GP-FL: Model-Based Hessian Estimation for Second-Order Over-the-Air Federated Learning
Abstract
Second-order methods are widely adopted to improve the convergence rate of learning algorithms. In federated learning (FL), these methods require the clients to share their local Hessian matrices with the parameter server (PS), which comes at a prohibitive communication cost. A classical solution to this issue is to approximate the global Hessian matrix from the first-order information. Unlike in idealized networks, this solution does not perform effectively in over-the-air FL settings, where the PS receives noisy versions of the local gradients. This paper introduces a novel second-order FL framework tailored for wireless channels. The pivotal innovation lies in the PS’s capability to directly estimate the global Hessian matrix from the received noisy local gradients via a non-parametric method: the PS models the unknown Hessian matrix as a Gaussian process, and then uses the temporal relation between the gradients and Hessian along with the channel model to find a stochastic estimator for the global Hessian matrix. We refer to this method as Gaussian process-based Hessian modeling for wireless FL (GP-FL) and show that it exhibits a linear-quadratic convergence rate. Numerical experiments on various datasets demonstrate that GP-FL outperforms all classical baseline first and second order FL approaches.
Index Terms:
Second-order federated learning, quasi-Newton method, non-parametric estimation, distributed learning, over-the-air computation.I Introduction
Traditionally, the training of machine learning (ML) models has followed a centralized approach, with the training data residing in a data center or cloud parameter server (PS). However, in numerous contemporary applications, there is a growing reluctance among devices to share their private data with a remote PS. Addressing this challenge, federated learning (FL) has emerged as a viable solution [1]. FL allows devices to actively contribute to the training of a global model by leveraging only their local datasets while being facilitated by a central PS. In the FL framework, devices transmit solely their local updates to the PS, thus sidestepping the need to disclose raw datasets. The process unfolds in several steps: initially, the PS disseminates the current global model parameters to all participating devices. Subsequently, each device conducts local model training based on its unique dataset and transmits the resulting local updates back to the PS. In the final step, the PS aggregates these local updates, producing a new global model parameters for the subsequent iteration of distributed training.
Considering the large sizes of the model updates, the iterative communication between the PS and clients incurs a significant communication cost. This can significantly decelerate the convergence of FL, since the communication are typically rate-limited in practice [2, 3, 4]. Several lines of research have been dedicated to theoretically characterizing the fundamental trade-offs between learning performance and communication cost, as well as improving the communication efficiency, within the FL framework [5, 6].
I-A Communication-Efficient FL
Early efforts to improve the communication efficiency in the FL framework can be categorized roughly into two approaches: () the first approach tries to reduce the communication overhead per round. One way to achieve this involves utilizing quantization [7] and sparsification [8] techniques. These techniques aim to diminish the transmitted bits and eliminate redundant parameter updates. In general, these approaches come with the trade-off of potentially degrading the model performance, and they must take into account the compatibility for the aggregation operation in FL [9]. () The second approach intends to minimize the total communication rounds. The most well-known example is the federated averaging (FedAvg) algorithm, in which clients execute multiple local iterations before sharing their models with the PS [1], which can significantly reduce the total number of rounds. Some variants of the gradient descent (GD) method have further demonstrated the ability to substantially reduce the overall communication rounds compared to the naive GD [10, 11].
These previous approaches ignore the properties of the communication network, and look at the communication links as rate-limited orthogonal noiseless channels. Nevertheless, later studies have shown that using the properties of the underlying network, further gain in terms of communication efficiency can be achieved [2]. A well-known case is wireless FL, in which clients can use the superposition property of multiple access channel (MAC) to perform the computation directly over the air and significantly reduce the communication costs [12]. In fact, in wireless networks the abstract view on communication links corresponds to the conventional digital transmission, where coded symbols are sent using techniques such as orthogonal frequency-division multiplexing (OFDM). For wireless FL, however, the clients can send their local parameters simultaneously via analog transmission, and the PS can apply the concept of over-the-air computation (AirComp) to aggregate the global parameter. This method allows aggregation to be performed directly over the air, significantly reducing the required bandwidth [12, 13]. This approach has gained traction in wireless FL as an effective strategy for mitigating communication costs [14, 15, 16, 17, 18, 19].
I-B Second-Order Wireless FL
A standard framework for wireless FL consider first-order algorithms, where the clients transmit their local gradients, and the PS aggregates them gradient directly over the air using the AirComp technique. We refer to this framework as first-order AirComp. Similar to other first-order methods, first-order AirComp at best achieves linear convergence, which leads to a relatively large number of iteration rounds to reach the desired accuracy. We further note that the analog nature of AirComp-aided computation leads to extra aggregation error from the channel. This can be seen as zero-mean fluctuations, which adds to the noiseless aggregated gradient, i.e., the estimator that PS computes in perfect FL settings. As a result, the estimator of global gradient computed in first-order AirComp has higher variance as compared with FL with noiseless aggregation. This leads to further degradation in terms of convergence behavior.
One potential solution is to incorporate second-order methods, e.g., Newton-type methods, into the wireless FL setting, as explored in [20]. Unlike first-order methods, second-order approaches benefit from a quadratic convergence rate by computing the update direction using both first and second-order derivatives of the loss function. The update direction computed in these methods is often called Newton direction.
Integrating second-order information into FL requires further access to the second-order information at the PS. This information is obtained by clients sharing their local Hessian matrices with the PS, which imposes a significant communication burden, especially in wireless settings with strictly-restricted links. To mitigate this issue, various studies have explored ways to approximate the Hessian matrix from the first-order information and/or reduced second-order information. For instance, GIANT [21] estimates the Newton direction by utilizing the global gradient and local Hessians on each client, combined with a global backtracking line search across all clients. Although this approach reduces the communication overhead, it still requires partial sharing of second-order information resulting in higher communication load as compared to first-order methods.
The study in [22] suggests an alternative approach, in which each client the computation of Newton direction is offloaded to the clients: the PS and devices invoke the conjugate gradient descent algorithm to compute iteratively an estimate of the global Newton direction. Although the information shared per communication round in this approach is the same as that of the first-order methods, a single iteration of gradient descent (on the model parameters) requires at least two rounds of communication. To circumvent further this overhead, the recent study in [23] proposes a novel second-order method that eliminates the aggregation of local gradients, enabling a single communication round per iteration. Motivated by this work, the authors in [20] develop a second-order wireless FL method, in which the clients compute their Newton directions locally and share them with the PS. The PS then estimates the global Newton direction from the aggregation of these local directions. This approach enables devices to communicate with the PS only once per iteration, reducing the communication overhead to that of the first-order methods.
