GNN-based Decentralized Perception in Multirobot Systems for Predicting Worker Actions
Abstract
In industrial environments, predicting human actions is essential for ensuring safe and effective collaboration between humans and robots. This paper introduces a perception framework that enables mobile robots to understand and share information about human actions in a decentralized way. The framework first allows each robot to build a spatial graph representing its surroundings, which it then shares with other robots. This shared spatial data is combined with temporal information to track human behavior over time. A swarm-inspired decision-making process is used to ensure all robots agree on a unified interpretation of the human’s actions. Results show that adding more robots and incorporating longer time sequences improve prediction accuracy. Additionally, the consensus mechanism increases system resilience, making the multi-robot setup more reliable in dynamic industrial settings.
I Introduction
Collaborative robots are poised to become a cornerstone of Industry 5.0 [1], emphasizing human-centric design solutions to meet the flexibility demands of hyper-customized industrial processes [2]. Significant efforts have been directed toward identifying key enabling technologies to enhance robotic systems with advanced situational awareness and robust safety features for human coworkers. Two pivotal technologies stand out: individualized human-machine interaction systems that merge the strengths of humans and machines, and the application of AI to improve workplace safety [3].
In highly collaborative and hazardous scenarios such as manufacturing facilities, robots must develop a holistic understanding of their environment to ensure efficiency and safety. While humans excel at anticipating events due to their spatial reasoning, understanding of others’ behavior, and planning under uncertainty [4], robotic systems lack such innate capabilities. However, they can leverage distributed sensing networks and algorithms to model spatial and temporal relationships within a scene.



Algorithms for predicting human behavior and future actions have been explored across domains such as pedestrian crossing prediction [5, 6, 7], intent interpretation in assistive robotics [8, 9], and forecasting human poses in collaborative workspaces [10, 11]. Most approaches rely on human detection and tracking, using local features like pose, velocity, and location [12, 13, 14, 15]. However, these methods often overlook the relationships between humans and surrounding objects, leading to poor performance when encountering unfamiliar human behavior and limiting their ability to anticipate further into the future.
Recent advancements in graph-based models show good potential for spatiotemporal intent prediction [16]. They demonstrate the potential of graph formalisms to emphasize relationships between entities rather than their individual properties, offering generalizable insights [17]. In parallel, Graph Neural Networks (GNNs) have gained prominence in applications such as multi-robot path planning [18], collaborative perception [19], and navigation in complex environments [20]. Building on this foundation, we extend GNN-based approaches to scenarios with a broader range of human actions, leveraging multi-robot systems to develop a shared understanding of the environment.
Multi-robot systems provide significant advantages over single-robot systems, including enhanced robustness, scalability, and flexibility [21]. While many implementations rely on centralized control, a decentralized approach offers additional benefits, such as improved system flexibility and fault tolerance [22]. Decentralization, however, presents its own challenges, particularly in achieving effective coordination and collective decision-making among robots [23]. These challenges arise because, in the absence of a central controller, robots must rely on distributed algorithms to interpret their environment and align their actions.
Consensus mechanisms in swarm intelligence have been widely explored to address these issues. In decentralized multi-robot systems, such as those used in swarm robotics, consensus ensures that robots can collectively make coherent decisions even with diverse inputs and local observations. In decentralized multi-robot systems, such as swarms of robots, consensus can be achieved using strategies like majority voting [24], ranked voting systems [25], and entropy-based local negotiation [26]. These methods enable efficient decision alignment while accommodating sensor variability and differences in information quality.
Our shared perception intent prediction pipeline employs graph-based methods to facilitate information exchange between robots. Implemented in ROS, the pipeline integrates data from multiple robots to model spatial relationships between humans and nearby objects using GNNs and temporal relations with Recurrent Neural Networks (RNNs), enabling accurate human intent prediction. This multi-robot strategy enhances robustness by compensating for individual sensor failures and ensuring safety in industrial environments.
The main contributions of this paper are as follows:
-
•
Development of a spatial understanding module leveraging graph neural networks to model relationships between humans and nearby objects.
-
•
Introduction of a temporal understanding module that aggregates spatial data from other robots in a decentralized manner to predict and forecast human actions.
-
•
Integration of a swarm intelligence-inspired consensus mechanism to ensure decision convergence across all robots in the system.
II Method
II-A Problem statement
In manufacturing setups, numerous dynamic processes such as machining, assembly, and material handling occur simultaneously. Human workers perform multiple tasks like machine tending and assembly, requiring adaptability. These dynamic conditions pose significant challenges for robots, which must operate efficiently while prioritizing human safety.
Although manufacturing represents just one subset of potential robot deployment scenarios, it serves as a baseline and motivation for designing our multi-robot system. We define intent prediction as the anticipation of a human operator’s future action within a specific time horizon. For this study, we consider time horizons of 1s, 2s, and 3s into the future, based on the Stopping time and distance metric outlined in ISO 10218-1:2011 safety standards, Annex B(normative) [27]. This metric relates to the time required for a robot to detect a human, initiate deceleration, and come to a complete stop, which establishes the minimum threshold for the perception pipeline’s prediction capabilities. Given the relatively low speeds of industrial mobile robots111MiR250 [28] and Otto 1500 [29] both have a top speed of 2.0 m/s, the selected time horizons are deemed sufficient for safety and operational efficiency. For instance, if a human is detected at a distance of 8 meters while both the robot and the human are moving towards each other, the robot has less than 2 seconds to react222Assuming a combined closing speed of 4.1 m/s (robot at 2.5 m/s and human at 1.6 m/s), the time to collision is approximately 1.95 seconds when starting 8 meters apart.. Instead of performing an emergency stop, our system can utilize intent prediction to smoothly adjust the robot’s path and avoid potential collisions by predicting into the future.
To evaluate our approach, we modeled a small manufacturing facility where multiple operations occur simultaneously. A human operator attends to various tasks while robots navigate the environment. The operator does not follow predefined or straight paths due to the dynamic nature of the tasks and the need to maneuver around moving robots. This unpredictability, coupled with robot mobility, increases the complexity of perception and intent prediction.
The modeled environment includes four key stations, each representing distinct human actions:
-
1.
Storage Area: Retrieving items from storage shelves.
-
2.
Workstation: Performing tasks at a workstation.
-
3.
Assembly Station: Assembling components.
-
4.
Manufacturing Station: Operating manufacturing equipment.
In this setup, the intent prediction problem consists in predicting the workers movement toward one of these stations. By analyzing the human’s trajectory and interaction with the environment, the model infers which station the human is heading toward, thereby determining their intended action.
II-B System Overview
Figure 2 shows an overview of the system architecture. The system is activated only when a human is detected in the scene. The image processing pipeline extracts objects from the scene, constructs graph structures, and quantifies the robot’s visibility (Section II-C). These graph structures are then processed through a Graph Neural Network (GNN) (Section II-D), generating a prediction for the current time step based on spatial understanding. Additionally, node embeddings from the final GNN layer are extracted and shared with other robots in the system. These embeddings are combined with human pose keypoints from an off-the-shelf object detection algorithm over time to form a sequence. This sequence is passed through a Recurrent Neural Network (RNN), chosen based on whether an ego-centric or collective prediction is required (see Section II-E). The RNN outputs predictions for the current time step and forecasts actions for future timesteps. The predicted output for the current timestep and a confidence value from the calibrated RNN are shared with other robots. This shared information is then processed within a swarm intelligence-inspired consensus mechanism (see Section II-G), where weighted calculations enable the multi-robot system to converge on a unified prediction.
| Serial No. | Category | Objects |
|---|---|---|
| 1 | Storage Area | Crates, Boxes, Pallets |
| 2 | Workstation | Desks, Chairs, Storage Drawers, |
| Computers | ||
| 3 | Assembly Station | Workbench, Chair |
| 4 | Manufacturing Station | CNC Machine, Table |
II-C Feature Extraction and Representation
We extract feature vectors for every object mentioned in Table I and the human in the scene using a ResNet50 [30] backbone, which outputs a one-dimensional vector of length 512. For each image, we construct a graph structure where each node represents a concatenation of two feature vectors. The first vector encodes the general appearance of the scene [31]. The second vector captures the local appearance of specific objects found in the image. Inspired by [31], we combine these global and local features by concatenating the two vectors, providing a comprehensive representation for each node in the graph.
