Goal-Oriented Tensor DecompositionsD. Dunlavy, E. Phipps, H. Kolla, J. Shadid, and E. Phillips
Goal-Oriented Low-Rank Tensor Decompositions for Numerical Simulation Data
Abstract
We introduce a new low-dimensional model of high-dimensional numerical simulation data based on low-rank tensor decompositions. Our new model aims to minimize differences between the model data and simulation data as well as functions of the model data and functions of the simulation data. This novel approach to dimensionality reduction of simulation data provides a means of directly incorporating quantities of interests and invariants associated with conservation principles associated with the simulation data into the low-dimensional model, thus enabling more accurate analysis of the simulation without requiring access to the full set of high-dimensional data. Computational results of applying this approach to two standard low-rank tensor decompositions of data arising from simulation of combustion and plasma physics are presented.
keywords:
tensor, low-rank, Tucker decomposition, canonical polyadic decomposition, goal-oriented15A69, 65F55
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed70aae9-524b-4c09-a18e-3773e7f8f4fc/x1.png)
Introduction High-dimensional numerical simulation data is ubiquitous across scientific computing disciplines, including plasma physics, fluids, earth systems, and mechanics. Often such data is generated on high-performance computing (HPC) resources and is too large to be stored, analyzed, or moved as a whole. To facilitate efficient post-simulation analysis of the data, scientists often use samples and/or low-dimensional models of the high-dimensional data to avoid these challenges. Here we present a new dimension reduction method for numerical simulation data that models both the high-dimensional data and functions of the high-dimensional data.
Numerical simulation data is naturally represented as a tensor, or multi-dimensional array, consisting of the value of each simulation variable at each point in space and time. Low-rank tensor decompositions—akin to low-rank matrix decompositions of two-dimensional data—provide low-dimensional models of tensor data and have been used effectively in a variety of data analysis tasks, including data compression, surrogate modeling, pattern identification, and anomaly detection. However, existing tensor decomposition methods target simple element-wise error metrics between the high-dimensional data and low-dimensional model of the data, often failing to faithfully represent important physics quantities of interest (QoIs) or invariants arising from conservation principles. In this work, we introduce goal-oriented low-rank tensor decompositions, which incorporate QoIs directly into the optimization problems used in fitting the low-rank models to high-dimensional tensor data. Specifically, we derive two such goal-oriented decompositions—extending the common Canonical Polyadic (CP) and Tucker models—and explore how well these new low-rank models better capture several standard QoIs typically used in analyzing data produced via combustion and plasma physics simulations.
The purpose of this paper is to introduce the new goal-oriented low-rank tensor decompositions and demonstrate that they lead to improvements of low-dimensional modeling of high-dimensional numerical simulation data. As such, the target audience for this work includes both tensor decomposition experts and computational scientists.
Background
In this section, we introduce tensors and two of the standard low-rank tensor decompositions that form the foundation of our new goal-oriented low-rank decompositions. We also discuss the connections of our approach to related work on constrained low-rank tensor decompositions.
Tensors, or multi-dimensional arrays, are a powerful means of representing relationships in multiway data [49]. For example, in the context of scientific simulations presented in this work, tensors represent the spatio-temporal solution of coupled systems of differential equations. Analysis of high-dimensional tensor data is usually facilitated through low-rank tensor decompositions, which approximate a given tensor in terms of simpler, structured tensors defined with fewer parameters than the number of elements in the high-dimensional data. In this work, we focus on two common tensor decompositions, the Canonical Polyadic (CP, also known as CANDECOMP/PARAFAC) and Tucker decompositions, summarized below.
The order of a tensor is the number of dimensions and each tensor dimension is called a mode. Following standard notation [49], lowercase letters denote scalars (tensors of order zero), e.g., ; bold lowercase letters denote vectors (tensors of order one), e.g., ; and bold uppercase letters denote matrices (tensors of order two), e.g., . Tensors of order three and higher are denoted with bold capital script letters, e.g., . We use multi-index notation to indicate tensor elements, i.e., denotes the entry of a -way tensor . Finally, given , we define for to be the mode- matricization of , which is a matrix of size whose rows are given by a linearization of the mode- slices.
Canonical Polyadic (CP) Decompositions
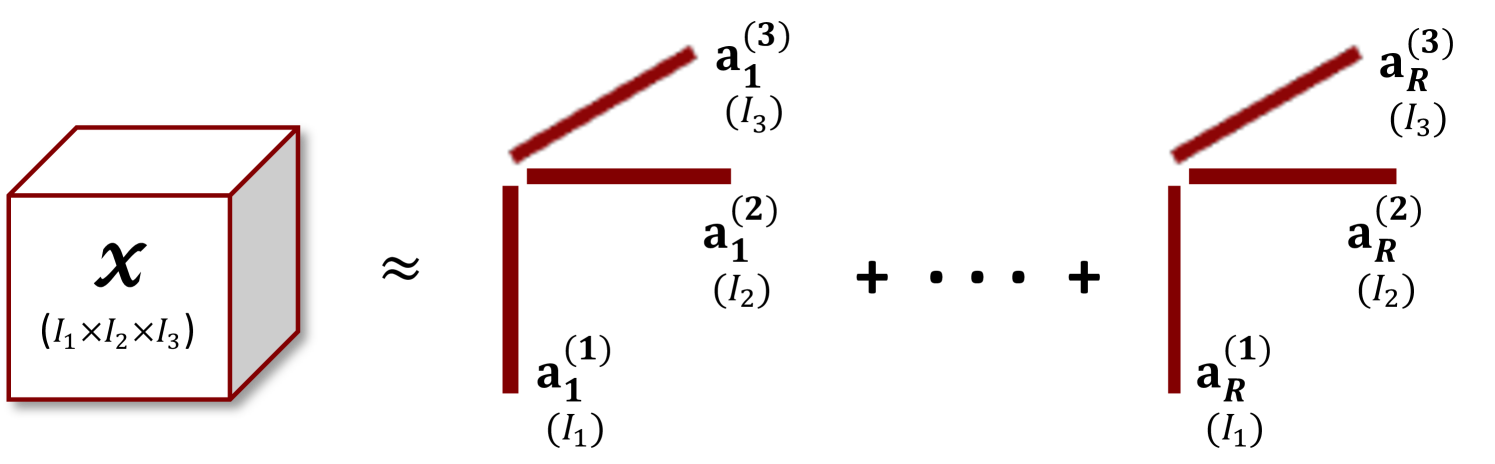
For a given -way tensor , the CP decomposition [43, 44, 19, 20, 18, 41] attempts to find a good approximating low-rank model tensor of the form
| (1) |
where is a column vector of size , represents the vector outer product, and is the approximate rank. See Fig. 1(a) for a graphical depiction. The column vectors for each mode are often collected into a matrix of size called a factor matrix. Given factor matrices , we use the notation [7]. For standard CP decompositions, is computed by solving the following optimization problem,
| (2) |
where denotes the tensor Frobenius (sum-of-squares) norm and , defined as above, denotes the set of all multi-indices of the tensor elements. Many approaches have been developed for efficiently solving Eq. 2 that are scalable to large, sparse or dense tensors including alternating least-squares (ALS) [18, 41], gradient-based optimization [2], nonlinear least-squares [55], and damped Gauss-Newton [56, 64] approaches, among others.
Tucker Decompositions
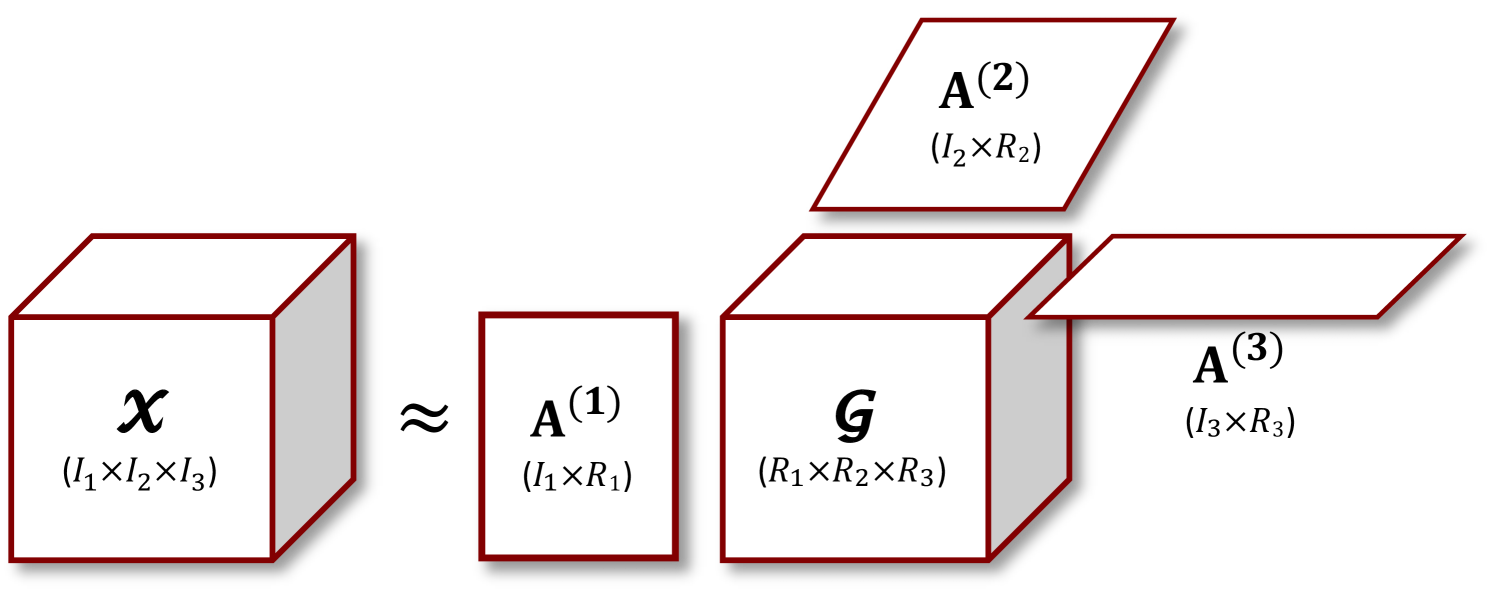
The Tucker decomposition [65] attempts to approximate a given tensor in the form
| (3) |
where is called the core tensor and the columns of each factor matrix , are usually orthonormal. See Fig. 1(b) for an example in three dimensions. Here the notation is called the -mode product and is defined in terms of matricized tensors as . As in the CP decomposition, we use the shorthand notation . If , , then the memory required to store is significantly smaller than , and hence Tucker decompositions have been used effectively for data compression [9, 5]. Each factor matrix is an approximate basis for the column space corresponding to the mode- matricization of ; thus, the Tucker decomposition is often considered to be a form of generalization of the matrix SVD or PCA to higher dimensions [29].
Similar to the problem for CP decompositions in Eq. 2, for standard Tucker decompositions, is computed by solving the following optimization problem
| (4) |
The only difference in the optimization problems between the CP and Tucker decompositions is the specific form of the low-rank tensor . Many approaches exist for computing Tucker decompositions, including the Higher-Order SVD (HOSVD) [29], sequentially truncated HOSVD (ST-HOSVD) [67], and Higher-Order Orthogonal Iteration (HOOI) [30]. For a given set of Tucker ranks, both the HOSVD and ST-HOSVD algorithms compute quasi-optimal solutions, with reconstruction error within a factor of of the optimal approximation as measured by a sum-of-squares (Frobenius) error [40]. For a given approximation error tolerance, both algorithms can select Tucker ranks in order to guarantee the error tolerance is satisfied with respect to the Frobenius norm, providing a continuous trade-off between data reduction and approximation error.
Constrained Tensor Decompositions
In general, when computing low-rank tensor decompositions via numerical optimization approaches, some loss function involving the tensor data and low-rank model is minimized—e.g., in Eq. 2 or Eq. 4—subject to the specific low-rank structure of the model —e.g., either the CP or Tucker structure described above. In addition to the constraint of the low-rank model, more general constraints can be included in the optimization problem to reflect additional information known about the data.
Much prior work exists on incorporating constraints into CP and Tucker decompositions [26], including non-negativity (and more general bound) constraints [8, 25, 27], linear constraints [24, 37], constraints on the rank of the decomposition [58], and constraints presented in the form of coupled matrix-tensor factorizations [3, 31]. However, such constraints amount to either bound or linear constraints, and the methods used to solve the associated constrained optimization problems are often not applicable to general nonlinear constraints. Most related to the work presented here is recent work that includes constraints on low-rank matrix and tensor decomposition factors via regularization penalties. For example, Huang, et al. introduced a general method for incorporating constraints through penalties on the factors and illustrated the use of non-negativity constraints, nuclear-norm regularization (for tensor completion), and sparsity-inducing regularization (for dictionary learning) [46]. More recently, that work was extended to support any proximable regularizer, broadening the types of constraints that could be placed on the factors [62]. As we show in Section 1, our approach presented here also incorporates constraints as penalties to the decomposition optimization problems in Eq. 2 or Eq. 4, but we illustrate the use on more general nonlinear constraints than this previous work.
Related Work
As mentioned above, low-rank approximation through tensor decomposition has applications to many different computational and analysis tasks, including data compression [9, 28], reduced-order modeling [38], surrogate modeling [48, 47], and anomaly detection [34, 52], and in many of these applications, including QoIs into the low-rank approximation could potentially improve the utility of the decomposition. Typically, only the error of primary state variables is minimized while computing the decomposition, and it has been observed that the errors in QoIs, which are derived from the primary variables, can be orders of magnitude higher [50]. In this work, we don’t focus on any particular application of tensor decomposition, but instead focus on the algorithmic, computational, and numerical consequences of computing the goal-oriented decomposition itself. Furthermore, we recognize that tensor methods are not the only approach for solving these problems and numerous other methods for the above applications have been developed, some also incorporating goal-oriented techniques. In particular, the literature on goal-oriented techniques for reduced order modeling of scientific simulations is vast, e.g., [17, 35, 15, 36, 23]. Furthermore, neural networks (NN) and neural operators (NO) have recently emerged as data-driven surrogate models of scientific systems, and ‘physics-informed’ variants of these that attempt to preserve physics in addition to minimizing state prediction error have been proposed, such as physics-informed neural networks (PINNs) [60] and physics-informed neural operators (PINOs) [53]. Finally, several data compression approaches that can preserve quantities of interest have recently been investigated, including MGARD [4], which can preserve linear quantities of interest, as well as [51], which proposes a hybrid approach based on tensor decompositions, autoencoders, MGARD for achieving a prescribed error guarantee, and QoI preservation as a post-processing step after reconstruction. Our approach differs in that it produces a reduced/compressed model that attempts to directly preserve the relevant QoIs (including nonlinear QoIs) without post-processing.
Goal-Oriented Tensor Decompositions
Problem Formulation
As described above, traditional tensor decompositions can often be formulated as the solution to optimization problem such as
| (5) |
where is chosen based on the statistical model of the data tensor . In this work, we use , i.e., sum-of-squares loss, which is appropriate when the error tensor is assumed to be normally distributed (however, many other choices are possible). We further assume the data tensor represents the spatio-temporal evolution of some multi-physics system on a fixed Cartesian grid, consisting of one or more spatial modes (our examples below contain either two or three spatial dimensions)111This includes the modeling of systems involving more complex geometries and unstructured meshes by collapsing all spatial dimensions into a single mode given by all of the vertices in the mesh., a variable mode representing the different physics variables present in the system (e.g., density, temperature, momentum, etc.), and a temporal mode. We model quantities-of-interest (QoIs), whether they be invariants that are satisfied by the data or merely quantities that are derived from the data, as scalar valued functions for a given set of time points , where represents a temporal slice of at time (i.e., for a tensor with three spatial modes) and is the set of indices in the temporal mode of the tensor used when computing the th QoI. To preserve these QoIs in the tensor decomposition, one would like to constrain the tensor decomposition to enforce . However, unless the data is exactly low rank, it is unlikely these constraints can be satisfied exactly and still obtain reasonable levels of reduction and some accuracy in the data reconstruction so that . We therefore attempt to preserve them through the following penalty formulation,
| (6) |
where is the number of QoIs and ,…,, are user-chosen weighting coefficients. Note that the quadratic penalty in Eq. 6 could be replaced with other penalty functions; e.g., an augmented Lagrangian penalty [54]. While not explored here, the use of alternate penalty functions to incorporate the QoIs into the low-rank decompositions could be explored through future work. We next discuss multiple derivative-based optimization approaches for solving Eq. 6 followed by several practical considerations that must be addressed for any optimization-based approach.
Optimization Approaches
In this section, we describe two derivative-based optimization methods proposed to solve the optimization problems defining the goal-oriented CP and Tucker decompositions above. The first is the Limited-Memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) quasi-Newton algorithm commonly used for tensor decomposition methods, followed by trust-region Newton methods employing truncated Conjugate-Gradient inner solvers and Gauss-Newton Hessian approximations.
Quasi-Newton
The L-BFGS algorithm has been widely used for tensor decomposition, including CP [2], generalized CP [45], and Tucker [42] decompositions, as it provides superlinear convergence rates but only requires specification of the gradient of the objective function. The algorithm works by constructing secant approximations of the Hessian matrix over multiple steps of the optimization algorithm, which can be implemented by low-rank updates to the Hessian and its inverse (see [54] for more details). Our experiments specifically employ the implementation provided by the L-BFGS-B code [68] available in the Tensor Toolbox for MATLAB. Formulas for computing the needed gradients for the goal-oriented Tucker and CP decompositions are described in References.
Trust-Region Newton
As will be demonstrated in Fig. 5, our numerical experiments indicated the above L-BFGS method had difficulty in achieving significant reduction in the goal terms compared to a traditional tensor decomposition, particularly for the Tucker method. However, Newton-type methods such as trust region-Newton, Gauss-Newton and Levenberg-Marquardt have proven to be effective for tensor decomposition in other contexts, e.g., [57, 56, 61, 66]. So we also explored applying such methods to the goal-oriented formulation, in particular focusing on trust-region Newton methods. The trust-region Newton method approximates the objective function at each step by a local quadratic model constructed from the objective function gradient and Hessian. The quadratic model is minimized in the trust-region via Newton’s method. The implementation used here was provided by the Manopt [16] MATLAB package for optimization on Riemannian manifolds (which would allow inclusion of constraints such as optimization over Grassmann manifolds for Tucker decompositions as described later in Fig. 1, but those capabilities are not explored here). In Euclidean space, the Manopt trust-region method [1] is equivalent to the method described in [54], using a truncated conjugate gradient (tCG) linear solve for the inexact Newton step. This provides much faster quadratic convergence over the L-BFGS method described above, but requires implementing (approximate) Hessian-vector products for use in CG. Since the optimization problems defining the goal-oriented CP and Tucker decompositions are a form of nonlinear least-squares, we found the Gauss-Newton Hessian approximation to be effective, which only requires implementation of the first derivative of the goal functions. Formulas for computing Gauss-Newton Hessian-vector products are derived in References for both CP and Tucker models. The truncated CG solves are also improved through the use of a preconditioner. In this work, we employed simple block-diagonal preconditioning in the CP case, only considering the Frobenius norm term in the objective function, where the diagonal blocks are explicitly constructed and inverted through Cholesky decompositions. In the Tucker case, even just forming these blocks was too memory intensive, so we resorted to diagonal preconditioning. Note that while it can be shown that each goal-oriented term introduces a rank- correction to the diagonal blocks arising from the Frobenius norm term, effective incorporation of these terms in the preconditioner will be studied in future work. Construction of the diagonal blocks and their inverses is standard in the CP and Tucker literature (e.g., [57, 10]), and they are summarized in References for reference.
