique for a large variety of text processing applications and continue to be a routinely used tool due to their expressiveness and flexibility[DBLP:conf/emnlp/LiKRVJ08]. Indeed, regular expressions have become an essential device in broadly different application domains, e.g., extraction of bibliographic citations[22] and signal processing hardware design[18].
Constructing a regular expression suitable for a specific task is a tedious and error-prone process, which requires specialized skills, including familiarity with the formalism used by practical engines[3]. Multiple approaches have been proposed to generate regular expressions to tackle this problem automatically. The proposal of these works significantly reduces the complexity of learning regular expressions for users. While multiple automatic learning techniques have been proposed, very little work can be applied to the industry directly since they cannot work well with examples containing exceptions.
Thus, this paper proposes a novel templated-based approach to generate regular expressions over noisy examples. Essential components of our implementation include the following. First, we design an abstract data form MetaParam that can extract example features, which is responsible for extracting the components of a string and the relative order of elements. For example, SMS_123456 would be translated to MetaParam X_d. Then, we propose an anomaly detection schema based on intelligent threshold setting to filter out MetaParam representing outliers. Crucially, we compute the frequency of each MetaParam to construct a cumulative probability distribution graph. Based on this graph, we can lightly pick the knee point as the anomaly threshold. Finally, we design a template-based regular expression generation scheme, which is efficient, interpretable, and extensible.
The learning algorithm presented in this work has two significant advantages. First, gMeta is more robust by filtering out abnormal example values. Second, gMeta is no longer committed to directly generating a complex regular expression but instead generates multiple simple regular expressions (depending on the number of MetaParams), significantly reducing the regular expression generation complexity. In summary, the contributions of this work can be outlined as follows:
-
1.
We propose a character-sensitive regular expression template generation scheme, which can capture the common features among multiple strings.
-
2.
We design an automatic template-based regular expression generation method gMeta, which can translate a finite of examples containing outliers to regular expressions.
-
3.
We formula example outlier filtering problem as a string clustering problem. Crucially, we present a simple and practical approach to extracting string features, namely MetaParam.
-
4.
We propose an intelligent anomaly threshold generation scheme by computing cumulative probability distribution graphs and knee points.
-
5.
Extensive experimental results over multiple datasets show the effectiveness of gMeta and a comparison study with the ReLIE algorithm.
2 Related Work
2.0.1 Programming-by-Example (PBE)
PBE techniques have been the subject of research in the past few decades and successful paradigms for program synthesis, allowing end-users to construct and run new programs by providing examples of the intended program behavior[11]. Recently, PBE techniques have been successfully used for string transformations[13] , data filtering[20] , data structure manipulations[21], table transformations[12] , SQL queries[19] , MapReduce programs[1] , and also regex synthesis[4] .
2.0.2 Regexes Synthesis.
The problem of automatic regex synthesis from examples has been explored in many domains[4, 5]. AlphaRegex[15] is an enumeration algorithm for synthesizing simple regexes over binary alphabets from examples. However, all the synthesized expressions are over alphabets of size 2. RegexGenerator [4] is a state-of-the-art approach for synthesizing regexes from examples. RegexGenerator++ utilizes genetic programming means that it is not guaranteed to generate a correct solution-i.e., accepting all the positive examples while rejecting all the negative ones. Many existing works focus on XML schemas inference[7, 8], via resorting to infer regexes from examples. These approaches usually aim to tackle restricted forms of deterministic regexes[9] from positive examples only. GP-RegexGolf[5] is an approach based on genetic programming for playing regex golf[2] automatically, i.e., for writing the shortest regex that matches all positive strings and does not match any negative string. Unlike many of these efforts, which aim to generalize beyond the provided examples, GPRegexGolf focuses on binary classifying input strings. It does not require a form of generalization, i.e., the ability to induce a general pattern from the provided examples. Several works from the Natural Language Processing community address the problem of generating regexes from natural language specifications based on sequence-to-sequence (seq2seq) model[14].