II-D Spatial Relationship
To establish a spatial understanding of the scene, we represent the human and surrounding objects as a star-shaped graph, with the human positioned at the center. Each object is connected to the human node with undirected edges weighted by their Euclidean distances (derived from 2D bounding boxes). These edges form an adjacency matrix , which is augmented with self-loops to create a modified adjacency matrix . The node features, initially , are are iteratively transformed through a 2-layer Graph Convolutional Network (GCN) [32], leveraging the modified adjacency and degree matrices to aggregate information effectively. This shallow 2-layer GCN effectively handles simple star-shaped graphs, minimizing overfitting while ensuring efficient, real-time inference on resource-constrained robotic platforms. Further architectural details are available on the project website.
II-E Temporal Relationship
To grasp the temporal relationship of the scenario, at least two options have been leveraged in the literature: Gated Recurrent Units (GRUs) [33] and Long Short-Term Memory networks (LSTMs) [34]. We select the first due to their lower memory consumption and overall efficiency [35]. We have implemented two instances of GRUs: the ego-GRU and the collective-GRU. The ego-GRU processes information from the ego robot without incorporating data from other robots, while the collective-GRU processes aggregated information from multiple robots.
Implementing these two GRUs allows us to gain insights into the multi-robot system. We can evaluate how a single robot performs in understanding the spatial scene and processing temporal information. Additionally, we can assess the improvement in prediction accuracy when a robot incorporates information from other robots, as well as how much it contributes to the overall prediction accuracy of the system.
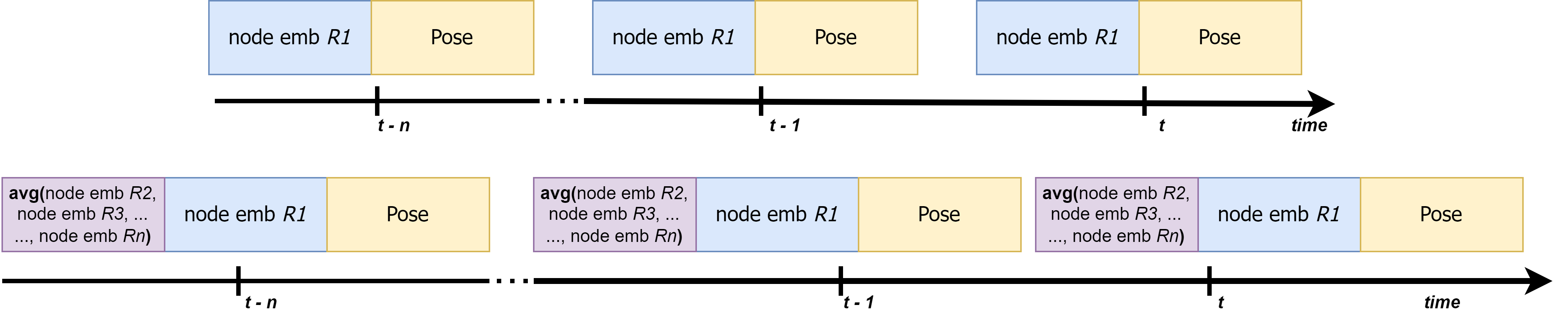
The input vectors for the ego-GRU and collective-GRU are illustrated in Figure 3. For the ego-GRU, we concatenate the output of the final layer of the GNN—which is a 1D vector of length 128—with the flattened output of the human keypoints detector (a 1D vector of length 34). This provides a local, ego-centric spatiotemporal prediction.
II-F Decentralized Collective Prediction
Messages are used to share node embeddings (outputs of GNNs from other robots) and combined in the collective-GRU model. We use Zenoh [36], which allows robots to share information efficiently and also serves as a middleware for ROS 2. We adopt a straightforward aggregation strategy, averaging all the node embeddings to produce a unified representation. This input format is designed to be both adaptable and scalable, as all inputs are reduced to a fixed-sized vector regardless of the number of participating robots. By leveraging this aggregated data, each robot enhances its predictions with information collected from other robots’ perspectives. However, at this stage, achieving convergence to a single, unified decision about human intent remains unresolved.
II-G Consensus Mechanism
To achieve consensus among multiple robots regarding human intent, we implement a consensus algorithm that aggregates individual predictions, weighting them by each robot’s visibility ratio and prediction confidence. Inspired by majority rule mechanisms in collective decision-making [37, 38, 39], this approach is designed to scale with varying numbers of robots.
We define the visibility ratio for each robot , where is the number of detections by robot and is the total number of detections across all robots. The prediction confidence is defined as , where is the logit score for the top selected class, and is a temperature parameter that tunes the softmax distribution. Let be the number of robots. We then normalize these values as and , where and denote the visibility ratio and confidence for each robot , respectively. The weighted vote for each robot is calculated as:
where and are scalar weights that balance the contributions of visibility and confidence, respectively. A higher visibility ratio indicates a more comprehensive view of the scene by robot . Each robot’s predicted action (from a four-class softmax) and its corresponding weighted vote are aggregated across all robots. For additional details, please refer to the project website.
III Experiments
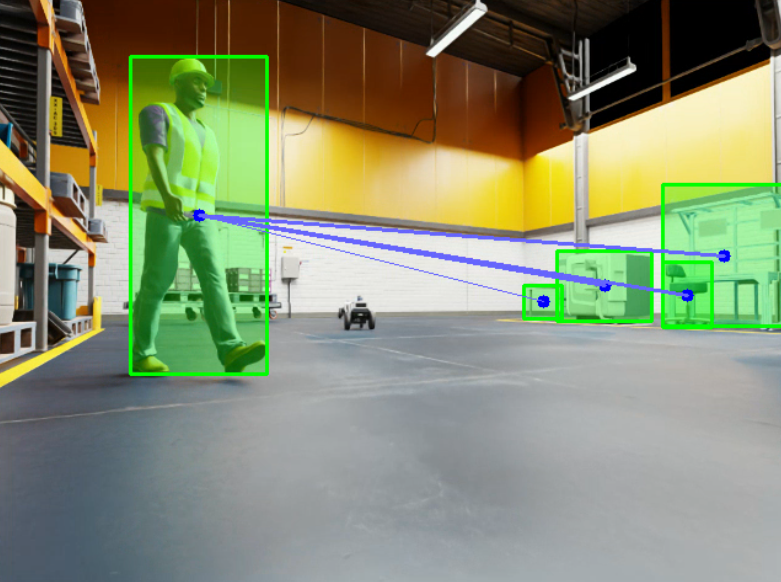
We evaluated our approach using a realistic simulation environment provided by NVIDIA’s IsaacSim [40]. This platform offers a lifelike industrial setting complete with ROS support, human trajectory planning, and synthetic dataset generation capabilities. The simulation environment we created is depicted in Figure 1.
Human motion and actions were simulated using IsaacSim’s default custom motion model [40], which incorporates reactive collision avoidance and velocity-based position estimation to navigate both static and dynamic obstacles. During experimentation, the human’s goal position for each station remained constant, while the initial position was randomly varied with each simulation run to generalize learning.
We deployed between one and four Carter robots [40] from IsaacSim’s library. Each robot operated independently, using its onboard sensors to perceive the environment. Robots shared their observations with others in the system, enabling collaborative inference of the human’s intended action.