Solution Procedure
Many multiphysics problems involve solution variables that exhibit a wide range of scales that can cause numerical difficulties when solving Eq. 6 if not handled appropriately. To obtain more accurate low-rank models of this data, we first perform centering and scaling of each variable slice in to produce a scaled tensor where, e.g., for a 5-way data tensor ,
| (7) |
The computation of and are problem dependent, with common choices of the variable mean for and standard deviation for . For traditional tensor decompositions, one can compute a corresponding low-rank model from and then transform back to unscaled variables by unscaling the corresponding variable factor matrix, e.g., for CP:
| (8) |
where is a length- vector of 1’s and is the function that maps the scaled data and model to the unscaled data and model. However, QoI evaluations often only make sense when evaluated on unscaled tensors, and thus we modify Eq. 6 to explicitly unscale data before QoI evaluation:
| (9) |
which requires modifying the derivative formulas presented in References to incorporate Eq. 8 when computing the goal derivatives.
Once the scaling vectors have been determined, the next steps in finding an approximate solution to Eq. 9 are obtaining a good initial guess and choosing the weighting coefficients. For the former, we first obtain an approximate solution to
| (10) |
using a traditional approach such as CP-ALS when is of CP form and ST-HOSVD when is of Tucker form, to provide the initial guess . We then fix the CP/Tucker rank of based on the corresponding rank of and choose the weighting coefficients as
| (11) | ||||
which ensures the tensor term and each goal-term contributes equally to the objective function.
When presenting results of the various low-rank decompositions in Figure 1 and Figure 4, we report relative tensor reconstruction error using the unscaled data and model , scaled data and model , or both.
Non-uniqueness and Stopping Criteria It is well-known that CP and Tucker models obtained from the solution of optimization problems such as Eq. 5 are not locally unique and instead lie along a manifold of equivalent solutions [10]. For CP, this non-uniqueness arises from the CP factor scaling ambiguity whereby any factor matrix column may be scaled by a nonzero value and not change the resulting tensor reconstruction as long as the same column of the factor matrices for the other dimensions are scaled appropriately so that the product of scales is unity. For Tucker, the situation is even worse since any factor matrix may be multiplied by a nonsingular matrix and not change the tensor reconstruction as long as the core is multiplied by the inverse of that matrix in the corresponding dimension. Since the QoI functions in Eq. 6 or Eq. 9 rely on tensor reconstructions, these same non-uniqueness properties are inherited within the goal-oriented formulation. This lack of uniqueness can cause problems when monitoring the norm of the gradient of the objective function to determine stopping criteria, because it often does not converge monotonically to zero and instead exhibits a saw-tooth pattern (while the objective function is constant along the manifold of equivalent solutions at a point, and the gradient is therefore orthogonal to the tangent space of the manifold at that point, steps with a nonzero component along the tangent space can cause the norm of the gradient to increase since the manifold is curved). Thus determining appropriate stopping criteria is somewhat challenging. However, in this work we are not aiming to find the CP/Tucker model that best minimizes the QoI error, but rather to reduce this error over what is obtained in a traditional, non-goal-oriented low-rank decomposition formulation. Thus our approach is to run the optimization method for a fixed number of iterations. In particular, because of the quick convergence of the trust-region Newton optimization method, we found 5 optimization iterations to be sufficient for achieving significant goal reduction in most of our experiments (however most of the experiments below used 20 iterations to ensure the results were near a local minimum). Furthermore, with the choice of weighting coefficients described above, the objective function evaluated at the initial guess satisfies , and if a solution is found that exactly preserves the QoIs such that while not changing the tensor loss (i.e., ), then . These provide approximate (though not strict) upper and lower bounds on the objective function , and by comparing to throughout the optimization process, one can gauge how well the solution to Eq. 6 has reduced the QoI error.
We note that the non-uniqueness challenges of these optimization formulations can be rectified by incorporating additional constraints into the problem formulation. For CP this is relatively straightforward by constraining each factor matrix column to unit-norm and introducing an additional weight variables (where is the CP rank) into the optimization problem. For Tucker, however, formulating explicit algebraic constraints that eliminate the above ambiguity is more challenging. Instead, one can formulate both CP and Tucker on Riemannian manifolds and leverage existing work on optimization methods over Riemannian manifolds (e.g., [1]). In the Tucker case, this is done by constraining the columns of the factor matrices to be orthonormal and recognizing the resulting core is not a free variable, but rather the projection of the data onto spaces spanned by the factor matrix columns in each dimension [33]. By eliminating the core, one can then pose and solve the Tucker minimization over a product of Grassmann manifolds [33, 32]. However, extending such a method to the goal-oriented Tucker formulation is non-trivial since the constraint between the core and factor matrices is no longer satisfied and therefore can’t be formulated as a product Riemannian manifold. While not explored here, this manifold optimization approach could be explored through future work.
Software Implementation For the numerical experiments below, we implemented the goal-oriented formulation in Eq. 9 in MATLAB, leveraging the Tensor Toolbox for MATLAB [6, 7] dense tensor, CP, and Tucker data structures as well as the Matricized Tensor Times Khatri-Rao Product (MTTKRP) and Tensor Times Matrix (TTM) operations needed for the gradient and Hessian calculations described in References. As described in Fig. 1 we used the Manopt trust region-Newton as the optimization solver. While effective for investigating the feasibility of this approach, this serial, Matlab-based implementation was found to be quite limiting in the size of simulation data sets that could be studied. In particular, the approach for MTTKRP in the Tensor Toolbox for MATLAB for dense tensors involves explicitly forming the Khatri-Rao product, which for large data sets and large CP ranks is memory prohibitive.
Computational Cost The goal-oriented formulation in Eq. 9 adds an additional terms to the objective function defining the CP/Tucker model, so the computational cost of the goal-oriented approach is necessarily greater than a traditional approach, even one based on similar optimization methods such as trust-region Newton/Gauss-Newton. Comparing Eq. 26 with Eq. 35 and Eq. 32 with Eq. 39, we see the cost of computing the gradient of the additional QoI terms is similar to the gradient cost for the Frobenius loss term, once each QoI derivative tensor has been computed. Note that these tensors can be combined across multiple QoIs to compute the goal-oriented gradient by applying Eq. 26/Eq. 32 once instead of times, and so the gradient cost of the goal-oriented approach is about twice that of a traditional, non-goal-oriented approach (not including the cost to calculate the QoI derivative tensors). Furthermore, comparing Eq. 32 and Eq. 34 with Eq. 39 and Eq. 40, we see the cost of Hessian-vector products is again similar between the QoI terms and the Frobenius loss term for the Tucker method. However, by comparing Eq. 26 and Eq. 29 with Eq. 36, we see the special structure of Frobenius loss does allow for more efficient Hessian-vector products for the traditional CP model than can be computed for the goal-oriented approach, since it requires CP model reconstructions. Moreover, the cost of computing the derivative tensor for each QoI can be large. Each derivative tensor is the same size and shape as the original data , and in most applications, the cost of computing it should be proportional to the total number of entries in . However, the finite element integrations defining the QoIs derivatives for the plasma physics examples shown below are challenging to vectorize within our Matlab-based implementation, making the goal-oriented approach substantially more expensive than a traditional CP or Tucker decomposition method. We would expect the cost to be more competitive with a (Newton-based) traditional optimization method in an HPC environment where such integrals can be implemented more efficiently.
Application Case Study I: Combustion
Background
We use a dataset of direct numerical simulation (DNS) of turbulent combustion in conditions representing a homogeneous charge compression ignition (HCCI) engine. The simulation [11] considers autoignition of a turbulent ethanol-air mixture in a 2D spatial domain, performed with the DNS code S3D [22] which solves a system of PDEs governing conservation of mass, momentum, energy, and chemical species mass fractions described in Table 1. S3D uses an explicit eighth-order finite difference scheme for spatial derivatives and explicit fourth-order Runge-Kutta scheme for temporal derivatives. A structured grid rectangular Cartesian domain with uniform grid spacing and uniform time step are also typical choices (although not strictly necessary).
| Mass | |
|---|---|
| Momentum | |
| Total Energy | |
| Species Mass Fractions |
The HCCI simulation is performed in a doubly-periodic spatial domain, discretized with an equi-spaced grid. The data contains, at each grid point, the solution primary variables that include velocities (), temperature, pressure, and 28 chemical species () that capture the finite-rate chemical kinetics of ethanol combustion. A total of 626 snapshots in time are considered. Accordingly, the HCCI data tensor is denoted as , where
-
•
represents the spatial discretization in ();
-
•
represents the spatial discretization in ();
-
•
represents the variables, including chemical species (); and
-
•
represents the temporal snapshots ().
Following [50], the HCCI data are provided in dimensionless units by dividing each variable slice by the maximum of magnitude of that variable across all spatial grid and time points, and therefore explicit scaling/unscaling operations as described in Fig. 1 are not required.
Quantities of Interest
The tensor entries for the combustion data represent solution values at the discrete mesh points which are uniformly spaced, which simplifies the expressions for the QoIs and the associated operations on the tensors. Any integral over the spatial domain is equivalent to a summation over the first two (or three for 3D cases) spatial modes times a constant factor that denotes an elemental volume:
Likewise, any integral over time is equivalent to a summation over the last tensor mode. QoIs that are functions of the solution variables imply an operation over the variables mode at each point in space/time.
Conservation of Mass Since the HCCI simulation is performed over a doubly periodic spatial domain, it is a closed system that does not exchange mass with the surroundings. Hence, the mass, computed as volume integral of density, is conserved in time222 Strictly speaking, a finite difference discretization is not conservative, but we expect the discretization errors to be much smaller than errors due to the low-rank tensor representation.. Note that density itself is not stored in the data files, rather it is implied by the species mass fractions vector, via the relationship
Accordingly, the point-wise density of the HCCI data tensor is
| (12) |
We denote the full density tensor as , and define our QoI functional for mass conservation at each time step as the volume integral of density
| (13) |
where the constant factor of has been dropped for simplicity.
Conservation of Kinetic Energy The point-wise velocities in the -direction and -direction are the last two quantities in the point-wise variables vector, and hence slices of the HCCI data tensor,
| (14) |
and
| (15) |
respectively. Kinetic energy is an important quantity in turbulent flows, and the point-wise kinetic energy is given by
| (16) |
We denote the full kinetic energy tensor as , which is defined as
| (17) |
where is the Hadamard (or element-wise) product of tensors and [59]. We now define our QoI functional for kinetic energy as
| (18) |
representing conservation at each timestep.
Results
In this section we present results of computing low-rank tensor decompositions on a subset of the HCCI data tensor. We focus on a subset of time steps of the simulation data where there exist interesting dynamics, specifically time steps 360 through 409 during an ignition phase. Thus, the HCCI data tensor is . As noted above in Fig. 1, explicit scaling/unscaling of each variable slice is not necessary for this data. Otherwise, we use the solution strategy described in Fig. 1, computing a traditional CP/Tucker decomposition via CP-ALS/ST-HOSVD using a supplied CP rank and ST-HOSVD error tolerance, respectively, which serves as the initial guess for the goal-oriented decomposition. For CP-ALS, we set a tight stopping tolerance of on the change in the tensor fit and a maximum of 100 iterations to ensure the relative tensor reconstruction error for the unscaled tensor data and the CP model is dominated by rank-truncation error rather than solver error. We then choose the weighting coefficients as described above and run 20 iterations of the trust region-Newton optimization method as described in Fig. 1.
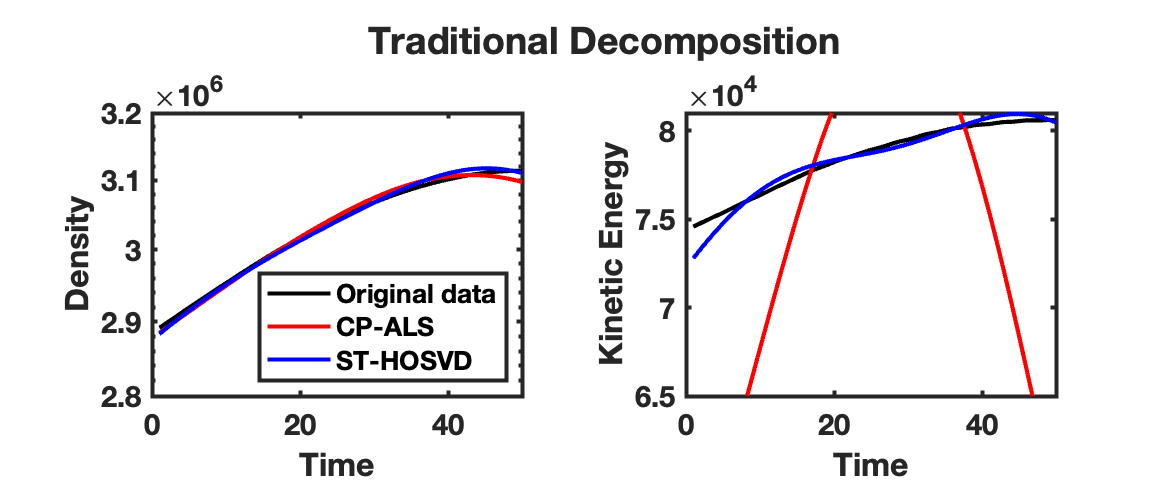
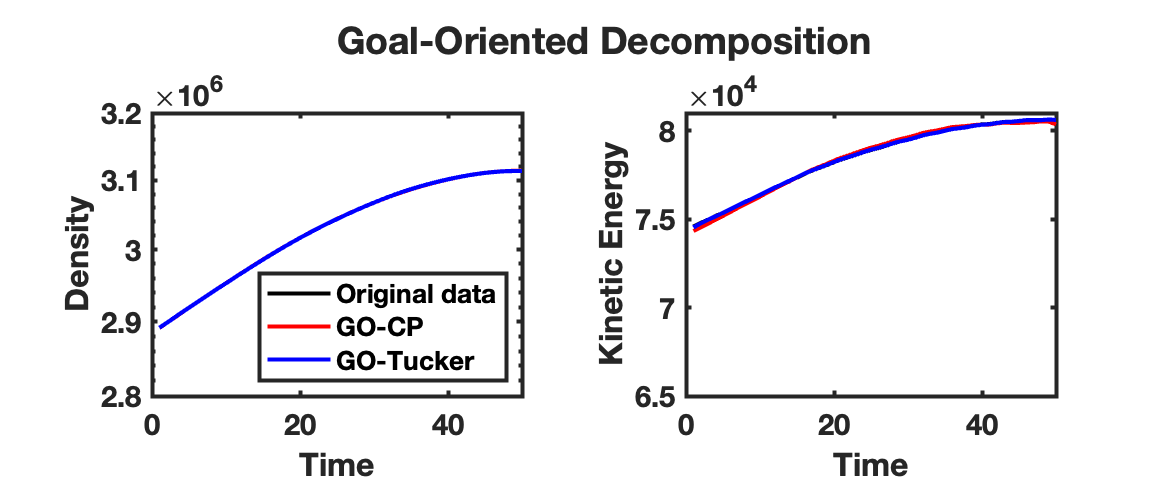
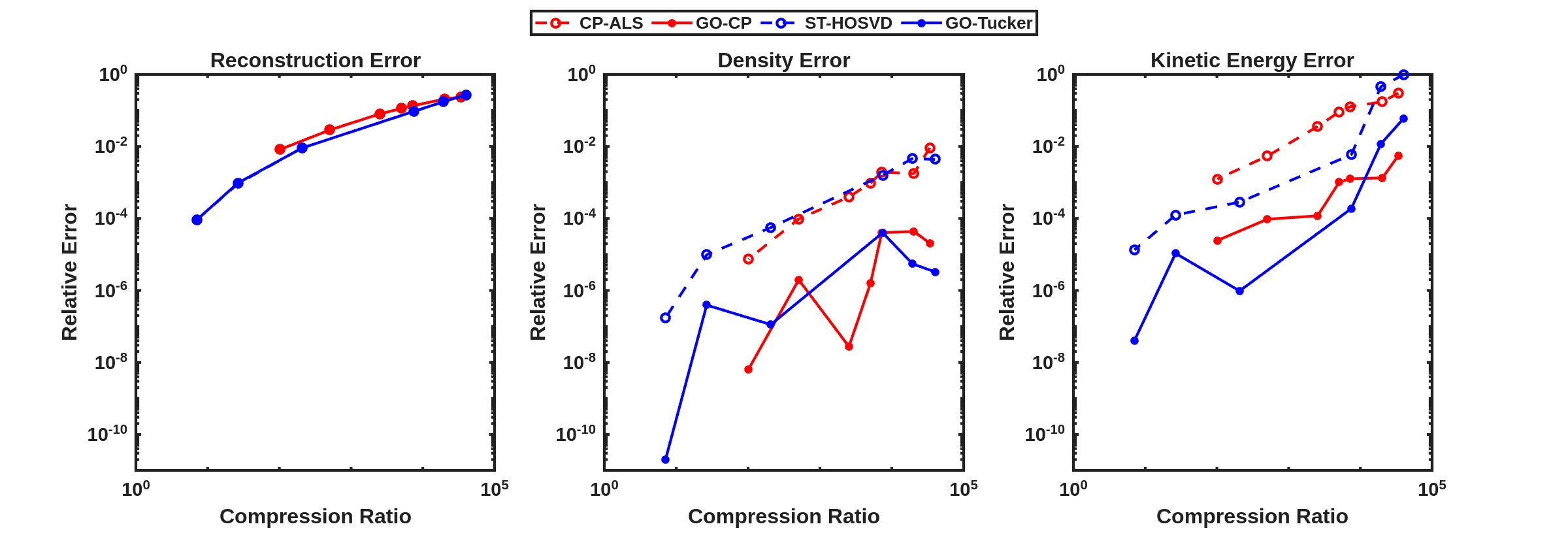
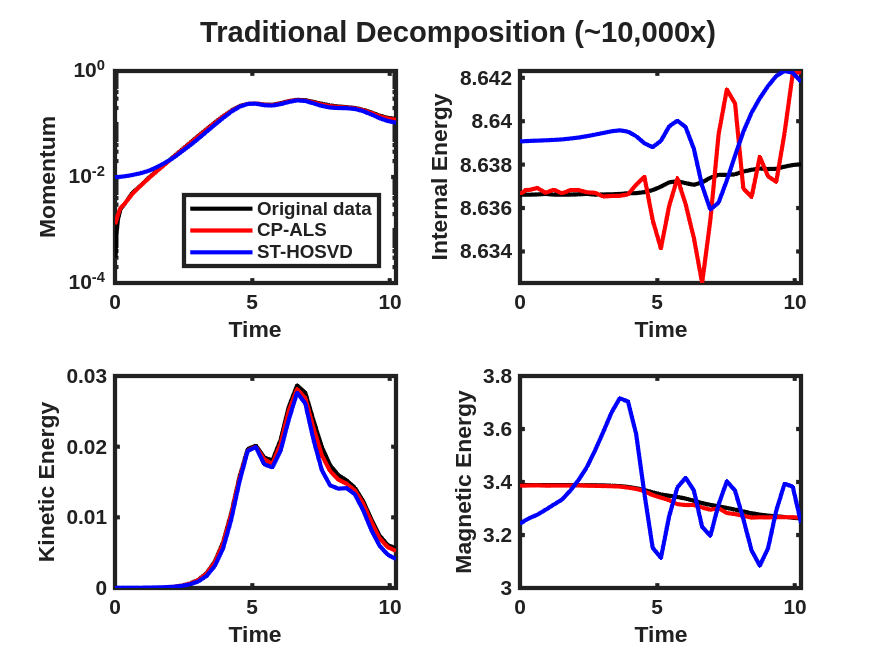
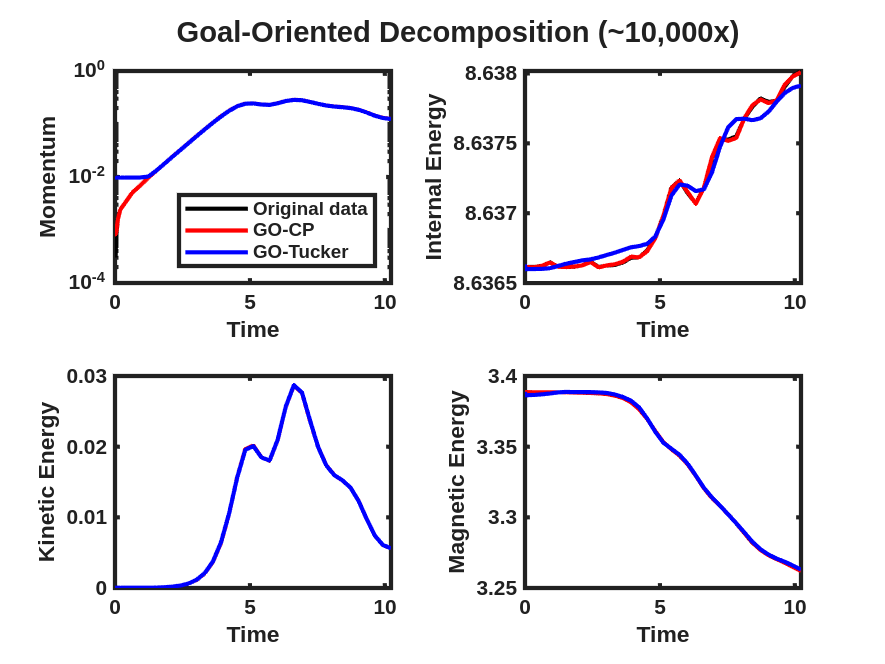
The density and kinetic energy QoIs described above are displayed for the HCCI data tensor and reconstruction obtained from a rank-70 CP-ALS decomposition and ST-HOSVD decomposition with truncation tolerance of in Fig. 2(a). For the density QoI, there are small but clearly visible differences observed between the data and traditional CP-ALS and ST-HOSVD decompositions. However, for the kinetic energy QoI, the differences are much more pronounced, especially for the CP-ALS decomposition. Such results are what motivated the development of the goal-oriented decompositions: when computing decompositions that simply aim to match the reconstructed low-rank model to the data—i.e., as in traditional tensor decompositions—it is often the case that QoIs associated with the data are not well modeled. In comparison, computing the goal-oriented decompositions—both GO-CP and GO-Tucker—leads to much more accurate modeling of the density and kinetic QoIs, as shown in Fig. 2(b). Furthermore, this increase in QoI modeling accuracy comes at minimal increase in the relative tensor reconstruction error—about for GO-CP and for GO-Tucker.