As a natural extension to available proposals, some recent studies have proposed integration of communication-efficient second-order FL algorithms into the analog computation framework [21, 20]. Experiments however show that, unlike their first-order counterparts, these second-order AirComp algorithms struggle to perform adequately. This observation can be intuitively explained as follows: the noisy aggregation of the second-order information in AirComp-aided approaches introduces significant biases to the estimate of the Newton direction, leading to suboptimal performance. The investigations reveal that such biases can severely deteriorates the convergence, and hence the overall efficiency, of these methods [21, 20]. This study aims to develop a novel second-order AirComp algorithm that addresses this challenge in a communication-efficient way.
I-C Motivation and Contributions
This work proposes a novel second-order AirComp scheme for FL which estimates the Newton direction directly from the aggregated first-order information. It is hence extremely communication-efficient, in the sense that it does not require the exchange of local Hessians or a functions of them: in each round, the clients leverage AirComp to share only their local gradients. The PS then estimates the global Hessian matrix from a finite sequence of its noisy aggregations. For Hessian estimation, we deviate from the classical deterministic schemes and develop a nonparametric model-based estimator. The proposed estimator assumes a Gaussian prior for the Hessian matrix and determines its posterior distribution conditional to a window of most recent noisy aggregations. It then computes an unbiased estimator of the Newton direction by sampling from the posterior distribution. We refer to this method as Gaussian process-based Hessian modeling for FL (GP-FL). Our analysis and numerical experiments demonstrate that the scheme can efficiently suppress the undesired directional bias.
In summary, the contributions of this paper are three-fold:
We introduce GP-FL, a novel second-order AirComp algorithm for wireless FL. The key innovation lies in the PS’s ability to estimate global Hessian matrix based on the received noisy sum of the gradients. This algorithm represents a fundamental departure from most existing works, which typically focus solely on stochastic gradient (SGD) during training. The incorporation of second-order information markedly diminishes the total communication rounds in AirComp-based FL, thereby enhancing communication efficiency even further.
We analyze the convergence behavior of GP-FL and show that it achieves a linear-quadratic convergence rate. Specifically, the number of communication rounds required to reach an -accurate solution, , is either or . This contrasts with GD-based FL methods, which typically have a linear convergence rate of .
Through extensive experiments on datasets—including three from the LIBSVM library [24], Fashion-MNIST [25], and CIFAR-{10,100} [26]—we show that GP-FL outperforms existing first- and second-order algorithms. The method is evaluated under varying levels of heterogeneity [27], and the impact of key hyperparameters is analyzed.
I-D Related Works
The FedAvg scheme relies solely on first-order gradients for updates [1], offering significantly faster computation compared to Hessian-based methods, especially in settings with fast communication. Adaptive step-size methods like AdaGrad [28] and ADAM [29] have also been adapted to distributed settings, showing improved convergence [30]. The adaptive step-size can be represented as a diagonal matrix , providing an alternative preconditioning to the Newton direction , where the direction is computed as .
The second-order methods studied in the literature can be categorized into two groups: () those that utilize second-order information implicitly [31, 32, 33], and () those that explicitly compute them [22, 21, 34]. DANE [31] computes a mirror descent update on the local loss functions, which is equivalent to the GIANT update for a quadratic function. The study in [32] proposes FedDANE as a variant of DANE, specifically tailored for FL, where it uses FedAvg as a baseline with 20 local epochs and observes no improvement with their proposed method. AIDE, proposed in [33], is an alternative accelerated inexact version of DANE. Another line of study in the first group, i.e., group , considers employing distributed quasi-Newton methods [35]. CoCoA [36] and its trust-region extension [37] also perform local steps on a second-order local subproblem, but they specifically address the special case of generalized linear model objectives.
The second group of studies employ the Hessian by computing it indirectly through the use of the so-called Hessian-free optimization approach. In DiSCO [22], the clients compute the Hessian-vector products, and subsequently the PS executes the conjugate gradient method [38]. This process entails one communication round for each iteration of the conjugate gradient method. GIANT [21] and LocalNewton [34] both employ the conjugate gradient method at the clients: GIANT utilizes the global gradient, while LocalNewton uses the local gradients. The study in [39] and its FL extension [40] iteratively approximate the global Hessian, requiring a similar number of communication rounds as GIANT but achieving better convergence rates. However, they lack experimental comparisons with FedAvg using multiple local steps.
In general, the performance of mentioned methods tends to degrade when integrated into the AirComp framework, in which the PS receives a distorted and noisy aggregation. The proposed scheme in this work, GP-FL, addresses this issue by explicitly accounting for the channel imperfections.
I-E Notation
The gradient and Hessian of a function are denoted by and , respectively. The operators and denote the transpose and Hermitian transpose, respectively; and represents the mathematical expectation. The notation refers to the -th entry of vector . The notation denotes a Gaussian process with mean and covariance .
For an integer , denotes . For a scalar or function , , and . Scalars are denoted by non-boldface letters (e.g. ), vectors by boldface lowercase letters (e.g. ), and matrices by boldface uppercase letters (e.g. ). The -th entry of vector is denoted by . The matrix represents the identity matrix. For two matrices and of the same size, implies that is positive semi-definite.
I-F Organization
The remainder of this paper is organized as follows: Section II provides an in-depth discussion of the preliminary knowledge on Newton and quasi-Newton methods. Section III formulates the problem. Section IV presents the proposed stochastic approach for estimating the quasi-Newton direction. Section V provides the convergence analysis for GP-FL. Numerical results and comparison with baselines are given in Section VI. Finally, Section VII concludes the paper.
II Preliminaries
Consider a wireless network with clients and a single PS. The clients aim to jointly train a common model for a supervised learning task over their local labeled datasets. Let denote the local dataset at client which contains independently-collected training tuples of the form with representing a sample input to the model and denoting its ground-truth label.
The clients agree on a global model with learnable parameters. Let vector represent the collection of these parameters into a vector. The ultimate goal is to train this common model by minimizing the global empirical loss that is defined as , where denotes the global dataset, i.e., and is the loss function measuring the prediction error of the model with parameters on input sample relative to the ground-truth .
With the dataset distributed among clients, the global training problem is expressed in terms of local empirical losses. The local empirical loss at client is . The global empirical loss is , where is the set of participating devices. The distributed training problem is formulated as
| (1) |
where is computed locally at client .
II-A First-Order Federated Learning
The de-facto solution to problem (1) is to employ the distributed (stochastic) gradient descent method (DGD/DSGD). In the -th round of DGD, the PS shares parameter with all clients. Each client computes its local gradient at , i.e., , and returns it to the PS. The PS then aggregates these local gradients into a global gradient as
| (2) |
and performs one step of gradient descent, i.e., it computes , where is the global learning rate at the -th round. First-order methods often converge slowly with linear (or sub-linear) convergence rates [41, 42], requiring many iterations to approach a local minimum. Since the number of communication rounds in FL corresponds to iterations, this increases communication overhead.