III-A Evaluation Strategy
We perform simulation-in-the-loop testing, where the starting positions of the robots and the navigation paths differed from those used during training. Ground truth values and predictions were recorded, and the ground truth data was aggregated to match the length of the prediction horizon.
To evaluate the system’s ability to infer human actions under varying conditions, we designed a comprehensive strategy incorporating three distinct scenarios, each progressively increasing in difficulty. These scenarios tested the robustness and adaptability of the system in action inference:
Scenario 1: Ideal Conditions In the first scenario, there are no obstacles present in the environment, and the robots remain stationary. This setting allows the human worker to move in a straight path toward the intended station.
Scenario 2: Static Obstacles Introduced In the second scenario, we introduce static obstacles into the environment while keeping the robots stationary. The presence of obstacles forces the human to navigate around them, resulting in less predictable trajectories.
Scenario 3: Dynamic Environment with Moving Robots The third scenario is the most complex and dynamic. In addition to static obstacles, the robots are also moving within the environment. This creates a highly dynamic setting where both the human and the robots are in motion, and the scene changes continuously.
To further challenge the system, two of the stations were placed in close proximity - details of the environment layout are available on the website - testing the system’s ability to distinguish between similar actions when potential destinations were very close together.
To validate our approach, we compared its performance against two alternative methods inspired by prior work [16]:
Constant Velocity Model (CVM) The CVM is a non-deep learning approach that predicts future states based on simple velocity assumptions. Using an object detection algorithm, we tracked the human’s head to extract keypoints and employed a Kalman filter for temporal tracking. The twelve latest states are used to calculate the average velocity and predict the worker’s goal.
1D Convolutional Neural Network (1D-CNN) The 1D-CNN served as a baseline to evaluate whether simpler models could suffice without requiring graph neural networks (GNNs). Given the one-dimensional nature of the input data, a 1D-CNN aligns well with the task. We implemented a five-layer 1D-CNN architecture inspired by [41], adapting the input and output to suit our application. The node feature of the human was used as input, and the output was integrated with GRUs to function similarly to our spatiotemporal pipeline.
III-B Dataset
We collected three datasets corresponding to three different simulation scenarios. These datasets were designed to capture the motion, appearance, and state of human operator within the scene from the perspectives of multiple mobile robots positioned at various locations. The datasets consist of temporal sequences; each sequence is a set of frames where the human is either: moving towards a goal, transitioning from one goal to another, and stationary. To ensure effective learning, we maintained an equal distribution of all three cases. Moreover, since we are dealing with a multi-robot system, we extended the datasets to include sequences for all possible combinations involving two robots, three robots, and four robots, respectively. A standard split of 60%/20%/20% was implemented for training, validation, and testing.
IV Results and Discussion
We present the simulation results for data processed at 10 Hz. Overall, implementing a multi-layered, multi-robot perception strategy significantly enhanced the robustness of predictions. Table II shows the system’s performance across different simulation scenarios described in Section III. As expected, the accuracy of the system decreases in more challenging scenarios.
| Scenario | GNN | Ego% | Collective% | Consensus | ||
|---|---|---|---|---|---|---|
| % | [, ] | [, ] | % | |||
| Scenario 1 | 71.21 | 84.2 | 80.5 | 92.80 | 90.30 | 90.3 |
| Scenario 2 | 73.40 | 82.45 | 79.82 | 91.83 | 91.02 | 89.33 |
| Scenario 3 | 70.73 | 77.7 | 73.5 | 88.87 | 88.1 | 88.5 |
| Robot | GNN | Ego% | Collective% | Consensus | ||
|---|---|---|---|---|---|---|
| % | [, ] | [, ] | % | |||
| Robot 1 | 69.2 | 76.1 | 72.3 | 86.3 | 86.1 | 88.5 |
| Robot 2 | 72.90 | 79.2 | 75.1 | 91.8 | 90.5 | 88.5 |
| Robot 3 | 70.1 | 77.8 | 73.10 | 88.5 | 87.8 | 88.5 |
| Overall | 70.73 | 77.7 | 73.5 | 88.87 | 88.1 | 88.5 |
The GNN models, which rely solely on spatial information, demonstrate consistent accuracy across all scenarios. This consistency indicates that spatial features alone provide a stable but limited understanding of the environment. This can be explained based on the fact that these rely only on the spatial information albeit without leveraging temporal data. Consequently, their performance remains limited to immediate spatial relationships. In contrast, the collective-GRU consistently outperforms the ego-GRU across all scenarios, demonstrating the value of incorporating data from multiple robots.
The consensus mechanism plays a crucial role in enhancing the robustness of the multi-robot system’s decisions. By aggregating individual predictions weighted by confidence and visibility, it ensures that the system’s overall decision is less affected by individual inaccuracies. While the consensus accuracies are close to the highest individual model accuracies, they remain relatively stable across different scenarios, providing consistent performance.
This trend can also be seen in Table III, which provides deeper insights into the contributions of each robot. For instance, in a specific case with three robots, where the system observes 2 seconds of past data and predicts 2 seconds into the future, individual robot accuracies vary. However, the consensus mechanism consistently achieves stable overall accuracy, demonstrating its effectiveness in leveraging collective insights to enhance prediction robustness. This pattern holds across all robots.
Additionally, a noticeable drop in performance was observed for the two stations placed in close proximity to each other, as shown in Figure 7
IV-A Effect of Number of Robots
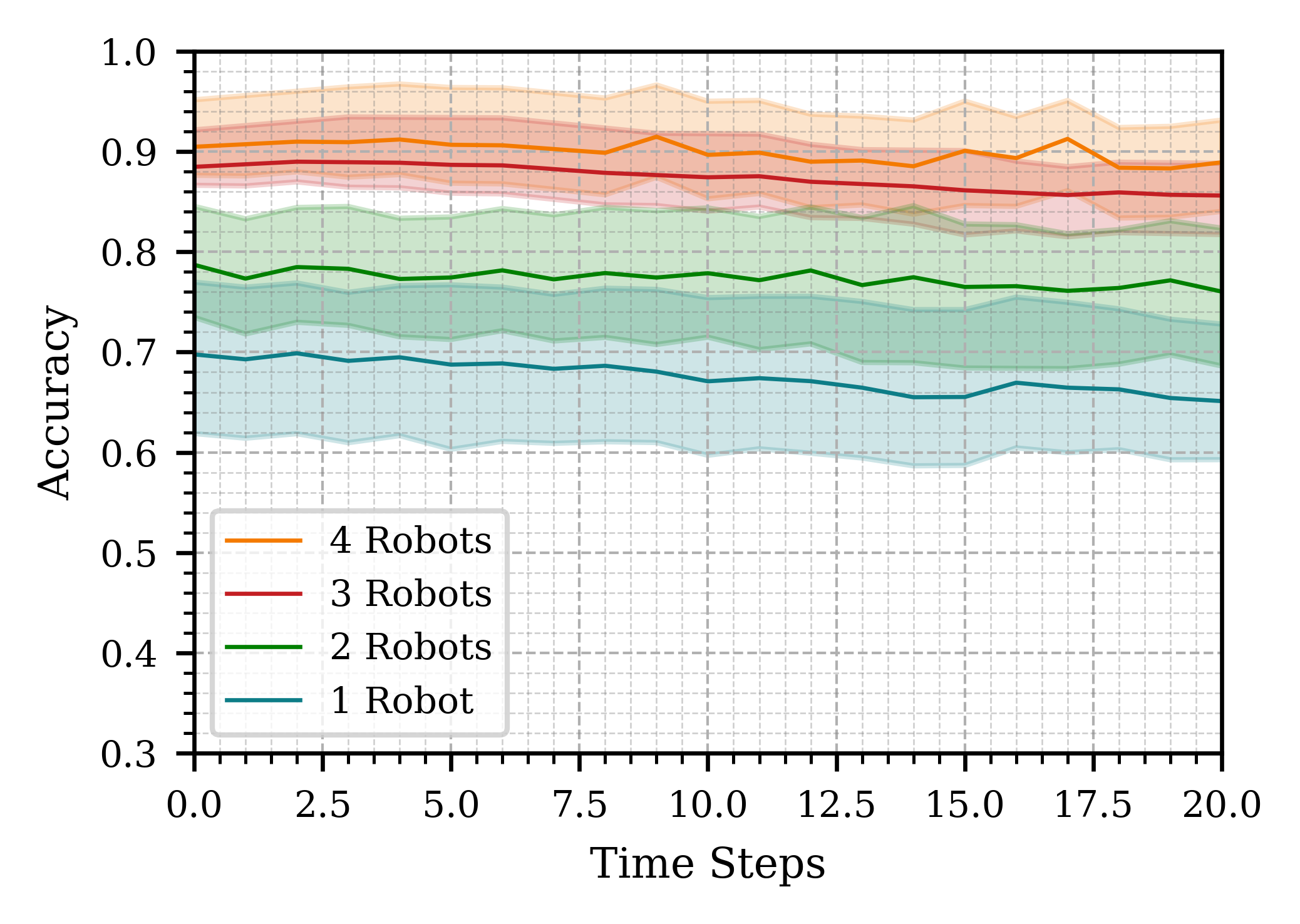
Figure 5 confirms the main advantage of our strategy: increasing the number of robots enhances the accuracy of action inference under the same conditions. For these experiments, we used Scenario 3 from our simulation setup (as described in Section III), observed data from the past 2 seconds, and predicted 2 seconds into the future while processing frames at 10Hz.