We next consider the performance of the goal-oriented approach compared to the traditional CP-ALS and ST-HOSVD approaches over a range of CP ranks and initial ST-HOSVD truncation tolerances. Figure 3 displays the relative tensor reconstruction error as well as the relative QoI error for the density and kinetic energy QoIs as functions of compression ratio of the CP/Tucker reduced models, for both traditional and goal-oriented methods. We make several observations:
-
•
The Tucker relative tensor reconstruction error is (slightly) less than the CP relative tensor reconstruction error for the same compression ratio, as is typically expected.
-
•
The relative tensor reconstruction errors are essentially identical between the traditional and goal-oriented approaches, for both CP and Tucker.
-
•
In all compression ratios tested in these experiment, the relative QoI errors were improved using the goal-oriented approach. For the density QoI, we see around 2–4 orders of magnitude improvement in both CP and Tucker decompositions, while for the kinetic energy QoI, we see around 1–3 orders of magnitude improvement.
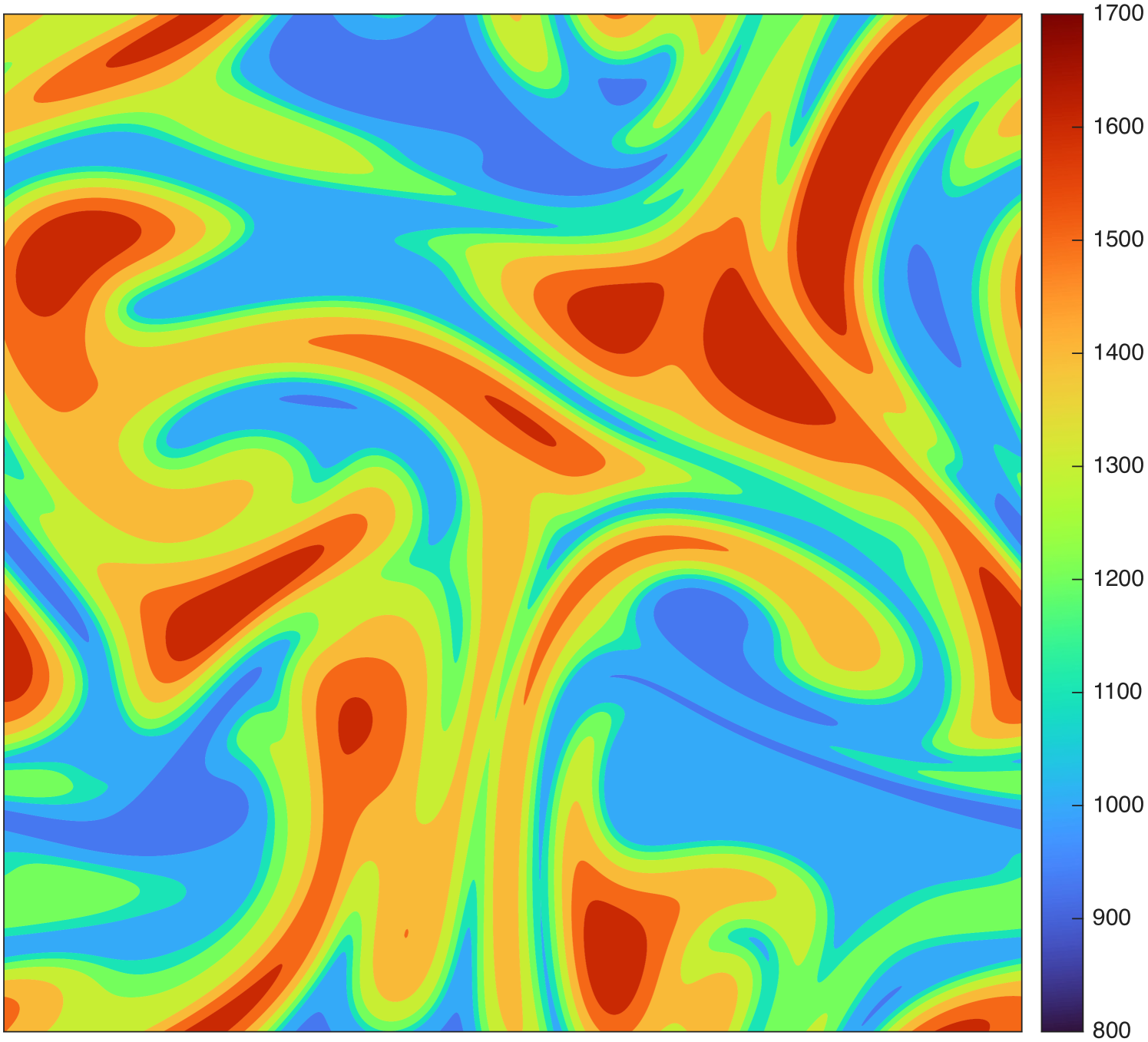
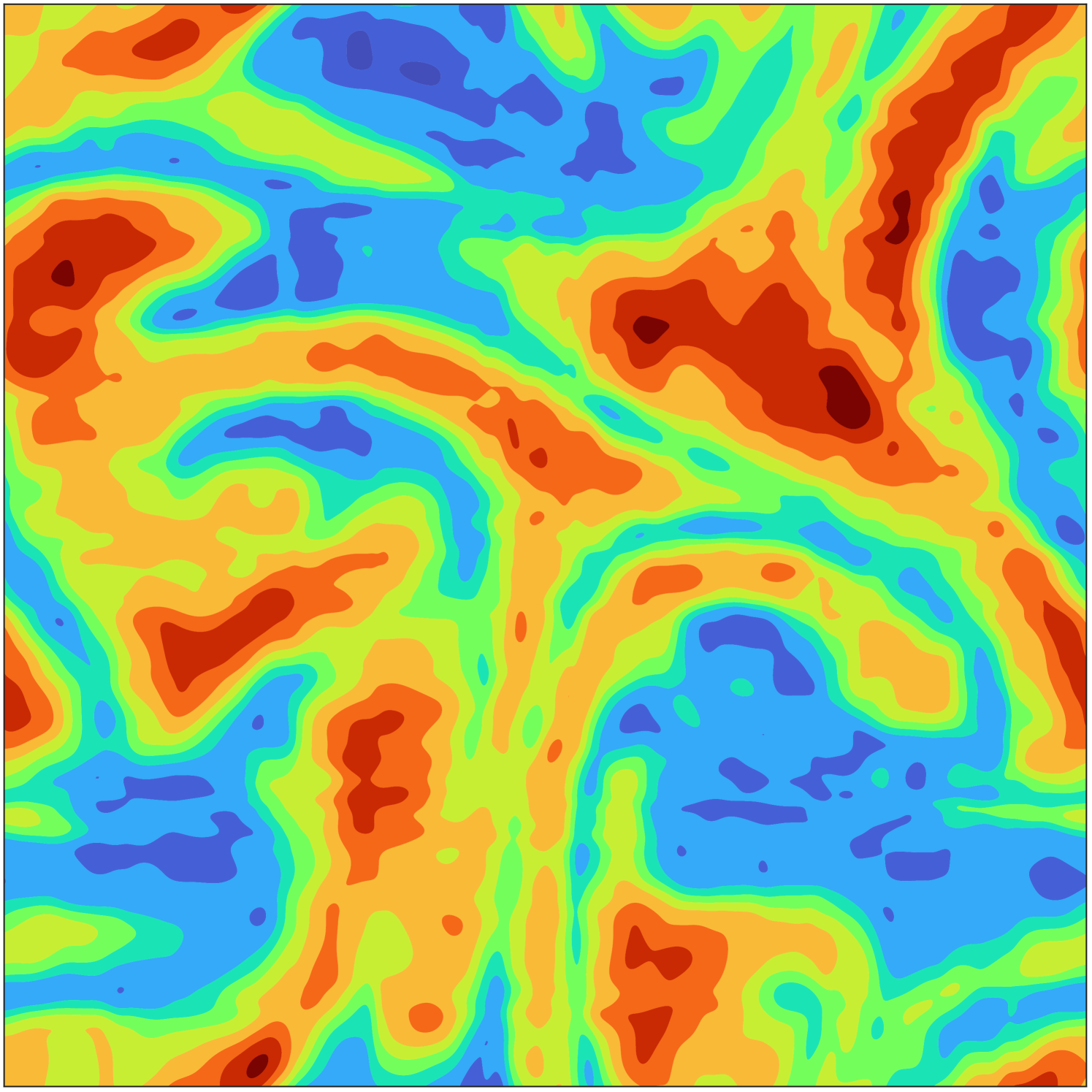
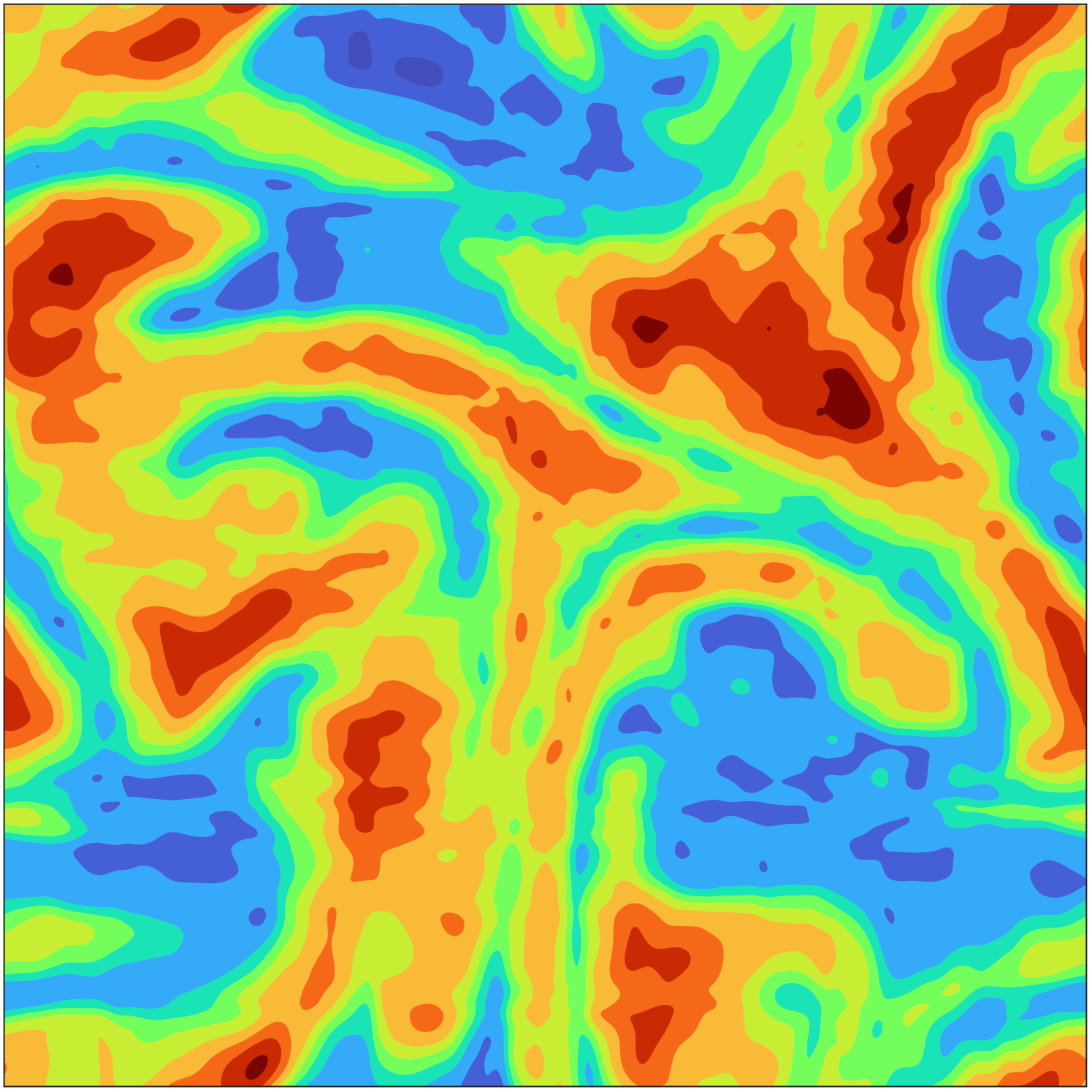
To illustrate the impact of the compression gained from computing the low-rank tensor decompositions of the HCCI data, Fig. 4(a) presents a slice of data for the temperature variable over all spatial grid points at time step 401 in the simulation. In Fig. 4(b) and Fig. 4(c), we see the corresponding reconstructions using the CP-ALS and GO-CP decompositions, respectively, noting there are no clearly visible differences, despite the relative QoI errors of GO-CP being dramatic improvements over those of CP-ALS. Similarly, in Fig. 4(d) and Fig. 4(e), we see the corresponding reconstructions using the ST-HOSVD and GO-Tucker decompositions, respectively, noting also here are no clearly visible differences despite the dramatic improvements in the relative QoI errors using GO-Tucker.
Application Case Study II: Plasma Physics
Background
The computational modeling of complex plasma physics systems is of critical importance in science and advanced technology. A heavily used base-level model is resistive magnetohydrodynamics (MHD) [39, 13]. This model is useful for describing the macroscopic dynamics of conducting fluids in the presence of electromagnetic fields and is often employed to study aspects of astrophysical phenomena (e.g., stellar interiors, solar flares), important science and technology applications (e.g., tokamak and stellarator devices, alternate pulsed fusion concepts), and basic plasma physics phenomena (e.g., magnetic reconnection, hydromagnetic instabilities) [39, 13]. The mathematical basis for the continuum modeling of these systems is the solution of the governing partial differential equations (PDEs) describing conservation of mass, momentum, and energy, augmented by an evolution equation for the magnetic field. The magnetic field leads to Lorentz forces in the momentum equation, , and a Joule heating energy dissipation term, , in the energy equation. An outline of these equations is provided in Table 2.
| Mass | |
|---|---|
| Momentum | |
| Energy | |
| Magnetic Field | |
| Plasma QoIs |
In the computational MHD simulations that are used in the results that follow, a fully-implicit variational multiscale (VMS) unstructured finite element (FE) discretization of the governing MHD system is employed. The fully-implicit time integration, based on RK methods, allow efficient solution of longer-time scale dynamics [63, 14] and the unstructured FE spatial discretization allows for complex geometries (e.g. ITER [14]) and local grid refinement. Simulations of transient, large, 3D simulations can generate solutions with – elements and – time-steps resulting in FE databases from – in size.
Quantities of Interest
In the pursuit of fundamental scientific understanding of complex plasma physics systems, accurate representations of the state (solution variables ) as well a number of scientific QoIs are important. As an example, magnetic reconnection is a fundamental process whereby a magnetic field is structurally altered via some dissipation mechanism, resulting in a rapid conversion of magnetic field energy into plasma energy and significant plasma transport/flow. Magnetic reconnection dominates the dynamics of many space and laboratory plasmas, and is at the root of phenomena such as solar flares, coronal mass ejections, and major disruptions in MCF energy (MFE) experiments [39, 12]. In this context, there are a number of important QoIs that include the internal plasma energy (IE), magnetic energy (ME), kinetic energy (KE), the total energy, , along with the total momentum, (see definitions in Table 2). In the evolution of the state variables and QoIs that are considered here, this transformation of energy components (ME, KE) in magnetic reconnection will be evident333It should be noted that due to energy transfer through the boundary there is a small decrease in the total energy in example problems that are presented.. Commonly in the evaluation of reconnection phenomena, an understanding of the growth rate of these transformations is of interest, and for example, the slope of provides such a metric. Alternatively, using , one could compute a decay rate for the transformation of magnetic energy.