II-B Newton’s Method in Federated Learning
A method to improve FL communication efficiency is to use faster-converging optimizers, such as second-order methods. These methods estimate the loss landscape’s local curvature, enabling faster and more adaptive updates. While computationally intensive per iteration, they require fewer iterations to converge. Second-order methods are Newton-type techniques. Specifically, Newton’s method updates the model using the second-order Taylor series approximation of the empirical loss. For a small , the Taylor series expansion of around up to the quadratic term is given by , with being the Hessian matrix of computed at . Assuming the Hessian is positive definite, the Newton direction that minimizes this quadratic approximation is given by . Newton’s method hence updates the model parameters by stepping proportional to .
Deploying Newton’s method for the distributed training task in (1), the PS needs to update the global model as
| (3a) | ||||
| (3b) | ||||
This requires transmitting local Hessians to the PS, creating a trade-off: second-order methods reduce communication rounds via faster convergence but increase communication costs per round due to larger transmission. Standard analyses show that the naive use of Newton’s method in distributed settings often leads to inefficiency, as communication overhead dominates.
II-C Quasi-Newton Search Directions
To address issues with Newton’s method in distributed settings, quasi-Newton methods provide an alternative by avoiding explicit computation of local Hessians. Instead of in (3a), an approximation matrix is built using the sequence of local gradients from previous iterations. This matrix is updated iteratively to include new information. To understand the quasi-Newton method, assume is twice continuously differentiable. We can hence write
| (4) |
By adding and subtracting the term to the right-hand side (r.h.s.) of (4), we have
| (5) |
Note that since the gradient function is continuous, the magnitude of the integral on the r.h.s. of (II-C) is . We now set and . This leads to
| (6) |
with . Note that when and reside in a region close to the minimizer, the r.h.s. of (6) is dominated by the first term. We can hence write
| (7) |
The approximation in (7) suggests estimating the Hessian matrix using a matrix that satisfies the relation in (7) as an identity. Specifically, by defining and , the quasi-Newton method computes Newton’s direction using that satisfies the following equation, commonly referred to as the secant equation:
| (8) |
which is an estimator of the Hessian matrix. A classic solution to (8) given by Broyden–Fletcher–Goldfarb–Shanno (BFGS) method [43], which iteratively updates matrix using information from according to , ensuring the positive-definiteness of and consequently making the following quasi-Newton search direction a descent direction:
| (9) |
Unlike Newton’s method, the quasi-Newton approach relies only on computed gradients, reducing communication requirements. However, this comes with higher variance in estimating the optimal direction. Studies show that the quasi-Newton method strikes a good trade-off, achieving faster convergence than first-order methods with similar communication costs.
II-D GP-FL: Quasi-Newton Method in Wireless Networks
We now develop the second-order algorithm GP-FL for FL in wireless networks based on the quasi-Newton method. The algorithm uses two key notions to adapt the quasi-Newton search directions approach to wireless networks: () it uses AirComp to realize the aggregation directly over the air, and () it models the quasi-Newton estimator of the Hessian matrix as a Gaussian process and employs the maximum-likelihood method to estimate it from noisy aggregations.
In the next sections, we present GP-FL, sketch its derivation and analyze its convergence. For the sake of simplicity, we use the following notation hereafter in the paper: we denote the local gradient of client in iteration as and global gradient as , i.e.,
| (10) |
Using this notation, we can summarize the vanilla quasi-Newton method as follows: in iteration ,
III GP-FL: Over-the-Air Aggregation
During each FL communication round, two parameter exchanges occur. The first is a downlink transmission where the PS broadcasts the global model. Since only one set of parameters is transmitted, the communication cost is negligible and can be handled via encoded data over the broadcast channel [15]. The other parameter exchange occurs over uplink channels, where clients send their local gradients to the PS. This is the main source of communication overhead in wireless FL: using conventional orthogonal multiple-access transmission, the time-frequency resources scale linearly with the number of clients . For large , this leads to substantial overhead. To address this, we use AirComp to perform gradient aggregation directly over the air [15, 19, 12, 14, 16, 18]. This approach completes the aggregation within a single coherent block, significantly reducing communication overhead.
III-A Uplink Channel Model
We consider a Gaussian fading multiple access channel with slow frequency-flat fading, where the coherence time exceeds symbol intervals. Clients synchronously transmit -dimensional local gradient entries over consecutive intervals within a single channel coherence interval. The PS is assumed to have an array of antennas, while each client has a single antenna.
We denote the channel coefficient vector between client and the PS in round as . Assuming perfect channel state information (CSI) at both ends, clients can adjust their transmitted signals based on the channel coefficients.
III-B Model Aggregation via AirComp
The AirComp-based model aggregation works as follows: client sends for some pre-processing function simultaneously with all other clients over the channel. The PS then receives a superimposed version of these transmissions. Denoting the received signal by , the PS estimates the aggregated gradient as for some post-processing function . The pre- and post-processing functions serve as analog filters aiming to fulfill the transmission constraints, e.g, transmit power constraint, and minimize the estimation error.
Due to the diversity of among devices, a universal pre- and post-processing function cannot guarantee the joint stationarity of the information-bearing symbols. i.e., local gradients. We hence opt for a data-and-CSI-aware design: prior to uplink transmission, client normalizes its local gradient as
| (12) |
As the normalized gradients are unit-norm, we can model them as jointly stationary processes. This means that for entry . After normalization, client sends
| (13) |
over its uplink channel, where is a power scaling factor satisfying
| (14) |
with denoting maximum transmit power of devices.
The PS receives the superimposed version of transmitted signals: let denotes the received signal of the PS in the -th symbol interval of iteration . Using the channel model, we can write
where is the effective channel, and is complex additive white Gaussian noise (AWGN) with mean zero and variance , i.e., .
The PS uses the received signals for to determine an estimator of the global gradient . Let denote the estimator of . Using linear post-processing, the PS determines from as
| (15) | ||||
| (16) |
for some linear receiver and the power factor .
Then, the PS employs a zero-forcing approach to estimate . It first computes a linear receiver using the CSI (details on computing will be discussed later) and determines the power scaling factor as:
| (17) |
This way, the PS guarantees that all clients satisfy their transmit power constraint, and then it broadcasts to the clients. Client upon receiving determines its scaling as
| (18) |
which satisfies the transmit power constraint (14).
The above coordination of clients realizes the desired superposition over the air in the absence of noise during uplink transmission. Substituting (17) and (18) in (15), it is concluded that the PS aggregates , which after scaling by concludes the following
| (19) |
The estimator of the gradient in iteration is hence given by
| (20) |
where, for notational simplicity, we defined the -dimensional column vector as
| (21) |
Remark 2.
In general we can assume to be complex, as we can represent every two entries of a complex gradient as a pair of in-phase and quadrature components.