The results show a significant improvement in accuracy when increasing the number of robots from one to two, and from two to three. However, the improvement is less pronounced when adding a fourth robot. This diminishing return can be attributed to the observation that one of the four robots had a lower-quality view of the scene, resulting in reduced contributions to the collective perception. We hypothesize that further increasing the number of robots would enhance accuracy, as larger swarms tend to exhibit greater fault tolerance. In such cases, the impact of one or even several faulty robots is mitigated by the redundancy and diversity of functioning agents [42].
IV-B Time Horizon Analysis
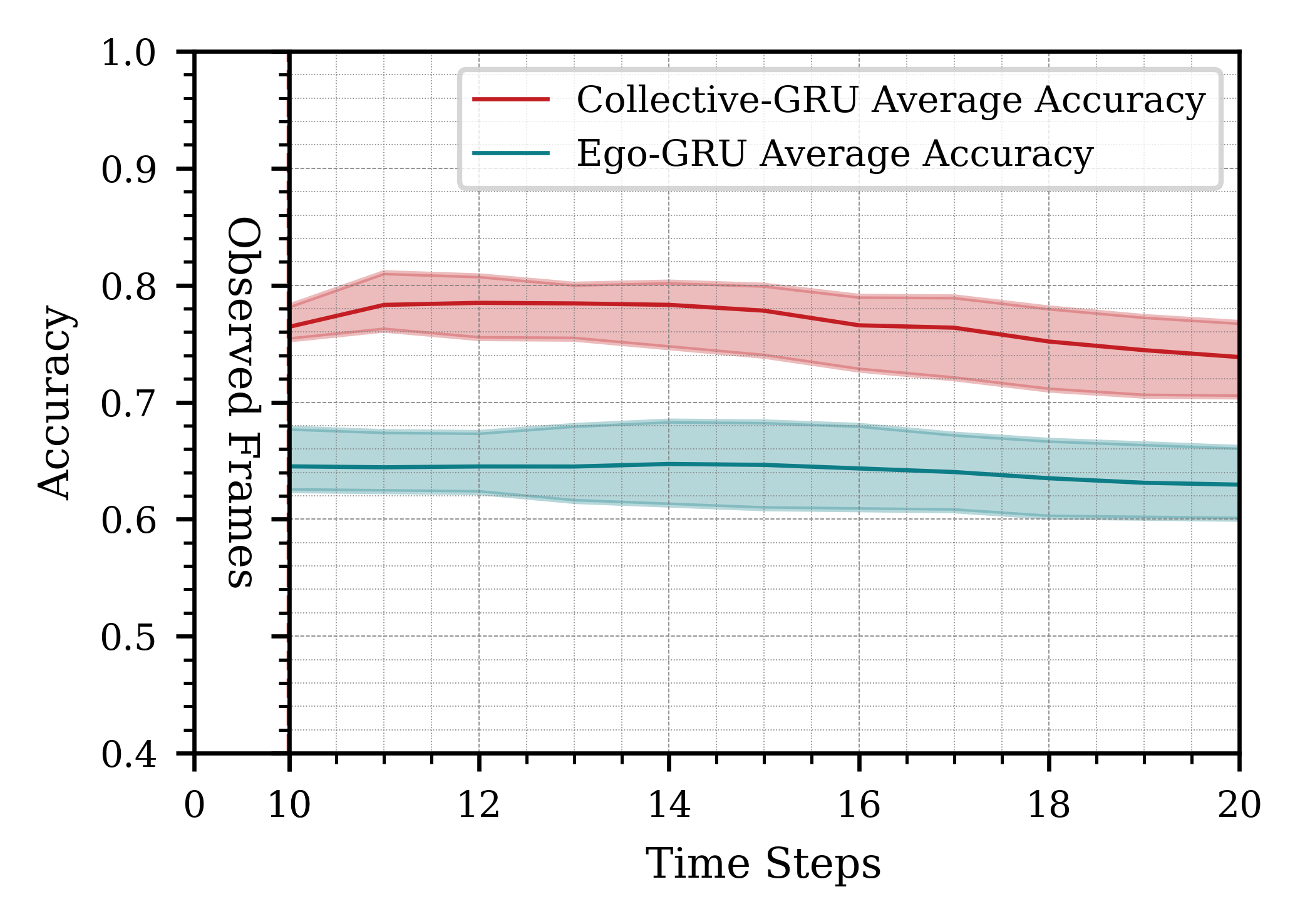
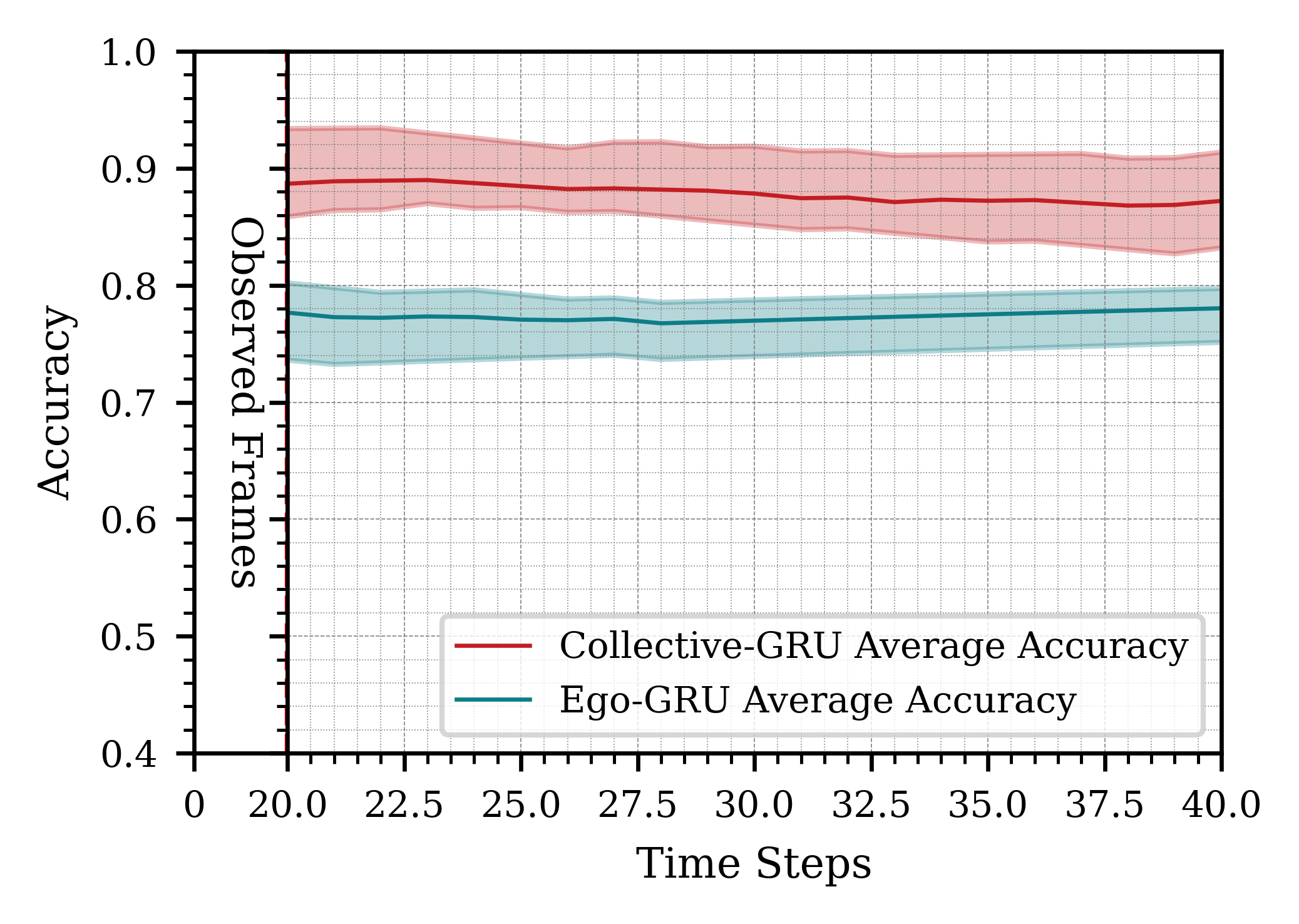
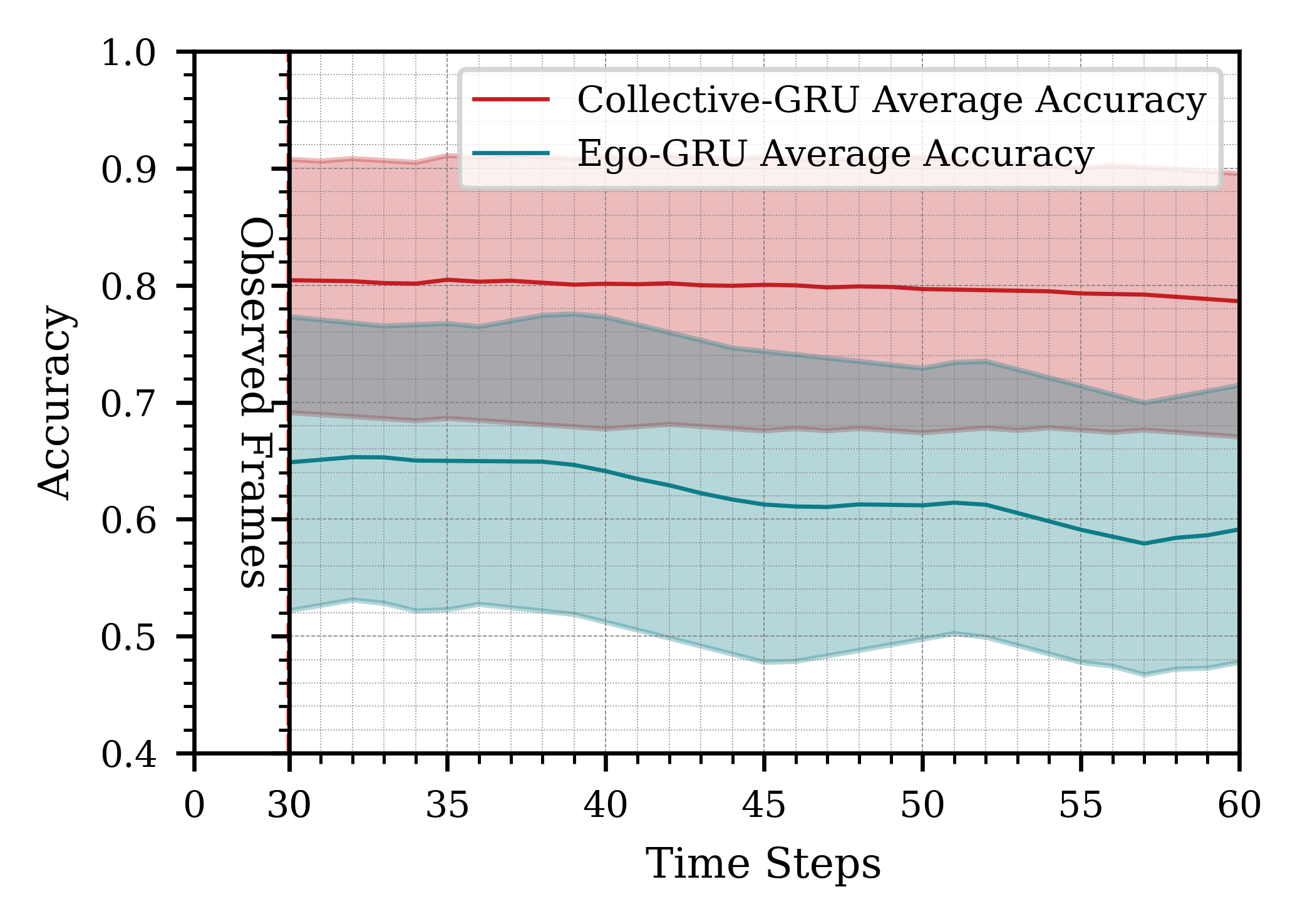
We present the results for different time horizons in Figure 4, comparing the performance of using one robot versus three robots, with all data processed at 10 Hz. Overall, the results show that having more past information improves prediction accuracy. Specifically, predictions based on 2 seconds (20 frames) of past data outperform those based on 1 second (10 frames). For these cases, predictions extend 10 and 20 frames into the future, respectively, demonstrating better performance with increased historical data aggregation.
When the observation and prediction windows were extended to 3 seconds (30 frames), the system’s performance became inconsistent. While the best-case predictions exceeded those of the 2-second case, the worst-case predictions were significantly worse. This inconsistency arises from the highly dynamic nature of the scene. Accumulating 30 frames increases the likelihood of encountering rapid movements or missed human detections, resulting in sequences of varying quality and more pronounced prediction fluctuations compared to shorter time horizons.
Additionally, processing longer time horizons required more computational resources and introduced greater latency. This highlights a trade-off between achieving higher potential accuracy and maintaining timely responsiveness, depending on the application’s requirements. For our purposes, a 2-second time window offered the optimal balance between prediction accuracy and system responsiveness.