In this work, we attempt to preserve IE, KE, ME as quantities of interest which then implicitly preserve TE. Together with the momentum QoI, this results in four QoI functions that are approximated using the finite element discretization scheme described above. Calculation of these QoIs is straightforward but substantially more complicated than the combustion QoIs described above, so descriptions of their evaluations are provided in Algorithm 1.
Results
2D Compressible Tearing Mode
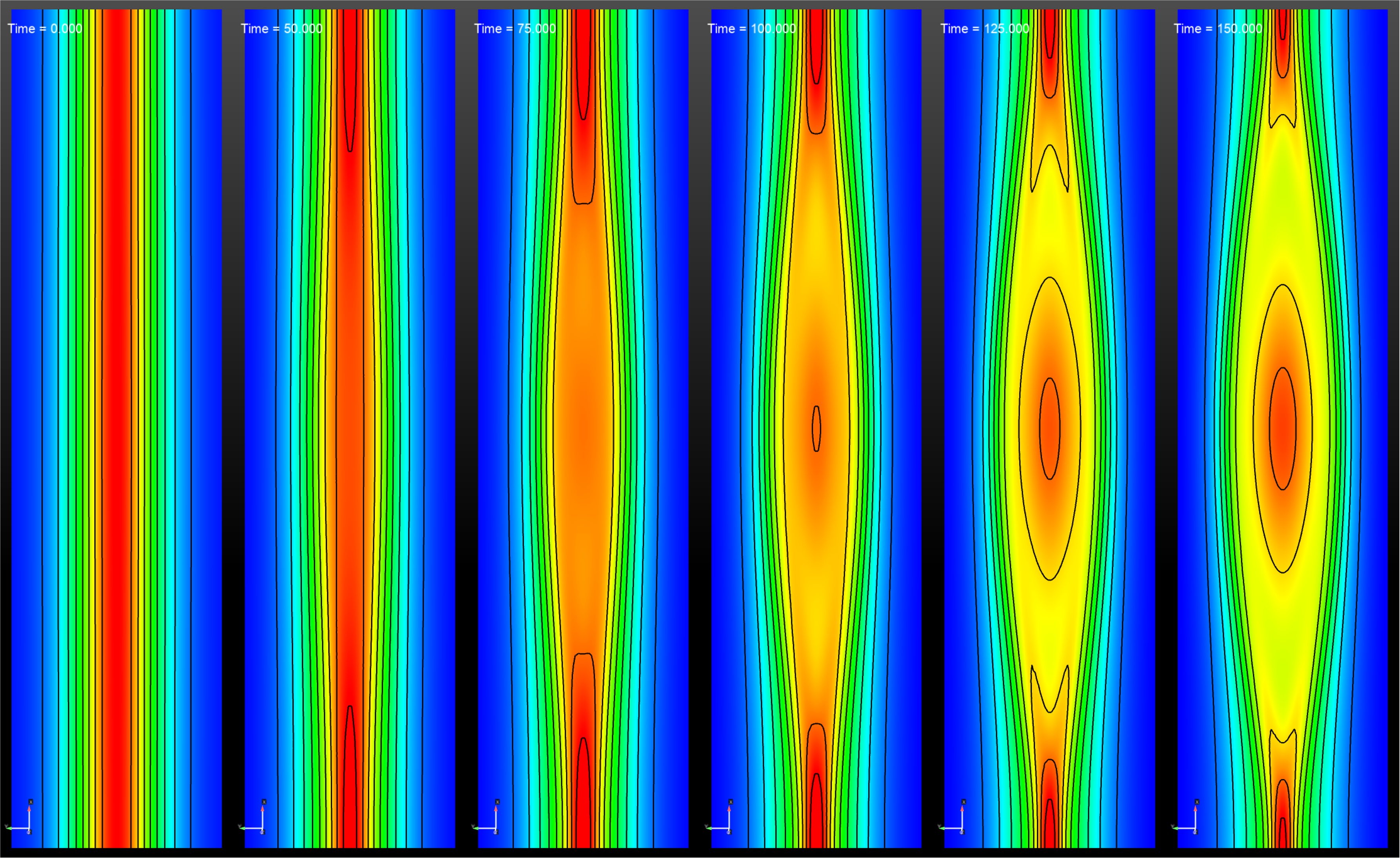
The magnetic reconnection problem is a 2D low flow-Mach number compressible tearing mode simulation that follows the unstable evolution of a thin current sheet formed by a sheared magnetic field (Harris sheet) within an initially stationary velocity field. The domain is a rectangle discretized on a uniform grid resulting in 501 and 201 grid points in the and directions, respectively. The computation is for a Lundquist number of and consists of 500 time steps. Details of the full problem setup can be found in [21, 14]. The thin current sheet becomes unstable and forms a magnetic island structure as presented in Fig. 5 with the -axis oriented in the vertical direction. The rate of the decay of the norm of the magnetic energy and the growth of the norm of momentum provide information of the time-scale of the linear phase of the instability [21]. These rates correspond to exponential fits of the slopes of these QoIs in Fig. 6.
We now consider goal-oriented CP and Tucker decomposition of the 2-D tearing mode plasma physics data stored as a 4-way tensor consisting of each of the 12 simulation variables at each grid and time point. We use the solution strategy described in Fig. 1 where we first center each variable slice by its mean and scale it by its standard deviation and then compute a traditional CP/Tucker decomposition via CP-ALS/ST-HOSVD using a supplied CP rank and ST-HOSVD error tolerance, respectively, which serves as the initial guess for the goal-oriented decomposition. As for the HCCI problem, we set a CP-ALS stopping tolerance of . Since the momentum values are near zero for the first few time steps, we only include time steps in the momentum QoI starting from the fifth time step—i.e., for the momentum QoI. We then choose the weighting coefficients as described above and run 20 iterations of the trust region-Newton optimization method as described in Fig. 1.
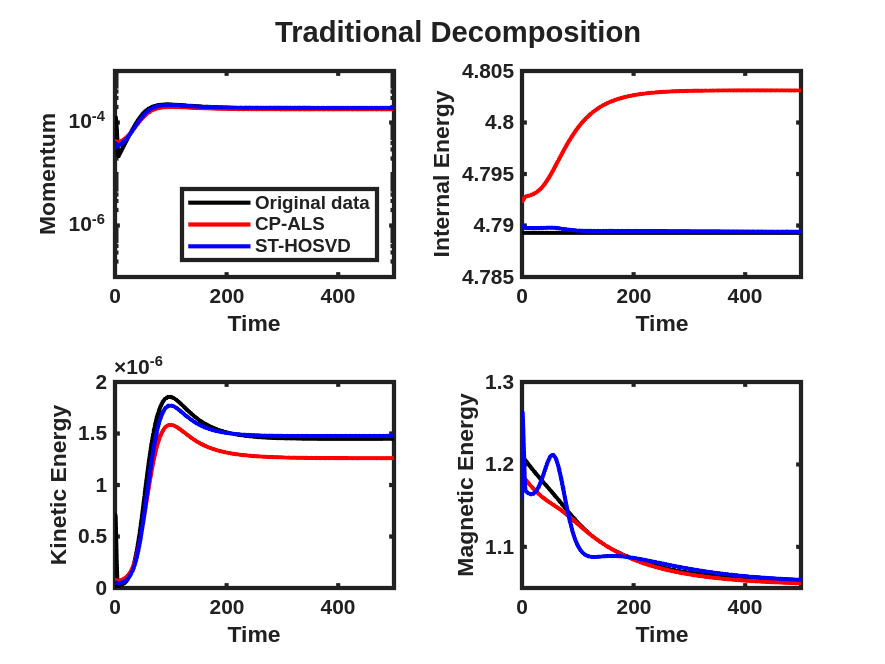
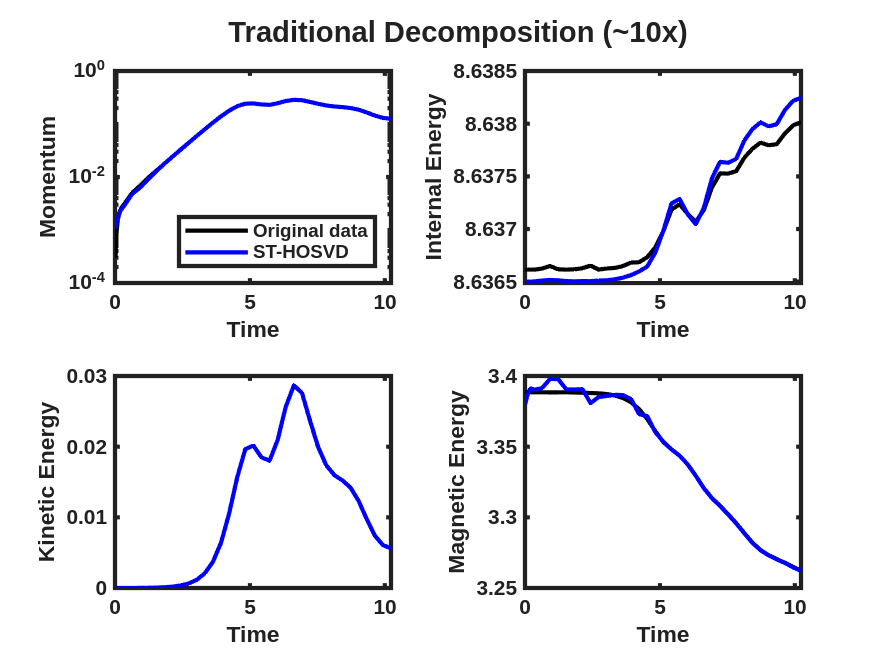
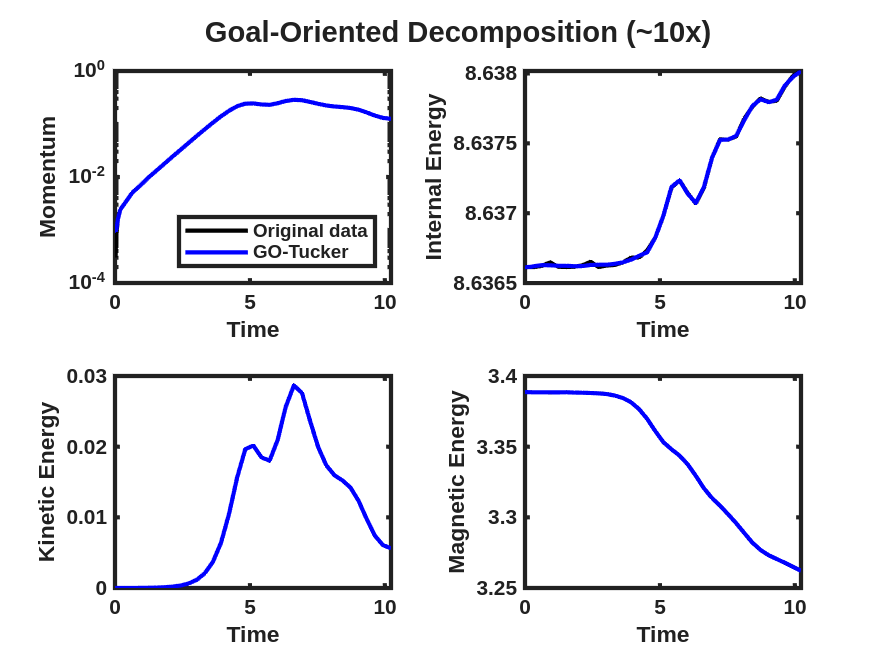
The momentum and energy QoIs described above are displayed for the data tensor and reconstruction obtained from a rank-7 CP-ALS decomposition and ST-HOSVD decomposition with truncation tolerance of in Fig. 6(a), where small but clearly visible differences are observed in these quantities, even though the relative tensor reconstruction error of the unscaled data and model is approximately for CP-ALS and for ST-HOSVD. These same QoIs are then displayed after the goal-oriented decomposition as described above using the trust-region Newton optimization method in Fig. 6(b), where these visual differences between the QoIs for the data and the low-rank models have largely disappeared. Furthermore, the relative tensor reconstruction error is again about and , respectively, indicating substantial reduction in relative QoI error with no increase in the relative tensor reconstruction error.
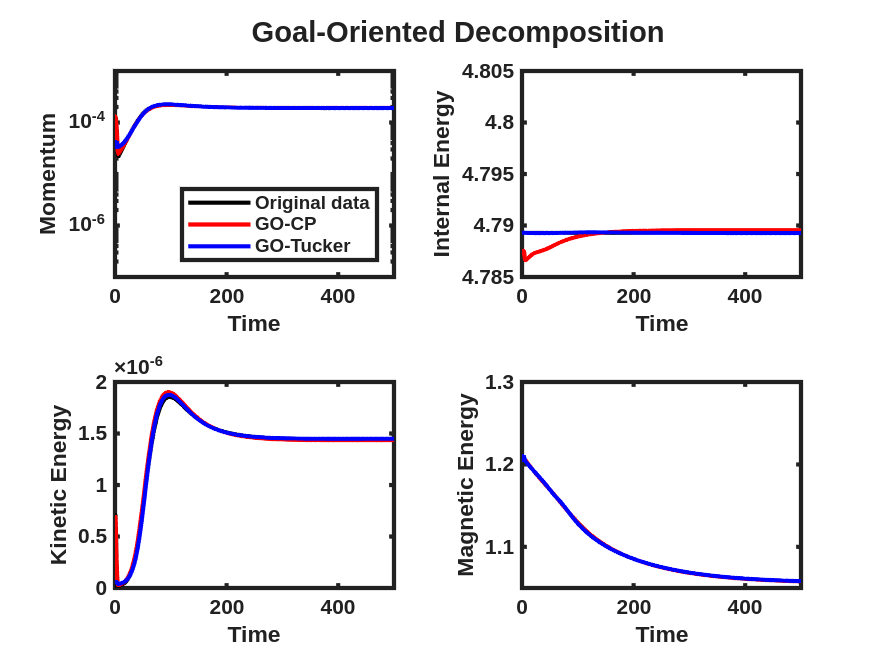
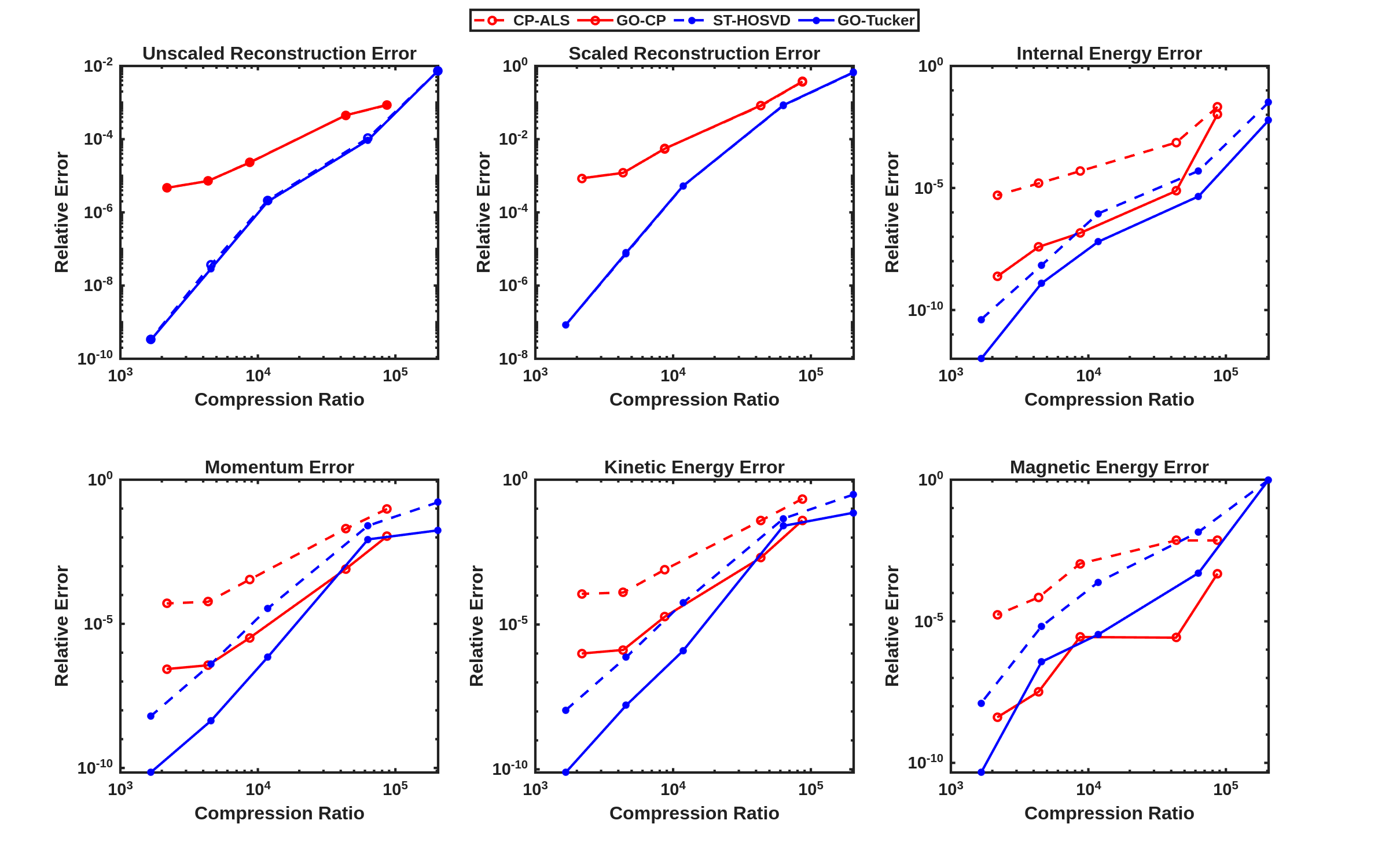
We now consider the performance of the goal-oriented approach compared to the traditional CP/Tucker approach over a range of CP ranks and initial ST-HOSVD truncation tolerances. Figure 7 displays the relative tensor reconstruction error (for both the scaled and unscaled data and models) as well as the relative QoI error for the momentum and energy QoIs as functions of compression ratio of the CP/Tucker reduced models, for both traditional and goal-oriented methods. We make several observations:
-
•
The Tucker relative tensor reconstruction error is typically less than the CP relative tensor reconstruction error for the same compression ratio, as is typically expected.
-
•
The relative QoI errors for Tucker is also typically less than for CP.
-
•
The relative tensor reconstruction errors for the traditional and goal-oriented approaches are essentially identical, for both CP and Tucker. This is true for both the scaled and unscaled data and models, indicating the goal improvements are not due to increased relative tensor reconstruction error of small variables relative to larger variables.
-
•
Around 2–3 orders of magnitude improvement in relative QoI error for all QoIs is typically observed for the goal-oriented CP method, whereas goal-oriented Tucker results in about 1–2 orders of magnitude improvement.