2.0.3 Regexes Repair.
several works target repairing or modifying regexes from examples, specifically the incorrect ones. We discuss two main paradigms of them. In the first paradigm, works only consider either positive or negative examples. Li et al.[6] proposed ReLIE, which can modify complex regexes by rejecting the newly-input negative examples. By contrast, Rebele et al.[17] proposed a novel way to generalize a given regex to accept the given positive examples. On the other hand, works in the second paradigm consider both positive and negative examples. Pan et al.[10] designed RFixer, a tool for repairing incorrect regexes using both examples. It used skeletons of regexes to prune out the search space effectively, and it employed SMT solvers to efficiently explore the sets of possible character classes and numerical quantifiers. Our work is similar to their work, yet differs in the effectiveness and quality of repaired regexes - we consider not only the correctness but also the ReDoS-invulnerability of the regexes.
3 System Design and Implementation
3.1 MetaParam
This subsection proposes a MapReduce-based Parameter abstraction approach, extracting the common features of an ocean of examples. Based on this, we can cluster examples and then compute the frequency of each MetaParam.
As shown in Algorithm 1, we take a two-stage approach: Mapper and Reducer, to extract common example features from an ocean of values. We emphasize two types of example features: character analysis and character relative sequence analysis. There are two main stages of the example abstraction:
Mapper: In the mapper stage, we mainly focus on extracting the local features of each example. Specifically,
-
•
Extracting Common Subsequence will extract the longest common subsequences in the example set .
-
•
Transformer And Compress will translate a specific example into an abstract form. The translation rules are as follows(See Table 1):
Table 1: Transform Rules Representation Description z The Chinese character x English lowercase characters X English uppercase characters d Number Other characters reserved The transformer stage is responsible for abstract examples. For instance, the number will be abstracted as , and the compressing stage will further translate it into a character .
Reducer: In this stage, the local example features are combined to extract the global features of examples. Crucially, we merge the MetaParams produced in the Mapper stage and compute the frequency of each MetaParam.
3.2 Outlier Filtering
To efficiently filter out outliers in massive examples, gMeta adopts a bottom-up strategy at the MetaParam level to shrink the solution space. More specifically, gMeta filters out most low-frequency MetaParam and then translate the remaining potentially normal examples into regular expressions.
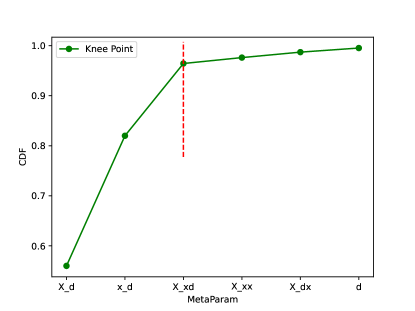
Theorem 3.1
Given a large number of examples, the number of "abnormal" examples in real industrial scenarios is usually much less than those of "normal" ones.
Similar to those anomaly detection algorithms, we apply a threshold to decide whether the MetaParam is an anomaly or not. Figure 1 shows the cumulative distribution of MetaParam frequencies. The skewed distribution naturally allows us to apply the knee-point method to pick the knee-point as the anomaly threshold automatically. For example, the vertical dashed line in Figure 1 marks the threshold the knee method gives for this example.
As shown in Figure 1, examples of abstract form X_d, x_d and x_xd will be parsed as regular expressions, respectively. Note that here we generate a regular expression for each MetaParam.
3.3 Regular Expression Generation
Given a set of normal examples, this stage will generate a finite of highly available regular expressions.
3.3.1 Template Generation
As shown in Figure 3, the template mainly comprises two types of elements, slot and character (i.e., the longest common subsequence). We extract the longest common subsequence in multiple normal examples to serve as template anchors, which can effectively capture common character features and relative position information between strings. Then, a variable component slot will be added to the middle of all non-consecutive common characters.