IV-C Temporal resolution
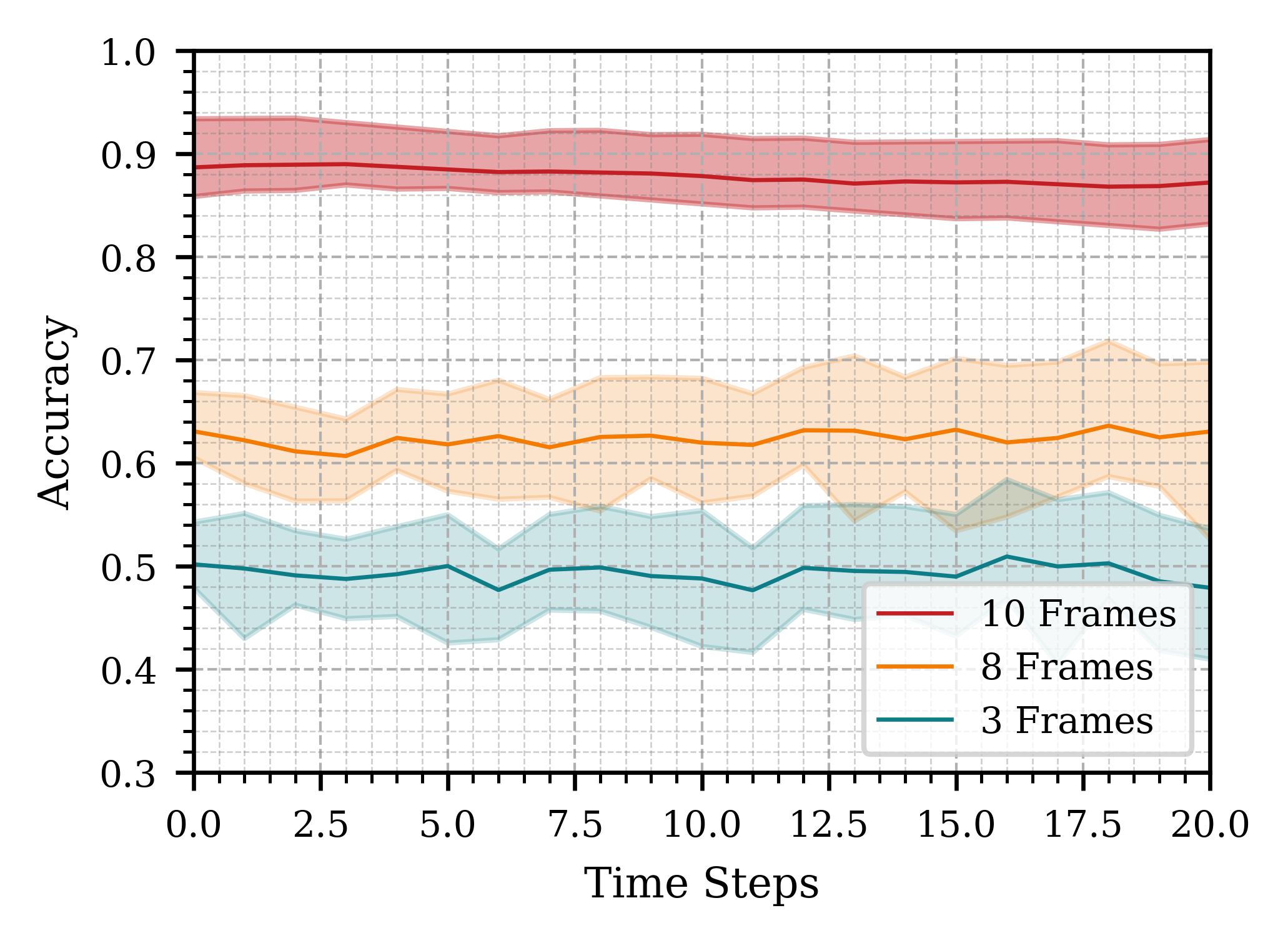
It is crucial to analyze how much temporal information is necessary to optimize computation and memory usage without compromising accuracy. We conducted additional experiments to compare the system’s performance based on the number of frames used for prediction. Processing frames at 10 fps, we examined the effect on accuracy when using all 10 frames, 5 frames, and 3 frames. At runtime, we first accumulate all 10 frames and then pick the required number of frames at uniform intervals. Figure 6 illustrates the results.
Our observations indicate that utilizing all 10 frames leads to better predictions, highlighting the importance of sufficient temporal data for accurate action inference.
| Serial No. | Model | Avg on Frame |
|---|---|---|
| 1 | GNN | 70.73% |
| 2 | Ego-GRU | 77.7% |
| 3 | Collective-GRU | 88.87% |
| 4 | CVM | 66.1% |
| 5 | 1D CNN | 63.31% |
| 6 | Collective-GRU + Consensus | 88.5% |
IV-D Comparison with Alternative Strategies
Table IV presents the results from Scenario 3 of the simulation, using a 2-second temporal window, and compares them against the CVM and 1D-CNN strategies. While the CVM [43] performs well in Scenario 1, where no obstacles are present and the human moves along a straight path, its accuracy significantly declines in more complex scenarios. Specifically, the CVM struggles to predict human actions when the human changes direction, remains stationary, or stops.
In contrast, our spatiotemporal approach outperforms the 1D-CNN, demonstrating the advantage of integrating spatial and temporal information through GNNs and GRUs. The combination of spatial modeling via GNNs and temporal modeling through RNNs provides a comprehensive understanding of the scene, capturing both relationships between objects and the temporal evolution of actions. This holistic perspective enables our spatiotemporal pipeline to deliver more accurate predictions than methods relying solely on temporal sequences (such as the 1D-CNN) or simplistic motion assumptions (as in the CVM).
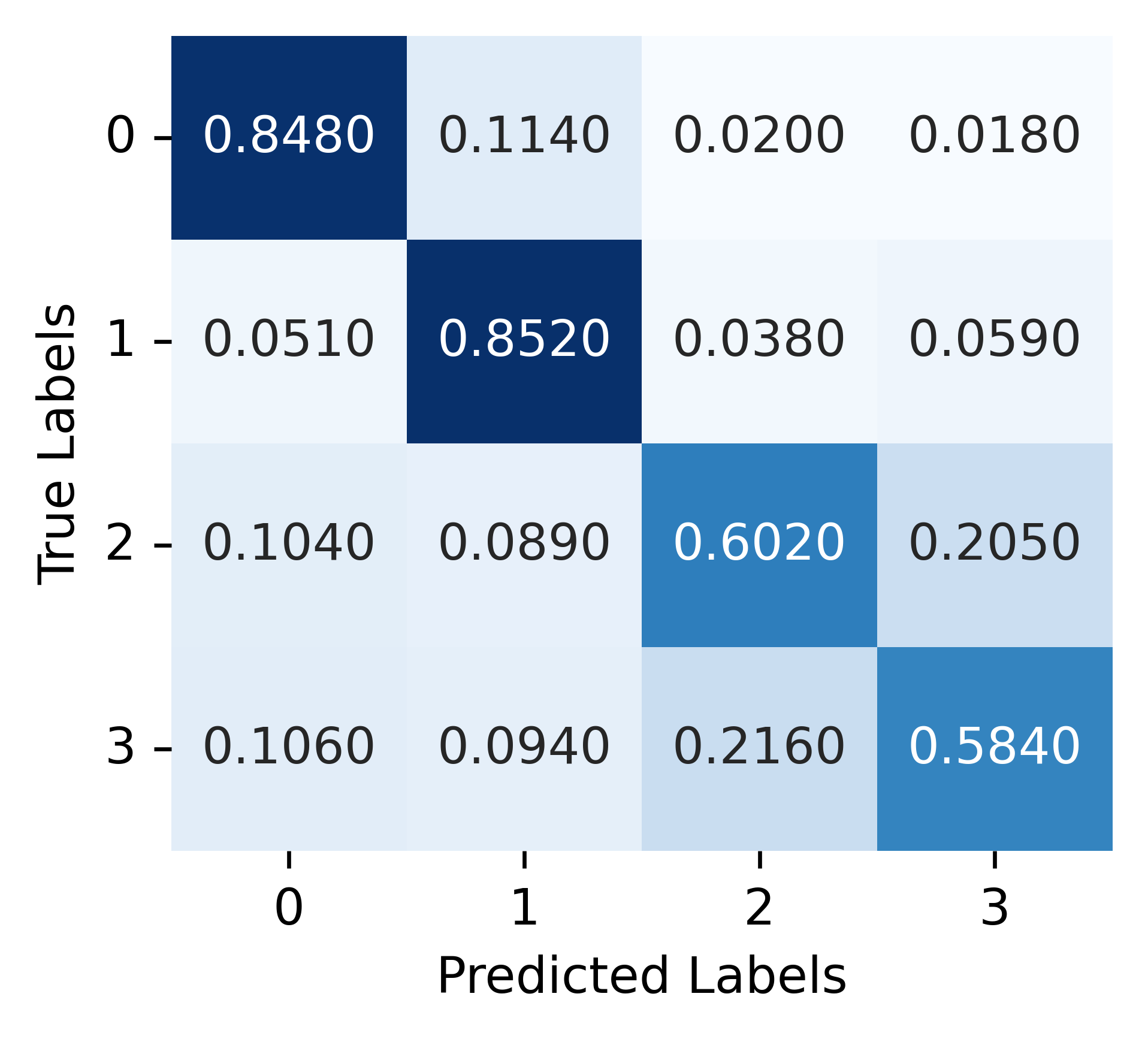
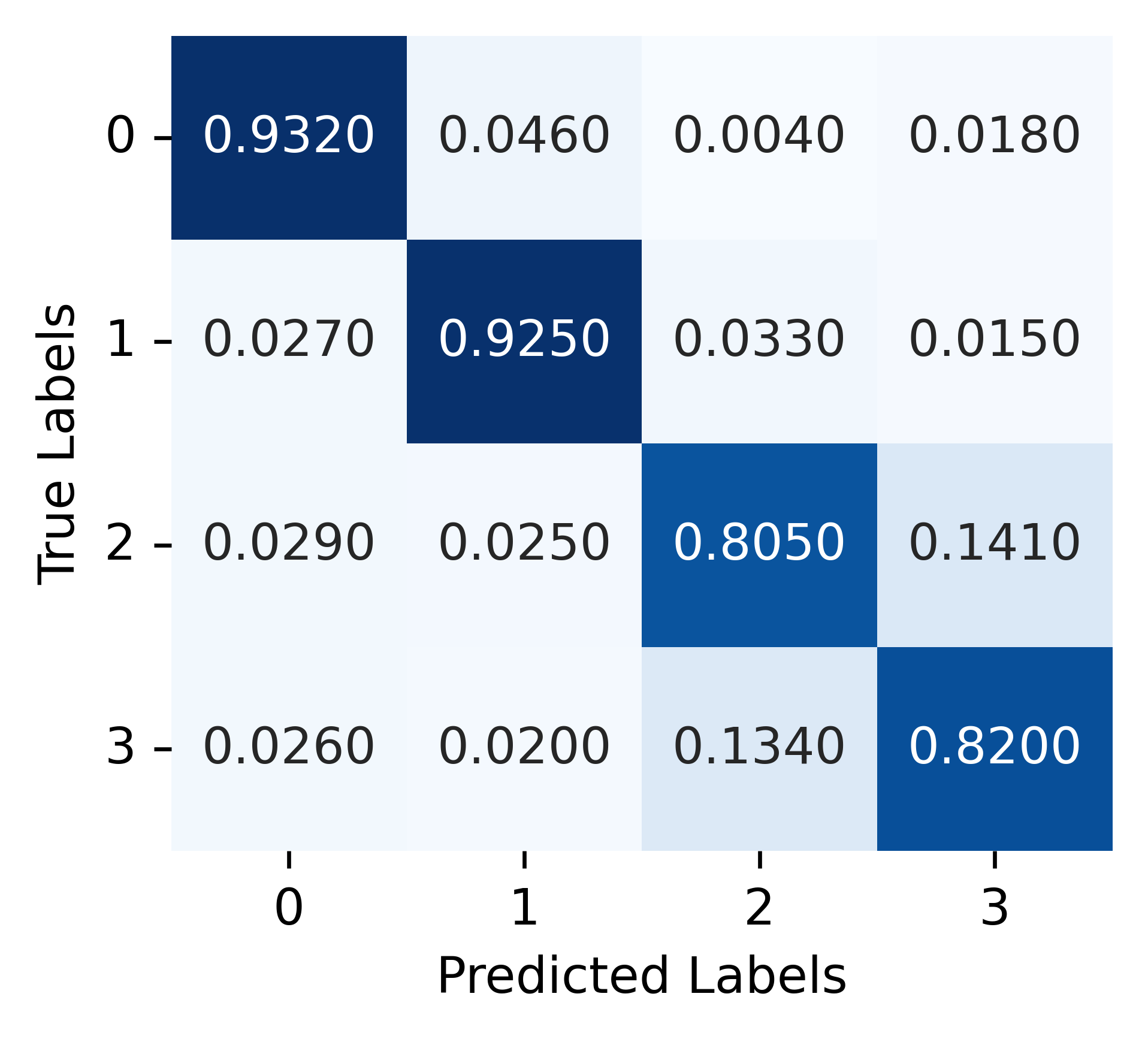
IV-E Additional performance parameters
Quality of graphs Robots with weaker or sparser graphs—where fewer objects in the scene are linked to the human node—tended to produce less accurate and more unpredictable predictions. The limited number of objects reduces the robot’s ability to model relationships within the scene effectively, leading to decreased prediction performance.
Furthermore, individual robot predictions improved when the graph explicitly linked the source (the human’s current position) to the destination (the intended goal or station). This highlights the importance of graph structures that capture critical relationships between key entities in the environment, as these connections enhance the robot’s spatial understanding.