Remark 3.
Note that , and thus is an unbiased estimator of . As such, assuming that itself is an unbiased estimator of the true gradient, is an unbiased estimator of the true gradient, as well.
III-C Receiver Design for Model Aggregation
The variance of which specifies the variance of the gradient estimator is given by . Substituting (17) in this term, we have
| (22) |
Thus, for a given set of selected devices , the optimal receiver that minimizes the estimation variance is given by a solution to the following optimization problem:
| (23) |
Using a similar analysis as in [45], the optimization problem in (23) can be reformulated as
| (24) |
which is a quadratically constrained quadratic programming problem that is computationally challenging. However, it can be transformed into a difference-of-convex-function (DC) program, as shown in Appendix A.
Remark 4.
The receiver is updated only once per channel coherence time, and hence it is realistic to assume that we coordinate the network after each update of , as it occurs with the same rate as for the CSI update.
III-D Device Selection Algorithm
The device selection is a combinatorial problem, which lies int the set of nondeterministic polynomial (NP) hard problems. We therefore invoke the sub-optimal approach developed in [20] to approximate its solution via Gibbs sampling (GS) method. The key idea in the GS method is to iteratively sample a device set from the neighboring devices based on a suitable distribution. This iterative process allows the selected devices to gradually converge towards an optimal set. We omit the details of the algorithm due to lack of space and refer the interested readers to [20] for more details.
IV GP-FL: Hessian Estimation
In the quasi-Newton approach, the PS estimates the Newton direction via computed from the subsequent gradient estimators and according to (8). With over-the-air aggregation, the gradient estimators, i.e., and , are further distorted by effective channel noise process resulting in higher error variances. As demonstrated in our numerical investigations in Section VI, the direct derivation of from the aggregated gradients and can significantly degrade the training performance as compared to the case with gradient estimators collected via noise-free aggregation. This observation can be intuitively explained as follows: the variance introduced by over-the-air aggregation leads (through the nonlinear procedure of solving (8)) to an estimator whose estimate of Newton’s direction is biased. The higher the aggregation variance is, the more this directional bias will be.
Unlike the primal estimation error in the mini-batch gradients, i.e., , whose statistics is unknown, the computation error introduced by the over-the-air aggregation is statistically known to us. This knowledge can be potentially used to suppress the impact of computation error and extract a better estimator of the Hessian matrix. The key challenge in this respect is however that the Hessian estimator is related to the noisy aggregations through a nonlinear transform, i.e., the solution to (8). To overcome this challenge we follow the model-based approach suggested in various lines of work in the literature, e.g., [46], to compute a better estimator of the Hessian matrix.
IV-A Model-based Hessian Estimation
In model-based estimation approach, the stochastic nature of the solution to (8) is described through a stochastic process, which approximates the original process. In the sequel, we adapt the Gaussian model for this problem. This choice is particularly useful as Gaussian processes offer non-parametric probabilistic models to capture complexities of nonlinear functions [47].111Modeling Hessians as Gaussian processes was proposed in [46] for use in noisy settings but has not yet been applied to tasks like FL.
To understand the idea of probabilistic modeling of Hessian, let us look more precisely into the noisy quasi-Newton matrix computed from the over-the-air aggregations: at round , the PS uses its latest two aggregations to compute
| (25) |
The quasi-Newton matrix , which is an estimator of Hessian, can then be computed from by solving
| (26) |
With ideal links, , and using a deterministic scheme like BFGS, the solution to (26) matches that of (8). However, with over-the-air computation, deterministic methods yield a Hessian estimate with potentially higher bias and variance compared to the standard case with perfect aggregation222This is demonstrated in the numerical results.. To address this, we deviate from the classical approach of using deterministic schemes to solve (26). Instead, we model and as jointly Gaussian random processes. We approximate their statistics from the observation sequence and use these to derive a more robust Hessian estimator, effectively mitigating the impact of aggregation noise.
IV-B Quasi-Newton Matrix as Gaussian Process
We start by modeling the prior: let be a Gaussian matrix with mean and covariance . For , entry of is an independent Gaussian process with mean and variance given by . For simplicity, we focus on a single entry of , denoting it as , dropping the index . This does not affect the generality of the analysis, as entries of are statistically independent and follow the same estimation procedure.
Our ultimate goal is to model from the observations collected through time . To this end, we collect the last gradient difference in a set , i.e.,
| (27) |
and model it jointly with entry as a Gaussian processes . More precisely, let us define , where is defined as the concatenation of entries in , i.e.,
| (28) |
We model as a Gaussian vector whose mean is and whose covariance matrix . Considering this statistical model, our goal is to use the sample data collected in the last communication rounds, i.e., , to find an estimate of the mean and covariance. We then use the assumed statistical model to find an alternative estimator for .
IV-C Estimating Parameters of Gaussian Process
To estimate the covariance matrix, we follow the conventional approach in the literature [48]: we estimate the covariance of from its samples using the kernel function . The choice of an appropriate kernel is based on assumptions such as smoothness and likely patterns that are expected in the data. Given the nature of data in this problem, i.e., the fact that is the gradient difference, one popular choice of the kernel is the radial basis function [48].
Definition 1 (Radial basis kernel).
For inputs and , the radial basis function computes an matrix whose entry in the -th row and -th column is obtained as
| (29) |
It is worth mentioning that using the radial basis kernel, the estimator of the covariance matrix computed from sampled from , i.e., , is a positive semi-definite matrix.
To use the above covariance estimator, we require a sample from . To this end, we use a deterministic solver to find a solution to (26) for the last communication rounds. This means that we find by solving (26) with for , where denotes to the sample gradient difference computed from the observed received signals.333Superscript is to distinguish random samples from stochastic processes. Let be an entry of . We sample as with
| (30) |
and estimate the covariance of with the sample covariance matrix computed by the radial basis kernel.
We next compute an estimator of the mean using a moving average: we estimate the mean of by arithmetic average of denoted by , and the mean of by the moving average of , i.e., we set the mean of to be the average of for . Let us denote this moving average by . We can then approximate the random process as
| (31) |
for scalar , vector , and symmetric and positive semi-definite matrix .
IV-D Estimating Hessian via Posterior Sampling
The statistical model considered for the quasi-Newton matrix and the sample observations enables us to find an alternative estimator for the Hessian matrix. To this end, we derive the posterior distribution of in the following lemma.
Lemma 1 (Posterior of quasi-Newton matrix).
Consider the Gaussian model for given in (31). The entry conditional to observation is distributed Gaussian with mean and variance that are given by
| (32a) | ||||
| (32b) | ||||
where is the solution to which can be computed via the conjugate gradient algorithm.
Proof.