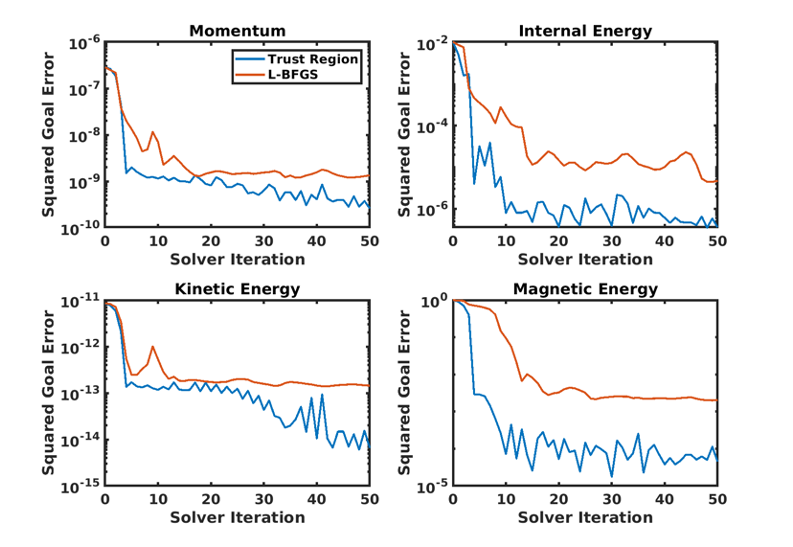
The above calculations all relied on use of the trust-region Newton optimization method with Gauss-Newton Hessian approximation and approximate block-diagonal preconditioner. We found this approach to be much more reliable than the L-BFGS method, often finding more accurate solutions (in terms of QoI error) in significantly fewer iterations. For example, Fig. 8 displays the convergence history for the trust-region Newton and L-BFGS methods for the above goal-oriented Tucker experiment with HOSVD truncation tolerance of , where we see lower achieved QoI error for the trust-region Newton method, yielding a good solution in just a few optimization iterations.
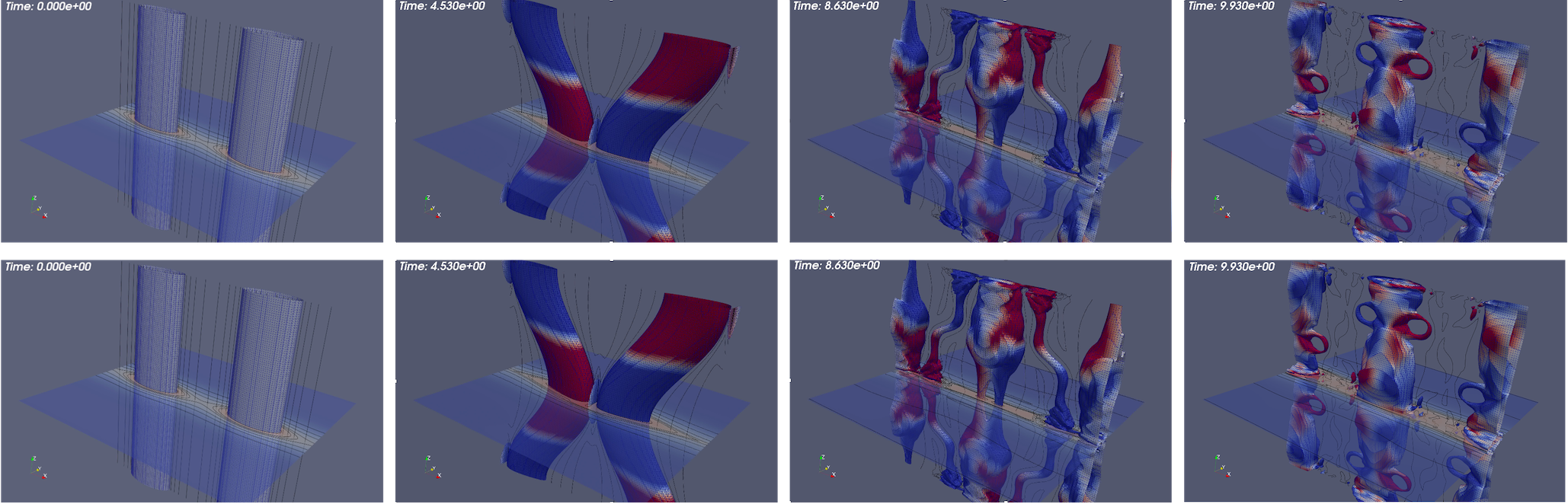
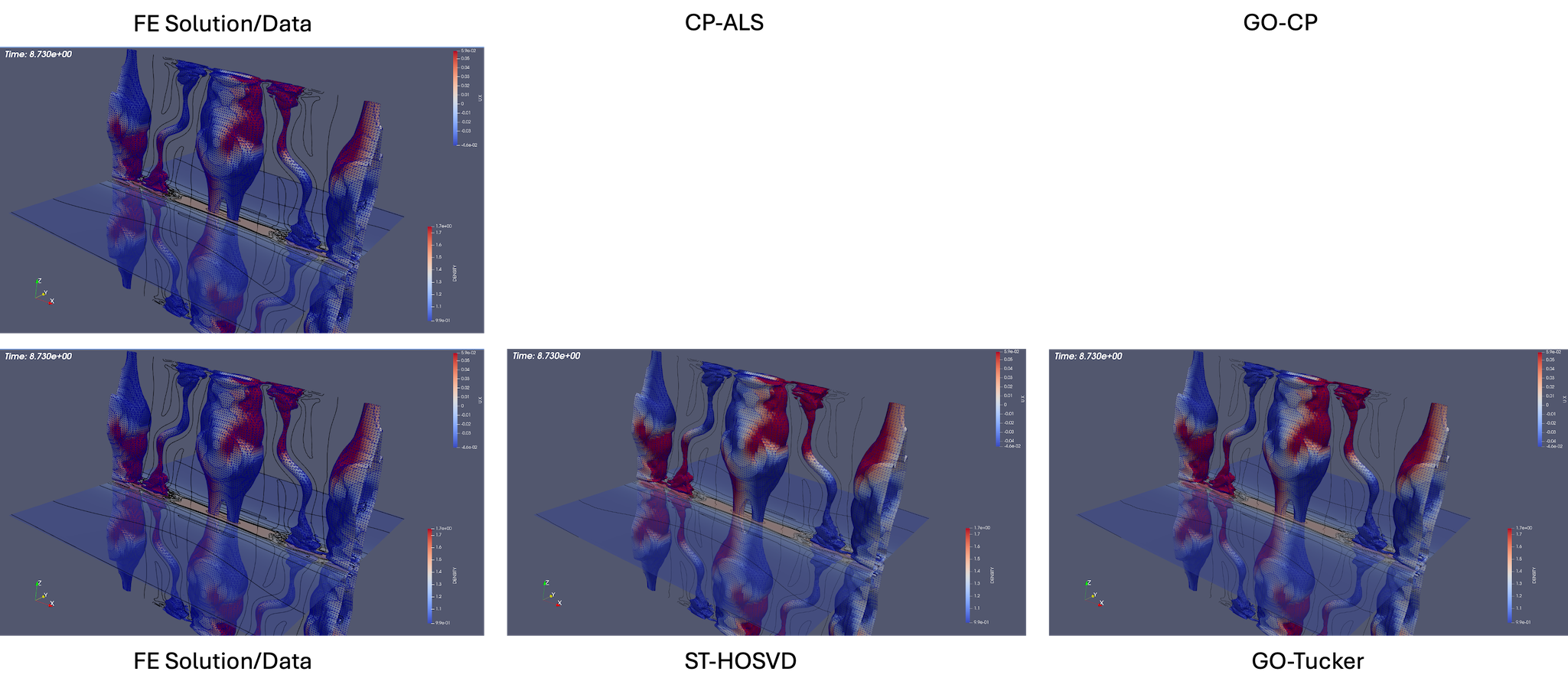
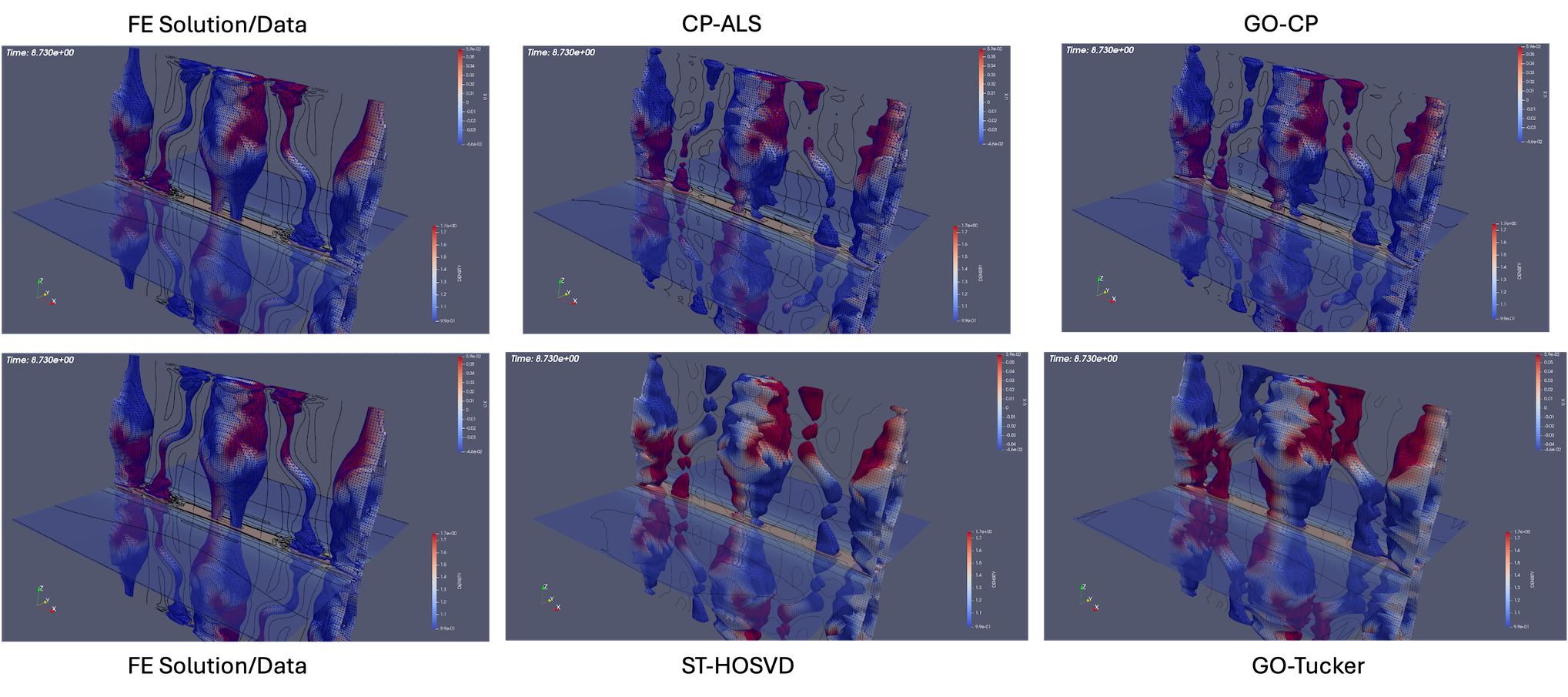
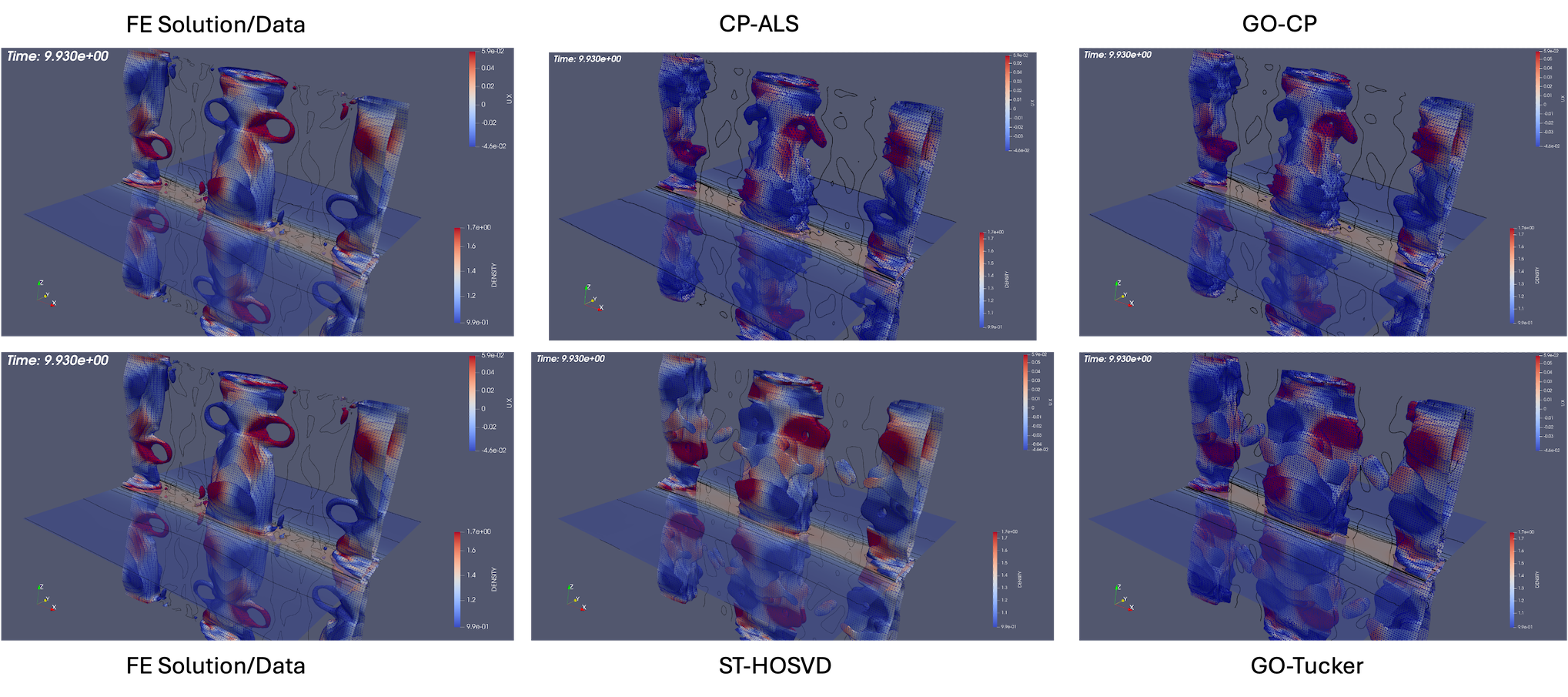
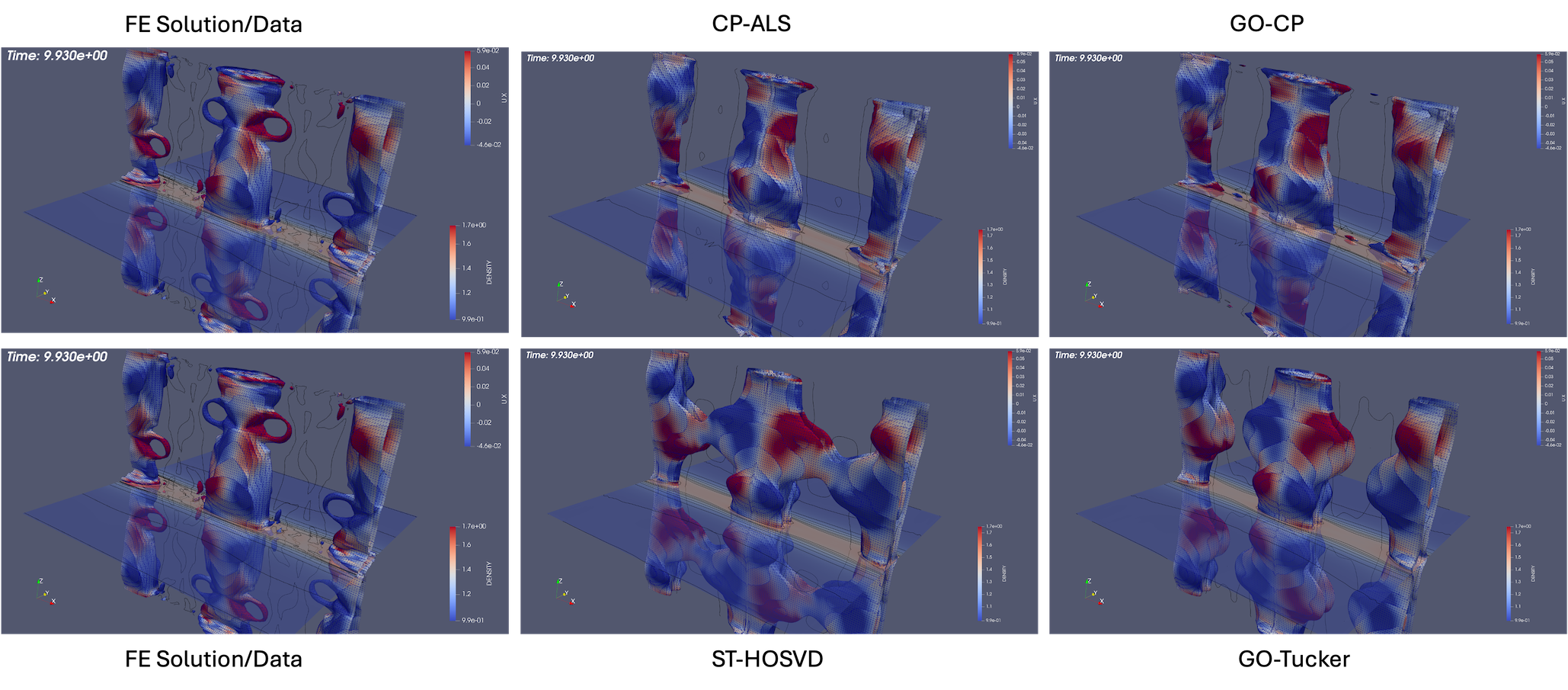
3D Island Coalescence The island coalescence problem follows the unstable evolution of two 3D current flux tubes (which in the cross plane become islands) embedded in a sheared magnetic field Harris sheet and is described in detail in [63]. The computational simulations presented here are for a higher Lundquist number that exhibit more significant dynamics in the evolution and reconnection [21, 63]. This example allows a demonstration of compression and evaluation of the evolution of appropriate QoIs, but also the more complex dynamics facilitate qualitative discussion of the reconstructions using low-rank tensor decompositions at various compression ratios shown in Fig. 9 and Fig. 10. Visualization of an iso-surface (in this case density) is a challenging qualitative metric for comparison of the reconstructions as small changes in the density distribution in space will modify the structure of the iso-surface at a given value. Fig. 9 compares the initial condition and three discrete times in the evolution of the reconnecting flux tubes for the original FE solution and ST-HOSVD decomposition at approximately 10x compression. Clearly evident is the quality of the ST-HOSVD reconstruction at 10x reduction.
In Fig. 10, the ST-HOSVD reconstruction for up to three orders of magnitude of reduction is visualized. Here it is evident that at the significant reduction of 100x, the reconstruction appears very representative of the original data for visualizing the structure of the iso-surface. Additionally, even up to a 1000x reduction, the major structural features of the iso-surface resemble reasonably well the original FE data with the existence of the loop structures on the three main island iso-surfaces at time .