Erroneous data in small teams In experiments with a relatively small multi-robot system of up to four robots, robots with weaker or sparser graphs not only made poor individual predictions but also negatively influenced the collective perception when their data was aggregated. This suggests that the quality of each robot’s perception plays a significant role in the effectiveness of the consensus mechanism, particularly in smaller teams. These findings align with prior research [42], underscoring the need for robust individual perception to ensure reliable collective decision-making in small multi-robot systems.
V Conclusion
This paper presents a decentralized multi-robot shared perception pipeline that predicts the intent of a human operator in the scene by exploiting the spatial and temporal relationships between the human and surrounding objects. We demonstrated that having multiple robots observing the same scene from different viewpoints and sharing information can help develop a robust and scalable perception system.
Currently, our system is limited to handling a single human in the scene, and expanding to multiple humans is a priority for future work. We also intend to enrich the GNN’s edge features—currently based only on Euclidean distances from 2D images—by incorporating higher-dimensional inputs derived from additional onboard sensors. Beyond that, we plan to integrate Vision-Language Models (VLMs) to enhance scene understanding in dynamic, unfamiliar environments. Such models could enable more robust semantic representations, improving the robot’s ability to interpret human actions and intentions in previously unseen scenarios.
Moreover, the consensus mechanism currently relies on the quantification of the robots’ visibility but does not account for the quality of the view. Future work will focus on integrating view quality metrics into the consensus mechanism. We also plan to expand the action library to include more complex and realistic scenarios, closely resembling real-world industrial environments. Finally, we intend to implement and test our approach on real robots to validate its effectiveness in practical applications.
References
- [1] X. Xu, Y. Lu, B. Vogel-Heuser, and L. Wang, “Industry 4.0 and industry 5.0—inception, conception and perception,” Journal of manufacturing systems, vol. 61, pp. 530–535, 2021.
- [2] P. K. R. Maddikunta, Q.-V. Pham, B. Prabadevi, N. Deepa, K. Dev, T. R. Gadekallu, R. Ruby, and M. Liyanage, “Industry 5.0: A survey on enabling technologies and potential applications,” Journal of industrial information integration, vol. 26, p. 100257, 2022.
- [3] J. Müller et al., “Enabling technologies for industry 5.0: Results of a workshop with europe’s technology leaders,” Directorate-General for Research and Innovation, 2020.
- [4] C. Thorpe and H. Durrant-Whyte, “Field robots,” in Robotics Research: The Tenth International Symposium. Springer, 2003, pp. 329–340.
- [5] S. Zhang, R. Benenson, M. Omran, J. Hosang, and B. Schiele, “Towards reaching human performance in pedestrian detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 4, pp. 973–986, 2017.