Since is Gaussian, the posterior distribution of is also Gaussian. After some standards derivations, the mean and variance of this conditional distribution are given by [48]
| (33a) | ||||
| (33b) | ||||
| By defining as in the lemma, the proof is concluded. | ||||
∎
Using this posterior distribution, we can compute various estimators for . Noting that this estimator is used to estimate Newton’s direction, we compute a simple unbiased estimator by sampling from the posterior distribution:444From the Bayesian viewpoint, one might consider setting the estimator to the posterior mean, as it describes the minimum mean squared error (MMSE) estimate. Although MMSE returns minimal variance, it is in general biased and hence can lead to directional misalignment. for every entry of , we compute the posterior mean and variance using the sample observation . Let be the posterior sample for entry . We build the Hessian estimator from entries and compute
| (34) |
The global model is then updated as .
Although validated numerically, it is insightful to explain why (34) provides a better estimate of the true Newton direction compared to deterministic approaches like BFGS. Classical deterministic methods rely only on the latest two gradient samples, which can result in highly inaccurate curvature estimates under noisy aggregation. In contrast, the proposed scheme uses information from the last gradient samples to estimate the loss curvature. This allows it to effectively mitigate the impact of aggregation noise and compute a more robust curvature estimate.
V Algorithm and Convergence Analysis
The derivations in Sections III and IV enable the realization of a second-order FL framework over the air, referred to as Gaussian Process FL (GP-FL). Compared to classical second-order FL, GP-FL introduces two key aspects: () it uses analog function computation to aggregate local models directly over the air, and () it invokes the Gaussian model to compute a more robust estimation for Hessian from a finite window of recent aggregated gradients. The final algorithm is summarized in Algorithm 1, outlining the framework with device scheduling. At communication round , the PS selects a set of participating clients from the available ones using a scheduling scheme, specifically the GS method from [20]. The PS shares with the devices. Upon receiving the global model, the devices compute local gradients and transmit them over their uplink channels. The PS aggregates the global gradient over the air and estimates the Hessian matrix using the method from Section IV, which is then used to update the model via (34).
Remark 6.
We assume the PS has high computational capabilities, rendering the complexity of calculating a direction via (34) negligible. Consequently, the overall running times for GP-FL and conventional second-order FL are nearly identical, as confirmed by our numerical experiments.
V-A Scheduling the Learning Rate
The remaining of this section provides convergence analysis for GP-FL under a set of regularity assumptions, which are commonly considered in the literature [2]. We start the analysis by stating the first assumption.
Assumption 1 (Smoothness and convexity).
The global loss function is twice continuously differentiable, -Lipschitz gradient (-smooth) and -strongly convex. As such, we have
| (35) |
The strong convexity of the global loss function implies that there exists a unique optimal model parameter, which we denote by hereafter in the paper.
For global convergence of GP-FL, as a stochastic estimator of the Newton method, under Assumption 1 the magnitude of model update should be controlled. The classical approach for update control is to resort backtracking line search methods. In this work, we deviate from this classical scheme and control the update magnitude by scheduling the global learning rate. To this end, we invoke the results of [49], which proposes an adaptive learning rate to facilitate the global convergence of Newton-type methods. Casting GP-FL on the proposed scheme in [49], it is shown that for convergence guarantee of GP-FL to the minimizer of an -smooth and -strongly convex loss, it is sufficient to schedule the learning rate as
| (36) |
We hence consider this scheduling throughout the analysis.
V-B Convergence Results
To present the convergence guarantee for GP-FL, we first need to define the concept of -approximate matrix.
Definition 2 (-approximate).
Matrix is said to be a -approximate of , if the following inequality holds
| (37) |
Using this definition, we can now present our first convergence result: Theorem 1 gives an upper-bound on the gap between the converging and optimal models.
Theorem 1.
Let Assumption 1 hold. Moreover, let the inverse of sample quasi-Hessian matrix drawn from the posterior in Lemma 1 in round be a -approximate of the inverse Hessian matrix, and define . Then, the distance between the global model updated in round , i.e., and the optimal model is bounded from above as
| (38) |
where and is given by
| (39) |
for and being
| (40a) | ||||
| (40b) | ||||
with and .
Proof.
The proof is given in Appendix B. ∎
Theorem (1) implies that the GP-FL algorithm exhibits a linear-quadratic convergence rate. In fact, the quadratic term in (65) is exactly the same as the one reported in [49] for Newton-type methods. Nevertheless, our result has an extra linear term, as a result of model-based estimation of the Hessian matrix and the AirComp aggregation error.
We next present Corollaries 1 and 2, which characterize the scenarios under which the GP-FL algorithm converges quadratically and linearly.
Corollary 1.
Let the initial model be in a bounded distance of the optimal model as
| (41) |
Then, the updated model in round satisfies
| (42) |
and lies within the -neighborhood of optimal model after rounds, i.e., , if and
| (43) |
which is also called super-linear convergence rate.
Proof.
See Appendix C. ∎
Corollary 1 presents an intuitive result: when GP-FL is initiated in a close enough vicinity of the optimal model, it can quadratically converge to the optimal model. We next consider the case with linear convergence.
Corollary 2.
Let the initial model satisfies
| (44) |
Then, the updated model in round satisfies
| (45) |
and lies within the -neighborhood of optimal model after rounds, i.e., , if and
| (46) |
Proof.
See Appendix D. ∎
It is worth mentioning that in classical distributed methods, the number of rounds required to achieve a desired precision , follows a linear convergence rate. Specifically, for vanilla federated averaging . This underscores the superiority of GP-FL in terms of convergence rate.
VI Simulation Results
We validate GP-FL by numerical experiments. Throughout the experiments, we elaborate the effectiveness of our proposed scheme by comparing it with several benchmarks, namely the following first-order and second-order FL algorithms:
AirComp-FedAvg (First-order)
Our first benchmark is AirComp-FedAvg proposed in [12]. The algorithm schedules devices using difference-of-convex programming.
GIANT (Second-order)
We consider GIANT algorithm [21] when realized directly over the air via AirComp. We note that GIANT requires an additional aggregation of local gradients, resulting in two communication rounds per iteration. The communication model for this gradient aggregation follows the same procedure as we discussed in Section III-A.
DANE (Second-order)
We deploy AirComp to realize the DANE algorithm proposed in [31]. Similar to GIANT, this algorithm requires two aggregations per communication round.
Sec-Order (Second-order)
We consider the Sec-Order algorithm [20], where the clients locally find a Newton direction and send them to the PS via AirComp. Note that this approach loads more computations on local devices.
BFGS
The PS uses BFGS to find quasi-Newton direction based on the AirComp-based noisy gradients.