3.3.2 Slot Generation
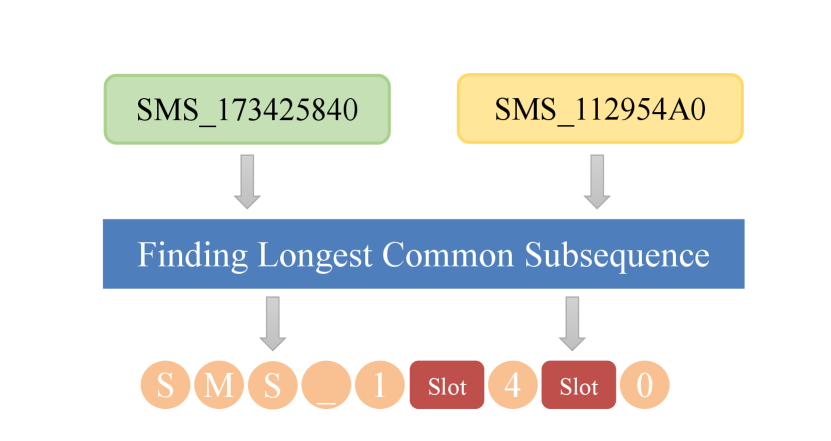
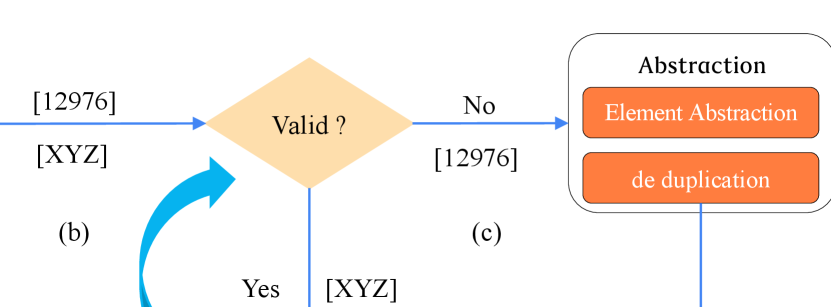
Figure 3(A) exhibits the abstract slot form, and Figure 3(B) is a slot example. Characters are short-hand notations for denoting the disjunction of a set of characters ( is equivalent to . Quantifiers are used to define the range of valid counts of a repetitive sequence. For instance, looks for a sequence of a’s of length at least and at most . Mode indicates the matching mode; for example, character denotes a non-greedy match. The regex learning task addressed in this subsection can now be formally stated as the following optimization problem:
Defination 1
Given a finite of strings, how to generate an appropriate regular expression, i.e., slot in this paper.
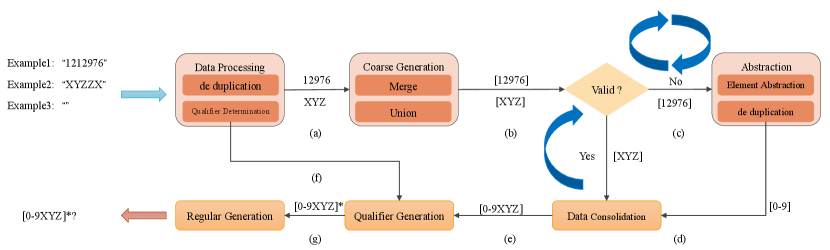
Figure 4 exhibits a running example of slot generation, and the steps are as follows:
-
•
The data processing module mainly plays two roles; one is to deduplicate the example. The second is to compute the length information of the string and pass the length information to the module Qualifier Generation.
-
•
The coarse-grained regular expression generation module generates a regular expression via adding special characters "[" and "]" on both sides of the string produced by the data processing module.
-
•
The valid module determines whether the generated coarse-grained regular expression is valid. In this paper, we limit the number of characters in the regular expression(i.e., The number of characters is less than 4).
-
•
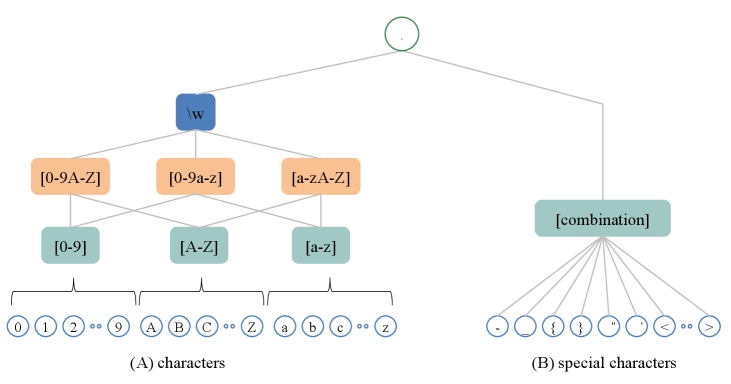
The abstraction module further abstracts coarse-grained regular expressions that do not satisfy predefined rules. As shown in Figure 5, the characters at the level closest to the leaf node in are abstracted upward (i.e., the parent node level). For instance, character 0 will be abstracted as its parent nodes [0-9], and the further abstracted regular expressions will be deduplicated. If the results still do not satisfy predefined rules, the abstract process will be repeated until they meet the requirements.