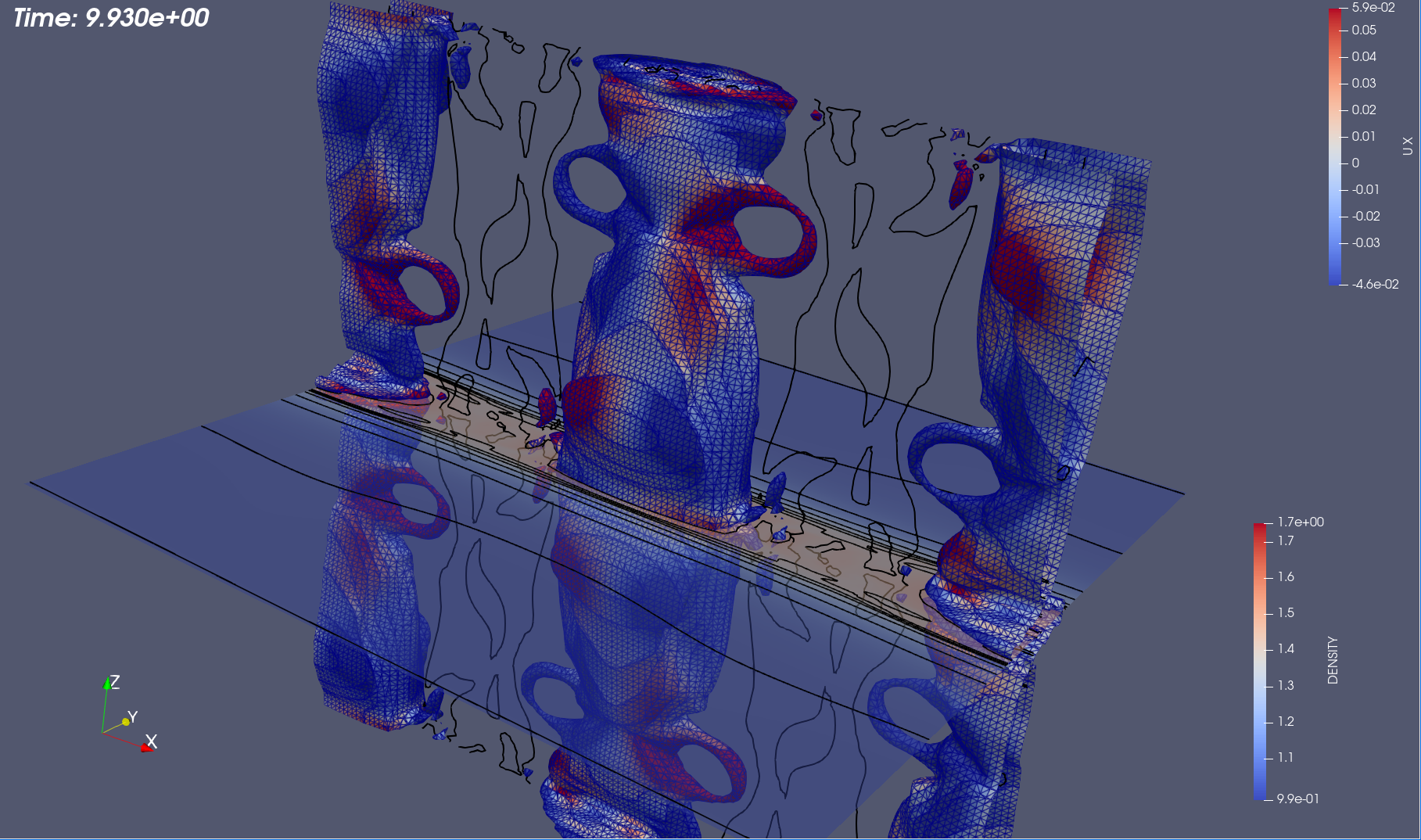
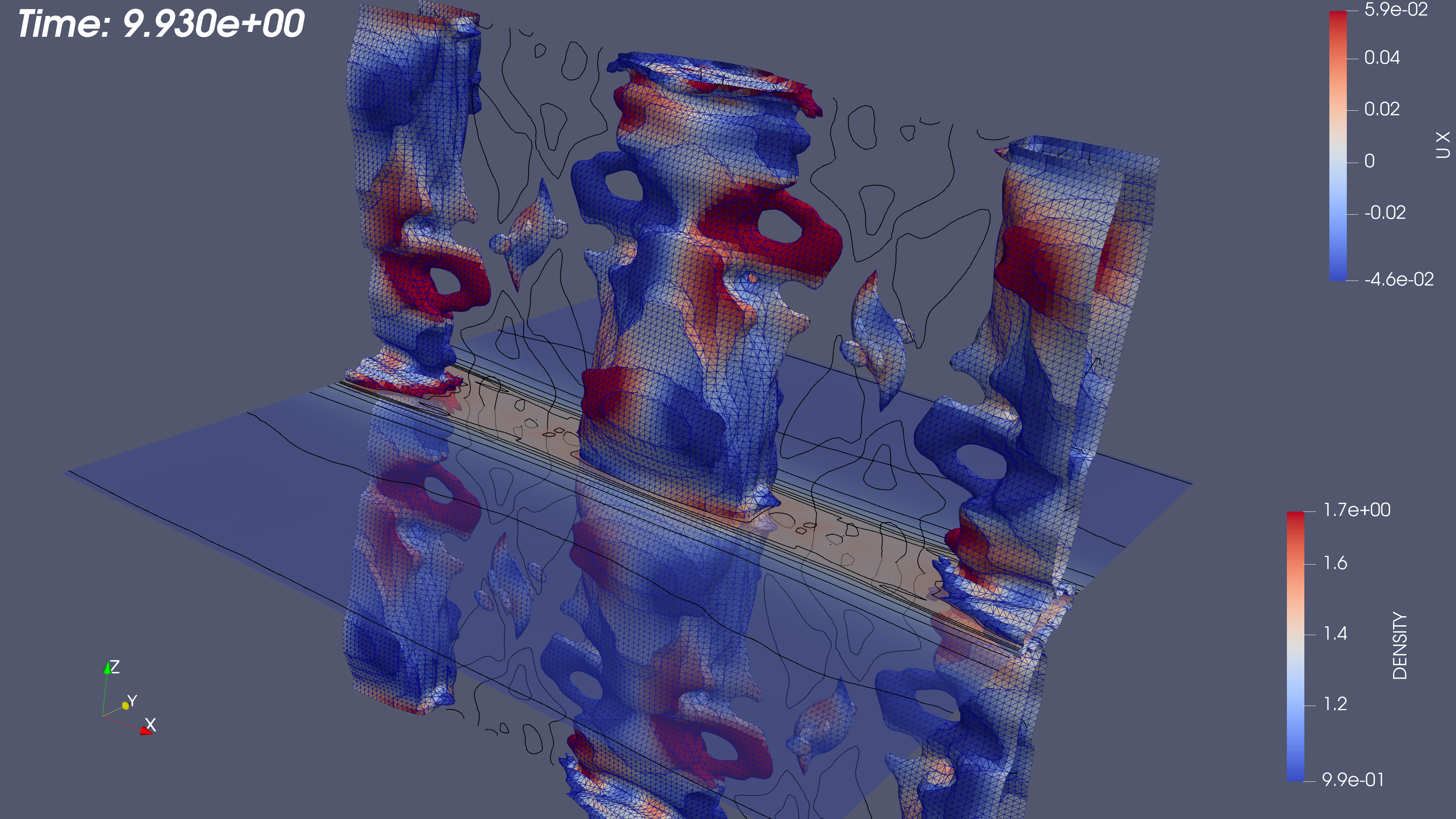

Next, a comparison of the reconstructions of the four plasma physics QoIs along with the quality of the iso-surface reconstruction for traditional and goal-oriented decompositions with varying levels of reduction is studied. The setup of the goal-oriented approach is identical to the tearing sheet problem described above, except the default stopping tolerance of for CP-ALS is used for the initial guess for goal-oriented CP. In this study, the original island coalescence data set produced by the simulation code was coarsened in time by selecting every third time-step to overcome memory and runtime limitations with our current serial, Matlab-based software implementation444These limitations are expected to be removed in a future software implementation.. It should be noted that, as expected, the temporal coarsening somewhat adversely affects the general quality of the reconstructions over what would have been obtained with the original data set for the same level of reduction, for both the traditional and goal-oriented approaches. This degradation is illustrated in Fig. 11 where the reference FE data, the full-database ST-HOSVD and coarsened-database reconstructions at a reduction of 1,000x are presented.
Figure 12 and Fig. 13 present the improvement in the satisfactions of the QoI evolution with the goal-oriented approaches, where the ranks/tolerances were chosen to yield compression ratios of approximately 10x, 100x, 1,000x, and 10,000x. Here we see significant error in the QoIs for the 1,000x and 10,000x compressions for the traditional approach, which are substantially reduced for the goal-oriented approach. As with the tearing mode data, essentially no change in the relative tensor reconstruction errors are observed.
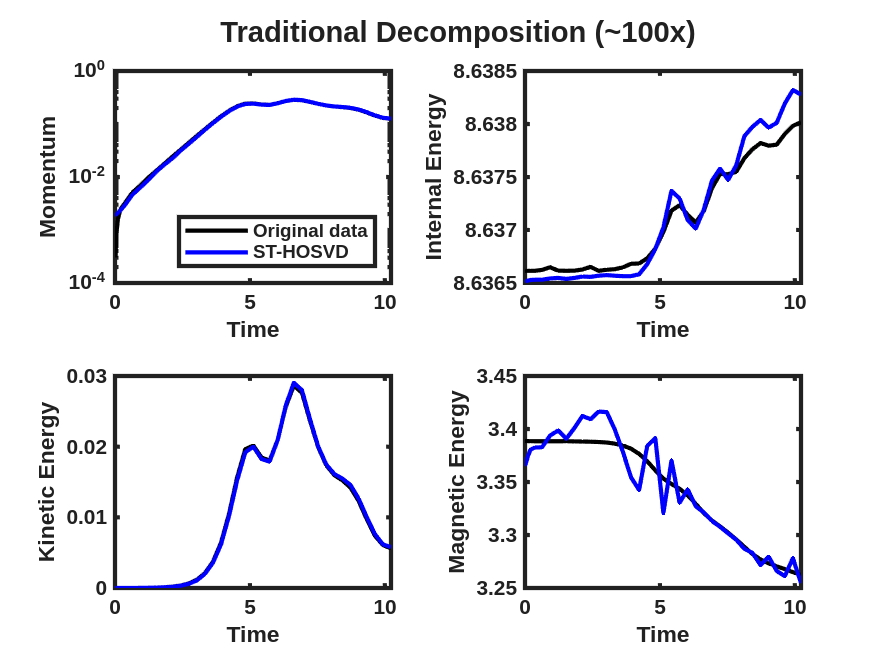
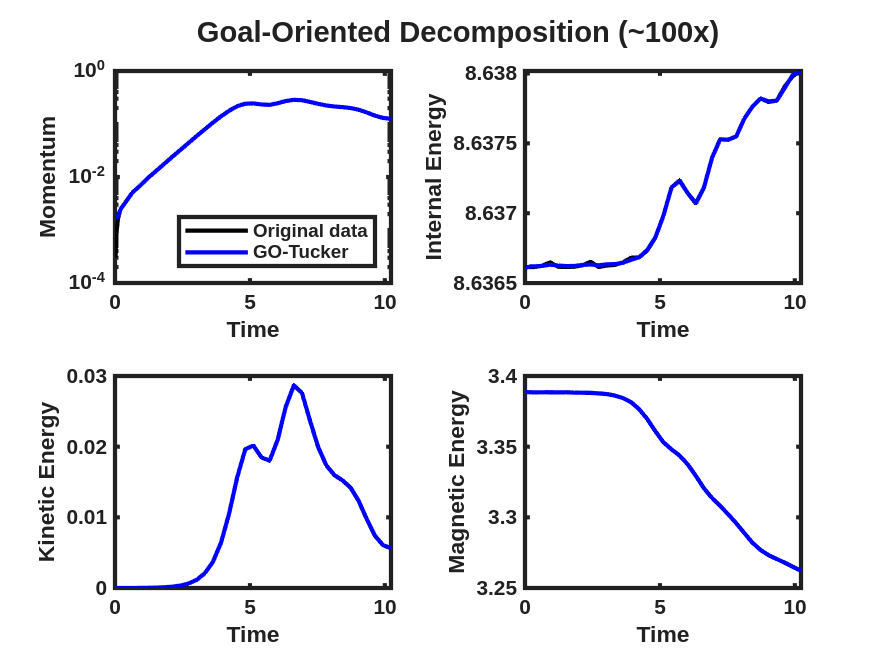
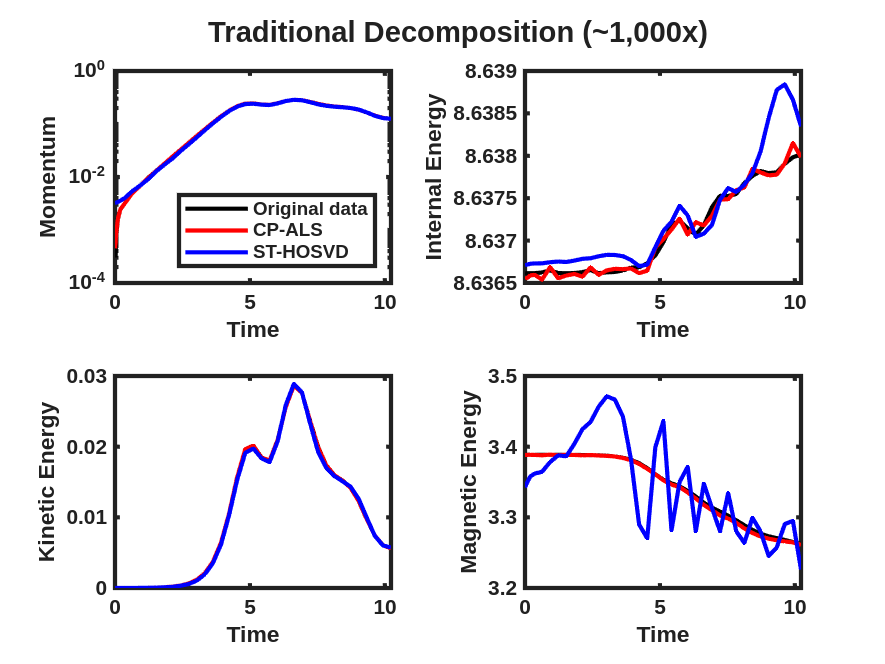
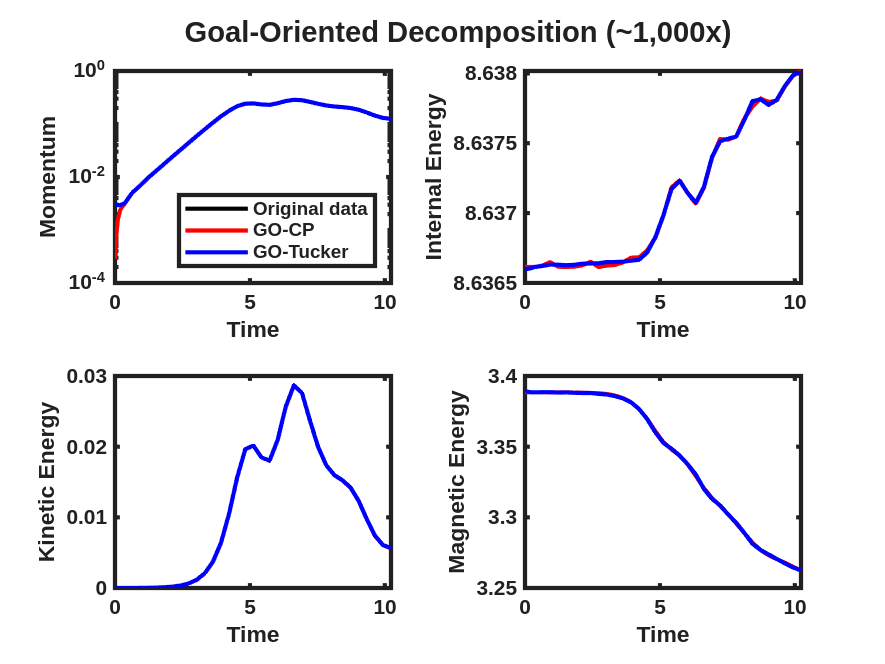
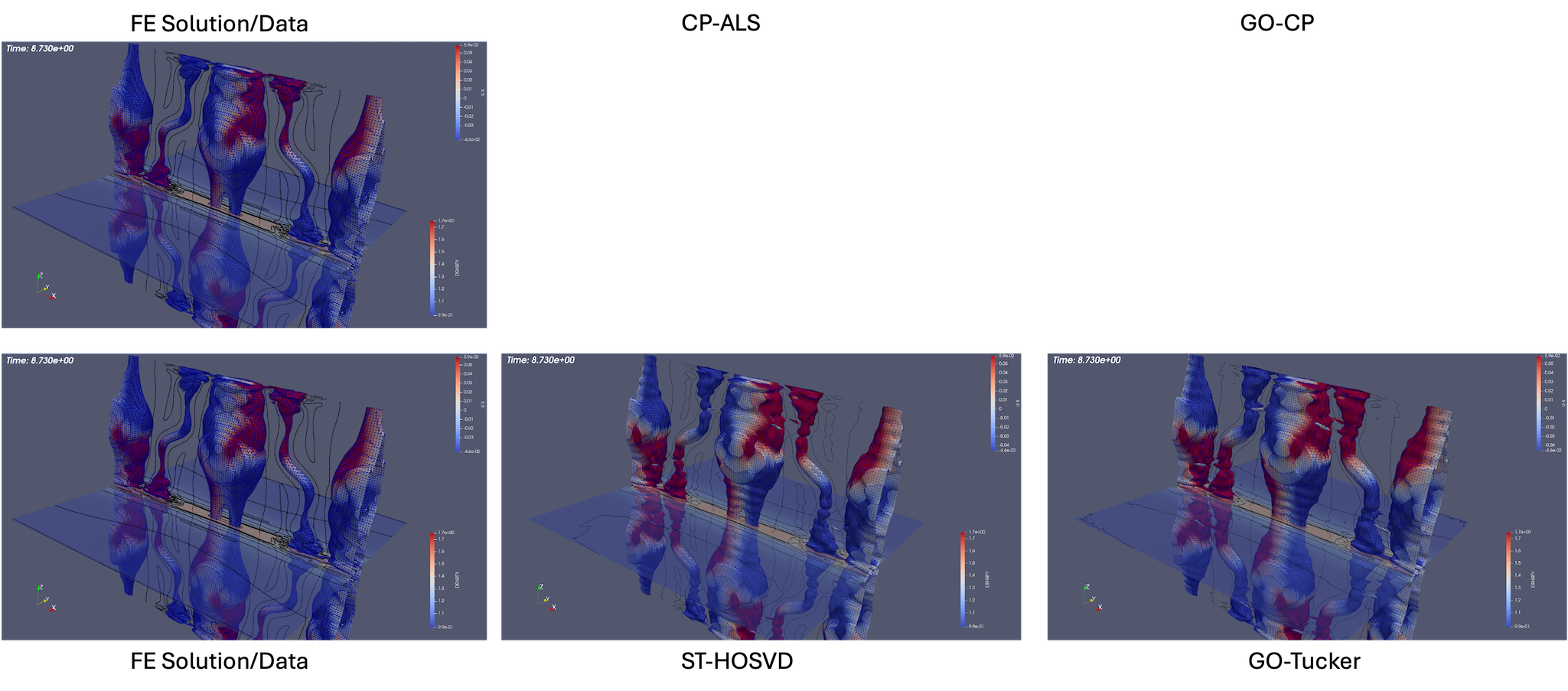
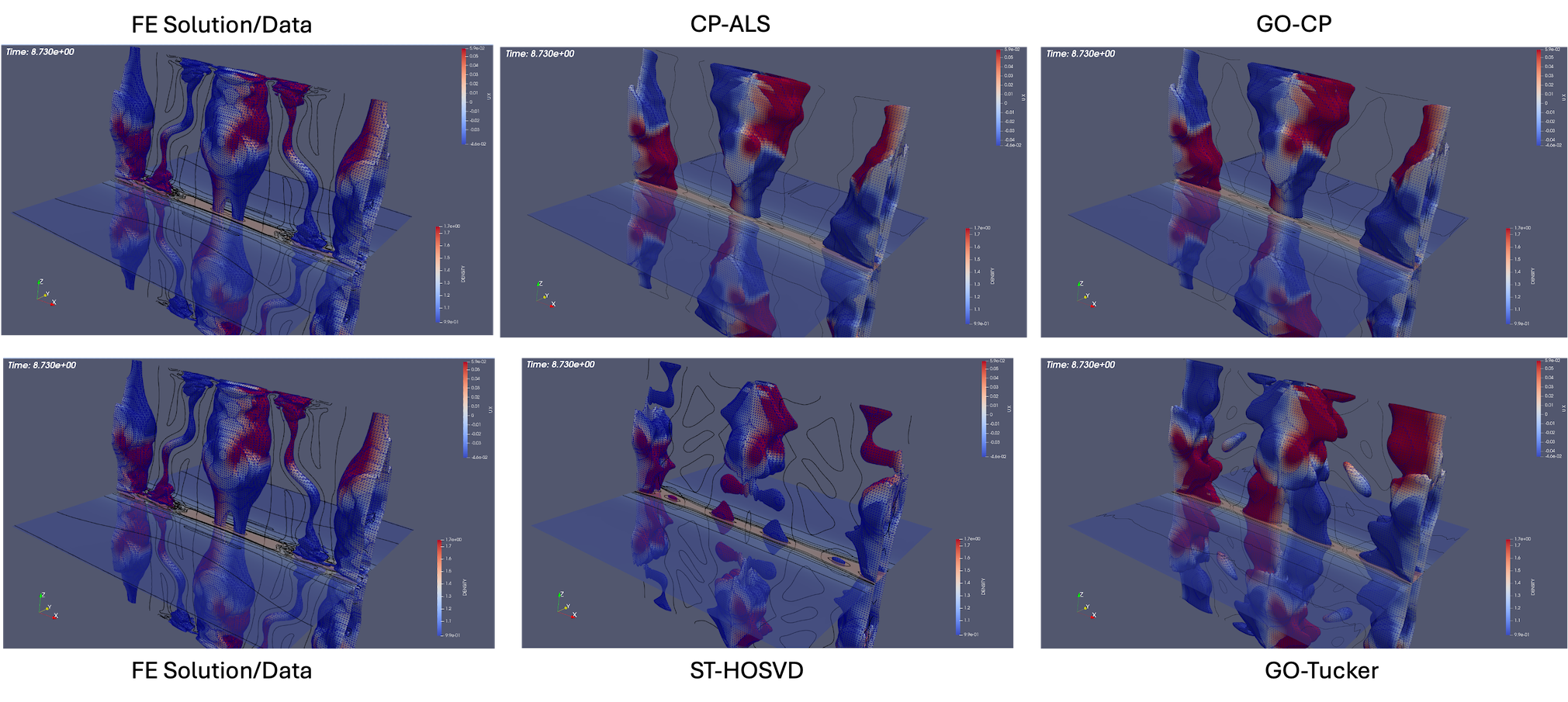
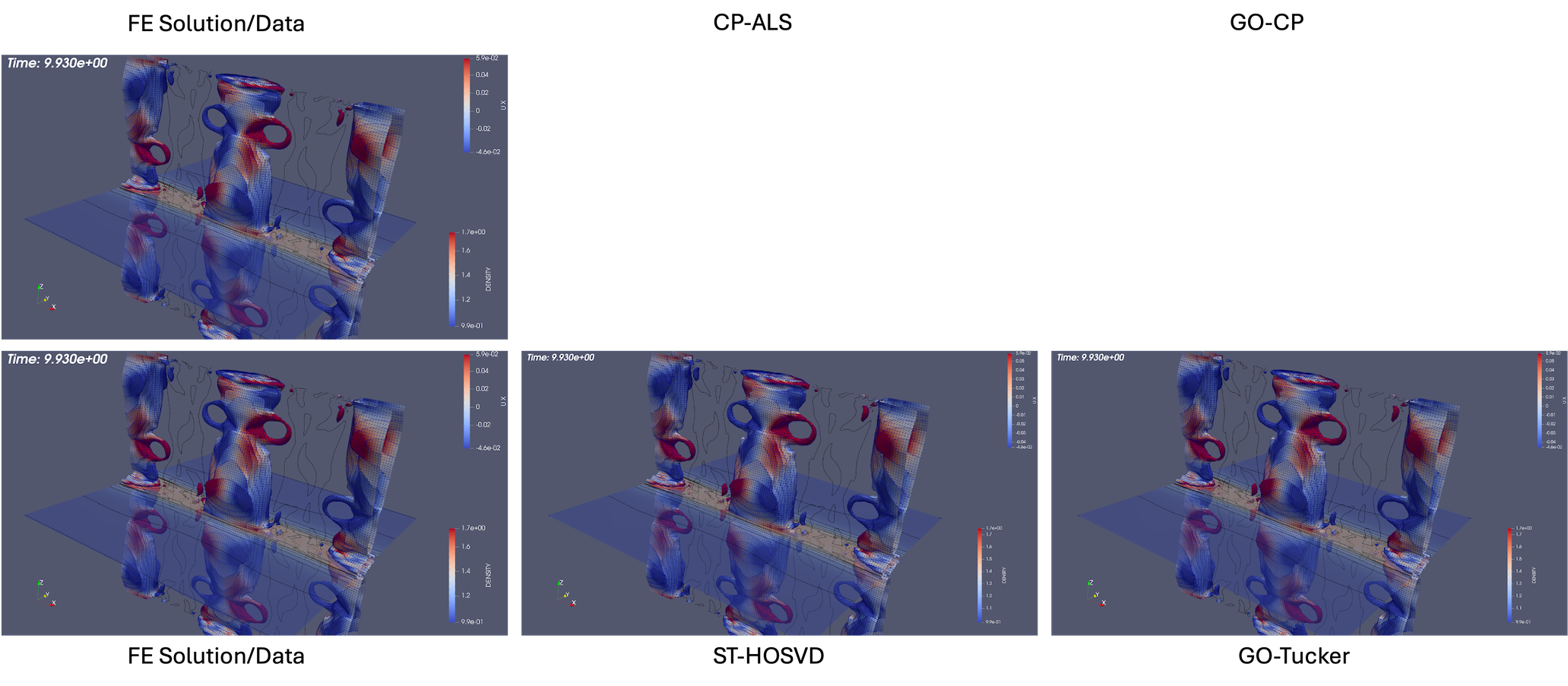
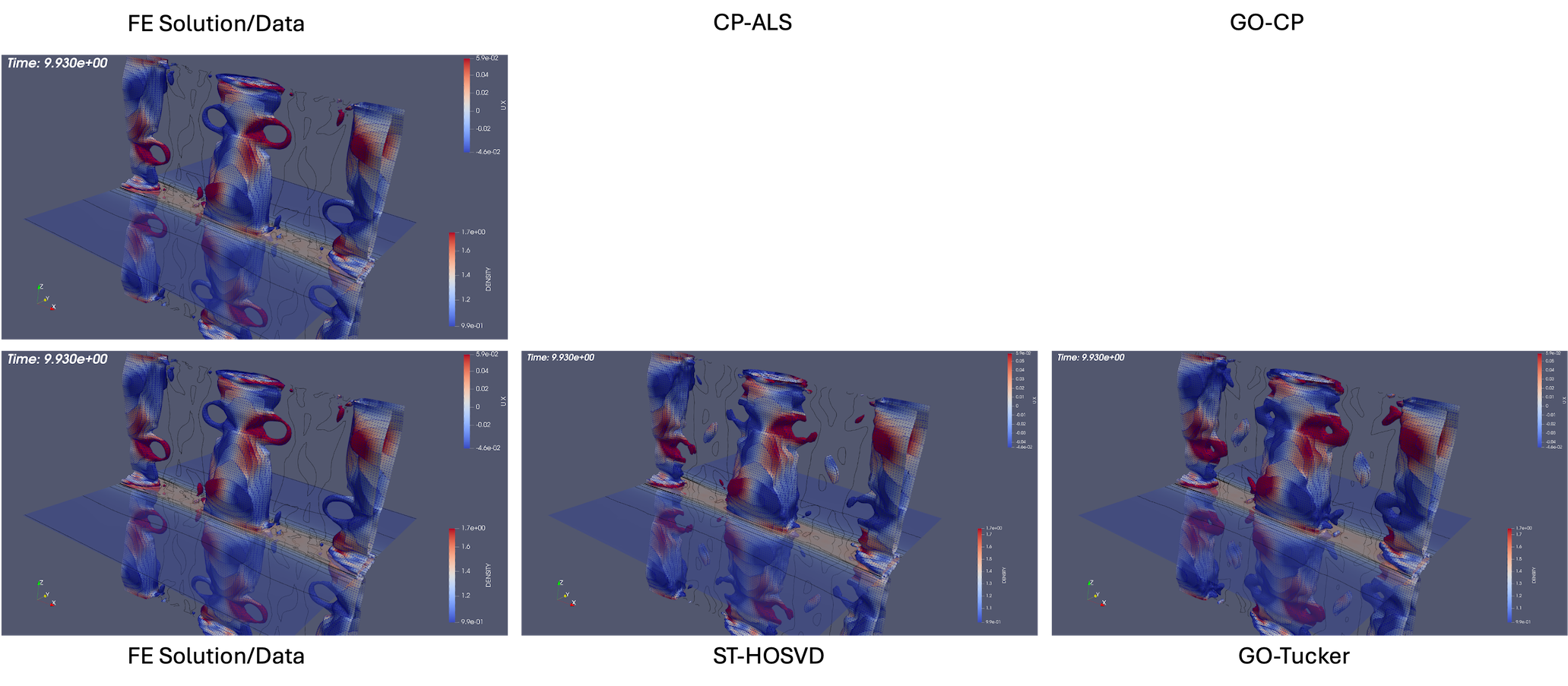
As described above, the goal-oriented methods do strongly improve the QoI reconstruction. In general these methods also appear to improve the iso-surface reconstructions in most cases but not uniformly. To illustrate this effect, Fig. 14 and Fig. 15 present results at times and respectively for reduction levels of 10x, 100x, 1,000x, and 10,000x. The results look very good even on this coarse-database for the 10x, 100x compression ratios for the goal-oriented approaches. For higher compression ratios, it is evident for the data that the goal-oriented methods appear to slightly improve the iso-surface reconstructions. This can most clearly be seen for the goal-oriented methods reconstructing some of the slender iso-surfaces at 1000x and for Tucker at 10,000x reforming the continuous surfaces of the central iso-surface that has two islands that exist on the intersection with the ( plane, whereas the ST-HOSVD and CP-ALS-based decompositions only show a single island outline.
For the latter time of the data is mixed. In Fig. 15, the 10x reductions look excellent, for 100x a slight improvement of the surface seems to appear with the loop structure reappearing in the goal-oriented Tucker reconstruction. Then for 1,000x a slight degradation in the loop structure seems evident in that the openings become closed surfaces compared to the standard ST-HOSVD. However, with a further increase in the compression rate to 10,000x the goal-oriented approach does isolate the three major iso-surfaces showing an improvement from the standard ST-HOSVD that merged these surfaces.
Conclusions and Future Work2
In this paper, we introduced a new approach for low-rank modeling of high-dimensional numerical simulation data based on tensor decompositions that augment the traditional optimization problems used to compute these tensor decompositions with additional functionals in the objective function that attempt to preserve application-specific quantities of interest and invariants. The method was introduced specifically for CP and Tucker decompositions, but the approach is general and could likely be applied to any tensor format that can be computed through an optimization-based method. Examples of applying the technique to large data sets arising from the numerical simulation of turbulent combustion and plasma physics relevant to fusion energy were presented, demonstrating several orders of magnitude reduction in the error for these QoIs while maintain the same level of accuracy in the overall tensor reconstruction. When incorporating multiple QoIs in the problem formulation, we found trust region-Newton optimization methods based on Gauss-Newton Hessian approximations effective in solving the resulting optimization problems where other methods such as L-BFGS struggled.