We follow the simulation setup in [7] and consider channels with 200 distinct noise standard deviation values, namely . For each value, we generate a corresponding channel. Then, based on the number of devices , we sample values from this noise set. The server is equipped with antennas. For a fair comparison, we apply the same receiver beamforming method described in Section III-C and the same client selection method discussed in Section III-D across all benchmark methods, including GP-FL. For all experiments, we use the SGD optimizer on local devices with a learning rate of , momentum set to 0.9, and weight decay of 0.0005. The batch size is set to 64. The hyper-parameters of the benchmark methods are aligned with those reported in their respective original papers. Additionally, we set the observation window width in GP-FL to . Other hyper-parameters are specified for each experiment separately.
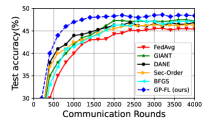
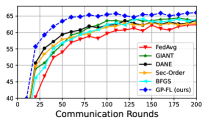
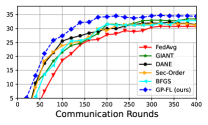
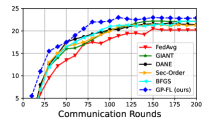
VI-A LIBSVM Dataset
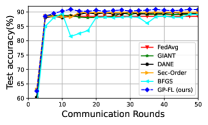
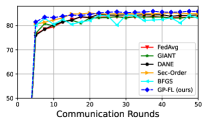
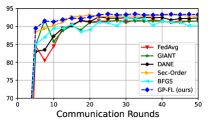
First, we show results for a binary classification task using logistic regression and three datasets from the LIBSVM library [24]: a9a, w8a, and phishing. The data samples are uniformly distributed across clients, all of whom participate in 50 communication rounds. We use the logistic regression model, a type of generalized linear model, as described in [50]. The results for a9a, w8a, and phishing datasets are depicted in Figures 1a, 1b and 1c. As observed, GP-FL achieves higher classification accuracy than benchmark methods.
VI-B Fashion-MNIST Dataset
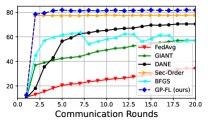
We next use a fully-connected neural network with two hidden layers and perform 300 communication rounds, with all clients participating in each round. The results are shown in Figure 1d. As observed, GP-FL not only achieves higher classification accuracy than the benchmark methods but also reaches 80% accuracy within just five rounds.
VI-C CIFAR-10 Dataset (Non-iid Settings)
We evaluate CIFAR-10 classification in two setups:
-
•
Setup I: Following [51, 52], we organize the dataset by class and divide it into 200 shards. Each client randomly selects two shards without replacement. We use a feedforward neural network with two hidden layers for the FL task, with clients, 4000 communication rounds, and a 10% client sampling rate per round.
-
•
Setup II: We distribute the dataset among them using Dirichlet allocation with . Using ResNet-18 with Group Normalization, we conduct 200 communication rounds, wherein all clients participate. We set .
The test accuracy curves for our method and the benchmark methods are depicted in Figures 1e and 1f. As illustrated, compared to the benchmark methods, GP-FL (i) achieves a higher test accuracy, and (ii) demonstrates a faster rate of convergence. For example, in Figure 1e, GP-FL reaches 45% test accuracy in approximately 700 rounds, whereas the best-performing second-order benchmark methods require around 1600 rounds to reach the same accuracy.
VI-D CIFAR-100 Dataset (Non-iid Settings)
CIFAR-100 shares the same sample size as CIFAR-10, yet it encompasses a broader diversity with 100 distinct classes. We next train the ResNet-18 model for this classification. Through training, we use Group Normalization and let all clients participate in each communication round. For this experiment, we consider the following two setups:
-
•
Setup I: We set and for Dirichlet allocation, and use 400 communication rounds.
-
•
Setup II: We set and for Dirichlet allocation, and use 200 communication rounds.
The test accuracy curve for our method and the benchmark methods are depicted in Figures 1g and 1h. Similar conclusions can be drawn from these figures as those from the CIFAR-10 dataset. For example, in Figure 1g, GP-FL reaches 30% test accuracy in just 120 rounds, whereas the best benchmark method requires 180 rounds to achieve the same performance.
VI-E Comments on Required Observation Window
From an implementation perspective, GP-FL requires the PS to select an efficient observation window . We empirically examine how different values affect GP-FL’s performance by repeating the experiment in Setup I with CIFAR-10 (see Subsection VI-C) for . Setting corresponds to the standard quasi-Newton algorithm. The results, summarized in Table I, show no improvement beyond , with accuracy dropping at . This is because recent gradients carry the most relevant curvature information. Thus, the algorithm can be efficiently implemented with a reasonably sized observation window.
| 0 | 5 | 10 | 15 | 20 | 50 | 100 | |
|---|---|---|---|---|---|---|---|
| Average Accuracy (%) | 45.24 | 46.75 | 47.88 | 48.41 | 48.59 | 48.61 | 48.55 |
VII Conclusion
While second-order methods are favored in FL for their fast convergence, the communication cost of sharing local Hessian matrices poses a challenge. Attempts to approximate these matrices with first-order information have limited effectiveness in real-world scenarios due to noisy updates from imperfect wireless channels. In this paper, we propose a novel second-order FL algorithm tailored for wireless channels, termed Gaussian process-based Hessian modeling for FL (GP-FL). The algorithm uses a non-parametric approach to estimate the global Hessian matrix from noisy local gradients received over uplink channels. Our analysis demonstrates that GP-FL achieves a linear-quadratic convergence rate. Extensive numerical experiments validate the proposed method’s efficiency. Extending GP-FL to other distributed learning approaches is a natural direction in this area.
Appendix A Solving Optimization (23)
To solve the joint optimization in (23), we begin by transforming it into a low-rank optimization problem. Specifically, let , where , and let . This allows us to reformulate (23) as
| (50) | |||
Effectively addressing the rank-one constraint is crucial for solving low-rank optimization problems. A common approach is semidefinite relaxation (SDR), which removes the constraint, reformulating the problem as semidefinite programming to approximate the solution. However, for larger problems, the rank-one constraint is often violated, requiring randomization methods to scale the solution.
An alternative approach to enforce the rank-one constraint is to express it as with . This reformulates the problem into a difference-of-convex-functions (DC) program, allowing for a more accurate solution by satisfying all constraints. Building on methods in [20], we introduce the following modified DC programming, incorporating the new constraint as a penalty term:
| (51) | |||
where is a regularizer. Although this remains a non-convex problem due to the concave term , we can linearize and transform it into the following convex iterative subproblem:
| (52) | |||
where is -th iterative of , is the sub-gradient of . For a complete description of the iterative algorithm, please refer to Algorithm 2 in [20].
Appendix B Proof of Theorem 1
Before starting the derivation, note that we frequently use the triangle inequality, which states that for two vectors and , . For clarity, we will omit explicitly mentioning its use when it is evident from the context.