-
•
The data consolidation module is responsible for merging multiple single regular expressions.
-
•
The qualifier generation module generates qualifiers according to the length information of the strings. For example, if there is an empty string, the qualifier will be set to "*".
-
•
The regular expression generation module will wrap the final result, such as adding "/ " for special characters "." .
4 Evaluation
This section presents an empirical study of the gMeta algorithm using four extraction tasks over three real-life data sets and a real Industrial scene dataset. This study aims to evaluate the effectiveness of gMeta and investigate how it compares with existing automatic regular expression generation work.
4.1 Experimental Setup
4.1.1 Datasets
We use 4 datasets presented in ReLIE[16] to validate the effectiveness of gMeta. The ReLIE dataset111http://dbgroup.eecs.umich.edu/project/regexLearning/ includes four tasks (phone numbers, course numbers, software names, and URLs). Each task comes with a set of documents. Each document contains a span of words and 100 characters of context to the left and right. Each span is annotated as a positive or a negative example. We manually cleaned the dataset by fixing obvious annotation errors, e.g., where a word is marked as a positive and a negative example in the same task. In total, the dataset contains 90807 documents. Furthermore, we construct a dataset named AliRegex, which contains an ocean of examples containing outliers extracted from API call logs.
4.1.2 Measures
We evaluated the precision, recall, and F-measure of gMeta on multiple datasets. In detail, we count an extraction when some (non-empty) string has been extracted from an example and a correct extraction when exactly the (non-empty) string associated with a positive example has been extracted. Accordingly, the precision of a regular expression is the ratio between the number of correct extractions and the number of extractions. The recall is the ratio between the number of correct extractions and the number of positive examples; F-measure is the harmonic mean of precision and recall. Note that the formula for computing precision on datasets containing anomalous examples is as follows:
| (1) |
4.2 Results
| Task | Dataset | Results (%) | ||
|---|---|---|---|---|
| Learning | Testing | F-measure | ||
| 25 | 12 | |||
| Phone Number | 50 | 25 | ||
| 100 | 50 | |||
| 25 | 12 | |||
| Course Number | 50 | 25 | ||
| 100 | 50 | |||
| Software Name | 25 | 12 | ||
| 50 | 25 | |||
| 100 | 50 | |||
| Urls | 25 | 12 | ||
| 50 | 25 | |||
| 100 | 50 | |||
Let Learning in Table 2 denotes how many examples are used to generate the regular expression. For example, Learning 12 means that gMeta will randomly sample 12 examples to generate a regular expression. We executed an extensive suite of experiments by varying the size of the learning set, as summarized in Table 2. The performance of gMeta on the four datasets varies widely. From the perspective of F1 indicators, the order from high to low is:
| (2) |
We find that gMeta has significant scene applicability. Specifically, gMeta usually works well if the correct expression contains fixed characters, special characters, or specific length information. However, if the example does not contain some implicit pattern, gMeta’s performance is not as good as it should be.
| gMeta | ReLIE | gMeta | ReLIE | gMeta | ReLIE | |
| AliRegex | ||||||
As shown in Table3, we compare the effectiveness of gMeta and ReLIE on datasets containing outliers, gMeta performs significantly better than ReLIE.
5 Conclusions
We have proposed a template-based approach for the automatic generation of regular expressions. The approach requires only a set of examples to describe the extraction task and does not require any hint about the regular expression that solves that task. Users thus require no specific skills in regular expressions. We assessed our proposal on three datasets from different application domains. The results in terms of precision are promising, even if compared to earlier state-of-the-art proposals ReLIE. The execution time is sufficiently short of making the approach practical. Crucially, different from previous research on automatic regular expression generation, gMeta no longer assumes that all input examples are correct but considers the existence of outliers, making gMeta more robust and scalable. The template-based generation method allows users to make targeted adjustments to make the generated regular expressions more aligned with industrial requirements. In addition, gMeta does not seek to cover all cases with one regular expression. Usually, gMeta will generate several regular expressions. In this case, we can significantly reduce the complexity of a single regular expression. Although the number of regular expressions has increased, their execution efficiency is still very optimistic in the current case of parallel computing.
6 Acknowledgments
This work was supported by Alibaba Group through Alibaba Innovative Research Program.