While our results compared the effectiveness of CP and Tucker decompositions for reduction of scientific data, our aim was not to claim that one these decompositions to be superior over the other. Generally, we found the level of error for a given compression ratio to be comparable between the two methods, with comparable levels of reduction in QoI error for the goal-oriented approach. We often found the Tucker method easier to deal with in practical settings however, particularly for high-accuracy decompositions. With Tucker, setting a tight ST-HOSVD solver tolerance is straightforward and not terribly expensive computationally. However, obtaining high-accuracy CP decompositions is challenging numerically due to the very high ranks (i.e., (10,000)) required which existing CP decomposition algorithms (e.g., CP-ALS) and computational kernels supporting them (e.g., MTTKRP) are often not optimized to handle effectively. Conversely, we found the optimization problem defining goal-oriented CP decompositions typically easier to solve numerically. In fact, the challenges with solving the optimization problem for Tucker decompositions motivated the trust-region Newton optimization approach studied here.
While the approach was demonstrated to be successful in achieving our goal of reducing QoI error in reconstructions arising from the low-rank models, several challenges remain that could be studied through future work. In particular, we found the goal-oriented approach to be substantially more expensive than the traditional solution methods the models are based on (i.e., CP-ALS and ST-HOSVD). Part of this is due to our serial Matlab-based implementation where vectorizing the evaluation of the QoI functions and their derivatives is challenging. We expect the approach to be much more competitive in terms of computational cost with a high-performance, parallel implementation. Other potential approaches for reducing cost include randomized algorithms, incremental update/streaming algorithms, and improved preconditioning that incorporates the QoI terms in some fashion. Effective stopping criteria beyond a fixed number of iterations were also not addressed in this work, and we suspect that extending the formulation to one on Riemannian manifolds to eliminate degeneracies arising from non-uniqueness where traditional stopping criteria based on gradient norms could be used would likely be fruitful. Finally, a theoretical study of how the goal-oriented approach can decrease QoI error without significantly increasing tensor reconstruction error, illustrating similarities and differences of the traditional and goal-oriented approaches, is needed.
Acknowledgments
This work was supported by the Laboratory Directed Research and Development program at Sandia National Laboratories, a multimission laboratory managed and operated by National Technology and Engineering Solutions of Sandia LLC, a wholly owned subsidiary of Honeywell International Inc. for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-NA0003525.
References
- [1] P.-A. Absil, C. G. Baker, and K. A. Gallivan, Trust-region methods on Riemannian manifolds, Foundations of Computational Mathematics, 7 (2007), pp. 303–330, https://doi.org/10.1007/s10208-005-0179-9.
- [2] E. Acar, D. M. Dunlavy, and T. G. Kolda, A scalable optimization approach for fitting canonical tensor decompositions, Journal of Chemometrics, 25 (2011), pp. 67–86, https://doi.org/10.1002/cem.1335.
- [3] E. Acar, T. G. Kolda, and D. M. Dunlavy, All-at-once optimization for coupled matrix and tensor factorizations. arXiv:1105.3422, 2011, https://arxiv.org/abs/1105.3422.
- [4] M. Ainsworth, O. Tugluk, B. Whitney, and S. Klasky, Multilevel techniques for compression and reduction of scientific data-quantitative control of accuracy in derived quantities, SIAM Journal on Scientific Computing, 41 (2019), pp. A2146–A2171, https://doi.org/10.1137/18M1208885.
- [5] W. Austin, G. Ballard, and T. G. Kolda, Parallel tensor compression for large-scale scientific data, in IPDPS’16: Proceedings of the 30th IEEE International Parallel and Distributed Processing Symposium, May 2016, pp. 912–922, https://doi.org/10.1109/IPDPS.2016.67.
- [6] B. W. Bader and T. G. Kolda, Algorithm 862: Matlab tensor classes for fast algorithm prototyping, ACM Trans. Math. Softw., 32 (2006), p. 635–653, https://doi.org/10.1145/1186785.1186794.
- [7] B. W. Bader and T. G. Kolda, Efficient MATLAB computations with sparse and factored tensors, SIAM Journal on Scientific Computing, 30 (2007), pp. 205–231, https://doi.org/10.1137/060676489.
- [8] G. Ballard, K. Hayashi, and R. Kannan, Parallel nonnegative CP decomposition of dense tensors, in 25th IEEE International Conference on High Performance Computing (HiPC), Dec 2018, pp. 22–31, https://ieeexplore.ieee.org/document/8638076.
- [9] G. Ballard, A. Klinvex, and T. G. Kolda, TuckerMPI: A parallel C++/MPI software package for large-scale data compression via the Tucker tensor decomposition, ACM Transactions on Mathematical Software, 46 (2020), 13 (31 pages), https://doi.org/10.1145/3378445.
- [10] G. Ballard and T. G. Kolda, Tensor Decompositions for Data Science, Cambridge University Press, 2025, https://www.mathsci.ai/post/tensor-textbook/.
- [11] A. Bhagatwala, J. H. Chen, and T. Lu, Direct numerical simulations of hcci/saci with ethanol, Combustion and Flame, 161 (2014), pp. 1826–1841, https://doi.org/https://doi.org/10.1016/j.combustflame.2013.12.027, https://www.sciencedirect.com/science/article/pii/S0010218014000030.
- [12] D. Biskamp, Magnetic reconnection, Physics Reports, 237 (1994), pp. 179–247.
- [13] J. A. Bittencourt, Fundamentals of plasma physics, Springer Science & Business Media, 2013.
- [14] J. Bonilla, J.N.Shadid, X. Tang, M. Crockatt, P. Ohm, E. G. Phillips, R. Pawlowski, and S. Conde, On a fully-implicit VMS-stabilized FE formulation for low Mach number compressible resistive MHD with application to MCF, Computer Methods in Applied Mechanics and Engineering, 417 (2023), p. 116359.