We aim to bound the distance to the optimal model at round , i.e., . This bound is derived by establishing a recursive relationship between the distances in consecutive communication rounds. To begin, we note that , where as given in (34). We hence have
| (53) |
where we define , and
| (54) |
The term is upper-bounded using the results reported in [49]. In particular, defining and as in Theorem 1, the result of [49] implies that
| (55) |
In the next step, we find an upper bound on . To this end, we use the triangular inequality once again to write
| (56a) | ||||
| (56b) | ||||
Noting that is -approximator of , we can write
| (57) |
with the latter inequality being concluded directly from the fact that . We further note that -strong convexity of the loss yields . We hence conclude that
| (58) |
and use the -smoothness of the global loss to write
| (59) |
Using (58) and (59), the first term in (56b) is straightforwardly bounded. To bound the second term, we have
| (60a) | ||||
| (60b) | ||||
Using this bound, we can finally write
| (61) |
with being defined as in Theorem 1.
The above bound leads to an instantaneous recursive bound. We now recall that in the AirComp-aided aggregation we have . By taking expectation from both sides of (61) w.r.t. to the randomness in communication links, we obtain
| (62) |
Using (21), we can further write
| (63a) | ||||
| (63b) | ||||
We finally take an expectation from both sides of (53), and use (62) and (63a) to write (note that as per (36))
| (64) |
where is defined as
| (65) |
for and that were defined in Theorem 1. Applying (64) recursively, the proof is concluded.
Appendix C Proof of Corollary 1
From Theorem (1), it is concluded that if
| (66) |
We aim to determine the growth order of . Assuming is sufficiently small, becomes large and satisfies . To remain within the -neighborhood of , it is sufficient to have: , which using the fact that , it reduces to
| (67) |
Since , as grows large ; therefore, the left-hand-side coefficient tends to . Noting that , we can further replace the first term inside the brackets with for large . By substituting into (67), and taking from both sides we finally have
| (68) |
As , the second term on the right-hand-side of (68) is positive. Noting that the first term does not scale, we can finally write , which concludes the proof.
Appendix D Proof of Corollary 2
Appendix E Proof of Theorem 2
As the global loss is -Lipschitz gradient, we have
| (71) |
Taking expectation from both sides, and noting that , we obtain
| (72) |
This implies that to bound , we should bound . From (53), we have
| (73) |
Using the bounds in (55) to (63a), we obtain
| (74) |
where is given by
| (75) |
with and being defined in Theorem 2. Using (74) recursively, we next obtain
| (76) |
References
- [1] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS). PMLR, 2017, pp. 1273–1282.
- [2] M. M. Amiri and D. Gündüz, “Federated learning over wireless fading channels,” IEEE Trans. Wirel. Commun., vol. 19, no. 5, pp. 3546–3557, 2020.
- [3] S. M. Hamidi, S. Herath, A. Bayesteh, and A. K. Khandani, “Systems and methods for communication resource usage control,” May 30 2019, uS Patent App. 15/824,352.
- [4] S. M. Hamidi, “Training neural networks on remote edge devices for unseen class classification,” IEEE Signal Processing Letters, vol. 31, pp. 1004–1008, 2024.
- [5] M. Braverman, A. Garg, T. Ma, H. L. Nguyen, and D. P. Woodruff, “Communication lower bounds for statistical estimation problems via a distributed data processing inequality,” in Proceedings of the Forty-eighth Annual ACM Symposium on Theory of Computing, 2016, pp. 1011–1020.
- [6] Y. Han, A. Özgür, and T. Weissman, “Geometric lower bounds for distributed parameter estimation under communication constraints,” in Proceedings of the 31st Conference On Learning Theory (COLT). PMLR, 2018, pp. 3163–3188.
- [7] M. Lan, Q. Ling, S. Xiao, and W. Zhang, “Quantization bits allocation for wireless federated learning,” IEEE Trans. Wirel. Commun., vol. 22, no. 11, pp. 8336–8351, 2023.
- [8] A. Bereyhi, B. Liang, G. Boudreau, and A. Afana, “Novel gradient sparsification algorithm via bayesian inference,” in Proceedings of IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP), 2024, pp. 1–6.
- [9] J. Wang, Z. Charles, Z. Xu et al., “A field guide to federated optimization,” 2021. [Online]. Available: https://arxiv.org/abs/2107.06917
- [10] S. J. Reddi, Z. Charles, M. Zaheer, K. Rush, J. Konečnỳ, S. Kumar, and H. B. McMahan, “Adaptive federated optimization,” in Proceedings of the International Conference on Learning Representations, 2020.
- [11] Q. Tong, G. Liang, and J. Bi, “Effective federated adaptive gradient methods with non-iid decentralized data,” 2020. [Online]. Available: https://arxiv.org/abs/2009.06557
- [12] K. Yang, T. Jiang, Y. Shi, and Z. Ding, “Federated learning via over-the-air computation,” IEEE Trans. Wirel. Commun., vol. 19, no. 3, pp. 2022–2035, 2020.
- [13] A. Bereyhi, A. Vagollari, S. Asaad, R. R. Müller, W. Gerstacker, and H. V. Poor, “Device scheduling in over-the-air federated learning via matching pursuit,” IEEE Trans. Signal Process., vol. 71, pp. 2188–2203, 2023.
- [14] G. Zhu, Y. Wang, and K. Huang, “Broadband analog aggregation for low-latency federated edge learning,” IEEE Trans. Wirel. Commun., vol. 19, no. 1, pp. 491–506, 2019.
- [15] M. M. Amiri and D. Gündüz, “Machine learning at the wireless edge: Distributed stochastic gradient descent over-the-air,” IEEE Trans. Signal Process., vol. 68, pp. 2155–2169, 2020.
- [16] T. Sery and K. Cohen, “On analog gradient descent learning over multiple access fading channels,” IEEE Trans. Signal Process., vol. 68, pp. 2897–2911, 2020.
- [17] S. M. Hamidi, M. Mehrabi, A. K. Khandani, and D. Gündüz, “Over-the-air federated learning exploiting channel perturbation,” in 2022 IEEE 23rd International Workshop on Signal Processing Advances in Wireless Communication (SPAWC), 2022, pp. 1–5.
- [18] D. Liu and O. Simeone, “Privacy for free: Wireless federated learning via uncoded transmission with adaptive power control,” IEEE J. Sel. Areas Commun., vol. 39, no. 1, pp. 170–185, 2020.
- [19] A. Elgabli, J. Park, C. B. Issaid, and M. Bennis, “Harnessing wireless channels for scalable and privacy-preserving federated learning,” IEEE Trans. Commun., vol. 69, no. 8, pp. 5194–5208, 2021.
- [20] P. Yang, Y. Jiang, T. Wang, Y. Zhou, Y. Shi, and C. N. Jones, “Over-the-air federated learning via second-order optimization,” IEEE Trans. Wirel. Commun., vol. 21, no. 12, pp. 10 560–10 575, 2022.