References
- [1] Ahmad, M.B.S., Cheung, A.: Leveraging parallel data processing frameworks with verified lifting. In: Piskac, R., Dimitrova, R. (eds.) Proceedings Fifth Workshop on Synthesis, SYNT@CAV 2016, Toronto, Canada, July 17-18, 2016. EPTCS, vol. 229, pp. 67–83 (2016). https://doi.org/10.4204/EPTCS.229.7, https://doi.org/10.4204/EPTCS.229.7
- [2] de Almeida Farzat, A., de Oliveira Barros, M.: Automatic generation of regular expressions for the regex golf challenge using a local search algorithm. Genet. Program. Evolvable Mach. 23(1), 105–131 (2022). https://doi.org/10.1007/s10710-021-09411-x, https://doi.org/10.1007/s10710-021-09411-x
- [3] Barrero, D.F., Rodríguez-Moreno, M.D., Camacho, D.: Adapting searchy to extract data using evolved wrappers. Expert Syst. Appl. 39(3), 3061–3070 (2012). https://doi.org/10.1016/j.eswa.2011.08.168, https://doi.org/10.1016/j.eswa.2011.08.168
- [4] Bartoli, A., Davanzo, G., Lorenzo, A.D., Medvet, E., Sorio, E.: Automatic synthesis of regular expressions from examples. Computer 47(12), 72–80 (2014). https://doi.org/10.1109/MC.2014.344, https://doi.org/10.1109/MC.2014.344
- [5] Bartoli, A., Lorenzo, A.D., Medvet, E., Tarlao, F.: Playing regex golf with genetic programming. In: Arnold, D.V. (ed.) Genetic and Evolutionary Computation Conference, GECCO ’14, Vancouver, BC, Canada, July 12-16, 2014. pp. 1063–1070. ACM (2014). https://doi.org/10.1145/2576768.2598333, https://doi.org/10.1145/2576768.2598333
- [6] Bartoli, A., Lorenzo, A.D., Medvet, E., Tarlao, F.: Active learning of predefined models for information extraction: Selecting regular expressions from examples. In: Tallón-Ballesteros, A.J. (ed.) Fuzzy Systems and Data Mining V - Proceedings of FSDM 2019, Kitakyushu City, Japan, October 18-21, 2019. Frontiers in Artificial Intelligence and Applications, vol. 320, pp. 645–651. IOS Press (2019). https://doi.org/10.3233/FAIA190232, https://doi.org/10.3233/FAIA190232
- [7] Bex, G.J., Gelade, W., Neven, F., Vansummeren, S.: Learning deterministic regular expressions for the inference of schemas from XML data. In: Huai, J., Chen, R., Hon, H., Liu, Y., Ma, W., Tomkins, A., Zhang, X. (eds.) Proceedings of the 17th International Conference on World Wide Web, WWW 2008, Beijing, China, April 21-25, 2008. pp. 825–834. ACM (2008). https://doi.org/10.1145/1367497.1367609, https://doi.org/10.1145/1367497.1367609
- [8] Bex, G.J., Neven, F., Schwentick, T., Vansummeren, S.: Inference of concise regular expressions and dtds. ACM Trans. Database Syst. 35(2), 11:1–11:47 (2010). https://doi.org/10.1145/1735886.1735890, https://doi.org/10.1145/1735886.1735890
- [9] Brüggemann-Klein, A.: Unambiguity of extended regular expressions in SGML document grammars. In: Lengauer, T. (ed.) Algorithms - ESA ’93, First Annual European Symposium, Bad Honnef, Germany, September 30 - October 2, 1993, Proceedings. Lecture Notes in Computer Science, vol. 726, pp. 73–84. Springer (1993). https://doi.org/10.1007/3-540-57273-2_45, https://doi.org/10.1007/3-540-57273-2_45
- [10] Chida, N., Terauchi, T.: Automatic repair of vulnerable regular expressions. CoRR abs/2010.12450 (2020), https://arxiv.org/abs/2010.12450
- [11] Ellis, K., Gulwani, S.: Learning to learn programs from examples: Going beyond program structure. In: Sierra, C. (ed.) Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017. pp. 1638–1645. ijcai.org (2017). https://doi.org/10.24963/ijcai.2017/227, https://doi.org/10.24963/ijcai.2017/227
- [12] Feng, Y., Martins, R., Geffen, J.V., Dillig, I., Chaudhuri, S.: Component-based synthesis of table consolidation and transformation tasks from examples. In: Cohen, A., Vechev, M.T. (eds.) Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2017, Barcelona, Spain, June 18-23, 2017. pp. 422–436. ACM (2017). https://doi.org/10.1145/3062341.3062351, https://doi.org/10.1145/3062341.3062351