- [6] W. Liu, S. Liao, W. Ren, W. Hu, and Y. Yu, “High-level semantic feature detection: A new perspective for pedestrian detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5187–5196.
- [7] S. Gilroy, D. Mullins, A. Parsi, E. Jones, and M. Glavin, “Replacing the human driver: An objective benchmark for occluded pedestrian detection,” Biomimetic Intelligence and Robotics, vol. 3, no. 3, p. 100115, 2023.
- [8] D. F. Gordon, A. Christou, T. Stouraitis, M. Gienger, and S. Vijayakumar, “Adaptive assistive robotics: a framework for triadic collaboration between humans and robots,” Royal Society open science, vol. 10, no. 6, p. 221617, 2023.
- [9] D. Vasquez, P. Stein, J. Rios-Martinez, A. Escobedo, A. Spalanzani, and C. Laugier, “Human aware navigation for assistive robotics,” in Experimental Robotics: The 13th International Symposium on Experimental Robotics. Springer, 2013, pp. 449–462.
- [10] M. Terreran, E. Lamon, S. Michieletto, and E. Pagello, “Low-cost scalable people tracking system for human-robot collaboration in industrial environment,” Procedia Manufacturing, vol. 51, pp. 116–124, 2020.
- [11] A. Bonci, P. D. Cen Cheng, M. Indri, G. Nabissi, and F. Sibona, “Human-robot perception in industrial environments: A survey,” Sensors, vol. 21, no. 5, p. 1571, 2021.
- [12] R. Quintero, I. Parra, D. F. Llorca, and M. Sotelo, “Pedestrian path prediction based on body language and action classification,” in 17th International IEEE Conference on Intelligent Transportation Systems (ITSC). IEEE, 2014, pp. 679–684.
- [13] Y. Li, H. Cheng, Z. Zeng, H. Liu, and M. Sester, “Autonomous vehicles drive into shared spaces: ehmi design concept focusing on vulnerable road users,” in 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021, pp. 1729–1736.
- [14] Y. Wang, L. Hespanhol, S. Worrall, and M. Tomitsch, “Pedestrian-vehicle interaction in shared space: Insights for autonomous vehicles,” in Proceedings of the 14th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, 2022, pp. 330–339.
- [15] V. Karasev, A. Ayvaci, B. Heisele, and S. Soatto, “Intent-aware long-term prediction of pedestrian motion,” in 2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016, pp. 2543–2549.
- [16] B. Liu, E. Adeli, Z. Cao, K.-H. Lee, A. Shenoi, A. Gaidon, and J. C. Niebles, “Spatiotemporal relationship reasoning for pedestrian intent prediction,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3485–3492, 2020.
- [17] W. L. Hamilton, Graph representation learning. Morgan & Claypool Publishers, 2020.
- [18] Q. Li, F. Gama, A. Ribeiro, and A. Prorok, “Graph neural networks for decentralized multi-robot path planning,” in 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2020, pp. 11 785–11 792.
- [19] Y. Zhou, J. Xiao, Y. Zhou, and G. Loianno, “Multi-robot collaborative perception with graph neural networks,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2289–2296, 2022.
- [20] X. Ji, H. Li, Z. Pan, X. Gao, and C. Tu, “Decentralized, unlabeled multi-agent navigation in obstacle-rich environments using graph neural networks,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 8936–8943.
- [21] L. E. Parker, D. Rus, and G. S. Sukhatme, “Multiple mobile robot systems,” Springer handbook of robotics, pp. 1335–1384, 2016.
- [22] M. Schranz, M. Umlauft, M. Sende, and W. Elmenreich, “Swarm robotic behaviors and current applications,” Frontiers in Robotics and AI, vol. 7, p. 36, 2020.
- [23] M. Brambilla, E. Ferrante, M. Birattari, and M. Dorigo, “Swarm robotics: a review from the swarm engineering perspective,” Swarm Intelligence, vol. 7, pp. 1–41, 2013.
- [24] G. Valentini, H. Hamann, M. Dorigo et al., “Self-organized collective decision making: The weighted voter model,” in AAMAS, vol. 14. Citeseer, 2014, pp. 45–52.
- [25] Q. Shan, A. Heck, and S. Mostaghim, “Discrete collective estimation in swarm robotics with ranked voting systems,” in 2021 IEEE symposium series on computational intelligence (SSCI). IEEE, 2021, pp. 1–8.
- [26] C. Zheng and K. Lee, “Consensus decision-making in artificial swarms via entropy-based local negotiation and preference updating,” Swarm Intelligence, vol. 17, no. 4, pp. 283–303, 2023.
- [27] ISO 10218-1:2011 - Robots and robotic devices — Safety requirements for industrial robots — Part 1: Robots, International Organization for Standardization Std., 2011, available from https://www.iso.org/standard/51330.html.
- [28] Mobile Industrial Robots, “Mir250 - a more flexible amr,” 2024, accessed: 2024-11-15. [Online]. Available: https://mobile-industrial-robots.com/products/robots/mir250
- [29] OTTO Motors, “Otto 1500 autonomous mobile robot,” 2024, accessed: 2024-11-15. [Online]. Available: https://ottomotors.com/1500/
- [30] B. Koonce and B. Koonce, “Resnet 50,” Convolutional neural networks with swift for tensorflow: image recognition and dataset categorization, pp. 63–72, 2021.
- [31] K.-H. Zeng, S.-H. Chou, F.-H. Chan, J. Carlos Niebles, and M. Sun, “Agent-centric risk assessment: Accident anticipation and risky region localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2222–2230.
- [32] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [33] R. Dey and F. M. Salem, “Gate-variants of gated recurrent unit (gru) neural networks,” in 2017 IEEE 60th international midwest symposium on circuits and systems (MWSCAS). IEEE, 2017, pp. 1597–1600.
- [34] R. C. Staudemeyer and E. R. Morris, “Understanding lstm–a tutorial into long short-term memory recurrent neural networks,” arXiv preprint arXiv:1909.09586, 2019.
- [35] R. Cahuantzi, X. Chen, and S. Güttel, “A comparison of lstm and gru networks for learning symbolic sequences,” in Science and Information Conference. Springer, 2023, pp. 771–785.
- [36] A. Corsaro, L. Cominardi, O. Hecart, G. Baldoni, J. Enoch, P. Avital, J. Loudet, C. Guimarães, M. Ilyin, and D. Bannov, “Zenoh: Unifying communication, storage and computation from the cloud to the microcontroller,” vol. DSD 2023, 09 2023.
- [37] M. A. Montes de Oca, E. Ferrante, A. Scheidler, C. Pinciroli, M. Birattari, and M. Dorigo, “Majority-rule opinion dynamics with differential latency: a mechanism for self-organized collective decision-making,” Swarm Intelligence, vol. 5, pp. 305–327, 2011.
- [38] G. Valentini, M. Birattari, and M. Dorigo, “Majority rule with differential latency: An absorbing markov chain to model consensus,” in Proceedings of the European Conference on Complex Systems 2012. Springer, 2013, pp. 651–658.
- [39] A. Scheidler, “Dynamics of majority rule with differential latencies,” Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, vol. 83, no. 3, p. 031116, 2011.
- [40] “NVIDIA Isaac Sim,” NVIDIA Corporation, accessed: 2024-03. [Online]. Available: https://developer.nvidia.com/isaac-sim
- [41] Y. Abu Farha, A. Richard, and J. Gall, “When will you do what?-anticipating temporal occurrences of activities,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5343–5352.
- [42] E. Milner, M. Sooriyabandara, and S. Hauert, “Swarm performance indicators: Metrics for robustness, fault tolerance, scalability and adaptability,” arXiv preprint arXiv:2311.01944, 2023.
- [43] C. Schöller, V. Aravantinos, F. Lay, and A. Knoll, “What the constant velocity model can teach us about pedestrian motion prediction,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1696–1703, 2020.