- [21] S. Wang, F. Roosta, P. Xu, and M. W. Mahoney, “GIANT: Globally improved approximate newton method for distributed optimization,” in Advances in Neural Information Processing Systems, 2018, pp. 2332–2342.
- [22] Y. Zhang and X. Lin, “Disco: Distributed optimization for self-concordant empirical loss,” in Proceedings of the International conference on machine learning. PMLR, 2015, pp. 362–370.
- [23] A. Ghosh, R. K. Maity, and A. Mazumdar, “Distributed newton can communicate less and resist byzantine workers,” Advances in Neural Information Processing Systems, vol. 33, pp. 18 028–18 038, 2020.
- [24] C.-C. Chang and C.-J. Lin, “LIBSVM: A library for support vector machines,” ACM transactions on intelligent systems and technology (TIST), vol. 2, no. 3, pp. 1–27, 2011.
- [25] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1708.07747
- [26] A. Krizhevsky, “Learning multiple layers of features from tiny images,” Ph.D. dissertation, University of Toronto, 2009, technical Report.
- [27] S. M. Hamidi, R. Tan, L. Ye, and E.-H. Yang, “Fed-it: Addressing class imbalance in federated learning through an information- theoretic lens,” in 2024 IEEE International Symposium on Information Theory (ISIT), 2024, pp. 1848–1853.
- [28] J. Duchi, E. Hazan, and Y. Singer, “Adaptive subgradient methods for online learning and stochastic optimization.” J. Mach. Learn. Res., vol. 12, no. 7, 2011.
- [29] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2017. [Online]. Available: https://arxiv.org/abs/1412.6980
- [30] S. P. Karimireddy, M. Jaggi, S. Kale, M. Mohri, S. J. Reddi, S. U. Stich, and A. T. Suresh, “Mime: Mimicking centralized stochastic algorithms in federated learning,” 2021. [Online]. Available: https://arxiv.org/abs/2008.03606
- [31] O. Shamir, N. Srebro, and T. Zhang, “Communication-efficient distributed optimization using an approximate newton-type method,” in Proceedings of the International Conference on Machine Learning. PMLR, 2014, pp. 1000–1008.
- [32] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smithy, “Feddane: A federated newton-type method,” in Proceedings of the 2019 53rd Asilomar Conference on Signals, Systems, and Computers. IEEE, 2019, pp. 1227–1231.
- [33] S. J. Reddi, J. Konečný, P. Richtárik, B. Póczós, and A. Smola, “Aide: Fast and communication efficient distributed optimization,” 2016. [Online]. Available: https://arxiv.org/abs/1608.06879
- [34] V. Gupta, A. Ghosh, M. Derezinski, R. Khanna, K. Ramchandran, and M. Mahoney, “Localnewton: Reducing communication bottleneck for distributed learning,” 2021. [Online]. Available: https://arxiv.org/abs/2105.07320
- [35] A. Agarwal, O. Chapelle, M. Dudík, and J. Langford, “A reliable effective terascale linear learning system,” J. Mach. Learn. Res., vol. 15, no. 1, pp. 1111–1133, 2014.
- [36] V. Smith, S. Forte, M. Chenxin, M. Takáč, M. I. Jordan, and M. Jaggi, “CoCoA: A general framework for communication-efficient distributed optimization,” J. Mach. Learn. Res., vol. 18, p. 230, 2018.
- [37] C. Duenner, A. Lucchi, M. Gargiani, A. Bian, T. Hofmann, and M. Jaggi, “A distributed second-order algorithm you can trust,” in Proceedings of the 35th International Conference on Machine Learning, vol. 80. PMLR, 10–15 Jul 2018, pp. 1358–1366.
- [38] M. R. Hestenes, E. Stiefel et al., Methods of conjugate gradients for solving linear systems. NBS Washington, DC, 1952, vol. 49, no. 1.
- [39] R. Islamov, X. Qian, and P. Richtárik, “Distributed second order methods with fast rates and compressed communication,” in International conference on machine learning. PMLR, 2021, pp. 4617–4628.
- [40] M. Safaryan, R. Islamov, X. Qian, and P. Richtarik, “Fednl: Making newton-type methods applicable to federated learning,” in Proceedings of the International Conference on Machine Learning. PMLR, 2022, pp. 18 959–19 010.
- [41] Y. Deng and M. Mahdavi, “Local stochastic gradient descent ascent: Convergence analysis and communication efficiency,” in Proceedings of the International Conference on Artificial Intelligence and Statistics. PMLR, 2021, pp. 1387–1395.
- [42] P. Sharma, R. Panda, G. Joshi, and P. Varshney, “Federated minimax optimization: Improved convergence analyses and algorithms,” in Proceedings of the International Conference on Machine Learning. PMLR, 2022, pp. 19 683–19 730.
- [43] J. Nocedal and S. J. Wright, Numerical Optimization. Springer, 1999.
- [44] J. Shermen and W. Morrison, “Adjustment of an inverse matrix corresponding to changes in the elements of a given column or a given row of the original matrix,” Annals of Mathmatical Statistics, vol. 20, pp. 621–625, 1949.
- [45] L. Chen, X. Qin, and G. Wei, “A uniform-forcing transceiver design for over-the-air function computation,” IEEE Wirel. Commun. Lett., vol. 7, no. 6, pp. 942–945, 2018.
- [46] A. G. Wills and T. B. Schön, “Stochastic quasi-newton with line-search regularisation,” Automatica, vol. 127, p. 109503, 2021.
- [47] E. Schulz, M. Speekenbrink, and A. Krause, “A tutorial on gaussian process regression: Modelling, exploring, and exploiting functions,” Journal of Mathematical Psychology, vol. 85, pp. 1–16, 2018.
- [48] C. B. Do and H. Lee, “Gaussian processes,” Stanford University, Stanford, CA, accessed Dec, vol. 5, p. 2017, 2007.
- [49] B. Polyak and A. Tremba, “New versions of newton method: step-size choice, convergence domain and under-determined equations,” Optimization Methods and Software, vol. 35, no. 6, pp. 1272–1303, 2020.
- [50] D. W. Hosmer Jr, S. Lemeshow, and R. X. Sturdivant, Applied Logistic Regression. John Wiley & Sons, 2013.
- [51] S. M. Hamidi and E.-H. YANG, “Adafed: Fair federated learning via adaptive common descent direction,” Transactions on Machine Learning Research, 2024. [Online]. Available: https://openreview.net/forum?id=rFecyFpFUp
- [52] S. Mohajer Hamidi and O. Damen, “Fair wireless federated learning through the identification of a common descent direction,” IEEE Communications Letters, vol. 28, no. 3, pp. 567–571, 2024.