- [13] Gulwani, S.: Automating string processing in spreadsheets using input-output examples. In: Ball, T., Sagiv, M. (eds.) Proceedings of the 38th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2011, Austin, TX, USA, January 26-28, 2011. pp. 317–330. ACM (2011). https://doi.org/10.1145/1926385.1926423, https://doi.org/10.1145/1926385.1926423
- [14] Kushman, N., Barzilay, R.: Using semantic unification to generate regular expressions from natural language. In: Vanderwende, L., III, H.D., Kirchhoff, K. (eds.) Human Language Technologies: Conference of the North American Chapter of the Association of Computational Linguistics, Proceedings, June 9-14, 2013, Westin Peachtree Plaza Hotel, Atlanta, Georgia, USA. pp. 826–836. The Association for Computational Linguistics (2013), https://aclanthology.org/N13-1103/
- [15] Lee, M., So, S., Oh, H.: Synthesizing regular expressions from examples for introductory automata assignments. In: Fischer, B., Schaefer, I. (eds.) Proceedings of the 2016 ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences, GPCE 2016, Amsterdam, The Netherlands, October 31 - November 1, 2016. pp. 70–80. ACM (2016). https://doi.org/10.1145/2993236.2993244, https://doi.org/10.1145/2993236.2993244
- [16] Li, Y., Krishnamurthy, R., Raghavan, S., Vaithyanathan, S., Jagadish, H.V.: Regular expression learning for information extraction. In: 2008 Conference on Empirical Methods in Natural Language Processing, EMNLP 2008, Proceedings of the Conference, 25-27 October 2008, Honolulu, Hawaii, USA, A meeting of SIGDAT, a Special Interest Group of the ACL. pp. 21–30. ACL (2008), https://aclanthology.org/D08-1003/
- [17] Rebele, T., Tzompanaki, K., Suchanek, F.M.: Adding missing words to regular expressions. In: Phung, D.Q., Tseng, V.S., Webb, G.I., Ho, B., Ganji, M., Rashidi, L. (eds.) Advances in Knowledge Discovery and Data Mining - 22nd Pacific-Asia Conference, PAKDD 2018, Melbourne, VIC, Australia, June 3-6, 2018, Proceedings, Part II. Lecture Notes in Computer Science, vol. 10938, pp. 67–79. Springer (2018). https://doi.org/10.1007/978-3-319-93037-4_6, https://doi.org/10.1007/978-3-319-93037-4_6
- [18] Sidhu, R., Prasanna, V.K.: Fast regular expression matching using fpgas. In: The 9th Annual IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM’01). pp. 227–238. IEEE (2001)
- [19] Wang, C., Cheung, A., Bodík, R.: Synthesizing highly expressive SQL queries from input-output examples. In: Cohen, A., Vechev, M.T. (eds.) Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2017, Barcelona, Spain, June 18-23, 2017. pp. 452–466. ACM (2017). https://doi.org/10.1145/3062341.3062365, https://doi.org/10.1145/3062341.3062365
- [20] Wang, X., Gulwani, S., Singh, R.: FIDEX: filtering spreadsheet data using examples. In: Visser, E., Smaragdakis, Y. (eds.) Proceedings of the 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA 2016, part of SPLASH 2016, Amsterdam, The Netherlands, October 30 - November 4, 2016. pp. 195–213. ACM (2016). https://doi.org/10.1145/2983990.2984030, https://doi.org/10.1145/2983990.2984030
- [21] Yaghmazadeh, N., Klinger, C., Dillig, I., Chaudhuri, S.: Synthesizing transformations on hierarchically structured data. In: Krintz, C., Berger, E.D. (eds.) Proceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2016, Santa Barbara, CA, USA, June 13-17, 2016. pp. 508–521. ACM (2016). https://doi.org/10.1145/2908080.2908088, https://doi.org/10.1145/2908080.2908088
- [22] Zhang, S., He, L., Vucetic, S., Dragut, E.: Regular expression guided entity mention mining from noisy web data. In: Proceedings of the 2018 conference on empirical methods in natural language processing. pp. 1991–2000 (2018)