- [15] J. Borggaard, Z. Wang, and L. Zietsman, A goal-oriented reduced-order modeling approach for nonlinear systems, Computers & Mathematics with Applications, 71 (2016), pp. 2155–2169.
- [16] N. Boumal, B. Mishra, P.-A. Absil, and R. Sepulchre, Manopt, a Matlab toolbox for optimization on manifolds, Journal of Machine Learning Research, 15 (2014), pp. 1455–1459, https://www.manopt.org.
- [17] T. Bui-Thanh, K. Willcox, O. Ghattas, and B. van Bloemen Waanders, Goal-oriented, model-constrained optimization for reduction of large-scale systems, Journal of Computational Physics, 224 (2007), pp. 880–896.
- [18] J. D. Carroll and J. J. Chang, Analysis of individual differences in multidimensional scaling via an N-way generalization of “Eckart-Young” decomposition, Psychometrika, 35 (1970), pp. 283–319, https://doi.org/10.1007/BF02310791.
- [19] R. B. Cattell, Parallel proportional profiles and other principles for determining the choice of factors by rotation, Psychometrika, 9 (1944), pp. 267–283, https://doi.org/10.1007/BF02288739.
- [20] R. B. Cattell, The three basic factor-analytic research designs — their interrelations and derivatives, Psychological Bulletin, 49 (1952), pp. 499–452, https://doi.org/10.1037/h0054245.
- [21] L. Chacón, An optimal, parallel, fully implicit newton-krylov solver for three-dimensional visco-resistive magnetohydrodynamics, Phys. Plasmas, 15 (2008), p. 056103.
- [22] J. H. Chen, A. Choudhary, B. de Supinski, M. DeVries, E. R. Hawkes, S. Klasky, W. K. Liao, K. L. Ma, J. Mellor-Crummey, N. Podhorszki, R. Sankaran, S. Shende, and C. S. Yoo, Terascale direct numerical simulations of turbulent combustion using s3d, Computational Science & Discovery, 2 (2009), p. 015001, https://doi.org/10.1088/1749-4699/2/1/015001, https://dx.doi.org/10.1088/1749-4699/2/1/015001.
- [23] L. Cheng, S. Mattei, P. W. Fick, and S. J. Hulshoff, A semi-continuous formulation for goal-oriented reduced-order models: 1d problems, International Journal for Numerical Methods in Engineering, 105 (2016), pp. 464–480.
- [24] D. Choi and L. Sael, SNeCT: Scalable network constrained Tucker decomposition for multi-platform data profiling, IEEE/ACM Transactions on Computational Biology and Bioinformatics, 17 (2020), pp. 1785–1796, https://doi.org/10.1109/TCBB.2019.2906205.
- [25] J. Cohen, R. C. Farias, and P. Comon, Fast decomposition of large nonnegative tensors, IEEE Signal Processing Letters, 22 (2015), pp. 862–866, https://doi.org/10.1109/LSP.2014.2374838.
- [26] J. Cohen, K. Usevich, and P. Comon, A tour of constrained tensor canonical polyadic decomposition, May 2016. lhttps://hal.archives-ouvertes.fr/hal-01311795/. Accessed 05/24/2021.
- [27] J. E. Cohen and V. Leplat, Efficient algorithms for regularized nonnegative scale-invariant low-rank approximation models, SIAM Journal on Mathematics of Data Science, 7 (2025), pp. 468–494, https://doi.org/10.1137/24M1657948.
- [28] S. De, E. Corona, P. Jayakumar, and S. Veerapaneni, Tensor-train compression of discrete element method simulation data, Journal of Terramechanics, 113-114 (2024), p. 100967, https://doi.org/https://doi.org/10.1016/j.jterra.2024.100967, https://www.sciencedirect.com/science/article/pii/S0022489824000090.
- [29] L. De Lathauwer, B. De Moor, and J. Vandewalle, A multilinear singular value decomposition, SIAM Journal on Matrix Analysis and Applications, 21 (2000), pp. 1253–1278, https://doi.org/10.1137/S0895479896305696.
- [30] L. De Lathauwer, B. De Moor, and J. Vandewalle, On the best rank-1 and rank- approximation of higher-order tensors, SIAM Journal on Matrix Analysis and Applications, 21 (2000), pp. 1324–1342, https://doi.org/10.1137/S0895479898346995.
- [31] L. De Lathauwer and E. Kofidis, Coupled matrix-tensor factorizations—the case of partially shared factors, in 2017 51st Asilomar Conference on Signals, Systems, and Computers, 2017, pp. 711–715, https://doi.org/10.1109/ACSSC.2017.8335436.
- [32] H. De Sterck and A. Howse, Nonlinearly preconditioned optimization on grassmann manifolds for computing approximate tucker tensor decompositions, SIAM Journal on Scientific Computing, 38 (2016), pp. A997–A1018, https://doi.org/10.1137/15M1037288.
- [33] L. Eldén and B. Savas, A Newton–Grassmann method for computing the best multilinear rank- approximation of a tensor, SIAM Journal on Matrix Analysis and Applications, 31 (2009), pp. 248–271, https://doi.org/10.1137/070688316.
- [34] H. Fanaee-T and J. Gama, Tensor-based anomaly detection: An interdisciplinary survey, Knowledge-Based Systems, 98 (2016), pp. 130–147, https://doi.org/https://doi.org/10.1016/j.knosys.2016.01.027, https://www.sciencedirect.com/science/article/pii/S0950705116000472.
- [35] F. Fang, C. Pain, I. M. Navon, and D. Xiao, An efficient goal-based reduced order model approach for targeted adaptive observations, International Journal for Numerical Methods in Fluids, 83 (2017), pp. 263–275.
- [36] O. T. Farrando, A goal-oriented, reduced-order modeling framework of wall-bounded shear flows, PhD thesis, Master’s thesis]. Delft University of Technology, 2022.
- [37] G. Favier and A. de Almeida, Overview of constrained parafac models, EURASIP Journal on Advances in Signal Processing, 2014 (2014), p. 142, https://doi.org/10.1186/1687-6180-2014-142.
- [38] B. Ghahremani and H. Babaee, Cross interpolation for solving high-dimensional dynamical systems on low-rank tucker and tensor train manifolds, Computer Methods in Applied Mechanics and Engineering, 432 (2024), p. 117385, https://doi.org/https://doi.org/10.1016/j.cma.2024.117385, https://www.sciencedirect.com/science/article/pii/S0045782524006406.
- [39] H. Goedbloed and S. Poedts, Principles of Magnetohydrodynamics with Applications to Laboratory and Astrophysical Plasmas, Cambridge Univ. Press, 2004.
- [40] W. Hackbusch, Tensor Spaces and Numerical Tensor Calculus, vol. 42 of Springer Series in Computational Mathematics, Springer-Verlag Berlin Heidelberg, 2012, https://doi.org/10.1007/978-3-642-28027-6.
- [41] R. A. Harshman, Foundations of the PARAFAC procedure: Models and conditions for an “explanatory” multi-modal factor analysis, UCLA working papers in phonetics, 16 (1970), pp. 1–84. Available at http://www.psychology.uwo.ca/faculty/harshman/wpppfac0.pdf.
- [42] Q. Heng, E. C. Chi, and Y. Liu, Robust low-rank tensor decomposition with the L2 criterion, Technometrics, 65 (2023), pp. 537–552, https://doi.org/10.1080/00401706.2023.2200541.
- [43] F. L. Hitchcock, The expression of a tensor or a polyadic as a sum of products, Journal of Mathematics and Physics, 6 (1927), pp. 164–189, https://doi.org/10.1002/sapm192761164.
- [44] F. L. Hitchcock, Multiple invariants and generalized rank of a p-way matrix or tensor, Journal of Mathematics and Physics, 7 (1927), pp. 39–79, https://doi.org/10.1002/sapm19287139.
- [45] D. Hong, T. G. Kolda, and J. A. Duersch, Generalized canonical polyadic tensor decomposition, SIAM Review, 62 (2020), pp. 133–163, https://doi.org/10.1137/18M1203626.
- [46] K. Huang, N. D. Sidiropoulos, and A. P. Liavas, A flexible and efficient algorithmic framework for constrained matrix and tensor factorization, IEEE Transactions on Signal Processing, 64 (2016), pp. 5052–5065, https://doi.org/10.1109/TSP.2016.2576427.
- [47] I. G. Ion, Low-rank tensor decompositions for surrogate modeling in forward and inverse problems, PhD thesis, Technische Universität Darmstadt, Darmstadt, March 2024, https://doi.org/https://doi.org/10.26083/tuprints-00026678, http://tuprints.ulb.tu-darmstadt.de/26678/.
- [48] U. Kizhakkinan, P. L. T. Duong, R. Laskowski, G. Vastola, D. W. Rosen, and N. Raghavan, Development of a surrogate model for high-fidelity laser powder-bed fusion using tensor train and gaussian process regression, Journal of Intelligent Manufacturing, 34 (2023), pp. 369–385, https://doi.org/https://doi.org/10.1007/s10845-022-02038-4.
- [49] T. G. Kolda and B. W. Bader, Tensor decompositions and applications, SIAM Review, 51 (2009), pp. 455–500, https://doi.org/10.1137/07070111X.
- [50] H. Kolla, K. Aditya, and J. H. Chen, Higher order tensors for dns data analysis and compression, in Data Analysis for Direct Numerical Simulations of Turbulent Combustion: From Equation-Based Analysis to Machine Learning, H. Pitsch and A. Attili, eds., Springer International Publishing, Cham, 2020, pp. 109–134, https://doi.org/10.1007/978-3-030-44718-2_6, https://doi.org/10.1007/978-3-030-44718-2_6.
- [51] J. Lee, Q. Gong, J. Choi, T. Banerjee, S. Klasky, S. Ranka, and A. Rangarajan, Error-bounded learned scientific data compression with preservation of derived quantities, Applied Sciences, 12 (2022), https://doi.org/10.3390/app12136718.
- [52] X. Li and Y. Yuan, A tensor-based hyperspectral anomaly detection method under prior physical constraints, IEEE Transactions on Geoscience and Remote Sensing, 61 (2023), pp. 1–12, https://doi.org/10.1109/TGRS.2023.3324147.
- [53] Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Azizzadenesheli, and A. Anandkumar, Physics-informed neural operator for learning partial differential equations, ACM / IMS J. Data Sci., 1 (2024), https://doi.org/10.1145/3648506, https://doi.org/10.1145/3648506.
- [54] J. Nocedal and S. J. Wright, Numerical Optimization, Springer Series in Operations Research, Springer-Verlag, New York, 2006.
- [55] P. Paatero, A weighted non-negative least squares algorithm for three-way “PARAFAC” factor analysis, Chemometrics and Intelligent Laboratory Systems, 38 (1997), pp. 223–242, https://doi.org/10.1016/S0169-7439(97)00031-2.
- [56] A.-H. Phan, P. Tichavský, and A. Cichocki, Low complexity damped Gauss–Newton algorithms for CANDECOMP/PARAFAC, SIAM Journal on Matrix Analysis and Applications, 34 (2013), pp. 126–147, https://doi.org/10.1137/100808034.
- [57] A. H. Phan, P. Tichavský, and A. Cichocki, Damped Gauss-Newton algorithm for nonnegative Tucker decomposition, in 2011 IEEE Statistical Signal Processing Workshop (SSP), 2011, pp. 665–668, https://doi.org/10.1109/SSP.2011.5967789.
- [58] A.-H. Phan, P. Tichavský, K. Sobolev, K. Sozykin, D. Ermilov, and A. Cichocki, Canonical polyadic tensor decomposition with low-rank factor matrices, in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 4690–4694, https://doi.org/10.1109/ICASSP39728.2021.9414606.
- [59] L. Qi and Z. Luo, Tensor Analysis: Spectral Theory and Special Tensors, Society for Industrial and Applied Mathematics, Philadelphia, PA, 2017, https://doi.org/10.1137/1.9781611974751.
- [60] M. Raissi, P. Perdikaris, and G. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics, 378 (2019), pp. 686–707, https://doi.org/https://doi.org/10.1016/j.jcp.2018.10.045, https://www.sciencedirect.com/science/article/pii/S0021999118307125.
- [61] T. M. Ranadive and M. M. Baskaran, Large-scale sparse tensor decomposition using a damped Gauss-Newton method, in 2020 IEEE High Performance Extreme Computing Conference (HPEC), 2020, pp. 1–8, https://doi.org/10.1109/HPEC43674.2020.9286202.
- [62] M. Roald, C. Schenker, V. D. Calhoun, T. Adali, R. Bro, J. E. Cohen, and E. Acar, An ao-admm approach to constraining parafac2 on all modes, SIAM Journal on Mathematics of Data Science, 4 (2022), pp. 1191–1222, https://doi.org/10.1137/21M1450033.
- [63] J. N. Shadid, R. P. Pawlowski, E. C. Cyr, R. S. Tuminaro, L. Chacon, and P. D. Weber, Scalable Implicit Incompressible Resistive MHD with Stabilized FE and Fully-coupled Newton-Krylov-AMG, Comput. Methods Appl. Mech. Engrg., 304 (2016), pp. 1–25.
- [64] N. Singh, L. Ma, H. Yang, and E. Solomonik, Comparison of accuracy and scalability of Gauss-Newton and alternating least squares for CP decomposition, 2020, https://arxiv.org/abs/1910.12331.
- [65] L. R. Tucker, Some mathematical notes on three-mode factor analysis, Psychometrika, 31 (1966), pp. 279–311, https://doi.org/10.1007/BF02289464.
- [66] M. Vandecappelle, N. Vervliet, and L. D. Lathauwer, Inexact generalized Gauss–Newton for scaling the canonical polyadic decomposition with non-least-squares cost functions, IEEE Journal of Selected Topics in Signal Processing, 15 (2021), pp. 491–505, https://doi.org/10.1109/JSTSP.2020.3045911.
- [67] N. Vannieuwenhoven, R. Vandebril, and K. Meerbergen, A new truncation strategy for the higher-order singular value decomposition, SIAM Journal on Scientific Computing, 34 (2012), pp. A1027–A1052, https://doi.org/10.1137/110836067.
- [68] C. Zhu, R. H. Byrd, P. Lu, and J. Nocedal, Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization, ACM Trans. Math. Softw., 23 (1997), p. 550–560, https://doi.org/10.1145/279232.279236.
Goal-oriented Gradient and Hessian
In this section, we derive formulas for the efficient evaluation of the gradient and Hessian of the objective function needed for the optimization methods described above. Calculation of these quantities for the tensor term (i.e., ) is standard within the literature, so we focus solely on the goal-oriented terms (formulas for the tensor term are provided in References for reference). For simplicity, we consider only a single goal term since the extension to multiple goals is straightforward, and therefore drop the subscript. We also ignore variable scaling as updating the goal derivatives to include it is straightforward, and assume . Define , which has the form of a nonlinear least-squares objective. Given a CP or Tucker model , let be the vector containing the factor matrix coefficients (and core coefficients for Tucker). Define the residual function
| (19) |
so that . Then where is the Jacobian matrix . Furthermore, the Gauss-Newton Hessian approximation is given by . For simplicity in what follows, we assume only contains a single spatial mode and therefore is a 3-way tensor. The generalization to higher-dimensional is straightforward. Given a corresponding CP/Tucker model for each , define such that is the tensor of partial derivatives with respect to the reconstructed tensor model entries.
Goal-oriented CP
Let be a given 3-way, rank- (unweighted) CP model. Then . Note that where . Let . Then we have
| (20) | ||||
where is the mode- perfect shuffle matrix such that and is the identity matrix. Thus
| (21) |
and through similar manipulations we obtain
| (22) | ||||
The Jacobian matrix has the block structure
| (23) |
where
| (24) | ||||
for . Similarly,
| (25) | ||||
Thus the Jacobian blocks are given by the well-known Matricized Tensor Times Khatri-Rao Product (MTTKRP) operation with the gradient tensors . Furthermore, one can efficiently compute Jacobian-vector and Jacobian-transpose-vector products using these formulas. Given one can easily show
| (26) |
where , which allows for efficient calculation of the gradient. Moreover, given ,
| (27) |
where, e.g.,
| (28) | ||||
Thus
| (29) |
Combining this with Eq. 26, one can efficiently compute Gauss-Newton Hessian-vector products.
Goal-oriented Tucker
Let be a given 3-way, rank- Tucker model. Then and where . With and using similar techniques as above, one can show the Jacobian matrix has a similar block structure
| (30) |
where
| (31) | ||||
Thus, as before,
| (32) |
with defined as above. Similarly,
| (33) |
with
| (34) |
Frobenius Gradient, Hessian, and Preconditioner
While the goal-oriented formulation in Eq. 6 is general and can be applied with any statistical loss function , our examples below focus specifically on Frobenius (sum-of-squares) loss with . While construction of the gradient, Gauss-Newton Hessian, and diagonal blocks for preconditioning is standard within the literature, we summarize these formulas here for completeness. As above, we restrict to the 3-way case for simplicity of exposition as these formulas naturally generalize to high-order tensors. First, in the CP case we have
| (35) | ||||
where is the matrix Hadamard (element-wise) product. Given as defined above, the corresponding Gauss-Newton Hessian-vector product is
| (36) |
Finally, the diagonal blocks of the Gauss-Newton Hessian are
| (37) | ||||
whose inverses can be efficiently applied through Cholesky decompositions of the above Hadamard product matrices.
For Tucker, the Gauss-Newton Jacobian is with
| (38) | ||||
Thus one can compute Jacobian-transpose products as
| (39) |
where . In particular, this allows calculation of the gradient where . Furthermore, Jacobian-vector products can be computed as
| (40) |
Finally, the Gauss-Newton Hessian diagonal blocks for preconditioning are
| (41) | ||||
Since these blocks can be quite large, our goal-oriented Tucker experiments only explicitly construct and invert the diagonal of these blocks.
Plasma Physics QoI Evaluations
The calculation of the QoI integrals for the plasma physics data are more complicated than simple sums as in the combustion data, owing to the finite element discretization approach taken in these simulations. Here the values stored in the tensor do not necessarily correspond to values of the solution variables at points in the mesh, but rather are coefficients for the projection of the solution onto a finite element basis. The QoI integrals are then given by integrating the discrete solution represented by these basis functions over the computational domain. This is summarized in Algorithm 1 for evaluation over a 3-dimensional mesh for the finite element approximation to the integral
| (42) |
assuming nodal finite element basis functions, which takes as input a data tensor , a set of variable indices indicating which variables are used in the QoI, a set of time indices indicating which time steps are used for the QoI, the coordinates , , and of the nodes in the mesh, a matrix that interpolates each variable to the Gauss points in the cell from the nodal values, and a set quadrature weights. For trilinear finite element basis functions using first-order Gaussian quadrature , is a vector of all ones, and where
| (43) |
It relies on several mappings/functions that must be initialized when reading the discrete mesh, including node_ind, which provides a list of indices of mesh nodes for the given element, tensor_ind, which provides the spatial indices of those nodes in the tensor , and det_jac, which computes the determinant of the Jacobian matrix of the transformation for a cell determined by its nodal coordinates to the reference cell. In addition to approximating the above QoI integral, Algorithm 1 also computes the QoI derivative needed for the Gauss-Newton gradient/Hessian computations described in References by approximating
| (44) |